背景
如果注意观察的话,在现实生活中,你一定会遇到下列几个场景,一起来看看有没有熟悉的感觉。
场景一、某周某,小明和朋友一起去某美食街进行聚餐,到了美食街找到一家推荐度非常高的美食店。由于推荐度非常高,需要等座,经过简单的扫码预约,小明拿到一个号(大桌xx号,还会显示前面有多少桌),同时在等待窗口会有一个大屏展示,当轮到小明可以去吃饭的吃饭,一定会有广播,“请XX号到XX桌就餐”,而且会广播好几遍,以提醒小明前往就餐。
场景二、某日,小张身体不舒服,前往市里某三甲医院就诊,医院也是人满为患。与场景一相同的是,小张在挂号后,在诊室门口也会同样的进行排队。不同的场景,相同的配方,都是会语音播报,“请XXX到506室就诊”。
场景三、某日,视障人士赵大爷(听力正常)要在某网站上浏览旅游网站,想去某地旅游。在老伴的帮助下,打开了网站,在进入到景点页面后,选择景点播报按钮,赵大爷可以听到关于景点的详细介绍,可以听到网友的旅游攻略。
如上等等,都有一个共同的特点,在现实场景中,需要能动态读取一段文字,然后进行相应的播放,以起到通知和广告的作用。本文将重点阐述基于Html5的speechSynthesis技术,实现文字自动播放功能,最后通过对静夜诗的赏析自动播报来展示具体API的实际开发调用。
一、关于SpeechSynthesis
1、SpeechSynthesis简介
SpeechSynthesis是HTML5的一个新特性,基于SpeechSynthesis可以实现在客户浏览器端进行动态文本的语音合成播放。在HTML5中和Web Speech相关的API实际上有两类,一类是“语音识别(Speech Recognition)”,另外一个就是“语音合成(Speech Synthesis)”,这两个名词听上去很高大上,实际上指的分别是“语音转文字”,和“文字变语音”。而本文要介绍的就是这里的“语音合成-文字变语音”。为什么称为“合成”呢?比方说你Siri发音“你好,世界!” 实际上是把“你”、“好”、“世”、“界”这4个字的读音给合并在一起,因此,称为“语音合成”。
2、SpeechSynthesis的核心类
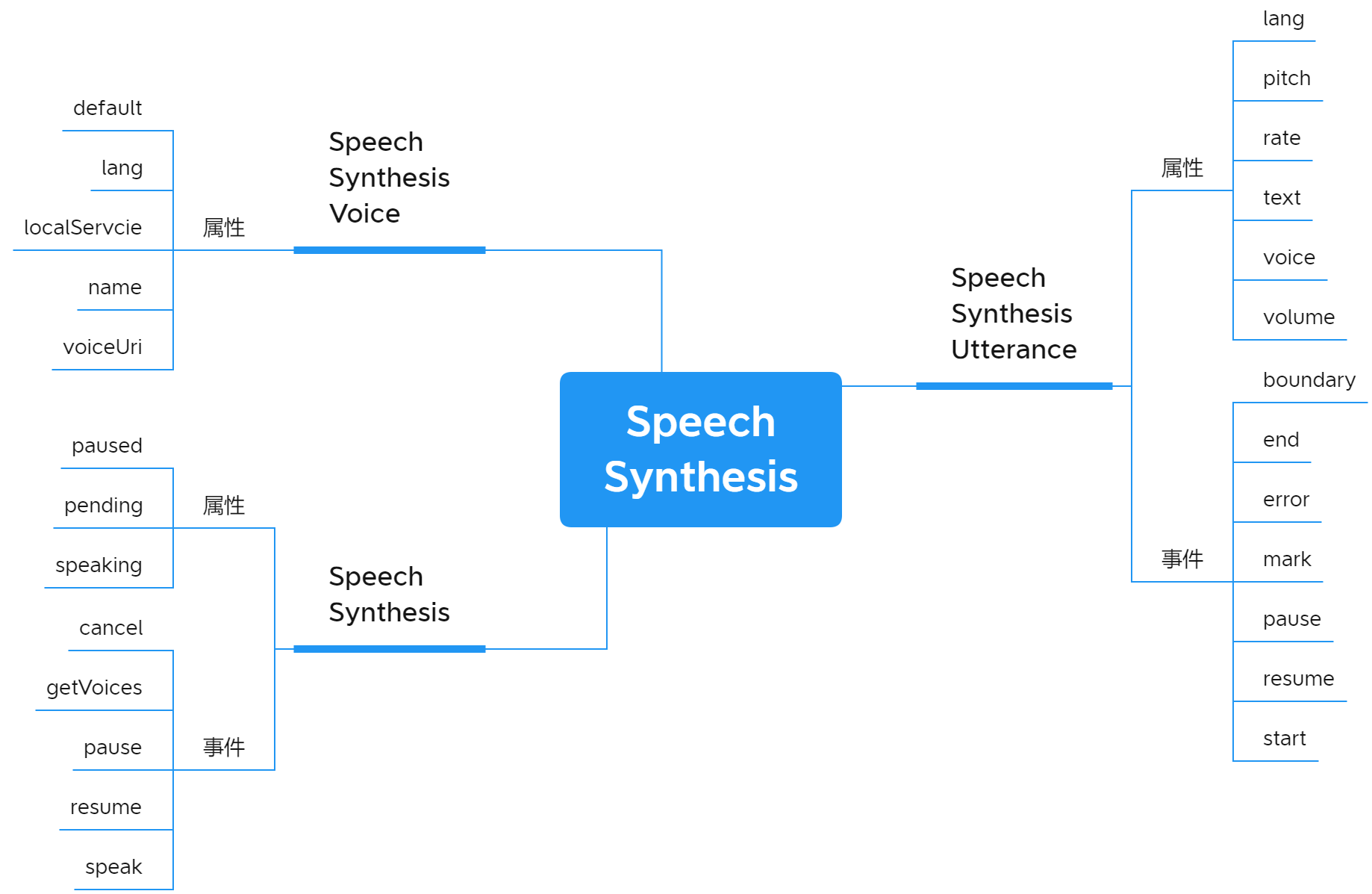
SpeechSyntehesisUtteranc这个类主要用于控制合成声音的属性配置,比如主要内容,语音模板,语速等等,通过这个核心类控制。它的属性信息如下:
序号 |
参数 |
解释 |
1 |
text |
要合成的文字内容,字符串 |
2 |
lang |
使用的语言,字符串, 例如:"zh-cn" |
3 |
voiceURI |
指定希望使用的声音和服务,字符串。 |
4 |
volume |
声音的音量,区间范围是0到1,默认是1 |
5 |
rate |
语速,数值,默认值是1,范围是0.1到10,表示语速的倍数,例如2表示正常语速的两倍。 |
