

项目背景
现在人们的日常生活方式和饮食结构发生了巨大的变化,大概就是吃好了,动少了。体内的过量的甘油三酯无法代谢,最终聚集在肝细胞内,导致人体中正常肝脏逐步变成脂肪肝。长期患有脂肪肝可能会导致肝硬化,并最终增加患慢性肝病的风险。医学影像学领域可以通过CT或者B超技术来判断患者是否患有脂肪肝,其中CT的脂肪肝检出比例高于B超,其用于诊断脂肪肝时准确率更高、特异性更强。在CT检查中,主要是通过计算肝脏与脾脏的CT值的比值来确定患者是否患有脂肪肝以及严重程度。根据中华医学会肝病学分会制定的标准,肝、脾CT比值大于1为正常肝脏,CT比值在[0.7,1.0]之间为轻度脂肪肝,[0.5,0.7]之间为中度脂肪肝,小于0.5为重度脂肪肝。
在日常工作中,放射医师需要手工选择肝脏和脾脏的最大层面,在一定范围内进行 ROI 的选取,之后计算 ROI 范围内肝脏和脾脏的CT总值以及计算两者 ROI 范围内CT总值的比值,从而确定患者是否患有脂肪肝。这个过程需要投入较多的工作量。
目前,深度学习技术中的语义分割正被广泛应用于医学领域。该技术可以通过训练模型来预测出影像中的不同组织类型的精确边界、位置和区域,在腹部CT上自动获得肝脏和脾脏的分割结果,对肝脏和脾脏多次随机取出一定体积的立方体来计算CT总值的比值,从而评估被检测者是否有脂肪肝以及脂肪肝的严重程度。这种方式减轻医生的工作强度,也避免人为的主观性带来的偏差。
如下图展示人工测量和基于语义分割自动测量之间的优劣。
关注 AI Studio 项目和我一起讨论️
-
项目链接
https://aistudio.baidu.com/aistudio/projectdetail/5574909

医学临床上进行诊断时会人为选择CT平扫肝、脾显示最大层面,各选取边长为1.0cm以上的正方形 ROI 对肝、脾取CT值。本项目为了降低随机选取 ROI 时可能纳入肝内血管和伪影部分,影响计算肝脾比值结果的真实性,提出如下解决方法:1.增加随机取出立方体 ROI 的个数;2.两两配对,增加肝脾比值的样本。
 自动分割与评估脂肪肝操作步骤
自动分割与评估脂肪肝操作步骤

