一、云计算预测
IT技术本身就具有足够的变个性,云本身正在转变为为一个更加有机、动态的网络,由不断变化、深度互连的节点组成的一个新的计算机(或未来我们称之为所有互连计算机的总和)。这使得成本降低的同时效率发生着指数级增长,但也带来巨大的挑战,使我们以不断加快速度开发新一代工具,以跟上我们创造的这台出色的云计算机。
云的“更少的基础设施,更多的商业价值”的核心理念适用至今。但是,云兑现这一承诺的方式,以及用户采用它的方式正在发生重大变化。
当然,对于像云基础设施这样年轻而充满活力的事物,总是很难做出预测,但我相信有四种不同的趋势可能会在未来十年加速发展,并且已经从根本上重塑了“云”的真正含义是:
1、更高级别的产品
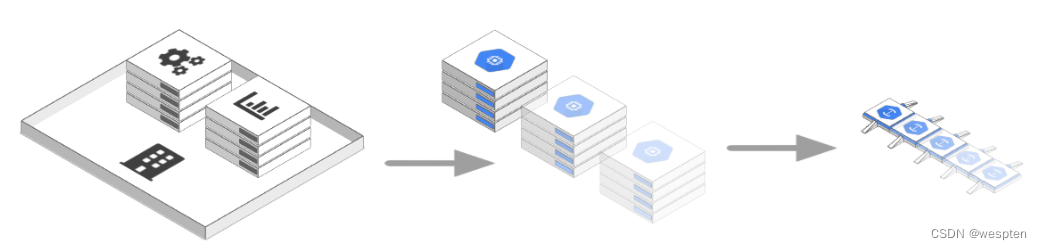
从家庭服务器到租用硬件,再到虚拟主机,再到虚拟机,再到容器,再到无服务器——科技界很少有趋势像向更高级别的产品迈进那样清晰,隐藏了越来越多的底层基础设施。
这对云服务提供商及其用户来说是一个积极的发展——因为它使前者能够更有效地使用他们的资源,而后者则不必担心运行他们代码的基础设施。但是为了成为使用云的标准方式,完全托管的产品仍然必须弄清楚如何真正扩展。
例如为了适应 Facebook 的 22.7 亿用户或为 Netflix 提供 15% 的全球互联网流量,需要大量的硬件和软件层面的定制解决方案。通常,这些专注于将一个大问题分解成许多更小的块,采用巧妙的分片、分布和复制策略,并根据平台的确切要求定制资源使用。
这与完全托管的云的前提根本不一致。AWS Lambda 或 Google Cloud Functions 等功能即服务产品的价值主张是“代码只是响应传入流量而运行”——用户无需担心规模问题。对于必须提供强一致性的托管数据库(例如 Azure 的 CosmosDB 或 AWS DynamoDB)而言,这一点更为重要:保证数据在检索时完全相同,无论其位于全球何处。
为了克服这些挑战,我们需要找到新一代的解决方案。FaaS 产品的智能分发和代码预加载、AI 驱动的流量峰值预期或Google 的 True Time等通过精确同步原子钟来保证可扩展一致性的系统正在铺平道路。
谁知道呢——我们仍然有希望利用量子隐形传态来实现信息和状态的零延迟传输,从而引入全新一代的分布式系统设计。

2、更多样化的环境相互连接

关于计算能力是 21 世纪的石油的文章已经有很多——这是理所当然的。然而我猜想,在任何时候,我们使用的都不到地球上全部计算资源的 10%。幸运的是,我们越来越意识到这一事实,并开始在云内外更广泛的设备上进行处理,一种称为边缘或雾计算的方法悄然而是。
那么,究竟什么是边缘?