6 |
pitch |
表示说话的音高,数值,范围从0(最小)到2(最大)。默认值为1 |
核心方法如下表所示:
序号 |
方法名 |
说明 |
1 |
onstart |
语音合成开始时候的回调。 |
2 |
onpause |
语音合成暂停时候的回调 |
3 |
onresume |
语音合成重新开始时候的回调 |
4 |
onend |
语音合成结束时候的回调 |
5 |
onmark |
Fired when the spoken utterance reaches a named SSML "mark" tag. |
其它更详细的介绍可以参考以下地址Html Web API 接口。这里有更详细的描述,还有详细的示例。
var synth = window.speechSynthesis;
var voices = synth.getVoices();
var inputForm = document.querySelector('form');
var inputTxt = document.querySelector('input');
var voiceSelect = document.querySelector('select');
for(var i = 0; i < voices.length; i++) {
var option = document.createElement('option');
option.textContent = voices[i].name + ' (' + voices[i].lang + ')';
option.value = i;
voiceSelect.appendChild(option);
}
inputForm.onsubmit = function(event) {
event.preventDefault();
var utterThis = new SpeechSynthesisUtterance(inputTxt.value);
utterThis.voice = voices[voiceSelect.value];
synth.speak(utterThis);
inputTxt.blur();
}
3、speechSynthesis对象
speechSynthesis是实际调用SpeechSynthesisUtterance对象进行合成播报的。他的属性和方法如下两个表格描述。
序号 |
名称 |
描述 |
1 |
paused |
当SpeechSynthesis 处于暂停状态时, Boolean (en-US) 值返回 true |
2 |
pending |
当语音播放队列到目前为止保持没有说完的语音时, Boolean (en-US) 值返回 true 。 |
3 |
speaking |
