文章目录
为什么需要协程
协程的本质是将一段数据的运行状态进行打包,可以在线程之间调度,所以协程就是在单线程的环境下实现的应用程序级别的并发,就是把本来由操作系统控制的切换+保存状态在应用程序里面实现了。
所以我们需要协程的目的其实就是它更加节省资源、可以在有限的资源内支持更高的并发,体现在以下三个方面:
- 资源利用:程可以利用任何的线程去运行,不需要等待CPU的调度。
- 快速调度:协程可以快速地调度(避开了系统调用和切换),快速的切换。
- 超高并发:有限的线程就可以并发很多的协程。
协程的本质
协程在go语言中使用runtime\runtime2.go下的g结构体来表示,这个结构体中包含了协程的很多信息,我们只挑选其中的重要字段来进行分析:
type g struct {
// 协程的栈帧,里面包含了两个字段:lo和hi,分别是协程栈的高位指针和低位指针
stack stack
// gobuf结构体中储存了很多与协程栈相关的指针,比如pc、sp
sched gobuf
// 用来标记协程当前的状态
atomicstatus uint32
// 每个协程的唯一标识,不向应用层暴露。但是goid的地址会存在寄存器里面,可以通过ebpf工具无侵入地去获取
goid int64
}

对线程的描述
我们知道,go语言中的协程是跑在线程上面的,那么go中肯定会有对线程的抽象描述,这个结构体也在runtime\runtime2.go中,我们只展示重要的部分:
type m struct {
// 每次启动一个M都会第一个创建的gourtine,用于操作调度器,所以它不指向任何函数,只负责调度
g0 *g // goroutine with scheduling stack
// 当前正在线程上运行的协程
curg *g // current running goroutine
// 线程id
id int64
// 记录每种操作系统对于线程额外的描述信息
mOS
}
协程如何在线程中执行
我们从最简单的单线程调度模型来看,协程在线程中的执行流程可以参考下图:
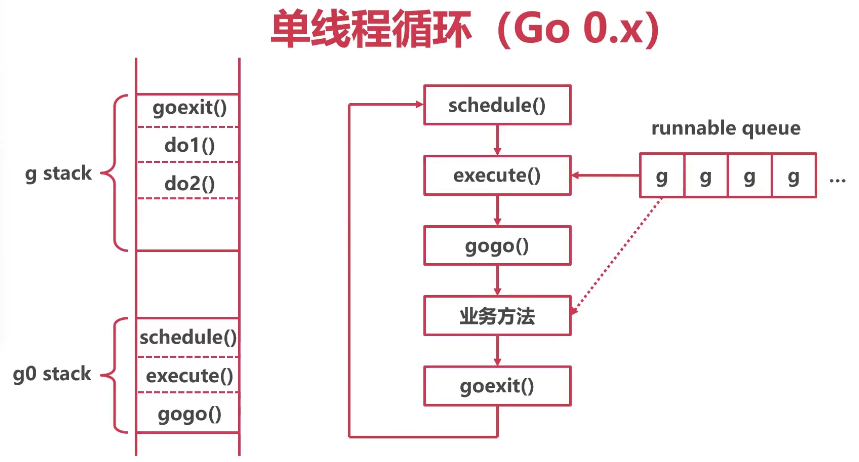
线程循环
在go中每个线程都是循环执行一系列工作,又称作单线程循环如下图所示:左侧为栈,右侧为线程执行的函数顺序,其中的业务方法就是协程方法。
普通协程栈只能记录业务方法的业务信息,且当线程没有获得协程之前是没有普通协程栈的。所以在内存中开辟了一个g0栈,专门用于记录函数调用跳转的信息,因此g0栈其实就是调度中心的栈。
线程循环会按顺序循环去执行上图右侧的函数:schedule->execute->gogo->业务方法->goexit。
schedule
schedule函数的作用是为当前的P获取一个可以执行的g,并执行它。
- 首先会有1/61的概率检查全局队列,确保全局队列中的G也会被调度。
- 然后有60/61的概率从本地队列中获取g。
- 如果从本地队列中没有获取到可执行的g,就会调用
findrunnable函数去获取。
findrunnable函数的流程:- 调用runqget函数来从P自己的runnable G队列中得到一个可以执行的G;
- 如果1失败,调用globrunqget函数从全局runnableG队列中得到一个可以执行的G;
- 如果2失败,调用netpoll(非阻塞)函数取一个异步回调的G;
- 如果3失败,尝试从其他P那里偷取一半数量的G过来;
- 如果4失败,再次调用globrunqget函数从全局runnableG队列中得到一个可以执行的G;
- 如果5失败,调用netpoll(阻塞)函数取一个异步回调的G;
- 如果6仍然没有取到G,那么调用stopm函数停止这个M。
- 如果获取到了可执行的g,就调用
execute函数去执行。
// One round of scheduler: find a runnable goroutine and execute it.
