磁盘
挂盘
1. 获取 UUID blkid /dev/sdb |awk '{print $2}'|sed 's/"//g'
2.修改配置文件 `/etc/fstab`, 并挂载数据盘`mount -a`
- 折算比0.88
Lsblk # 确定数据盘的盘符
mkfs.ext4 /dev/sdb # 格式化分区
# 通过UUID挂载到/data,并设置开机挂载
# 注意: 该条命令会修改/etc/fstab, 请不要重复执行
SDBUUID=`blkid -s UUID /dev/sdb | awk '{print $2}' | sed "s/\"//g"`; # 会输出UUID=b497267d-c79f-45c3-8237-5797d31a440a
echo "$SDBUUID /data ext4 defaults 0 0" >> /etc/fstab; \
mkdir /data;
mount $SDBUUID /data
挂移动硬盘
https://blog.csdn.net/baobingji/article/details/84310435
mount /dev/sdf1 /fengxiandata/ # 注意移动硬盘要挂他的分区盘
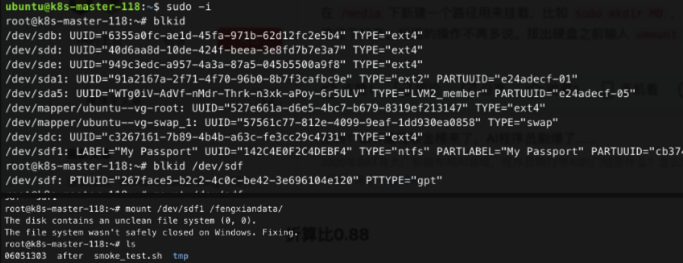
查看磁盘大小
- 一般如果磁盘满了的话, 尤其是系统盘, 会导致整个机器上其他服务出问题, 这时可以用以下命令排查
- 查看目录下文件夹/文件大小
du -h -d 1- 过滤大文件 加
grep | G, 或 M
- 过滤大文件 加
- 查看目录下文件大小
ls -alh(目录只会显示 4k)
查看磁盘类型为SSD或SATA
- 最靠谱的办法就是用
dd命令测磁盘速度, 一般SATA=100Mb/s, SSD=400Mb/s, 其中fdatasync是指写到os的缓存并落盘到磁盘介质
dd if=/dev/zero of=/sda/y123 bs=8k count=200000 conv=fdatasync
rsync代替rm快速删除文件
昨天遇到了要在Linux下删除海量文件的情况,需要删除数十万个文件。这个是之前的程序写的日志,增长很快,而且没什么用。这个时候,我们常用的删除命令rm -fr * 就不好用了,因为要等待的时间太长。所以必须要采取一些非常手段。我们可以使用rsync来实现快速删除大量文件。
文件夹
rsync -av --delete /tmp/test/ testDir/
文件
1、先安装rsync:
yum install rsync
2、建立一个空的文件夹:
mkdir /tmp/test
3、用rsync删除目标目录:
rsync --delete-before -a -H -v --progress --stats /tmp/test/ testDir/
这样我们要删除的log目录就会被清空了,删除的速度会非常快。rsync实际上用的是替换原理,处理数十万个文件也是秒删。
选项说明:
–delete-before 接收者在传输之前进行删除操作
–progress 在传输时显示传输过程
-a 归档模式,表示以递归方式传输文件,并保持所有文件属性
-H 保持硬连接的文件
-v 详细输出模式
–stats 给出某些文件的传输状态
内存
free -m #看机器的内存(只有 used 是真正占用的内存) (而不是看 htop, htop 一般更悲观..)