当语音谈话正在进行的时候,即使SpeechSynthesis处于暂停状态, Boolean (en-US) 返回 true 。 |
var synth = window.speechSynthesis;
var inputForm = document.querySelector('form');
var inputTxt = document.querySelector('.txt');
var voiceSelect = document.querySelector('select');
var pitch = document.querySelector('#pitch');
var pitchValue = document.querySelector('.pitch-value');
var rate = document.querySelector('#rate');
var rateValue = document.querySelector('.rate-value');
var voices = [];
function populateVoiceList() {
voices = synth.getVoices();
for(i = 0; i < voices.length ; i++) {
var option = document.createElement('option');
option.textContent = voices[i].name + ' (' + voices[i].lang + ')';
if(voices[i].default) {
option.textContent += ' -- DEFAULT';
}
option.setAttribute('data-lang', voices[i].lang);
option.setAttribute('data-name', voices[i].name);
voiceSelect.appendChild(option);
}
}
populateVoiceList();
if (speechSynthesis.onvoiceschanged !== undefined) {
speechSynthesis.onvoiceschanged = populateVoiceList;
}
inputForm.onsubmit = function(event) {
event.preventDefault();
var utterThis = new SpeechSynthesisUtterance(inputTxt.value);
var selectedOption = voiceSelect.selectedOptions[0].getAttribute('data-name');
for(i = 0; i < voices.length ; i++) {