环境版本要求


数据集介绍

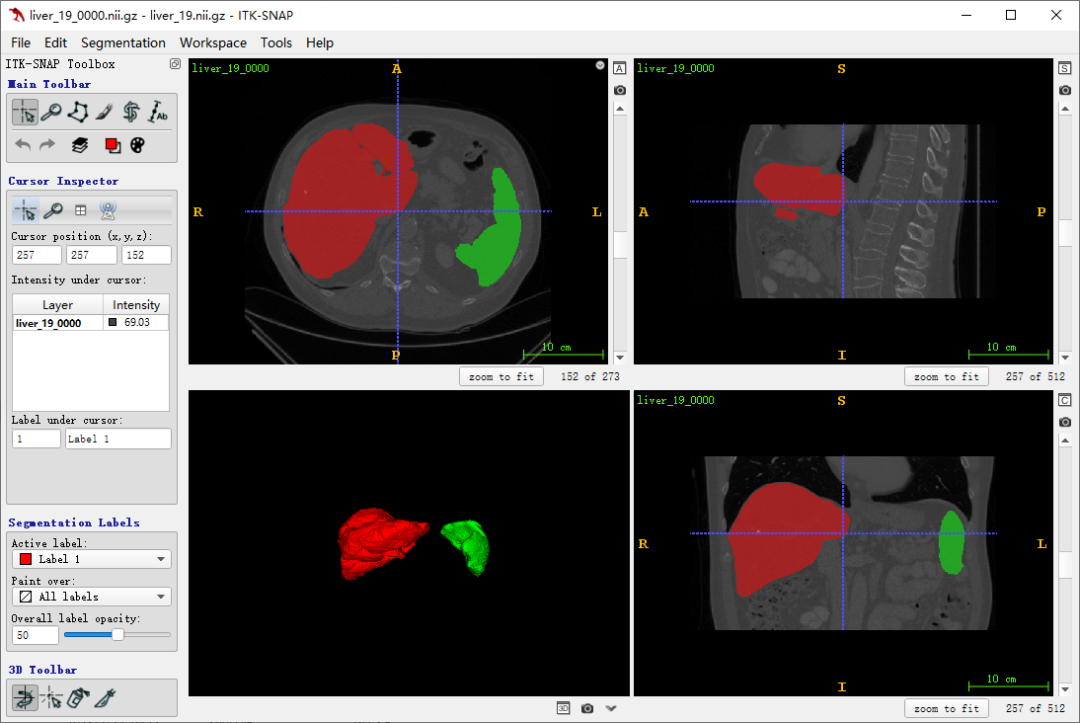
用医疗软件 itk-snap 软件读取原始数据和对应分割标签,展示效果如下图:
 VNet 模型和医疗分割套件 MedicalSeg
VNet 模型和医疗分割套件 MedicalSeg
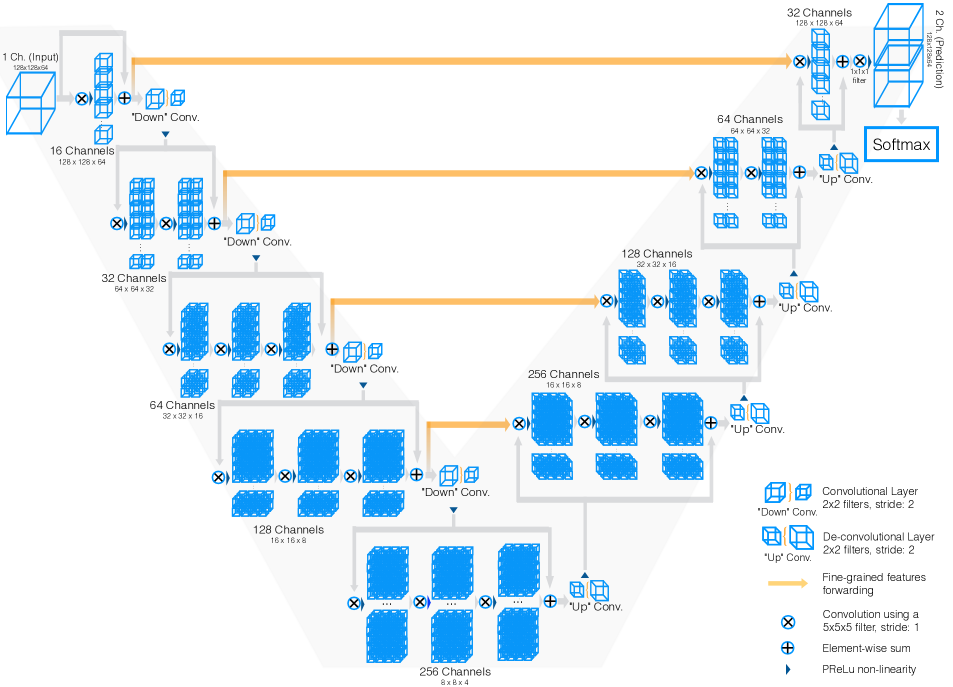
相对于二维语义分割,三维语义分割利用体素的三维结构信息来分割医学影像,具有更强的抓取空间信息的能力。因为三维分割利用了周围邻近切片及沿着z轴的轴向信息,具有更好的上下文信息,进一步提高了模型的泛化能力。此外,三维语义分割相较二维语义分割也有利于消除噪声和伪影的影响。当前使用的医疗影像数据具有较高的空间分辨率且为三维影像数据,因此使用三维语义分割模型进行分割通常是更适合的处理方式。这次使用的三维语义分割模型 VNet 采用了一种自下而上的方法,并且使用了 U 形连接搭建网络结构,以捕捉到影像数据的不同尺度的细节信息。由于相邻的体素往往具有密切的相关性,因此 VNet 引入了 3D 卷积、转置卷积操作以及残差 U 形连接来捕获和应用融合上下文信息,从而提高模型的精度和泛化能力。 分割医疗影像数据时,由于病变区域可能会占整个影像的很小一部分,导致标注数据的分布不均衡,VNet 提出 Dice 损失函数,来减少不平衡分布对模型训练的影响,使模型更加稳定。VNet 整体结构如下。
MedicalSeg 是一个简易、强大、全流程的3D医学图像分割工具,作为 PaddleSeg 分割套件中的分割工具,继承了 PaddleSeg 配置化训练的模式,一行代码实现对医疗数据的处理和模型的训练,本项目就是基于 MedicalSeg 分割套件实现在腹部CT上对肝脏和脾脏的3D分割。

