近两年,越来越多的企业在生产环境中,基于Docker、Kubernetes构建容器云平台,例如国内阿里巴巴、腾讯、京东、奇虎360等公司。互联网公司使用容器技术份额在持续上升,企业容器化部署已成为趋势。
一、Kubernetes概述
1、Kubernetes简介
Kubernetes是一个轻便的和可扩展的开源平台,用于管理容器化应用和服务。通过Kubernetes能够进行应用的自动化部署和扩缩容。在Kubernetes中,会将组成应用的容器组合成一个逻辑单元以更易管理和发现。Kubernetes积累了作为Google生产环境运行工作负载15年的经验,并吸收了来自于社区的最佳想法和实践。Kubernetes经过这几年的快速发展,形成了一个大的生态环境,Google在2014年将Kubernetes作为开源项目。Kubernetes的关键特性包括:
- 自动化装箱:在不牺牲可用性的条件下,基于容器对资源的要求和约束自动部署容器。同时,为了提高利用率和节省更多资源,将关键和最佳工作量结合在一起。
- 自愈能力:当容器失败时,会对容器进行重启;当所部署的Node节点有问题时,会对容器进行重新部署和重新调度;当容器未通过监控检查时,会关闭此容器;直到容器正常运行时,才会对外提供服务。
- 水平扩容:通过简单的命令、用户界面或基于CPU的使用情况,能够对应用进行扩容和缩容。
- 服务发现和负载均衡:开发者不需要使用额外的服务发现机制,就能够基于Kubernetes进行服务发现和负载均衡。
- 自动发布和回滚:Kubernetes能够程序化的发布应用和相关的配置。如果发布有问题,Kubernetes将能够回归发生的变更。
- 保密和配置管理:在不需要重新构建镜像的情况下,可以部署和更新保密和应用配置。
- 存储编排:自动挂接存储系统,这些存储系统可以来自于本地、公共云提供商(例如:GCP和AWS)、网络存储(例如:NFS、iSCSI、Gluster、Ceph、Cinder和Floker等)。
2、Kubernetes整体架构
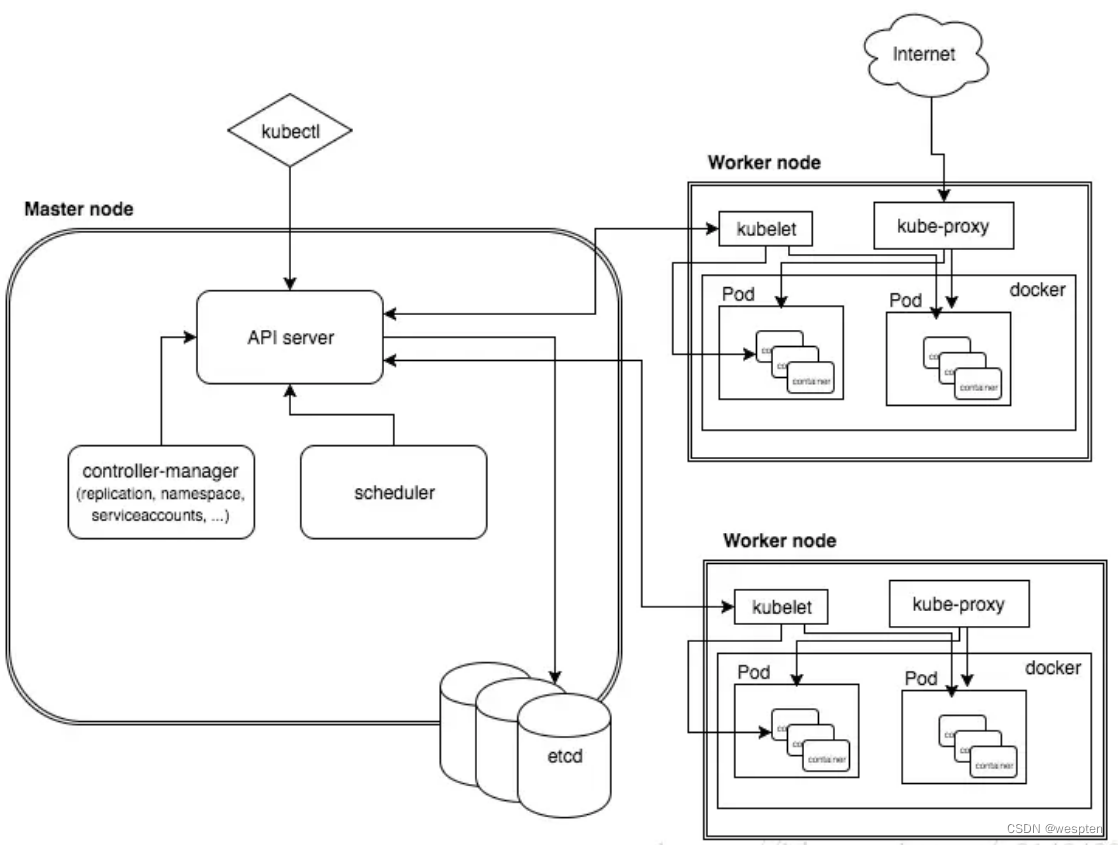
- Master节点: 作为控制节点,对集群进行调度管理;Master由kube-apiserver、kube-scheduler和kube-controller-manager所组成。
- Node节点: 作为真正的工作节点,运行业务应用的容器;Node包含kubelet、kube-proxy和Container Runtime;kubectl用于通过命令行与API Server进行交互,而对Kubernetes进行操作,实现在集群中进行各种资源的增删改查等操作。
- ETCD:是Kubernetes用来备份所有集群数据的数据库。它存储集群的整个配置和状态。主节点查询etcd以检索节点,容器和容器的状态参数。
- Add-on:是对Kubernetes核心功能的扩展,例如增加网络和网络策略等能力。
1. Master节点
kube-apiserver:主要用来处理REST的操作,确保它们生效,并执行相关业务逻辑,以及更新etcd(或者其他存储)中的相关对象。API Server是所有REST命令的入口,它的相关结果状态将被保存在etcd(或其他存储)中。API Server的基本功能包括:
- REST语义,监控,持久化和一致性保证,API 版本控制,放弃和生效
- 内置准入控制语义,同步准入控制钩子,以及异步资源初始化
- API注册和发现
另外,API Server也作为集群的网关。默认情况,客户端通过API Server对集群进行访问,客户端需要通过认证,并使用API Server作为访问Node和Pod(以及service)的堡垒和代理/通道。
kube-controller-manager:用于执行大部分的集群层次的功能,它既执行生命周期功能(例如:命名空间创建和生命周期、事件垃圾收集、已终止垃圾收集、级联删除垃圾收集、node垃圾收集),也执行API业务逻辑(例如:pod的弹性扩容)。控制管理提供自愈能力、扩容、应用生命周期管理、服务发现、路由、服务绑定和提供。Kubernetes默认提供Replication Controller、Node Controller、Namespace Controller、Service Controller、Endpoints Controller、Persistent Controller、DaemonSet Controller等控制器。
kube-scheduler:scheduler组件为容器自动选择运行的主机。依据请求资源的可用性,服务请求的质量等约束条件,scheduler监控未绑定的pod,并将其绑定至特定的node节点。Kubernetes也支持用户自己提供的调度器,Scheduler负责根据调度策略自动将Pod部署到合适Node中,调度策略分为预选策略和优选策略,Pod的整个调度过程分为两步:
- 预选Node:遍历集群中所有的Node,按照具体的预选策略筛选出符合要求的Node列表。如没有Node符合预选策略规则,该Pod就会被挂起,直到集群中出现符合要求的Node。
- 优选Node:预选Node列表的基础上,按照优选策略为待选的Node进行打分和排序,从中获取最优Node。
2. Node节点
kubelet:Kubelet是Kubernetes中最主要的控制器,它是Pod和Node API的主要实现者,Kubelet负责驱动容器执行层。在Kubernetes中,应用容器彼此是隔离的,并且与运行其的主机也是隔离的,这是对应用进行独立解耦管理的关键点。
在Kubernets中,Pod作为基本的执行单元,它可以拥有多个容器和存储数据卷,能够方便在每个容器中打包一个单一的应用,从而解耦了应用构建时和部署时的所关心的事项,已经能够方便在物理机/虚拟机之间进行迁移。API准入控制可以拒绝或者Pod,或者为Pod添加额外的调度约束,但是Kubelet才是Pod是否能够运行在特定Node上的最终裁决者,而不是scheduler或者DaemonSet。kubelet默认情况使用cAdvisor进行资源监控。负责管理Pod、容器、镜像、数据卷等,实现集群对节点的管理,并将容器的运行状态汇报给Kubernetes API Server。
Container Runtime:每一个Node都会运行一个Container Runtime,其负责下载镜像和运行容器。Kubernetes本身并不停容器运行时环境,但提供了接口,可以插入所选择的容器运行时环境。kubelet使用Unix socket之上的gRPC框架与容器运行时进行通信,kubelet作为客户端,而CRI shim作为服务器。常用于docker。不过1.24版本已经不支持docker-shim。
protocol buffers API提供两个gRPC服务,ImageService和RuntimeService。ImageService提供拉取、查看、和移除镜像的RPC。RuntimeSerivce则提供管理Pods和容器生命周期管理的RPC,以及与容器进行交互(exec/attach/port-forward)。容器运行时能够同时管理镜像和容器(例如:Docker和Rkt),并且可以通过同一个套接字提供这两种服务。在Kubelet中,这个套接字通过–container-runtime-endpoint和–image-service-endpoint字段进行设置。Kubernetes CRI支持的容器运行时包括docker、rkt、cri-o、frankti、kata-containers和clear-containers等。
kube-proxy:基于一种公共访问策略(例如:负载均衡),服务提供了一种访问一群pod的途径。此方式通过创建一个虚拟的IP来实现,客户端能够访问此IP,并能够将服务透明的代理至Pod。每一个Node都会运行一个kube-proxy,kube proxy通过iptables规则引导访问至服务IP,并将重定向至正确的后端应用,通过这种方式kube-proxy提供了一个高可用的负载均衡解决方案。服务发现主要通过DNS实现。
在Kubernetes中,kube proxy负责为Pod创建代理服务;引到访问至服务;并实现服务到Pod的路由和转发,以及通过应用的负载均衡。
二、Kubernetes高可用集群部署
1、kubeadm部署
sudo hostnamectl set-hostname <HOSTNAME>注:<HOSTNAME> 根据实际的填写。
sudo systemctl stop firewalld && sudo systemctl disable firewalld
sudo setenforce 0
sudo sed -i 's/^SELINUX=enforcing$/SELINUX=permissive/' /etc/selinux/configcat <<EOF | sudo tee /etc/modules-load.d/k8s.conf
overlay
br_netfilter
EOF
sudo modprobe overlay
sudo modprobe br_netfilter
# 设置所需的 sysctl 参数,参数在重新启动后保持不变
cat <<EOF | sudo tee /etc/sysctl.d/k8s.conf
net.bridge.bridge-nf-call-iptables = 1
net.bridge.bridge-nf-call-ip6tables = 1
net.ipv4.ip_forward = 1
EOF
# 应用 sysctl 参数而不重新启动
sudo sysctl --systemcat <<-EOF | sudo tee /etc/yum.repos.d/kubernetes.repo > /dev/null
[kubernetes]
name=Aliyun-kubernetes
baseurl=https://mirrors.aliyun.com/kubernetes/yum/repos/kubernetes-el7-x86_64/
enabled=1
gpgcheck=0
EOF
sudo yum install -y kubelet kubeadm kubectl --disableexcludes=kubernetes2、二进制安装基础组件
1. 环境变量
规划端口:
| - | 端口范围 |
|---|---|
| etcd数据库 | 2379、2380、2381; |
| k8s组件端口 | 6443、10257、10257、10250、10249、10256 |
| k8s插件端口 | Calico: 179、9099; |
| k8s NodePort端口 | 30000 - 32767 |
| ip_local_port_range | 32768 - 65535 |
下面对上面的各端口类型进行解释:
- etcd端口:所需端口
- k8s组件端口:基础组件
- k8s插件端口:calico端口、nginx-ingress-controller端口
- k8s NodePort端口:跑在容器里面的应用,可以通过这个范围内的端口向外暴露服务,所以应用的对外端口要在这个范围内
- ip_local_port_range:主机上一个进程访问外部应用时,需要与外部应用建立TCP连接,TCP连接需要本机的一个端口,主机会从这个范围内选择一个没有使用的端口建立TCP连接;
设置主机名:
$ hostnamectl set-hostname k8s-master01
$ hostnamectl set-hostname k8s-node01
$ hostnamectl set-hostname k8s-node02注意:主机名不要用 _ 。不然启动 kubelet 有问题。识别不到主机名。
设置主机名映射:
$ cat >> /etc/hosts <<-EOF
192.168.31.103 k8s-master01
192.168.31.95 k8s-node01
192.168.31.78 k8s-node02
192.168.31.253 k8s-node03
EOF关闭防火墙:
$ sudo systemctl stop firewalld
$ sudo systemctl disable firewalld关闭selinux:
#临时生效
$ sudo setenforce 0
sed -ri 's/(SELINUX=).*/\1disabled/g' /etc/selinux/config关闭交换分区:
#临时生效
$ swapoff -a
#永久生效,需要重启
$ sed -i '/ swap / s/^\(.*\)$/#\1/g' /etc/fstab加载ipvs模块:
$ cat > /etc/sysconfig/modules/ipvs.modules <<-EOF
#!/bin/bash
modprobe -- ip_vs
modprobe -- ip_vs_rr
modprobe -- ip_vs_wrr
modprobe -- ip_vs_sh
modprobe -- nf_conntrack_ipv4
modprobe -- br_netfilter
modprobe -- ipip
EOF
# 生效ipvs模块
$ chmod 755 /etc/sysconfig/modules/ipvs.modules && bash /etc/sysconfig/modules/ipvs.modules
# 验证
$ lsmod | grep -e ip_vs -e nf_conntrack_ipv4 -e br_netfilter注意:在 /etc/sysconfig/modules/ 目录下的modules文件,重启会自动加载。
安装ipset依赖包:
$ yum install ipvsadm wget vim -y # 确保安装ipset包优化内核参数:
$ cat > /etc/sysctl.d/kubernetes.conf << EOF
net.bridge.bridge-nf-call-iptables=1
net.bridge.bridge-nf-call-ip6tables=1
net.ipv4.tcp_tw_recycle=0
vm.swappiness=0
vm.overcommit_memory=1
vm.panic_on_oom=0
fs.inotify.max_user_watches=89100
fs.file-max=52706963
fs.nr_open=52706963
net.ipv6.conf.all.disable_ipv6=1
net.netfilter.nf_conntrack_max=2310720
net.ipv4.conf.all.rp_filter=1
kernel.sem=250 32000 100 128
net.core.netdev_max_backlog = 32768
net.core.rmem_default = 8388608
net.core.rmem_max = 16777216
net.core.somaxconn = 32768
net.core.wmem_default = 8388608
net.core.wmem_max = 16777216
net.ipv4.ip_local_port_range = 32768 65535
net.ipv4.ip_forward = 1
net.ipv4.tcp_fin_timeout = 30
net.ipv4.tcp_keepalive_time = 1200
net.ipv4.tcp_max_orphans = 3276800
net.ipv4.tcp_max_syn_backlog = 65536
net.ipv4.tcp_max_tw_buckets = 6000
net.ipv4.tcp_mem = 94500000 91500000 92700000
net.ipv4.tcp_rmem = 32768 436600 873200
net.ipv4.tcp_syn_retries = 2
net.ipv4.tcp_synack_retries = 2
net.ipv4.tcp_syncookies = 1
net.ipv4.tcp_tw_reuse = 1
net.ipv4.tcp_wmem = 8192 436600 873200
EOF
# 生效 kubernetes.conf 文件
$ sysctl -p /etc/sysctl.d/kubernetes.conf
# 设置资源限制
cat >> /etc/security/limits.conf <<-EOF
* - nofile 65535
* - core 65535
* - nproc 65535
* - stack 65535
EOF设置时间同步:
$ yum install ntp -y
$ vim /etc/ntp.conf
#server 0.centos.pool.ntp.org iburst 注释以下四行
#server 1.centos.pool.ntp.org iburst
#server 2.centos.pool.ntp.org iburst
#server 3.centos.pool.ntp.org iburst
server ntp1.aliyun.com iburst #添加同步 ntp.aliyun.com
#启动并加入开机自启
$ systemctl start ntpd.service
$ systemctl enable ntpd.service2. 安装etcd
创建etcd目录及加入环境变量:
$ mkdir -p /data/etcd/{bin,conf,certs,data}
$ chmod 700 /data/etcd/data
$ echo 'PATH=/data/etcd/bin:$PATH' > /etc/profile.d/etcd.sh && source /etc/profile.d/etcd.sh下载生成证书工具:
$ mkdir ~/cfssl && cd ~/cfssl/
$ wget https://pkg.cfssl.org/R1.2/cfssl_linux-amd64
$ wget https://pkg.cfssl.org/R1.2/cfssljson_linux-amd64
$ wget https://pkg.cfssl.org/R1.2/cfssl-certinfo_linux-amd64
$ cp cfssl-certinfo_linux-amd64 /usr/local/bin/cfssl-certinfo
$ cp cfssljson_linux-amd64 /usr/local/bin/cfssljson
$ cp cfssl_linux-amd64 /usr/local/bin/cfssl
$ chmod u+x /usr/local/bin/cfssl*创建根证书(CA):
$ cat > /data/etcd/certs/ca-config.json <<-EOF
{
"signing": {
"default": {
"expiry": "87600h"
},
"profiles": {
"kubernetes": {
"usages": [
"signing",
"key encipherment",
"server auth",
"client auth"
],
"expiry": "87600h"
}
}
}
}
EOF创建证书签名请求文件:
$ cat > /data/etcd/certs/ca-csr.json <<-EOF
{
"CN": "etcd CA",
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF生成CA证书和私钥:
$ cd /data/etcd/certs/ && cfssl gencert -initca ca-csr.json | cfssljson -bare ca -分发CA证书和私钥到etcd节点:
$ scp /data/etcd/certs/ca*pem root@k8s-node01:/data/etcd/certs/
$ scp /data/etcd/certs/ca*pem root@k8s-node02:/data/etcd/certs/
$ scp /data/etcd/certs/ca*pem root@k8s-node03:/data/etcd/certs/创建etcd证书签名请求:
$ cat > /data/etcd/certs/etcd-csr.json << EOF
{
"CN": "etcd",
"hosts": [
"192.168.31.95",
"192.168.31.78",
"192.168.31.253"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF说明:需要修改上面的 IP 地址。上述文件 hosts 字段中IP为所有 etcd 节点的集群内部通信IP,一个都不能少!为了方便后期扩容可以多写几个预留的IP。
生成证书与私钥:
$ cd /data/etcd/certs/ && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes etcd-csr.json | cfssljson -bare etcd -
说明:-profile对应根(CA)证书的profile。
分发etcd证书和私钥到各个节点:
$ scp /data/etcd/certs/etcd*pem root@k8s-node01:/data/etcd/certs/
$ scp /data/etcd/certs/etcd*pem root@k8s-node02:/data/etcd/certs/
$ scp /data/etcd/certs/etcd*pem root@k8s-node03:/data/etcd/certs/载etcd包:
$ mkdir ~/etcd && cd ~/etcd
$ wget https://mirrors.huaweicloud.com/etcd/v3.4.18/etcd-v3.4.18-linux-amd64.tar.gz
$ tar xf etcd-v3.4.18-linux-amd64.tar.gz
$ cd etcd-v3.4.18-linux-amd64
$ cp -r etcd* /data/etcd/bin/分发etcd程序到各个etcd节点:
$ scp -r /data/etcd/bin/etcd* root@k8s-node01:/data/etcd/bin/
$ scp -r /data/etcd/bin/etcd* root@k8s-node02:/data/etcd/bin/
$ scp -r /data/etcd/bin/etcd* root@k8s-node03:/data/etcd/bin/创建etcd配置文件:
$ cat > /data/etcd/conf/etcd.conf << EOF
#[Member]
ETCD_NAME="etcd01"
ETCD_DATA_DIR="/data/etcd/data/"
ETCD_LISTEN_PEER_URLS="https://192.168.31.95:2380"
ETCD_LISTEN_CLIENT_URLS="https://192.168.31.95:2379"
#[Clustering]
ETCD_INITIAL_ADVERTISE_PEER_URLS="https://192.168.31.95:2380"
ETCD_ADVERTISE_CLIENT_URLS="https://192.168.31.95:2379"
ETCD_INITIAL_CLUSTER="etcd01=https://192.168.31.95:2380,etcd02=https://192.168.31.78:2380,etcd03=https://192.168.31.253:2380"
ETCD_INITIAL_CLUSTER_TOKEN="etcd-cluster"
ETCD_INITIAL_CLUSTER_STATE="new"
EOF说明:需要修改上面的IP地址。
分发etcd配置文件:
$ scp /data/etcd/conf/etcd.conf root@k8s-node01:/data/etcd/conf/
$ scp /data/etcd/conf/etcd.conf root@k8s-node02:/data/etcd/conf/
$ scp /data/etcd/conf/etcd.conf root@k8s-node03:/data/etcd/conf/说明:需要在各个节点修改上面的IP地址和ETCD_NAME 。
创建etcd的systemd模板:
$ cat > /usr/lib/systemd/system/etcd.service <<EOF
[Unit]
Description=Etcd Server
After=network.target
After=network-online.target
Wants=network-online.target
Documentation=https://github.com/coreos
[Service]
Type=notify
EnvironmentFile=/data/etcd/conf/etcd.conf
ExecStart=/data/etcd/bin/etcd \\
--cert-file=/data/etcd/certs/etcd.pem \\
--key-file=/data/etcd/certs/etcd-key.pem \\
--peer-cert-file=/data/etcd/certs/etcd.pem \\
--peer-key-file=/data/etcd/certs/etcd-key.pem \\
--trusted-ca-file=/data/etcd/certs/ca.pem \\
--peer-trusted-ca-file=/data/etcd/certs/ca.pem
LimitNOFILE=65536
Restart=always
RestartSec=30
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF**注意:**确认ExecStart启动参数是否正确。
分发etcd 的systemd 模板:
$ scp /usr/lib/systemd/system/etcd.service k8s-node01:/usr/lib/systemd/system/
$ scp /usr/lib/systemd/system/etcd.service k8s-node02:/usr/lib/systemd/system/
$ scp /usr/lib/systemd/system/etcd.service k8s-node03:/usr/lib/systemd/system/启动etcd:
$ systemctl daemon-reload
$ systemctl start etcd.service
$ systemctl enable etcd.service验证etcd:
$ ETCDCTL_API=3 /data/etcd/bin/etcdctl --cacert=/data/etcd/certs/ca.pem --cert=/data/etcd/certs/etcd.pem --key=/data/etcd/certs/etcd-key.pem --endpoints="https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379" endpoint health -w table
说明:需要修改上面的IP地址。
下载docker二进制包:
$ mkdir ~/docker && cd ~/docker
$ wget https://download.docker.com/linux/static/stable/x86_64/docker-19.03.15.tgz创建docker安装目录及环境变量:
$ mkdir -p /data/docker/{bin,conf,data}
$ echo 'PATH=/data/docker/bin:$PATH' > /etc/profile.d/docker.sh && source /etc/profile.d/docker.sh解压二进制包:
$ tar xf docker-19.03.15.tgz
$ cd docker/
$ cp * /usr/local/bin/分发docker命令:
$ scp /data/docker/bin/* k8s-node01:/usr/local/bin/
$ scp /data/docker/bin/* k8s-node02:/usr/local/bin/
$ scp /data/docker/bin/* k8s-node03:/usr/local/bin/创建docker的systemd模板:
$ cat > /usr/lib/systemd/system/docker.service <<EOF
[Unit]
Description=Docker Application Container Engine
Documentation=https://docs.docker.com
After=network-online.target firewalld.service
Wants=network-online.target
[Service]
Type=notify
ExecStart=/usr/local/bin/dockerd --config-file=/data/docker/conf/daemon.json
ExecReload=/bin/kill -s HUP
LimitNOFILE=infinity
LimitNPROC=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF创建daemon.json文件:
$ cat > /data/docker/conf/daemon.json << EOF
{
"data-root": "/data/docker/data/",
"exec-opts": ["native.cgroupdriver=systemd"],
"registry-mirrors": [
"https://1nj0zren.mirror.aliyuncs.com",
"https://docker.mirrors.ustc.edu.cn",
"http://f1361db2.m.daocloud.io",
"https://registry.docker-cn.com"
],
"log-driver": "json-file",
"log-level": "info"
}
}
EOF分发docker配置文件:
$ scp /usr/lib/systemd/system/docker.service k8s_node01:/usr/lib/systemd/system/
$ scp /usr/lib/systemd/system/docker.service k8s_node02:/usr/lib/systemd/system/
$ scp /usr/lib/systemd/system/docker.service k8s_node03:/usr/lib/systemd/system/
$ scp /data/docker/conf/daemon.json k8s_node01:/data/docker/conf/
$ scp /data/docker/conf/daemon.json k8s_node02:/data/docker/conf/
$ scp /data/docker/conf/daemon.json k8s_node03:/data/docker/conf/启动docker:
$ systemctl daemon-reload
$ systemctl start docker.service
$ systemctl enable docker.service安装docker-compose:
curl -L https://get.daocloud.io/docker/compose/releases/download/1.28.6/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose4. 部署master节点
1)master节点环境配置
创建k8s目录及环境变量:
$ mkdir -p /data/k8s/{bin,conf,certs,logs,data}
$ echo 'PATH=/data/k8s/bin:$PATH' > /etc/profile.d/k8s.sh && source /etc/profile.d/k8s.sh创建CA签名请求文件:
$ cp /data/etcd/certs/ca-config.json /data/k8s/certs/
$ cp /data/etcd/certs/ca-csr.json /data/k8s/certs/
$ sed -i 's/etcd CA/kubernetes CA/g' /data/k8s/certs/ca-csr.json说明:需要使用同一个CA根证书。
生成证书与私钥:
$ cd /data/k8s/certs && cfssl gencert -initca ca-csr.json | cfssljson -bare ca -下载kubernetes二进制包:
kubernetes官方地址,需要 科 学 上 网。
$ mkdir ~/kubernetes && cd ~/kubernetes
$ wget https://github.com/kubernetes/kubernetes/releases/download/v1.18.18/kubernetes.tar.gz
$ tar xf kubernetes.tar.gz
$ cd kubernetes/
$ ./cluster/get-kube-binaries.sh说明:./cluster/get-kube-binaries.sh 这一步需要上外网。亲测没有外网可以下载。但是可以会出现超时,或者连接错误。可以重试几次。下载到 kubernetes-server-linux-amd64.tar.gz压缩包就可以了。后面还会下载 kubernetes-manifests.tar.gz 的压缩可以。可以直接 CTRL + C退出下载。
解压kubernetes的安装包:
$ cd ~/kubernetes/kubernetes/server && tar xf kubernetes-server-linux-amd64.tar.gz说明:进入到server目录下,要是上面操作下载成功的话,会有 kubernetes-server-linux-amd64.tar.gz 压缩包。
2)安装kube-apiserver
拷贝命令:
$ cd ~/kubernetes/kubernetes/server/kubernetes/server/bin
$ cp kube-apiserver kubectl /data/k8s/bin/创建日志目录:
$ mkdir /data/k8s/logs/kube-apiserver生成apiserver证书与私钥:
$ cat > /data/k8s/certs/apiserver-csr.json <<EOF
{
"CN": "system:kube-apiserver",
"hosts": [
"10.183.0.1",
"127.0.0.1",
"192.168.31.103",
"192.168.31.79",
"192.168.31.95",
"192.168.31.78",
"192.168.31.253",
"192.168.31.100",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"name": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF
$ cd /data/k8s/certs && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes apiserver-csr.json | cfssljson -bare apiserver -说明:需要改 IP地址,不可以使用IP地址段。hosts 里面需要写上 service IP地址的x.x.x.1的地址。
创建kube-apiserver的启动参数:
$ cat > /data/k8s/conf/kube-apiserver.conf << EOF
KUBE_APISERVER_OPTS="--alsologtostderr=true \\
--logtostderr=false \\
--v=4 \\
--log-dir=/data/k8s/logs/kube-apiserver \\
--audit-log-maxage=7 \\
--audit-log-maxsize=100 \\
--audit-log-path=/data/k8s/logs/kube-apiserver/kubernetes.audit \\
--audit-policy-file=/data/k8s/conf/kube-apiserver-audit.yml \\
--etcd-servers=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 \\
--bind-address=0.0.0.0 \\
--insecure-port=0 \\
--secure-port=6443 \\
--allow-privileged=true \\
--service-cluster-ip-range=10.183.0.0/24 \\
--enable-admission-plugins=NamespaceLifecycle,LimitRanger,ServiceAccount,ResourceQuota,NodeRestriction,PodPreset \\
--runtime-config=settings.k8s.io/v1alpha1=true \\
--authorization-mode=RBAC,Node \\
--enable-bootstrap-token-auth=true \\
--token-auth-file=/data/k8s/conf/token.csv \\
--service-node-port-range=30000-32767 \\
--kubelet-client-certificate=/data/k8s/certs/apiserver.pem \\
--kubelet-client-key=/data/k8s/certs/apiserver-key.pem \\
--tls-cert-file=/data/k8s/certs/apiserver.pem \\
--tls-private-key-file=/data/k8s/certs/apiserver-key.pem \\
--client-ca-file=/data/k8s/certs/ca.pem \\
--service-account-key-file=/data/k8s/certs/ca-key.pem \\
--etcd-cafile=/data/etcd/certs/ca.pem \\
--etcd-certfile=/data/etcd/certs/etcd.pem \\
--etcd-keyfile=/data/etcd/certs/etcd-key.pem"
EOF说明:需要修改 IP地址 和 service-cluster-ip-range(service IP段) 。
创建审计策略配置文件:
cat > /data/k8s/conf/kube-apiserver-audit.yml <<-EOF
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
# 所有资源都记录请求的元数据(请求的用户、时间戳、资源、动词等等), 但是不记录请求或者响应的消息体。
- level: Metadata
EOF创建上述配置文件中token文件:
$ cat > /data/k8s/conf/token.csv <<EOF
0fb61c46f8991b718eb38d27b605b008,kubelet-bootstrap,10001,"system:kubelet-bootstrap"
EOF
#可以用使用下面命令生成token
$ head -c 16 /dev/urandom | od -An -t x | tr -d ' '创建kube-apiserver的systemd模板:
$ cat > /usr/lib/systemd/system/kube-apiserver.service <<EOF
[Unit]
Description=Kubernetes API Server
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/data/k8s/conf/kube-apiserver.conf
ExecStart=/data/k8s/bin/kube-apiserver \$KUBE_APISERVER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动kube-apiserver:
$ systemctl daemon-reload
$ systemctl start kube-apiserver.service
$ systemctl enable kube-apiserver.service3)安装kube-controller-manager
拷贝命令:
$ cd ~/kubernetes/kubernetes/server/kubernetes/server/bin/
$ cp kube-controller-manager /data/k8s/bin/创建日志目录:
$ mkdir /data/k8s/logs/kube-controller-manager生成证书与私钥:
$ cat > /data/k8s/certs/controller-manager.json << EOF
{
"CN": "system:kube-controller-manager",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF
$ cd /data/k8s/certs && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes controller-manager.json | cfssljson -bare controller-manager -生成连接集群的kubeconfig文件:
$ KUBE_APISERVER="https://192.168.31.103:6443"
$ kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/data/k8s/certs/controller-manager.kubeconfig
$ kubectl config set-credentials system:kube-controller-manager \
--client-certificate=/data/k8s/certs/controller-manager.pem \
--client-key=/data/k8s/certs/controller-manager-key.pem \
--embed-certs=true \
--kubeconfig=/data/k8s/certs/controller-manager.kubeconfig
$ kubectl config set-context default \
--cluster=kubernetes \
--user=system:kube-controller-manager \
--kubeconfig=/data/k8s/certs/controller-manager.kubeconfig
$ kubectl config use-context default \
--kubeconfig=/data/k8s/certs/controller-manager.kubeconfig启动kube-controller-manager参数:
$ cat > /data/k8s/conf/kube-controller-manager.conf <<EOF
KUBE_CONTROLLER_MANAGER_OPTS="--alsologtostderr=true \\
--logtostderr=false \\
--v=4 \\
--log-dir=/data/k8s/logs/kube-controller-manager \\
--master=https://192.168.31.103:6443 \\
--bind-address=0.0.0.0 \\
--port=0 \\
--secure-port=10257 \\
--leader-elect=true \\
--allocate-node-cidrs=true \\
--cluster-cidr=20.0.0.0/16 \\
--service-cluster-ip-range=10.183.0.0/24 \\
--authentication-kubeconfig=/data/k8s/certs/controller-manager.kubeconfig \\
--authorization-kubeconfig=/data/k8s/certs/controller-manager.kubeconfig \\
--client-ca-file=/data/k8s/certs/ca.pem \\
--cluster-signing-cert-file=/data/k8s/certs/ca.pem \\
--cluster-signing-key-file=/data/k8s/certs/ca-key.pem \\
--root-ca-file=/data/k8s/certs/ca.pem \\
--service-account-private-key-file=/data/k8s/certs/ca-key.pem \\
--kubeconfig=/data/k8s/certs/controller-manager.kubeconfig \\
--controllers=*,bootstrapsigner,tokencleaner \\
--node-cidr-mask-size=26 \\
--requestheader-client-ca-file=/data/k8s/certs/controller-manager.pem \\
--use-service-account-credentials=true \\
--experimental-cluster-signing-duration=87600h0m0s"
EOF说明:需要修改 service-cluster-ip-range(service IP段)、cluster-cidr(pod IP段) 和 master 的值。
kube-controller-manager的systemd模板:
$ cat > /usr/lib/systemd/system/kube-controller-manager.service <<EOF
[Unit]
Description=Kubernetes Controller Manager
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/data/k8s/conf/kube-controller-manager.conf
ExecStart=/data/k8s/bin/kube-controller-manager \$KUBE_CONTROLLER_MANAGER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动kube-controller-manager:
$ systemctl daemon-reload
$ systemctl start kube-controller-manager.service
$ systemctl enable kube-controller-manager.service4)安装kube-scheduler
拷贝命令:
$ cd ~/kubernetes/kubernetes/server/kubernetes/server/bin/
$ cp kube-scheduler /data/k8s/bin/创建日志目录:
$ mkdir /data/k8s/logs/kube-scheduler生成证书与私钥:
$ cat > /data/k8s/certs/scheduler.json << EOF
{
"CN": "system:kube-scheduler",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF
$ cd /data/k8s/certs && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes scheduler.json | cfssljson -bare scheduler -生成连接集群的kubeconfig文件:
$ KUBE_APISERVER="https://192.168.31.103:6443"
$ kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/data/k8s/certs/scheduler.kubeconfig
$ kubectl config set-credentials system:kube-scheduler \
--client-certificate=/data/k8s/certs/scheduler.pem \
--client-key=/data/k8s/certs/scheduler-key.pem \
--embed-certs=true \
--kubeconfig=/data/k8s/certs/scheduler.kubeconfig
$ kubectl config set-context default \
--cluster=kubernetes \
--user=system:kube-scheduler \
--kubeconfig=/data/k8s/certs/scheduler.kubeconfig
$ kubectl config use-context default \
--kubeconfig=/data/k8s/certs/scheduler.kubeconfig创建启动kube-scheduler参数:
$ cat > /data/k8s/conf/kube-scheduler.conf <<EOF
KUBE_SCHEDULER_OPTS="--alsologtostderr=true \\
--logtostderr=false \\
--v=4 \\
--log-dir=/data/k8s/logs/kube-scheduler \\
--master=https://192.168.31.103:6443 \\
--authentication-kubeconfig=/data/k8s/certs/scheduler.kubeconfig \\
--authorization-kubeconfig=/data/k8s/certs/scheduler.kubeconfig \\
--bind-address=0.0.0.0 \\
--port=0 \\
--secure-port=10259 \\
--kubeconfig=/data/k8s/certs/scheduler.kubeconfig \\
--client-ca-file=/data/k8s/certs/ca.pem \\
--requestheader-client-ca-file=/data/k8s/certs/scheduler.pem \\
--leader-elect=true"
EOF说明:需要修改 master 的值。
创建kube-scheduler的systemd模板:
$ cat > /usr/lib/systemd/system/kube-scheduler.service <<EOF
[Unit]
Description=Kubernetes Scheduler
Documentation=https://github.com/kubernetes/kubernetes
[Service]
EnvironmentFile=-/data/k8s/conf/kube-scheduler.conf
ExecStart=/data/k8s/bin/kube-scheduler \$KUBE_SCHEDULER_OPTS
Restart=on-failure
[Install]
WantedBy=multi-user.target
EOF启动kube-scheduler:
$ systemctl daemon-reload
$ systemctl start kube-scheduler.service
$ systemctl enable kube-scheduler.service5)客户端设置及验证
客户端设置:
$ cat > /data/k8s/certs/admin-csr.json << EOF
{
"CN": "system:admin",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF
$ cd /data/k8s/certs && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes admin-csr.json | cfssljson -bare admin -
$ KUBE_APISERVER="https://192.168.31.103:6443"
$ kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/data/k8s/certs/admin.kubeconfig
$ kubectl config set-credentials system:admin \
--client-certificate=/data/k8s/certs/admin.pem \
--client-key=/data/k8s/certs/admin-key.pem \
--embed-certs=true \
--kubeconfig=/data/k8s/certs/admin.kubeconfig
$ kubectl config set-context default \
--cluster=kubernetes \
--user=system:admin \
--kubeconfig=/data/k8s/certs/admin.kubeconfig
$ kubectl config use-context default \
--kubeconfig=/data/k8s/certs/admin.kubeconfig
$ sed -ri "s/(--insecure-port=0)/#\1/g" /data/k8s/conf/kube-apiserver.conf
$ systemctl restart kube-apiserver
$ kubectl create clusterrolebinding system:admin --clusterrole=cluster-admin --user=system:admin
$ kubectl create clusterrolebinding system:kube-apiserver --clusterrole=cluster-admin --user=system:kube-apiserver
$ sed -ri "s/#(--insecure-port=0)/\1/g" /data/k8s/conf/kube-apiserver.conf
$ systemctl restart kube-apiserver
$ cp /data/k8s/certs/admin.kubeconfig ~/.kube/config验证:
# http方式验证
$ kubectl get cs
NAME STATUS MESSAGE ERROR
controller-manager Healthy ok
scheduler Healthy ok
etcd-1 Healthy {"health":"true"}
etcd-2 Healthy {"health":"true"}
etcd-0 Healthy {"health":"true"}
# https方式验证
$ curl -sk --cacert /data/k8s/certs/ca.pem --cert /data/k8s/certs/admin.pem --key /data/k8s/certs/admin-key.pem https://192.168.31.103:10257/healthz && echo
$ curl -sk --cacert /data/k8s/certs/ca.pem --cert /data/k8s/certs/admin.pem --key /data/k8s/certs/admin-key.pem https://192.168.31.103:10259/healthz && echo5. 部署节点(master)
1)安装kubelet
授权kubelet-bootstrap用户允许请求证书:
$ kubectl create clusterrolebinding kubelet-bootstrap \
--clusterrole=system:node-bootstrapper \
--user=kubelet-bootstrap创建日志目录:
$ mkdir /data/k8s/logs/kubelet拷贝命令:
$ cd ~/kubernetes/kubernetes/server/kubernetes/server/bin
$ cp kubelet /data/k8s/bin/创建kubelet启动参数:
$ cat > /data/k8s/conf/kubelet.conf <<EOF
KUBELET_OPTS="--alsologtostderr=true \\
--logtostderr=false \\
--v=4 \\
--log-dir=/data/k8s/logs/kubelet \\
--hostname-override=192.168.31.103 \\
--network-plugin=cni \\
--cni-conf-dir=/etc/cni/net.d \\
--cni-bin-dir=/opt/cni/bin \\
--kubeconfig=/data/k8s/certs/kubelet.kubeconfig \\
--bootstrap-kubeconfig=/data/k8s/certs/bootstrap.kubeconfig \\
--config=/data/k8s/conf/kubelet-config.yaml \\
--cert-dir=/data/k8s/certs/ \\
--root-dir=/data/k8s/data/kubelet/ \\
--pod-infra-container-image=ecloudedu/pause-amd64:3.0"
EOF说明:修改 hostname-override 为当前的 IP地址。cni-conf-dir 默认是 /etc/cni/net.d,cni-bin-dir 默认是/opt/cni/bin。指定 cgroupdriver 为systemd,默认也是systemd,root-dir 默认是/var/lib/kubelet目录。
创建kubelet配置参数文件:
$ cat > /data/k8s/conf/kubelet-config.yaml <<EOF
kind: KubeletConfiguration
apiVersion: kubelet.config.k8s.io/v1beta1
address: 0.0.0.0
port: 10250
readOnlyPort: 0
cgroupDriver: systemd
clusterDNS:
- 10.183.0.2
clusterDomain: cluster.local
failSwapOn: false
authentication:
anonymous:
enabled: false
webhook:
cacheTTL: 2m0s
enabled: true
x509:
clientCAFile: /data/k8s/certs/ca.pem
anthorization:
mode: Webhook
Webhook:
cacheAuthorizedTTL: 5m0s
cacheUnauthorizedTTL: 30s
evictionHard:
imagefs.available: 15%
memory.available: 100Mi
nodefs.available: 10%
nodefs.inodesFree: 5%
maxOpenFiles: 1000000
maxPods: 100
EOF说明:需要修改 clusterDNS 的IP地址为 server IP段。
参考地址:
GitHub - kubernetes/kubelet: kubelet component configs
Kubelet 配置 (v1beta1) | Kubernetes
v1beta1 package - k8s.io/kubelet/config/v1beta1 - Go Packages
生成bootstrap.kubeconfig文件:
$ KUBE_APISERVER="https://192.168.31.103:6443" #master IP
$ TOKEN="0fb61c46f8991b718eb38d27b605b008" #跟token.csv文件的token一致
# 设置集群参数
$ kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/data/k8s/certs/bootstrap.kubeconfig
# 设置客户端认证参数
$ kubectl config set-credentials "kubelet-bootstrap" \
--token=${TOKEN} \
--kubeconfig=/data/k8s/certs/bootstrap.kubeconfig
# 设置上下文参数
$ kubectl config set-context default \
--cluster=kubernetes \
--user="kubelet-bootstrap" \
--kubeconfig=/data/k8s/certs/bootstrap.kubeconfig
# 设置默认上下文
$ kubectl config use-context default \
--kubeconfig=/data/k8s/certs/bootstrap.kubeconfig创建kubelet的systemd模板:
$ cat > /usr/lib/systemd/system/kubelet.service <<EOF
[Unit]
Description=Kubernetes Kubelet
After=docker.service
[Service]
EnvironmentFile=/data/k8s/conf/kubelet.conf
ExecStart=/data/k8s/bin/kubelet \$KUBELET_OPTS
Restart=on-failure
LimitNOFILE=65535
[Install]
WantedBy=multi-user.target
EOF启动kubelet:
$ systemctl daemon-reload
$ systemctl start kubelet.service
$ systemctl enable kubelet.service批准kubelet加入集群:
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-C0QE1O0aWVJc-H5AObkjBJ4iqhQY2BiUqIyUVe9UBUM 6m22s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
$ kubectl certificate approve node-csr-DaJ36jEFJwOPQwFGY3uWmsyfS-4_LFYuTsYA71yCOZY
certificatesigningrequest.certificates.k8s.io/node-csr-DaJ36jEFJwOPQwFGY3uWmsyfS-4_LFYuTsYA71yCOZY approved说明:node-csr-C0QE1O0aWVJc-H5AObkjBJ4iqhQY2BiUqIyUVe9UBUM是kubectl get csr获取的name的值。
验证:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.31.103 NotReady <none> 27s v1.18.182)安装kube-proxy
创建日志目录:
$ mkdir /data/k8s/logs/kube-proxy拷贝命令:
$ cd ~/kubernetes/kubernetes/server/kubernetes/server/bin/
$ cp kube-proxy /data/k8s/bin/创建启动kube-proxy的参数:
$ cat > /data/k8s/conf/kube-proxy.conf << EOF
KUBE_PROXY_OPTS="--alsologtostderr=true \\
--logtostderr=false \\
--v=4 \\
--log-dir=/data/k8s/logs/kube-proxy \\
--config=/data/k8s/conf/kube-proxy-config.yml"
EOF创建配置参数文件:
$ cat > /data/k8s/conf/kube-proxy-config.yml << EOF
kind: KubeProxyConfiguration
apiVersion: kubeproxy.config.k8s.io/v1alpha1
bindAddress: 0.0.0.0
metricsBindAddress: 0.0.0.0:10249
clientConnection:
kubeconfig: /data/k8s/certs/proxy.kubeconfig
hostnameOverride: 192.168.31.103
clusterCIDR: 20.0.0.0/16
mode: ipvs
ipvs:
minSyncPeriod: 5s
syncPeriod: 5s
scheduler: "rr"
EOF说明:修改hostnameOverride的值为IP地址。clusterCIDR的值为pod IP段。
参考地址:
GitHub - kubernetes/kube-proxy: kube-proxy component configs
v1alpha1 package - k8s.io/kube-proxy/config/v1alpha1 - Go Packages
kube-proxy 配置 (v1alpha1) | Kubernetes
生成证书与私钥:
$ cat > /data/k8s/certs/proxy.json << EOF
{
"CN": "system:kube-proxy",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "Guangzhou",
"O": "Personal",
"OU": "Personal"
}
]
}
EOF
$ cd /data/k8s/certs && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes proxy.json | cfssljson -bare proxy -生成kube-proxy.kubeconfig文件:
$ KUBE_APISERVER="https://192.168.31.103:6443"
# 设置集群参数
$ kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER} \
--kubeconfig=/data/k8s/certs/proxy.kubeconfig
# 设置客户端认证参数
$ kubectl config set-credentials system:kube-proxy \
--client-certificate=/data/k8s/certs/proxy.pem \
--client-key=/data/k8s/certs/proxy-key.pem \
--embed-certs=true \
--kubeconfig=/data/k8s/certs/proxy.kubeconfig
# 设置上下文参数
$ kubectl config set-context default \
--cluster=kubernetes \
--user=system:kube-proxy \
--kubeconfig=/data/k8s/certs/proxy.kubeconfig
# 设置默认上下文
$ kubectl config use-context default \
--kubeconfig=/data/k8s/certs/proxy.kubeconfig创建kube-proxy的systemd模板:
$ cat > /usr/lib/systemd/system/kube-proxy.service << EOF
[Unit]
Description=Kubernetes Proxy
After=network.target
[Service]
EnvironmentFile=-/data/k8s/conf/kube-proxy.conf
ExecStart=/data/k8s/bin/kube-proxy \$KUBE_PROXY_OPTS
Restart=on-failure
LimitNOFILE=65536
[Install]
WantedBy=multi-user.target
EOF启动kube-proxy:
$ systemctl daemon-reload
$ systemctl start kube-proxy.service
$ systemctl enable kube-proxy.service解决ROLES不显示:
kubectl label node 192.168.31.103 node-role.kubernetes.io/master=如果标签打错了,使用kubectl label node 192.168.31.103 node-role.kubernetes.io/node-取消标签。
6. 新增node节点
创建k8s目录及环境变量:
$ mkdir -p /data/k8s/{bin,conf,certs,logs} && mkdir /data/k8s/logs/kubelet
$ echo 'PATH=/data/k8s/bin:$PATH' > /etc/profile.d/k8s.sh && source /etc/profile.d/k8s.sh获取kubelet文件:
scp root@k8s-master:/data/k8s/bin/kubelet /data/k8s/bin/kubelet启动参数:
$ scp k8s-master01:/data/k8s/conf/kubelet.conf /data/k8s/conf/kubelet.conf
$ scp k8s-master:/data/k8s/conf/kubelet-config.yaml /data/k8s/conf/注意:修改 kubelet.conf 配置文件中的hostname-override的值。
获取相关证书:
$ scp root@k8s-master01:/data/k8s/certs/{ca*pem,bootstrap.kubeconfig} /data/k8s/certs/
创建kubelet的systemd模板:
$ scp k8s-master01:/usr/lib/systemd/system/kubelet.service /usr/lib/systemd/system/kubelet.service
启动kubelet:
$ systemctl daemon-reload
$ systemctl start kubelet.service
$ systemctl enable kubelet.service
批准kubelet加入集群:
$ kubectl get csr
NAME AGE SIGNERNAME REQUESTOR CONDITION
node-csr-i8aN5Ua8282QMSOERSZFCr26dzmSmXod-kv5fCm5Kf8 26s kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Pending
node-csr-sePBDxehlZbf8B4DwMvObQpRp-a5fOKNbx3NpDYcKeA 12m kubernetes.io/kube-apiserver-client-kubelet kubelet-bootstrap Approved,Issued
$ kubectl certificate approve node-csr-i8aN5Ua8282QMSOERSZFCr26dzmSmXod-kv5fCm5Kf8
certificatesigningrequest.certificates.k8s.io/node-csr-i8aN5Ua8282QMSOERSZFCr26dzmSmXod-kv5fCm5Kf8 approved
说明:node-csr-i8aN5Ua8282QMSOERSZFCr26dzmSmXod-kv5fCm5Kf8是kubectl get csr 获取的name的值。
验证:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.31.103 NotReady master 15h v1.18.18
192.168.31.253 NotReady <none> 15h v1.18.18
192.168.31.78 NotReady <none> 4s v1.18.18
192.168.31.95 NotReady <none> 4s v1.18.182)安装kube-proxy服务
创建日志目录:
mkdir /data/k8s/logs/kube-proxy
拷贝kube-proxy文件:
scp root@k8s-master:/data/k8s/bin/kube-proxy /data/k8s/bin/
拷贝启动服务参数:
scp k8s-master:/data/k8s/conf/kube-proxy.conf /data/k8s/conf/kube-proxy.conf
scp root@k8s-master:/data/k8s/conf/kube-proxy-config.yml /data/k8s/conf/
注意:修改 kube-proxy-config.yml 文件中 hostnameOverride与kubelet的hostnameOverride 一致。
拷贝相关证书:
scp root@k8s-master:/data/k8s/certs/{ca*.pem,proxy.kubeconfig} /data/k8s/certs/
创建kube-proxy的systemd模板:
scp k8s-master:/usr/lib/systemd/system/kube-proxy.service /usr/lib/systemd/system/kube-proxy.service
启动kube-proxy服务:
systemctl daemon-reload
systemctl start kube-proxy.service
systemctl enable kube-proxy.service
验证:
journalctl -xeu kube-proxy.service
注意:日志如果出现这个 can't set sysctl net/ipv4/vs/conn_reuse_mode, kernel version must be at least 4.1 需要升级内核。
7. 补充
k8s命令补全:
$ yum install -y bash-completion
$ source /usr/share/bash-completion/bash_completion
$ source <(kubectl completion bash)
$ echo "source <(kubectl completion bash)" >> ~/.bashrc附加iptables规则:
# ssh 服务
iptables -t filter -A INPUT -p icmp --icmp-type 8 -j ACCEPT
iptables -t filter -A INPUT -p tcp --dport 22 -m comment --comment "sshd service" -j ACCEPT
iptables -t filter -A INPUT -m state --state ESTABLISHED,RELATED -j ACCEPT
iptables -t filter -A INPUT -i lo -j ACCEPT
iptables -t filter -P INPUT DROP
# etcd数据库
iptables -t filter -I INPUT -p tcp --dport 2379:2381 -m comment --comment "etcd Component ports" -j ACCEPT
# matster服务
iptables -t filter -I INPUT -p tcp -m multiport --dport 6443,10257,10259 -m comment --comment "k8s master Component ports" -j ACCEPT
# node服务
iptables -t filter -I INPUT -p tcp -m multiport --dport 10249,10250,10256 -m comment --comment "k8s node Component ports" -j ACCEPT
# k8s使用到的端口
iptables -t filter -I INPUT -p tcp --dport 32768:65535 -m comment --comment "ip_local_port_range ports" -j ACCEPT
iptables -t filter -I INPUT -p tcp --dport 30000:32767 -m comment --comment "k8s service nodeports" -j ACCEPT
# calico服务端口
iptables -t filter -I INPUT -p tcp -m multiport --dport 179,9099 -m comment --comment "k8s calico Component ports" -j ACCEPT
iptables -t filter -I INPUT -p tcp --dport 9091 -m comment --comment "k8s calico metrics ports" -j ACCEPT
# coredns服务端口
iptables -t filter -I INPUT -p udp -m udp --dport 53 -m comment --comment "k8s coredns ports" -j ACCEPT
# pod 到 service 网络。没有设置的话,启动coredns失败。
iptables -t filter -I INPUT -p tcp -s 20.0.0.0/16 -d 10.183.0.0/24 -m comment --comment "pod to service" -j ACCEPT
# 记录别drop的数据包,日志在 /var/log/messages,过滤关键字"iptables-drop: "
iptables -t filter -A INPUT -j LOG --log-prefix='iptables-drop: '3、插件部署
1. 安装calico
详细的参数信息,请查看calico官网
下载calico部署yaml文件:
mkdir ~/calico && cd ~/calico
curl https://docs.projectcalico.org/archive/v3.18/manifests/calico-etcd.yaml -o calico.yaml
修改calico yaml文件:
1.修改 Secret 类型,calico-etcd-secrets 的 `etcd-key` 、 `etcd-cert` 、 `etcd-ca`
将 cat /data/etcd/certs/ca.pem | base64 -w 0 && echo 输出的所有内容复制到 `etcd-ca`
将 cat /data/etcd/certs/etcd.pem | base64 -w 0 && echo 输出的所有内容复制到 `etcd-cert`
将 cat /data/etcd/certs/etcd-key.pem | base64 -w 0 && echo 输出的所有内容复制到 `etcd-key`
2.修改 ConfigMap 类型,calico-config 的 `etcd_endpoints`、`etcd_ca`、`etcd_cert`、`etcd_key`
`etcd_endpoints`:"https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379"
`etcd_ca`: "/calico-secrets/etcd-ca" # "/calico-secrets/etcd-ca"
`etcd_cert`: "/calico-secrets/etcd-cert" # "/calico-secrets/etcd-cert"
`etcd_key`: "/calico-secrets/etcd-key" # "/calico-secrets/etcd-key"
根据后面注释的内容填写。
3.修改 DaemonSet 类型,calico-node 的 `CALICO_IPV4POOL_CIDR`、`calico-etcd-secrets`
将注释打开,填上你预计的pod IP段
- name: CALICO_IPV4POOL_CIDR
value: "20.0.0.0/16"
4.修改 DaemonSet 类型,calico-node 的 spec.template.spec.containers.env 下添加一段下面的内容
# 是指定使用那个网卡,可以使用 | 分隔开,表示或者的关系。
- name: IP_AUTODETECTION_METHOD
value: "interface=eth.*|em.*|enp.*"
5.修改 Deployment 类型,calico-kube-controllers 的 spec.template.spec.volumes
将默认权限400,修改成644。
- name: etcd-certs
secret:
secretName: calico-etcd-secrets
defaultMode: 0644
6.修改 DaemonSet 类型,calico-node 的 spec.template.spec.volumes
将默认权限400,修改成644。
- name: etcd-certs
secret:
secretName: calico-etcd-secrets
defaultMode: 0644
7.暴露metrics接口,calico-node 的 spec.template.spec.containers.env 下添加一段下面的内容
- name: FELIX_PROMETHEUSMETRICSENABLED
value: "True"
- name: FELIX_PROMETHEUSMETRICSPORT
value: "9091"
8. calico-node 的 spec.template.spec.containers 下添加一段下面的内容
ports:
- containerPort: 9091
name: http-metrics
protocol: TCP
需要监控calico才设置 7、8 步骤,metric接口需要暴露 9091 端口。
部署calico:
kubectl apply -f calico.yaml
验证calico:
$ kubectl -n kube-system get pod
NAME READY STATUS RESTARTS AGE
calico-kube-controllers-f4c6dbf-tkq77 1/1 Running 1 42h
calico-node-c4ccj 1/1 Running 1 42h
calico-node-crs9k 1/1 Running 1 42h
calico-node-fm697 1/1 Running 1 42h
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
192.168.31.103 Ready master 5d23h v1.18.18
192.168.31.253 Ready <none> 5d23h v1.18.18
192.168.31.78 Ready <none> 5d23h v1.18.18
192.168.31.95 Ready <none> 5d23h v1.18.18
**注意**:status不是为ready的话,稍等一段时间再看看。一直都没有变成ready,请检查 kubelet 配置文件是否设置cni-bin-dir参数。默认是 `/opt/cni/bin`、`/etc/cni/net.d/`
$ kubectl run busybox --image=jiaxzeng/busybox:1.24.1 sleep 3600
$ kubectl run nginx --image=nginx
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
busybox 1/1 Running 6 42h 20.0.58.194 192.168.31.78 <none> <none>
nginx 1/1 Running 1 42h 20.0.85.194 192.168.31.95 <none> <none>
$ kubectl exec busybox -- ping 20.0.85.194 -c4
PING 20.0.85.194 (20.0.85.194): 56 data bytes
64 bytes from 20.0.85.194: seq=0 ttl=62 time=0.820 ms
64 bytes from 20.0.85.194: seq=1 ttl=62 time=0.825 ms
64 bytes from 20.0.85.194: seq=2 ttl=62 time=0.886 ms
64 bytes from 20.0.85.194: seq=3 ttl=62 time=0.840 ms
--- 20.0.85.194 ping statistics ---
4 packets transmitted, 4 packets received, 0% packet loss
round-trip min/avg/max = 0.820/0.842/0.886 ms
除ping不通跨节点容器外,其他都没有问题的话。
可能是IP隧道的原因。可以手动测试一下两台主机IP隧道是否可以通信。
modprobe ipip
ip tunnel add ipip-tunnel mode ipip remote 对端外面IP local 本机外网IP
ifconfig ipip-tunnel 虚IP netmask 255.255.255.0
如上述不通,请核查主机IP隧道通信问题。如果是openstack创建的虚机出现这种情况,可以禁用安全端口功能。
openstack server show 主机名称
openstack server remove security group 主机名称 安全组名称
openstack port set --disable-port-security `openstack port list | grep '主机IP地址' | awk '{print $2}'`
安装calicoctl客户端:
curl -L https://github.com/projectcalico/calicoctl/releases/download/v3.18.6/calicoctl -o /usr/local/bin/calicoctl
chmod +x /usr/local/bin/calicoctl
配置calicoctl:
mkdir -p /etc/calico
cat <<EOF | sudo tee /etc/calico/calicoctl.cfg > /dev/null
apiVersion: projectcalico.org/v3
kind: CalicoAPIConfig
metadata:
spec:
etcdEndpoints: https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379
etcdKeyFile: /data/etcd/certs/etcd-key.pem
etcdCertFile: /data/etcd/certs/etcd.pem
etcdCACertFile: /data/etcd/certs/ca.pem
EOF2. 部署coreDNS
下载coredns部署yaml文件:
$ mkdir ~/coredns && cd ~/coredns
$ wget https://raw.githubusercontent.com/kubernetes/kubernetes/v1.18.18/cluster/addons/dns/coredns/coredns.yaml.sed -O coredns.yaml
修改参数:
$ vim coredns.yaml
...
kubernetes $DNS_DOMAIN in-addr.arpa ip6.arpa {
...
memory: $DNS_MEMORY_LIMIT
...
clusterIP: $DNS_SERVER_IP
...
image: k8s.gcr.io/coredns:1.6.5
# 添加 pod 反亲和,在 deploy.spec.template.spec 添加以下内容
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
k8s-app: kube-dns
- 将
$DNS_DOMAIN替换成cluster.local.。默认 DNS_DOMAIN 就是 cluster.local. 。 - 将
$DNS_MEMORY_LIMIT替换成合适的资源。 - 将
$DNS_SERVER_IP替换成和 kubelet-config.yaml 的clusterDNS字段保持一致 - 如果不能上外网的话,将 image 的镜像设置为
coredns/coredns:x.x.x。 - 生产环境只有一个副本数不合适,所以在
deployment控制器的spec字段下,添加一行replicas: 3参数。
部署coredns:
$ kubectl apply -f coredns.yaml
验证:
$ kubectl get pod -n kube-system -l k8s-app=kube-dns
NAME READY STATUS RESTARTS AGE
coredns-75d9bd4f59-df94b 1/1 Running 0 7m55s
coredns-75d9bd4f59-kh4rp 1/1 Running 0 7m55s
coredns-75d9bd4f59-vjkpb 1/1 Running 0 7m55s
$ kubectl run dig --rm -it --image=jiaxzeng/dig:latest /bin/sh
If you don't see a command prompt, try pressing enter.
/ # nslookup kubernetes.default.svc.cluster.local.
Server: 10.211.0.2
Address: 10.211.0.2#53
Name: kubernetes.default.svc.cluster.local
Address: 10.211.0.1
/ # nslookup kube-dns.kube-system.svc.cluster.local.
Server: 10.211.0.2
Address: 10.211.0.2#53
Name: kube-dns.kube-system.svc.cluster.local
Address: 10.211.0.23. 安装metrics-server
创建证书签名请求文件:
cat > /data/k8s/certs/proxy-client-csr.json <<-EOF
{
"CN": "aggregator",
"hosts": [],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [
{
"C": "CN",
"ST": "GuangDong",
"L": "GuangDong",
"O": "k8s"
}
]
}
EOF
生成proxy-client证书和私钥:
cd /data/k8s/certs/ && cfssl gencert -ca=ca.pem -ca-key=ca-key.pem -config=ca-config.json -profile=kubernetes proxy-client-csr.json | cfssljson -bare proxy-client -
下载yaml文件:
mkdir ~/metrics-server && cd ~/metrics-server
wget https://github.com/kubernetes-sigs/metrics-server/releases/download/v0.5.2/components.yaml -O metrics-server.yaml
修改配置文件,修改metrics-server容器中的 deployment.spec.template.spec.containers.args 的参数:
- args:
- --cert-dir=/tmp
- --secure-port=4443
- --kubelet-preferred-address-types=InternalIP,ExternalIP,Hostname
- --kubelet-use-node-status-port
- --kubelet-insecure-tls # 添加的
kube-apiserver 服务开启API聚合功能:
# /data/k8s/conf/kube-apiserver.conf 添加以下内容
--runtime-config=api/all=true \
--requestheader-allowed-names=aggregator \
--requestheader-group-headers=X-Remote-Group \
--requestheader-username-headers=X-Remote-User \
--requestheader-extra-headers-prefix=X-Remote-Extra- \
--requestheader-client-ca-file=/data/k8s/certs/ca.pem \
--proxy-client-cert-file=/data/k8s/certs/proxy-client.pem \
--proxy-client-key-file=/data/k8s/certs/proxy-client-key.pem \
--enable-aggregator-routing=true"
- –requestheader-allowed-names: 允许访问的客户端 common names 列表,通过 header 中 –requestheader-username-headers 参数指定的字段获取。客户端 common names 的名称需要在 client-ca-file 中进行设置,将其设置为空值时,表示任意客户端都可访问。
- –requestheader-username-headers: 参数指定的字段获取。
- –requestheader-group-headers 请求头中需要检查的组名。
- –requestheader-extra-headers-prefix: 请求头中需要检查的前缀名。
- –requestheader-username-headers 请求头中需要检查的用户名。
- –requestheader-client-ca-file: 客户端CA证书。
- –proxy-client-cert-file: 在请求期间验证Aggregator的客户端CA证书。
- –proxy-client-key-file: 在请求期间验证Aggregator的客户端私钥。
- --enable-aggregator-routing=true 如果 kube-apiserver 所在的主机上没有运行 kube-proxy,即无法通过服务的 ClusterIP 进行访问,那么还需要设置以下启动参数。
重启kube-apiserver服务:
systemctl daemon-reload && systemctl restart kube-apiserver
部署metrics-server:
cd ~/metrics-server
kubectl apply -f metrics-server.yaml
如果出现拉取镜像失败的话,可以更换仓库地址。修改 metrics-server.yaml, 将 k8s.gcr.io/metrics-server/metrics-server:v0.5.2 修改成 bitnami/metrics-server:0.5.2。
4. 部署dashboard
下载dashboard.yaml文件:
$ mkdir ~/dashboard && cd ~/dashboard
$ wget https://raw.githubusercontent.com/kubernetes/dashboard/master/aio/deploy/recommended.yaml -O dashboard.yaml
修改dashboard.yml:
kind: Service
apiVersion: v1
metadata:
labels:
k8s-app: kubernetes-dashboard
name: kubernetes-dashboard
namespace: kubernetes-dashboard
spec:
ports:
- port: 443
targetPort: 8443
nodePort: 30088 #添加
type: NodePort #添加
selector:
k8s-app: kubernetes-dashboard
添加两个参数nodePort、type 。请仔细看配置文件,有两个Service配置文件。
部署dashboard:
$ kubectl apply -f dashboard.yaml
创建sa并绑定cluster-admin:
$ kubectl create serviceaccount dashboard-admin -n kube-system
$ kubectl create clusterrolebinding dashboard-admin --clusterrole=cluster-admin --serviceaccount=kube-system:dashboard-admin
验证:
$ kubectl get pod -n kubernetes-dashboard
NAME READY STATUS RESTARTS AGE
dashboard-metrics-scraper-78f5d9f487-8gn6n 1/1 Running 0 5m47s
kubernetes-dashboard-7d8574ffd9-cgwvq 1/1 Running 0 5m47s
获取token:
$ kubectl -n kube-system describe secret $(kubectl -n kube-system get secret | grep dashboard-admin | awk '{print $1}')
Name: dashboard-admin-token-dw4zw
Namespace: kube-system
Labels: <none>
Annotations: kubernetes.io/service-account.name: dashboard-admin
kubernetes.io/service-account.uid: 50d8dc6a-d75c-41e3-b9a6-82006d0970f9
Type: kubernetes.io/service-account-token
Data
====
ca.crt: 1314 bytes
namespace: 11 bytes
token: eyJhbGciOiJSUzI1NiIsImtpZCI6InlPZEgtUlJLQ3lReG4zMlEtSm53UFNsc09nMmQ0YWVOWFhPbEUwUF85aEUifQ.eyJpc3MiOiJrdWJlcm5ldGVzL3NlcnZpY2VhY2NvdW50Iiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9uYW1lc3BhY2UiOiJrdWJlLXN5c3RlbSIsImt1YmVybmV0ZXMuaW8vc2VydmljZWFjY291bnQvc2VjcmV0Lm5hbWUiOiJkYXNoYm9hcmQtYWRtaW4tdG9rZW4tZHc0enciLCJrdWJlcm5ldGVzLmlvL3NlcnZpY2VhY2NvdW50L3NlcnZpY2UtYWNjb3VudC5uYW1lIjoiZGFzaGJvYXJkLWFkbWluIiwia3ViZXJuZXRlcy5pby9zZXJ2aWNlYWNjb3VudC9zZXJ2aWNlLWFjY291bnQudWlkIjoiNTBkOGRjNmEtZDc1Yy00MWUzLWI5YTYtODIwMDZkMDk3MGY5Iiwic3ViIjoic3lzdGVtOnNlcnZpY2VhY2NvdW50Omt1YmUtc3lzdGVtOmRhc2hib2FyZC1hZG1pbiJ9.sgEroj26ANWX1PzzEMZlCIa1ZxcPkYuP5xolT1L6DDdlaJFteaZZffOqv3hIGQBSUW02n6-nZz4VvRZAitrcA9BCW2VPlqHiQDE37UueU8UE1frQ4VtUkLXAKtMc7CUgHa1stod51LW2ndIKiwq-qWdNC1CQA0KsiBi0t2mGgjNQSII9-7FBTFruDwHUp6RRRqtl_NUl1WQanhHOPXia5wScfB37K8MVB0A4jxXIxNCwpd7zEVp-oQPw8XB500Ut94xwUJY6ppxJpnzXHTcoNt6ClapldTtzTY-HXzy0nXv8QVDozTXC7rTX7dChc1yDjMLWqf-KwT1ZYrKzk-2RHg4、高可用master
环境配置与上面的一样。
1. 安装master节点
创建k8s目录及环境变量:
$ mkdir -p /data/k8s/{bin,conf,certs,logs,data}
$ mkdir -p /data/etcd/certs
$ echo 'PATH=/data/k8s/bin:$PATH' > /etc/profile.d/k8s.sh && source /etc/profile.d/k8s.sh
拷贝命令:
$ scp k8s-master01:/data/k8s/bin/{kube-apiserver,kubectl} /data/k8s/bin/
创建日志目录:
$ mkdir /data/k8s/logs/kube-api-server
获取证书:
$ scp k8s-master01:/data/k8s/certs/{apiserver*.pem,ca*.pem} /data/k8s/certs/
$ scp k8s-node01:/data/etcd/certs/{ca*.pem,etcd*.pem} /data/etcd/certs/
获取审计配置文件:
$ scp k8s-master01:/data/k8s/conf/kube-apiserver-audit.yml /data/k8s/conf/
获取kube-apiserver的启动参数:
$ scp k8s-master01:/data/k8s/conf/kube-apiserver.conf /data/k8s/conf/
说明:需要修改advertise-address为IP地址 。
获取token文件:
$ scp k8s-master01:/data/k8s/conf/token.csv /data/k8s/conf/
创建kube-apiserver的systemd模板:
$ scp k8s-master01:/usr/lib/systemd/system/kube-apiserver.service /usr/lib/systemd/system/kube-apiserver.service
启动kube-apiserver:
$ systemctl daemon-reload
$ systemctl start kube-apiserver.service
$ systemctl enable kube-apiserver.service
拷贝命令:
$ scp k8s-master01:/data/k8s/bin/kube-controller-manager /data/k8s/bin/
创建日志目录:
$ mkdir /data/k8s/logs/kube-controller-manager
获取证书:
$ scp k8s-master01:/data/k8s/certs/controller-manager*.pem /data/k8s/certs/
生成连接集群的kubeconfig文件:
scp k8s-master01:/data/k8s/certs/controller-manager.kubeconfig /data/k8s/certs/
sed -ri 's/192.168.31.103/192.168.31.79/g' /data/k8s/certs/controller-manager.kubeconfig
获取kube-controller-manager参数:
$ scp k8s-master01:/data/k8s/conf/kube-controller-manager.conf /data/k8s/conf/
说明:需要修改master的值。
kube-controller-manager的systemd模板:
$ scp k8s-master01:/usr/lib/systemd/system/kube-controller-manager.service /usr/lib/systemd/system/kube-controller-manager.service
启动kube-controller-manager:
$ systemctl daemon-reload
$ systemctl start kube-controller-manager.service
$ systemctl enable kube-controller-manager.service
拷贝命令:
$ scp k8s-master01:/data/k8s/bin/kube-scheduler /data/k8s/bin
创建日志目录:
$ mkdir /data/k8s/logs/kube-scheduler
获取证书:
$ scp k8s-master01:/data/k8s/certs/scheduler*.pem /data/k8s/certs
生成连接集群的kubeconfig文件:
scp k8s-master01:/data/k8s/certs/scheduler.kubeconfig /data/k8s/certs/
sed -ri 's/192.168.31.103/192.168.31.79/g' /data/k8s/certs/scheduler.kubeconfig
获取启动kube-scheduler参数:
$ scp k8s-master01:/data/k8s/conf/kube-scheduler.conf /data/k8s/conf/
说明:需要修改master的值。
创建kube-scheduler的systemd模板:
$ scp k8s-master01:/usr/lib/systemd/system/kube-scheduler.service /usr/lib/systemd/system/kube-scheduler.service
启动kube-scheduler:
$ systemctl daemon-reload
$ systemctl start kube-scheduler.service
$ systemctl enable kube-scheduler.service
mkdir -p ~/.kube/
scp k8s-master01:~/.kube/config ~/.kube/config2. 负载均衡服务器
非集群节点上安装以下的服务。
curl -L https://get.daocloud.io/docker/compose/releases/download/1.29.2/docker-compose-`uname -s`-`uname -m` > /usr/local/bin/docker-compose
chmod +x /usr/local/bin/docker-compose
在尝试部署 haproxy 容器之前,主机必须允许 ipv4 地址的非本地绑定。为此,请配置 sysctl 可调参数net.ipv4.ip_nonlocal_bind=1。
# 持久化系统参数
$ cat <<-EOF | sudo tee /etc/sysctl.d/kubernetes.conf > /dev/null
net.ipv4.ip_nonlocal_bind = 1
EOF
# 生效配置文件
$ sysctl -p /etc/sysctl.d/kubernetes.conf
# 验证
$ cat /proc/sys/net/ipv4/ip_nonlocal_bind
1
haproxy配置:
$ cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local7 info
defaults
log global
mode tcp
option tcplog
maxconn 4096
balance roundrobin
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats
bind *:10086
mode http
stats enable
stats uri /stats
stats auth admin:admin
stats admin if TRUE
listen kubernetes
bind 192.168.31.100:6443
mode tcp
balance roundrobin
server master01 192.168.31.103:6443 weight 1 check inter 1000 rise 3 fall 5
server master02 192.168.31.79:6443 weight 1 check inter 1000 rise 3 fall 5
server:修改主机IP和端口。
其他配置可以保持不变,其中haproxy统计页面默认账号密码为admin:admin。
docker-compose配置:
$ cat /etc/haproxy/docker-compose.yaml
version: "3"
services:
haproxy:
container_name: haproxy
image: haproxy:2.3-alpine
volumes:
- "./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg"
network_mode: "host"
restart: always
启动haproxy:
docker-compose -f /etc/haproxy/docker-compose.yaml up -d
配置keepalived:
$ cat /etc/keepalived/keepalived.conf
include /etc/keepalived/keepalived_apiserver.conf
$ cat /etc/keepalived/keepalived_apiserver.conf
! Configuration File for keepalived
global_defs {
# 标识机器的字符串(默认:本地主机名)
router_id lb01
}
vrrp_script apiserver {
# 检测脚本路径
script "/etc/keepalived/chk_apiserver.sh"
# 执行检测脚本的用户
user root
# 脚本调用之间的秒数
interval 1
# 转换失败所需的次数
fall 5
# 转换成功所需的次数
rise 3
# 按此权重调整优先级
weight -50
}
# 如果多个 vrrp_instance,切记名称不可以重复。包含上面的 include 其他子路径
vrrp_instance apiserver {
# 状态是主节点还是从节点
state MASTER
# inside_network 的接口,由 vrrp 绑定。
interface eth0
# 虚拟路由id,根据该id进行组成主从架构
virtual_router_id 100
# 初始优先级
# 最后优先级权重计算方法
# (1) weight 为正数,priority - weight
# (2) weight 为负数,priority + weight
priority 200
# 加入集群的认证
authentication {
auth_type PASS
auth_pass pwd100
}
# vip 地址
virtual_ipaddress {
192.168.31.100
}
# 健康检查脚本
track_script {
apiserver
}
}
keepalived检测脚本:
$ cat /etc/keepalived/chk_apiserver.sh
#!/bin/bash
count=$(ss -lntup | egrep '6443' | wc -l)
if [ "$count" -ge 1 ];then
# 退出状态为0,代表检查成功
exit 0
else
# 退出状态为1,代表检查不成功
exit 1
fi
$ chmod +x /etc/keepalived/chk_apiserver.sh
docker-compose文件:
$ cat /etc/keepalived/docker-compose.yaml
version: "3"
services:
keepalived:
container_name: keepalived
image: arcts/keepalived:1.2.2
environment:
KEEPALIVED_AUTOCONF: "false"
KEEPALIVED_DEBUG: "true"
volumes:
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/localtime"
- ".:/etc/keepalived"
cap_add:
- NET_ADMIN
network_mode: "host"
restart: always
4)启动keepalived
$ docker-compose -f /etc/keepalived/docker-compose.yaml up -d3. 修改服务连接地址
k8s所有的master节点:
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/bootstrap.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/admin.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/kubelet.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/proxy.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' ~/.kube/config
systemctl restart kubelet kube-proxy
k8s所有的node节点:
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/bootstrap.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/kubelet.kubeconfig
sed -ri 's#(server: https://).*#\1192.168.31.100:6443#g' /data/k8s/certs/proxy.kubeconfig
systemctl restart kubelet kube-proxy4. 附加iptables规则
# haproxy
iptables -t filter -I INPUT -p tcp --dport 6443 -m comment --comment "k8s vip ports" -j ACCEPT
iptables -t filter -I INPUT -p tcp --source 192.168.31.1 --dport 10086 -m comment --comment "haproxy stats ports" -j ACCEPT
# keepalived心跳
iptables -t filter -I INPUT -p vrrp -s 192.168.31.0/24 -d 224.0.0.18 -m comment --comment "keepalived Heartbeat" -j ACCEPT三、ingress使用
1、ingress安装
环境说明:
| kubernetes版本 | nginx-ingress-controller版本 | 使用端口情况 |
|---|---|---|
| 1.18.18 | 0.45.0 | 80、443、8443 |
官方说明:

下载所需的 yaml 文件:
mkdir ~/ingress && cd ~/ingress
wget https://raw.githubusercontent.com/kubernetes/ingress-nginx/controller-v0.45.0/deploy/static/provider/baremetal/deploy.yaml 修改配置文件,将原本的 nodeport 修改成 clusterIP:
# 在 ingress-nginx-controller service的 svc.spec 注释掉 type: NodePort
spec:
# type: NodePort
type: ClusterIP
将容器端口映射到宿主机:
# 在 ingress-nginx-controller 容器的 deploy.spec.template.spec 添加 hostNetwork: true
spec:
hostNetwork: true
修改DNS的策略:
# 在 ingress-nginx-controller 容器的 deploy.spec.template.spec 修改 dnsPolicy
spec:
dnsPolicy: ClusterFirstWithHostNet
修改下载镜像路径:
# 在 ingress-nginx-controller 容器的 deploy.spec.template.spec.containers 修改 image 字段
containers:
- name: controller
image: jiaxzeng/nginx-ingress-controller:v0.45.0
指定 pod 调度特定节点:
# 节点添加标签
kubectl label node k8s-node02 kubernetes.io/ingress=nginx
kubectl label node k8s-node03 kubernetes.io/ingress=nginx
# 在 ingress-nginx-controller 容器的 deploy.spec.template.spec 修改 nodeSelector
nodeSelector:
kubernetes.io/ingress: nginx
$ kubectl apply -f deploy.yaml
namespace/ingress-nginx created
serviceaccount/ingress-nginx created
configmap/ingress-nginx-controller created
clusterrole.rbac.authorization.k8s.io/ingress-nginx created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx created
role.rbac.authorization.k8s.io/ingress-nginx created
rolebinding.rbac.authorization.k8s.io/ingress-nginx created
service/ingress-nginx-controller-admission created
service/ingress-nginx-controller created
deployment.apps/ingress-nginx-controller created
validatingwebhookconfiguration.admissionregistration.k8s.io/ingress-nginx-admission created
serviceaccount/ingress-nginx-admission created
clusterrole.rbac.authorization.k8s.io/ingress-nginx-admission created
clusterrolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
role.rbac.authorization.k8s.io/ingress-nginx-admission created
rolebinding.rbac.authorization.k8s.io/ingress-nginx-admission created
job.batch/ingress-nginx-admission-create created
job.batch/ingress-nginx-admission-patch created
$ kubectl -n ingress-nginx get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
ingress-nginx-admission-create-tm6hb 0/1 Completed 0 21s 20.0.85.198 192.168.31.95 <none> <none>
ingress-nginx-admission-patch-64bgc 0/1 Completed 1 21s 20.0.32.136 192.168.31.103 <none> <none>
ingress-nginx-controller-656cf6c7fd-lw9dx 1/1 Running 0 21s 192.168.31.253 192.168.31.253 <none> <none>
iptables -t filter -I INPUT -p tcp -m multiport --dport 80,443,8443 -m comment --comment "nginx ingress controller ports" -j ACCEPT
iptables -t filter -I INPUT -p tcp --source 192.168.31.0/24 --dport 10254 -m comment --comment "nginx ingress metrics ports" -j ACCEPT2、ingress高可用
将原基础的 ingress-nginx 一个副本提升到多个副本。然后再提供VIP进行访问。
以下三种方式都可以实现高可用
- LoadBalancer
- nodeport + VIP
- hostpath + VIP
- 其中
LoadBalancer是在公有云上使用,不过自管集群也可以安装Metallb也可以实现LoadBalancer的方式。 Metallb的官网为 MetalLB, bare metal load-balancer for Kubernetes
这里演示 hostpath + keepalived + haproxy 的组合方式。实现高可用和高并发。
haproxy的配置文件:
$ cat /etc/haproxy/haproxy.cfg
global
log 127.0.0.1 local7 info
defaults
log global
mode tcp
option tcplog
maxconn 4096
balance roundrobin
timeout connect 5000ms
timeout client 50000ms
timeout server 50000ms
listen stats
bind *:10086
mode http
stats enable
stats uri /stats
stats auth admin:admin
stats admin if TRUE
listen nginx_igress_http
bind 192.168.31.188:80
mode tcp
server master01 192.168.31.103:80 weight 1 check inter 1000 rise 3 fall 5 send-proxy
server master02 192.168.31.79:80 weight 1 check inter 1000 rise 3 fall 5 send-proxy
listen nginx_igress_https
bind 192.168.31.188:443
mode tcp
server master01 192.168.31.103:443 weight 1 check inter 1000 rise 3 fall 5 send-proxy
server master02 192.168.31.79:443 weight 1 check inter 1000 rise 3 fall 5 send-proxy
- server: 修改主机IP和端口
- 其他配置可以保持不变,其中haproxy统计页面默认账号密码为
admin:admin send-proxy是开启 use-proxy 功能,ingress获取真实IP地址
haproxy的docker-compose:
$ cat /etc/haproxy/docker-compose.yaml
version: "3"
services:
haproxy:
container_name: haproxy
image: haproxy:2.3-alpine
volumes:
- "./haproxy.cfg:/usr/local/etc/haproxy/haproxy.cfg"
network_mode: "host"
restart: always
注意:经测试 2.4.9、2.5.0 镜像启动绑定不了低于1024端口。
启动haproxy:
docker-compose -f /etc/haproxy/docker-compose.yaml up -d
keepalived配置:
$ cat /etc/keepalived/keepalived.conf
include /etc/keepalived/keepalived_ingress.conf
$ cat /etc/keepalived/keepalived_ingress.conf
! Configuration File for keepalived
global_defs {
# 标识机器的字符串(默认:本地主机名)
router_id lb02
}
vrrp_script ingress {
# 检测脚本路径
script "/etc/keepalived/chk_ingress.sh"
# 执行检测脚本的用户
user root
# 脚本调用之间的秒数
interval 1
# 转换失败所需的次数
fall 5
# 转换成功所需的次数
rise 3
# 按此权重调整优先级
weight -50
}
vrrp_instance ingress {
# 状态是主节点还是从节点
state MASTER
# inside_network 的接口,由 vrrp 绑定。
interface eth0
# 虚拟路由id,根据该id进行组成主从架构
virtual_router_id 200
# 初始优先级
# 最后优先级权重计算方法
# (1) weight 为正数,priority - weight
# (2) weight 为负数,priority + weight
priority 200
# 加入集群的认证
authentication {
auth_type PASS
auth_pass pwd200
}
# vip 地址
virtual_ipaddress {
192.168.31.188
}
# 健康检查脚本
track_script {
ingress
}
}
keepalived检测脚本:
$ cat /etc/keepalived/chk_ingress.sh
#!/bin/bash
count=$(ss -lntup | egrep ":443|:80" | wc -l)
if [ "$count" -ge 2 ];then
# 退出状态为0,代表检查成功
exit 0
else
# 退出状态为1,代表检查不成功
exit 1
fi
$ chmod +x /etc/keepalived/chk_ingress.sh
keepalived的docker-compose:
$ cat /etc/keepalived/docker-compose.yaml
version: "3"
services:
keepalived:
container_name: keepalived
image: arcts/keepalived:1.2.2
environment:
KEEPALIVED_AUTOCONF: "false"
KEEPALIVED_DEBUG: "true"
volumes:
- "/usr/share/zoneinfo/Asia/Shanghai:/etc/localtime"
- ".:/etc/keepalived"
cap_add:
- NET_ADMIN
network_mode: "host"
restart: always
启动keepalived:
docker-compose -f /etc/keepalived/docker-compose.yaml up -d
# 在 deploy 添加或修改replicas
replicas: 2
# 在 deploy.spec.template.spec 下面添加affinity
affinity:
podAntiAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 100
podAffinityTerm:
labelSelector:
matchLabels:
app.kubernetes.io/name: ingress-nginx
topologyKey: kubernetes.io/hostname
需要重启ingress-nginx-controller容器。
iptables -I INPUT -p tcp -m multiport --dports 80,443,8443 -m comment --comment "nginx ingress controller external ports" -j ACCEPT
iptables -I INPUT -p tcp --dport 10086 -m comment --comment "haproxy stats ports" -j ACCEPT3、ingress基本使用
创建测试应用:
cat > nginx.yaml <<-EOF
apiVersion: apps/v1
kind: Deployment
metadata:
name: my-nginx
spec:
selector:
matchLabels:
app: my-nginx
template:
metadata:
labels:
app: my-nginx
spec:
containers:
- name: my-nginx
image: nginx
resources:
limits:
memory: "200Mi"
cpu: "500m"
requests:
memory: "100Mi"
cpu: "100m"
ports:
- name: web
containerPort: 80
---
apiVersion: v1
kind: Service
metadata:
name: nginx-service
spec:
selector:
app: my-nginx
ports:
- port: 80
targetPort: web
EOF
$ kubectl apply -f nginx.yaml
deployment.apps/my-nginx created
service/nginx-service created
$ kubectl get pod -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
my-nginx-759cf4d696-vkj4q 1/1 Running 0 4m10s 20.0.85.199 k8s-node01 <none> <none>
$ cat > nginx-ingress.yaml <<-EOF
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: nginx-ingress
labels:
name: nginx-ingress
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /
backend:
serviceName: nginx-service
servicePort: 80
EOF
$ kubectl apply -f nginx-ingress.yaml
ingress.extensions/nginx-ingress created
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
nginx-ingress <none> www.ecloud.com 192.168.31.103,192.168.31.79 80 21s
$ echo '192.168.31.103 www.ecloud.com' >> /etc/hosts
$ curl www.ecloud.com
<!DOCTYPE html>
<html>
<head>
<title>Welcome to nginx!</title>
<style>
html { color-scheme: light dark; }
body { width: 35em; margin: 0 auto;
font-family: Tahoma, Verdana, Arial, sans-serif; }
</style>
</head>
<body>
<h1>Welcome to nginx!</h1>
<p>If you see this page, the nginx web server is successfully installed and
working. Further configuration is required.</p>
<p>For online documentation and support please refer to
<a href="http://nginx.org/">nginx.org</a>.<br/>
Commercial support is available at
<a href="http://nginx.com/">nginx.com</a>.</p>
<p><em>Thank you for using nginx.</em></p>
</body>
</html>
可以通过 keepalived + LVS 高可用,使用 VIP 做域名解析。这里就不实现了。
4、Rewrite配置
由于域名和公网费用昂贵。通常是只有一个域名,但是有多个应用需要上线。通常都会域名+应用名称(www.ecloud.com/app)。原本应用已经开发好的了,访问是在 / 。那就需要改写上下文来实现。
原应用演示:
$ kubectl get svc app demo
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
app ClusterIP 10.183.0.36 <none> 8001/TCP 6m13s
demo ClusterIP 10.183.0.37 <none> 8002/TCP 2m47s
$ curl 10.183.0.36:8001
app
$ curl 10.183.0.37:8002/test/demo/
demo
现在有两个应用分别是 app 、demo。分别的访问路径为:/、/test/demo。现在只有一个域名是 www.ecloud.com 且需要把两个网页都放在同一个域名访问。
1)添加上下文路径
现在的目标是把 app 应用,可以通过 www.ecloud.com/app/ 来展示。
创建ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2 # 真实到服务的上下文
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /app(/|)(.*) # 浏览器访问上下文
backend:
serviceName: app
servicePort: 8001
$ curl www.ecloud.com/app/
app
$ curl www.ecloud.com/app/index.html
app
现在的目标是把 demo 应用,可以通过 www.ecloud.com/demo/ 来展示。
创建ingress:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: demo
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /test/demo/$2 # 真实到服务的上下文
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /demo(/|)(.*) # 浏览器访问上下文
backend:
serviceName: demo
servicePort: 8002
$ curl www.ecloud.com/demo
demo
$ curl www.ecloud.com/demo/
demo
$ curl www.ecloud.com/demo/index.html
demo
应该给应用设置一个 app-root 的注解,这样当我们访问主域名的时候会自动跳转到我们指定的 app-root 目录下面。如下所示:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: demo
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /test/demo/$2 # 真实到服务的上下文
nginx.ingress.kubernetes.io/app-root: /demo/ # 这里写浏览器访问的路径
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /demo(/|)(.*) # 浏览器访问上下文
backend:
serviceName: demo
servicePort: 8002
验证:
$ curl www.ecloud.com
<html>
<head><title>302 Found</title></head>
<body>
<center><h1>302 Found</h1></center>
<hr><center>nginx</center>
</body>
</html>
# nginx-ingress-controller 的日志
192.168.31.103 - - [16/Sep/2021:08:22:39 +0000] "GET / HTTP/1.1" 302 138 "-" "curl/7.29.0" 78 0.000 [-] [] - - - - 5ba35f028edbd48ff316bd544ae60746
$ curl www.ecloud.com -L
demo
# nginx-ingress-controller 的日志
192.168.31.103 - - [16/Sep/2021:08:22:56 +0000] "GET / HTTP/1.1" 302 138 "-" "curl/7.29.0" 78 0.000 [-] [] - - - - 4ffa0129b9fab80b9e904ad9716bd8ca
192.168.31.103 - - [16/Sep/2021:08:22:56 +0000] "GET /demo/ HTTP/1.1" 200 5 "-" "curl/7.29.0" 83 0.003 [default-demo-8002] [] 20.0.32.159:8002 5 0.002 200 3d17d7cb25f3eacc7eb848955a28675f
不能定义默认的 ingress.spec.backend 字段。否则会发生不符合预期的跳转。
模拟定义 ingress.spec.backend 字段:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
ingressClassName: nginx
backend: # 设置默认的backend
serviceName: app
servicePort: 8001
rules:
- host: www.ecloud.com
http:
paths:
- path: /app(/|$)(.*)
backend:
serviceName: app
servicePort: 8001
查看ingress资源情况:
$ kubectl get ingress
NAME CLASS HOSTS ADDRESS PORTS AGE
app nginx www.ecloud.com 192.168.31.79 80 20m
$ kubectl describe ingress app
Name: app
Namespace: default
Address: 192.168.31.79
Default backend: app:8001 (20.0.32.157:8001)
Rules:
Host Path Backends
---- ---- --------
www.ecloud.com
/app(/|$)(.*) app:8001 (20.0.32.157:8001)
Annotations: nginx.ingress.kubernetes.io/rewrite-target: /$2
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 7m52s (x5 over 21m) nginx-ingress-controller Scheduled for sync
测试访问:
$ curl www.ecloud.com
app
$ curl www.ecloud.com/fskl/fskf/ajfk
app
发现不符合 /app 的上下文也可以匹配到 / 的页面,这个是不符合我们的预期的。
查看nginx的配置文件:
$ kubectl -n ingress-nginx exec -it ingress-nginx-controller-6c979c5b47-bpwf6 -- bash
$ vi /etc/nginx/nginx.conf
# 找到 `server_name` 为设置的域名,找到为 `location ~* "^/"`
# 没有匹配到 `/app` 的上下文,则进入该location。
# 该location读取app应用的 `/` 。所以访问 `/fskl/fskf/ajfk` 都可以访问到 `/` 的页面
# 原本我们的预期是访问错了上下文,应该是报 `404` 的,而不是访问主域名页面
location ~* "^/" {
set $namespace "default";
set $ingress_name "app";
set $service_name "app";
set $service_port "8001";
set $location_path "/"
...
}
虽然没有定义默认的 ingress.spec.backend 字段。在 kubectl describe ingress 查看ingress详情时,会有 Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>) 提示,但是影响正常使用。
5、tls安全路由
互联网越来越严格,很多网站都配置了https的协议了。这里聊一下ingress的tls安全路由,分为以下两种方式:
- 配置安全的路由服务
- 配置HTTPS双向认证
生成一个证书文件tls.crt和一个私钥文件tls.key:
$ openssl req -x509 -nodes -days 365 -newkey rsa:2048 -keyout tls.key -out tls.crt -subj "/CN=foo.ecloud.com"
创建密钥:
$ kubectl create secret tls app-v1-tls --key tls.key --cert tls.crt
创建一个安全的Nginx Ingress服务:
$ cat <<EOF | kubectl create -f -
apiVersion: networking.k8s.io/v1beta1
kind: Ingress
metadata:
name: app-v1-tls
spec:
ingressClassName: nginx
tls:
- hosts:
- foo.ecloud.com
secretName: app-v1-tls
rules:
- host: foo.ecloud.com
http:
paths:
- path: /
backend:
serviceName: app-v1
servicePort: 80
EOF
查看ingress服务:
$ kubectl describe ingress app-v1-tls
Name: app-v1-tls
Namespace: default
Address: 192.168.31.103,192.168.31.79
Default backend: default-http-backend:80 (<error: endpoints "default-http-backend" not found>)
TLS:
app-v1-tls terminates foo.ecloud.com
Rules:
Host Path Backends
---- ---- --------
foo.ecloud.com
/ app-v1:80 (20.0.122.173:80,20.0.32.173:80,20.0.58.236:80)
Annotations: Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Sync 66s (x2 over 85s) nginx-ingress-controller Scheduled for sync
Normal Sync 66s (x2 over 85s) nginx-ingress-controller Scheduled for sync
验证:
$ curl -Lk -H "Host: foo.ecloud.com" 192.168.31.79
<b>version: v1</b>, <br>IP: 20.0.58.236 , <br>hostname: app-v1-68db595855-bv958
$ curl -k -H "Host: foo.ecloud.com" https://192.168.31.79
<b>version: v1</b>, <br>IP: 20.0.122.173 , <br>hostname: app-v1-68db595855-xkc9j
访问 ingress-nginx-controller 的IP地址的 80 端口,会自动调转到 443 端口。
- -H 是设置该IP的域名是 foo.ecloud.com
- -L 是自动调转,-k 跳过证书认证
ingress-nginx 默认使用 TLSv1.2 TLSv1.3 版本。
参考文章 ConfigMap - NGINX Ingress Controller
6、ingress发布管理
1)背景信息
灰度及蓝绿发布是为新版本创建一个与老版本完全一致的生产环境,在不影响老版本的前提下,按照一定的规则把部分流量切换到新版本,当新版本试运行一段时间没有问题后,将用户的全量流量从老版本迁移至新版本。
其中AB测试就是一种灰度发布方式,一部分用户继续使用老版本的服务,将一部分用户的流量切换到新版本,如果新版本运行稳定,则逐步将所有用户迁移到新版本。
使用Nginx Ingress实现灰度发布适用场景主要取决于业务流量切分的策略,目前Nginx Ingress支持基于Header、Cookie和服务权重三种流量切分的策略,基于这三种策略可实现以下两种发布场景
-
切分部分用户流量到新版本
假设线上已运行了一套对外提供七层服务的Service A,此时开发了一些新的特性,需要发布上线一个新的版本Service A',但又不想直接替换原有的Service A,而是期望将Header中包含foo=bar或者Cookie中包含foo=bar的用户请求转发到新版本Service A'中。待运行一段时间稳定后,再逐步全量上线新版本,平滑下线旧版本。 -
切分一定比例的流量到新版本
假设线上已运行了一套对外提供七层服务的Service B,此时修复了一些问题,需要发布上线一个新的版本Service B',但又不想直接替换原有的Service B,而是期望将20%的流量切换到新版本Service B'中。待运行一段时间稳定后,再将所有的流量从旧版本切换到新版本中,平滑下线旧版本。
Nginx Ingress支持通过配置注解(Annotations)来实现不同场景下的发布和测试,可以满足灰度发布、蓝绿发布、A/B测试等业务场景。具体实现过程如下:为服务创建两个Ingress,一个为常规Ingress,另一个为带nginx.ingress.kubernetes.io/canary: "true"注解的Ingress,称为Canary Ingress;为Canary Ingress配置流量切分策略Annotation,两个Ingress相互配合,即可实现多种场景的发布和测试。Nginx Ingress的Annotation支持以下几种规则:
-
nginx.ingress.kubernetes.io/canary-by-header
基于Header的流量切分,适用于灰度发布。如果请求头中包含指定的header名称,并且值为“always”,就将该请求转发给Canary Ingress定义的对应后端服务。如果值为“never”则不转发,可用于回滚到旧版本。如果为其他值则忽略该annotation,并通过优先级将请求流量分配到其他规则。 -
nginx.ingress.kubernetes.io/canary-by-header-value
必须与canary-by-header一起使用,可自定义请求头的取值,包含但不限于“always”或“never”。当请求头的值命中指定的自定义值时,请求将会转发给Canary Ingress定义的对应后端服务,如果是其他值则忽略该annotation,并通过优先级将请求流量分配到其他规则。 -
nginx.ingress.kubernetes.io/canary-by-header-pattern
与canary-by-header-value类似,唯一区别是该annotation用正则表达式匹配请求头的值,而不是某一个固定值。如果该annotation与canary-by-header-value同时存在,该annotation将被忽略。 -
nginx.ingress.kubernetes.io/canary-by-cookie
基于Cookie的流量切分,适用于灰度发布。与canary-by-header类似,该annotation用于cookie,仅支持“always”和“never”,无法自定义取值。 -
nginx.ingress.kubernetes.io/canary-weight
基于服务权重的流量切分,适用于蓝绿部署。表示Canary Ingress所分配流量的百分比,取值范围[0-100]。例如,设置为100,表示所有流量都将转发给Canary Ingress对应的后端服务。
- 以上注解规则会按优先级进行评估,优先级为:canary-by-header -> canary-by-cookie -> canary-weight。
- 当Ingress被标记为Canary Ingress时,除了nginx.ingress.kubernetes.io/load-balance和nginx.ingress.kubernetes.io/upstream-hash-by外,所有其他非Canary的注解都将被忽略。
- 相同服务的Canary Ingress(Ingress的YAML文件中host/path相同)仅能够定义一个,从而使后端服务最多支持两个版本。
- 即使流量完全切到了Canary Ingress上,旧版服务仍需存在,否则会出现报错。
- 更多内容请参阅官方文档Annotations。
在集群中部署两个版本的Nginx服务,并通过Nginx Ingress对外提供七层域名访问。
创建第一个版本的Deployment和Service,本文以app-v1为例。YAML示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-v1
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: app-v1
template:
metadata:
labels:
app: app-v1
spec:
containers:
- name: nginx
image: nginx:1.21.4
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "echo \\<b\\>version: v1\\</b\\>, \\<br\\>IP: $(hostname -I), \\<br\\>hostname: $(hostname) > /usr/share/nginx/html/index.html"
---
apiVersion: v1
kind: Service
metadata:
name: app-v1
namespace: default
spec:
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
selector:
app: app-v1
创建第二个版本的Deployment和Service,本文以app-v2为例。YAML示例如下:
apiVersion: apps/v1
kind: Deployment
metadata:
name: app-v2
namespace: default
spec:
replicas: 3
selector:
matchLabels:
app: app-v2
template:
metadata:
labels:
app: app-v2
spec:
containers:
- name: nginx
image: nginx:1.21.4
imagePullPolicy: IfNotPresent
lifecycle:
postStart:
exec:
command:
- /bin/sh
- -c
- "echo \\<b\\>version: v2\\</b\\>, \\<br\\>IP: $(hostname -I), \\<br\\>hostname: $(hostname) > /usr/share/nginx/html/index.html"
---
apiVersion: v1
kind: Service
metadata:
name: app-v2
namespace: default
spec:
type: ClusterIP
ports:
- name: http
port: 80
targetPort: 80
selector:
app: app-v2
查看两个服务的运行状况
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
app-v1-68db595855-99j89 1/1 Running 2 25h
app-v1-68db595855-l8q6h 1/1 Running 0 25h
app-v1-68db595855-z8kwv 1/1 Running 1 25h
app-v2-595cf6b7f-8kh74 1/1 Running 0 25h
app-v2-595cf6b7f-jbp5q 1/1 Running 2 25h
app-v2-595cf6b7f-kspjd 1/1 Running 0 25h
创建Ingress,对外暴露服务,指向app-v1版本的服务。YAML示例如下
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-v1
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /nginx(/|)(.*)
backend:
serviceName: app-v1
servicePort: 80
验证服务:
- 命令行验证
$ for i in `seq 3`;do curl www.ecloud.com/nginx ;sleep 1 ;done
<b>version: v1</b>, <br>IP: 20.0.122.151 , <br>hostname: app-v1-68db595855-l8q6h
<b>version: v1</b>, <br>IP: 20.0.58.213 , <br>hostname: app-v1-68db595855-z8kwv
<b>version: v1</b>, <br>IP: 20.0.32.154 , <br>hostname: app-v1-68db595855-99j89
- 浏览器验证

