A Lightweight and Accurate Recognition Framework for Signs of X-ray Weld Images
一种轻量级准确的X射线焊缝图像识别框架
简介:本文提出了一种高性能的轻量级焊接图像手势识别框架,将GRNet和GYNet连接起来完成整个任务。其中基于组卷积的ResNet (GRNet)用于交叉标记分类,Greater-YOLO网络(GYNet)用于焊缝信息识别。
ResNet在层数和内部模块上还有进一步优化的空间,提出新的GRNet。
Abstract
X-ray images are commonly used to ensure the security of devices in quality in- spection industry. The recognition of signs printed on X-ray weld images plays an essential role in digital traceability system of manufacturing industry.the scales of objects vary different greatly in weld images, and it hinders us to achieve satisfactory recognition.
在质量检测行业中,x射线图像是保证设备安全的常用手段。x射线焊缝图像标识识别在制造业数字化溯源系统中起着至关重要的作用。焊缝图像中物体的尺度差异较大,难以实现理想的识别。
In this paper, we propose a signs recognition framework based on convolutional neural networks (CNNs) for weld images.The proposed framework firstly contains a shallow classification network for correct- ing the pose of images. Moreover, we present a novel spatial and channel enhance- ment (SCE) module to address the above scale problem.This module can inte- grate multi-scale features and adaptively assign weights for each feature source.
本文提出了一种基于卷积神经网络(cnn)的焊缝图像符号识别框架。该框架首先包含一个用于图像位姿校正的浅层分类网络。此外,我们提出了一个新的空间和通道增强(SCE)模块来解决上述尺度问题。该模块可以集成多尺度特征,并对每个特征源自适应分配权重。
Based on SCE module, a narrow network is designed for final weld information recognition.
以SCE模块为基础,设计了一种窄网的焊缝最终信息识别系统。
To enhance the practicability of our framework, we carefully design the architecture of framework with a few parameters and computations.
为了提高框架的实用性,我们精心设计了框架的结构,只需要少量的参数和计算量。
1. Introduction
However, since size distribution of weld infor- mation is consistent and single, the features at one scale are often more important than at other scales, so it is crucial to assign weights for different feature sources at weld information recognition task.
然而,由于焊缝信息的尺寸分布是一致的和单一的,一个尺度上的特征往往比其他尺度上的特征更重要,因此在焊缝信息识别任务中对不同的特征源分配权重是至关重要的。
Our framework is compact and high-performant, consisting of two CNNs, i.e., Group convolution-based ResNet (GRNet) for crossmark classification and Greater-YOLO network (GYNet) for weld information recognition.
我们的框架紧凑、高性能,由两个cnn组成,即用于交叉标记分类的基于组卷积的ResNet (GRNet)和用于焊缝信息识别的Greater-YOLO网络(GYNet)。
3. Method
GRNet for cross mark classification and GYNet for weld information recognition.
