目录

一、MySQL储存过程
1、存储过程简介
存储过程与函数的直接效果类似,只不过存储过程,封装的是一组sql语句。
① mysql数据库过程是一组为了完成特定功能的sql语句的集合。
② 存储过程这个功能时从5.0版本才开始支持的,它可以加快数据库的处理速度,增强数据库在实际应用中的灵活性。
③ 存储过程在使用过程中是将常用或复杂的工作预先使用sql语句写好,并用一个指定的名称存储起来,这个过程编译和优化后存储在数据库服务器中,当需要使用该存储过程时,只需要调用它即可。
④ 操作数据库的传统sql语句在执行时,需要先编译,然后再去执行,跟存储过程一对比,明显存储过程在执行速度更快,效率更高。存储过程在数据库中创建并保存。它不仅仅是sql了语句的集合,还可以加入一些特殊的控制结构,也可以控制数据的访问方式。
2、存储过程的优点
① 执行一次后,会将生成的二进制代码驻留缓冲区,提高执行效率
② sql语句加上控制语句的集合,灵活性高
③ 在服务器端存储,客户端调用时,降低网络负载
④ 可多次重复被调用,可随时修改,不影响客户端调用。
⑤ 可完成所有的数据库操作,也可控制数据库的信息访问权限
3、语法
1、create procedure <过程名> ([过程参数....]) <过程体>
2、[过程参数....] 格式
3、<过程名>:尽量避免与内置的函数或字段重名
4、<过程体>:语句 [in|out|inout] <参数名><类型>
3.1 参数分类
存储过程的主题部分,即过程体
以begin 开始,end结束,若只有一条sql语句,可省略begin 和end
以delimiter 开始和结束
3.2 不加参数的存储过程
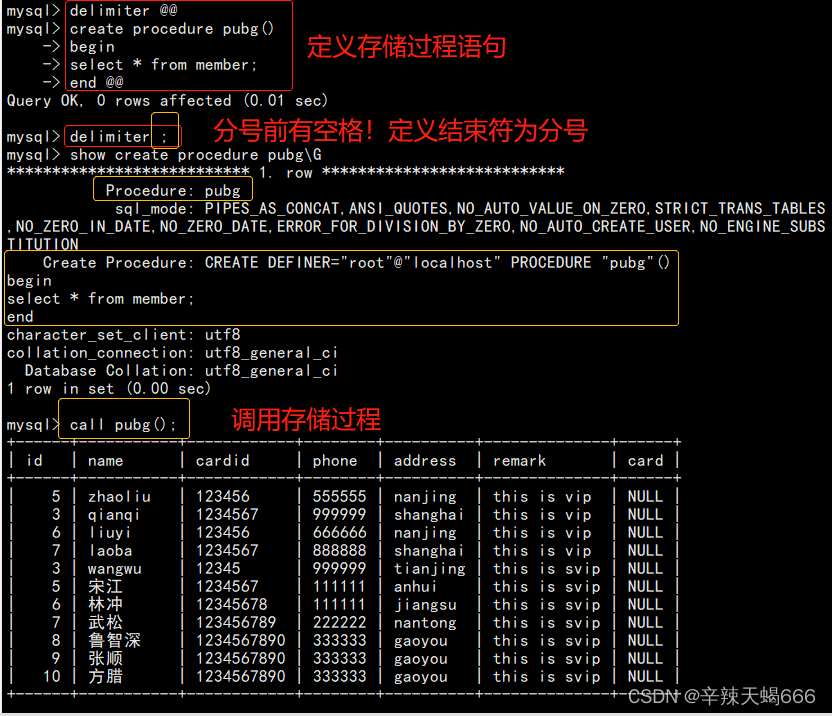
1、delimiter @@ ##将语句的结束符号从分号临时修改为@@,以防出问题,可以自定义
2、create proceduer PUBG() #创建存储过程,过程自定义,()可带参数
3、begin #过程体以关键字begin开始
4、select * from member; #过程体语句(可有多条)
5、end @@ #过程体以关键字end结尾
6、delimiter ; #将语句的结束符号恢复为分号
7、show create proceduer PUBG\G #查看存储过程信息
8、call PUBG(); #调用存储过程
以下面两个表,写出内连查询的存储过程
3.3、带参数的存储过程
in输入参数:in 表示调用者向过程传入值(传入值可以是字面量或变量)
out输出参数:out表示过程向调用者传出值(可以返回多个值)(传出值之只能是变量)
inout输出/输出参数:inout,即表示调用者向过程传入值,又表示过程向调用者传入值(只能是变量)
delimiter $$
create procedure pro(in inname varchar(20))
begin
select * from member where name=inname;
end $$
delimiter ;
call pro('ggb'); #括号里的必须是表里的人名