if(voices[i].name === selectedOption) {
utterThis.voice = voices[i];
}
}
utterThis.pitch = pitch.value;
utterThis.rate = rate.value;
synth.speak(utterThis);
inputTxt.blur();
}在了解了SpeechSynthesis的相关对象的属性和方法之后,就可以用来实现自己的语音播报功能。下一节中重点描述。
二、SpeechSynthesi文本实例合成
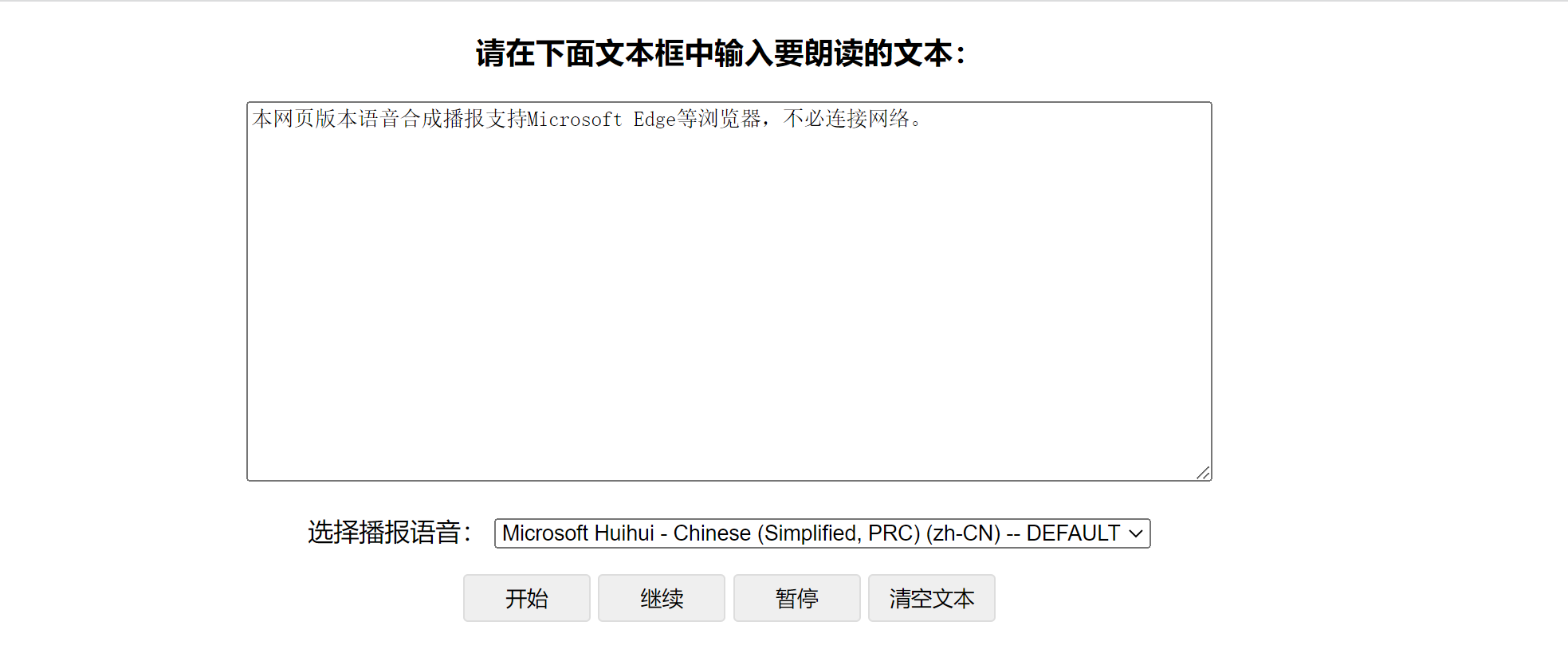
1、新建test.html
<!DOCTYPE html>
<html>
<head>
<meta charset="UTF-8">
<meta name="viewport" content="width=device-width, initial-scale=1">
<title>网页版文字转语音朗读功能</title>
<style>
article {margin: 0 auto;max-width: 800px;text-align: center;}
textarea {max-width: 600px;width:100%;text-align: left;}
button{border-radius: 3px;border: 1px solid #dddddd;height: 30px;width: 80px;cursor: pointer;}
</style>
</head>
<body>
<article>
<h3 align="center">请在下面文本框中输入要朗读的文本:</h3>
<p>
<textarea id="texts" rows="15" class="_play">本网页版本语音合成播报支持Microsoft Edge等浏览器,不必连接网络。</textarea>
</p>
<p>
<label>选择播报语音:</label>
<select id="voiceSelect" onchange="play()"></select>
</p>
<button class="_search" onclick="play()">开始</button>
<button onclick="resume()">继续</button>
<button onclick="pause()">暂停</button>
<!-- <button onclick="cancel()">清除队列</button> -->
<button onclick="cls()">清空文本</button>
</article>
</body>