6)灰度发布新版本
基于Header、Cookie和服务权重三种流量切分策略均可实现灰度发布;基于服务权重的流量切分策略,调整新服务权重为100%,即可实现蓝绿发布。您可以在下述示例中了解具体使用方法。
(1)基于客户端Header的流量切分场景
1. 创建Canary Ingress,指向新版本的后端服务,并增加annotation。
YAML示例如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-v2
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-header: canary
nginx.ingress.kubernetes.io/canary-by-header-value: "true"
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /nginx(/|)(.*)
backend:
serviceName: app-v2
servicePort: 80
2. 验证服务。
- 命令行验证
$ for i in `seq 3`;do curl -s -H "canary:true" www.ecloud.com/nginx ;sleep 1 ;done
<b>version: v2</b>, <br>IP: 20.0.32.155 , <br>hostname: app-v2-595cf6b7f-jbp5q
<b>version: v2</b>, <br>IP: 20.0.122.152 , <br>hostname: app-v2-595cf6b7f-8kh74
<b>version: v2</b>, <br>IP: 20.0.135.154 , <br>hostname: app-v2-595cf6b7f-kspjd
- 浏览器验证

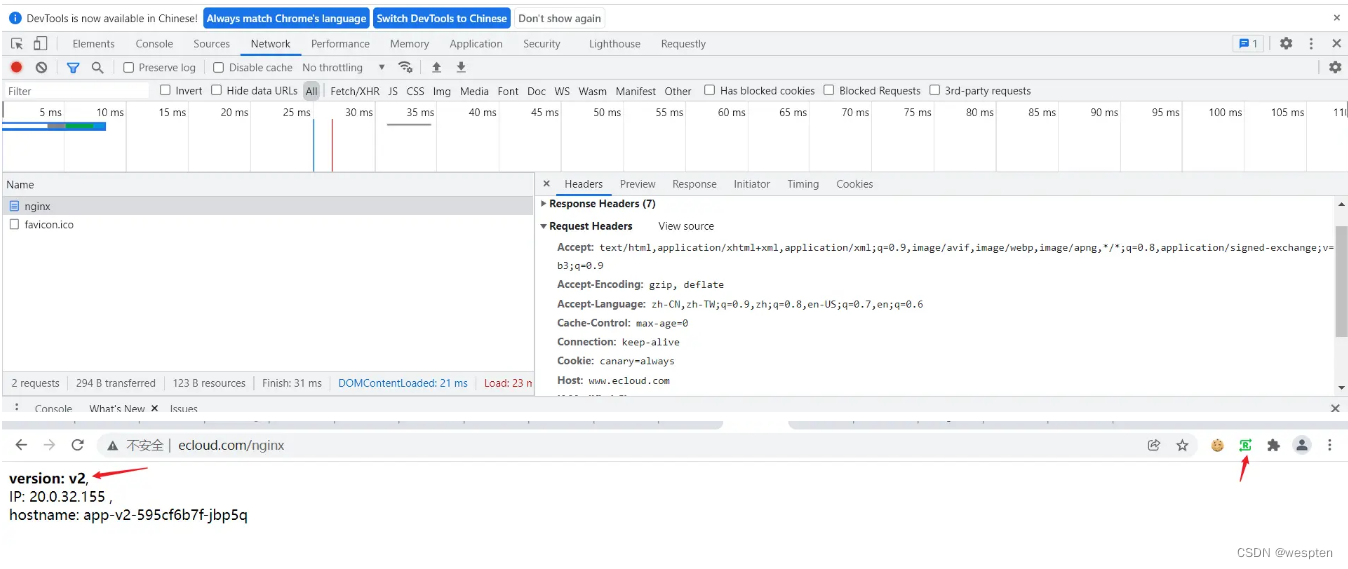
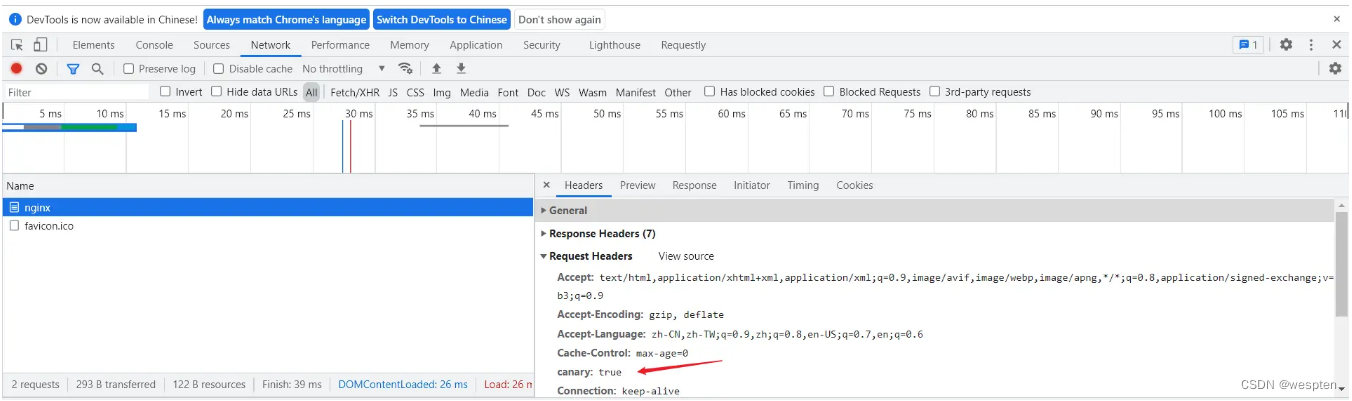
Google浏览器安装 Requestly: Modify Headers, Mock API, Redirect 插件,可以添加 header 键值对。
(2)基于客户端Cookie的流量切分场景
1. 创建Canary Ingress,指向新版本的后端服务,并增加annotation。
YAML示例如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-v2
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-by-cookie: canary
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /nginx(/|)(.*)
backend:
serviceName: app-v2
servicePort: 80
2. 验证服务。
- 命令行验证
$ for i in `seq 3`;do curl -s -H "Cookie: canary=always" -H "Host: www.ecloud.com" http://192.168.31.188/nginx ;sleep 1 ;done
<b>version: v2</b>, <br>IP: 20.0.32.155 , <br>hostname: app-v2-595cf6b7f-jbp5q
<b>version: v2</b>, <br>IP: 20.0.122.152 , <br>hostname: app-v2-595cf6b7f-8kh74
<b>version: v2</b>, <br>IP: 20.0.135.154 , <br>hostname: app-v2-595cf6b7f-kspjd
- 浏览器验证

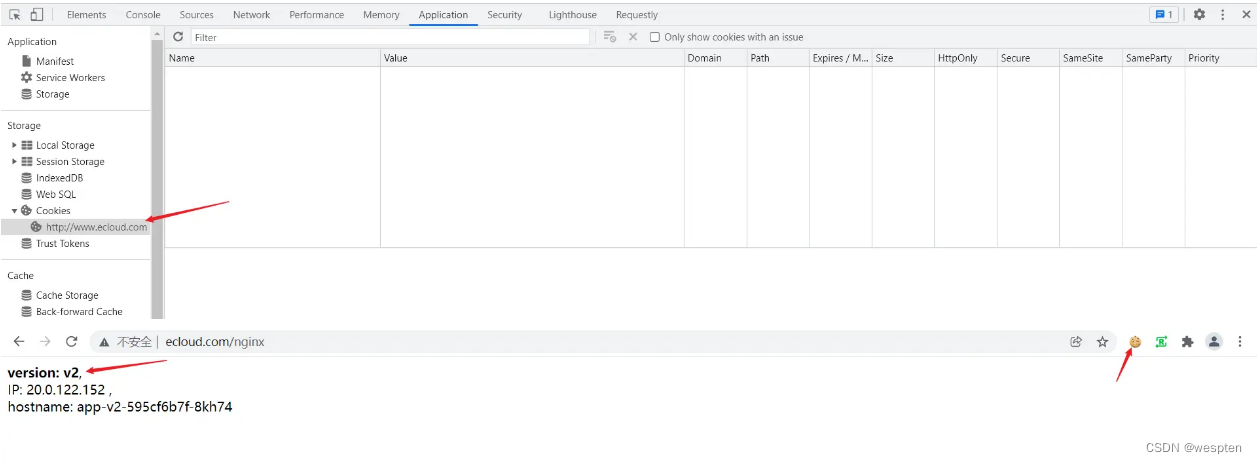
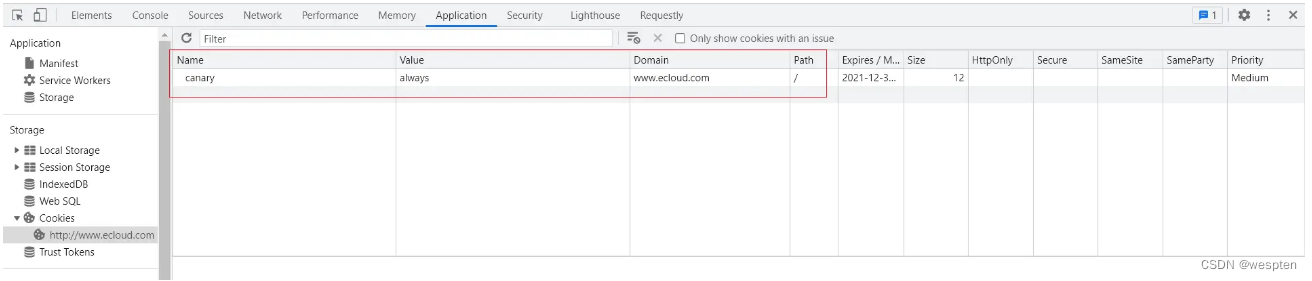
Google浏览器安装EditCookie插件,可以添加 cookie。
(3)基于服务权重的流量切分场景
1. 创建Canary Ingress,指向新版本的后端服务,并增加annotation。
YAML示例如下:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: app-v2
namespace: default
annotations:
nginx.ingress.kubernetes.io/rewrite-target: /$2
nginx.ingress.kubernetes.io/canary: "true"
nginx.ingress.kubernetes.io/canary-weight: "30"
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /nginx(/|)(.*)
backend:
serviceName: app-v2
servicePort: 80
2. 验证服务。
$for i in `seq 10`;do curl -s -H "Cookie: canary=always" www.ecloud.com/nginx ;sleep 1 ;done
<b>version: v1</b>, <br>IP: 20.0.32.154 , <br>hostname: app-v1-68db595855-99j89
<b>version: v1</b>, <br>IP: 20.0.32.154 , <br>hostname: app-v1-68db595855-99j89
<b>version: v1</b>, <br>IP: 20.0.32.154 , <br>hostname: app-v1-68db595855-99j89
<b>version: v1</b>, <br>IP: 20.0.58.213 , <br>hostname: app-v1-68db595855-z8kwv
<b>version: v2</b>, <br>IP: 20.0.32.155 , <br>hostname: app-v2-595cf6b7f-jbp5q
<b>version: v1</b>, <br>IP: 20.0.58.213 , <br>hostname: app-v1-68db595855-z8kwv
<b>version: v1</b>, <br>IP: 20.0.122.151 , <br>hostname: app-v1-68db595855-l8q6h
<b>version: v2</b>, <br>IP: 20.0.135.154 , <br>hostname: app-v2-595cf6b7f-kspjd
<b>version: v1</b>, <br>IP: 20.0.58.213 , <br>hostname: app-v1-68db595855-z8kwv
<b>version: v2</b>, <br>IP: 20.0.122.152 , <br>hostname: app-v2-595cf6b7f-8kh74
注意:
基于权重(30%)进行流量切分后,访问到新版本的概率接近30%,流量比例可能会有小范围的浮动,这属于正常现象。
将百分比拉到100,则成功实现了蓝绿发布。
7)附件
Google浏览器插件 Modify Headers、EditCookie 上传到百度云盘上,有需要的的话,请到百度云上下载。
链接:百度网盘 请输入提取码
提取码:3a60
安装方法:打开 Google浏览器 ,输入 chrome://extensions/ 进入到扩展程序,然后把下载好的插件拖拽到浏览器即可。
7、代理k8s集群外的web应用
1)背景说明
原有一套web页面系统,部署并非在kubernetes集群中。现在需要通过 ingress-nginx-controller 发布出来访问。
原系统访问地址是 http://192.168.31.235:5601/kibana 。现在需要通过 ingress 方式发布出来。使用 www.ecloud.com 的域名来访问。
2)创建service清单
这个 yaml 文件功能主要是访问该service的流量,转发到 http://192.168.31.235:5601 上:
apiVersion: v1
kind: Service
metadata:
name: kibana
spec:
externalName: 192.168.31.235
ports:
- name: http
port: 5601
protocol: TCP
targetPort: 5601
sessionAffinity: None
type: ExternalName
3)创建ingress清单
这个 yaml 文件功能主要是访问 http://www.ecloud.com/kibana 的流量,转发到上面定义的 service 上。
也相对于访问 http://192.168.31.235:5601/kibana:
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: kibana
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /kibana
backend:
serviceName: kibana
servicePort: 5601
浏览器访问:http://www.ecloud.com/kibana

8、ingress自定义日志
修改 ingress-nginx-controller 配置文件:
$ kubectl -n ingress-nginx edit configmap ingress-nginx-controller
# 在 data 字段添加下面内容
data:
log-format-upstream:
'{"time": "$time_iso8601", "namespace": "$namespace", "service_name": "$service_name",
"service_port": $service_port, "domain": " $host", "path": "$uri", "request_id": "$req_id",
"remote_user": "$remote_user", "request_query": "$args", "bytes_sent": $bytes_sent,
"status": $status, "request_time": $request_time, "request_proto": "$server_protocol",
"request_length": $request_length, "duration": $request_time, "method": "$request_method",
"http_referrer": "$http_referer", "remote_addr":"$remote_addr", "remote_port": "$remote_port",
"proxy_protocol_addr": "$proxy_protocol_addr", "proxy_add_x_forwarded_for": "$proxy_add_x_forwarded_for",
"x_forwarded_for": "$http_x_forwarded_for", "http_user_agent": "$http_user_agent"
}'
重启ingress-nginx-controller容器:
$ kubectl -n ingress-nginx delete pod -l app.kubernetes.io/component=controller
pod "ingress-nginx-controller-6c979c5b47-n6stn" deleted
pod "ingress-nginx-controller-6c979c5b47-5wixe" deleted9、ingress日志记录真实IP地址
有时候我们需要在容器中获取客户端真实的IP等信息,而经过NginxIngressController转发后,这些信息不一定拿得到,所以我们需要对NginxIngressController进行配置。
1)负载均衡使用四层代理
$ kubectl -n ingress-nginx edit configmap ingress-nginx-controller
# 在 data 字段添加下面几行
data:
compute-full-forwarded-for: "true"
enable-underscores-in-headers: "true"
forwarded-for-header: X-Forwarded-For
use-forwarded-headers: "true"
use-proxy-protocol: "true"
# 重启 ingress-nginx-controller 容器
$ kubectl -n ingress-nginx delete pod -l app.kubernetes.io/component=controller
pod "ingress-nginx-controller-6c979c5b47-hrb4k" deleted
请注意:如果在 ingress-nginx-controller 高可用上的负载均衡器没有启动 proxy protocol 的话,访问服务都会异常。
harbor的配置如下:
listen ingress_nginx_http
bind 192.168.31.188:80
mode tcp
balance roundrobin
server master01 192.168.31.103:80 weight 1 check inter 1000 rise 3 fall 5 send-proxy
server master02 192.168.31.79:80 weight 1 check inter 1000 rise 3 fall 5 send-proxy
listen ingress_nginx_https
bind 192.168.31.188:443
mode tcp
balance roundrobin
server master01 192.168.31.103:443 weight 1 check inter 1000 rise 3 fall 5 send-proxy
server master02 192.168.31.79:443 weight 1 check inter 1000 rise 3 fall 5 send-proxy
server参数必须包含有 send-proxy 选项。
下面的日志是通过 ingress 设置的域名访问,客户端收集的日志:
{"time": "2022-09-15T16:56:15+08:00", "namespace": "default", "service_name": "hearder", "service_port": 80, "domain": " www.ecloud.com", "path": "/hearder", "request_id": "8ee4be46fb1799f75553fa9c3dee716a", "remote_user": "admin", "request_query": "-", "bytes_sent": 919, "status": 200, "request_time": 0.003, "request_proto": "HTTP/1.1", "request_length": 501, "duration": 0.003, "method": "GET", "http_referrer": "-", "remote_addr":"192.168.31.245", "remote_port": "54328", "proxy_protocol_addr": "192.168.31.245", "proxy_add_x_forwarded_for": "192.168.31.245", "x_forwarded_for": "-", "http_user_agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/105.0.0.0 Safari/537.36" }
- remote_addr是真实客户端IP地址;
- haproxy 的 x_forwarded_for 参数使用 remote_addr 直接覆盖,则只有真实客户端IP地址,没有具体的调用IP链;
10、自定义参数
1)记录真实IP地址
有时候我们需要在容器中获取客户端真实的IP等信息,而经过NginxIngressController转发后,这些信息不一定拿得到,所以我们需要对NginxIngressController进行配置。
$ kubectl -n ingress-nginx edit configmap ingress-nginx-controller
# 在 data 字段添加下面三行
data:
compute-full-forwarded-for: "true"
forwarded-for-header: X-Forwarded-For
use-forwarded-headers: "true"
# 重启 ingress-nginx-controller 容器
$ kubectl -n ingress-nginx delete pod -l app.kubernetes.io/component=controller
pod "ingress-nginx-controller-6c979c5b47-hrb4k" deleted
请注意:如果在 ingress-nginx-controller 高可用上的负载均衡器没有传递 X-Forwarded-For 的话,同样是获取不到真实IP地址的。
如果 ingress-nginx-controller 是高可用的话,那么会出现多个节点有pod,必定是有一个负载均衡器。那么就获取不到真实IP地址,使用 nginx 做七层代理的话,需要在 location 加上以下几行参数:
map $http_x_forwarded_for $full_x_forwarded_for {
default "$http_x_forwarded_for, $realip_remote_addr";
'' "$realip_remote_addr";
}
# Allow websocket connections
proxy_set_header Upgrade $http_upgrade;
proxy_set_header X-Real-IP $remote_addr;
proxy_set_header X-Forwarded-For $full_x_forwarded_for;
# Pass the original X-Forwarded-For
proxy_set_header X-Original-Forwarded-For $http_x_forwarded_for;
完整的nginx示例:

下面的日志是通过ingress设置的域名访问,客户端收集的日志:
20.0.135.128 - - [24/Sep/2021:07:04:29 +0000] "GET /test/demo/ HTTP/1.1" 304 0 "-" "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/93.0.4577.82 Safari/537.36" "192.168.31.1, 192.168.31.103"
该行的第一个段是指上一级的访问IP地址 。最后一段是指 真实客户端IP地址, 反向代理的后端IP地址。
2)优化参数
$ kubectl -n ingress-nginx edit cm ingress-nginx-controller
# 在 data 字段添加下面内容
data:
# 客户端请求头部的缓冲区大小,这个可以根据你的系统分页大小来设置,一般一个请求头的大小不会超过 1k,不过由于一般系统分页都要大于1k,所以这里设置为分页大小。分页大小可以用命令getconf PAGESIZE取得。
client-header-buffer-size: 4k
# 设置保持活动的客户端连接在服务器端保持打开状态的时间
keep-alive: "60"
# 设置可以通过一个保持活动连接提供的最大请求数。
# nginx 与 client 保持的一个长连接能处理的请求数量,默认 100,高并发场景建议调高。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#keep-alive-requests
keep-alive-requests: "10000"
# 设置每个工作进程可以打开的最大并发连接数
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#max-worker-connections
max-worker-connections: "65535"
# 设置每个工作进程可以打开的最大文件数
max-worker-open-files: "65535"
# nginx 与 upstream 保持长连接的最大空闲连接数 (不是最大连接数),默认 32,在高并发下场景下调大,避免频繁建联导致 TIME_WAIT 飙升。
# 参考: https://kubernetes.github.io/ingress-nginx/user-guide/nginx-configuration/configmap/#upstream-keepalive-connections
upstream-keepalive-connections: "10000"
# 设置可以通过一个 keepalive 连接服务的最大请求数。 发出最大请求数后,连接关闭。
upstream-keepalive-requests: "100"
# 设置超时,在此期间,与 upstream servers 的空闲保持连接将保持打开状态。
upstream-keepalive-timeout: "60"
# 重启 ingress-nginx-controller 容器
$ kubectl -n ingress-nginx delete pod -l app.kubernetes.io/component=controller
pod "ingress-nginx-controller-6c979c5b47-csmcj" deleted
3)内核调优
# 临时临时
kubectl patch deployment -n ingress-nginx nginx-ingress-controller \
--patch="$(curl https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/docs/examples/customization/sysctl/patch.json)"
# 永久生效
# 在 ingress-nginx-controller 容器的 deploy.spec.template.spec 添加 initContainers
initContainers:
- name: sysctl
image: alpine:3.13
securityContext:
privileged: true
command:
- sh
- -c
- |
sysctl -w net.core.somaxconn=32768
sysctl -w net.ipv4.ip_local_port_range='32768 65535'
sysctl -w net.ipv4.tcp_tw_reuse=1
变化:
- 积压队列设置net.core.somaxconn从128到32768;
- 临时端口设置net.ipv4.ip_local_port_range从32768 60999到32768 65535(符合端口规划);
- 开启 TIME_WAIT 重用,即允许将 TIME_WAIT 连接重新用于新的 TCP 连接;
四、外部存储
1、对接NFS
pod 中的文件在磁盘上是临时存放的,这给容器中运行的较重要的应用程序带来一些问题。
- 当容器崩溃时文件丢失。kubelet 会重新启动容器, 但容器会以干净的状态重启。
- 在同一个
pod中运行多个容器并需要共享文件。
kubernetes解决上面的方法,提出volumes的抽象概念来解决。
Kubernetes 支持很多类型的卷。 Pod 可以同时使用任意数目的卷类型。 临时卷类型的生命周期与 Pod 相同,但持久卷可以比 Pod 的存活期长。 当 Pod 不再存在时,Kubernetes 也会销毁临时卷;不过 Kubernetes 不会销毁持久卷。对于给定 Pod 中任何类型的卷,在容器重启期间数据都不会丢失。
该文章围绕kubernetes如何使用NFS存储。
注意:应该每个k8s节点都安装nfs客户端。
CentOS发行版:nfs-utils,验证 rpm -qa nfs-utils
下载nfs-utils:
$ yum install nfs-utils -y
修改配置文件:
$ cat > /etc/exports <<-EOF
/data/nfs 192.168.200.0/24(rw,root_squash,all_squash,sync)
EOF
$ mkdir -p /data/nfs
$ chown nfsnobody.nfsnobody /data/nfs
参数说明:
- rw: 读写
- root_squash:客户端使用root用户映射成nobody用户
- all_squash:客户端使用普通用户映射成nobody用户
- sync:将数据同步写入内存缓冲区与磁盘中,效率低,但可以保证数据的一致性;
启动nfs:
$ systemctl start nfs
如果有开防火墙的话,请将 nfs 的相关端口放通。通过 rpcinfo -p 查看当前使用的端口。
启动NFS会开启如下端口:
- portmapper 端口:111 udp/tcp;
- nfs/nfs_acl 端口:2049 udp/tcp;
- mountd 端口:"32768--65535" udp/tcp
- nlockmgr 端口:"32768--65535" udp/tcp
固定上面的随机端口:
$ cat >> /etc/sysconfig/nfs <<-EOF
RQUOTAD_PORT=4001
LOCKD_TCPPORT=4002
LOCKD_UDPPORT=4002
MOUNTD_PORT=4003
STATD_PORT=4004
EOF
$ systemctl restart nfs
放通 iptables 规则
iptables -I INPUT -p tcp -m multiport --dports 111,2049,4001,4002,4003,4004 -m comment --comment "nfs tcp ports" -j ACCEPT
iptables -I INPUT -p udp -m multiport --dports 111,2049,4001,4002,4003,4004 -m comment --comment "nfs udp ports" -j ACCEPT
volumes 的核心是一个目录,其中可能存有数据,Pod 中的容器可以访问该目录中的数据。 所采用的特定的卷类型将决定该目录如何形成的、使用何种介质保存数据以及目录中存放 的内容。
使用卷时, 在 .spec.volumes 字段中设置为 Pod 提供的卷,并在.spec.containers[*].volumeMounts 字段中声明卷在容器中的挂载位置。
容器中的进程看到的是由它们的 Docker 镜像和卷组成的文件系统视图。 Docker镜像位于文件系统层次结构的根部。各个卷则挂载在镜像内的指定路径上。 卷不能挂载到其他卷之上,也不能与其他卷有硬链接。 Pod 配置中的每个容器必须独立指定各个卷的挂载位置。
部署以下模板,创建pod:
apiVersion: v1
kind: Pod
metadata:
name: test-volume
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28.1
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- sleep 3600
volumeMounts:
- name: nfs
mountPath: /nfs
volumes:
- name: nfs
nfs:
server: 192.168.31.136
path: /data/nfs
部署pod:
$ kubectl apply -f test-volume.yml
pod/test-volume created
存储的管理是一个与计算实例的管理完全不同的问题。PersistentVolume 子系统为用户 和管理员提供了一组 API,将存储如何供应的细节从其如何被使用中抽象出来。 为了实现这点,我们引入了两个新的 API 资源:PersistentVolume 和 PersistentVolumeClaim。
持久卷(PersistentVolume,PV)是集群中的一块存储,可以由管理员事先供应,或者 使用存储类(Storage Class)来动态供应。 持久卷是集群资源,就像节点也是集群资源一样。PV 持久卷和普通的 Volume 一样,也是使用 卷插件来实现的,只是它们拥有独立于任何使用 PV 的 Pod 的生命周期。 此 API 对象中记述了存储的实现细节,无论其背后是 NFS、iSCSI 还是特定于云平台的存储系统。
持久卷申领(PersistentVolumeClaim,PVC)表达的是用户对存储的请求。概念上与 Pod 类似。 Pod 会耗用节点资源,而 PVC 申领会耗用 PV 资源。Pod 可以请求特定数量的资源(CPU 和内存);同样 PVC 申领也可以请求特定的大小和访问模式 (例如,可以要求 PV 卷能够以 ReadWriteOnce、ReadOnlyMany 或 ReadWriteMany 模式之一来挂载,参见访问模式)。
尽管 PersistentVolumeClaim 允许用户消耗抽象的存储资源,常见的情况是针对不同的 问题用户需要的是具有不同属性(如,性能)的 PersistentVolume 卷。 集群管理员需要能够提供不同性质的 PersistentVolume,并且这些 PV 卷之间的差别不 仅限于卷大小和访问模式,同时又不能将卷是如何实现的这些细节暴露给用户。 为了满足这类需求,就有了 存储类(StorageClass) 资源。
PV 卷是集群中的资源。PVC 申领是对这些资源的请求,也被用来执行对资源的申领检查。PV 卷的供应有两种方式:静态供应或动态供应。
(1)静态供应
PersistentVolume 对象:
apiVersion: v1
kind: PersistentVolume
metadata:
name: nfs-pv001
spec:
capacity:
storage: 5Gi
volumeMode: Filesystem
accessModes:
- ReadWriteMany
persistentVolumeReclaimPolicy: Recycle
storageClassName: nfs
nfs:
path: /data/nfs
server: 192.168.31.136
创建pv:
$ kubectl apply -f pv.yml
persistentvolume/nfs-pv001 created
查看pv状态:
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-pv001 5Gi RWX Recycle Available nfs 23s
每个卷会处于以下阶段(Phase)之一:
- Available(可用)-- 卷是一个空闲资源,尚未绑定到任何申领;
- Bound(已绑定)-- 该卷已经绑定到pvc;
- Released(已释放)-- 所绑定的pvc已被删除,但是资源尚未被集群回收;
- Failed(失败)-- 卷的自动回收操作失败。
PersistentVolumeClaims对象:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: pvc-001
spec:
accessModes:
- ReadWriteMany
volumeMode: Filesystem
resources:
requests:
storage: 3Gi
storageClassName: nfs
注意:
- accessModes 和 storageClassName 与 PersistentVolume 资源清单必须一致。
- resources.requests.storage 小于 PersistentVolume 资源清单的 capacity.storage
创建PVC:
$ kubectl apply -f pvc.yml
persistentvolumeclaim/pvc-001 created
查看pvc状态:
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
pvc-001 Bound nfs-pv001 5Gi RWX nfs 3m
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
nfs-pv001 5Gi RWX Recycle Bound default/pvc-001 nfs 14m
pod使用pvc资源:
apiVersion: v1
kind: Pod
metadata:
name: test-volume
namespace: default
spec:
containers:
- name: busybox
image: busybox:1.28.1
imagePullPolicy: IfNotPresent
args:
- /bin/sh
- -c
- sleep 3600
volumeMounts:
- name: nfs
mountPath: /nfs
volumes:
- name: nfs
nfs:
server: 192.168.31.136
path: /data/nfs
创建pod:
$ kubectl apply -f test-pvc.yml
pod/test-pvc created
查看pod:
$ kubectl get pod test-volume
NAME READY STATUS RESTARTS AGE
test-volume 1/1 Running 1 70m
$ kubectl exec test-volume -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 40.0G 9.9G 30.0G 25% /
192.168.31.136:/data/nfs
40.0G 21.2G 18.8G 53% /nfs
/dev/sda3 40.0G 9.9G 30.0G 25% /dev/termination-log
/dev/sda3 40.0G 9.9G 30.0G 25% /etc/localtime
/dev/sda3 40.0G 9.9G 30.0G 25% /etc/resolv.conf
/dev/sda3 40.0G 9.9G 30.0G 25% /etc/hostname
/dev/sda3 40.0G 9.9G 30.0G 25% /etc/hosts
...
StorageClass 为管理员提供了描述存储 "类" 的方法。 不同的类型可能会映射到不同的服务质量等级或备份策略,或是由集群管理员制定的任意策略。
每个 StorageClass 都有一个提供商(Provisioner),用来决定使用哪个卷插件创建PV。 这个使用的 nfs 存储介质。所以安装 nfs-Provisioner 。
安装nfs-provisioner:
rbac权限:
apiVersion: v1
kind: ServiceAccount
metadata:
name: nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: nfs-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["create", "update", "patch"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: run-nfs-provisioner
subjects:
- kind: ServiceAccount
name: nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: ClusterRole
name: nfs-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
rules:
- apiGroups: [""]
resources: ["endpoints"]
verbs: ["get", "list", "watch", "create", "update", "patch"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: leader-locking-nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
subjects:
- kind: ServiceAccount
name: nfs-provisioner
# replace with namespace where provisioner is deployed
namespace: kube-system
roleRef:
kind: Role
name: leader-locking-nfs-provisioner
apiGroup: rbac.authorization.k8s.io
deployment清单:
apiVersion: apps/v1
kind: Deployment
metadata:
name: nfs-provisioner
labels:
app: nfs-provisioner
namespace: kube-system
spec:
replicas: 1
strategy:
type: Recreate
selector:
matchLabels:
app: nfs-provisioner
template:
metadata:
labels:
app: nfs-provisioner
spec:
serviceAccountName: nfs-provisioner
containers:
- name: nfs-provisioner
image: jiaxzeng/nfs-subdir-external-provisioner:v4.0.2
env:
# 可以自定义名称
- name: PROVISIONER_NAME
value: k8s/nfs-provisioner
- name: NFS_SERVER
value: 192.168.31.136
- name: NFS_PATH
value: /data/nfs
volumeMounts:
- name: nfs-provisioner-root
mountPath: /persistentvolumes
volumes:
- name: nfs-provisioner-root
nfs:
server: 192.168.31.136
path: /data/nfs
创建nfs-provisioner:
$ kubectl apply -f rbac.yaml
serviceaccount/nfs-provisioner created
clusterrole.rbac.authorization.k8s.io/nfs-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/run-nfs-provisioner created
role.rbac.authorization.k8s.io/leader-locking-nfs-provisioner created
rolebinding.rbac.authorization.k8s.io/leader-locking-nfs-provisioner created
$ kubectl apply -f deploy.yml
deployment.apps/nfs-provisioner created
StorageClass清单:
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: managed-nfs-storage
provisioner: k8s/nfs-provisioner # must match deployment's env PROVISIONER_NAME'
parameters:
archiveOnDelete: "false"
创建StorageClass:
$ kubectl apply -f class.yml
storageclass.storage.k8s.io/managed-nfs-storage created
创建pvc清单:
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: test-claim
spec:
storageClassName: managed-nfs-storage
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1024Mi
创建pod清单:
apiVersion: v1
kind: Pod
metadata:
name: test-pod
spec:
containers:
- name: test-pod
image: busybox:1.28.1
command:
- "/bin/sh"
args:
- "-c"
- "sleep 3600"
volumeMounts:
- name: nfs-pvc
mountPath: "/mnt"
restartPolicy: "Never"
volumes:
- name: nfs-pvc
persistentVolumeClaim:
claimName: test-claim
创建pvc和deployment:
$ kubectl apply -f test-claim.yaml
persistentvolumeclaim/test-claim created
$ kubectl apply -f test-pod.yml
pod/test-pod created
查看pv和pvc状态:
$ kubectl get pv
NAME CAPACITY ACCESS MODES RECLAIM POLICY STATUS CLAIM STORAGECLASS REASON AGE
pvc-470a0959-0313-4d4a-8e1c-3543fa79e737 1Gi RWX Delete Bound default/test-claim managed-nfs-storage 84s
$ kubectl get pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
test-claim Bound pvc-470a0959-0313-4d4a-8e1c-3543fa79e737 1Gi RWX managed-nfs-storage 96s
查看pod挂载情况:
$ kubectl exec test-pod -- df -h
Filesystem Size Used Available Use% Mounted on
overlay 40.0G 10.8G 29.2G 27% /
192.168.31.136:/data/nfs/default-test-claim-pvc-470a0959-0313-4d4a-8e1c-3543fa79e737
40.0G 10.1G 29.9G 25% /mnt
/dev/sda3 40.0G 10.8G 29.2G 27% /dev/termination-log
/dev/sda3 40.0G 10.8G 29.2G 27% /etc/localtime
/dev/sda3 40.0G 10.8G 29.2G 27% /etc/resolv.conf
/dev/sda3 40.0G 10.8G 29.2G 27% /etc/hostname
/dev/sda3 40.0G 10.8G 29.2G 27% /etc/hosts
如上述截图,pod上挂载点有 /mnt 的话,那就没问题。大功告成
volume的模式:
安装nfs-provisioner:
2、对接ceph-rbd
版本说明:
| CSI 版本 | kubernetes 版本 |
|---|---|
| 3.5.1 | 1.18.18 |
详细的对应的版本,请查看下面的参考文章。
ceph创建kubernetes存储池:
$ ceph osd pool create kubernetes 128 128
pool 'kubernetes' created
初始化存储池:
$ rbd pool init kubernetes
为 Kubernetes 和 ceph-csi 创建一个新用户:
ceph auth get-or-create client.kubernetes mon 'profile rbd' osd 'profile rbd pool=kubernetes' mgr 'profile rbd pool=kubernetes'
获取ceph相关信息:
$ ceph mon dump
epoch 2
fsid b87d2535-406b-442d-8de2-49d86f7dc599
last_changed 2022-06-15T17:35:37.096336+0800
created 2022-06-15T17:35:05.828763+0800
min_mon_release 15 (octopus)
0: [v2:192.168.31.69:3300/0,v1:192.168.31.69:6789/0] mon.ceph01
1: [v2:192.168.31.102:3300/0,v1:192.168.31.102:6789/0] mon.ceph02
2: [v2:192.168.31.165:3300/0,v1:192.168.31.165:6789/0] mon.ceph03
dumped monmap epoch 2
这里的ceph-csi部署在kube-storage命名空间下。
创建命名空间:
$ cat << EOF | sudo tee 0.namespace.yml >> /dev/null
apiVersion: v1
kind: Namespace
metadata:
name: kube-storage
EOF
$ kubectl apply -f 0.namespace.yml
namespace/kube-storage created
生成类似于以下示例的 csi-config-map.yaml 文件,将 fsid 替换为“clusterID”,并将监视器地址替换为“monitors”:
$ cat << EOF | sudo tee 1.csi-config-map.yml >> /dev/null
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
[
{
"clusterID": "b87d2535-406b-442d-8de2-49d86f7dc599",
"monitors": [
"192.168.31.69:6789",
"192.168.31.102:6789",
"192.168.31.165:6789"
]
}
]
metadata:
name: ceph-csi-config
namespace: kube-storage
EOF
$ kubectl apply -f 1.csi-config-map.yml
configmap/ceph-csi-config created
根据ceph侧执行的返回结果来填写内容。
创建csi的kvs配置文件:
$ cat << EOF | sudo tee 2.csi-kms-config-map.yml >> /dev/null
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
{}
metadata:
name: ceph-csi-encryption-kms-config
namespace: kube-storage
EOF
$ kubectl apply -f 2.csi-kms-config-map.yml
configmap/ceph-csi-encryption-kms-config createdv
创建rbd的访问权限:
$ cat << EOF | sudo tee 3.csi-rbd-secret.yml >> /dev/null
apiVersion: v1
kind: Secret
metadata:
name: csi-rbd-secret
namespace: kube-storage
stringData:
userID: kubernetes
# ceph auth get-key client.kubernetes 获取key,不需要base64。
userKey: AQCfkKpidBhVHBAAJTzhkRKlSMuWDDibrlbPDA==
EOF
$ kubectl apply -f 3.csi-rbd-secret.yml
secret/csi-rbd-secret created
创建ceph配置文件以及密钥文件:
$ kubectl -n kube-storage create configmap ceph-config --from-file=/etc/ceph/ceph.conf --from-file=keyring=/etc/ceph/ceph.client.kubernetes.keyring
configmap/ceph-config created
创建相关的rbac权限:
$ cat << EOF | sudo tee 4.csi-provisioner-rbac.yml >> /dev/null
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: rbd-csi-provisioner
# replace with non-default namespace name
namespace: kube-storage
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-external-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "update", "delete", "patch"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: [""]
resources: ["persistentvolumeclaims/status"]
verbs: ["update", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshots"]
verbs: ["get", "list", "patch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshots/status"]
verbs: ["get", "list", "patch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotcontents"]
verbs: ["create", "get", "list", "watch", "update", "delete", "patch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments"]
verbs: ["get", "list", "watch", "update", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments/status"]
verbs: ["patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["csinodes"]
verbs: ["get", "list", "watch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotcontents/status"]
verbs: ["update", "patch"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get"]
- apiGroups: [""]
resources: ["serviceaccounts"]
verbs: ["get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-csi-provisioner-role
subjects:
- kind: ServiceAccount
name: rbd-csi-provisioner
# replace with non-default namespace name
namespace: kube-storage
roleRef:
kind: ClusterRole
name: rbd-external-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
# replace with non-default namespace name
namespace: kube-storage
name: rbd-external-provisioner-cfg
rules:
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list", "watch", "create", "update", "delete"]
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["get", "watch", "list", "delete", "update", "create"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-csi-provisioner-role-cfg
# replace with non-default namespace name
namespace: kube-storage
subjects:
- kind: ServiceAccount
name: rbd-csi-provisioner
# replace with non-default namespace name
namespace: kube-storage
roleRef:
kind: Role
name: rbd-external-provisioner-cfg
apiGroup: rbac.authorization.k8s.io
EOF
$ cat << EOF | sudo tee 5.csi-nodeplugin-rbac.yml >> /dev/null
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: rbd-csi-nodeplugin
# replace with non-default namespace name
namespace: kube-storage
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-csi-nodeplugin
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get"]
# allow to read Vault Token and connection options from the Tenants namespace
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get"]
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get"]
- apiGroups: [""]
resources: ["serviceaccounts"]
verbs: ["get"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments"]
verbs: ["list", "get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: rbd-csi-nodeplugin
subjects:
- kind: ServiceAccount
name: rbd-csi-nodeplugin
# replace with non-default namespace name
namespace: kube-storage
roleRef:
kind: ClusterRole
name: rbd-csi-nodeplugin
apiGroup: rbac.authorization.k8s.io
EOF
$ kubectl apply -f 4.csi-provisioner-rbac.yml
serviceaccount/rbd-csi-provisioner created
clusterrole.rbac.authorization.k8s.io/rbd-external-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-provisioner-role created
role.rbac.authorization.k8s.io/rbd-external-provisioner-cfg created
rolebinding.rbac.authorization.k8s.io/rbd-csi-provisioner-role-cfg created
$ kubectl apply -f 5.csi-nodeplugin-rbac.yml
serviceaccount/rbd-csi-nodeplugin created
clusterrole.rbac.authorization.k8s.io/rbd-csi-nodeplugin created
clusterrolebinding.rbac.authorization.k8s.io/rbd-csi-nodeplugin created
创建 ceph-csi 配置器:
$ cat << EOF | sudo tee 6.csi-rbdplugin-provisioner.yml >> /dev/null
---
kind: Service
apiVersion: v1
metadata:
name: csi-rbdplugin-provisioner
# replace with non-default namespace name
namespace: kube-storage
labels:
app: csi-metrics
spec:
selector:
app: csi-rbdplugin-provisioner
ports:
- name: http-metrics
port: 8080
protocol: TCP
targetPort: 8680
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: csi-rbdplugin-provisioner
# replace with non-default namespace name
namespace: kube-storage
spec:
replicas: 3
selector:
matchLabels:
app: csi-rbdplugin-provisioner
template:
metadata:
labels:
app: csi-rbdplugin-provisioner
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- csi-rbdplugin-provisioner
topologyKey: "kubernetes.io/hostname"
serviceAccountName: rbd-csi-provisioner
priorityClassName: system-cluster-critical
containers:
- name: csi-provisioner
image: k8s.gcr.io/sig-storage/csi-provisioner:v3.1.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--retry-interval-start=500ms"
- "--leader-election=true"
# set it to true to use topology based provisioning
- "--feature-gates=Topology=false"
# if fstype is not specified in storageclass, ext4 is default
- "--default-fstype=ext4"
- "--extra-create-metadata=true"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-snapshotter
image: k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--leader-election=true"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-attacher
image: k8s.gcr.io/sig-storage/csi-attacher:v3.4.0
args:
- "--v=5"
- "--csi-address=\$(ADDRESS)"
- "--leader-election=true"
- "--retry-interval-start=500ms"
env:
- name: ADDRESS
value: /csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-resizer
image: k8s.gcr.io/sig-storage/csi-resizer:v1.3.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--leader-election"
- "--retry-interval-start=500ms"
- "--handle-volume-inuse-error=false"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-rbdplugin
# for stable functionality replace canary with latest release version
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--nodeid=\$(NODE_ID)"
- "--type=rbd"
- "--controllerserver=true"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--csi-addons-endpoint=\$(CSI_ADDONS_ENDPOINT)"
- "--v=5"
- "--drivername=rbd.csi.ceph.com"
- "--pidlimit=-1"
- "--rbdhardmaxclonedepth=8"
- "--rbdsoftmaxclonedepth=4"
- "--enableprofiling=false"
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
# - name: KMS_CONFIGMAP_NAME
# value: encryptionConfig
- name: CSI_ENDPOINT
value: unix:///csi/csi-provisioner.sock
- name: CSI_ADDONS_ENDPOINT
value: unix:///csi/csi-addons.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- mountPath: /dev
name: host-dev
- mountPath: /sys
name: host-sys
- mountPath: /lib/modules
name: lib-modules
readOnly: true
- name: ceph-csi-config
mountPath: /etc/ceph-csi-config/
- name: ceph-csi-encryption-kms-config
mountPath: /etc/ceph-csi-encryption-kms-config/
- name: keys-tmp-dir
mountPath: /tmp/csi/keys
- name: ceph-config
mountPath: /etc/ceph/
- name: csi-rbdplugin-controller
# for stable functionality replace canary with latest release version
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--type=controller"
- "--v=5"
- "--drivername=rbd.csi.ceph.com"
- "--drivernamespace=\$(DRIVER_NAMESPACE)"
env:
- name: DRIVER_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: ceph-csi-config
mountPath: /etc/ceph-csi-config/
- name: keys-tmp-dir
mountPath: /tmp/csi/keys
- name: ceph-config
mountPath: /etc/ceph/
- name: liveness-prometheus
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--type=liveness"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--metricsport=8680"
- "--metricspath=/metrics"
- "--polltime=60s"
- "--timeout=3s"
env:
- name: CSI_ENDPOINT
value: unix:///csi/csi-provisioner.sock
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: socket-dir
mountPath: /csi
imagePullPolicy: "IfNotPresent"
volumes:
- name: host-dev
hostPath:
path: /dev
- name: host-sys
hostPath:
path: /sys
- name: lib-modules
hostPath:
path: /lib/modules
- name: socket-dir
emptyDir: {
medium: "Memory"
}
- name: ceph-config
configMap:
name: ceph-config
- name: ceph-csi-config
configMap:
name: ceph-csi-config
- name: ceph-csi-encryption-kms-config
configMap:
name: ceph-csi-encryption-kms-config
- name: keys-tmp-dir
emptyDir: {
medium: "Memory"
}
EOF
$ kubectl apply -f 6.csi-rbdplugin-provisioner.yml
service/csi-rbdplugin-provisioner created
deployment.apps/csi-rbdplugin-provisioner created
$ kubectl -n kube-storage get pod -l app=csi-rbdplugin-provisioner
NAME READY STATUS RESTARTS AGE
csi-rbdplugin-provisioner-6bd5bd5fd9-psp58 7/7 Running 0 19m
csi-rbdplugin-provisioner-6bd5bd5fd9-sl4kq 7/7 Running 0 19m
csi-rbdplugin-provisioner-6bd5bd5fd9-wwzzp 7/7 Running 0 19m
创建 ceph-csi 节点器:
$ cat << EOF | sudo tee 7.csi-rbdplugin.yml >> /dev/null
---
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: csi-rbdplugin
# replace with non-default namespace name
namespace: kube-storage
spec:
selector:
matchLabels:
app: csi-rbdplugin
template:
metadata:
labels:
app: csi-rbdplugin
spec:
serviceAccountName: rbd-csi-nodeplugin
hostNetwork: true
hostPID: true
priorityClassName: system-node-critical
# to use e.g. Rook orchestrated cluster, and mons' FQDN is
# resolved through k8s service, set dns policy to cluster first
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: driver-registrar
# This is necessary only for systems with SELinux, where
# non-privileged sidecar containers cannot access unix domain socket
# created by privileged CSI driver container.
securityContext:
privileged: true
image: k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.4.0
args:
- "--v=5"
- "--csi-address=/csi/csi.sock"
- "--kubelet-registration-path=/var/lib/kubelet/plugins/rbd.csi.ceph.com/csi.sock"
env:
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: registration-dir
mountPath: /registration
- name: csi-rbdplugin
securityContext:
privileged: true
capabilities:
add: ["SYS_ADMIN"]
allowPrivilegeEscalation: true
# for stable functionality replace canary with latest release version
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--nodeid=\$(NODE_ID)"
- "--pluginpath=/var/lib/kubelet/plugins"
- "--stagingpath=/var/lib/kubelet/plugins/kubernetes.io/csi/pv/"
- "--type=rbd"
- "--nodeserver=true"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--csi-addons-endpoint=\$(CSI_ADDONS_ENDPOINT)"
- "--v=5"
- "--drivername=rbd.csi.ceph.com"
- "--enableprofiling=false"
# If topology based provisioning is desired, configure required
# node labels representing the nodes topology domain
# and pass the label names below, for CSI to consume and advertise
# its equivalent topology domain
# - "--domainlabels=failure-domain/region,failure-domain/zone"
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: POD_NAMESPACE
valueFrom:
fieldRef:
fieldPath: metadata.namespace
# - name: KMS_CONFIGMAP_NAME
# value: encryptionConfig
- name: CSI_ENDPOINT
value: unix:///csi/csi.sock
- name: CSI_ADDONS_ENDPOINT
value: unix:///csi/csi-addons.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- mountPath: /dev
name: host-dev
- mountPath: /sys
name: host-sys
- mountPath: /run/mount
name: host-mount
- mountPath: /etc/selinux
name: etc-selinux
readOnly: true
- mountPath: /lib/modules
name: lib-modules
readOnly: true
- name: ceph-csi-config
mountPath: /etc/ceph-csi-config/
- name: ceph-csi-encryption-kms-config
mountPath: /etc/ceph-csi-encryption-kms-config/
- name: plugin-dir
mountPath: /var/lib/kubelet/plugins
mountPropagation: "Bidirectional"
- name: mountpoint-dir
mountPath: /var/lib/kubelet/pods
mountPropagation: "Bidirectional"
- name: keys-tmp-dir
mountPath: /tmp/csi/keys
- name: ceph-logdir
mountPath: /var/log/ceph
- name: ceph-config
mountPath: /etc/ceph/
- name: liveness-prometheus
securityContext:
privileged: true
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--type=liveness"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--metricsport=8680"
- "--metricspath=/metrics"
- "--polltime=60s"
- "--timeout=3s"
env:
- name: CSI_ENDPOINT
value: unix:///csi/csi.sock
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: socket-dir
mountPath: /csi
imagePullPolicy: "IfNotPresent"
volumes:
- name: socket-dir
hostPath:
path: /var/lib/kubelet/plugins/rbd.csi.ceph.com
type: DirectoryOrCreate
- name: plugin-dir
hostPath:
path: /var/lib/kubelet/plugins
type: Directory
- name: mountpoint-dir
hostPath:
path: /var/lib/kubelet/pods
type: DirectoryOrCreate
- name: ceph-logdir
hostPath:
path: /var/log/ceph
type: DirectoryOrCreate
- name: registration-dir
hostPath:
path: /var/lib/kubelet/plugins_registry/
type: Directory
- name: host-dev
hostPath:
path: /dev
- name: host-sys
hostPath:
path: /sys
- name: etc-selinux
hostPath:
path: /etc/selinux
- name: host-mount
hostPath:
path: /run/mount
- name: lib-modules
hostPath:
path: /lib/modules
- name: ceph-config
configMap:
name: ceph-config
- name: ceph-csi-config
configMap:
name: ceph-csi-config
- name: ceph-csi-encryption-kms-config
configMap:
name: ceph-csi-encryption-kms-config
- name: keys-tmp-dir
emptyDir: {
medium: "Memory"
}
---
# This is a service to expose the liveness metrics
apiVersion: v1
kind: Service
metadata:
name: csi-metrics-rbdplugin
# replace with non-default namespace name
namespace: kube-storage
labels:
app: csi-metrics
spec:
ports:
- name: http-metrics
port: 8080
protocol: TCP
targetPort: 8680
selector:
app: csi-rbdplugin
EOF
$ kubectl apply -f 7.csi-rbdplugin.yml
daemonset.apps/csi-rbdplugin created
service/csi-metrics-rbdplugin created
$ kubectl -n kube-storage get pod -l app=csi-rbdplugin
NAME READY STATUS RESTARTS AGE
csi-rbdplugin-747x8 3/3 Running 0 7m38s
csi-rbdplugin-8l5pj 3/3 Running 0 7m38s
csi-rbdplugin-d9pnv 3/3 Running 0 7m38s
csi-rbdplugin-rslnz 3/3 Running 0 7m38s
csi-rbdplugin-tcrs4 3/3 Running 0 7m38s
如果kubelet数据目录有做修改的话,请修改相关的配置。
例如,kubelet数据目录在/data/k8s/data/kubelet目录下。那么请执行 sed -ri 's#/var/lib/kubelet#/data/k8s/data/kubelet#g' 7.csi-rbdplugin.yml 来修改配置文件
创建SC动态供应:
$ cat << EOF | sudo tee 8.csi-rbd-sc.yaml >> /dev/null
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-rbd-sc
provisioner: rbd.csi.ceph.com
parameters:
clusterID: b87d2535-406b-442d-8de2-49d86f7dc599
pool: kubernetes
imageFeatures: layering
csi.storage.k8s.io/provisioner-secret-name: csi-rbd-secret
csi.storage.k8s.io/provisioner-secret-namespace: kube-storage
csi.storage.k8s.io/controller-expand-secret-name: csi-rbd-secret
csi.storage.k8s.io/controller-expand-secret-namespace: kube-storage
csi.storage.k8s.io/node-stage-secret-name: csi-rbd-secret
csi.storage.k8s.io/node-stage-secret-namespace: kube-storage
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
- discard
EOF
$ kubectl apply -f 8.csi-rbd-sc.yaml
storageclass.storage.k8s.io/csi-rbd-sc created
注意修改clusterID字段内容。
4)验证
创建一个1Gb的pvc:
$ cat << EOF | sudo tee 9.raw-block-pvc.yaml >> /dev/null
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: raw-block-pvc
spec:
accessModes:
- ReadWriteOnce
volumeMode: Block
resources:
requests:
storage: 1Gi
storageClassName: csi-rbd-sc
EOF
$ kubectl apply -f 9.raw-block-pvc.yaml
persistentvolumeclaim/raw-block-pvc created
$ kubectl get pvc raw-block-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
raw-block-pvc Bound pvc-b89dd991-4b74-432c-bebf-97098f9b8740 1Gi RWO csi-rbd-sc 25s
链接:百度网盘 请输入提取码
提取码:hvnq
ceph官网文章:Block Devices and Kubernetes — Ceph Documentation
Kubernetes CSI 开发者文档:Drivers - Kubernetes CSI Developer Documentation
ceph-csi文档:https://github.com/ceph/ceph-csi/tree/v3.5.1
3、对接cephfs
版本说明:
| CSI 版本 | kubernetes 版本 |
|---|---|
| 3.5.1 | 1.18.18 |
详细的对应的版本,请查看下面的参考文章。
1)ceph侧执行
ceph创建cephfs-metadata、cephfs-data存储池:
$ ceph osd pool create cephfs-metadata 64 64
pool 'cephfs-metadata' created
$ ceph osd pool create cephfs-data 64 64
pool 'cephfs-data' created
创建cephFS:
$ ceph fs new cephfs cephfs-metadata cephfs-data
new fs with metadata pool 7 and data pool 8
获取ceph相关信息:
$ ceph mon dump
epoch 2
fsid b87d2535-406b-442d-8de2-49d86f7dc599
last_changed 2022-06-15T17:35:37.096336+0800
created 2022-06-15T17:35:05.828763+0800
min_mon_release 15 (octopus)
0: [v2:192.168.31.69:3300/0,v1:192.168.31.69:6789/0] mon.ceph01
1: [v2:192.168.31.102:3300/0,v1:192.168.31.102:6789/0] mon.ceph02
2: [v2:192.168.31.165:3300/0,v1:192.168.31.165:6789/0] mon.ceph03
dumped monmap epoch 2
创建访问ceph密钥:
$ cat << EOF | sudo tee 0.csi-cephfs-secret.yml >> /dev/null
apiVersion: v1
kind: Secret
metadata:
name: csi-cephfs-secret
namespace: kube-storage
stringData:
# Required for statically provisioned volumes
# 通过 ceph auth get-key client.admin 获取 userkey,无需base64
userID: admin
userKey: AQDmp6lihkf5FxAA809mwZ32rx6tKiihamkh0g=
# Required for dynamically provisioned volumes
# 通过 ceph auth get-key client.admin 获取 userkey,无需base64
adminID: admin
adminKey: AQDmp6lihkf5FxAA809mwZ32rx6tKiihamkh0g=
EOF
$ kubectl apply -f 0.csi-cephfs-secret.yml
secret/csi-cephfs-secret created
创建相关rbac权限:
$ cat << EOF | sudo tee 1.csi-provisioner-rbac.yml >> /dev/null
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cephfs-csi-provisioner
namespace: kube-storage
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-external-provisioner-runner
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get", "list", "watch"]
- apiGroups: [""]
resources: ["secrets"]
verbs: ["get", "list"]
- apiGroups: [""]
resources: ["events"]
verbs: ["list", "watch", "create", "update", "patch"]
- apiGroups: [""]
resources: ["persistentvolumes"]
verbs: ["get", "list", "watch", "create", "delete", "patch"]
- apiGroups: [""]
resources: ["persistentvolumeclaims"]
verbs: ["get", "list", "watch", "update"]
- apiGroups: ["storage.k8s.io"]
resources: ["storageclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshots"]
verbs: ["get", "list"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotcontents"]
verbs: ["create", "get", "list", "watch", "update", "delete"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotclasses"]
verbs: ["get", "list", "watch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments"]
verbs: ["get", "list", "watch", "update", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["volumeattachments/status"]
verbs: ["patch"]
- apiGroups: [""]
resources: ["persistentvolumeclaims/status"]
verbs: ["update", "patch"]
- apiGroups: ["storage.k8s.io"]
resources: ["csinodes"]
verbs: ["get", "list", "watch"]
- apiGroups: ["snapshot.storage.k8s.io"]
resources: ["volumesnapshotcontents/status"]
verbs: ["update"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-csi-provisioner-role
subjects:
- kind: ServiceAccount
name: cephfs-csi-provisioner
namespace: kube-storage
roleRef:
kind: ClusterRole
name: cephfs-external-provisioner-runner
apiGroup: rbac.authorization.k8s.io
---
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
# replace with non-default namespace name
namespace: kube-storage
name: cephfs-external-provisioner-cfg
rules:
# remove this once we stop supporting v1.0.0
- apiGroups: [""]
resources: ["configmaps"]
verbs: ["get", "list", "create", "delete"]
- apiGroups: ["coordination.k8s.io"]
resources: ["leases"]
verbs: ["get", "watch", "list", "delete", "update", "create"]
---
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-csi-provisioner-role-cfg
# replace with non-default namespace name
namespace: kube-storage
subjects:
- kind: ServiceAccount
name: cephfs-csi-provisioner
# replace with non-default namespace name
namespace: kube-storage
roleRef:
kind: Role
name: cephfs-external-provisioner-cfg
apiGroup: rbac.authorization.k8s.io
EOF
$ cat << EOF | sudo tee 2.csi-nodeplugin-rbac.yml >> /dev/null
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: cephfs-csi-nodeplugin
namespace: kube-storage
---
kind: ClusterRole
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-csi-nodeplugin
rules:
- apiGroups: [""]
resources: ["nodes"]
verbs: ["get"]
---
kind: ClusterRoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cephfs-csi-nodeplugin
subjects:
- kind: ServiceAccount
name: cephfs-csi-nodeplugin
namespace: kube-storage
roleRef:
kind: ClusterRole
name: cephfs-csi-nodeplugin
apiGroup: rbac.authorization.k8s.io
EOF
$ kubectl apply -f 1.csi-provisioner-rbac.yml
serviceaccount/cephfs-csi-provisioner created
clusterrole.rbac.authorization.k8s.io/cephfs-external-provisioner-runner created
clusterrolebinding.rbac.authorization.k8s.io/cephfs-csi-provisioner-role created
role.rbac.authorization.k8s.io/cephfs-external-provisioner-cfg created
rolebinding.rbac.authorization.k8s.io/cephfs-csi-provisioner-role-cfg created
$ kubectl apply -f 2.csi-nodeplugin-rbac.yml
serviceaccount/cephfs-csi-nodeplugin created
clusterrole.rbac.authorization.k8s.io/cephfs-csi-nodeplugin created
clusterrolebinding.rbac.authorization.k8s.io/cephfs-csi-nodeplugin created
创建ceph配置文件:
$ cat << EOF | sudo tee 3.csi-config-map.yml >> /dev/null
---
apiVersion: v1
kind: ConfigMap
data:
config.json: |-
[
{
"clusterID": "b87d2535-406b-442d-8de2-49d86f7dc599",
"monitors": [
"192.168.31.69:6789",
"192.168.31.102:6789",
"192.168.31.165:6789"
]
}
]
metadata:
name: ceph-csi-config
namespace: kube-storage
EOF
$ kubectl apply -f 3.csi-config-map.yml
configmap/ceph-csi-config created
$ kubectl -n kube-storage create configmap ceph-config --from-file=/etc/ceph/ceph.conf --from-file=keyring=/etc/ceph/ceph.client.kubernetes.keyring
configmap/ceph-config created
根据ceph侧执行的返回结果来填写内容。
创建ceph-csi配置器:
$ cat << EOF | sudo tee 4.csi-cephfsplugin-provisioner.yml >> /dev/null
---
kind: Service
apiVersion: v1
metadata:
name: csi-cephfsplugin-provisioner
namespace: kube-storage
labels:
app: csi-metrics
spec:
selector:
app: csi-cephfsplugin-provisioner
ports:
- name: http-metrics
port: 8080
protocol: TCP
targetPort: 8681
---
kind: Deployment
apiVersion: apps/v1
metadata:
name: csi-cephfsplugin-provisioner
namespace: kube-storage
spec:
selector:
matchLabels:
app: csi-cephfsplugin-provisioner
replicas: 3
template:
metadata:
labels:
app: csi-cephfsplugin-provisioner
spec:
affinity:
podAntiAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- labelSelector:
matchExpressions:
- key: app
operator: In
values:
- csi-cephfsplugin-provisioner
topologyKey: "kubernetes.io/hostname"
serviceAccountName: cephfs-csi-provisioner
priorityClassName: system-cluster-critical
containers:
- name: csi-provisioner
image: k8s.gcr.io/sig-storage/csi-provisioner:v3.1.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--leader-election=true"
- "--retry-interval-start=500ms"
- "--feature-gates=Topology=false"
- "--extra-create-metadata=true"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-resizer
image: k8s.gcr.io/sig-storage/csi-resizer:v1.3.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--leader-election"
- "--retry-interval-start=500ms"
- "--handle-volume-inuse-error=false"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-snapshotter
image: k8s.gcr.io/sig-storage/csi-snapshotter:v4.2.0
args:
- "--csi-address=\$(ADDRESS)"
- "--v=5"
- "--timeout=150s"
- "--leader-election=true"
env:
- name: ADDRESS
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-cephfsplugin-attacher
image: k8s.gcr.io/sig-storage/csi-attacher:v3.4.0
args:
- "--v=5"
- "--csi-address=\$(ADDRESS)"
- "--leader-election=true"
- "--retry-interval-start=500ms"
env:
- name: ADDRESS
value: /csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: csi-cephfsplugin
# for stable functionality replace canary with latest release version
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--nodeid=\$(NODE_ID)"
- "--type=cephfs"
- "--controllerserver=true"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--v=5"
- "--drivername=cephfs.csi.ceph.com"
- "--pidlimit=-1"
- "--enableprofiling=false"
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: CSI_ENDPOINT
value: unix:///csi/csi-provisioner.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: host-sys
mountPath: /sys
- name: lib-modules
mountPath: /lib/modules
readOnly: true
- name: host-dev
mountPath: /dev
- name: ceph-config
mountPath: /etc/ceph/
- name: ceph-csi-config
mountPath: /etc/ceph-csi-config/
- name: keys-tmp-dir
mountPath: /tmp/csi/keys
- name: liveness-prometheus
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--type=liveness"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--metricsport=8681"
- "--metricspath=/metrics"
- "--polltime=60s"
- "--timeout=3s"
env:
- name: CSI_ENDPOINT
value: unix:///csi/csi-provisioner.sock
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: socket-dir
mountPath: /csi
imagePullPolicy: "IfNotPresent"
volumes:
- name: socket-dir
emptyDir: {
medium: "Memory"
}
- name: host-sys
hostPath:
path: /sys
- name: lib-modules
hostPath:
path: /lib/modules
- name: host-dev
hostPath:
path: /dev
- name: ceph-config
configMap:
name: ceph-config
- name: ceph-csi-config
configMap:
name: ceph-csi-config
- name: keys-tmp-dir
emptyDir: {
medium: "Memory"
}
EOF
$ kubectl apply -f 4.csi-cephfsplugin-provisioner.yml
service/csi-cephfsplugin-provisioner created
deployment.apps/csi-cephfsplugin-provisioner created
$ kubectl -n kube-storage get pod -l app=csi-cephfsplugin-provisioner
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-provisioner-b4fff46dc-dzcm6 6/6 Running 0 2m58s
csi-cephfsplugin-provisioner-b4fff46dc-qp67j 6/6 Running 0 2m58s
csi-cephfsplugin-provisioner-b4fff46dc-r7cs9 6/6 Running 0 2m58s
创建ceph-csi节点器:
$ cat << EOF | sudo tee 5.csi-cephfsplugin.yml >> /dev/null
---
kind: DaemonSet
apiVersion: apps/v1
metadata:
name: csi-cephfsplugin
namespace: kube-storage
spec:
selector:
matchLabels:
app: csi-cephfsplugin
template:
metadata:
labels:
app: csi-cephfsplugin
spec:
serviceAccountName: cephfs-csi-nodeplugin
priorityClassName: system-node-critical
hostNetwork: true
# to use e.g. Rook orchestrated cluster, and mons' FQDN is
# resolved through k8s service, set dns policy to cluster first
dnsPolicy: ClusterFirstWithHostNet
containers:
- name: driver-registrar
# This is necessary only for systems with SELinux, where
# non-privileged sidecar containers cannot access unix domain socket
# created by privileged CSI driver container.
securityContext:
privileged: true
image: k8s.gcr.io/sig-storage/csi-node-driver-registrar:v2.4.0
args:
- "--v=5"
- "--csi-address=/csi/csi.sock"
- "--kubelet-registration-path=/var/lib/kubelet/plugins/cephfs.csi.ceph.com/csi.sock"
env:
- name: KUBE_NODE_NAME
valueFrom:
fieldRef:
fieldPath: spec.nodeName
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: registration-dir
mountPath: /registration
- name: csi-cephfsplugin
securityContext:
privileged: true
capabilities:
add: ["SYS_ADMIN"]
allowPrivilegeEscalation: true
# for stable functionality replace canary with latest release version
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--nodeid=\$(NODE_ID)"
- "--type=cephfs"
- "--nodeserver=true"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--v=5"
- "--drivername=cephfs.csi.ceph.com"
- "--enableprofiling=false"
# If topology based provisioning is desired, configure required
# node labels representing the nodes topology domain
# and pass the label names below, for CSI to consume and advertise
# its equivalent topology domain
# - "--domainlabels=failure-domain/region,failure-domain/zone"
env:
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
- name: NODE_ID
valueFrom:
fieldRef:
fieldPath: spec.nodeName
- name: CSI_ENDPOINT
value: unix:///csi/csi.sock
imagePullPolicy: "IfNotPresent"
volumeMounts:
- name: socket-dir
mountPath: /csi
- name: mountpoint-dir
mountPath: /var/lib/kubelet/pods
mountPropagation: Bidirectional
- name: plugin-dir
mountPath: /var/lib/kubelet/plugins
mountPropagation: "Bidirectional"
- name: host-sys
mountPath: /sys
- name: etc-selinux
mountPath: /etc/selinux
readOnly: true
- name: lib-modules
mountPath: /lib/modules
readOnly: true
- name: host-dev
mountPath: /dev
- name: host-mount
mountPath: /run/mount
- name: ceph-config
mountPath: /etc/ceph/
- name: ceph-csi-config
mountPath: /etc/ceph-csi-config/
- name: keys-tmp-dir
mountPath: /tmp/csi/keys
- name: liveness-prometheus
securityContext:
privileged: true
image: quay.io/cephcsi/cephcsi:v3.5.1
args:
- "--type=liveness"
- "--endpoint=\$(CSI_ENDPOINT)"
- "--metricsport=8681"
- "--metricspath=/metrics"
- "--polltime=60s"
- "--timeout=3s"
env:
- name: CSI_ENDPOINT
value: unix:///csi/csi.sock
- name: POD_IP
valueFrom:
fieldRef:
fieldPath: status.podIP
volumeMounts:
- name: socket-dir
mountPath: /csi
imagePullPolicy: "IfNotPresent"
volumes:
- name: socket-dir
hostPath:
path: /var/lib/kubelet/plugins/cephfs.csi.ceph.com/
type: DirectoryOrCreate
- name: registration-dir
hostPath:
path: /var/lib/kubelet/plugins_registry/
type: Directory
- name: mountpoint-dir
hostPath:
path: /var/lib/kubelet/pods
type: DirectoryOrCreate
- name: plugin-dir
hostPath:
path: /var/lib/kubelet/plugins
type: Directory
- name: host-sys
hostPath:
path: /sys
- name: etc-selinux
hostPath:
path: /etc/selinux
- name: lib-modules
hostPath:
path: /lib/modules
- name: host-dev
hostPath:
path: /dev
- name: host-mount
hostPath:
path: /run/mount
- name: ceph-config
configMap:
name: ceph-config
- name: ceph-csi-config
configMap:
name: ceph-csi-config
- name: keys-tmp-dir
emptyDir: {
medium: "Memory"
}
---
# This is a service to expose the liveness metrics
apiVersion: v1
kind: Service
metadata:
name: csi-metrics-cephfsplugin
namespace: kube-storage
labels:
app: csi-metrics
spec:
ports:
- name: http-metrics
port: 8080
protocol: TCP
targetPort: 8681
selector:
app: csi-cephfsplugin
EOF
$ kubectl apply -f 5.csi-cephfsplugin.yml
daemonset.apps/csi-cephfsplugin created
service/csi-metrics-cephfsplugin created
$ kubectl -n kube-storage get pod -l app=csi-cephfsplugin
NAME READY STATUS RESTARTS AGE
csi-cephfsplugin-9z8jl 3/3 Running 0 57s
csi-cephfsplugin-jtgwt 3/3 Running 0 57s
csi-cephfsplugin-twzpw 3/3 Running 0 57s
csi-cephfsplugin-xxm6x 3/3 Running 0 57s
csi-cephfsplugin-zjjh5 3/3 Running 0 57s
如果kubelet数据目录有做修改的话,请修改相关的配置。
例如,kubelet数据目录在/data/k8s/data/kubelet目录下。那么请执行 sed -ri 's#/var/lib/kubelet#/data/k8s/data/kubelet#g' 7.csi-rbdplugin.yml 来修改配置文件。
创建SC动态供应:
$ cat << EOF | sudo tee 6.storageclass.yml >> /dev/null
---
apiVersion: storage.k8s.io/v1
kind: StorageClass
metadata:
name: csi-cephfs-sc
provisioner: cephfs.csi.ceph.com
parameters:
clusterID: b87d2535-406b-442d-8de2-49d86f7dc599
fsName: cephfs
csi.storage.k8s.io/provisioner-secret-name: csi-cephfs-secret
csi.storage.k8s.io/provisioner-secret-namespace: kube-storage
csi.storage.k8s.io/controller-expand-secret-name: csi-cephfs-secret
csi.storage.k8s.io/controller-expand-secret-namespace: kube-storage
csi.storage.k8s.io/node-stage-secret-name: csi-cephfs-secret
csi.storage.k8s.io/node-stage-secret-namespace: kube-storage
reclaimPolicy: Delete
allowVolumeExpansion: true
mountOptions:
- debug
EOF
$ kubectl apply -f 6.storageclass.yml
storageclass.storage.k8s.io/csi-cephfs-sc created
注意修改clusterID字段内容。
3)验证
创建一个1Gb的pvc:
$ cat << EOF | sudo tee 7.cephfs-pvc.yaml >> /dev/null
---
apiVersion: v1
kind: PersistentVolumeClaim
metadata:
name: csi-cephfs-pvc
spec:
accessModes:
- ReadWriteMany
resources:
requests:
storage: 1Gi
storageClassName: csi-cephfs-sc
EOF
$ kubectl apply -f 7.cephfs-pvc.yaml
persistentvolumeclaim/csi-cephfs-pvc created
$ kubectl get pvc csi-cephfs-pvc
NAME STATUS VOLUME CAPACITY ACCESS MODES STORAGECLASS AGE
csi-cephfs-pvc Bound pvc-a603e082-2bef-4696-9a22-222be55d0d46 1Gi RWX csi-cephfs-sc 46s
链接:百度网盘 请输入提取码
提取码:gcuj
ceph-csi:https://github.com/ceph/ceph-csi/tree/v3.5.1/deploy/cephfs/kubernetes
五、监控平台
1、Prometheus
1. Prometheus安装
1)简介
Prometheus 最初是 SoundCloud 构建的开源系统监控和报警工具,是一个独立的开源项目,于2016年加入了 CNCF 基金会,作为继 Kubernetes 之后的第二个托管项目。Prometheus 相比于其他传统监控工具主要有以下几个特点:
* 具有由 metric 名称和键/值对标识的时间序列数据的多维数据模型
* 有一个灵活的查询语言
* 不依赖分布式存储,只和本地磁盘有关
* 通过 HTTP 的服务拉取时间序列数据
* 也支持推送的方式来添加时间序列数据
* 还支持通过服务发现或静态配置发现目标
* 多种图形和仪表板支持
Prometheus 由多个组件组成,但是其中有些组件是可选的:
* Prometheus Server:用于抓取指标、存储时间序列数据
* exporter:暴露指标让任务来抓
* pushgateway:push 的方式将指标数据推送到该网关
* alertmanager:处理报警的报警组件 adhoc:用于数据查询
大多数 Prometheus 组件都是用 Go 编写的,因此很容易构建和部署为静态的二进制文件。下图是 Prometheus 官方提供的架构及其一些相关的生态系统组件:
整体流程比较简单,Prometheus 直接接收或者通过中间的 Pushgateway 网关被动获取指标数据,在本地存储所有的获取的指标数据,并对这些数据进行一些规则整理,用来生成一些聚合数据或者报警信息,Grafana 或者其他工具用来可视化这些数据。
2)安装Prometheus
由于我们这里是要运行在 Kubernetes 系统中,所以我们直接用 Docker 镜像的方式运行。为了方便管理,我们将监控相关的所有资源对象都安装在 kube-mon 这个 namespace 下面,没有的话可以提前创建。
能够方便的管理配置文件,我们这里将 prometheus.yml 文件用 ConfigMap 的形式进行管理:(prometheus-config.yaml)
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-config
namespace: kube-mon
data:
prometheus.yml: |
global:
scrape_interval: 15s
scrape_timeout: 15s
scrape_configs:
- job_name: 'prometheus'
metrics_path: /prometheus/metrics
static_configs:
- targets: ['localhost:9090']
我们这里暂时只配置了对 prometheus 本身的监控,直接创建该资源对象:
$ kubectl create namespace kube-mon
$ kubectl apply -f prometheus-config.yaml
configmap/prometheus-config created
由于 prometheus 可以访问 Kubernetes 的一些资源对象,所以需要配置 rbac 相关认证,这里我们使用了一个名为 prometheus 的 serviceAccount 对象(prometheus-rbac.yaml):
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-mon
由于我们要获取的资源信息,在每一个 namespace 下面都有可能存在,所以我们这里使用的是 ClusterRole 的资源对象,值得一提的是我们这里的权限规则声明中有一个 nonResourceURLs 的属性,是用来对非资源型 metrics 进行操作的权限声明,这个在以前我们很少遇到过,然后直接创建上面的资源对象即可:
$ kubectl apply -f prometheus-rbac.yaml
clusterrole.rbac.authorization.k8s.io "prometheus" created clusterrolebinding.rbac.authorization.k8s.io "prometheus" created
配置文件创建完成了,以后如果我们有新的资源需要被监控,我们只需要将上面的 ConfigMap 对象更新即可。现在我们来创建 prometheus 的 Pod 资源(prometheus-deploy.yaml):
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-mon
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: prometheus
namespace: kube-mon
labels:
app: prometheus
spec:
selector:
matchLabels:
app: prometheus
template:
metadata:
labels:
app: prometheus
spec:
serviceAccountName: prometheus # 访问集群资源需要用到的用户
nodeSelector:
kubernetes.io/node: monitor
containers:
- image: prom/prometheus:v2.25.0
name: prometheus
args:
- "--config.file=/etc/prometheus/prometheus.yml"
- "--storage.tsdb.path=/prometheus" # 指定tsdb数据路径
- "--storage.tsdb.retention.time=24h"
- "--web.enable-admin-api" # 控制对admin HTTP API的访问,其中包括删除时间序列等功能
- "--web.enable-lifecycle" # 支持热更新,直接执行localhost:9090/-/reload立即生效
- "--web.console.libraries=/usr/share/prometheus/console_libraries"
- "--web.console.templates=/usr/share/prometheus/consoles"
- "--web.external-url=/prometheus" # 添加上下文,健康检查也需要修改。
ports:
- containerPort: 9090
name: http
livenessProbe:
httpGet:
path: /prometheus/-/healthy
port: 9090
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
successThreshold: 1
readinessProbe:
httpGet:
path: /prometheus/-/ready
port: 9090
initialDelaySeconds: 5
periodSeconds: 5
failureThreshold: 3
successThreshold: 1
volumeMounts:
- mountPath: "/etc/prometheus"
name: config-volume
- mountPath: "/prometheus"
name: data
resources:
requests:
cpu: 100m
memory: 512Mi
limits:
cpu: 100m
memory: 512Mi
securityContext:
runAsUser: 0
volumes:
- name: data
hostPath:
path: /data/prometheus/
- configMap:
name: prometheus-config
name: config-volume
另外为了 prometheus 的性能和数据持久化我们这里是直接将通过 hostPath 的方式来进行数据持久化的,通过 --storage.tsdb.path=/prometheus 指定数据目录,然后将该目录声明挂载到 /data/prometheus 这个主机目录下面,为了防止 Pod 漂移,所以我们使用 nodeSelector 将 Pod 固定到了一个具有 node=monitor 标签的节点上,如果没有这个标签则需要为你的目标节点打上这个标签:
$ kubectl label node k8s-node01 kubernetes.io/node=monitor
node/k8s-node02 labeled
$ kubectl apply -f prometheus-deploy.yaml
serviceaccount/prometheus created
deployment.apps/prometheus created
Pod 创建成功后,为了能够在外部访问到 prometheus 的 webui 服务,我们还需要创建一个 Service 对象(prometheus-svc.yaml):
apiVersion: v1
kind: Service
metadata:
name: prometheus
namespace: kube-mon
labels:
app: prometheus
spec:
type: ClusterIP
selector:
app: prometheus
ports:
- name: web
port: 9090
targetPort: http
创建service资源:
$ kubectl apply -f prometheus-svc.yaml
service/prometheus created
$ kubectl -n kube-mon get svc
NAME TYPE CLUSTER-IP EXTERNAL-IP PORT(S) AGE
prometheus ClusterIP 10.183.0.209 <none> 9090/TCP 28s
2)设置ingress
cat <<EOF | sudo tee ingress.yml > /dev/null
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: prometheus
namespace: kube-mon
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /prometheus
backend:
serviceName: prometheus
servicePort: 9090
EOF
3)创建ingress资源
$ kubectl apply -f ingress.yml
ingress.extensions/prometheus created
如果出现有告警提示时间不同步的,例如 Warning: Error fetching server time: Detected 32.164000034332275 seconds time difference between your browser and the server. Prometheus relies on accurate time and time drift might cause unexpected query results.
解决方法:
通常是服务器的时间与客户端的时间不同步导致的一个问题。服务器是同步阿里云的,所以修改客户端也是同步阿里云即可。

