一、优化整体思路
• 0. 硬件优化
• 1. 数据库设计与规划--以后再修改很麻烦,估计数据量,使用什么存储引擎
• 2. 数据的应用--怎样取数据,sql 语句的优化
• 3. 磁盘 io 优化
• 4. 操作系统的优化--内核、tcp 连接数量
• 5. mysql 服务优化--内存的使用,磁盘的使用
• 6. my.cnf 内参数的优化:
• 7. 分库分表思路和优劣
优化详情,请参考Mysql5.7官方文档:
MySQL :: MySQL 5.7 Reference Manual
二、硬件优化
CPU—— 64 位、高主频、高缓存,高并行处理能力。
内存——大内存、主频高,尽量不要用SWAP。
硬盘——15000转、RAID5、raid10 ,使用SSD。
网络——标配的千兆网卡,10G网卡,bond0,msyql服务器尽可能和使用它的web服务器在同一局域网内,尽量避免诸如防火墙策略等不必要的开销。
三、数据库规划设计
纵向拆解:专机专用 。
例:现在公司一台服务器同时负责 web、ftp、数据库等多个角色。 R720 dell ,内存 :768G。
纵向拆解后就是:数据库服务器专机专用,避免额外的服务可能导致的性能下降和不稳定性。

横向拆解:主从同步、负载均衡、高可用性集群,当单个 mysql 数据库无法满足日益增加的需求时,可以考虑在数据库这个逻辑层面增加多台服务器,以达到稳定、高效的效果。
四、SQL优化策略
1、避免全表扫描
对查询优化,要尽量的避免全表扫描,首先应该考虑在where以及order by 涉及的列上建立索引。
2、避免使用null字段
应尽量避免在where子句中对字段的null进行判断,否则将会导致引擎放弃使用索引而进行全表扫描。
例如:
select id from t where num is null对于上述sql最好不要给数据库留NULL,尽可能的使用 NOT NULL填充数据库.
备注、描述、评论之类的可以设置为 NULL,其他的,最好不要使用NULL。
不要以为 NULL 不需要空间,比如:char(100) 型,在字段建立时,空间就固定了, 不管是否插入值(NULL也包含在内),都是占用 100个字符的空间的,如果是varchar这样的变长字段, null 不占用空间。
可以在num上设置默认值0,确保表中num列没有null值,然后这样查询:
select id from t where num = 03、避免使用操作符
应尽量避免在 where 子句中使用 != 或 <> 操作符,否则将引擎放弃使用索引而进行全表扫描。
4、避免使用or
应尽量避免在 where 子句中使用 or 来连接条件,如果一个字段有索引,一个字段没有索引,将导致引擎放弃使用索引而进行全表扫描,如:
select id from t where num=10 or Name = 'admin'可以这样查询:
select id from t where num = 10union allselect id from t where Name = 'admin'5、in 和 not in 慎用
in 和 not in 也要慎用,否则会导致全表扫描,如:
select id from t where num in(1,2,3)对于连续的数值,能用 between 就不要用 in 了:
select id from t where num between 1 and 3很多时候用 exists 代替 in 是一个好的选择:
select num from a where num in(select num from b)用下面的语句替换:
select num from a where exists(select 1 from b where num=a.num)6、全文检索
下面的查询也将导致全表扫描:
select id from t where name like ‘%abc%’若要提高效率,可以考虑全文检索。
7、强制索引
如果在 where 子句中使用参数,也会导致全表扫描。因为SQL只有在运行时才会解析局部变量,但优化程序不能将访问计划的选择推迟到运行时;它必须在编译时进行选择。然 而,如果在编译时建立访问计划,变量的值还是未知的,因而无法作为索引选择的输入项。如下面语句将进行全表扫描:
select id from t where num = @num可以改为强制查询使用索引:
select id from t with(index(索引名)) where num = @num8、避免使用表达式操作
应尽量避免在 where 子句中对字段进行表达式操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where num/2 = 100应改为:
select id from t where num = 100*29、函数操作