</html>生成本地支持的语音模板,不同的浏览器获取到的支持信息可能不一样,大家可以根据实际情况添加,而且有的添加了也不一定支持播放。
//创建选择语言的select标签
function populateVoiceList() {
voices = speechSynthesis.getVoices();
for(i = 0; i < voices.length; i++) {
var option = document.createElement('option');
option.textContent = voices[i].name + ' (' + voices[i].lang + ')';
if(voices[i].default) {
option.textContent += ' -- DEFAULT';
}
option.setAttribute('data-lang', voices[i].lang);
option.setAttribute('data-name', voices[i].name);
voiceSelect.appendChild(option);
}
}
setTimeout(function() {
populateVoiceList();
}, 500) //2、定义相关播放方法
if(!('speechSynthesis' in window)) {
throw alert("对不起,您的浏览器不支持")
}
var _play = document.querySelector("._play"),
to_speak = window.speechSynthesis,
dataName, voiceSelect = document.querySelector("#voiceSelect"),
voices = [];
function play() {
myCheckFunc();//检查文本框是否为空
cancel(); //
to_speak = new SpeechSynthesisUtterance(_play.value);
//to_speak.rate = 1.4;// 设置播放语速,范围:0.1 - 10之间
var selectedOption = voiceSelect.selectedOptions[0].getAttribute('data-name');
for(i = 0; i < voices.length; i++) {
if(voices[i].name === selectedOption) {
to_speak.voice = voices[i];
}
}
window.speechSynthesis.speak(to_speak);
}
//暂停
function pause() {
myCheckFunc();//检查文本框是否为空
window.speechSynthesis.pause();