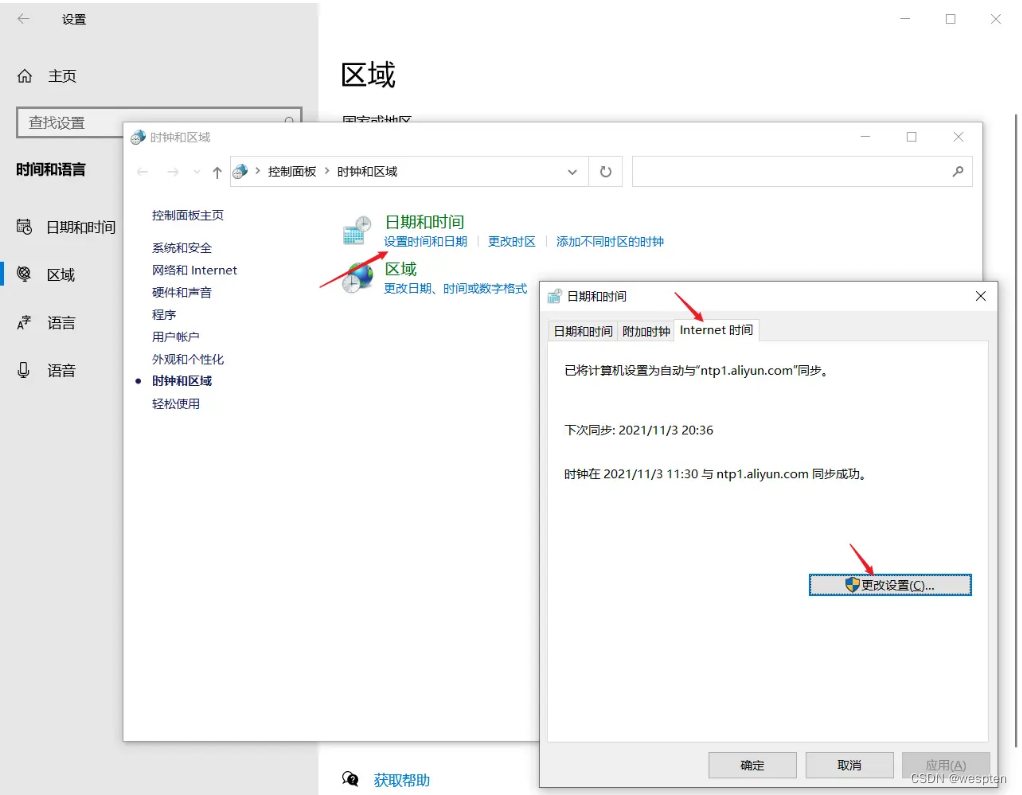
2. Prometheus监控配置
Prometheus 的配置文件总共分从 6 部分,分别如下:
- global:全局配置
- rule_files: 规则文件指定了一个 glob 列表。 从所有匹配的文件中读取规则和警报
- scrape_configs: 抓取配置列表
- alerting: 警报指定与警报管理器相关的设置
- remote_write: 与远程写入功能相关的设置
- remote_read: 与远程读取功能相关的设置
1)global全局配置
这个是全局配置文件,根据实际情况来修改。
scrape_interval: 默认情况下抓取目标的频率,默认1m
scrape_timeout: 抓取请求超时需要多长时间,默认10s
evaluation_interval: 评估规则的频率,默认1m
external_labels: 与外部系统(联合、远程存储、警报管理器)通信时添加到任何时间序列或警报的标签
query_log_file: PromQL 查询记录到的文件,重新加载配置将重新打开文件
这个只是添加配置文件,没有配置项,参考下面的示例示例:
rule_files:
[ - <filepath_glob> ... ]是列表格式,要在前面添加一个 - 符号。
3)【重点】scrape_configs采集规则
这个是监控的关键,是根据下面的配置来实现监控的。下面列举常用的配置想,请看所有的配置,请查看Prometheus官方文档
- job_name:任务的名称;
- scrape_interval:抓取目标的频率,没有设置则使用全局配置;
- scrape_timeout:抓取请求超时需要多长时间,没有设置则使用全局配置;
- metrics_path:从目标获取指标的 HTTP 资源路径,默认是
/metrics; - scheme:配置用于请求的协议方案,默认是http;
- params:可选的 HTTP URL 参数;
- relabel_configs:可以在目标被抓取之前动态地重写目标的标签;
- basic_auth:在每个抓取请求上设置
Authorization标头配置的用户名和密码,password 和 password_file 是互斥的; - authorization:使用配置的凭据在每个抓取请求上设置
Authorization标头; - tls_config:配置抓取请求的 TLS 设置;
- static_configs:标记的静态配置的警报管理器列表;
- file_sd_config: 文件服务发现配置列表;
- consul_sd_config: Consul 服务发现配置列表;
- docker_sd_config: Docker 服务发现配置列表;
- kubernetes_sd_config:Kubernetes SD 配置允许从 Kubernetes 的 REST API 检索抓取目标并始终与集群状态保持同步;
scrape_configs采集规则有两类:
- 静态配置(上面列举的倒数第五个就是静态配置),每次配置后都需要重启Prometheus服务
- 服务发现(上面列举的后四个都是,其他服务发现的请看官方文档)。prometheus-server自动发现target。无需重启Prometheus服务【推荐】
监控应用,应当有暴露出 metrics 接口。如果应用没有的话,可以找第三方的exporters。Prometheus社区也提供常用的exporters,请查看该链接
(1)基于静态配置
使用shell获取监控指标:
$ kubectl -n kube-mon get pod -l app=prometheus -owide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
prometheus-6c65c7787f-gmjj9 1/1 Running 0 7m58s 20.0.85.201 k8s-node01 <none> <none>
$ curl -s 20.0.85.201:9090/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.7762e-05
go_gc_duration_seconds{quantile="0.25"} 0.000101175
go_gc_duration_seconds{quantile="0.5"} 0.00016822
go_gc_duration_seconds{quantile="0.75"} 0.000428428
go_gc_duration_seconds{quantile="1"} 0.00079745
go_gc_duration_seconds_sum 0.002778413
go_gc_duration_seconds_count 11
# HELP go_goroutines Number of goroutines that currently exist.
使用Prometheus获取监控指标:
- job_name: "prometheus"
static_configs:
- targets:
- "localhost:9090"
验证Prometheus的targets的界面:

基于文件的服务发现提供了一种更通用的方式来配置静态目标,并用作插入自定义服务发现机制的接口。
监控集群节点(node-exporter):
使用shell获取监控指标:
curl -s 192.168.31.103:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.6659e-05
go_gc_duration_seconds{quantile="0.25"} 8.684e-05
go_gc_duration_seconds{quantile="0.5"} 0.00018778
go_gc_duration_seconds{quantile="0.75"} 0.000327928
go_gc_duration_seconds{quantile="1"} 0.092123081
go_gc_duration_seconds_sum 0.200803256
go_gc_duration_seconds_count 50
# HELP go_goroutines Number of goroutines that currently exist.
使用Prometheus获取监控指标:
# 基于文件服务发现
- job_name: "node-exporter"
file_sd_configs:
- files:
- "targets/*.yaml"
# 刷新间隔以重新读取文件
refresh_interval: 1m
---
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-node-exporter
namespace: kube-mon
data:
node-exporter.yaml: |
- targets:
- "192.168.31.103:9100"
- "192.168.31.79:9100"
- "192.168.31.95:9100"
- "192.168.31.78:9100"
- "192.168.31.253:9100"
验证Prometheus的targets的界面:

etcd如果是https服务的话,需要将证书挂载到Prometheus的pod中。
使用shell获取监控指标:
curl -sk --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --cacert /data/etcd/certs/ca.pem https://192.168.31.95:2379/metrics | head
# HELP etcd_cluster_version Which version is running. 1 for 'cluster_version' label with current cluster version
# TYPE etcd_cluster_version gauge
etcd_cluster_version{cluster_version="3.4"} 1
# HELP etcd_debugging_auth_revision The current revision of auth store.
# TYPE etcd_debugging_auth_revision gauge
etcd_debugging_auth_revision 1
# HELP etcd_debugging_disk_backend_commit_rebalance_duration_seconds The latency distributions of commit.rebalance called by bboltdb backend.
# TYPE etcd_debugging_disk_backend_commit_rebalance_duration_seconds histogram
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.001"} 74365
etcd_debugging_disk_backend_commit_rebalance_duration_seconds_bucket{le="0.002"} 74367
使用Prometheus获取监控指标:
- job_name: "Service/etcd"
scheme: https
# 这里使用的是etcd证书,需要挂载给容器使用
tls_config:
ca_file: /etc/prometheus/tls/etcd/ca.pem
cert_file: /etc/prometheus/tls/etcd/etcd.pem
key_file: /etc/prometheus/tls/etcd/etcd-key.pem
insecure_skip_verify: true
file_sd_configs:
- files:
- targets/etcd.yaml
refresh_interval: 1m
---
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-files-sd-etcd
namespace: kube-mon
data:
etcd.yaml: |
- targets:
- 192.168.31.95:2379
- 192.168.31.78:2379
- 192.168.31.253:2379
etcd证书挂载给Prometheus的容器使用,使用到的命令:
kubectl create configmap -n kube-mon etcd-certs --from-file=/data/etcd/certs/ca.pem --from-file=/data/etcd/certs/etcd.pem --from-file=/data/etcd/certs/etcd-key.pem
configmap/etcd-certs created
# 部署Prometheus的文件,在 spec.template.spec.containers.volumeMounts 添加下面两行
- mountPath: "/etc/prometheus/tls/etcd"
name: prometheus-etcd-certs
# 部署Prometheus的文件,在 spec.template.spec.volumes 添加下面三行
- configMap:
name: etcd-certs
name: prometheus-etcd-certs
# 重新apply一下Prometheus的部署文件
kubectl apply -f prometheus-deploy.yaml
serviceaccount/prometheus unchanged
deployment.apps/prometheus configured
验证Prometheus的targets的界面:

(3)基于kubernetes node的服务发现
节点角色为每个集群节点发现一个目标,其地址默认为 Kubelet 的 HTTP 端口。 目标地址默认为NodeInternalIP、NodeExternalIP、NodeLegacyHostIP、NodeHostName的地址类型顺序中Kubernetes节点对象的第一个现有地址,按照顺序往下匹配。匹配成功则赋值 __address__的值。

docker没有提供 metrics 接口,那只能安装 exporter 来暴露监控信息。监控容器有一个很好的 exporter,那就是 cadvisor 。cadvisor是一个谷歌开发的容器监控工具,本次就是使用该exporter来监控容器。
cadvisor 监控容器工具被内嵌到 k8s 的 kubelet 服务中,所以不需要额外安装监控容器的工具了。cadvisor 在 kubelet 服务的暴露接口为 /metrics/cadvisor。
使用shell获取监控指标:
curl -sk --cacert /data/k8s/certs/ca.pem --cert /data/k8s/certs/admin.pem --key /data/k8s/certs/admin-key.pem https://192.168.31.103:10250/metrics/cadvisor | head
# HELP cadvisor_version_info A metric with a constant '1' value labeled by kernel version, OS version, docker version, cadvisor version & cadvisor revision.
# TYPE cadvisor_version_info gauge
cadvisor_version_info{cadvisorRevision="",cadvisorVersion="",dockerVersion="19.03.15",kernelVersion="3.10.0-957.el7.x86_64",osVersion="CentOS Linux 7 (Core)"} 1
# HELP container_cpu_cfs_periods_total Number of elapsed enforcement period intervals.
# TYPE container_cpu_cfs_periods_total counter
container_cpu_cfs_periods_total{container="",id="/kubepods.slice/kubepods-pod388eddee_5085_4f0a_a1f8_e92d07153ce4.slice",image="",name="",namespace="kube-mon",pod="node-exporter-26b9p"} 59 1636511205534
container_cpu_cfs_periods_total{container="node-exporter",id="/kubepods.slice/kubepods-pod388eddee_5085_4f0a_a1f8_e92d07153ce4.slice/docker-9ca146246a96384896d761161f63a79decea54aa96057915289493dc0cdfa7aa.scope",image="sha256:15a32669b6c2116e70469216e8350dbd59ebd157f0fc6eb4543b15e6239846c0",name="k8s_node-exporter_node-exporter-26b9p_kube-mon_388eddee-5085-4f0a-a1f8-e92d07153ce4_7",namespace="kube-mon",pod="node-exporter-26b9p"} 35 1636511200395
# HELP container_cpu_cfs_throttled_periods_total Number of throttled period intervals.
# TYPE container_cpu_cfs_throttled_periods_total counter
container_cpu_cfs_throttled_periods_total{container="",id="/kubepods.slice/kubepods-pod388eddee_5085_4f0a_a1f8_e92d07153ce4.slice",image="",name="",namespace="kube-mon",pod="node-exporter-26b9p"} 30 1636511205534
使用Prometheus获取监控指标:
- job_name: "containers"
scheme: https
# tls_config 和 bearer_token_file 参数与 https 验证有关。
# 这个两个参数都是通过部署Prometheus的serviceaccount上传的。
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# 监控k8s的所有节点容器
kubernetes_sd_configs:
- role: node
metrics_path: /metrics/cadvisor
# 修改标签名称
# 原来是__meta_kubernetes_node_label_xxx 没有在`Labels`显示出来的
# 只能通过鼠标放在 `Labels` 位置才能显示。现在想直接显示出来。
# 可以通过 `labelmap` 的动作来实现,正则表示式匹配到的(.+)直接变成标签名,对应的值不变的显示出来。
relabel_configs:
- regex: __meta_kubernetes_node_label_(.+)
action: labelmap
修改Prometheus配置文件文件,需要重启服务。
# 重启服务
kubectl -n kube-mon delete pod -l app=prometheus
# 【推荐】触发Prometheus的api接口,使得重新加载配置文件
curl -X POST "http://`kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload"
验证Prometheus的targets的界面:

使用shell获取监控指标:
curl -sk --cacert /data/k8s/certs/ca.pem --cert /data/k8s/certs/admin.pem --key /data/k8s/certs/admin-key.pem https://192.168.31.103:10250/metrics | head
# HELP apiserver_audit_event_total [ALPHA] Counter of audit events generated and sent to the audit backend.
# TYPE apiserver_audit_event_total counter
apiserver_audit_event_total 0
# HELP apiserver_audit_requests_rejected_total [ALPHA] Counter of apiserver requests rejected due to an error in audit logging backend.
# TYPE apiserver_audit_requests_rejected_total counter
apiserver_audit_requests_rejected_total 0
# HELP apiserver_client_certificate_expiration_seconds [ALPHA] Distribution of the remaining lifetime on the certificate used to authenticate a request.
# TYPE apiserver_client_certificate_expiration_seconds histogram
apiserver_client_certificate_expiration_seconds_bucket{le="0"} 0
apiserver_client_certificate_expiration_seconds_bucket{le="1800"} 0
使用Prometheus获取监控指标:
- job_name: "kubelet"
scheme: https
# tls_config 和 bearer_token_file 参数与 https 验证有关。
# 这个两个参数都是通过部署Prometheus的serviceaccount上传的。
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
上面使用文件服务发现的方式,如果是通过kubernetes上部署的node-exporter的服务。更加推荐使用kubernetes的服务发现功能。
宿主机有暴露端口(kube-controller-manager、kube-scheduler、kube-proxy)。可以通过这种方式来获取指标数据。
使用shell获取监控指标:
curl -s 192.168.31.103:9100/metrics | head
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 3.6659e-05
go_gc_duration_seconds{quantile="0.25"} 8.684e-05
go_gc_duration_seconds{quantile="0.5"} 0.00018778
go_gc_duration_seconds{quantile="0.75"} 0.000327928
go_gc_duration_seconds{quantile="1"} 0.092123081
go_gc_duration_seconds_sum 0.200803256
go_gc_duration_seconds_count 50
# HELP go_goroutines Number of goroutines that currently exist.
使用Prometheus获取监控指标:
- job_name: "node-exporters"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
# 修改后的标签名称
target_label: __address__
# 修改后的标签值
replacement: $1:9100
(4)基于kubernetes endpoints的服务发现
使用shell获取监控指标:
curl -sk --cacert /data/k8s/certs/ca.pem --cert /data/k8s/certs/admin.pem --key /data/k8s/certs/admin-key.pem https://192.168.31.103:6443/metrics | head
# HELP aggregator_openapi_v2_regeneration_count [ALPHA] Counter of OpenAPI v2 spec regeneration count broken down by causing APIService name and reason.
# TYPE aggregator_openapi_v2_regeneration_count counter
aggregator_openapi_v2_regeneration_count{apiservice="*",reason="startup"} 0
aggregator_openapi_v2_regeneration_count{apiservice="k8s_internal_local_delegation_chain_0000000002",reason="update"} 0
aggregator_openapi_v2_regeneration_count{apiservice="v1beta1.metrics.k8s.io",reason="add"} 0
aggregator_openapi_v2_regeneration_count{apiservice="v1beta1.metrics.k8s.io",reason="update"} 0
# HELP aggregator_openapi_v2_regeneration_duration [ALPHA] Gauge of OpenAPI v2 spec regeneration duration in seconds.
# TYPE aggregator_openapi_v2_regeneration_duration gauge
aggregator_openapi_v2_regeneration_duration{reason="add"} 8.731698517
aggregator_openapi_v2_regeneration_duration{reason="startup"} 1.016954282
使用Prometheus获取监控指标:
- job_name: "kube-apiserver"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# kubernetes 自动发现 endpoints 资源
# 当匹配到对应的标签值才会被保留
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
source_labels:源标签从现有标签中选择值。 它们的内容使用配置的分隔符连接,并与配置的替换、保留和删除操作的正则表达式匹配。regex: source_labels提取的值与之匹配的正则表达式action:基于正则表达式匹配执行的操作target_label: 结果值在替换操作中写入的标签。 替换操作是强制性的。 正则表达式捕获组可用replacement:如果正则表达式匹配,则对其执行正则表达式替换的替换值。 正则表达式捕获组可用,默认是regex匹配的$1
<relabel_action> 确定要采取的重新标记操作:
- replace:将正则表达式与连接的 source_labels 匹配。 然后,将 target_label 设置为替换,替换中的匹配组引用 (${1}, ${2}, ...) 替换为它们的值。 如果正则表达式不匹配,则不进行替换。
- keep:删除正则表达式与连接的 source_labels 不匹配的目标。
- drop:删除正则表达式与连接的 source_labels 匹配的目标。
- hashmod:将 target_label 设置为连接的 source_labels 的哈希模数。
- labelmap:将正则表达式与所有标签名称匹配。 然后将匹配标签的值复制到由替换给出的标签名称,替换为匹配组引用 (${1}, ${2}, ...) 替换为它们的值。
- labeldrop:将正则表达式与所有标签名称匹配。 任何匹配的标签都将从标签集中删除。
- labelkeep:将正则表达式与所有标签名称匹配。 任何不匹配的标签都将从标签集中删除。
验证Prometheus的targets的界面:

4)监控kubernetes基础组件示例
kube-apiserver:
- job_name: "Service/kube-apiserver"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
kube-controller-manager:
- job_name: "Service/kube-controller-manager"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
# 根据主机名来保留对主机的监控
- source_labels: [__meta_kubernetes_node_name]
action: keep
regex: k8s-master(.*)
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10257
kube-scheduler:
- job_name: "Service/kube-scheduler"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
kubernetes_sd_configs:
- role: node
relabel_configs:
# 根据标签来保留对主机的监控。【注意】主机需要有 node-role.kubernetes.io/master=true 的标签
- source_labels: [__meta_kubernetes_node_label_node_role_kubernetes_io_master]
action: keep
regex: true
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10259
注意:根据节点标签配置监控节点
kubectl label node k8s-master01 node-role.kubernetes.io/master=truekubelet:
- job_name: "Service/kubelet"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# kuberbetes node自动发现,默认是监控kubelet的服务端口
kubernetes_sd_configs:
- role: node
kube-proxy:
# kube-proxy服务的scheme是http
- job_name: "Service/kube-proxy"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10249
etcd:
本文示例etcd是https的,所以需要挂载tls证书。
$ kubectl create configmap -n kube-mon etcd-certs --from-file=/data/etcd/certs/ca.pem --from-file=/data/etcd/certs/etcd.pem --from-file=/data/etcd/certs/etcd-key.pem
configmap/etcd-certs created
Prometheus监控etcd配置文件:
- job_name: "Service/etcd"
scheme: https
tls_config:
ca_file: /etc/prometheus/tls/etcd/ca.pem
cert_file: /etc/prometheus/tls/etcd/etcd.pem
key_file: /etc/prometheus/tls/etcd/etcd-key.pem
insecure_skip_verify: true
file_sd_configs:
- files:
- targets/etcd.yaml
refresh_interval: 1m
本文示例etcd不在kubernetes创建的,这里使用文件发现机制来监控:
$ cat targets-files-sd-config.yaml
apiVersion: v1
kind: ConfigMap
metadata:
name: targets-files-sd-config
namespace: kube-mon
data:
etcd.yaml: |
- targets:
- 192.168.31.95:2379
- 192.168.31.78:2379
- 192.168.31.253:2379
$ kubectl apply -f targets-files-sd-config.yaml
$ kubectl -n kube-mon edit deploy prometheus
# 在 spec.template.spec.containers.volumeMounts 添加下面几行
- mountPath: /etc/prometheus/targets
name: targets-files-sd-config
- mountPath: "/etc/prometheus/tls/etcd"
name: prometheus-etcd-certs
# 在 spec.template.spec.volumes 添加下面几行
- configMap:
name: targets-files-sd-config
name: targets-files-sd-config
- configMap:
name: etcd-certs
name: prometheus-etcd-certs
calico:
默认没有暴露metrics端口,需要设置开启metrics接口。
$ kubectl -n kube-system edit ds calico-node
1. 暴露metrics接口,calico-node 的 spec.template.spec.containers.env 下添加一段下面的内容
- name: FELIX_PROMETHEUSMETRICSENABLED
value: "True"
- name: FELIX_PROMETHEUSMETRICSPORT
value: "9091"
2. calico-node 的 spec.template.spec.containers 下添加一段下面的内容
ports:
- containerPort: 9091
name: http-metrics
protocol: TCP
如果有设置防火墙,需要放通 Prometheus 到 calico-node 所在节点的 9091 端口:
iptables -t filter -I INPUT -p tcp --dport 9091 -m comment --comment "k8s calico metrics ports" -j ACCEPT - job_name: "Service/calico"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:9091
coredns:
- job_name: "Service/coredns"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-dns;metrics
ingress-nginx:
新建ingress-nginx的service,通过service来发现并监控。
$ cat ingress/service-metrics.yaml
apiVersion: v1
kind: Service
metadata:
name: ingress-nginx-metrics
namespace: ingress-nginx
spec:
selector:
app.kubernetes.io/name: ingress-nginx
app.kubernetes.io/instance: ingress-nginx
app.kubernetes.io/component: controller
ports:
- name: metrics
port: 10254
targetPort: 10254
$ kubectl apply -f ingress/service-metrics.yaml
- job_name: "Service/ingress-nginx"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: ingress-nginx;ingress-nginx-metrics;metrics
如果有设置防火墙,需要放通 Prometheus 到 ingress 所在节点的 10254 端口:
iptables -t filter -I INPUT -p tcp --dport 10254 -m comment --comment "ingress nginx metrics ports" -j ACCEPTcontainers:
- job_name: "containers"
scheme: https
tls_config:
ca_file: /var/run/secrets/kubernetes.io/serviceaccount/ca.crt
insecure_skip_verify: true
bearer_token_file: /var/run/secrets/kubernetes.io/serviceaccount/token
# 监控k8s的所有节点容器
kubernetes_sd_configs:
- role: node
metrics_path: /metrics/cadvisor
# 修改标签名称
# 原来是__meta_kubernetes_node_label_xxx 没有在`Labels`显示出来的
# 只能通过鼠标放在 `Labels` 位置才能显示。现在想直接显示出来。
# 可以通过 `labelmap` 的动作来实现,正则表示式匹配到的(.+)直接变成标签名,对应的值不变的显示出来。
relabel_configs:
- regex: __meta_kubernetes_node_label_(.+)
action: labelmap
上面配置的target展示:

3. node_exporter安装
1)监控集群节点
要监控节点其实我们已经有很多非常成熟的方案了,比如 Nagios、zabbix,甚至我们自己来收集数据也可以,我们这里通过 Prometheus 来采集节点的监控指标数据,可以通过 node_exporter 来获取,顾名思义,node_exporter就是抓取用于采集服务器节点的各种运行指标,目前node_exporter支持几乎所有常见的监控点,比如 conntrack,cpu,diskstats,filesystem,loadavg,meminfo,netstat 等,详细的监控点列表可以参考其 Github 仓库。
我们可以通过 DaemonSet 控制器来部署该服务,这样每一个节点都会自动运行一个这样的 Pod,如果我们从集群中删除或者添加节点后,也会进行自动扩展。
在部署node-exporter的时候有一些细节需要注意,如下资源清单文件(prometheus-node-exporter.yaml):
apiVersion: apps/v1
kind: DaemonSet
metadata:
name: node-exporter
namespace: kube-mon
labels:
app: node-exporter
spec:
selector:
matchLabels:
app: node-exporter
template:
metadata:
labels:
app: node-exporter
spec:
# 需要获取宿主机的信息,所以需要相关权限。
hostPID: true
hostIPC: true
hostNetwork: true
nodeSelector:
kubernetes.io/os: linux
containers:
- name: node-exporter
image: prom/node-exporter:v1.1.1
args:
- --web.listen-address=$(HOSTIP):9100
- --collector.filesystem.ignored-mount-points=^/(dev|proc|sys|data/docker/data)($|/)
- --collector.filesystem.ignored-fs-types=^(rootfs)$
ports:
- containerPort: 9100
env:
- name: HOSTIP
valueFrom:
fieldRef:
fieldPath: status.hostIP
resources:
requests:
cpu: 150m
memory: 180Mi
limits:
cpu: 150m
memory: 180Mi
securityContext:
runAsNonRoot: true
runAsUser: 65534
volumeMounts:
- name: proc
mountPath: /host/proc
- name: sys
mountPath: /host/sys
- name: root
mountPath: /host/root
mountPropagation: HostToContainer
readOnly: true
# 容忍所有节点的污点,比如 kubeamd 安装的集群,master 节点就有污点存在。
tolerations:
- operator: "Exists"
volumes:
- name: proc
hostPath:
path: /proc
- name: dev
hostPath:
path: /dev
- name: sys
hostPath:
path: /sys
- name: root
hostPath:
path: /
由于我们要获取到的数据是主机的监控指标数据,而我们的 node-exporter 是运行在容器中的,所以我们在 Pod 中需要配置一些 Pod 的安全策略,这里我们就添加了 hostPID: true、hostIPC: true、hostNetwork: true 3个策略,用来使用主机的 PID namespace、IPC namespace 以及主机网络,这些 namespace 就是用于容器隔离的关键技术,要注意这里的 namespace 和集群中的 namespace 是两个完全不相同的概念。
另外我们还将主机的 /dev、/proc、/sys这些目录挂载到容器中,这些因为我们采集的很多节点数据都是通过这些文件夹下面的文件来获取到的,比如我们在使用 top 命令可以查看当前 cpu 使用情况,数据就来源于文件 /proc/stat,使用 free 命令可以查看当前内存使用情况,其数据来源是来自 /proc/meminfo 文件。
$ kubectl apply -f node-exporter.yaml
daemonset.apps/node-exporter create
$ kubectl get pods -n kube-mon -l app=node-exporter -o wide
NAME READY STATUS RESTARTS AGE IP NODE NOMINATED NODE READINESS GATES
node-exporter-q42fg 1/1 Running 0 16m 172.20.0.14 k8s-master <none> <none>
node-exporter-r54ds 1/1 Running 1 22h 172.20.0.13 k8s-node01 <none> <none>
node-exporter-tdwgt 1/1 Running 1 22h 172.20.0.9 k8s-node02 <none> <none>
部署完成后,我们可以看到在3个节点上都运行了一个 Pod,由于我们指定了 hostNetwork=true,所以在每个节点上就会绑定一个端口 9100,我们可以通过这个端口去获取到监控指标数据:
$ curl 172.20.0.14:9100/metrics
# HELP go_gc_duration_seconds A summary of the pause duration of garbage collection cycles.
# TYPE go_gc_duration_seconds summary
go_gc_duration_seconds{quantile="0"} 0.098513621
go_gc_duration_seconds{quantile="0.25"} 0.098513621
go_gc_duration_seconds{quantile="0.5"} 0.098513621
go_gc_duration_seconds{quantile="0.75"} 0.098513621
go_gc_duration_seconds{quantile="1"} 0.098513621
go_gc_duration_seconds_sum 0.098513621
go_gc_duration_seconds_count 1
有些指标没有对应的exporter来收集,那么只能通过自定义指标来实现。node_exporter 可在启动时指定路径,并将该路径下的 *.prom 识别为监控数据文件。
编写脚本:
mkdir -p /opt/exports/{scripts,values}
cat > /opt/exports/scripts/pids.sh <<-EOF
#!/bin/bash
echo \# Number of system pids.
echo node_pids_kernel_use_number \$(ps -eLf | wc -l)
echo node_pids_kernel_total_number \$(sysctl kernel.pid_max | awk -F= '{print \$2}')
echo \# Number of user pids.
echo node_pids_user_use_number \$(ps -eLf | egrep "^root" | wc -l)
echo node_pids_user_total_number \$(ulimit -u)
echo \# Number of Cgroups pids.
echo node_pids_cgroup_use_number \$(cat /sys/fs/cgroup/pids/kubepods.slice/pids.current)
echo node_pids_cgroup_total_number \$(cat /sys/fs/cgroup/pids/kubepods.slice/pids.max)
EOF
设置定时任务获取值:
echo "* * * * * root bash /opt/exports/scripts/pids.sh > /opt/exports/values/pids.prom" >> /etc/crontab
添加参数及挂载文件:
kubectl -n kube-mon edit ds node-exporter
# 在 secp.template.containers.args 下,新增一行
- --collector.textfile.directory=/opt/exports/values/
# 在 secp.template.containers.volumeMounts 下,新增两行
- name: custom-indicator
mountPath: /opt/exports/values/
# 在 spec.template.volumes 下,新增三行
- name: custom-indicator
hostPath:
path: /opt/exports/values/
curl -s 192.168.31.103:9100/metrics | grep pids | egrep -v "^#"
node_pids_cgroup_total_number。
5)Prometheus抓取数据
- job_name: "node-exporters"
kubernetes_sd_configs:
- role: node
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:9100
metric_relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: instance
replacement: $1
6)附加iptables规则
iptables -t filter -I INPUT -p tcp --dport 9100 -m comment --comment "k8s node exporter ports" -j ACCEPT4. kube-state-metrics安装
kube-state-metrics 是关于在不修改的情况下从 Kubernetes API 对象生成指标。这确保了 kube-state-metrics 提供的特性与 Kubernetes API 对象本身具有相同等级的稳定性。反过来,这意味着 kube-state-metrics 在某些情况下可能不会显示与 kubectl 完全相同的值,因为 kubectl 应用某些启发式方法来显示可理解的消息。kube-state-metrics 公开了未经 Kubernetes API 修改的原始数据,这样用户就拥有了他们需要的所有数据,并在他们认为合适的时候执行启发式算法。
1)版本兼容性
2)部署安装
rbac清单文件:
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
rules:
- apiGroups:
- ""
resources:
- configmaps
- secrets
- nodes
- pods
- services
- resourcequotas
- replicationcontrollers
- limitranges
- persistentvolumeclaims
- persistentvolumes
- namespaces
- endpoints
verbs:
- list
- watch
- apiGroups:
- apps
resources:
- statefulsets
- daemonsets
- deployments
- replicasets
verbs:
- list
- watch
- apiGroups:
- batch
resources:
- cronjobs
- jobs
verbs:
- list
- watch
- apiGroups:
- autoscaling
resources:
- horizontalpodautoscalers
verbs:
- list
- watch
- apiGroups:
- authentication.k8s.io
resources:
- tokenreviews
verbs:
- create
- apiGroups:
- authorization.k8s.io
resources:
- subjectaccessreviews
verbs:
- create
- apiGroups:
- policy
resources:
- poddisruptionbudgets
verbs:
- list
- watch
- apiGroups:
- certificates.k8s.io
resources:
- certificatesigningrequests
verbs:
- list
- watch
- apiGroups:
- storage.k8s.io
resources:
- storageclasses
- volumeattachments
verbs:
- list
- watch
- apiGroups:
- admissionregistration.k8s.io
resources:
- mutatingwebhookconfigurations
- validatingwebhookconfigurations
verbs:
- list
- watch
- apiGroups:
- networking.k8s.io
resources:
- networkpolicies
- ingresses
verbs:
- list
- watch
- apiGroups:
- coordination.k8s.io
resources:
- leases
verbs:
- list
- watch
---
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRoleBinding
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: kube-state-metrics
subjects:
- kind: ServiceAccount
name: kube-state-metrics
namespace: kube-mon
---
apiVersion: v1
kind: ServiceAccount
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-mon
deployment清单文件:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-mon
spec:
replicas: 1
selector:
matchLabels:
app.kubernetes.io/name: kube-state-metrics
template:
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
spec:
containers:
- image: bitnami/kube-state-metrics:2.3.0
livenessProbe:
httpGet:
path: /healthz
port: 8080
initialDelaySeconds: 5
timeoutSeconds: 5
name: kube-state-metrics
ports:
- containerPort: 8080
name: http-metrics
- containerPort: 8081
name: telemetry
readinessProbe:
httpGet:
path: /
port: 8081
initialDelaySeconds: 5
timeoutSeconds: 5
securityContext:
runAsUser: 65534
nodeSelector:
kubernetes.io/os: linux
serviceAccountName: kube-state-metrics
service清单文件:
apiVersion: v1
kind: Service
metadata:
labels:
app.kubernetes.io/component: exporter
app.kubernetes.io/name: kube-state-metrics
app.kubernetes.io/version: 2.3.0
name: kube-state-metrics
namespace: kube-mon
spec:
clusterIP: None
ports:
- name: http-metrics
port: 8080
targetPort: http-metrics
- name: telemetry
port: 8081
targetPort: telemetry
selector:
app.kubernetes.io/name: kube-state-metrics
创建相关资源:
$ kubectl apply -f rbac.yml
clusterrole.rbac.authorization.k8s.io/kube-state-metrics created
clusterrolebinding.rbac.authorization.k8s.io/kube-state-metrics created
serviceaccount/kube-state-metrics created
$ kubectl apply -f deploy.yml
deployment.apps/kube-state-metrics created
$ kubectl apply -f service.yml
service/kube-state-metrics created
验证:
$ kubectl -n kube-system get pod -l app.kubernetes.io/name=kube-state-metrics
NAME READY STATUS RESTARTS AGE
kube-state-metrics-6544d5656d-sjnhh 1/1 Running 0 53m
$ kubectl -n kube-system get endpoints kube-state-metrics
NAME ENDPOINTS AGE
kube-state-metrics 20.0.32.184:8081,20.0.32.184:8080 54m
$ curl -s 20.0.32.184:8080/metrics | head -20
# HELP kube_certificatesigningrequest_annotations Kubernetes annotations converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_annotations gauge
# HELP kube_certificatesigningrequest_labels Kubernetes labels converted to Prometheus labels.
# TYPE kube_certificatesigningrequest_labels gauge
# HELP kube_certificatesigningrequest_created Unix creation timestamp
# TYPE kube_certificatesigningrequest_created gauge
# HELP kube_certificatesigningrequest_condition The number of each certificatesigningrequest condition
# TYPE kube_certificatesigningrequest_condition gauge
# HELP kube_certificatesigningrequest_cert_length Length of the issued cert
# TYPE kube_certificatesigningrequest_cert_length gauge
# HELP kube_configmap_annotations Kubernetes annotations converted to Prometheus labels.
# TYPE kube_configmap_annotations gauge
kube_configmap_annotations{namespace="kube-mon",configmap="alertmanager-config"} 1
kube_configmap_annotations{namespace="kube-mon",configmap="prometheus-config"} 1
kube_configmap_annotations{namespace="kube-system",configmap="cert-manager-cainjector-leader-election"} 1
kube_configmap_annotations{namespace="kube-system",configmap="extension-apiserver-authentication"} 1
kube_configmap_annotations{namespace="kube-system",configmap="cert-manager-controller"} 1
kube_configmap_annotations{namespace="kube-mon",configmap="etcd-certs"} 1
kube_configmap_annotations{namespace="kube-system",configmap="coredns"} 1
kube_configmap_annotations{namespace="kube-system",configmap="calico-config"} 1
监控获取指标:
- job_name: "kube-state-metrics"
kubernetes_sd_configs:
- role: endpoints
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-mon;kube-state-metrics;http-metrics
需要重新加载Prometheus配置文件。
查看Prometheus的targets:

5. Prometheus黑盒监控
在监控体系里面,通常我们认为监控分为:白盒监控 和 黑盒监控。
黑盒监控:主要关注的现象,一般都是正在发生的东西,例如出现一个告警,业务接口不正常,那么这种监控就是站在用户的角度能看到的监控,重点在于能对正在发生的故障进行告警。
白盒监控:主要关注的是原因,也就是系统内部暴露的一些指标,例如 redis 的 info 中显示 redis slave down,这个就是 redis info 显示的一个内部的指标,重点在于原因,可能是在黑盒监控中看到 redis down,而查看内部信息的时候,显示 redis port is refused connection。
1)Blackbox Exporter
Blackbox Exporter 是 Prometheus 社区提供的官方黑盒监控解决方案,其允许用户通过:HTTP、HTTPS、DNS、TCP 以及 ICMP 的方式对网络进行探测。
- HTTP 测试
定义 Request Header 信息
判断 Http status / Http Respones Header / Http Body 内容 - TCP 测试
业务组件端口状态监听
应用层协议定义与监听 - ICMP 测试
主机探活机制 - POST 测试
接口联通性 - SSL 证书过期时间
详细的配置请查看黑盒监控官方文档
2)安装Blackbox Exporter
安装blackbox exporter的yaml文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-blackbox-exporter
namespace: kube-mon
data:
blackbox.yml: |-
modules:
http_2xx: # 这里写的名称是定义,Prometheus的使用该名称即可
prober: http
timeout: 10s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
valid_status_codes: []
method: GET
preferred_ip_protocol: "ip4"
http_post_2xx: # http post 监测模块
prober: http
timeout: 10s
http:
valid_http_versions: ["HTTP/1.1", "HTTP/2"]
method: POST
preferred_ip_protocol: "ip4"
tcp_connect:
prober: tcp
timeout: 10s
icmp:
prober: icmp
timeout: 10s
icmp:
preferred_ip_protocol: "ip4"
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: blackbox-exporter
namespace: kube-mon
spec:
replicas: 1
selector:
matchLabels:
app: blackbox-exporter
template:
metadata:
labels:
app: blackbox-exporter
spec:
containers:
- name: blackbox-exporter
image: prom/blackbox-exporter:v0.19.0
imagePullPolicy: IfNotPresent
args:
- --config.file=/etc/blackbox_exporter/blackbox.yml
- --log.level=debug
- --web.listen-address=:9115
ports:
- containerPort: 9115
name: blackbox-port
protocol: TCP
readinessProbe:
failureThreshold: 3
initialDelaySeconds: 5
periodSeconds: 10
successThreshold: 1
tcpSocket:
port: 9115
timeoutSeconds: 5
resources:
limits:
cpu: 200m
memory: 60Mi
requests:
cpu: 100m
memory: 50Mi
volumeMounts:
- mountPath: /etc/blackbox_exporter
name: config
volumes:
- configMap:
defaultMode: 420
name: prometheus-blackbox-exporter
name: config
---
apiVersion: v1
kind: Service
metadata:
name: blackbox-exporter
namespace: kube-mon
spec:
type: ClusterIP
selector:
app: blackbox-exporter
ports:
- name: http
port: 9115
启动blackbox_exporter:
kubectl apply -f blackbox-exporter.yaml
3)Prometheus使用黑盒监控网页
(1)监控有域名解析的网页
prometheus配置如下:
- job_name: "target-http-probe"
# 使用blackbox exporter的接口
metrics_path: /probe
params:
# http_2xx 是于blackbox exporter的 `configMap` 中的配置文件名称一致
module: [ http_2xx ]
# 这里使用文件发现的方式,可以随时添加和删减网页的监控
file_sd_configs:
- files:
- targets/http*.yml
relabel_configs:
# 用targets/http*.yml的网页域名替换原instance的值
- source_labels: [__address__]
target_label: __param_target
- source_labels: [__param_target]
target_label: instance
# 用blackbox-exporter的service地址值"prometheus-blackbox-exporter:9115"替换原__address__的值
- target_label: __address__
replacement: blackbox-exporter:9115
这里演示的网页是 baidu.com ,所有主机有网且有配置正确的dns都可以访问到该域名。因为该域名是有在dns域名服务上做解析的。
apiVersion: v1
kind: ConfigMap
metadata:
name: targets-files-sd-config
namespace: kube-mon
data:
# 如果有多个文件的话,也可以写在同一个configmap中的。
http.yml: |
- targets:
- baidu.com
更新配置文件以及重新reload Prometheus服务:
kubectl apply -f prometheus-config.yaml
configmap/prometheus-config unchanged
configmap/targets-files-sd-config configured
curl -X POST "http://`kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload"
Prometheus展示:
例如Prometheus使用nginx-ingress作为网关,给外部系统通过域名来访问集群内部的Prometheus。现在需要通过Prometheus来检查域名的状态是否为200状态码。
这里只需要在http.yml文件中添加一个域名即可。稍等几分钟即可在Prometheus看到:
apiVersion: v1
kind: ConfigMap
metadata:
name: prometheus-files-sd-config
namespace: kube-mon
data:
http.yml: |
- targets:
- baidu.com
- www.ecloud.com/prometheus
只需要更新configMap即可:
kubectl apply -f prometheus-config.yaml
configmap/prometheus-config unchanged
configmap/prometheus-files-sd configured
Prometheus展示:

从promSQL获取到的域名 www.ecloud.com/prometheus 的状态码为403。出现该原因是blockbox exporter直接使用dns服务器解析 www.ecloud.com 的域名(可以通过查看blockbox exporter日志发现问题)。固然这不是我们想要的结果。从尝试过将设置域名映射为本地IP地址,但是发现是无效的。
解决方法:
blockbox exporter容器先使用内部的dns服务进行域名解析,如果解析不成功,会通过 /etc/resolv.conf 的域名解析地址进行解析。
所以只需要在内部dns服务添加A记录进行解析即可。
# 添加A记录
kubectl -n kube-system edit cm coredns
apiVersion: v1
data:
Corefile: |
.:53 {
errors
health {
lameduck 5s
}
ready
kubernetes cluster.local. in-addr.arpa ip6.arpa {
pods insecure
fallthrough in-addr.arpa ip6.arpa
ttl 30
}
# 添加hosts{}的字段,有多个域名加添加多行
# 【注意】最后一行固定是fallthrough
hosts {
192.168.31.188 www.ecloud.com
fallthrough
}
prometheus :9153
forward . /etc/resolv.conf {
max_concurrent 1000
}
cache 30
loop
reload
loadbalance
}
# 重启coredns服务
kubectl -n kube-system delete pod -l k8s-app=kube-dns
pod "coredns-8587764bd6-b898r" deleted
pod "coredns-8587764bd6-tlxpd" deleted
pod "coredns-8587764bd6-tts8x" deleted
再次查看PromSQL就可以看到状态码为200了。

4)prometheus使用黑盒监控service资源
(1)http检测
prometheus配置如下:
- job_name: "service-http-probe"
scrape_interval: 1m
metrics_path: /probe
# 使用blackbox exporter配置文件的http_2xx的探针
params:
module: [ http_2xx ]
kubernetes_sd_configs:
- role: service
relabel_configs:
# 保留service注释有prometheus.io/scrape: true和prometheus.io/http-probe: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape, __meta_kubernetes_service_annotation_prometheus_io_http_probe]
action: keep
regex: true;true
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
regex: (.*)
target_label: service_name
# 将原标签名__meta_kubernetes_namespace改成namespace
- source_labels: [__meta_kubernetes_namespace]
action: replace
regex: (.*)
target_label: namespace
# 将instance改成 `clusterIP:port` 地址
- source_labels: [__meta_kubernetes_service_cluster_ip, __meta_kubernetes_service_annotation_prometheus_io_http_probe_port, __meta_kubernetes_service_annotation_pr
ometheus_io_http_probe_path]
action: replace
regex: (.*);(.*);(.*)
target_label: __param_target
replacement: $1:$2$3
- source_labels: [__param_target]
target_label: instance
# 将__address__的值改成 `blackbox-exporter:9115`
- target_label: __address__
replacement: blackbox-exporter:9115
总结:需要service服务使用http-probe监控。则需要在service上添加注释必须有以下三行
prometheus.io/http-probe: "true"、prometheus.io/scrape: "true" 和 prometheus.io/http-probe-port: "8002"。
如果域名上下文不是为 / 的话,需要在注释添加 prometheus.io/http-probe-path: "/test/demo"
更新配置文件以及重新reload Prometheus服务:
kubectl apply -f prometheus-config.yaml
configmap/prometheus-config configured
curl -X POST "http://`kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload"
Prometheus展示:

(2)tcp检测
- job_name: "service-tcp-probe"
scrape_interval: 1m
metrics_path: /probe
# 使用blackbox exporter配置文件的tcp_connect的探针
params:
module: [ tcp_connect ]
kubernetes_sd_configs:
- role: service
relabel_configs:
# 保留prometheus.io/scrape: "true"和prometheus.io/tcp-probe: "true"的service
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape, __meta_kubernetes_service_annotation_prometheus_io_tcp_probe]
action: keep
regex: true;true
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
regex: (.*)
target_label: service_name
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_namespace]
action: replace
regex: (.*)
target_label: namespace
# 将instance改成 `clusterIP:port` 地址
- source_labels: [__meta_kubernetes_service_cluster_ip, __meta_kubernetes_service_annotation_prometheus_io_http_probe_port]
action: replace
regex: (.*);(.*)
target_label: __param_target
replacement: $1:$2
- source_labels: [__param_target]
target_label: instance
# 将__address__的值改成 `blackbox-exporter:9115`
- target_label: __address__
replacement: blackbox-exporter:9115
总结:需要service服务使用http-probe监控。则需要在service上添加注释必须有以下三行
prometheus.io/tcp-probe: "true"、prometheus.io/scrape: "true" 和 prometheus.io/http-probe-port: "xxx"。
更新配置文件以及重新reload Prometheus服务:
kubectl apply -f prometheus-config.yaml
configmap/prometheus-config configured
curl -X POST "http://`kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}`:9090/-/reload"
Prometheus展示:

6. Prometheus告警
Prometheus 警报分为两部分:
- Prometheus server 中的警报规则向 Alertmanager 发送警报。
- Alertmanager 然后管理这些警报,包括静音、抑制、聚合和通过电子邮件、钉钉、微信和 webhook 等方法发送通知。
1)安装Alertmanager
安装alertmanager的yaml文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-mon
data:
# 最简单的配置。
# 必须要有route和receivers的配置
alertmanager.yml: |-
global:
resolve_timeout: 3m
route:
receiver: email
receivers:
- name: email
---
apiVersion: apps/v1
kind: Deployment
metadata:
name: alertmanager
namespace: kube-mon
spec:
replicas: 1
selector:
matchLabels:
app: alertmanager
template:
metadata:
labels:
app: alertmanager
spec:
containers:
- name: alertmanager
image: prom/alertmanager:v0.23.0
args:
- --config.file=/etc/alertmanager/alertmanager.yml
- --cluster.advertise-address=0.0.0.0:9093
resources:
requests:
cpu: 50m
memory: 100Mi
limits:
cpu: 100m
memory: 256Mi
ports:
- name: http
containerPort: 9093
volumeMounts:
- name: config
mountPath: /etc/alertmanager
volumes:
- name: config
configMap:
name: alertmanager-config
---
apiVersion: v1
kind: Service
metadata:
name: alertmanager
namespace: kube-mon
spec:
type: ClusterIP
selector:
app: alertmanager
ports:
- name: http
port: 9093
安装alertmanager服务:
kubectl apply -f alertmanager-deploy.yml
configmap/alertmanager-config create
deployment.apps/alertmanager create
service/alertmanager create
kubectl -n kube-mon get pod -l app=alertmanager
NAME READY STATUS RESTARTS AGE
alertmanager-55785ddf67-kdrgt 1/1 Running 0 73s
2) 自定义告警模板
自定义告警模板:
# 查看文件
$ cat monitor/alertmanager/template.yml
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-template
namespace: kube-mon
data:
email.tmpl: |
{
{ define "email.to.html" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ .StartsAt.Format "2006-01-02 15:04:05" }} <br>
恢复时间: {
{ .EndsAt.Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- end }}
# 执行文件
$ kubectl apply -f monitor/alertmanager/template.yml
alertmanager配置自定义模板:
# 挂载自定告警模板
$ kubectl -n kube-mon edit deploy alertmanager
- mountPath: /etc/alertmanager/templates
name: templates
- configMap:
name: alert-template
name: templates
# alertmanager配置添加自定义告警模板路径,与global是同级
$ kubectl -n kube-mon edit configmap alertmanager-config
templates:
- '/etc/alertmanager/templates/*.tmpl'
3)配置告警通知
设置警报和通知的主要步骤是:
- 配置 Prometheus 与 Alertmanager 对话 (在Prometheus配置)
- 在 Prometheus 中创建警报规则 (在Prometheus配置)
- 配置Alertmanager
配置之前需要知道知道一些配置的意义,否则很容易发生邮件、短信轰炸。
(1)邮件告警
1. 配置 Prometheus 与 Alertmanager 对话 (在Prometheus配置):
alerting:
alertmanagers:
- static_configs:
- targets: ["alertmanager:9093"]
2. 在 Prometheus 中创建警报规则 (在Prometheus配置):
- 在Prometheus配置告警规则文件
- 新增告警规则文件
- 将configmap挂载到Prometheus
在Prometheus配置告警规则文件 (在Prometheus配置):
rule_files:
- /etc/prometheus/rules/*.yaml
新增告警规则文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: rules-files-sd-config
namespace: kube-mon
data:
rules.yaml: |
groups:
- name: hosts
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 10m
labels:
team: hosts
annotations:
summary: "{
{$labels.instance}}: High Memory usage detected"
description: "{
{$labels.instance}}: Memory usage is above 80% (current value is: {
{ $value }}"
labels:是 alertmanager 的分组的(group_by)标签。
将configmap挂载到Prometheus:
$ kubectl -n kube-mon edit deploy prometheus
# 在 spec.template.spec.containers.volumeMounts 添加下面几行
- mountPath: /etc/prometheus/targets
name: rules-files-sd-config
# 在 spec.template.spec.volumes 添加下面几行
- configMap:
name: rules-files-sd-config
name: rules-files-sd-config
3. 配置Alertmanager:
apiVersion: v1
kind: ConfigMap
metadata:
name: alertmanager-config
namespace: kube-mon
data:
alertmanager.yml: |-
global:
resolve_timeout: 3m
# 邮件配置
smtp_from: '[email protected]'
smtp_smarthost: 'smtp.126.com:25'
smtp_auth_username: '[email protected]'
# 邮箱的授权码
smtp_auth_password: 'xxxx'
route:
# 默认告警媒介
receiver: default
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知
# 这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 30s
# 相同的group之间发送告警通知的时间间隔
group_interval: 5m
# 已经成功发送警报,再次发送通知之前等待多长时间
repeat_interval: 2h
# 分组,对应Prometheus的告警规则的labels
group_by: ["cluster", "team"]
# 子路由
routes:
- receiver: email
matchers:
- team = hosts
# 告警媒介方式
receivers:
- name: default
- name: email
email_configs:
- to: "[email protected]"
send_resolved: true
4. Prometheus和alertmanager重新加载配置:
curl -X POST `kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}`:9090/prometheus/-/reload
curl -X POST "http://`kubectl -n kube-mon get endpoints alertmanager -o jsonpath={.subsets[0].addresses[0].ip}`:9093/-/reload"
(2)钉钉告警
(3)企业微信告警
总体也是分为三步,前面两步和邮箱告警一致,这个只说alertmanager配置的差异。
configmap的alertmanager配置文件中添加下面内容:
# 在配置文件 receivers 告警媒介添加企业微信告警
- name: wechat
wechat_configs:
- corp_id: ww31554c46xxxx # 企业微信中,企业ID
to_party: 2 # 企业微信中,部门ID
agent_id: 1000002 # 企业微信中,应用的AgentId
api_secret: LNqXxz8U5DBGHem3mMB5aQQHqw8aAW2_xxxxx # 企业微信中,应用的Secret
send_resolved: true
# 在配置文件 routes 子路由添加告警媒介方式
- receiver: wechat
matchers:
- team = kubernetes
重新加载alertmanager:
$ curl -X POST `kubectl -n kube-mon get endpoints alertmanager -ojsonpath={.subsets[0].addresses[0].ip}`:9093/-/reload
(1)邮箱告警
创建邮件告警模板的yaml文件:
apiVersion: v1
kind: ConfigMap
metadata:
name: alert-template
namespace: kube-mon
data:
email.tmpl: |
{
{ define "email.to.html" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
恢复时间: {
{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- end }}
将 configmap 挂载到 alertmanager 容器中:
# deploy.spec.templates.volumes 添加下面三行
- name: templates
configMap:
name: alert-template
# deploy.spec.template.spec.containers.volumeMounts 添加下面两行
- name: templates
mountPath: /etc/alertmanager/templates
配置生效:
$ kubectl apply -f monitor/alertmanager/template.yml
$ kubectl apply -f monitor/alertmanager/deploy.yml
(2)钉钉告警
(3)企业微信告警
# 在对应configmap的 data 添加模板
wechat.tmpl: |
{
{ define "wechat.default.message" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
==========异常告警==========
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{$alert.Annotations.summary}}; {
{$alert.Annotations.description }}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
============END============
{
{- end }}
{
{- end }}
{
{- end }}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{- range $index, $alert := .Alerts -}}
{
{- if eq $index 0 }}
==========异常恢复==========
告警类型: {
{ $alert.Labels.alertname }}
告警级别: {
{ $alert.Labels.severity }}
告警详情: {
{$alert.Annotations.summary}};{
{ $alert.Annotations.description }}
故障时间: {
{ ($alert.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
恢复时间: {
{ ($alert.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }}
{
{- if gt (len $alert.Labels.instance) 0 }}
实例信息: {
{ $alert.Labels.instance }}
{
{- end }}
{
{- if gt (len $alert.Labels.namespace) 0 }}
命名空间: {
{ $alert.Labels.namespace }}
{
{- end }}
{
{- if gt (len $alert.Labels.node) 0 }}
节点信息: {
{ $alert.Labels.node }}
{
{- end }}
{
{- if gt (len $alert.Labels.pod) 0 }}
实例名称: {
{ $alert.Labels.pod }}
{
{- end }}
============END============
{
{- end }}
{
{- end }}
{
{- end }}
{
{- end }}
注意:如果有多个告警模板的话,可以放在一个configmap。
上面的 define 不能替换,保持默认不变即可。
7. grafana安装
创建grafana的yaml文件:
apiVersion: apps/v1
kind: Deployment
metadata:
name: grafana
namespace: kube-mon
spec:
selector:
matchLabels:
app: grafana
template:
metadata:
labels:
app: grafana
spec:
volumes:
- name: storage
hostPath:
path: /data/grafana/
nodeSelector:
kubernetes.io/node: monitor
securityContext:
runAsUser: 0
containers:
- name: grafana
image: grafana/grafana:7.5.2
imagePullPolicy: IfNotPresent
ports:
- containerPort: 3000
name: grafana
env:
# 所有的grafana配置都可以修改
# 请参考 https://grafana.com/docs/grafana/latest/administration/configuration/#override-configuration-with-environment-variables
# 下面两项配置账号密码
- name: GF_SECURITY_ADMIN_USER
value: admin
- name: GF_SECURITY_ADMIN_PASSWORD
value: admin321
# 下面两项配置上下文的
- name: GF_SERVER_ROOT_URL
value: "%(protocol)s://%(domain)s:%(http_port)s/grafana"
- name: GF_SERVER_SERVE_FROM_SUB_PATH
value: "true"
readinessProbe:
failureThreshold: 10
httpGet:
path: /api/health
port: 3000
scheme: HTTP
initialDelaySeconds: 60
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 30
livenessProbe:
failureThreshold: 3
httpGet:
path: /api/health
port: 3000
scheme: HTTP
periodSeconds: 10
successThreshold: 1
timeoutSeconds: 1
resources:
limits:
cpu: 150m
memory: 512Mi
requests:
cpu: 150m
memory: 512Mi
volumeMounts: # 存放数据目录
- mountPath: /var/lib/grafana
name: storage
---
apiVersion: v1
kind: Service
metadata:
name: grafana
namespace: kube-mon
spec:
type: ClusterIP
ports:
- name: grafana
port: 3000
targetPort: 3000
protocol: TCP
selector:
app: grafana
apiVersion: extensions/v1beta1
kind: Ingress
metadata:
name: grafana-ingress
namespace: kube-mon
spec:
ingressClassName: nginx
rules:
- host: www.ecloud.com
http:
paths:
- path: /grafana
backend:
serviceName: grafana
servicePort: 3000
kubectl apply -f glafana-deploy.yaml
kubectl apply -f glafana-ingress.yaml
在本地电脑做域名映射(hosts文件)自行配置。配置之后,可以通过浏览器输入 http://www.ecloud.com/grafana 进行访问。
8. grafana仪表盘设置
安装好grafana并不能直接看到监控数据,需要自行设置dashboard或plugins。
展示 kubernetes、ingress-nginx-controller 和 etcd 三个组件的漂亮的仪表盘。
1)kubernetes
这个使用的是现成的插件(devopsprodigy-kubegraf-app),不需要写dashboard文件内容。只需要导入证书和填写服务器信息即可。
要求:
- Grafana > 5.0.0
- Prometheus + node-exporter + kube-state-metrics (version >= 1.4.0)
- Grafana-piechart-panel
- 安装插件
-
在线安装
登录容器,下载插件
grafana-cli plugins install devopsprodigy-kubegraf-app -
离线安装
在grafana的主机,找到数据目录($PATH/plugins)
kubectl -n kube-mon cp grafana-piechart-panel/ grafana-6dcb54fd8d-2zw9f:/var/lib/grafana/plugins/
kubectl -n kube-mon cp devopsprodigy-kubegraf-app grafana-6dcb54fd8d-2zw9f:/var/lib/grafana/plugins/
-
上面两种方法安装,都是需要重启grafana容器的:
kubectl -n kube-mon delete pod -l app=grafana配置插件:
配置数据源:

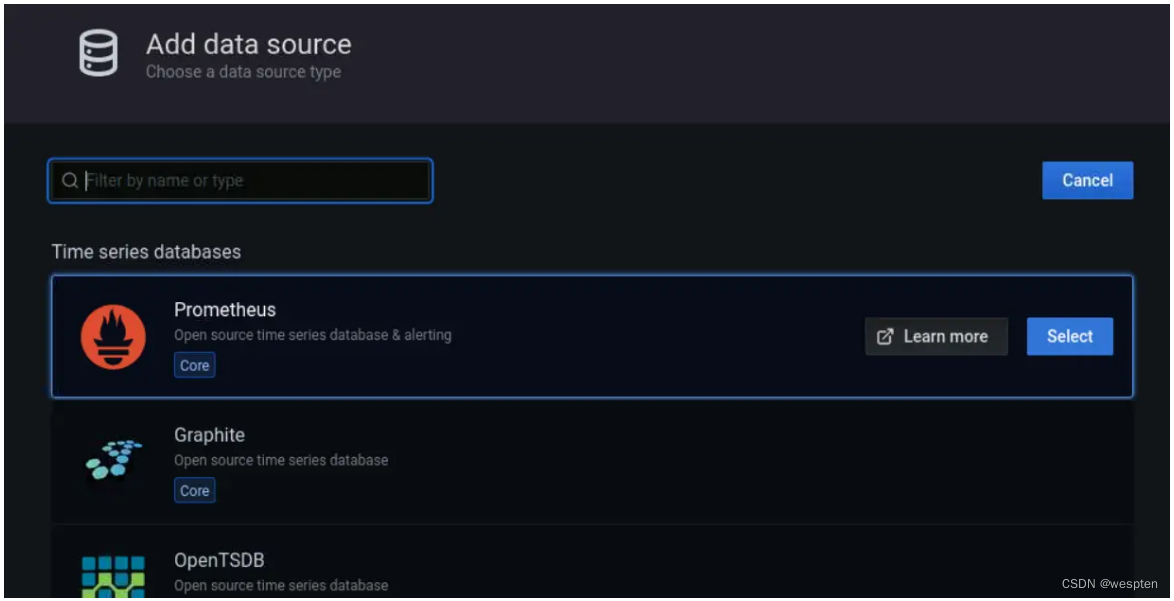
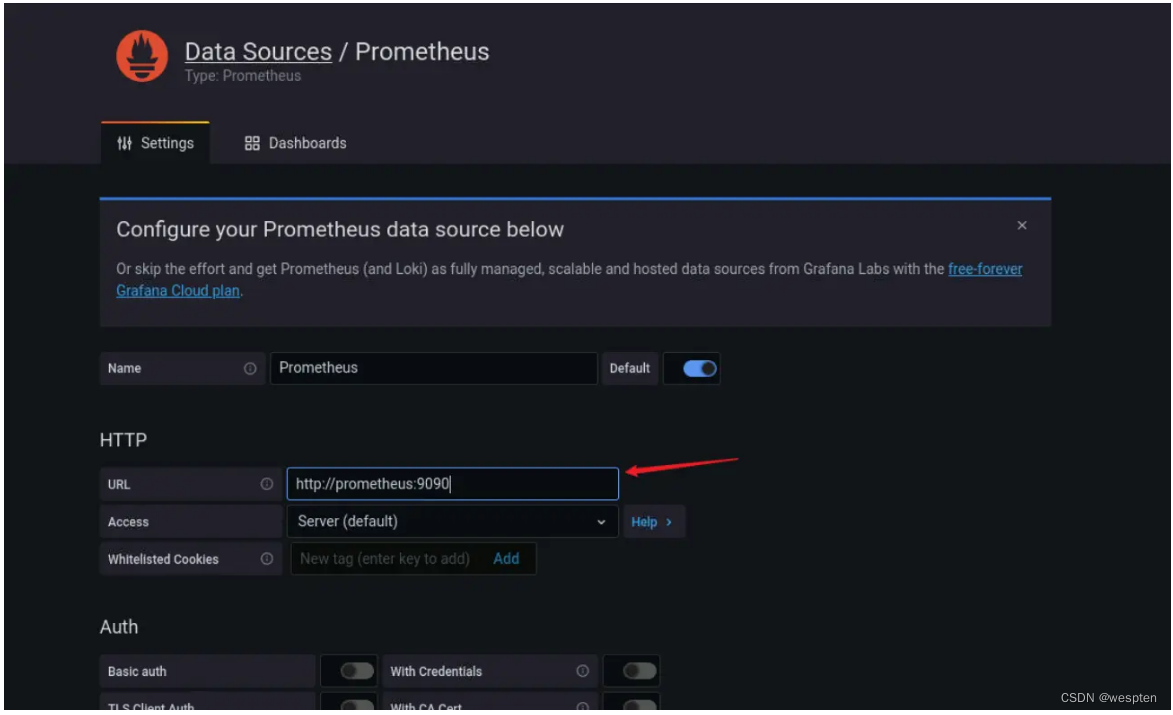
注意:如果promtheus有添加上下文的话,URL也需要添加上对应的上下文。
启动插件:

配置插件:

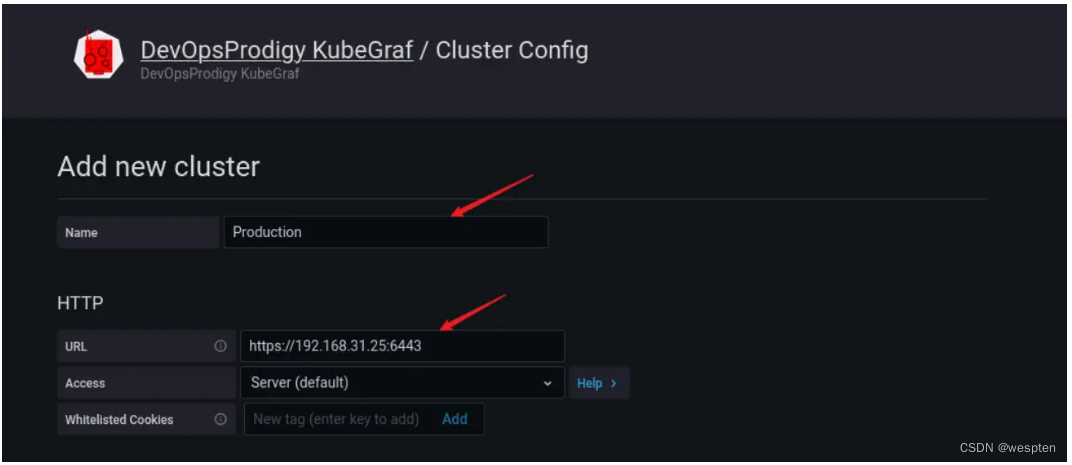


获取上面的数据的方法:
#URL框
cat /root/.kube/config | grep server | awk '{print $2}'
#CA Cert框
cat /root/.kube/config | grep certificate-authority-data | awk '{print $2}' | base64 -d
#Client Cert框
cat /root/.kube/config | grep client-certificate-data | awk '{print $2}' | base64 -d
#Client Key框
cat /root/.kube/config | grep client-key-data | awk '{print $2}' | base64 -d保存完后,会跳转到配置插件页面。如果没有出现配置好的集群信息的话,重新刷新一下即可。
查看仪表盘:

2)ingress-nginx-controller
下载官方提供的dashboard文件
下载地址:https://raw.githubusercontent.com/kubernetes/ingress-nginx/main/deploy/grafana/dashboards/nginx.json
导入dashboard文件:
验证:
3)etcd
etcd官网也提供有dashboard文件,不过文件好像有些问题。不能够直接导入,这里提供一个修改好的文件。请查看附件的章节。
导入方法与 ingress-nginx-controller 的方法一致,这里就不赘述。
4)minio
参考文章:Collect MinIO Metrics Using Prometheus — MinIO Object Storage for Linux
将新主机添加到配置文件:
$ mc config host add monitor http://192.168.31.199:9000 admin ak+JLouROYaP
Added `monitor` successfully.
查看是否添加成功:
$ mc config host list monitor
monitor
URL : http://192.168.31.199:9000
AccessKey : admin
SecretKey : ak+JLouROYaP
API : s3v4
Path : auto
该命令将生成 prometheus.yml 的 scrape_configs 部分:
$ mc admin prometheus generate monitor
scrape_configs:
- job_name: minio-job
bearer_token: eyJhbGciOiJIUzUxMiIsInR5cCI6IkpXVCJ9.eyJleHAiOjQ4MDkwNDgyNDksImlzcyI6InByb21ldGhldXMiLCJzdWIiOiJhZG1pbiJ9.oX7aSpbySO8LtHm3PwPQAB1EnHCTfwNY3_LH7B1-YYArCOlbd_4SUY0l2SMIW7_SjpAr_5x3qqEhHNvwOBThuQ
metrics_path: /minio/v2/metrics/cluster
scheme: http
static_configs:
- targets: ['192.168.31.199:9000']
注意:如果是https协议的话,需要添加取消证书验证。
Prometheus配置添加上面信息:

重启加载Prometheus配置文件:
curl -X POST "http://kubectl -n kube-mon get endpoints prometheus -o jsonpath={.subsets[0].addresses[0].ip}:9090/prometheus/-/reload"验证:

添加dashboard:

上图就是有两个相同的数据字,提供的json文件有些瑕疵。这里提供一个修改好的文件。请查看附件的章节。
参考文章:Prometheus Module — Ceph Documentation
开通ceph mgr模块的Prometheus:
$ ceph mgr module enable prometheus
注意:报错提示:
Error ENOENT: module 'prometheus' reports that it cannot run on the active manager daemon: No module named 'cherrypy' (pass --force to force enablement)需要安装一下cherrypy模块:
sudo pip3 install cherrypy 安装即可。
验证是否开启成功:
$ ceph mgr module ls | grep -A5 enabled_modules
"enabled_modules": [
"iostat",
"prometheus",
"restful"
],
设置Prometheus暴露地址和端口:
$ ceph config set mgr mgr/prometheus/server_addr 0.0.0.0
$ ceph config set mgr mgr/prometheus/server_port 9283
验证设置:
## ceph config get mgr.主机名
$ ceph config get mgr.ceph02
WHO MASK LEVEL OPTION VALUE RO
mgr advanced mgr/prometheus/server_addr 0.0.0.0 *
mgr advanced mgr/prometheus/server_port 9283 *
$ ceph mgr services
{
"prometheus": "http://ceph01.ecloud.com:9283/"
}
Prometheus配置段:
- job_name: "Ceph"
static_configs:
- targets:
# 所有mgr主机
- 192.168.31.132:9283
- 192.168.31.69:9283
- 192.168.31.177:9283
labels:
cluster: production
验证Prometheus的target:

grafana安装dashboard:
使用 2842 的dashboard页面。
验证dashboard:
DevOpsProdigy KubeGraf plugin for Grafana | Grafana Labs
Prometheus and Grafana installation - NGINX Ingress Controller
Monitoring etcd | etcd
所需的dashboard和plugins文件都放在百度网盘上
链接:百度网盘 请输入提取码
提取码:7jfu
2、thanos
1. thanos简介
Thanos 在单个二进制文件中提供了全局查询视图、高可用性、数据备份以及历史、廉价数据访问作为其核心功能。
Thanos 旨在建立一个简单的部署和维护模型。唯一的依赖是:
- 使用永久性磁盘安装一个或多个 Prometheus v2.2.1+。
注意:由于 Prometheus 远程读取改进,强烈建议使用 Prometheus v2.13+。
1)组件
thanos组件说明:
- Sidecar:连接到 Prometheus,读取其数据进行查询或将其上传到云存储。
- Store Gateway:在云存储桶内提供指标。
- Compactor:对存储在云存储桶中的数据进行压缩、下采样和保留。
- Receiver:从 Prometheus 的远程写入 WAL 接收数据,将其公开和/或上传到云存储。
- Rule:根据 Thanos 中的数据评估记录和警报规则,以进行展示和/或上传。
- Query:实现 Prometheus 的 v1 API 以聚合来自底层组件的数据。
- Frontend:实现 Prometheus 的 v1 API 代理它到查询,同时缓存响应和可选的查询天分割。
非上述所说的需要安装,可以选择你需要的组件进行安装即可。
2)架构图
使用Sidecar部署:
使用Receiver部署:

两种架构中,官网给出的建议是以下两种情况使用 Receiver 部署:
- Prometheus 仅有出口模式
- 各个Prometheus与query需要复杂网络拓扑进行通讯
thanos文档:Thanos - Highly available Prometheus setup with long term storage capabilities
GitHub thanos文档:GitHub - thanos-io/thanos: Highly available Prometheus setup with long term storage capabilities. A CNCF Incubating project.
2. Prometheus组件
推荐使用 2.37.1 的版本,是长期支持版本。
prometheus是多副本。仅Prometheus配置文件的 external_labels 值不一样,其他步骤都是都是一样的。
下载Prometheus:
wget https://github.com/prometheus/prometheus/releases/download/v2.37.1/prometheus-2.37.1.linux-amd64.tar.gz -O /opt/prometheus-2.37.1.linux-amd64.tar.gz
cd /opt && tar xf prometheus-2.37.1.linux-amd64.tar.gz
mkdir -p /data/prometheus/data
cp -r /opt/prometheus-2.37.1.linux-amd64/console* /data/prometheus/
cp /opt/prometheus-2.37.1.linux-amd64/prometheus /opt/prometheus-2.37.1.linux-amd64/promtool /usr/local/bin/
cp /opt/prometheus-2.37.1.linux-amd64/prometheus.yml /data/prometheus/
# global字段下添加标签,每个Prometheus的replica值都需要设置不一致
vim /data/prometheus/prometheus.yml
global:
...
external_labels:
replica: A
chown -R ops. /data/prometheus
cat <<-EOF | sudo tee /usr/lib/systemd/system/prometheus.service > /dev/null
[Unit]
Description=prometheus
Documentation=https://prometheus.io/
After=network.target
[Service]
Type=simple
User=ops
Group=ops
ExecStartPre=/usr/local/bin/promtool check config /data/prometheus/prometheus.yml
ExecStart=/usr/local/bin/prometheus \\
--config.file=/data/prometheus/prometheus.yml \\
--web.listen-address=127.0.0.1:9090 \\
--web.enable-lifecycle --web.enable-admin-api \\
--web.console.templates=/data/prometheus/consoles \\
--web.console.libraries=/data/prometheus/console_libraries \\
--storage.tsdb.path=/data/prometheus/data/ \\
--storage.tsdb.min-block-duration=2h \\
--storage.tsdb.max-block-duration=2h \\
--storage.tsdb.retention.time=2h \\
--log.level=info --log.format=json
ExecReload=/usr/bin/curl -s -X POST http://127.0.0.1:9090/-/reload
TimeoutStartSec=20s
Restart=always
LimitNOFILE=20480000
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable prometheus --now
systemctl is-active prometheus.service
$ curl 127.0.0.1:9090/-/healthy
Prometheus Server is Healthy.
二进制安装Prometheus:Installation | Prometheus
下载Prometheus地址:Download | Prometheus
3. Sidecar组件
thanos sidecar 命令运行一个与 Prometheus 实例一起部署的组件。这允许 Sidecar 有选择地将指标上传到对象存储,并允许查询者使用通用、高效的 StoreAPI 查询 Prometheus 数据。
详细说明:
- 它在 Prometheus 的远程读取 API 之上实现了 Thanos 的 Store API。这允许查询者将 Prometheus 服务器视为时间序列数据的另一个来源,而无需直接与其 API 对话。
- 可选地,边车将 TSDB 块上传到对象存储桶,因为 Prometheus 每 2 小时生成一次。这允许 Prometheus 服务器以相对较低的保留率运行,同时它们的历史数据通过对象存储变得持久和可查询。
注意:这仍然不意味着 Prometheus 可以完全无状态,因为如果它崩溃并重新启动,您将丢失大约 2 小时的指标,因此强烈建议 Prometheus 使用永久性磁盘。您可以获得的最接近无状态的是使用远程写入(Thanos 支持,请参阅 Receiver。远程写入还有其他风险和后果,如果崩溃,您仍然会丢失几秒钟的指标数据,因此在所有情况下都建议使用永久性磁盘。
- 可选的,Thanos sidecar 能够监视 Prometheus 规则和配置,如果需要,解压缩和替换环境变量,并 ping Prometheus 以重新加载它们。
通过sidecar连接到Thanos集群的Prometheus服务器,受到一些安全操作的限制和建议:
- 推荐的 Prometheus 版本为 2.2.1 或更高版本(包括最新版本)。这是由于 Prometheus 在以前的版本中不稳定以及缺少标志端点。
- (!) Prometheus 配置文件的 Prometheus external_labels 部分在整个 Thanos 系统中具有唯一的标签。这些外部标签将被边车使用,然后在许多地方被thanos使用。
- 启用 --web.enable-admin-api 标志以支持 sidecar 从 Prometheus 获取元数据,如外部标签。
- 如果要使用边车重载功能(--reload.* 标志),则启用 --web.enable-lifecycle 标志。
wget https://github.com/thanos-io/thanos/releases/download/v0.28.1/thanos-0.28.1.linux-amd64.tar.gz -O /opt/thanos-0.28.1.linux-amd64.tar.gz
cd /opt && tar xf thanos-0.28.1.linux-amd64.tar.gz
cp /opt/thanos-0.28.1.linux-amd64/thanos /usr/local/bin
cat <<-EOF | sudo tee /usr/lib/systemd/system/thanos-sidecar.service > /dev/null
[Unit]
Description=thanos-sidecar
Documentation=https://thanos.io/
Requires=network.target prometheus.service
[Service]
Type=simple
User=ops
Group=ops
ExecStart=/usr/local/bin/thanos sidecar \\
--grpc-address=0.0.0.0:10901 --http-address=127.0.0.1:10902 \\
--prometheus.url=http://127.0.0.1:9090 \\
--tsdb.path=/data/prometheus/data --log.format=json
ExecReload=/usr/bin/kill -HUP
TimeoutStartSec=20s
Restart=always
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable thanos-sidecar.service --now
systemctl is-active thanos-sidecar.service
$ curl localhost:10902/-/healthy && echo
OK
thanos sidecar官方文档:
Thanos - Highly available Prometheus setup with long term storage capabilities
4. Store Gateway组件
thanos store 命令(也称为 Store Gateway)在对象存储桶中的历史数据之上实现 Store API。 它主要充当 API 网关,因此不需要大量的本地磁盘空间。 它在启动时加入一个 thanos 集群,并公布它可以访问的数据。 它在本地磁盘上保留有关所有远程块的少量信息,并使其与存储桶保持同步。 这些数据通常可以安全地在重新启动时删除,但会增加启动时间。
thanos store 是多副本形成高可用。多个副本的安装步骤都是一样
前置环境:
这里使用 minion 提供 S3 存储,需要安装minion集群。
1)安装minion集群
创建用户并授权:
useradd minio
echo 123456 | passwd --stdin minio
echo "minio ALL=(ALL) NOPASSWD: ALL" | sudo tee /etc/sudoers.d/minio
sudo chmod 0440 /etc/sudoers.d/minio
下载二进制文件:
su - minio
wget https://dl.min.io/server/minio/release/linux-amd64/minio
wget https://dl.min.io/client/mc/release/linux-amd64/mc
sudo mv minio mc /usr/local/bin
sudo chmod +x /usr/local/bin/{minio,mc}
非tls模式:
创建所需目录:
sudo mkdir -p /data/minio/{data,config}
sudo chown -R minio.minio /data/minio
注意:数据目录不能是在根分区下的目录。
minio配置参数:
cat <<EOF | tee /data/minio/config/minio.cnf
MINIO_ROOT_USER=admin
MINIO_ROOT_PASSWORD=ak+JLouROYaP
CONSOLE_OPTS="--console-address :9999"
HOST_OPTS="http://192.168.32.187:9000/data/minio/data http://192.168.32.188:9000/data/minio/data http://192.168.32.189:9000/data/minio/data http://192.168.32.168:9000/data/minio/data"
EOF
minio的systemd配置:
cat <<EOF | sudo tee /usr/lib/systemd/system/minio.service
[Unit]
Description=Minio
Documentation=https://docs.minio.io
Wants=network-online.target
After=network-online.target
[Service]
User=minio
Group=minio
EnvironmentFile=-/data/minio/config/minio.cnf
ExecStart=/usr/local/bin/minio server \$CONSOLE_OPTS \$HOST_OPTS
StandardOutput=journal
StandardError=inherit
# Specifies the maximum file descriptor number that can be opened by this process
LimitNOFILE=65536
# Disable timeout logic and wait until process is stopped
TimeoutStopSec=0
# SIGTERM signal is used to stop Minio
KillSignal=SIGTERM
SendSIGKILL=no
SuccessExitStatus=0
[Install]
WantedBy=multi-user.target
EOF
启动minio:
sudo systemctl daemon-reload
sudo systemctl start minio
sudo systemctl enable minio
tls模式:
与非tls模式基本一致,请先操作非tls模式。但是不要启动非tls。如果启动过的话,请将数据目录删除重新创建。
生成证书:
mkdir -p ~/.minio/certs/
cd ~/.minio/certs/
openssl genrsa -out private.key 2048
cat > openssl.conf <<-EOF
[req]
distinguished_name = req_distinguished_name
x509_extensions = v3_req
prompt = no
[req_distinguished_name]
C = CN
ST = GuangDong
L = GuangZhou
O = Personal
OU = Personal
[v3_req]
subjectAltName = @alt_names
[alt_names]
IP.1 = 192.168.32.168
IP.2 = 192.168.32.187
IP.3 = 192.168.32.188
IP.4 = 192.168.32.189
EOF
openssl req -new -x509 -nodes -days 730 -keyout private.key -out public.crt -config openssl.conf
注意:需要修改 IP.x 的IP地址。
修改minio的配置文件:
将 /data/minio/config/minio.cnf 文件中的 HOST_OPTS 全部主机的 http 协议改成 https 即可。
启动minio:
sudo systemctl daemon-reload
sudo systemctl start minio
sudo systemctl enable minio
mc客户端:
wget https://dl.min.io/client/mc/release/linux-amd64/mc
sudo mv mc /usr/local/bin/
sudo chmod +x /usr/local/bin/mc2)创建 Serice Accounts


3)创建thanos桶


下载thanos:
wget https://github.com/thanos-io/thanos/releases/download/v0.28.0/thanos-0.28.0.linux-amd64.tar.gz
tar xf thanos-0.28.0.linux-amd64.tar.gz -C /opt/
cp /opt/thanos-0.28.0.linux-amd64/thanos /usr/local/bin
mkdir -p /data/thanos/store
cat <<-EOF | sudo tee /data/thanos/thanos-minio.yml > /dev/null
type: s3
config:
bucket: "thanos"
endpoint: "192.168.31.177:9000"
access_key: "voV6fk04dK40x8qx"
insecure: true
secret_key: "jOqC75LNJIN9hIgDyr1M0O9Pe35k7Dlk"
http_config:
idle_conn_timeout: 5m
response_header_timeout: 10m
insecure_skip_verify: true
EOF
chown -R ops. /data/thanos/
注意:access_key和secret_key是前置环境创建Serice Accounts保存的。
cat <<-EOF | sudo tee /usr/lib/systemd/system/thanos-store.service > /dev/null
[Unit]
Description=thanos-store
Documentation=https://thanos.io/
After=network.target
[Service]
Type=simple
User=ops
Group=ops
ExecStart=/usr/local/bin/thanos store \\
--grpc-address=0.0.0.0:10903 --http-address=127.0.0.1:10904 \\
--data-dir=/data/thanos/store --chunk-pool-size=8GB --max-time=30d \\
--block-sync-concurrency=200 --store.grpc.series-max-concurrency=200 \\
--objstore.config-file=/data/thanos/thanos-minio.yml
ExecReload=/usr/bin/kill -HUP
TimeoutStartSec=20s
Restart=always
LimitNOFILE=20480000
[Install]
WantedBy=multi-user.target
EOF
启动服务:
systemctl daemon-reload
systemctl enable --now thanos-store.service
systemctl is-active thanos-store.service
$ curl localhost:10904/-/healthy && echo
OK
vim /usr/lib/systemd/system/thanos-sidecar.service
# 启动参数添加下面的参数(文件内容,和store的objstore.config-file参数值一样)
--objstore.config-file=/data/thanos/thanos-minio.yml
systemctl daemon-reload
systemctl restart thanos-sidecar.service
curl localhost:10902/-/healthy && echo
Thanos - Highly available Prometheus setup with long term storage capabilities
5. Querier组件
thanos query 命令(也称为“Querier”)实现 Prometheus HTTP v1 API 以通过 PromQL 查询 Thanos 集群中的数据。简而言之,它从底层 StoreAPI 收集评估查询所需的数据,评估查询并返回结果。
Querier 是完全无状态的和水平可扩展的,本质上允许在单个 Prometheus Query 端点下聚合和可选地去重多个指标后端。
因为对于 Querier,“后端”是任何实现 gRPC StoreAPI 的东西,我们可以从任意数量的不同存储中聚合数据,例如:
- Prometheus(sidecar)
- Store Gateway
- Ruler
- Receiver
- other querier
- 非Prometheus系统,例如OpenTSDB
wget https://github.com/thanos-io/thanos/releases/download/v0.28.0/thanos-0.28.0.linux-amd64.tar.gz
tar xf thanos-0.28.0.linux-amd64.tar.gz -C /opt/
cp /opt/thanos-0.28.0.linux-amd64/thanos /usr/local/bin
mkdir /data/thanos/certs && cd /data/thanos/certs
openssl req -x509 -newkey rsa:4096 -nodes -subj "/C=CN/ST=ShangDong/O=Personal/CN=*" -keyout server.key -out server.crt
cat <<-EOF | sudo tee /data/thanos/query-web-config.yml > /dev/null
tls_server_config:
cert_file: /data/thanos/certs/server.crt
key_file: /data/thanos/certs/server.key
EOF
CN是 * 匹配所有访问的方式。不局限于域名,还可以使用IP进行访问。
$ htpasswd -nBC 10 '' | tr -d ":"
New password: # 输入密码
Re-type new password: # 再次输入密码确认
$2y$10$NMj2j1J.O2e964B0Dd7oauN3c/hWF6MmuEvCb7RGuYWZpa7SU8Iui
cat <<-EOF | sudo tee -a /data/thanos/query-web-config.yml > /dev/null
basic_auth_users:
admin: $2y$10$NMj2j1J.O2e964B0Dd7oauN3c/hWF6MmuEvCb7RGuYWZpa7SU8Iui
EOF
htpasswd 命令依赖 httpd-tools 安装包。
cat <<-EOF | sudo tee /usr/lib/systemd/system/thanos-query.service > /dev/null
[Unit]
Description=thanos-query
Documentation=https://thanos.io/
After=network.target
[Service]
Type=simple
User=ops
Group=ops
ExecStart=/usr/local/bin/thanos query \\
--grpc-address=0.0.0.0:10905 --http-address=0.0.0.0:10906 \\
--store=192.168.31.103:10901 --store=192.168.31.79:10901 \\
--store=192.168.31.103:10903 --store=192.168.31.79:10903 \\
--web.external-prefix=/prometheus --query.timeout=10m \\
--query.max-concurrent=200 --query.max-concurrent-select=40 \\
--http.config=/data/thanos/query-web-config.yml \\
--query.replica-label=replica --log.format=json
ExecReload=/usr/bin/kill -HUP
TimeoutStartSec=20s
Restart=always
LimitNOFILE=20480000
[Install]
WantedBy=multi-user.target
EOF
注意:--store 定义两台主机的 sidecar 和 store 服务,共上面定义的四个。
验证:
$ curl --cacert /data/thanos/certs/ecloud.com.crt https://www.ecloud.com:10906/-/healthy && echo
OK
query官方文档:Thanos - Highly available Prometheus setup with long term storage capabilities
basic-auth使用方法:Basic auth | Prometheus
tls使用方法:TLS encryption | Prometheus
6. Compactor组件
**注意:**通常不需要 Compactor 的高可用性。
thanos compact 命令应用 Prometheus 2.0 存储引擎的压缩过程来阻止存储在对象存储中的数据。它通常在语义上不是并发安全的,并且必须部署为针对存储桶的单例。
Compactor、Sidecar、Receive 和 Ruler 是唯一应该对对象存储具有写访问权限的 Thanos 组件,只有 Compactor 能够删除数据。
sudo mkdir -p /data/thanos/compact
sudo chown -R ops. /data/thanos/
cat <<-EOF | sudo tee /usr/lib/systemd/system/thanos-compact.service > /dev/null
[Unit]
Description=thanos-compact
Documentation=https://thanos.io/
After=network.target
[Service]
Type=simple
User=ops
Group=ops
ExecStart=/usr/local/bin/thanos compact --log.format=json \\
--http-address=127.0.0.1:10909 \\
--data-dir=/data/thanos/compact \\
--compact.concurrency=8 --wait \\
--objstore.config-file=/data/thanos/thanos-minio.yml
ExecReload=/usr/bin/kill -HUP
TimeoutStartSec=20s
Restart=always
LimitNOFILE=20480000
[Install]
WantedBy=multi-user.target
EOF
- 默认情况下,thanos compact 将运行完成,这使得它可以作为 cronjob 执行。使用参数 --wait 和 --wait-interval=5m 可以让它保持运行。
- 建议提供 --compact.concurrency 数量的 CPU 内核。
启动服务:
systemctl daemon-reload
systemctl enable --now thanos-compact.service
systemctl is-active thanos-compact.service
验证:
$ curl localhost:10909/-/healthy && echo
OK
Thanos - Highly available Prometheus setup with long term storage capabilities
7. Prometheus监控项
注意:
- Prometheus使用普通用户启动,注意创建文件的用户;
- 多个节点Prometheus文件中的target配置保持一致;
1)静态监控
- job_name: "Prometheus"
static_configs:
- "localhost:9090"
创建target目标:
- job_name: "node-exporter"
file_sd_configs:
- files:
- "targets/node-exporter.yml"
# 刷新间隔以重新读取文件
refresh_interval: 1m
创建监控文件:
mkdir /data/prometheus/targets
cat <<-EOF | sudo tee /data/prometheus/targets/node-exporter.yml > /dev/null
- targets:
- 192.168.31.103:9100
- 192.168.31.79:9100
- 192.168.31.95:9100
- 192.168.31.78:9100
- 192.168.31.253:9100
EOF
chown -R ops. /data/prometheus
热加载配置文件:
sudo systemctl reload prometheus
将文件同步给其他节点:
# 主配置文件 及 文件发现目录
cd /data/prometheus && scp -r prometheus.yml targets ops@k8s-master02:/data/prometheus
# 修改其他节点特有的labal
ssh ops@k8s-master02 "sed -ri 's@(replica).*@\1: B@g' /data/prometheus/prometheus.yml"
# 检测配置文件
ssh ops@k8s-master02 "promtool check config /data/prometheus/prometheus.yml"
# 热加载配置文件
ssh ops@k8s-master02 "sudo systemctl reload prometheus"
由于 thanos 是二进制部署的,需要在 kubernetes 集群上创建 sa 的相关监控权限。
创建Prometheus监控kubernetes集群的权限(k8s master节点执行):
cat <<-EOF | kubectl apply -f -
apiVersion: rbac.authorization.k8s.io/v1
kind: ClusterRole
metadata:
name: prometheus
rules:
- apiGroups:
- ""
resources:
- nodes
- services
- endpoints
- pods
- nodes/proxy
verbs:
- get
- list
- watch
- apiGroups:
- "extensions"
resources:
- ingresses
verbs:
- get
- list
- watch
- apiGroups:
- ""
resources:
- configmaps
- nodes/metrics
verbs:
- get
- nonResourceURLs:
- /metrics
verbs:
- get
---
apiVersion: v1
kind: ServiceAccount
metadata:
name: prometheus
namespace: kube-system
---
apiVersion: rbac.authorization.k8s.io/v1beta1
kind: ClusterRoleBinding
metadata:
name: prometheus
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: ClusterRole
name: prometheus
subjects:
- kind: ServiceAccount
name: prometheus
namespace: kube-system
EOF
获取监控kubernetes的token(k8s master节点执行):
kubectl -n kube-system get secret `kubectl -n kube-system get sa prometheus -o jsonpath={.secrets[0].name}` -ojsonpath={.data.token} | base64 --decode > /data/prometheus/token
示例(thanos节点):
- job_name: "Service/kube-apiserver"
scheme: https
tls_config:
insecure_skip_verify: true
# 上面获取的token
bearer_token_file: /data/prometheus/token
kubernetes_sd_configs:
- role: endpoints
# 访问集群的入口
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
热加载配置文件:
sudo systemctl reload prometheus
将文件同步给其他节点:
# 主配置文件 及 文件发现目录
cd /data/prometheus && scp -r prometheus.yml targets ops@k8s-master02:/data/prometheus
# 修改其他节点特有的labal
ssh ops@k8s-master02 "sed -ri 's@(replica): .*@\1: B@g' /data/prometheus/prometheus.yml"
# 检测配置文件
ssh ops@k8s-master02 "promtool check config /data/prometheus/prometheus.yml"
# 热加载配置文件
ssh ops@k8s-master02 "sudo systemctl reload prometheus"
下面有证书,token,文件发现目录等等,需要自行手工创建或者拷贝,这里只是主配文件示例:
scrape_configs:
# 基于文件服务发现
- job_name: "node-exporter"
file_sd_configs:
- files:
- "targets/node-exporter.yml"
# 刷新间隔以重新读取文件
refresh_interval: 1m
relabel_configs:
metric_relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: instance
replacement: $1
# 基于kubernetes服务发现
- job_name: "Service/kube-apiserver"
scheme: https
tls_config:
insecure_skip_verify: true
# 请参考上面方式创建token
bearer_token_file: /data/prometheus/token
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: default;kubernetes;https
- job_name: "Service/kube-controller-manager"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
kubernetes_sd_configs:
- role: node
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_node_labelpresent_node_role_kubernetes_io_master]
action: keep
regex: true
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10257
- job_name: "Service/kube-scheduler"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
kubernetes_sd_configs:
- role: node
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_node_labelpresent_node_role_kubernetes_io_master]
action: keep
regex: true
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10259
- job_name: "Service/kubelet"
scheme: https
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
kubernetes_sd_configs:
- role: node
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
- job_name: "Service/kube-proxy"
kubernetes_sd_configs:
- role: node
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:10249
- job_name: "Service/etcd"
scheme: https
tls_config:
ca_file: targets/certs/ca.pem
cert_file: targets/certs/etcd.pem
key_file: targets/certs/etcd-key.pem
insecure_skip_verify: true
file_sd_configs:
- files:
- targets/etcd.yml
- job_name: "Service/calico"
kubernetes_sd_configs:
- role: node
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__address__]
action: replace
regex: (.*):10250
target_label: __address__
replacement: $1:9091
- job_name: "Service/coredns"
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-dns;metrics
- job_name: "Service/ingress-nginx"
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: ingress-nginx;ingress-nginx-metrics;metrics
- job_name: "kube-state-metrics"
kubernetes_sd_configs:
- role: endpoints
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
- source_labels: [__meta_kubernetes_namespace, __meta_kubernetes_endpoints_name, __meta_kubernetes_endpoint_port_name]
action: keep
regex: kube-system;kube-state-metrics;http-metrics
- job_name: "service-http-probe"
scrape_interval: 1m
metrics_path: /probe
# 使用blackbox exporter配置文件的http_2xx的探针
params:
module: [ http_2xx ]
kubernetes_sd_configs:
- role: service
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
# 保留service注释有prometheus.io/scrape: true和prometheus.io/http-probe: true
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape, __meta_kubernetes_service_annotation_prometheus_io_http_probe]
action: keep
regex: true;true
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
regex: (.*)
target_label: service_name
# 将原标签名__meta_kubernetes_namespace改成namespace
- source_labels: [__meta_kubernetes_namespace]
action: replace
regex: (.*)
target_label: namespace
# 将instance改成 `clusterIP:port` 地址
- source_labels: [__meta_kubernetes_service_cluster_ip, __meta_kubernetes_service_annotation_prometheus_io_http_probe_port, __meta_kubernetes_service_annotation_pretheus_io_http_probe_path]
action: replace
regex: (.*);(.*);(.*)
target_label: __param_target
replacement: $1:$2$3
- source_labels: [__param_target]
target_label: instance
# 将__address__的值改成 `blackbox-exporter:9115`
- target_label: __address__
replacement: blackbox-exporter:9115
- job_name: "service-tcp-probe"
scrape_interval: 1m
metrics_path: /probe
# 使用blackbox exporter配置文件的tcp_connect的探针
params:
module: [ tcp_connect ]
kubernetes_sd_configs:
- role: service
api_server: https://192.168.31.100:6443
tls_config:
insecure_skip_verify: true
bearer_token_file: /data/prometheus/token
relabel_configs:
# 保留prometheus.io/scrape: "true"和prometheus.io/tcp-probe: "true"的service
- source_labels: [__meta_kubernetes_service_annotation_prometheus_io_scrape, __meta_kubernetes_service_annotation_prometheus_io_tcp_probe]
action: keep
regex: true;true
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_service_name]
action: replace
regex: (.*)
target_label: service_name
# 将原标签名__meta_kubernetes_service_name改成service_name
- source_labels: [__meta_kubernetes_namespace]
action: replace
regex: (.*)
target_label: namespace
# 将instance改成 `clusterIP:port` 地址
- source_labels: [__meta_kubernetes_service_cluster_ip, __meta_kubernetes_service_annotation_prometheus_io_http_probe_port]
action: replace
regex: (.*);(.*)
target_label: __param_target
replacement: $1:$2
- source_labels: [__param_target]
target_label: instance
# 将__address__的值改成 `blackbox-exporter:9115`
- target_label: __address__
replacement: blackbox-exporter:91158. grafana
下载grafana:
wget https://dl.grafana.com/oss/release/grafana-8.5.10.linux-amd64.tar.gz
tar xf grafana-8.5.10.linux-amd64.tar.gz -C /opt
mv /opt/grafana-8.5.10 /opt/grafana
创建数据目录:
mkdir -p /data/grafana/{data,logs,plugins}
vim /opt/grafana/conf/defaults.ini
[paths]
data = /data/grafana/data
logs = /data/grafana/logs
plugins = /data/grafana/plugins
[server]
root_url = %(protocol)s://%(domain)s:%(http_port)s/grafana
serve_from_sub_path = true
默认账号密码都是admin,且要求第一次必须修改admin密码。
cat > /usr/lib/systemd/system/grafana.service <<EOF
[Unit]
Description=Grafana
Documentation=https://grafana.com/
After=network-online.target
[Service]
Type=notify
ExecStart=/opt/grafana/bin/grafana-server -homepath /opt/grafana
LimitNOFILE=infinity
LimitNPROC=infinity
TimeoutStartSec=0
Delegate=yes
KillMode=process
Restart=on-failure
StartLimitBurst=3
StartLimitInterval=60s
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl start grafana.service
参考文档:
官方文档:Install Grafana | Grafana documentation
9. Querier对接grafana
添加数据源:

大概的步骤:
Configuration -> Add data source -> Prometheus -> URL -> Basic auth -> TLS Client Auth -> Skip TLS Verify -> User -> Password -> Client Cert -> Client key -> Save & test
Client Cert内容:
cat `cat /data/thanos/web-secret.yml | awk '/cert_file/ {print $2}'`
Client Key内容:
cat `cat /data/thanos/web-secret.yml | awk '/key_file/ {print $2}'`10. alertmanager
Prometheus 的警报分为两部分。 Prometheus 服务器中的警报规则将警报发送到警报管理器。然后,Alertmanager 管理这些警报,包括静音、抑制、聚合和通过电子邮件、待命通知系统和聊天平台等方法发送通知。
wget https://github.com/prometheus/alertmanager/releases/download/v0.24.0/alertmanager-0.24.0.linux-amd64.tar.gz
tar xf alertmanager-0.24.0.linux-amd64.tar.gz -C /opt/
cp /opt/alertmanager-0.24.0.linux-amd64/{alertmanager,amtool} /usr/local/bin/
mkdir -p /data/alertmanager/data
cat <<-EOF | sudo tee /data/alertmanager/alertmanager.yml > /dev/null
global:
resolve_timeout: 3m
route:
receiver: default
receivers:
- name: default
templates: []
inhibit_rules: []
EOF
chown -R ops. /data/alertmanager
$ amtool check-config /data/alertmanager/alertmanager.yml
Checking '/data/alertmanager/alertmanager.yml' SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 1 receivers
- 0 templates
cat <<-EOF | sudo tee /usr/lib/systemd/system/alertmanager.service > /dev/null
[Unit]
Description=alertmanager
Documentation=https://prometheus.io/docs/alerting/latest/overview/
After=network.target
[Service]
Type=simple
User=ops
Group=ops
ExecStart=/usr/local/bin/alertmanager \\
--web.listen-address=:9093 \\
--web.route-prefix=/alertmanager \\
--storage.path=/data/alertmanager/data \\
--config.file=/data/alertmanager/alertmanager.yml
ExecReload=/usr/bin/curl -s -X POST http://127.0.0.1:9093/alertmanager/-/reload
TimeoutStartSec=20s
Restart=always
LimitNOFILE=20480000
[Install]
WantedBy=multi-user.target
EOF
systemctl daemon-reload
systemctl enable --now alertmanager.service
systemctl is-active alertmanager.service
官方文档:Alerting overview | Prometheus
- 11. Prometheus对接alertmanager