应尽量避免在where子句中对字段进行函数操作,这将导致引擎放弃使用索引而进行全表扫描。如:
select id from t where substring(name,1,3) = ’abc’ -–name以abc开头的idselect id from t where datediff(day,createdate,’2005-11-30′) = 0 -–‘2005-11-30’ --生成的id
应改为:
select id from t where name like 'abc%'select id from t where createdate >= '2005-11-30' and createdate < '2005-12-1'
10、“=” 左边避免使用函数与表达式运算
不要在 where 子句中的“=”左边进行函数、算术运算或其他表达式运算,否则系统将可能无法正确使用索引。
11、复合索引
在使用索引字段作为条件时,如果该索引是复合索引,那么必须使用到该索引中的第一个字段作为条件时才能保证系统使用该索引,否则该索引将不会被使用,并且应尽可能的让字段顺序与索引顺序相一致。
12、避免无意义查询
不要写一些没有意义的查询,如需要生成一个空表结构:
select col1,col2 into #t from t where 1=0这类代码不会返回任何结果集,但是会消耗系统资源的,应改成这样:
create table #t(…)13、避免update全部
update 语句,如果只更改1、2个字段,不要update全部字段,否则频繁调用会引起明显的性能消耗,同时带来大量日志。
14、先分页再join
对于多张大数据量(这里几百条就算大了)的表JOIN,要先分页再JOIN,否则逻辑读会很高,性能很差。
15、合理使用count(*)
select count(*) from table;这样不带任何条件的count会引起全表扫描,并且没有任何业务意义,是一定要杜绝的。
16、合理索引
索引并不是越多越好,索引固然可以提高相应的 select 的效率,但同时也降低了 insert 及 update 的效率,因为 insert 或 update 时有可能会重建索引,所以怎样建索引需要慎重考虑,视具体情况而定。一个表的索引数最好不要超过6个,若太多则应考虑一些不常使用到的列上建的索引是否有 必要。
17、避免更新 clustered 索引数据列
应尽可能的避免更新 clustered 索引数据列,因为 clustered 索引数据列的顺序就是表记录的物理存储顺序,一旦该列值改变将导致整个表记录的顺序的调整,会耗费相当大的资源。若应用系统需要频繁更新 clustered 索引数据列,那么需要考虑是否应将该索引建为 clustered 索引。
18、使用数字型字段
尽量使用数字型字段,若只含数值信息的字段尽量不要设计为字符型,这会降低查询和连接的性能,并会增加存储开销。这是因为引擎在处理查询和连接时会逐个比较字符串中每一个字符,而对于数字型而言只需要比较一次就够了。
19、使用varchar/nvarchar
尽可能的使用 varchar/nvarchar 代替 char/nchar ,因为首先变长字段存储空间小,可以节省存储空间,其次对于查询来说,在一个相对较小的字段内搜索效率显然要高些。
20、select查询避免 *
任何地方都不要使用 select * from t ,用具体的字段列表代替“*”,不要返回用不到的任何字段。
21、使用表变量来代替临时表
尽量使用表变量来代替临时表。如果表变量包含大量数据,请注意索引非常有限(只有主键索引)。
22、避免频繁操作临时表
避免频繁创建和删除临时表,以减少系统表资源的消耗。临时表并不是不可使用,适当地使用它们可以使某些例程更有效,例如,当需要重复引用大型表或常用表中的某个数据集时。但是,对于一次性事件, 最好使用导出表。
23、临时表插入
在新建临时表时,如果一次性插入数据量很大,那么可以使用 select into 代替 create table,避免造成大量 log ,以提高速度;如果数据量不大,为了缓和系统表的资源,应先create table,然后insert。
24、临时表删除
如果使用到了临时表,在存储过程的最后务必将所有的临时表显式删除,先 truncate table ,然后 drop table ,这样可以避免系统表的较长时间锁定。
25、避免使用游标
尽量避免使用游标,因为游标的效率较差,如果游标操作的数据超过1万行,那么就应该考虑改写。
26、基于结果集方案
使用基于游标的方法或临时表方法之前,应先寻找基于集的解决方案来解决问题,基于集的方法通常更有效。
27、合理使用游标
