一、U-net网络
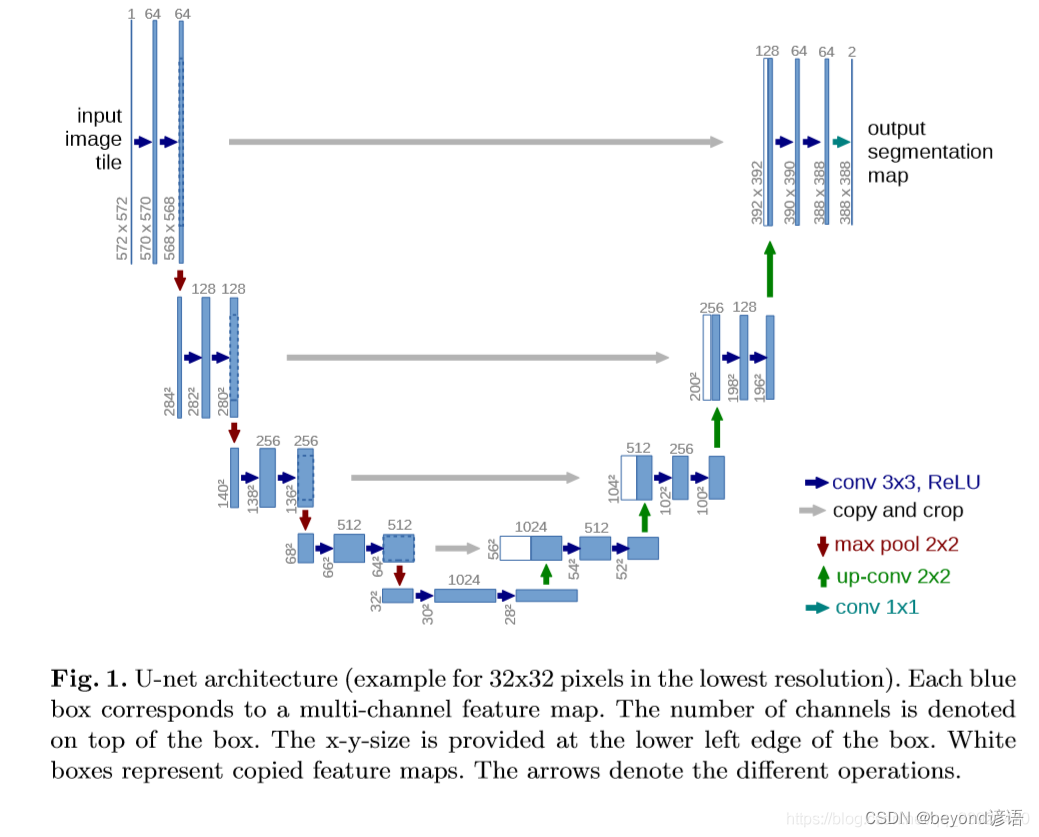
二、复现U-net网络
左半部分
1,卷积+ReLU激活函数

①(572,572,1)—>(570,570,64)
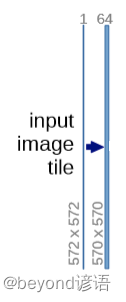
首先输入一张(572,572,1)的单通道图像,处理的是灰度图
由图中的蓝色箭头解释可得其为(3,3)的卷积+ReLU操作
之后得到(570,570,64)的图像
查看下官网给的卷积层padding的计算公式


求出来padding为0,也就是不加边
CONV2D卷积使用
经过上述的分析可得:输入图像为1通道,输出为64通道,卷积核为(3,3),stride为1,padding为0
torch.nn.Conv2d(in_channels=1,out_channels=64,kernel_size=3,stride=1,padding=0)
torch.nn.ReLU(inplace=True)#其中inplace为True时,计算结果会对原来的结果进行覆盖
②(570,570,64)—>(568,568,64)
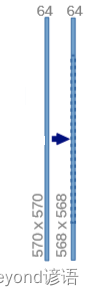
接着对处理的(570,570,64)特征再次进行(3,3)卷积操作和ReLU激活函数
同样按照公式进行计算padding

