原创

文章目录
-
- 初学者问题 (10)
- 中级问题 (15)
- 高级问题 (10)
-
- 1. 给你一个数据集,其中缺失值沿着中位数 1 个标准差分布。有多少百分比的数据不受影响?
- 2. 你被告知你的回归模型存在多重共线性。如何验证这是真的并建立更好的模型?
- 3、为什么XGBoost比SVM表现更好?
- 4. 你构建了一个包含 10,000 棵树的随机森林模型。训练误差为 0.00,但验证误差为 34.23。解释出了什么问题。
- 5. 解释构建 ML 模型的阶段。
- 6. 下面混淆矩阵的召回率、特异度和准确率是多少?
- 7. 对于 NLP,使用编码器-解码器模型的主要目的是什么?
- 8. 对于使用 TensorFlow 的深度学习,需要哪个值作为评估的输入EstimatorSpec?
- 9. 使用 scikit-learn 时,当特征值变化很大时,我们是否需要缩放特征值?
- 10. 你的数据集有 50 个变量,但有 8 个变量的缺失值高于 30%。你如何解决这个问题?
- 赠书福利
初学者问题 (10)
1. 偏差和方差之间的权衡是什么?
偏差(模型与数据的拟合程度)是指由于 ML 算法中的不准确或简单假设导致的错误,这会导致过度拟合。
方差(模型根据输入发生的变化有多少)是指由于 ML 算法的复杂性而导致的错误,这会对训练数据和过度拟合的高度变化产生敏感性。
换句话说,简单模型是稳定的(低方差)但有很大偏差。复杂模型容易过度拟合,但表达了模型的真实性(低偏差)。误差的最佳减少需要偏差和方差的权衡,以避免高方差和高偏差。
2.解释有监督和无监督机器学习的区别
监督学习需要训练标记数据。换句话说,监督学习使用基本事实,这意味着我们对我们的输出和样本有现有的了解。这里的目标是学习一个近似输入和输出之间关系的函数。
另一方面,无监督学习不使用带标签的输出。这里的目标是推断数据集中的自然结构。
3. 监督学习和无监督学习最常用的算法是什么?

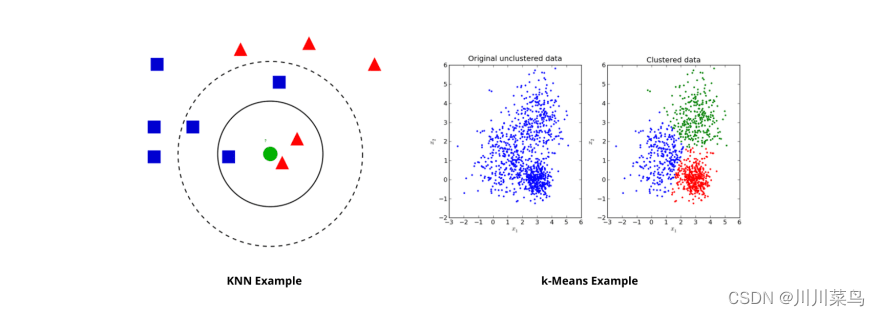
4.解释KNN和k-means聚类的区别
主要区别是KNN需要标注点(分类算法,监督学习),而k-means不需要(聚类算法,无监督学习)。
要使用 K 最近邻,可以使用要分类为未标记点的标记数据。K 均值聚类采用未标记的点并学习如何使用点之间的距离的平均值对它们进行分组。
5. 什么是贝叶斯定理?我们为什么用它?
贝叶斯定理是我们如何在知道其他概率时找到概率。换句话说,它提供了先验知识事件的后验概率。该定理是计算条件概率的一种原则性方法。
在 ML 中,贝叶斯定理用于将模型拟合到训练数据集的概率框架中,并用于构建分类预测建模问题(即朴素贝叶斯、贝叶斯最优分类器)。
6. 什么是朴素贝叶斯分类器?我们为什么要使用它们?
