传统运维模式

需要各个环境保持一致性,测试,生产。
想做自动化的流水线也缺少工具链的支持,早期更多自动化部署的时候是将部署的通过shell脚本,然后去部署。
以为缺少统一的平台,实现灰度是比较难的,一种是手工,一种是公司提供强大的pass团队,然后将整个能力自动化全部构建出来,所以这里每家公司就需要去做投入,缺少统一的监控和运维的能力。
建立持续交付的服务体系

基于Docker的开发模式驱动持续集成
有了容器它就是一个利器了,得益于它的隔离性和封装性,一次构建到处运行,交付的不是一个一个的应用包,而是一个容器镜像。
所谓的持续集成就是你每次发代码变更的时候,我就要将你的代码,构建成二进制文件,然后构建为容器镜像,那么整个自动化的流水线最终输出的就是容器镜像。
应用交付容器化,真正一个应用部署到生产系统上面去,也是通过容器镜像去交付的,所有的环境都是容器镜像。
这样就可以避免在研发环境测试的在生产系统跑不起来。
devops 流程定义
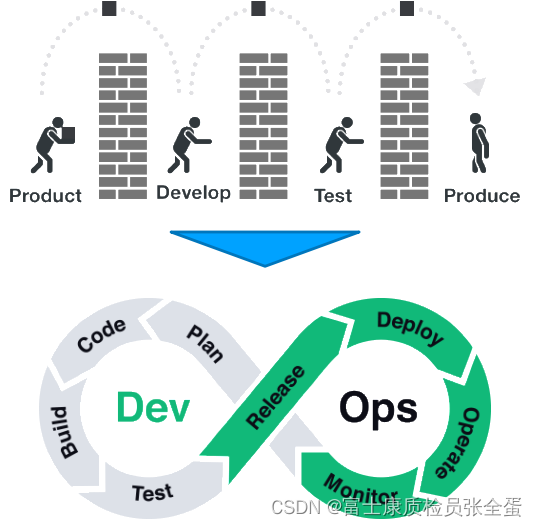
产品经理只收集需求,交付一大堆文档给研发,研发交付的是代码,代码在本地测试完之后交给测试,测试跑不通去找研发,在开放的辅助下测试跑完了,之后交付软件包,交给运维。
如果产线的运维部署出现问题,那么可能问题出现在任意一个环节,那么运维人员的压力是很大的,这样彼此之间就有冲突了。
所谓的devops就是既然都是微服务架构,会为每个能力设置一些负责人,这个负责人就需要为这个能力的全生命周期负责。全生命周期包含规划,代码编写,包含构建测试,发布,部署,日常运维,监控。
如果拉通了devops,那么就需要为软件的全生命周期负责。
Dev和Ops的边界定义
Programming vs. Engineering
- Programming更多的是系统设计和编码实现。
- Engineering 包含更大范围概念,除了功能层面的实现,还需为运维服务。
定义 production readiness

单体架构下的人员配置

一个网站就是一个WAR包,比如我用了MVC的框架,前端和后端的人员就会去分离开来,然后还有数据库管理员,前后端的业务逻辑是分离开来的,最后还有数据库管理员。
系统架构是前端和后端的业务逻辑,但是所有的业务逻辑是糅合在一起的。
微服务架构下的人员配置
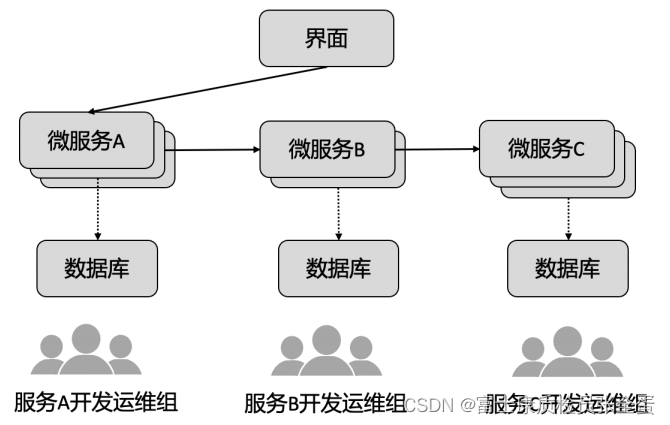
将一个一个系统拆分为不同的微服务。
devops下人员的划分
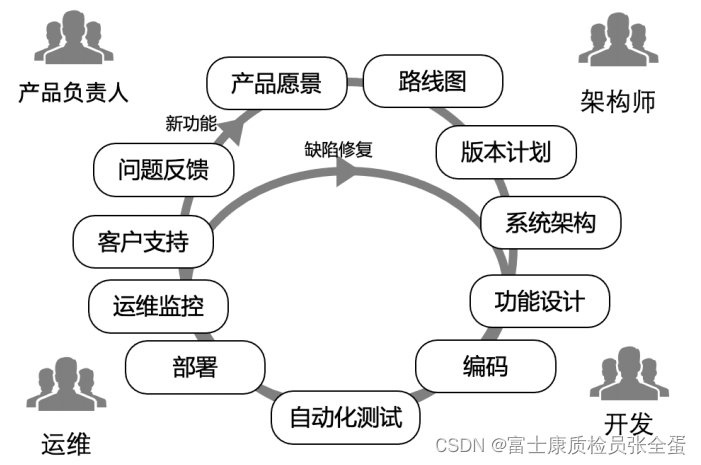
此组织结构的优缺点