求出来padding为0,也就是不加边
经过上述的分析可得:输入图像为64通道,输出为64通道,卷积核为(3,3),stride为1,padding为0
卷积:torch.nn.Conv2d(in_channels=64,out_channels=64,kernel_size=3,stride=1,padding=0)
ReLU:nn.ReLU(inplace=True),其中inplace为True时,计算结果会对原来的结果进行覆盖
到此,可以得到(568,568,64)的特征图
2,池化核为(2,2)的最大池化

通过(2,2)的maxpool之后,通道数没变,只是特征图的H和W变成了原来的一半
即:(568,568,64)--->(284,284,64)
MAXPOOL2D最大池化使用
nn.MaxPool2d(2)
3,卷积+ReLU激活函数
接下来的操作和第一步类似
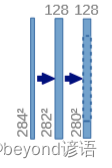
①(284,284,64)—>(284,284,128)
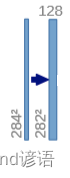
对(284,284,64)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为64通道,输出为128通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(282,282,128)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由284减小到了282
torch.nn.Conv2d(in_channels=64, out_channels=128, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
②(282,282,128)—>(280,280,128)
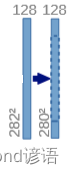
对(282,282,128)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为128通道,输出为128通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(280,280,128)特征图
因为卷积的时候不加边,导致特征图的H和W会减小,由282减小到了280
torch.nn.Conv2d(in_channels=128, out_channels=128, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
4,池化核为(2,2)的最大池化

通过(2,2)的maxpool之后,通道数没变,只是特征图的H和W变成了原来的一半
即:(280,280,128)--->(140,140,128)
nn.MaxPool2d(2)
5,卷积+ReLU激活函数

①(140,140,128)—>(138,138,256)
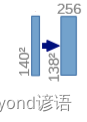
对(140,140,128)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为128通道,输出为256通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(138,138,256)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由140减小到了138
torch.nn.Conv2d(in_channels=128, out_channels=256, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
②(138,138,256)—>(136,136,256)
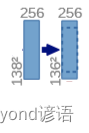
对(138,138,256)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为256通道,输出为256通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(136,136,256)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由138减小到了136
torch.nn.Conv2d(in_channels=256, out_channels=256, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
6,池化核为(2,2)的最大池化
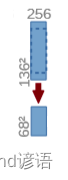
通过(2,2)的maxpool之后,通道数没变,只是特征图的H和W变成了原来的一半
即:(136,136,256)--->(68,68,256)
nn.MaxPool2d(2)
7,卷积+ReLU激活函数
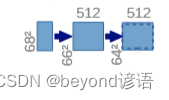
①(68,68,256)—>(66,66,512)

对(68,68,256)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为256通道,输出为512通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(66,66,512)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由68减小到了66
torch.nn.Conv2d(in_channels=256, out_channels=512, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
②(66,66,512)—>(64,64,512)
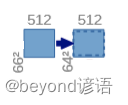
对(66,66,512)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为512通道,输出为512通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(64,64,512)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由66减小到了64
torch.nn.Conv2d(in_channels=66, out_channels=64, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
8,池化核为(2,2)的最大池化
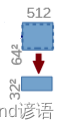
通过(2,2)的maxpool之后,通道数没变,只是特征图的H和W变成了原来的一半
即:(64,64,512)--->(32,32,512)
nn.MaxPool2d(2)
9,卷积+ReLU激活函数
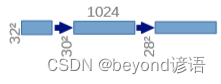
①(32,32,512)—>(30,30,1024)
对(32,32,512)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为512通道,输出为1024通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(30,30,1024)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由32减小到了30
torch.nn.Conv2d(in_channels=512, out_channels=1024, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
②(30,30,1024)—>(28,28,1024)

