一、分布式系统核心技术
1、分布式 Session
1. Session粘滞
即粘性Session,当用户访问集群中某台机器后,强制指定后续所有请求都落到此台机器上。
使用场景:机器数适中,对稳定性要求不是非常苛刻。
优点:实现简单,配置方便,没有额外网络开销。
缺点:网络中有机器Down掉时,用户Session会丢失,容易造成单点故障。
方案:Nginx的ip_hash负载均衡方案。
2. Session复制
将一台机器上的Session数据广播复制到集群中其余机器上。
使用场景:机器较少,网络流量较小。
优点:实现简单,配置较少,当网络中有机器Down掉时不影响用户访问。
缺点:广播复制到其余机器有一定延迟,带来一定网络开销。
方案:开源方案Tomcat-Redis-Session-manager,暂不支持Tomcat8。
3. 缓存集中式管理
将Session存入分布式缓存集群中的某台机器上,当用户访问不同节点时,先从缓存中拿Session信息。
使用场景:集群中机器数较多,网络环境复杂。
优点:可靠性好。
缺点:实现复杂,稳定性依赖于缓存的稳定性,Session信息方入缓存时要有合理的策略写入。
方案:开源方案Spring-Session,也可以自己实现,主要重写HttpServletRequestWrapper中的getSession方法。
2、分布式配置中心
在分布式系统中,一次构建,发布,上线是非常重要的一个过程,它不像单机时代那样重启一台机器,一个进程就可以了,在分布式系统中,它涉及到将软件包(例如war包)分发到可能几百台机器上,然后将几百台机器上的应用一一重启,这么一个过程需要很长的时间。
那么如何在不停集群的情况下,调整整个集群的运行时的行为特征,是一个分布式系统必须回答的一个问题,从这个角度讲,我们认为,每一个大型分布式系统都应该有一个配置中心。
3、分布式事务
分布式事务解决的用户最本质的诉求是什么?---》数据一致。
解决数据一致性的几个典型方案:
1. XA事务方案
2. 柔性事务
3. 基于消息的最终一致性
4. 业务补偿与人工订正
常见的分布式锁的实现方案:
1. MySQL
2. 内存数据库(Redis,memchached)
3. zookeeper
4、分布式定时任务
什么是分布式定时任务?
把分散的,可靠性差的计划任务纳入统一的平台,并实现集群管理调度和分布式部署的一种定时任务的管理方式,叫做分布式定时任务。
分布式定时任务框架:
1. Quartz:Quartz是Java领域最著名的开源任务调度工具,Quartz提供了极为广泛的特性,如持久化任务,集群和分布式任务。
Elastic-Job:Elastic-Job是ddFrame中的dd-job的作业模块中分离出来的分布式弹性作业框架,该项目基于成熟的开源产品Quartz和Zookeeper及其客户端Curator进行二次开发。
二、CAP与BASE理论
1、CAP理论
CAP 理论告诉我们,一个分布式系统不可能同时满足一致性(C:Consistency),可用性(A: Availability)和分区容错性(P:Partition tolerance)这三个基本需求,最多只能同时满足其中的2个。
C(Consistence)一致性:指数据在多个副本之间能够保持一致的特性(严格的一致性)
A(Availability)可用性:指系统提供的服务必须一直处于可用的状态,每次请求都能获取到非错的响应——但是不保证获取的数据为最新数据
P(Network partitioning)分区容错性:分布式系统在遇到任何网络分区故障的时候,仍然能够对外提供满足一致性和可用性的服务,除非整个网络环境都发生了故障
什么是分区?
在分布式系统中,不同的节点分布在不同的子网络中,由于一些特殊的原因,这些子节点之间出现了网络不通的状态,但他们的内部子网络是正常的。从而导致了整个系统的环境被切分成了若干个孤立的区域,这就是分区。
在这三个基本需求中,最多只能同时满足其中的两项,P 是必须的,因此只能在 CP 和 AP 中选择,zookeeper 保证的是 CP,对比 spring cloud 系统中的注册中心 eruka 实现的是 AP。

2、BASE理论
BASE:全称:Basically Available(基本可用),Soft state(软状态),和 Eventually consistent(最终一致性)三个短语的缩写,来自 ebay 的架构师提出。
Base理论是对 CAP 中一致性和可用性权衡的结果,其来源于对大型互联网分布式实践的总结,是基于 CAP 定理逐步演化而来的。其核心思想是:
既是无法做到强一致性(Strong consistency),但每个应用都可以根据自身的业务特点,采用适当的方式来使系统达到最终一致性(Eventual consistency)。
1)Basically Available(基本可用)
什么是基本可用呢?假设系统,出现了不可预知的故障,但还是能用,相比较正常的系统而言:
1. 响应时间上的损失:正常情况下的搜索引擎 0.5 秒即返回给用户结果,而基本可用的搜索引擎可以在 1 秒作用返回结果。
2. 功能上的损失:在一个电商网站上,正常情况下,用户可以顺利完成每一笔订单,但是到了大促期间,为了保护购物系统的稳定性,部分消费者可能会被引导到一个降级页面。
2)Soft state(软状态)
什么是软状态呢?相对于原子性而言,要求多个节点的数据副本都是一致的,这是一种 “硬状态”。
软状态指的是:允许系统中的数据存在中间状态,并认为该状态不影响系统的整体可用性,即允许系统在多个不同节点的数据副本存在数据延时。
3)Eventually consistent(最终一致性)
上面说软状态,然后不可能一直是软状态,必须有个时间期限。在期限过后,应当保证所有副本保持数据一致性。从而达到数据的最终一致性。这个时间期限取决于网络延时,系统负载,数据复制方案设计等等因素。
稍微官方一点的说法就是:系统能够保证在没有其他新的更新操作的情况下,数据最终一定能够达到一致的状态,因此所有客户端对系统的数据访问最终都能够获取到最新的值。
而在实际工程实践中,最终一致性分为 5 种:
1. 因果一致性(Causal consistency)
指的是:如果节点 A 在更新完某个数据后通知了节点 B,那么节点 B 之后对该数据的访问和修改都是基于 A 更新后的值。于此同时,和节点 A 无因果关系的节点 C 的数据访问则没有这样的限制。
2. 读己之所写(Read your writes)
这种就很简单了,节点 A 更新一个数据后,它自身总是能访问到自身更新过的最新值,而不会看到旧值。其实也算一种因果一致性。
3. 会话一致性(Session consistency)
会话一致性将对系统数据的访问过程框定在了一个会话当中:系统能保证在同一个有效的会话中实现 “读己之所写” 的一致性,也就是说,执行更新操作之后,客户端能够在同一个会话中始终读取到该数据项的最新值。
4. 单调读一致性(Monotonic read consistency)
单调读一致性是指如果一个节点从系统中读取出一个数据项的某个值后,那么系统对于该节点后续的任何数据访问都不应该返回更旧的值。
5. 单调写一致性(Monotonic write consistency)
指一个系统要能够保证来自同一个节点的写操作被顺序的执行。
然而,在实际的实践中,这 5 种系统往往会结合使用,以构建一个具有最终一致性的分布式系统。实际上,不只是分布式系统使用最终一致性,关系型数据库在某个功能上,也是使用最终一致性的,比如备份,数据库的复制过程是需要时间的,这个复制过程中,业务读取到的值就是旧的。当然,最终还是达成了数据一致性,这也算是一个最终一致性的经典案例。
三、Zookeeper 简介
1、Zookeeper 介绍
首先需要了解zookeeper是什么,ZooKeeper 是 Apache 软件基金会的一个软件项目,它为大型分布式计算提供开源的分布式配置服务、同步服务和命名注册。
Zookeeper是一个分布式协调服务。所谓分布式协调主要是来解决分布式系统中多个进程之间的同步限制,防止出险脏读,例如我们常说的分布式锁。
ZooKeeper的架构通过冗余服务实现高可用性。
Zookeeper 的设计目标是将那些复杂且容易出错的分布式一致性服务封装起来,构成一个高效可靠的原语集,并以一系列简单易用的接口提供给用户使用。
一个典型的分布式数据一致性的解决方案,分布式应用程序可以基于它实现诸如数据发布/订阅、负载均衡、命名服务、分布式协调/通知、集群管理、Master 选举、分布式锁和分布式队列等功能。
2、Zookeeper 重要特性
1)顺序一致性:来自客户端的相关指令会按照顺序执行,不会出现乱序的情况,客户端发送到服务的指令1->2->3->4,那个这些指令就会按照顺序执行;
2)原子性:更新只有成功和失败,没有中间状态;
3)可靠性:也可以称之为持久性,节点更新以后,在下次更新之前,它的数据不会发生变更;
4)准实时性:也可以称之为最终一致性,在zk集群中,一个客户端修改了其中的一个节点,一定时间以后,所有可用的服务对应的节点都会变成更新以后的值。
3、Zookeeper 能做什么
1. 统一命名服务:在分布式系统中,通过使用命名服务,客户端应用能够根据指定名字来获取资源或服务的地址,提供者等信息,其中比较常见的就是一些分布式服务框架中的服务地址列表,通过调用ZK提供的创建节点的API,能够很容易的创建一个全局唯一的path,这个path就可以作为一个名称。
2. 配置中心:在分布式系统中的配置信息都是一样的,这样的配置信息可以完全交给Zookeeper来管理,将配置信息保存在zookeeper的某个目录节点中,然后将所有需要修改的应用机器监控配置信息的状态,一旦配置信息发生变化,每台应用机器就会收到Zookeeper的通知,然后从Zookeeper获取最新的配置信息到应用系统中。
3. 集群管理与Master管理。
4. 分布式锁:这个主要得益于Zookeeper为我们保证了数据的强一致性,锁服务可以分为两类:一个是保持独占,一个是控制时序。
4、Zookeeper 集群中的角色
1. 领导者(leader):负责进行投票的发起和决议,最终更新状态
2. 跟随者(follower):用于接收客户请求并返回客户结果,参与leader发起的投票
3. 观察者(observer):可以接收客户端连接,将写请求转发给leader节点,但是observer不参与投票过程,只是同步leader状态,observer为系统扩展提供了一种方法。
4. 学习者(learner):和leader进行状态同步的server统称为learner,上述的follower和observer都是learner。
为什么要有Observer?
Zookeeper服务中的每个Server可服务于多个Client,并且Client可连接到ZK服务中的任何一台Server来提交请求,若是读请求,则由每台Server本地副本数据直接响应,若是改变Server状态的写请求,需要通过一致性协议来处理,这个协议就是Zab协议。
简单来说,Zab协议规定:来自Client的所有写请求,都要转发给ZK服务中唯一的Server-Leader,由Leader根据该请求发起一个Proposal,然后,其他的Server对该Proposal进行投票,之后,leader对投票进行收集,当投票数量过半时Leader会向所有的Server发送一个通知消息。最后,当Client所连接的Server收到该消息时,会把该操作更新到内存中并对Client的写请求作出回应。
Zookeeper服务器在上述协议中实际扮演了两个职能,他们一方面从客户端接受连接与操作请求,另一方面对操作结果进行投票,这两个职能在Zookeeper集群扩展的时候彼此制约。例如:当我们希望增加Zk服务中Client数量的时候,那么我们就需要增加Server的数量,来支持这么多的客户端,然而,从Zab协议对写请求的处理过程中我们可以发现,增加服务器的数量,则增加了对协议中投票过程的压力,因为Leader节点必须等待集群中过半Server响应投票,于是节点的增加使得部分计算机运行较慢,从而拖慢了整个投票过程,写操作也会随之下降,这正是我们在实际操作中遇到的问题--》随着Zookeeper集群变大,写操作的吞吐量会下降。所以,我们不得不在增加Client数量的期望和我们希望保持较好的吞吐量的期望之间做个权衡。所以我们引入了不参与投票的服务器,称之为Observer,Observer可以接收客户端的连接,并将写请求转发给Leader节点,但是,Leader节点不会要求Observer参加投票。Observer不参与投票过程,仅仅和其他服务节点一起得到投票结果。
这个简单的扩展,给Zookeeper的可伸缩性带来了全新的景象,我们可以加入很多的Observer节点,而无需担心降低吞吐量。但是这样也会有一些小问题,就是在协议中的通知阶段,仍然与服务器的数量成线性关系,但是这里的串行开销非常低,不会成为主要瓶颈。
5、Zookeeper CAP现象
Zookeeper至少满足的CP,牺牲了可用性,比如现在集群中有Leader和Follower两种角色,那么当其中任意一台服务器挂掉了,都要重新进行选举,在选举过程中集群是不可用的,这就是牺牲了可用性,保证了一致性。
但是如果集群中有Leader,Follower,Observer三种角色,那么如果挂掉的是Observer,那么对于集群来说是没有影响的,集群还可以用,只是Observer节点的数据不同了,从这个角度来说,Zookeeper又是牺牲了一致性,保证了可用性。
6、Zookeeper Session原理
客户端与服务端之间的连接是基于 TCP 长连接,client 端连接 server 端默认的 2181 端口,也就是 session 会话。
从第一次连接建立开始,客户端开始会话的生命周期,客户端向服务端的ping包请求,每个会话都可以设置一个超时时间。
1. Session 的创建
sessionID:会话ID,用来唯一标识一个会话,每次客户端创建会话的时候,zookeeper 都会为其分配一个全局唯一的 sessionID。zookeeper 创建 sessionID 类 SessionTrackerImpl 中的源码。

