一、背景
某业务采取mysql的主从架构,但因为存储的问题,导致备库一直无法存储,数据同步一致性问题一直也未恢复,某次安全检查要求完成主备倒换演练,必须限期恢复主备,但是在恢复过程中,同步显示正常一段时间后,便会出现sql线程异常,主备数据不一致导致的同步错误情况。

二、可能原因
1、网络的延迟
由于mysql主从复制是基于binlog的一种异步复制通过网络传送binlog文件,理所当然网络延迟是主从不同步的绝大多数的原因,特别是跨机房的数据同步出现这种几率非常的大,所以做读写分离,注意从业务层进行前期设计。
2、主从两台机器的负载不一致
由于mysql主从复制是主数据库上面启动1个io线程,而从上面启动1个sql线程和1个io线程,当中任何一台机器的负载很高,忙不过来,导致其中的任何一个线程出现资源不足,都将出现主从不一致的情况。
3、max_allowed_packet设置不一致
主数据库上面设置的max_allowed_packet比从数据库大,当一个大的sql语句,能在主数据库上面执行完毕,从数据库上面设置过小,无法执行,导致的主从不一致。
4、自增键不一致
key自增键开始的键值跟自增步长设置不一致引起的主从不一致。
5、同步参数设置问题
mysql异常宕机情况下,如果未设置sync_binlog=1或者innodb_flush_log_at_trx_commit=1很有可能出现binlog或者relaylog文件出现损坏,导致主从不一致。
6、自身bug
mysql本身的bug引起的主从不同步,一般不会
7、版本不一致
特别是高版本是主,低版本为从的情况下,主数据库上面支持的功能,从数据库上面不支持该功能的情况。
三、处理
3.1、手动执行同步+忽略错误(在业务不保证数据强一致性的情况下,可以选择忽略)
1)先进入主库,进行锁表,防止数据写入
mysql> flush tables with read lock;
mysql> show master status
2)数据导出备份然后倒入从库
mysqldump -uroot -p --lock-all-tables --flush-logs db_name > /data/master.sql
3)登录从库停止slave从节点
stop slave;
4)倒入数据
mysql -u root -p db_name < /temp/master.sql
或mysql> source /temp/master.sql
5)配置重新主从同步
5.7及之后版本
mysql> update mysql.user set authentication_string = password (‘Password4’) where user = ‘testuser’ and host = ‘%’;
Query OK, 1 row affected, 1 warning (0.06 sec)
Rows matched: 1 Changed: 1 Warnings: 1
mysql> flush privileges;
Query OK, 0 rows affected (0.01 sec)
#5.6及之前版本
update mysql.user set password=password(‘新密码’) where user=‘用户名’ and host=‘host’;
mysql> change master to master_host=‘172.18.1.20’, master_port=3306, master_user=‘repl’,master_password=‘123456’, master_log_file=‘mysql-bin.000031’,master_log_pos=932;
6)开启slave
start slave;
7)查看slave状态
show slave status\G //正常输出如下
Slave_IO_Running: Yes
Slave_SQL_Running: Yes
……
Seconds_Behind_Master:0
8)如果一段时间后,出现了报错,停止slave:
set global sql_slave_skip_counter =1;
9)start slave再次验证,重复几次,把所有错误忽略掉;
3.2、手动执行同步+手动更正
前7步同上;
通过第7步的报错位置,在主库执行:
mysqlbinlog -v --stop-position=xxx ./data/master-bin.xxx > ./binlog.update
cat ./binlog.update |awk ‘/end_log_pos xxx/ {print NR}’
根据上面的NR行数,查看附近的行,定位数据不一致的地方,后续手动补全
cat ./binlog.update |awk ‘NRxxx-50,NRxxx+50’|grep -i update -A 200|grep xxxx -B 200|less
找到数据位置,@1表第一个字段值
主库创建临时表:
Create table xxl_job_temp like xxl_job_log_report;
将该段数据写入临时表导出导入到备库;
start slave;
show slave status\G
结果说明:
Slave_IO_Running: 该参数可作为io_thread的监控项,Yes表示io_thread的和主库连接正常并能实施复制工作,No则说明与主库通讯异常,多数情况是由主从间网络引起的问题;
Slave_SQL_Running: 该参数代表sql_thread是否正常,具体就是语句是否执行通过,常会遇到主键重复或是某个表不存在。
Seconds_Behind_Master:是通过比较sql_thread执行的event的timestamp和io_thread复制好的event的timestamp(简写为ts)进行比较,而得到的这么一个差值;NULL—表示io_thread或是sql_thread有任何一个发生故障,也就是该线程的Running状态是No,而非Yes。0 — 该值为零,是我们极为渴望看到的情况,表示主从复制良好,可以认为lag不存在。正值 — 表示主从已经出现延时,数字越大表示从库落后主库越多。负值 — 几乎很少见,我只是听一些资深的DBA说见过,其实,这是一个BUG值,该参数是不支持负值的,也就是不应该出现。
四、第三方工具pt-table-sync来辅助实现

Percona Toolkit是mysql运维的一组命令的集合, 是 Percona 支持人员用来执行各种 MySQL、MongoDB 和系统任务的高级命令行工具集,它们是完全独立的,不依赖与特定的库,因此安装也很简单;该工具中最主要的三个组件分别是:
| 项目 | Value |
|---|---|
| pt-table-checksum | 负责监测mysql主从数据一致性 |
| pt-table-sync | 负责当主从数据不一致时修复数据,让它们保存数据的一致性 |
| pt-heartbeat | 负责监控mysql主从同步延迟 |
官网:https://docs.percona.com/percona-toolkit/index.html
文档:https://docs.percona.com/percona-toolkit/installation.html
下载:https://www.percona.com/downloads/percona-toolkit/LATEST/
1)安装前准备
#percona-toolkit的yum仓库
yum install https://repo.percona.com/yum/percona-release-latest.noarch.rpm -y
#MYSQL的yum仓库
yum install -y https://repo.mysql.com//mysql80-community-release-el7-3.noarch.rpm
yum install percona-release-0.1-6.noarch.rpm
yum list | grep mysql | grep libs-compat
mysql-community-libs-compat.i686 5.7.30-1.el7 mysql57-community
mysql-community-libs-compat.x86_64 5.7.30-1.el7 mysql57-community
yum -y install mysql-community-libs-compat.x86_64
yum install perl-IO-Socket-SSL perl-DBD-MySQL perl-Time-HiRes perl perl-DBI -y
#下载
wget https://www.percona.com/redir/downloads/percona-release/redhat/0.1-6/percona-release-0.1-6.noarch.rpm

2)安装
sudo yum install percona-toolkit //直接
yum list | grep percona-toolkit
#验证
pt-table-checksum --version //现场版本3.4.0
pt-query-digest --version


3)配置使用
#主库授权,从库也验证下
grant select,process,super,replication slave,create,delete,insert,update on *.* to 'repl'@'%' identified by '123456';
# 主库执行命令,检查主从数据一致性
pt-table-checksum --nocheck-replication-filters --no-check-binlog-format --replicate=test.checksums --create-replicate-table --databases=mysql h=172.18.1.19,u=repl,p='123456',P=3306


五、附录及FAQ
5.1 主从同步报无法连接数据库,测试报:Host is blocked because of many connection errors
原因:
当同一个ip在短时间内产生太多(超过数据库max_connection_errors的最大值)中断的数据库连接而导致的阻塞;当slave与master出现未正常连接时,master后续新提交的事务无法在后续主从连接同步给slave,即master如果想删除了数据,同步到slave,而slave没有这条数据,也就无法完成同步删除操作,两边不一致,这就会导致slave_sql_running停止运行,状态显示NO;

#检查当前连接数情况:
show status like '%connect%';
#重置连接错误数
flush hosts;
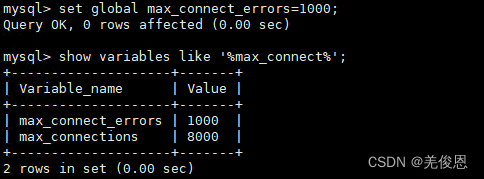
#设置最大连接错误数
set global max_connect_errors = 1000;
#查看最大连接错误数
show variables like 'max_connect_errors';
#主从同步一致性跳过错误重新同步
mysql> stop slave;
mysql> set global sql_slave_skip_counter=1; #跳过当前错误
mysql> start slave;
#如果错误数太多,主从不一致,从库执行如下,尝试重新同步,逐步加大数字
#This statement skips the next N events from the master. This is useful for recovering from replication stops caused by a statement.
mysql> set global sql_slave_skip_counter=N #这里的N是指跳过N个event
#验证
mysql> show slave status\G;
#如果数据量不大,一致性要求较高,手动锁定主库,从新的位置让slave重新同步
mysql> set global read_only=on/off
mysql> CHANGE MASTER TO MASTER_HOST='172.28.2.20',
MASTER_PORT=3306,
MASTER_USER='repl',
MASTER_PASSWORD='123456',
MASTER_LOG_FILE='mysql-bin.000305',
MASTER_LOG_POS=3303782;
#查看语句记录功能开启状态
mysql> select * from performance_schema.setup_consumers where name like 'events_statements%';
#结果中指标意义如下
events_statements_current ## 默认只记录每个线程最近的一条SQL信息
events_statements_history ## 默认记录每个线程最近的十条SQL信息
events_statements_history_long ## 默认记录每个线程最近的10000条SQL信息
#开启语句记录
mysql> update performance_schema.setup_consumers set enabled = 'YES' where name in ('events_statements_history','events_statements_history_long');
#根据slave上错误号查找详情
mysql> select * from performance_schema.events_statements_history_long where mysql_errno=1062\G;
#查看binlog位置信息;其中:IN 'log_name' 指定要查询的binlog文件名(不指定就是第一个binlog文件)
#FROM pos 指定从哪个pos起始点开始查起(不指定就是从整个文件首个pos点开始算)
#LIMIT [offset,] 偏移量(不指定就是0)
#row_count 查询总条数(不指定就是所有行)
#log_name, pos 可从slave上报错信息获取
mysql> show binlog events [IN 'log_name'] [FROM pos] [LIMIT [offset,] row_count];
mysql> show binlog events IN 'master-bin.000307' FROM 968029214 LIMIT 20;
#当前也可以编辑slave配置文件来跳过报错
vi /etc/my.cnf //如下
[mysqld]
slave-skip-errors=1062,1053,1146 #跳过指定error no类型的错误
slave-skip-errors=all #跳过所有错误
#对于采用GTID协议主从复制时,当报错某位置(比如33)上发生错误,手动调整SLAVE已清除的GTID列表 GTID_PURGED,通知SLAVE哪些事务已经被清除了,如下处理:
mysql> STOP SLAVE;
mysql> RESET MASTER;
mysql> SET @@GLOBAL.GTID_PURGED = “3a16ef7a-75f5-11e4-8960-deadeb54b599:1-283,f2b6c829-9c87-11e4-84e8-deadeb54b599:1-33”; //跳过/忽略33这个错误
mysql> START SLAVE;
//注意:在GTID主从的建立初期,slave的数据一定要是从master mysqldump过去的并且更加--all-databases参数。否则手动补齐的数据会出现slave_sql_running为NO的情况,这是因为主的操作记录会保存在GTID与binlog中,然后slave会同步主的GTID与binlog并进行相应的操作,这时两边的数据虽然是一致的,但是同步过来master的GTID中包含了主做过的一些sql操作,而此时slave的环境不满足sql语句的执行就会冲突。
//解决办法是:
//1.)不断的执行跳过事务的操作直到没有报错。
//2.)刷新master的GTID“reset master”然后重新再slave执行change同步。
//master确认已经purge的部分,stop slave,在slave上通过set global gtid_purged='xxxx'的方式,跳过已经purge的部分;注意开启主从复制之后,就不可以在从的上面进行操作,否则会出现slave_sql_running为NO的提示
mysql> show global variables like '%gtid%';


