文章目录
其他相关系列文章
原理篇
1、深入了解MySQL中内部组件架构(连接器,查询缓存,分析器,优化器,执行器等)
2、深入了解MYSQL之InnoDB一次数据更新流程
3、深入了解Buffer Pool原理与优化(未)
4、深入了解写入一行数据在磁盘如何存储(未)
工作实战篇
一文解决SQL调优实战
生产经验篇(1)——删库,怎么修复?
生产经验篇(2)——真实环境的MySQL机器配置规划
生产经验篇(3)——生产MySQL全链路压测
生产经验篇(4)——多个Buffer Pool来优化数据库的并发性能,chunk运行期间动态调整buffer pool(未)
生产经验篇(5)——基于当前机器合理设计bufferpool(未)
1、内部组件结构
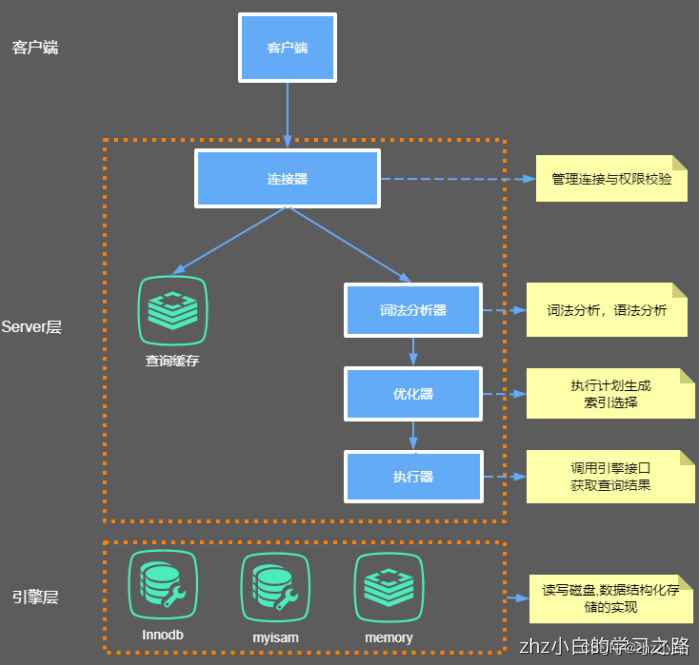
解释:主要分为两部分:Server层,Store层,分别为:
- Server层
- 架构层面
- 连接器
- 查询缓存
- 分析器
- 优化器
- 执行器
- 其他层面
- 内置函数 (如日期、时间、数学和加密函数等)
- 存储过程
- 触发器
- 视图
- 架构层面
- Store层
- 特点:
- 插件式:主要有10种支持的存储引擎,分别为
- innodb(最常用,5.5.5之后默认的存储引擎)
- mysiam
- memory
- archive
- federated
- example
- blackhole
- merge
- ndbcluster
- csv
- 存储引擎层主要负责数据的存储与提取
- 插件式:主要有10种支持的存储引擎,分别为
- 特点:
1.1、连接器
作用:
- 连接器负责跟客户端建立连接、获取权限、维持和管理连接
表现形式为:
mysql ‐h host[数据库地址] ‐u root[用户] ‐p root[密码] ‐P 3306[端口]
当我们输入上面那条命令之后,MYSQL客户端工具**(navicat,mysql front,jdbc,SQLyog等)**会使用跟服务端建立连接,然后经历TCP连接(三次握手),连接器会去验证你的用户名密码是否正确。然后会进行相应的数据返回。
1、如果用户名或密码不对,你就会收到一个"Access denied for user"的错误,然后客户端程序结束执行。
2、如果用户名密码认证通过,连接器会到权限表里面查出你拥有的权限。之后,这个连接里面的权限判断逻辑,都将依赖于此时读到的权限。
一个用户建立成功之后,即使管理员对其权限进行修改,也不会有影响,只有断开连接之后,才会进行更新权限,而在没有断开连接之前,只会更新在系统表空间的mysql的user表中。

其中修改密码权限等的SQL为:
1、CREATE USER ‘username’@‘host’ IDENTIFIED BY ‘password’; //创建新用户
2、grant all privileges on . to ‘username’@‘%’; //赋权限,%表示所有(host)
3、flush privileges //刷新数据库
4、update user set password=password(”123456″) where user=’root’;(设置用户名密码)
5、show grants for root@“%”; 查看当前用户的权限
当我们连接成功之后,如果我们没有对当前连接进行任何操作,那么他就会进入一个空闲状态,我们可以使用show processlist去查看
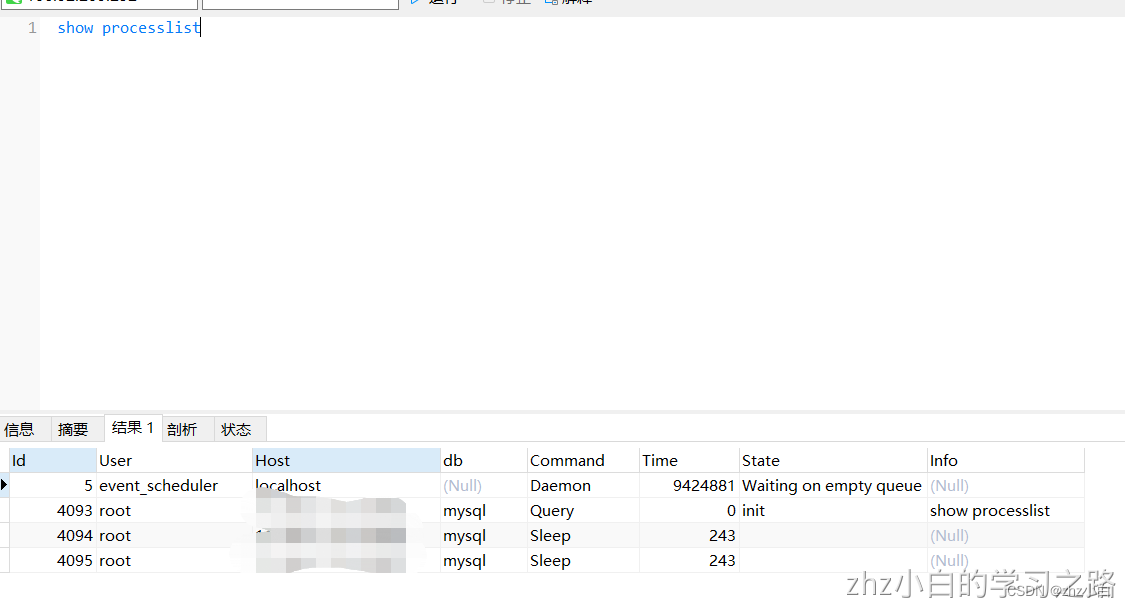
解释:Command代表当前连接的状态
daemon:守护线程,代表后台挂着
query:代表正在查询
sleep:代表空闲状态
。。。以此类推
当我们的server端长时间不接受到客户端的请求,那么连接器就会断开,默认是由wait_timout控制,默认为8h。
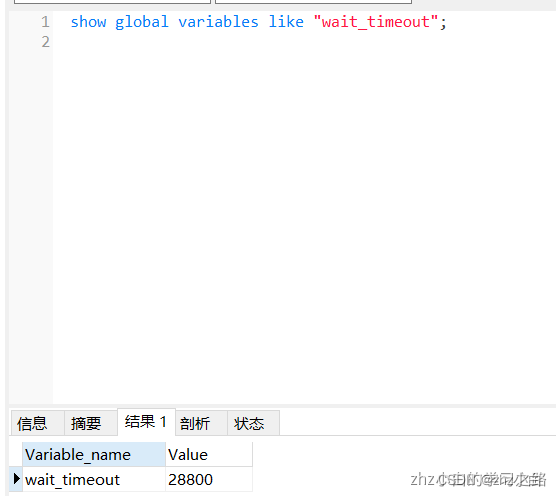
由图上可知,28800s/60/60=8h。
当我们想设置这个时间的时候,也可以使用以下命令:
set global wait_timeout=28800; 设置全局服务器关闭非交互连接之前等待活动的秒数
当我们断开连接之后,客户端再请求服务端,那么就会报错:
Lost connection to MySQL server during query
然后,如果我们想继续操作,重连即可。
1.1.1、为什么我们一般在生产中会出现Mysql内存占用太大,导致被系统强行干掉(OOM)呢?
因为我们在开发过程中,一般使用的是连接池(长连接),而MySQL是使用临时内存去管理连接对象的,也就是个内存,那么长期下来,肯定会有内存过大问题,可以参考下HashMap本地缓存是不是也是这个道理。
那么我们怎么解决这个问题呢?