模型训练和推理
数据处理
因为医疗数据较为特殊,需要进行预处理操作,例如重采样、像素裁剪,再转换成 NumPy 格式。需要自定义数据预处理脚本 prepare_SpleenAndLiver.py 。脚本主要设置数据的路径和像素裁剪等参数设置。设置如下:
1. self.preprocess = {
2. "images": [
3. wrapped_partial(
4. HUnorm, HU_min=-100, HU_max=300),#设置窗宽窗位的裁剪范围
5. wrapped_partial(
6. resample, new_shape=[128,128,128], order=1)#设置输入网络的数据形状,顺序是[z,y,x]
7. ],
8. "labels": [
9. wrapped_partial(
10. resample, new_shape=[128,128,128], order=0),
11. ],
12. "images_test":[
13. wrapped_partial(
14. HUnorm, HU_min=-100, HU_max=300),
15. wrapped_partial(
16. resample, new_shape=[128, 128, 128], order=1)
17. ]
18. }
然后通过一行代码转换数据,并按一定比例分割训练集和验证集。
1.#运行预处理文件,把SimpleITK文件转换成numpy文件,生成对应的train.txt和val.txt,和数据参数有关的json文件
2.!python tools/prepare_SpleenAndLiver.py
模型训练
MedicalSeg 采用配置化训练,需要新建一个配置化 Yaml 文件,然后再以代码进行训练。配置文件主要设置数据的路径、数据增强方式、优化器、学习率和分割模型等主要参数。不过一般情况下主要设置数据的路径,其它设置只需要保持默认即可。当训练效果不好的时候,可以根据经验对数据增强、学习率等参数进行修改。Yaml 配置如下:
1.data_root: /home/aistudio/work/
2.batch_size: 2 #32GB显存,shape=256x128x128,batchsize可以设置2
3.iters: 10000 #训练轮次
4.train_dataset:
5. type: MedicalDataset
6. dataset_root: /home/aistudio/work/SpleenAndLiver_Np #转换后的Numpy文件路径
7. result_dir: /home/aistudio/result
8.#设置数据增强
9. transforms:
10. - type: RandomRotation3D #3d选择
11. degrees: 90
12. - type: RandomFlip3D #水平翻转
13. mode: train
14. num_classes: 3 #分割类别数
15.val_dataset:
16. type: MedicalDataset
17. dataset_root: /home/aistudio/work/SpleenAndLiver_Np
18. result_dir: /home/aistudio/result
19. num_classes: 3
20. transforms: []
21. mode: val
22. dataset_json_path: "/home/aistudio/work/dataset.json"
23.#设置优化器
24.optimizer:
25. type: sgd
26. momentum: 0.9
27. weight_decay: 1.0e-4
28.#设置学习率
29.lr_scheduler:
30. type: PolynomialDecay
31. decay_steps: 10000
32. learning_rate: 0.05
33. end_lr: 0
34. power: 0.9
35.#设置损失函数
36.loss:
37. types:
38. - type: MixedLoss
39. losses:
40. - type: CrossEntropyLoss
41. - type: DiceLoss
42. coef: [0.3, 0.7]
43. coef: [1]
44.#设置VNet模型参数
45.model:
46. type: VNet
47. elu: False
48. in_channels: 1
49. num_classes: 3
50. pretrained: null
51. kernel_size: [[2,2,4], [2,2,2], [2,2,2], [2,2,2]]
52. stride_size: [[2,2,1], [2,2,1], [2,2,2], [2,2,2]]配置好 Yaml 文件之后,就可以实现一行代码进行训练。
1.!python3 train.py --config /home/aistudio/SpleenAndLiver.yml \
2. --save_dir "/home/aistudio/output/SpleenAndLiver_vent_128" \
3. --save_interval 70 --log_iters 20 \
