一、数据操作
1、读取用户的输入
我们如何读取用户的键盘(控制台)输入呢?从键盘和标准输入 os.Stdin 读取输入,最简单的办法是使用 fmt 包提供的 Scan 和 Sscan 开头的函数。请看以下程序:
示例: readinput1.go:
// 从控制台读取输入:
package main
import "fmt"
var (
firstName, lastName, s string
i int
f float32
input = "56.12 / 5212 / Go"
format = "%f / %d / %s"
)
func main() {
fmt.Println("Please enter your full name: ")
fmt.Scanln(&firstName, &lastName)
// fmt.Scanf("%s %s", &firstName, &lastName)
fmt.Printf("Hi %s %s!\n", firstName, lastName) // Hi Chris Naegels
fmt.Sscanf(input, format, &f, &i, &s)
fmt.Println("From the string we read: ", f, i, s)
// 输出结果: From the string we read: 56.12 5212 Go
}
Scanln 扫描来自标准输入的文本,将空格分隔的值依次存放到后续的参数内,直到碰到换行。Scanf 与其类似,除了Scanf 的第一个参数用作格式字符串,用来决定如何读取。Sscan 和以 Sscan 开头的函数则是从字符串读取,除此之外,与 Scanf 相同。如果这些函数读取到的结果与您预想的不同,您可以检查成功读入数据的个数和返回的错误。
您也可以使用 bufio 包提供的缓冲读取(buffered reader)来读取数据,正如以下例子所示:
示例: readinput2.go:
package main
import (
"fmt"
"bufio"
"os"
)
var inputReader *bufio.Reader
var input string
var err error
func main() {
inputReader = bufio.NewReader(os.Stdin)
fmt.Println("Please enter some input: ")
input, err = inputReader.ReadString('\n')
if err == nil {
fmt.Printf("The input was: %s\n", input)
}
}
inputReader 是一个指向 bufio.Reader 的指针。inputReader := bufio.NewReader(os.Stdin) 这行代码,将会创建一个读取器,并将其与标准输入绑定。
bufio.NewReader() 构造函数的签名为:func NewReader(rd io.Reader) *Reader
该函数的实参可以是满足 io.Reader 接口的任意对象(任意包含有适当的 Read() 方法的对象),函数返回一个新的带缓冲的 io.Reader 对象,它将从指定读取器(例如 os.Stdin)读取内容。
返回的读取器对象提供一个方法 ReadString(delim byte),该方法从输入中读取内容,直到碰到 delim 指定的字符,然后将读取到的内容连同 delim 字符一起放到缓冲区。
ReadString 返回读取到的字符串,如果碰到错误则返回 nil。如果它一直读到文件结束,则返回读取到的字符串和io.EOF。如果读取过程中没有碰到 delim 字符,将返回错误 err != nil。
在上面的例子中,我们会读取键盘输入,直到回车键(\n)被按下。
屏幕是标准输出 os.Stdout;os.Stderr 用于显示错误信息,大多数情况下等同于 os.Stdout。
一般情况下,我们会省略变量声明,而使用 :=,例如:
inputReader := bufio.NewReader(os.Stdin)
input, err := inputReader.ReadString('\n')
我们将从现在开始使用这种写法。
第二个例子从键盘读取输入,使用了 switch 语句:
示例: switch_input.go:
package main
import (
"fmt"
"os"
"bufio"
)
func main() {
inputReader := bufio.NewReader(os.Stdin)
fmt.Println("Please enter your name:")
input, err := inputReader.ReadString('\n')
if err != nil {
fmt.Println("There were errors reading, exiting program.")
return
}
fmt.Printf("Your name is %s", input)
// For Unix: test with delimiter "\n", for Windows: test with "\r\n"
switch input {
case "Philip\r\n": fmt.Println("Welcome Philip!")
case "Chris\r\n": fmt.Println("Welcome Chris!")
case "Ivo\r\n": fmt.Println("Welcome Ivo!")
default: fmt.Printf("You are not welcome here! Goodbye!")
}
// version 2:
switch input {
case "Philip\r\n": fallthrough
case "Ivo\r\n": fallthrough
case "Chris\r\n": fmt.Printf("Welcome %s\n", input)
default: fmt.Printf("You are not welcome here! Goodbye!\n")
}
// version 3:
switch input {
case "Philip\r\n", "Ivo\r\n": fmt.Printf("Welcome %s\n", input)
default: fmt.Printf("You are not welcome here! Goodbye!\n")
}
}
注意:Unix和Windows的行结束符是不同的!
2、读文件
在 Go 语言中,文件使用指向 os.File 类型的指针来表示的,也叫做文件句柄。我们在前面章节使用到过标准输入os.Stdin 和标准输出 os.Stdout,他们的类型都是 *os.File。让我们来看看下面这个程序:
示例: fileinput.go:
package main
import (
"bufio"
"fmt"
"io"
"os"
)
func main() {
inputFile, inputError := os.Open("input.dat")
if inputError != nil {
fmt.Printf("An error occurred on opening the inputfile\n" +
"Does the file exist?\n" +
"Have you got acces to it?\n")
return // exit the function on error
}
defer inputFile.Close()
inputReader := bufio.NewReader(inputFile)
for {
inputString, readerError := inputReader.ReadString('\n')
if readerError == io.EOF {
return
}
fmt.Printf("The input was: %s", inputString)
}
}
变量 inputFile 是 *os.File 类型的。该类型是一个结构,表示一个打开文件的描述符(文件句柄)。然后,使用 os包里的 Open 函数来打开一个文件。该函数的参数是文件名,类型为 string。在上面的程序中,我们以只读模式打开 input.dat 文件。
如果文件不存在或者程序没有足够的权限打开这个文件,Open函数会返回一个错误:inputFile, inputError = os.Open("input.dat")。如果文件打开正常,我们就使用 defer.Close() 语句确保在程序退出前关闭该文件。然后,我们使用 bufio.NewReader 来获得一个读取器变量。
通过使用 bufio 包提供的读取器(写入器也类似),如上面程序所示,我们可以很方便的操作相对高层的 string 对象,而避免了去操作比较底层的字节。
接着,我们在一个无限循环中使用 ReadString('\n') 或 ReadBytes('\n') 将文件的内容逐行(行结束符 '\n')读取出来。
注意:
在之前的例子中,我们看到,Unix和Linux的行结束符是 \n,而Windows的行结束符是 \r\n。在使用 ReadString 和ReadBytes 方法的时候,我们不需要关心操作系统的类型,直接使用 \n 就可以了。另外,我们也可以使用 ReadLine()方法来实现相同的功能。
一旦读取到文件末尾,变量 readerError 的值将变成非空(事实上,常亮 io.EOF 的值是 true),我们就会执行 return语句从而退出循环。
其他类似函数:
1)将整个文件的内容读到一个字符串里:
如果您想这么做,可以使用 io/ioutil 包里的 ioutil.ReadFile() 方法,该方法第一个返回值的类型是 []byte,里面存放读取到的内容,第二个返回值是错误,如果没有错误发生,第二个返回值为 nil。请看下面示例。类似的,函数WriteFile() 可以将 []byte 的值写入文件。
示例: read_write_file1.go:
package main
import (
"fmt"
"io/ioutil"
"os"
)
func main() {
inputFile := "products.txt"
outputFile := "products_copy.txt"
buf, err := ioutil.ReadFile(inputFile)
if err != nil {
fmt.Fprintf(os.Stderr, "File Error: %s\n", err)
// panic(err.Error())
}
fmt.Printf("%s\n", string(buf))
err = ioutil.WriteFile(outputFile, buf, 0x644)
if err != nil {
panic(err. Error())
}
}
2)带缓冲的读取
在很多情况下,文件的内容是不按行划分的,或者干脆就是一个二进制文件。在这种情况下,ReadString()就无法使用了,我们可以使用 bufio.Reader 的 Read(),它只接收一个参数:
buf := make([]byte, 1024)
...
n, err := inputReader.Read(buf)
if (n == 0) { break}
变量 n 的值表示读取到的字节数.
3)按列读取文件中的数据
如果数据是按列排列并用空格分隔的,你可以使用 fmt 包提供的以 FScan 开头的一系列函数来读取他们。请看以下程序,我们将 3 列的数据分别读入变量 v1、v2 和 v3 内,然后分别把他们添加到切片的尾部。
示例: read_file2.go:
package main
import (
"fmt"
"os"
)
func main() {
file, err := os.Open("products2.txt")
if err != nil {
panic(err)
}
defer file.Close()
var col1, col2, col3 []string
for {
var v1, v2, v3 string
_, err := fmt.Fscanln(file, &v1, &v2, &v3)
// scans until newline
if err != nil {
break
}
col1 = append(col1, v1)
col2 = append(col2, v2)
col3 = append(col3, v3)
}
fmt.Println(col1)
fmt.Println(col2)
fmt.Println(col3)
}
输出结果:
[ABC FUNC GO]
[40 56 45]
[150 280 356]
注意:path 包里包含一个子包叫 filepath,这个子包提供了跨平台的函数,用于处理文件名和路径。例如 Base() 函数用于获得路径中的最后一个元素(不包含后面的分隔符):
import "path/filepath"
filename := filepath.Base(path)
关于解析 CSV 文件,encoding/csv 包提供了相应的功能。具体请参考 http://golang.org/pkg/encoding/csv/
compress包提供了读取压缩文件的功能,支持的压缩文件格式为:bzip2、flate、gzip、lzw 和 zlib。
下面的程序展示了如何读取一个 gzip 文件。
示例: gzipped.go:
package main
import (
"fmt"
"bufio"
"os"
"compress/gzip"
)
func main() {
fName := "MyFile.gz"
var r *bufio.Reader
fi, err := os.Open(fName)
if err != nil {
fmt.Fprintf(os.Stderr, "%v, Can't open %s: error: %s\n", os.Args[0], fName,
err)
os.Exit(1)
}
fz, err := gzip.NewReader(fi)
if err != nil {
r = bufio.NewReader(fi)
} else {
r = bufio.NewReader(fz)
}
for {
line, err := r.ReadString('\n')
if err != nil {
fmt.Println("Done reading file")
os.Exit(0)
}
fmt.Println(line)
}
}
3、写文件
请看以下程序:
示例 fileoutput.go:
package main
import (
"os"
"bufio"
"fmt"
)
func main () {
// var outputWriter *bufio.Writer
// var outputFile *os.File
// var outputError os.Error
// var outputString string
outputFile, outputError := os.OpenFile("output.dat", os.O_WRONLY|os.O_CREATE, 0666)
if outputError != nil {
fmt.Printf("An error occurred with file opening or creation\n")
return
}
defer outputFile.Close()
outputWriter := bufio.NewWriter(outputFile)
outputString := "hello world!\n"
for i:=0; i<10; i++ {
outputWriter.WriteString(outputString)
}
outputWriter.Flush()
}
除了文件句柄,我们还需要 bufio 的写入器。我们以只读模式打开文件 output.dat,如果文件不存在则自动创建:
outputFile, outputError := os.OpenFile(“output.dat”, os.O_WRONLY|os.O_ CREATE, 0666)
可以看到,OpenFile 函数有三个参数:文件名、一个或多个标志(使用逻辑运算符“|”连接),使用的文件权限。
我们通常会用到以下标志: os.O_RDONLY:只读
os.WRONLY:只写
os.O_CREATE:创建:如果指定文件不存在,就创建该文件。
os.O_TRUNC:截断:如果指定文件已存在,就将该文件的长度截为0。
在读文件的时候,文件的权限是被忽略的,所以在使用 OpenFile 时传入的第三个参数可以用0。而在写文件时,不管是 Unix 还是 Windows,都需要使用 0666。
然后,我们创建一个写入器(缓冲区)对象:
outputWriter := bufio.NewWriter(outputFile)
接着,使用一个 for 循环,将字符串写入缓冲区,写 10 次:outputWriter.WriteString(outputString)
缓冲区的内容紧接着被完全写入文件:outputWriter.Flush()
如果写入的东西很简单,我们可以使用 fmt.Fprintf(outputFile, “Some test data.\n”) 直接将内容写入文件。fmt 包里的 F 开头的 Print 函数可以直接写入任何 io.Writer,包括文件。
程序 filewrite.go 展示了不使用 fmt.FPrintf 函数,使用其他函数如何写文件:
示例 filewrite.go:
package main
import "os"
func main() {
os.Stdout.WriteString("hello, world\n")
f, _ := os.OpenFile("test", os.O_CREATE|os.O_WRONLY, 0)
defer f.Close()
f.WriteString("hello, world in a file\n")
}
使用 os.Stdout.WriteString(“hello, world\n”),我们可以输出到屏幕。
我们以只写模式创建或打开文件“test”,并且忽略了可能发生的错误:f, _ := os.OpenFile(“test”, os.O_CREATE|os.O_WRONLY, 0)
我们不使用缓冲区,直接将内容写入文件:f.WriteString( )
4、文件拷贝
如何拷贝一个文件到另一个文件?最简单的方式就是使用io包:
示例 filecopy.go:
// filecopy.go
package main
import (
"fmt"
"io"
"os"
)
func main() {
CopyFile("target.txt", "source.txt")
fmt.Println("Copy done!")
}
func CopyFile(dstName, srcName string) (written int64, err error) {
src, err := os.Open(srcName)
if err != nil {
return
}
defer src.Close()
dst, err := os.OpenFile(dstName, os.O_WRONLY|os.O_CREATE, 0644)
if err != nil {
return
}
defer dst.Close()
return io.Copy(dst, src)
}
注意要使用defer:当打开目标文件时发生了错误,那么defer仍然能够确保src.Close()执行。如果不这么做,那么文件会一直保持打开状态并占用资源。
5、从命令行读取参数
os包中有一个string类型的切片变量os.Args,其用来处理一些基本的命令行参数,它在程序启动后读取命令行输入的参数。
来看下面的打招呼程序:
示例 os_args.go:
// os_args.go
package main
import (
"fmt"
"os"
"strings"
)
func main() {
who := "Alice "
if len(os.Args) > 1 {
who += strings.Join(os.Args[1:], " ")
}
fmt.Println("Good Morning", who)
}
我们在IDE或编辑器中直接运行这个程序输出:Good Morning Alice
我们在命令行运行os_args or ./os_args会得到同样的结果。
但是我们在命令行加入参数,像这样:os_args John Bill Marc Luke,将得到这样的输出:Good Morning Alice John Bill Marc Luke
这个命令行参数会放置在切片os.Args[]中(以空格分隔),从索引1开始(os.Args[0]放的是程序本身的名字,在本例中是os_args)。函数strings.Join函数用来连接这些参数,以空格作为间隔。
flag包有一个扩展功能用来解析命令行选项。但是通常被用来替换基本常量,例如,在某些情况下我们希望在命令行给常量一些不一样的值。
在flag包中一个Flag被定义成一个含有如下字段的结构体:
type Flag struct {
Name string // name as it appears on command line
Usage string // help message
Value Value // value as set
DefValue string // default value (as text); for usage message
}
下面的程序echo.go模拟了Unix的echo功能:
package main
import (
"flag" // command line option parser
"os"
)
var NewLine = flag.Bool("n", false, "print newline") // echo -n flag, of type *bool
const (
Space = " "
Newline = "\n"
)
func main() {
flag.PrintDefaults()
flag.Parse() // Scans the arg list and sets up flags
var s string = ""
for i := 0; i < flag.NArg(); i++ {
if i > 0 {
s += " "
if *NewLine { // -n is parsed, flag becomes true
s += Newline
}
}
s += flag.Arg(i)
}
os.Stdout.WriteString(s)
}
flat.Parse()扫描参数列表(或者常量列表)并设置flag, flag.Arg(i)表示第i个参数。Parse()之后所有flag.Arg(i)全部可用,flag.Arg(0)就是第一个真实的flag,而不是像os.Args(o)放置程序的名字。
flag.Narg()返回参数的数量。解析后flag或常量就可用了。flag.Bool()定义了一个默认值是false的flag:当在命令行出现了第一个参数(这里是"n"),flag被设置成'true'(NewLine是*bool类型)。如果*NewLine表示对flag解引用,所以当值是true时将添加一个newline。
flag.PrintDefaults()打印flag的使用帮助信息,本例中打印的是:
-n=false: print newline
flag.VisitAll(fn func(*Flag))是另一个有用的功能:按照字典顺序遍历flag,并且对每个标签调用fn。
当在命令行(Windows)中执行:echo.exe A B C,将输出:A B C;执行echo.exe -n A B C,将输出:
A
B
C
每个字符的输出都新起一行,每次都在输出的数据前面打印使用帮助信息:-n=false: print newline
对于flag.Bool你可以设置布尔型flag来测试你的代码,例如定义一个flag processedFlag:
var processedFlag = flag.Bool(“proc”, false, “nothing processed yet”)
在后面用如下代码来测试:
if *processedFlag { // found flag -proc
r = process()
}
要给flag定义其它类型,可以使用flag.Int(),flag.Float64,flag.String()。
6、用buffer读取文件
在下面的例子中,我们联合使用了缓冲读取文件和命令行flag解析这两项技术。如果不加参数,那么你输入什么屏幕就打印什么。
参数被认为是文件名,如果文件存在的话就打印文件内容到屏幕。命令行执行cat test测试输出。
示例 cat.go:
package main
import (
"bufio"
"flag"
"fmt"
"io"
"os"
)
func cat(r *bufio.Reader) {
for {
buf, err := r.ReadBytes('\n')
if err == io.EOF {
break
}
fmt.Fprintf(os.Stdout, "%s", buf)
}
return
}
func main() {
flag.Parse()
if flag.NArg() == 0 {
cat(bufio.NewReader(os.Stdin))
}
for i := 0; i < flag.NArg(); i++ {
f, err := os.Open(flag.Arg(i))
if err != nil {
fmt.Fprintf(os.Stderr, "%s:error reading from %s: %s\n", os.Args[0], flag.Arg(i), err.Error())
continue
}
cat(bufio.NewReader(f))
}
}7、用切片读写文件
切片提供了 Go 中处理 I/O 缓冲的标准方式,下面 cat 函数的第二版中,在一个切片缓冲内使用无限 for 循环(直到文件尾部 EOF)读取文件,并写入到标准输出(os.Stdout)。
func cat(f *os.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, err := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading: %s\n", err.Error())
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := os.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: error writing: %s\n", ew.Error())
}
}
}
}
下面的代码来自于 cat2.go,使用了 os 包中的 os.file 和 Read 方法;cat2.go 与 cat.go 具有同样的功能。
示例 cat2.go:
package main
import (
"flag"
"fmt"
"os"
)
func cat(f *os.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, err := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading: %s\n", err.Error())
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := os.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: error writing: %s\n", ew.Error())
}
}
}
}
func main() {
flag.Parse() // Scans the arg list and sets up flags
if flag.NArg() == 0 {
cat(os.Stdin)
}
for i := 0; i < flag.NArg(); i++ {
f, err := os.Open(flag.Arg(i))
if f == nil {
fmt.Fprintf(os.Stderr, "cat: can't open %s: error %s\n", flag.Arg(i), err)
os.Exit(1)
}
cat(f)
f.Close()
}
}8、用 defer 关闭文件
defer 关键字对于在函数结束时关闭打开的文件非常有用,例如下面的代码片段:
func data(name string) string {
f := os.Open(name, os.O_RDONLY, 0)
defer f.Close() // idiomatic Go code!
contents := io.ReadAll(f)
return contents
}
在函数 return 后执行了 f.Close()。
9、使用接口的实际例子:fmt.Fprintf
例子程序 io_interfaces.go 很好的阐述了 io 包中的接口概念。
示例 io_interfaces.go:
// interfaces being used in the GO-package fmt
package main
import (
"bufio"
"fmt"
"os"
)
func main() {
// unbuffered
fmt.Fprintf(os.Stdout, "%s\n", "hello world! - unbuffered")
// buffered: os.Stdout implements io.Writer
buf := bufio.NewWriter(os.Stdout)
// and now so does buf.
fmt.Fprintf(buf, "%s\n", "hello world! - buffered")
buf.Flush()
}
输出:
hello world! - unbuffered
hello world! - buffered
下面是 fmt.Fprintf() 函数的实际签名:
func Fprintf(w io.Writer, format string, a ...interface{}) (n int, err error)
其不是写入一个文件,而是写入一个 io.Writer 接口类型的变量,下面是 Writer 接口在 io 包中的定义:
type Writer interface {
Write(p []byte) (n int, err error)
}
fmt.Fprintf() 依据指定的格式向第一个参数内写入字符串,第一参数必须实现了 io.Writer 接口。Fprintf() 能够写入任何类型,只要其实现了 Write 方法,包括 os.Stdout,文件(例如 os.File),管道,网络连接,通道等等,同样的也可以使用 bufio 包中缓冲写入。bufio 包中定义了 type Writer struct{...}
bufio.Writer 实现了 Write 方法:
func (b *Writer) Write(p []byte) (nn int, err error)
它还有一个工厂函数:传给它一个 io.Writer 类型的参数,它会返回一个缓冲的 bufio.Writer 类型的 io.Writer:
func NewWriter(wr io.Writer) (b *Writer)
其适合任何形式的缓冲写入。
在缓冲写入的最后千万不要忘了使用 Flush(),否则最后的输出不会被写入。
我们将介绍 fmt.Fprint 函数向 http.ResponseWriter 写入,其同样实现了 io.Writer 接口。
10、Json 数据格式
数据结构要在网络中传输或保存到文件,就必须对其编码和解码;目前存在很多编码格式:JSON,XML,gob,Google 缓冲协议等等。Go 语言支持所有这些编码格式;在后面的章节,我们将讨论前三种格式。
结构可能包含二进制数据,如果将其作为文本打印,那么可读性是很差的。另外结构内部可能包含匿名字段,而不清楚数据的用意。
通过把数据转换成纯文本,使用命名的字段来标注,让其具有可读性。这样的数据格式可以通过网络传输,而且是与平台无关的,任何类型的应用都能够读取和输出,不与操作系统和编程语言的类型相关。
下面是一些术语说明:
- 数据结构 --> 指定格式 = 序列化 或 编码(传输之前)
- 指定格式 --> 数据格式 = 反序列化 或 解码(传输之后)
序列化是在内存中把数据转换成指定格式(data -> string),反之亦然(string -> data structure)
编码也是一样的,只是输出一个数据流(实现了 io.Writer 接口);解码是从一个数据流(实现了 io.Reader)输出到一个数据结构。
我们都比较熟悉 XML 格式;但有些时候 JSON(JavaScript Object Notation,参阅 http://json.org)被作为首选,主要是由于其格式上非常简洁。通常 JSON 被用于 web 后端和浏览器之间的通讯,但是在其它场景也同样的有用。
这是一个简短的 JSON 片段:
{
"Person": {
"FirstName": "Laura",
"LastName": "Lynn"
}
}
尽管 XML 被广泛的应用,但是 JSON 更加简洁、轻量(占用更少的内存、磁盘及网络带宽)和更好的可读性,这也说明它越来越受欢迎。
Go 语言的 json 包可以让你在程序中方便的读取和写入 JSON 数据。
我们将在下面的例子里使用 json 包,并使用练习 vcard.go 中一个简化版本的 Address 和 VCard 结构(为了简单起见,我们忽略了很多错误处理,不过在实际应用中你必须要合理的处理这些错误)
示例 json.go:
// json.go.go
package main
import (
"encoding/json"
"fmt"
"log"
"os"
)
type Address struct {
Type string
City string
Country string
}
type VCard struct {
FirstName string
LastName string
Addresses []*Address
Remark string
}
func main() {
pa := &Address{"private", "Aartselaar", "Belgium"}
wa := &Address{"work", "Boom", "Belgium"}
vc := VCard{"Jan", "Kersschot", []*Address{pa, wa}, "none"}
// fmt.Printf("%v: \n", vc) // {Jan Kersschot [0x126d2b80 0x126d2be0] none}:
// JSON format:
js, _ := json.Marshal(vc)
fmt.Printf("JSON format: %s", js)
// using an encoder:
file, _ := os.OpenFile("vcard.json", os.O_CREATE|os.O_WRONLY, 0)
defer file.Close()
enc := json.NewEncoder(file)
err := enc.Encode(vc)
if err != nil {
log.Println("Error in encoding json")
}
}
json.Marshal() 的函数签名是 func Marshal(v interface{}) ([]byte, error),下面是数据编码后的 JSON 文本(实际上是一个 []bytes):
{
"FirstName": "Jan",
"LastName": "Kersschot",
"Addresses": [{
"Type": "private",
"City": "Aartselaar",
"Country": "Belgium"
}, {
"Type": "work",
"City": "Boom",
"Country": "Belgium"
}],
"Remark": "none"
}
出于安全考虑,在 web 应用中最好使用 json.MarshalforHTML() 函数,其对数据执行HTML转码,所以文本可以被安全地嵌在 HTML <script> 标签中。
JSON 与 Go 类型对应如下:
- bool 对应 JSON 的 booleans
- float64 对应 JSON 的 numbers
- string 对应 JSON 的 strings
- nil 对应 JSON 的 null
不是所有的数据都可以编码为 JSON 类型:只有验证通过的数据结构才能被编码:
- JSON 对象只支持字符串类型的 key;要编码一个 Go map 类型,map 必须是 map[string]T(T是
json包中支持的任何类型) - Channel,复杂类型和函数类型不能被编码
- 不支持循环数据结构;它将引起序列化进入一个无限循环
- 指针可以被编码,实际上是对指针指向的值进行编码(或者指针是 nil)
UnMarshal() 的函数签名是 func Unmarshal(data []byte, v interface{}) error 把 JSON 解码为数据结构。
我们首先创建一个结构 Message 用来保存解码的数据:var m Message 并调用 Unmarshal(),解析 []byte 中的 JSON 数据并将结果存入指针 m 指向的值
虽然反射能够让 JSON 字段去尝试匹配目标结构字段;但是只有真正匹配上的字段才会填充数据。字段没有匹配不会报错,而是直接忽略掉。
json 包使用 map[string]interface{} 和 []interface{} 储存任意的 JSON 对象和数组;其可以被反序列化为任何的 JSON blob 存储到接口值中。
来看这个 JSON 数据,被存储在变量 b 中:
b == []byte({"Name": "Wednesday", "Age": 6, "Parents": ["Gomez", "Morticia"]})
不用理解这个数据的结构,我们可以直接使用 Unmarshal 把这个数据编码并保存在接口值中:
var f interface{}
err := json.Unmarshal(b, &f)
f指向的值是一个 map,key 是一个字符串,value 是自身存储作为空接口类型的值:
map[string]interface{} {
"Name": "Wednesday",
"Age": 6,
"Parents": []interface{} {
"Gomez",
"Morticia",
},
}
要访问这个数据,我们可以使用类型断言
m := f.(map[string]interface{})
我们可以通过 for range 语法和 type switch 来访问其实际类型:
for k, v := range m {
switch vv := v.(type) {
case string:
fmt.Println(k, "is string", vv)
case int:
fmt.Println(k, "is int", vv)
case []interface{}:
fmt.Println(k, "is an array:")
for i, u := range vv {
fmt.Println(i, u)
}
default:
fmt.Println(k, "is of a type I don’t know how to handle")
}
}
通过这种方式,你可以处理未知的 JSON 数据,同时可以确保类型安全。
如果我们事先知道 JSON 数据,我们可以定义一个适当的结构并对 JSON 数据反序列化。下面的例子中,我们将定义:
type FamilyMember struct {
Name string
Age int
Parents []string
}
并对其反序列化:
var m FamilyMember
err := json.Unmarshal(b, &m)
程序实际上是分配了一个新的切片。这是一个典型的反序列化引用类型(指针、切片和 map)的例子。
json 包提供 Decoder 和 Encoder 类型来支持常用 JSON 数据流读写。NewDecoder 和 NewEncoder 函数分别封装了 io.Reader 和 io.Writer 接口。
func NewDecoder(r io.Reader) *Decoder
func NewEncoder(w io.Writer) *Encoder
要想把 JSON 直接写入文件,可以使用 json.NewEncoder 初始化文件(或者任何实现 io.Writer 的类型),并调用 Encode();反过来与其对应的是使用 json.Decoder 和 Decode() 函数:
func NewDecoder(r io.Reader) *Decoder
func (dec *Decoder) Decode(v interface{}) error
来看下接口是如何对实现进行抽象的:数据结构可以是任何类型,只要其实现了某种接口,目标或源数据要能够被编码就必须实现 io.Writer 或 io.Reader 接口。由于 Go 语言中到处都实现了 Reader 和 Writer,因此 Encoder 和 Decoder 可被应用的场景非常广泛,例如读取或写入 HTTP 连接、websockets 或文件。
11、XML 数据格式
XML案例:
<Person>
<FirstName>Laura</FirstName>
<LastName>Lynn</LastName>
</Person>
如同 json 包一样,也有 Marshal() 和 UnMarshal() 从 XML 中编码和解码数据;但这个更通用,可以从文件中读取和写入(或者任何实现了 io.Reader 和 io.Writer 接口的类型)
和 JSON 的方式一样,XML 数据可以序列化为结构,或者从结构反序列化为 XML 数据;这些可以在例子 15.8(twitter_status.go)中看到。
encoding/xml 包实现了一个简单的 XML 解析器(SAX),用来解析 XML 数据内容。下面的例子说明如何使用解析器:
示例 xml.go:
// xml.go
package main
import (
"encoding/xml"
"fmt"
"strings"
)
var t, token xml.Token
var err error
func main() {
input := "<Person><FirstName>Laura</FirstName><LastName>Lynn</LastName></Person>"
inputReader := strings.NewReader(input)
p := xml.NewDecoder(inputReader)
for t, err = p.Token(); err == nil; t, err = p.Token() {
switch token := t.(type) {
case xml.StartElement:
name := token.Name.Local
fmt.Printf("Token name: %s\n", name)
for _, attr := range token.Attr {
attrName := attr.Name.Local
attrValue := attr.Value
fmt.Printf("An attribute is: %s %s\n", attrName, attrValue)
// ...
}
case xml.EndElement:
fmt.Println("End of token")
case xml.CharData:
content := string([]byte(token))
fmt.Printf("This is the content: %v\n", content)
// ...
default:
// ...
}
}
}
/* Output:
Token name: Person
Token name: FirstName
This is the content: Laura
End of token
Token name: LastName
This is the content: Lynn
End of token
End of token
*/
包中定义了若干 XML 标签类型:StartElement,Chardata(这是从开始标签到结束标签之间的实际文本),EndElement,Comment,Directive 或 ProcInst。
包中同样定义了一个结构解析器:NewParser 方法持有一个 io.Reader(这里具体类型是 strings.NewReader)并生成一个解析器类型的对象。还有一个 Token() 方法返回输入流里的下一个 XML token。在输入流的结尾处,会返回(nil,io.EOF)
XML 文本被循环处理直到 Token() 返回一个错误,因为已经到达文件尾部,再没有内容可供处理了。通过一个 type-switch 可以根据一些 XML 标签进一步处理。Chardata 中的内容只是一个 []byte,通过字符串转换让其变得可读性强一些。
12、用 Gob 传输数据
Gob 是 Go 自己的以二进制形式序列化和反序列化程序数据的格式;可以在 encoding 包中找到。这种格式的数据简称为 Gob (即 Go binary 的缩写)。类似于 Python 的 "pickle" 和 Java 的 "Serialization"。
Gob 通常用于远程方法调用(RPCs)参数和结果的传输,以及应用程序和机器之间的数据传输。 它和 JSON 或 XML 有什么不同呢?Gob 特定地用于纯 Go 的环境中,例如,两个用 Go 写的服务之间的通信。这样的话服务可以被实现得更加高效和优化。 Gob 不是可外部定义,语言无关的编码方式。因此它的首选格式是二进制,而不是像 JSON 和 XML 那样的文本格式。 Gob 并不是一种不同于 Go 的语言,而是在编码和解码过程中用到了 Go 的反射。
Gob 文件或流是完全自描述的:里面包含的所有类型都有一个对应的描述,并且总是可以用 Go 解码,而不需要了解文件的内容。
只有可导出的字段会被编码,零值会被忽略。在解码结构体的时候,只有同时匹配名称和可兼容类型的字段才会被解码。当源数据类型增加新字段后,Gob 解码客户端仍然可以以这种方式正常工作:解码客户端会继续识别以前存在的字段。并且还提供了很大的灵活性,比如在发送者看来,整数被编码成没有固定长度的可变长度,而忽略具体的 Go 类型。
假如在发送者这边有一个有结构 T:
type T struct { X, Y, Z int }
var t = T{X: 7, Y: 0, Z: 8}
而在接收者这边可以用一个结构体 U 类型的变量 u 来接收这个值:
type U struct { X, Y *int8 }
var u U
在接收者中,X 的值是7,Y 的值是0(Y的值并没有从 t 中传递过来,因为它是零值)
和 JSON 的使用方式一样,Gob 使用通用的 io.Writer 接口,通过 NewEncoder() 函数创建 Encoder 对象并调用Encode();相反的过程使用通用的 io.Reader 接口,通过 NewDecoder() 函数创建 Decoder 对象并调用 Decode。
我们把示例的信息写进名为 vcard.gob 的文件作为例子。这会产生一个文本可读数据和二进制数据的混合,当你试着在文本编辑中打开的时候会看到。
在下面示例中你会看到一个编解码,并且以字节缓冲模拟网络传输的简单例子:
示例 gob1.go:
// gob1.go
package main
import (
"bytes"
"fmt"
"encoding/gob"
"log"
)
type P struct {
X, Y, Z int
Name string
}
type Q struct {
X, Y *int32
Name string
}
func main() {
// Initialize the encoder and decoder. Normally enc and dec would be
// bound to network connections and the encoder and decoder would
// run in different processes.
var network bytes.Buffer // Stand-in for a network connection
enc := gob.NewEncoder(&network) // Will write to network.
dec := gob.NewDecoder(&network) // Will read from network.
