原文网址:ElasticSearch--写入数据的流程(原理)_IT利刃出鞘的博客-CSDN博客
简介
本文介绍ES是如何将数据写入磁盘并返回的。
分片的路由原理
见 :ElasticSearch--分片的路由原理_IT利刃出鞘的博客-CSDN博客
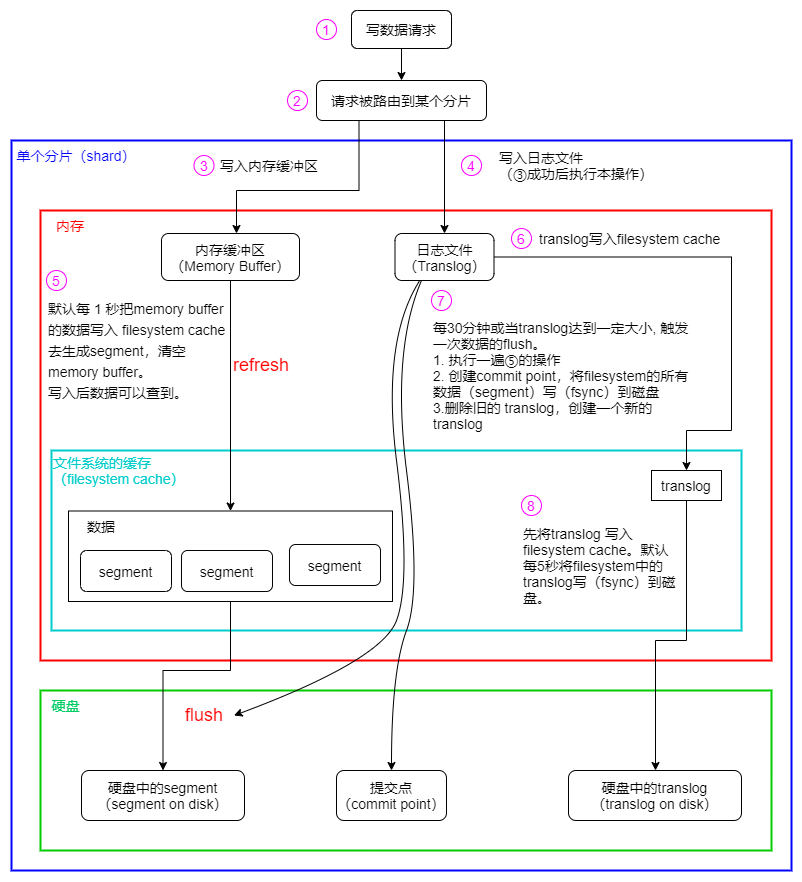
ES写到分片中的流程
ES与MySQL的写入的对比
| 项 | MySQL | ES |
| 记录日志 | redo log | translog |
| 复制日志 | binlog | translog |
近实时的原理(refresh)
ES 默认每隔 1 秒会从内存 buffer 中的数据写入 filesystem cache,这个过程叫做 refresh。这也是为什么说 ES 是近实时搜索的原因,因为数据写入到 filesystem cache 后才会被搜索到。
Elasticsearch提供了一个refresh操作,会定时地调用lucene的reopen(新版本为openIfChanged)为内存中新写入的数据生成一个新的segment,此时被处理的文档均可以被检索到。refresh操作的时间间隔由refresh_interval参数控制,默认为1s。还可以在写入请求中带上refresh表示写入后立即refresh,另外还可以调用refresh API显式refresh。
分段(segment)
每个 shard 都是一个 Lucene Index,包含多个 segment 文件和一个 commit point 文件。每个 segment 都是一个倒排索引,存储的是一个个 Document。commit point 记录了segment 文件信息。
在查询的时,会把所有的 segment 查询结果汇总归并后转为最终的分片查询结果返回。
合并分段(merge)
refresh默认间隔为1s中,因此会产生大量的小segment。为此ES会运行一个任务检测当前磁盘中的segment,对符合条件的segment进行合并操作,减少lucene中的segment个数,提高查询速度,降低负载。
merge也是文档删除和更新操作后,旧的doc真正被删除的时候。
用户还可以手动调用_forcemerge API来主动触发merge,以减少集群的segment个数和清理已删除或更新的文档。
提交点(commit point)
commit point记录当前所有可用的 segment,每个 commit point 都会维护一个.del 文件(ES 删除数据本质是不属于物理删除)。
当 ES 做删改操作时首先会在 .del 文件中声明某个 document 已经被删除,.del文件记录了在某个 segment 内某个文档已经被删除。当查询请求过来时在 segment 中被删除的文件是能够查出来的,但是当返回结果时会根据 commit point 维护的那个 .del 文件把已经删除的文档过滤掉。
部分更新
Lucene只支持对文档的整体更新。ES为了支持局部更新,在Lucene的Store索引中存储了一个_source字段,该字段的key值是文档ID, 内容是文档的原文。当进行更新操作时先从_source中获取原文,与更新部分合并后,再调用lucene API进行全量更新, 对于写入了ES但是还没有refresh的文档,可以从translog中获取。
为了防止读取文档过程后执行更新前有其他线程修改了文档,ES增加了版本机制,当执行更新操作时发现当前文档的版本与预期不符,则会重新获取文档再更新。
保证数据可靠新
translog(记录日志)
ES数据是先写入缓存中,如果在写入数据时ES节点突然宕机可能会造成数据丢失。为保证数据存储的可靠性,当进行文档写操作时会先将文档写入Lucene,然后写入一份到translog,写入translog是落盘的,这样就可以防止服务器宕机后数据的丢失
translog会每隔5秒或者在一个变更请求完成之后执行一次fsync操作,将translog从缓存刷入磁盘。如果对可靠性要求不是很高,也可以设置异步落盘,可以提高性能,由配置index.translog.durability和index.translog.sync_interval控制。
ES 在写入缓存后,再写入 translog 日志文件(因为有可能缓存写入失败,为了减少写入失败回滚的复杂度,因此先写入缓存)。
由于 translog 是追加写入,因此性能要比随机写入要好。
flush(写入磁盘)
每30分钟或当translog达到一定大小(由index.translog.flush_threshold_size控制,默认512mb), ES会触发一次flush操作,此时ES会先执行refresh操作将buffer中的数据生成segment,然后调用lucene的commit方法将所有内存中的segment 写(fsync)到磁盘。此时Lucene中的数据就完成了持久化,会清空translog中的数据(6.x版本为了实现sequenceIDs,不删除translog)