// Never returns.
func schedule() {
......
// 新建一个gp变量,gp就是即将要运行的协程指针
var gp *g
var inheritTime bool
// 垃圾回收相关的工作
......
// 调度过程中有1/61的概率检查全局队列,确保全局队列中的G也会被调度。
// M绑定的P首先有1/61概率从全局队列获取G,60/61概率从本地队列获取G
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}
// 从本地队列中获取g
if gp == nil {
gp, inheritTime = runqget(_g_.m.p.ptr())
// We can see gp != nil here even if the M is spinning,
// if checkTimers added a local goroutine via goready.
}
// 如果从本地队列获取失败,就会调用findrunnable函数去获取g
if gp == nil {
gp, inheritTime = findrunnable() // blocks until work is available
}
......
execute(gp, inheritTime)
}
execute
execute函数会为schedule获取到的可执行协程初始化相关结构体,然后以sched结构体为参数调用gogo函数:
func execute(gp *g, inheritTime bool) {
_g_ := getg()
// 初始化g结构体
// Assign gp.m before entering _Grunning so running Gs have an
// M.
_g_.m.curg = gp
gp.m = _g_.m
casgstatus(gp, _Grunnable, _Grunning)
gp.waitsince = 0
gp.preempt = false
gp.stackguard0 = gp.stack.lo + _StackGuard
if !inheritTime {
_g_.m.p.ptr().schedtick++
}
......
// 汇编实现的函数,通过gobuf结构体中的信息,跳转到执行业务的方法
gogo(&gp.sched)
gogo
gogo函数实际上是汇编实现的,每个操作系统实现的gogo方法是不同的,它会通过传进来的gobuf结构体,先向普通协程栈中压入goexit函数,然后跳转到执行业务的方法,协程栈也会被切换成业务协程自己的栈。
业务方法
业务方法就是协程中需要执行的相关函数。
goexit
goexit也是汇编实现的,当执行完协程栈中的业务方法之后,就会退到goexit方法中,它会将业务协程的栈切换成调度器的栈(也就是g0栈),然后重新调用schedule函数,形成一个闭环。
GMP调度模型
上述的调度模型是单线程的,但是现代CPU往往是多核的,应用采用的也是多线程,因此单线程调度模型有些浪费资源。所以我们在实际使用中,其实是一种多线程循环。但是多个线程在获取可执行g的时候就会存在并发冲突的问题,所以就有了GMP调度模型。
GMP调度模型简单来说是这样的:
G是指协程goroutine,M是指操作系统线程,P是指调度器。
首先,GMP调度模型中有一个全局队列,用于存放等待运行的G。然后每个P都有自己的本地队列,存放的也是等待运行的G,但是存的数量有限,不会超过256个。我们新建goroutine的时候,是优先放到P的本地队列中的,如果队列满了,会把本地队列中一半的G都移到全局队列中。
线程想运行任务就得获取P,从P的本地队列获取G,G执行之后,M会从P获取下一个G,不断重复下去。P队列为空时,M会尝试从全局队列拿一批G放到P的本地队列,如果获取不到就会从其他P的本地队列偷一半放到自己P的本地队列。
当M执行某一个G时候如果发生了系统调用或者其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P。当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中。
P的底层结构
我们发现GMP调度模型中有一个P,P就是调度器,我们来看一下P的底层数据结构,同样在runtime\runtime2.go文件中:
type p struct {
id int32
status uint32 // one of pidle/prunning/...