dmseg -i | grep memory # 看什么程序占内存多
关闭 swap
- swapoff -a
执行后,swap分区逐步减少
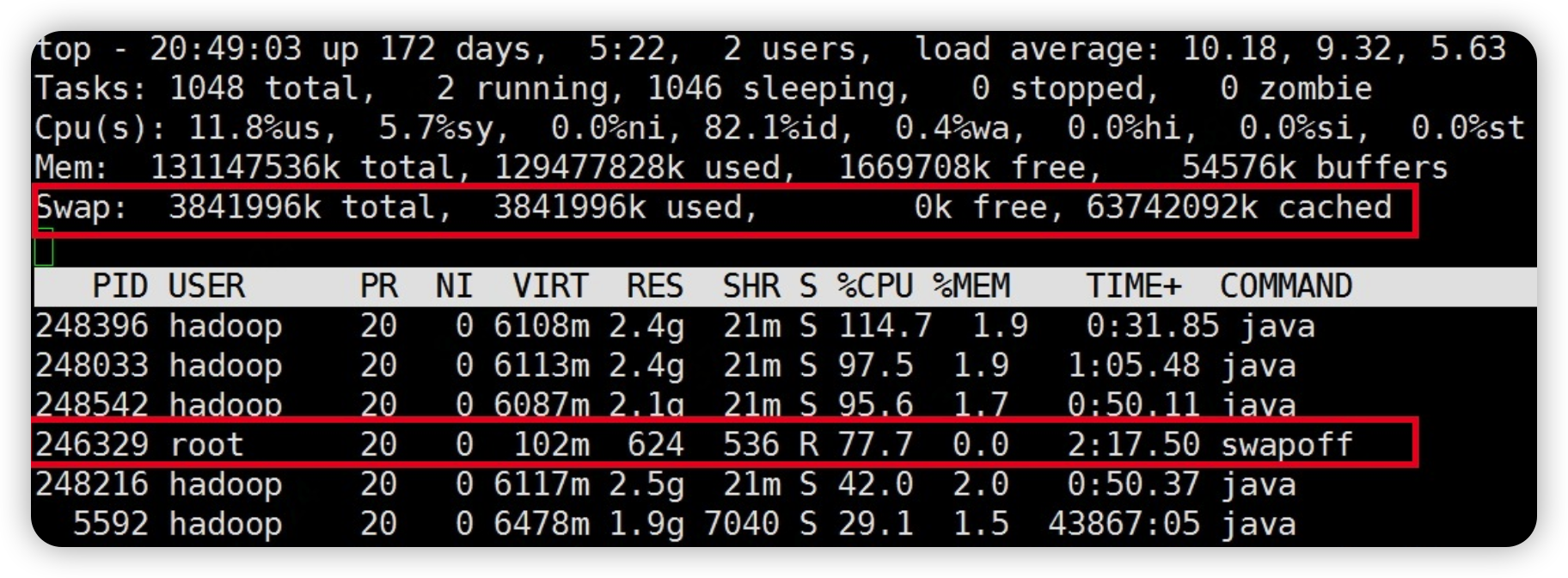
等待一段时间后,swap分区会彻底关闭
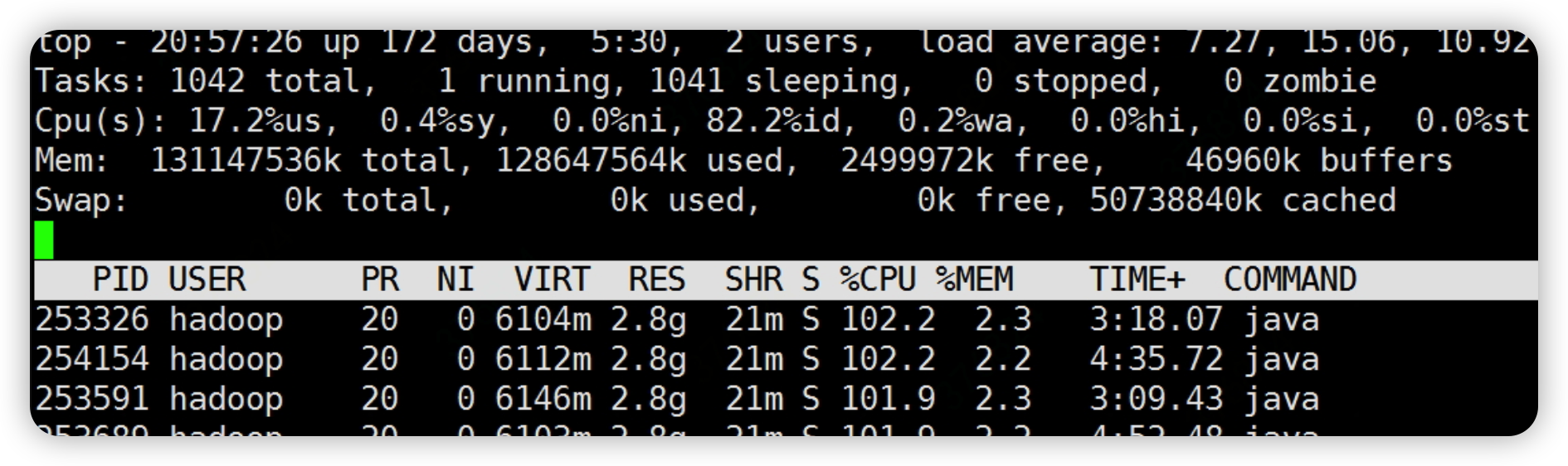
- vi /etc/fstab
# 删除活注释此行
# /dev/mapper/centos-swap swap swap defaults 0 0
-
vim /proc/sys/vm/swappiness 临时生效
echo 0 > /proc/sys/vm/swappiness # 临时生效 -
vim /etc/sysctl.conf 永久生效
vm.swappiness=0
sysctl -p # 使配置生效
cron
- man 5 crontab
生效方式
法1
- 使用命令 crontab -e然后直接编辑定时脚本, (不要直接改/var/spool/cron/crontab/userxxx).
这样执行以后,属于用户自定义的,会被写到 /var/spool/cron 目录下,生成一个和用户名一致的文件,文件内容就是我们编辑的定时脚本。
如:
[root@localhost cron.d]# cd /var/spool/cron
[root@localhost cron]# ll
总用量 4
-rw-------. 1 root root 52 12月 9 10:58 root
[root@localhost cron]# pwd
/var/spool/cron
[root@localhost cron]# cat root
30 03 * * * /root/automysqlbackup.sh
法2
使用命令 vi /etc/crontab 编辑定时脚本。
如:
[root@localhost ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
HOME=/
# run-parts
30 * * * * root /usr/sbin/ntpdate 210.72.145.44
#30 8 * * * root /usr/sbin/ntpdate 132.228.90.101
01 * * * * root run-parts /etc/cron.hourly
02 4 * * * root run-parts /etc/cron.daily
22 4 * * 0 root run-parts /etc/cron.weekly
42 4 1 * * root run-parts /etc/cron.monthly
*/1 * * * * root run-parts /opt/openoffice.org3/program/start.sh
############################################
30 4 * * * root /usr/bin/rsync -vzrtopg --progress --delete [email protected]::resource /hyy/bak/resource
30 4 * * * root /usr/bin/rsync -vzrtopg --progress --delete [email protected]::log /hyy/bak/log
############################################
[root@localhost ~]#
(系统级的)做系统级配置我们会直接配置 /etc/crontab
(用户级的)一般还是建议大家使用 crontab -e ,这样系统也会帮着检查我们配置的脚本语法。
格式
空行和注释
- 空行会被忽略, 行首的空格, tab会被忽略
- 如果第一个字符是
#则整行会被忽略 - 不要把
#注释字符写在行尾, 因为其会被视为整行命令的一部分而被执行; 故注释请另起一行写. - cron要求crontab中的每个条目都以换行符结尾。如果crontab中的最后一个条目缺少换行符(即,以EOF结尾),cron将考虑
crontab(至少部分)损坏。系统日志中将写入警告。
环境变量
crontab中的活动行可以是环境设置,也可以是cron命令。crontab文件是从上到下解析的,因此任何环境设置都将
仅影响文件中位于其下方的cron命令。环境设置的形式为
name = value
其中等号(=)周围的空格是可选的,值中的任何后续非前导空格都将是分配给name的值的一部分。值字符串
可以放在引号中(单引号或双引号,但匹配)以保留前导或尾随空格。要定义空变量,必须使用引号。值字符串为
不解析环境替换或变量替换,因此如下所示的代码行PATH = $HOME/bin:$PATH不会按预期工作
- 如下方式也不行
A=1
B=2
C=$A $B
There will not be any subsitution for the defined variables in the last value.
6位或7位的格式
定时任务的执行频率表达式普遍使用的crontab,crontab表达式至少6位,也有7位的,7位表达式多了一个秒级位。
*就是代表first-last- 可用范围, Ranges of numbers are allowed. Ranges are two numbers separated with a hyphen. The specified range is inclusive. For example, 8-11 for an ``hours’’ entry specifies execution at hours 8, 9, 10 and 11.
- List允许, Lists are allowed. A list is a set of numbers (or ranges) separated by commas. Examples:
1,2,5,9'',0-4,8-12’'. - 步长: Step values can be used in conjunction with ranges. Following a range with
/<number>'' specifies skips of the number's value through the range. For example,0-23/2’’ can be used in the hours field to specify command execution every other hour (the alternative in the V7 standard is0,2,4,6,8,10,12,14,16,18,20,22''). Steps are also permitted after an asterisk, so if you want to sayevery two hours’‘, just use ``*/2’'. - 名称: Names can also be used for the
month'' andday of week’’ fields. Use the first three letters of the particular day or month (case doesn’t matter). Ranges or lists of names are not allowed. Ranges can include “steps”, so “1-9/2” is the same as “1,3,5,7,9”. - 其中每个元素可以是一个值(如6),一个连续区间(9-12),一个间隔时间(8-18/4)(/表示每隔4小时),一个列表(1,3,5),通配符。由于"月份中的日期"和"星期中的日期"这两个元素互斥的,必须要对其中一个设置?.