4. --keep_checkpoint_max 3 \
5. --num_workers 1 --do_eval --use_vdl模型验证
训练完之后,模型验证也只需要一行代码即可完成。
1.!python3 val.py --config /home/aistudio/SpleenAndLiver.yml \
2. --model_path /home/aistudio/output/SpleenAndLiver_vent_128/best_model/model.pdparams \
3. --save_dir /home/aistudio/output/SpleenAndLiver_vent_128/best_model最终通过10000 iters 的训练,验证集达到平均 Dice 0.9531,肝脏 Dice0.944 ,脾脏 Dice0.918。整体分割效果达到不错的精度。
1.2023-03-22 04:57:21 [INFO] [EVAL] #Images: 18, Dice: 0.9531, Loss: 0.097088
2.2023-03-22 04:57:21 [INFO] [EVAL] Class dice:
3.[0.9964 0.9444 0.9183]模型导出
为了模型推理,需要导出训练模型,实现代码如下。
1.!python export.py --config /home/aistudio/SpleenAndLiver.yml \
2.--model_path /home/aistudio/output/SpleenAndLiver_vent_128/best_model/model.pdparams \
3.--save_dir /home/aistudio/export_model 判断是否脂肪肝以及脂肪肝的严重程度
判断是否脂肪肝以及脂肪肝的严重程度
实现自动判断脂肪肝,需要对预测的分割结果进行处理。处理步骤如下:
1)对分割结果的每一类保留最大连通域;
2)根据原始图像的图像参数,把分割结果转换成 Nifit 格式;
3)在分割结果中分别训练肝脏、脾脏的最小边界范围;
4)分别在肝脏、脾脏的范围里,切割n个立方体;
5)对两组立方体,两两配对,计算两者的CT比值;
6)对所有两两配对的CT比值,求均值,即为肝脏与脾脏的CT比值;
7)根据CT比值对应诊断标准判断是否脂肪肝以及严重程度。
部分关键代码如下:
-
保留最大连通域
1.def GetLargestConnectedCompont(binarysitk_image):
2. # 最大连通域提取,binarysitk_image 是掩膜
3. cc = sitk.ConnectedComponent(binarysitk_image)
4. stats = sitk.LabelIntensityStatisticsImageFilter()
5. stats.SetGlobalDefaultNumberOfThreads(8)
6. stats.Execute(cc, binarysitk_image)#根据掩膜计算统计量
7. maxlabel = 0
8. maxsize = 0
9. for l in stats.GetLabels():#掩膜中存在的标签类别
10. size = stats.GetPhysicalSize(l)
11. if maxsize < size:#只保留最大的标签类别
12. maxlabel = l
13. maxsize = size
14. labelmaskimage = sitk.GetArrayFromImage(cc)
15. outmask = labelmaskimage.copy()
16. if len(stats.GetLabels()):
17. outmask[labelmaskimage == maxlabel] = 255
18. outmask[labelmaskimage != maxlabel] = 0
19. return outmask-
缩小肝脏、脾脏的范围
1.def maskcroppingbox(mask):
2. #寻找mask范围的3D最大边界范围
3. mask_2 = np.argwhere(mask)
4. (zstart, ystart, xstart), (zstop, ystop, xstop) = mask_2.min(axis=0), mask_2.max(axis=0) + 1
5. if zstart- zstop < 0 : zmax,zmin = zstop,zstart
6. if ystart- ystop < 0 : ymax,ymin = ystop,ystart
7. if xstart- xstop < 0 : xmax,xmin = xstop,xstart
8. return zmax,zmin,ymax,ymin,xmax,xmin-
两两配对计算肝脏和脾脏的CT比值
1.#现在有5个肝脏的立方体和5个脾脏的立方体,找出两个的所有组合,然后计算它们比值
2.tupleNums = list(itertools.product(label[1], label[2]))
3.cts = [tupleNum[0]/tupleNum[1] for tupleNum in tupleNums] 结论
结论