朴素贝叶斯分类器是分类算法的集合。这些分类器是具有共同原理的一系列算法。朴素贝叶斯分类器假设一个特征的出现或不存在不会影响另一个特征的存在或不存在。
换句话说,我们称之为“朴素”,因为它假设所有数据集特征都同等重要且独立。
朴素贝叶斯分类器用于分类。当独立性假设成立时,它们很容易实施,并且比其他复杂的预测器产生更好的结果。它们用于垃圾邮件过滤、文本分析和推荐系统。
7. 解释第一类错误和第二类错误的区别
I 类错误是误报(声称没有发生某事),II 类错误是假阴性(声称什么都没有发生,但实际发生了)。
8. 判别模型和生成模型有什么区别?
判别模型学习不同类别数据之间的区别。生成模型学习数据类别。 判别模型通常在分类任务上表现更好。
9. 什么是参数模型?举个例子
参数模型具有有限数量的参数。只需要知道模型的参数即可进行数据预测。常见的例子如下:线性支持向量机、线性回归和逻辑回归。
非参数模型具有无限数量的参数以提供灵活性。对于数据预测,您需要模型的参数和观察数据的状态。常见的例子如下:k近邻、决策树、主题模型。
10. 解释数组和链表的区别
数组是对象的有序集合。它假设每个元素都具有相同的大小,因为整个数组存储在一个连续的内存块中。数组的大小在声明时指定,之后不能更改。数组的搜索选项是线性搜索和二进制搜索(如果已排序)。
链表是一系列带有指针的对象。不同的元素存储在不同的内存位置,并且可以在需要时添加或删除数据项。
链表的唯一搜索选项是线性的。
其他初学者问题可能包括:
哪个更重要:模型性能还是准确性?为什么?
F1分数是多少?它是如何使用的?
什么是维度诅咒?
我们什么时候应该使用分类而不是回归?
解释深度学习。它与其他技术有何不同?
解释可能性和概率之间的区别。
中级问题 (15)
1. 会为时间序列数据集选择哪种交叉验证技术?
时间序列不是随机分布的,而是按时间顺序排列的。想使用前向链接之类的东西,这样您就可以在查看未来数据之前基于过去的数据进行建模。例如:
Fold 1 : training [1], test [2]
Fold 2 : training [1 2], test [3]
Fold 3 : training [1 2 3], test [4]
Fold 4 : training [1 2 3 4], test [5]
Fold 5 : training [1 2 3 4 5], test [6]
2. 如何根据训练集大小选择分类器?
对于小型训练集,具有高偏差和低方差模型的模型更好,因为它不太可能过度拟合。一个例子是朴素贝叶斯。
对于大型训练集,具有低偏差和高方差模型的模型更好,因为它表达了更复杂的关系。一个例子是逻辑回归。
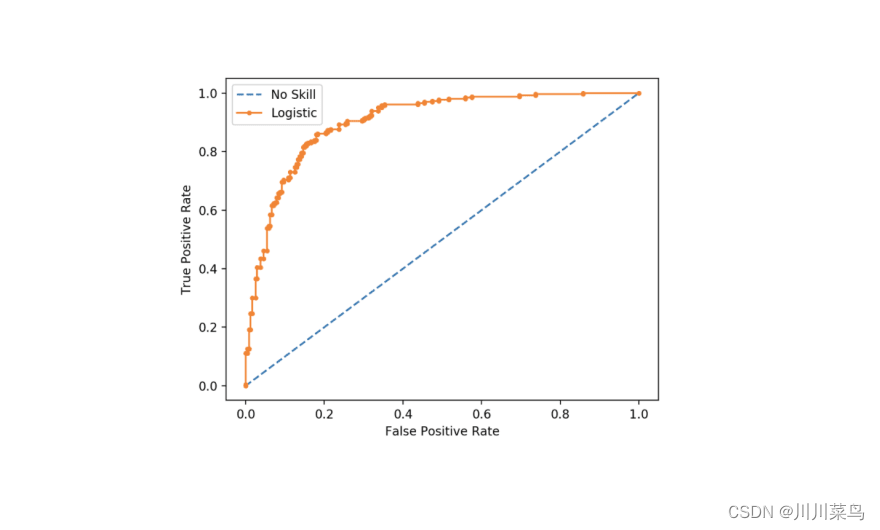
3.解释ROC曲线和AUC
ROC 曲线是分类模型在所有阈值下性能的图形表示。它有两个阈值:真阳性率和假阳性率。