// Encode (send) the value.
err := enc.Encode(P{3, 4, 5, "Pythagoras"})
if err != nil {
log.Fatal("encode error:", err)
}
// Decode (receive) the value.
var q Q
err = dec.Decode(&q)
if err != nil {
log.Fatal("decode error:", err)
}
fmt.Printf("%q: {%d,%d}\n", q.Name, *q.X, *q.Y)
}
// Output: "Pythagoras": {3,4}
示例 gob2.go 编码到文件:
// gob2.go
package main
import (
"encoding/gob"
"log"
"os"
)
type Address struct {
Type string
City string
Country string
}
type VCard struct {
FirstName string
LastName string
Addresses []*Address
Remark string
}
var content string
func main() {
pa := &Address{"private", "Aartselaar","Belgium"}
wa := &Address{"work", "Boom", "Belgium"}
vc := VCard{"Jan", "Kersschot", []*Address{pa,wa}, "none"}
// fmt.Printf("%v: \n", vc) // {Jan Kersschot [0x126d2b80 0x126d2be0] none}:
// using an encoder:
file, _ := os.OpenFile("vcard.gob", os.O_CREATE|os.O_WRONLY, 0)
defer file.Close()
enc := gob.NewEncoder(file)
err := enc.Encode(vc)
if err != nil {
log.Println("Error in encoding gob")
}
}13、Go 中的密码学
通过网络传输的数据必须加密,以防止被 hacker(黑客)读取或篡改,并且保证发出的数据和收到的数据检验和一致。 鉴于 Go 母公司的业务,我们毫不惊讶地看到 Go 的标准库为该领域提供了超过 30 个的包:
- hash 包:实现了 adler32、crc32、crc64 和 fnv 校验;
- crypto 包:实现了其它的 hash 算法,比如 md4、md5、sha1 等。以及完整地实现了aes、blowfish、rc4、rsa、xtea 等加密算法。
下面的示例用 sha1 和 md5 计算并输出了一些校验值。
示例 hash_sha1.go:
// hash_sha1.go
package main
import (
"fmt"
"crypto/sha1"
"io"
"log"
)
func main() {
hasher := sha1.New()
io.WriteString(hasher, "test")
b := []byte{}
fmt.Printf("Result: %x\n", hasher.Sum(b))
fmt.Printf("Result: %d\n", hasher.Sum(b))
//
hasher.Reset()
data := []byte("We shall overcome!")
n, err := hasher.Write(data)
if n!=len(data) || err!=nil {
log.Printf("Hash write error: %v / %v", n, err)
}
checksum := hasher.Sum(b)
fmt.Printf("Result: %x\n", checksum)
}
/* Output:
Result: a94a8fe5ccb19ba61c4c0873d391e987982fbbd3
Result: [169 74 143 229 204 177 155 166 28 76 8 115 211 145 233 135 152 47 187 211]
Result: e2222bfc59850bbb00a722e764a555603bb59b2a
*/
通过调用 sha1.New() 创建了一个新的 hash.Hash 对象,用来计算 SHA1 校验值。Hash 类型实际上是一个接口,它实现了 io.Writer 接口:
type Hash interface {
// Write (via the embedded io.Writer interface) adds more data to the running hash.
// It never returns an error.
io.Writer
// Sum appends the current hash to b and returns the resulting slice.
// It does not change the underlying hash state.
Sum(b []byte) []byte
// Reset resets the Hash to its initial state.
Reset()
// Size returns the number of bytes Sum will return.
Size() int
// BlockSize returns the hash's underlying block size.
// The Write method must be able to accept any amount
// of data, but it may operate more efficiently if all writes
// are a multiple of the block size.
BlockSize() int
}
通过 io.WriteString 或 hasher.Write 计算给定字符串的校验值。
14、Go操作Mysql数据库
下载依赖:
go get -u github.com/go-sql-driver/mysql
func Open(driverName, dataSourceName string) (*DB, error)
- Open方法打开一个指定的数据库.
- driverName为驱动名称,例mysql
- dataSourceName为数据库连接信息
- 返回DB和error
demo1:
func main() {
// dsn: Data Source Name
// 用户名为root,密码为123456,数据库为test
dsn := "root:123456@tcp(127.0.0.1:3306)/test"
// Open()方法对dsn的一个格式校验,并没有实际连接到数据库
db, err := sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
defer db.Close()
}
// 定义一个全局变量
var db *sql.DB
// 定义初始化mysql的方法
func initMysql() (err error) {
// dsn: Data Source Name
// 用户名为root,密码为123456,数据库为test
dsn := "root:123456@tcp(127.0.0.1:3306)/test"
// Open()方法对dsn的一个格式校验,并没有实际连接到数据库
db, err = sql.Open("mysql", dsn)
if err != nil {
panic(err)
}
// 与数据库建立连接
err = db.Ping()
if err != nil {
fmt.Printf("connect to db failed, err:%v\n", err)
return
}
return
}
func main() {
if err := initMysql(); err != nil {
panic(err)
}
defer db.Close()
fmt.Println("connected to db...")
}
单行查询db.QueryRow()执行一次查询,并期望返回最多一行结果(即Row)。QueryRow总是返回非nil的值,直到返回值的Scan方法被调用时,才会返回被延迟的错误。
func (db *DB) QueryRow(query string, args ...interface{}) *Row
代码示例:
// 单行查询
func queryRowDemo() {
// sql语句
sqlStr := "select id, name, age from user where id=?"
var u user
err := db.QueryRow(sqlStr, 1).Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("scan failed, err:%v\n", err)
return
}
fmt.Printf("id:%d name:%s age:%d\n", u.id, u.name, u.age)
}
多行查询db.Query()执行一次查询,返回多行结果(即Rows),一般用于执行select命令。参数args表示query中的占位参数。
func (db *DB) Query(query string, args ...interface{}) (*Rows, error)
代码示例:
// 多行查询
func queryMultiRowDemo() {
sqlStr := "select id, name, age from user where id > ?"
rows, err := db.Query(sqlStr, 0)
if err != nil {
fmt.Printf("query failed, err:%v\n", err)
return
}
// 关闭rows释放持有的数据库链接
defer rows.Close()
// 循环读取结果集中的数据
for rows.Next() {
var u user
err := rows.Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("scan failed, err:%v\n", err)
return
}
fmt.Printf("id:%d name:%s age:%d\n", u.id, u.name, u.age)
}
}
插入、更新和删除操作都使用Exec方法。
func (db *DB) Exec(query string, args ...interface{}) (Result, error)
Exec执行一次命令(包括查询、删除、更新、插入等),返回的Result是对已执行的SQL命令的总结。参数args表示query中的占位参数。
代码示例:
// 插入数据
func insertRowDemo(name string, age int) {
sqlStr := "insert into user(name, age) values (?,?)"
result, err := db.Exec(sqlStr, name, age)
if err != nil {
fmt.Printf("insert failed, err:%v\n", err)
return
}
// RowsAffected()方法,表示影响的行数
// num, err := result.RowsAffected()
lastId, err := result.LastInsertId() // 新插入数据的id
if err != nil {
fmt.Printf("get lastinsert ID failed, err:%v\n", err)
return
}
fmt.Printf("insert successfully, the id is %d.\n", lastId)
}
// 更新数据
func updateRowDemo() {
sqlStr := "update user set age=? where id = ?"
result, err := db.Exec(sqlStr, 23, 1)
if err != nil {
fmt.Printf("update data failed, err:%v\n", err)
return
}
// 操作影响的行数
num, err := result.RowsAffected()
if err != nil {
fmt.Printf("get RowsAffected failed, err:%v\n", err)
return
}
fmt.Printf("update data successfully, %d rows affected\n", num)
}
// 删除数据
func deleteRowDemo() {
sqlStr := "delete from user where id = ?"
result, err := db.Exec(sqlStr, 3)
if err != nil {
fmt.Printf("delete failed, err:%v\n", err)
return
}
num, err := result.RowsAffected() // 操作影响的行数
if err != nil {
fmt.Printf("get RowsAffected failed, err:%v\n", err)
return
}
fmt.Printf("delete success, affected rows:%d\n", num)
}
为什么要预处理?
-
优化MySQL服务器重复执行SQL的方法,可以提升服务器性能,提前让服务器编译,一次编译多次执行,节省后续编译的成本。
-
避免SQL注入问题
database/sql中使用下面的Prepare方法来实现预处理操作。
func (db *DB) Prepare(query string) (*Stmt, error)
// 预处理
func prepareQueryDemo() {
sqlStr := "select id, name, age from user where id > ?"
stmt, err := db.Prepare(sqlStr)
if err != nil {
fmt.Printf("prepare failed, err:%v\n", err)
return
}
defer stmt.Close()
rows, err := stmt.Query(0)
if err != nil {
fmt.Printf("query failed, err:%v\n", err)
return
}
defer rows.Close()
// 循环读取结果集中的数据
for rows.Next() {
var u user
err := rows.Scan(&u.id, &u.name, &u.age)
if err != nil {
fmt.Printf("scan failed, err:%v\n", err)
return
}
fmt.Printf("id:%d name:%s age:%d\n", u.id, u.name, u.age)
}
}
Go语言中使用以下三个方法实现MySQL中的事务操作。
开始事务:
func (db *DB) Begin() (*Tx, error)
提交事务:
func (tx *Tx) Commit() error
回滚事务:
func (tx *Tx) Rollback() error
示例代码:
// 事务操作
func transactionDemo() {
tx, err := db.Begin() // 开启事务
if err != nil {
if tx != nil {
tx.Rollback() // 回滚
}
fmt.Printf("begin trans failed, err:%v\n", err)
return
}
sqlStr1 := "update user set age=30 where id=?"
result1, err := tx.Exec(sqlStr1, 1)
if err != nil {
tx.Rollback() // 回滚
fmt.Printf("exec sql failed, err:%v\n", err)
return
}
num1, err := result1.RowsAffected()
if err != nil {
tx.Rollback() // 回滚
fmt.Printf("exec result.RowsAffected failed, err:%v\n", err)
return
}
sqlStr2 := "update user set age=30 where id=?"
result2, err := tx.Exec(sqlStr2, 2)
if err != nil {
tx.Rollback() // 回滚
fmt.Printf("exec sql failed, err:%v\n", err)
return
}
num2, err := result2.RowsAffected()
if err != nil {
tx.Rollback() // 回滚
fmt.Printf("exec result.RowsAffected failed, err:%v\n", err)
return
}
fmt.Println(num1, num2)
if num1 == 1 && num2 == 1 {
fmt.Println("事务提交啦。。。")
tx.Commit()
} else {
tx.Rollback()
fmt.Println("事务回滚啦。。。")
}
fmt.Println("exec trans success!")
}15、Go操作redis
go get -u github.com/go-redis/redis
// 声明全局变量
var rdb *redis.Client
func initRedis() (err error) {
rdb = redis.NewClient(&redis.Options{
Addr: "192.168.0.141:6379",
Password: "",
DB: 0,
})
// 检查是否连接上了redis
_, err = rdb.Ping().Result()
if err != nil {
return err
}
return nil
}
func main() {
err := initRedis()
if err != nil {
fmt.Printf("init redis failed, err:%v\n", err)
return
}
defer rdb.Close()
fmt.Println("Connected to redis....")
}16、mongo-driver
go get go.mongodb.org/mongo-driver
func main() {
clientOptions := options.Client().ApplyURI("mongodb://localhost:27017")
client, err := mongo.Connect(context.TODO(), clientOptions)
if err != nil {
log.Fatal(err)
}
err = client.Ping(context.TODO(), nil)
if err != nil {
log.Fatal(err)
}
fmt.Println("connected to MongoDB!")
}
err = client.Disconnect(context.TODO())
if err != nil {
log.Fatal(err)
}
fmt.Println("Connection to MongoDB closed.")
// 插入一条
func InsertOne(u User) {
insertResult, err := collection.InsertOne(context.TODO(), u)
if err != nil {
log.Fatal(err)
}
fmt.Println("Inserted a single document: ", insertResult.InsertedID)
}
// 插入多条
func InsertMany(userList []interface{}) {
insertManyResult, err := collection.InsertMany(context.TODO(), userList)
if err != nil {
log.Fatal(err)
}
fmt.Println("Inserted many documents: ",insertManyResult.InsertedIDs)
}
func UpdateOne() {
filter := bson.D{
{"name", "Alice"}}
update := bson.D{
{"$inc", bson.D{
{"age", 101},
}},
}
updateResult, err := collection.UpdateOne(context.TODO(), filter, update)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Matched %v documents and updated %v documents.\n", updateResult.MatchedCount, updateResult.ModifiedCount)
}
// 查找单个
func FindOne() {
var user User
filter := bson.D{
{"name", "Alice"}}
err := collection.FindOne(context.TODO(), filter).Decode(&user)
if err != nil {
log.Fatal(err)
}
fmt.Printf("Found a single document: %+v\n", user)
}
// 查找多个
```
func FindMany() {
findOptions := options.Find()
findOptions.SetLimit(2)
var user []*User
cur, err := collection.Find(context.TODO(), bson.D{
{}}, findOptions)
if err != nil {
log.Fatal(err)
}
for cur.Next(context.TODO()) {
var u User
err := cur.Decode(&u)
if err != nil {
log.Fatal(err)
}
user = append(user, &u)
}
if err := cur.Err(); err != nil {
log.Fatal(err)
}
cur.Close(context.TODO())
fmt.Printf("Found multiple documents (array of pointers): %+v\n", user)
for _, v := range user {
fmt.Println(*v)
}
}
collection.DeleteOne()collection.DeleteMany() 删除单个、多个
Collection.Drop() 删除整个集合
示例:
func main() {
uri := "mongodb://localhost:27017"
client, err := mongo.Connect(context.TODO(), options.Client().ApplyURI(uri))
if err != nil {
panic(err)
}
defer func() {
if err := client.Disconnect(context.TODO()); err != nil {
panic(err)
}
}()
coll := client.Database("test").Collection("user")
name := "Alice"
var result bson.M
err = coll.FindOne(context.TODO(), bson.D{
{"name", name}}).Decode(&result)
if err == mongo.ErrNoDocuments {
fmt.Printf("No document was found with the title %s\n", name)
return
}
if err != nil {
panic(err)
}
jsonData, err := json.MarshalIndent(result, "", " ")
if err != nil {
panic(err)
}
fmt.Printf("%s\n", jsonData)
}17、sqlx库
go get github.com/jmoiron/sqlx
连接数据库:
var db *sqlx.DB
func initDB() (err error) {
dsn := "root:123456@tcp(127.0.0.1:3306)/test?charset=utf8mb4&parseTime=True"
db, err = sqlx.Connect("mysql", dsn)
if err != nil {
fmt.Printf("connect DB failed, err:%v\n", err)
return
}
db.SetMaxOpenConns(20)
db.SetMaxIdleConns(10)
return
}
func main() {
err := initDB()
if err != nil {
fmt.Printf("init db failed, err:%v\n", err)
return
}
defer db.Close()
fmt.Println("connected to db...")
}
// 插入数据
func insertRowDemo() {
sqlStr := "insert into user(name, age) values (?, ?)"
result, err := db.Exec(sqlStr, "Cindy", 23)
if err != nil {
fmt.Printf("insert data failed, err:%v\n", err)
return
}
lastID, err := result.LastInsertId()
if err != nil {
fmt.Printf("get last id failed, err:%v\n", err)
return
}
fmt.Printf("insert successfully, last id is %d.\n", lastID)
}
DB.NamedExec方法用来绑定SQL语句与结构体或map中的同名字段:
func insertUserDemo() {
sqlStr := "insert into user(name, age) values(:name, :age)"
db.NamedExec(sqlStr,
map[string]interface{}{
"name": "ddd",
"age": 30,
})
fmt.Printf("insert data successfully.")
return
}18、msgpack
Go语言中的json包在序列化空接口存放的数字类型(整型、浮点型等)都序列化成float64类型:
func jsonDemo() {
var s1 = s{
data: make(map[string]interface{}, 8),
}
s1.data["count"] = 1
ret, err := json.Marshal(s1.data)
if err != nil {
fmt.Println("marshal failed ", err)
}
fmt.Printf("%#v\n", string(ret))
var s2 = s{
data: make(map[string]interface{}, 8),
}
err = json.Unmarshal(ret, &s2.data)
if err != nil {
fmt.Println("marshal failed ", err)
}
fmt.Println(s2)
for _, v := range s2.data {
fmt.Printf("value:%v, type:%T\n", v, v)
}
}
// 输出:
"{\"count\":1}"
{map[count:1]}
value:1, type:float64
gob序列化:
// gob序列化
func gobDemo() {
var s1 = s{
data: make(map[string]interface{}, 8),
}
s1.data["count"] = 1
// encode
buf := new(bytes.Buffer)
enc := gob.NewEncoder(buf)
err := enc.Encode(s1.data)
if err != nil {
fmt.Println("gob encode failed, err: ", err)
return
}
b := buf.Bytes()
fmt.Println(b)
var s2 = s{
data: make(map[string]interface{}, 8),
}
// decode
dec := gob.NewDecoder(bytes.NewBuffer(b))
err = dec.Decode(&s2.data)
if err != nil {
fmt.Println("gob encode failed, err: ", err)
return
}
fmt.Println(s2.data)
for _, v := range s2.data {
fmt.Printf("value:%v, type:%T\n", v, v)
}
}
msgpack序列化:
func main() {
p1 := Person{
Name: "alice",
Age: 18,
Gender: "男",
}
// marshal
b, err := msgpack.Marshal(p1)
if err != nil {
fmt.Printf("msgpack marshal failed, err:%v", err)
return
}
// unmarshal
var p2 Person
err = msgpack.Unmarshal(b, &p2)
if err != nil {
fmt.Printf("msgpack unmarshal failed, err:%v", err)
return
}
fmt.Printf("p2:%#v\n", p2)
}
// 输出:
p2:main.Person{Name:"alice", Age:18, Gender:"男"}二、 错误处理与测试
1、错误处理
Go 有一个预先定义的 error 接口类型:
type error interface {
Error() string
}
errors 包中有一个 errorString 结构体实现了 error 接口。当程序处于错误状态时可以用 os.Exit(1)来中止运行。
任何时候当你需要一个新的错误类型,都可以用 errors(必须先 import)包的 errors.New 函数接收合适的错误信息来创建,像下面这样:
err := errors.New(“math - square root of negative number”)
你可以看到一个简单的用例:
示例 errors.go:
// errors.go
package main
import (
"errors"
"fmt"
)
var errNotFound error = errors.New("Not found error")
func main() {
fmt.Printf("error: %v", errNotFound)
}
// error: Not found error
可以把它用于计算平方根函数的参数测试:
func Sqrt(f float64) (float64, error) {
if f < 0 {
return 0, errors.New (“math - square root of negative number”)
}
// implementation of Sqrt
}
你可以像下面这样调用 Sqrt 函数:
if f, err := Sqrt(-1); err != nil {
fmt.Printf(“Error: %s\n”, err)
}
由于 fmt.Printf 会自动调用 String() 方法 ,所以错误信息 “Error: math - square root of negative number” 会打印出来。通常(错误信息)都会有像 “Error:” 这样的前缀,所以你的错误信息不要以大写字母开头。
在大部分情况下自定义错误结构类型很有意义的,可以包含除了(低层级的)错误信息以外的其它有用信息,例如,正在进行的操作(打开文件等),全路径或名字。看下面例子中 os.Open 操作触发的 PathError 错误:
// PathError records an error and the operation and file path that caused it.
type PathError struct {
Op string // “open”, “unlink”, etc.
Path string // The associated file.
Err error // Returned by the system call.
}
func (e *PathError) String() string {
return e.Op + “ ” + e.Path + “: “+ e.Err.Error()
}
如果有不同错误条件可能发生,那么对实际的错误使用类型断言或类型判断(type-switch)是很有用的,并且可以根据错误场景做一些补救和恢复操作。
// err != nil
if e, ok := err.(*os.PathError); ok {
// remedy situation
}
或:
switch err := err.(type) {
case ParseError:
PrintParseError(err)
case PathError:
PrintPathError(err)
...
default:
fmt.Printf(“Not a special error, just %s\n”, err)
}
作为第二个例子考虑用 json 包的情况。当 json.Decode 在解析 JSON 文档发生语法错误时,指定返回一个 SyntaxError 类型的错误:
type SyntaxError struct {
msg string // description of error
// error occurred after reading Offset bytes, from which line and columnnr can be obtained
Offset int64
}
func (e *SyntaxError) String() string { return e.msg }
在调用代码中你可以像这样用类型断言测试错误是不是上面的类型:
if serr, ok := err.(*json.SyntaxError); ok {
line, col := findLine(f, serr.Offset)
return fmt.Errorf(“%s:%d:%d: %v”, f.Name(), line, col, err)
}
包也可以用额外的方法(methods)定义特定的错误,比如 net.Errot:
package net
type Error interface {
Timeout() bool // Is the error a timeout?
Temporary() bool // Is the error temporary?
}
正如你所看到的一样,所有的例子都遵循同一种命名规范:错误类型以 “Error” 结尾,错误变量以 “err” 或 “Err” 开头。
syscall 是低阶外部包,用来提供系统基本调用的原始接口。它们返回整数的错误码;类型 syscall.Errno 实现了 Error 接口。
大部分 syscall 函数都返回一个结果和可能的错误,比如:
r, err := syscall.Open(name, mode, perm)
if err != 0 {
fmt.Println(err.Error())
}
os 包也提供了一套像 os.EINAL 这样的标准错误,它们基于 syscall 错误:
var (
EPERM Error = Errno(syscall.EPERM)
ENOENT Error = Errno(syscall.ENOENT)
ESRCH Error = Errno(syscall.ESRCH)
EINTR Error = Errno(syscall.EINTR)
EIO Error = Errno(syscall.EIO)
...
)
通常你想要返回包含错误参数的更有信息量的字符串,例如:可以用 fmt.Errorf() 来实现:它和 fmt.Printf() 完全一样,接收有一个或多个格式占位符的格式化字符串和相应数量的占位变量。和打印信息不同的是它用信息生成错误对象。
比如在前面的平方根例子中使用:
if f < 0 {
return 0, fmt.Errorf(“math: square root of negative number %g”, f)
}
第二个例子:从命令行读取输入时,如果加了 help 标志,我们可以用有用的信息产生一个错误:
if len(os.Args) > 1 && (os.Args[1] == “-h” || os.Args[1] == “--help”) {
err = fmt.Errorf(“usage: %s infile.txt outfile.txt”, filepath.Base(os.Args[0]))
return
}2、运行时异常和panic
当发生像数组下标越界或类型断言失败这样的运行错误时,Go 运行时会触发运行时 panic,伴随着程序的崩溃抛出一个runtime.Error 接口类型的值。这个错误值有个 RuntimeError() 方法用于区别普通错误。
panic 可以直接从代码初始化:当错误条件(我们所测试的代码)很严苛且不可恢复,程序不能继续运行时,可以使用panic 函数产生一个中止程序的运行时错误。panic 接收一个做任意类型的参数,通常是字符串,在程序死亡时被打印出来。Go 运行时负责中止程序并给出调试信息。
package main
import "fmt"
func main() {
fmt.Println("Starting the program")
panic("A severe error occurred: stopping the program!")
fmt.Println("Ending the program")
}
输出如下:
Starting the program
panic: A severe error occurred: stopping the program!
panic PC=0x4f3038
runtime.panic+0x99 /go/src/pkg/runtime/proc.c:1032
runtime.panic(0x442938, 0x4f08e8)
main.main+0xa5 E:/Go/GoBoek/code examples/chapter 13/panic.go:8
main.main()
runtime.mainstart+0xf 386/asm.s:84
runtime.mainstart()
runtime.goexit /go/src/pkg/runtime/proc.c:148
runtime.goexit()
---- Error run E:/Go/GoBoek/code examples/chapter 13/panic.exe with code Crashed
---- Program exited with code -1073741783
一个检查程序是否被已知用户启动的具体例子:
var user = os.Getenv(“USER”)
func check() {
if user == “” {
panic(“Unknown user: no value for $USER”)
}
}
可以在导入包的 init() 函数中检查这些。
当发生错误必须中止程序时,panic 可以用于错误处理模式:
if err != nil {
panic(“ERROR occurred:” + err.Error())
}
Go panicking:
在多层嵌套的函数调用中调用 panic,可以马上中止当前函数的执行,所有的 defer 语句都会保证执行并把控制权交还给接收到 panic 的函数调用者。这样向上冒泡直到最顶层,并执行(每层的) defer,在栈顶处程序崩溃,并在命令行中用传给 panic 的值报告错误情况:这个终止过程就是 panicking。
标准库中有许多包含 Must 前缀的函数,像 regexp.MustComplie 和 template.Must;当正则表达式或模板中转入的转换字符串导致错误时,这些函数会 panic。
不能随意地用 panic 中止程序,必须尽力补救错误让程序能继续执行。
3、从 panic 中恢复(Recover)
正如名字一样,这个(recover)内建函数被用于从 panic 或 错误场景中恢复:让程序可以从 panicking 重新获得控制权,停止终止过程进而恢复正常执行。
recover 只能在 defer 修饰的函数中使用:用于取得 panic 调用中传递过来的错误值,如果是正常执行,调用 recover 会返回 nil,且没有其它效果。
总结:panic 会导致栈被展开直到 defer 修饰的 recover() 被调用或者程序中止。
下面例子中的 protect 函数调用函数参数 g 来保护调用者防止从 g 中抛出的运行时 panic,并展示 panic 中的信息:
func protect(g func()) {
defer func() {
log.Println(“done”)
// Println executes normally even if there is a panic
if err := recover(); err != nil {
log.Printf(“run time panic: %v”, err)
}
}()
log.Println(“start”)
g() // possible runtime-error
}
这跟 Java 和 .NET 这样的语言中的 catch 块类似。
log 包实现了简单的日志功能:默认的 log 对象向标准错误输出中写入并打印每条日志信息的日期和时间。除了 Println 和Printf 函数,其它的致命性函数都会在写完日志信息后调用 os.Exit(1),那些退出函数也是如此。而 Panic 效果的函数会在写完日志信息后调用 panic;可以在程序必须中止或发生了临界错误时使用它们,就像当 web 服务器不能启动时那样。
log 包用那些方法(methods)定义了一个 Logger 接口类型,如果你想自定义日志系统的话可以参考(参见http://golang.org/pkg/log/#Logger)。
这是一个展示 panic,defer 和 recover 怎么结合使用的完整例子:
示例 panic_recover.go:
// panic_recover.go
package main
import (
"fmt"
)
func badCall() {
panic("bad end")
}
func test() {
defer func() {
if e := recover(); e != nil {
fmt.Printf("Panicing %s\r\n", e)
}
}()
badCall()
fmt.Printf("After bad call\r\n") // <-- wordt niet bereikt
}
func main() {
fmt.Printf("Calling test\r\n")
test()
fmt.Printf("Test completed\r\n")
}
输出:
Calling test
Panicing bad end
Test completed
defer-panic-recover 在某种意义上也是一种像 if,for 这样的控制流机制。
Go 标准库中许多地方都用了这个机制,例如,json 包中的解码和 regexp 包中的 Complie 函数。Go 库的原则是即使在包的内部使用了 panic,在它的对外接口(API)中也必须用 recover 处理成返回显式的错误。
4、自定义包中的错误处理和 panicking
这是所有自定义包实现者应该遵守的最佳实践:
1)在包内部,总是应该从 panic 中 recover:不允许显式的超出包范围的 panic()
2)向包的调用者返回错误值(而不是 panic)。
在包内部,特别是在非导出函数中有很深层次的嵌套调用时,对主调函数来说用 panic 来表示应该被翻译成错误的错误场景是很有用的(并且提高了代码可读性)。
这在下面的代码中被很好地阐述了。我们有一个简单的 parse 包用来把输入的字符串解析为整数切片;这个包有自己特殊的 ParseError。
当没有东西需要转换或者转换成整数失败时,这个包会 panic(在函数 fields2numbers 中)。但是可导出的 Parse 函数会从 panic 中 recover 并用所有这些信息返回一个错误给调用者。为了演示这个过程,在 panic_recover.go 中 调用了 parse 包;不可解析的字符串会导致错误并被打印出来。
示例 parse.go:
// parse.go
package parse
import (
"fmt"
"strings"
"strconv"
)
// A ParseError indicates an error in converting a word into an integer.
type ParseError struct {
Index int // The index into the space-separated list of words.
Word string // The word that generated the parse error.
Err error // The raw error that precipitated this error, if any.
}
// String returns a human-readable error message.
func (e *ParseError) String() string {
return fmt.Sprintf("pkg parse: error parsing %q as int", e.Word)
}
// Parse parses the space-separated words in in put as integers.
func Parse(input string) (numbers []int, err error) {
defer func() {
if r := recover(); r != nil {
var ok bool
err, ok = r.(error)
if !ok {
err = fmt.Errorf("pkg: %v", r)
}
}
}()
fields := strings.Fields(input)
numbers = fields2numbers(fields)
return
}
func fields2numbers(fields []string) (numbers []int) {
if len(fields) == 0 {
panic("no words to parse")
}
for idx, field := range fields {
num, err := strconv.Atoi(field)
if err != nil {
panic(&ParseError{idx, field, err})
}
numbers = append(numbers, num)
}
return
}
示例 panic_package.go:
// panic_package.go
package main
import (
"fmt"
"./parse/parse"
)
func main() {
var examples = []string{
"1 2 3 4 5",
"100 50 25 12.5 6.25",
"2 + 2 = 4",
"1st class",
"",
}
for _, ex := range examples {
fmt.Printf("Parsing %q:\n ", ex)
nums, err := parse.Parse(ex)
if err != nil {
fmt.Println(err) // here String() method from ParseError is used
continue
}
fmt.Println(nums)
}
}
输出:
Parsing "1 2 3 4 5":
[1 2 3 4 5]
Parsing "100 50 25 12.5 6.25":
pkg parse: error parsing "12.5" as int
Parsing "2 + 2 = 4":
pkg parse: error parsing "+" as int
Parsing "1st class":
pkg parse: error parsing "1st" as int
Parsing "":
pkg: no words to parse5、一种用闭包处理错误的模式
每当函数返回时,我们应该检查是否有错误发生:但是这会导致重复乏味的代码。结合 defer/panic/recover 机制和闭包可以得到一个我们马上要讨论的更加优雅的模式。不过这个模式只有当所有的函数都是同一种签名时可用,这样就有相当大的限制。一个很好的使用它的例子是 web 应用,所有的处理函数都是下面这样:
func handler1(w http.ResponseWriter, r *http.Request) { ... }
假设所有的函数都有这样的签名:
func f(a type1, b type2)
参数的数量和类型是不相关的。
我们给这个类型一个名字:
fType1 = func f(a type1, b type2)
在我们的模式中使用了两个帮助函数:
1)check:这是用来检查是否有错误和 panic 发生的函数:
func check(err error) { if err != nil { panic(err) } }
2)errorhandler:这是一个包装函数。接收一个 fType1 类型的函数 fn 并返回一个调用 fn 的函数,里面就包含有 defer/recover 机制。
func errorHandler(fn fType1) fType1 {
return func(a type1, b type2) {
defer func() {
if e, ok := recover().(error); ok {
log.Printf(“run time panic: %v”, err)
}
}()
fn(a, b)
}
}
当错误发生时会 recover 并打印在日志中;除了简单的打印,应用也可以用 template 包为用户生成自定义的输出。
check() 函数会在所有的被调函数中调用,像这样:
func f1(a type1, b type2) {
...
f, _, err := // call function/method
check(err)
t, err := // call function/method
check(err)
_, err2 := // call function/method
check(err2)
...
}
通过这种机制,所有的错误都会被 recover,并且调用函数后的错误检查代码也被简化为调用 check(err) 即可。在这种模式下,不同的错误处理必须对应不同的函数类型;它们(错误处理)可能被隐藏在错误处理包内部。可选的更加通用的方式是用一个空接口类型的切片作为参数和返回值。
6、启动外部命令和程序
os 包有一个 StartProcess 函数可以调用或启动外部系统命令和二进制可执行文件;它的第一个参数是要运行的进程,第二个参数用来传递选项或参数,第三个参数是含有系统环境基本信息的结构体。
这个函数返回被启动进程的 id(pid),或者启动失败返回错误。
exec 包中也有同样功能的更简单的结构体和函数;主要是 exec.Command(name string, arg ...string) 和 Run()。首先需要用系统命令或可执行文件的名字创建一个 Command 对象,然后用这个对象作为接收者调用 Run()。下面的程序(因为是执行 Linux 命令,只能在 Linux 下面运行)演示了它们的使用:
示例 exec.go:
// exec.go
package main
import (
"fmt"
"os/exec"
"os"
)
func main() {
// 1) os.StartProcess //
/*********************/
/* Linux: */
env := os.Environ()
procAttr := &os.ProcAttr{
Env: env,
Files: []*os.File{
os.Stdin,
os.Stdout,
os.Stderr,
},
}
// 1st example: list files
pid, err := os.StartProcess("/bin/ls", []string{"ls", "-l"}, procAttr)
if err != nil {
fmt.Printf("Error %v starting process!", err) //
os.Exit(1)
}
fmt.Printf("The process id is %v", pid)
输出:
The process id is &{2054 0}total 2056
-rwxr-xr-x 1 ivo ivo 1157555 2011-07-04 16:48 Mieken_exec
-rw-r--r-- 1 ivo ivo 2124 2011-07-04 16:48 Mieken_exec.go
-rw-r--r-- 1 ivo ivo 18528 2011-07-04 16:48 Mieken_exec_go_.6
-rwxr-xr-x 1 ivo ivo 913920 2011-06-03 16:13 panic.exe
-rw-r--r-- 1 ivo ivo 180 2011-04-11 20:39 panic.go
// 2nd example: show all processes
pid, err = os.StartProcess("/bin/ps", []string{"-e", "-opid,ppid,comm"}, procAttr)
if err != nil {
fmt.Printf("Error %v starting process!", err) //
os.Exit(1)
}
fmt.Printf("The process id is %v", pid)
// 2) exec.Run //
/***************/
// Linux: OK, but not for ls ?
// cmd := exec.Command("ls", "-l") // no error, but doesn't show anything ?