GRNet用于交叉标记分类,GYNet用于焊缝信息识别。
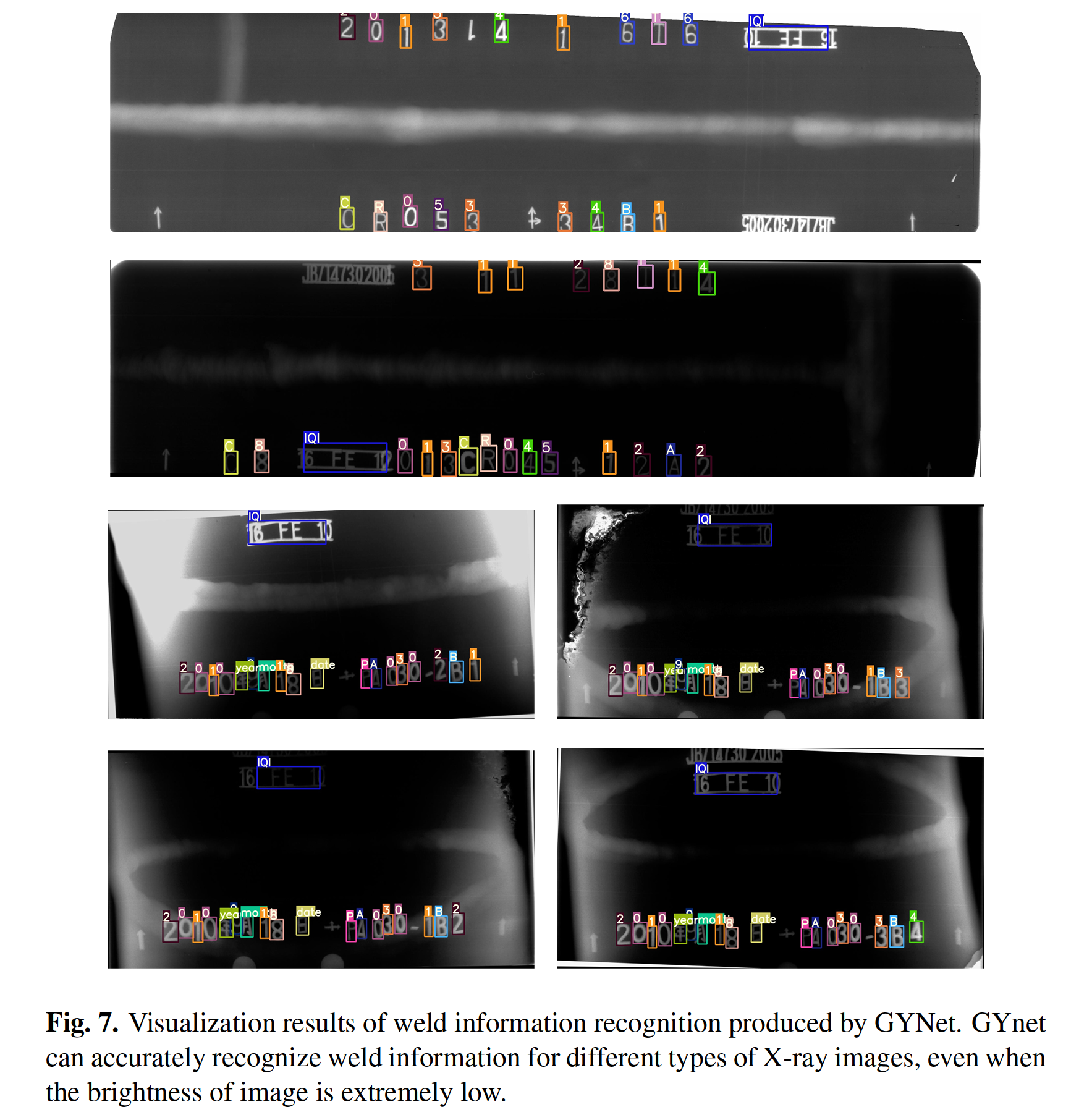
The architecture of our framework is represented in Fig. 2. GRNet is a lightweight yet effective clas- sifier with only 14 convolution (Conv) layers. GYNet is a compressed but high- performing network designed by a few number of channels on high-level layers.
我们的框架架构如图2所示。GRNet是一个轻量级而有效的类划分器,只有14个卷积(Conv)层。GYNet是一种压缩但高性能的网络,由高层的几个信道设计而成。

3.1. GRNet for Cross Mark Classification
However, the pose of these digital images is random and casual in actual production. Thus we need to classify the direction mark, i,e, the cross mark at first, and then adjust image to correct pose. A compact and efficient classifi- cation network can redirect faster, improving the overall efficiency of recognition framework.
然而,这些数字图像的姿态在实际生产中是随机和随意的。因此,我们需要首先对方向标记(i,e,交叉标记)进行分类,然后调整图像以纠正姿态。一个紧凑、高效的分类网络可以更快地重定向,提高识别框架的整体效率。
ResNet is still room for further optimization in terms of the number of layers and internal modules.To achieve this goal, we propose a novel GRNet.