3.4、删除存储过程
show procedure status like '%pro%'\G
#可以查看当前库中存储过程信息
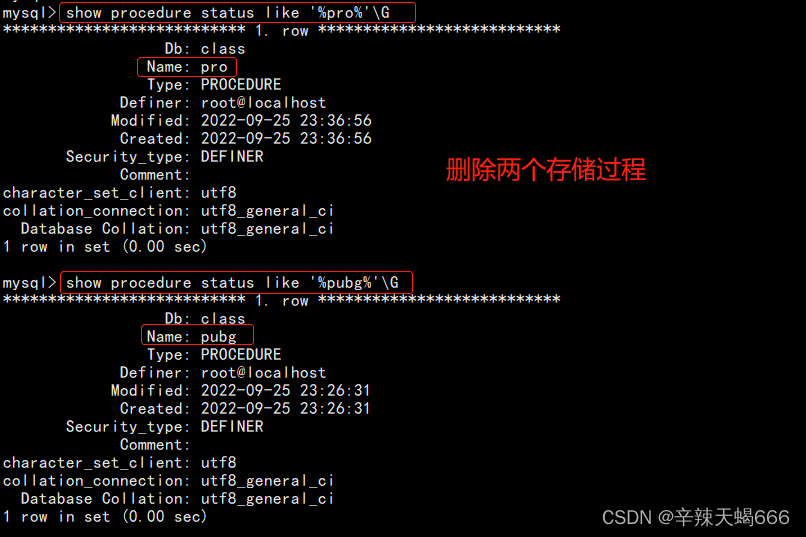
drop procedure if exists pro;
#删除pro存储过程
show create procedure pro\G
#查看确认

3.5、事务和存储过程有什么区别
实际而言,是存储引擎的特性
目的性: 事务,是为了保证数据的一致性、完整性、原子性、持久性(ACID)
存储过程中,包含了事务。(要看具体的存储引擎,因为myisam不支持事务)
存储过程的目的性: 简化复杂性操作
减少数据库资源消耗
可以通过传参,方便、灵活的进行sql查询类操作
3.6、存储引擎和存储过程的区别
存储引擎
mysql中的数据用各种不同的技术存储在文件中,每一种技术都适用不同的存储机制、索引技巧、锁定水平并最终提供不同的能力和功能,这些不同的技术以及配套的功能在mysql中被称为存储引擎。存储引擎是mysql将数据存储在文件系统中的存储方式或者存储格式。
存储过程
存储过程是事先经过编译并粗暴处在数据库中的一段sql语句的集合。调用存储过程可以简化应用开发人员的很多工作,减少数据在数据库和应用服务之间的传输,对于提高数据处理能力和效率是很有好处的。
3.7、mysql死锁的原因以及解决方法如下
1、一个用户A访问表A(锁住了表A),然后又访问表B;另一个用户B访问表B(锁住了表B),然后企图访问表A;这时用户A由于用户B已经锁住表B,它必须等待用户B释放表B才能继续,同样用户B要等用户A释放表A才能继续,这就死锁就产生了。
解决方法为:这种死锁比较常见,是由于程序的BUG产生的,除了调整的程序的逻辑没有其它的办法。仔细分析程序的逻辑,对于数据库的多表操作时,尽量按照相同的顺序进行处理,尽量避免同时锁定两个资源,如操作A和B两张表时,总是按先A后B的顺序处理,必须同时锁定两个资源时,要保证在任何时刻都应该按照相同的顺序来锁定资源。
2、用户A查询一条纪录,然后修改该条纪录;这时用户B修改该条纪录,这时用户A的事务里锁的性质由查询的共享锁企图上升到独占锁,而用户B里的独占锁由于A有共享锁存在所以必须等A释放掉共享锁,而A由于B的独占锁而无法上升的独占锁也就不可能释放共享锁,于是出现了死锁。这种死锁比较隐蔽,但在稍大点的项目中经常发生。如在某项目中,页面上的按钮点击后,没有使按钮立刻失效,使得用户会多次快速点击同一按钮,这样同一段代码对数据库同一条记录进行多次操作,很容易就出现这种死锁的情况。解决方法为:对于按钮等控件,点击后使其立刻失效,不让用户重复点击,避免对同时对同一条记录操作。