对(30,30,1024)的特征图执行卷积核为(3,3)和ReLU操作
经过上述的分析可得:
先进行卷积操作:输入图像为1024通道,输出为1024通道,卷积核为(3,3),stride为1,padding为0,之后再进行ReLU激活函数操作,最终得到(64,64,512)特征图。
因为卷积的时候不加边,导致特征图的H和W会减小,由30减小到了28
torch.nn.Conv2d(in_channels=1024, out_channels=1024, kernel_size=3, stride=1, padding=0)
torch.nn.ReLU(inplace=True)
至此,左半部分的网络已经搭建完成
可以发现这里面好多都是重复的模块

这里可以将两次卷积进行封装成一个类
两次卷积
class Double_conv_block(nn.Module):
def __init__(self, in_channels, out_channels):
super(Double_conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=0),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
右半部分
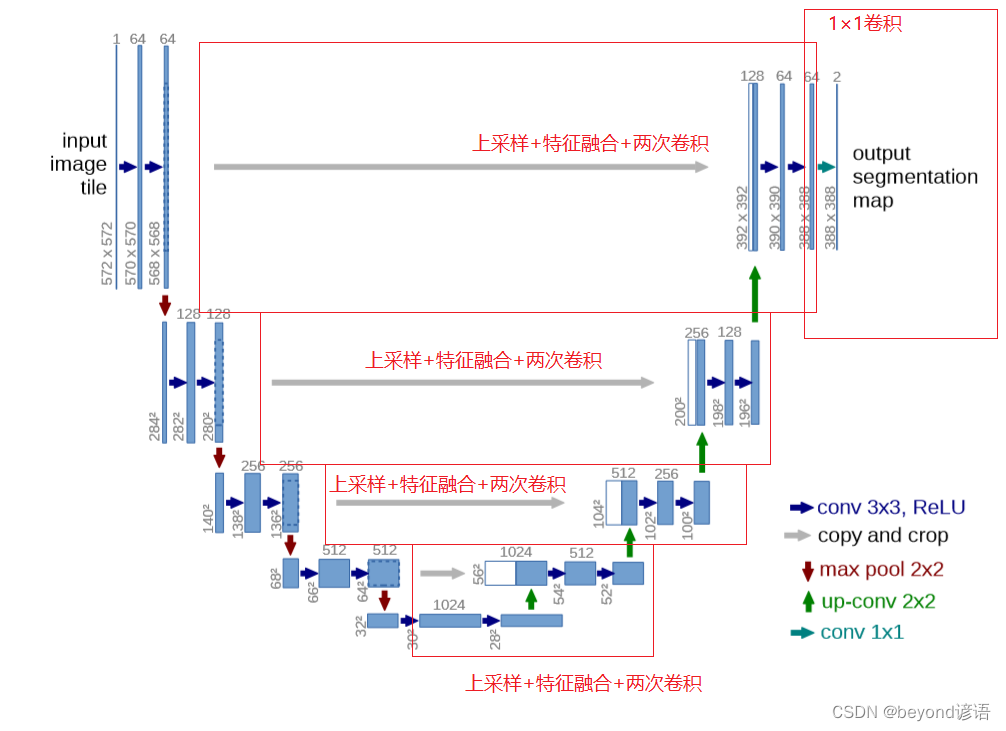
1,上采样选择(2,2)的卷积核
torch.nn.MaxPool2d(kernel_size=2, stride=2)
2,特征融合需要获取左半部分的特征图
特征融合也就是cat在dim=1方向的拼接
3,两次卷积可以调用上述封装的类Double_conv_block
4,最后通过(1,1)的卷积核输出
torch.nn.Conv2d(64, out_channels, kernel_size=1, stride=1, padding=0)
三、完整代码
整体模块架构
test_unet.py
import torch.nn as nn
import torch
# 两次卷积
class Double_conv_block(nn.Module):
def __init__(self, in_channels, out_channels):
super(Double_conv_block, self).__init__()
self.conv = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
nn.Conv2d(out_channels, out_channels, kernel_size=3, stride=1, padding=1, bias=True),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True)
)
def forward(self, x):
x = self.conv(x)
return x
class yy_unet(nn.Module):
def __init__(self,in_channels=1, out_channels=2):# 论文配图中输入图像通道数为1,输出为2
super(yy_unet, self).__init__()
self.Maxpool = nn.MaxPool2d(kernel_size=2, stride=2) #下采样
self.Upsample = nn.Upsample(scale_factor=2) #上采样
self.Conv_1x1 = nn.Conv2d(64, out_channels, kernel_size=1, stride=1, padding=0) #最后输出
self.Conv_1_down = Double_conv_block(in_channels=in_channels, out_channels=64) # 64
self.Conv_2_down = Double_conv_block(in_channels=64, out_channels=128) # 64 128
self.Conv_3_down = Double_conv_block(in_channels=128, out_channels=256) # 128 256
self.Conv_4_down = Double_conv_block(in_channels=256, out_channels=512) # 256 512
self.Conv_5_down = Double_conv_block(in_channels=512, out_channels=1024) # 512 1024
self.Conv_4_up = Double_conv_block(in_channels=1024,out_channels=512)
self.Conv_3_up = Double_conv_block(in_channels=512, out_channels=256)
self.Conv_2_up = Double_conv_block(in_channels=256, out_channels=128)
self.Conv_1_up = Double_conv_block(in_channels=128, out_channels=64)
def forward(self, x):
x1 = self.Conv_1_down(x)