1、定期断开长连接。使用一段时间,或者程序里面判断执行过一个占用内存的大查询后,断开连接,之后要查询再重连。
2、如果你用的是 MySQL 5.7 或更新版本,可以在每次执行一个比较大的操作后,通过执行mysql_reset_connection 来重新初始化连接资源。这个过程不需要重连和重新做权限验证,但是会将连接恢复到刚刚创建完时的状态。
扩展:
长连接:
- 指连接成功后,如果客户端持续有请求,则一直使用同一个连接。
短连接:
- 指每次执行完很少的几次查询就断开连接,下次查询再重新建立一个
1.1.2、连接器深入探究
1.1.2.1、准备抓包
可以通过配置my.cnf文件加入skip_ssl指令 关闭ssl,配置:
[mysqld]
skip_ssl
1.1.2.2、查询ssl
show global variables like 'have_ssl%';
1.1.2.3、开始连接,解包
mysql -h localhost -u root -p'489773' -- protocol=tcp
1.1.2.4、总体流程执行情况流程图
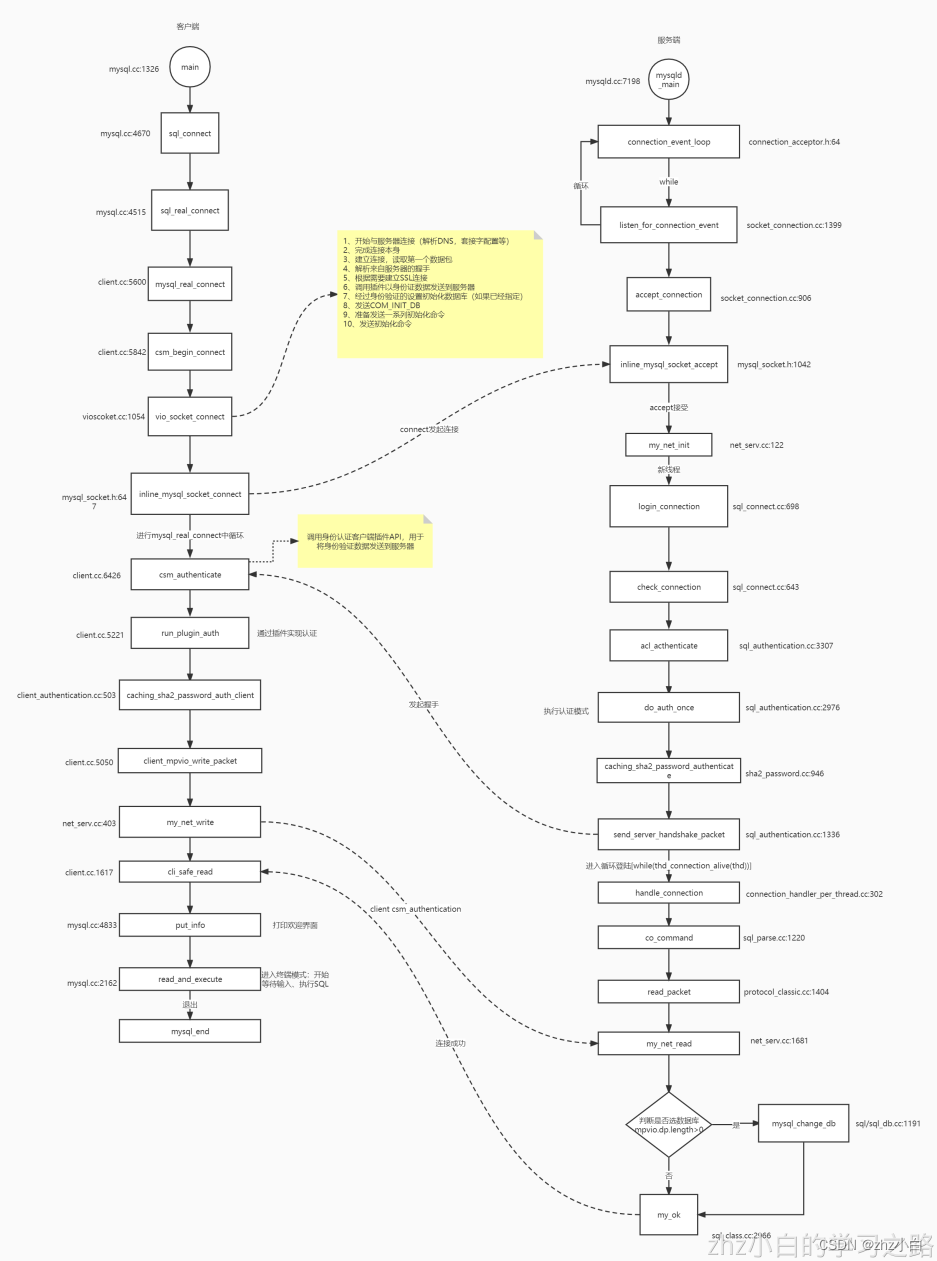
https://www.processon.com/view/link/62fa96706376897acca09661
1.1.2.5、断点
客户端
- sql_connect
- csm_begin_connect
- csm_authenticate
- run_plugin_auth
- caching_sha2_password_auth_client
- my_net_write
- cli_safe_read
- read_and_execute
- mysql_end
服务端
- connection_event_loop
- accept_connection
- login_connection
- acl_authenticate
- caching_sha2_password_authenticate
- do_command
- my_ok
1.2、查询缓存
1.2.1、常用操作:
show databases; 显示所有数据库
use dbname; 打开数据库:
show tables; 显示数据库mysql中所有的表;
describe user; 显示表mysql数据库中user表的列信息);
1.2.2、查询缓存的步骤:(用于select查询)
1、首先MySQL会把执行的SQL语句与执行SQL的返回值以key-value对的形式直接缓存在内存中。key:查询的语句,value:查询的结果。
2、如果key在缓存中能直接查询到,那么就直接把返回值(value)返回给客户端。
3、如果不在缓存,那么就会走下面的流程,然后把他缓存到内存当中。
1.2.3、那什么情况下可以使用查询缓存呢?
1、静态表(指的是很少会更新的表,比如配置表,字典表等)
2、如果需要开启,开启把my.cnf的参数**query_cache_type **设置成 DEMAND。
如下:
# query_cache_type有3个值
# 0代表关闭查询缓存OFF,
# 1代表开启ON,2(DEMAND)代表当sql语句中有SQL_CACHE 关键词时才缓存
query_cache_type=2
3、默认情况下,一个表中,是可以指定要使用查询缓存的语句,可以用SQL_CACHE显示去指定。如下:
select SQL_CACHE * from test where id=10;
4、也可以去查询当前实例是否开启缓存机制
show global variables like "%query_cache_type%";
5、也可以监控查询缓存的命中率
show status like'%Qcache%'; //查看运行的缓存信息
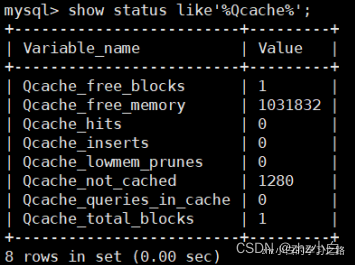
Qcache_free_blocks:表示查询缓存中目前还有多少剩余的blocks,如果该值显示较大,则说明查询缓存中的内存碎片 过多了,可能在一定的时间进行整理。
Qcache_free_memory:查询缓存的内存大小,通过这个参数可以很清晰的知道当前系统的查询内存是否够用,是多 了,还是不够用,DBA可以根据实际情况做出调整。
Qcache_hits:表示有多少次命中缓存。我们主要可以通过该值来验证我们的查询缓存的效果。数字越大,缓存效果越理想。
Qcache_inserts:表示多少次未命中然后插入,意思是新来的SQL请求在缓存中未找到,不得不执行查询处理,执行 查询处理后把结果insert到查询缓存中。这样的情况的次数,次数越多,表示查询缓存应用到的比较少,效果也就不理 想。当然系统刚启动后,查询缓存是空的,这很正常。
Qcache_lowmem_prunes:该参数记录有多少条查询因为内存不足而被移除出查询缓存。通过这个值,用户可以适当的 调整缓存大小。
Qcache_not_cached:表示因为query_cache_type的设置而没有被缓存的查询数量。
Qcache_queries_in_cache:当前缓存中缓存的查询数量。
Qcache_total_blocks:当前缓存的block数量。
1.2.4、那么MySQL为什么在8.0之后会删除查询缓存呢?
1、如果对当前表进行更新,那么内存中的数据就要全部清空。
2、对于更新压力大的数据库来说,查询缓存效率低
3、所以8.0之后把查询缓存删除了
1.3、分析器
MYSQL中的SQL解析其实本质上跟我们平常写的Java的.java结尾的文件或者C/C++中的.cpp文件本质上是一样的,他们都是编译器去解析的,主要分为:
-
词法解析
-
语法/语义解析
-
优化
-
执行代码生成
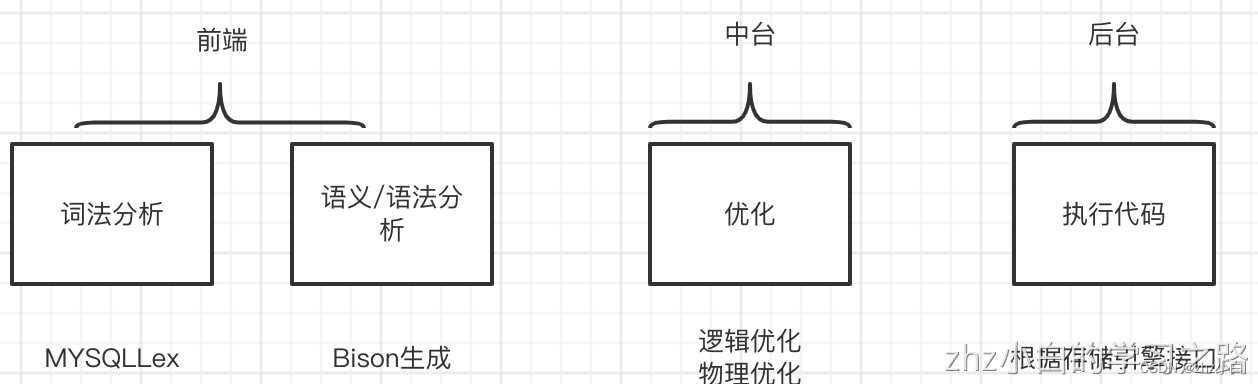
https://www.processon.com/view/link/62e1056c1e08535944de14c9
SQL分析步骤:
1.3.1、词法分析
1.3.1.1、介绍
百度百科介绍:
- 词法分析(英语:lexical analysis)是计算机科学中将字符序列转换为单词(Token)序列的过程。进行词法分析的程序或者函数叫作词法分析器(Lexical analyzer,简称Lexer),也叫扫描器(Scanner)。词法分析器一般以函数的形式存在,供语法分析器调用。 完成词法分析任务的程序称为词法分析程序或词法分析器或扫描器。
- 完成词法分析任务的程序称为词法分析程序或词法分析器或扫描器。从左至右地对源程序进行扫描,按照语言的词法规则识别各类单词,并产生相应单词的属性字。
- 词法分析是编译程序的第一个阶段且是必要阶段;词法分析的核心任务是扫描、识别单词且对识别出的单词给出定性、定长的处理;实现词法分析程序的常用途径:自动生成,手工生成。
1.3.1.2、词法解析状态机
词法解析状态机是在词法解析的扫描阶段执行的过程,下图2-1-1是状态解析token的执行过程:
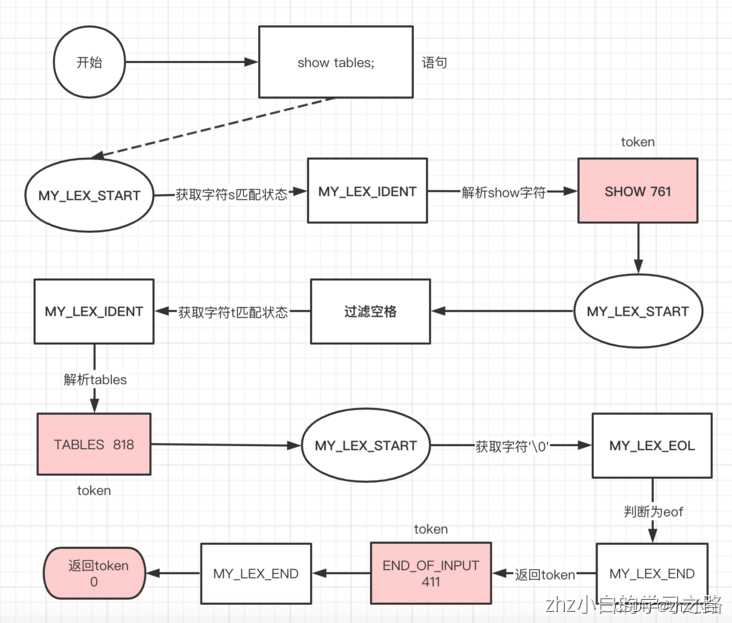
- 状态机的主要用途就是解析token时的执行过程,比如MY_LEX_IDENT状态机会循环匹配字符后,解析字符并返回对应的token。
| 对应状态机 | 备注 |
|---|---|
| MY_LEX_START | 开始解析token |
| MY_LEX_CHAR | 解析单个字符例如*、:、; |
| MY_LEX_IDENT | 解析字符串,匹配关键词,例如“table”、“select” 等 |
| MY_LEX_IDENT_SEP | 找到字符’.’ |
| MY_LEX_IDENT_START | 从’.'开始解析token |
| MY_LEX_REAL | 不完全实数 |