边缘是比另一台计算机更靠近您的计算机。而已。当然,事情并没有那么简单:
AWS、Google Cloud 或 Microsoft Azure 等云提供商的商业模式主要基于规模经济。如果每个希望托管网站的人都必须运行自己的数据中心,并配备设施范围内的气候控制、水冷服务器塔、高度专业化的全职员工和物理访问控制,那么事情确实会非常昂贵。
云提供商在这个范围的另一端运营。运行数据中心的成本很少会与其提供的计算能力成线性关系。因此,云计算价格的大幅下降主要是由于更高效的硬件利用(虚拟化、无服务器按需调度等)以及 - 最重要的是 - 越来越大的数据中心。
这意味着云提供商最大化利润率的最佳策略是集中化。每增加一台共享设施现有资源的服务器都意味着该站点的盈利能力增加。
但是集中化是有代价的:物理位置会面临灾难性的环境事件、电网故障以及——最糟糕的是——互联网连接中断。并且集中度越高,受事件影响的客户份额就越高。
然而,即使没有任何大地震、停电或流星撞击,还有一个更普遍的问题:网络延迟。信息以大约三分之二的光速通过光纤传播。在此过程中添加几个交换机、路由器和其他网络跃点,伦敦和旧金山之间的实际传输时间最终约为 150 毫秒。这对于网站加载和 HTTP 流量来说是可以接受的,对于在线游戏玩家来说是一种麻烦,对于需要做出实时决策的自动驾驶汽车来说是一场灾难。
为了缓解这两个问题,云提供商运行了多个数据中心——但其动机是在成本和延迟/分布之间取得平衡。在撰写本文时,三个最大的竞争者分别运行 18 个数据中心 (AWS)、50 个数据中心 (Azure) 和 17 个数据中心 (Google Cloud),每个数据中心都有自己的细分为隔离网络和可用区。
这满足了对延迟敏感的用例,例如视频会议、多人游戏、聊天或协作 - 但对于需要亚毫秒延迟和持续可用性的情况来说还不够:物联网指标处理和控制、自动驾驶汽车、金融分析等领域o 交易(不包括带有自身挑战的高频交易)。但即使没有生死攸关的延迟和稳定性要求——能够更快地处理数据并更早地获得洞察力也可能是一个非常真实的业务优势。
那么我们如何才能达到这种延迟和稳定性水平呢?通过将计算资源移动到更靠近数据产生或消费的地方——也就是“边缘”。再次强调,没有“边缘”本身是很重要的——只是计算资源的近似范围。
-
例如,当 AWS Cloudfront、Amazon 的内容交付网络谈到“边缘缓存”时,它只是指最靠近请求站点的人的 Amazon 数据中心。
-
对于其他情况,例如工业物联网、设施自动化或传感器数据处理,“边缘”往往是同一建筑物或站点内的物理计算机,在数据转发到更广泛的云之前运行预处理步骤。这种计算能力的前层也被称为“雾计算”或“露计算”。
-
但边缘可以更近。随着移动设备和浏览器变得越来越强大,越来越多的计算任务(例如,在上传之前调整图像大小或主动 P2P 通信)甚至可以在涉及云之前处理。
愤世嫉俗的人当然可能会争辩说,我们已经完成了一个完整的循环,从胖客户端到云再到胖客户端,但这会忽略“边缘”的意义所在:在一个计算能力日益普及的世界中,我们得到了很好的建议反思我们的计算发生在哪里,以及我们如何最有效地利用我们可以支配的资源。

