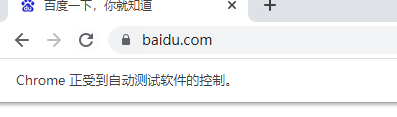
使用selenium爬取信息时,经常会因为,谷歌正在受到自动化软件控制,而抓取失败,下面代码可以解除该状态
# 下载谷歌驱动
from selenium import webdriver
# 1. 导入配置
from selenium.webdriver.chrome.options import Options
# 2. 实力化对象
option = Options()
# 3. 配置无界面的谷歌浏览器
# option.add_argument('--headless')
# 配置ua
# option.add_argument('user-agent="Mozilla/5.0 (Linux; U; Android 8.1.0; zh-cn; BLA-AL00 Build/HUAWEIBLA-AL00) AppleWebKit/537.36 (KHTML, like Gecko) Version/4.0 Chrome/57.0.2987.132 MQQBrowser/8.9 Mobile Safari/537.36"')
# 启动开发者模式(关闭chrome控制)
# option.add_experimental_option("excludeSwitches",["enable-automation"])
# option.add_experimental_option("useAutomationExtension",'False')
# 调用谷歌浏览器
driver = webdriver.Chrome()
# 发起请求
driver.get(url='https://www.baidu.com')
# 最大化窗口
driver.maximize_window()
# 注意:爬虫最好将窗口最大化后再进行抓取
# 原因:如果获取的数据如果在窗口中没有,可能会获取不到