| MY_LEX_HEX_NUMBER | hex字符串 |
| MY_LEX_BIN_NUMBER | bin字符串 |
| MY_LEX_CMP_OP | 不完全比较运算符 |
| MY_LEX_LONG_CMP_OP | 不完全比较运算符 |
| MY_LEX_STRING | 字符串 |
| MY_LEX_COMMENT | Comment |
| MY_LEX_END | 结束 |
| MY_LEX_NUMBER_IDENT | 数字 |
| MY_LEX_INT_OR_REAL | 完全整数或不完全实数 |
| MY_LEX_REAL_OR_POINT | 解析.返回不完全实数,或者字符’.’ |
| MY_LEX_BOOL | 布尔 |
| MY_LEX_EOL | 如果是eof,则设置状态end结束, |
| MY_LEX_LONG_COMMENT | 长注释 |
| MY_LEX_END_LONG_COMMENT | 备注结束 |
| MY_LEX_SEMICOLON | 分隔符; |
| MY_LEX_SET_VAR | 检查:= |
| MY_LEX_USER_END | 结束’@’ |
| MY_LEX_HOSTNAME | 解析hostname |
| MY_LEX_SKIP | 空格 |
| MY_LEX_USER_VARIABLE_DELIMITER | 引号字符 |
| MY_LEX_SYSTEM_VAR | 例如解析user@hostname,解析到@ |
| MY_LEX_IDENT_OR_KEYWORD | 判断返回字符串状态或者键盘键值 |
| MY_LEX_IDENT_OR_HEX | hex-数字 |
| MY_LEX_IDENT_OR_BIN | bin-数字 |
| MY_LEX_IDENT_OR_NCHAR | 判断返回字符状态,或字符串状态 |
| MY_LEX_STRING_OR_DELIMITER | 判断返回字符串状态或者空格字符状态 |
1.3.1.3、调试解析源码
我们开始调试,首先要先启动下mysql8.0.30。然后准备两个终端:一个终端用于操作mysql语句、另外一个终端用于调试使用,如下图。
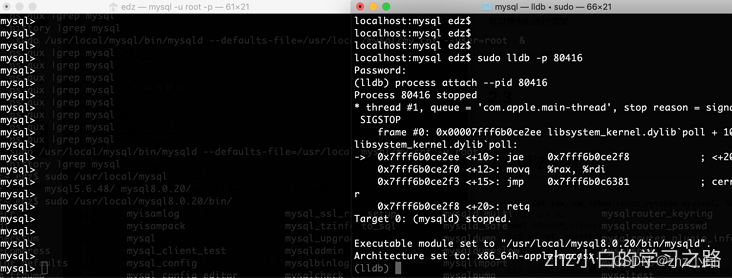
可以用lldb进行调试:
lldb -p 进程ID
词法解析调用过程:
https://www.processon.com/view/link/62fb03805653bb3108f40e4f
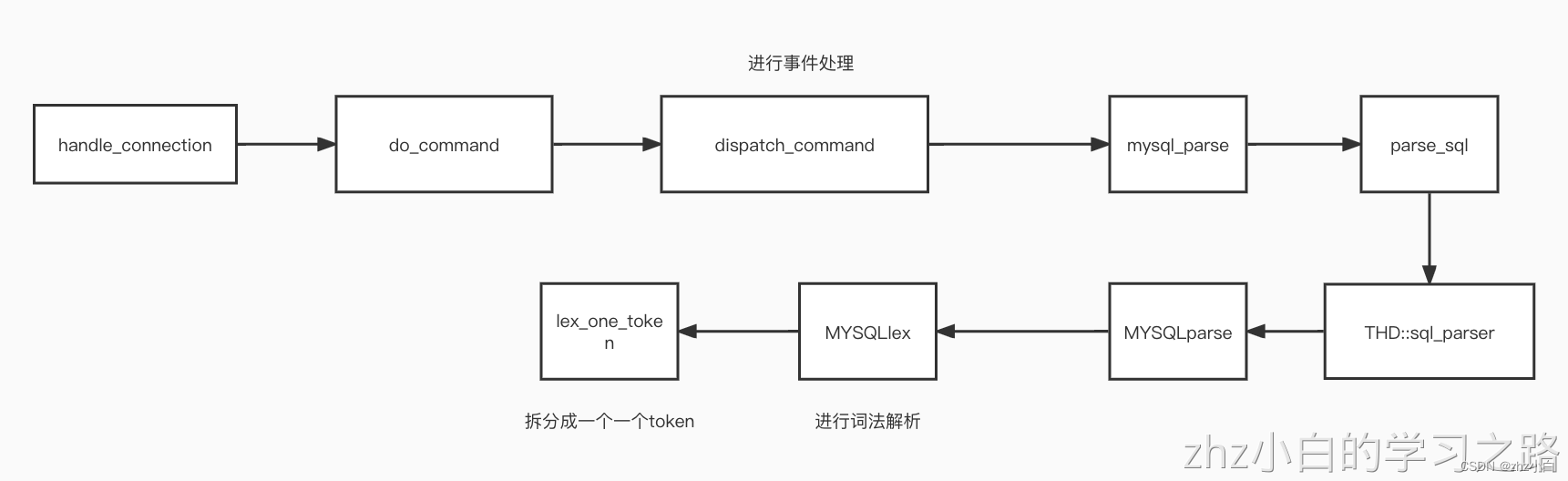
根据上图我们可以得知,Mysql8.0.30会调用MYSQLlex方法进行词法解析、MYSQLlex中会调用lex_one_token进行单个token解析。如果我们要调试可以对lex_one_token去下一个断点。
(lldb)b lex_one_token
下断点后在mysql操作终端操作做一条语句例如“select * from t1;”,此时调试终端会捕获到断点,调试到下图。
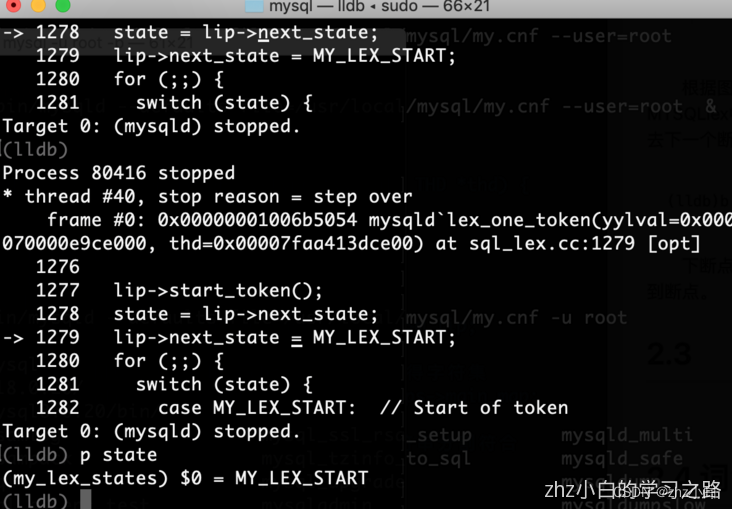
根据上图我们得知第一个状态机为MY_LEX_START,执行状态机进入switch后,会通过yyPeek方法获取一个字符(下图)。来判断这个字符是否为空格,不是空格后,通过“state = state_map[c];” 返回一个状态机。判断时通过state_map解析。
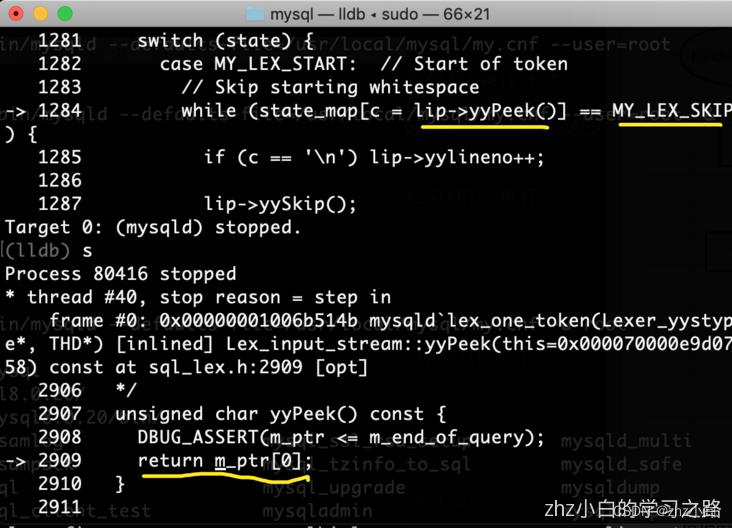
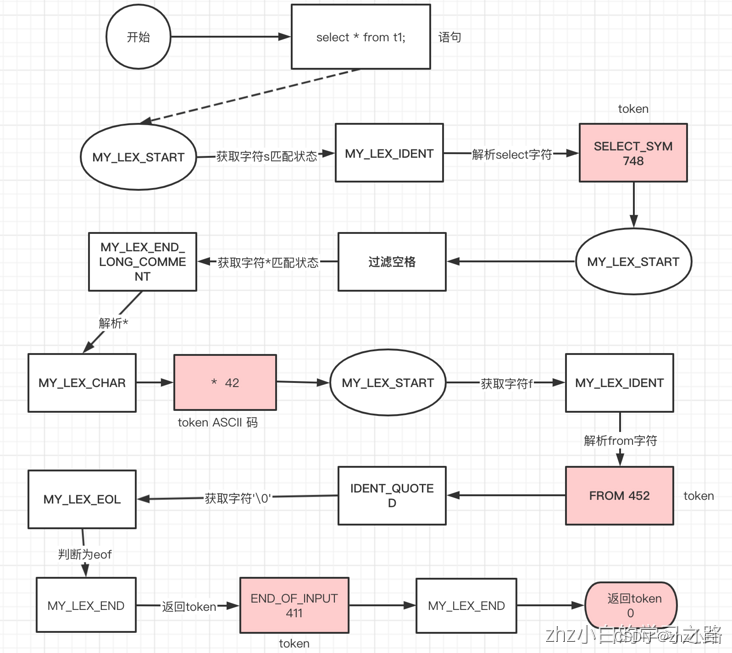
由于获取单个字符是s,s对应state_map中的状态机是MY_LEX_IDENT,MY_LEX_IDENT状态机会去匹配对应的关键词返回token。第一个匹配的关键词就是select。
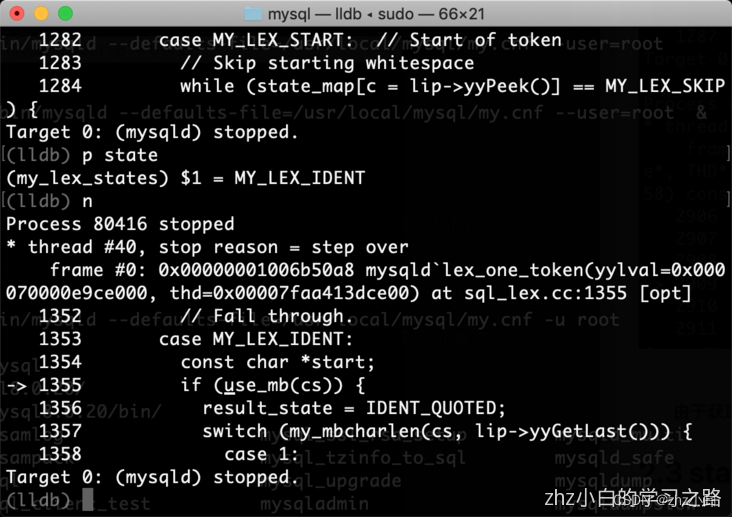
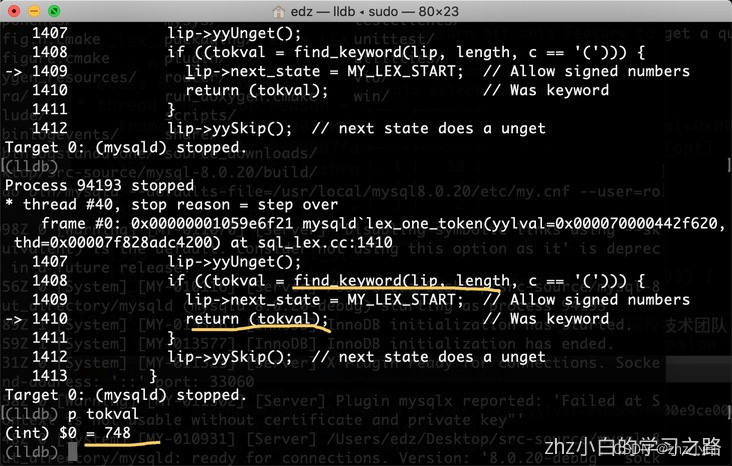
根据图我们得知通过find_keyword方法可以匹配对应的token。第一次匹配“select”后我们得到一个token(748),748这个token对应SELECT_SYM,可以在/mysql-8.0.30/sql/sql_yacc.h文件中查找到。此时m_ptr参数值为“ * from t1”,该参数由返回前调用lip->yyUnget()进行左移。lip->next_state的状态再次设置为MY_LEX_START。
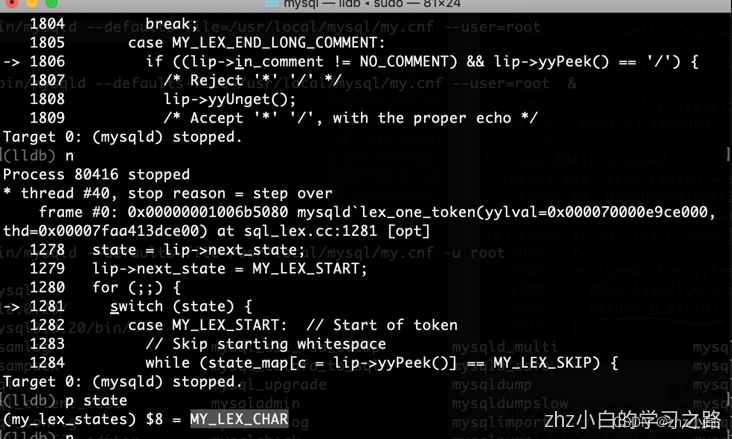
当我们再次调用lex_one_token时,处理MY_LEX_START状态机时,会过滤调一个空格字符。继续执行获取,获取到“”字符,又会将状态机设置为MY_LEX_END_LONG_COMMENT,然后执行状态机会设置为MY_LEX_CHAR,返回时下一次的状态设置成了MY_LEX_START。最后返回一个token(42),其实这个42是ASCII到“”。此时m_ptr参数值为“ from t1”。再次执行MY_LEX_START过程,会设置状态机为MY_LEX_IDENT,执行MY_LEX_IDENT状态机后会返回token(452),可以在/mysql-8.0.30/sql/sql_yacc.h文件中查找到。对应FROM。再次执行后会返回状态机IDENT_QUOTED,最终返回状态机MY_LEX_EOL,最终返回MY_LEX_END结束。
1.3.1.3.1、 state_map介绍
state_map是验证状态机的关键步骤,初始化该过程主要在/mysql-8.0.20/mysys/sql_chars.cc文件的init_state_maps方法中,方法实现如下:
bool init_state_maps(CHARSET_INFO *cs) {
uint i;
uchar *ident_map;
enum my_lex_states *state_map = nullptr;
lex_state_maps_st *lex_state_maps = (lex_state_maps_st *)my_once_alloc(
sizeof(lex_state_maps_st), MYF(MY_WME));
if (lex_state_maps == nullptr) return true; // 空指针OOM
cs->state_maps = lex_state_maps;
state_map = lex_state_maps->main_map;
if (!(cs->ident_map = ident_map = (uchar *)my_once_alloc(256, MYF(MY_WME))))
return true; // OOM
hint_lex_init_maps(cs, lex_state_maps->hint_map);
/* 填充状态以获得更快的解析器 */
for (i = 0; i < 256; i++) {
if (my_isalpha(cs, i))
state_map[i] = MY_LEX_IDENT; //字符串状态机
else if (my_isdigit(cs, i))
state_map[i] = MY_LEX_NUMBER_IDENT;
else if (my_ismb1st(cs, i))
/* To get whether it's a possible leading byte for a charset. */
state_map[i] = MY_LEX_IDENT;
else if (my_isspace(cs, i))
state_map[i] = MY_LEX_SKIP; //空格状态机