Timeout:会话超时时间。客户端在构造 Zookeeper 实例时候,向服务端发送配置的超时时间,server 端会根据自己的超时时间限制最终确认会话的超时时间。
TickTime:下次会话超时时间点,默认 2000 毫秒。可在 zoo.cfg 配置文件中配置,便于 server 端对 session 会话实行分桶策略管理。
isClosing:该属性标记一个会话是否已经被关闭,当 server 端检测到会话已经超时失效,该会话标记为"已关闭",不再处理该会话的新请求。
2. Session 的状态
下面介绍几个重要的状态:
-
connecting:连接中,session 一旦建立,状态就是 connecting 状态,时间很短。
-
connected:已连接,连接成功之后的状态。
-
closed:已关闭,发生在 session 过期,一般由于网络故障客户端重连失败,服务器宕机或者客户端主动断开。
3. 会话超时管理(分桶策略+会话激活)
zookeeper 的 leader 服务器再运行期间定时进行会话超时检查,时间间隔是 ExpirationInterval,单位是毫秒,默认值是 tickTime,每隔 tickTime 进行一次会话超时检查。

ExpirationTime 的计算方式:
ExpirationTime = CurrentTime + SessionTimeout;
ExpirationTime = (ExpirationTime / ExpirationInterval + 1) * ExpirationInterval;在 zookeeper 运行过程中,客户端会在会话超时过期范围内向服务器发送请求(包括读和写)或者 ping 请求,俗称心跳检测完成会话激活,从而来保持会话的有效性。
会话激活流程:

激活后进行迁移会话的过程,然后开始新一轮:

四、Zookeeper 集群与客户端安装配置
1、Zookeeper安装配置
① Linux安装
Zookeeper 下载地址为:Apache ZooKeeper

选择一稳定版本,本教程使用的 release 版本为3.4.14,下载并安装。
打开网址 Apache Download Mirrors,看到如下界面:

选择一个下载地址,使用 wget 命令下载并安装:
$ wget https://mirror.bit.edu.cn/apache/zookeeper/zookeeper-3.4.14/zookeeper-3.4.14.tar.gz
$ tar -zxvf zookeeper-3.4.14.tar.gz
$ cd zookeeper-3.4.14
$ cd conf/
$ cp zoo_sample.cfg zoo.cfg
$ cd ..
$ cd bin/
$ sh zkServer.sh start执行后,服务端启动成功:

查看服务端状态(启动单机节点):

启动客户端:
$ sh zkCli.sh帮助命令:
ZooKeeper -server host:port cmd args
stat path [watch]
set path data [version]
ls path [watch]
delquota [-n|-b] path
ls2 path [watch]
setAcl path acl
setquota -n|-b val path
history
redo cmdno
printwatches on|off
delete path [version]
sync path
listquota path
rmr path
get path [watch]
create [-s] [-e] path data acl
addauth scheme auth
quit
getAcl path
close
connect host:port② Windows安装
zookeeper 下载地址为: Apache ZooKeeper。
选择一个地址点击版本下载:

下载后解压:

将 conf 目录下的 zoo_sample.cfg 文件,复制一份,重命名为 zoo.cfg:

在安装目录下面新建一个空的 data 文件夹和 log 文件夹:

修改 zoo.cfg 配置文件,将 dataDir=/tmp/zookeeper 修改成 zookeeper 安装目录所在的 data 文件夹,再添加一条添加数据日志的配置(需要根据自己的安装路径修改)。

双击 zkServer.cmd 启动程序:

控制台显示 bind to port 0.0.0.0/0.0.0.0:2181,表示服务端启动成功!

双击zkCli.cmd 启动客户端:

出现 Welcome to Zookeeper!,表示我们成功启动客户端。
2、Zookeeper linux 服务端集群搭建
将三台 zookeeper 服务端做为集群搭建:

所需准备工作,创建三台虚拟机环境并安装好 java 开发工具包 JDK,可以使用 VM 或者 vagrant+virtualbox 搭建 centos/ubuntu 环境,本案例基于宿主机 windows10 系统同时使用 vagrant+virtualbox 搭建的 centos7 环境,如果直接使用云服务器或者物理机同理。
步骤一:环境准备
准备三台Zookeeper环境和并按照上一教程下载 zookeeper 压缩包,三台集群 centos 环境如下:
机器一:192.168.3.33

机器二:192.168.3.35

机器三:192.168.3.37

提示:查看 ip 地址可以用 ifconfig 命令。
步骤二:别修改 zoo.cfg 配置信息
zookeeper 的三个端口作用:
- 1、2181 : 对 client 端提供服务
- 2、2888 : 集群内机器通信使用
- 3、3888 : 选举 leader 使用
按 server.id = ip:port:port 修改集群配置文件,三台虚拟机 zoo.cfg 文件末尾添加配置:
server.1=192.168.3.33:2888:3888
server.2=192.168.3.35:2888:3888
server.3=192.168.3.37:2888:3888根据 id 和对应的地址分别配置 myid:
vim /tmp/zookeeper/myid本案例配置完成后查询显示如下:
IP 192.168.3.33 机器配置 myid,因为这台机器上个教程单机启动过,所以出现 version-2,没有也没关系。

IP 192.168.3.35 机器配置 myid。

IP192.168.3.37 机器配置 myid。

步骤三:启动集群
启动前需要关闭防火墙(生产环境需要打开对应端口):
systemctl stop firewalld启动 192.168.3.33 并查看日志,此时日志出现报错是正常现象,因为另外两台还没启动,暂时连接不上。

另两台分别启动后,查看三台机器状态:
IP 192.168.3.33

IP 192.168.3.35

IP 192.168.3.37

最后显示集群搭建成功!Mode:leader 代表主节点,follower 代表从节点,一主二从。
3、Zookeeper Java 客户端搭建
1. 安装jdk
2. 安装maven
下载maven:
wget https://dlcdn.apache.org/maven/maven-3/3.8.4/binaries/apache-maven-3.8.4-bin.tar.gz解压:
tar -zxvf apache-maven-3.8.4-bin.tar.gz 加入环境变量:
vi /etc/profile
使修改环境变量生效:
source /etc/profile
mvn -version使用 IntelliJ IDEA创建一个 maven 工程,命名为 zookeeper-demo,并且引入如下依赖,可以自行在maven中央仓库选择合适的版本,介绍原生 API 和 Curator 两种方式。
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.11</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.apache.zookeeper</groupId>
<artifactId>zookeeper</artifactId>
<version>3.4.8</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-framework</artifactId>
<version>4.0.0</version>
</dependency>
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>4.0.0</version>
</dependency>maven 工程目录结构:

3. 客户端的 zookeeper 原生 API
使用 zookeeper 原生 API,连接上一教程搭建的三台服务组成的集群,因为连接需要时间,用 countDownLatch 阻塞,等待连接成功,控制台输出连接状态!
...public static void main(String[] args) {
try {
final CountDownLatch countDownLatch=new CountDownLatch(1);
ZooKeeper zooKeeper=
new ZooKeeper("192.168.3.33:2181," +
"192.168.3.35:2181,192.168.3.37:2181",
4000, new Watcher() {
@Override
public void process(WatchedEvent event) {
if(Event.KeeperState.SyncConnected==event.getState()){
//如果收到了服务端的响应事件,连接成功
countDownLatch.countDown();
}
}
});
countDownLatch.await();
//CONNECTED
System.out.println(zooKeeper.getState());
}
}
...控制台输出 connected 显示连接成功!

简单示例添加节点 API:
zooKeeper.create("/runoob","0".getBytes(),ZooDefs.Ids.OPEN_ACL_UNSAFE,CreateMode.PERSISTENT);同时在服务端终端执行命令,显示设置成功。

4. 客户端的curator连接
Curator 是 Netflix 公司开源的一套 zookeeper 客户端框架,解决了很多 Zookeeper 客户端非常底层的细节开发工作,包括连接重连、反复注册 Watcher 和 NodeExistsException 异常等。
Curator 包含了几个包:
- curator-framework:对 zookeeper 的底层 api 的一些封装。
- curator-client:提供一些客户端的操作,例如重试策略等。
- curator-recipes:封装了一些高级特性,如:Cache 事件监听、选举、分布式锁、分布式计数器、分布式 Barrier 等。
简单使用示例:
public class CuratorDemo {
public static void main(String[] args) throws Exception {
CuratorFramework curatorFramework=CuratorFrameworkFactory.
builder().connectString("192.168.3.33:2181," +
"192.168.3.35:2181,192.168.3.37:2181").
sessionTimeoutMs(4000).retryPolicy(new
ExponentialBackoffRetry(1000,3)).
namespace("").build();
curatorFramework.start();
Stat stat=new Stat();
//查询节点数据
byte[] bytes = curatorFramework.getData().storingStatIn(stat).forPath("/runoob");
System.out.println(new String(bytes));
curatorFramework.close();
}
}上一步设置了 /runoob 节点值,所以控制台输出。

curator详情,请参考: Apache Curator –
4、Zookeeper可视化客户端zkui
1. 创建zkui目录
mkdir zkui2. 安装git
yum -y install git3. 下载zkui
git clone https://github.com/DeemOpen/zkui.git
4. 编译zkui,生成jar包

5. 进入target目录下

6. 修改配置文件config.cfg

关于配置文件的说明:
1)scmRepo=192.168.31.43:2181,192.168.31.44:2181,192.168.31.45:2181
注意如果是zk集群,此处需填写集群各个成员服务器(即Zookeeper节点)的IP地址加端口号2181,我这里的zookeeper 模式是standalone,因此只填写本机IP地址即可。
若报KeeperErrorCode = ConnectionLoss for / 错误,增大zkSessionTimeout超时时间,设置zkSessionTimeout=20。
2)默认用户信息
用户名:Admin(Admin权限,支持CRUD操作)
密码:manager
用户名:appconfig(Readonly权限,支持读取操作)
密码:appconfig
3)LDAP的配置
如果你想使用 LDAP 身份验证,则提供 LDAP url,这将优先于 roleSet property 文件认证。
dapUrl=ldap://<ldap_host>:<ldap_port>/dc=mycom,dc=com如果不提供此功能,则将使用默认 roleSet 文件认证。
7. 启动zkui
nohup java -jar zkui-2.0-SNAPSHOT-jar-with-dependencies.jar &
8. 浏览器访问
http://192.168.31.43:9090/login,账号admin 密码manager

9. 登录zkui,选择导航“Host”
出现错误提示:KeeperErrorCode = NoNode for /appconfig/hosts ,报错原因是/appconfig/hosts这个节点找不到,就自己手动创建一个。

五、Zookeeper 数据模型与znode结构
在Zookeeper中,可以说Zookeeper中的所有存储的数据是由 znode 组成的,节点也称为 znode,并以 key/value 形式存储数据。
1、Znode类型
1. 永久节点,所谓持久节点,是指在节点创建后,就一直存在,直到有删除操作来主动清除这个节点。
2. 临时节点,临时节点与session有关,每个客户端与zk建立链接的时候会生成一个session,这个session不会因为链接zk服务器节点的变化而变化,只有当客户端断开连接以后,该session才会消失,而临时节点会随着session的消失而消失。
3. 永久顺序节点,这类节点的基本特性和持久节点是一致的。额外的特性是,在ZK中,每个父节点会为他的第一级子节点维护一份时序,会记录每个子节点创建的先后顺序,基于这个特性,在创建子节点的时候,可以设置这个属性,那么在创建节点过程中,ZK会自动为给定节点名加上一个数字后缀,作为新的节点名,这个数字后缀的范围是整型的最大值。
4. 临时顺序节点,类似临时节点和顺序节点。
整体结构类似于linux文件系统的模式以树形结构存储,其中根路径以 / 开头。
进入Zookeeper安装的 bin 目录,通过sh zkCli.sh打开命令行终端,执行 "ls /" 命令显示:
$ ls /
$ ls /zookeeper
$ ls /zookeeper/quota可以查看对应的节点结构,命令行终端执行 get /zookeeper/quota 显示此节点的属性。
Zookeeper中的数据是存储在内存当中的,因此它的效率十分高效。它内部的存储方式十分类似于文件存储结构,采用了分层存储结构。但是它和文件存储结构的区别是,它的各个节点中是允许存储数据的,需要注意的是zk的每个节点存储数据不能超过1M。
它的内存数据结果如下图:

我们可以通过不同的路径访问到不同的节点,因为它是分层结构,我们也可以通过某一个父节点,获取到该节点下的所有子节点信息。
2、Znode api
Zookeeper只提供了几个简单的api,但是我们可以通过灵活使用这些api的组合,来实现我们复杂的业务要求:
1)create:创建一个新节点,通过指定路径的方式创建节点,例如创建路径为/A/A1/demo,则会在A1节点下创建一个demo节点;
2)delete:删除节点,通过路径的方式删除节点,如果删除路径为/A/A1/demo,则会删除A1节点下的demo节点;
3)exists:判断指定路径下的节点是否存在,例如判断路径为/A/A1/demo,则会判断A1节点下的demo节点是否存在;
4)get:获取指定路径下某个节点的值是什么,例如获取路径为/A/A1/demo,则会获取A1节点下的demo节点的值什么;
5)set:为指定路径的节点进行赋值操作,例如修改路径为/A/A1/demo,则会修改A1节点下的demo节点的值;
6)get children:获取指定路径节点下的子节点信息,例如获取路径为/A,则会获取A节点下的A1和A2节点;
7)sync:获取到同步数据,这个涉及到了zk的原理,zk集群属于最终一致性,调用该方法,可以获取到最终的结果值,如果不使用该方法,在查询的时候可能获取到的值是中间值;
1. 创建节点
用给定的路径创建一个节点,flag参数指定创建的节点是临时的,持久的还是顺序的。默认情况下,所有节点都是持久的,当会话过期或客户端断开连接时,临时节点(flag:-e)将会被自动删除。顺序节点保证节点路径将是唯一的,Zookeeper集合将向节点路径填充10位序列号,例如,如果节点路径/myapp 将转换成/myapp000000001,下一个序列号将为/myapp0000000002.如果没有指定flag,节点默认为持久节点。
创建持久节点:
create /firstNode first创建顺序节点,请添加flag:-s:
create -s /firstNode second创建临时节点,请添加flag:-e
create -e /firstNode ephemeral当客户端断开连接时,临时节点将会被删除。
2. 获取数据
它返回节点的关联数据和指定节点的元数据:
get /firstNode要访问顺序节点,必须输出znode的完整路径:例如:get /firstNode00000000001。
3. 设置数据
设置指定znode的数据:
set /firstNode first_update4. 创建子节点
创建子节点类似于创建一个新的znode,唯一的区别是,子znode的路径也将具有父路径:
create /firstNode/children firstChildren5. 列出子节点
此命令用于列出和显示znode的子项:
ls /firstNode6. 检查状态
状态描述指定的znode的元数据,它包含时间戳,版本号,acl,数据长度和子znode等细项:
stat /firstNode7. 移除znode
移除指定的znode并递归其所有子节点:
rmr /firstNode删除(delete /path)类似于remove命令,但是只限定于没有子节点的znode。
3、Znode watch机制
一个zk节点是可以被监控的,包括这个目录中存储的数据的修改,子节点目录的变化,一旦变化可以通知设置监控的客户端,这个功能是Zookeeper对于应用最重要的特性,通过这个特性可以实现的功能包括配置的集中管理,集群管理,分布式锁等。
watch机制官方说明:一个watch事件是一个一次性的触发器,当被设置了watch的数据发生了改变的时候,则服务器将这个改变发送给设置了watch的客户端,以便通知他们。
可以注册watcher的方法:getData,exists,getChildren。
可以触发watcher的方法:create,delete,setData.连接断开的情况下触发的watcher会丢失。
watch支持响应式编程模式,一个watcher实例是一个回调函数,被回调一次后就被移除了,如果还需要关注数据的变化,需要再次注册watcher。对某个路径的终节点及其子节点的变更进行监视,当其发生变更以后,会调用注册的callback方法,然后进行具体的业务逻辑。
例如监测路径为/A/A1,那么它会加测A1节点,以及附属于A1的所有子节点,这个子不单单只一层子节点,是指所有层的子节点。
4、Znode状态
| cZxid | 创建节点时的事务ID |
|---|---|
| ctime | 创建节点时的时间 |
| mZxid | 最后修改节点时的事务ID |
| mtime | 最后修改节点时的时间 |
| pZxid | 表示该节点的子节点列表最后一次修改的事务ID,添加子节点或删除子节点就会影响子节点列表,但是修改子节点的数据内容则不影响该ID(注意,只有子节点列表变更了才会变更pzxid,子节点内容变更不会影响pzxid) |
| cversion | 子节点版本号,子节点每次修改版本号加1 |
| dataversion | 数据版本号,数据每次修改该版本号加1 |
| aclversion | 权限版本号,权限每次修改该版本号加1 |
| ephemeralOwner | 创建该临时节点的会话的sessionID。(**如果该节点是持久节点,那么这个属性值为0)** |
| dataLength | 该节点的数据长度 |
| numChildren | 该节点拥有子节点的数量(只统计直接子节点的数量) |
架设有个runnob节点,,并且通过 java 客户端设置值 0,现在我们在命令行终端执行 get /runoob 显示此节点的属性:
$ get /runoob
其中第一行显示的 0 是该节点的 value 值。
我们对 /runoob 节点做一次修改,执行命令 set /runoob 1 ,如下图所示:
$ set /runoob 1
对比上面结果,可以看到 mZxid、mtime、dataVersion 都发生了变化。
在 /runoob 节点下,我们再添加一子节点,执行:
$ create -e /runoob/child 0
$ get /runoob执行完终端命令行显示:

可见 /runoob 节点的 pZxid、cversion、numChildren 都发生了相应的改变。
5、原生Zookeeper客户端存在的问题
客户端在连接服务端时会设置一个sessionTimeout(session过期时间),并且客户端会给服务端发送心跳以刷新服务端的session时间,当网络断开后,服务端无法接收到心跳,会进行session倒计时,判断是否超过了session过期时间,一旦超过了过期时间,就会发送session过期,这样就算后来网络通了,客户端从新连接上了服务端,就会接收到session过期的事件,从而删除临时节点和watcher等,原生客户端不会重新建session。
六、Zookeeper 核心API
zookeeper 命令用于在 zookeeper 服务上执行操作。
首先执行命令,打开新的 session 会话,进入终端。
$ sh zkCli.sh1、基本命令
1. ls 命令
ls 命令用于查看某个路径下目录列表。
格式:
ls path- path:代表路径。
以下实例查看 /runoob 节点:
$ ls /runoob
2. ls2 命令
ls2 命令用于查看某个路径下目录列表,它比 ls 命令列出更多的详细信息。
格式:
ls2 path- path:代表路径。
以下实例查看 /runoob 节点:
$ ls2 /runoob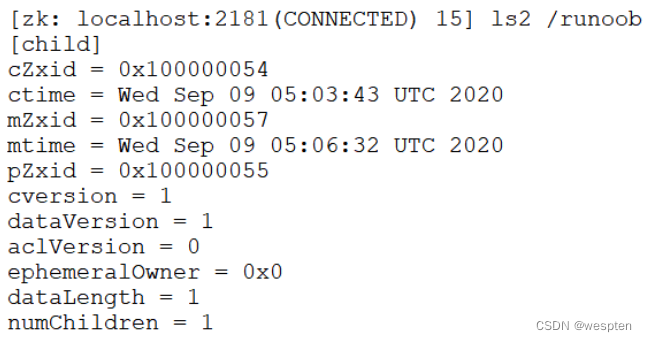
3. get 命令
get 命令用于获取节点数据和状态信息。
格式:
get path [watch]- path:代表路径。
- [watch]:对节点进行事件监听。
以下实例查看同时开启两个终端。
终端一:
$ get /runoob watch
在终端二对此节点进行修改:
$ set /runoob 1
终端一自动显示 NodeDataChanged 事件:

4. stat 命令
stat 命令用于查看节点状态信息。
格式:
stat path [watch]- path:代表路径。
- [watch]:对节点进行事件监听。
以下实例查看 /runoob 节点状态:
$ stat /runoob
5. create 命令
create 命令用于创建节点并赋值。
格式:
create [-s] [-e] path data acl- [-s] [-e]:-s 和 -e 都是可选的,-s 代表顺序节点, -e 代表临时节点,注意其中 -s 和 -e 可以同时使用的,并且临时节点不能再创建子节点。
- path:指定要创建节点的路径,比如 /runoob。
- data:要在此节点存储的数据。
- acl:访问权限相关,默认是 world,相当于全世界都能访问。
以下实例添加临时顺序节点:
$ create -s -e /runoob 0
创建的节点既是有序,又是临时节点。
6. set 命令
set 命令用于修改节点存储的数据。
格式:
set path data [version]- path:节点路径。
- data:需要存储的数据。
- [version]:可选项,版本号(可用作乐观锁)。
以下实例开启两个终端,也可以在同一终端操作:
$ get /runoob
下图可见,只有正确的版本号才能设置成功:
$ set /runoob 0 1
$ set /runoob 0 2
$ set /runoob 0 10
$ set /runoob 0 6
7. delete 命令
delete 命令用于删除某节点。
格式:
delete path [version]- path:节点路径。
- [version]:可选项,版本号(同 set 命令)。
以下实例删除 /runoob 节点的子节点:
$ ls /runoob
$ delete /runoob/child
$ get /runoob/child
2、四字命令
zookeeper 支持某些特定的四字命令与其交互,用户获取 zookeeper 服务的当前状态及相关信息,用户在客户端可以通过 telenet 或者 nc(netcat) 向 zookeeper 提交相应的命令。
安装 nc 命令:
$ yum install nc # centos
或
$ sudo apt install netcat # ubuntu四字命令格式:
echo [command] | nc [ip] [port]ZooKeeper 常用四字命令主要如下:
| 四字命令 | 功能描述 |
|---|---|
| conf | 3.3.0版本引入的。打印出服务相关配置的详细信息。 |
| cons | 3.3.0版本引入的。列出所有连接到这台服务器的客户端全部连接/会话详细信息。包括"接受/发送"的包数量、会话id、操作延迟、最后的操作执行等等信息。 |
| crst | 3.3.0版本引入的。重置所有连接的连接和会话统计信息。 |
| dump | 列出那些比较重要的会话和临时节点。这个命令只能在leader节点上有用。 |
| envi | 打印出服务环境的详细信息。 |
| reqs | 列出未经处理的请求 |
| ruok | 测试服务是否处于正确状态。如果确实如此,那么服务返回"imok",否则不做任何相应。 |
| stat | 输出关于性能和连接的客户端的列表。 |
| srst | 重置服务器的统计。 |
| srvr | 3.3.0版本引入的。列出连接服务器的详细信息 |
| wchs | 3.3.0版本引入的。列出服务器watch的详细信息。 |
| wchc | 3.3.0版本引入的。通过session列出服务器watch的详细信息,它的输出是一个与watch相关的会话的列表。 |
| wchp | 3.3.0版本引入的。通过路径列出服务器watch的详细信息。它输出一个与session相关的路径。 |
| mntr | 3.4.0版本引入的。输出可用于检测集群健康状态的变量列表 |
详情,请参考:ZooKeeper: Because Coordinating Distributed Systems is a Zoo
1. stat 命令
stat 命令用于查看 zk 的状态信息,实例如下:
$ echo stat | nc 192.168.3.38 2181
2. ruok 命令
ruok 命令用于查看当前 zkserver 是否启动,若返回 imok 表示正常。
实例如下:
$ echo ruok | nc 192.168.3.38 2181
3. dump 命令
dump 命令用于列出未经处理的会话和临时节点。实例如下:
$ echo dump | nc 192.168.3.38 2181
4. conf 命令
用于查看服务器配置。实例如下:
$ echo conf | nc 192.168.3.38 2181
5. cons 命令
cons 命令用于展示连接到服务器的客户端信息。
实例如下:
$ echo cons | nc 192.168.3.38 2181
6. envi 命令
envi 命令用于查看环境变量。
实例如下:
$ echo envi | nc 192.168.3.38 2181
3、权限控制 ACL
Zookeeper作为分布式架构中的重要中间件,通常会在上面以节点的方式存储一些关键信息,默认情况下,所有应用都可以读写任何节点,在复杂的应用中,这样不太安全,所以,zk通过ACL机制来解决访问权限的问题。
- Zookeeper的权限控制是基于每个znode节点的,需要对每个节点设置权限
- 每个znode支持设置多种权限控制方案和多个权限
- 子节点不会继承父节点的访问权限,客户端无权访问某个节点,但是可以访问他的子节点。
ACL权限控制,使用 schema:id:permission来标识,主要涵盖三个方面:
- 权限模式(schema):鉴权的策略
- 授权对象(id)
- 权限(permission)
schema:
- world:只有一个用户:anyone,代表所有人(默认)
- ip:使用IP地址认证
- auth:使用已添加认证的用户认证
- digest:使用“用户名:密码”方式认证
id:授权对象id是指,权限赋予的用户或者一个实体,例如:IP地址或者机器。授权模式schema与授权对象id之间关系:
- world:只有一个id即anyone
- ip:通常是一个IP地址或者地址段,比如192.168.0.110或者192.168.0.1/24
- auth:用户名
- digest:自定义加密方式
权限:
CREATE,简写为c,可以创建子节点
DELETE,简写为d,可以删除子节点(仅下以及节点),注意不是本节点
READ,简写为r,可以读取节点数据及显示子节点列表
WRITE,简写为w,可设置节点数据
ADMIN,简写为a,可以设置节点访问控制列表
Zookeeper 的 ACL(Access Control List,访问控制表)权限在生产环境是特别重要的,ACL 权限可以针对节点设置相关读写等权限,保障数据安全性。
permissions 可以指定不同的权限范围及角色。
ACL 命令行
- getAcl 命令:获取某个节点的 acl 权限信息。默认创建的节点的权限是最开放的,所有都可以增删改查管理。
- setAcl 命令:设置某个节点的 acl 权限信息,设置节点对所有人都有写和管理权限。
- addauth 命令:输入认证授权信息,注册时输入明文密码,加密形式保存。
ACL 构成
zookeeper 的 acl 通过 [scheme:id:permissions] 来构成权限列表。
- 1、scheme:代表采用的某种权限机制,包括 world、auth、digest、ip、super 几种。
- 2、id:代表允许访问的用户。
- 3、permissions:权限组合字符串,由 cdrwa 组成,其中每个字母代表支持不同权限, 创建权限 create(c)、删除权限 delete(d)、读权限 read(r)、写权限 write(w)、管理权限admin(a)。
1. world 实例
查看默认节点权限,再更新节点 permissions 权限部分为 crwa,结果删除节点失败。其中 world 代表开放式权限。
$ getAcl /runoob/child
$ setAcl /runoob/child world:anyone:crwa
$ delete /runoob/child
2. auth 实例
auth 用于授予权限,setACl设置节点ACL后是无法读取这个节点的,需要新创建一个用户,然后设置权限,这里只有user1拥有这个节点的所有权限。
$ setAcl /runoob/child auth:user1:123456:cdrwa
$ addauth digest user1:123456
$ setAcl /runoob/child auth:user1:123456:cdrwa
$ getAcl /runoob/child
3. digest 实例
退出当前用户,重新连接终端,digest 可用于账号密码登录和验证。
$ ls /runoob
$ create /runoob/child01 runoob
$ getAcl /runoob/child01
$ setAcl /runoob/child01 digest:user1:HYGa7IZRm2PUBFiFFu8xY2pPP/s=:cdra
$ getAcl /runoob/child01
$ addauth digest user1:123456
$ getAcl /runoob/child01提示:加密密码是上一步创建的。

