题目以及数据自取:
链接:https://pan.baidu.com/s/1UkzMxcsHOryGJotaXkYObQ?pwd=1234
提取码:1234
文章目录
一、题目
1、问题背景
数字支付正在发展,但网络犯罪也在发展。电信诈骗案件持续高发,消费者受损比例持续走高。报告显示,64%的被调查者曾使用手机号码同时注册多个账 户,包括金融类账户、社交类账户和消费类账户等,其中遭遇过电信诈骗并发生损失的比例过半。用手机同时注册金融类账户及其他账户,如发生信息泄露,犯罪分子更易接管金融支付账户盗取资金。
随着移动支付产品创新加快,各类移动支付在消费群体中呈现分化趋势,第三方支付的手机应用丰富的场景受到年轻人群偏爱,支付方式变多也导致个人信息也极易被不法分子盗取。根据数据泄露指数,每天有超过 500 万条记录被盗,这一令人担忧的统计数据表明 - 对于有卡支付和无卡支付类型的支付,欺诈仍然非常普遍。
在今天的数字世界,每天有数万亿的银行卡交易发生,检测欺诈行为的发生 是一个严峻挑战。
2、数据描述
该数据来自一些匿名的数据采集机构,数据共有七个特征和一列类标签。下面对数据特征进行一些简单的解释(每列的含义对我们来说并不重要,但对于机 器学习来说,它可以很容易地发现含义。它有点抽象,但并不需要真正了解每个功能的真正含义。只需了解如何使用它以便您的模型可以学习。许多数据集,尤 其是金融领域的数据集,通常会隐藏一条数据所代表的内容,因为它是敏感信息。 数据所有者不想让他人知道,并且数据开发人员从法律上讲也无权知道)
| 属性 | 描述 |
|---|---|
| distance_from_home | 银行卡交易地点与家的距离; |
| distance_from_last_transaction | 与上次交易发生的距离; |
| ratio_to_median_purchase_price | 近一次交易与以往交易价格中位数的比率; |
| repeat_retailer | 交易是否发生在同一个商户; |
| used_chip | 是通过芯片(银行卡)进行的交易; |
| used_pin_number | 交易时是否使用了 PIN 码; |
| online_order | 是否是在线交易订单; |
| fraud | 诈骗行为(分类标签); |
二、数据预处理
import pandas as pd
data=pd.read_csv('card_transdata.csv')
data.head(10)

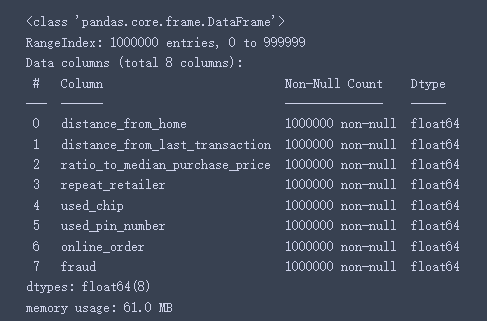
1、列数据类型和缺失值汇总
# 列数据类型和缺失值汇总
data.info()
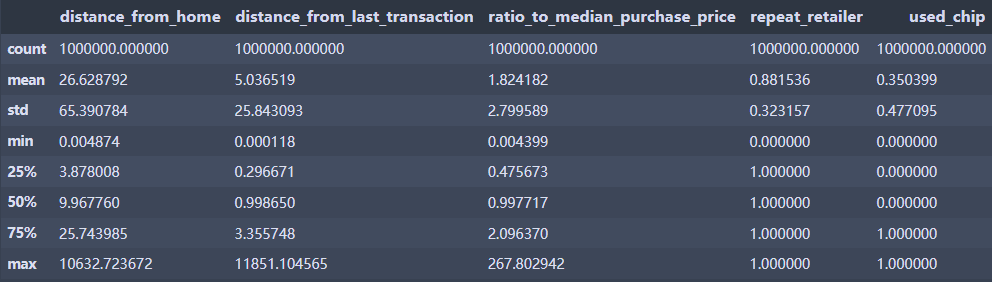
2、查看数据整体描述
data.describe() # 查看数据整体描述
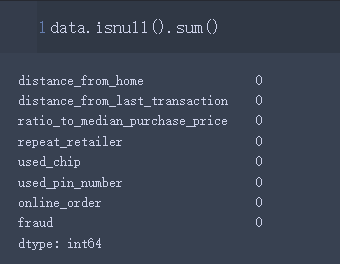
data.isnull().sum()
根据以上输出可以看到,没有缺失值
3、使用箱型图查看异常值
import pandas as pd
import matplotlib.pyplot as plt
import seaborn as sns # 可视化w
plt.rcParams['font.sans-serif'] = ['SimHei'] # 用来正常显示中文标签
plt.rcParams['axes.unicode_minus'] = False # 用来正常显示负号
# 绘制不同参数的箱型图
plt.style.use('ggplot')
fig,axes = plt.subplots(1,2)
color = dict(boxes='DarkGreen', whiskers='DarkOrange',
medians='DarkBlue', caps='Red')
# boxes表示箱体,whisker表示触须线
# medians表示中位数,caps表示最大与最小值界限
data[['distance_from_home', 'distance_from_last_transaction',
]].plot(kind='box',ax=axes,subplots=True,
title='异常值箱型图检测',color=color,sym='r+', figsize=(26,44) ,fontsize=13)
# sym参数表示异常值标记的方式
axes[0].set_ylabel()
axes[1].set_ylabel()
fig.subplots_adjust(wspace=2,hspace=2) # 调整子图之间的间距
# fig.savefig("p1.png") # 将绘制的图片保存为p1.png
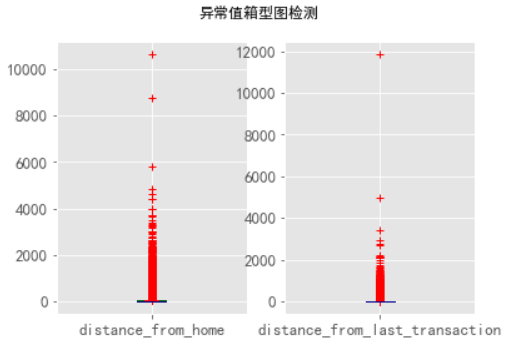