// cmd := exec.Command("ls") // no error, but doesn't show anything ?
cmd := exec.Command("gedit") // this opens a gedit-window
err = cmd.Run()
if err != nil {
fmt.Printf("Error %v executing command!", err)
os.Exit(1)
}
fmt.Printf("The command is %v", cmd)
// The command is &{/bin/ls [ls -l] [] <nil> <nil> <nil> 0xf840000210 <nil> true [0xf84000ea50 0xf84000e9f0 0xf84000e9c0] [0xf84000ea50 0xf84000e9f0 0xf84000e9c0] [] [] 0xf8400128c0}
}
// in Windows: uitvoering: Error fork/exec /bin/ls: The system cannot find the path specified. starting process!7、Go中的单元测试和基准测试
首先所有的包都应该有一定的必要文档,然后同样重要的是对包的测试。
名为 testing 的包被专门用来进行自动化测试,日志和错误报告。并且还包含一些基准测试函数的功能。
备注:gotest 是 Unix bash 脚本,所以在 Windows 下你需要配置 MINGW 环境;在 Windows 环境下把所有的 pkg/linux_amd64 替换成 pkg/windows。
对一个包做(单元)测试,需要写一些可以频繁(每次更新后)执行的小块测试单元来检查代码的正确性。于是我们必须写一些 Go 源文件来测试代码。测试程序必须属于被测试的包,并且文件名满足这种形式 *_test.go,所以测试代码和包中的业务代码是分开的。
_test 程序不会被普通的 Go 编译器编译,所以当放应用部署到生产环境时它们不会被部署;只有 gotest 会编译所有的程序:普通程序和测试程序。
测试文件中必须导入 "testing" 包,并写一些名字以 TestZzz 打头的全局函数,这里的 Zzz 是被测试函数的字母描述,如 TestFmtInterface,TestPayEmployees 等。
测试函数必须有这种形式的头部:
func TestAbcde(t *testing.T)
T 是传给测试函数的结构类型,用来管理测试状态,支持格式化测试日志,如 t.Log,t.Error,t.ErrorF 等。在函数的结尾把输出跟想要的结果对比,如果不等就打印一个错误。成功的测试则直接返回。
用下面这些函数来通知测试失败:
1)func (t *T) Fail()
标记测试函数为失败,然后继续执行(剩下的测试)。
2)func (t *T) FailNow()
标记测试函数为失败并中止执行;文件中别的测试也被略过,继续执行下一个文件。
3)func (t *T) Log(args ...interface{})
args 被用默认的格式格式化并打印到错误日志中。
4)func (t *T) Fatal(args ...interface{})
结合 先执行 3),然后执行 2)的效果。
运行 go test 来编译测试程序,并执行程序中所有的 TestZZZ 函数。如果所有的测试都通过会打印出 PASS。
gotest 可以接收一个或多个函数程序作为参数,并指定一些选项。
结合 --chatty 或 -v 选项,每个执行的测试函数以及测试状态会被打印。
例如:
go test fmt_test.go --chatty
=== RUN fmt.TestFlagParser
--- PASS: fmt.TestFlagParser
=== RUN fmt.TestArrayPrinter
--- PASS: fmt.TestArrayPrinter
...
testing 包中有一些类型和函数可以用来做简单的基准测试;测试代码中必须包含以 BenchmarkZzz 打头的函数并接收一个*testing.B 类型的参数,比如:
func BenchmarkReverse(b *testing.B) {
...
}
命令 go test –test.bench=.* 会运行所有的基准测试函数;代码中的函数会被调用 N 次(N是非常大的数,如 N = 1000000),并展示 N 的值和函数执行的平均时间,单位为 ns(纳秒,ns/op)。如果是用 testing.Benchmark 调用这些函数,直接运行程序即可。
8、测试的具体例子
写了一个叫 main_oddeven.go 的程序用来测试前 100 个整数是否是偶数,这个函数属于 even 包。
下面是一种可能的方案:
示例 even_main.go:
package main
import (
"fmt"
"even/even"
)
func main() {
for i:=0; i<=100; i++ {
fmt.Printf("Is the integer %d even? %v\n", i, even.Even(i))
}
}
上面使用了 even.go 中的 even 包:
示例 even/even.go:
package even
func Even(i int) bool { // Exported function
return i%2 == 0
}
func Odd(i int) bool { // Exported function
return i%2 != 0
}
在 even 包的路径下,我们创建一个名为 oddeven_test.go 的测试程序:
package even
import "testing"
func TestEven(t *testing.T) {
if !Even(10) {
t.Log(" 10 must be even!")
t.Fail()
}
if Even(7) {
t.Log(" 7 is not even!")
t.Fail()
}
}
func TestOdd(t *testing.T) {
if !Odd(11) {
t.Log(" 11 must be odd!")
t.Fail()
}
if Odd(10) {
t.Log(" 10 is not odd!")
t.Fail()
}
}
由于测试需要具体的输入用例且不可能测试到所有的用例(非常像一个无穷的数),所以我们必须对要使用的测试用例思考再三。
至少应该包括:
- 正常的用例
- 反面的用例(错误的输入,如用负数或字母代替数字,没有输入等)
- 边界检查用例(如果参数的取值范围是 0 到 1000,检查 0 和 1000 的情况)
可以直接执行 go install 安装 even 或者创建一个 以下内容的 Makefile:
include $(GOROOT)/src/Make.inc
TARG=even
GOFILES=\
even.go\
include $(GOROOT)/src/Make.pkg
然后执行 make(或 gomake)命令来构建归档文件 even.a
测试代码不能在 GOFILES 参数中引用,因为我们不希望生成的程序中有测试代码。如果包含了测试代码,go test 会给出错误提示!go test 会生成一个单独的包含测试代码的 _test 程序。
现在我们可以用命令:go test(或 make test)来测试 even 包。
为了看到失败时的输出,把函数 TestEven 改为:
func TestEven(t *testing.T) {
if Even(10) {
t.Log(“Everything OK: 10 is even, just a test to see failed output!”)
t.Fail()
}
}
现在会调用 t.Log 和 t.Fail,得到的结果如下:
--- FAIL: even.TestEven (0.00 seconds)
Everything OK: 10 is even, just a test to see failed output!
FAIL9、用(测试数据)表驱动测试
编写测试代码时,一个较好的办法是把测试的输入数据和期望的结果写在一起组成一个数据表:表中的每条记录都是一个含有输入和期望值的完整测试用例,有时还可以结合像测试名字这样的额外信息来让测试输出更多的信息。
实际测试时简单迭代表中的每条记录,并执行必要的测试。
可以抽象为下面的代码段:
var tests = []struct{ // Test table
in string
out string
}{
{“in1”, “exp1”},
{“in2”, “exp2”},
{“in3”, “exp3”},
...
}
func TestFunction(t *testing.T) {
for i, tt := range tests {
s := FuncToBeTested(tt.in)
if s != tt.out {
t.Errorf(“%d. %q => %q, wanted: %q”, i, tt.in, s, tt.out)
}
}
}
如果大部分函数都可以写成这种形式,那么写一个帮助函数 verify 对实际测试会很有帮助:
func verify(t *testing.T, testnum int, testcase, input, output, expected string) {
if input != output {
t.Errorf(“%d. %s with input = %s: output %s != %s”, testnum, testcase, input, output, expected)
}
}
TestFunction 则变为:
func TestFunction(t *testing.T) {
for i, tt := range tests {
s := FuncToBeTested(tt.in)
verify(t, i, “FuncToBeTested: “, tt.in, s, tt.out)
}
} 10、单元测试
测试函数:函数名前缀为Test,测试程序的一些逻辑行为是否正确。
基准函数:函数名前缀为Benchmark,测试函数的性能
示例函数:函数名前缀为Example,为文档提供示例文档。go test命令会遍历所有的*_test.go文件中符合上述命名规则的函数,并生成一个临时的main包用于调用相应的测试函数,然后构建并运行、报告测试结果,最后清理测试中生成的临时文件。
func TestSplit(t *testing.T) { // 测试函数名必须以Test开头,必须接收一个*testing.T类型参数
got := Split("a:b:c", ":") // 程序输出的结果
want := []string{"a", "b", "c"} // 期望的结果
if !reflect.DeepEqual(want, got) { // 因为slice不能比较直接,借助反射包中的方法比较
t.Errorf("expected:%v, got:%v", want, got) // 测试失败输出错误提示
}
}
func TestMoreSplit(t *testing.T) {
got := Split("abcd", "bc")
want := []string{"a", "d"}
if !reflect.DeepEqual(want, got) {
t.Errorf("expected:%v, got:%v", want, got)
}
}
go test // 执行 test文件
go test -v // 查看测试函数名称和运行时间
go test -v -run="more" //-run参数对应正则表达式。 11、性能调试:分析并优化 Go 程序
可以用这个便捷脚本 xtime 来测量:
#!/bin/sh
/usr/bin/time -f ‘%Uu %Ss %er %MkB %C’ “$@”
在 Unix 命令行中像这样使用 xtime goprogexec,这里的 progexec 是一个 Go 可执行程序,这句命令行输出类似:56.63u 0.26s 56.92r 1642640kB progexec,分别对应用户时间,系统时间,实际时间和最大内存占用。
如果代码使用了 Go 中 testing 包的基准测试功能,我们可以用 gotest 标准的 -cpuprofile 和 -memprofile 标志向指定文件写入 CPU 或 内存使用情况报告。
使用方式:go test -x -v -cpuprofile=prof.out -file x_test.go
编译执行 x_test.go 中的测试,并向 prof.out 文件中写入 cpu 性能分析信息。
你可以在单机程序 progexec 中引入 runtime/pprof 包;这个包以 pprof 可视化工具需要的格式写入运行时报告数据。对于 CPU 性能分析来说你需要添加一些代码:
var cpuprofile = flag.String(“cpuprofile”, “”, “write cpu profile to file”)
func main() {
flag.Parse()
if *cpuprofile != “” {
f, err := os.Create(*cpuprofile)
if err != nil {
log.Fatal(err)
}
pprof.StartCPUProfile(f)
defer pprof.StopCPUProfile()
}
...
代码定义了一个名为 cpuprofile 的 flag,调用 Go flag 库来解析命令行 flag,如果命令行设置了 cpuprofile flag,则开始 CPU 性能分析并把结果重定向到那个文件。(os.Create 用拿到的名字创建了用来写入分析数据的文件)。这个分析程序最后需要在程序退出之前调用 StopCPUProfile 来刷新挂起的写操作到文件中;我们用 defer 来保证这一切会在 main 返回时触发。
现在用这个 flag 运行程序:progexec -cpuprofile=progexec.prof
然后可以像这样用 gopprof 工具:gopprof progexec progexec.prof
gopprof 程序是 Google pprofC++ 分析器的一个轻微变种;关于此工具更多的信息,参见http://code.google.com/p/google-perftools/。
如果开启了 CPU 性能分析,Go 程序会以大约每秒 100 次的频率阻塞,并记录当前执行的 goroutine 栈上的程序计数器样本。
此工具一些有趣的命令:
1)topN
用来展示分析结果中最开头的 N 份样本,例如:top5 它会展示在程序运行期间调用最频繁的 5 个函数,输出如下:
Total: 3099 samples
626 20.2% 20.2% 626 20.2% scanblock
309 10.0% 30.2% 2839 91.6% main.FindLoops
...
第 5 列表示函数的调用频度。
2)web 或 web 函数名
该命令生成一份 SVG 格式的分析数据图表,并在网络浏览器中打开它(还有一个 gv 命令可以生成 PostScript 格式的数据,并在 GhostView 中打开,这个命令需要安装 graphviz)。函数被表示成不同的矩形(被调用越多,矩形越大),箭头指示函数调用链。
3)list 函数名 或 weblist 函数名
展示对应函数名的代码行列表,第 2 列表示当前行执行消耗的时间,这样就很好地指出了运行过程
中消耗最大的代码。
如果发现函数 runtime.mallocgc(分配内存并执行周期性的垃圾回收)调用频繁,那么是应该进行内存分析的时候了。找出垃圾回收频繁执行的原因,和内存大量分配的根源。
为了做到这一点必须在合适的地方添加下面的代码:
var memprofile = flag.String(“memprofile”, “”, “write memory profile to this file”)
...
CallToFunctionWhichAllocatesLotsOfMemory()
if *memprofile != “” {
f, err := os.Create(*memprofile)
if err != nil {
log.Fatal(err)
}
pprof.WriteHeapProfile(f)
f.Close()
return
}
用 -memprofile flag 运行这个程序:progexec -memprofile=progexec.mprof
然后你可以像这样再次使用 gopprof 工具:gopprof progexec progexec.mprof
top5,list 函数名 等命令同样适用,只不过现在是以 Mb 为单位测量内存分配情况,这是 top 命令输出的例子:
Total: 118.3 MB
66.1 55.8% 55.8% 103.7 87.7% main.FindLoops
30.5 25.8% 81.6% 30.5 25.8% main.*LSG·NewLoop
...
从第 1 列可以看出,最上面的函数占用了最多的内存。
同样有一个报告内存分配计数的有趣工具:
gopprof --inuse_objects progexec progexec.mprof
对于 web 应用来说,有标准的 HTTP 接口可以分析数据。在 HTTP 服务中添加
import _ “http/pprof”
会为 /debug/pprof/ 下的一些 URL 安装处理器。然后你可以用一个唯一的参数——你服务中的分析数据的 URL 来执行 gopprof 命令——它会下载并执行在线分析。
gopprof http://localhost:6060/debug/pprof/profile # 30-second CPU profile
gopprof http://localhost:6060/debug/pprof/heap # heap profile
三、并发编程
作为一门 21 世纪的语言,Go 原生支持应用之间的通信(网络,客户端和服务端,分布式计算)和程序的并发。程序可以在不同的处理器和计算机上同时执行不同的代码段。Go 语言为构建并发程序的基本代码块是 协程 (goroutine) 与通道 (channel)。他们需要语言,编译器,和runtime的支持。Go 语言提供的垃圾回收器对并发编程至关重要。
不要通过共享内存来通信,而通过通信来共享内存。
通信强制协作。
1、并发、并行和协程
1)什么是协程
一个应用程序是运行在机器上的一个进程;进程是一个运行在自己内存地址空间里的独立执行体。一个进程由一个或多个操作系统线程组成,这些线程其实是共享同一个内存地址空间的一起工作的执行体。几乎所有'正式'的程序都是多线程的,以便让用户或计算机不必等待,或者能够同时服务多个请求(如 Web 服务器),或增加性能和吞吐量(例如,通过对不同的数据集并行执行代码)。一个并发程序可以在一个处理器或者内核上使用多个线程来执行任务,但是只有同一个程序在某个时间点同时运行在多核或者多处理器上才是真正的并行。
并行是一种通过使用多处理器以提高速度的能力。所以并发程序可以是并行的,也可以不是。
公认的,使用多线程的应用难以做到准确,最主要的问题是内存中的数据共享,它们会被多线程以无法预知的方式进行操作,导致一些无法重现或者随机的结果(称作 竞态)。
不要使用全局变量或者共享内存,它们会给你的代码在并发运算的时候带来危险。
解决之道在于同步不同的线程,对数据加锁,这样同时就只有一个线程可以变更数据。在 Go 的标准库 sync 中有一些工具用来在低级别的代码中实现加锁。不过过去的软件开发经验告诉我们这会带来更高的复杂度,更容易使代码出错以及更低的性能,所以这个经典的方法明显不再适合现代多核/多处理器编程:thread-per-connection 模型不够有效。
Go 更倾向于其他的方式,在诸多比较合适的范式中,有个被称作 Communicating Sequential Processes(顺序通信处理)(CSP, C. Hoare 发明的)还有一个叫做 message passing-model(消息传递)(已经运用在了其他语言中,比如 Erlang)。
在 Go 中,应用程序并发处理的部分被称作 goroutines(协程),它可以进行更有效的并发运算。在协程和操作系统线程之间并无一对一的关系:协程是根据一个或多个线程的可用性,映射(多路复用,执行于)在他们之上的;协程调度器在 Go 运行时很好的完成了这个工作。
协程工作在相同的地址空间中,所以共享内存的方式一定是同步的;这个可以使用 sync 包来实现,不过我们很不鼓励这样做:Go 使用 channels 来同步协程。
当系统调用(比如等待 I/O)阻塞协程时,其他协程会继续在其他线程上工作。协程的设计隐藏了许多线程创建和管理方面的复杂工作。
协程是轻量的,比线程更轻。它们痕迹非常不明显(使用少量的内存和资源):使用 4K 的栈内存就可以在堆中创建它们。因为创建非常廉价,必要的时候可以轻松创建并运行大量的协程(在同一个地址空间中 100,000 个连续的协程)。并且它们对栈进行了分割,从而动态的增加(或缩减)内存的使用;栈的管理是自动的,但不是由垃圾回收器管理的,而是在协程退出后自动释放。
协程可以运行在多个操作系统线程之间,也可以运行在线程之内,让你可以很小的内存占用就可以处理大量的任务。由于操作系统线程上的协程时间片,你可以使用少量的操作系统线程就能拥有任意多个提供服务的协程,而且 Go 运行时可以聪明的意识到哪些协程被阻塞了,暂时搁置它们并处理其他协程。
存在两种并发方式:确定性的(明确定义排序)和非确定性的(加锁/互斥从而未定义排序)。Go 的协程和通道理所当然的支持确定性的并发方式(例如通道具有一个 sender 和一个 receiver)。
协程是通过使用关键字 go 调用(执行)一个函数或者方法来实现的(也可以是匿名或者 lambda 函数)。这样会在当前的计算过程中开始一个同时进行的函数,在相同的地址空间中并且分配了独立的栈,比如:go sum(bigArray),在后台计算总和。
协程的栈会根据需要进行伸缩,不出现栈溢出;开发者不需要关心栈的大小。当协程结束的时候,它会静默退出:用来启动这个协程的函数不会得到任何的返回值。
任何 Go 程序都必须有的 main() 函数也可以看做是一个协程,尽管它并没有通过 go 来启动。协程可以在程序初始化的过程中运行(在 init() 函数中)。
在一个协程中,比如它需要进行非常密集的运算,你可以在运算循环中周期的使用 runtime.Gosched():这会让出处理器,允许运行其他协程;它并不会使当前协程挂起,所以它会自动恢复执行。使用 Gosched() 可以使计算均匀分布,使通信不至于迟迟得不到响应。
Go 的并发原语提供了良好的并发设计基础:表达程序结构以便表示独立地执行的动作;所以Go的的重点不在于并行的首要位置:并发程序可能是并行的,也可能不是。并行是一种通过使用多处理器以提高速度的能力。但往往是,一个设计良好的并发程序在并行方面的表现也非常出色。
在当前的运行时(2012 年一月)实现中,Go 默认没有并行指令,只有一个独立的核心或处理器被专门用于 Go 程序,不论它启动了多少个协程;所以这些协程是并发运行的,但他们不是并行运行的:同一时间只有一个协程会处在运行状态。
这个情况在以后可能会发生改变,不过届时,为了使你的程序可以使用多个核心运行,这时协程就真正的是并行运行了,你必须使用 GOMAXPROCS 变量。
这会告诉运行时有多少个协程同时执行。
并且只有 gc 编译器真正实现了协程,适当的把协程映射到操作系统线程。使用 gccgo 编译器,会为每一个协程创建操作系统线程。
在 gc 编译器下(6g 或者 8g)你必须设置 GOMAXPROCS 为一个大于默认值 1 的数值来允许运行时支持使用多于 1 个的操作系统线程,所有的协程都会共享同一个线程除非将 GOMAXPROCS 设置为一个大于 1 的数。当 GOMAXPROCS 大于 1 时,会有一个线程池管理许多的线程。通过 gccgo 编译器 GOMAXPROCS 有效的与运行中的协程数量相等。假设 n 是机器上处理器或者核心的数量。如果你设置环境变量 GOMAXPROCS>=n,或者执行 runtime.GOMAXPROCS(n),接下来协程会被分割(分散)到 n 个处理器上。更多的处理器并不意味着性能的线性提升。有这样一个经验法则,对于 n 个核心的情况设置 GOMAXPROCS 为 n-1 以获得最佳性能,也同样需要遵守这条规则:协程的数量 > 1 + GOMAXPROCS > 1。
所以如果在某一时间只有一个协程在执行,不要设置 GOMAXPROCS!
还有一些通过实验观察到的现象:在一台 1 颗 CPU 的笔记本电脑上,增加 GOMAXPROCS 到 9 会带来性能提升。在一台 32 核的机器上,设置 GOMAXPROCS=8 会达到最好的性能,在测试环境中,更高的数值无法提升性能。如果设置一个很大的 GOMAXPROCS 只会带来轻微的性能下降;设置 GOMAXPROCS=100,使用 top 命令和 H 选项查看到只有 7 个活动的线程。
增加 GOMAXPROCS 的数值对程序进行并发计算是有好处的;
总结:GOMAXPROCS 等同于(并发的)线程数量,在一台核心数多于1个的机器上,会尽可能有等同于核心数的线程在并行运行。
使用 flags 包,如下:
var numCores = flag.Int("n", 2, "number of CPU cores to use")
in main()
flag.Pars()
runtime.GOMAXPROCS(*numCores)
协程可以通过调用runtime.Goexit()来停止,尽管这样做几乎没有必要。
示例 -goroutine1.go 介绍了概念:
package main
import (
"fmt"
"time"
)
func main() {
fmt.Println("In main()")
go longWait()
go shortWait()
fmt.Println("About to sleep in main()")
// sleep works with a Duration in nanoseconds (ns) !
time.Sleep(10 * 1e9)
fmt.Println("At the end of main()")
}
func longWait() {
fmt.Println("Beginning longWait()")
time.Sleep(5 * 1e9) // sleep for 5 seconds
fmt.Println("End of longWait()")
}
func shortWait() {
fmt.Println("Beginning shortWait()")
time.Sleep(2 * 1e9) // sleep for 2 seconds
fmt.Println("End of shortWait()")
}
输出:
In main()
About to sleep in main()
Beginning longWait()
Beginning shortWait()
End of shortWait()
End of longWait()
At the end of main() // after 10s
main(),longWait() 和 shortWait() 三个函数作为独立的处理单元按顺序启动,然后开始并行运行。每一个函数都在运行的开始和结束阶段输出了消息。为了模拟他们运算的时间消耗,我们使用了 time 包中的 Sleep 函数。Sleep() 可以按照指定的时间来暂停函数或协程的执行,这里使用了纳秒(ns,符号 1e9 表示 1 乘 10 的 9 次方,e=指数)。
他们按照我们期望的顺序打印出了消息,几乎都一样,可是我们明白这是模拟出来的,以并行的方式。我们让 main() 函数暂停 10 秒从而确定它会在另外两个协程之后结束。如果不这样(如果我们让 main() 函数停止 4 秒),main() 会提前结束,longWait() 则无法完成。如果我们不在 main() 中等待,协程会随着程序的结束而消亡。
当 main() 函数返回的时候,程序退出:它不会等待任何其他非 main 协程的结束。这就是为什么在服务器程序中,每一个请求都会启动一个协程来处理,server() 函数必须保持运行状态。通常使用一个无限循环来达到这样的目的。
另外,协程是独立的处理单元,一旦陆续启动一些协程,你无法确定他们是什么时候真正开始执行的。你的代码逻辑必须独立于协程调用的顺序。
为了对比使用一个线程,连续调用的情况,移除 go 关键字,重新运行程序。
现在输出:
In main()
Beginning longWait()
End of longWait()
Beginning shortWait()
End of shortWait()
About to sleep in main()
At the end of main() // after 17 s
协程更有用的一个例子应该是在一个非常长的数组中查找一个元素。
将数组分割为若干个不重复的切片,然后给每一个切片启动一个协程进行查找计算。这样许多并行的协程可以用来进行查找任务,整体的查找时间会缩短(除以协程的数量)。
5)Go 协程(goroutines)和协程(coroutines)
(译者注:标题中的“Go协程(goroutines)” 协程指的是 Go 语言中的协程。而“协程(coroutines)”指的是其他语言中的协程概念,仅在本节出现。)
在其他语言中,比如 C#,Lua 或者 Python 都有协程的概念。这个名字表明它和 Go协程有些相似,不过有两点不同:
- Go 协程意味着并行(或者可以以并行的方式部署),协程一般来说不是这样的
- Go 协程通过通道来通信;协程通过让出和恢复操作来通信
Go 协程比协程更强大,也很容易从协程的逻辑复用到 Go 协程。
2、GMP原理
1)协程和线程
协程跟线程是有区别的,线程由CPU调度是抢占式的,协程由用户态调度是协作式的,一个协程让出CPU后,才执行下一个协程。
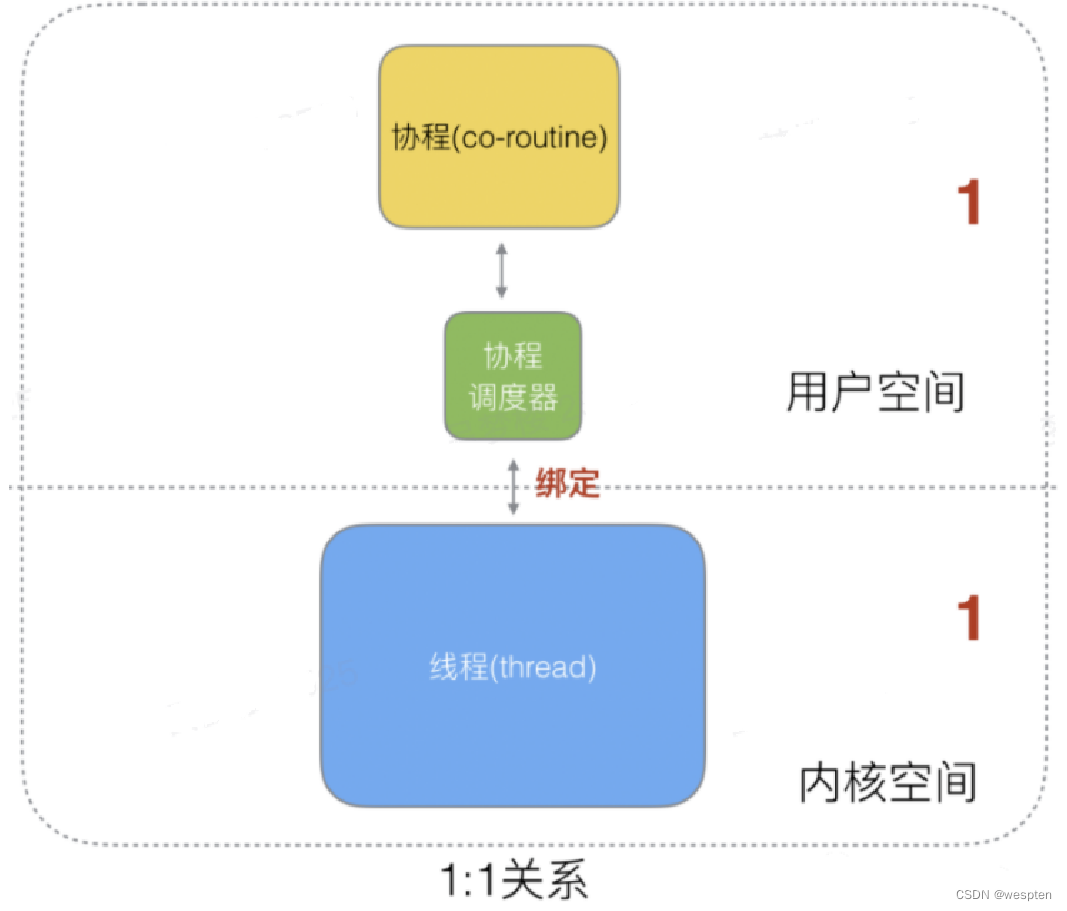
1:1关系
-
优点:1个协程绑定1个线程,这种最容易实现,协程的调度都由CPU完成了。
-
缺点:协程的创建、删除和切换的代价都由CPU完成,有点略显昂贵了。
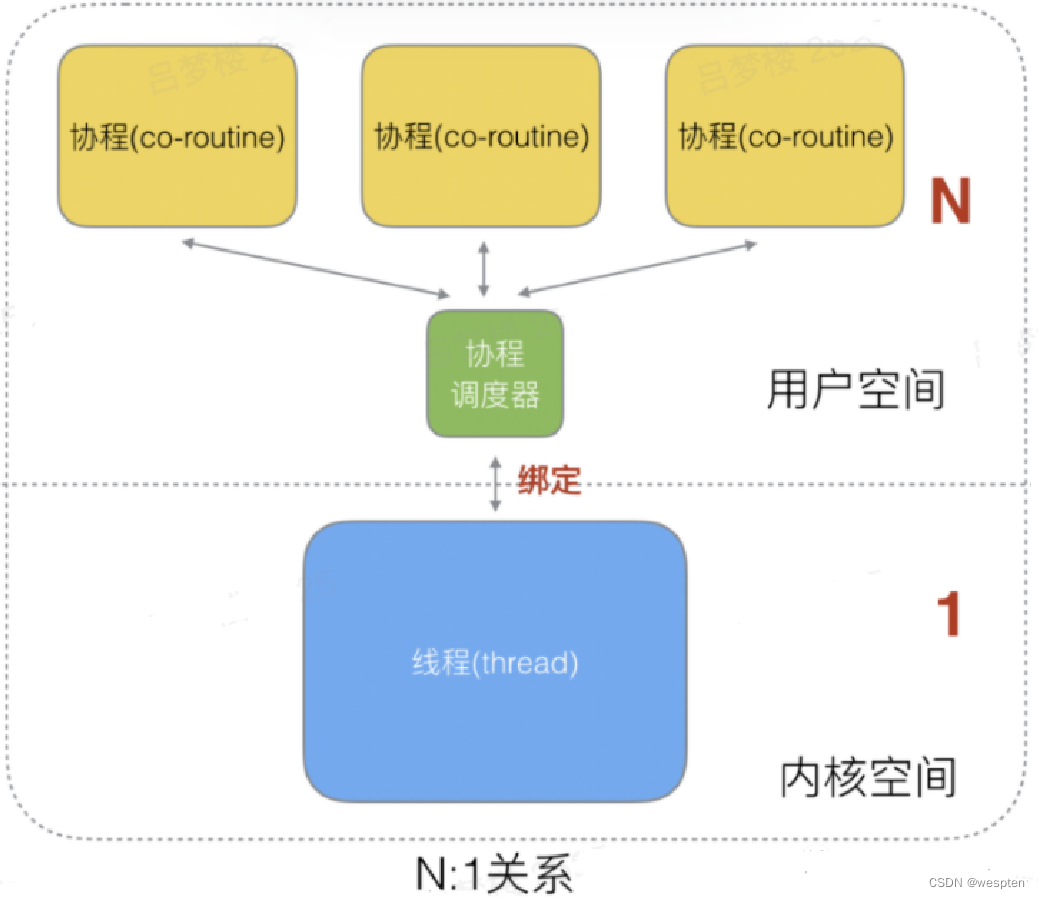
N:1关系
-
优点:N个协程绑定1个线程,协程在用户态线程即完成切换,不会陷入到内核态,这种切换非常的轻量快速。
-
缺点:1个进程的所有协程都绑定在1个线程上,某个程序用不了硬件的多核加速能力,一旦某协程阻塞,造成线程阻塞,本进程的其他协程都无法执行了,根本就没有并发的能力了。
M:N关系
-
优点:M个协程绑定1个线程,是N:1和1:1类型的结合,克服了以上2种模型的缺点。
-
缺点:实现起来最为复杂。

2)GMP模型
Go为了提供更容易使用的并发方法,使用了goroutine和channel。goroutine来自协程的概念,让一组可复用的函数运行在一组线程之上,即使有协程阻塞,该线程的其他协程也可以被runtime调度,转移到其他可运行的线程上。最关键的是,程序员看不到这些底层的细节,这就降低了编程的难度,提供了更容易的并发。
goroutine非常轻量,一个goroutine只占几KB,并且这几KB就足够goroutine运行完,这就能在有限的内存空间内支持大量goroutine,支持了更多的并发。虽然一个goroutine的栈只占几KB,但实际是可伸缩的,如果需要更多内容,runtime会自动为goroutine分配。
模型说明
G来表示Goroutine,M来表示线程,P来表示Processor:
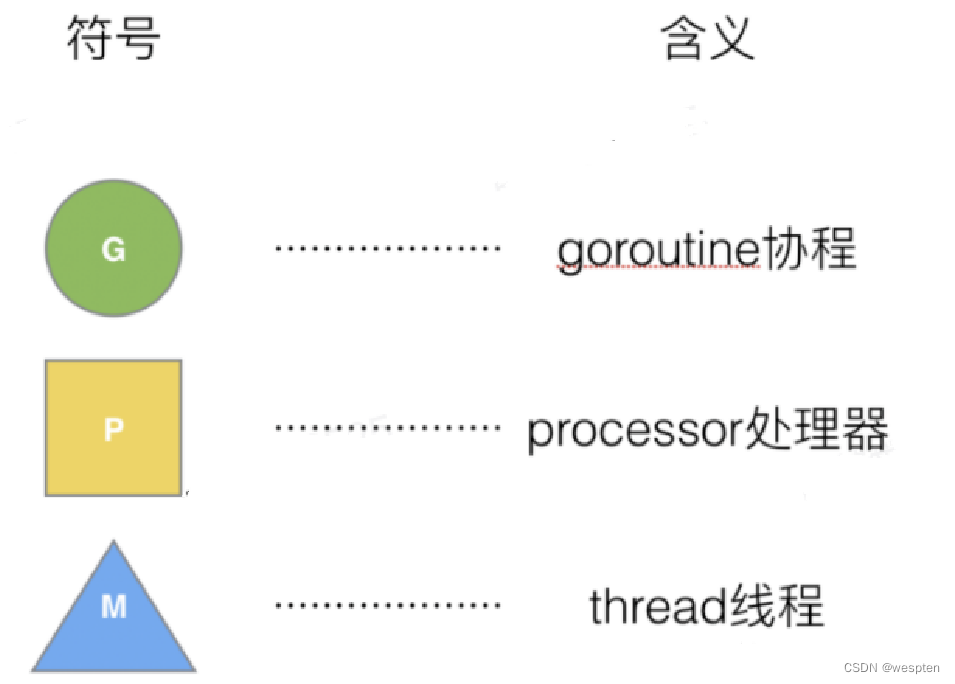
线程是运行goroutine的实体,调度器的功能是把可运行的goroutine分配到工作线程上:

Goroutine调度器和OS调度器是通过M结合起来的,每个M都代表了1个内核线程,OS调度器负责把内核线程分配到CPU的核上执行,对上图的解读如下:
-
全局队列(Global Queue):存放等待运行的G。
-
P的本地队列:同全局队列类似,存放的也是等待运行的G,存的数量有限,不超过256个。新建G'时,G'优先加入到P的本地队列,如果队列满了,则会把本地队列中一半的G移动到全局队列。
-
P列表:所有的P都在程序启动时创建,并保存在数组中,最多有GOMAXPROCS(可配置)个。
-
M:线程想运行任务就得获取P,从P的本地队列获取G,P队列为空时,M也会尝试从全局队列拿一批G放到P的本地队列,或从其他P的本地队列偷一半放到自己P的本地队列。M运行G,G执行之后,M会从P获取下一个G,不断重复下去。
调度流程
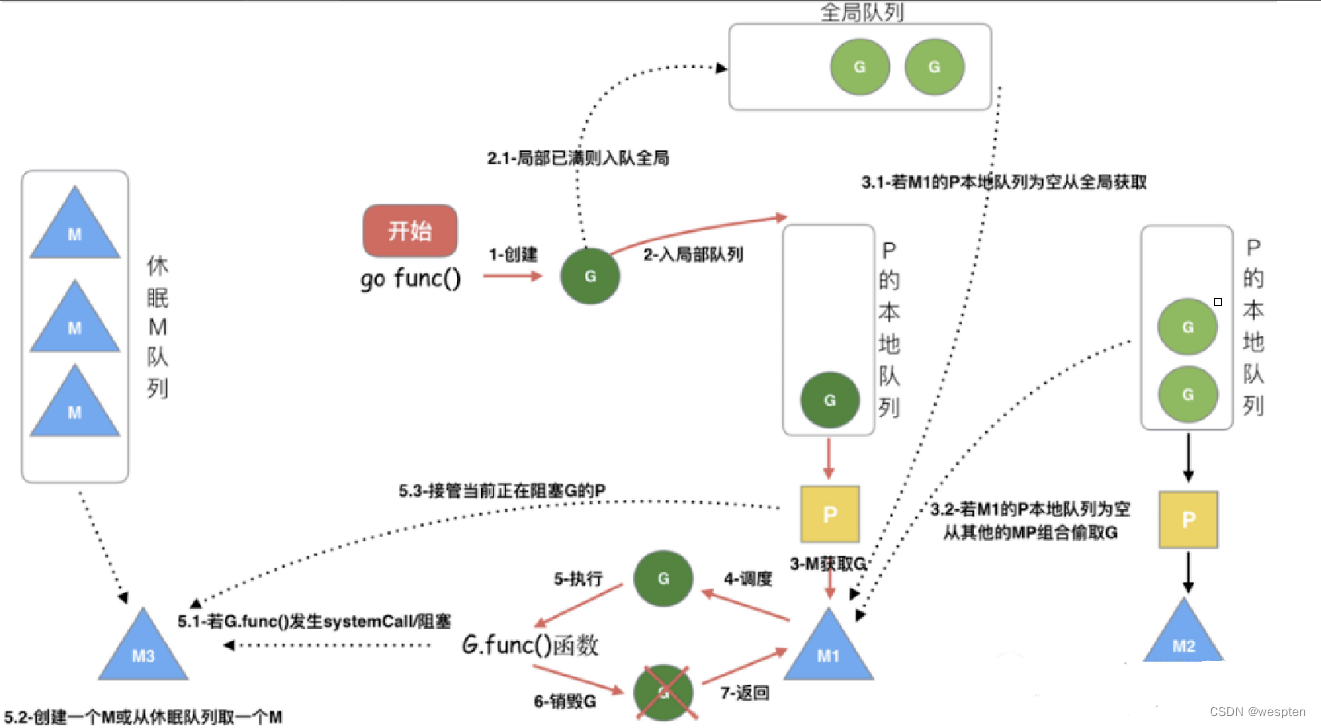
从上图我们可以分析出几个结论:
-
我们通过 go func()来创建一个goroutine;
-
有两个存储G的队列,一个是局部调度器P的本地队列、一个是全局G队列。新创建的G会先保存在P的本地队列中,如果P的本地队列已经满了就会保存在全局的队列中;
-
G只能运行在M中,一个M必须持有一个P,M与P是1:1的关系。M会从P的本地队列弹出一个可执行状态的G来执行,如果P的本地队列为空,就会想其他的MP组合偷取一个可执行的G来执行;
-
一个M调度G执行的过程是一个循环机制;
-
当M执行某一个G时候如果发生了syscall或则其余阻塞操作,M会阻塞,如果当前有一些G在执行,runtime会把这个线程M从P中摘除(detach),然后再创建一个新的操作系统的线程(如果有空闲的线程可用就复用空闲线程)来服务于这个P;
-
当M系统调用结束时候,这个G会尝试获取一个空闲的P执行,并放入到这个P的本地队列。如果获取不到P,那么这个线程M变成休眠状态, 加入到空闲线程中,然后这个G会被放入全局队列中。
3、使用通道进行协程间通信
1)通道定义
协程是独立执行的,他们之间没有通信。他们必须通信才会变得更有用:彼此之间发送和接收信息并且协调/同步他们的工作。协程可以使用共享变量来通信,但是很不提倡这样做,因为这种方式给所有的共享内存的多线程都带来了困难。
而Go有一个特殊的类型,通道(channel),像是通道(管道),可以通过它们发送类型化的数据在协程之间通信,可以避开所有内存共享导致的坑;通道的通信方式保证了同步性。数据通过通道:同一时间只有一个协程可以访问数据:所以不会出现数据竞争,设计如此。数据的归属(可以读写数据的能力)被传递。
工厂的传送带是个很有用的例子。一个机器(生产者协程)在传送带上放置物品,另外一个机器(消费者协程)拿到物品并打包。
通道服务于通信的两个目的:值的交换,同步的,保证了两个计算(协程)任何时候都是可知状态。
通常使用这样的格式来声明通道:var identifier chan datatype
未初始化的通道的值是nil。
所以通道只能传输一种类型的数据,比如 chan int 或者 chan string,所有的类型都可以用于通道,空接口 interface{} 也可以。甚至可以(有时非常有用)创建通道的通道。
通道实际上是类型化消息的队列:使数据得以传输。它是先进先出(FIFO)结构的所以可以保证发送给他们的元素的顺序(有些人知道,通道可以比作 Unix shells 中的双向管道(tw-way pipe))。通道也是引用类型,所以我们使用 make() 函数来给它分配内存。这里先声明了一个字符串通道 ch1,然后创建了它(实例化):
var ch1 chan string
ch1 = make(chan string)
当然可以更短: ch1 := make(chan string)。
这里我们构建一个int通道的通道: chanOfChans := make(chan int)。
或者函数通道:funcChan := chan func()。
所以通道是对象的第一类型:可以存储在变量中,作为函数的参数传递,从函数返回以及通过通道发送它们自身。另外它们是类型化的,允许类型检查,比如尝试使用整数通道发送一个指针。
下面是创建几种不同的通道:
ch1 := make(chan int) // 无缓冲通道
ch2 := make(chan int, 3) // 有缓冲通道
ch3 := make(chan<- int, 1) // 单向通道:只能发送不能接收
ch4 := make(<-chan int, 1) // 单向通道:只能接收不能发送下面举一个简单的示例:
func main() {
done := make(chan struct{})
c := make(chan string)
go func() {
s := <-c // 接收消息
println(s)
close(done) // 关闭通道,作为结束通知
}()
c <- "lvmenglou" // 发送消息
<-done // 阻塞,知道有数据或者通道关闭
}
//最后输出:lvmenglou通道发送和接收操作基本特性:
-
元素复制:进入通道的并不是在接收操作符右边的那个元素值,而是它的副本(发送操作包括“复制元素值”和“放入通道”2步,接收操作包括“复制通道内的元素值”、“放置副本到接收方”和“删掉原值”3步);
-
不可分割:一个数据进入通道时,不会存在还没有复制完毕,就被接收的情况;
这个操作符直观的标示了数据的传输:信息按照箭头的方向流动。
流向通道(发送)
ch <- int1 表示:用通道 ch 发送变量 int1(双目运算符,中缀 = 发送)
从通道流出(接收),三种方式:
int2 = <- ch 表示:变量 int2 从通道 ch(一元运算的前缀操作符,前缀 = 接收)接收数据(获取新值);假设 int2 已经声明过了,如果没有的话可以写成:int2 := <- ch。
<- ch 可以单独调用获取通道的(下一个)值,当前值会被丢弃,但是可以用来验证,所以以下代码是合法的:
if <- ch != 1000{
...