AUC(Area Under the ROC Curve)简单来说就是ROC曲线下的面积。AUC 测量 ROC 曲线下方从 (0,0) 到 (1,1) 的二维面积。它用作评估二元分类模型的性能指标。
4. 解释无监督学习的 LDA
Latent Dirichlet Allocation (LDA) 是主题建模的常用方法。它是一种将文档表示为主题组合的生成模型,每个主题都有自己的概率分布。
LDA旨在将高维空间的特征投影到低维空间。这有助于避免维数灾难。
5. 你如何确保你没有过度拟合模型?
我们可以使用三种方法来防止过拟合:
- 使用交叉验证技术(如 k 折交叉验证)
- 保持模型简单(即采用较少的变量)以减少方差
- 使用正则化技术(如 LASSO)来惩罚可能导致过度拟合的模型参数
6. SQL中,主键和外键是如何关联的?
外键允许根据相应表的主键匹配和连接表。
7. 会使用哪些评估方法来衡量 ML 模型的有效性?
首先,会将数据集拆分为训练集和测试集。您还可以使用交叉验证技术来分割数据集。然后,您将选择并实施绩效指标。例如,您可以使用混淆矩阵、F1 分数和准确性。
8. 解释如何处理数据集中丢失或损坏的数据
需要识别查找数据并删除行/列,或将它们替换为其他值。
Pandas提供了执行此操作的有用方法:isnull()和dropna(). 这些允许识别和删除损坏的数据。fillna()方法可用于用占位符填充无效值。
9. 解释将如何开发数据管道
数据管道使我们能够采用数据科学模型并对其进行自动化或扩展。常见的数据管道工具是 Apache Airflow,Google Cloud、Azure 和 AWS 用于托管它们。
10. 如何修复模型中的高方差?
如果模型具有低方差和高偏差,我们使用装袋算法,该算法使用随机抽样将数据集划分为子集。我们使用这些样本生成一组具有单一学习算法的模型。
此外,我们可以使用正则化技术,其中较高的模型系数受到惩罚以降低整体复杂性。
11.什么是超参数?它们与模型参数有何不同?
模型参数是模型内部的变量。参数的值是根据训练数据估计的。
超参数是模型外部的变量。该值无法从数据中估计,它们通常用于估计模型参数。
12.你正在处理一个数据集。你如何选择重要变量?
- 在选择重要变量之前删除相关变量
- 使用随机森林和绘制变量重要性图表
- 使用套索回归
- 使用线性回归根据 p 值选择变量
- 使用正向选择、逐步选择和反向选择
13. 如何选择数据集使用的算法?
选择 ML 算法取决于相关数据的类型。业务需求是选择算法所必需的,构建算法也是构建模型的必要条件,因此在回答这个问题时,说明需要更多信息。
例如,如果你的数据以线性方式组织,线性回归将是一个很好的算法。或者,如果数据由非线性交互组成,则最好使用 bagging 或 boosting 算法。或者,如果你正在处理图像,神经网络将是最好的选择。
14. 使用神经网络有哪些优点和缺点?