我眼中的devops

敏捷开发
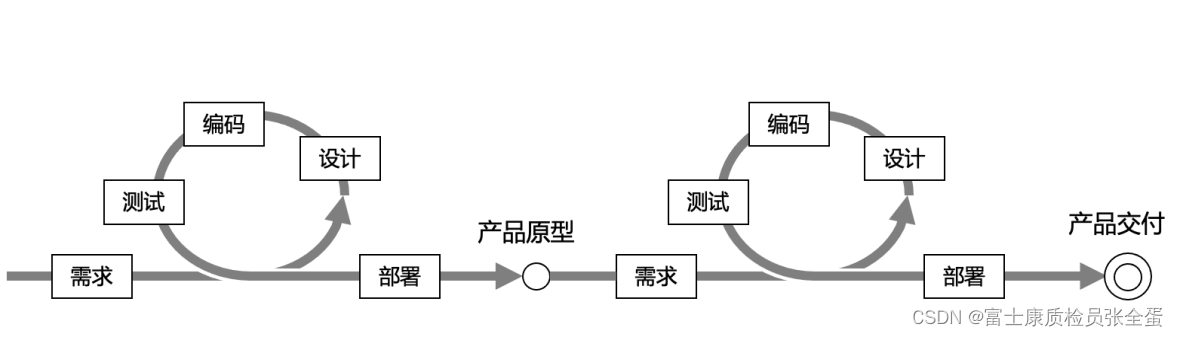
devops流程概览
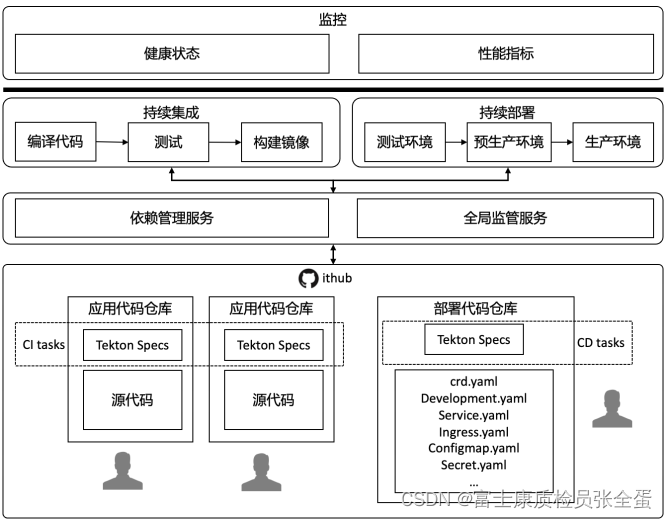
基于云原生工具链完成持续集成,持续部署,那么就需要工具上的支持。
将所有的东西都提交到github里面去,GitHub是可以有一个一个的webhook的,webhhok就可以去监听我的GitHub的变动,如果是源代码的变动就说明我要去做持续集成了, 如果是部署代码变动那么我去做持续部署了。
那么它就会去驱动持续集成和持续部署的流水线,来完成我的持续构建和持续部署。
代码分支管理
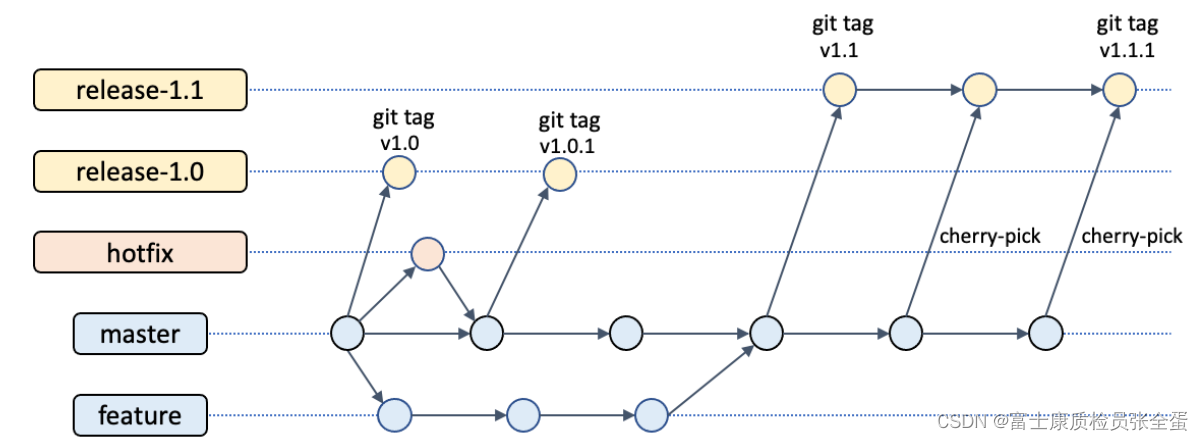
当有任何功能要进主版本,那我们会去拉取一个分支版本,或者通过fork的repo来做,最后通过合并到主版本里面。每个人人都会去拉自己的分支版本,最后去做合并,合并之后master上面就有所有人的变更了。
