一、torch.optim
torch.optim.Optimizer(params, defaults)优化器官网说明
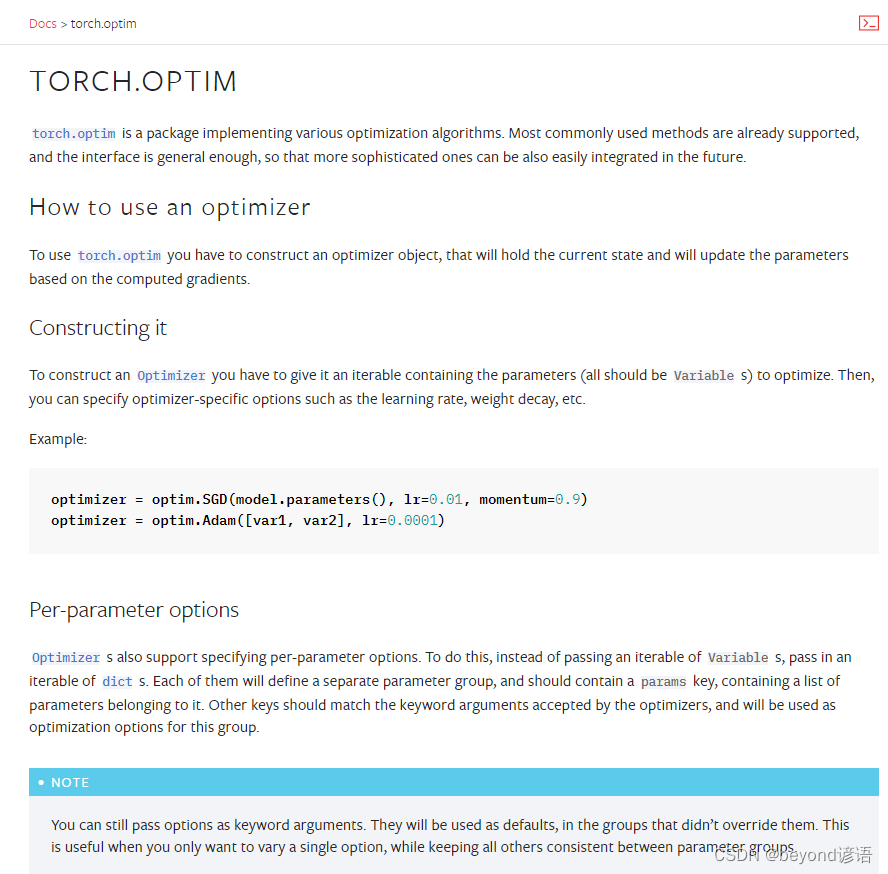
由官网给的使用说明打开看出来优化器实验步骤:
①构造选择优化器
例如采用随机梯度下降优化器SGD
torch.optim.SGD(beyond.parameters(),lr=0.01),放入beyond模型的参数parameters;学习率learning rate;
每个优化器都有其特定独有的参数
②把网络中所有的可用梯度全部设置为0
optim.zero_grad()
梯度为tensor中的一个属性,这就是为啥神经网络传入的数据必须是tensor数据类型的原因,grad这个属性其实就是求导,常用在反向传播中,也就是通过先通过正向传播依次求出结果,再通过反向传播求导来依次倒退,其目的主要是对参数进行调整优化,详细的学习了解可自行百度。
③通过反向传播获取损失函数的梯度
result_loss.backward()
这里使用的损失函数为loss,其对象为result_loss,当然也可以使用其他的损失函数
从而得到每个可以调节参数的梯度
④调用step方法,对每个梯度参数进行调优更新
optim.step()
使用优化器的step方法,会利用之前得到的梯度grad,来对模型中的参数进行更新
二、优化器的使用
使用CIFAR-10数据集的测试集,使用之前实现的网络模型,二、复现网络模型训练CIFAR-10数据集
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_testset = torchvision.datasets.CIFAR10("CIFAR_10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset_testset,batch_size=2)
class Beyond(nn.Module):
def __init__(self):
super(Beyond,self).__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3,32,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32,32,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32,64,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024,64),
torch.nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()#构建选择损失函数为交叉熵
beyond = Beyond()
#print(beyond)
optim = torch.optim.SGD(beyond.parameters(),lr=0.01)
for epoch in range(30):#进行30轮训练
sum_loss = 0.0
for data in dataloader:
imgs, targets = data
output = beyond(imgs)
# print(output)
# print(targets)
result_loss = loss(output, targets)
# print(result_loss)
optim.zero_grad()#把网络模型中所有的梯度都设置为0
result_loss.backward()#反向传播获得每个参数的梯度从而可以通过优化器进行调优
optim.step()
#print(result_loss)
sum_loss = sum_loss + result_loss
print(sum_loss)
"""
tensor(9431.9678, grad_fn=<AddBackward0>)
tensor(7715.2842, grad_fn=<AddBackward0>)
tensor(6860.3115, grad_fn=<AddBackward0>)
......
"""
在optim.zero_grad()及其下面三行处,左击打个断点,进入Debug模式(Shift+F9)下,
网络模型名称---Protected Attributes---__modules---0-8随便选一个,例如'0'---weight---grad就是参数的梯度

三、自动调整学习速率设置
torch.optim.lr_scheduler.ExponentialLR(optimizer=optim,gamma=0.1)
optimizer为优化器的名称,gamma表示每次都会将原来的lr乘以gamma
使用optim优化器,每次就会在原来的学习速率的基础上乘以0.1
import torch
import torchvision
from torch import nn
from torch.nn import Conv2d
from torch.optim.lr_scheduler import StepLR, ExponentialLR
from torch.utils.data import DataLoader
from torch.utils.tensorboard import SummaryWriter
dataset_testset = torchvision.datasets.CIFAR10("CIFAR_10",train=False,transform=torchvision.transforms.ToTensor(),download=True)
dataloader = DataLoader(dataset_testset,batch_size=2)
class Beyond(nn.Module):
def __init__(self):
super(Beyond,self).__init__()
self.model = torch.nn.Sequential(
torch.nn.Conv2d(3,32,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32,32,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Conv2d(32,64,5,padding=2),
torch.nn.MaxPool2d(2),
torch.nn.Flatten(),
torch.nn.Linear(1024,64),
torch.nn.Linear(64,10)
)
def forward(self,x):
x = self.model(x)
return x
loss = nn.CrossEntropyLoss()#构建选择损失函数为交叉熵
beyond = Beyond()
#print(beyond)
optim = torch.optim.SGD(beyond.parameters(),lr=0.01)
scheduler = ExponentialLR(optimizer=optim,gamma=0.1)#在原来的lr上乘以gamma
for epoch in range(30):#进行30轮训练
sum_loss = 0.0
for data in dataloader:
imgs, targets = data
output = beyond(imgs)
# print(output)
# print(targets)
result_loss = loss(output, targets)
# print(result_loss)
optim.zero_grad()#把网络模型中所有的梯度都设置为0
result_loss.backward()#反向传播获得每个参数的梯度从而可以通过优化器进行调优
optim.step()
#print(result_loss)
sum_loss = sum_loss + result_loss
scheduler.step()#这里就需要不能用优化器,而是使用自动学习速率的优化器
print(sum_loss)
"""
tensor(9469.4385, grad_fn=<AddBackward0>)
tensor(7144.1514, grad_fn=<AddBackward0>)
tensor(6734.8311, grad_fn=<AddBackward0>)
......
"""