前言
在了解操作系统 内存管理 分页/分段/段页式管理、操作系统 虚拟内存技术两篇文章后,接下来继续看看现代操作系统基本内存管理方式,本文详细介绍Linux操作系统下的内存管理单元MMU和TLB。
内存管理子系统
内存管理子系统的架构如图所示,分为用户空间、内核空间和硬件3个层面。
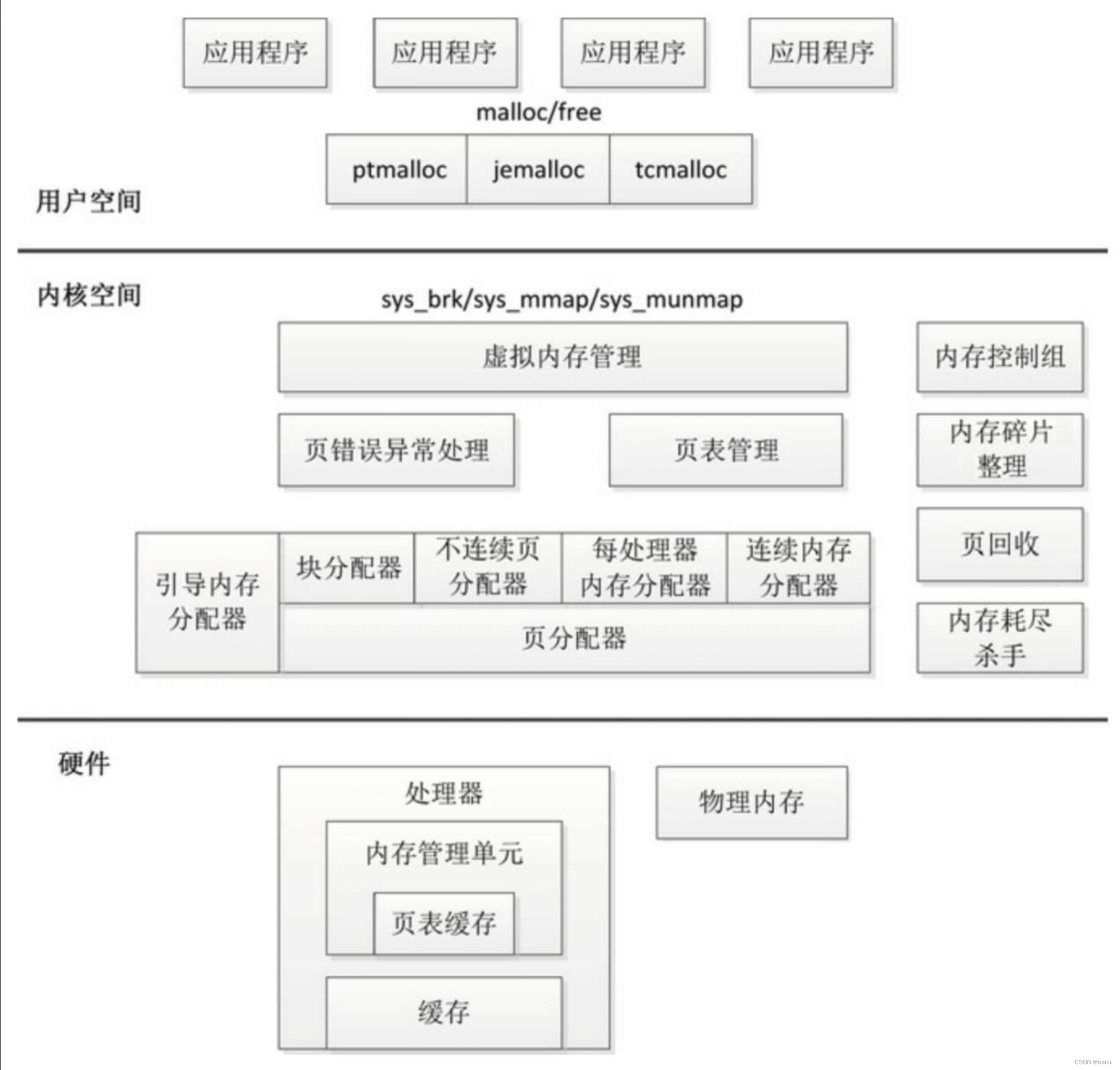
用户空间
用户空间应用程序使用malloc()申请内存,使用free()释放内存。
malloc()和free()是glibc库的内存分配器ptmalloc提供的接口,ptmalloc使用系统调用brk或mmap向内核以页为单位申请内存,然后划分成小内存块分配给应用程序。
用户空间的内存分配器,除了glibc库的ptmalloc,还有谷歌公司的tcmalloc和FreeBSD的jemalloc。
内核空间
虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,sys_brk用来扩大或收缩堆,sys_mmap用来在内存映射区域分配虚拟页,sys_munmap用来释放虚拟页。
内核使用延迟分配物理内存的策略,进程第一次访问虚拟页的时候,触发页错误异常,页错误异常处理程序从页分配器申请物理页,在进程的页表中把虚拟页映射到物理页。
在内核初始化的过程中,页分配器还没准备好,需要使用临时的引导内存分配器分配内存。
页分配器负责分配物理页,当前使用的页分配器是伙伴分配器。
内核空间提供了把页划分成小内存块分配的块分配器,提供分配内存的接口kmalloc()和释放内存的接口kfree(),支持3种块分配器:SLAB分配器、SLUB分配器和SLOB分配器。
硬解层面
处理器包含一个称为内存管理单元(Memory Management Unit, MMU) 的部件,负责把虚拟地址转换成物理地址。
内存管理单元包含一个称为页表缓存(Translation Lookaside Buffer, TLB) 的部件,保存最近使用过的页表映射,避免每次把虚拟地址转换成物理地址都需要查询内存中的页表。
为了解决处理器的执行速度和内存的访问速度不匹配的问题,在处理器和内存之间增加了缓存。缓存通常分为一级缓存和二级缓存,为了支持并行地取指令和取数据,一级缓存分为数据缓存和指令缓存。
MMU内存管理单元
MMU(Memory Management Unit),即内存管理单元,是现代CPU架构中不可或缺的一部分。
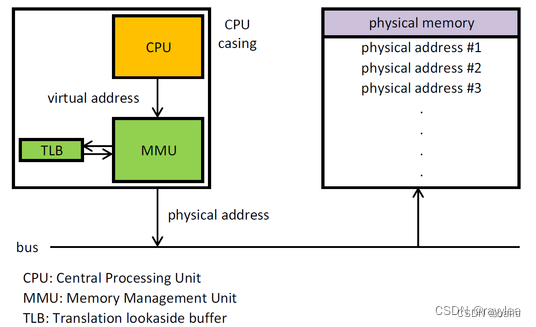
MMU功能
- 虚实地址翻译
在用户访问内存时,将用户访问的虚拟地址翻译为实际的物理地址,以便CPU对实际的物理地址进行访问。 - 访问权限控制
可以对一些虚拟地址进行访问权限控制,以便于对用户程序的访问权限和范围进行管理,如代码段一般设置为只读,如果有用户程序对代码段进行写操作,系统会触发异常。 - 引申的物理内存管理