else
state_map[i] = MY_LEX_CHAR; //字符状态机
}
state_map[(uchar)'_'] = state_map[(uchar)'$'] = MY_LEX_IDENT;
state_map[(uchar)'\''] = MY_LEX_STRING;
state_map[(uchar)'.'] = MY_LEX_REAL_OR_POINT;
state_map[(uchar)'>'] = state_map[(uchar)'='] = state_map[(uchar)'!'] =
MY_LEX_CMP_OP; //操作符合匹配状态机
state_map[(uchar)'<'] = MY_LEX_LONG_CMP_OP;
state_map[(uchar)'&'] = state_map[(uchar)'|'] = MY_LEX_BOOL;
state_map[(uchar)'#'] = MY_LEX_COMMENT;
state_map[(uchar)';'] = MY_LEX_SEMICOLON;
state_map[(uchar)':'] = MY_LEX_SET_VAR;
state_map[0] = MY_LEX_EOL; //结束标志状态机
state_map[(uchar)'/'] = MY_LEX_LONG_COMMENT;
state_map[(uchar)'*'] = MY_LEX_END_LONG_COMMENT; //*字符匹配状态机
state_map[(uchar)'@'] = MY_LEX_USER_END; //@字符匹配状态机
state_map[(uchar)'`'] = MY_LEX_USER_VARIABLE_DELIMITER;
state_map[(uchar)'"'] = MY_LEX_STRING_OR_DELIMITER;
/*
创建第二个映射以加快查找标识符的速度
*/
for (i = 0; i < 256; i++) {
ident_map[i] = (uchar)(state_map[i] == MY_LEX_IDENT ||
state_map[i] == MY_LEX_NUMBER_IDENT);
}
/* Special handling of hex and binary strings */
state_map[(uchar)'x'] = state_map[(uchar)'X'] = MY_LEX_IDENT_OR_HEX;
state_map[(uchar)'b'] = state_map[(uchar)'B'] = MY_LEX_IDENT_OR_BIN;
state_map[(uchar)'n'] = state_map[(uchar)'N'] = MY_LEX_IDENT_OR_NCHAR;
return false;
}
代码中能快速匹配状态机,就是因为初始化好了一堆的状态机map,根据字符可以匹配不同的状态机。状态机的宏在mysql-8.0.30/include/sql_chars.h文件中。
1.3.1.3.2、源码解析
关键代码lex_one_token解析:
static int lex_one_token(Lexer_yystype *yylval, THD *thd) {
uchar c = 0;
bool comment_closed;
int tokval, result_state;
uint length;
enum my_lex_states state;
Lex_input_stream *lip = &thd->m_parser_state->m_lip; //获得输入信息
const CHARSET_INFO *cs = thd->charset(); //获得字符集
const my_lex_states *state_map = cs->state_maps->main_map; //获得状态
const uchar *ident_map = cs->ident_map; //字符串分割符合
lip->yylval = yylval; // 全局状态
lip->start_token(); //初始化token字符串
state = lip->next_state; //获得下一个状态
lip->next_state = MY_LEX_START; //设置下一个状态
for (;;) {
//循环解析状态机
switch (state) {
case MY_LEX_START: // 开始解析token
while (state_map[c = lip->yyPeek()] == MY_LEX_SKIP) {
//解析token,判断是否为空格
if (c == '\n') lip->yylineno++;
lip->yySkip(); //处理空格
}
/* Start of real token */
lip->restart_token(); //设置m_tok_start和m_cpp_tok_start
c = lip->yyGet(); //获得单个字符,并设置m_cpp_ptr,并且m_ptr移位
state = state_map[c]; //如果是字符串返回MY_LEX_IDENT 状态
break;
//...
case MY_LEX_IDENT: //解析字符串关键词,比如select、tables等
const char *start;
if (use_mb(cs)) {
result_state = IDENT_QUOTED;
switch (my_mbcharlen(cs, lip->yyGetLast())) {
case 1:
break;
case 0:
if (my_mbmaxlenlen(cs) < 2) break;
/* else fall through */
default:
int l =
my_ismbchar(cs, lip->get_ptr() - 1, lip->get_end_of_query());
if (l == 0) {
state = MY_LEX_CHAR;
continue;
}
lip->skip_binary(l - 1);
}
while (ident_map[c = lip->yyGet()]) {
//循环获取字符串
switch (my_mbcharlen(cs, c)) {
case 1:
break;
case 0:
if (my_mbmaxlenlen(cs) < 2) break;
/* else fall through */
default:
int l;
if ((l = my_ismbchar(cs, lip->get_ptr() - 1,
lip->get_end_of_query())) == 0)
break;
lip->skip_binary(l - 1);
}
}
} else {
for (result_state = c; ident_map[c = lip->yyGet()]; result_state |= c)
;
/* If there were non-ASCII characters, mark that we must convert */
result_state = result_state & 0x80 ? IDENT_QUOTED : IDENT;
}
length = lip->yyLength();
start = lip->get_ptr();
if (lip->ignore_space) {
/*
If we find a space then this can't be an identifier. We notice this
below by checking start != lex->ptr.