我们还将更多的东西连接到互联网,我们越来越习惯于整合从我们全球分布的生产链到我们的银行和金融业务再到云的一切。
最后但同样重要的是,云本身正在变得更加多样化。长期以来,我们一直将本地内部基础设施与云资源联系起来——但我们也越来越多地涉足多云部署,并且看到越来越多的小型专业云供应商将自己限制在特定的 API 或功能(例如电子邮件、支付、机器学习、对话式 UI/NLP 等)或特定行业,如银行、医疗保健或汽车。
然而,要真正互连和利用我们掌握的计算资源,我们仍然必须克服两个主要障碍:
-
我们需要让计算资源更容易被发现和访问。诸如用于分布式计算的以太坊或用于分布式存储的IPFS等项目是有希望的开端,但我们离高效的“计算共享经济”还很远
-
我们需要融合一套更广泛接受的标准,使我们能够将云间通信从一个实质性的集成练习转变为一个简单的即插即用事务。
虽然 WWW 本身可以说已经达到了整合的状态,其中央协议栈以太网 -> IP -> TCP -> HTTP 被普遍使用和理解,但 HTTP 之上的层仍然在广泛变化。早期的 API 标准(如 SOAP、WSCL 或 XML-RPC)大多已被丢弃,较新的方法(如 GraphQL、gRPC 或 Falcor)尚未产生明确的标准。云间数据交换也是如此,它仍然非常像当前时代的 Betamax/Laserdisk 时代。
3、自动编排取代配置

我仍然记得我的第一次云体验:在(当时)全新的 AWS 服务(称为“弹性计算云”或简称 EC2)上启动两个虚拟机。我使用终端连接到两者,安装了我需要的软件并编写了一个自动启动脚本。
故事到此结束。这两个实例是我所拥有的。如果没有人使用我的服务,他们就会无所事事。如果流量激增,它们就会减速或最终崩溃。
从那时起,云提供商和开源社区都经历了无数次改进这种方法的迭代。AWS Elastic Beanstalk 等早期尝试最终被“容器化”取代——将软件捆绑成易于部署和扩展的独立商品单元。
容器的引入引发了编排和管理工具开发的雪崩式发展——这仍在进行中,以令人眼花缭乱的速度发展。
Kubernetes 等技术可能已处于领先地位,但也不乏挑战者。总的来说,可以公平地说,云编排空间仍处于早期阶段,使用人工智能进行更高效和预测性编排等关键技术尚未出现。
4、通信将越来越多地融入网络

这无疑是这份名单上的最新趋势——也是最难预测轨迹的趋势。
简而言之,复杂网络中的通信越来越分散。在单片 Web 服务器时代,消息传递可以由集中式总线处理 - 但随着基础设施越来越分散到微服务中,通过中央集线器进行的服务间通信很快就会变得过于复杂并成为性能瓶颈。
动态环境中服务发现的挑战加剧了这种情况:使(全球分布式)网络中的短期节点能够以最有效的方式找到并相互交谈并非易事。
最近的一个解决方案是将微服务组合到服务网格中,或者使用诸如Hashicorp 的 Consul 之类的编排服务器或诸如Linkerd之类的“sidecars” 。
然而,感觉这是一个更基本的挑战——随着由更小的服务组成的更大网络的兴起——越来越重要的挑战可以在较低的层次上得到更好的解决。对于万维网本身,发现和路由由全球分布但相当静态的域名系统 (DNS) 处理。当然可以想象,一个更动态的 DNS 化身,深度集成到我们的网络中,可能会成为全球分布式服务新时代的催化剂。
二、云安全的基本原则
我们现在面临的威胁已经从挥舞着剑的入侵者变成了敲击键盘的黑客,我们的防御从长城变成了防火墙和 VPN——但基本原理保持不变。
事实上,以下原则仍然构成保护任何 AWS、谷歌云、Azure 或类似部署的基础——并且可以帮助我们理解所需的 VPC、子网、密钥存储、身份提供者、安全组、NAT 和互联网网关的丛林这样做。
需要强调的是,这份原则清单是——而且必然是不完整的。根据特定的基础架构,可能需要额外的或完全不同的步骤来保护应用程序。
那么我们如何利用这些原则来保护我们的云基础设施呢?
1、建立信任区
公共互联网是一个可怕的地方,如果与它无关,互联网应用程序将是最安全的。不幸的是,它们也毫无用处。话虽如此,实际上只有一小部分组件需要能够访问互联网,所有其他组件,例如应用程序逻辑、数据库、缓存、消息队列等,最好与它隔离开来。这通常使用虚拟专用网络 (VPN) 或虚拟私有云 (VPC) 来实现。