}
操作符 <- 也被用来发送和接收,Go 尽管不必要,为了可读性,通道的命名通常以 ch 开头或者包含 chan。通道的发送和接收操作都是自动的:它们通常一气呵成。下面的示例展示了通信操作。
示例 -goroutine2.go
package main
import (
"fmt"
"time"
)
func main() {
ch := make(chan string)
go sendData(ch)
go getData(ch)
time.Sleep(1e9)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
}
func getData(ch chan string) {
var input string
// time.Sleep(1e9)
for {
input = <-ch
fmt.Printf("%s ", input)
}
}
输出:
Washington Tripoli London Beijing Tokio
main() 函数中启动了两个协程:sendData() 通过通道 ch 发送了 5 个字符串,getData() 按顺序接收它们并打印出来。
如果2个协程需要通信,你必须给他们同一个通道作为参数才行。
尝试一下如果注释掉 time.Sleep(1e9) 会如何。
我们发现协程之间的同步非常重要:
- main() 等待了 1 秒让两个协程完成,如果不这样,sendData() 就没有机会输出。
- getData() 使用了无限循环:它随着 sendData() 的发送完成和 ch 变空也结束了。
- 如果我们移除一个或所有
go关键字,程序无法运行,Go 运行时会抛出 panic:
---- Error run E:/Go/Goboek/code examples/chapter 14/goroutine2.exe with code Crashed ---- Program exited with code -2147483645: panic: all goroutines are asleep-deadlock!
为什么会这样?运行时会检查所有的协程(也许只有一个是这种情况)是否在等待(可以读取或者写入某个通道),意味着程序无法处理。这是死锁(deadlock)形式,运行时可以检测到这种情况。
注意:不要使用打印状态来表明通道的发送和接收顺序:由于打印状态和通道实际发生读写的时间延迟会导致和真实发生的顺序不同。
默认情况下,通信是同步且无缓冲的:在有接受者接收数据之前,发送不会结束。可以想象一个无缓冲的通道在没有空间来保存数据的时候:必须要一个接收者准备好接收通道的数据然后发送者可以直接把数据发送给接收者。所以通道的发送/接收操作在对方准备好之前是阻塞的:
1)对于同一个通道,发送操作(协程或者函数中的),在接收者准备好之前是阻塞的:如果ch中的数据无人接收,就无法再给通道传入其他数据:新的输入无法在通道非空的情况下传入。所以发送操作会等待 ch 再次变为可用状态:就是通道值被接收时(可以传入变量)。
2)对于同一个通道,接收操作是阻塞的(协程或函数中的),直到发送者可用:如果通道中没有数据,接收者就阻塞了。
尽管这看上去是非常严格的约束,实际在大部分情况下工作的很不错。
程序 channel_block.go 验证了以上理论,一个协程在无限循环中给通道发送整数数据。不过因为没有接收者,只输出了一个数字 0。
示例 -channel_block.go
package main
import "fmt"
func main() {
ch1 := make(chan int)
go pump(ch1) // pump hangs
fmt.Println(<-ch1) // prints only 0
}
func pump(ch chan int) {
for i := 0; ; i++ {
ch <- i
}
}
输出:
0
pump() 函数为通道提供数值,也被叫做生产者。
为通道解除阻塞定义了 suck 函数来在无限循环中读取通道,参见示例 -channel_block2.go:
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
在 main() 中使用协程开始它:
go pump(ch1)
go suck(ch1)
time.Sleep(1e9)
给程序 1 秒的时间来运行:输出了上万个整数。
通信是一种同步形式:通过通道,两个协程在通信(协程会和)中某刻同步交换数据。无缓冲通道成为了多个协程同步的完美工具。
甚至可以在通道两端互相阻塞对方,形成了叫做死锁的状态。Go 运行时会检查并 panic,停止程序。死锁几乎完全是由糟糕的设计导致的。
无缓冲通道会被阻塞。设计无阻塞的程序可以避免这种情况,或者使用带缓冲的通道。
练习 blocking.go
解释为什么下边这个程序会导致 panic:所有的协程都休眠了 - 死锁!
package main
import (
"fmt"
)
func f1(in chan int) {
fmt.Println(<-in)
}
func main() {
out := make(chan int)
out <- 2
go f1(out)
}
一个无缓冲通道只能包含 1 个元素,有时显得很局限。我们给通道提供了一个缓存,可以在扩展的 make 命令中设置它的容量,如下:
buf := 100
ch1 := make(chan string, buf)
buf 是通道可以同时容纳的元素(这里是 string)个数
在缓冲满载(缓冲被全部使用)之前,给一个带缓冲的通道发送数据是不会阻塞的,而从通道读取数据也不会阻塞,直到缓冲空了。
缓冲容量和类型无关,所以可以(尽管可能导致危险)给一些通道设置不同的容量,只要他们拥有同样的元素类型。内置的cap 函数可以返回缓冲区的容量。
如果容量大于 0,通道就是异步的了:缓冲满载(发送)或变空(接收)之前通信不会阻塞,元素会按照发送的顺序被接收。如果容量是0或者未设置,通信仅在收发双方准备好的情况下才可以成功。
同步:ch :=make(chan type, value)
- value == 0 -> synchronous, unbuffered (阻塞)
- value > 0 -> asynchronous, buffered(非阻塞)取决于value元素
若使用通道的缓冲,你的程序会在“请求”激增的时候表现更好:更具弹性,专业术语叫:更具有伸缩性(scalable)。要在首要位置使用无缓冲通道来设计算法,只在不确定的情况下使用缓冲。
为了知道计算何时完成,可以通过信道回报。在例子 go sum(bigArray) 中,要这样写:
ch := make(chan int)
go sum(bigArray, ch) // bigArray puts the calculated sum on ch
// .. do something else for a while
sum := <- ch // wait for, and retrieve the sum
也可以使用通道来达到同步的目的,这个很有效的用法在传统计算机中称为信号量(semaphore)。或者换个方式:通过通道发送信号告知处理已经完成(在协程中)。
在其他协程运行时让 main 程序无限阻塞的通常做法是在 main 函数的最后放置一个{}。
也可以使用通道让 main 程序等待协程完成,就是所谓的信号量模式,我们会在接下来的部分讨论。
下边的片段阐明:协程通过在通道 ch 中放置一个值来处理结束的信号。main 协程等待 <-ch 直到从中获取到值。
我们期望从这个通道中获取返回的结果,像这样:
func compute(ch chan int){
ch <- someComputation() // when it completes, signal on the channel.
}
func main(){
ch := make(chan int) // allocate a channel.
go compute(ch) // stat something in a goroutines
doSomethingElseForAWhile()
result := <- ch
}
这个信号也可以是其他的,不返回结果,比如下面这个协程中的匿名函数(lambda)协程:
ch := make(chan int)
go func(){
// doSomething
ch <- 1 // Send a signal; value does not matter
}
doSomethingElseForAWhile()
<- ch // Wait for goroutine to finish; discard sent value.
或者等待两个协程完成,每一个都会对切片s的一部分进行排序,片段如下:
done := make(chan bool)
// doSort is a lambda function, so a closure which knows the channel done:
doSort := func(s []int){
sort(s)
done <- true
}
i := pivot(s)
go doSort(s[:i])
go doSort(s[i:])
<-done
<-done
下边的代码,用完整的信号量模式对长度为N的 float64 切片进行了 N 个doSomething() 计算并同时完成,通道 sem 分配了相同的长度(切包含空接口类型的元素),待所有的计算都完成后,发送信号(通过放入值)。在循环中从通道 sem 不停的接收数据来等待所有的协程完成。
type Empty interface {}
var empty Empty
...
data := make([]float64, N)
res := make([]float64, N)
sem := make(chan Empty, N)
...
for i, xi := range data {
go func (i int, xi float64) {
res[i] = doSomething(i, xi)
sem <- empty
} (i, xi)
}
// wait for goroutines to finish
for i := 0; i < N; i++ { <-sem }
注意闭合:i、xi 都是作为参数传入闭合函数的,从外层循环中隐藏了变量 i 和 xi。让每个协程有一份 i 和 xi 的拷贝;另外,for 循环的下一次迭代会更新所有协程中 i 和 xi 的值。切片 res 没有传入闭合函数,因为协程不需要单独拷贝一份。切片 res 也在闭合函数中但并不是参数。
for 循环的每一个迭代是并行完成的:
for i, v := range data {
go func (i int, v float64) {
doSomething(i, v)
...
} (i, v)
}
在 for 循环中并行计算迭代可能带来很好的性能提升。不过所有的迭代都必须是独立完成的。有些语言比如 Fortress 或者其他并行框架以不同的结构实现了这种方式,在 Go 中用协程实现起来非常容易:
信号量是实现互斥锁(排外锁)常见的同步机制,限制对资源的访问,解决读写问题,比如没有实现信号量的 sync 的 Go 包,使用带缓冲的通道可以轻松实现:
- 带缓冲通道的容量和要同步的资源容量相同
- 通道的长度(当前存放的元素个数)与当前资源被使用的数量相同
- 容量减去通道的长度就是未处理的资源个数(标准信号量的整数值)
不用管通道中存放的是什么,只关注长度;因此我们创建了一个长度可变但容量为0(字节)的通道:
type Empty interface {}
type semaphore chan Empty
将可用资源的数量N来初始化信号量 semaphore:sem = make(semaphore, N)
然后直接对信号量进行操作:
// acquire n resources
func (s semaphore) P(n int) {
e := new(Empty)
for i := 0; i < n; i++ {
s <- e
}
}
// release n resouces
func (s semaphore) V(n int) {
for i:= 0; i < n; i++{
<- s
}
}
可以用来实现一个互斥的例子:
/* mutexes */
func (s semaphore) Lock() {
s.P(1)
}
func (s semaphore) Unlock(){
s.V(1)
}
/* signal-wait */
func (s semaphore) Wait(n int) {
s.P(n)
}
func (s semaphore) Signal() {
s.V(1)
}
习惯用法:通道工厂模式
编程中常见的另外一种模式如下:不将通道作为参数传递给协程,而用函数来生成一个通道并返回(工厂角色);函数内有个匿名函数被协程调用。
在 channel_block2.go 加入这种模式便有了示例-channel_idiom.go:
package main
import (
"fmt"
"time"
)
func main() {
stream := pump()
go suck(stream)
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
for {
fmt.Println(<-ch)
}
}
for 循环的 range 语句可以用在通道 ch 上,便可以从通道中获取值,像这样:
for v := range ch {
fmt.Printf("The value is %v\n", v)
}
它从指定通道中读取数据直到通道关闭,才继续执行下边的代码。很明显,另外一个协程必须写入 ch(不然代码就阻塞在 for 循环了),而且必须在写入完成后才关闭。suck 函数可以这样写,且在协程中调用这个动作,程序变成了这样:
示例 -channel_idiom2.go:
package main
import (
"fmt"
"time"
)
func main() {
suck(pump())
time.Sleep(1e9)
}
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
func suck(ch chan int) {
go func() {
for v := range ch {
fmt.Println(v)
}
}()
}
习惯用法:通道迭代模式
这个模式用到了前边示例中的模式,通常,需要从包含了地址索引字段 items 的容器给通道填入元素。为容器的类型定义一个方法 Iter(),返回一个只读的通道tems,如下:
func (c *container) Iter () <- chan items {
ch := make(chan item)
go func () {
for i:= 0; i < c.Len(); i++{ // or use a for-range loop
ch <- c.items[i]
}
} ()
return ch
}
在协程里,一个 for 循环迭代容器 c 中的元素(对于树或图的算法,这种简单的 for 循环可以替换为深度优先搜索)。
调用这个方法的代码可以这样迭代容器:
for x := range container.Iter() { ... }
可以运行在自己的协程中,所以上边的迭代用到了一个通道和两个协程(可能运行在两个线程上)。就有了一个特殊的生产者-消费者模式。如果程序在协程给通道写完值之前结束,协程不会被回收;设计如此。这种行为看起来是错误的,但是通道是一种线程安全的通信。在这种情况下,协程尝试写入一个通道,而这个通道永远不会被读取,这可能是个 bug 而并非期望它被静默的回收。
习惯用法:生产者消费者模式
假设你有 Produce() 函数来产生 Consume 函数需要的值。它们都可以运行在独立的协程中,生产者在通道中放入给消费者读取的值。整个处理过程可以替换为无限循环:
for {
Consume(Produce())
}
通道类型可以用注解来表示它只发送或者只接收:
var send_only chan<- int // channel can only send data
var recv_only <-chan int // channel can onley receive data
只接收的通道(<-chan T)无法关闭,因为关闭通道是发送者用来表示不再给通道发送值了,所以对只接收通道是没有意义的。通道创建的时候都是双向的,但也可以分配有方向的通道变量,就像以下代码:
var c = make(chan int) // bidirectional
go source(c)
go sink(c)
func source(ch chan<- int){
for { ch <- 1 }
}
func sink(ch <-chan int) {
for { <-ch }
}
习惯用法:管道和选择器模式
更具体的例子还有协程处理它从通道接收的数据并发送给输出通道:
sendChan := make(chan int)
reciveChan := make(chan string)
go processChannel(sendChan, receiveChan)
func processChannel(in <-chan int, out chan<- string) {
for inValue := range in {
result := ... /// processing inValue
out <- result
}
}
通过使用方向注解来限制协程对通道的操作。
这里有一个来自 Go 指导的很赞的例子,打印了输出的素数,使用选择器(‘筛’)作为它的算法。
版本1:示例 -sieve1.go
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.package main
package main
import "fmt"
// Send the sequence 2, 3, 4, ... to channel 'ch'.
func generate(ch chan int) {
for i := 2; ; i++ {
ch <- i // Send 'i' to channel 'ch'.
}
}
// Copy the values from channel 'in' to channel 'out',
// removing those divisible by 'prime'.
func filter(in, out chan int, prime int) {
for {
i := <-in // Receive value of new variable 'i' from 'in'.
if i%prime != 0 {
out <- i // Send 'i' to channel 'out'.
}
}
}
// The prime sieve: Daisy-chain filter processes together.
func main() {
ch := make(chan int) // Create a new channel.
go generate(ch) // Start generate() as a goroutine.
for {
prime := <-ch
fmt.Print(prime, " ")
ch1 := make(chan int)
go filter(ch, ch1, prime)
ch = ch1
}
}
协程 filter(in, out chan int, prime int) 拷贝整数到输出通道,丢弃掉可以被 prime 整除的数字。然后每个 prime 又开启了一个新的协程,生成器和选择器并发请求。
输出:
2 3 5 7 11 13 17 19 23 29 31 37 41 43 47 53 59 61 67 71 73 79 83 89 97 101
103 107 109 113 127 131 137 139 149 151 157 163 167 173 179 181 191 193 197 199 211 223
227 229 233 239 241 251 257 263 269 271 277 281 283 293 307 311 313 317 331 337 347 349
353 359 367 373 379 383 389 397 401 409 419 421 431 433 439 443 449 457 461 463 467 479
487 491 499 503 509 521 523 541 547 557 563 569 571 577 587 593 599 601 607 613 617 619
631 641 643 647 653 659 661 673 677 683 691 701 709 719 727 733 739 743 751 757 761 769
773 787 797 809 811 821 823 827 829 839 853 857 859 863 877 881 883 887 907 911 919 929
937 941 947 953 967 971 977 983 991 997 1009 1013...
第二个版本引入了上边的习惯用法:函数 sieve、generate 和 filter 都是工厂;它们创建通道并返回,而且使用了协程的 lambda 函数。main 函数现在短小清晰:它调用 sieve() 返回了包含素数的通道,然后通过 fmt.Println(<-primes) 打印出来。
版本2:示例 -sieve2.go
// Copyright 2009 The Go Authors. All rights reserved.
// Use of this source code is governed by a BSD-style
// license that can be found in the LICENSE file.
package main
import (
"fmt"
)
// Send the sequence 2, 3, 4, ... to returned channel
func generate() chan int {
ch := make(chan int)
go func() {
for i := 2; ; i++ {
ch <- i
}
}()
return ch
}
// Filter out input values divisible by 'prime', send rest to returned channel
func filter(in chan int, prime int) chan int {
out := make(chan int)
go func() {
for {
if i := <-in; i%prime != 0 {
out <- i
}
}
}()
return out
}
func sieve() chan int {
out := make(chan int)
go func() {
ch := generate()
for {
prime := <-ch
ch = filter(ch, prime)
out <- prime
}
}()
return out
}
func main() {
primes := sieve()
for {
fmt.Println(<-primes)
}
}4、协程同步:关闭通道-对阻塞的通道进行测试
通道可以被显式的关闭;尽管它们和文件不同:不必每次都关闭。只有在当需要告诉接收者不会再提供新的值的时候,才需要关闭通道。只有发送者需要关闭通道,接收者永远不会需要。
继续看示例 goroutine2.go:我们如何在通道的 sendData() 完成的时候发送一个信号,getData() 又如何检测到通道是否关闭或阻塞?
第一个可以通过函数 close(ch) 来完成:这个将通道标记为无法通过发送操作 <- 接受更多的值;给已经关闭的通道发送或者再次关闭都会导致运行时的 panic。在创建一个通道后使用 defer 语句是个不错的办法(类似这种情况):
ch := make(chan float64)
defer close(ch)
第二个问题可以使用逗号,ok 操作符:用来检测通道是否被关闭。
如何来检测可以收到没有被阻塞(或者通道没有被关闭)?
v, ok := <-ch // ok is true if v received value
通常和 if 语句一起使用:
if v, ok := <-ch; ok {
process(v)
}
或者在 for 循环中接收的时候,当关闭或者阻塞的时候使用 break:
v, ok := <-ch
if !ok {
break
}
process(v)
可以通过 _ = ch <- v 来实现非阻塞发送,因为空标识符获取到了发送给 ch 的任何东西。
实现非阻塞通道的读取,需要使用 select。
示例 -goroutine3.go:
package main
import "fmt"
func main() {
ch := make(chan string)
go sendData(ch)
getData(ch)
}
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
close(ch)
}
func getData(ch chan string) {
for {
input, open := <-ch
if !open {
break
}
fmt.Printf("%s ", input)
}
}
改变了以下代码:
- 现在只有
sendData()是协程,getData()和main()在同一个线程中:
go sendData(ch)
getData(ch)
- 在
sendData()函数的最后,关闭了通道:
func sendData(ch chan string) {
ch <- "Washington"
ch <- "Tripoli"
ch <- "London"
ch <- "Beijing"
ch <- "Tokio"
close(ch)
}
- 在 for 循环的
getData()中,在每次接收通道的数据之前都使用if !open来检测:
for {
input, open := <-ch
if !open {
break
}
fmt.Printf("%s ", input)
}
使用 for-range 语句来读取通道是更好的办法,因为这会自动检测通道是否关闭:
for input := range ch {
process(input)
}
阻塞和生产者-消费者模式:
在通道迭代器中,两个协程经常是一个阻塞另外一个。如果程序工作在多核心的机器上,大部分时间只用到了一个处理器。可以通过使用带缓冲(缓冲空间大于 0)的通道来改善。比如,缓冲大小为 100,迭代器在阻塞之前,至少可以从容器获得 100 个元素。如果消费者协程在独立的内核运行,就有可能让协程不会出现阻塞。
由于容器中元素的数量通常是已知的,需要让通道有足够的容量放置所有的元素。这样,迭代器就不会阻塞(尽管消费者协程仍然可能阻塞)。然后,这样有效的加倍了迭代容器所需要的内存使用量,所以通道的容量需要限制一下最大值。记录运行时间和性能测试可以帮助你找到最小的缓存容量带来最好的性能。
5、使用 select 切换协程
从不同的并发执行的协程中获取值可以通过关键字select来完成,它和switch控制语句非常相似也被称作通信开关;它的行为像是“你准备好了吗”的轮询机制;select监听进入通道的数据,也可以是用通道发送值的时候。
select {
case u:= <- ch1:
...
case v:= <- ch2:
...
...
default: // no value ready to be received
...
}
default 语句是可选的;fallthrough 行为,和普通的 switch 相似,是不允许的。在任何一个 case 中执行 break 或者 return,select 就结束了。
select 做的就是:选择处理列出的多个通信情况中的一个。
- 如果都阻塞了,会等待直到其中一个可以处理
- 如果多个可以处理,随机选择一个
- 如果没有通道操作可以处理并且写了
default语句,它就会执行:default永远是可运行的(这就是准备好了,可以执行)。
在 select 中使用发送操作并且有 default可以确保发送不被阻塞!如果没有 case,select 就会一直阻塞。
select 语句实现了一种监听模式,通常用在(无限)循环中;在某种情况下,通过 break 语句使循环退出。
在程序 goroutine_select.go 中有 2 个通道 ch1 和 ch2,三个协程 pump1()、pump2() 和 suck()。这是一个典型的生产者消费者模式。在无限循环中,ch1 和 ch2 通过 pump1() 和 pump2() 填充整数;suck() 也是在无限循环中轮询输入的,通过select 语句获取 ch1 和 ch2 的整数并输出。选择哪一个 case 取决于哪一个通道收到了信息。程序在 main 执行 1 秒后结束。
示例 -goroutine_select.go:
package main
import (
"fmt"
"time"
)
func main() {
ch1 := make(chan int)
ch2 := make(chan int)
go pump1(ch1)
go pump2(ch2)
go suck(ch1, ch2)
time.Sleep(1e9)
}
func pump1(ch chan int) {
for i := 0; ; i++ {
ch <- i * 2
}
}
func pump2(ch chan int) {
for i := 0; ; i++ {
ch <- i + 5
}
}
func suck(ch1, ch2 chan int) {
for {
select {
case v := <-ch1:
fmt.Printf("Received on channel 1: %d\n", v)
case v := <-ch2:
fmt.Printf("Received on channel 2: %d\n", v)
}
}
}
输出:
Received on channel 2: 5
Received on channel 2: 6
Received on channel 1: 0
Received on channel 2: 7
Received on channel 2: 8
Received on channel 2: 9
Received on channel 2: 10
Received on channel 1: 2
Received on channel 2: 11
...
Received on channel 2: 47404
Received on channel 1: 94346
Received on channel 1: 94348
一秒内的输出非常惊人,如果我们给它计数(goroutine_select2.go),得到了 90000 个左右的数字。
计算执行时间
再次声明这只是为了一边练习协程的概念一边找点乐子。
如果你需要的话可使用 math.pi 中的 Pi;而且不使用协程会运算的更快。一个急速版本:使用 GOMAXPROCS,开启和GOMAXPROCS 同样多个协程。
习惯用法:后台服务模式
服务通常是是用后台协程中的无限循环实现的,在循环中使用 select 获取并处理通道中的数据:
// Backend goroutine.
func backend() {
for {
select {
case cmd := <-ch1:
// Handle ...
case cmd := <-ch2:
...
case cmd := <-chStop:
// stop server
}
}
}
在程序的其他地方给通道 ch1,ch2 发送数据,比如:通道 stop 用来清理结束服务程序。
另一种方式(但是不太灵活)就是(客户端)在 chRequest 上提交请求,后台协程循环这个通道,使用 switch 根据请求的行为来分别处理:
func backend() {
for req := range chRequest {
switch req.Subjext() {
case A1: // Handle case ...
case A2: // Handle case ...
default:
// Handle illegal request ..
// ...
}
}
}6、通道,超时和计时器(Ticker)
time 包中有一些有趣的功能可以和通道组合使用。
其中就包含了 time.Ticker 结构体,这个对象以指定的时间间隔重复的向通道 C 发送时间值:
type Ticker struct {
C <-chan Time // the channel on which the ticks are delivered.
// contains filtered or unexported fields
...
}
时间间隔的单位是 ns(纳秒,int64),在工厂函数 time.NewTicker 中以 Duration 类型的参数传入:func Newticker(dur) *Ticker。
在协程周期性的执行一些事情(打印状态日志,输出,计算等等)的时候非常有用。
调用 Stop() 使计时器停止,在 defer 语句中使用。这些都很好的适应 select 语句:
ticker := time.NewTicker(updateInterval)
defer ticker.Stop()
...
select {
case u:= <-ch1:
...
case v:= <-ch2:
...
case <-ticker.C:
logState(status) // call some logging function logState
default: // no value ready to be received
...
}
time.Tick() 函数声明为 Tick(d Duration) <-chan Time,当你想返回一个通道而不必关闭它的时候这个函数非常有用:它以 d 为周期给返回的通道发送时间,d是纳秒数。如果需要像下边的代码一样,限制处理频率(函数 client.Call() 是一个 RPC 调用,这里暂不赘述):
import "time"
rate_per_sec := 10
var dur Duration = 1e9 / rate_per_sec
chRate := time.Tick(dur) // a tick every 1/10th of a second
for req := range requests {
<- chRate // rate limit our Service.Method RPC calls
go client.Call("Service.Method", req, ...)
}
这样只会按照指定频率处理请求:chRate 阻塞了更高的频率。每秒处理的频率可以根据机器负载(和/或)资源的情况而增加或减少。
问题:扩展上边的代码,思考如何承载周期请求数的暴增(提示:使用带缓冲通道和计时器对象)。
定时器(Timer)结构体看上去和计时器(Ticker)结构体的确很像(构造为 NewTimer(d Duration)),但是它只发送一次时间,在 Dration d 之后。
还有 time.After(d) 函数,声明如下:
func After(d Duration) <-chan Time
在 Duration d 之后,当前时间被发到返回的通道;所以它和 NewTimer(d).C 是等价的;它类似 Tick(),但是 After() 只发送一次时间。下边有个很具体的示例,很好的阐明了 select 中 default 的作用:
package main
import (
"fmt"
"time"
)
func main() {
tick := time.Tick(1e8)
boom := time.After(5e8)
for {
select {
case <-tick:
fmt.Println("tick.")
case <-boom:
fmt.Println("BOOM!")
return
default:
fmt.Println(" .")
time.Sleep(5e7)
}
}
}
输出:
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
.
.
tick.
BOOM!