从上图可以看出:distance_from_home、distance_from_last_transaction、ratio_to_median_purchase_price中异常值较多,repeat_retailer、used_chip,used_pin_number、online_order是二分类的类别特征。
3、对二分类属性进行分析
对诈骗行为做类别分析:0和1分别表示一种欺诈行为,属于二分类。
data.fraud.value_counts()

(data.fraud.value_counts()/len(data))*100
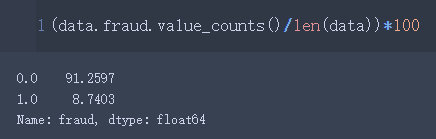
- 标签0的比例为91.2598%
- 标签1的比例为8.7403%
4、绘制相关系数图
df.corr() 计算列的成对相关性。相关性显示两个变量如何相互关联。正值显示一个变量增加,其他变量也增加。 负值表示一个变量增加另一个变量减少。值越大,两个变量的相关性越强,反之亦然。
使用皮尔逊系数计算列与列的相关性:
import seaborn as sns
import matplotlib.pyplot as plt
from matplotlib.font_manager import FontProperties
myfont=FontProperties(fname=r'C:\Windows\Fonts\simhei.ttf',size=40)
sns.set(font=myfont.get_name(), color_codes=True)
#corr = df.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
#corr = df.corr(method='kendall') # 肯德尔秩相关系数
#corr = df.corr(method='spearman') # 斯皮尔曼秩相关系数
data_corr = data.corr(method='pearson') # 使用皮尔逊系数计算列与列的相关性
plt.figure(figsize=(20,15))#figsize可以规定热力图大小
fig=sns.heatmap(data_corr,annot=True,fmt='.2g')#annot为热力图上显示数据;fmt='.2g'为数据保留两位有效数字
fig
fig.get_figure().savefig('dingding_corr.png')#保留图片