*/
for (; state_map[c] == MY_LEX_SKIP; c = lip->yyGet()) {
if (c == '\n') lip->yylineno++;
}
}
if (start == lip->get_ptr() && c == '.' && ident_map[lip->yyPeek()]) //判断字符是否为'.' '
lip->next_state = MY_LEX_IDENT_SEP;
else {
// '(' must follow directly if function
lip->yyUnget();
if ((tokval = find_keyword(lip, length, c == '('))) {
//查找token
lip->next_state = MY_LEX_START; // Allow signed numbers
return (tokval); // 返回token
}
lip->yySkip(); // next state does a unget
}
yylval->lex_str = get_token(lip, 0, length);
//...
return (result_state); // IDENT or IDENT_QUOTED
//...
case MY_LEX_EOL: //'\0'结束符
if (lip->eof()) {
lip->yyUnget(); // Reject the last '\0'
lip->set_echo(false);
lip->yySkip();
lip->set_echo(true);
/* Unbalanced comments with a missing '*' '/' are a syntax error */
if (lip->in_comment != NO_COMMENT) return (ABORT_SYM);
lip->next_state = MY_LEX_END; // 设置下一个状态机为MY_LEX_END,继续循环
return (END_OF_INPUT); // 返回token
}
}
}
}
1.3.1.3.3、Mysql 8.0.30词法解析有哪些优化?
在解析select * from t1; 语句过程中,mysql5会多一步MY_LEX_OPERATOR_OR_IDENT的过程。在mysql 8.0.30中优化了该过程,如下图。
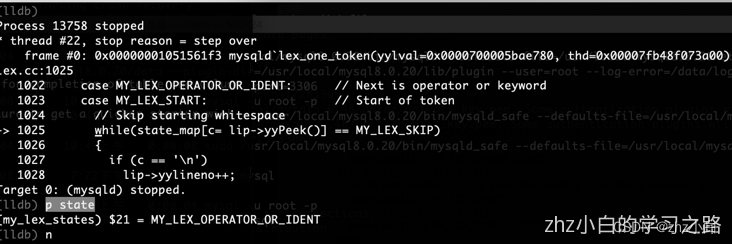
1.3.2、语法分析
语法分析具体实现算法细节:https://blog.csdn.net/weixin_43894553/article/details/110347056
- 语法分析就是使⽤了**Yacc(Yet Another Compiler Compiler)来完成将sql语句词法分析后的token生成抽象语法树(AST)**的过程
1.3.2.1、什么叫抽象语法树?
1.3.2.1.1、含义:
- 抽象语法树(abstract syntax code,AST)是源代码的抽象语法结构的树状表示,树上的每个节点都表示源代码中的一种结构,这所以说是抽象的,是因为抽象语法树并不会表示出真实语法出现的每一个细节,比如说,嵌套括号被隐含在树的结构中,并没有以节点的形式呈现。抽象语法树并不依赖于源语言的语法,也就是说语法分析阶段所采用的上下文无文文法,因为在写文法时,经常会对文法进行等价的转换(消除左递归,回溯,二义性等),这样会给文法分析引入一些多余的成分,对后续阶段造成不利影响,甚至会使合个阶段变得混乱。因些,很多编译器经常要独立地构造语法分析树,为前端,后端建立一个清晰的接口
- 抽象语法树在很多领域有广泛的应用,比如浏览器,智能编辑器,编译器。
1.3.2.1.2、样例:
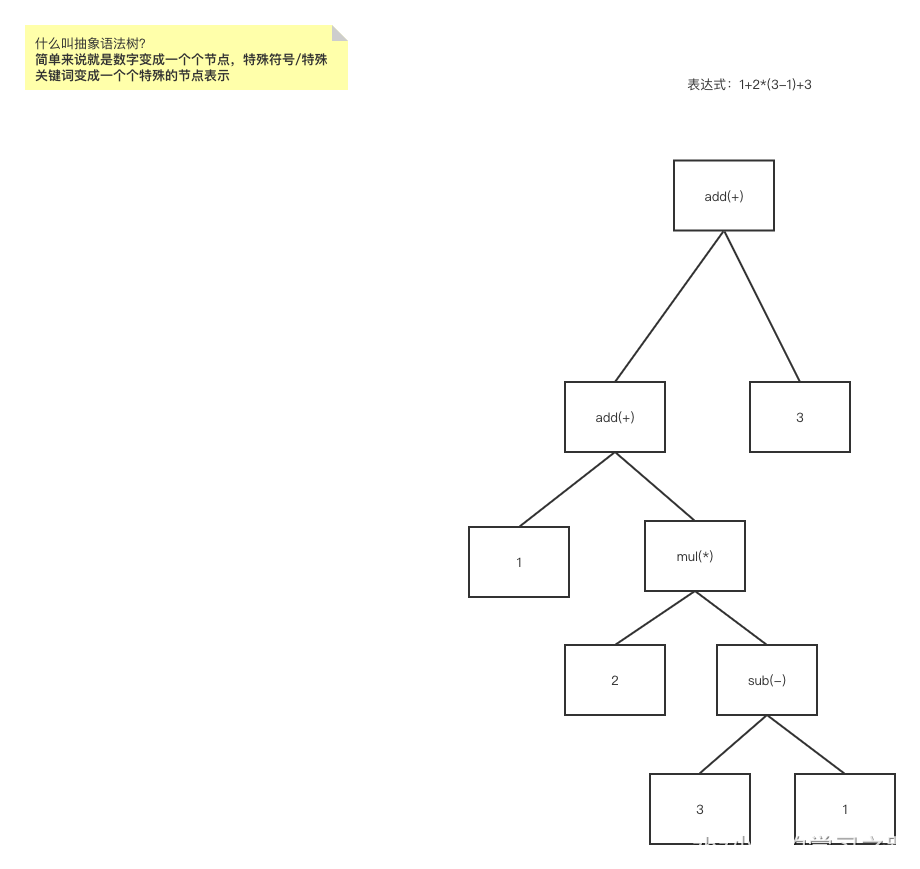
1、算术表达式
比如1+2*(3-1)+3,他会被解析成抽象语法树,如下图
https://www.processon.com/view/link/62fb3b110791293111b2e1d3
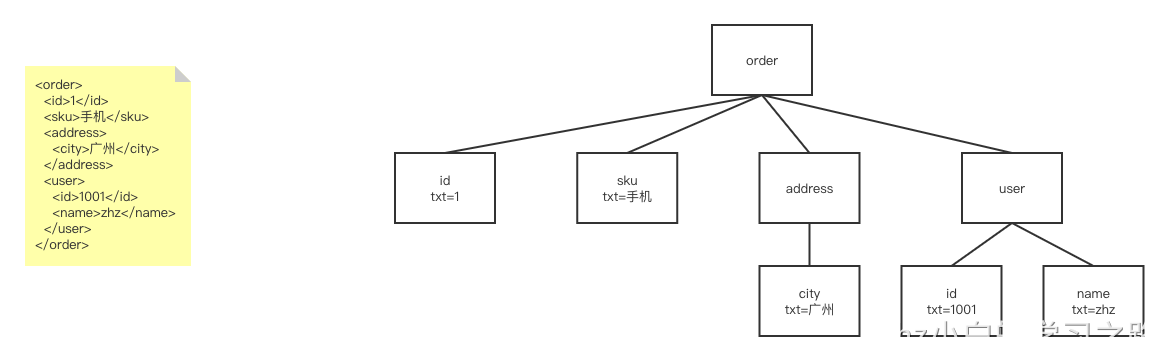
2、xml表达式
<order>
<id>1</id>
<sku>手机</sku>
<address>
<city>广州</city>
</address>
<user>
<id>1001</id>
<name>zhz</name>
</user>
</order>
他的抽象语法树(AST)是
https://www.processon.com/view/link/62fb3d5b1e085305de1c09d4
3、程序表达式
while(b != 0){
if (a > b)
a = a-b;
else{
b = b-a;
}
}
return a;
抽象语法树:
https://www.processon.com/view/link/62fb4159f346fb3fe99d97c8

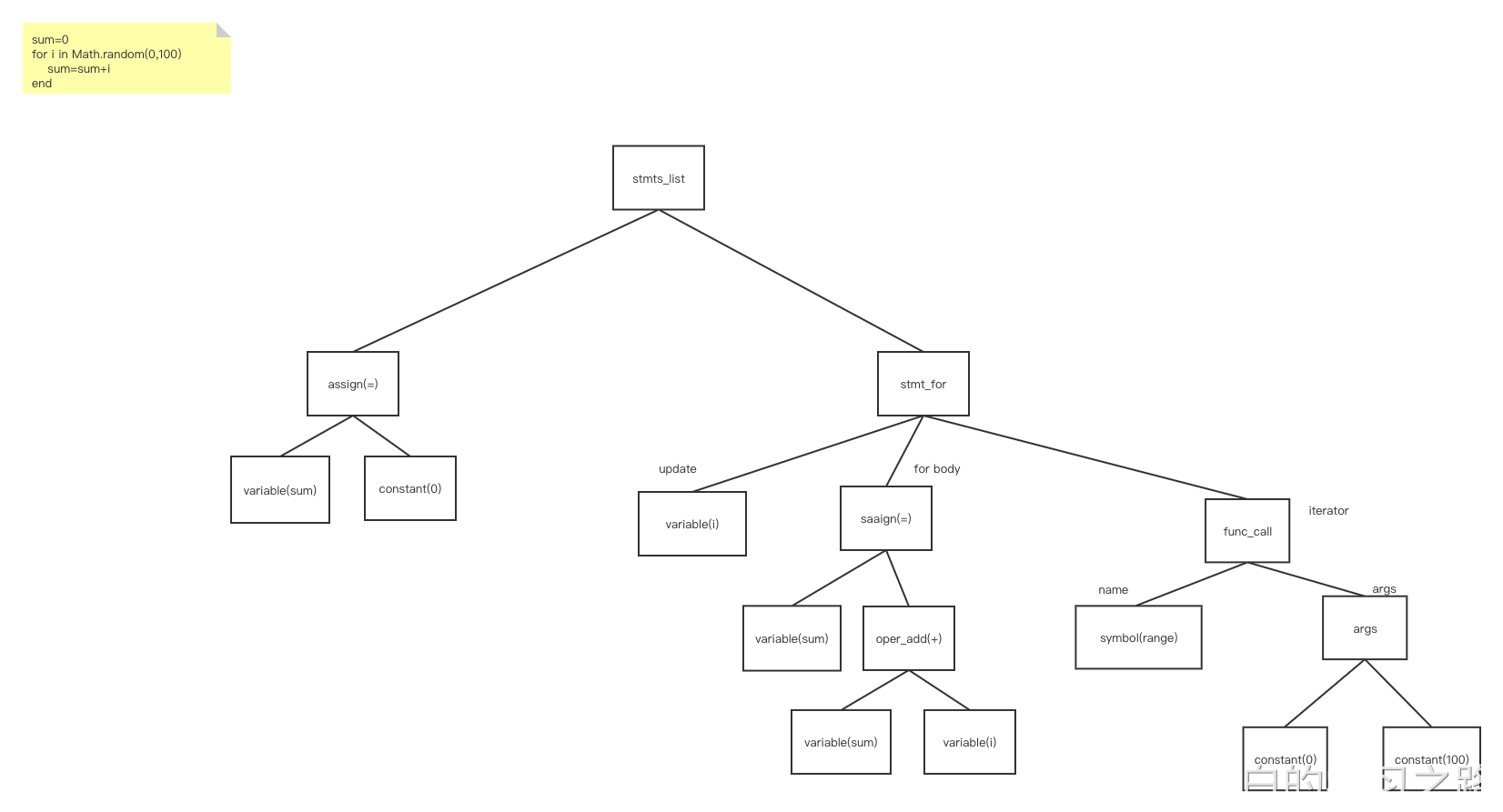
表达式:
sum=0
for i in Math.random(0,100)
sum=sum+i
end
https://www.processon.com/view/link/62fb40560791293111b30df8
1.3.2.1.3、为什么需要抽象语法树?