ResNet在层数和内部模块上还有进一步优化的空间,为了实现这一目标,我们提出了一种新的GRNet。
The backbone of our GRNet has 9 modules with only 14 Conv layers, and its architecture is shown in Table 2.
我们GRNet的骨干有9个模块,只有14个Conv层,其架构如表2所示。
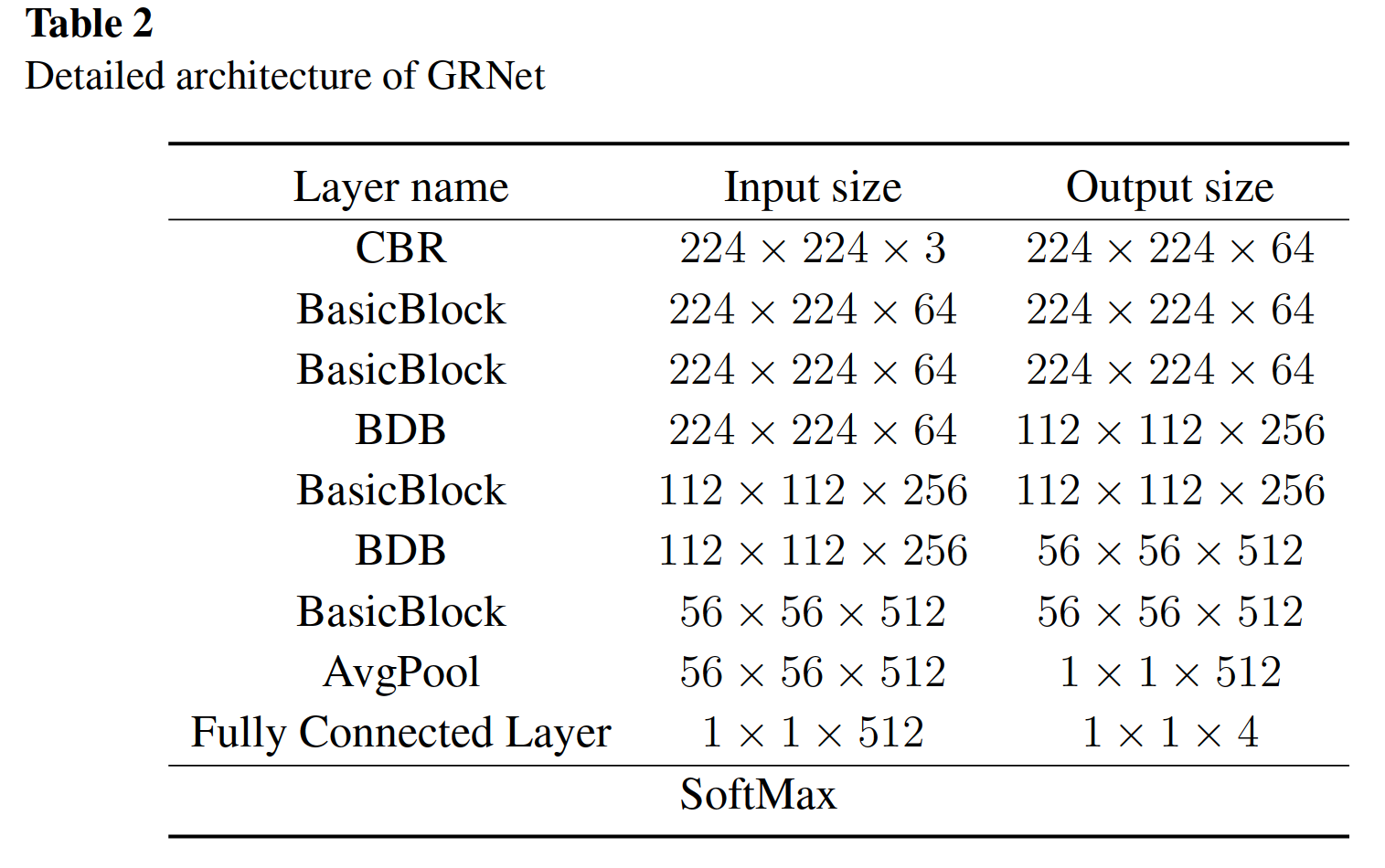
To further cut down the parameters and model size of GRNet, we use group convolution to replace all 3×3 normal convolution.