优点:
- . 将数据存储在整个网络上,而不是数据库上
- 并行处理
- 分布式存储器
- 即使在有限的信息下也能提供很高的精度
缺点:
- 需要复杂的处理器
- 过于依赖误差值
- 是个黑匣子
15.决策树的默认分裂方法是什么?
默认方法是Gini Index,它是特定节点不纯度的度量。本质上,它计算错误分类的特定特征的概率。
也可以使用随机森林,但首选基尼指数,因为它不是计算密集型的,也不涉及对数函数。
其它问题:
解释决策树的优点和缺点。
使用反向传播技术时的梯度爆炸问题是什么?
什么是混淆矩阵?你为什么需要它?
高级问题 (10)
1. 给你一个数据集,其中缺失值沿着中位数 1 个标准差分布。有多少百分比的数据不受影响?
数据分布在中位数上,因此我们可以假设我们使用的是正态分布。这意味着大约68%的数据位于距均值 1 个标准差的位置。因此,大约32%的数据不受影响。
2. 你被告知你的回归模型存在多重共线性。如何验证这是真的并建立更好的模型?
应该创建一个相关矩阵来识别和删除相关性高于 75% 的变量。请记住,我们这里的这个阙值是主观的。
还可以计算VIF(方差膨胀因子)来检查是否存在多重共线性。VIF 值大于或等于 4 表明不存在多重共线性。小于或等于 10 的值告诉我们存在严重的多重共线性问题。
不能只删除变量,因此应该使用惩罚回归模型或在相关变量中添加随机噪声,但这种方法不太理想。
3、为什么XGBoost比SVM表现更好?
XGBoost 是一种使用许多树的集成方法。这意味着它会随着自身的重复而改善。
SVM 是一个线性分离器。所以,如果我们的数据不是线性可分的,SVM 需要一个 Kernel 来让数据达到可以分离的状态。这可能会限制我们,因为每个给定数据集都没有完美的内核。
4. 你构建了一个包含 10,000 棵树的随机森林模型。训练误差为 0.00,但验证误差为 34.23。解释出了什么问题。
模型可能过度拟合。0.00 的训练误差意味着分类器模仿了训练数据模式。这意味着它们不可用于我们看不见的数据,从而返回更高的错误。
使用随机森林时,如果我们使用大量树,就会出现这种情况。
5. 解释构建 ML 模型的阶段。
这在很大程度上取决于手头的模型,因此您可以提出澄清问题。但一般来说,流程是这样的:
- 了解商业模式和最终目标
- 收集数据采集
- 做数据清洗
- 基本探索性数据分析
- 使用机器学习算法开发模型
- 使用未知数据集检查准确性
6. 下面混淆矩阵的召回率、特异度和准确率是多少?
- TP / True Positive:案例为阳性,预测为阳性
- TN/True Negative:案例为阴性,预测为阴性
- FN / False Negative:案例为阳性,但被预测为阴性
- FP / False Positive:案例为阴性,但被预测为阳性
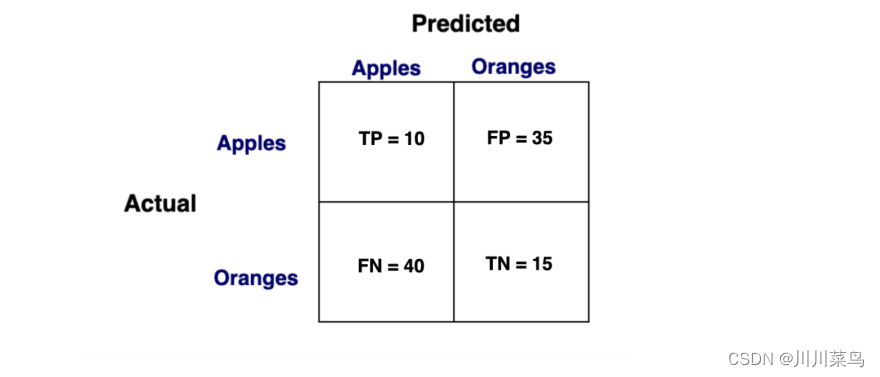
计算如下:
召回 = 20%
特异性 = 30%
精度 = 22%
计算过程:
召回率 = TP / (TP+FN) = 10/50 = 0.2 = 20%
特异性 = TN / (TN+FP) = 15/50 = 0.3 = 30%
精度 = TP/ (TP + FP) = 10 / 45 = 0.2 = 22%
7. 对于 NLP,使用编码器-解码器模型的主要目的是什么?