与临时表一样,游标并不是不可使用。对小型数据集使用 FAST_FORWARD 游标通常要优于其他逐行处理方法,尤其是在必须引用几个表才能获得所需的数据时。在结果集中包括“合计”的例程通常要比使用游标执行的速度快。如果开发时间允许,基于游标的方法和基于集的方法都可以尝试一下,看哪一种方法的效果更好。
28、合理使用存储过程
在所有的存储过程和触发器的开始处设置 SET NOCOUNT ON ,在结束时设置 SET NOCOUNT OFF。无需在执行存储过程和触发器的每个语句后向客户端发送 DONE_IN_PROC消息。
29、避免大事物操作
尽量避免大事务操作,提高系统并发能力。
30、避免返回大数据
尽量避免向客户端返回大数据量,若数据量过大,应该考虑相应需求是否合理。
31、实际案例分析
如果你需要在一个在线的网站上去执行一个大的 DELETE 或 INSERT 查询,你需要非常小心,要避免你的操作让你的整个网站停止相应。因为这两个操作是会锁表的,表一锁住了,别的操作都进不来了。
Apache 会有很多的子进程或线程。所以,其工作起来相当有效率,而我们的服务器也不希望有太多的子进程,线程和数据库链接,这是极大的占服务器资源的事情,尤其是内存。
如果你把你的表锁上一段时间,比如30秒钟,那么对于一个有很高访问量的站点来说,这30秒所积累的访问进程/线程,数据库链接,打开的文件数,可能不仅仅会让你的WEB服务崩溃,还可能会让你的整台服务器马上挂了。 所以,如果你有一个大的处理,你一定把其拆分,使用 LIMIT oracle(rownum),sqlserver(top)条件是一个好的方法。
下面是一个mysql示例:
while(1){
//每次只做1000条
mysql_query(“delete from logs where log_date <= ’2012-11-01’ limit 1000”);
if(mysql_affected_rows() == 0){ //删除完成,退出! break; }
//每次暂停一段时间,释放表让其他进程/线程访问。usleep(50000)
}总结:
1. 建表时表结构要合理,每个表不宜过大;在任何情况下均应使用最精确的类型。例如,如果ID列用int是一个好主意,而用text类型则是个蠢办法;TIME列酌情使用DATE或者DATETIME。
2. 索引,建立合适的索引。
3. 查询时尽量减少逻辑运算(与运算、或运算、大于小于某值的运算)。
4. 减少不当的查询语句,不要查询应用中不需要的列,比如说select * from 等操作。
5. 减小事务包的大小。
6. 将多个小的查询适当合并成一个大的查询,减少每次建立/关闭查询时的开销。
7. 将某些过于复杂的查询拆解成多个小查询,和上一条恰好相反。
8. 建立和优化存储过程来代替大量的外部程序交互。
五、磁盘IO优化
最好使用 raid0 或 SSD。
磁盘分区:将数据库目录放到一个分区上或一个磁盘上的物理分区. 存储数据的硬盘或分区和系统所在的硬盘分开。

设置主从时,由于binlog日志频繁记录操作,开销非常大,需要把binlog日志放到其它硬盘分区上:
#vim /etc/my.cnf
[mysqld]
datadir=/data/ 放在独立的硬盘上SSD
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0 #在原配置文件中,添加以下内容:
log-bin=/data/mysqllog #启用二进制日志,默认存在/var/lib/mysql 下面
server-id=1 #本机数据库ID 标示。
binlog-do-db=db #可以被从服务器复制的库。二进制需要同步的数据库名六、操作系统层面优化
1. 网卡 bonding 技术。
2. 设置tcp 连接数量限制,优化系统打开文件的最大限制。
3. 使用64位操作系统,64位系统可以分给单个进程更多的内存, 计算更快 。
4. 禁用不必要启动的服务
5. 文件系统调优,给数据仓库一个单独的文件系统,推荐使用XFS,一般效率更高、更可靠。
6. 可以考虑在挂载分区时启用 noatime 选项,不记录访问时间。
最小化原则:
1) 安装系统最小化
2) 开启程序服务最小化原则
3) 操作最小化原则
4) 登录最小化原则
5) 权限最小化
例:关文件系统atime选项:
[root@xuegod63 ~]# vim /etc/fstab #在挂载项中添加noatime选项就可以了。
UUID=46cb104c-e4dc-4f84-8afc-552f21279c65 /boot
t4 defaults,noatime 1 2
[root@xuegod63 ~]# mount #查看添加前mount挂载选项
/dev/sda1 on /boot type ext4 (rw) 使设置立即生效,可运行:
[root@xuegod63 ~]# mount -o remount /boot/
[root@xuegod63 ~]# mount
....
