有人说:他曾在一台配置较好的机子上对
Kafka进行性能压测,压测结果是Kafka单个节点的极限处理能力接近每秒2000万条消息,吞吐量达到每秒600MB。
那 Kafka 为什么这么快?如何做到这个高的性能?
本篇文章主要从这 3 个角度来分析:
-
生产端
-
服务端
Broker -
消费端

先来看下生产端发送消息,Kafka 做了哪些优化?
(1)生产端 Producer

先来回顾下 Producer 生产者发送消息的流程:
-
首先指定消息发送到哪个
Topic。 -
选择一个
Topic的分区partitiion,默认是轮询来负载均衡。也可以指定一个分区
key,根据key的hash值来分发到指定的分区。也可以自定义
partition来实现分区策略。 -
找到这个分区的
leader partition。 -
与所在机器的
Broker的socket建立通信。 -
发送
Kafka自定义协议格式的请求(包含携带的消息、批量消息)。
将思绪集中在消息发送时候,可发现这两个华点:批量消息和自定义协议格式。
-
批量发送:减少了与服务端
Broker处理请求的次数,从而提升总体的处理能力。调用
send()方法时,不会立刻把消息发送出去,而是缓存起来,选择恰当时机把缓存里的消息划分成一批数据,按批次发送给服务端Broker。 -
自定义协议格式:序列化方式和压缩格式都能减少数据体积,从而节省网络资源消耗。
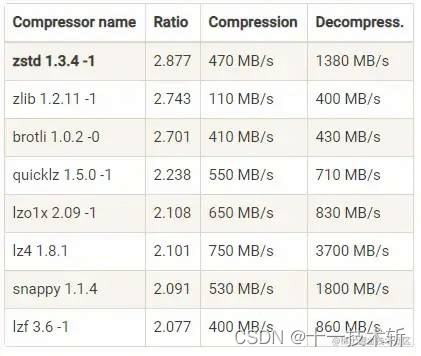
各种压缩算法对比:
-
吞吐量方面:
LZ4>Snappy>zstd和GZIP -
压缩比方面:
zstd>LZ4>GZIP>Snappy
(2)服务端 Broker
Broker 的高性能主要从这 3 个方面体现:
-
PageCache缓存 -
Kafka的文件布局 以及 磁盘文件顺序写入 -
零拷贝
sendfile:加速消费流程
下面展开讲讲。
1)PageCache 加速消息读写
使用 PageCache 主要能带来如下好处:
-
写入文件的时候:操作系统会先把数据写入到内存中的
PageCache,然后再一批一批地写到磁盘上,从而减少磁盘IO开销。

-
读取文件的时候:也是从
PageCache中来读取数据。如果消息刚刚写入到服务端就会被消费,按照
LRU的“优先清除最近最少使用的页”这种策略,读取的时候,对于这种刚刚写入的PageCache,命中的几率会非常高。
2)Kafka 的文件布局 以及 磁盘文件顺序写入
文件布局如下图所示:

**主要特征是:**文件的组织方式是“topic + 分区”,每一个 topic 可以创建多个分区,每一个分区包含单独的文件夹。
Kafka 在分区级别实现文件顺序写:即多个文件同时写入,更能发挥磁盘 IO 的性能。
-
相对比
RocketMQ:RocketMQ在消息写入时追求极致的顺序写,所有的消息不分主题一律顺序写入commitlog文件,topic和 分区数量的增加不会影响写入顺序。 -
弊端:
Kafka在消息写入时的IO性能,会随着topic、分区数量的增长先上升,后下降。所以使用
Kafka时,要警惕Topic和 分区数量。
3)零拷贝 sendfile:加速消费流程
当不使用零拷贝技术读取数据时:

流程如下:
-
消费端
Consumer:向Kafka Broker请求拉取消息 -
Kafka Broker从OS Cache读取消息到 应用程序的内存空间:-
若
OS Cache中有消息,则直接读取 -
若
OS Cache中无消息,则从磁盘里读取
-
-
再通过网卡,
socket将数据发送给 消费端Consumer
当使用零拷贝技术读取数据:

Kafka 使用零拷贝技术可以把这个复制次数减少一次,直接从 PageCache 中把数据复制到 Socket 缓冲区中。
-
这样不用将数据复制到用户内存空间。
-
DMA控制器直接完成数据复制,不需要CPU参与,速度更快。
(3)消费端 Consumer
消费者只从
Leader分区批量拉取消息。
为了提高消费速度,多个消费者并行消费比不可少。Kafka 允许创建消费组(唯一标识 group.id),在同一个消费组的消费者共同消费数据。
举个栗子:
-
有两个
Kafka Broker,即有 2个机子 -
有一个主题:
TOPICA,有 3 个分区(0, 1, 2)

如上图,举例 4 中情况:
-
group.id = 1,有一个消费者:这个消费者要处理所有数据,即 3 个分区的数据。 -
group.id = 2,有两个消费者:consumer 1消费者需处理 2个分区的数据,consumer2消费者需处理 1个分区的数据 -
group.id = 3,有三个消费者:消费者数量与分区数量相等,刚好每个消费者处理一个分区 -
group.id = 4,有四个消费者:消费者数量 > 分区数量,第四个消费者则会处于空闲状态
如果本文对你有帮助,别忘记给我个3连 ,点赞,转发,评论,
学习更多JAVA知识与技巧,关注博主学习JAVA 课件,源码,安装包,还有最新大厂面试资料等等等
咱们下期见。
收藏 等于白嫖,点赞才是真情。
