“文心一言”对标ChatGPT,饱含争议。文心一言作为一款语言大模型,并提出了自己在技术对就业的影响方面的理解,现阶段正处于摸着OpenAI过河的时候,路该如何走?
GPT-4太惊艳,压力给到文心一言
这段时间,GPT-4和文心一言前后脚和大家见面,因为GPT-4亮相太惊艳,压力直接给到百度。文心一言的率先抢跑,也必然会刺激腾讯、阿里、字节等国内大厂的追赶步伐。李彦宏坦言,“文心一言对标ChatGPT、甚至是对标GPT-4,门槛是很高的。

ChatGPT惊艳亮相之前,GPT的1~3版本,都是在长期低调开源测试后,才达到了后面的结果。文心一言这位有些“偏科”的选手,是目前唯一能够直接进行“文生图”的模型,在文学创作例如诗词上有着“天赋”,但在“数学课”、“计算机编程课”较为差劲。
一顿操作猛如虎,让人误以为百度已经完完全全准备好了,但在发布会表示文心一言还不够成熟,自3月16日下午两点发布会开始之后,百度一度大跌10%。
股价跌也跌了,涨也涨了,大家骂也骂了。这位有些“偏科”的选手,路该如何走?

“文心一言”对线“GPT-4”
王海峰介绍:
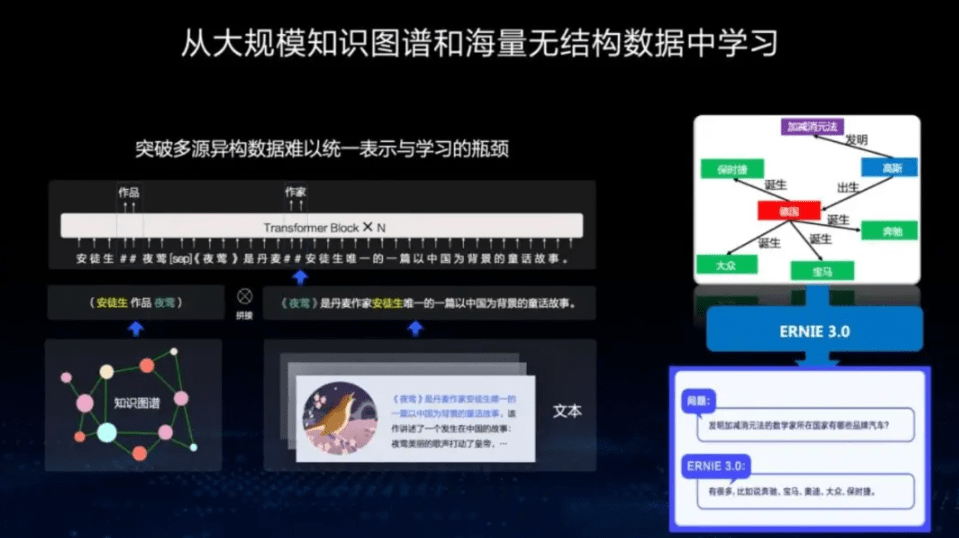
“文心一言主要脱胎于两大模型,百度ERNIE系列知识增强千亿大模型,以及百度大规模开放域对话模型PLATO。此基础上,主要采用了六项核心技术,包括监督精调、人类反馈强化学习、提示构建、知识增强、检索增强和对话增强技术。”
李彦宏提到:
“从某种意义上说,我们已经为此准备了多年,十几年前就开始投入AI研究,2019年就推出了文心大语言模型,今天的文心一言是过去多年努力的延续。”
百度构建了世界上最大规模的知识图谱,拥有超过50亿实体,5500亿事实,能够通过语言、听觉、视觉等获得对世界的统一认知,突破了实际应用中场景复杂多变、数据稀缺等难题。当用户问出一个问题后,文心一言会先通过搜索引擎将知识在知识图谱检索一遍,然后再筛选整合其中有用的信息作为输出。

摸着OpenAI过河
说白了,现在大家都在摸着GPT过河,在琢磨更优质的模型方案,并从中总结“中国经验”。首先,ChatGPT和GPT-4能表现出类人的图片和语言理解能力,就是因为“涌现现象”,大模型的数规模达到一定程度时,其解决问题的能力就会发生突变,你可以理解为“大力出奇迹”
但模型越来越大,产业落地方面的消耗就会越来越多,这样很多场景都无法负担,所以现在的技术方向是如何将模型做“小”。确保这个模型的精准和有效利用率,但要实现这个问题,找到合适的指令就变得非常重要,毕竟不同的任务、不同的样本、用什么样的提示语才能获得更好结果是需要去尝试的。
所以OpenAI选择免费开放ChatGPT,它需要通过这种方式收集全球的问题指令,来完成大模型的进一步优化。李彦宏也在文心一言发布会上也提到,之所以选择在这个时候发布文心一言,也因为文心一言本身需要通过用户使用来收集数据。

得到一个好答案,不如提出一个好问题
兴奋之后,技术进步带来的总是焦虑,GPT-4依然在不断突破着人们对AI认知的可能性,人们争相讨论的焦点仍然是“谁将会被替代”的问题,别担心,但这些强大的能力背后仍然需要人去操作,这其中甚至需要人具备更多的专业知识。
普通人确实可以随机让ChatGPT编写一条程序,但是系统整体代码需要如何架构、程序如何编写运行更有效率、AI生成的程序是否存在错误等等都是需要人工确认的,也就是说,关于数据集规模、参数规模等,OpenAI却并没有回复此前大家的猜想。

低代码更适合被采纳
是否能够在各类场景中得到广泛应用,还取决于不同场景下的具体业务逻辑。需要对业务进行拆解后,进一步甄别是否具有多模态理解的需求,以及如何接入这样的能力。相比之下,低代码可能会在应用层被更迅速地采纳。
开源地址:https://www.yinmaisoft.com/?from=csdn
JNPF,依托代码开发技术原理,区别于传统开发交付周期长、二次开发难、技术门槛高的痛点,大部分的应用搭建都是通过拖拽控件实现,通过为开发者提供可视化的应用开发环境,降低或去除应用开发对原生代码编写的需求量,进而实现便捷构建应用程序的一种开发平台,快速助力研发人员快速搭建出一套适合企业发展的方案,故 一套完善的底座意味着在大部分领域通用的解决方案能力。
所以,在AI席卷的未来,人类工作者如何找到新的定位,不仅是某一个人的问题,也是整个社会的问题。所以,至少目前而言,那些月薪几万的岗位可能会被替代,但你月薪3000搬砖的岗位暂时会比较牢靠。
毕竟,AI大模型也是有成本的,它可比你贵多了。