4. IP 实例
限制 IP 地址的访问权限,把权限设置给 IP 地址为 192.168.3.7 后,IP 为 192.168.3.38 已经没有访问权限。
$ create /runoob/ip 0
$ getAcl /runoob/ip
$ setAcl /runoob/ip ip:192.168.3.7:cdrwa
$ get /runoob/ip
4、节点案例
Zookeeper的节点特性和简单使用场景:
1. 同一级节点 key 名称是唯一的
实例:
$ ls /
$ create /runoob 2

已存在 /runoob 节点,再次创建会提示已经存在。
2. 创建节点时,必须要带上全路径
实例:
$ ls /runoob
$ create /runoob/child 0
$ create /runoob/child/ch01 0
3. session 关闭,临时节点清除
实例:
$ ls /runoob
$ create -e /runoob/echild 0
同时终端二查看该节点:
$ ls /runoob
ctrl+c 关闭终端一连接后,查询终端二 /runoob/echild 节点消失。
$ ls /runoob
4. 自动创建顺序节点
实例:
$ create -s -e /runoob 0
5. watch 机制,监听节点变化
事件监听机制类似于观察者模式,watch 流程是客户端向服务端某个节点路径上注册一个 watcher,同时客户端也会存储特定的 watcher,当节点数据或子节点发生变化时,服务端通知客户端,客户端进行回调处理。特别注意:监听事件被单次触发后,事件就失效了。
提示:参考常用命令章节 get 命令监听 watch 使用,后面章节将详细介绍 watch 实现原理。
6. delete 命令只能一层一层删除
实例:
$ ls /
$ delete /runoob
提示:新版本可以通过 deleteall 命令递归删除。
有了上述众多节点特性,使得 zookeeper 能开发不出不同的经典应用场景,比如:
- 1. 数据发布/订阅
- 2. 负载均衡
- 3. 分布式协调/通知
- 4. 集群管理
- 5. 集群管理
- 6. master 管理
- 7. 分布式锁
- 8. 分布式队列
5、watcher 事件机制原理剖析
zookeeper 的 watcher 机制,可以分为四个过程:
- 客户端注册 watcher。
- 服务端处理 watcher。
- 服务端触发 watcher 事件。
- 客户端回调 watcher。
其中客户端注册 watcher 有三种方式,调用客户端 API 可以分别通过 getData、exists、getChildren 实现,
新建 WatcherDemo 类,以 exists 方法举例说明其原理:
public class WatcherDemo implements Watcher {
static ZooKeeper zooKeeper;
static {
try {
zooKeeper = new ZooKeeper("192.168.3.39:2181", 4000,new WatcherDemo());
} catch (IOException e) {
e.printStackTrace();
}
}
@Override
public void process(WatchedEvent event) {
System.out.println("eventType:"+event.getType());
if(event.getType()==Event.EventType.NodeDataChanged){
try {
zooKeeper.exists(event.getPath(),true);
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
}
public static void main(String[] args) throws IOException, KeeperException, InterruptedException {
String path="/watcher";
if(zooKeeper.exists(path,false)==null) {
zooKeeper.create("/watcher", "0".getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.PERSISTENT);
}
Thread.sleep(1000);
System.out.println("-----------");
//true表示使用zookeeper实例中配置的watcher
Stat stat=zooKeeper.exists(path,true);
System.in.read();
}
}运行完程序,控制台显示:

此时启动 zookeeper 命令行终端,查看并且删除 watcher 节点:

IDE 控制台输出,触发了节点删除事件:

客户端发送请求给服务端是通过 TCP 长连接建立网络通道,底层默认是通过 java 的 NIO 方式,也可以配置 netty 实现方式。

注册 watcher 监听事件流程图:

1. 客户端发送事件通知请求
在 Zookeeper 类调用 exists 方法时候,把创建事件监听封装到 request 对象中,watch 属性设置为 true,待服务端返回 response 后把监听事件封装到客户端的 ZKWatchManager 类中。

2. 服务端处理 watcher 事件的请求
服务端 NIOServerCnxn 类用来处理客户端发送过来的请求,最终调用到 FinalRequestProcessor,其中有一段源码添加客户端发送过来的 watcher 事件:

然后进入 statNode 方法,在 DataTree 类方法中添加 watcher 事件,并保存至 WatchManager 的 watchTable 与 watchTable 中。


3. 服务端触发 watcher 事件流程
若服务端某个被监听的节点发生事务请求,服务端处理请求过程中调用 FinalRequestProcessor 类 processRequest 方法中的代码如下所示:

删除调用链最终到 DataTree 类中删除节点分支的触发代码段:

进入 WatchManager 类的 triggerWatch 方法:

继续跟踪进入 NIOServerCnxn,构建了一个 xid 为 -1,zxid 为 -1 的 ReplyHeader 对象,然后再调用 sendResonpe 方法。

4. 客户端回调 watcher 事件
客户端 SendThread 类 readResponse 方法接收服务端触发的事件通知,进入 xid 为 -1 流程,处理 Event 事件。

七、Zookeeper 分布式数据一致性
Zookeeper服务一般上是以集群状态提供服务,多个Zookeeper节点之间的数据一致性是通过zap(原子广播)协议来保证的。
在 Zookeeper 中,主要依赖 ZAB 协议来实现分布式数据一致性。
ZAB 协议分为两部分:
- 消息广播
- 崩溃恢复
1、消息广播
Zookeeper使用单一的主进程 Leader 来接收和处理客户端所有事务请求,并采用 ZAB 协议的原子广播协议,将事务请求以 Proposal 提议广播到所有 Follower 节点,当集群中有过半的Follower 服务器进行正确的 ACK 反馈,那么Leader就会再次向所有的 Follower 服务器发送commit 消息,将此次提案进行提交。这个过程可以简称为 2pc 事务提交,整个流程可以参考下图,注意 Observer 节点只负责同步 Leader 数据,不参与 2PC 数据同步过程。

2、崩溃恢复
在正常情况消息广播情况下能运行良好,但是一旦 Leader 服务器出现崩溃,或者由于网络原理导致 Leader 服务器失去了与过半 Follower 的通信,那么就会进入崩溃恢复模式,需要选举出一个新的 Leader 服务器。在这个过程中可能会出现两种数据不一致性的隐患,需要 ZAB 协议的特性进行避免。
- 1、Leader 服务器将消息 commit 发出后,立即崩溃
- 2、Leader 服务器刚提出 proposal 后,立即崩溃
ZAB 协议的恢复模式使用了以下策略:
- 1、选举 zxid 最大的节点作为新的 leader
- 2、新 leader 将事务日志中尚未提交的消息进行处理
Zookeeper的数据一致性为最终一致性,需要注意的是他不是实时的,比如node1,node2,node3,其中node3为leader,node1和node2为follower,当node1进行节点创建以后,leader节点肯定为实时更新,但是follower节点不一定为实时更新,因为只要过半通过就算节点已经创建成功,可能会有的节点当前的数据还不是最终态,但是它的更新指令是存在,只是可能还没执行。我们的客户端如果想要读取最终态的数据,那么可以通过使用上面的sync命令,来获取最终数据。
先看一下下面的流程图,然后再进行详细解释:

1)首先由客户端发送创建节点的指令给到zk节点,假设这个zk节点为follower1节点;
2)follower1节点发现是写操作节点,则将该指令通过2888端口转发到leader节点执行;
3)leader节点更新自己zxid信息,也就是事务id信息;
4)leader节点先将创建节点信息同步到log日志中,然后再follower1和follower2各自的队列中放入创建节点写日志的指令,当follower节点接收到指令以后,执行写日志操作,写入日志成功以后,告诉leader写入完成;leader会判断目前是否已经有过半的节点(包含自己)已经写入完成,如果完成,则先在自己的内存中创建节点,然后将在follower对应的节点中加入在内存中创建节点的指令,然后follower接收到指令以后进行内存操作,操作完成以后告诉leader写入完成,同样需要过半完成;
5)将创建结束的消息返回给调用的follower,然后返回给客户端,节点创建结束;
上面步骤中的第四步其实就是对原子广播协议的一个大致解释,原子广播协议可以看成两部分,首先原子就代表这只有成功或者失败,没有中间状态;而广播就是并不意味着所有节点都完成相关操作才算完成,只要过半节点是成功的,那么本次操作就算成功完成了。
在第四步中提到的队列就是对最终一致性的一个解释,leader会将所有指令按照顺序放入每个follower对应的队列中,每个follower按顺序去执行队列中的指令,达到一个最终一致性的结果。
八、Zookeeper选举算法
Zookeeper的设计目标就是高可用性,那么也就意味着,在使用Zookeeper的时候一般都是使用集群而不是单点模式。
Leader选举是保证分布式数据一致性的关键所在。当Zookeeper集群中的一台服务器出现以下两种情况之一时,需要进入Leader选举:
- 服务器初始化启动
- Leader挂掉
在分析选举原理前,先介绍几个重要的参数。每个投票中包含了两个最基本的信息,所推举服务器的sid和Zxid,投票(Vote)在Zookeeper中包含字段如下:
- id:被推举的Leader的sid
- 服务器 ID(myid):编号越大在选举算法中权重越大
- 事务 ID(zxid):被推举的Leader的事务id,值越大说明数据越新,权重越大
- 逻辑时钟(electionEpoch):逻辑时钟,用来判断多个投票是否在同一轮选举周期中。该值在服务端是一个自增序列,每次进入新一轮的投票后,都会对该值进行加1操作。同一轮投票过程中的逻辑时钟值是相同的,每投完一次值会增加
- peerEpoch:被推举的Leader的epoch
- state:当前服务器的状态
服务器状态:
服务器具有四种状态,分别是LOOKING ,FOLLOWING, LEADING, OBSERVING。
- LOOKING: 寻找Leader状态,当服务器处于该状态时,它会认为当前集群中没有Leader,因此需要进入Leader选举状态。
- FOLLOWING: 跟随者状态,表名当前服务器的角色是Follower,同步 leader 状态,参与投票
- OBSERVING: 观察者状态,表名当前服务器角色是Observer,同步 leader 状态,不参与投票
- LEADING: 领导者状态,表名当前服务器角色是Leader
1、服务器启动时的 leader 选举
每个节点启动的时候都 LOOKING 观望状态,接下来就开始进行选举主流程。这里选取三台机器组成的集群为例。第一台服务器 server1启动时,无法进行 leader 选举,当第二台服务器 server2 启动时,两台机器可以相互通信,进入 leader 选举过程。
-
(1)每台 server 发出一个投票,由于是初始情况,server1 和 server2 都将自己作为 leader 服务器进行投票,每次投票包含所推举的服务器myid、zxid、epoch,使用(myid,zxid)表示,此时 server1 投票为(1,0),server2 投票为(2,0),然后将各自投票发送给集群中其他机器。
-
(2)接收来自各个服务器的投票。集群中的每个服务器收到投票后,首先判断该投票的有效性,如检查是否是本轮投票(epoch)、是否来自 LOOKING 状态的服务器。
-
(3)分别处理投票。针对每一次投票,服务器都需要将其他服务器的投票和自己的投票进行对比,对比规则如下:
- a. 优先比较 epoch
- b. 检查 zxid,zxid 比较大的服务器优先作为 leader
- c. 如果 zxid 相同,那么就比较 myid,myid 较大的服务器作为 leader 服务器
-
(4)统计投票。每次投票后,服务器统计投票信息,判断是都有过半机器接收到相同的投票信息。server1、server2 都统计出集群中有两台机器接受了(2,0)的投票信息,此时已经选出了 server2 为 leader 节点。
-
(5)改变服务器状态。一旦确定了 leader,每个服务器响应更新自己的状态,如果是 follower,那么就变更为 FOLLOWING,如果是 Leader,变更为 LEADING。此时 server3继续启动,直接加入变更自己为 FOLLOWING。

zxid指的是当前节点的事物id,通俗点说就是当前节点完成的数据同步情况,该值越大,越能说明该节点的数据同步情况越完整,丢失数据的情况越小或者丢失数据越少。myid是在创建zk集群的时候,我们给它的赋值。
先假设现在有4个zk节点,分别为node1,node2,node3,node4,他们的myid分别为1,2,3,4选主流程主要分为以下两种情况:
初始启动,在启动阶段时,此时各个服务节点的zxid都为0,只与myid有关。假设启动顺序为node1->node2->node3->node4,当启动动1和2的时候,该zk集群是不可用状态,因为zk的选主必须是过半服务节点同意(包含自己),最低需要启动三个节点才可以进行选举,因此只有node1和node2启动的时候,此时只有两台服务,不满足条件,当第三台节点启动以后,才满足了选主的最低条件,然后进入到选举流程,因为node3的myid最大,所以此时3号节点为leader,然后启动node4,由于此时已经选举出3位leader节点并且过半通过,则不再选取新的主节点。则该集群的leader节点为node3。
2、运行过程中的 leader 选举
在Zookeeper运行期间,Leader与非Leader服务器各司其职,即便当有非Leader服务器宕机或者新加入,此时也不会影响Leader,但是一旦Leader服务器挂了,那么整个集群将暂停对外服务,或者Follower挂掉了导致进入新一轮Leader选举,其过程和启动时期的Leader选举过程基本一致。
假设正在运行的有Server1,Server2和Server3三台服务器,当前Leader是Server2,若某一时刻Leader挂掉了,此时便开始Leader选举,选举过程如下:
1. 变更状态:Leader挂了之后,余下的服务器都会将自己的服务状态变更为LOOKING,然后,开始进入Leader选举过程,这个时候可以开启只读模式让服务器可以读数据。
2. 每个Server会发出一个投票:在运行期间,每个服务器上的Zxid可能不同,此时假设Server1的Zxid为123,Server3的Zxid为122,在新一轮投票中,Server1和Server3都会投自己,产生投票(1,123),(3,122),然后各自将投票发给集群中的所有机器。
3. 接收来自各个服务器的投票:与启动时过程相同。
4. 处理投票:与启动过程相同,此时,Server1将会成为Leader(只是投票为Leader阶段,真正修改为Leader状态在第六步)
5. 统计投票:与启动过程相同。
6. 改变服务器的状态:与启动过程相同。
首先来看一下zk的集群模式。
如下图:

该图为zk集群的可用状态,从上图中可以看到,zk的集群是主从集群,客户端可以随意与任何zk服务节点进行连接,并且各个客户端都可以进行读写操作,这是一个核redis主从集群的区别,redis的主从集群,如果客户端是写操作,那么只能连接redis的主节点才可以。
zk的每个客户端是随机连接到zk服务节点的,并且每个客户端都可以进行读写操作,读操作都是在客户端连接的zk节点进行操作;而写操作是有区别的,如果该客户端连接的是leader节点,那么直接进行写操作;如果该客户端连接的是follower节点,那么zk的服务节点会自动将该写操作转到leader节点进行。
zk的集群为主从集群,那么也就意味着主节点只有一个,那么当主节点挂了以后,该zk集群则会处于不可用状态,既然zk的设计目的是高可用,也就意味着当主节点挂了以后,zk会有一定的方式来快速的选出主节点,让服务恢复可用状态,zk的官方文档中给出的压测报告,7台zk服务,选主耗时大概200ms。
zk的follower节点和leader节点是通过心跳,来查看服务是否可用。在这其中,只要有有一台follower节点发现主节点挂掉,他就开始向其它follower节点发送选主请求,整个集群进入选主流程,不再向外提供服务。
运行过程中,初始启动过程中的leader(node3)节点挂掉,假设此时只有node4节点发现leader已经挂掉,node1和node2的Zxid都是10,node4的Zxid为9,选主的时候需要比较zxid和myid,需要注意他们的优先级,zxid为第一优先级,myid为第二优先级,选举流程大致分为以下几步:
1)node4节点给自己投票,然后将自己的zxid和myid发送给node1和node2节点。

2)node1和node2通过比较zxid和myid,发现node4不能成为leader节点,将各自的zxid和myid发送给node4,然后node4接收到以后,发现node1和node2都比自己时候成为leader节点,会给它们进行投票。

3)node1和node2反驳完node4的选主请求以后,开始进行各自的选主流程,起过程与node4的过程一致,通过上面的优先级,我们可以知道最终node2会成为leader节点,那么以node2为例说一下接下来的流程。node2首先给自己投票,然后将自己zxid和myid推送给node1和node4,此时会发现node2适合成为主节点,则会给node2节点进行投票,最终选出node2成为主节点,zk集群恢复成可用状态。
运行过程中选举总结:
- (1)变更状态。leader 挂后,其他非 Oberver服务器将自身服务器状态变更为 LOOKING。
- (2)每个 server 发出一个投票。在运行期间,每个服务器上 zxid 可能不同。
- (3)处理投票。规则同启动过程。
- (4)统计投票。与启动过程相同。
- (5)改变服务器状态。与启动过程相同。
3、Leader选举实现细节
每台服务器在启动的过程中,会启动一个QuorumCnxManager,负责每台服务器之间的底层Leader选举过程中的网络通信,对应的类就是QuorumCnxManager。
1. 消息队列:QuorumCnxManager内部维护了一系列的队列,用来保存接收到的,待发送的消息以及消息的发送器,除接收队列以外,其他队列都按照sid分组形成队列集合,如一个集群中除了自身还有3台机器,那么就会为这3台机器分别创建一个发送队列,互不干扰。
1.1:recvQueue:消息接收队列,用于存放哪些从其他服务器接收到的消息。
1.2:queueSendMap:消息发送队列,用于保存哪些待发送的消息,按照sid进行分组。
1.3:senderWorkerMap:发送器集合,每个senderWorker消息发送器,都对应一台远程Zookeeper服务器,负责消息的发送,也按照sid进行分组。
1.4:lastMessageSent:最近发送过的消息,为每个sid保留最近发送过的一个消息。
2. 建立连接:为了能够互相投票,Zookeeper集群中的所有机器都需要两两建立起网络连接,QuorumCnxManager在启动时会创建一个ServerSocket来监听Leader选举的通信端口(默认3888),开启监听后,Zookeeper能够不断的接收来自其他服务器的创建连接请求,在接收到其他服务器的tcp连接请求时,会进行处理,为了避免两台机器之间重复的创建tcp连接,Zookeeper只允许sid大的服务器主动和其他服务器建立连接,否则断开连接,在接收到创建连接请求后,服务器通过对比自己和远程服务器的sid值来判断是否接收连接请求,如果当前服务器发现自己的sid更大,那么会断开当前连接,然后自己主动和远程服务器建立连接(自己作为客户端)。一旦连接建立,就会根据远程服务器的sid来创建相应的消息发送器sendWorker和消息接收器RecvWorker,并启动。
3. 消息接收与发送:
3.1:消息接收:由消息接收器RecvWorker负责,由于Zookeeper为每个远程服务器都分配一个单独的RecvWorker,因此每个RecvWorker只需要不断的从这个tcp连接中读取消息,并将其保存到recvQueue队列中,RecvWorker是一个单独的线程。
3.2:消息发送:由于Zookeeper为每个远程服务器都分配一个单独的SendWorker,因此,每个SendWorker只需要不断的从对应的消息发送队列中获取出一个消息发送即可,同时将这个消息放入lastMessageSent中,在SendWorker中,一旦Zookeeper发现针对当前服务器的消息发送队列为空,那么此时需要从lastMessageSent中取出一个最近发送过的消息来进行再次发送。这是为了解决接收方在消息接收前或者接收到消息后服务器挂了,导致消息未被正确处理,同时,Zookeeper能够保证接收方在处理消息时,会对重复消息进行正确的处理,SendWorker是一个单独的线程。
4、选举算法核心
FastLeaderElectin模块是如何与底层网络I/O进行交互的,Leader选举的基本流程如下:

说明:
1)选举算法核心
外部投票:只其他服务器发来的投票。
内部投票:服务器自身当前的投票。
选举轮次:Zookeeper服务器Leader选举的轮次,即logicalclock。
PK:对内部投票和外部投票进行对比来确定是否需要变更内部投票。
2)选票管理
sendqueue:选票发送队列,用于保存待发送的选票。
recvqueue:选票接收队列,用于保存接收到的外部投票。
workerReceiver:选票接收器,其会不断的从QuorumCnxManager中获取其他服务器发来的选举信息,并将其转换成一个选票,然后保存到recvqueue中,在选票接收过程中,如果发现该外部选票的选举轮次小于当前服务器的,那么忽略该外部投票,同时立即发送自己的内部投票。
workerSender:选票发送器,不断的从sendqueue中获取待发送的选票,并将其传递到底层QuorumCnxManager中。
3)选举流程
1. 自增选举轮次:Zookeeper规定所有有效的投票都必须在同一轮次中,在开始新一轮投票时,会先对logicalclock进行自增。
2. 初始化选票:在开始进行新一轮投票之前,每个服务器都会初始化自身的选票,并且在初始化阶段,没台服务器都会将自己推举为Leader。
3. 发送初始化选票:完成选票的初始化后,服务器就会发起第一次投票,Zookeeper会将刚刚初始化好的选票放入sendqueue中,由发送器WorkerSender负责发送出去。
4. 接收外部投票:每台服务器会不断的从recvqueue队列中获取外部选票,如果服务器发现无法获取到任何外部投票,那么就会立即确认自己是否和集群中其他服务器保持着有效连接,如果没有连接,则马上建立连接,如果已经建立连接,则再次发送自己当前的内部投票。
5. 判断选举轮次:在发送完初始化选票之后,接着开始处理外部投票,在处理外部投票时,会根据选举轮次来进行不同的处理。
5.1:外部投票的选举轮次大于内部投票:若服务器自身的选举轮次落后于该外部投票对应服务器的选举轮次,那么就会立即更新自己的选举轮次(logicalclock),并且清空所有已接收到的投票,然后使用初始化的投票来进行PK以确定是否变更内部投票,最终再将内部投票发送出去。
5.2:外部投票的选举轮次小于内部投票:若服务器接收的外部选票的选举轮次落后于自身的选举轮次,那么Zookeeper就会直接忽略该外部投票,不做任何处理,并返回步骤4.
6.选票PK:在进行选票PK时,符合任意一个条件就需要变更投票。
6.1:若外部投票中推举的Leader服务器的选举轮次大于内部投票,那么需要变更投票。
6.2:若选举轮次一致,那么就对比两者的Zxid,若外部投票的Zxid大,那么需要变更投票。
6.3:若两者的Zxid不一致,那么就对比两者的sid,若外部投票的sid大,那么就需要变更投票。
7. 变更投票:经过PK后,若确定了外部投票优于内部投票,那么就变更投票,即使使用外部投票的选票信息来覆盖内部投票,变更完成后,再次将这个变更后的内部投票发送出去。
8. 选票归档:无论是否变更了投票,都会将刚刚收到的那份外部投票放入选票集合,recvset中进行归档,recvset用于记录当前服务器在本轮次的Leader选举中收到的所有外部投票(按照服务端的sid区别,如:{(1,vote1),(2.vote2)...}).
9. 统计投票:完成选票归档后,就可以开始统计投票,统计投票是为了统计集群中是否已经有过半的服务器认可了当前的内部投票,如果确定已经有过半的服务器认可了该投票,则终止投票,否则返回步骤4.
10. 更新服务器状态。若已经可以确定终止投票,那么就开始更新服务器状态,服务器首先判断当前被过半服务器认可的投票所对应的Leader服务器是否是自己,若是自己,则将自己的服务器状态更新为LEADING,若不是,则根据具体情况来确定自己是FOLLOWING或则OBSERVING.
以上10个步骤就是FastLeaderElection的核心,其中步骤4~9会经过几次循环,直到有Leader选举产生。
九、分布式锁实现方案
分布式锁是控制分布式系统之间同步访问共享资源的一种方式。
1、分布式锁简介
在分布式系统中,为了保证对数据的修改有最终一致性,通常使用分布式锁或者分布式事务。比如常见的多个系统同时修改商品,既依赖于现有数据也要修改数据,如果没有限制,高并发情况下很可能最终数据是错误的。
与单机锁不同,分布式锁更加复杂,需要考虑网络延迟、服务阻塞等,通常具有如下特点:
-
同一时间只能有一个线程拥有锁;
-
高可用,获取和释放锁必须可靠;
-
高性能,获取和释放锁必须快速完成;
-
可重入,已获取锁的线程可以再次获取锁而不会发生死锁;
-
过期失效,避免死锁;
-
阻塞(根据业务需要)。
2、为什么用分布式锁
我们先来看一个业务场景:
系统A是一个电商系统,目前是一台机器部署,系统中有一个用户下订单的接口,但是用户下订单之前一定要去检查一下库存,确保库存足够了才会给用户下单。
由于系统有一定的并发,所以会预先将商品的库存保存在redis中,用户下单的时候会更新redis的库存。
此时系统架构如下:

但是这样一来会产生一个问题:假如某个时刻,redis里面的某个商品库存为1,此时两个请求同时到来,其中一个请求执行到上图的第3步,更新数据库的库存为0,但是第4步还没有执行。
而另外一个请求执行到了第2步,发现库存还是1,就继续执行第3步。
这样的结果,是导致卖出了2个商品,然而其实库存只有1个。
很明显不对啊!这就是典型的库存超卖问题
此时,我们很容易想到解决方案:用锁把2、3、4步锁住,让他们执行完之后,另一个线程才能进来执行第2步。

按照上面的图,在执行第2步时,使用Java提供的synchronized或者ReentrantLock来锁住,然后在第4步执行完之后才释放锁。
这样一来,2、3、4 这3个步骤就被“锁”住了,多个线程之间只能串行化执行。
但是好景不长,整个系统的并发飙升,一台机器扛不住了。现在要增加一台机器,如下图:

增加机器之后,系统变成上图所示,我的天!
假设此时两个用户的请求同时到来,但是落在了不同的机器上,那么这两个请求是可以同时执行了,还是会出现库存超卖的问题。
为什么呢?因为上图中的两个A系统,运行在两个不同的JVM里面,他们加的锁只对属于自己JVM里面的线程有效,对于其他JVM的线程是无效的。
因此,这里的问题是:Java提供的原生锁机制在多机部署场景下失效了
这是因为两台机器加的锁不是同一个锁(两个锁在不同的JVM里面)。
那么,我们只要保证两台机器加的锁是同一个锁,问题不就解决了吗?
此时,就该分布式锁隆重登场了,分布式锁的思路是:
在整个系统提供一个全局、唯一的获取锁的“东西”,然后每个系统在需要加锁时,都去问这个“东西”拿到一把锁,这样不同的系统拿到的就可以认为是同一把锁。
至于这个“东西”,可以是Redis、Zookeeper,也可以是数据库。
文字描述不太直观,我们来看下图:

通过上面的分析,我们知道了库存超卖场景在分布式部署系统的情况下使用Java原生的锁机制无法保证线程安全,所以我们需要用到分布式锁的方案。
3、基于数据库实现分布式锁
1. 基于表主键唯一实现分布式锁
利用数据库主键唯一的特性,可以基于唯一主键保证多次操作只有一次成功。在数据库中创建一个表,表中包含方法名等字段,并在方法名字段上创建唯一索引,想要执行某个方法,就使用这个方法名向表中插入数据,成功插入则获取锁,执行完成后删除对应的行数据释放锁。释放锁时,直接删除数据库记录即可。
此方案存在的问题是强依赖数据库,容易形成热点,数据库锁表导致的超时会影响性能,或者数据库宕机会导致服务不可用。并且,数据库本身没有失效机制,如果任务崩溃会导致数据库中的锁不能被释放。数据库插入操作本身没有阻塞机制,故无法实现分布式锁的阻塞等待,任务线程可能需要重复尝试插入。由于唯一主键的存在,持有锁的线程也无法重复获得锁,其他线程竞争锁的过程中也无法根据优先级进行分配。
2. 基于表字段版本号做分布式锁
在数据库中为表增加一个版本号字段,每次操作时判断版本号,只有版本号一致才能进行对应的修改,修改后版本号加 1,通过 CAS 的方式进行修改。
此实现会增加数据库操作的次数,高并发情况下可能性能不好。
3. 基于数据库排他锁做分布式锁
for update是一种行级锁,又叫排它锁,一旦用户对某个行施加了行级加锁,则该用户可以查询也可以更新被加锁的数据行,其它用户只能查询但不能更新被加锁的数据行。我们可以认为获得排他锁的线程即获得分布式锁,任务执行完成后通过 commit 来释放锁。for update 语句会在执行成功后立即返回,在执行失败时一直处于阻塞状态,直到成功。
注意:InnoDB 引擎在加锁的时候,只有通过索引进行检索的时候才会使用行级锁,否则会使用表级锁。这里我们希望使用行级锁,就要给要执行的方法字段名添加索引,值得注意的是,这个索引一定要创建成唯一索引,否则会出现多个重载方法之间无法同时被访问的问题。重载方法的话建议把参数类型也加上。
但是 MySQL 会对查询进行优化,即便在条件中使用了索引字段,但是否使用索引来检索数据是由 MySQL 通过判断不同执行计划的代价来决定的,如果 MySQL 认为全表扫效率更高,比如对一些很小的表,它就不会使用索引,这种情况下 InnoDB 将使用表锁,而不是行锁。
4. Mysql 实现分布式锁
首先,我们需要创建一个锁表:
CREATE TABLE `resource_lock` (
`id` int(11) unsigned NOT NULL AUTO_INCREMENT,
`resource_name` varchar(128) NOT NULL DEFAULT '' COMMENT '资源名称',
'node_info' varchar(128) DEFAULT '0' COMMENT '节点信息',
'count' int(11) NOT NULL DEFAULT '0' COMMENT '锁的次数,统计可重入锁',
'desc' varchar(128) DEFAULT NULL COMMENT '额外的描述信息',
`create_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP COMMENT '创建时间',
`update_time` DATETIME NOT NULL DEFAULT CURRENT_TIMESTAMP ON UPDATE CURRENT_TIMESTAMP COMMENT '更新时间',
PRIMARY KEY ('id'),
UNIQUE KEY 'un_resource_name' ('resource_name')
) ENGINE=InnoDB DEFAULT CHARSET = utf8mb4;先进行查询,如果有值,那么需要比较 node_info 是否一致,这里的 node_info 可以用机器 IP 和线程名字来表示,如果一致那么就加可重入锁 count 的值,如果不一致那么就返回 false 。如果没有值那么直接插入一条数据。
lock伪代码如下:
// 添加事务,原子性
@Transaction
public void lock() {
if (select * from resource_lock where resource_name = 'xxx' for update;) {
// 判断节点信息是否一致
if (currentNodeInfo == resultNodeInfo) {
// 保住锁的可重入性
update resource_lock set count = count + 1 where resource_name = 'xxx';
return true;
} else {
return false;
}
} else {
// 插入新数据
insert into resourceLock;
return true;
}
}tryLock 伪代码如下:
public boolean tryLock(long timeOut) {
long stTime = System.currentTimeMillis();
long endTimeOut = stTime + timeOut;
while (endTimeOut > stTime) {
if (mysqlLock.lock()) {
return true;
}
// 休眠3s后重试
LockSupport.parkNanos(1000 * 1000 * 1000 * 1);
stTime = System.currentTimeMillis();
}
return false;
}unlock 伪代码如下:
@Transaction
public boolean unlock() {
// 查询是否有数据
if (select * from resource_lock where resource_name = 'xxx' for update;) {
// count为1那么可以删除,如果大于1那么需要减去1。
if (count > 1) {
update count = count - 1;
} else {
delete;
}
} else {
return false;
}
}定时清理因为机器宕机导致的锁未被释放的问题,启动一个定时任务,当这个锁远超过任务的执行时间,没有被释放我们就可以认定是节点挂了然后将其直接释放。
4、基于 Redis 实现分布式锁
1. setnx()、expire() 方法实现分布式锁
setnx 的含义就是 SET if Not Exists,主要有两个参数 setnx(key, value)。该方法是原子的,如果 key 不存在,则设置当前 key 成功,返回 1;如果当前 key 已经存在,则设置当前 key 失败,返回 0。setnx 命令不能设置 key 的超时时间,只能通过 expire() 来设置。
锁的实现步骤:
-
调用 setnx(lockkey, 1) 获取锁。如果返回 1,则获取锁成功。
-
调用 expire() 命令对 lockkey 设置超时时间。
-
执行完业务代码后,通过 delete 命令删除 lockkey。
这个方案如果在第一步 setnx 执行成功后,在 expire() 命令执行成功前,发生了宕机的现象,那么就依然会出现死锁的问题。
2. setnx()、get()、getset()方法实现分布式锁
这个方案是对上一个方案的优化版本。
getset() 命令主要有两个参数 getset(key,newValue)。该方法是原子的,对 key 设置 newValue 这个值,并且返回 key 原来的旧值。假设 key 原来是不存在的,那么首次执行的返回值是 null。
锁的实现步骤:
-
调用 setnx(lockkey, 当前时间+过期超时时间) 获取锁。如果返回 1,则获取锁成功。如果返回 0,则获取锁失败,进一步调用 get 方法判断。
-
get(lockkey) 获取上次设置的过期时间 oldExpireTime 。如果 oldExpireTime 小于当前系统时间,则认为这个锁已经超时,进一步调用 getset 方法判断。
-
getset(lockkey, newExpireTime 当前时间+过期超时时间) 设置新的过期时间 newExpireTime,并返回之前的值 currentExpireTime。如果 currentExpireTime 与 oldExpireTime 相等,则获取锁成功,不相等则说明锁被其他请求抢走了。
-
执行完业务代码后,要判断下锁有没有超时,如果没有超时通过 delete 命令删除 lockkey,如果超时了则不处理(可能已被抢走)。
这个方案在任务处理超时或发生宕机时,无需担心锁超时问题,下次请求可以判断出实际上锁已经超时了。
3. Redis 实现分布式锁
首先,Redis客户端为了获取锁,向Redis节点发送如下命令:
SET resource_name my_random_value NX PX 30000上面的命令如果执行成功,则客户端成功获取到了锁,接下来就可以访问共享资源了;而如果上面的命令执行失败,则说明获取锁失败。
注意,在上面的SET命令中:
- my_random_value是由客户端生成的一个随机字符串,它要保证在足够长的一段时间内在所有客户端的所有获取锁的请求中都是唯一的。
- NX表示只有当resource_name对应的key值不存在的时候才能SET成功。这保证了只有第一个请求的客户端才能获得锁,而其它客户端在锁被释放之前都无法获得锁。
- PX 30000表示这个锁有一个30秒的自动过期时间。当然,这里30秒只是一个例子,客户端可以选择合适的过期时间。
最后,当客户端完成了对共享资源的操作之后,执行下面的Redis Lua脚本来释放锁:
// 获取锁
// NX是指如果key不存在就成功,key存在返回false,PX可以指定过期时间
SET anyLock unique_value NX PX 30000
// 释放锁:通过执行一段lua脚本
// 释放锁涉及到两条指令,这两条指令不是原子性的
// 需要用到redis的lua脚本支持特性,redis执行lua脚本是原子性的
if redis.call("get",KEYS[1]) == ARGV[1] then
return redis.call("del",KEYS[1])
else
return 0
end这段Lua脚本在执行的时候要把前面的my_random_value作为 ARGV[1] 的值传进去,把 resource_name 作为 KEYS[1] 的值传进去。
这种方式有几大要点:
-
一定要用SET key value NX PX milliseconds 命令
如果不用,先设置了值,再设置过期时间,这个不是原子性操作,有可能在设置过期时间之前宕机,会造成死锁(key永久存在)
-
value要具有唯一性
这个是为了在解锁的时候,需要验证value是和加锁的一致才删除key。
这是避免了一种情况:假设A获取了锁,过期时间30s,此时35s之后,锁已经自动释放了,A去释放锁,但是此时可能B获取了锁。A客户端就不能删除B的锁了。

4. Redis会产生的问题
第一点:过期时间
首先第一个问题,这个锁必须要设置一个过期时间。否则的话,当一个客户端获取锁成功之后,假如它崩溃了,或者由于发生了网络分割(network partition)导致它再也无法和Redis节点通信了,那么它就会一直持有这个锁,而其它客户端永远无法获得锁了,而且把这个过期时间称为锁的有效时间(lock validity time)。获得锁的客户端必须在这个时间之内完成对共享资源的访问。
第二点:获取锁
第二个问题,第一步获取锁的操作,网上不少文章把它实现成了两个Redis命令:
SETNX resource_name my_random_value EXPIRE resource_name 30
虽然这两个命令和前面算法描述中的一个SET命令执行效果相同,但却不是原子的。如果客户端在执行完SETNX后崩溃了,那么就没有机会执行EXPIRE了,导致它一直持有这个锁。
第三点:my_random_value
第三个问题,设置一个随机字符串 my_random_value 是很有必要的,它保证了一个客户端释放的锁必须是自己持有的那个锁。
假如获取锁时SET的不是一个随机字符串,而是一个固定值,那么可能会发生下面的执行序列:
- 客户端1获取锁成功。
- 客户端1在某个操作上阻塞了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,释放掉了客户端2持有的锁。
- 之后,客户端2在访问共享资源的时候,就没有锁为它提供保护了。
第四点:Lua脚本
第四个问题,释放锁的操作必须使用Lua脚本来实现。释放锁其实包含三步操作:获取、判断和删除,用Lua脚本来实现能保证这三步的原子性。
否则,如果把这三步操作放到客户端逻辑中去执行的话,就有可能发生与前面第三个问题类似的执行序列:
- 客户端1获取锁成功。
- 客户端1访问共享资源。
- 客户端1为了释放锁,先执行'GET'操作获取随机字符串的值。
- 客户端1判断随机字符串的值,与预期的值相等。
- 客户端1由于某个原因阻塞住了很长时间。
- 过期时间到了,锁自动释放了。
- 客户端2获取到了对应同一个资源的锁。
- 客户端1从阻塞中恢复过来,执行DEL操纵,释放掉了客户端2持有的锁。
实际上,在上述第三个问题和第四个问题的分析中,如果不是客户端阻塞住了,而是出现了大的网络延迟,也有可能导致类似的执行序列发生。
这四个问题,只要实现分布式锁的时候加以注意,就都能够被正确处理。
但除此之外,还有一个问题,是由 failover(故障转移) 引起的,却是基于单Redis节点的分布式锁无法解决的。正是这个问题催生了Redlock的出现。
5. 多个Redis节点会产生的问题
redis有3种部署方式:
-
单机模式
-
master-slave + sentinel选举模式
-
redis cluster模式
使用redis做分布式锁的缺点在于:如果采用单机部署模式,会存在单点问题,只要redis故障了。加锁就不行了。
采用master-slave模式,加锁的时候只对一个节点加锁,即便通过sentinel做了高可用,但是如果master节点故障了,发生主从切换,系统自动切到Slave上(failover)。但由于Redis的主从复制(replication)是异步的,这可能导致在failover过程中丧失锁的安全性。
例如下面的执行序列:
- 客户端1从Master获取了锁。
- Master宕机了,存储锁的key还没有来得及同步到Slave上。
- Slave升级为Master。
- 客户端2从新的Master获取到了对应同一个资源的锁。
于是,客户端1和客户端2同时持有了同一个资源的锁,锁的安全性被打破。
基于以上的考虑,其实redis的作者也考虑到这个问题,他提出了一个RedLock的算法,这个算法的意思大概是这样的。
运行Redlock算法的客户端依次执行下面各个步骤,来完成获取锁的操作:
1. 获取当前时间(毫秒数)。
2. 按顺序依次向N个Redis节点执行获取锁的操作。这个获取操作跟前面基于单Redis节点的获取锁的过程相同,包含随机字符串my_random_value,也包含过期时间(比如PX 30000,即锁的有效时间)。
为了保证在某个Redis节点不可用的时候算法能够继续运行,这个获取锁的操作还有一个超时时间(time out),它要远小于锁的有效时间(几十毫秒量级)。客户端在向某个Redis节点获取锁失败以后,应该立即尝试下一个Redis节点。
这里的失败,应该包含任何类型的失败,比如该Redis节点不可用,或者该Redis节点上的锁已经被其它客户端持有(注:Redlock原文中这里只提到了Redis节点不可用的情况,但也应该包含其它的失败情况)。
3. 计算整个获取锁的过程总共消耗了多长时间,计算方法是用当前时间减去第1步记录的时间。如果客户端从大多数Redis节点(>= N/2+1)成功获取到了锁,并且获取锁总共消耗的时间没有超过锁的有效时间(lock validity time),那么这时客户端才认为最终获取锁成功;否则,认为最终获取锁失败。
4. 如果最终获取锁成功了,那么这个锁的有效时间应该重新计算,它等于最初的锁的有效时间减去第3步计算出来的获取锁消耗的时间。
5. 如果最终获取锁失败了(可能由于获取到锁的Redis节点个数少于N/2+1,或者整个获取锁的过程消耗的时间超过了锁的最初有效时间),那么客户端应该立即向所有Redis节点发起释放锁的操作(即前面介绍的Redis Lua脚本)。
上面描述的只是获取锁的过程,而释放锁的过程比较简单:客户端向所有Redis节点发起释放锁的操作,不管这些节点当时在获取锁的时候成功与否。
由于N个Redis节点中的大多数能正常工作就能保证Redlock正常工作,因此理论上它的可用性更高。我们前面讨论的单Redis节点的分布式锁在failover的时候锁失效的问题,在Redlock中不存在了,但如果有节点发生崩溃重启,还是会对锁的安全性有影响的。具体的影响程度跟Redis对数据的持久化程度有关。