为了进一步减小GRNet的参数和模型大小,我们使用组卷积来代替所有的3×3普通卷积。
In this paper, we define the g as the greatest common divisor of input and output channel numbers. If the dimensions of input and output are the same, the number of parameters in normal convolution is g times that of group convolution.
本文将g定义为输入和输出通道数的最大公约数。如果输入和输出的维数相同,则普通卷积的参数数是群卷积的g倍。
3.2. GYNet for Weld Information Recognition
Channel weighted block is a type of attention mechanism method. It can learn the relationship between different channels and obtain the weight of each channel.
通道加权块法是一种注意机制方法。它可以学习不同通道之间的关系,得到每个通道的权值。
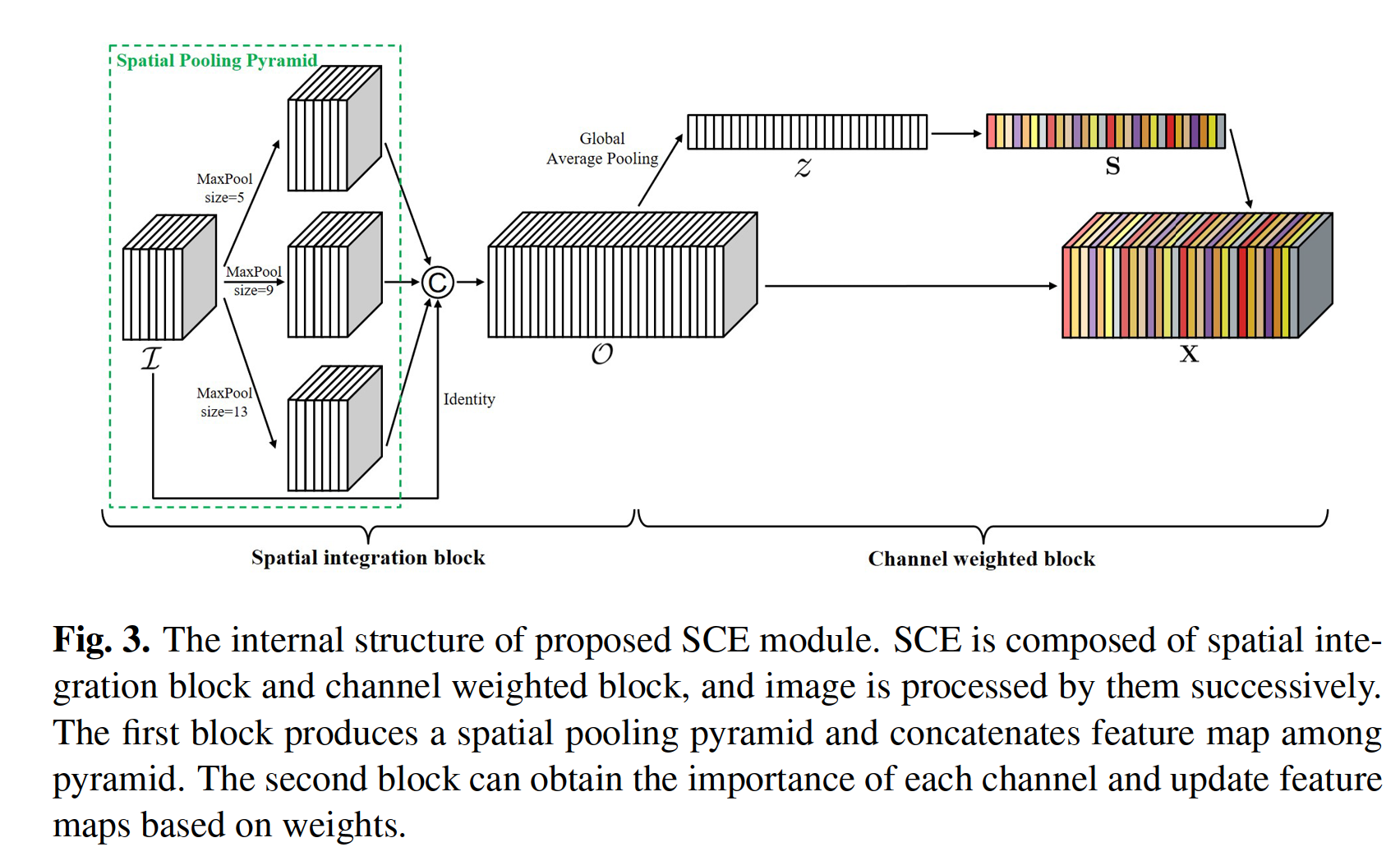
Channel weighted block is an adaptive adjuster whose function is to learn the importance of each channel information, and further can show which scale feature is more significant.
信道加权块是一种自适应调节器,它的作用是学习每个信道信息的重要性,进而可以显示出哪个尺度特征更显著。
when the sizes of recognized objects are similar, there is only one scale that is essential for final prediction theoretically.