分割预测效果
需要把预测结果转换成和原始数据的空间、维度、尺度等参数一致的 Nifit 格式医疗数据文件。对预测的分割结果处理后得到的位置映射到原始数据上才能保证取 ROI 计算CT值时,没有额外的插值。因为肝脏和脾脏都是一个整体连续的器官,因此预测结果转换之前,还需对结果只保留最大连通域,去掉小目标。对88例带标签的数据,经过以上的处理,再重新计算 Dice 。最终反馈肝脏有0.954mDice,脾脏有0.911mDice。

在临床中的现实效果
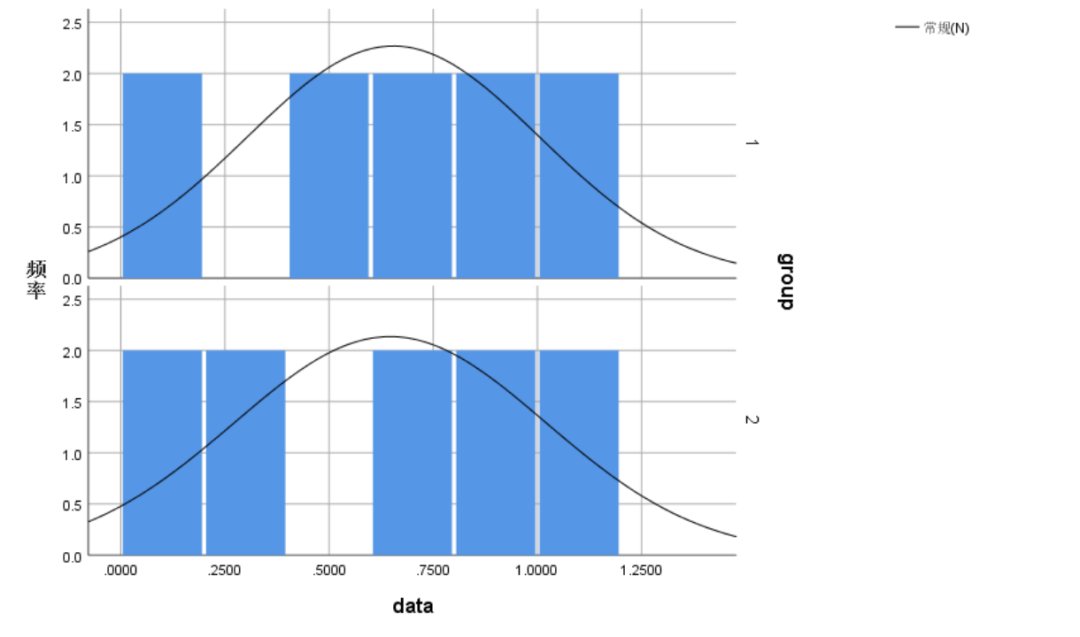
为了检验“基于3D分割实现自动判断脂肪肝和严重程度”在实际临床上的效果,随机选择10名病例,分别使用手动测量和自动测量的方法对10名病例进行肝、脾CT值的测量,并使用非参数检验方法对结果进行检验。测量数据如下:

使用 Mann-Whitney U 检验判断手动测量与自动测量水平是否有差异。根据直方图判断两组测量结果分布的形状基本一致。人工测量的中位数为0.714,自动测量的中位数为0.740。Mann-Whitney U 检验结果显示,人工测量与自动测量差异无统计学意义(U=48.000,P=0.912)。

项目意义
目前自动判断脂肪肝的方法大多使用阈值或者直方图等传统分割方式。本项目是使用深度学习中三维语义分割来实现肝脏和脾脏的精准分割,再采用多次随机取三维 ROI 来计算比值。从而减轻了医生的工作量和主观性偏差,提高医疗质量和效率。
以上就是基于3D分割实现自动判断脂肪肝和其严重程度的相关内容。欢迎大家来我的 AI Studio 页面互关交流,与我共同体验飞桨的乐趣!
https://aistudio.baidu.com/aistudio/personalcenter/thirdview/181096