// 指向调度器服务的那个线程
m muintptr // back-link to associated m (nil if idle)
// Queue of runnable goroutines. Accessed without lock.
// 调度器的本地队列,因为只服务于一个线程,所以可以无锁的访问,队列本身实际上是一个大小为256的指针数组
runqhead uint32
runqtail uint32
runq [256]guintptr
// 指向下一个可用g的指针
runnext guintptr
}
协程并发
我们上面介绍的调度模型实际上是非抢占式的,非抢占式模型的特点就是只有当协程主动让出后,M才会去运行本地队列后面的协程,那么这样就很容易造成队列尾部的协程饿死。
其实Go语言的协程是基于抢占式来实现的,也就是当协程执行一段时间后将当前任务暂定,执行后续协程任务,防止时间敏感携程执行失败。如下图所示:
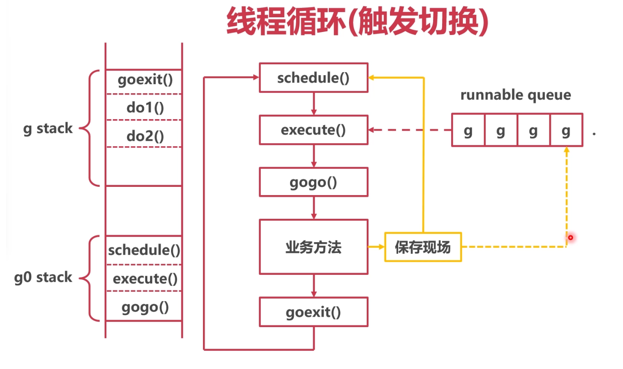
抢占式调度
当目前线程中执行的协程是一个超长时间的任务,此时先保存该协程的运行状态也就是保护现场,若是后续还需继续执行就将其放入本地队列中去,如果不需要执行就将其处于休眠状态,然后直接跳转到schedule函数中。
实现:
- 主动挂取:gopark方法,当业务调用这个方法线程就会直接回到schedule函数并切换协程栈,当前运行的协程将会处于等待状态,等待状态的协程是无法立即进入任务队列中的。程序员无法主动调用gopark函数,但是我们可以通过Sleep等具有gopark的函数来进行主动挂取,Sleep五秒之后系统将会把任务的等待状态更改为运行状态放入队列中。
- 系统调用完成时:go程序在运行状态中进行了系统调用,那么当系统的底层调用完成后就会调用exitsyscall函数,线程就会停止执行当前协程,将当前协程放入队列中去。
- 标记抢占morestack():当函数跳转时都会调用这个方法,它的本意在于检查当前协程栈空间是否有足够内存,如果不够就要扩大该栈空间。当系统监控到协程运行超过
10ms,就将g.stackguard0置为0xfffffade(该值是一个抢占标志),让程序在只执行morestack函数时顺便判断一下是否将g中的stackguard置为抢占,如果的确被标记抢占,就回到schedule方法,并将当前协程放回队列中。
全局队列的饥饿问题
上述操作让本地队列成了一个小循环,但是如果目前系统中的线程的本地队列中都拥有一个超大的协程任务,那么所有的线程都将在一段时间内处于忙碌状态,全局队列中的任务将会长期无法运行,这个问题又称为全局队列饥饿问题,解决方式就是在本地队列循环时,以一定的概率从全局队列中取出某个任务,让它也参与到本地循环当中去。
其实在执行schedule函数寻找可运行g的时候,首先会去执行下面的代码,即调度过程中有1/61的概率去全局队列中获取可执行的协程,防止全局队列中的协程被饿死。
// 调度过程中有1/61的概率检查全局队列,确保全局队列中的G也会被调度。
if gp == nil {
// Check the global runnable queue once in a while to ensure fairness.
// Otherwise two goroutines can completely occupy the local runqueue
// by constantly respawning each other.
if _g_.m.p.ptr().schedtick%61 == 0 && sched.runqsize > 0 {
lock(&sched.lock)
gp = globrunqget(_g_.m.p.ptr(), 1)
unlock(&sched.lock)
}
}