习惯用法:简单超时模式
要从通道 ch 中接收数据,但是最多等待1秒。先创建一个信号通道,然后启动一个 lambda 协程,协程在给通道发送数据之前是休眠的:
timeout := make(chan bool, 1)
go func() {
time.Sleep(1e9) // one second
timeout <- true
}()
然后使用 select 语句接收 ch 或者 timeout 的数据:如果 ch 在 1 秒内没有收到数据,就选择到了 time 分支并放弃了 ch的读取。
select {
case <-ch:
// a read from ch has occured
case <-timeout:
// the read from ch has timed out
break
}
第二种形式:取消耗时很长的同步调用
也可以使用 time.After() 函数替换 timeout-channel。可以在 select 中使用以发送信号超时或停止协程的执行。以下代码,在 timeoutNs 纳秒后执行 select 的 timeout 分支时,client.Call 不会给通道 ch 返回值:
ch := make(chan error, 1)
go func() { ch <- client.Call("Service.Method", args, &reply) } ()
select {
case resp := <-ch
// use resp and reply
case <-time.After(timeoutNs):
// call timed out
break
}
注意缓冲大小设置为 1 是必要的,可以避免协程死锁以及确保超时的通道可以被垃圾回收。
第三种形式:假设程序从多个复制的数据库同时读取。只需要一个答案,需要接收首先到达的答案,Query 函数获取数据库的连接切片并请求。并行请求每一个数据库并返回收到的第一个响应:
func Query(conns []conn, query string) Result {
ch := make(chan Result, 1)
for _, conn := range conns {
go func(c Conn) {
select {
case ch <- c.DoQuery(query):
default:
}
}(conn)
}
return <- ch
}
再次声明,结果通道 ch 必须是带缓冲的:以保证第一个发送进来的数据有地方可以存放,确保放入的首个数据总会成功,所以第一个到达的值会被获取而与执行的顺序无关。正在执行的协程可以总是可以使用 runtime.Goexit() 来停止。
在应用中缓存数据:
应用程序中用到了来自数据库(或者常见的数据存储)的数据时,经常会把数据缓存到内存中,因为从数据库中获取数据的操作代价很高;如果数据库中的值不发生变化就没有问题。但是如果值有变化,我们需要一个机制来周期性的从数据库重新读取这些值:缓存的值就不可用(过期)了,而且我们也不希望用户看到陈旧的数据。
7、协程和恢复(recover)
一个用到 recover 的程序停掉了服务器内部一个失败的协程而不影响其他协程的工作。
func server(workChan <-chan *Work) {
for work := range workChan {
go safelyDo(work) // start the goroutine for that work
}
}
func safelyDo(work *Work) {
defer func {
if err := recover(); err != nil {
log.Printf("Work failed with %s in %v", err, work)
}
}()
do(work)
}
上边的代码,如果 do(work) 发生 panic,错误会被记录且协程会退出并释放,而其他协程不受影响。
因为 recover 总是返回 nil,除非直接在 defer 修饰的函数中调用,defer 修饰的代码可以调用那些自身可以使用 panic 和recover 避免失败的库例程(库函数)。举例,safelyDo() 中 deffer 修饰的函数可能在调用 recover 之前就调用了一个logging 函数,panicking 状态不会影响 logging 代码的运行。因为加入了恢复模式,函数 do(以及它调用的任何东西)可以通过调用 panic 来摆脱不好的情况。但是恢复是在 panicking 的协程内部的:不能被另外一个协程恢复。
8、底层原理
1)数据结构
channel的数据结构如下:
type hchan struct {
qcount uint // 当前队列中剩余元素个数
dataqsiz uint // 环形队列长度,即可以存放的元素个数
buf unsafe.Pointer // 环形队列指针
elemsize uint16 // 每个元素的大小
closed uint32 // 标识关闭状态
elemtype *_type // 元素类型
sendx uint // 队列下标,指示元素写入时存放到队列中的位置
recvx uint // 队列下标,指示元素从队列的该位置读出
recvq waitq // 等待读消息的goroutine队列
sendq waitq // 等待写消息的goroutine队列
lock mutex // 互斥锁,chan不允许并发读写
}chan内部实现了一个环形队列作为其缓冲区,队列的长度是创建chan时指定的,下图展示了一个可缓存6个元素的channel示意图:

图展示了一个没有缓冲区的channel,有几个goroutine阻塞等待读数据:

2)发送
向一个channel中写数据简单过程如下:
-
如果等待接收队列recvq不为空,说明缓冲区中没有数据或者没有缓冲区,此时直接从recvq取出G,并把数据写入,最后把该G唤醒,结束发送过程;
-
如果缓冲区中有空余位置,将数据写入缓冲区,结束发送过程;
-
如果缓冲区中没有空余位置,将待发送数据写入G,将当前G加入sendq,进入睡眠,等待被读goroutine唤醒。

阻塞情况:
-
nil阻塞:向nil通道发送数据会被阻塞。
ch := make(chan int, 2)
ch = nil
ch <- 4 // all goroutines are asleep - deadlock!-
无缓冲channel + 读未ready:向无缓冲 channel写数据,如果读协程没有准备好,会阻塞。
-
有缓冲channel + 缓冲已满:向有缓冲 channel写数据,如果缓冲已满,会阻塞。
重要知识点:
-
panic:closed的channel,写数据会panic。
ch := make(chan int, 2)
ch <- 4
close(ch)
ch <- 3 // panic: send on closed channel-
资源回收:channel使用完后,需要close掉,否则资源不会回收(包括channel资源,以及channel里面存储的数据资源)。
-
数据交换:就算是有缓冲的 channel ,也不是每次发送、接收都要经过缓存,如果发送的时候,刚好有等待接收的协程,那么会直接交换数据。
3)接收
从一个channel读数据简单过程如下:
-
如果等待发送队列sendq不为空,且没有缓冲区,直接从sendq中取出G,把G中数据读出,最后把G唤醒,结束 读取过程;
-
如果等待发送队列sendq不为空,此时说明缓冲区已满,从缓冲区中首部读出数据,把G中数据写入缓冲区尾部,把G唤醒,结束读取过程;
-
如果缓冲区中有数据,则从缓冲区取出数据,结束读取过程;
-
将当前goroutine加入recvq,进入睡眠,等待被写goroutine唤醒。

阻塞情况:
-
nil阻塞:从nil通道接收数据会被阻塞。
-
无缓冲channel + 写未ready:从无缓冲channel读数据,如果写协程没有准备好,会阻塞。
-
有缓冲channel + 缓冲为空:从有缓冲 channel读数据,如果缓冲为空,会阻塞。
重要知识点:
-
关闭channel数据接收:从已关闭channel接收数据,如果通道有数据,会返回已缓冲数据;如果没有数据,会读到通道传输数据类型的零值,比如指针类型,读到nil。(可以通过x, ok:=<-c中的ok,判断数据是否读取完毕)
c := make(chan int, 3)
c <- 11
c <- 12
close(c)
for i := 0; i < cap(c)+1; i++ {
x, ok := <-c
println(i, ":", ok, x)
}
// 输出
// 0: true 11
// 1: true 12
// 2: false 0
// 3: false 04)关闭
关闭channel时会把recvq中的G全部唤醒,本该写入G的数据位置为nil。把sendq中的G全部唤醒,但这些G会panic。
重要知识点:
-
close panic:重复关闭,或关闭nil通道会引发panic。
ch := make(chan int, 2)
ch <- 4
close(ch)
close(ch) // panic: close of closed channel多线程通道关闭原则:由于close的channel,写数据是会panic,所以在多线程写入和读取时,需要遵循“谁写入,谁负责关闭”原则。
5)for-range读取
我们常常会用for-range来读取channel的数据:
ch := make(chan int, 1)
go func(ch chan int) {
for i := 0; i < 10; i++ {
ch <- i
}
close(ch)
}(ch)
for val := range ch {
fmt.Println(val)
}重要知识点:
-
如果channel已经关闭,它还是会继续执行,直到所有值被取完,然后退出执行;
-
如果channel没有关闭,但是channel没有可读取的数据,它则会阻塞在range这句位置,直到被唤醒;
-
如果channel是nil,读取会被阻塞,也就是会一直阻塞在range位置。
6)select
select是跟channel关系最亲密的语句,它是被专门设计出来处理通道的,因为每个 case 后面跟的都是通道表达式,可以是读,也可以是写。下面看一个简单的示例:
// 准备好几个通道。
intChannels := [3]chan int{
make(chan int, 1),
make(chan int, 1),
make(chan int, 1),
}
// 随机选择一个通道,并向它发送元素值。
index := rand.Intn(3)
fmt.Printf("The index: %d\n", index)
intChannels[index] <- index
// 哪一个通道中有可取的元素值,哪个对应的分支就会被执行。
select {
case <-intChannels[0]:
fmt.Println("The first candidate case is selected.")
case <-intChannels[1]:
fmt.Println("The second candidate case is selected.")
case elem := <-intChannels[2]:
fmt.Printf("The third candidate case is selected, the element is %d.\n", elem)
default:
fmt.Println("No candidate case is selected!")
}我们用一个包含了三个候选分支的select语句,分别尝试从上述三个通道中接收元素值,哪一个通道中有值,哪一个对应的候选分支就会被执行。后面还有一个默认分支,不过在这里它是不可能被选中的。
在使用select语句的时候,我们需要注意下面几个事情:
-
有default情况:select只要有默认语句,就不会被阻塞,换句话说,如果没有default,然后case又都不能读或者写,则会被阻塞。
-
无default情况:如果没有加入默认分支,那么一旦所有的case表达式都没有满足求值条件,那么select语句就会被阻塞。直到至少有一个case表达式满足条件为止。
-
multi-valued assignment:select不能够像for-range一样发现channel被关闭而终止执行,我们可能会因为通道关闭了,而直接从通道接收到一个其元素类型的零值。所以,在很多时候,我们需要通过接收表达式的第二个结果值来判断通道是否已经关闭。一旦发现某个通道关闭了,我们就应该及时地屏蔽掉对应的分支或者采取其他措施。这对于程序逻辑和程序性能都是有好处的。
-
select + for:select语句只能对其中的每一个case表达式各求值一次。所以,如果我们想连续或定时地操作其中的通道的话,就往往需要通过在for语句中嵌入select语句的方式实现。但这时要注意,简单地在select语句的分支中使用break语句,只能结束当前的select语句的执行,而并不会对外层的for语句产生作用。这种错误的用法可能会让这个for语句无休止地运行下去。
intChan := make(chan int, 1)
// 一秒后关闭通道。
time.AfterFunc(time.Second, func() {
close(intChan)
})
select {
case _, ok := <-intChan:
if !ok {
fmt.Println("The candidate case is closed.")
break
}
fmt.Println("The candidate case is selected.")
}-
随机选择case:如果同时有多个case足了条件,会使用伪随机选择一个case来执行。
-
先全部扫描,再选择:每次select语句的执行,是会扫码完所有的case后才确定如何执行,而不是说遇到合适的case就直接执行了。
-
nil阻塞:nil的channel,不管读写都会被阻塞。
上面的知识需要牢记,面试常考,下面是讲解select执行的流程:
-
对于每一个case表达式,都至少会包含一个代表发送操作的发送表达式或者一个代表接收操作的接收表达式,同时也可能会包含其他的表达式。比如,如果case表达式是包含了接收表达式的短变量声明时,那么在赋值符号左边的就可以是一个或两个表达式,不过此处的表达式的结果必须是可以被赋值的。当这样的case表达式被求值时,它包含的多个表达式总会以从左到右的顺序被求值。
-
select语句包含的候选分支中的case表达式都会在该语句执行开始时先被求值,并且求值的顺序是依从代码编写的顺序从上到下的。结合上一条规则,在select语句开始执行时,排在最上边的候选分支中最左边的表达式会最先被求值,然后是它右边的表达式。仅当最上边的候选分支中的所有表达式都被求值完毕后,从上边数第二个候选分支中的表达式才会被求值,顺序同样是从左到右,然后是第三个候选分支、第四个候选分支,以此类推。
-
对于每一个case表达式,如果其中的发送表达式或者接收表达式在被求值时,相应的操作正处于阻塞状态,那么对该case表达式的求值就是不成功的。在这种情况下,我们可以说,这个case表达式所在的候选分支是不满足选择条件的。
-
仅当select语句中的所有case表达式都被求值完毕后,它才会开始选择候选分支。这时候,它只会挑选满足选择条件的候选分支执行。如果所有的候选分支都不满足选择条件,那么默认分支就会被执行。如果这时没有默认分支,那么select语句就会立即进入阻塞状态,直到至少有一个候选分支满足选择条件为止。一旦有一个候选分支满足选择条件,select语句(或者说它所在的goroutine)就会被唤醒,这个候选分支就会被执行。
-
如果select语句发现同时有多个候选分支满足选择条件,那么它就会用一种伪随机的算法在这些分支中选择一个并执行。注意,即使select语句是在被唤醒时发现的这种情况,也会这样做。
-
一条select语句中只能够有一个默认分支。并且,默认分支只在无候选分支可选时才会被执行,这与它的编写位置无关。
-
select语句的每次执行,包括case表达式求值和分支选择,都是独立的。不过,至于它的执行是否是并发安全的,就要看其中的case表达式以及分支中,是否包含并发不安全的代码了。
上面写的有些多,简单总结一下:执行select时,会从左到右,从上到下,对每个case表达式求值,当所有case求值完毕后,会挑选满足的case执行,如果有多条都满足,就随机选择一条;如果都没有满足,就执行default;如果连default都没有,就阻塞住,等有满足条件的case出现时,再执行。
9、并发实例
关于channel,零碎的知识点非常多,我还是想通过一个完整的示例,将这些知识点全部串起来,下面就以海外商城Push为例,将上面知识应用到实际场景中。
海外商城需要对W个业务方发送Push,针对每个业务方,为了提高Push的并发能力,采用N个协程从EMQ中读取数据(EMQ中都一个消息队列,里面缓存了大量的Push数据),数据读取后进行处理,然后将处理后的数据写到channel中。同时,服务有M个协程从channel中取出数据并消费,然后通过小米Push SDK,给用户发送Push。整体发送链路如下:

在看后面的内容前,我先抛出几个问题:
-
生成者往关闭的Channel写数据,会Panic,那么Channel该如何关闭呢?
-
当Channel关闭后(比如服务重启),需要继续消费Channel里面的Push,该如何操作呢?
-
每消费一条Channel数据,需要记录Push发送成功,但是一条Channel数据包含2-3个Push内容(IOS/Android/PC),程序记录Push成功前,如何保证这2-3个Push都发送完毕了呢?
1)初始化
初始化channel数组,数组里面是每个业务方appTypes的channel,channel的缓存区大小为30,并启动10个消费者协程:
var (
messageChan map[string]chan *WorkMessage // channel
stopMasterChan chan bool // 消费者结束通知
appTypes = map[int32]string{1: "shop", 2: "bbs", 3: "sharesave"}
)
func initPushChannel() {
maxSize = 30 // channel缓存区大小
workNum = 10 // goroutine个数
stopMasterChan = make(chan bool)
messageChan = make(map[string]chan *WorkMessage)
for _, name := range appTypes {
workChan := make(chan *WorkMessage, maxSize)
messageChan[name] = workChan
for i := 0; i < workNum; i++ {
go startMaster(name, workChan) // 启动消费者协程
}
}
}
func startMaster(name string, workChan chan *WorkMessage) {
for {
if exit := dostartMaster(name, workChan); exit {
return
}
}
}初始化EMQ的Client,并启动10个生产者协程:
var (
clientFactory client.ClientFactory // EMQ Client
stopChan chan bool // 生产者结束通知
)
func initEmq() {
// 初始化EMQ的Client和单次读取数据条数,该处代码省略...
maxConsumerNum := 10
stopChan = make(chan bool)
for i := 0; i < maxConsumerNum; i++ {
go receiveMsg(i) // 启动生产者协程
}
}
func receiveMsg(queueID int) {
for {
if exit := doReceiveMsg(queueID); exit {
logz.Info("stop receive msg ...", logz.F("queueID", queueID))
return
}
}
}主方法调用:
func InitWorker() {
// 初始化push SDK,逻辑省略...
initPushChannel() // 初始化Channel,启动消费者
initEmq() // 启动生产者
}2)发送
func doReceiveMsg(queueID int) bool {
defer func() {
if err := recover(); err != nil {
println("[panic] recover from error.")
}
}()
ticker := time.NewTicker(time.Second)
for {
select {
case <-ticker.C:
// 1. 从EMQ获取数据List,逻辑省略...
// 2. 遍历List,获取业务类型,逻辑省略...
// 3. 根据业务类型,获取对应的channel
name := "sharesave" // 示例数据
pushChannel, _ := messageChan[name]
// 4. 构造Push数据,然后放入channel
pushData := &WorkMessage{AppLocal: "id", AppType: 1} // 示例数据
pushChannel <- pushData
case <-stopChan:
println("stop to send data to channel.")
return true
}
}
}这部分代码我做了大量简化,这里主要做了2件事情:
-
通过select + 定时器,每隔1S就会从EMQ中获取数据,然后将构造后的数据放入对应业务的channel;
-
当收到stopChan事件时,会通知所有的生产者协程,退出goroutine,这里其实就是协程退出的方式之一。
3)接收
func dostartMaster(name string, workChan chan *WorkMessage) bool {
defer func() {
if err := recover(); err != nil {
println("[panic] recover from error.")
}
}()
for {
select {
case t := <-workChan:
if t != nil {
for _, message := range t.PushMessages {
// 接受channel数据t,将数据推给Push SDK
// 逻辑省略...
}
}
case <-stopMasterChan:
println("stop to get data from channel.")
return true
}
}
}这部分代码同样做了大量简化,这里主要做了2件事情:
-
通过select,如果channel里面有数据,直接读取,然后给用户发送Push;
-
当收到stopMasterChan事件时,会通知所有的生产者协程,退出goroutine。
4)关闭
// 通知生产者协程关闭,协程不再写channel
func stopRecvMsgFromQueue() {
close(stopChan)
}
// 通知消费者协程关闭,协程不再读channel,并关闭channel,消费完channel中剩余消息
func stopPushChannel() {
close(stopMasterChan)
time.Sleep(time.Second)
for _, c := range messageChan {
close(c)
for msg := range c {
if msg != nil {
for _, message := range msg.PushMessages {
// 接受channel数据t,将数据推给Push SDK
// 逻辑省略...
}
}
}
}
}
// 主方法调用
func StopWorker() {
stopRecvMsgFromQueue()
time.Sleep(time.Second * 2)
stopPushChannel()
}比如服务重启,需要关闭协程时,主要做以下事情:
-
执行close(stopChan),先通知生产者协程,不再往channel里面写数据;
-
执行close(stopMasterChan),通知消费者协程,不再从channel里面读取数据;
-
关闭数组messageChan的每个channel;
-
继续读取channel中剩余的数据,因为使用的是for-range方式,所以当channel里面所有的数据读取完毕后,for-range会自动退出。
这里有两个地方sleep了一下,分别有以下作用:
-
调用stopPushChannel()前sleep:关闭生成者后,消费者继续消费剩余的数据;
-
调用close(c)前sleep:避免协程未完全关闭,导致往关闭的channel写数据,导致panic。
总结
如果你能回答我提的这些问题,你应该就掌握了本章的内容:
-
发送和接收时,分别有哪些情况会导致channel阻塞呢?
-
对于发送和关闭channel,有哪些情况会导致panic呢?
-
当channel关闭后,继续读取里面的数据,能读取到么?如何保证数据读取完毕呢?
-
对于生产者和消费者模型,如何才能优雅关闭channel,避免写channel导致的panic呢?
-
for-range读取channel数据,对于channel关闭和未关闭的情况,是如何处理的呢?会存在阻塞情况么?
-
使用select时,有哪些注意事项呢?你知道select执行的流程么?
最后就是Push的并发示例,强烈建议大家能掌握,掌握了这个示例,后续你应该也能很容易通过channel实现数据共享,并结合goroutine写出你自己的高并发程序。
四、网路编程
1、互联网协议
1)数据链路层
Ethernet协议
Ethernet协议规定一组电信号构成一个数据包,叫做“帧”(Frame)。
帧(Frame)
每一帧分成标头(Head)和数据(Data)。
Head包含数据包的一些说明项,如发送者、接收者,数据类型等;Data则是数据包的具体内容。
Head的长度固定为18字节,Data最短为46字节,最长为1500字节;所以一帧最短为64字节,最长为1518字节。
如何表示发送者和接收者
以太网规定接入网络的设备必须具有“网卡”接口。数据包是从一块网卡传送到另一块网卡。网卡的地址为AC地址。
MAC地址
MAC地址唯一。长度为48个二进制位,通常用12个十六进制数表示。前6个十六进制数是厂商编号,后6个是该厂商的网卡流水号。
通过ARP协议来获取接收方的MAC地址。通过“广播”(broadcasting)向本网络内所有计算机发送,让每台计算机读取Head。找到接收方的MAC地址与自身的MAC地址比较。如果相同接收,作进一步处理;反之则丢弃。
区别MAC地址是否属于同一个子网络,如果是则用“广播”方式发送;若不是则用“路由”的方式发送。为此引用网络地址概念。
每台计算机有两个地址MAC地址和网络地址。网络地址确定计算机所在的子网络,MAC地址将数据包发送到该子网络中的目标网卡。先处理网络地址,再处理MAC地址。
IP协议
规定网络地址的协议为IP协议,所定义的地址为IP地址。目前广泛使用的是IPv4,IP协议的第四版。
IPv4规定网络地址由32个二进制位组成,通常使用分成四段的十进制数表示IP地址,从0.0.0.0到255.255.255.255
IP数据包
根据IP协议发送的数据叫做IP数据包。IP数据包也分为标头和数据两个部分,标头主要包括版本、长度,IP地址等信息;数据则是数据包的具体内容。标头的长度为20到60字节,整个数据包的总长度最大为65535字节。
有MAC地址和网络地址之后,就可以在互联网任意两台主机上建立通信。通过“端口”(port)来讲数据包区别发送到指定的程序。
“端口”是0到65535之间的一个整数,16个二进制位。0到1023的端口被系统占用。有了IP和端口,就能确定互联网上的一个程序,进而实现网络间的通信。
UDP协议
因需要在数据包中加入端口信息,从而引入新的协议。UDP协议的格式几乎就是在数据前面加上端口号。
UDP数据包由“标头”和“数据”组成,标头主要定义了发出端口和接收端口;数据就是具体内容。
UDP数据包“标头”一共只有8个字节,总长度不超过65535字节,正好放进一个IP数据包。
UDP的缺点:可靠性较差,发出之后无法知道对方是否收到,诞生了TCP协议。
TCP数据包没有长度限制,但为了保证网络的效率,通常TCP数据包的长度不会超过IP数据包的长度,以确保单个TCP数据包不会再被分割。
应用程序接收到“传输层”的数据,就要对数据进行解包。数据来源各不一样,就需要事先规定好通信的数据格式,否则接收方无法获得真正发送的数据内容。“应用层”的作用就是规定好应用程序使用的数据格式,常见HTTP,FTP等。

2、socket编程
Socket是BSD UNIX的进程通信机制,通常称作“套接字”,用于描述IP地址和端口,是一个通信链的句柄。
Socket可以理解为TCP/IP网络的API。
这部分我们将使用TCP协议和程范式编写一个简单的客户端-服务器应用,一个(web)服务器应用需要响应众多客户端的并发请求:go会为每一个客户端产生一个协程用来处理请求。我们需要使用net包中网络通信的功能。它包含了用于TCP/IP以及UDP协议、域名解析等方法。
服务器代码,单独的一个文件:
示例 server.go:
package main
import (
"fmt"
"net"
)
func main() {
fmt.Println("Starting the server ...")
// 创建 listener
listener, err := net.Listen("tcp", "localhost:50000")
if err != nil {
fmt.Println("Error listening", err.Error())
return //终止程序
}
// 监听并接受来自客户端的连接
for {
conn, err := listener.Accept()
if err != nil {
fmt.Println("Error accepting", err.Error())
return // 终止程序
}
go doServerStuff(conn)
}
}
func doServerStuff(conn net.Conn) {
for {
buf := make([]byte, 512)
_, err := conn.Read(buf)
if err != nil {
fmt.Println("Error reading", err.Error())
return //终止程序
}
fmt.Printf("Received data: %v", string(buf))
}
}
我们在main()创建了一个net.Listener的变量,他是一个服务器的基本函数:用来监听和接收来自客户端的请求(来自localhost即IP地址为127.0.0.1端口为50000基于TCP协议)。这个Listen()函数可以返回一个error类型的错误变量。
用一个无限for循环的listener.Accept()来等待客户端的请求。客户端的请求将产生一个net.Conn类型的连接变量。然后一个独立的携程使用这个连接执行doServerStuff(),开始使用一个512字节的缓冲data来读取客户端发送来的数据并且把它们打印到服务器的终端;当客户端发送的所有数据都被读取完成时,携程就结束了。这段程序会为每一个客户端连接创建一个独立的携程。必须先运行服务器代码,再运行客户端代码。
客户端代码写在另外一个文件client.go中:
示例 client.go:
package main
import (
"bufio"
"fmt"
"net"
"os"
"strings"
)
func main() {
//打开连接:
conn, err := net.Dial("tcp", "localhost:50000")
if err != nil {
//由于目标计算机积极拒绝而无法创建连接
fmt.Println("Error dialing", err.Error())
return // 终止程序
}
inputReader := bufio.NewReader(os.Stdin)
fmt.Println("First, what is your name?")
clientName, _ := inputReader.ReadString('\n')
// fmt.Printf("CLIENTNAME %s", clientName)
trimmedClient := strings.Trim(clientName, "\r\n") // Windows 平台下用 "\r\n",Linux平台下使用 "\n"
// 给服务器发送信息直到程序退出:
for {
fmt.Println("What to send to the server? Type Q to quit.")
input, _ := inputReader.ReadString('\n')
trimmedInput := strings.Trim(input, "\r\n")
// fmt.Printf("input:--s%--", input)
// fmt.Printf("trimmedInput:--s%--", trimmedInput)
if trimmedInput == "Q" {
return
}
_, err = conn.Write([]byte(trimmedClient + " says: " + trimmedInput))
}
}
客户端通过net.Dial创建了一个和服务器之间的连接。
它通过无限循环中的os.Stdin接收来自键盘的输入直到输入了“Q”。注意使用\r和\n换行符分割字符串(在windows平台下使用\r\n)。接下来分割后的输入通过connection的Write方法被发送到服务器。
当然,服务器必须先启动好,如果服务器并未开始监听,客户端是无法成功连接的。
如果在服务器没有开始监听的情况下运行客户端程序,客户端会停止并打印出以下错误信息:对tcp 127.0.0.1:50000发起连接时产生错误:由于目标计算机的积极拒绝而无法创建连接。
打开控制台并转到服务器和客户端可执行程序所在的目录,Windows系统下输入server.exe(或者只输入server),Linux系统下输入./server。
接下来控制台出现以下信息:Starting the server ...
在Windows系统中,我们可以通过CTRL/C停止程序。
然后开启2个或者3个独立的控制台窗口,然后分别输入client回车启动客户端程序。
以下是服务器的输出(在移除掉512字节的字符串中内容为空的区域后):
Starting the Server ...
Received data: IVO says: Hi Server, what's up ?
Received data: CHRIS says: Are you busy server ?
Received data: MARC says: Don't forget our appointment tomorrow !
当客户端输入 Q 并结束程序时,服务器会输出以下信息:
Error reading WSARecv tcp 127.0.0.1:50000: The specified network name is no longer available.
在网络编程中net.Dial函数是非常重要的,一旦你连接到远程系统,就会返回一个Conn类型接口,我们可以用它发送和接收数据。Dial函数巧妙的抽象了网络结构及传输。所以IPv4或者IPv6,TCP或者UDP都可以使用这个公用接口。
下边这个示例先使用TCP协议连接远程80端口,然后使用UDP协议连接,最后使用TCP协议连接IPv6类型的地址:
示例 dial.go
// make a connection with www.example.org:
package main
import (
"fmt"
"net"
"os"
)
func main() {
conn, err := net.Dial("tcp", "192.0.32.10:80") // tcp ipv4
checkConnection(conn, err)
conn, err = net.Dial("udp", "192.0.32.10:80") // udp
checkConnection(conn, err)
conn, err = net.Dial("tcp", "[2620:0:2d0:200::10]:80") // tcp ipv6
checkConnection(conn, err)
}
func checkConnection(conn net.Conn, err error) {
if err != nil {
fmt.Printf("error %v connecting!")
os.Exit(1)
}
fmt.Println("Connection is made with %v", conn)
}
下边也是一个使用net包从socket中打开,写入,读取数据的例子:
示例 socket.go
package main
import (
"fmt"
"io"
"net"
)
func main() {
var (
host = "www.apache.org"
port = "80"
remote = host + ":" + port
msg string = "GET / \n"
data = make([]uint8, 4096)
read = true
count = 0
)
// 创建一个socket
con, err := net.Dial("tcp", remote)
// 发送我们的消息,一个http GET请求
io.WriteString(con, msg)
// 读取服务器的响应
for read {
count, err = con.Read(data)
read = (err == nil)
fmt.Printf(string(data[0:count]))
}
con.Close()
}
练习:编写新版本的客户端和服务器(client1.go / server1.go):
- 增加一个检查错误的函数
checkError(error);讨论如下方案的利弊:为什么这个重构可能并没有那么理想?看看在示例15.14中它是如何被解决的 - 使客户端可以通过发送一条命令SH来关闭服务器
- 让服务器可以保存已经连接的客户端列表(他们的名字);当客户端发送WHO指令的时候,服务器将显示如下列表:
This is the client list: 1:active, 0=inactive
User IVO is 1
User MARC is 1
User CHRIS is 1
注意:当服务器运行的时候,你无法编译/连接同一个目录下的源码来产生一个新的版本,因为server.exe正在被操作系统使用而无法被替换成新的版本。
下边这个版本的 simple_tcp_server.go 从很多方面优化了第一个tcp服务器的示例 server.go 并且拥有更好的结构,它只用了80行代码!
// Simple multi-thread/multi-core TCP server.
package main
import (
"flag"
"fmt"
"net"
"os"
)
const maxRead = 25
func main() {
flag.Parse()
if flag.NArg() != 2 {
panic("usage: host port")
}
hostAndPort := fmt.Sprintf("%s:%s", flag.Arg(0), flag.Arg(1))
listener := initServer(hostAndPort)
for {
conn, err := listener.Accept()
checkError(err, "Accept: ")
go connectionHandler(conn)
}
}
func initServer(hostAndPort string) *net.TCPListener {
serverAddr, err := net.ResolveTCPAddr("tcp", hostAndPort)
checkError(err, "Resolving address:port failed: '"+hostAndPort+"'")
listener, err := net.ListenTCP("tcp", serverAddr)
checkError(err, "ListenTCP: ")
println("Listening to: ", listener.Addr().String())
return listener
}
func connectionHandler(conn net.Conn) {
connFrom := conn.RemoteAddr().String()
println("Connection from: ", connFrom)
sayHello(conn)
for {
var ibuf []byte = make([]byte, maxRead+1)
length, err := conn.Read(ibuf[0:maxRead])
ibuf[maxRead] = 0 // to prevent overflow
switch err {
case nil:
handleMsg(length, err, ibuf)
case os.EAGAIN: // try again
continue
default:
goto DISCONNECT
}
}
DISCONNECT:
err := conn.Close()
println("Closed connection: ", connFrom)
checkError(err, "Close: ")
}
func sayHello(to net.Conn) {
obuf := []byte{'L', 'e', 't', '\'', 's', ' ', 'G', 'O', '!', '\n'}
wrote, err := to.Write(obuf)
checkError(err, "Write: wrote "+string(wrote)+" bytes.")
}
func handleMsg(length int, err error, msg []byte) {
if length > 0 {
print("<", length, ":")
for i := 0; ; i++ {
if msg[i] == 0 {
break
}
fmt.Printf("%c", msg[i])
}
print(">")
}
}
func checkError(error error, info string) {
if error != nil {
panic("ERROR: " + info + " " + error.Error()) // terminate program
}
}
(应该是由于go版本的更新,会提示os.EAGAIN undefined ,修改后的代码:simple_tcp_server_v1.go)
都有哪些改进?
- 服务器地址和端口不再是硬编码,而是通过命令行传入参数并通过
flag包来读取这些参数。这里使用了flag.NArg()检查是否按照期望传入了2个参数:
if flag.NArg() != 2{
panic("usage: host port")
}
传入的参数通过fmt.Sprintf函数格式化成字符串:
hostAndPort := fmt.Sprintf("%s:%s", flag.Arg(0), flag.Arg(1))
- 在
initServer函数中通过net.ResolveTCPAddr指定了服务器地址和端口,这个函数最终返回了一个*net.TCPListener - 每一个连接都会以携程的方式运行
connectionHandler函数。这些开始于当通过conn.RemoteAddr()获取到客户端的地址 - 它使用
conn.Write发送改进的go-message给客户端 - 它使用一个25字节的缓冲读取客户端发送的数据并一一打印出来。如果读取的过程中出现错误,代码会进入
switch语句的default分支关闭连接。如果是操作系统的EAGAIN错误,它会重试。 - 所有的错误检查都被重构在独立的函数'checkError'中,用来分发出现的上下文错误。
在命令行中输入simple_tcp_server localhost 50000来启动服务器程序,然后在独立的命令行窗口启动一些client.go的客户端。当有两个客户端连接的情况下服务器的典型输出如下,这里我们可以看到每个客户端都有自己的地址:
E:\Go\GoBoek\code examples\chapter 14>simple_tcp_server localhost 50000
Listening to: 127.0.0.1:50000
Connection from: 127.0.0.1:49346
<25:Ivo says: Hi server, do y><12:ou hear me ?>
Connection from: 127.0.0.1:49347
<25:Marc says: Do you remembe><25:r our first meeting serve><2:r?>
net.Error: 这个net包返回错误的错误类型,下边是约定的写法,不过net.Error接口还定义了一些其他的错误实现,有些额外的方法。
package net
type Error interface{
Timeout() bool // 错误是否超时
Temporary() bool // 是否是临时错误
}
通过类型断言,客户端代码可以用来测试net.Error,从而区分哪些临时发生的错误或者必然会出现的错误。举例来说,一个网络爬虫程序在遇到临时发生的错误时可能会休眠或者重试,如果是一个必然发生的错误,则他会放弃继续执行。
// in a loop - some function returns an error err
if nerr, ok := err.(net.Error); ok && nerr.Temporary(){
time.Sleep(1e9)
continue // try again
}
if err != nil{
log.Fatal(err)
}3、网络 爬 虫
获取页面:
func Fetch(url string) {
resp, err := http.Get(url)
if err != nil {
panic(err)
}
defer resp.Body.Close()
if resp.StatusCode != http.StatusOK {
fmt.Printf("wrong status code, %d\n", resp.StatusCode)
}
all, err := ioutil.ReadAll(resp.Body)
if err != nil {
panic(err)
}
fmt.Println(string(all))
}五、Go Web
1、一个简单的web服务器
Http是一个比tcp更高级的协议,它描述了客户端浏览器如何与网页服务器进行通信。Go有自己的net/http包,我们来看看它。我们从一些简单的示例开始, 首先编写一个“Hello world!”:
我们引入了http包并启动了网页服务器,和net.Listen("tcp", "localhost:50000")函数的tcp服务器是类似的,使用http.ListenAndServe("localhost:8080", nil)函数,如果成功会返回空,否则会返回一个错误(可以指定localhost为其他地址,8080是指定的端口号)
http.URL描述了web服务器的地址,内含存放了url字符串的Path属性;http.Request描述了客户端请求,内含一个URL属性
如果req请求是一个POST类型的html表单,“var1”就是html表单中一个输入属性的名称,然后用户输入的值就可以通过GO代码:req.FormValue("var1")获取到。还有一种方法就是先执行request.ParseForm()然后再获取`request.Form["var1"]的第一个返回参数,就像这样:
var1, found := request.Form["var1"]
第二个参数found就是true,如果var1并未出现在表单中,found就是false
表单属性实际上是一个map[string][]string类型。网页服务器返回了一个http.Response,它是通过http.ResponseWriter对象输出的,这个对象整合了HTTP服务器的返回结果;通过对它写入内容,我们就讲数据发送给了HTTP客户端。
现在我们还需要编写网页服务器必须执行的程序,它是如何处理请求的呢。这是在http.HandleFunc函数中完成的,就是在这个例子中当根路径“/”(url地址是http://localhost:8080)被请求的时候(或者这个服务器上的其他地址),HelloServer函数就被执行了。这个函数是http.HandlerFunc类型的,它们通常用使用Prehandler来命名,在前边加了一个Pref前缀。
http.HandleFunc注册了一个处理函数(这里是HelloServer)来处理对应/的请求。
/可以被替换为其他特定的url比如/create,/edit等等;你可以为每一个特定的url定义一个单独的处理函数。这个函数需要两个参数:第一个是ReponseWriter类型的w;第二个是请求req。程序向w写入了Hello和r.URL.Path[1:]组成的字符串后边的[1:]表示“创建一个从第一个字符到结尾的子切片”,用来丢弃掉路径开头的“/”,fmt.Fprintf()函数完成了本次写入;另外一种写法是io.WriteString(w, "hello, world!\n")
总结:第一个参数是请求的路径,第二个参数是处理这个路径请求的函数的引用。
package main
import (
"fmt"
"log"
"net/http"
)
func HelloServer(w http.ResponseWriter, req *http.Request) {
fmt.Println("Inside HelloServer handler")
fmt.Fprintf(w, "Hello,"+req.URL.Path[1:])
}
func main() {
http.HandleFunc("/", HelloServer)
err := http.ListenAndServe("localhost:8080", nil)
if err != nil {
log.Fatal("ListenAndServe: ", err.Error())
}
}
使用命令行启动程序,会打开一个命令窗口显示如下文字:
Starting Process E:/Go/GoBoek/code_examples/chapter_14/hello_world_webserver.exe
...