5.2 MySQL的GTID主从 与 传统主从复制的区别
1)传统主从复制:
普通主从复制主要是基于二进制日志文件位置的复制,因此主必须启动二进制日志记录并建立唯一的服务器ID,复制组中的每个服务器都必须配置唯一的服务器ID。如果您省略server-id(或者明确地将其设置为其默认值0),则主设备将拒绝来自从设备的任何连接。
在传统的主从复制slave端,binlog是不用开启的,但是在GTID中slave端的binlog是必须开启的,目的是记录执行过的GTID(强制)。
传统一主多从(mysql5.6之前)的模型中当master down掉后,我们不只是需要将一个slave提成master就可以,还要将其他slave的同步目的地从以前的master改成现在master,而且bin-log的序号和偏移量也要去查看,这是十分不方便和耗时的,但mysql5.6引入gtid之后解决了这个问题。
2) GTID (Global Transaction ID)主从: 主从复制更简单,一致性更可靠
从MySQL 5.6.5 开始新增了一种基于 GTID 的复制方式。全局事务标识符(GTID)是MySQL 5.6 的新特性之一,它会创建唯一标识符,并与在源(主)服务器上与提交的每个事务相关联。此标识符的唯一是在复制组中所有服务器上都是唯一的。所有交易和所有GTID之间都有一对一的映射关系 。它由服务器ID以及事务ID组合而成。这个全局事务ID不仅仅在原始服务器上唯一,在所有存在主从关系 的mysql服务器上也是唯一的。正是因为这样一个特性使得mysql的主从复制变得更加简单,以及数据库一致性更可靠。一个GTID在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
一个GTID被表示为一对坐标,用冒号(:)分隔,如下所示:GTID = source_id:transaction_id,source_id标识的源服务器。通常情况下,服务器 server_uuid用于这个目的。这transaction_id是一个序列号,由在此服务器上提交事务的顺序决定 。当在主库上提交事务或者被从库应用时,可以定位和追踪每一个事务,从而无需手工去定位偏移量的值了,而是通过CHANGE MASTER TO MASTER_HOST=‘xxx’, MASTER_AUTO_POSITION=1;即可方便的搭建从库,在故障修复中也可以采用MASTER_AUTO_POSITION=‘X’的方式。
总之,通过 GTID 保证了每个在主库上提交的事务在集群中有一个唯一的ID。这种方式强化了数据库的主备一致性,故障恢复以及容错能力。更多参看官网
GTID = server_uuid:transaction_id //GTID实际上是由UUID+TID组成的
注意: 其中UUID是一个MySQL实例的唯一标识。TID代表了该实例上已经提交的事务数量,并且随着事务提交单调递增。server_uuid 一般是发起事务的uuid, 标识了该事务执行的源节点,存储在数据目录中的auto.cnf文件中,transaction_id 是在该主库上生成的事务序列号,从1开始,1-2代表第二个事务;第1-n代表n个事务。

- 当一个事务在主库端执行并提交时,产生 GTID,一同记录到 binlog 日志中。
- binlog 传输到 slave,并存储到 slave 的 relaylog 后,读取这个 GTID 的这个值设置 gtid_next 变量,即告诉 Slave,下一个要执行的 GTID 值。
- sql 线程从 relay log 中获取 GTID,然后对比 slave 端的 binlog 是否有该 GTID。
- 如果有记录,说明该 GTID 的事务已经执行,slave 会忽略。
- 如果没有记录,slave 就会执行该 GTID 事务,并记录该 GTID 到自身的 binlog;其中,IO thread 决定了Retrieved_Gtid_Set;SQL thread 决定了Executed_Gtid_Set;负责获取master上的binary log, 然后多个sql threads负责执行。由于IO thread先于SQL thread;
- 在解析过程中会判断是否有主键,如果没有就用二级索引,如果没有就用全部扫描。下图为GTID生命周期:

在主从复制中,尤其是半同步复制中, 由于Master 的dump进程一边要发送binlog给Slave,一边要等待Slave的ACK消息,这个过程是串行的,即前一个事物的ACK没有收到消息,那么后一个事物只能排队候着; 这样将会极大地影响性能;有了GTID后,SLAVE就直接可以通过数据流获得GTID信息,而且可以同步;
另外,主从故障切换中,如果一台MASTER down,需要提取拥有最新日志的SLAVE做MASTER,这个是很好判断,而有了GTID,就只要以GTID为准即可方便判断;而有了GTID后,SLAVE就不需要一直保存这bin-log 的文件名和Position了;只要启用MASTER_AUTO_POSITION即可。当MASTER crash的时候,GTID有助于保证数据一致性,因为每个事物都对应唯一GTID,如果在恢复的时候某事物被重复提交,SLAVE会直接忽略;因GTID因为是全局唯一,所以适合用于分布式环境中,很容易识别。
GTID的优点:
- 根据 GTID 可以快速的确定事务最初是在哪个实例上提交的。
- 实现 failover更简单,无需再找 log_file 和 log_pos了。
- 主从复制搭建更简单,确保了每个事务只会被执行一次。
- 比传统的复制更加安全,一个 GTID 在一个服务器上只执行一次,避免重复执行导致数据混乱或者主从不一致。
- GTID是连续的没有空洞的,保证数据的一致性,零丢失
- GTID 用来代替classic的复制方法,不再使用 binlog+pos 开启复制。而是使用 master_auto_postion=1 的方式自动匹配 GTID 断点进行复制。
- GTID 的引入,让每一个事务在集群事务的海洋中有了秩序,使得 在运维中做集群变更时更加方便。
GTID的缺点:
- 主从库的表存储引擎必须是一致的
主从库的表存储引擎不一致,就会导致数据不一致。如果主从库的存储引擎不一致,例如一个是事务存储引擎,一个是非事务存储引擎,则会导致事务和 GTID 之间一对一的关系被破坏,结果就会导致基于 GTID 的复制不能正确运行;
master:对一个innodb表做一个多sql更新的事物,效果是产生一个GTID。
slave:假设对应的表是MYISAM引擎,执行这个GTID的第一个语句后就会报错,因为非事务引擎一个sql就是一个事务。
当从库报错时简单的stop slave; start slave;就能够忽略错误。但是这个时候主从的一致性已经出现问题,需要手工的把slave差的数据补上,这里要将引擎调整为一样的,slave也改为事务引擎。
\- 不允许一个SQL同时更新一个事务引擎和非事务引擎的表
事务中混合多个存储引擎,就会产生多个 GTID。当使用 GTID 时,如果在同一个事务中,更新包括了非事务引擎(如 MyISAM)和事务引擎(如 InnoDB)表的操作,就会导致多个 GTID 分配给了同一个事务。
\- 在一个复制组中,必须要求统一开启GTID或是关闭GTID;
\- 不支持create table….select 语句复制(主库直接报错);
create table xxx as select的语句,其实会被拆分为两部分,create语句和insert语句,但是如果想一次搞定,MySQL会抛出如下的错误。
ERROR 1786 (HY000): Statement violates GTID consistency: CREATE TABLE … SELECT.
create table xxx as select 的方式可以拆分成两部分,如下:
create table xxxx like data_mgr;
insert into xxxx select *from data_mgr;
\- 对于create temporary table 和 drop temporary table语句不支持
使用GTID复制模式时,不支持create temporary table 和 drop temporary table。但是在autocommit=1的情况下可以创建临时表,Master端创建临时表不产生GTID信息,所以不会同步到slave,但是在删除临时表的时候会产生GTID会导致,主从中断.
\- 不支持sql_slave_skip_counter.
mysql在主从复制时如果要跳过报错,可以采取以下方式跳过SQL(event)组成的事务,但GTID不支持以下方式。
set global SQL_SLAVE_SKIP_COUNTER=1;
start slave sql_thread;
配置参考:
#主master:
[mysqld]
#GTID主从:
server_id=1 #服务器id,与slave的server_id区分开来
gtid_mode=on #开启gtid模式
log_slave_updates ## 表示可以当从也可以当主
enforce_gtid_consistency=on #强制gtid一致性,开启后对于特定create table不被支持
#binlog
log_bin=master-binlog
#log-bin=/data/mysql/mysql-bin.log //binlog日志文件,(文件名如果是绝对路径,必须指定索引文件)
#log_bin_index =/var/lib/mysql/mysql-bin.index //是binlog文件的索引文件,这个文件管理了所有的binlog文件的目录
log-slave-updates=1
binlog_format=row #binlog日志格式,强烈建议,其他格式可能造成数据不一致
expire_logs_days=7 //binlog过期清理时间
#relay logskip_slave_start=1
#登录MySQL授权允许登录从库
mysql> GRANT REPLICATION SLAVE ON *.* TO [email protected] IDENTIFIED BY '123456';
mysql> flush privileges;
#从slave配置: 注意跟MASTER_AUTO_POSITION=1参数
##MASTER_AUTO_POSITION: (mysql5.6.5及其后续版本)进行change master to时使用MASTER_AUTO_POSITION = 1,slave连接master将使用基于GTID的复制协议。等于0则恢复到老的文件复制协议
CHANGE MASTER TO MASTER_HOST='10.18.1.12',MASTER_PORT=3306,MASTER_USER='repl',MASTER_PASSWORD='123456',MASTER_AUTO_POSITION=1;
#启动验证
mysql> start slave;
mysql> show slave status\G;
#结果说明
Retrieved_Gtid_Set:aaa-bbb-ccc-ddd:N #表示收到的事务
Executed_Gtid_Set:aaa-bbb-ccc-ddd:N #表示已经执行完的事务