6位表达式格式
Commands are executed by cron(8) when the minute, hour, and month of year fields match the current time, and when at least one of the two day fields (day of month, or
day of week) match the current time (see ``Note’’ below). cron(8) examines cron entries once every minute. The time and date fields are:
field allowed values
----- --------------
minute 0-59
hour 0-23
day of month 1-31
month 1-12 (or names, see below)
day of week 0-7 (0 or 7 is Sun, or use names忽略大小写, 如SUN,MON,TUE,WED,THU,FRI,SAT)
年 (1970-2099)
自定义例子
The following lists an example of a user crontab file.
# use /bin/bash to run commands, instead of the default /bin/sh
SHELL=/bin/bash
# mail any output to `paul', no matter whose crontab this is
MAILTO=paul
#
# run five minutes after midnight, every day
5 0 * * * $HOME/bin/daily.job >> $HOME/tmp/out 2>&1
# run at 2:15pm on the first of every month -- output mailed to paul
15 14 1 * * $HOME/bin/monthly
# run at 10 pm on weekdays, annoy Joe
0 22 * * 1-5 mail -s "It's 10pm" joe%Joe,%%Where are your kids?%
23 0-23/2 * * * echo "run 23 minutes after midn, 2am, 4am ..., everyday"
5 4 * * sun echo "run at 5 after 4 every sunday"
# Run on every second Saturday of the month
0 4 8-14 * * test $(date +\%u) -eq 6 && echo "2nd Saturday"
系统例子
The following lists the content of a regular system-wide crontab file. Unlinke a user’s crontab, this file has the username field, as used by /etc/crontab.
# /etc/crontab: system-wide crontab
# Unlike any other crontab you don't have to run the `crontab'
# command to install the new version when you edit this file
# and files in /etc/cron.d. These files also have username fields,
# that none of the other crontabs do.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
# m h dom mon dow usercommand
17 * * * * root cd / && run-parts --report /etc/cron.hourly
25 6 * * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.daily )
47 6 * * 7 root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.weekly )
52 6 1 * * root test -x /usr/sbin/anacron || ( cd / && run-parts --report /etc/cron.monthly )
7位表达式
秒(0~59)
分(0~59)
时(0~23)
日(0~31,但是你需要考虑你月的天数)
月(0~11)
周(0~6 0=SUN 或 SUN,MON,TUE,WED,THU,FRI,SAT)
年(1970-2099)
"0 0 10,14,16 * * ?" 每天上午10点,下午2点,4点
"0 0/30 9-17 * * ?" 朝九晚五工作时间内每半小时
"0 0 12 ? * WED" 表示每个星期三中午12点
"0 0 12 * * ?" 每天中午12点触发
"0 15 10 ? * *" 每天上午10:15触发
"0 15 10 * * ?" 每天上午10:15触发
"0 15 10 * * ? *" 每天上午10:15触发
"0 15 10 * * ? 2005" 2005年的每天上午10:15触发
"0 * 14 * * ?" 在每天下午2点到下午2:59期间的每1分钟触发
"0 0/5 14 * * ?" 在每天下午2点到下午2:55期间的每5分钟触发
"0 0/5 14,18 * * ?" 在每天下午2点到2:55期间和下午6点到6:55期间的每5分钟触发
"0 0-5 14 * * ?" 在每天下午2点到下午2:05期间的每1分钟触发
"0 10,44 14 ? 3 WED" 每年三月的星期三的下午2:10和2:44触发
"0 15 10 ? * MON-FRI" 周一至周五的上午10:15触发
"0 15 10 15 * ?" 每月15日上午10:15触发
"0 15 10 L * ?" 每月最后一日的上午10:15触发
"0 15 10 ? * 6L" 每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6L 2002-2005" 2002年至2005年的每月的最后一个星期五上午10:15触发
"0 15 10 ? * 6#3" 每月的第三个星期五上午10:15触发
- 例子
0 12-45/3 10 * * ? 2005
首先,这是7位表达式,执行频率精确到s
0 表示每分钟的第0秒命中
12-45/3 表示每小时的第12~45min,每隔3min命中
10 表示每天的第10小时命中
* 表示每月的每天都命中
* 表示每年的每月都命中
? 表示无意义,不考虑周几是否命中
2025 表示2025年命中
8个特殊表达式
string meaning
------ -------
@reboot Run once, at startup.
@yearly Run once a year, "0 0 1 1 *".
@annually (same as @yearly)
@monthly Run once a month, "0 0 1 * *".
@weekly Run once a week, "0 0 * * 0".
@daily Run once a day, "0 0 * * *".
@midnight (same as @daily)
@hourly Run once an hour, "0 * * * *".