}
//继续播放
function resume() {
myCheckFunc();//检查文本框是否为空
window.speechSynthesis.resume(); //继续
}
//清除所有语音播报创建的队列
function cancel() {
window.speechSynthesis.cancel();
}
//清空文本框
function cls() {
document.getElementById("texts").value=""; 清空文本框
}
//检查文本框是否为空
function myCheckFunc() {
let x;
x = document.getElementById("texts").value;
try {
if (x === "")
throw "文本框为空";
} catch (error) {
alert( "提示" + error);
}
}3、本地语言支持
//创建选择语言的select标签
function populateVoiceList() {
voices = speechSynthesis.getVoices();
for(i = 0; i < voices.length; i++) {
var option = document.createElement('option');
option.textContent = voices[i].name + ' (' + voices[i].lang + ')';
if(voices[i].default) {
option.textContent += ' -- DEFAULT';
}
option.setAttribute('data-lang', voices[i].lang);
option.setAttribute('data-name', voices[i].name);
voiceSelect.appendChild(option);
}
}
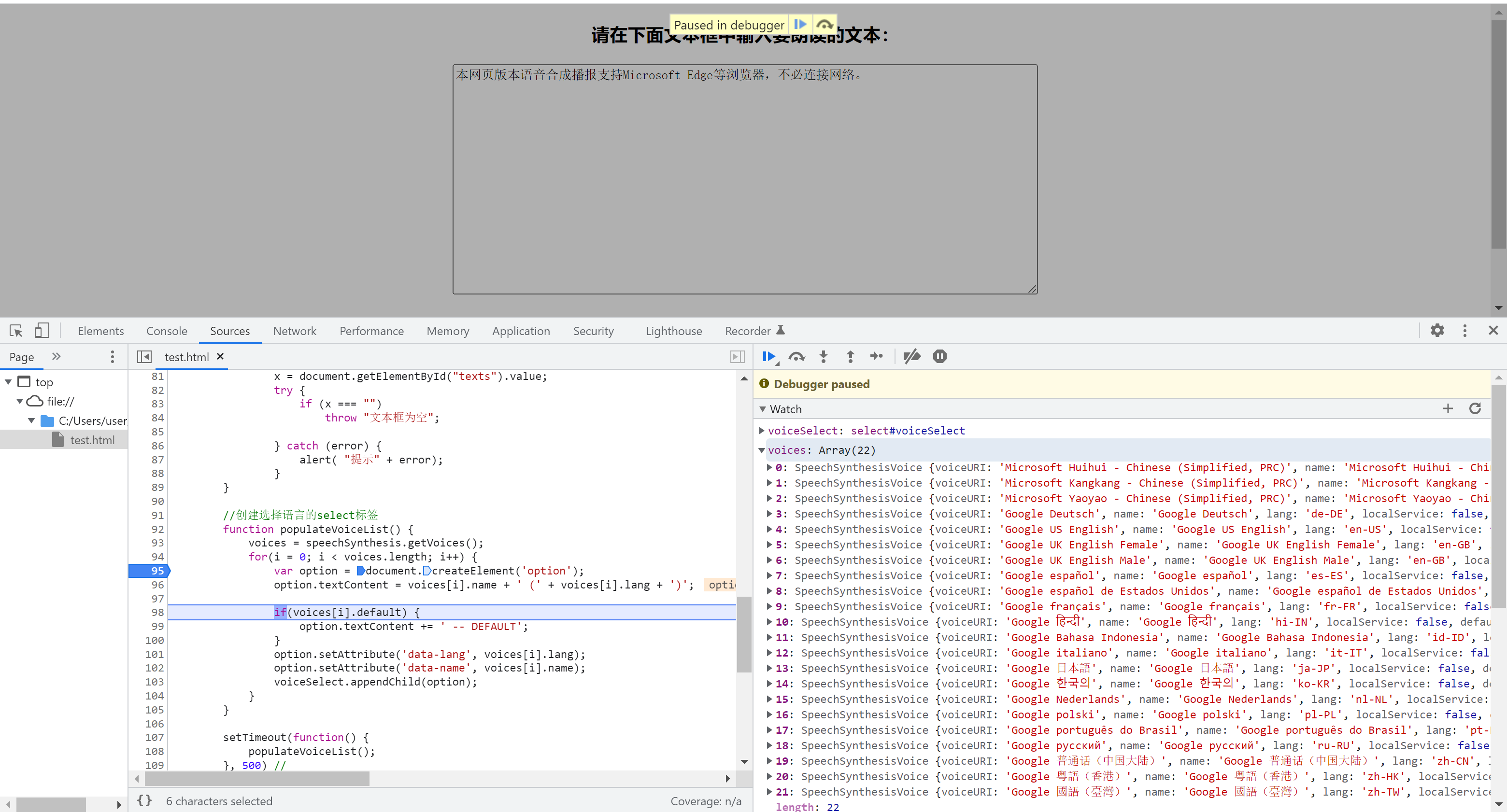

浏览器支持
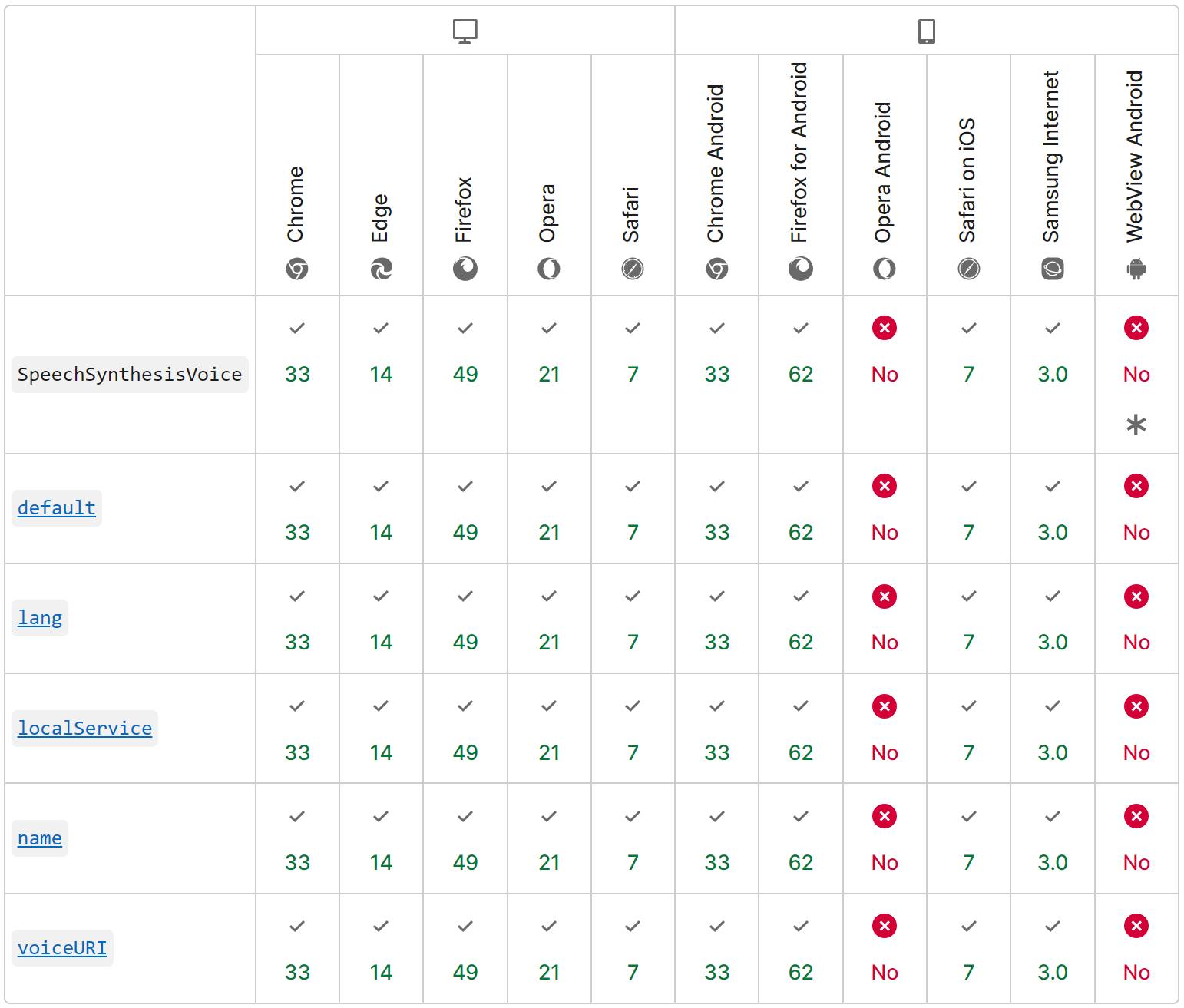
以下是浏览器的支持情况,从图中可以看到它的浏览器支持是不太全的,但基本覆盖了主流浏览器,从使用场景上来说基本可以完成覆盖。
三、总结
以上就是本文的主要内容,本章重点介绍了Html5中SpeechSynthesis这个类,通过这个类完成了一个诗词类赏析文本的播报功能,原始文件可以从基于HTML的文本语音自动播报下载。带上耳机,您可以听到真实的语音播报。再回到本文最开始,如果要你实现一个排队播报的功能,是否可以自行设计并达到要求呢?可以请大家自行尝试。还有许多有意思的场景可以去探讨,做成有意义的实际项目,行文仓促,权当抛砖引玉,如有不当,敬请谅解。