分析:交易到家里的距离(distance_from_home)与近一次交易与以往交易价格中位数的比率(ratio_to_median_purchase_price)关系最大为0.19,几乎可以说没啥关系了。其它的甚至都有负数。
所以分析出这些变量之间是没有相互影响关系。
三、解决问题
问题如下:
(1) 使用多种用于数据挖掘的机器学习模型对给定数据集进行建模;
(2) 对样本数据进一步挖掘分析,通过交叉验证、网格调优对不同模型的参数进行调整,寻找最优解,将多个最优模型进行进一步比较;
(3) 通过对 precision(预测精度)、recall(召回率)、f1-score(F1 分 数值)进行计算,给出选择某一种预测模型的理由;
(4) 将模型性能评价通过多种作图方式进行可视化
1、第一问
from sklearn.model_selection import train_test_split # 将数据拆分为训练/测试
X = data.drop('fraud', axis=1)
y = data['fraud']
from sklearn.model_selection import train_test_split
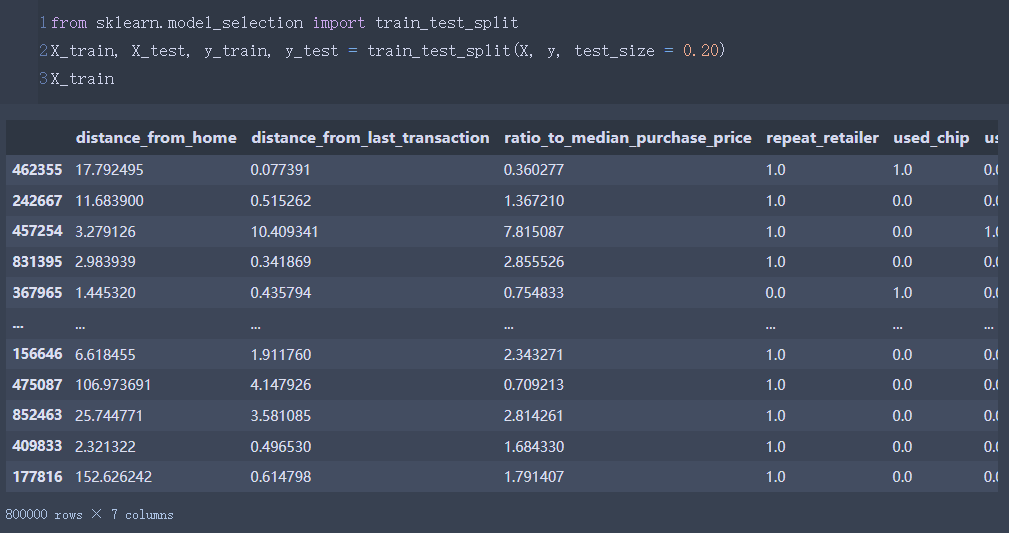
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size = 0.20) #8:2的比例
X_train
数据的80%作为训练集,20%作为测试集。
由于不同变量之间相差较大,考虑使用标准化
建立模型:
from sklearn.preprocessing import StandardScaler
sc = StandardScaler()
# 只需要对输入的值x缩放
X_train = sc.fit_transform(X_train)
X_test = sc.transform(X_test)
【1】决策树
#导入决策树算法
from sklearn.tree import DecisionTreeClassifier
# entropy参数表示信息增益。使用信息增益方法从数据集中构建一棵树。
model = DecisionTreeClassifier(criterion='entropy', random_state=0)
# 训练
model.fit(X_train,y_train)
y_pred = model.predict(X_test)# 预测
y_pred
# 导入准确度分数方法
from sklearn.metrics import accuracy_score
# 计算准确度
accuracy_score(y_pred,y_test)


【2】其他模型
由于要使用多种模型,这里再试试其他的模型:
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
import seaborn as sns
# 正常显示中文
from pylab import mpl
mpl.rcParams['font.sans-serif'] = ['SimHei']
# 正常显示符号
from matplotlib import rcParams
rcParams['axes.unicode_minus']=False
from sklearn.pipeline import Pipeline
from sklearn.model_selection import train_test_split
from sklearn.linear_model import LinearRegression
from sklearn.preprocessing import PolynomialFeatures
#Linear Regression
from sklearn import linear_model
model_LinearRegression = linear_model.LinearRegression()
#Decision Tree Regressor
from sklearn import tree
model_DecisionTreeRegressor = tree.DecisionTreeRegressor()
#SVM Regressor
from sklearn import svm
model_SVR = svm.SVR()
#K Neighbors Regressor
from sklearn import neighbors
model_KNeighborsRegressor = neighbors.KNeighborsRegressor()
#Random Forest Regressor
from sklearn import ensemble
model_RandomForestRegressor = ensemble.RandomForestRegressor(n_estimators=20)
#Adaboost Regressor
from sklearn import ensemble
model_AdaBoostRegressor = ensemble.AdaBoostRegressor(n_estimators=50)
#Gradient Boosting Random Forest Regressor
from sklearn import ensemble
model_GradientBoostingRegressor = ensemble.GradientBoostingRegressor(n_estimators=100)
#bagging Regressor
from sklearn.ensemble import BaggingRegressor
model_BaggingRegressor = BaggingRegressor()
#ExtraTree Regressor
from sklearn.tree import ExtraTreeRegressor
model_ExtraTreeRegressor = ExtraTreeRegressor()
#线性回归
model = LinearRegression()
model.fit(X_train, y_train)
print('线性回归')
print(model.score(X_test,y_test))
# 决策树回归
model = model_DecisionTreeRegressor
model.fit(X_train, y_train)
print('决策树回归')
print(model.score(X_test,y_test))
# k近邻回归
model = model_KNeighborsRegressor
model.fit(X_train, y_train)
print('k近邻回归')
print(model.score(X_test,y_test))
# Adaboost 回归
model = model_AdaBoostRegressor
model.fit(X_train, y_train)
print('Adaboost回归')
print(model.score(X_test,y_test))