Please note that startup, as far as @reboot is concerned, is the time when the cron(8) daemon startup. In particular, it may be before some system daemons, or other
facilities, were startup. This is due to the boot order sequence of the machine.
cpu
查看几个核
# 总核数 = 物理CPU个数 X 每颗物理CPU的核数
# 总逻辑CPU数 = 物理CPU个数 X 每颗物理CPU的核数 X 超线程数
# 查看物理CPU个数
cat /proc/cpuinfo| grep "physical id"| sort| uniq| wc -l
# 查看每个物理CPU中core的个数(即核数)
cat /proc/cpuinfo| grep "cpu cores"| uniq
# 查看逻辑CPU的个数
cat /proc/cpuinfo| grep "processor"| wc -l
# 查看CPU信息(型号)
cat /proc/cpuinfo | grep name | cut -f2 -d: | uniq -c
make file
- 每行要加分号,否则是在子进程执行的
- 例如下述是正确的
build:
@pwd; cd ..; pwd
- 例如下述是错误的
build:
@pwd
@cd ..
@pwd
网络
查看某个进程的连接
- 那个11517是进程号即 docker inspect里面的 Pid
sudo lsof -p 11517 | grep 'CLOSE_WAIT' | wc -l
查看最大连接
ulimit -n
ulimit -a
在/proc/114906/net 可以看到某个进程的最大连接数上限
supervisor 默认会限制其下属的服务为1024,如果希望达到机器的ulimit -n是65535,需在supervisor 配置文件添加如下:
minfds=65535 ; min. avail startup file descriptors; default 1024
minprocs=65535 ; min. avail process descriptors;default 200
查看网络
nload
根据端口找进程
lsof -i:3000
netstat -tunlpa | grep 9092
// n: 禁用域名解析, 加速命令查询的速度
// l: listen: 只列出后台监听的端口
// t: tcp
// p: 列出 pid/program name
// a: all: 所有的连接, 和 listen 是互斥项
改DNS
vim /etc/resolve.conf增加一行nameserver 192.168.2.1
nameserver 114.114.114.114
sudo apt install software-properties-common -y
sudo add-apt-repository ppa:deadsnakes/ppa
sudo apt update && sudo apt upgrade -y
改hostname
- 例如改为
masterNode
sudo vim /etc/hostname 改127.0.0.1那一行, 如127.0.0.1 masterNode
sudo hostnamectl set-hostname masterNode
iptables
部分现场某些组件如果不想被其它服务器访问,可以通过iptables限制只允许集群内的服务器访问,其它的ip无法访问。可以解决漏洞扫描或者限制访问
例如现场有3台postgres集群,ip分别为192.168.2.27,192.168.2.28,192.168.2.29,需要访问数据库的ip有192.168.2.50,192.168.2.147
一、数据库服务器设置所有机器无法访问5432端口
每台数据库机器都需要设置
iptables -A INPUT -p tcp --dport 5432 -j DROP
设置完后,可以用telnet命令测试一下,从其他服务器看5432端口能否访问,正常情况下已经无法访问
[外链图片转存失败,源站可能有防盗链机制,建议将图片保存下来直接上传(img-1kShrxSE-1666859831861)(https://note.youdao.com/yws/res/123315/WEBRESOURCEca6db5ff8e9c9f202ba8b87b2ddd19f4)]
二、设置需要访问数据库的ip可以访问集群内的数据库
设置数据库集群ip可以访问
iptables -I INPUT -s 127.0.0.1 -p tcp --dport 5432 -j ACCEPT
iptables -I INPUT -s 192.168.2.27 -p tcp --dport 5432 -j ACCEPT
iptables -I INPUT -s 192.168.2.28 -p tcp --dport 5432 -j ACCEPT
iptables -I INPUT -s 192.168.2.29 -p tcp --dport 5432 -j ACCEPT
设置其他需要访问数据的ip
iptables -I INPUT -s 192.168.2.50 -p tcp --dport 5432 -j ACCEPT
iptables -I INPUT -s 192.168.2.147 -p tcp --dport 5432 -j ACCEPT
设置完后,可以用telnet命令测试一下,从需要访问数据库的服务器,telnet 5432端口能否访问,正常情况下可以访问

k8s端口
因k8s端口一般都是10.244.xxx.xxx, 可通过kubectl get po -n ullr -o wide

故下述命令即可使k8s均可连此自己
iptables -I INPUT -s 10.244.0.0/16 -p tcp --dport 1:65535 -j ACCEPT
三、检查业务是否受影响
检查应用服务器,需要访问数据库的组件,是否有报连接数据库的错误,如果没有,表示正常,如果有,可以检查一下是否将业务服务器ip,在上面的iptables规则里放行
查看规则
iptables -L INPUT -n --line-numbers

too many open files
排查命令:
netstat -an|grep 2013
netstat -n | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}'
