二、AI视频智能分析有那些技术?
3、动作行为识别技术
动作行为识别是预测目标在当前时刻或一段时间内的状态。该技术广泛应用至动作识别、流程规范化识别以及视频分类等场景。如校园打架暴力检测、工厂工人操作流程规范性检测、摔倒行为检测等。此外还可用于视频分类。例如,抖音视频、快手视频、百度视频每天上传数以万计的长短视频,这些视频需要进行分类并赋予泛标签,从而进行视频推荐、广告推荐。因此,高效准确的视频理解至关重要。
图19. 动作行为识别示意图
视频识别与图像识别两者的重要区别是是否对时间序列建模。因为,视频是多帧图像的组合,同时具有时间序列特性。比如,开门与关门两个动作,从一个时间方向预测是关门,相反方向是开门。如果不考虑时序特性,仅进行图像融合,神经网络对两个视频动作的预测可能是同一个结果。
如图19所示,每个视频片段经解码处理成为单帧图像,对单帧图像进行特征提取获得空间特征,同时采样时间方向建模,获取帧时序特征,最后经过特征融合与分类输出视频类别。这是常规的视频分类方法。对于时序特征的提取,常用的方法包括3D-CNN,RNN, LSTM等。而这些模型参数量大、计算开销大。对于视频分类高效、准确尤为重要,特别是对于算力有限的边缘嵌入式设备的在线视频分析。
下面介绍动作行为预测中的典型网络模型TSM(Temporal Shift Module)。

图20. TSM模块
核心思想:在时间方向上对特征通道数据移动,实现时序信息交换,同时不增加计算成本。
解释一下,神经网络对输入张量进行特征提取获取特征图,假设当前帧获取的特征图的个数为C,为了使下一帧能够获取当前帧的特征信息,从当前帧C个特征图中选取一部分(假设C/8)传至下一帧,当前帧的部分特征图(C/8)与下一帧的特征图(7*C/8)共同构成了下一帧的特征图。这样就实现了时序间的信息传递。
如图20所示,(b)在时间方向上进行特征移动,即当前时刻的一部分特征移向了前一时刻;一部分特征移向了下一时刻。该移动方式适用于离线的视频分析。(c)在时间方向上进行单向移动,即当前时刻的部分特征移向下一时刻,该移动方式适用于在线视频分析。
问题1:为什么TSM不增加计算成本?
卷积操作可以分为移动与乘积两部分操作。移动是常规的指针偏移操作几乎不消耗计算量;卷积核与张量的乘积耗费计算量。因此,TSM选择在通道方向上的移动操作,既降低了计算量,同时实现时序特征交换。
问题2:TSM移动的特征图比例多少合适?
如果移动的当前帧的特征图比例过多,虽然不会增加计算量不会产生计算耗时,但是会涉及到数据在内存中的移动,这部分移动也会增加耗时。数据移动量越大,耗时越大。同时特征图移动比例过大,会造成当前帧特征图空间建模能力下降。为此,对于双向移动的TSM模块,比例选择1/4,即每个方向上移动1/8特征图;对于单向移动的TSM模块,比例选择1/8。经测试,该比例下的预测精度高,同时由于数据移动产生的耗时低。
问题3:TSM模块特征提取放在什么位置?