我们使用编码器-解码器模型根据输入序列生成输出序列。
使编码器-解码器模型如此强大的原因在于解码器使用编码器的最终状态作为其初始状态。这使解码器可以访问编码器从输入序列中提取的信息。
8. 对于使用 TensorFlow 的深度学习,需要哪个值作为评估的输入EstimatorSpec?
损失指标是必需的。在使用 TensorFlow 执行模型时,我们使用EstimatorSpec对象来组织训练、评估和预测。
EstimatorSpec对象使用一个称为模式的必需参数进行初始化。该模式可以采用以下三个值之一
- tf.estimator.ModeKeys.TRAIN
- tf.estimator.ModeKeys.EVAL
- tf.estimator.ModeKeys.PREDICT
9. 使用 scikit-learn 时,当特征值变化很大时,我们是否需要缩放特征值?
是的。大多数机器学习算法使用欧氏距离作为衡量两个数据点之间距离的度量。如果取值范围相差很大,同样的变化在不同的特征上的结果就会有很大的不同。
10. 你的数据集有 50 个变量,但有 8 个变量的缺失值高于 30%。你如何解决这个问题?
可以采用三种通用方法:
- 只需删除它们(不理想)
- 为缺失值分配一个唯一类别,以查看是否存在产生此问题的趋势
- 检查目标变量的分布。如果找到模式,保留缺失值,将它们分配给新类别,并删除其他值。
其它问题:
对于 k-means 或 kNN,为什么我们使用欧氏距离而不是曼哈顿距离?
解释正常软间隔 SVM 和具有线性核的 SVM 之间的区别。
赠书福利
书籍介绍
人工智能(Artifificial Intelligence, AI)作为一门前沿交叉学科,是研究和开发用于模拟、延伸和扩展人的智能的理论、方法、技术及应用系统的一门新的技术科学。中国科学院院士徐宗本认为:“人工智能的基础是数学,人工智能要走得远,需要把数学的基本问题解决好。同时,人工智能的一些原理和方法也给数学研究带来了特别的启示,有些甚至是革命性的。”
没有有基础科学的强力支持,应用科学是不可能做出顶尖成绩的。例如,人工智能的深度学习目前存在许多不足,例如大样本依赖,可解释性差,易受欺骗等,但当前没有更好的算法来替代。要解决这些问题,需要对相关数学理论进行深入的研究,了解大数据内在的数学结构和原理。《人工智能数学基础》这本书以零基础讲解为宗旨,面向学习数据科学与人工智能的读者,通俗地讲解每一个知识点,帮助读者快速打下数学基础,适合准备从事数据科学与人工智能相关行业的读者。

图书购买:
当当:http://product.dangdang.com/29145839.html
京东:https://item.jd.com/13009168.html
活动规则
本次活动,请针对本文中的知识点进行评价,在评论区评论,如果别人对你的评论点赞量多(可以转发给其他同学帮你点赞),我将会对点赞数量top2的同学每人赠送一本以上书籍,其它未中奖同学感兴趣可以自行购买。本次活动同时在公众号举行,即:CSDN活动处送两本,公众号处送两本,公众号具体活动请关注:玩转大数据。两者截止时间:2022年12月12日。
关注我:

可以参考上次活动:https://chuanchuan.blog.csdn.net/article/details/128088582
获奖者为以下三名,获奖同学请联系我把收货地址给我: