文章目录
前言
本篇文章接着来解析JDK8中HashMap的底层源码:treeifyBin和splite方法。其中,treeifyBin和链表转红黑树有关,splite和扩容时红黑树的转移有关。
一、treeifyBin方法
在putVal的源码中,当链表的长度超过8时,会调用treeifBin方法判断是否要转换成红黑树。

在学习treeifBin方法之前我们先来看一下JDK8源码中这个方法上面的注释:
/**
* Replaces all linked nodes in bin at index for given hash unless
* table is too small, in which case resizes instead.
*/
final void treeifyBin(Node<K,V>[] tab, int hash) {
翻译成中文就是:替换给定哈希索引处bin中的所有链接节点,除非表太小,在这种情况下会调整大小。
由这段话我们可以知道,不是链表长度超过8就会转红黑树,还有一些附加条件,接下来我们直接解析treeifyBin方法的源码:
final void treeifyBin(Node<K,V>[] tab, int hash) {
int n, index; Node<K,V> e;
//数组⻓度如果⼩于MIN_TREEIFY_CAPACITY(默认为64),则会扩容
if (tab == null || (n = tab.length) < MIN_TREEIFY_CAPACITY)
resize();
else if ((e = tab[index = (n - 1) & hash]) != null) {
//把链表改造为双向链表,并且把节点类型改为TreeNode
TreeNode<K,V> hd = null, tl = null;
do {
TreeNode<K,V> p = replacementTreeNode(e, null);
if (tl == null)
hd = p;
else {
p.prev = tl;
tl.next = p;
}
tl = p;
} while ((e = e.next) != null);
if ((tab[index] = hd) != null)
// 改造为红⿊树
hd.treeify(tab);
}
}
从上面这个方法也可以看出,如果当前数组长度如果小于MIN_TREEIFY_CAPACITY(默认为64),则会进行扩容,不会直接转红黑树,为什么要这样设计?
解答:如果数组的长度较小,应该尽量避开红黑树。因为红黑树需要进行左旋,右旋,变色操作来保持平衡,所以当数组长度小于64时,使用数组加链表比使用红黑树查询速度要更快、效率要更高。
与此同时,我们可以看见,如果要转红黑树,需要把链表改造为双向链表,并且把节点类型改为TreeNode。这一点之前的文章就提到过,JKD8中HashMap的数据结构为数组+单向链表+双向链表+红黑树,转换为双向链表是为了操作红黑树时更方便。
一个TreeNode代表红黑树的一个节点,关于TreeNode的定义如下所示,

TreeNode<K,V>继承了LinkedHashMap.Entry<K,V>,而后者又继承了HashMap.Node<K,V>,所以TreeNode依然保有Node的属性(Node.next这个属性依然有效),同时由于添加了prev这个前驱指针使得链表变为了双向的。
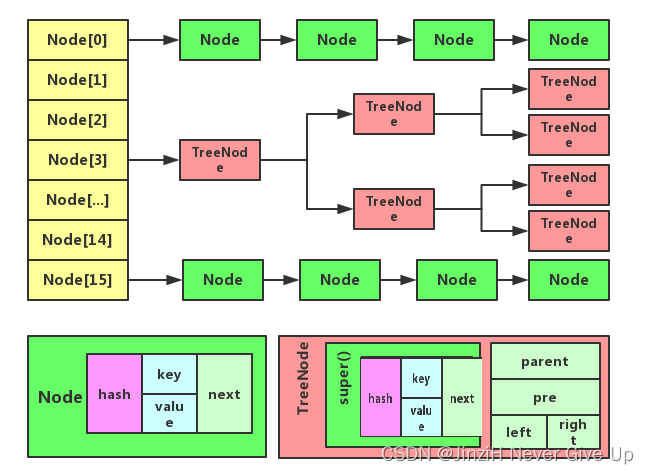
小结:所以一个TreeNode拥有四个属性:left,right,next,prev,前两个和红黑树特性有关,后两个跟链表有关,所以说红⿊树是由链表改造⽽成,链表其实还是存在的。
二、splite方法
在之前resize()方法中我们就已经知道,如果扩容时转移元素的时候要转移的是一颗红黑树,则会调用splite方法()。

现在我们来直接看一下splite方法的源码:
final void split(HashMap<K,V> map, Node<K,V>[] tab, int index, int bit) {
TreeNode<K,V> b = this;
// Relink into lo and hi lists, preserving order 重新链接到lo和hi列表,保持顺序
TreeNode<K,V> loHead = null, loTail = null;
TreeNode<K,V> hiHead = null, hiTail = null;
int lc = 0, hc = 0;
// 由于红⿊树是由链表改造⽽成,所以链表其实还是存在的
// 对链表进⾏⾼低拆分
for (TreeNode<K,V> e = b, next; e != null; e = next) {
next = (TreeNode<K,V>)e.next;
e.next = null;
if ((e.hash & bit) == 0) {
if ((e.prev = loTail) == null)
loHead = e;
else
loTail.next = e;
loTail = e;
++lc;
}
else {
if ((e.prev = hiTail) == null)
hiHead = e;
else
hiTail.next = e;
hiTail = e;
++hc;
}
}
// 拆分之后,如果存在低位链表,则看链表⻓度,如果⼩于等于UNTREEIFY_THRESHOLD,则退化成链表,并把节点类型改为Node类型
if (loHead != null) {
if (lc <= UNTREEIFY_THRESHOLD)
//退化为链表,调用untreeify
tab[index] = loHead.untreeify(map);
else {
// 否则,把头结点转移到新节点(红⿊树的根节点⼀定是链表的头节点)
tab[index] = loHead;
// 如果存在⾼位链表,则说明之前的红黑树被拆分了,需重新根据低位链表的元素重新生成一个红黑树
if (hiHead != null) // (else is already treeified)
loHead.treeify(tab);
}
}
// 和上面的逻辑类似
if (hiHead != null) {
if (hc <= UNTREEIFY_THRESHOLD)
tab[index + bit] = hiHead.untreeify(map);
else {
tab[index + bit] = hiHead;
if (loHead != null)
hiHead.treeify(tab);
}
}
}
因为红黑树在转移元素的时候,不一定所有的结点都在一个位置上,很可能一部分在高位,一部分在低位。所以在转移红黑树的时候刚开始的逻辑和我们转移链表的时候一模一样:
- 维持一个高位和低位链表
- 遍历红黑树(实质上也是在遍历链表,红⿊树是由链表改造⽽成),判断结点在高位还是低位,这样就能统计出哪些结点在低位,哪些结点在高位。
- 最终判断低位的结点个数(lc)和高位结点个数(hc),如果个数小于等于6则会转换成链表(untreeify方法),如果不小于6则会判断是否需要使用链表的元素重新生成一个红黑树(如果同时存在低位和高位链表,说明之前的红黑树已经被分割了,这时候如果分割了的链表长度还大于6,则需要重新生成一个红黑树)
final Node<K,V> untreeify(HashMap<K,V> map) {
Node<K,V> hd = null, tl = null;
for (Node<K,V> q = this; q != null; q = q.next) {
Node<K,V> p = map.replacementNode(q, null);
if (tl == null)
hd = p;
else
tl.next = p;
tl = p;
}
return hd;
}
简单的说:untreeify这个方法就是要把原来的TreeNode改造成Node,改造成Node之后自然成为了一个链表。
总结
本篇文章解析了treeifyBin和splite方法,如果链表长度大于8且数组长度大于64,先把链表改造为双向链表,并且把节点类型改为TreeNode,在调用treeify()方法改造成红黑树。扩容时转移元素的时候要转移的是一颗红黑树,则会调用splite方法()去分割红黑树,分割成高位和低位链表,如果链表个数小于等于6则会转换成链表(untreeify方法),如果同时存在低位和高位链表,说明之前的红黑树已经被分割了,这时候如果分割了的链表长度还大于6,则需要重新生成一个红黑树。