TSM模块提供了两种插入位置,一种是放到残差网络之前,另一种是放到残差分支中。
对于第一种,如图21(a), 该方式将时移特征作为主干特征,残差分支与直连分支均基于主干特征操作。该方式会损坏当前时刻特征的空间学习能力,特别是时移比例较大的情况。
对于第二种,如图21(b),该方式将时移特征插入至残差分支,不仅能够保留原始空间特征,同时能够学习到时移特征,解决了方式第一种特征学习能力不足导致的网络退化问题。
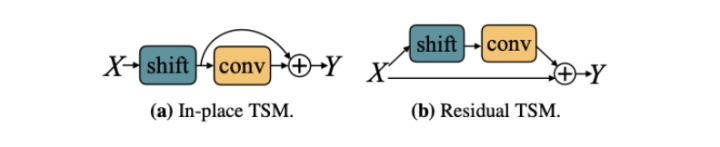
图21. TSM模块类型
如图22所示,当前层的Feature Map X经时移操作得到新的特征图Shift,后接卷积操作得到的结果与输入X进行Add操作,从而得到输出。
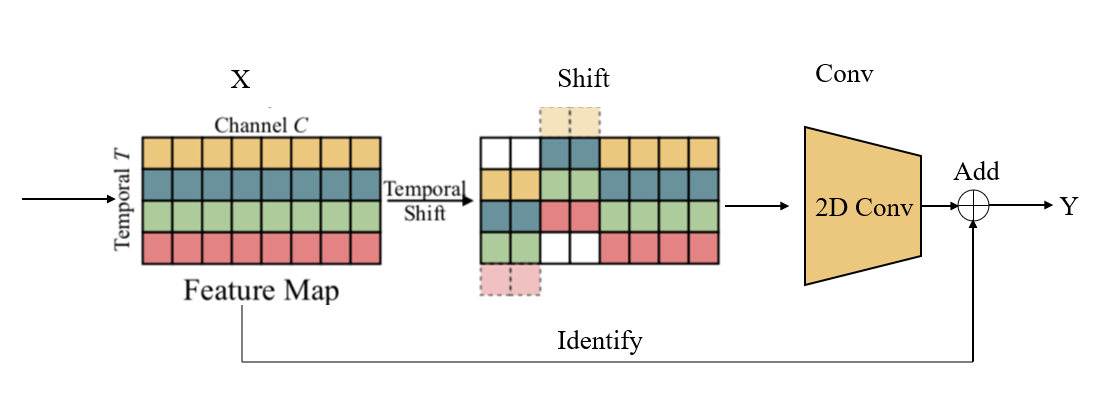
图22. Residual TSM
可自定义对特征提取网络的某些层,实现Residual TSM,并将时移特征传递至下一时刻。
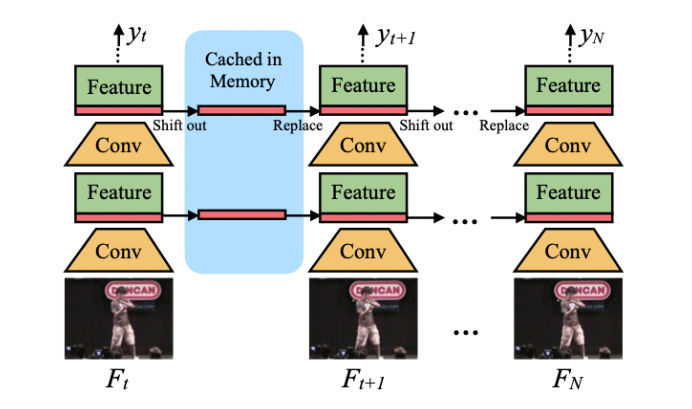
图23. TSM在线预测网络结构
TSM在线预测推理过程如下:
简单的说,对于每一帧,保存残差块的前1/8个特征图至缓存中。下一帧将当前特征图的前1/8用缓存中的特征图代替,1/8的旧特征图与7/8的当前特征图组合生成下一层,并重复该过程。