cat /etc/supervisor/supervisord.conf
ls /proc/142111/fd | wc -l
cat /proc/142111/limits
ulimit -a
ss命令
进程
查进程启动路径
root@node:/data/prometheus_data/data/wal# ll /proc/4371/exe
lrwxrwxrwx 1 root root 0 Dec 20 07:00 /proc/4371/exe -> /opt/Aegis/prometheus/prometheus-2.25.0.linux-amd64/prometheus*
Ubuntu
制作deb离线包
一.应用场景
a.当我们需要在多台电脑安装同一个软件,并且这个软件很大,下载需要很长时间
b.需要安装软件的ubuntu不能上网
二.离线安装包的制作
2.1.通过如下指令下载XXXX软件所需要的deb包,首先在可联网的机器上配置网络apt源
$ sudo apt-get -d install XXXXX
执行完上述指令后,XXXX软件的安装包就下载到了/var/cache/apt/archives目录下
2.2.生成依赖关系
1.根目录下新建一个文件夹
$ sudo mkdir A
2.将下载的deb包拷贝到上述新建的文件夹下
$ sudo cp -r /var/cache/apt/archives A
3.修改文件夹的权限,可读可写可执行
$ sudo chmod 777 -R A/
4.建立deb包的依赖关系
$ sudo dpkg-scanpackages A/ /dev/null |gzip >A/Packages.gz
如果出现错误:sudo: dpkg-scanpackages: command not found
则需要安装dpkg-dev工具:
$ sudo apt-get install dpkg-dev
5.压缩制作好的离线包
$ tar zcvf A.tar.gz A
6.复制压缩包到不能联网的机器上
7.配置本地apt源
$tar xf A.tar.gz -C /opt
$ vim /etc/apt/sources.list
deb [ trusted=yes ] file:///opt/ A/
8.安装离线包
$ apt-get update
$ apt-get install XXXXX
apt源
debian系的包管理工具是dpkg,而apt-get,apt,aptitude都可以算是这个包管理体系的命令行前端,整合了更多功能而已。
apt-get无疑是其中几个做得最差的,没有搜索功能就是硬伤。
aptitude跟apt都有搜索,但实际搜索结果的呈现方面aptitude更好。不过apt因为有彩色进度条,界面交互更好用。
- vim /etc/apt/sources.list
#deb file:///opt/ software_package/
deb http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-security main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-updates main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-proposed main restricted universe multiverse
deb-src http://mirrors.aliyun.com/ubuntu/ bionic-backports main restricted universe multiverse
在 Ubuntu 上如何添加 Apt 软件源
Ubuntu 16.04配置国内高速apt-get更新源
Linux中apt与apt-get命令的区别与解释
报错
Unmet dependencies
是由于之前安装过程中断导致安装包损坏了, 用-f install修复即可
apt -f install --修复
apt-get update --更新
apt-get upgrade --升级
locale设置
此示例为把语言环境变量改为英文
将Ubuntu系统语言环境改为英文的en_US.UTF-8
查看当前系统语言环境locale
编辑配置文件,将zh_US.UTF-8改为en_US.UTF-8,zh改为en
sudo vim /etc/default/locale
LANG="en_US.UTF-8"
LANGUAGE="en_US:en"
继续查看更改后的系统语言变量,如果出现下列错误,说明没安装en_US的local
alien@Noah-s-Ark:~$ locale
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_MESSAGES to default locale: No such file or directory
locale: Cannot set LC_ALL to default locale: No such file or directory
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
查看系统内安装的locale
alien@Noah-s-Ark:~$ locale -a
locale: Cannot set LC_CTYPE to default locale: No such file or directory
locale: Cannot set LC_MESSAGES to default locale: No such file or directory
locale: Cannot set LC_COLLATE to default locale: No such file or directory
C
POSIX
zh_CN.utf8
zh_SG.utf8
看吧,没装en_US.UTF-8, 接下来就安装
sudo locale-gen en_US.UTF-8
cd /usr/share/locales
sudo ./install-language-pack en_US
然后就一切正常了
alien@Noah-s-Ark:/usr/share/locales$ locale
LANG=en_US.UTF-8
LANGUAGE=en_US:en
LC_CTYPE="en_US.UTF-8"
LC_NUMERIC="en_US.UTF-8"
LC_TIME="en_US.UTF-8"
LC_COLLATE="en_US.UTF-8"