/dev/sda1 on /boot type ext4 (rw,noatime)这样以后系统在读此分区下的文件时,将不会再修改atime属性。
说明:测试效果,结果没有太大的意义。
七、mysql服务优化
1、存储引擎选择
myisam 引擎,表级锁,表级锁开销小,影响范围大,适合读多写少的表,不支持事务。 表锁定不存在死锁 (也有例外)。
innodb 引擎,行级锁,锁定行的开销要比锁定全表要大。影响范围小,适合写操作比较频繁的数据表。行级锁可能存在死锁。
MySQL的锁机制比较简单,其最显著的特点是不同的存储引擎支持不同的锁机制。
2、死锁
mysql的InnoDB,支持事务和行级锁,可以使用行锁来处理用户提现等业务。使用mysql锁的时候有时候会出现死锁,要做好死锁的预防。
1)MySQL行级锁
行级锁又分共享锁和排他锁。
共享锁:
共享锁又叫做读锁,所有的事务只能对其进行读操作不能写操作,加上共享锁后其他事务不能再加排他锁了只能加行级锁。
用法:
SELECT `id` FROM table WHERE id in(1,2) LOCK IN SHARE MODE
结果集的数据都会加共享锁。
排他锁:
若某个事物对某一行加上了排他锁,只能这个事务对其进行读写,其他事务不能对其进行加任何锁,其他进程可以读取,不能进行写操作,需等待其释放。
用法:
SELECT `id` FROM mk_user WHERE id=1 FOR UPDATE
应用:
<?php
$uid=$_SESSION['uid'];
//开启事务
sql:begin
//开启行级锁的排他锁
sql:SELECT `coin` FROM user WHERE id=$uid FOR UPDATE
//扣除用户账户钱币
$res=update user set coin=coin-value where id=1;
if($res){
//将用户的提现信息添加到提现表
sql:insert into user values(null,"{$uid}",value);
//判断添加结果
if(add_cash_result){
sql:commit
}else{
sql:rollback
}
}else{
sql:rollback;
}其实步骤不复杂,就是开启事务判断各个结果为真就提交为假就回滚。单个排他锁没有什么问题,当一个表关联到多个排他锁的时候要注意防止发生死锁。
2)死锁
`id` 主键索引
`name` index 索引
`age` 普通字段
死锁产生的根本原因是因为多线程对资源的强占,你要我的,我也要你的,两人堵在路上谁都不让,所以死锁了,在代码上是因为两个或者以上的事务都要求另一个释放资源。
死锁产生的四个必要条件:互斥条件、环路条件、请求保持、不可剥夺,缺一不可,相对应的只要破坏其中一种条件死锁就不会产生。
例如下面两条语句,第一条语句会优先使用`name`索引,因为name不是主键索引,还会用到主键索引
第二条语句是首先使用主键索引,再使用name索引 如果两条语句同时执行,第一条语句执行了name索引等待第二条释放主键索引,第二条执行了主键索引等待第一条的name索引,这样就造成了死锁。
解决方法:改造第一条语句 使其根据主键值进行更新
#①
update mk_user set name ='1' where `name`='idis12';
#②
update mk_user set name='12' where id=12;
//改造后
update mk_user set name='1' where id=(select id from mk_user where name='idis12' );3)开启死锁记录日志
innodb_print_all_deadlocks = 1
innodb_sort_buffer_size = 16M开启后会将所有的死锁记录到error_log中 错误日志在my.cnf配置为log-error=/var/log/mysqld.log。
3、数据库服务状态查看
查看数据库服务的状态,登录mysql:
mysql> show status; 看系统的状态
mysql> show engine innodb status \G #显示 InnoDB 存储引擎的状态
mysql> show variables; 看变量,在 my.cnf 配置文件里定义的变量值例如:
log_error | /var/log/mysqld.log 查看警告信息:
mysql> show warnings; 查看最近一个 sql 语句产生的错误警告例如:
mysql> adadfs; #随便输入一些内容,回车。将看到以下一些错误信息
ERROR 1064 (42000): You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near 'adadfs' at line 1
mysql> show warnings;
mysql> show processlist ; #显示mysql系统中正在运行的所有线程。 可以看到每个客户端正在执行的命令 
本语句TCP/IP连接的主机名称(采用host_name:client_port格式),以方便地判定哪个客户端正在做什么。
看其他的错误信息,需要看日志/var/log/mysqld.log。
4、启用慢查询日志
开启慢查询日志,分析SQL语句,找到影响效率的 SQL。
[root@xuegod63 ~]# vim /etc/my.cnf
[mysqld]
slow_query_log = 1 #开启慢查询日志