- 当在源程序语法分析工作时,是在相应程序设计语言的语法规则指导下进行的。语法规则描述了该语言的各种语法成分的组成结构,通常可以用所谓的前后文无关文法或与之等价的Backus-Naur范式(BNF)将一个程序设计语言的语法规则确切的描述出来。前后文无关文法有分为这么几类:LL(1),LR(0),LR(1), LR(k) ,LALR(1)等。每一种文法都有不同的要求,如LL(1)要求文法无二义性和不存在左递归。当把一个文法改为LL(1)文法时,需要引入一些隔外的文法符号与产生式。
例如,四则运算表达式的文法为:
文法****1.1
E->T|EAT
T->F|TMF
F->(E)|i
A->+|-
M->*|/
改为LL(1)后为:
文法****1.2
E->TE’
E’->ATE’|e_symbol
T->FT’
T’->MFT’|e_symbol
F->(E)|i
A->+|-
M->*|/
例如,当在开发语言时,可能在开始的时候,选择LL(1)文法来描述语言的语法规则,编译器前端生成LL(1)语法树,编译器后端对LL(1)语法树进行处理,生成字节码或者是汇编代码。但是随着工程的开发,在语言中加入了更多的特性,用LL(1)文法描述时,感觉限制很大,并且编写文法时很吃力,所以这个时候决定采用LR(1)文法来描述语言的语法规则,把编译器前端改生成LR(1)语法树,但在这个时候,你会发现很糟糕,因为以前编译器后端是对LL(1)语树进行处理,不得不同时也修改后端的代码。
抽象语法树的第一个特点为:不依赖于具体的文法。无论是LL(1)文法,还是LR(1),或者还是其它的方法,都要求在语法分析时候,构造出相同的语法树,这样可以给编译器后端提供了清晰,统一的接口。即使是前端采用了不同的文法,都只需要改变前端代码,而不用连累到后端。即减少了工作量,也提高的编译器的可维护性。
抽象语法树的第二个特点为:不依赖于语言的细节。在编译器家族中,大名鼎鼎的gcc算得上是一个老大哥了,它可以编译多种语言,例如c,c++,java,ADA,Object C, FORTRAN, PASCAL,COBOL等等。在前端gcc对不同的语言进行词法,语法分析和语义分析后,产生抽象语法树形成中间代码作为输出,供后端处理。要做到这一点,就必须在构造语法树时,不依赖于语言的细节,例如在不同的语言中,类似于if-condition-then这样的语句有不同的表示方法
在c中为:
if(condition)
{
do_something();
}
在fortran中为:
If condition then
do_somthing()
end if
在构造if-condition-then语句的抽象语法树时,只需要用两个分支节点来表于,一个为condition,一个为if_body。如下图:
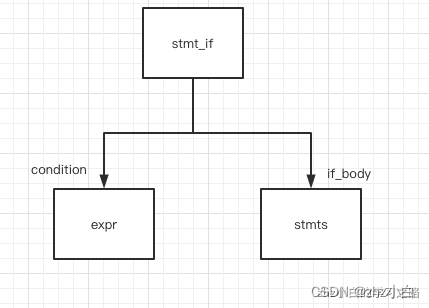
在源程序中出现的括号,或者是关键字,都会被丢掉。
1.3.2.2、yacc(语法分析器)
- 描述语法包括三部分:定义段、规则段和⽤户⼦程序段
...定义段...
%%
...规则段...
%%
...用户子例程段...
1.3.2.2.1、符号
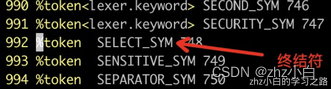
- yacc 语法由符号组成,即语法的“词”。符号是⼀串不以数字开头的字母、数字、句点和下划线。
- 由词法分析程序产⽣的符号叫做终结符号或者标记。定义在规则左侧的叫做⾮终结符号或者⾮终结。
- 标记也可能是字⾯上引⽤的字符,通常遵循约定:标记(终结符号)⼤写,⾮终结符号⼩写。
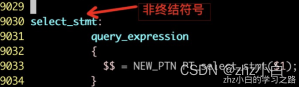
1.3.2.2.2、定义段
- 定义段包括⽂字块,逐字拷贝到⽣成的C⽂件开头部分的C代码。
- 包括标志(token)定义,如%union %start %token %type %left %right 和 %nonassoc 声明,也可以包含C代码(⽤“%{”和“%}”括起来),所有这些都是可选的,在简单的语法分析程序中,定义段可能完全是空的。
1.3.2.2.3、规则段
- 规则段由语法规则和包括C代码的动作组成。规则中⽬标或⾮终结符放在左边,后跟⼀个冒号(:),然后是产⽣式(body),之后是对应的动作(⽤{}包含)
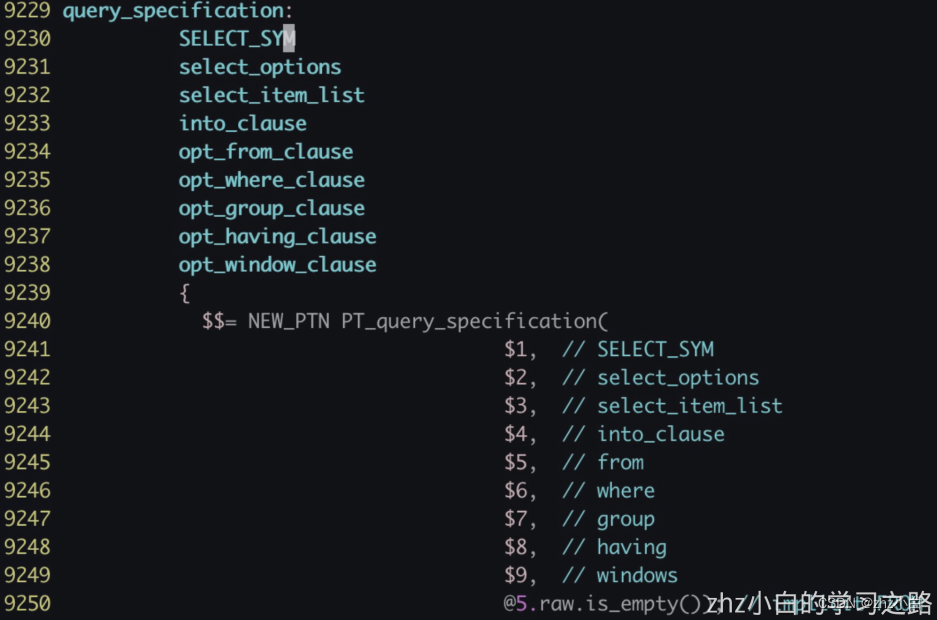
1.3.2.2.4、语法示例
mysql的yacc描述⽂件路径:sql/sql_yacc.yy
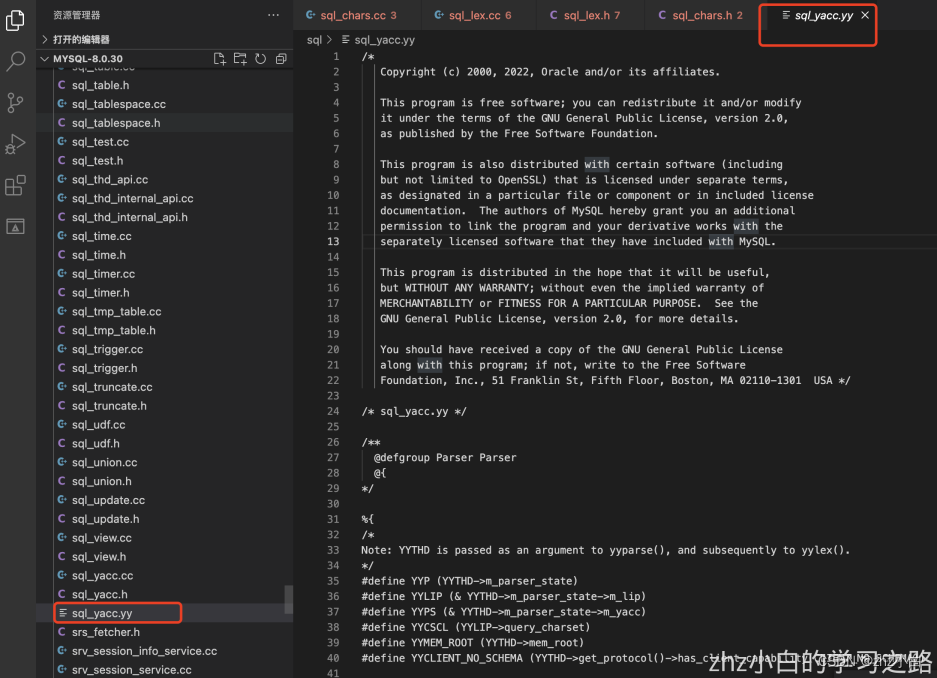
1.3.2.2.5、mysql中应用的yacc关键字
| 关键字 | 描述 |
|---|---|
| token | 标志0-255被保留作为字符值,⾃定义产⽣的token标志从258开始 |
| type | 为⾮终结符指明类型 |
| left | 表示左结合(left-associative) |
| right | 表示右结合(right-associative) |
| nonassoc | 表示⽆结合 |
| parse-param | 通过%parse-param {param} 来给 yyparse(param)传参数 |
| lex-param | 通过%lex-param {param} 来给 yylex(param)传参数 |
| start | 指定起始符号 |
| pure-parser | 指定希望解析器是可重⼊的 |
| expect | 告诉编译器预⻅多少次的移动归约冲突 |
1.3.2.2.6、常见SQL报错
可以看share/messages_to_clients.txt
1.3.2.2.7、sql语法解析过程的调⽤堆栈
#1 ./sql/conn_handler/connection_handler_per_thread.cc::handle_connection
#2.1 ./sql/sql_parse.cc::bool do_command(THD *thd)
#2.2 ./sql/sql_parse.cc::dispatch_command
#3 ./sql/sql_parse.cc::mysql_parse
#4.1 ./sql/sql_lex.cc:bool lex_start(THD *thd)
#4.2 ./sql/sql_parse.cc::parse_sql
#5 ./sql_class.cc: bool THD::sql_parser()
#6.1 ./sql_yacc.cc:int MYSQLparse
#6.2 ./sql_lex.cc:bool LEX::make_sql_cmd(Parse_tree_root *parse_tree) {
1.3.2.2.8、sql语句预处理的调⽤堆栈
#1 sql/sql_parse.cc:int mysql_execute_command(THD *thd, bool first_level) {
#2 sql/sql_select.cc:bool Sql_cmd_dml::execute(THD *thd) {
#3 sql/sql_select.cc:bool Sql_cmd_dml::prepare(THD *thd) {
#4 sql/sql_select.cc:bool Sql_cmd_select::precheck(THD *thd) {
#5 auth/sql_authorization.cc::bool check_table_access
#6 auth/sql_authorization.cc::bool check_grant
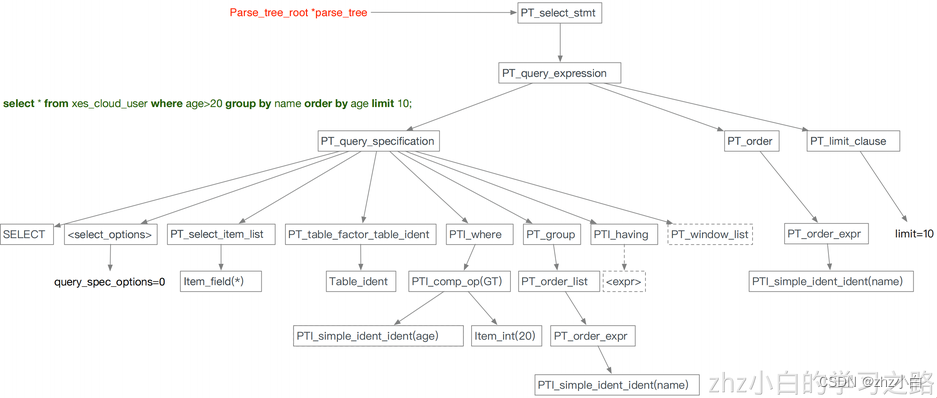
1.3.2.2.9、⼀条select sql语句的解析树
1.4、优化器(底层实现逻辑)
可以看一下这篇文章:https://blog.csdn.net/taoerchun/article/details/121376459,里面主要讲optimizer_trace的成本计算。或者看后面的SQL优化章节会有optimizer_trace实战
定义:
- 对 SQL 语法树进行逻辑优化和物理优化,最终生成执行计划交给执行引擎执行 SQL。
扩展:
- 逻辑优化
- 会将 SQL 语法树中的谓词转化为逻辑代数操作符,从而把语法树转化为关系代数语法树,然后进行语义优化、子查询优化、裁减冗余操作、连接提取公共表达式等一系列逻辑优化,最后生成逻辑查询执行计划
- 物理优化
- 会在逻辑优化后继续对 SQL 语法树进行改造,如果是多表连接的话会对表的连接顺序进行调整,SQL 语法树也会做相应的调整,另外还会使用代价估算器对单个表的扫描和多个表的连接顺序进行代价评估,并且选择一个代价最小的方案作为下一步优化的基础,最后生成物理查询执行计划。
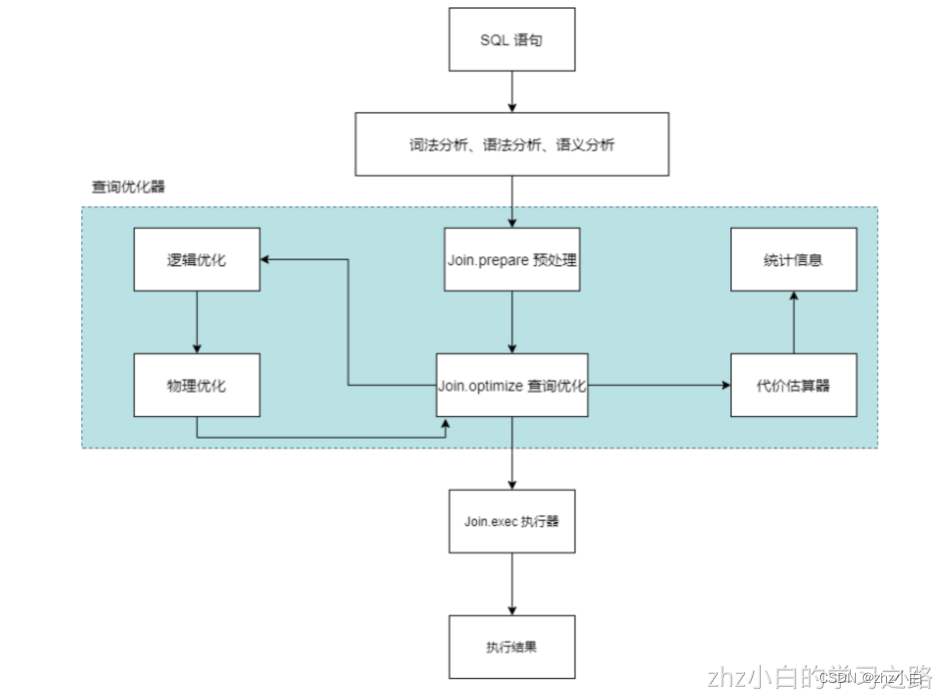
- 会在逻辑优化后继续对 SQL 语法树进行改造,如果是多表连接的话会对表的连接顺序进行调整,SQL 语法树也会做相应的调整,另外还会使用代价估算器对单个表的扫描和多个表的连接顺序进行代价评估,并且选择一个代价最小的方案作为下一步优化的基础,最后生成物理查询执行计划。
1.4.1、条件化简
1.4.1.1、移除不必要的括号
比如我们平常工作中有时候是不是范懵逼,写成(a=1 and b=c) or ((a>c) and (c<1)),其实这个时候优化器会帮我们优化成(a=1 and b=c) or (a>c and c<1)
1.4.1.1、常量传递
- 如a=1 and b=a ,那么优化器就会优化成a=1 and b=1
- 如a = b and b = c and c = 2,那么优化器就会优化成 a=2 and b=2 and c=2
1.4.1.1、移除没用的条件
比如select * from A where ((a<1 and b=b ) and 1=1 )or (a=2 or 1!=1)
此时优化器会把他优化成select * from A where a<1 or a=2
1.4.1.1、表达式计算
当表达式中只包含常量时,表达式就会优化,比如
a=1+2会被优化成a=3
而abs(a)>2或者**-a>-1**这种就不会被优化器优化
1.4.1.1、常量表检测
常量表定义:指的是主键索引或者唯一二级索引等值匹配所查询的表称之为常量表。优化器一般在分析一个sql时,会先执行常量表查询,然后再把查询语句中所有涉及到该表的条件全部换成常量,然后再分析其整体sql的成本计算(optimizer_trace)。
比如下面这条sql
SELECT * FROM A INNER JOIN B ON A.uid = B.uid WHERE A.id = 1001;
这个时候优化器会先根据A表的主键索引去查询A表的各个字段常量值,然后换成
SELECT A表的各大字段常量值,B.* FROM A INNER JOIN B ON A表的uid列的常量值 = B.uid
啥意思呢,你可以用下面这个例子来理解,比如
A表中有
| id | name | uid |
|---|---|---|
| 1001 | zhz | 1 |
| 1002 | zhz1 | 2 |
B表中有
| uid | name | age |
|---|---|---|
| 1 | zhangsan | 18 |
| 2 | lisi | 21 |
这个时候我们再去看整条sql:SELECT * FROM A INNER JOIN B ON A.uid = B.uid WHERE A.id = 1001;他是不是会先把A表中1001的数据拿出来,然后最终结果就会变成**select “1001”,“zhz”,1,B.uid,B.name,B.age FROM A INNER JOIN B ON 1 = B.uid **
1.4.2、外连接消除
- 内连接
- 内连接的驱动表的记录如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录会被舍弃
- 外连接
- 对于外连接的驱动表的记录来说,如果无法在被驱动表中找到匹配ON子句中的过滤条件的记录,那么该记录仍然会被加入到 结果集中,对应的被驱动表记录的各个字段使用NULL值填充
什么叫做外连接消除呢?
- 指的是某些情况外连接可以转成内连接,比如
SELECT * FROM e1 LEFT JOIN e2 ON e1.m1 = e2.m2 WHERE e2.m2 = 2;
就可以转成
SELECT * FROM e1 INNER JOIN e2 ON e1.m1 = e2.m2 WHERE e2.m2 = 2;
为什么可以转呢?
- 首先我们了解一下空值拒绝,空值拒绝指的是**指定的WHERE子句中包含被驱动表中的列不为NULL值的条件。**在被驱动表的WHERE子句符合空值拒绝的条 件后,外连接和内连接可以相互转换。
为什么要有这种转换呢?