第一步:将当前时刻该层的特征图的前1/8用缓存中旧的1/8来代替,并将1/8旧特征图与7/8当前特征图组合生成至下一层;
第二步:当前时刻的下一层,重复第一步的方法,依次循环完成当前时刻所有残差层的特征图更新,同时完成缓存更新。
第三步:对于历史前N个时刻的logit输出进行平均,输出这N个时刻的所构成的视频片段的预测结果,完成动作预测。
TSM通过时间维度上的特征移动实现了不同时刻特征信息的交换与融合,同时基于多个时刻预测值的均值预测类别,兼顾了速度与性能,为视频分类经典模型。
4、时序动作定位技术
时序动作定位简称TAL(Temporal Action Localization)是视频理解中的重要分支。其解决的主要问题为,定位动作发生的开始时刻与结束时刻。
TAL技术应用广泛,如流程性动作的始末点分析;海量视频的智能剪辑;广告的智能检测与插播等场景都离不开时序动作定位技术。比如机场中通过TAL技术来定位飞机在什么时间段完成了什么节点动作,电视台通过TAL技术鉴别广告播放与结束时刻,从而进行目标广告植入。
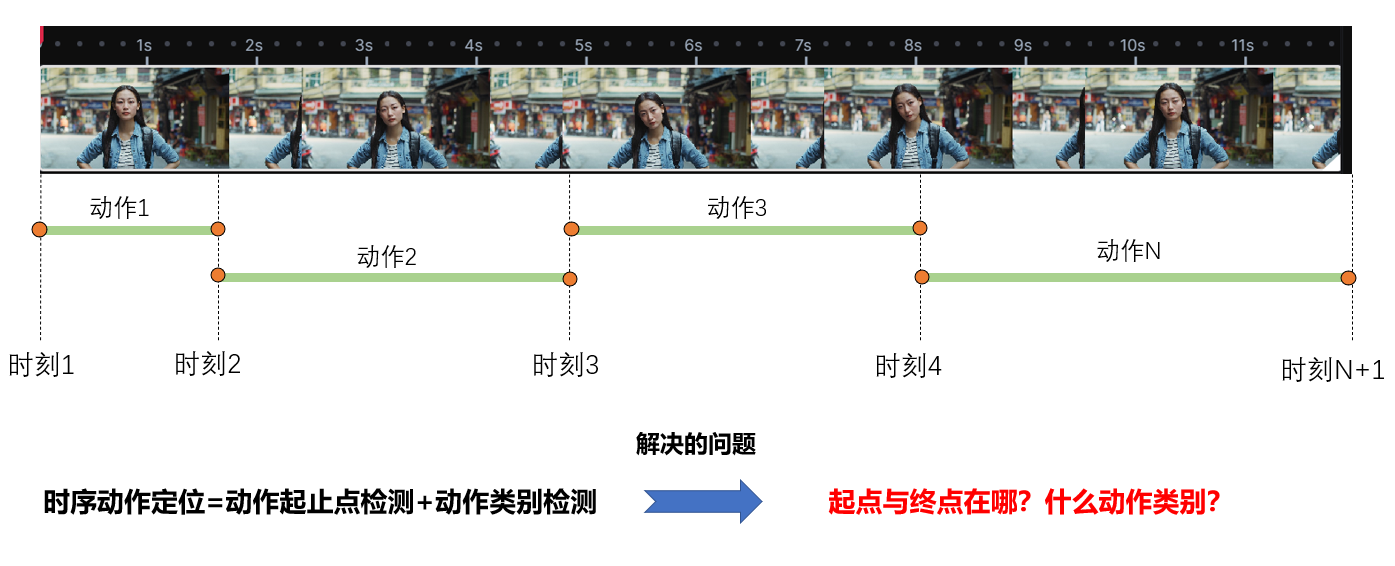
图24. 时序动作定位示意图
如图24所示,时序动作定位核心问题为在时间方向上预测动作的起点与终点,同时给出起点终点之间的视频类别。
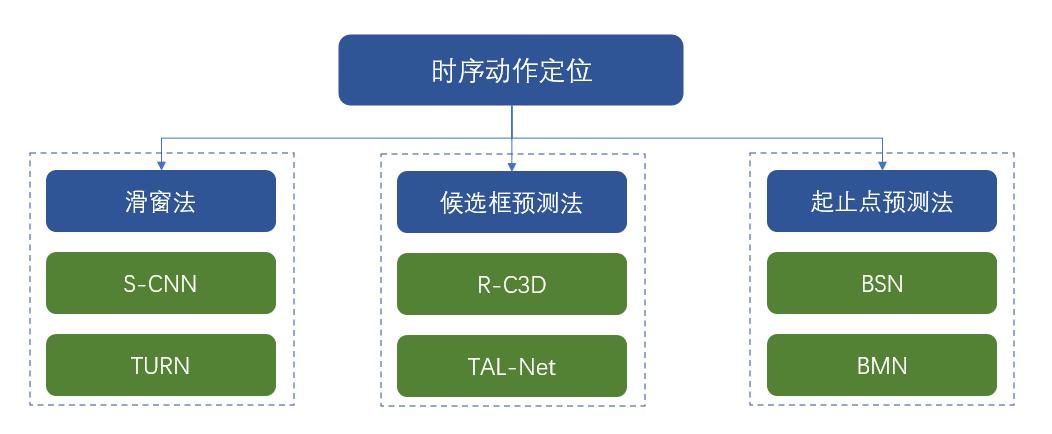
图25. 时序动作定位方法
怎样预测起止点与动作类别?