摘要官方的一句话。建议在本地相关 Prometheus 服务器内继续部署规则。
如果的确需要安装 rule 组件,请参考 Rule文章 。该文章演示Prometheus与alertmanager对接
设置警报和通知的主要步骤是:
- 安装和配置 alertmanager
- Prometheus 关联 alertmanager
- 在Prometheus中创建警报规则
配置alertmanager邮件告警:
global:
# 邮件配置
smtp_from: '[email protected]'
smtp_smarthost: 'smtp.126.com:25'
smtp_auth_username: '[email protected]'
smtp_auth_password: 'FHWBDWBEUMQExxxx' # 邮箱的授权码
route:
# 当一个新的报警分组被创建后,需要等待至少 group_wait 时间来初始化通知
# 这种方式可以确保您能有足够的时间为同一分组来获取多个警报,然后一起触发这个报警信息。
group_wait: 1m
# 已经成功发送警报,再次发送通知之前等待多长时间
repeat_interval: 4h
# 相同的group之间发送告警通知的时间间隔
group_interval: 15m
# 分组,对应Prometheus的告警规则的labels
group_by: ["cluster", "team"]
# 子路由
# 当 team=hosts(Prometheus传递过来) 的 labels ,告警媒介走 email 方式。如果没有到对于的labels,告警媒介则走default
routes:
- receiver: email
matchers:
- team = hosts
receivers:
- name: email
email_configs:
- to: "[email protected]" # 收件邮箱地址
html: '{
{ template "email.to.html" . }}' # 发送邮件的内容
headers: { Subject: '{
{ if eq .Status "firing" }}【监控告警正在发生】{
{ else if eq .Status "resolved" }}【监控告警已恢复】{
{ end }} {
{ .CommonLabels.alertname }}' } # 邮件的主题
send_resolved: true # 是否接受已解决的告警信息
templates:
- "/data/alertmanager/email.tmpl" # 模板路径
添加模板:
cat <<-EOF | sudo tee /data/alertmanager/email.tmpl > /dev/null
{
{ define "email.to.html" }}
{
{- if gt (len .Alerts.Firing) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- if gt (len .Alerts.Resolved) 0 -}}
{
{ range .Alerts }}
=========start==========<br>
告警程序: prometheus_alert <br>
告警级别: {
{ .Labels.severity }} <br>
告警类型: {
{ .Labels.alertname }} <br>
告警主机: {
{ .Labels.instance }} <br>
告警主题: {
{ .Annotations.summary }} <br>
告警详情: {
{ .Annotations.description }} <br>
触发时间: {
{ (.StartsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
恢复时间: {
{ (.EndsAt.Add 28800e9).Format "2006-01-02 15:04:05" }} <br>
=========end==========<br>
{
{ end }}{
{ end -}}
{
{- end }}
EOF
第一行 define 定义的内容是 alertmanager 配置文件的 receivers.email_configs.html 的值保持一致,否则告警邮件内容为空。
检测配置文件是否正常:
$ amtool check-config /data/alertmanager/alertmanager.yml
Checking '/data/alertmanager/alertmanager.yml' SUCCESS
Found:
- global config
- route
- 0 inhibit rules
- 2 receivers
- 1 templates
SUCCESS
热加载alertmanager:
systemctl reload alertmanager
alerting:
alert_relabel_configs:
- action: labeldrop
regex: replica
alertmanagers:
- path_prefix: "/alertmanager"
static_configs:
- targets:
- "192.168.31.103:9093"
请注意以下三点:
- 所有Prometheus节点都需要配置;
- 配置alert_relabel_configs 是因为Prometheus有添加额外的标签,如果告警时不删除该标签,则会出现重发告警邮件;
- 配置path_prefix 是因为 alertmanager 添加子路径,如果没有添加的话,则不需要该配置行;
Prometheus配置告警规则路径:
rule_files:
- "rules/*.yml"
创建告警规则:
mkdir /data/prometheus/rules
cat <<-EOF | sudo tee /data/prometheus/rules/hosts.yml > /dev/null
groups:
- name: hosts
rules:
- alert: NodeMemoryUsage
expr: (node_memory_MemTotal_bytes - node_memory_MemFree_bytes - node_memory_Cached_bytes - node_memory_Buffers_bytes) / node_memory_MemTotal_bytes * 100 > 80
for: 1m
labels:
team: hosts
annotations:
summary: "节点内存使用率过高"
description: "{
{$labels.instance}} 节点内存使用率超过 80% (当前值: {
{ $value }})"
- alert: NodeCpuUsage
expr: (1 - (sum(increase(node_cpu_seconds_total{mode="idle"}[1m])) by(instance) / sum(increase(node_cpu_seconds_total[1m])) by(instance))) * 100 > 80
for: 1m
labels:
team: hosts
annotations:
summary: "节点CPU使用率过高"
description: "{
{$labels.instance}} 节点最近一分钟CPU使用率超过 80% (当前值: {
{ $value }})"
- alert: NodeDiskUsage
expr: ((node_filesystem_size_bytes{fstype !~ "tmpfs|rootfs"} - node_filesystem_free_bytes{fstype !~ "tmpfs|rootfs"}) / node_filesystem_size_bytes{fstype !~ "tmpfs|rootfs"})*100 > 40
for: 1m
labels:
team: hosts
annotations:
summary: "节点磁盘分区使用率过高"
description: "{
{$labels.instance}} 节点 {
{$labels.mountpoint}} 分区超过 80% (当前值: {
{ $value }})"
EOF
promtool check rules /data/thanos/rule/rules/hosts.yml
sudo systemctl reload thanos-rule.service
# 告警目录
scp -r /data/thanos/rule/rules ops@k8s-master02:/data/thanos/rule
# 检测配置文件
ssh ops@k8s-master02 "promtool check rules /data/thanos/rule/rules/hosts.yml"
# 热加载配置文件
ssh ops@k8s-master02 "sudo systemctl reload thanos-rule.service"
如果Prometheus没有暴露可以访问的地址,这里使用api进行验证:
# 告警规则名称
curl -s http://localhost:9090/api/v1/rules | jq .data.groups[].rules[].name
# 正在发生的告警
curl -s http://localhost:9090/api/v1/alerts | jq .data.alerts[].labels六、资源预留
1、节点资源预留
节点压力驱逐是 kubelet 主动终止 Pod 以回收节点上资源的过程。kubelet 监控集群节点的 CPU、内存、磁盘空间和文件系统的 inode 等资源。 当这些资源中的一个或者多个达到特定的消耗水平, kubelet 可以主动地使节点上一个或者多个 Pod 失效,以回收资源防止资源不足。
kubelet中有几个参数,通过这几个参数可以为系统进程预留资源,不至于pod把计算资源耗尽,而导致系统操作都无法正常进行。
--enforce-node-allocatable
--system-reserved
--system-reserved-cgroup
--kube-reserved
--kube-reserved-cgroup
--eviction-hard
在kubernetes 1.6版本后,引入了Node的Allocatable特性,通过该特性我们可以控制每个节点可分配的资源。
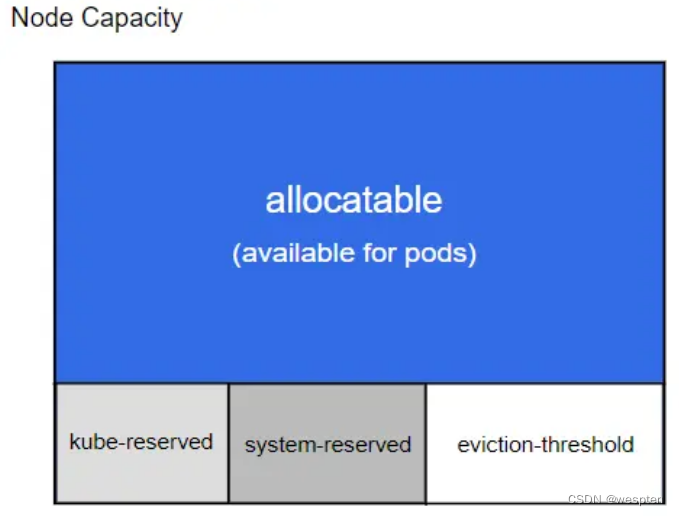
Kubernetes 节点上的 'Allocatable' 被定义为 pod 可用计算资源量。 调度器不会超额申请 'Allocatable'。 目前支持 'CPU', 'memory' 和 'ephemeral-storage' 这几个参数。
Capacity是指Node的容量,allocatable的值为:
allocatable = capacity - kube_reserved - system_reserved - eviction_threshhold当kubelet启动后,Node的allocatable就是固定的,不会因为pod的创建与销毁而改变。
1)allocatable、 requests 和 limits 三者关系
在pod的yaml文件中,我们可以为pod设置requests与limits。其中limits与allocatable没有什么关系。但requests与allocatable关系紧密。调度到某个节点上的Pod的requests总和不能超过该节点的allocatable。limits的总和没有上限。
比如某个节点的内存的allocatable为10Gi,有三个Pod(requests.memory=3Gi)已经调度到该节点上,那么第4个Pod就无法调度到该节点上,即使该Node上的空闲内存大于3Gi。
系统资源预留分为两种不设cgroup 和 设置cgroup。
- 不设cgroup:Pod使用的资源上限不会超过allocatable,如超过则被系统oom掉。系统使用资源超过kube-reserved和system-reserved阈值。可以使用allocatable的资源
- 设置cgroup:Pod使用的资源上限还是不会超过allocatable。但是系统使用资源超过kube-reserved和system-reserved阈值的话,会被cgroup杀掉。所以推荐使用第一种。
假设我们现在需要为系统预留一定的资源,那么我们可以配置如下的kubelet参数(在这里不设置对应的cgroup参数):
--enforce-node-allocatable=pods
--kube-reserved=memory=...
--system-reserved=memory=...
--eviction-hard=...
设置kubelet参数:
这里的设置是将kubelet的配置写在配置文件中,使用--config 的参数指定配置文件即可。上面的参数设置会在某个版本移除。官方推荐将配置写在文件中。
enforceNodeAllocatable: ["pods"]
systemReserved:
cpu: 1000m
memory: 500Mi
kubeReserved:
cpu: 1000m
memory: 500Mi
evictionHard:
memory.available: 10%
imagefs.available: 10%
imagefs.inodesFree: 10%
nodefs.available: 10%
nodefs.inodesFree: 10%
查看capacity及allocatable,查看到Node的capacity及allocatable的值如下:
$ kubectl describe node k8s-master01
...
Capacity:
cpu: 8
ephemeral-storage: 40940Mi
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 3861512Ki
pods: 100
Allocatable:
cpu: 6
ephemeral-storage: 36635831233
hugepages-1Gi: 0
hugepages-2Mi: 0
memory: 2510193454
pods: 100
以内存为例,可以计算出allocatable的值,刚好与上面的一致:
allocatable = capacity - kube_reserved - system_reserved - eviction_threshhold
2510193454/1024Ki = 3861512Ki - 500*1024Ki - 500*1024Ki - 3861512*10%Ki
查看kubepods控制组:
查看kubepods控制组中对内存的限制,该值决定了Node上所有的Pod能使用的资源上限。
$ cat /sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes
2905612288
2905612288Bytes = 2837512Ki = Allocatable + 1000Mi根据上面的计算可知,Node上Pod能实际使用的资源上限值为:
kubepods/memory.limit_in_bytes = capacity - kube_reserved - system_reserved
注意:根据上面的公式,我们可以知道,一个节点上所有Pod能使用的内存总和,与eviction-hard无关。
假设我们现在需要为系统预留一定的资源,那么我们可以配置如下的kubelet参数(在这里设置对应的cgroup参数):
--enforce-node-allocatable=pods,kube-reserved,system-reserved
--kube-reserved=memory=...
--kube-reserved-cgroup=...
--system-reserved=memory=...
--system-reserved-cgroup=...
--eviction-hard=..
如果还设置了对应的 --system-reserved-cgroup 和 --kube-reserved-cgroup参数,Pod能实际使用的资源上限不会改变(即kubepods.limit_in_bytes不变),但系统进程与kube进程也会受到资源上限的限制。如果系统进程超过了预留资源,那么系统进程会被cgroup杀掉。
但是如果不设这两个参数,那么系统进程可以使用超过预留的资源上限。
--enforce-node-allocatable=pods
--kube-reserved=cpu=xx,memory=xx,ephemeral-storage=xx
--system-reserved=cpu=xx,memory=xx,ephemeral-storage=xx
--eviction-hard=memory.available<10%,nodefs.available<10%
一般来说,我们不希望资源的使用率超过70%,所以kube-reserved、system-reserved、eviction-hard都应该设为10%。但由于kube-reserved与system-reserved不能设置百分比,所以它们要设置为绝对值。
- Node的allocatable在kubelet启动后是一个固定的值,不会因为pod的创建与删除而改变;
- 当我们为Pod设置了resources.requests时,调度到Node上的Pod的resources.requests的总和不会超过Node的allocatable。但Pod的resources.limits总和可以超过Node的allocatable;
- 一个Pod能否成功调度到某个Node,关键看该Pod的resources.request是否小于Node剩下的request,而不是看Node实际的资源空闲量。即使空闲资源小于Pod的requests,Pod也可以调度到该Node上;
- 当Pod的内存资源实际使用量超过其limits时,docker(实际是cgroup)会把该Pod内超出限额的进程杀掉(OOM);如果CPU超过,不会杀掉进程,只是进程会一直等待CPU;
- allocatable与kubepods.limit的值不一样,它们之间相差一个 eviction_hard;
- 当我们不设置cgroup时,可以达到为系统预留资源的效果,即Pod的资源实际使用量不会超过allocatable的值(因为kubepods控制组中memory.limit_in_bytes的值就为allocatable的值)。即使系统本身没有使用完预留的那部分资源,Pod也无法使用。当系统超出了预留的那部分资源时,系统进程可以抢占allocatable中的资源,即对系统使用的资源没有限制;
- 当我们设置了cgroup参数,还设置了对应的cgroup时(如下),那么除了Pod使用的资源上限不会超过allocatable外,系统使用的资源上限也不会超过预留资源。当系统进程超过预留资源时,系统进程也会被cgroup杀掉。所以推荐使用上面的设置方法;
参考:
https://kubernetes.io/zh/docs/tasks/administer-cluster/out-of-resource/
节点压力驱逐 | Kubernetes
2、imagefs与nodefs验证
kubelet 服务对磁盘检查是有两个参数的,分别是 imagefs 与 nodefs。其中
- imagefs:监控docker启动参数
data-root 或者 graph目录所在的分区。默认/var/lib/docker - nodefs:监控kubelet启动参数
--root-dir指定的目录所在分区。默认/var/lib/kubelet
kubernetes版本:
$ kubectl get nodes
NAME STATUS ROLES AGE VERSION
k8s-master01 Ready master 85d v1.18.18
k8s-master02 Ready master 85d v1.18.18
k8s-node01 Ready <none> 85d v1.18.18
k8s-node02 Ready <none> 85d v1.18.18
k8s-node03 Ready <none> 85d v1.18.18
节点状态:
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 01 Dec 2021 11:39:29 +0800 Wed, 01 Dec 2021 11:39:29 +0800 CalicoIsUp Calico is running on this node
MemoryPressure False Wed, 01 Dec 2021 13:59:51 +0800 Wed, 01 Dec 2021 11:39:25 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure False Wed, 01 Dec 2021 13:59:51 +0800 Wed, 01 Dec 2021 11:39:25 +0800 KubeletHasNoDiskPressure kubelet has no disk pressure
PIDPressure False Wed, 01 Dec 2021 13:59:51 +0800 Wed, 01 Dec 2021 11:39:25 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 01 Dec 2021 13:59:51 +0800 Wed, 01 Dec 2021 11:39:25 +0800 KubeletReady kubelet is posting ready status
docker数据目录:
$ docker info | grep "Docker Root Dir"
Docker Root Dir: /data/docker/data
kubelet数据目录:
$ ps -ef | grep kubelet
/data/k8s/bin/kubelet --alsologtostderr=true --logtostderr=false --v=4 --log-dir=/data/k8s/logs/kubelet --hostname-override=k8s-master01 --network-plugin=cni --cni-conf-dir=/etc/cni/net.d --cni-bin-dir=/opt/cni/bin --kubeconfig=/data/k8s/certs/kubelet.kubeconfig --bootstrap-kubeconfig=/data/k8s/certs/bootstrap.kubeconfig --config=/data/k8s/conf/kubelet-config.yaml --cert-dir=/data/k8s/certs/ --root-dir=/data/k8s/data/kubelet/ --pod-infra-container-image=ecloudedu/pause-amd64:3.0
分区使用率:
$ df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 40G 8.8G 32G 23% /
/dev/sdb 40G 1.9G 39G 10% /data/docker/data
...
2)验证方案
- 验证nodefs超过阈值;
- 验证imagefs超过阈值;
- 验证imagefs和nodefs超过阈值;
kubelet 的 --root-dir 参数在所分区(/)已使用23%,现在修改imagefs的阈值为78%,node应该nodefs超标:
evictionHard:
memory.available: 10%
nodefs.available: 78%
nodefs.inodesFree: 10%
imagefs.available: 10%
imagefs.inodesFree: 10%
然后我们查看节点的状态,Attempting to reclaim ephemeral-storage,意思为尝试回收磁盘空间:
$ kubectl describe node k8s-master01
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 01 Dec 2021 14:18:56 +0800 Wed, 01 Dec 2021 14:18:56 +0800 CalicoIsUp Calico is running on this node
MemoryPressure False Wed, 01 Dec 2021 15:03:52 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure True Wed, 01 Dec 2021 15:03:52 +0800 Wed, 01 Dec 2021 14:56:13 +0800 KubeletHasDiskPressure kubelet has disk pressure
PIDPressure False Wed, 01 Dec 2021 15:03:52 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 01 Dec 2021 15:03:52 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletReady kubelet is posting ready status
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 6m45s kubelet Starting kubelet.
Normal NodeAllocatableEnforced 6m45s kubelet Updated Node Allocatable limit across pods
Normal NodeHasSufficientMemory 6m45s kubelet Node k8s-master01 status is now: NodeHasSufficientMemory
Normal NodeHasDiskPressure 6m45s kubelet Node k8s-master01 status is now: NodeHasDiskPressure
Normal NodeHasSufficientPID 6m45s kubelet Node k8s-master01 status is now: NodeHasSufficientPID
Warning EvictionThresholdMet 105s (x31 over 6m45s) kubelet Attempting to reclaim ephemeral-storage
docker 存储目录(/data/docker/data)在所分区已使用10%,现在修改imagefs的阈值为91%,node应该imagefs超标:
evictionHard:
memory.available: 10%
nodefs.available: 10%
nodefs.inodesFree: 10%
imagefs.available: 91%
imagefs.inodesFree: 10%
然后我们查看节点的状态,Attempting to reclaim ephemeral-storage,意思为尝试回收磁盘空间:
$ kubectl describe node k8s-master01
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 01 Dec 2021 14:18:56 +0800 Wed, 01 Dec 2021 14:18:56 +0800 CalicoIsUp Calico is running on this node
MemoryPressure False Wed, 01 Dec 2021 15:17:31 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure True Wed, 01 Dec 2021 15:17:31 +0800 Wed, 01 Dec 2021 14:56:13 +0800 KubeletHasDiskPressure kubelet has disk pressure
PIDPressure False Wed, 01 Dec 2021 15:17:31 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 01 Dec 2021 15:17:31 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletReady kubelet is posting ready status
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal NodeHasSufficientPID 18s kubelet Node k8s-master01 status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 18s kubelet Updated Node Allocatable limit across pods
Warning EvictionThresholdMet 18s kubelet Attempting to reclaim ephemeral-storage
Normal NodeHasSufficientMemory 18s kubelet Node k8s-master01 status is now: NodeHasSufficientMemory
Normal NodeHasDiskPressure 18s kubelet Node k8s-master01 status is now: NodeHasDiskPressure
Normal Starting 18s kubelet Starting kubelet.
现在修改imagefs的阈值为91%和nodefs的阈值为78%,node应该imagefs和nodefs超标:
evictionHard:
memory.available: 10%
nodefs.available: 78%
nodefs.inodesFree: 10%
imagefs.available: 91%
imagefs.inodesFree: 10%
然后我们查看节点的状态,Attempting to reclaim ephemeral-storage,意思为尝试回收磁盘空间:
$ kubectl describe node k8s-master01
Conditions:
Type Status LastHeartbeatTime LastTransitionTime Reason Message
---- ------ ----------------- ------------------ ------ -------
NetworkUnavailable False Wed, 01 Dec 2021 14:18:56 +0800 Wed, 01 Dec 2021 14:18:56 +0800 CalicoIsUp Calico is running on this node
MemoryPressure False Wed, 01 Dec 2021 15:23:03 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientMemory kubelet has sufficient memory available
DiskPressure True Wed, 01 Dec 2021 15:23:03 +0800 Wed, 01 Dec 2021 15:23:03 +0800 KubeletHasDiskPressure kubelet has disk pressure
PIDPressure False Wed, 01 Dec 2021 15:23:03 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletHasSufficientPID kubelet has sufficient PID available
Ready True Wed, 01 Dec 2021 15:23:03 +0800 Wed, 01 Dec 2021 14:14:34 +0800 KubeletReady kubelet is posting ready status
...
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal Starting 2m9s kubelet Starting kubelet.
Normal NodeHasSufficientPID 2m9s kubelet Node k8s-master01 status is now: NodeHasSufficientPID
Normal NodeAllocatableEnforced 2m9s kubelet Updated Node Allocatable limit across pods
Normal NodeHasSufficientMemory 2m9s kubelet Node k8s-master01 status is now: NodeHasSufficientMemory
Normal NodeHasDiskPressure 2m7s (x2 over 2m9s) kubelet Node k8s-master01 status is now: NodeHasDiskPressure
Warning EvictionThresholdMet 8s (x13 over 2m9s) kubelet Attempting to reclaim ephemeral-storage
- nodefs是--root-dir目录所在分区,imagefs是docker安装目录所在的分区;
- 建议nodefs与imagefs共用一个分区,但是这个分区要设置的大一些;
- 当nodefs与imagefs共用一个分区时,kubelet中的其他几个参数--root-dir、--cert-dir;
3、资源预留 vs 驱逐 vs OOM
有三个概念我们要分清楚:资源预留、驱逐、OOM。
- 资源预留:影响的是节点的Allocatable的值。
- 驱逐:kubelet对Pod进行驱逐时,只根据--eviction-hard参数(支持的指标参考本文),与system-reserved等参数无关。
- OOM:当某个进程的内存超过自己的限制时,该进程会被docker(cgroup)杀掉。容器发生OOM的情况可能有两种:
- 容器所使用的内存超出了自身的limit限制;
- 所有Pod使用的内存总和超出了/sys/fs/cgroup/memory/kubepods.slice/memory.limit_in_bytes;
七、Helm
1、安装helm
每个Helm 版本都提供了各种操作系统的二进制版本,这些版本可以手动下载和安装。
下载 需要的版本
wget https://get.helm.sh/helm-v3.8.2-linux-amd64.tar.gz
解压(tar -zxvf helm-v3.0.0-linux-amd64.tar.gz):
tar xf helm-v3.8.2-linux-amd64.tar.gz
在解压目中找到helm程序:
cp ./linux-amd64/helm /usr/local/bin/
2、补全helm命令
source <(helm completion bash)
helm completion bash > /etc/bash_completion.d/helm
3、helm插件
$ wget https://github.com/chartmuseum/helm-push/releases/download/v0.10.2/helm-push_0.10.2_linux_amd64.tar.gz
$ helm env | grep HELM_PLUGINS
HELM_PLUGINS="/root/.local/share/helm/plugins"
$ mkdir -p $(helm env | grep HELM_PLUGINS | awk -F= '{print $2}' | sed 's/"//g')/helm-push
$ tar xf helm-push_0.10.2_linux_amd64.tar.gz -C $(helm env | grep HELM_PLUGINS | awk -F= '{print $2}' | sed 's/"//g')/helm-push
$ helm plugin list
NAME VERSION DESCRIPTION
cm-push 0.10.1 Push chart package to ChartMuseum八、安全
1、apiserver审计日志
Kubernetes 审计(Auditing) 功能提供了与安全相关的、按时间顺序排列的记录集, 记录每个用户、使用 Kubernetes API 的应用以及控制面自身引发的活动。
它能帮助集群管理员处理以下问题:
- 发生了什么?
- 什么时候发生的?
- 谁触发的?
- 活动发生在哪个(些)对象上?
- 在哪观察到的?
- 它从哪触发的?
- 活动的后续处理行为是什么?
审计记录最初产生于 kube-apiserver 内部。每个请求在不同执行阶段都会生成审计事件;这些审计事件会根据特定策略 被预处理并写入后端。策略确定要记录的内容和用来存储记录的后端。 当前的后端支持 日志文件 和 webhook。
每个请求都可被记录其相关的 阶段(stage)。已定义的阶段有:
RequestReceived- 此阶段对应审计处理器接收到请求后,并且在委托给 其余处理器之前生成的事件。ResponseStarted- 在响应消息的头部发送后,响应消息体发送前生成的事件。 只有长时间运行的请求(例如 watch)才会生成这个阶段。ResponseComplete- 当响应消息体完成并且没有更多数据需要传输的时候。Panic- 当 panic 发生时生成。
审计日志记录功能会增加 API server 的内存消耗,因为需要为每个请求存储审计所需的某些上下文。 此外,内存消耗取决于审计日志记录的配置。
1)审计策略
审计政策定义了关于应记录哪些事件以及应包含哪些数据的规则。 审计策略对象结构定义在 audit.k8s.io API 组 处理事件时,将按顺序与规则列表进行比较。第一个匹配规则设置事件的 审计级别(Audit Level)。已定义的审计级别有:
None- 符合这条规则的日志将不会记录。Metadata- 记录请求的元数据(请求的用户、时间戳、资源、动词等等), 但是不记录请求或者响应的消息体。Request- 记录事件的元数据和请求的消息体,但是不记录响应的消息体。 这不适用于非资源类型的请求。RequestResponse- 记录事件的元数据,请求和响应的消息体。这不适用于非资源类型的请求。
你可以使用 --audit-policy-file 标志将包含策略的文件传递给 kube-apiserver。 如果不设置该标志,则不记录事件。 注意 rules 字段 必须 在审计策略文件中提供。没有(0)规则的策略将被视为非法配置。
2)审计后端
审计后端实现将审计事件导出到外部存储。Kube-apiserver 默认提供两个后端:
- Log 后端,将事件写入到文件系统
- Webhook 后端,将事件发送到外部 HTTP API
这里分析log后端。
Log 后端将审计事件写入 JSONlines 格式的文件。 你可以使用以下 kube-apiserver 标志配置 Log 审计后端:
--audit-log-path指定用来写入审计事件的日志文件路径。不指定此标志会禁用日志后端。- 意味着标准化--audit-log-maxage定义保留旧审计日志文件的最大天数--audit-log-maxbackup定义要保留的审计日志文件的最大数量--audit-log-maxsize定义审计日志文件的最大大小(兆字节)
3)审计策略示例
创建审计策略:
apiVersion: audit.k8s.io/v1beta1
kind: Policy
rules:
# 所有资源都记录请求的元数据(请求的用户、时间戳、资源、动词等等), 但是不记录请求或者响应的消息体。
- level: Metadata
# 只有pods资源记录事件的元数据和请求的消息体,但是不记录响应的消息体。
- level: Request
resources:
- group: ""
resources: ["pods"]
创建log后端审计:
在 kube-apiserver 服务配置文件中添加以下几行:
# 审计策略文件位置
--audit-policy-file=/data/k8s/conf/kube-apiserver-audit.yml \
# 根据文件名中编码的时间戳保留旧审计日志文件的最大天数。
--audit-log-maxage=3 \
# 轮换之前,审计日志文件的最大大小(以兆字节为单位)
--audit-log-maxsize=100 \
# 审计日志路径
--audit-log-path=/data/k8s/logs/kubernetes.audit \
重启kube-apiserver服务:
systemctl restart kube-apiserver.service
kube-apiserver | Kubernetes
kube-apiserver Audit 配置 (v1) | Kubernetes
kube-apiserver Audit 配置 (v1) | Kubernetes
2、RBAC鉴权
基于角色(Role)的访问控制(RBAC)是一种基于组织中用户的角色来调节控制对 计算机或网络资源的访问的方法。
RBAC 鉴权机制使用 rbac.authorization.k8s.io API组来驱动鉴权决定,允许你通过 Kubernetes API 动态配置策略。
要启用 RBAC,在启动 kube-apiserver 时将 --authorization-mode 参数设置为一个逗号分隔的列表并确保其中包含 RBAC。
1)Role 和 ClusterRole
RBAC 的 Role 或 ClusterRole 中包含一组代表相关权限的规则。 这些权限是纯粹累加的(不存在拒绝某操作的规则)。
Role 总是用来在某个名字空间 内设置访问权限;在你创建 Role 时,你必须指定该 Role 所属的名字空间。
与之相对,ClusterRole 则是一个集群作用域的资源。这两种资源的名字不同(Role 和 ClusterRole)是因为 Kubernetes 对象要么是名字空间作用域的,要么是集群作用域的, 不可两者兼具。
Role 示例:
apiVersion: rbac.authorization.k8s.io/v1
kind: Role
metadata:
name: jiaxzeng
namespace: default
rules:
# pod资源只有create get list watch的操作
- apiGroups: [""]
resources: ["pods"]
verbs: ["create", "get", "list", "watch"]
# 登录pod容器,查看pod日志
- apiGroups: [""]
resources: ["pods/exec", "pods/log"]
verbs: ["get", "create"]
# deployment资源只有get list watch的操作,其他权限均没有
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "watch"]
- Role 与 ClusterRole,除了 kind 和 ClusterRole 资源清单不需要 cluster.namespace 字段外,其他都一致。
- verbs具体有什么操作,请看下面的 查看资源操作 的段落
apiVersion: v1
kind: ServiceAccount
metadata:
name: jiaxzeng
namespace: default
查看 kube-apiserver 的配置文件,确定 ca 证书的相关文件路径。这里演示路径是在 /data/k8s/certs/。
创建一个 JSON 配置文件,用来为 kube-apiserver 生成秘钥和证书,例如:server-csr.json。 确认用你需要的值替换掉尖括号中的值。USER 是为 kube-apiserver绑定的用户名,MASTER_CLUSTER_IP 是为 kube-apiserver 指定的服务集群IP,就像前面小节描述的那样。
以下示例假定你的默认 DSN 域名为cluster.local:
{
"CN": "<USER>",
"hosts": [
"127.0.0.1",
"<MASTER_IP>",
"<MASTER_CLUSTER_IP>",
"kubernetes",
"kubernetes.default",
"kubernetes.default.svc",
"kubernetes.default.svc.cluster",
"kubernetes.default.svc.cluster.local"
],
"key": {
"algo": "rsa",
"size": 2048
},
"names": [{
"C": "CN",
"L": "GuangDong",
"O": "ecloud",
"OU": "ecloud"
}]
}
为 kube-apiserver 生成秘钥和证书,默认会分别存储为server-key.pem 和 server.pem 两个文件。
$ cfssl gencert -ca /data/k8s/certs/ca.pem -ca-key /data/k8s/certs/ca-key.pem --config /data/k8s/certs/ca-config.json -profile kubernetes jiaxzeng-csr.json | cfssljson -bare jiaxzeng
2022/01/28 15:51:28 [INFO] generate received request
2022/01/28 15:51:28 [INFO] received CSR
2022/01/28 15:51:28 [INFO] generating key: rsa-2048
2022/01/28 15:51:28 [INFO] encoded CSR
2022/01/28 15:51:28 [INFO] signed certificate with serial number 89734874854127747600656517401688932704615436370
2022/01/28 15:51:28 [WARNING] This certificate lacks a "hosts" field. This makes it unsuitable for
websites. For more information see the Baseline Requirements for the Issuance and Management
of Publicly-Trusted Certificates, v.1.1.6, from the CA/Browser Forum (https://cabforum.org);
specifically, section 10.2.3 ("Information Requirements").
踩坑:第二行的CN要填写用户名,hosts添加主机的IP地址。
3)RoleBinding 和 ClusterRoleBinding
角色绑定(Role Binding)是将角色中定义的权限赋予一个或者一组用户。 它包含若干 主体(用户、组或服务账户)的列表和对这些主体所获得的角色的引用。 RoleBinding 在指定的名字空间中执行授权,而 ClusterRoleBinding 在集群范围执行授权。
一个 RoleBinding 可以引用同一的名字空间中的任何 Role。 或者,一个 RoleBinding 可以引用某 ClusterRole 并将该 ClusterRole 绑定到 RoleBinding 所在的名字空间。 如果你希望将某 ClusterRole 绑定到集群中所有名字空间,你要使用 ClusterRoleBinding。
创建了绑定之后,你不能再修改绑定对象所引用的 Role 或 ClusterRole。 试图改变绑定对象的 roleRef 将导致合法性检查错误。 如果你想要改变现有绑定对象中 roleRef 字段的内容,必须删除重新创建绑定对象。
RoleBinding ServiceAccount:
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jiaxzeng
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jiaxzeng
subjects:
- apiGroup: ""
kind: ServiceAccount
name: jiaxzeng
apiVersion: rbac.authorization.k8s.io/v1
kind: RoleBinding
metadata:
name: jiaxzeng
namespace: default
roleRef:
apiGroup: rbac.authorization.k8s.io
kind: Role
name: jiaxzeng
subjects:
- apiGroup: "rbac.authorization.k8s.io"
kind: User
name: jiaxzeng
# 获取sa的token
TOKEN=$(kubectl describe secrets "$(kubectl describe serviceaccount jiaxzeng | grep -i Tokens | awk '{print $2}')" | grep token: | awk '{print $2}')
# 设置集群信息。如果有集群信息,则无需再设置
kubectl config set-cluster jiaxzeng-k8s --server=https://192.168.31.103:6443 --insecure-skip-tls-verify
# 设置token
kubectl config set-credentials jiaxzeng --token=$TOKEN
# 设置上下文
kubectl config set-context jiaxzeng --cluster=jiaxzeng-k8s --user=jiaxzeng
# 切换上下文
kubectl config use-context jiaxzeng
# 设置集群信息。如果有集群信息,则无需再设置
KUBE_APISERVER="https://192.168.31.103:6443"
kubectl config set-cluster kubernetes \
--certificate-authority=/data/k8s/certs/ca.pem \
--embed-certs=true \
--server=${KUBE_APISERVER}
# 设置证书
kubectl config set-credentials jiaxzeng \
--client-certificate=jiaxzeng.pem \
--client-key=jiaxzeng-key.pem \
--embed-certs=true
# 设置上下文
kubectl config set-context jiaxzeng \
--cluster=kubernetes \
--user=jiaxzeng
# 切换上下文
kubectl config use-context jiaxzeng
5)查看资源操作
kubectl proxy --address='192.168.31.103' --port=8001 --accept-hosts='^*$'
启动 kubectl proxy 使用网卡IP,从其他机器访问, --accept-hosts='^*$' 表示接受所有源IP,否则会显示不被授权。
访问 http://192.168.31.103:8001/ ,显示所有可用的api接口。根据 apiVersion 来找出对应的api接口。进入对应的api接口,查看 resources 类型,resources 类型可以还有子资源。可根据 kind 的关键字来确认。
这里演示的查看deployment的资源情况以及有什么可用的操作。
查看deployment的 apiVersion 信息:
kubectl explain deployment | grep 'VERSION'
VERSION: apps/v1
查看对应的deployment api接口信息:
过滤deployment类型, 确认资源以及可用操作:
说明:
- 访问的url,根据上面查出来的接口查询;
- 过滤kind的类型,显示如果有多少条记录,则有多个资源。资源名称是name对应的值;
- 资源对应的操作是verbs中的值;
# 确认使用的上下文
$ kubectl config get-contexts
CURRENT NAME CLUSTER AUTHINFO NAMESPACE
default kubernetes system:admin
* jiaxzeng kubernetes jiaxzeng
# 切换上下文
$ kubectl config use-context jiaxzeng
Switched to context "jiaxzeng".
# 检验权限
$ kubectl auth can-i get deployment
yes
$ kubectl auth can-i create deployment
no
$ kubectl auth can-i create pod
yes
$ kubectl auth can-i watch pod
yes
$ kubectl auth can-i get pod -n kube-system
no
- 创建证书:手动生成证书 | Kubernetes
- rbdc文档:使用 RBAC 鉴权 | Kubernetes
- api文档:Kubernetes API Reference Docs
3、namespace资源限制
资源配额,通过 ResourceQuota 对象来定义,对每个命名空间的资源消耗总量提供限制。 它可以限制命名空间中某种类型的对象的总数目上限,也可以限制命令空间中的 Pod 可以使用的计算资源的总上限。
1)启用资源配额
资源配额的支持在很多 Kubernetes 版本中是默认启用的。 当 API 服务器 的命令行标志 --enable-admission-plugins= 中包含 ResourceQuota 时, 资源配额会被启用。
grep enable-admission-plugins /data/k8s/conf/kube-apiserver.conf
2)限制资源配置
apiVersion: v1
kind: ResourceQuota
metadata:
name: quota
namespace: test
spec:
hard:
requests.cpu: "4"
requests.memory: "1Gi"
requests.storage: "100Gi"
pods: "4"
说明:
如果所使用的是 CRI 容器运行时,容器日志会被计入临时存储配额。 这可能会导致存储配额耗尽的 Pods 被意外地驱逐出节点。 参考日志架构 了解详细信息。
3)生效资源限制
$ kubectl apply -f test-namespaces.yml
resourcequota/quota create
验证内存:
创建一个1Gi 的deployment清单文件:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: client
name: client
spec:
replicas: 1
selector:
matchLabels:
app: client
strategy: {}
template:
metadata:
labels:
app: client
spec:
containers:
- image: busybox:1.24.1
name: busybox
args:
- sh
- -c
- "sleep 3600"
resources:
requests:
memory: 2Gi
创建容器:
$ kubectl apply -f client.yml -n test
deployment.apps/client created
$ kubectl -n test get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
client 0/1 0 0 38s
$ kubectl -n test describe deployments.apps client
Name: client
Namespace: test
CreationTimestamp: Wed, 09 Feb 2022 11:21:25 +0800
Labels: app=client
Annotations: deployment.kubernetes.io/revision: 1
Selector: app=client
Replicas: 1 desired | 0 updated | 0 total | 0 available | 1 unavailable
StrategyType: RollingUpdate
MinReadySeconds: 0
RollingUpdateStrategy: 25% max unavailable, 25% max surge
Pod Template:
Labels: app=client
Containers:
busybox:
Image: busybox:1.24.1
Port: <none>
Host Port: <none>
Args:
sh
-c
sleep 3600
Requests:
cpu: 50m
memory: 2Gi
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
Progressing True NewReplicaSetCreated
Available False MinimumReplicasUnavailable
ReplicaFailure True FailedCreate
OldReplicaSets: <none>
NewReplicaSet: client-9d57dfdf6 (0/1 replicas created)
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal ScalingReplicaSet 20s deployment-controller Scaled up replica set client-9d57dfdf6 to 1
$ kubectl -n test describe rs client-9d57dfdf6
Name: client-9d57dfdf6
Namespace: test
Selector: app=client,pod-template-hash=9d57dfdf6
Labels: app=client
pod-template-hash=9d57dfdf6
Annotations: deployment.kubernetes.io/desired-replicas: 1
deployment.kubernetes.io/max-replicas: 2
deployment.kubernetes.io/revision: 1
Controlled By: Deployment/client
Replicas: 0 current / 1 desired
Pods Status: 0 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=client
pod-template-hash=9d57dfdf6
Containers:
busybox:
Image: busybox:1.24.1
Port: <none>
Host Port: <none>
Args:
sh
-c
sleep 3600
Requests:
cpu: 50m
memory: 2Gi
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
ReplicaFailure True FailedCreate
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Warning FailedCreate 29s replicaset-controller Error creating: pods "client-9d57dfdf6-9x74f" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 29s replicaset-controller Error creating: pods "client-9d57dfdf6-62kxp" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 29s replicaset-controller Error creating: pods "client-9d57dfdf6-nx9bs" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 29s replicaset-controller Error creating: pods "client-9d57dfdf6-zs9jl" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 28s replicaset-controller Error creating: pods "client-9d57dfdf6-llrdj" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 28s replicaset-controller Error creating: pods "client-9d57dfdf6-25qrk" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 28s replicaset-controller Error creating: pods "client-9d57dfdf6-2tlxl" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 28s replicaset-controller Error creating: pods "client-9d57dfdf6-fdl4j" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 27s replicaset-controller Error creating: pods "client-9d57dfdf6-hjfnf" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=1Gi, limited: requests.memory=1Gi
Warning FailedCreate 8s (x4 over 26s) replicaset-controller (combined from similar events): Error creating: pods "client-9d57dfdf6-5xkj7" is forbidden: exceeded quota: quota, requested: requests.memory=2Gi, used: requests.memory=0, limited: requests.memory=1Gi
创建一个5副本的deployment清单文件:
apiVersion: apps/v1
kind: Deployment
metadata:
labels:
app: web
name: web
spec:
replicas: 5
selector:
matchLabels:
app: web
strategy: {}
template:
metadata:
labels:
app: web
spec:
containers:
- image: nginx
name: nginx
resources:
requests:
memory: 100m
cpu: 50m
创建容器:
$ kubectl apply -f web.yml -n test
deployment.apps/web created
$ kubectl -n test get pod
NAME READY STATUS RESTARTS AGE
web-584b96b57-24pk5 1/1 Running 0 43s
web-584b96b57-czr6q 1/1 Running 0 43s
web-584b96b57-m9hkv 1/1 Running 0 43s
web-584b96b57-szg9x 1/1 Running 0 43s
$ kubectl -n test get deployments.apps
NAME READY UP-TO-DATE AVAILABLE AGE
web 4/5 4 4 30s
$ kubectl -n test describe rs web-584b96b57
Name: web-584b96b57
Namespace: test
Selector: app=web,pod-template-hash=584b96b57
Labels: app=web
pod-template-hash=584b96b57
Annotations: deployment.kubernetes.io/desired-replicas: 5
deployment.kubernetes.io/max-replicas: 7
deployment.kubernetes.io/revision: 1
Controlled By: Deployment/web
Replicas: 4 current / 5 desired
Pods Status: 4 Running / 0 Waiting / 0 Succeeded / 0 Failed
Pod Template:
Labels: app=web
pod-template-hash=584b96b57
Containers:
nginx:
Image: nginx
Port: <none>
Host Port: <none>
Requests:
cpu: 50m
memory: 100m
Environment: <none>
Mounts: <none>
Volumes: <none>
Conditions:
Type Status Reason
---- ------ ------
ReplicaFailure True FailedCreate
Events:
Type Reason Age From Message
---- ------ ---- ---- -------
Normal SuccessfulCreate 70s replicaset-controller Created pod: web-584b96b57-m9hkv
Normal SuccessfulCreate 70s replicaset-controller Created pod: web-584b96b57-24pk5
Normal SuccessfulCreate 70s replicaset-controller Created pod: web-584b96b57-szg9x
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-4ttxz" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Normal SuccessfulCreate 70s replicaset-controller Created pod: web-584b96b57-czr6q
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-jv9mp" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-7vsjh" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-7pbxc" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-sdlgw" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-ksjzx" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-gqk28" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-spczj" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 70s replicaset-controller Error creating: pods "web-584b96b57-8kzvt" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
Warning FailedCreate 20s (x12 over 69s) replicaset-controller (combined from similar events): Error creating: pods "web-584b96b57-rjkxh" is forbidden: exceeded quota: quota, requested: pods=1, used: pods=4, limited: pods=4
请自行测试,这里就不进行一一验证。
说明:
- 创建deployment必须设置 requests.memory 和 requests.cpu,否则创建pod失败;
- 查看deployment创建成功,但是pod没有创建出来。那得看 rs 创建的情况;
4、加密Secret数据
原来没有加密secret数据直接存储在etcd数据库上的,这样子存在一定的风险。
kubernetes 提供静态加密 Secret 数据的方法。
重要: 如果通过加密配置无法读取资源(因为密钥已更改),唯一的方法是直接从底层 etcd 中删除该密钥。 任何尝试读取资源的调用将会失败,直到它被删除或提供有效的解密密钥。
1)加密数据
创建新的加密配置文件:
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- secretbox:
keys:
- name: key1
secret: <BASE 64 ENCODED SECRET>
- identity: {}
- head -c 32 /dev/urandom | base64 生成一个 32 字节的随机密钥并进行 base64 编码,将这个值放入到 secret 字段中。
- 【重要】secret 字段不能被改,或者该文件不能丢失
修改 kube-apiserver 的配置文件:
设置 kube-apiserver 的 --experimental-encryption-provider-config 参数,将其指向 配置文件所在位置。
示例:
--encryption-provider-config=/root/secret.yml重启 kube-apiserver:
systemctl restart kube-apiserver.service
验证:
$ kubectl create secret generic secret1 -n default --from-literal=mykey=mydata
secret/secret1 created
# 新建的secret,不合protobuf格式,所以解析不到。由于被加密的原因
$ etcdhelper get /registry/secrets/default/secret1
WARN: unable to decode /registry/secrets/default/secret1: yaml: control characters are not allowed
# 新建的secret,呈现乱码
etcdctl --cacert /data/etcd/certs/ca.pem --cert /data/etcd/certs/etcd.pem --key /data/etcd/certs/etcd-key.pem --endpoints=https://192.168.31.95:2379,https://192.168.31.78:2379,https://192.168.31.253:2379 get /registry/secrets/default/secret1
/registry/secrets/default/secret1
k8s:enc:secretbox:v1:key1:uKAE+G>\$e29&u/9oisX_]s#!9-=تD4ɯ02
# 以前的secret,还可以正常解析
$ etcdhelper get /registry/secrets/default/app-v1-tls
/v1, Kind=Secret
{
"kind": "Secret",
"apiVersion": "v1",
"metadata": {
"name": "app-v1-tls",
"namespace": "default",
"uid": "55d3ce46-1f18-4b7a-9e6a-8dff6f49ea9b",
"creationTimestamp": "2022-01-12T06:18:06Z",
"managedFields": [
...
}
确保所有 Secret 都被加密:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
修改加密配置文件:
请将 identity provider 作为配置中的第一个条目。
apiVersion: apiserver.config.k8s.io/v1
kind: EncryptionConfiguration
resources:
- resources:
- secrets
providers:
- identity: {} # 将此项移动到 provider 第一项
- secretbox:
keys:
- name: key1
secret: uXl5US+HQCIGZL6IRvLXgq11O9dZbbqODJ8onZINhaA=
其他内部都不变。
重启kube-apiserver:
systemctl restart kube-apiserver.service
确保所有 Secret 都被解密:
kubectl get secrets --all-namespaces -o json | kubectl replace -f -
验证:
$ etcdhelper get /registry/secrets/default/secret1
/v1, Kind=Secret
{
"kind": "Secret",
"apiVersion": "v1",
"metadata": {
"name": "secret1",
"namespace": "default",
"uid": "2171177e-4392-4ce3-9391-2aea38364a0e",
"creationTimestamp": "2022-01-28T09:03:35Z",
"managedFields": [
{
"manager": "kubectl",
"operation": "Update",
"apiVersion": "v1",
"time": "2022-01-28T09:03:35Z",
"fieldsType": "FieldsV1",
"fieldsV1": {"f:data":{".":{},"f:mykey":{}},"f:type":{}}
}
]
},
"data": {
"mykey": "bXlkYXRh"
},
"type": "Opaque"
}
$ kubectl get secrets
NAME TYPE DATA AGE
app-v1-tls kubernetes.io/tls 2 16d
app-v2-tls-ca Opaque 1 11d
app-v2-tls-server Opaque 2 11d
default-token-zmhtw kubernetes.io/service-account-token 3 144d
jiaxzeng-token-fwk7j kubernetes.io/service-account-token 3 174m
secret1 Opaque 1 19m
-
修改 kube-apiserver 的配置文件
移除 kube-apiserver 的 --experimental-encryption-provider-config 参数。 -
重启kube-apiserver
systemctl restart kube-apiserver.service