对系统的物理内存资源进行管理,为用户程序提供物理内存的申请、释放等操作接口。
MMU优势
- 提升物理内存的利用率
- 物理内存按需申请,如代码段的内存在执行时进行映射和转换,进程fork后,t通过写时复制(Copy-On-Write)进行真正的物理内存分配。
- 解决内存管理碎片化的问题,即在系统运行一段时间后,频繁的内存申请和释放会导致内存碎片化,无法申请到一块足够大的地址连续的内存。
- 对内存地址的访问进行控制
如上述代码段只读权限控制,多线程的栈内存之间的空洞页隔离可以防止栈溢出后改写其他线程的栈内存,不同进程之间的地址隔离等等。 - 将进程的地址空间隔离
不同进程之间可以使用相同的虚拟内存地址空间,而进程间的物理内存又可以做到隔离,这保证了进程的独立性同时,又简化了地址的访问方式,如在早期32位CPU上,为了支持4G以上的物理内存,一般物理地址有36-bit(如PowerPC-604系列),但是用户的虚地址仍然使用32-bit,做法就是将用户的不同进程的32-bit虚地址在MMU转换时,转换为36-bit的物理地址,这样每个进程仍然能访问0-3G虚地址范围,将多个进程的3G空间映射到36-bit的物理内存空间中去。
MMU地址转换流程
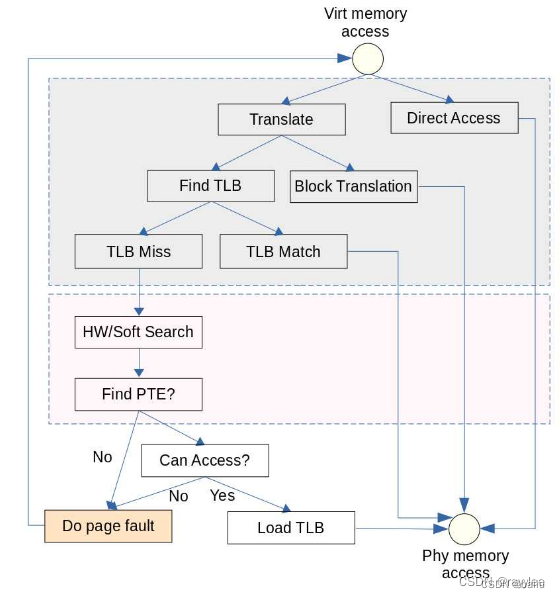
MMU地址转换流程主要分为几个阶段:
- 用户进程访问虚存地址。
- 触发TLB查找过程,该部分通过硬件完成(灰色背景),没有软件参与。
- TLB miss场景下,查找PTE(粉色背景),该部分在不同CPU上实现不同,像X86都是硬件查找,PowerPC有些处理器使用软件查找,即在内核实现一个TLB miss的异常处理,可以灵活做到TLB查找。
- Do Page Fault,分为几种情况:
- 新申请内存第一次读写,触发物理内存分配
- 进程fork后子进程写内存触发Copy-On-Write
- 非法内存读写,错误处理
TLB快表
Translation lookaside buffer,即旁路转换缓冲,或称为页表缓冲;里面存放的是一些页表文件(虚拟地址到物理地址的转换表)。又称为快表技术。里面存放的是一些页表文件(虚拟地址到物理地址的转换表)。
当cpu要访问一个虚拟地址/线性地址时,CPU会首先根据虚拟地址的高20位(20是x86特定的,不同架构有不同的值)在TLB中查找。如果是表中没有相应的表项,称为TLB miss,需要通过访问慢速RAM中的页表计算出相应的物理地址。同时,物理地址被存放在一个TLB表项中,以后对同一线性地址的访问,直接从TLB表项中获取物理地址即可,称为TLB hit。
处理器的性能就和寻址的命中率有很大的关系,因为局部性原理,一般来说快表的命中率可以达到90%以上。
- 基于快表的地址变换流程如下:

参考:
内存管理单元MMU简介