slow-query-log-file=/var/lib/mysql/slow.log #这个路径对 mysql 用户具有可写权限
long_query_time=5 #查询超过 5 秒钟的语句记录下来
log-queries-not-using-indexes =1 #没有使用索引的查询这三个设置一起使用,可以记录执行时间超过5 秒和没有使用索引的查询。请注意有关log-queries-not-using-indexes的警告,慢速查询日志都保存在/var/lib/mysql/slow.log。
Create trable test (id int,name varchar(20));
Insert into test values (1, ‘man’)
Select * from test;查看:

八、my.cnf内参数优化
优化思路:给 mysql 的资源太少,则 mysql 施展不开:给 mysql 的资源太多,可能会拖累整个 OS,一般40%资源给OS, 60%-70% 给mysql (内存和CPU)。
1)对查询进行缓存
大多数LAMP应用都严重依赖于数据库查询,查询的大致过程如下:
PHP发出查询请求->数据库收到指令对查询语句进行分析->确定如何查询->从磁盘中加载信息->返回结果。
如果反复查询,就反复执行这些。MySQL 有一个特性称为查询缓存,他可以将查询的结果保存在内存中,在很多情况下,这会极大地提高性能。不过,问题是查询缓存在默认情况下是禁用的。
启动查询缓存:
vim /etc/my.cnf 添加:
[mysqld] #在此字段中添加
query_cache_size = 32M 查询缓存:
Systemctl restart mysqld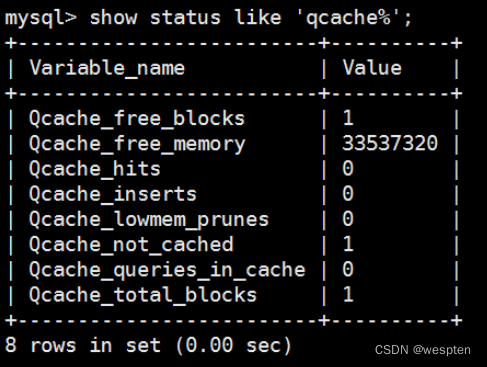
说明:
变量名 说明
Qcache_free_blocks 缓存中相邻内存块的个数。数目大说明可能有碎片。
如果数目比较大,可以执行:
mysql> flush query cache;
#对缓存中的碎片进行整理,从而得到一个空闲块。
Qcache_free_memory 缓存中的空闲内存大小
Qcache_hits 每次查询在缓存中命中时就增大。
Qcache_inserts 每次插入一个查询时就增大。即没有从缓存中找到数据
Qcache_lowmem_prunes #因内存不足删除缓存次数,缓存出现内存不足并且必须要进行清理,以便为更多查询提供空间的次数。返个数字最好长时间来看;如果返个数字在不断增长,就表示可能碎片非常严重,或者缓存内存很少。
如果Qcache_free_blocks比较大,说明碎片严重。 如果 free_memory 很小,说明缓存不够用了。
Qcache_not_cached # 没有进行缓存的查询的数量,通常是这些查询未被缓存或其类型不允许被缓存
Qcache_queries_in_cache # 在当前缓存的查询(和响应)的数量。
Qcache_total_blocks #缓存中块的数量。案例:使用mysql查询缓存
[root@xuegod63 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
query_cache_size = 32m #至少4M以存储数据结构,可扩展。整体100G,若此服务器只运行mysql服务器。70-80G给mysql
[root@xuegod63 ~]# Systemctl restart mysqld;#重启服务
mysql> create database aa;
mysql> use aa;
mysql> create table test3 (id int, name varchar(255)) ;
mysql> insert into test3 values (1,'aaaa'), (2,'aaaa');
mysql> select * from test3;
mysql> show status like "qcache%";
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 33535112 |
| Qcache_hits | 0 |#没有命中
| Qcache_inserts | 1 |#第一次插入一个语句
| Qcache_lowmem_prunes | 0 |
| Qcache_not_cached | 3 |
| Qcache_queries_in_cache | 1 |
| Qcache_total_blocks | 4 |再查询:
mysql> select * from test3;
mysql> show status like "qcache%";
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 33535112 |
| Qcache_hits | 1|#第二次查询时,就命中了。
| Qcache_inserts | 1 |
Qcache_hits/(Qcache_inserts+ Qcache_hits) 命中率经过多次select,命中的次数也会增加:
mysql> show status like 'qcache%';
+-------------------------+----------+
| Variable_name | Value |
+-------------------------+----------+
| Qcache_free_blocks | 1 |
| Qcache_free_memory | 33535344 |
| Qcache_hits | 3 |#第四次查询时,就命中3次。