但是这样的这种算法还是颇具争议的,可能还会存在不少的问题,无法保证加锁的过程一定正确、节点崩溃可能导致的问题:
假设一共有5个Redis节点:A, B, C, D, E。设想发生了如下的事件序列:
1、客户端1成功锁住了A, B, C,获取锁成功(但D和E没有锁住)。
2、节点C崩溃重启了,但客户端1在C上加的锁没有持久化下来,丢失了。
3、节点C重启后,客户端2锁住了C, D, E,获取锁成功。
4、这样,客户端1和客户端2同时获得了锁(针对同一资源)。
在默认情况下,Redis的AOF持久化方式是每秒写一次磁盘(即执行fsync),因此最坏情况下可能丢失1秒的数据。为了尽可能不丢数据,Redis允许设置成每次修改数据都进行fsync,但这会降低性能。当然,即使执行了fsync也仍然有可能丢失数据(这取决于系统而不是Redis的实现)。
所以,上面分析的由于节点重启引发的锁失效问题,总是有可能出现的。为了应对这一问题,antirez又提出了延迟重启(delayed restarts)的概念。
也就是说,一个节点崩溃后,先不立即重启它,而是等待一段时间再重启,这段时间应该大于锁的有效时间(lock validity time)。这样的话,这个节点在重启前所参与的锁都会过期,它在重启后就不会对现有的锁造成影响。
客户端应该向所有Redis节点发起释放锁的操作?
在最后释放锁的时候,antirez在算法描述中特别强调,客户端应该向所有Redis节点发起释放锁的操作。也就是说,即使当时向某个节点获取锁没有成功,在释放锁的时候也不应该漏掉这个节点。这是为什么呢?
设想这样一种情况,客户端发给某个Redis节点的获取锁的请求成功到达了该Redis节点,这个节点也成功执行了SET操作,但是它返回给客户端的响应包却丢失了。这在客户端看来,获取锁的请求由于超时而失败了,但在Redis这边看来,加锁已经成功了。
因此,释放锁的时候,客户端也应该对当时获取锁失败的那些Redis节点同样发起请求。实际上,这种情况在异步通信模型中是有可能发生的:客户端向服务器通信是正常的,但反方向却是有问题的。
6. Redisson
此外,实现Redis的分布式锁,除了自己基于redis client原生api来实现之外,还可以使用开源框架:Redission
Redisson是一个企业级的开源Redis Client,也提供了分布式锁的支持。我也非常推荐大家使用,为什么呢?
回想一下上面说的,如果自己写代码来通过redis设置一个值,是通过下面这个命令设置的。
-
SET anyLock unique_value NX PX 30000
这里设置的超时时间是30s,假如我超过30s都还没有完成业务逻辑的情况下,key会过期,其他线程有可能会获取到锁。
这样一来的话,第一个线程还没执行完业务逻辑,第二个线程进来了也会出现线程安全问题。所以我们还需要额外的去维护这个过期时间,太麻烦了~
我们来看看redisson是怎么实现的?先感受一下使用redission的爽:
Config config = new Config();
config.useClusterServers()
.addNodeAddress("redis://192.168.31.101:7001")
.addNodeAddress("redis://192.168.31.101:7002")
.addNodeAddress("redis://192.168.31.101:7003")
.addNodeAddress("redis://192.168.31.102:7001")
.addNodeAddress("redis://192.168.31.102:7002")
.addNodeAddress("redis://192.168.31.102:7003");
RedissonClient redisson = Redisson.create(config);
RLock lock = redisson.getLock("anyLock");
lock.lock();
lock.unlock();就是这么简单,我们只需要通过它的api中的lock和unlock即可完成分布式锁,他帮我们考虑了很多细节:
-
redisson所有指令都通过lua脚本执行,redis支持lua脚本原子性执行
-
redisson设置一个key的默认过期时间为30s,如果某个客户端持有一个锁超过了30s怎么办?
redisson中有一个
watchdog的概念,翻译过来就是看门狗,它会在你获取锁之后,每隔10秒帮你把key的超时时间设为30s这样的话,就算一直持有锁也不会出现key过期了,其他线程获取到锁的问题了。
-
redisson的“看门狗”逻辑保证了没有死锁发生。
(如果机器宕机了,看门狗也就没了。此时就不会延长key的过期时间,到了30s之后就会自动过期了,其他线程可以获取到锁)

这里稍微贴出来其实现代码:
// 加锁逻辑
private <T> RFuture<Long> tryAcquireAsync(long leaseTime, TimeUnit unit, final long threadId) {
if (leaseTime != -1) {
return tryLockInnerAsync(leaseTime, unit, threadId, RedisCommands.EVAL_LONG);
}
// 调用一段lua脚本,设置一些key、过期时间
RFuture<Long> ttlRemainingFuture = tryLockInnerAsync(commandExecutor.getConnectionManager().getCfg().getLockWatchdogTimeout(), TimeUnit.MILLISECONDS, threadId, RedisCommands.EVAL_LONG);
ttlRemainingFuture.addListener(new FutureListener<Long>() {
@Override
public void operationComplete(Future<Long> future) throws Exception {
if (!future.isSuccess()) {
return;
}
Long ttlRemaining = future.getNow();
// lock acquired
if (ttlRemaining == null) {
// 看门狗逻辑
scheduleExpirationRenewal(threadId);
}
}
});
return ttlRemainingFuture;
}
<T> RFuture<T> tryLockInnerAsync(long leaseTime, TimeUnit unit, long threadId, RedisStrictCommand<T> command) {
internalLockLeaseTime = unit.toMillis(leaseTime);
return commandExecutor.evalWriteAsync(getName(), LongCodec.INSTANCE, command,
"if (redis.call('exists', KEYS[1]) == 0) then " +
"redis.call('hset', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"if (redis.call('hexists', KEYS[1], ARGV[2]) == 1) then " +
"redis.call('hincrby', KEYS[1], ARGV[2], 1); " +
"redis.call('pexpire', KEYS[1], ARGV[1]); " +
"return nil; " +
"end; " +
"return redis.call('pttl', KEYS[1]);",
Collections.<Object>singletonList(getName()), internalLockLeaseTime, getLockName(threadId));
}
// 看门狗最终会调用了这里
private void scheduleExpirationRenewal(final long threadId) {
if (expirationRenewalMap.containsKey(getEntryName())) {
return;
}
// 这个任务会延迟10s执行
Timeout task = commandExecutor.getConnectionManager().newTimeout(new TimerTask() {
@Override
public void run(Timeout timeout) throws Exception {
// 这个操作会将key的过期时间重新设置为30s
RFuture<Boolean> future = renewExpirationAsync(threadId);
future.addListener(new FutureListener<Boolean>() {
@Override
public void operationComplete(Future<Boolean> future) throws Exception {
expirationRenewalMap.remove(getEntryName());
if (!future.isSuccess()) {
log.error("Can't update lock " + getName() + " expiration", future.cause());
return;
}
if (future.getNow()) {
// reschedule itself
// 通过递归调用本方法,无限循环延长过期时间
scheduleExpirationRenewal(threadId);
}
}
});
}
}, internalLockLeaseTime / 3, TimeUnit.MILLISECONDS);
if (expirationRenewalMap.putIfAbsent(getEntryName(), new ExpirationEntry(threadId, task)) != null) {
task.cancel();
}
}另外,redisson还提供了对redlock算法的支持,
它的用法也很简单:
RedissonClient redisson = Redisson.create(config);
RLock lock1 = redisson.getFairLock("lock1");
RLock lock2 = redisson.getFairLock("lock2");
RLock lock3 = redisson.getFairLock("lock3");
RedissonRedLock multiLock = new RedissonRedLock(lock1, lock2, lock3);
multiLock.lock();
multiLock.unlock();对于redis的分布式锁而言,它有以下缺点:
-
它获取锁的方式简单粗暴,获取不到锁直接不断尝试获取锁,比较消耗性能。
-
另外来说的话,redis的设计定位决定了它的数据并不是强一致性的,在某些极端情况下,可能会出现问题。锁的模型不够健壮
-
即便使用redlock算法来实现,在某些复杂场景下,也无法保证其实现100%没有问题,关于redlock的讨论可以看How to do distributed locking
-
redis分布式锁,其实需要自己不断去尝试获取锁,比较消耗性能。
但是另一方面使用redis实现分布式锁在很多企业中非常常见,而且大部分情况下都不会遇到所谓的“极端复杂场景”
所以使用redis作为分布式锁也不失为一种好的方案,最重要的一点是redis的性能很高,可以支撑高并发的获取、释放锁操作。
因为redis是有可能存在隐患的,可能会导致数据不对的情况,如果公司里面有Zookeeper集群条件,优先选用Zookeeper实现分布式锁。
5、基于 ZooKeeper 实现分布式锁
1. Zookeeper实现分布式锁的优点与缺点
Zookeeper是以Paxos算法为基础分布式应用程序协调服务,Zookeeper的数据节点和文件目录类似,所以我们可以用此特性实现分布式锁。
Zookeeper由多个节点构成(单数),采用 zab 一致性协议。Zookeeper可以看成一个单点结构,对其修改数据其内部自动将所有节点数据进行修改而后才提供查询服务。
Zookeeper数据是目录树的形式,每个目录称为 znode, znode 中可存储数据(一般不超过 1M),还可以在其中增加子节点。
子节点有三种类型。
-
序列化节点,每在该节点下增加一个节点自动给该节点的名称上自增。
-
临时节点,一旦创建这个 znode 的客户端与服务器失去联系,这个 znode 也将自动删除。
-
普通节点。
Zookeeper节点存在临时节点,它的生命周期与session有关,它会随着session的消失而消失,这就比较完美的解决了使用redis作为分布式锁时可能出现的死锁问题。
如果获取不到锁,只需要添加一个监听器就可以了,也不用一直轮询,性能消耗较小。
但是Zookeeper也有其缺点:如果有较多的客户端频繁的申请加锁、释放锁,对于zk集群的压力会比较大。
实际上,每个客户端都与Zookeeper的某台服务器维护着一个Session,这个Session依赖定期的心跳(heartbeat)来维持。如果Zookeeper长时间收不到客户端的心跳(这个时间称为Sesion的过期时间),那么它就认为Session过期了,通过这个Session所创建的所有的ephemeral类型的znode节点都会被自动删除。
假如按照下面的顺序执行:
1. 客户端1创建了znode节点/lock,获得了锁。
2. 客户端1进入了长时间的GC pause。
3. 客户端1连接到ZooKeeper的Session过期了。znode节点/lock被自动删除。
4. 客户端2创建了znode节点/lock,从而获得了锁。
5. 客户端1从GC pause中恢复过来,它仍然认为自己持有锁。
由上面的执行顺序,可以发现最后客户端1和客户端2都认为自己持有了锁,冲突了。所以说,用Zookeeper实现的分布式锁也不一定就是安全的,该有的问题它还是有。
2. Zookeepe的watch机制
Zookeeper有个很特殊的机制--watch机制。这个机制可以这样来使用,比如当客户端试图创建 /lock 节点的时候,发现它已经存在了,这时候创建失败,但客户端不一定就此对外宣告获取锁失败。
客户端可以进入一种等待状态,监控每个节点的变化,等待当/lock节点被删除的时候,Zookeeper通过watch机制通知它,这样它就可以继续完成创建操作(获取锁)。这可以让分布式锁在客户端用起来就像一个本地的锁一样:加锁失败就阻塞住,直到获取到锁为止。
可以利用临时节点与 watch 机制实现分布式锁。每个锁占用一个普通节点 /lock,当需要获取锁时在 /lock 目录下创建一个临时节点,创建成功则表示获取锁成功,失败则 watch/lock 节点,有删除操作后再去争锁,临时节点好处在于当进程挂掉后锁的节点自动删除不会发生死锁。
缺点在于所有取锁失败的进程都监听父节点,很容易发生羊群效应,即当释放锁后所有等待进程一起来创建节点,并发量很大。
一个可行的优化方案是上锁改为创建临时有序节点,每个上锁的节点均能创建节点成功,只是其序号不同。只有序号最小的可以拥有锁,如果这个节点序号不是最小的则 watch 序号比本身小的前一个节点 (公平锁)。watch 事件到来后,再次判断是否序号最小。取锁成功则执行代码,最后释放锁(删除该节点)。
3. Zookeeper实现分布式锁的落地方案
-
使用zk的临时节点和有序节点,每个线程获取锁就是在zk创建一个临时有序的节点,比如在/lock/目录下。
-
创建节点成功后,获取/lock目录下的所有临时节点,再判断当前线程创建的节点是否是所有的节点的序号最小的节点
-
如果当前线程创建的节点是所有节点序号最小的节点,则认为获取锁成功。
-
如果当前线程创建的节点不是所有节点序号最小的节点,则对节点序号的前一个节点添加一个事件监听。
比如当前线程获取到的节点序号为/lock/003,然后所有的节点列表为[/lock/001,/lock/002,/lock/003],则对/lock/002这个节点添加一个事件监听器。
如果锁释放了,会唤醒下一个序号的节点,然后重新执行第3步,判断是否自己的节点序号是最小。
比如/lock/001释放了,/lock/002监听到时间,此时节点集合为[/lock/002,/lock/003],则/lock/002为最小序号节点,获取到锁。
整个过程如下:

性能上可能没有缓存服务那么高,因为每次在创建锁和释放锁的过程中,都要动态创建、销毁临时节点来实现锁功能。zookeeper 中创建和删除节点只能通过 Leader 服务器来执行,然后将数据同步到所有的 Follower 机器上。
Zookeeper支持两种类型的分布式锁:
1. 排他锁
排他锁(Exclusive Locks),又被称为写锁或独占锁,如果事务T1对数据对象O1加上排他锁,那么整个加锁期间,只允许事务T1对O1进行读取和更新操作,其他任何事务都不能进行读或写。
定义锁:
/exclusive_lock/lock实现方式:
利用 zookeeper 的同级节点的唯一性特性,在需要获取排他锁时,所有的客户端试图通过调用 create() 接口,在 /exclusive_lock 节点下创建临时子节点 /exclusive_lock/lock,最终只有一个客户端能创建成功,那么此客户端就获得了分布式锁。同时,所有没有获取到锁的客户端可以在 /exclusive_lock 节点上注册一个子节点变更的 watcher 监听事件,以便重新争取获得锁。
2. 共享锁
共享锁(Shared Locks),又称读锁。如果事务T1对数据对象O1加上了共享锁,那么当前事务只能对O1进行读取操作,其他事务也只能对这个数据对象加共享锁,直到该数据对象上的所有共享锁都释放。
定义锁:
/shared_lock/[hostname]-请求类型W/R-序号实现方式:
1. 客户端调用 create 方法创建类似定义锁方式的临时顺序节点。

2. 客户端调用 getChildren 接口来获取所有已创建的子节点列表。
3. 判断是否获得锁,对于读请求如果所有比自己小的子节点都是读请求或者没有比自己序号小的子节点,表明已经成功获取共享锁,同时开始执行度逻辑。对于写请求,如果自己不是序号最小的子节点,那么就进入等待。
4. 如果没有获取到共享锁,读请求向比自己序号小的最后一个写请求节点注册 watcher 监听,写请求向比自己序号小的最后一个节点注册watcher 监听。
实际开发过程中,可以 curator 工具包封装的API帮助我们实现分布式锁。
<dependency>
<groupId>org.apache.curator</groupId>
<artifactId>curator-recipes</artifactId>
<version>x.x.x</version>
</dependency>4. Zookeeper分布式锁代码编写
第一部分代码为连接Zookeeper时的watch代码,用于监测zk的连接情况,它只需要实现Watcher即可。可以根据不同连接状态,进行不同的处理,我们本次只关心连接状态,因为Zookeeper是异步连接,为了保证Zookeeper连接成功以后再做接下来的加锁操作,通过CountDownLatch进行阻塞。
/**
* 连接watcher,主要用来监测zk连接状态
*/
public class ConnectionWatch implements Watcher {
/**
* 由于zk获取信息为异步,通过countDownLatch进行阻塞,保证连接成功
*/
private CountDownLatch countDownLatch;
public void setCountDownLatch(CountDownLatch countDownLatch){
this.countDownLatch = countDownLatch;
}
@Override
public void process(WatchedEvent watchedEvent) {
System.out.println(watchedEvent.toString());
switch (watchedEvent.getState()){
case Unknown:
break;
case Disconnected:
break;
case NoSyncConnected:
break;
case SyncConnected:
// 连接成功,去除阻塞
countDownLatch.countDown();
break;
case AuthFailed:
break;
case ConnectedReadOnly:
break;
case SaslAuthenticated:
break;
case Expired:
break;
case Closed:
break;
}
}
}第二部分代码为zk的工具类,用于获取zk实例,用于业务代码调用。
public class ZkUtils {
private static volatile ZooKeeper zooKeeper;
/**
* zk服务器节点地址,以及锁的主目录
*/
private final static String url = "127.0.0.1:2181,127.0.0.2:2181,127.0.0.3:2181/orderLock";
private static ConnectionWatch watch = new ConnectionWatch();
private static CountDownLatch countDownLatch = new CountDownLatch(1);
/**
* 采创建zk
* @return
* @throws IOException
* @throws InterruptedException
*/
public static ZooKeeper getInstance() throws IOException, InterruptedException {
watch.setCountDownLatch(countDownLatch);
// 创建zk实例,1000代表的是session过期时间
zooKeeper = new ZooKeeper(url, 1000, watch);
// 在zk连接成功之前进行阻塞
countDownLatch.await();
return zooKeeper;
}
}第三部分为在加锁过程中相关操作的watch以及callback操作,主要功能有创建节点,获取子节点,检查节点是否存在。zk的加锁过程就是创建节点的过程,当创建节点成功并且成功返回,则证明该线程加锁成功,继续进行业务逻辑处理,在加锁的时候,一定要考虑锁的可重入性。下面这段代码实现的是公平锁,谁先创建了临时节点,那么谁就能先获得锁。
加锁的大致逻辑是:
1)先创建带有序列的临时节点;
2)在回调函数中获取父节点的所有子节点,判断当前线程创建的临时节点是否位于第一个,如果是则获取锁,如果不是则判断前一个节点是否存在,然后一直循环该逻辑;
public class LockWatch implements Watcher, AsyncCallback.StringCallback, AsyncCallback.Children2Callback, AsyncCallback.StatCallback {
private ZooKeeper zooKeeper;
/**
* 当前线程名称
*/
private String threadName;
/**
* 当前线程创建的节点名称
*/
private String nodeName;
/**
* 用来进行锁阻塞,只有获取到锁,才放行,否则进行阻塞
*/
private CountDownLatch countDownLatch = new CountDownLatch(1);
public void setZooKeeper(ZooKeeper zooKeeper) {
this.zooKeeper = zooKeeper;
}
public void setThreadName(String threadName) {
this.threadName = threadName;
}
/**
* 加锁操作,也就是往zk的指定目录下插入带有序列的临时节点
* 需要考虑锁的可重入
*/
public void tryLock() throws InterruptedException {
zooKeeper.create("/lock", threadName.getBytes(), ZooDefs.Ids.OPEN_ACL_UNSAFE, CreateMode.EPHEMERAL_SEQUENTIAL,
this, "orderLock");
countDownLatch.await();
}
/**
* 解锁操作
* @throws InterruptedException
* @throws KeeperException
*/
public void unLock() throws InterruptedException, KeeperException {
// -1代表不考虑版本号,在zk中获取,删除等相关操作允许版本号的传入
zooKeeper.delete(nodeName, -1);
}
/**
* 节点创建回调方法
* @param i
* @param path
* @param ctx
* @param name
*/
@Override
public void processResult(int i, String path, Object ctx, String name) {
if (Objects.nonNull(name) && !"".equals(name)){
System.out.println(threadName + " create node:" + name);
nodeName = name.substring(1);
zooKeeper.getChildren("/", false, this, ctx);
}
}
/**
* 获取子节点信息的回调方法
* @param i
* @param path
* @param o
* @param children
* @param stat
*/
@Override
public void processResult(int i, String path, Object o, List<String> children, Stat stat) {
if (children == null || children.isEmpty()){
System.out.println("children is null......");
return;
}
// 将子节点进行排序,找序号由低到高
Collections.sort(children);
// 获取当前创建节点排序以后的下标
int index = children.indexOf(nodeName);
// 如果当前节点为第一个节点,则加锁成功
try {
if (index < 1){
System.out.println(threadName +" get lock...");
// -1代表不考虑版本
zooKeeper.setData("/", threadName.getBytes(), -1);
countDownLatch.countDown();
} else {
System.out.println(threadName +" not get lock...");
// 判断该节点的前一个节点是否存在,目的是为了注册节点监控事件,监测删除节点操作
zooKeeper.exists("/" + children.get(i-1), this, this, o);
}
} catch (KeeperException e) {
e.printStackTrace();
} catch (InterruptedException e) {
e.printStackTrace();
}
}
/**
* 判断节点是否存在的watch方法
* @param watchedEvent
*/
@Override
public void process(WatchedEvent watchedEvent) {
switch (watchedEvent.getType()){
case None:
break;
case NodeCreated:
break;
case NodeDeleted:
// 当节点删除的时候,代表着解锁,触发后续的抢锁操作
zooKeeper.getChildren("/", false, this, "orderLock");
break;
case NodeDataChanged:
break;
case NodeChildrenChanged:
break;
case DataWatchRemoved:
break;
case ChildWatchRemoved:
break;
case PersistentWatchRemoved:
break;
}
}
/**
* 校验节点是否存在回调方法
* @param i
* @param s
* @param o
* @param stat
*/
@Override
public void processResult(int i, String s, Object o, Stat stat) {
}
}第四部分则为锁的简单应用,使用了junit进行测试,代码如下:
public class ZkLock {
private ZooKeeper zooKeeper;
/**
* 没有业务意义,只是为了阻塞主线程
*/
private CountDownLatch countDownLatch = new CountDownLatch(1);
/**
* 初始化的时候,首先保证获取到zk的链接实例
* @throws IOException
* @throws InterruptedException
*/
@BeforeAll
public void connect() throws IOException, InterruptedException {
zooKeeper = ZkUtils.getInstance();
}
/**
* 使用完以后,关闭zk连接
* @throws InterruptedException
*/
@AfterAll
public void close() throws InterruptedException {
zooKeeper.close();
}
/**
* 使用10个线程模拟抢锁
*/
@Test
public void testLock() throws InterruptedException {
for(int i = 0; i < 10; i++){
new Thread(){
@Override
public void run() {
String threadName =Thread.currentThread().getName();
LockWatch lockWatch = new LockWatch();
lockWatch.setThreadName(threadName);
lockWatch.setZooKeeper(zooKeeper);
try {
lockWatch.tryLock();
System.out.println(threadName + "deal business...");
lockWatch.unLock();
} catch (InterruptedException | KeeperException e) {
e.printStackTrace();
}
}
}.start();
}
countDownLatch.await();
}
}补充:zk服务中,2888端口用于follower调用leader进行写操作,3888端口为选主使用端口,2181端口为客户端连接zk服务节点端口。
5. Curator方式实现分布式锁
Curator是一个zookeeper的开源客户端,也提供了分布式锁的实现。
curator的几种锁:
- InterProcessMutex:分布式可重入排它锁
- InterProcessSemaphoreMutex:分布式排它锁
- InterProcessReadWriteLock:分布式读写锁
使用方式也比较简单:
InterProcessMutex interProcessMutex = new InterProcessMutex(client,"/anyLock");
interProcessMutex.acquire();
interProcessMutex.release();实现分布式锁的核心源码如下:
private boolean internalLockLoop(long startMillis, Long millisToWait, String ourPath) throws Exception
{
boolean haveTheLock = false;
boolean doDelete = false;
try {
if ( revocable.get() != null ) {
client.getData().usingWatcher(revocableWatcher).forPath(ourPath);
}
while ( (client.getState() == CuratorFrameworkState.STARTED) && !haveTheLock ) {
// 获取当前所有节点排序后的集合
List<String> children = getSortedChildren();
// 获取当前节点的名称
String sequenceNodeName = ourPath.substring(basePath.length() + 1); // +1 to include the slash
// 判断当前节点是否是最小的节点
PredicateResults predicateResults = driver.getsTheLock(client, children, sequenceNodeName, maxLeases);
if ( predicateResults.getsTheLock() ) {
// 获取到锁
haveTheLock = true;
} else {
// 没获取到锁,对当前节点的上一个节点注册一个监听器
String previousSequencePath = basePath + "/" + predicateResults.getPathToWatch();
synchronized(this){
Stat stat = client.checkExists().usingWatcher(watcher).forPath(previousSequencePath);
if ( stat != null ){
if ( millisToWait != null ){
millisToWait -= (System.currentTimeMillis() - startMillis);
startMillis = System.currentTimeMillis();
if ( millisToWait <= 0 ){
doDelete = true; // timed out - delete our node
break;
}
wait(millisToWait);
}else{
wait();
}
}
}
// else it may have been deleted (i.e. lock released). Try to acquire again
}
}
}
catch ( Exception e ) {
doDelete = true;
throw e;
} finally{
if ( doDelete ){
deleteOurPath(ourPath);
}
}
return haveTheLock;
}这里我们用一张图详细描述其原理:

下面例子模拟 50 个线程使用重入排它锁 InterProcessMutex 同时争抢锁:
public class InterprocessLock {
public static void main(String[] args) {
CuratorFramework zkClient = getZkClient();
String lockPath = "/lock";
InterProcessMutex lock = new InterProcessMutex(zkClient, lockPath);
//模拟50个线程抢锁
for (int i = 0; i < 50; i++) {
new Thread(new TestThread(i, lock)).start();
}
}
static class TestThread implements Runnable {
private Integer threadFlag;
private InterProcessMutex lock;
public TestThread(Integer threadFlag, InterProcessMutex lock) {
this.threadFlag = threadFlag;
this.lock = lock;
}
@Override
public void run() {
try {
lock.acquire();
System.out.println("第"+threadFlag+"线程获取到了锁");
//等到1秒后释放锁
Thread.sleep(1000);
} catch (Exception e) {
e.printStackTrace();
}finally {
try {
lock.release();
} catch (Exception e) {
e.printStackTrace();
}
}
}
}
private static CuratorFramework getZkClient() {
String zkServerAddress = "192.168.3.39:2181";
ExponentialBackoffRetry retryPolicy = new ExponentialBackoffRetry(1000, 3, 5000);
CuratorFramework zkClient = CuratorFrameworkFactory.builder()
.connectString(zkServerAddress)
.sessionTimeoutMs(5000)
.connectionTimeoutMs(5000)
.retryPolicy(retryPolicy)
.build();
zkClient.start();
return zkClient;
}
}控制台每间隔一秒钟输出一条记录:
