
HarmonyOS应用数据管理不仅支持单设备的各种结构化数据的持久化,还支持跨设备之间数据的同步、共享及搜索功能,因此,开发者基于Harmony OS应用数据管理功能,能实现应用程序数据在不同终端设备之间的无缝衔接,从而保证用户在跨设备使用数据时所用数据的一致性。
HarmonyOS对象关系映射数据库是HarmonyOS中的本地数据库之一,是在SQLite数据库的基础上提供的一个抽象层。它屏蔽了底层SQLite数据库的SQL操作,将实例对象映射到关系上,并提供增、删、改、查等一系列面向对象的接口,使应用程序使用操作实例对象的语法来操作关系型数据库,因此,开发者可以不必编写那些复杂的SQL语句,从而既可以提升效率也能聚焦于业务开发。HarmonyOS中对象关系映射数据库的运作机制如图1所示。
从图1可以看出,对象关系映射数据库的3个主要组件包括:
(1) 数据库: 通过@Database注解,且继承自OrmDatabase的类,对应关系型数据库。
(2) 实体对象: 通过@Entity注解,且继承自OrmObject的类,对应关系型数据库中的表。
(3) 对象数据操作接口: 包括数据库操作的入口OrmContext 类和谓词接口(OrmPredicate)等。
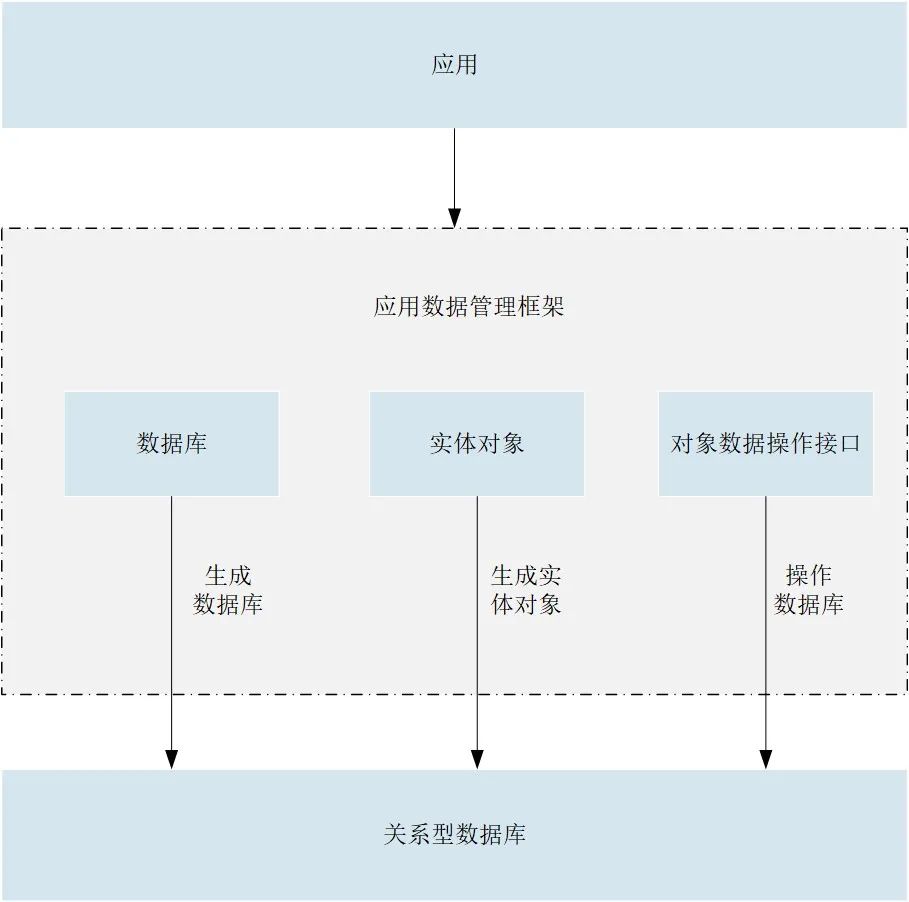
图1 对象关系映射数据库的运作机制
创建Phone设备下的Java模板新项目。在进行开发之前,首先要进行build.gradle文件的配置,否则无法识别相关数据库的类的包。
一般情况下,使用的注解处理器的模块为com.huawei.ohos.hap模块,需要在模块的build.gradle文件的ohos节点中添加以下配置,代码如下:
compileOptions{
annotationEnabled true
}如果使用注解处理器的模块为com.huawei.ohos.library,则需要在模块的build.gradle文件dependencies节点中配置注解处理器,此外,还需要在本地的HUAWEI SDK中找到orm_annotations_java.jar、orm_annotations_processor_java.jar和javapoet_java.jar这3个jar包的对应目录,并将这3个jar包的路径导入,代码如下:
dependencies {
compile files("orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
annotationProcessor files("orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
}如果使用注解处理器的模块为java-library,则还需要导入ohos.jar的路径,具体代码如下:
dependencies {
compile files("ohos.jar的路径","orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
annotationProcessor files("orm_annotations_java.jar的路径","orm_annotations_processor_java.jar的路径","javapoet_java.jar的路径")
}配置完成之后,就可以开始新建数据库并对其进行操作了,具体步骤如下。
01、新建数据库及属性配置
创建数据库时,首先需要定义一个表示数据库的类,继承OrmDatabase,再通过@Database注解内的entities属性指定哪些数据模型类属于这个数据库,version属性指明数据库版本号。
在本例中,首先新建一个数据库类BookStore.java,选择entry→src→main→com.huawei.ormdb,右击选择并新建Class,命名为BookStore,如图2所示。
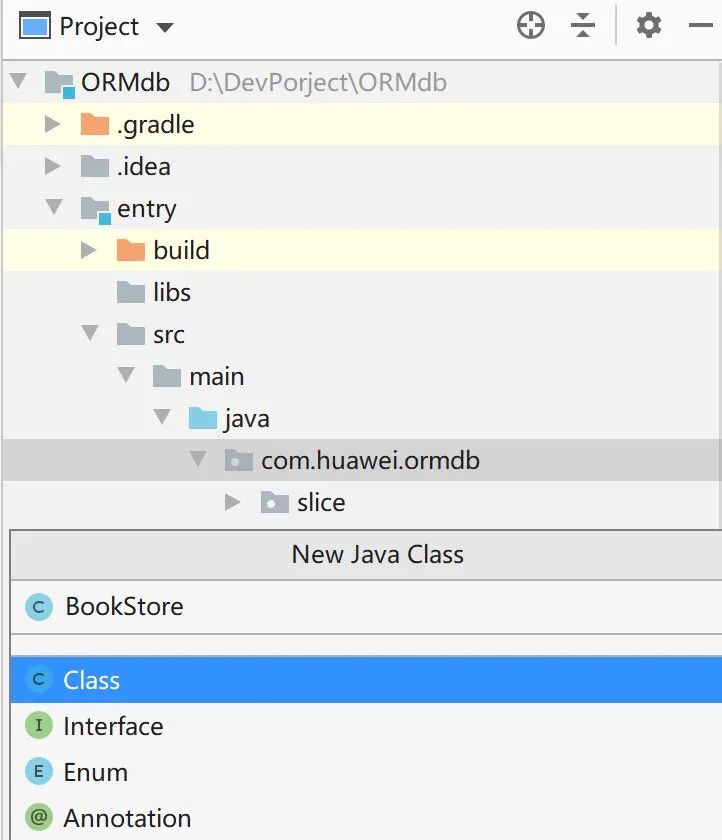
图2 新建一个数据库类
数据库类BookStore.java包含了User和Book两个表,版本号为1,将数据库类设置为虚类。具体代码如下:
import ohos.data.orm.OrmDatabase;
import ohos.data.orm.annotation.Database;
@Database(entities = {User.class, Book.class}, version = 1)
public abstract class BookStore extends OrmDatabase {
}02、构造数据表
构造数据表,即创建数据库实体类并配置对应的属性(如对应表的主键、外键等)。可通过创建一个继承了OrmObject并用@Entity注解的类,获取数据库实体对象,也就是表的对象。需要注意的是,数据表必须与其所在的数据库在同一个模块中。以新建的User表为例,新建的User类与BookStore类位于同一模块下,相应的目录如图3所示。
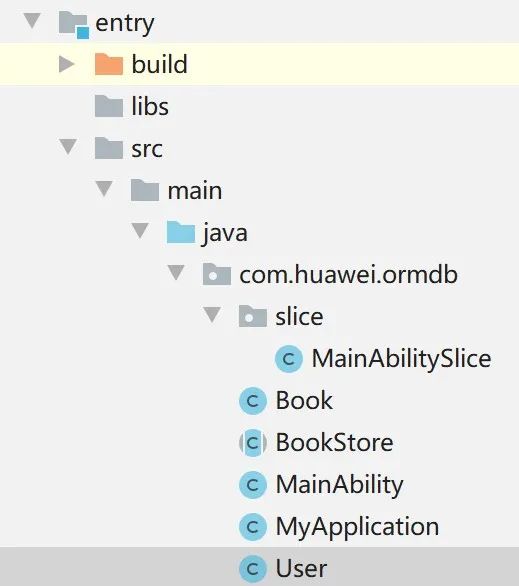
图3 BookStore数据库与User表位于同一模块
具体的构建过程代码如下:
//新建User表
import ohos.data.orm.OrmObject;
import ohos.data.orm.annotation.Entity;
import ohos.data.orm.annotation.Index;
import ohos.data.orm.annotation.PrimaryKey;
@Entity(tableName = "user", ignoredColumns = {"ignoreColumn1", "ignoreColumn2"},
indices = {@Index(value = {"firstName", "lastName"}, name = "name_index", unique = true)})
public class User extends OrmObject {
//此处将userId设为了自增的主键。注意只有在数据类型为包装类型时,自增主键才能生效。
@PrimaryKey(autoGenerate = true)
private Integer userId;
private String firstName;
private String lastName;
private int age;
private double balance;
private int ignoreColumn1;
private int ignoreColumn2;
//设置字段的getter和setter方法,此处仅给出示例,读者可以根据所设置的属性自行补全方法
public void setBalance(double balance) {
this.balance = balance;
}
...
public Integer getUserId() {
return userId;
}
...
}在新建的User类中进行属性配置,tableName = "user"即在对应数据库内的表名为user,indices为属性列表,@Index注解的内容对应数据表索引的属性,本例中indices为firstName和lastName两个字段建立了复合索引,索引名为name_index,并且索引值是唯一的。ignoreColumns 表示该字段不需要添加到user 表的属性中,即类中定义的ignoreColumn1和ignoreColumn2不属于user表的属性。被@PrimaryKey注解的变量对应数据表的主键,一个表里只能有一个主键,在本例的user表中,将userId设为自增的主键。
数据库内还包含了Book表,Book表的构建和对其操作的实现过程同User表相同,具此处不再赘述其体实现。
03、创建数据库
在MainAbilitySlice的onStart()方法中完成数据库的创建,使用对象数据操作接口OrmContext创建数据库,实现代码如下:
public void onStart(Intent intent) {
super.onStart(intent);
super.setUIContent(ResourceTable.Layout_ability_main);
//使用对象数据操作接口OrmContext创建数据库
DatabaseHelper helper = new DatabaseHelper(this);
OrmContext context = helper.getOrmContext("BookStore", "BookStore.db", BookStore.class);
//对数据库进行操作
//增加数据
...
//查询数据
...
//修改数据
...
//删除数据
...
}与构建关系型数据库不同的是,此处new DatabaseHelper(context)方法中context的入参类型为ohos.app.Context,必须直接传入slice而不能使用slice.getContext()获取context,否则会出现找不到类的报错。到这里,就成功创建了一个别名为BookStore且数据库文件名为BookStore.db的数据库。如果数据库已经存在,则执行上述代码并不会重复建库。通过context.getDatabaseDir()可以获取创建的数据库文件所在的目录。
04、数据操作
对象数据操作接口OrmContext提供了对数据库进行增、删、改、查的一系列方法,接下来进行详细介绍。
(1)增加数据 。
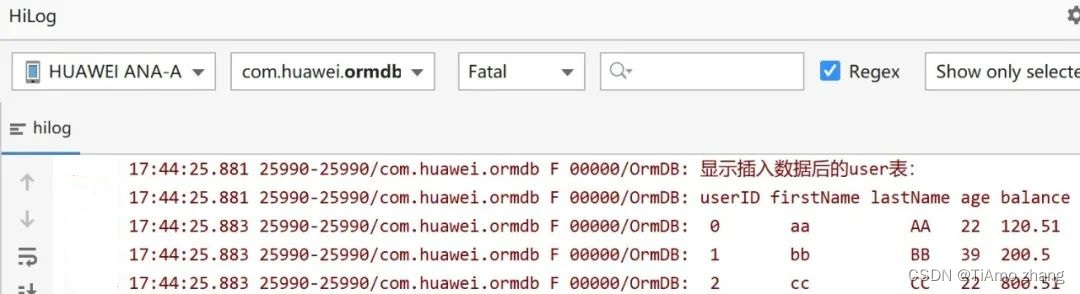
例如,在名为user 的表中,新建一个User 对象并设置其属性。OrmContext提供insert()方法将对象插入数据库。执行完insert()方法后,数据被保存在内存中,只有在flush()被调用后才会将数据持久化到数据库中。以HiLog形式显示插入数据后的user表,如图4所示。此处涉及对数据库的查询操作,将在稍后进行详细讲解。具体代码如下:
//增加数据
//新建User对象
User user = new User();
//设置对象属性
user.setUserId(0);
user.setFirstName("aa");
user.setLastName("AA");
user.setAge(22);
user.setBalance(120.51);
//再新建两个User对象,设置属性后将其持久化到数据库中,此处读者可以自行添加代码
...
//将新建对象插入并持久化到数据库中
boolean isSuccessed = context.insert(user);
isSuccessed = context.flush();
//以HiLog形式显示新增数据后的user表,以userID升序显示
HiLogLabel logLabel = new HiLogLabel(HiLog.LOG_APP,0,"OrmDB");
String s = new String("userID");
s = s.concat(" firstName");
s = s.concat(" lastName");
s = s.concat(" age");
s = s.concat(" balance");
HiLog.fatal(logLabel,"显示插入数据后的user表:");
HiLog.fatal(logLabel,s);
//查询数据
OrmPredicates query = context.where(User.class).orderByAsc("userID");
List<User> users = context.query(query);
int i = 0;
while (i != users.size()) {
int id = users.get(i).getUserId();
String s1 = "\t" + id + "\t\t";
s1 = s1.concat(users.get(i).getFirstName() + "\t");
s1 = s1.concat("\t\t" + users.get(i).getLastName());
s1 = s1.concat("\t " + users.get(i).getAge() + "\t");
s1 = s1.concat(" " + users.get(i).getBalance());
HiLog.fatal(logLabel, s1);
i = i + 1;
}
(2) 查询数据。
OrmContext提供query()方法查询满足指定条件的对象实例。例如,在user表中查询age=22的对象,在查询之前,依旧需要先设置谓词query1,利用query()方法查找user表中满足query1 的数据,得到一个User的列表user1,遍历user1,获取user1中各个对象的属性值,实现代码如下:
//查询age=22的数据并显示
//设置谓词
OrmPredicates query1 = context.where(User.class).equalTo("age", "22");
//查询
List<User> users1 = context.query(query1);
//将查询结果以HiLog形式显示
HiLogLabel logLabel1 = new HiLogLabel(HiLog.LOG_APP,0,"OrmDB");
HiLog.fatal(logLabel1,"显示user表中age值为22的数据:");
HiLog.fatal(logLabel1,s);
i = 0;
while (i != users1.size()){
int id = users1.get(i).getUserId();
String s1 = "\t" + id +"\t\t";
s1 = s1.concat(users1.get(i).getFirstName()+"\t");
s1 = s1.concat("\t\t"+users1.get(i).getLastName());
s1 = s1.concat("\t "+users1.get(i).getAge()+"\t");
s1 = s1.concat(" "+users1.get(i).getBalance());
HiLog.fatal(logLabel1,s1);
i = i + 1;
}查询结果如图5所示。

图5 查询user表中age=22的数据
(3) 修改数据。
修改数据包括两种方式,一种是通过直接传入OrmObject对象的接口来更新数据,需要先从表中查到需要更新的结果对象列表,然后修改选定对象的值,再调用更新接口将数据持久化到数据库中。例如,将user表中age=39的数据的firstName更新为sd,需要先查找user表中对应的数据,得到一个结果列表,然后选择列表中需要更新的User对象,设置更新值,并调用update接口传入被更新的User对象。最后调用flush接口将数据持久化到数据库中。具体代码如下:
//更新数据
OrmPredicates predicates = context.where(User.class);
predicates.equalTo("age", 39);
//获取满足条件的数据集
List<User> users2 = context.query(predicates);
//选定要更新的数据
User userUD = users2.get(0);
//设置更新
userUD.setFirstName("sd");
context.update(userUD);
context.flush();
HiLog.fatal(logLabel, "显示更新数据后的user表:");
HiLog.fatal(logLabel, s);
query = context.where(User.class).orderByAsc("userID");
users = context.query(query);
i = 0;
while (i != users.size()) {
int id = users.get(i).getUserId();
String s1 = "\t" + id + "\t\t";
s1 = s1.concat(users.get(i).getFirstName() + "\t");
s1 = s1.concat("\t\t" + users.get(i).getLastName());
s1 = s1.concat("\t " + users.get(i).getAge() + "\t");
s1 = s1.concat(" " + users.get(i).getBalance());
HiLog.fatal(logLabel, s1);
i = i + 1;
}另一种方式,可以通过传入谓词的接口来更新和删除数据,方法与OrmObject对象的接口类似,只是无须flush就可以将数据持久化到数据库中。通过这种方式将user表中age=39的数据的firstName更新为sd,具体代码如下:
//使用valuesBucket来改变数据
ValuesBucket valuesBucket = new ValuesBucket();
valuesBucket.putString("firstName", "sd");
OrmPredicates update = context.where(User.class).equalTo("age", 39);
context.update(update, valuesBucket);分别利用两种方式进行数据更新,更新后的结果如图6所示。

(4) 删除数据。
同修改数据一样,也包括两种方式。区别只是删除数据不需要更新对象的值。这里通过直接传入OrmObject对象的接口删除数据的方式删除满足firstName="aa"的第一个User对象,并用flush接口将数据持久化到数据库中,代码如下
//删除满足firstName = "aa"的第一个对象
OrmPredicates del = context.where(User.class).equalTo("firstName", "aa");
List<User> usersdel = context.query(del);
User userd = usersdel.get(0);
context.delete(userd);
context.flush();
HiLog.fatal(logLabel, "显示删除数据后的user表:");
HiLog.fatal(logLabel, s);
query = context.where(User.class).orderByAsc("userID");
users = context.query(query);
i = 0;
while (i != users.size()) {
int id = users.get(i).getUserId();
String s1 = "\t" + id + "\t\t";
s1 = s1.concat(users.get(i).getFirstName() + "\t");
s1 = s1.concat("\t\t" + users.get(i).getLastName());
s1 = s1.concat("\t " + users.get(i).getAge() + "\t");
s1 = s1.concat(" " + users.get(i).getBalance());
HiLog.fatal(logLabel, s1);
i = i + 1;
}
显示删除数据后的表,如图7所示。

图7 删除数据后的结果显示