x2 = self.Maxpool(x1)
x2 = self.Conv_2_down(x2)
x3 = self.Maxpool(x2)
x3 = self.Conv_3_down(x3)
x4 = self.Maxpool(x3)
x4 = self.Conv_4_down(x4)
x5 = self.Maxpool(x4)
x5 = self.Conv_5_down(x5)
y4 = self.Upsample(x5)
y4 = torch.cat((x4, y4), dim=1)
y4 = self.Conv_4_up(y4)
y3 = self.Upsample(y4)
y3 = torch.cat((x3, y3), dim=1)
y3 = self.Conv_3_up(y3)
y2 = self.Upsample(y3)
y2 = torch.cat((x2, y2), dim=1)
y2 = self.Conv_2_up(y2)
y1 = self.Upsample(y2)
y1 = torch.cat((x1, y1), dim=1)
y1 = self.Conv_1_up(y1)
y = self.Conv_1x1(y1)
return y
if __name__ == '__main__':
net = yy_unet()
print(net)
yy_unet(
(Maxpool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(Upsample): Upsample(scale_factor=2.0, mode=nearest)
(Conv_1x1): Conv2d(64, 2, kernel_size=(1, 1), stride=(1, 1))
(Conv_1_down): Double_conv_block(
(conv): Sequential(
(0): Conv2d(1, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_2_down): Double_conv_block(
(conv): Sequential(
(0): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_3_down): Double_conv_block(
(conv): Sequential(
(0): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_4_down): Double_conv_block(
(conv): Sequential(
(0): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_5_down): Double_conv_block(
(conv): Sequential(
(0): Conv2d(512, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(1024, 1024, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(1024, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_4_up): Double_conv_block(
(conv): Sequential(
(0): Conv2d(1024, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(512, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_3_up): Double_conv_block(
(conv): Sequential(
(0): Conv2d(512, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(256, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_2_up): Double_conv_block(
(conv): Sequential(
(0): Conv2d(256, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(128, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
(Conv_1_up): Double_conv_block(
(conv): Sequential(
(0): Conv2d(128, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(2): ReLU(inplace=True)
(3): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(4): BatchNorm2d(64, eps=1e-05, momentum=0.1, affine=True, track_running_stats=True)
(5): ReLU(inplace=True)
)
)
)
因为特征融合的时候需要考虑左右两边特征图,是个变量,故没法使用Sequential进行优化代码