# Randomforest回归
model =model_RandomForestRegressor
model.fit(X_train, y_train)
print('Randomforest回归')
print(model.score(X_test,y_test))

综上:决策树和随机森林的模型正确率最好,还可以试试其他的模型。
2、第二问
第二问:这里使用决策树
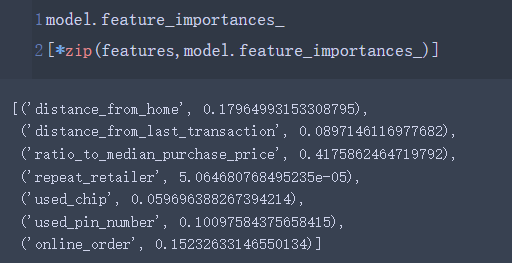
model.feature_importances_
[*zip(features,model.feature_importances_)]
查看所有参数的重要程度表:
【1】参数重要性可视化
将参数的重要性进行可视化:
import numpy as np
import matplotlib.pyplot as plt
import random
# 准备数据
x_data = [features]
y_data = [model.feature_importances_]
# 正确显示中文和负号
plt.rcParams["font.sans-serif"] = ["SimHei"]
plt.rcParams["axes.unicode_minus"] = False
# 画图,plt.bar()可以画柱状图
for i in range(len(x_data)):
plt.barh(x_data[i],y_data[i])
plt.title("参数重要性分析")
plt.xlabel("重要性")
plt.ylabel("参数")
plt.show()
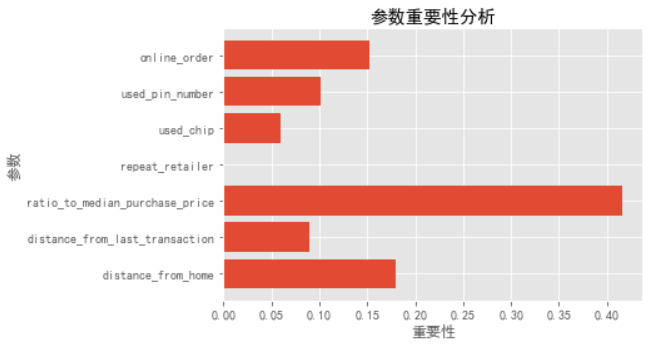
【2】观察不同max_depth下拟合状况
利用学习曲线观察深度是多少的时候能得到最好的:
import matplotlib.pyplot as plt
test=[]
for i in range(10):
clf=tree.DecisionTreeClassifier(max_depth=i+1 # 1-10层
,criterion="entropy"
,random_state=30
,splitter="random"
)
clf=model.fit(X_train,y_train)
score=model.score(X_test,y_test) # 分别计算测试集上面的表现
test.append(score)
plt.plot(range(1,11),test,color="red",label="max_depth")
plt.legend()
plt.show()