LC_MONETARY="en_US.UTF-8"
LC_MESSAGES="en_US.UTF-8"
LC_PAPER="en_US.UTF-8"
LC_NAME="en_US.UTF-8"
LC_ADDRESS="en_US.UTF-8"
LC_TELEPHONE="en_US.UTF-8"
LC_MEASUREMENT="en_US.UTF-8"
LC_IDENTIFICATION="en_US.UTF-8"
LC_ALL=
systemctl
systemd是系统服务进程,注册到其中的服务会被systemd管理,并开机启动
- 配置文件
root@k8s-master-163:/etc/systemd/system# ll /etc/systemd/system
total 88
drwxr-xr-x 17 root root 4096 Nov 29 10:08 ./
drwxr-xr-x 5 root root 4096 Dec 28 2020 ../
-rw-r--r-- 1 root root 215 Nov 26 2018 aksusbd.service
-rw-r--r-- 1 root root 519 Jul 2 07:19 clickhouse-server.service.bak
drwxr-xr-x 2 root root 4096 Dec 2 2020 cloud-final.service.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 default.target.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 docker.service.d/
drwxr-xr-x 2 root root 4096 Dec 2 2020 final.target.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 getty.target.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 graphical.target.wants/
-rw-r--r-- 1 root root 216 Nov 26 2018 hasplmd.service
lrwxrwxrwx 1 root root 38 Dec 2 2020 iscsi.service -> /lib/systemd/system/open-iscsi.service
drwxr-xr-x 2 root root 4096 Dec 2 2020 kubelet.service.d/
lrwxrwxrwx 1 root root 38 Dec 2 2020 multipath-tools.service -> /lib/systemd/system/multipathd.service
drwxr-xr-x 2 root root 4096 Oct 9 18:17 multi-user.target.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 network-online.target.wants/
-rw-r--r-- 1 root root 246 Jun 15 16:07 node.service
drwxr-xr-x 2 root root 4096 Dec 2 2020 open-vm-tools.service.requires/
drwxr-xr-x 2 root root 4096 Dec 2 2020 paths.target.wants/
-rwxr-xr-x 1 root root 273 Apr 7 2021 prometheus.service*
drwxr-xr-x 2 root root 4096 Dec 2 2020 remote-fs.target.wants/
drwxr-xr-x 2 root root 4096 Dec 2 2020 sockets.target.wants/
lrwxrwxrwx 1 root root 31 Dec 2 2020 sshd.service -> /lib/systemd/system/ssh.service
drwxr-xr-x 2 root root 4096 Dec 2 2020 sysinit.target.wants/
lrwxrwxrwx 1 root root 35 Dec 2 2020 syslog.service -> /lib/systemd/system/rsyslog.service
drwxr-xr-x 2 root root 4096 Dec 2 2020 timers.target.wants/
- 重新加载配置
systemctl daemon-reload
- pg服务路径
/etc/systemd/system/multi-user.target.wants/postgresql.service
命令
grep
grep -v -P '^\s*#' postgresql.conf|grep -v -P '^\s*$' > origin.config.temp
- -i忽略大小写
- tail -f xxx.file | grep “keyword” 可以实时刷
- grep “keyword” xxx.file 可以过滤文件内出所有的关键字
sort
https://www.cnblogs.com/regit/p/7837879.html
- 文件夹 du -sh ./* | sort -hr
- 文件 ls -lSh
管道
- 可以选出某一列, 可以排序, 很强大
| awk `{
print $7}` | sort
sed
替换文本内容+备份原文件
- 把 C O N F I G F I L E 备份为 CONFIG_FILE备份为 CONFIGFILE备份为CONFIG_FILE.bak, 同时把$CONFI_FILE的内容改掉
sed -i.bak "s/^bind.*/bind\ ${IP}/g" $CONFIG_FILE
sed -i.bak "s/6379/${PORT}/g" $CONFIG_FILE
cut
- 按空格截断, 取第一个
IP=`hostname -I | cut -d' ' -f1`
hostname -I
192.168.2.163 172.17.0.1 10.244.0.0 10.244.0.1
find与exec搭配
find是我们很常用的一个Linux命令,但是我们一般查找出来的并不仅仅是看看而已,还会有进一步的操作,这个时候exec的作用就显现出来了。