然后打开你的浏览器并输入url地址:http://localhost:8080/world,浏览器就会出现文字:Hello, world,网页服务器会响应你在:8080/后边输入的内容
使用fmt.Println在控制台打印状态,在每个handler被请求的时候,在他们内部打印日志会很有帮助
注:
1)前两行(没有错误处理代码)可以替换成以下写法:
http.ListenAndServe(":8080", http.HandlerFunc(HelloServer))
2)fmt.Fprint和fmt.Fprintf都是用来写入http.ResponseWriter的不错的函数(他们实现了io.Writer)。 比如我们可以使用
fmt.Fprintf(w, "<h1>%s<h1><div>%s</div>", title, body)
来构建一个非常简单的网页并插入title和body的值。
如果你需要使用安全的https连接,使用http.ListenAndServeTLS()代替http.ListenAndServe() 4)http.HandleFunc("/", Hfunc)中的HFunc是一个处理函数,如下:
func HFunc(w http.ResponseWriter, req *http.Request) {
...
}
也可以使用这种方式:http.Handle("/", http.HandlerFunc(HFunc))
上边的HandlerFunc只是一个类型名称,它定义如下:
type HandlerFunc func(ResponseWriter, *Request)
它是一个可以把普通的函数当做HTPP处理器的适配器。如果f函数声明的合适,HandlerFunc(f)就是一个执行了f函数的处理器对象。
http.Handle的第二个参数也可以是T的一个obj对象:http.Handle("/", obj)给T提供了SereHTTP方法,实现了http的Handler接口:
func (obj *Typ) ServeHTTP(w http.ResponseWriter, req *http.Request) {
...
}
只要实现了http.Handler,http包就可以处理任何HTTP请求。
2、访问并读取页面数据
在下边这个程序中,数组中的url都将被访问:会发送一个简单的http.Head()请求查看返回值;它的声明如下:func Head(url string) (r *Response, err error)。
返回状态码会被打印出来。
示例 poll_url.go:
package main
import (
"fmt"
"net/http"
)
var urls = []string{
"http://www.google.com/",
"http://golang.org/",
"http://blog.golang.org/",
}
func main() {
// Execute an HTTP HEAD request for all url's
// and returns the HTTP status string or an error string.
for _, url := range urls {
resp, err := http.Head(url)
if err != nil {
fmt.Println("Error:", url, err)
}
fmt.Print(url, ": ", resp.Status)
}
}
输出为:
http://www.google.com/ : 302 Found
http://golang.org/ : 200 OK
http://blog.golang.org/ : 200 OK
由于国内的网络环境现状,很有可能见到如下超时错误提示:
Error: http://www.google.com/ Head http://www.google.com/: dial tcp 216.58.221.100:80: connectex: A connection attempt failed because the connected pa
rty did not properly respond after a period of time, or established connection failed because connected host has failed to respond.
在下边的程序中我们使用http.Get()获取网页内容; Get的返回值res中的Body属性包含了网页内容,然后我们用ioutil.ReadAll把它读出来:
示例 http_fetch.go:
package main
import (
"fmt"
"io/ioutil"
"log"
"net/http"
)
func main() {
res, err := http.Get("http://www.google.com")
checkError(err)
data, err := ioutil.ReadAll(res.Body)
checkError(err)
fmt.Printf("Got: %q", string(data))
}
func checkError(err error) {
if err != nil {
log.Fatalf("Get : %v", err)
}
}
当访问不存在的网站时,这里有一个CheckError输出错误的例子:
2011/09/30 11:24:15 Get: Get http://www.google.bex: dial tcp www.google.bex:80:GetHostByName: No such host is known.
和上一个例子相似,你可以把google.com更换为一个国内可以顺畅访问的网址进行测试
在下边的程序中,我们获取一个twitter用户的状态,通过xml包将这个状态解析成为一个结构:
package main
import (
"encoding/xml"
"fmt"
"net/http"
)
/*这个结构会保存解析后的返回数据。
他们会形成有层级的XML,可以忽略一些无用的数据*/
type Status struct {
Text string
}
type User struct {
XMLName xml.Name
Status Status
}
func main() {
// 发起请求查询推特Goodland用户的状态
response, _ := http.Get("http://twitter.com/users/Googland.xml")
// 初始化XML返回值的结构
user := User{xml.Name{"", "user"}, Status{""}}
// 将XML解析为我们的结构
xml.Unmarshal(response.Body, &user)
fmt.Printf("status: %s", user.Status.Text)
}
输出:
status: Robot cars invade California, on orders from Google: Google has been testing self-driving cars ... http://bit.ly/cbtpUN http://retwt.me/97p<exit code="0" msg="process exited normally"/>
译者注 和上边的示例相似,你可能无法获取到xml数据,另外由于go版本的更新,xml.Unmarshal函数的第一个参数需是[]byte类型,而无法传入Body。
ttp包中的其他重要的函数:
http.Redirect(w ResponseWriter, r *Request, url string, code int):这个函数会让浏览器重定向到url(是请求的url的相对路径)以及状态码。http.NotFound(w ResponseWriter, r *Request):这个函数将返回网页没有找到,HTTP 404错误。http.Error(w ResponseWriter, error string, code int):这个函数返回特定的错误信息和HTTP代码。- 另
http.Request对象的一个重要属性req:req.Method,这是一个包含GET或POST字符串,用来描述网页是以何种方式被请求的。
go为所有的HTTP状态码定义了常量,比如:
http.StatusContinue = 100
http.StatusOK = 200
http.StatusFound = 302
http.StatusBadRequest = 400
http.StatusUnauthorized = 401
http.StatusForbidden = 403
http.StatusNotFound = 404
http.StatusInternalServerError = 500
你可以使用`w.header().Set("Content-Type", "../..")设置头信息
比如在网页应用发送html字符串的时候,在输出之前执行w.Header().Set("Content-Type", "text/html")。
3、写一个简单的网页应用
下边的程序在端口8088上启动了一个网页服务器;SimpleServer会处理/test1url使它在浏览器输出hello world。FormServer会处理'/test2url:如果url最初由浏览器请求,那么它就是一个GET请求,并且返回一个form常量,包含了简单的input表单,这个表单里有一个文本框和一个提交按钮。当在文本框输入一些东西并点击提交按钮的时候,会发起一个POST请求。FormServer中的代码用到了switch来区分两种情况。
在POST情况下,使用request.FormValue("inp")通过文本框的name属性inp来获取内容,并写回浏览器页面。在控制台启动程序并在浏览器中打开urlhttp://localhost:8088/text2`来测试这个程序:
package main
import (
"io"
"net/http"
)
const form = `
<html><body>
<form action="#" method="post" name="bar">
<input type="text" name="in" />
<input type="submit" value="submit"/>
</form>
</body></html>
`
/* handle a simple get request */
func SimpleServer(w http.ResponseWriter, request *http.Request) {
io.WriteString(w, "<h1>hello, world</h1>")
}
func FormServer(w http.ResponseWriter, request *http.Request) {
w.Header().Set("Content-Type", "text/html")
switch request.Method {
case "GET":
/* display the form to the user */
io.WriteString(w, form)
case "POST":
/* handle the form data, note that ParseForm must
be called before we can extract form data */
//request.ParseForm();
//io.WriteString(w, request.Form["in"][0])
io.WriteString(w, request.FormValue("in"))
}
}
func main() {
http.HandleFunc("/test1", SimpleServer)
http.HandleFunc("/test2", FormServer)
if err := http.ListenAndServe(":8088", nil); err != nil {
panic(err)
}
}
注:当使用字符串常量表示html文本的时候,包含<html><body></body></html>对于让浏览器识别它收到了一个html非常重要。
更安全的做法是在处理器中使用w.Header().Set("Content-Type", "text/html")在写入返回之前将header的content-type设置为text/html
content-type会让浏览器认为它可以使用函数http.DetectContentType([]byte(form))来处理收到的数据
4、gin框架
1)快速入门
安装Gin:
go get -u github.com/gin-gonic/gin
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
r.GET("/", func(c *gin.Context) {
c.JSON(http.StatusOK, gin.H{
"message": "HelloWorld",
})
})
r.Run() // 默认为8080
}
r.NoRoute(func(c *gin.Context) {
c.String(http.StatusNotFound, "404 not found111111111")
})2)HTML渲染
使用 LoadHTMLGlob() 或者 LoadHTMLFiles():
package main
import (
"github.com/gin-gonic/gin"
"net/http"
)
func main() {
r := gin.Default()
//r.LoadHTMLFiles("templates/index.tmpl") // 加载到指定文件名
r.LoadHTMLGlob("templates/*") // 加载templates下所有文件
r.GET("/index", func(c *gin.Context) {
c.HTML(http.StatusOK, "index.tmpl", gin.H{
"title": "Hello Gin",
})
})
r.Run(":8888") // 监听8888端口
}
templates/index.tmpl:
<html>
<h1>
{
{ .title }}
</h1>
</html>3)JSONP
使用 JSONP 向不同域的服务器请求数据。如果查询参数存在回调,则将回调添加到响应体中。
实例:
func main() {
r := gin.Default()
r.GET("/JSONP", func(c *gin.Context) {
data := map[string] interface {} {
"foo": "bar",
}
c.JSONP(200, data)
})
r.Run(":8888")
}
curl http://127.0.0.1:8888/JSONP
#返回
{"foo":"bar"}
curl http://127.0.0.1:8888/JSONP?callback=x
#返回
x({"foo":"bar"});4)Multipart/Urlencoded绑定
type LoginForm struct {
User string `form:"user" binding:"required"`
Password string `form:"password" binding:"required"`
}
func main() {
r := gin.Default()
r.POST("/login", func(c *gin.Context) {
var form LoginForm
if c.ShouldBind(&form) == nil {
if form.User == "user" && form.Password == "password" {
c.JSON(200, gin.H{"status": "login successfully!"})
} else {
c.JSON(401, gin.H{"status": "login failed!"})
}
}
})
r.Run(":8888")
}
func main() {
r := gin.Default()
r.POST("/form_post", func(c *gin.Context) {
message := c.PostForm("message")
nick := c.DefaultPostForm("nick", "anonymous")
c.JSON(200, gin.H{
"status": "posted",
"message": message,
"nick": nick,
})
})
r.Run(":8888")
}5)PureJSON
通常,JSON 使用 unicode 替换特殊 HTML 字符,例如 < 变为 \ u003c。
如果要按字面对这些字符进行编码,则可以使用 PureJSON。
func main() {
r := gin.Default()
r.GET("/json", func(c *gin.Context) {
c.JSON(200, gin.H{
"html": "<b>Hello World!</b>",
})
})
// 返回 {"html":"\u003cb\u003eHello World!\u003c/b\u003e"}
r.GET("/purejson", func(c *gin.Context) {
c.PureJSON(200, gin.H{
"html": "<b>Hello World!</b>",
})
})
// 返回 {"html":"<b>Hello World!</b>"}
r.Run(":8888")
}5、beego框架
1)Bee工具安装
安装:
go get -u github.com/beego/bee/v2
在$GOPATH/bin下生成bee.exe,需要将$GOPATH/bin添加到环境变量中。
在$GOPATH/src下执行该命令。
bee new [project_name]2)配置模块
Beego目前支持INI、XML、JSON、YAML格式的配置文件解析,也支持以etcd作为远程配置中心。
默认采用INI格式解析。
- 使用
config.xxxx:依赖于全局配置实例 - 使用
Configer实例
Beego默认解析conf/app.conf文件。
package main
import (
"github.com/beego/beego/v2/core/config"
"github.com/beego/beego/v2/core/logs"
)
func main() {
s, _ := config.String("appname")
logs.Info(s)
}
指定配置文件的类型,如使用json,使用匿名引入:
var configFile = "./conf.json"
config.InitGlobalInstance("json", "configFile")
如果是读取多个配置文件或者使用自定义的配置实例:
package main
import (
"github.com/beego/beego/v2/core/config"
"github.com/beego/beego/v2/core/logs"
)
func main() {
configer, err := config.NewConfig("ini", "conf.ini")
if err != nil {
logs.Error(err)
}
s, _ := configer.String("name")
logs.Info(s)
}
如果环境变量中ProRunMode和ProPort有值,则runmode 和httpport 使用的环境变量的值,否则使用"dev"和"9090"
runmode = "${ProRunMode||dev}"
httpport = "${ProPort||9090}"
INI是默认格式,支持include方式,加载多个配置文件。
app.ini:
appname = test
httpaddr = "127.0.0.1"
httpport = 9090
include "app2.ini"
app2.ini:
runmode ="dev"
autorender = false
recoverpanic = false
viewspath = "myview"
[dev]
httpport = 8080
[prod]
httpport = 8088
[test]
httpport = 88883)路由
(1)注册控制器风格的路由
controller里处理http请求的方法必须是公共方法,首字母大写、没有参数、没有返回值。
方法接收器可以不是指针,并不强制。
package main
import "github.com/beego/beego/v2/server/web"
type UserController struct {
web.Controller
}
type IndexController struct {
web.Controller
}
func (i *IndexController) Show() {
i.Ctx.WriteString("this is index website")
}
func (u *UserController) HelloWorld() {
u.Ctx.WriteString("hello, world")
}
func main() {
web.AutoRouter(&UserController{})
web.AutoRouter(&IndexController{})
web.Run()
}
以上定义了UserController 和 IndexController,那它们的名字分别是User和Index。
大小写不敏感的时候,userController和 indexController也是合法的名字。
AutoRouter解析出来的路由规则由RouterCaseSensitive的值,Controller的名字和方法名字共同决定。
UserController 名字是User,方法是HelloWorld;如果RouterCaseSensitive为true,
那么AutoRouter会注册两个路由,/user/helloworld/*,/User/HelloWorld/*;
否则会注册一个路由,/user/helloworld/*;RouterCaseSensitive为Config结构体bool类型的字段。
使用AutoPrefix的时候,注册的路由符合prefix/controllerName/methodName这种样式。
package main
import "github.com/beego/beego/v2/server/web"
type IndexController struct {
web.Controller
}
func (i *IndexController) Show() {
i.Ctx.WriteString("this is index website")
}
func main() {
index := &IndexController{}
web.AutoPrefix("api", index ) //http://localhost:8080/api/index/show
web.Run()
}
func main() {
web.Get("/hello", func(ctx *context.Context) {
ctx.WriteString("hello, world")
})
web.Run()
}
在注册路由的时候,需要按照一定的规律组织。
举例说明:
- 整个应用分成两块,一个对安卓提供的API,一个对IOS,就划分成两个命名空间。
- 版本的划分,v1、v2、v3。
代码示例:
package main
import (
"github.com/beego/beego/v2/server/web"
"github.com/beego/beego/v2/server/web/context"
)
type MainController struct {
web.Controller
}
func (mc *MainController) Home() {
mc.Ctx.WriteString("this is home")
}
type UserController struct {
web.Controller
}
func (uc *UserController) Get() {
uc.Ctx.WriteString("get user")
}
func Health(ctx *context.Context) {
ctx.WriteString("health")
}
func main() {
uc := &UserController{}
ns := web.NewNamespace("/v1",
web.NSCtrlGet("/home", (*MainController).Home),
web.NSRouter("/user", uc),
web.NSGet("/health", Health),
)
web.AddNamespace(ns)
web.Run()
}
func main() {
uc := &UserController{}
// 初始化 namespace
ns := web.NewNamespace("/v1",
web.NSCtrlGet("/home", (*MainController).Home),
web.NSRouter("/user", uc),
web.NSGet("/health", Health),
// 嵌套 namespace
web.NSNamespace("/admin",
web.NSRouter("/user", uc),
),
)
//注册 namespace
web.AddNamespace(ns)
web.Run()
}
Beego的namespace提供了一种条件判断机制,只有符合条件的情况下,该namespace下的路由才会被执行。
func main() {
uc := &UserController{}
ns := web.NewNamespace("/v1",
web.NSCond(func(b *context.Context) bool {
return b.Request.Header["x-trace-id"][0] != ""
}),
web.NSCtrlGet("/home", (*MainController).Home),
web.NSRouter("/user", uc),
web.NSGet("/health", Health),
)
web.AddNamespace(ns)
web.Run()
}
建议实现一个filter,代码理解性更高;该方法未来将移除。
func main() {
uc := &UserController{}
ns := web.NewNamespace("/v1",
web.NSCond(func(b *context.Context) bool {
return b.Request.Header["x-trace-id"][0] != ""
}),
web.NSBefore(func(ctx *context.Context) {
fmt.Println("before filter")
}),
web.NSAfter(func(ctx *context.Context) {
fmt.Println("after filter")
}),
web.NSCtrlGet("/home", (*MainController).Home),
web.NSRouter("/user", uc),
web.NSGet("/health", Health),
web.NSNamespace("/admin",
web.NSRouter("/user", uc),
),
)
ns.Filter("before", func(ctx *context.Context) {
fmt.Println("this is filter for health")
})
web.AddNamespace(ns)
web.Run()
}六、标准库
1、IO操作
1)Reader接口
定义:
type Reader interface {
Read(p []byte) (n int, err error)
}
func ReadFrom(reader io.Reader, num int) ([]byte, error) {
p := make([]byte, num)
n, err := reader.Read(p)
if err != nil {
panic(err)
}
if n > 0 {
return p[:n], nil
}
return p, err
}
func main() {
reader := strings.NewReader("Hello Golang")
data, err := ReadFrom(reader, 12)
if err != nil {
panic(err)
}
fmt.Println(data)
}
定义:
type Writer interface {
Write(p []byte) (n int, err error)
}2、文件操作
1)开、关闭文件
func main() {
file, err := os.Open("./main.go")
if err != nil {
fmt.Println("open file failed")
return
}
defer file.Close()
fmt.Println("open file successfully")
}
func (f *File) Read(b []byte) (n int, err error)
func main() {
file, err := os.Open("./test.txt")
if err != nil {
fmt.Println("open file failed, err: ", err)
return
}
defer file.Close()
// Read方法来读取文件内容
// 声明长度为128的字节切片来存放读取到的数据
var tmp = make([]byte, 128)
n, err := file.Read(tmp)
if err == io.EOF {
fmt.Println("文件读取完毕")
return
}
if err != nil {
fmt.Println("read file failed, err: ", err)
return
}
fmt.Printf("读取了%d个字节\n", n)
// 转成字符串
fmt.Println(string(tmp[:n]))
}
func readFromFile() {
file, err := os.Open("./test.txt")
if err != nil {
fmt.Println("open file failed, err: ", err)
return
}
defer file.Close()
var content []byte
var tmp = make([]byte, 128)
for {
n, err := file.Read(tmp)
if err == io.EOF {
fmt.Println("文件读取完毕")
break
}
if err != nil {
fmt.Println("read file failed, err: ", err)
return
}
content = append(content, tmp[:n]...)
}
fmt.Println(string(content))
}
func readFromFile() {
file, err := os.Open("./test.txt")
if err != nil {
fmt.Println("open file failed, err: ", err)
return
}
defer file.Close()
reader := bufio.NewReader(file)
for {
line, err := reader.ReadString('\n')
if err == io.EOF {
if len(line) != 0 {
fmt.Println(line)
}
fmt.Println("文件读取完毕!")
break
}
if err != nil {
fmt.Println("read file failed, err: ", err)
return
}
fmt.Print(line)
}
}
func readFromFile() {
content, err := ioutil.ReadFile("./test.txt")
if err != nil {
fmt.Println("read file failed, err: ", err)
return
}
fmt.Println(string(content))
}
os.OpenFile()以指定模式打开文件,从而实现文件写入相关功能:
const (
// Exactly one of O_RDONLY, O_WRONLY, or O_RDWR must be specified.
O_RDONLY int = syscall.O_RDONLY // open the file read-only.
O_WRONLY int = syscall.O_WRONLY // open the file write-only.
O_RDWR int = syscall.O_RDWR // open the file read-write.
// The remaining values may be or'ed in to control sbehavior.
O_APPEND int = syscall.O_APPEND // append data to the file when writing.
O_CREATE int = syscall.O_CREAT // create a new file if none exists.
O_EXCL int = syscall.O_EXCL // used with O_CREATE, file must not exist.
O_SYNC int = syscall.O_SYNC // open for synchronous I/O.
O_TRUNC int = syscall.O_TRUNC // truncate regular writable file when opened.
)
7)Write和WriteString
func writeToFile() {
file, err := os.OpenFile("./test.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("open file failed, err: ", err)
return
}
defer file.Close()
str := "superman\n"
file.Write([]byte(str))
file.WriteString("flash")
}
8)bufio.NewWriter
func writeToFile() {
file, err := os.OpenFile("./test.txt", os.O_CREATE|os.O_TRUNC|os.O_WRONLY, 0666)
if err != nil {
fmt.Println("open file failed, err: ", err)
return
}
defer file.Close()
writer := bufio.NewWriter(file)
for i := 0; i < 10; i++ {
writer.WriteString("hello world\n") // 将数据写入缓存
}
writer.Flush() // 将缓存中的数据写入文件
9)ioutil.WriteFile
func writeToFile() {
str := "hello world"
err := ioutil.WriteFile("./test.txt", []byte(str), 0666)
if err != nil {
fmt.Println("write file failed, err:", err)
return
}
}
10)拷贝文件
func CopyFile(dstName, srcName string) (written int64, err error) {
// open需要拷贝的源文件
src, err := os.Open(srcName)
if err != nil {
fmt.Printf("open %s failed, err:%v.\n", srcName, err)
return
}
defer src.Close()
// 写入目标文件
dst, err := os.OpenFile(dstName, os.O_WRONLY|os.O_CREATE, 0644)
if err != nil {
fmt.Printf("open %s failed, err:%v.\n", dstName, err)
return
}
defer dst.Close()
return io.Copy(dst, src)
}3、格式化输出
1)通用占位符
%v 值的默认格式表示
%+v 类似%v,但输出结构体时会添加字段名
%#v 值的Go语法表示
%T 打印值的类型
%% 百分号
%t true或false
3)整型
%b 表示为二进制
%c 该值对应的unicode码值
%d 表示为十进制
%o 表示为八进制
%x 表示为十六进制,使用a-f
%X 表示为十六进制,使用A-F
%U 表示为Unicode格式:U+1234,等价于”U+%04X”
%q 该值对应的单引号括起来的go语法字符字面值,必要时会采用安全的转义表示4、flag
1)获取命令行参数
os.Args获取命令行参数:
// test.go
func main() {
if len(os.Args) > 0 {
for index, arg := range os.Args {
fmt.Printf("args[%d]=%v\n", index, arg)
}
}
}
// 编译
go build -o test.exe test.go
// 执行
test.exe a b c
// 输出:
args[0]=test.exe
args[1]=a
args[2]=b
args[3]=c
os.Args是一个存储命令行参数的字符串切片,第一个参数是命令本身。
flag包支持的参数类型bool、int、int64、uint、uint64、float、float64、string、duration
flag.Type(flag名, 默认值, 帮助信息) *Type:
name := flag.String("name", "张三", "姓名")
age := flag.Int("age", 18, "年龄")
married := flag.Bool("married", false, "婚否")
delay := flag.Duration("d", 0, "时间间隔")
flag.TypeVar(Type指针, flag名, 默认值, 帮助信息):
var name string
var age int
var married bool
var delay time.Duration
flag.StringVar(&name, "name", "张三", "姓名")
flag.IntVar(&age, "age", 18, "年龄")
flag.BoolVar(&married, "married", false, "婚否")
flag.DurationVar(&delay, "d", 0, "时间间隔")
flag.Args() 返回命令行参数后的其他参数,以[]string类型
flag.NArg() //返回命令行参数后的其他参数个数
flag.NFlag() //返回使用的命令行参数个数
示例:
func main() {
//定义命令行参数方式1
var name string
var age int
var married bool
var delay time.Duration
flag.StringVar(&name, "name", "张三", "姓名")
flag.IntVar(&age, "age", 18, "年龄")
flag.BoolVar(&married, "married", false, "婚否")
flag.DurationVar(&delay, "d", 0, "延迟的时间间隔")
//解析命令行参数
flag.Parse()
fmt.Println(name, age, married, delay)
//返回命令行参数后的其他参数
fmt.Println(flag.Args())
//返回命令行参数后的其他参数个数
fmt.Println(flag.NArg())
//返回使用的命令行参数个数
fmt.Println(flag.NFlag())5、log
func main() {
log.Println("这是一条很普通的日志。")
v := "很普通的"
log.Printf("这是一条%s日志。\n", v)
log.Fatalln("这是一条会触发fatal的日志。")
log.Panicln("这是一条会触发panic的日志。")
}
func Flags() int
func SetFlags(flag int)
log库中使用SetFlags方法来设置日志的输出格式:
func main() {
log.SetFlags(log.Ldate | log.Ltime) // 日期 和 时间
log.Println("这是一条很普通的日志")
}
// 输出:
2022/06/08 11:13:42 这是一条很普通的日志
const (
// 控制输出日志信息的细节,不能控制输出的顺序和格式。
// 输出的日志在每一项后会有一个冒号分隔:例如2009/01/23 01:23:23.123123 /a/b/c/d.go:23: message
Ldate = 1 << iota // 日期:2009/01/23
Ltime // 时间:01:23:23
Lmicroseconds // 微秒级别的时间:01:23:23.123123(用于增强Ltime位)
Llongfile // 文件全路径名+行号: /a/b/c/d.go:23
Lshortfile // 文件名+行号:d.go:23(会覆盖掉Llongfile)
LUTC // 使用UTC时间
LstdFlags = Ldate | Ltime // 标准logger的初始值
)
func Prefix() string
func SetPrefix(prefix string)
// 配置日志的前缀
func main() {
log.SetFlags(log.LstdFlags)
log.Println("这是一条普通的日志")
log.SetPrefix("[INFO]\t")
log.Println("这是一条普通的日志")
}
func SetOutput(w io.Writer)
// 配置日志输出位置
func main() {
logFile, err := os.OpenFile("./test.log", os.O_CREATE|os.O_WRONLY|os.O_APPEND, 0644)
if err != nil {
fmt.Println("open log file failed: err: ", err)
return
}
log.SetOutput(logFile)
log.SetFlags(log.LstdFlags)
log.Println("这是一条普通的日志")
log.SetPrefix("[INFO]\t")
log.Println("这是一条普通的日志")
}
func New(out io.Writer, prefix string, flag int) *Logger
// 创建logger
func main() {
logger := log.New(os.Stdout, "<INFO>\t", log.LstdFlags)
logger.Println("这是自定义的logger记录的日志")
}6、time
1)获取当前时间,依次打印年月日
func getNow() {
now := time.Now()
fmt.Println(now)
year := now.Year()
month := now.Month()
day := now.Day()
hour := now.Hour()
minute := now.Minute()
second := now.Second()
fmt.Println(year, int(month), day, hour, minute, second)
}
func main() {
getNow()
}
// 输出:
2022-06-09 15:04:36.5725912 +0800 CST m=+0.003092201
2022 6 9 15 4 36
2)时间戳
// timestamp 时间戳
func getTimestamp() {
now := time.Now() // 获取当前时间
timestamp := now.Unix() // 秒级时间戳
milli := now.UnixMilli() // 毫秒时间戳 Go1.17+
micro := now.UnixMicro() // 微秒时间戳 Go1.17+
nano := now.UnixNano() // 纳秒时间戳
fmt.Println(timestamp, milli, micro, nano)
}
// 输出:
1654758994
1654758994831
1654758994831770
16547589948317701007、strconv
1)string与int类型相互转换
Atoi()将字符串类型的整数转换为int类型:
func Atoi(s string) (i int, err error)
func main() {
s1 := "100"
i1, err := strconv.Atoi(s1)
if err != nil {
fmt.Println("can't convert to int")
} else {
fmt.Printf("type:%T value:%#v\n", i1, i1)
}
}
// 输出:
type:int value:100
Itoa()将int类型数据转换为对应的字符串:
func Itoa(i int) string
i2 := 200
s2 := strconv.Itoa(i2)
fmt.Printf("type:%T value:%#v\n", s2, s2)
// 输出:
type:string value:"200"
Parse类函数用于转换字符串为给定类型的值:ParseBool()、ParseFloat()、ParseInt()、ParseUint()。
ParseBool()源码:
func ParseBool(str string) (bool, error) {
switch str {
case "1", "t", "T", "true", "TRUE", "True":
return true, nil
case "0", "f", "F", "false", "FALSE", "False":
return false, nil
}
return false, syntaxError("ParseBool", str)
}8、template
1)模板引擎的使用
Go语言模板引擎的使用可以分为三部分:定义模板文件、解析模板文件和模板渲染。
定义模板文件:
<!doctype html>
<html lang="en">
<head>
<meta charset="UTF-8">
<meta name="viewport"
content="width=device-width, user-scalable=no, initial-scale=1.0, maximum-scale=1.0, minimum-scale=1.0">
<meta http-equiv="X-UA-Compatible" content="ie=edge">
<title>Hello</title>
</head>
<body>
<p>Hello {
{.}}</p>
</body>
</html>
2)解析和渲染模板文件
func sayHello(w http.ResponseWriter, r *http.Request) {
tmpl, err := template.ParseFiles("./hello.tmpl")
if err != nil {
fmt.Println("create template failed, err: ", err)
return
}
tmpl.Execute(w, "Alice Cooper")
}
func main() {
http.HandleFunc("/", sayHello)
err := http.ListenAndServe(":9000", nil)
if err != nil {
fmt.Println("HTTP server failed, err: ", err)
return
}
}
Go模板语法中的条件判断有以下几种:
{
{if pipeline}} T1 {
{end}}
{
{if pipeline}} T1 {
{else}} T0 {
{end}}
{
{if pipeline}} T1 {
{else if pipeline}} T0 {
{end}}9、os
os.Setenv()设置环境值的值。os.Getenv()获取指定键对应的环境变量值。os.Unsetenv()删除指定键命名对应的单个环境值,如果我们再尝试使用os.Getenv()来获取该环境值,将返回一个空值。os.ExpandEnv根据环境变量的值替换字符串中的${var}或$var。如果不存在任何环境变量,则将使用空字符串替换它。os.LookupEnv()获取指定键对应的环境变量值。如果系统中不存在该变量,则返回值将为空,并且布尔值将为 false。否则,它将返回值(可以为空),并且布尔值为 true。
七、第三方库
1、zap库
安装zap:
go get -u go.uber.org/zap
Zap提供了两种类型的日志记录器—Sugared Logger和Logger。
在性能很好但不是很关键的上下文中,使用SugaredLogger。它比其他结构化日志记录包快4-10倍,并且支持结构化和printf风格的日志记录。
在每一微秒和每一次内存分配都很重要的上下文中,使用Logger。它甚至比SugaredLogger更快,内存分配次数也更少,但它只支持强类型的结构化日志记录。
var logger *zap.Logger
func initLogger() {
logger, _ = zap.NewProduction()
}
func simpleHttpGet(url string) {
resp, err := http.Get(url)
if err != nil {
logger.Error("Error fetching url...", zap.String("url", url), zap.Error(err))
} else {
logger.Info("Success..", zap.String("StatusCode", resp.Status), zap.String("url", url))
resp.Body.Close()
}
}
func main() {
initLogger()
defer logger.Sync()
simpleHttpGet("www.baidu.com")
simpleHttpGet("http://www.baidu.com")
}2、GORM
安装gorm:
go get github.com/jinzhu/gorm
快速开始:
package main
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/sqlite"
)
func main() {
db, err := gorm.Open("sqlite3", "test.db")
if err != nil {
panic("failed to connect database")
}
defer db.Close()
gorm.Model包含基本字段,ID、CreatedAt、UpdatedAt、DeletedAt:
package gorm
import "time"
type Model struct {
ID uint `gorm:"primary_key"`
CreatedAt time.Time
UpdatedAt time.Time
DeletedAt *time.Time `sql:"index"`
}
GORM默认使用ID作为主键名。如果定义的结构体中有ID字段,将被作为主键名;也可将其他字段设为主键。
user_id `gorm:"primary_key"`
导入对应的数据库驱动:
import _ "github.com/jinzhu/gorm/dialects/mysql"
// import _ "github.com/jinzhu/gorm/dialects/postgres"
// import _ "github.com/jinzhu/gorm/dialects/sqlite"
// import _ "github.com/jinzhu/gorm/dialects/mssql"
MySQL:
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mysql"
)
func main() {
db, err := gorm.Open("mysql", "user:password@/dbname?charset=utf8&parseTime=True&loc=Local")
defer db.Close()
}
PostgreSQL:
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/postgres"
)
func main() {
db, err := gorm.Open("postgres", "host=myhost port=myport user=gorm dbname=gorm password=mypassword")
defer db.Close()
}
Sqlite3:
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/sqlite"
)
func main() {
db, err := gorm.Open("sqlite3", "/tmp/gorm.db")
defer db.Close()
}
SQL Server:
import (
"github.com/jinzhu/gorm"
_ "github.com/jinzhu/gorm/dialects/mssql"
)
func main() {
db, err := gorm.Open("mssql", "sqlserver://username:password@localhost:1433?database=dbname")
defer db.Close()
}八、Go GUI
1、fyne
安装:
go get fyne.io/fyne/v2
示例:
type App struct {
output *widget.Label
}
var myapp App
func main() {
a := app.New()
w := a.NewWindow("Hello World")
output, entry, btn := myapp.makeUI()
w.SetContent(container.NewVBox(output, entry, btn))
w.Resize(fyne.Size{Width: 500, Height: 500})
w.ShowAndRun()
}
func (app *App) makeUI() (*widget.Label, *widget.Entry, *widget.Button) {
output := widget.NewLabel("Hello, World!")
entry := widget.NewEntry()
btn := widget.NewButton("Enter", func() {
app.output.SetText(entry.Text)
})
app.output = output
return output, entry, btn
}2、显示时间
func updateTime(clock *widget.Label) {
formatted := time.Now().Format("Time: 03:04:05")
clock.SetText(formatted)
}
func main() {
a := app.New()
w := a.NewWindow("天下第一")
clock := widget.NewLabel("")
w.SetContent(clock)
go func() {
for range time.Tick(time.Second) {
updateTime(clock)
}
}()
w.Resize(fyne.NewSize(500, 300))
w.ShowAndRun()
}九、常见错误处理
在之前的内容中,有时候使用!!...!!标记警告go语言中的一些错误使用方式。为了方便起见,这里列出了一些常见陷进,以便于你能发现更多的解释和例子:
- 永远不要使用形如
var p*a声明变量,这会混淆指针声明和乘法运算 - 永远不要在
for循环自身中改变计数器变量 - 永远不要在
for-range循环中使用一个值去改变自身的值 - 永远不要将
goto和前置标签一起使用 - 永远不要忘记在函数名后加括号(),尤其调用一个对象的方法或者使用匿名函数启动一个协程时
- 永远不要使用
new()一个map,一直使用make - 当为一个类型定义一个String()方法时,不要使用
fmt.Print或者类似的代码 - 永远不要忘记当终止缓存写入时,使用
Flush函数 - 永远不要忽略错误提示,忽略错误会导致程序奔溃
- 不要使用全局变量或者共享内存,这会使并发执行的代码变得不安全
println函数仅仅是用于调试的目的
最佳实践:对比以下使用方式:
- 使用正确的方式初始化一个元素是切片的映射,例如
map[type]slice - 一直使用逗号,ok或者checked形式作为类型断言
- 使用一个工厂函数创建并初始化自己定义类型
- 仅当一个结构体的方法想改变结构体时,使用结构体指针作为方法的接受者,否则使用一个结构体值类型
本章主要汇总了go语言使用过程中最常见的错误和注意事项。在之前的章节已经涉及到了完整的示例和解释,你应该做的不仅仅是阅读这段的标题。
1、误用短声明导致变量覆盖
var remember bool = false
if something {
remember := true //错误
}
// 使用remember
在此代码段中,remember变量永远不会在if语句外面变成true,如果something为true,由于使用了短声明:=,if语句内部的新变量remember将覆盖外面的remember变量,并且该变量的值为true,但是在if语句外面,变量remember的值变成了false,所以正确的写法应该是:
if something {
remember = true
}
此类错误也容易在for循环中出现,尤其当函数返回一个具名变量时难于察觉 ,例如以下的代码段:
func shadow() (err error) {
x, err := check1() // x是新创建变量,err是被赋值
if err != nil {
return // 正确返回err
}
if y, err := check2(x); err != nil { // y和if语句中err被创建
return // if语句中的err覆盖外面的err,所以错误的返回nil!