(1)滑窗法
预测起止点与类别,最直接的方法是给定不同大小的滑窗,在时序视频上进行滑动,然后判断滑窗内的动作类别。

图26. 滑窗法时序动作预测
(2)候选框预测法
类比于两阶段的目标检测算法,第一阶段通过RPN网络生成候选框,第二阶段对候选框进行分类与坐标修正。基于候选框法的时序动作定位遵循类似的思路。首先,原始视频经2D CNN或3D CNN提取1D卷积特征;其次,通过模型生成动作候选区间,最后预测每个候选区间内动作类别,并对候选区间进行修正。
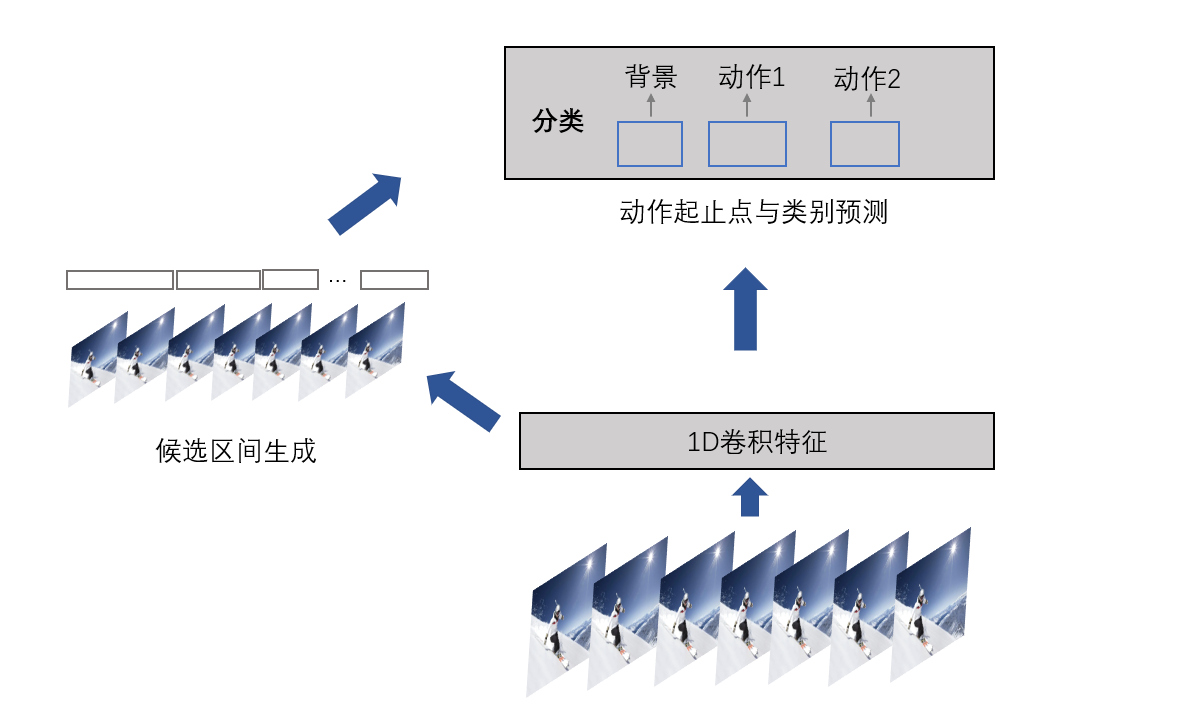
图27. 候选框预测法
滑窗法与候选区间法,本质上都是基于预先设定的区域间框对区间内动作类别进行预测,同时修正区间边界。这类方法统称为自顶向下方法。听着很熟悉,没错,类似于姿态识别当中的自顶向下方法。受限于预先设定的窗口,所定位的动作的起止位置不够准确。
(3)起止点预测法
起止点预测法属于自底向上的预测方法也称作local to global先局部后整体。首先,通过局部特征预测动作的开始时刻与结束时刻;其次,将开始时刻与结束时刻合成候选区间;最后,预测候选区间内的动作类别。
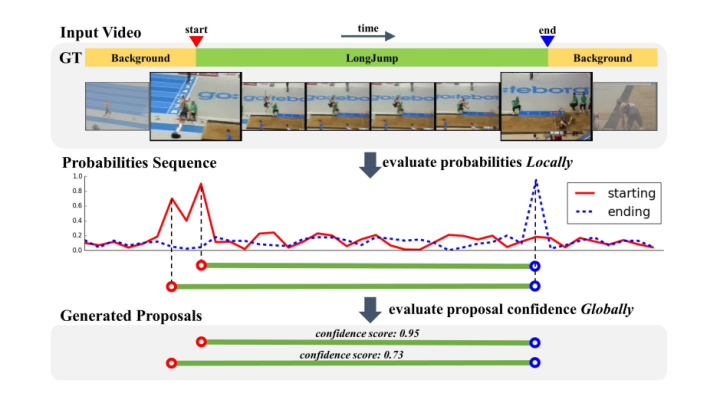
图28. BSN网络结构
下面介绍自底向上时序动作定位算法BSN(BSN: Boundary Sensitive Network for Temporal Action Proposal Generation)该方法主要分为以下三步:
第一步:BSN在视频片段的每个时间点上预测输出一个动作开始的概率,结束的概率以及当前时间点属于某个动作的概率,同时生成<start prob, end prob, action prob>时间序列作为局部信息;
第二步:使用local to global方式组合高概率值的开始点与结束点,生成不同大小,不同边界准确性的proposal;
第三步:利用proposal level特征来评估每个proposal的置信度,并从第二步中检索出高置信度的proposal。
随着自注意力Transformer在图像分类、目标检测中表现出的强大能力,在时序动作定位中也产生了令人印象深刻的性能,并出现了如ActionFormer等模型,鉴于篇幅限制,暂不做详细介绍。
5、视频内容检索技术
什么是视频内容检索?
视频内容检索即通过检索关键词、图片、视频从海量视频底库中检索出目标视频。本质上是向量检索,即对底库视频进行数字化编码形成能表征视频特征的向量T,同时对检索内容进行向量数字化编码形成检索向量S。检索即通过特征比对从海量底库视频T中检索出检索出S。
能检索什么?
视频内容检索区别于传统的基于关键词的检索,是一种新型的内容检索方式,更符合用户习惯与用户检索需求。视频内容检索可检索视频文字、视频目标、相似内容视频、相似语义视频。
应用场景?
该技术广泛应用至数字资产管理、海量视频检索、视频侵权检测以及视频推荐系统中。
单从检索精度上来说,涉及两个问题:
问题1:如何有效对视频内容进行向量化形成Embedding?
问题2:如何度量检索S与底库T之间的相似性?