- 这种转换带来的好处就是查询优化器可以通过评 估表的不同连接顺序的成本,选出成本最低的那种连接顺序来执行查询
1.4.3、子查询MySQL内部优化规则
SQL语句:SELECT m, n FROM (SELECT m2 + 1 AS m, n2 AS n FROM e2 WHERE m2 > 2) AS t
子查询:SELECT m2 + 1 AS m, n2 AS n FROM e2 WHERE m2 > 2
派生表:t,也就是说子查询本质就是一个生成一个派生表,比如上面哪个子查询,他会生成一个m,n列的符合条件的结果集表,就是派生表。
1.4.3.1、按返回的结果集区分子查询
1.4.3.1.1、标量子查询
含义:
- 只返回一个单一值的子查询
比如
- select (select id from a limit 1)
- select * from a where id= (select min(uid) from b)
- select * from a where id< (select max(uid) from b)
1.4.3.1.2、行子查询
含义:
- 返回一条记录的子查询,不过这条记录需要包含多个列
比如
- SELECT * FROM a WHERE (id, name) = (SELECT id, name FROM b LIMIT 1);
1.4.3.1.3、列子查询
含义:
- 是查询出一个列的数据,不过这个列的数据需要包含多条记录
比如:
- SELECT * FROM a WHERE id in (SELECT id FROM b LIMIT 1);
1.4.3.1.4、表子查询
含义:
- 子查询的结果既包含很多条记录,又包含很多个列
比如
- SELECT * FROM a WHERE (id, name) = (SELECT id, name FROM b);
1.4.3.2、按与外层查询关系来区分子查询
1.4.3.2.1、不相关子查询
- 如果子查询可以单独运行出结果,而不依赖于外层查询的值,我们就可以把这个子查询 称之为不相关子查询。
- 上面的所有sql都是不相关子查询
1.4.3.2.2、相关子查询
- 如果子查询的执行需要依赖于外层查询的值,我们就可以把这个子查询称之为相关子查询
- 比如
- SELECT * FROM a WHERE id in (SELECT name FROM b where a.a1=b.a2);
1.4.3.3、[NOT] IN/ANY/SOME/ALL子查询
IN/NOT IN
- 是用来判断某个操作数在不在由子查询结果集组成的集合中
- 比如下边的查询的意思是找出a表中的某些记录,这些记录存在于子查询的结果集中
SELECT * FROM a WHERE (a1, a2) IN (SELECT b1, b2 FROM b);
ANY/SOME(同义词)
- 大于最小,小于最大
- 比如下面这条语句:
- 对于a表的某条记录的a1列的值来说,如果子查询(SELECT b1 FROM b)的结果集中存在一个小于a1列的值,那么整个布尔表达式的值就是TRUE,否则为 FALSE,也就是说只要a1列的值大于子查询结果集中最小的值,整个表达式的结果就是 TRUE,所以上边的查询本质上等价于这个查询:
SELECT * FROM a WHERE a1 > ANY(SELECT b1 FROM b);
等价于
SELECT * FROM a WHERE a1 > (SELECT MIN(b1) FROM b);
ALL
- 大于最大,小于最小
- 比如
SELECT * FROM a WHERE a1 > ALL(SELECT b1 FROM b);
等价于
SELECT * FROM a WHERE a1 > (SELECT Max(b1) FROM b);
1.4.3.4、EXISTS子查询
- 有的时候我们仅仅需要判断子查询的结果集中是否有记录,而不在乎它的记录具体是个 啥,可以使用把EXISTS或者NOT EXISTS放在子查询语句前边
- 比如下面这条语句,我们只需要观察exists后面的语句即可,他为true,则为true,反之,false
SELECT * FROM e1 WHERE EXISTS (SELECT 1 FROM e2);
1.4.3.5、子查询语句注意事项
- 1、必须用小括号扩起来
- 2、在SELECT子句中的子查询必须是标量子查询,如果子查询结果集中有多个列或者多个行,都不允许放在SELECT子句中,在想要得到标量子查询或者行子查询,但又不能保证子查询的结果集只有一条记录时,应该使用LIMIT 1语句来限制记录数量。
- 3、对于[NOT] IN/ANY/SOME/ALL子查询来说,子查询中不允许有LIMIT语句,而且这类子查 询中ORDER BY子句、DISTINCT语句、没有聚集函数以及HAVING子句的GROUP BY子句没有什么意义。因为子查询的结果其实就相当于一个集合,集合里的值排不排序等一点儿都 不重要
- 4、不允许在一条语句中增删改某个表的记录时同时还对该表进行子查询。
1.4.3.6、子查询在MySQL中是怎么执行的
1.4.3.6.1、标量子查询、行子查询的执行方式
不相关标量子查询或者行子查询
SELECT * FROM s1 WHERE order_note = (SELECT order_note FROM s2 WHERE key3 = 'a' LIMIT 1);
执行思路
1、先执行 SELECT order_note FROM s2 WHERE key3 = 'a' LIMIT 1 ,假设结果为A
2、再把上一次的结果拿出来,替换成
SELECT * FROM s1 WHERE order_note = A
相关的标量子查询或者行子查询
SELECT * FROM s1 WHERE order_note = (SELECT order_note FROM s2 WHERE s1.order_no= s2.order_no LIMIT 1);
执行思路:
1、先从外层查询中获取一条记录,本例中也就是先从s1表中获取一条记录。
2、后从上一步骤中获取的那条记录中找出子查询中涉及到的值,本例中就是从s1表中获 取的那条记录中找出s1.order_no列的值,然后执行子查询。
3、最后根据子查询的查询结果来检测外层查询WHERE子句的条件是否成立,如果成立,就把 外层查询的那条记录加入到结果集,否则就丢弃
1.4.3.6.2、MySQL对IN子查询的优化
1.4.3.6.2.1、物化表
比如下面这个不相关的in查询
SELECT * FROM tbl_name WHERE column IN (a, b, c ..., ...);
这上面这条sql如果是基于mysql本身不做优化来说,会每一次查询一条记录,对比n次,性能极低,因此mysql为了优化这种sql的改进措施是:不直接将不相关子查询的结果集
临时表写入过程:
- 1、该临时表的列就是子查询结果集中的列。
- 2、写入临时表的记录会被去重,临时表也是个表,只要为表中记录的所有列建立主键或 者唯一索引。
- 小于等于tmp_table_size或者小于等于max_heap_table_size,所以会为它建立基于内存的使用Memory存储引擎的临时表,而且会为该表建立哈希索引
- 大于tmp_table_size或者大于max_heap_table_size,临时表会转而使用基于磁盘的存储引擎来保存结果集中的记录, 索引类型也对应转变为B+树索引
最后:
- 我们把这种存储子查询结果集的临时表称之为物化表。
- 正因为物化表中的记录都建立了索引(基于内存的物化表有哈希索引,基于磁盘的 有B+树索引),通过索引执行IN语句判断某个操作数在不在子查询结果集中变得非常 快,从而提升了子查询语句的性能。
1.4.3.6.2.2、物化表转连接
我们以下面这条sql为例:
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE order_no = 'a');
假设子查询的物化表叫做temp_table,对应的列叫做temp_val。那么我们此时是不是相当于可以理解为是上面的sql,等价于下面这条
SELECT s1.* FROM s1 INNER JOIN temp_table ON order_note = temp_val;
也就是说他其实相当于表s1和子查询物化表temp_table进行内连接。那么mysql就会进入下面这一步,去评估内连接不同的连接顺序的成本是多少了,如:
- 1、如果使用s1表作为驱动表的话,总查询成本由下边几个部分组成:
- 物化子查询时需要的成本
- 扫描s1表时的成本
- s1表中的记录数量 × 通过temp_val= xxx对temp_table表进行单表访问的成本
- 2、如果使用temp_table 表作为驱动表的话,总查询成本由下边几个部分组成:
- 物化子查询时需要的成本
- 扫描物化表时的成本
- 物化表中的记录数量 × 通过order_note= xxx对s1表进行单表访问的成本
- 最终,会选择成本最低的方案,一般小表驱动大表最好
1.4.3.6.2.3、将子查询转换为semi-join(半连接)->mysql内部转用
半连接 (semi-join):对于s1表的某条记录来说,我们只关心在s2表中 是否存在与之匹配的记录,而不关心具体有多少条记录与之匹配,最终的结果集中只保留s1表的记录。
举个例子:下面这条sql
SELECT * FROM s1 WHERE order_note IN (SELECT order_note FROM s2 WHERE order_no = 'a');
我们可以把这个查询理解成:对于s1表中的某条记录,如果我们能在s2表(准确的说是 执行完WHERE s2.order_no= 'a’之后的结果集)中找到一条或多条记录,这些记录的 order_note的值等于s1表记录的order_note列的值,那么该条s1表的记录就会被加入到最终的结果集。我们可以发现s1,s2两个表的连接很像下面这条sql
SELECT s1.* FROM s1 INNER JOIN s2 ON s1.order_note = s2.order_note WHERE s2.order_no= 'a';
只不过我们不能保证对于s1表的某条记录来说,在s2表(准确的说是执行完WHERE s2.order_no= 'a’之后的结果集)中有多少条记录满足s1.order_no = s2.order_no这个
条件,他会分成三种情况:
- 1、对于s1表的某条记录来说,s2表中没有任何记录满足s1.order_note = s2.order_note 这个条件,那么该记录自然也不会加入到最后的结果集。
- 2、对于s1表的某条记录来说,s2表中有且只有1条记录满足s1.order_note = s2.order_note 这个条件,那么该记录会被加入最终的结果集。
- 3、对于s1表的某条记录来说,s2表中至少有2条记录满足s1.order_note = s2.order_note 这个条件,那么该记录会被多次加入最终的结果集。
因此我们可以发现in子查询和表內连接不相等,那么mysql为了解决这样一个问题,他出了一种新的东西,也就是半连接。他会优化成
SELECT s1.* FROM s1 SEMI JOIN s2 ON s1.order_note = s2.order_note WHERE order_no= 'a';
半连接的实现方法概述 (自行研究)
- Table pullout (子查询 中的表上拉)
- 当子查询的查询列表处只有主键或者唯一索引列时,可以直接把子查询中的表上拉到外层查询的FROM子句中,并把子查询中的搜索条件合并到外层查询的搜索条件中,比如假设s2中存在这个一个key2列,列上有唯一性索引:
SELECT * FROM s1 WHERE key2 IN (SELECT key2 FROM s2 WHERE key3 = 'a');
- 由于key2列是s2表的一个唯一性二级索引列,所以我们可以直接把s2表上拉到外层查询的FROM子句中,并且把子查询中的搜索条件合并到外层查询的搜索条件中,上拉之后的查询就是这样的:
SELECT s1.* FROM s1 INNER JOIN s2 ON s1.key2 = s2.key2 WHERE s2.key3 = 'a';
- 为啥当子查询的查询列表处只有主键或者唯一索引列时,就可以直接将子查询转换为连接查询呢?因为主键或者唯一索引列中的数据本身就是不重复的嘛!所以对于同一条s1表中的记录,你不可能找到两条以上的符合s1.key2 = s2.key2的记录。
- DuplicateWeedout execution strategy (重复值消除)
- LooseScan execution strategy (松散扫描)
- Semi-join Materializationa半连接物化
- FirstMatch execution strategy (首次匹配)
1.4.3.6.2.4、不能转为semi-join查询的子查询优化
mysql内部会转成exist
比如下面这一个sql
SELECT * FROM s1 WHERE order_no IN (SELECT order_no FROM s2 where s1.order_note = s2.order_note) OR insert_time > '2021-03-22 18:28:28'; show WARNINGS;
具体的可以用explain分析。
1.4.3.6.2.5、ANY/ALL子查询优化
| 原SQL | 优化后的SQL |
|---|---|
| < ANY (SELECT inner_expr …) | < (SELECT MAX(inner_expr) …) |
| > ANY (SELECT inner_expr …) | > (SELECT MIN(inner_expr) …) |
| < ALL (SELECT inner_expr …) | < (SELECT MIN(inner_expr) …) |
| > ALL (SELECT inner_expr …) | > (SELECT MAX(inner_expr) …) |
1.4.3.6.2.6、[NOT] EXISTS子查询的执行
不相关子查询
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 WHERE expire_time= 'a') OR order_no> ‘2022-08-18 01:18:28’0;
优化思路:
1、因为是不相关子查询,所以我们可以知道,他首先执行的是SELECT 1 FROM s2 WHERE expire_time= 'a',假设他有记录,那么编译器会把这条sql优化(重写)成为
SELECT * FROM s1 WHERE true OR order_no> ‘2022-08-18 01:18:28’0;
2、接着我们可以发现还可以优化成
SELECT * FROM s1 WHERE true,
3、至此一条优化完的sql如上!
相关子查询
SELECT * FROM s1 WHERE EXISTS (SELECT 1 FROM s2 WHERE s1.order_note = s2.order_note);
优化思路,由上面哪个sql得知,我们是不能优化的,必须是先把子查询执行,才能执行外层,当然我们可以加个普通索引(idx_order_note)
1.5、执行器
- 执行器就会去根据我们的优化器生成的一套执行计划,然后不停的调用存储引擎的各种接口去完成SQL
语句的执行计划
- 执行器可能会先调用存储引擎的一个接口,去获取“users”表中的第一行数据,然后判断一下这个数据的
“id”字段的值是否等于我们期望的一个值,如果不是的话,那就继续调用存储引擎的接口,去获取“users”表的下一行数 据。
2、参考
- https://segmentfault.com/a/1190000023554495?utm_source=tag-newest
- http://t.zoukankan.com/jacksplwxy-p-10676578.html
3、个人信息
我是小白弟弟,一个在互联网行业的小白,立志成为一名架构师
https://blog.csdn.net/zhouhengzhe?t=1