} else {
fmt.Println(y)
}
return
}2、误用字符串
当需要对一个字符串进行频繁的操作时,谨记在go语言中字符串是不可变的(类似java和c#)。使用诸如a += b形式连接字符串效率低下,尤其在一个循环内部使用这种形式。这会导致大量的内存开销和拷贝。应该使用一个字符数组代替字符串,将字符串内容写入一个缓存中。例如以下的代码示例:
var b bytes.Buffer
...
for condition {
b.WriteString(str) // 将字符串str写入缓存buffer
}
return b.String()
注意:由于编译优化和依赖于使用缓存操作的字符串大小,当循环次数大于15时,效率才会更佳。
3、发生错误时使用defer关闭一个文件
如果你在一个for循环内部处理一系列文件,你需要使用defer确保文件在处理完毕后被关闭,例如:
for _, file := range files {
if f, err = os.Open(file); err != nil {
return
}
// 这是错误的方式,当循环结束时文件没有关闭
defer f.Close()
// 对文件进行操作
f.Process(data)
}
但是在循环结尾处的defer没有执行,所以文件一直没有关闭!垃圾回收机制可能会自动关闭文件,但是这会产生一个错误,更好的做法是:
for _, file := range files {
if f, err = os.Open(file); err != nil {
return
}
// 对文件进行操作
f.Process(data)
// 关闭文件
f.Close()
}
defer仅在函数返回时才会执行,在循环的结尾或其他一些有限范围的代码内不会执行。
4、不需要将一个指向切片的指针传递给函数
我们已经知道,切片实际是一个指向潜在数组的指针。我们常常需要把切片作为一个参数传递给函数是因为:实际就是传递一个指向变量的指针,在函数内可以改变这个变量,而不是传递数据的拷贝。
因此应该这样做:
`func findBiggest( listOfNumbers []int ) int {}`
而不是:
`func findBiggest( listOfNumbers *[]int ) int {}`
当切片作为参数传递时,切记不要解引用切片。
5、使用指针指向接口类型
查看如下程序:nexter是一个接口类型,并且定义了一个next()方法读取下一字节。函数nextFew将nexter接口作为参数并读取接下来的num个字节,并返回一个切片:这是正确做法。但是nextFew2使用一个指向nexter接口类型的指针作为参数传递给函数:当使用next()函数时,系统会给出一个编译错误:n.next undefined (type *nexter has no field or method next) (译者注:n.next未定义(*nexter类型没有next成员或next方法))
例 pointer_interface.go (不能通过编译):
package main
import (
“fmt”
)
type nexter interface {
next() byte
}
func nextFew1(n nexter, num int) []byte {
var b []byte
for i:=0; i < num; i++ {
b[i] = n.next()
}
return b
}
func nextFew2(n *nexter, num int) []byte {
var b []byte
for i:=0; i < num; i++ {
b[i] = n.next() // 编译错误:n.next未定义(*nexter类型没有next成员或next方法)
}
return b
}
func main() {
fmt.Println(“Hello World!”)
}6、使用值类型时误用指针
将一个值类型作为一个参数传递给函数或者作为一个方法的接收者,似乎是对内存的滥用,因为值类型一直是传递拷贝。但是另一方面,值类型的内存是在栈上分配,内存分配快速且开销不大。如果你传递一个指针,而不是一个值类型,go编译器大多数情况下会认为需要创建一个对象,并将对象移动到堆上,所以会导致额外的内存分配:因此当使用指针代替值类型作为参数传递时,我们没有任何收获。
7、误用协程和通道
由于需要和对协程的工作原理有一个直观的了解,需要使用了一些简单的算法,举例说明了协程和通道的使用,例如生产者或者迭代器。在实际应用中,你不需要并发执行,或者你不需要关注协程和通道的开销,在大多数情况下,通过栈传递参数会更有效率。
但是,如果你使用break、return或者panic去跳出一个循环,很有可能会导致内存溢出,因为协程正处理某些事情而被阻塞。在实际代码中,通常仅需写一个简单的过程式循环即可。当且仅当代码中并发执行非常重要,才使用协程和通道。
8、闭包和协程的使用
请看下面代码:
package main
import (
"fmt"
"time"
)
var values = [5]int{10, 11, 12, 13, 14}
func main() {
// 版本A:
for ix := range values { // ix是索引值
func() {
fmt.Print(ix, " ")
}() // 调用闭包打印每个索引值
}
fmt.Println()
// 版本B: 和A版本类似,但是通过调用闭包作为一个协程
for ix := range values {
go func() {
fmt.Print(ix, " ")
}()
}
fmt.Println()
time.Sleep(5e9)
// 版本C: 正确的处理方式
for ix := range values {
go func(ix interface{}) {
fmt.Print(ix, " ")
}(ix)
}
fmt.Println()
time.Sleep(5e9)
// 版本D: 输出值:
for ix := range values {
val := values[ix]
go func() {
fmt.Print(val, " ")
}()
}
time.Sleep(1e9)
}
输出:
0 1 2 3 4
4 4 4 4 4
1 0 3 4 2
10 11 12 13 14
版本A调用闭包5次打印每个索引值,版本B也做相同的事,但是通过协程调用每个闭包。按理说这将执行得更快,因为闭包是并发执行的。如果我们阻塞足够多的时间,让所有协程执行完毕,版本B的输出是:4 4 4。为什么会这样?在版本B的循环中,ix变量 实际是一个单变量,表示每个数组元素的索引值。因为这些闭包都只绑定到一个变量,这是一个比较好的方式,当你运行这段代码时,你将看见每次循环都打印最后一个索引值4,而不是每个元素的索引值。因为协程可能在循环结束后还没有开始执行,而此时ix值是4。
版本C的循环写法才是正确的:调用每个闭包是将ix作为参数传递给闭包。ix在每次循环时都被重新赋值,并将每个协程的ix放置在栈中,所以当协程最终被执行时,每个索引值对协程都是可用的。注意这里的输出可能是0 2 1 3 4或者0 3 1 2 4或者其他类似的序列,这主要取决于每个协程何时开始被执行。
在版本D中,我们输出这个数组的值,为什么版本B不能而版本D可以呢?
因为版本D中的变量声明是在循环体内部,所以在每次循环时,这些变量相互之间是不共享的,所以这些变量可以单独的被每个闭包使用。
9、 糟糕的错误处理
像下面代码一样,创建一个布尔型变量用于测试错误条件是多余的:
var good bool
// 测试一个错误,`good`被赋为`true`或者`false`
if !good {
return errors.New("things aren’t good")
}
立即检测一个错误:
... err1 := api.Func1()
if err1 != nil { … }
避免写出这样的代码:
... err1 := api.Func1()
if err1 != nil {
fmt.Println("err: " + err.Error())
return
}
err2 := api.Func2()
if err2 != nil {
...
return
}
首先,包括在一个初始化的if语句中对函数的调用。但即使代码中到处都是以if语句的形式通知错误(通过打印错误信息)。通过这种方式,很难分辨什么是正常的程序逻辑,什么是错误检测或错误通知。还需注意的是,大部分代码都是致力于错误的检测。通常解决此问题的好办法是尽可能以闭包的形式封装你的错误检测,例如下面的代码:
func httpRequestHandler(w http.ResponseWriter, req *http.Request) {
err := func () error {
if req.Method != "GET" {
return errors.New("expected GET")
}
if input := parseInput(req); input != "command" {
return errors.New("malformed command")
}
// 可以在此进行其他的错误检测
} ()
if err != nil {
w.WriteHeader(400)
io.WriteString(w, err)
return
}
doSomething() ...
这种方法可以很容易分辨出错误检测、错误通知和正常的程序逻辑。
10、关于逗号ok模式
我们经常在一个表达式返回2个参数时使用这种模式:,ok,第一个参数是一个值或者nil,第二个参数是true/false或者一个错误error。在一个需要赋值的if条件语句中,使用这种模式去检测第二个参数值会让代码显得优雅简洁。这种模式在go语言编码规范中非常重要。
下面总结了所有使用这种模式的例子:
(1)在函数返回时检测错误
value, err := pack1.Func1(param1)
if err != nil {
fmt.Printf(“Error %s in pack1.Func1 with parameter %v”, err.Error(), param1)
return err
}
// 函数Func1没有错误:
Process(value)
e.g.: os.Open(file) strconv.Atoi(str)
这段代码中的函数将错误返回给它的调用者,当函数执行成功时,返回的错误是nil,所以使用这种写法:
func SomeFunc() error {
…
if value, err := pack1.Func1(param1); err != nil {
…
return err
}
…
return nil
}
这种模式也常用于通过defer使程序从panic中恢复执行。
要实现简洁的错误检测代码,更好的方式是使用闭包。
(2)检测映射中是否存在一个键值:key1在映射map1中是否有值?
if value, isPresent = map1[key1]; isPresent {
Process(value)
}
// key1不存在
…
(3)检测一个接口类型变量varI是否包含了类型T:类型断言:
if value, ok := varI.(T); ok {
Process(value)
}
// 接口类型varI没有包含类型T
(4)检测一个通道ch是否关闭:
for input := range ch {
Process(input)
}
或者:
for {
if input, open := <-ch; !open {
break // 通道是关闭的
}
Process(input)
}11、windows下使用endless报错
endless报错:undefined: syscall.SIGUSR1。
Go\src\syscall\types_windows.go:
var signals = [...]string{
// 这里省略N行。。。。
/** 兼容windows start */
16: "SIGUSR1",
17: "SIGUSR2",
18: "SIGTSTP",
/** 兼容windows end */
}
/** 兼容windows start */
func Kill(...interface{}) error {
return nil;
}
const (
SIGUSR1 = Signal(16)
SIGUSR2 = Signal(17)
SIGTSTP = Signal(18)
)
/** 兼容windows end *十、知识碎片
1、sync.WaitGroup
这个是通过通道,来控制goroutine协程结束的示例:
func coordinateWithChan() {
sign := make(chan struct{}, 2)
num := int32(0)
fmt.Printf("The number: %d [with chan struct{}]\n", num)
max := int32(10)
go addNum(&num, 1, max, func() {
sign <- struct{}{}
})
go addNum(&num, 2, max, func() {
sign <- struct{}{}
})
<-sign
<-sign
}sign通道读取数据时,如果命中“有缓冲channel + 缓冲为空”的情况,会阻塞,只有两个go协程全部执行完毕,往sign塞数据后,程序才会退出,但是这种方式非常繁琐。
在这种应用场景下,我们可以选用另外一个同步工具sync.WaitGroup(以下简称WaitGroup类型),它比通道更加适合实现这种一对多的 goroutine 协作流程。WaitGroup类型是开箱即用的,也是并发安全的,它拥有三个指针方法:Add、Done和Wait,你可以想象该类型中有一个计数器,它的默认值是0,我们可以通过调用该类型值的Add方法来增加,或者减少这个计数器的值,代码升级如下:
func coordinateWithWaitGroup() {
var wg sync.WaitGroup
wg.Add(2) // 计数器加2
num := int32(0)
fmt.Printf("The number: %d [with sync.WaitGroup]\n", num)
max := int32(10)
go addNum(&num, 3, max, wg.Done) // 计数器减1
go addNum(&num, 4, max, wg.Done) // 计数器减1
wg.Wait() // 会阻塞,直到计数器值为0,然后就会被唤醒
}Add会增加计数器的值,Done会减少计数器的值,Wait会一直阻塞,直到计数器的值重新回归为0,然后才会被唤醒,继续往后面执行。
常见的坑
如果使用不当,容易抛出Panic,我就把相关知识点列出来:
-
坑1(计数器为负数):sync.WaitGroup类型值中计数器的值如果小于0,会直接抛出Panic。
-
坑2(同时调用Add和Wait):如果我们对它的Add方法的首次调用,与对它的Wait方法的调用是同时发起的,比如,在同时启用的两个 goroutine 中,分别调用这两个方法,那么就有可能会让这里的Add方法抛出一个 panic。
-
坑3(跨越计数周期):如果在一个此类值的Wait方法被执行期间,跨越了两个计数周期,那么就会引发一个 panic。
对于坑1,当调用Add方法,传入一个负数的时候可能会出现,所以我们使用WaitGroup时,需要保证计数一直大于0。对于坑2,需要说明一点,虽然WaitGroup值本身并不需要初始化,但是尽早地增加其计数器的值,还是非常有必要的。对于坑3,我们需要先了解WaitGroup的计数周期:

计数周期:WaitGroup中计数器值由0变为了某个正整数,而后又经过一系列的变化,最终由某个正整数又变回了0。也就是说,只要计数器的值始于0又归为0,就可以被视为一个计数周期。在一个此类值的生命周期中,它可以经历任意多个计数周期。但是,只有在它走完当前的计数周期之后,才能够开始下一个计数周期。
那坑3什么情况会出现呢?场景如下:当前的goroutine因调用Wait方法被阻塞的时候,另一个goroutine调用了该值的Done方法,并使其计数器的值变为了0,这会唤醒当前的goroutine,并使它试图继续执行Wait方法中其余的代码。但在这时,又有一个goroutine调用了它的Add方法,并让其计数器的值又从0变为了某个正整数。此时,这里的Wait方法就会立即抛出一个panic。
根据坑2和坑3,总结如下:不要把增加其计数器值的操作和调用其Wait方法的代码,放在不同的 goroutine 中执行。换句话说,要杜绝对同一个WaitGroup值的两种操作的并发执行,标准方式应该为“先统一Add,再并发Done,最后Wait”。
并发实例:Push
对于上一章的并发示例,当时提了一个问题:每消费一条Channel数据,需要记录Push发送成功,但是一条Channel数据包含2-3个Push内容(IOS/Android/PC),程序记录Push成功前,如何保证这2-3个Push都发送完毕了呢?根据“先统一Add,再并发Done,最后Wait”原则,看下面代码:
var (
wg sync.WaitGroup
succs []*NotifyMessage
fails []*NotifyMessage
)
for _, message := range t.PushMessages {
wg.Add(1) // 计数加1
go func(message mipush.PushMessage) {
defer func() {
wg.Done() // 计数减1
}()
// 发送IOS/Android/PC等渠道的Push
// 代码省略...
}(message)
}
wg.Wait() // 阻塞,直到计数器值为0,然后就会被唤醒
// 数据统计
SendNotify(t.ID, t.TotalPage, t.TaskPage, t.AppType, t.AppLocal, fails, succs)总结:
WaitGroup是开箱即用和并发安全的,可以通过它很方便地实现一对多goroutine协作流程,即:一个分发子任务的goroutine,和多个执行子任务的goroutine,共同来完成一个较大的任务。
在使用WaitGroup值的时候,我们一定要注意,千万不要让其中的计数器的值小于0,否则就会引发 panic。另外,我们最好用“先统一Add,再并发Done,最后Wait”这种标准方式,来使用WaitGroup值, 尤其不要在调用Wait方法的同时,并发地通过调用Add方法去增加其计数器的值,因为这也有可能引发 panic。
2、互斥锁
对写操作的锁定和解锁,简称“写锁定”和“写解锁”:
func (*RWMutex)Lock()
func (*RWMutex)Unlock()对读操作的锁定和解锁,简称为“读锁定”与“读解锁”:
func (*RWMutex)RLock()
func (*RWMutex)RUnlock()看个不使用锁的示例:
func printer(str string) {
for _, data := range str {
fmt.Printf("%c", data)
}
fmt.Println()
}
func person1() {
printer("hello")
}
func person2() {
printer("world")
}
func main() {
go person1()
person2()
time.Sleep(time.Second)
}
//输出结果
//worhello
//ld加上互斥锁的示例:
var mut sync.Mutex
func printer(str string) {
mut.Lock()
defer mut.Unlock()
for _, data := range str {
fmt.Printf("%c", data)
}
fmt.Println()
}
func person1() {
printer("hello")
}
func person2() {
printer("world")
}
func main() {
go person1()
person2()
time.Sleep(time.Second)
}
//输出结果
//world
//hello注意事项:
1)互斥锁
-
不要重复锁定互斥锁:对一个已经被锁定的互斥锁进行锁定,是会立即阻塞当前的goroutine,这个 goroutine所执行的流程,会一直停滞在调用该互斥锁的Lock方法的那行代码上。(注意:这种由 Go 语言运行时系统自行抛出的 panic 都属于致命错误,都是无法被恢复的,调用recover函数对它们起不到任何作用。也就是说,一旦产生死锁,程序必然崩溃。)
-
不要忘记解锁互斥锁,必要时使用defer语句:因为在一个 goroutine 执行的流程中,可能会出现诸如“锁定、解锁、再锁定、再解锁”的操作,所以如果我们忘记了中间的解锁操作,那就一定会造成重复锁定。
var mutex sync.Mutex
func write() {
defer mutex.Unlock() // 通过defer解锁
mutex.Lock()
// 获取临界资源,执行具体逻辑...
}不要对尚未锁定或者已解锁的互斥锁解锁:这个程序会直接panic。
var mutex sync.Mutex // 定义互斥锁变量 mutex
mutex.Lock()
mutex.Unlock()
mutex.Unlock() // fatal error: sync: unlock of unlocked mutex
return不要在多个函数之间直接传递互斥锁:互斥锁是一结构体类型,即值类型,把它传给一个函数、将它从函数中返回、把它赋给其他变量、让它进入某个通道都会导致它的副本的产生。因此,原值和它的副本、以及多个副本之间都是完全独立的,它们都是不同的互斥锁。
2)读写锁
-
在写锁已被锁定的情况下再试图锁定写锁,会阻塞当前的 goroutine;
-
在写锁已被锁定的情况下试图锁定读锁,也会阻塞当前的 goroutine;
-
在读锁已被锁定的情况下试图锁定写锁,同样会阻塞当前的 goroutine;
-
在读锁已被锁定的情况下再试图锁定读锁,并不会阻塞当前的 goroutine;
-
解锁“读写锁中未被锁定的写锁”,会立即引发 panic,对于读锁也是如此。
上面写的有点啰嗦,我用大白话总结一下:我读数据时,你可以去读,因为我两的数据是一样的;我读数据时,你不能写,你写了,数据就变了,我还读个鬼啊;我写数据时,你不能读,也不能写,我就是这么强势。
下面看一个实例:
var count int
var mutex sync.RWMutex
func write(n int) {
rand.Seed(time.Now().UnixNano())
fmt.Printf("写 goroutine %d 正在写数据...\n", n)
mutex.Lock()
num := rand.Intn(500)
count = num
fmt.Printf("写 goroutine %d 写数据结束,写入新值 %d\n", n, num)
mutex.Unlock()
}
func read(n int) {
mutex.RLock()
fmt.Printf("读 goroutine %d 正在读取数据...\n", n)
num := count
fmt.Printf("读 goroutine %d 读取数据结束,读到 %d\n", n, num)
mutex.RUnlock()
}
func main() {
for i := 0; i < 10; i++ {
go read(i + 1)
}
for i := 0; i < 10; i++ {
go write(i + 1)
}
time.Sleep(time.Second*5)
}
//输出结果
读 goroutine 1 正在读取数据...
读 goroutine 1 读取数据结束,读到 0
读 goroutine 7 正在读取数据...
读 goroutine 7 读取数据结束,读到 0
读 goroutine 3 正在读取数据...
读 goroutine 3 读取数据结束,读到 0
读 goroutine 10 正在读取数据...
读 goroutine 10 读取数据结束,读到 0
读 goroutine 8 正在读取数据...
读 goroutine 8 读取数据结束,读到 0
读 goroutine 6 正在读取数据...
读 goroutine 5 正在读取数据...
读 goroutine 5 读取数据结束,读到 0
写 goroutine 2 正在写数据...
读 goroutine 4 正在读取数据...
读 goroutine 4 读取数据结束,读到 0
写 goroutine 4 正在写数据...
写 goroutine 3 正在写数据...
读 goroutine 2 正在读取数据...
读 goroutine 2 读取数据结束,读到 0
写 goroutine 9 正在写数据...
读 goroutine 6 读取数据结束,读到 0
写 goroutine 7 正在写数据...
读 goroutine 9 正在读取数据...
读 goroutine 9 读取数据结束,读到 0
写 goroutine 6 正在写数据...
写 goroutine 1 正在写数据...
写 goroutine 8 正在写数据...
写 goroutine 10 正在写数据...
写 goroutine 5 正在写数据...
写 goroutine 2 写数据结束,写入新值 365
写 goroutine 4 写数据结束,写入新值 47
写 goroutine 3 写数据结束,写入新值 468
写 goroutine 9 写数据结束,写入新值 155
写 goroutine 7 写数据结束,写入新值 112
写 goroutine 6 写数据结束,写入新值 490
写 goroutine 1 写数据结束,写入新值 262
写 goroutine 8 写数据结束,写入新值 325
写 goroutine 10 写数据结束,写入新值 103
写 goroutine 5 写数据结束,写入新值 353可以看出前面10个协程可以并行读取数据,后面10个协程,就全部阻塞在了“...正在写数据...”过程,等读完了,然后10个协程就开始依次写。
总结:
内容不多,主要需要注意互斥锁和读写锁的几条注意事项,读写锁其实就是更细粒度的锁划分,为了能让程序更好并发,上面已经讲述的非常清楚,这里就不再啰嗦。唯一再强调的一点,无论是互斥锁还是读写锁,我们都不要试图去解锁未锁定的锁,因为这样会引发不可恢复的 panic。
3、原子操作
互斥锁是一个很有用的同步工具,它可以保证每一时刻进入临界区的goroutine只有一个。通过对互斥锁的合理使用,我们可以使一个goroutine在执行临界区中的代码时,不被其他的goroutine打扰,但是它仍然可能会被中断(interruption)。
那什么是原子操作呢?我们已经知道,原子操作即是进行过程中不能被中断的操作。也就是说,针对某个值的原子操作在被进行的过程当中,CPU绝不会再去进行其它的针对该值的操作。为了实现这样的严谨性,原子操由 CPU 提供芯片级别的支持,所以绝对有效,即使在拥有多 CPU 核心,或者多 CPU 的计算机系统中,原子操作的保证也是不可撼动的。这使得原子操作可以完全地消除竞态条件,并能够绝对地保证并发安全性,它的执行速度要比其他的同步工具快得多,通常会高出好几个数量级。
不过它的缺点也很明显,正因为原子操作不能被中断,所以它需要足够简单,并且要求快速。你可以想象一下,如果原子操作迟迟不能完成,而它又不会被中断,那么将会给计算机执行指令的效率带来多么大的影响,所以操作系统层面只对针对二进制位或整数的原子操作提供了支持。
因此,我们可以结合实际情况,来判断是否可以将锁替换成原子操作。
1)增或减
atomic包中提供了如下以Add为前缀的增减操作:
func AddInt32(addr *int32, delta int32) (new int32)
func AddInt64(addr *int64, delta int64) (new int64)
func AddUint32(addr *uint32, delta uint32) (new uint32)
func AddUint64(addr *uint64, delta uint64) (new uint64)
func AddUintptr(addr *uintptr, delta uintptr) (new uintptr)需要注意的是,第一个参数必须是指针类型的值,通过指针变量可以获取被操作数在内存中的地址,从而施加特殊的CPU指令,确保同一时间只有一个goroutine能够进行操作,看个简单的示例:
var opts int64 = 0
for i := 0; i < 50; i++ {
// 注意第一个参数必须是地址
atomic.AddInt64(&opts, 3) //加操作
//atomic.AddInt64(&opts, -1) 减操作
time.Sleep(time.Millisecond)
}
time.Sleep(time.Second)
fmt.Println("opts: ", atomic.LoadInt64(&opts))用于原子加法操作的函数可以做原子减法吗?比如atomic.AddInt32函数可以用于减小那个被操作的整数值吗?atomic.AddInt32函数的第二个参数代表差量,它的类型int32是有符号的,如果我们想做原子减法,那么把这个差量设置为负整数就可以了,对于atomic.AddInt64函数来说也是类似的。
不过如果想用atomic.AddUint32和atomic.AddUint64函数做原子减法,因为它们的第二个参数的类型uint32和uint64都是无符号的,就不能同AddInt32进行相同处理,但是可以依据下面这个表达式来给定atomic.AddUint32函数的第二个参数值:
^uint32(-N-1))其中的N代表由负整数表示的差量,我们先要把差量的绝对值减去1,然后再把得到的这个无类型的整数常量,转换为uint32类型的值,最后在该值之上做按位异或操作,就可以获得最终的参数值。简单来说,此表达式的结果值的补码,与使用前一种方法得到的值的补码相同,所以这两种方式是等价的。
2)比较并交换
该操作简称 CAS(Compare And Swap),第一个参数的值应该是指向被操作值的指针值,该值的类型即为*int32,后两个参数的类型都是int32类型,它们的值应该分别代表被操作值的旧值和新值,函数在被调用之后会先判断参数addr指向的被操作值与参数old的值是否相等。仅当此判断得到肯定的结果之后,该函数才会用参数new代表的新值替换掉原先的旧值。否则,后面的替换操作就会被忽略。
func CompareAndSwapInt32(addr *int32, old, new int32) (swapped bool)
func CompareAndSwapInt64(addr *int64, old, new int64) (swapped bool)
func CompareAndSwapPointer(addr *unsafe.Pointer, old, new unsafe.Pointer) (swapped bool)
func CompareAndSwapUint32(addr *uint32, old, new uint32) (swapped bool)
func CompareAndSwapUint64(addr *uint64, old, new uint64) (swapped bool)
func CompareAndSwapUintptr(addr *uintptr, old, new uintptr) (swapped bool)当有大量的goroutine 对变量进行读写操作时,可能导致CAS操作无法成功,这时可以利用for循环多次尝试:
var value int64
func atomicAddOp(tmp int64) {
for {
oldValue := value
if atomic.CompareAndSwapInt64(&value, oldValue, oldValue+tmp) {
return
}
}
}比较并交换操作与交换操作相比有什么不同,优势在哪里呢?比较并交换操作即 CAS 操作,是有条件的交换操作,只有在条件满足的情况下才会进行值的交换。CAS 操作并不是单一的操作,而是一种操作组合,这与其他的原子操作都不同。正因为如此,它的用途要更广泛一些,例如我们将它与for语句联用就可以实现一种简易的自旋锁(spinlock):
for {
if atomic.CompareAndSwapInt32(&num2, 10, 0) {
fmt.Println("The second number has gone to zero.")
break
}
time.Sleep(time.Millisecond * 500)
}3)载入
atomic包中提供了如下以Load为前缀的增减操作:
func LoadInt32(addr *int32) (val int32)
func LoadInt64(addr *int64) (val int64)
func LoadPointer(addr *unsafe.Pointer) (val unsafe.Pointer)
func LoadUint32(addr *uint32) (val uint32)
func LoadUint64(addr *uint64) (val uint64)
func LoadUintptr(addr *uintptr) (val uintptr)载入操作能够保证原子的读变量的值,当读取的时候,任何其他CPU操作都无法对该变量进行读写,其实现机制受到底层硬件的支持。假设我已经保证了对一个变量的写操作都是原子操作,比如:加或减、存储、交换等等,那我对它进行读操作的时候,还有必要使用原子操作吗?
