Conception
Apache Tika(TM) is a toolkit for detecting and extracting metadata and structured text content from various documents using existing parser libraries.
Tika is a project of the Apache Software Foundation.
Apache Tika, Tika, Apache, the Apache feather logo, and the Apache Tika project logo are trademarks of The Apache Software Foundation.
The Tika toolkit detects and extracts metadata and text from over a thousand different file types (such as PPT, XLS, and PDF). All of these file types can be parsed through a single interface, making Tika useful for search engine indexing, content analysis, translation, and much more.
So, we have understand what the tika was. Then several keys conception should be attention:
1. Tika
2. Parser
3. Meta
4. LanguageIdentifier
2. Parser
3. Meta
4. LanguageIdentifier
The org.apache.tika.parser.Parser interface is the key concept of Apache Tika,which hides the complexity of different file formats and parsing libraries while providing a simple and powerful mechanism for client applications to extract structured text content and metadata from all sorts of documents.
void parse(
InputStream stream, ContentHandler handler, Metadata metadata,
ParseContext context) throws IOException, SAXException, TikaException; all of that was archived with the single method.
besides you can see the history of tika.

comparison
if u want to get the document's content into your procedure,eg: txt,you can write like this:
public static String GetIdentified() throws Exception { //
File f = new File("D://1_fcar_loan_dml.txt");
FileInputStream input = new FileInputStream(f);
BufferedInputStream buf = new BufferedInputStream(input);
byte[] b = new byte[(int) f.length()];
input.read(b);
input.close();
String identified=new String(b);
return identified;
}
public static void main(String[] args){
try{
String result = GetIdentified();
System.out.println(result);
}catch(Exception e){
e.printStackTrace();
}
} By the **Inputstream, load the file into u'r procedure, then convert to String, please pay attention the byte array, which contains the content and metadata, however you can't get the author's information & creatime and so.
If using Tika, you can parser thounds of type documents, vidieos, Audio and so on. eg:
public static String GetIdentified() throws Exception { //
String content;
AutoDetectParser parser = new AutoDetectParser();
BodyContentHandler handler = new BodyContentHandler();
Metadata metadata = new Metadata();
try (InputStream stream = TikaTest.class.getResourceAsStream("/doc/vincent-info.doc")) {
parser.parse(stream, handler, metadata);
content = handler.toString();
}
System.out.println(content);
} so, it's very easy to use AutoDetectPaser interface to parse thounds of types.
Application
for these days, i was research Searching Engineer, when i look through the architecture diagram of Lucene, I know the Tika's importance.
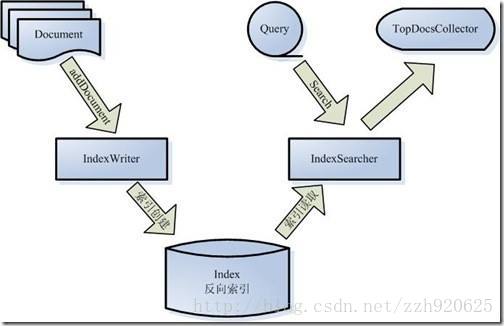
From this picture, Tika can be used in the Index Writer for the Searching Architecture.
So Tika is very usful if u r contact with IO.