这种 VPC 的行为就像一个孤立的网络,与更广泛的互联网断开连接。这个结构是纯虚拟的,这一事实使它非常强大。您的 VPN/VPC 不必位于同一物理位置 - 它可以将您的云提供商和本地计算机结合起来,将您的全球分布式基础设施变成易于管理的 LAN 等价物在你朋友的地下室聚会。
 VPC 也可以组织成多个称为“子网”的独立区域——每个区域都有自己的 IP 空间和访问设置。拥有至少两个这样的子网是一种常见的做法——一个托管所有服务器、数据库等的私有子网,一个可以访问互联网的公共子网:
VPC 也可以组织成多个称为“子网”的独立区域——每个区域都有自己的 IP 空间和访问设置。拥有至少两个这样的子网是一种常见的做法——一个托管所有服务器、数据库等的私有子网,一个可以访问互联网的公共子网:
2、创建一个信任度较低、可访问性较高的区域
第二个子网通常托管需要向外通信的组件——例如调用外部 API 的 Web 服务。它还可以用作 DMZ(非军事区),为面向 Web 的服务(例如处理传入请求的反向代理或静态资产服务器)提供隔离环境。

子网使用两个额外的结构来允许 Internet 访问:NAT(网络地址转换)和 Internet 网关。NAT 的工作方式有点像办公楼中的邮局——它接收所有定向到建筑物地址的传入邮件,并将其路由到办公桌上的各个收件人。互联网网关就是这样 - 通往互联网的网关。
3、不能直接访问/只能通过代理访问
面向 Internet 的子网通常是一组进程的所在地,这些进程接收来自 Internet 的请求并将它们转发到我们的内部基础设施。它们有多种形式和大小,例如反向代理、API 网关或负载平衡器 - 但它们都有一些共同点:它们充当最前面的防御层和传入流量的看门人。这可能涉及验证语法错误请求、检查会话令牌和凭据或评估权限和访问权限。这种方法的美妙之处在于无效请求甚至不会进入网络的受信任部分。
4、尽可能少的接入点
但即使有一个隔离区域和看门人,仍然存在攻击媒介。服务器倾向于暴露管理 GUI 和监控端口,机器可能会运行创建漏洞的后台进程等等。为确保只有强化系统可公开访问,通常的做法是默认关闭所有访问路径,仅显式打开绝对需要的访问路径。这包括配置安全组以将流量限制到特定 IP、仅打开面向 Web 的端口或使用防火墙根据复杂标准预过滤传入连接。
5、访问检查
由于传入请求只有一个瓶颈可以通过,我们已经为凭证验证建立了一个完美的检查点。这是一项重要而复杂的任务,值得拥有自己的博文 - 有无数自建和预制的解决方案可供选择,从第三方 oauth 到云身份提供商再到企业级访问控制系统。就本列表而言,可以说,如果用户可以直接穿过前门,那么最好的网络安全并没有多大帮助就足够了。

通过上述所有步骤,就常见的最佳实践而言,系统可以被认为是“安全的”。然而,这是对该术语的一个相当有限的定义,因为上述所有步骤只能防止来自公共互联网的外部攻击。
根据公司结构和安全要求,可能有必要防止来自内部的攻击,例如窃取商业机密(如 Google 的 Waymo 项目所发生的)或心怀不满的前雇员希望在离开时删除数据库。
除此之外,网络安全的进步已经引发了社会工程攻击,因为黑客发现越来越容易甚至不用费心破坏安全系统,而是直接以蓝色整体出现并询问接待员通往服务器机房的路- 因此,将安全作为措施和对策之间的无休止的斗争,它一直是中世纪的卡尔卡松,并且可能会永远存在。