答案是很有必要,你可以对照一下读写锁,为什么在读写锁保护下的写操作和读操作之间是互斥的?这是为了防止读操作读到没有被修改完的值,如果写操作还没有进行完,读操作就来读了,那么就只能读到仅修改了一部分的值,这显然破坏了值的完整性。因此一旦决定要对一个共享资源进行保护,那就要做到完全的保护,不完全的保护基本上与不保护没有什么区别。
4)存储
atomic包中提供了如下以Store为前缀的存储操作:
func StoreInt32(addr *int32, val int32)
func StoreInt64(addr *int64, val int64)
func StorePointer(addr *unsafe.Pointer, val unsafe.Pointer)
func StoreUint32(addr *uint32, val uint32)
func StoreUint64(addr *uint64, val uint64)
func StoreUintptr(addr *uintptr, val uintptr)此类操作确保了写变量的原子性,避免其他操作读到了修改变量过程中的脏数据。然后对于存储,需要掌握2条规则:
-
我们不能把nil作为参数值传入原子值的Store方法,否则就会引发一个panic。这里要注意,如果有一个接口类型的变量,它的动态值是nil,但动态类型却不是nil,那么它的值就不等于nil,这样一个变量的值是可以被存入原子值,这块知识可以在接口这一章中查看。
-
我们向原子值存储的第一个值,决定了它今后能且只能存储哪一个类型的值。例如,我第一次向一个原子值存储了一个string类型的值,那我在后面就只能用该原子值来存储字符串了。如果我又想用它存储结构体,那么在调用它的Store方法的时候就会引发一个panic,这个panic会告诉我,这次存储的值的类型与之前的不一致。
5)交换
atomic包中提供了如下以Swap为前缀的交换操作:
func SwapInt32(addr *int32, new int32) (old int32)
func SwapInt64(addr *int64, new int64) (old int64)
func SwapPointer(addr *unsafe.Pointer, new unsafe.Pointer) (old unsafe.Pointer)
func SwapUint32(addr *uint32, new uint32) (old uint32)
func SwapUint64(addr *uint64, new uint64) (old uint64)
func SwapUintptr(addr *uintptr, new uintptr) (old uintptr)相对于CAS,明显此类操作更为暴力直接,并不管变量的旧值是否被改变,直接赋予新值然后返回背替换的值。
扩展知识
对于原子操作,还有几条具体的使用建议:
-
不要把内部使用的原子值暴露给外界。比如,声明一个全局的原子变量并不是一个正确的做法,这个变量的访问权限最起码也应该是包级私有的。
-
如果不得不让包外,或模块外的代码使用你的原子值,那么可以声明一个包级私有的原子变量,然后再通过一个或多个公开的函数,让外界间接地使用到它。注意,这种情况下不要把原子值传递到外界,不论是传递原子值本身还是它的指针值。
-
如果通过某个函数可以向内部的原子值存储值的话,那么就应该在这个函数中先判断被存储值类型的合法性。若不合法,则应该直接返回对应的错误值,从而避免 panic 的发生。
-
如果可能的话,我们可以把原子值封装到一个数据类型中,比如一个结构体类型。这样,我们既可以通过该类型的方法更加安全地存储值,又可以在该类型中包含可存储值的合法类型信息。
除了上述使用建议之外,我还要再特别强调一点:尽量不要向原子值中存储引用类型的值。因为这很容易造成安全漏洞。请看下面的代码:
var box6 atomic.Value
v6 := []int{1, 2, 3}
box6.Store(v6)
v6[1] = 4 // 注意,此处的操作不是并发安全的!我把一个[]int类型的切片值v6存入了原子值box6,由于切片类型属于引用类型,我在外面改动这个切片值,就等于修改了box6中存储的那个值,这相当于绕过了原子值而进行了非并发安全的操作,那么应该怎样修补这个漏洞呢?可以这样做:
store := func(v []int) {
replica := make([]int, len(v))
copy(replica, v)
box6.Store(replica)
}
store(v6)
v6[2] = 5 // 此处的操作是安全的。我先为切片值v6创建了一个完全的副本,这个副本涉及的数据已经与原值毫不相干,然后再把这个副本存入box6,因此无论我再对v6的值做怎样的修改,都不会破坏box6提供的安全保护。
场景:环形队列
// 环形队列
type RingBuffer struct {
err error
count int32
size int32
head int32
tail int32
buf []unsafe.Pointer
}
// Get方法从buf中取出对象
func (r *RingBuffer) Get() interface{} {
// 在高并发开始的时候,队列容易空,直接判断空性能最优
if atomic.LoadInt32(&r.count) <= 0 {
return nil
}
// 当扣减数量后没有超,就从队列里取出对象
if atomic.AddInt32(&r.count, -1) >= 0 {
idx := (atomic.AddInt32(&r.head, 1) - 1) % r.size
if obj := atomic.LoadPointer(&r.buf[idx]); obj != unsafe.Pointer(nil) {
o := *(*interface{})(obj)
atomic.StorePointer(&r.buf[idx], nil)
return o
}
} else {
// 当减数量超了,再加回去
atomic.AddInt32(&r.count, 1)
}
return nil
}
// Put方法将对象放回到buf中。如果buf满了,返回false
func (r *RingBuffer) Put(obj interface{}) bool {
// 在高并发结束的时候,队列容易满,直接判满性能最优
if atomic.LoadInt32(&r.count) >= r.size {
return false
}
// 当增加数量后没有超,就将对象放到队列里
if atomic.AddInt32(&r.count, 1) <= r.size {
idx := (atomic.AddInt32(&r.tail, 1) - 1) % r.size
atomic.StorePointer(&r.buf[idx], unsafe.Pointer(&obj))
return true
}
// 当加的数量超了,再减回去
atomic.AddInt32(&r.count, -1)
return false
}总结:
原子值类型的优势很明显,但它的使用规则也更多一些。首先,在首次真正使用后,原子值就不应该再被复制了。其次,原子值的Store方法对其参数值(也就是被存储值)有两个强制的约束。一个约束是参数值不能为nil。另一个约束是,参数值的类型不能与首个被存储值的类型不同。也就是说,一旦一个原子值存储了某个类型的值,那它以后就只能存储这个类型的值了。最后在扩展知识中,提出了几条使用建议,包括:不要对外暴露原子变量、不要传递原子值及其指针值、尽量不要在原子值中存储引用类型的值等。
4、context.Context
回顾之前的知识,我们先看一个关于WaitGroup的示例:
func main() {
var wg sync.WaitGroup
wg.Add(2)
go func() {
time.Sleep(2*time.Second)
fmt.Println("1号完成")
wg.Done()
}()
go func() {
time.Sleep(2*time.Second)
fmt.Println("2号完成")
wg.Done()
}()
wg.Wait()
fmt.Println("好了,大家都干完了,放工")
}示例比较简单,main协程等待两个goroutine的结束。如果是希望主协程关闭,通知goutoutine关闭,我们可以使用select + chan的方式:
func main() {
stop := make(chan bool)
go func() {
for {
select {
case <-stop:
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}()
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
stop<- true
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}这种chan+select的方式,是比较优雅的结束一个goroutine的方式,不过这种方式也有局限性,如果有很多goroutine都需要控制结束怎么办呢?如果这些goroutine又衍生了其他更多的goroutine怎么办呢?如果一层层的无穷尽的goroutine呢?这就非常复杂了,即使我们定义很多chan也很难解决这个问题,因为goroutine的关系链就导致了这种场景非常复杂。
上面说的这种场景是存在的,比如一个网络请求Request,每个Request都需要开启一个goroutine做一些事情,这些goroutine又可能会开启其他的goroutine。所以我们需要一种可以跟踪goroutine的方案,才可以达到控制他们的目的,这就是Go语言为我们提供的Context,称之为上下文非常贴切,它就是goroutine的上下文,我们对上面示例进行改造:
func main() {
ctx, cancel := context.WithCancel(context.Background())
go func(ctx context.Context) {
for {
select {
case <-ctx.Done():
fmt.Println("监控退出,停止了...")
return
default:
fmt.Println("goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}(ctx)
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel()
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}当执行cancel()时,goroutine会接收到ctx.Done()的信号,协程退出,对于控制多个goroutine的示例如下:
func main() {
ctx, cancel := context.WithCancel(context.Background())
go watch(ctx,"【监控1】")
go watch(ctx,"【监控2】")
go watch(ctx,"【监控3】")
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel()
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
func watch(ctx context.Context, name string) {
for {
select {
case <-ctx.Done():
fmt.Println(name,"监控退出,停止了...")
return
default:
fmt.Println(name,"goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}1)Context接口
Context的接口定义的比较简洁,我们看下这个接口的方法:
type Context interface {
Deadline() (deadline time.Time, ok bool)
Done() <-chan struct{}
Err() error
Value(key interface{}) interface{}
}这个接口共有4个方法,了解这些方法的意思非常重要,这样我们才可以更好的使用他们:
-
Deadline方法是获取设置的截止时间的意思,第一个返回式是截止时间,到了这个时间点,Context会自动发起取消请求;第二个返回值ok==false时表示没有设置截止时间,如果需要取消的话,需要调用取消函数进行取消。
-
Done方法返回一个只读的chan,类型为struct{},我们在goroutine中,如果该方法返回的chan可以读取,则意味着parent context已经发起了取消请求,我们通过Done方法收到这个信号后,就应该做清理操作,然后退出goroutine,释放资源。
-
Err方法返回取消的错误原因,因为什么Context被取消。
-
Value方法获取该Context上绑定的值,是一个键值对,所以要通过一个Key才可以获取对应的值,这个值一般是线程安全的。
2)顶层Context
Context接口并不需要我们实现,Go内置已经帮我们实现了2个,我们代码中最开始都是以这两个内置的作为最顶层的partent context,衍生出更多的子Context:
var (
background = new(emptyCtx)
todo = new(emptyCtx)
)
func Background() Context {
return background
}
func TODO() Context {
return todo
}一个是Background,主要用于main函数、初始化以及测试代码中,作为Context这个树结构的最顶层的Context,也就是根Context。一个是TODO,它目前还不知道具体的使用场景,如果我们不知道该使用什么Context的时候,可以使用这个。他们两个本质上都是emptyCtx结构体类型,是一个不可取消,没有设置截止时间,没有携带任何值的Context。
type emptyCtx int
func (*emptyCtx) Deadline() (deadline time.Time, ok bool) {
return
}
func (*emptyCtx) Done() <-chan struct{} {
return nil
}
func (*emptyCtx) Err() error {
return nil
}
func (*emptyCtx) Value(key interface{}) interface{} {
return nil
}这就是emptyCtx实现Context接口的方法,可以看到,这些方法什么都没做,返回的都是nil或者零值。
3)子Context
有了如上的根Context,那么是如何衍生更多的子Context的呢?这就要靠context包为我们提供的With系列的函数了:
func WithCancel(parent Context) (ctx Context, cancel CancelFunc)
func WithDeadline(parent Context, deadline time.Time) (Context, CancelFunc)
func WithTimeout(parent Context, timeout time.Duration) (Context, CancelFunc)
func WithValue(parent Context, key, val interface{}) Context这四个With函数,接收的都有一个partent参数,就是父Context,我们要基于这个父Context创建出子Context的意思,这种方式可以理解为子Context对父Context的继承,也可以理解为基于父Context的衍生。通过这些函数,就创建了一颗Context树,树的每个节点都可以有任意多个子节点,节点层级可以有任意多个。
-
WithCancel函数,传递一个父Context作为参数,返回子Context,以及一个取消函数用来取消Context。
-
WithDeadline函数,和WithCancel差不多,它会多传递一个截止时间参数,意味着到了这个时间点,会自动取消Context,当然我们也可以不等到这个时候,可以提前通过取消函数进行取消。
-
WithTimeout和WithDeadline基本上一样,这个表示是超时自动取消,是多少时间后自动取消Context的意思。
-
WithValue函数和取消Context无关,它是为了生成一个绑定了一个键值对数据的Context,这个绑定的数据可以通过Context.Value方法访问到,后面我们会专门讲。
大家可能留意到,前三个函数都返回一个取消函数CancelFunc,这就是取消函数的类型,该函数可以取消一个Context,以及这个节点Context下所有的所有的Context,不管有多少层级。
4)元数传递
通过Context我们也可以传递一些必须的元数据,这些数据会附加在Context上以供使用。
var key string="name"
func main() {
ctx, cancel := context.WithCancel(context.Background())
//附加值
valueCtx:=context.WithValue(ctx,key,"【监控1】")
go watch(valueCtx)
time.Sleep(10 * time.Second)
fmt.Println("可以了,通知监控停止")
cancel()
//为了检测监控过是否停止,如果没有监控输出,就表示停止了
time.Sleep(5 * time.Second)
}
func watch(ctx context.Context) {
for {
select {
case <-ctx.Done():
//取出值
fmt.Println(ctx.Value(key),"监控退出,停止了...")
return
default:
//取出值
fmt.Println(ctx.Value(key),"goroutine监控中...")
time.Sleep(2 * time.Second)
}
}
}在前面的例子,我们通过传递参数的方式,把name的值传递给监控函数。在这个例子里,我们实现一样的效果,但是通过的是Context的Value的方式。我们可以使用context.WithValue方法附加一对K-V的键值对,这里Key必须是等价性的,也就是具有可比性;Value值要是线程安全的。这样我们就生成了一个新的Context,这个新的Context带有这个键值对,在使用的时候,可以通过Value方法读取ctx.Value(key)。
5)知识扩展
这里我们主要先讨论一下撤销的操作。Done方法会返回一个元素类型为struct{}的接收通道,不过,这个接收通道的用途并不是传递元素值,而是让调用方去感知“撤销”当前Context值的那个信号,一旦当前的Context值被撤销,这里的接收通道就会被立即关闭,因为对于一个未包含任何元素值的通道来说,它的关闭会使任何针对它的接收操作立即结束。这里解释的可能有点绕,或者换句话来说,如果Context取消的时候,它其实主要是关闭chan,关闭的chan是可以读取的,所以只要可以读取的时候,就意味着可以通过Done收到Context取消的信号了。
除了让Context值的使用方感知到撤销信号,让它们得到“撤销”的具体原因,有时也是很有必要的。后者即是Context类型的Err方法的作用。该方法的结果是error类型的,并且其值只可能等于context.Canceled变量的值,或者context.DeadlineExceeded变量的值,我们看一个经典用法:
func Stream(ctx context.Context, out chan<- Value) error {
for {
v, err := DoSomething(ctx)
if err != nil {
return err
}
select {
case <-ctx.Done():
return ctx.Err()
case out <- v:
}
}
}我们再讨论撤销信号是如何在上下文树中传播的,在撤销函数被调用之后,对应的Context值会先关闭它内部的接收通道,也就是它的Done方法会返回的那个通道。然后,它会向它的所有子值(或者说子节点)传达撤销信号,这些子值会如法炮制,把撤销信号继续传播下去。最后,这个Context值会断开它与其父值之间的关联。先看一幅图:

我们通过调用context包的WithDeadline函数或者WithTimeout函数生成的Context值也是可撤销的。它们不但可以被手动撤销,还会依据在生成时被给定的过期时间,自动地进行定时撤销,这里定时撤销的功能是借助它们内部的计时器来实现的。当过期时间到达时,这两种Context值的行为与Context值被手动撤销时的行为是几乎一致的,只不过前者会在最后停止并释放掉其内部的计时器。最后要注意,通过调用context.WithValue函数得到的Context值是不可撤销的,撤销信号在被传播时,若遇到它们则会直接跨过,并试图将信号直接传给它们的子值。
6)实战场景:上下游调用
package main
import (
"context"
"fmt"
"math/rand"
"time"
)
// 作用:1.随机sleep一会;2.如果入参ch不为空,会把sleep的时间给到ch
func sleepRandom(fromFunction string, ch chan int) {
defer func() { fmt.Println(fromFunction, "sleepRandom complete") }()
seed := time.Now().UnixNano()
r := rand.New(rand.NewSource(seed))
randomNumber := r.Intn(100)
sleeptime := randomNumber + 100
fmt.Println(fromFunction, "Starting sleep for", sleeptime, "ms")
time.Sleep(time.Duration(sleeptime) * time.Millisecond)
fmt.Println(fromFunction, "Waking up, slept for ", sleeptime, "ms")
if ch != nil {
ch <- sleeptime
}
}
func sleepRandomContext(ctx context.Context, ch chan bool) {
defer func() {
fmt.Println("sleepRandomContext complete")
// 通过channel,通知上游执行完毕
ch <- true
}()
sleeptimeChan := make(chan int)
// 开启新的协程G2,让该协程执行逻辑,执行完毕后,通过sleeptimeChan通知执行完毕
go sleepRandom("sleepRandomContext", sleeptimeChan)
select {
case <-ctx.Done():
// 场景1:main()调用cancelFunction()
// 场景2:doWorkContext()调用cancelFunction()
// 场景3:doWorkContext()自动超时
fmt.Println("sleepRandomContext: Time to return")
case sleeptime := <-sleeptimeChan:
// 当新的协程G2执行完毕,调用ch<-sleeptime时
fmt.Println("Slept for ", sleeptime, "ms")
}
}
func doWorkContext(ctx context.Context) {
// 生成新的ctx,超时时间为150ms
ctxWithTimeout, cancelFunction := context.WithTimeout(ctx, time.Duration(150)*time.Millisecond)
defer func() {
fmt.Println("doWorkContext complete")
// 下游所有的ctx都会关闭
cancelFunction()
}()
ch := make(chan bool)
// 启动新的协程G1
go sleepRandomContext(ctxWithTimeout, ch)
select {
case <-ctx.Done():
// 当main退出,调用main的cancelFunction()时
fmt.Println("doWorkContext: Time to return")
case <-ch:
// 当新的协程G1退出,执行ch<-true时
fmt.Println("sleepRandomContext returned")
}
}
func main() {
ctx := context.Background()
ctxWithCancel, cancelFunction := context.WithCancel(ctx)
defer func() {
fmt.Println("Main Defer: canceling context")
// 下游所有的ctx都会关闭
cancelFunction()
}()
go func() {
// main函数sleep一会
sleepRandom("Main", nil)
// 下游所有的ctx都会关闭
cancelFunction()
fmt.Println("Main Sleep complete. canceling context")
}()
doWorkContext(ctxWithCancel)
}对于上面这个示例,我描述一下每种场景:
-
场景1:main函数调用cancelFunction()后,main()会直接退出,同时doWorkContext和sleepRandomContext函数会同时调用里面的ctx.Done()操作,全部一起退出;
-
场景2:doWorkContext函数超时150ms后,sleepRandomContext函数会直接执行ctx.Done()操作,然后sleepRandomContext函数退出前执行ch <- true,doWorkContext函数接收到case <-ch的信号后,doWorkContext()退出,main()退出;
-
场景3:sleepRandomContext函数执行sleepRandom(),当sleepRandom执行ch <- sleeptime后,sleepRandomContext通过sleeptime := <-sleeptimeChan收到信号后,程序退出,退出前会执行ch <- true,然后doWorkContext函数接收到case <-ch的信号后,doWorkContext()退出,main()退出;
-
场景4:main()异常,通过defer执行cancelFunction()后,main()退出,后面逻辑同“场景1”;
-
场景5:doWorkContext()异常,通过defer执行cancelFunction()后,sleepRandomContext函数会直接执行ctx.Done()操作,sleepRandomContext()退出,cancelFunction()退出,main()退出;
-
场景6:sleepRandomContext异常,通过defer执行ch <- true,doWorkContext函数接收到case <-ch的信号后,doWorkContext()退出,main()退出;
前面3个是正常场景,后面3个是异常场景,无论哪种场景,设计思路是,当前函数退出时,下游所有context需要全部关闭,这个是依赖context可传递的特性,同时也能通知上游“我已经关闭了,请你继续你后续的操作”。
总结:
context包中的函数和Context类型,该包中的函数都是用于产生新的Context类型值的,Context类型是一个可以帮助我们实现多goroutine 协作流程的同步工具,不但如此,我们还可以通过此类型的值传达撤销信号或传递数据。
Context类型的实际值大体上分为三种,即:根Context值、可撤销的Context值和含数据的Context值。所有的Context值共同构成了一颗上下文树,这棵树的作用域是全局的,而根Context值就是这棵树的根,它是全局唯一的,并且不提供任何额外的功能。
可撤销的Context值又分为:只可手动撤销的Context值,和可以定时撤销的Context值,我们可以通过生成它们时得到的撤销函数来对其进行手动的撤销。对于后者,定时撤销的时间必须在生成时就完全确定,并且不能更改,不过我们可以在过期时间达到之前,对其进行手动的撤销,一旦撤销函数被调用,撤销信号就会立即被传达给对应的Context值,并由该值的Done方法返回的接收通道表达出来。“撤销”这个操作是Context值能够协调多个 goroutine 的关键所在,撤销信号总是会沿着上下文树叶子节点的方向传播开来。含数据的Context值不能被撤销,而可撤销的Context值又无法携带数据,由于它们共同组成了一个有机的整体(即上下文树),所以在功能上要比sync.WaitGroup强大得多。
5、sync.Pool
在 golang 中有一个池,它特别神奇,你只要和它有个约定,你要什么它就给什么,你用完了还可以还回去,但是下次拿的时候呢,确不一定是你上次存的那个,这个池就是 sync.Pool。
sync.Pool类型只有两个方法——Put和Get。Put 用于在当前的池中存放临时对象,它接受一个interface{}类型的参数;而 Get 则被用于从当前的池中获取临时对象,它会返回一个interface{}类型的值。更具体地说,这个类型的Get方法可能会从当前的池中删除掉任何一个值,然后把这个值作为结果返回。如果此时当前的池中没有任何值,那么这个方法就会使用当前池的New字段创建一个新值,并直接将其返回,先看个简单的示例:
var strPool = sync.Pool{
New: func() interface{} {
return "test str"
},
}
func main() {
str := strPool.Get()
fmt.Println(str)
strPool.Put(str)
}通过New去定义你这个池子里面放的究竟是什么东西,在这个池子里面你只能放一种类型的东西,比如在上面的例子中我就在池子里面放了字符串。我们随时可以通过Get方法从池子里面获取我们之前在New里面定义类型的数据,当我们用完了之后可以通过Put方法放回去,或者放别的同类型的数据进去。
那么这个池子的目的是什么呢?其实一句话就可以说明白,就是为了复用已经使用过的对象,来达到优化内存使用和回收的目的。说白了,一开始这个池子会初始化一些对象供你使用,如果不够了呢,自己会通过new产生一些,当你放回去了之后这些对象会被别人进行复用,当对象特别大并且使用非常频繁的时候可以大大的减少对象的创建和回收的时间。
源码解析:
1) Pool
type Pool struct {
noCopy noCopy
local unsafe.Pointer // 数组指针,指向[P]poolLocal
localSize uintptr // 大小为P
victim unsafe.Pointer // 用于存放“幸存者”
victimSize uintptr // “幸存者”size
// New optionally specifies a function to generate
// a value when Get would otherwise return nil.
// It may not be changed concurrently with calls to Get.
New func() interface{}
}
type poolLocalInternal struct {
private interface{} // Can be used only by the respective P.
shared poolChain // Local P can pushHead/popHead; any P can popTail.
}
type poolLocal struct {
poolLocalInternal
// Prevents false sharing on widespread platforms with
// 128 mod (cache line size) = 0 .
pad [128 - unsafe.Sizeof(poolLocalInternal{})%128]byte
}我们可以看到其实结构并不复杂,但是如果自己看的话有点懵,注意几个细节就可以:
-
local这里面真正的是[P]poolLocal其中P就是GPM模型中的P,有多少个P数组就有多大,也就是每个P维护了一个本地的poolLocal。
-
poolLocal里面维护了一个private一个shared,看名字其实就很明显了,private是给自己用的,而shared的是一个队列,可以给别人用的。注释写的也很清楚,自己可以从队列的头部存然后从头部取,而别的P可以从尾部取。
-
victim这个从字面上面也可以知道,幸存者嘛,当进行gc的stw时候,会将local中的对象移到victim中去,也就是说幸存了一次gc。
2)Get
func (p *Pool) Get() interface{} {
// ......
l, pid := p.pin()
// Step1: 先直接获取自己的private,如果有,直接返回
x := l.private
l.private = nil
if x == nil {
// Step2: 如果private为空,就从自己的shared随便取一个
x, _ = l.shared.popHead()
if x == nil {
x = p.getSlow(pid)
}
}
runtime_procUnpin()
// ......
if x == nil && p.New != nil {
// Step5: 找了一圈都没有,自己New一个
x = p.New()
}
return x
}
func (p *Pool) getSlow(pid int) interface{} {
size := atomic.LoadUintptr(&p.localSize)
locals := p.local
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i+1)%int(size))
// Step3: 从其它的P中随便偷一个出来
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
size = atomic.LoadUintptr(&p.victimSize)
if uintptr(pid) >= size {
return nil
}
// Step4: 从“幸存者”中找一个,找的逻辑和前面的一样,先private,再shared
locals = p.victim
l := indexLocal(locals, pid)
if x := l.private; x != nil {
l.private = nil
return x
}
for i := 0; i < int(size); i++ {
l := indexLocal(locals, (pid+i)%int(size))
if x, _ := l.shared.popTail(); x != nil {
return x
}
}
atomic.StoreUintptr(&p.victimSize, 0)
return nil
}我去掉了其中一些竞态分析的代码,代码里面我也标明了每个step,Get的逻辑其实非常清晰:
-
如果 private 不是空的,那就直接拿来用;
-
如果 private 是空的,那就先去本地的shared队列里面从头 pop 一个;
-
如果本地的 shared 也没有了,那 getSlow 去拿,其实就是去别的P的 shared 里面偷,偷不到回去 victim 幸存者里面找;
-
如果最后都没有,那就只能调用 New 方法创建一个了。

3)Put
func (p *Pool) Put(x interface{}) {
if x == nil {
return
}
// ......
l, _ := p.pin()
if l.private == nil {
l.private = x
x = nil
}
if x != nil {
l.shared.pushHead(x)
}
runtime_procUnpin()
// ......
}Put主要做2件事情:
-
如果 private 没有,就放在 private;
-
如果 private 有了,那么就放到 shared 队列的头部。
4)GMP调度
我们先回顾一下GMP的知识:
-
G表示Goroutine协程,M表示thread线程,P表示processor处理器;
-
M是G运行的实体,P的作用就是将G分配到M上;
-
一个P有个本地队列,专门用于存放G。
再回顾一下GMP核心的调度流程:
-
当程序运行时,P会从本地队列中随机取一个G,然后给到M运行;
-
当P的本地队列没有G时,会从全局对列中找一批G,然后放到自己的本地队列,然后再取出G;
-
当本地队列为空时,P会从其它的P的本地队列中抢一批G,然后放到自己的本地队列,然后再取出G;
-
当没有抢到时,M就自动挂起来,不运行了。
一句话总结一下,G和P都属于Goroutine调度器,就是通过G和P的各种协作,找一个P给到M,然后OS调度器就会去运行这个M,详细的知识可以阅读“GMP原理”章节。
我们再回到sync.Pool,它的Get代码是不是和GMP中P去抢G中很像呢?我们再深度解读一下:在程序调用临时对象池的Put方法或Get方法的时候,总会先试图从该临时对象池的本地池列表中,获取与之对应的本地池,依据的就是与当前的goroutine关联的那个P的ID。换句话说,一个临时对象池的Put方法或Get方法会获取到哪一个本地池,完全取决于调用它的代码所在的goroutine关联的那个 P。
总结:
pool在掌握基础用法的同时,需要知道Get和Push方法的实现逻辑,其中最重要的一点,是需要将pool和GMP的调度原理结合起来,其中两者的P的原理其实是一样的,只是对于资源抢占这一块,GMP抢占的是G,pool抢占的是pool数据。
6、sync.Once
当一个函数不希望程序在一开始的时候就被执行的时候,我们可以使用sync.Once。Once类型的Do方法只接受一个参数,这个参数的类型必须是func(),即:无参数声明和结果声明的函数。该方法的功能并不是对每一种参数函数都只执行一次,而是只执行“首次被调用时传入的”那个函数,并且之后不会再执行任何参数函数。所以,如果你有多个只需要执行一次的函数,那么就应该为它们中的每一个都分配一个sync.Once类型的值(以下简称Once值),看个示例:
unc main() {
var once sync.Once
onceBody := func() {
fmt.Println("Only once")
}
done := make(chan bool)
for i := 0; i < 10; i++ {
go func() {
once.Do(onceBody)
done <- true
}()
}
for i := 0; i < 10; i++ {
<-done
}
}
// 输出
Only oncesync.Once使用变量done来记录函数的执行状态,使用sync.Mutex和sync.atomic来保证线程安全的读done,我们看一下源码:
type Once struct {
m Mutex
done uint32
}
func (o *Once) Do(f func()) {
if atomic.LoadUint32(&o.done) == 1 {
return
}
o.m.Lock()
defer o.m.Unlock()
if o.done == 0 {
defer atomic.StoreUint32(&o.done, 1)
f()
}
}你可能会问,既然done字段的值不是0就是1,那为什么还要使用需要四个字节的uint32类型呢?原因很简单,因为对它的操作必须是“原子”的,Do方法在一开始就会通过调用atomic.LoadUint32函数来获取该字段的值,并且一旦发现该值为1,就会直接返回。这也初步保证了“Do方法,只会执行首次被调用时传入的函数”。不过,单凭这样一个判断的保证是不够的,因为,如果有两个 goroutine 都调用了同一个新的Once值的Do方法,并且几乎同时执行到了其中的这个条件判断代码,那么它们就都会因判断结果为false,而继续执行Do方法中剩余的代码。在这个条件判断之后,Do方法会立即锁定其所属值中的那个sync.Mutex类型的字段m。然后,它会在临界区中再次检查done字段的值,并且仅在条件满足时,才会去调用参数函数,以及用原子操作把done的值变为1。
如果你熟悉 GoF 设计模式中的单例模式的话,那么肯定能看出来,这个Do方法的实现方式,与那个单例模式有很多相似之处。它们都会先在临界区之外,判断一次关键条件,若条件不满足则立即返回,这通常被称为“快速失败路径”。如果条件满足,那么到了临界区中还要再对关键条件进行一次判断,这主要是为了更加严谨,这两次条件判断常被统称为(跨临界区的)“双重检查”。由于进入临界区之前,肯定要锁定保护它的互斥锁m,显然会降低代码的执行速度,所以其中的第二次条件判断,以及后续的操作就被称为“慢路径”或者“常规路径”。别看Do方法中的代码不多,但它却应用了一个很经典的编程范式。下面我们再看看Do方法的两个特点:
-
阻塞问题:由于Do方法只会在参数函数执行结束之后把done字段的值变为1,因此,如果参数函数的执行需要很长时间或者根本就不会结束(比如执行一些守护任务),那么就有可能会导致相关 goroutine 的同时阻塞。例如,有多个 goroutine 并发地调用了同一个Once值的Do方法,并且传入的函数都会一直执行而不结束。那么,这些 goroutine 就都会因调用了这个Do方法而阻塞。因为,除了那个抢先执行了参数函数的 goroutine 之外,其他的 goroutine 都会被阻塞在锁定该Once值的互斥锁m的那行代码上。
-
重试机制问题:Do方法在参数函数执行结束后,对done字段的赋值用的是原子操作,并且,这一操作是被挂在defer语句中的。因此,不论参数函数的执行会以怎样的方式结束,done字段的值都会变为1。也就是说,即使这个参数函数没有执行成功(比如引发了一个 panic),我们也无法使用同一个Once值重新执行它了。所以,如果你需要为参数函数的执行设定重试机制,那么就要考虑Once值的适时替换问题。
在很多时候,我们需要依据Do方法的这两个特点来设计与之相关的流程,以避免不必要的程序阻塞和功能缺失。
十一、应用案例
1、字符串
(1)如何修改字符串中的一个字符
str:="hello"
c:=[]byte(str)
c[0]='c'
s2:= string(c) // s2 == "cello"
(2)如何获取字符串的子串
substr := str[n:m]
(3)如何使用for或者for-range遍历一个字符串
// gives only the bytes:
for i:=0; i < len(str); i++ {
… = str[i]
}
// gives the Unicode characters:
for ix, ch := range str {
…
}
(4)如何获取一个字符串的字节数:len(str)
如何获取一个字符串的字符数:
最快速:utf8.RuneCountInString(str)
len([]int(str))
(5)如何连接字符串
最快速: with a bytes.Buffer
Strings.Join()
使用+=:
str1 := "Hello "
str2 := "World!"
str1 += str2 //str1 == "Hello World!"
2、数组和切片
创建:
arr1 := new([len]type)
slice1 := make([]type, len)初始化:
arr1 := [...]type{i1, i2, i3, i4, i5}
arrKeyValue := [len]type{i1: val1, i2: val2}
var slice1 []type = arr1[start:end](1)如何截断数组或者切片的最后一个元素:
line = line[:len(line)-1](2)如何使用for或者for-range遍历一个数组(或者切片):
for i:=0; i < len(arr); i++ {
… = arr[i]
}
for ix, value := range arr {
…
}
(3)如何在一个二维数组或者切片arr2Dim中查找一个指定值V:
found := false
Found: for row := range arr2Dim {
for column := range arr2Dim[row] {
if arr2Dim[row][column] == V{
found = true
break Found
}
}
}3、映射
创建: map1 := make(map[keytype]valuetype)
初始化: map1 := map[string]int{"one": 1, "two": 2}
(1)如何使用for或者for-range遍历一个映射
for key, value := range map1 {
…
}
(2)如何在一个映射中检测键key1是否存在
val1, isPresent = map1[key1]返回值:键key1对应的值或者0, true或者false
(3)如何在映射中删除一个键
delete(map1, key1)4、结构体
创建:
type struct1 struct {
field1 type1
field2 type2
…
}
ms := new(struct1)
初始化:
ms := &struct1{10, 15.5, "Chris"}
当结构体的命名以大写字母开头时,该结构体在包外可见。 通常情况下,为每个结构体定义一个构建函数,并推荐使用构建函数初始化结构体:
ms := Newstruct1{10, 15.5, "Chris"}
func Newstruct1(n int, f float32, name string) *struct1 {
return &struct1{n, f, name}
}5、接口
(1)如何检测一个值v是否实现了接口Stringer
if v, ok := v.(Stringer); ok {
fmt.Printf("implements String(): %s\n", v.String())
}
(2)如何使用接口实现一个类型分类函数
func classifier(items ...interface{}) {
for i, x := range items {
switch x.(type) {
case bool:
fmt.Printf("param #%d is a bool\n", i)
case float64:
fmt.Printf("param #%d is a float64\n", i)
case int, int64:
fmt.Printf("param #%d is an int\n", i)
case nil:
fmt.Printf("param #%d is nil\n", i)
case string:
fmt.Printf("param #%d is a string\n", i)
default:
fmt.Printf("param #%d’s type is unknown\n", i)
}
}
}6、函数
如何使用内建函数recover终止panic过程:
func protect(g func()) {
defer func() {
log.Println("done")
// Println executes normally even if there is a panic
if x := recover(); x != nil {
log.Printf("run time panic: %v", x)
}
}()
log.Println("start")
g()
}7、文件
(1)如何打开一个文件并读取
file, err := os.Open("input.dat")
if err != nil {
fmt.Printf("An error occurred on opening the inputfile\n" +
"Does the file exist?\n" +
"Have you got acces to it?\n")
return
}
defer file.Close()
iReader := bufio.NewReader(file)
for {
str, err := iReader.ReadString('\n')
if err != nil {
return // error or EOF
}
fmt.Printf("The input was: %s", str)
}
(2)如何通过切片读写文件
func cat(f *file.File) {
const NBUF = 512
var buf [NBUF]byte
for {
switch nr, er := f.Read(buf[:]); true {
case nr < 0:
fmt.Fprintf(os.Stderr, "cat: error reading from %s: %s\n",
f.String(), er.String())
os.Exit(1)
case nr == 0: // EOF
return
case nr > 0:
if nw, ew := file.Stdout.Write(buf[0:nr]); nw != nr {
fmt.Fprintf(os.Stderr, "cat: error writing from %s: %s\n",
f.String(), ew.String())
}
}
}
}8、协程(goroutine)与通道(channel)
出于性能考虑的建议:
实践经验表明,如果你使用并行运算获得高于串行运算的效率:在协程内部已经完成的大部分工作,其开销比创建协程和协程间通信还高。
1 出于性能考虑建议使用带缓存的通道:
使用带缓存的通道可以很轻易成倍提高它的吞吐量,某些场景其性能可以提高至10倍甚至更多。通过调整通道的容量,甚至可以尝试着更进一步的优化其性能。
2 限制一个通道的数据数量并将它们封装成一个数组:
如果使用通道传递大量单独的数据,那么通道将变成性能瓶颈。然而,将数据块打包封装成数组,在接收端解压数据时,性能可以提高至10倍。
创建:
ch := make(chan type,buf)(1)如何使用for或者for-range遍历一个通道
for v := range ch {
// do something with v
}
(2)如何检测一个通道ch是否关闭
//read channel until it closes or error-condition
for {
if input, open := <-ch; !open {
break
}
fmt.Printf("%s", input)
}
或者使用(1)自动检测。
(3)如何通过一个通道让主程序等待直到协程完成(信号量模式)
ch := make(chan int) // Allocate a channel.
// Start something in a goroutine; when it completes, signal on the channel.
go func() {
// doSomething
ch <- 1 // Send a signal; value does not matter.
}()
doSomethingElseForAWhile()
<-ch // Wait for goroutine to finish; discard sent value.
如果希望程序一直阻塞,在匿名函数中省略 ch <- 1即可。
(4)通道的工厂模板:以下函数是一个通道工厂,启动一个匿名函数作为协程以生产通道
func pump() chan int {
ch := make(chan int)
go func() {
for i := 0; ; i++ {
ch <- i
}
}()
return ch
}
(5)通道迭代器模板:
(6)如何限制并发处理请求的数量
(7)如何在多核CPU上实现并行计算
(8)如何终止一个协程:runtime.Goexit()
(9)简单的超时模板
timeout := make(chan bool, 1)
go func() {
time.Sleep(1e9) // one second
timeout <- true
}()
select {
case <-ch:
// a read from ch has occurred
case <-timeout:
// the read from ch has timed out
}
(10)如何使用输入通道和输出通道代替锁
func Worker(in, out chan *Task) {
for {
t := <-in
process(t)
out <- t
}
}
(11)如何在同步调用运行时间过长时将之丢弃
(12)如何在通道中使用计时器和定时器
(13)典型的服务器后端模型
9、网络和网页应用
制作、解析并使模板生效:
var strTempl = template.Must(template.New("TName").Parse(strTemplateHTML))
在网页应用中使用HTML过滤器过滤HTML特殊字符:
{ {html .}} 或者通过一个字段 FieldName { { .FieldName |html }}
使用缓存模板。
10、其他
如何在程序出错时终止程序:
if err != nil {
fmt.Printf(“Program stopping with error %v”, err)
os.Exit(1)
}
或者:
if err != nil {
panic(“ERROR occurred: “ + err.Error())
}11、出于性能考虑的最佳实践和建议
(1)尽可能的使用:=去初始化声明一个变量(在函数内部);
(2)尽可能的使用字符代替字符串;
(3)尽可能的使用切片代替数组;
(4)尽可能的使用数组和切片代替映射;
(5)如果只想获取切片中某项值,不需要值的索引,尽可能的使用for range去遍历切片,这比必须查询切片中的每个元素要快一些;
(6)当数组元素是稀疏的(例如有很多0值或者空值nil),使用映射会降低内存消耗;
(7)初始化映射时指定其容量;
(8)当定义一个方法时,使用指针类型作为方法的接受者;
(9)在代码中使用常量或者标志提取常量的值;
(10)尽可能在需要分配大量内存时使用缓存;
(11)使用缓存模板;