看例子:
find ./ -name "*.txt" -exec ls -l "{}" \;
查找当前目录的.txt文件并以列表形式列出来
find ./ -name "*.txt" -exec mv "{}" "{}d" \;
批量修改当前目录下.txt文件的后缀名改为.txtd
解释:
-exec 参数后面跟的是command命令,它的终止是以;为结束标志的,所以这句命令后面的分号是不可缺少的,考虑到各个系统中分号会有不同的意义,所以前面加反斜杠。
{} 花括号代表前面find查找出来的文件名。
例子:
find ./ -name "*.tmp" -exec rm -rf "{}" \;
删除所有的临时文件
-exec语法格式为:
-exec COMMAND {} \; //注意{} \; 之间必须要有空格
shell的内建命令exec将并不启动新的shell,而是用要被执行命令替换当前的shell进程,并且将老进程的环境清理掉,而且exec命令后的其它命令将不再执行。
因此,如果你在一个shell里面,执行exec ls那么,当列出了当前目录后,这个shell就自己退出了,因为这个shell进程已被替换为仅仅执行ls命令的一个进程,执行结束自然也就退出了。为 了避免这个影响我们的使用,一般将exec命令放到一个shell脚本里面,用主脚本调用这个脚本,调用点处可以用bash a.sh,(a.sh就是存放该命令的脚本),这样会为a.sh建立一个sub shell去执行,当执行到exec后,该子脚本进程就被替换成了相应的exec的命令。
source命令或者”.”,不会为脚本新建shell,而只是将脚本包含的命令在当前shell执行。
不过,要注意一个例外,当exec命令来对文件描述符操作的时候,就不会替换shell,而且操作完成后,还会继续执行接下来的命令。
exec 3<&0:这个命令就是将操作符3也指向标准输入。
别处,这个命令还可以作为find命令的一个选项,如下所示:
(1)在当前目录下(包含子目录),查找所有txt文件并找出含有字符串”bin”的行
find ./ -name "*.txt" -exec grep "bin" {} \;
(2)在当前目录下(包含子目录),删除所有txt文件
find ./ -name "*.log" -exec rm {} \;
转自:http://blog.51cto.com/professor/1571873
ntp
- 可用于盒子
ntpdate ntp1.aliyun.com
service ntpd start
忘记密码
如果忘记密码 怎么在ubuntu上找回, 如下面的链接
https://blog.csdn.net/weixin_42425970/article/details/92771338, 重启过程中一直按键盘的SHIFT和E, 进到recovery模式, 编辑一行文件, 然后就可以改密码了, 改完密码正常重启就行了
键盘同时按ctrl + alt + delete 重启
tar和gz
gzip 只是一个流压缩程序,输入一个流,输出压缩后的数据流。给它一个文件,文件本身自然就是一个流,读入、压缩、输出,还是保存成一个文件,没有问题。然而,如果是一个文件夹、多个文件,该怎么办呢?按什么顺序?怎么存储文件以外的信息?(例如路径、权限。)操作系统没有提供一种可以把若干个文件组织成一个流的 API ,gzip 就无能为力。
tar 则相反,它就是一个打包程序。天生就是为了处理打包多个文件的问题,它有专门的 manifest 来存储一些 metadata ,包括包里有什么文件、(相对)路径是什么、在包里的偏移量是什么……不过,它(最早)没有压缩功能。
想要打包多个文件,很简单,先 tar 再 gzip ,一个管道就搞定了。后缀名自然而然就是 .tar.gz 了。
以上说的都是历史上最早的 UNIX 工具。这些工具的设计很好地体现了 UNIX 一个工具只做一件事情、使用管道组合多个工具的思想。
当然,到了后来,大家也都觉得这样很麻烦,而且这个功能太过常用了。所以 GNU 项目在复刻 UNIX tar 的时候,选择了把各种常用的压缩解压都集成进 tar (详见下段),然后提供了一套(丧心病狂的)命令行参数,现在一条命令就可以完成打包加压缩了。解压也是一样,使用 GNU 的 tar 的话,一条命令就可以自动完成压缩加解包,不需要先 gunzip 。
关于 tar 调用其他压缩解压程序,之前误以为是链接了 zlib 、 bzip2 等等这些库,然而只需要简单的 ldd which tar 或者看各个发行版里 tar 软件包的依赖信息,就可以知道事情并非如此。 tar 的依赖仍然是非常少的。而压缩解压其实仍然是通过管道调用了这些独立的外部程序来实现的。这可以通过看 tar 的源代码、看 tar 二进制里的 strings (有很多常见压缩解压程序的命令名)、或者看压缩解压时的进程来发现。
JAVA
配置JAVA_HOME
若机器未设置JAVA_HOME,则可以java -version确认是否安装
root@node:~# echo $JAVA_HOME
root@k8s-master-163:~# find / -name java
/etc/alternatives/java
/etc/apparmor.d/abstractions/ubuntu-browsers.d/java
/etc/ssl/certs/java
find: ‘/proc/5220’: No such file or directory
find: ‘/proc/33843’: No such file or directory
/var/lib/dpkg/alternatives/java
/usr/share/bash-completion/completions/java
/usr/share/java
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java
/usr/lib/jvm/java-8-openjdk-amd64/bin/java
接下来在 /etc/profile 中设置 /usr/lib/jvm/java-8-openjdk-amd64 如下:
export JAVA_HOME=/usr/lib/jvm/java-8-openjdk-amd64
export PATH=$JAVA_HOME/bin:$PATH
export CLASSPATH=.:$JAVA_HOME/lib
source /etc/profile 即可生效,效果如下:
root@node:~# echo $JAVA_HOME
/usr/lib/jvm/java-8-openjdk-amd64/jre/bin/java