当被识别物体的大小相似时,理论上只有一个尺度对最终预测至关重要。
channel weighted block is designed to weight different scale adaptively during network learning, and more significant channel, in other words, more meaningful scale feature would be assigned more weight.
通道加权块被设计为在网络学习过程中自适应地对不同的尺度进行加权,并且越重要的通道,换句话说,越有意义的尺度特征被赋予更多的权重。
Overall, the proposed SCE module improves the contextual representation ability of feature maps through integrating more information sources, and fur- ther weight them adaptively based on their importance.
总体而言,该模型通过整合更多的信息源,提高了特征图的上下文表示能力,并根据信息源的重要性对其进行自适应加权。
GYNet has the same numbers of Conv and MaxPool layer compared with Tiny-YOLO v3.More narrow model can decrease the parameters and FLOPs more directly.
与Tiny-YOLO v3相比,GYNet具有相同的Conv和MaxPool层数。更窄的模型可以更直接地降低参数和跳跃
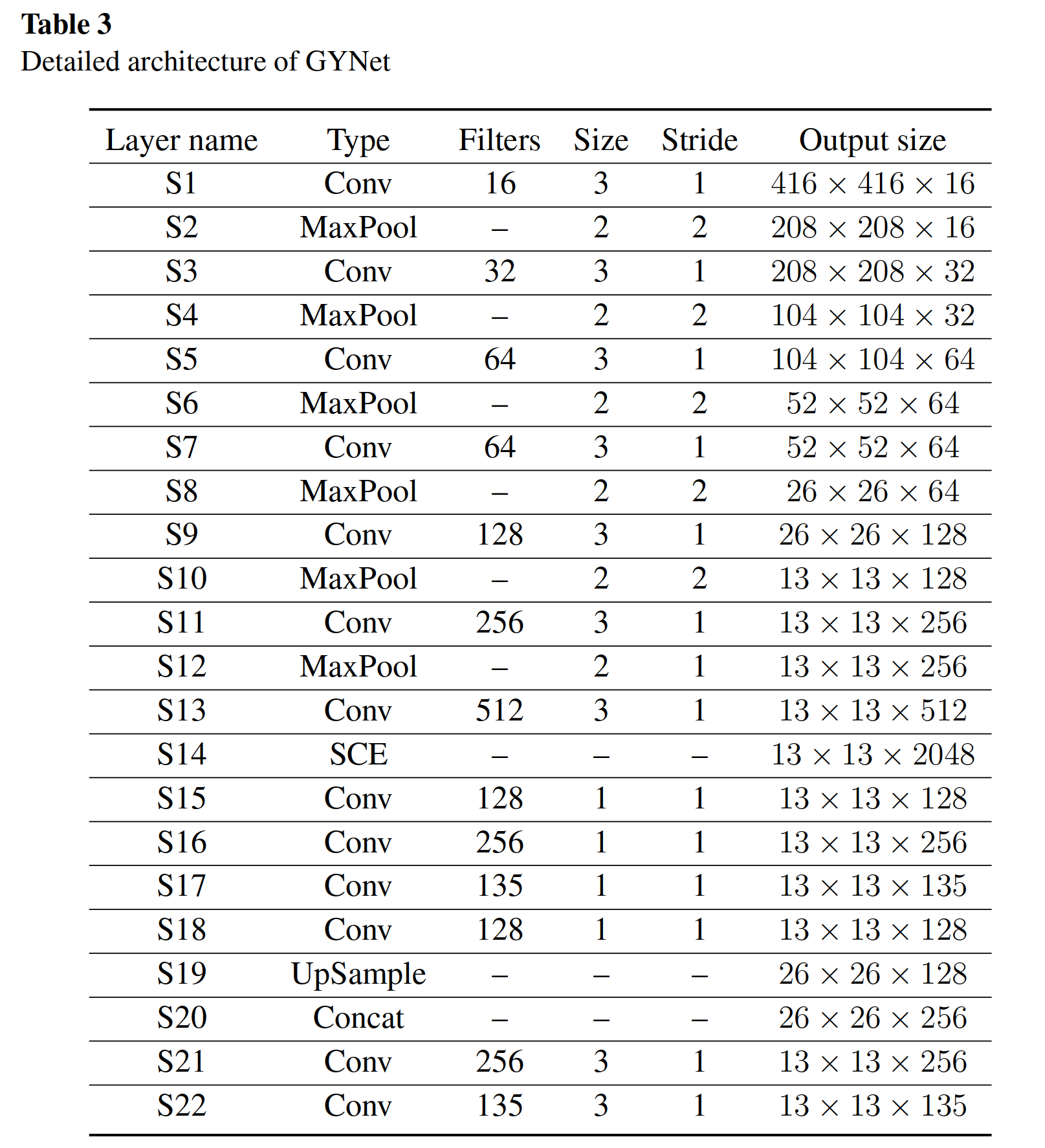
we strictly limit the number of channels in each layer. this design strategy makes network bring few burden on computation device.
我们严格限制每一层中的通道数量。这种设计策略使得网络给计算设备带来的负担很小。
We embed SCE module at the tail of backbone to ensure it process more meaningful information, and make the enhanced features closer to the output layer for more accurate recognition results.
我们在主干的尾部嵌入SCE模块,使其处理更有意义的信息,并使增强后的特征更接近输出层,以获得更准确的识别结果。
4. Experiments
We use the flip and minor operation to augment our dataset for obtaining a more robust network.
我们使用翻转和次要操作来扩大我们的数据集,以获得更健壮的网络。
Cross mark classification dataset has four classes to represent the direction of images.
十字标记分类数据集有四个类别来表示图像的方向。
For the recognition subtask, we resize the whole image to 416×416 pixels for adapting to the normal input size of YOLO.
对于识别子任务,我们将整个图像的大小调整到416×416像素,以适应YOLO的正常输入大小。
5 .Conclusion
In this paper, we propose a high-performing lightweight framework for signs recognition of weld images, in which GRNet and GYNet are connected to com- plete whole task.
本文提出了一种高性能的轻量级焊接图像手势识别框架,将GRNet和GYNet连接起来完成整个任务。