持续集成
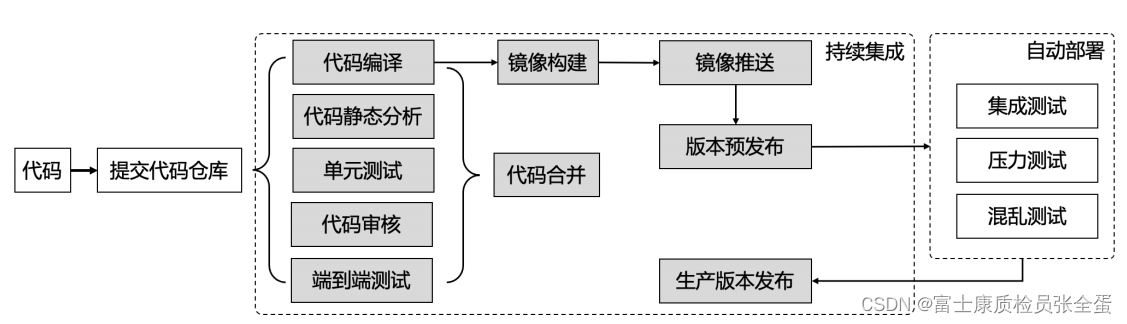
持续部署

GItops

在基于kubernetes技术栈之后,所有生产系统变更都可以通过github这种代码变更来触发的,如果变更都存在GitHub上面,那么GitHub里面是有迹可循的,我可以查到历史的commit,这些事情都是可以追溯的,使用这样的方式去管理生产系统那么生产系统会更加的规范。
gitops的理念就是,无论是应用的源代码还是配置,那它最终都是源代码,我们可以将GitHub作为开发和运维人员的一个主要的面向平台,无论我要去构建新的版本还是要去发布新的版本,都是通过GitHub来发起的,经过一些人的审批做代码的合并。
代码合并之后会自动的触发流水线,无论是持续构建还是持续部署的流水线,那最终实现我的容器镜像部署这样一个目的。
也即是所有的运维,其实你不需要去碰生产系统,你只需要将生产系统的配置存在GitHub里面,最终通过GitHub的pr来触发的。