| Qcache_inserts | 1 |2)强制限制mysql 资源设置
您可以在mysqld中强制一些限制来确保系统负载不会导致资源耗尽的情况出现。
[root@xuegod63 ~]# vim /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
query_cache_size = 32M
max_connections=500 #上限是看硬件配置
wait_timeout=10
max_connect_errors = 100说明:
第一行:最大连接数,在服务器没有崩溃之前确保只建立服务允许数目的连接。
该参数设置过小的最明显特征是出现“Too many connections”错误;
第二行:mysqld将终止等待时间(空闲时间)超过10秒的连接。在LAMP应用程序中,连接数据库的时间通常就是Web 服务器处理请求所花费的时间。有时候如果负载过重,连接会挂起,并且会占用连接表空间。如果有多个交互用户使用了到数据库的持久连接,那么应该将这个值设低一点。
第三行:如果一个主机在连接到服务器时有问题,并重试很多次后放弃,那么这个主机就会被锁定,直到执行:
mysql> FLUSH HOSTS;
Query OK, 0 rows affected (0.00 sec)
之后才能运行。默认情况下,10 次失败就足以导致锁定了。将这个值修改为100 会给服务器足够的时间来从问题中恢复。如果重试100 次都无法建立连接,那么使用再高的值也不会有太多帮助,可能它根本就无法连接。案例:在配置文件中增加:max_connections、wait_timeout、max_connect_errors。
[root@xuegod63 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
socket=/var/lib/mysql/mysql.sock
user=mysql
# Disabling symbolic-links is recommended to prevent assorted security risks
symbolic-links=0
query_cache_size = 32M
max_connections=500
wait_timeout=10
max_connect_errors = 100
[root@xuegod63 ~]# service mysqld restart验证:
mysql> show status like 'max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 1 |#当前有一个mysql
+----------------------+-------+
1 row in set (0.00 sec)再另一个客户端打开一个mysql连接,执行一下查询,可以看到有两个:
mysql> show status like 'max_used_connections';
+----------------------+-------+
| Variable_name | Value |
+----------------------+-------+
| Max_used_connections | 2 |总结:
mysql有超过100个可以调节的设置,要记住那么多基本是不可能的,但是幸运的是你只需要记住很少一部分你就可以基本满足你的需求了,我们还可以通过“SHOW STATUS”命令来查看mysql是否按照我们的期望在运行。
3)表高速缓存
数据库中的每个表存储在一个文件中,要读取文件的内容,你必须先打开文件,然后再读取。为了加快从文件中读取数据的过程,mysqld 对这些打开文件进行了缓存,其最大数目由 /etc/my.cnf中的 table_cache 指定。
[root@xuegod63 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
……
table_open_cache=23 #缓存23个表
mysql> show global status like 'open%_tables';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Open_tables | 1 |
| Opened_tables | 114 |
+---------------+-------+ 说明:
Open_tables 表示打开表的数量,Opened_tables表示打开过的表数量,如果Opened_tables数量过大,说明配置中 table_cache(5.1.3之后这个值叫做table_open_cache)值可能太小。
table_cache 的值在 2G 内存以下的机器中的值默认从 256 到 512个,对于有 1G 内存的机器,推荐值是 128-256。
4)关键字缓冲区
key_buffer_size指定索引缓冲区的大小,它决定索引处理的速度,尤其是索引读的速度。
案例:关键字缓存 , 缓存来缓存索引
[root@xuegod63 ~]# cat /etc/my.cnf
[mysqld]
datadir=/var/lib/mysql
……
key_buffer_size=512M
#只跑一个mysql服务。结合所有缓存,mysql整体使用的缓存可以使用物理内存的80%
[root@xuegod63 ~]# systemctl restart mysqld
查看:
mysql> show status like '%key_read%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Key_read_requests | 0 |
| Key_reads | 0 |
+-------------------+-------+Key_reads 代表命中磁盘的请求个数,Key_read_requests 是总数, 命中磁盘的读请求数除以读请求总数就是不中比率。
命中率:(1-(Key_reads / Key_read_requests ) )*100,如果每 1,000 个请求中命中磁盘的数目超过 1 个,就应该考虑增大关键字缓冲区了。
案例:
mysql> create database mk;
mysql> use mk;
mysql> create table t3 (id int,name varchar(24));
mysql> insert into t3 values (1,'aaaaa'),(2,'aaaaa'),(3,'aaaaa');
mysql> create index idx_name on t3(name);
mysql> show status like '%key_read%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Key_read_requests | 2|
| Key_reads | 0 |
+-------------------+-------+
mysql> select name from t3;
mysql> show status like '%key_read%';
+-------------------+-------+
| Variable_name | Value |
+-------------------+-------+
| Key_read_requests | 4|
| Key_reads | 1 |
+-------------------+-------+总结:
1)看机器配置,指三大件:cpu、内存、硬盘。
2)看mysql配置参数。
3)查看mysql行状态。
4)查看mysql的慢查询。
依次解决了以上问题之后,再来查找程序方面的问题。
5)禁用DNS解析功能
不进行域名反解析,注意由此带来的权限/授权问题。关闭mysql 的dns 反查功能,这样速度就快了。
skip-name-resolve
该选项就能禁用DNS解析,连接速度会快很多。不过,这样的话就不能在MySQL 的授权表中使用主机名了而只能用ip格式。
6)索引缓存
索引缓存,根据内存大小而定,如果是独立的db服务器,可以设置高达80%的内存总量。
key_buffer_size= 512M7)打开表缓存总个数
打开表缓存总个数,可以避免频繁的打开数据表产生的开销。
table_open_cache = 20
query_cache_size = 128M
max_connections=10000# 最大连接数 内存8)设置超时时间
设置超时时间,能避免长连接。
wait_timeout=609)记录慢查询,
记录慢查询,然后对慢查询一一优化单位:秒。
slow-queries- log-file= /var/lib/mysql/slow.log
long_query_time = 5九、分库分表思路和优劣
1、之什么是分库分表
从字面上简单理解,就是把原本存储于一个库的数据分块存储到多个库上,把原本存储于一个表的数据分块存储到多个表上。
2、为什么要分库分表
数据库中的数据量不一定是可控的,在未进行分库分表的情况下,随着时间和业务的发展,库中的表会越来越多,表中的数据量也会越来越大,相应地,数据操作,增删改查的开销也会越来越大;另外,一台服务器的资源(CPU、磁盘、内存、IO等)是有限的,最终数据库所能承载的数据量、数据处理能力都将遭遇瓶颈,。
3、分库分表的实施策略
如果你的单机性能很低了,那可以尝试分库。分库,业务透明,在物理实现上分成多个服务器,不同的分库在不同服务器上。分区可以把表分到不同的硬盘上,但不能分配到不同服务器上。一台机器的性能是有限制的,用分库可以解决单台服务器性能不够,或者成本过高问题。
当分区之后,表还是很大,处理不过来,这时候可以用分库。
orderid,userid,ordertime,.....
userid%4=0,用分库1
userid%4=1,用分库2
userid%4=2, 用分库3
userid%4=3,用分库4上面这个就是一个简单的分库路由,根据userid选择分库,即不同的服务器。
4、分库分表存在的问题
1)事务问题
在执行分库分表之后,由于数据存储到了不同的库上,数据库事务管理出现了困难。如果依赖数据库本身的分布式事务管理功能去执行事务,将付出高昂的性能代价;如果由应用程序去协助控制,形成程序逻辑上的事务,又会造成编程方面的负担。
2)跨库跨表的join问题
在执行了分库分表之后,难以避免会将原本逻辑关联性很强的数据划分到不同的表、不同的库上,这时,表的关联操作将受到限制,我们无法join位于不同分库的表,也无法join分表粒度不同的表,结果原本一次查询能够完成的业务,可能需要多次查询才能完成。
3)额外的数据管理负担和数据运算压力
额外的数据管理负担,最显而易见的就是数据的定位问题和数据的增删改查的重复执行问题,这些都可以通过应用程序解决,但必然引起额外的逻辑运算,例如,对于一个记录用户成绩的用户数据表userTable,业务要求查出成绩最好的100位,在进行分表之前,只需一个order by语句就可以搞定,但是在进行分表之后,将需要n个order by语句,分别查出每一个分表的前100名用户数据,然后再对这些数据进行合并计算,才能得出结果。