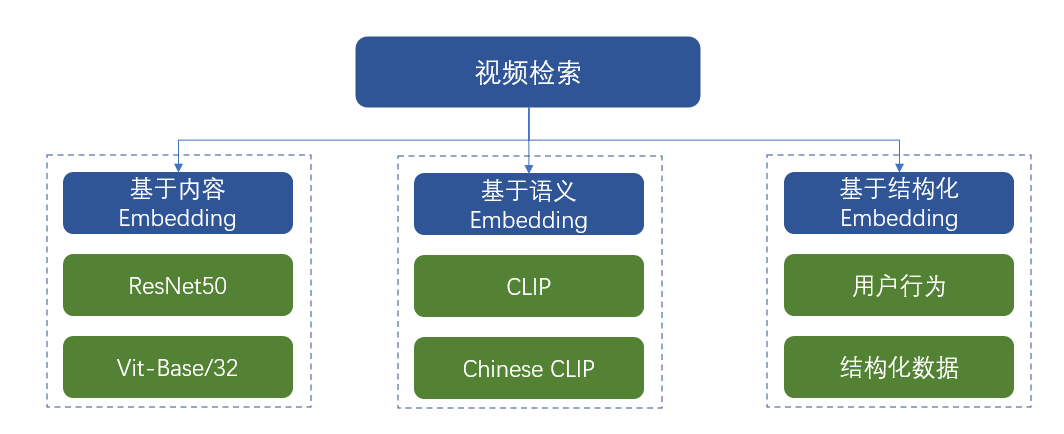
图29. 视频内容Embedding方法
如图29所示,对视频进行Embedding的方法大致分为三类:
第一类:基于内容的Embedding
该类方法主要采用特征提取网络对视频中序列帧进行向量化编码,形成2048或768维度的向量。通过非时序或时序网络提取每帧特征,同时进行特征融合形成表征该视频特征的全局Embedding。同时,细粒度的内容Embedding还包括视频中的目标、人脸、文字Embedding。
第二类:基于语义的Embedding
该类方法主要采用视觉编码器如ResNet50,Vit-Base/32等对视频中的图片进行Embedding。在此基础上通过映射网络将视觉特征映射至语义空间,得到每帧图片的语义Embedding。其中映射网络通过CLIP/Chinese CLIP训练得到,即通过数亿对的图文对训练获取。
第三类:基于结构化的Embedding
该类方法主要采用视频图像中的结构化数据进行Embedding。比如页面点赞量、收藏量、关注量信息、用户的观看时长、是否评论等行为信息对视频进行Embedding。在推荐系统中应用居多。
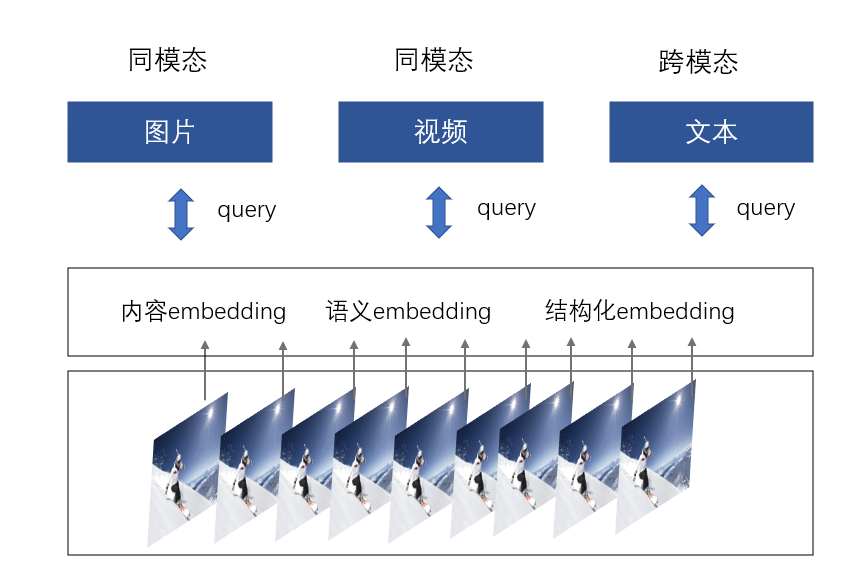
图30. 视频内容检索方法
如图30. 视频内容检索方法根据模态的不同可分为同模态检索与跨模态检索。
同模态检索表示检索内容与底库内容形式相同(同为文本、图片、视频),跨模态检索表示检索内容与底库形式异同(文本->视频),相似性对量方法与上文所述deepsort中的度量方式类似,以余弦距离度量为主,因为余弦距离值域0-1,阈值选取简单。