应该是由于数据量比较大,所以使用决策树训练出来的模型很好~
【3】用网格搜索调整参数
网格搜索:
它是通过遍历给定的参数组合来优化模型表现的方法。网格搜索从候选参数集合中,选出一系列参数并把他们组合起来,得到候选参数列表。然后遍历参数列表,把候选参数放在模型中,计算得到该参数组合的得分。而后再从候选参数列表中,选择得分最高的参数,作为模型的最优参数。
# 用网格搜索调整参数,枚举参数
import numpy as np
gini_thresholds = np.linspace(0,0.5,20)
parameters = {
'splitter':('best','random')
,'criterion':("gini","entropy")
,"max_depth":[*range(1,10)]
,'min_samples_leaf':[*range(1,50,5)]
,'min_impurity_decrease':[*np.linspace(0,0.5,20)]
}
clf = DecisionTreeClassifier(random_state=25)
GS = GridSearchCV(clf, parameters, cv=10)
GS.fit(X_train,y_train)
GS.best_params_
3、第三问
这里还是以决策树训练的模型为例:
# 导入准确度分数方法
from sklearn.metrics import accuracy_score
# 计算准确度
accuracy_score(y_pred,y_test)
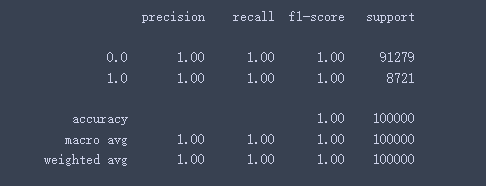
来解释一下上面这张图怎么看:这是sklearn提供的分类报告功能。
sklearn中的classification_report函数用于显示主要分类指标的文本报告。在报告中显示每个类的精确度,召回率,F1值等信息。
1、precision:精确率,意思是预测为x的样本中,有多少被正确预测为x。
2、recall:召回率,意思是实际为x的类别中,有多少预测为x。
3、f1-score: F1值,是精确度和召回率的调和平均值。
4、support:支持,也就是说真实结果中有多少是该类别。可以看到有91279个样本是0类别,8721个样本是1类别。
4、第四问(以决策树为例绘图)
没有调整参数的情况下,画的图有很多层:
from sklearn import tree
# 画树
features=['distance_from_home', 'distance_from_last_transaction',
'ratio_to_median_purchase_price', 'repeat_retailer', 'used_chip',
'used_pin_number', 'online_order',]
import graphviz
dot_data=tree.export_graphviz(model,feature_names=features
,class_names=["nofraud","fraud"]
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph
图片太大了,这里放一个缩略图:
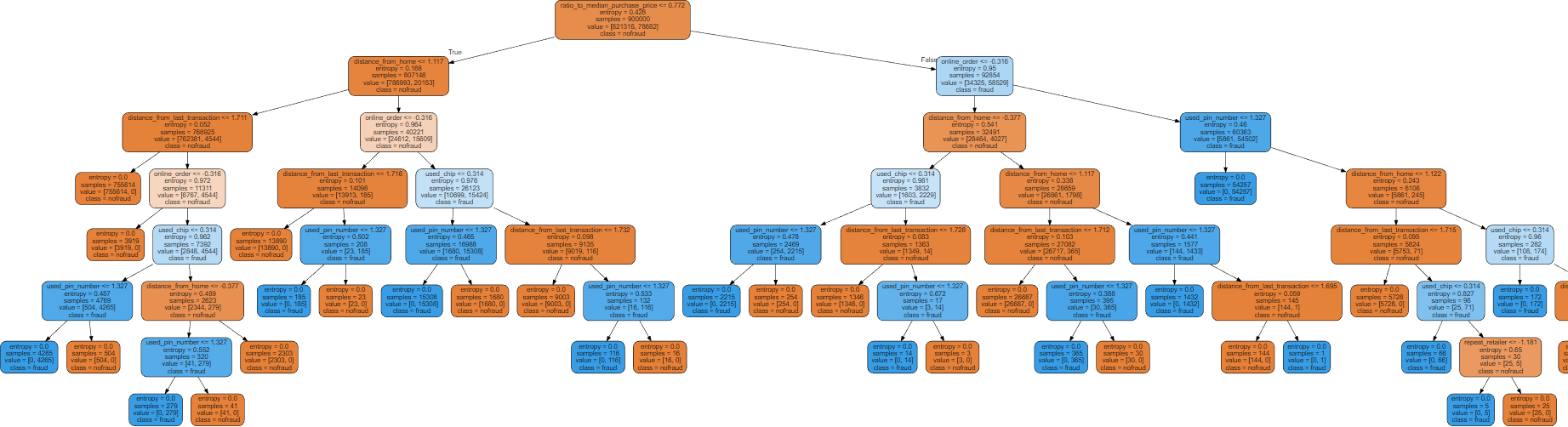
由第二问可知,树的层数不重要,因为准确率都是100%,因此选取前三层绘图:
clf=tree.DecisionTreeClassifier(criterion="entropy"
,random_state=30
,splitter="random"
,max_depth=3 # 树只留3层
)
clf=clf.fit(X_train,y_train)
dot_data=tree.export_graphviz(clf
,feature_names=features
,class_names=["yes","no"]
,filled=True
,rounded=True)
graph=graphviz.Source(dot_data)
graph

#同样,我们也可以可视化测试数据集形成的决策树。
from sklearn.tree import DecisionTreeClassifier, plot_tree
clf = DecisionTreeClassifier()
plt.figure(figsize=(40,20))
# 提供测试集训练
clf = clf.fit(X_test, y_test)
plot_tree(clf, filled=True)
plt.title("测试集训练决策树可视化")
plt.show()
