Redis 提供了 RDB 和 AOF 两种数据持久化方式,其中 RDB 是数据快照,而 AOF 会记录每一条写命令到日志文件中。
前文回顾:
文章目录
1 Master 宕机导致 Slave 数据丢失
如果 Redis 按照以下模式部署,就有可能发生数据丢失问题:
- 主从 + 哨兵部署;
- Master 没有开启数据持久化;
- Redis 进程使用 supervisor 管理,并配置为「进程宕机,自动重启」 。
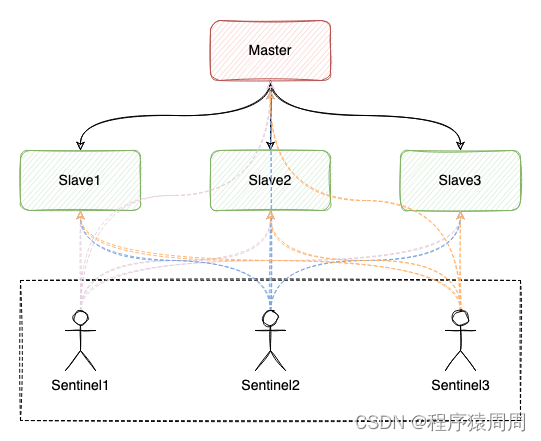
如果此时 Master 实例宕机,就会产生下面问题:
- Master 宕机,哨兵还未发起切换,此时 Master 进程立即被 supervisor 自动拉起;
- 但由于 Master 没有开启任何数据持久化,启动后是一个「空」实例;
- 此时 Slave 为了与 Master 保持一致,它会自动「清空」实例中的所有数据。
2 AOF 的 everysec 阻塞主线程
当使用 Redis 的 AOF 时,需要配置 AOF 的刷盘策略。基于性能和数据安全的平衡,会采用 appendfsync ****everysec 的方案。即:Redis 的后台线程每间隔 1 秒,就把 AOF page cache 的数据,刷到磁盘(fsync)上。
这样的优势在于可以把 AOF 刷盘的耗时操作,放到了后台线程中去执行,避免了对主线程的影响。
但此种方案真的不会影响主线程吗?
答案是否定的。想象一种场景:Redis 后台线程在执行 AOF page cache 刷盘(fysnc)时,如果磁盘 IO 负载过高,那么调用 fsync 就会被阻塞住。但此时的主线程仍然接收写请求进来,那么此时的主线程会先判断,上一次后台线程是否已刷盘成功。
Redis 如何判断是否刷盘成呢?
后台线程在刷盘成功后,都会记录刷盘的时间。主线程会根据这个时间来判断,距离上一次刷盘已经过去多久了。整个流程是这样的:
1)主线程在写 AOF page cache(write系统调用)前,先检查后台 fsync 是否已完成;
2)fsync 已完成,主线程直接写 AOF page cache;
3)fsync 未完成,则检查距离上次 fsync 过去多久:
4)如果距离上次 fysnc 成功在 2 秒内,那么主线程会直接返回,不写 AOF page cache
5)如果距离上次 fysnc 成功超过了 2 秒,那主线程会强制写 AOF page cache(write系统调用)
6)由于磁盘 IO 负载过高,此时,后台线程 fynsc 会发生阻塞,那主线程在写 AOF page cache 时,也会发生阻塞等待(操作同一个 fd,fsync 和 write 是互斥的,一方必须等另一方成功才可以继续执行,否则阻塞等待)
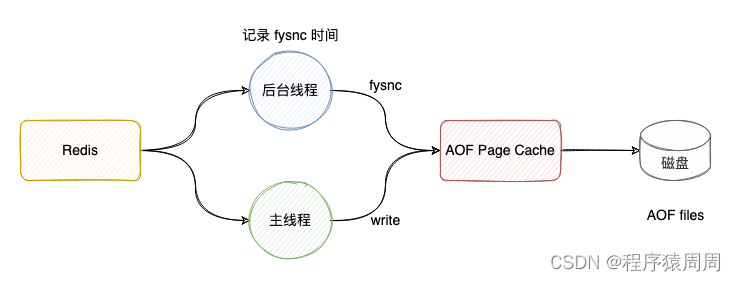
通过上面分析可以发现,即使配置的 AOF 刷盘策略是 appendfsync everysec,也依旧会有阻塞主线程的风险:磁盘 IO 负载过高导致 fsync 阻塞,进而导致主线程写 AOF page cache 也发生阻塞。
所以,一定要保证磁盘有充足的 IO 资源,避免这个问题。
3 AOF everysec 不只丢 1 秒数据
我么接着上面的问题继续分析,当执行到上述的步骤 4) 时,也就是主线程在写 AOF page cache 时,会先判断上一次 fsync 成功的时间,如果距离上次 fysnc 成功在 2 秒内,那么主线程会直接返回,不再写 AOF page cache。
这就意味着,后台线程在执行 fsync 刷盘时,主线程最多等待 2 秒不会写 AOF page cache。如果此时 Redis 发生了宕机,那么,AOF 文件中丢失是 2 秒的数据,而不是 1 秒。
Redis 主线程为什么要等待 2 秒不写 AOF page cache 呢?
其实,**Redis AOF 配置为 appendfsync everysec 时,理论上后台线程每隔 1 秒执行一次 fsync 刷盘,如果磁盘资源充足,是不会被阻塞住的。**但是,Redis 作者考虑到,如果此时的磁盘 IO 资源比较紧张,那么后台线程 fsync 就有概率发生阻塞风险。所以作者在主线程写 AOF page cache 之前,先检查一下距离上一次 fsync 成功的时间,如果大于 1 秒没有成功,那么主线程此时就能知道,fsync 可能阻塞了。
所以,主线程会等待 2 秒不写 AOF page cache,其目的在于:
- 降低主线程阻塞的风险(如果无脑写 AOF page cache,主线程则会立即阻塞住)
- 如果 fsync 阻塞,主线程就会给后台线程留出 1 秒的时间,等待 fsync 成功
这个方案应该是 Redis 作者对性能和数据安全性的进一步权衡。所以导致即使 AOF 配置为每秒刷盘,在发生上述极端情况时,AOF 丢失的数据其实是 2 秒。
4 RDB 和 AOF rewrite 时 OOM
Redis 在做 RDB 快照和 AOF 日志重写时,会采用创建子进程的方式,把实例中的数据持久化到磁盘上。而创建子进程时就会调用操作系统的 fork 函数, 执行完成后,父进程和子进程会同时共享同一份内存数据。
但此时的主进程依旧是可以接收写请求的,而进来的写请求会采用 Copy On Write(写时复制)的方式操作内存数据。
如果父进程要修改一个 key,就需要拷贝原有的内存数据,到新内存中,这个过程涉及到了「新内存」的申请。
如果业务特点是「写多读少」,而且 OPS 非常高,那在 RDB 和 AOF rewrite 期间,就会产生大量的内存拷贝工作。
如果机器内存资源不足,这就会导致 Redis 面临被 OOM 的风险!
所以:
为了避免在 RDB 和 AOF rewrite 期间,防止 Redis OOM,要给 Redis 机器预留内存