点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
点击进入—> CV 微信技术交流群
羿阁 发自 凹非寺
转载自:量子位(QbitAI)
有了这个发明,以后演员拍戏再也不用抠图了?
答:可以直接一键合成。(手动狗头)
让我们赶紧来看看,这个由苹果最新研发的NeuMan框架:
只需输入一段10s左右的人物视频,就能合成该人物在新场景下做着各种新动作的影像。
前空翻?so easy!
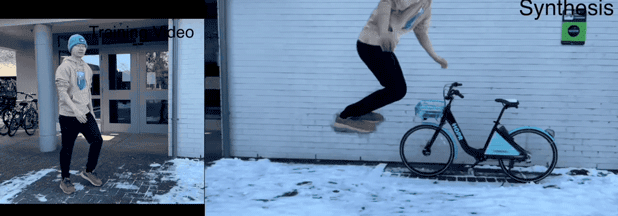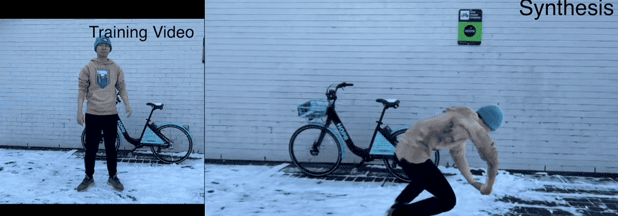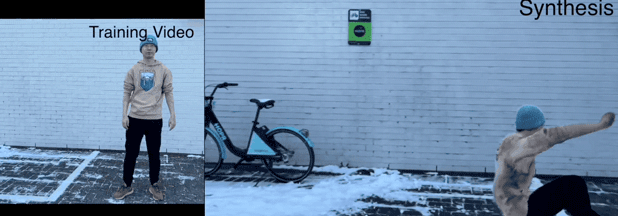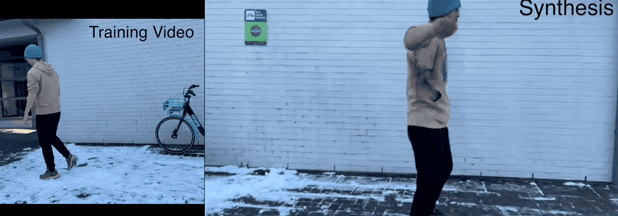
跳舞那也是不在话下。
这妖娆的舞姿,看来NeuMan心里也有一个舞魂~

有网友看完就表示:喔~简直是电影界未来的发展方向。

目前,有关NeuMan的研究论文已被ECCV’22收录,并且已在GitHub上开源。

全新场景渲染
在介绍NeuMan的原理之前,让我们再来欣赏几个酷炫的例子~
如下图所示,左上角是输入的训练视频,左下角是新的背景,右边则是合成后小哥在新背景下跳跃的效果。

不仅是跳跃这种常规操作,广播体操也完全没问题。

更厉害的是,NeuMan还可以将上面例子中的两个人合成到一起。

再加上一个人,立马变成魔性的广场舞视频。

这微笑的小表情,真的很难解释不是本人亲自跳的(手动狗头)。
那么话说回来,这个神奇的NeuMan背后的原理是什么呢?
基于NeRF的新突破
事实上,自从伯克利和谷歌联合打造的NeRF(Neural Radiance Fields神经辐射场)横空出世,各种重建三维场景的研究层出不穷。
NeuMan原理也是基于此,简单来说,就是用单个视频训练一个人物NeRF模型和一个场景NeRF模型,然后再合成在一起生成新的场景。
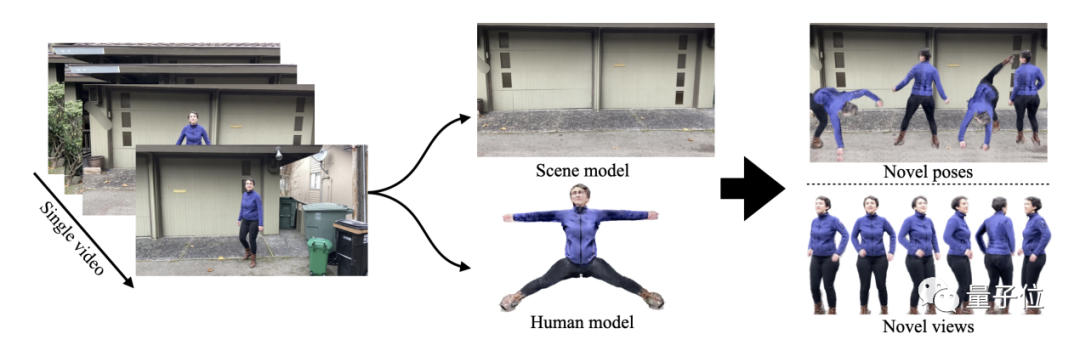
首先,在训练场景NeRF模型时,我们先从输入的视频中提取相机姿态、稀疏场景模型和多视角-立体深度图。
对于原视频中被人体遮挡的部分,则使用Mask R-CNN进行图像实体分割,将人体掩模膨胀4倍,以确保人体被完全遮蔽。此时,就能做到仅在背景上训练场景NeRF模型。
至于人体NeRF模型训练,研究人员引入了一种端到端的SMPL优化(end-to-end SMPL optimization)和纠错神经网络(error-correction network)。
SMPL(Skinned Multi-Person Linear Model)是一种基于顶点的人体三维模型,能够精确地表示人体的不同形状和姿态。
如下图所示,使用端到端的SMPL优化的人体模型,能够更好地表现人体的典型体积。
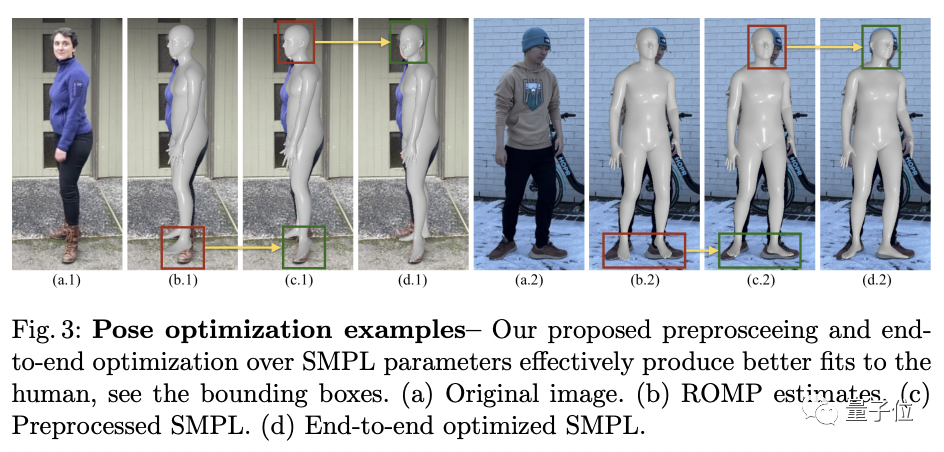
纠错神经网络则是用来弥补SMPL模型无法表达的细节。值得一提的是,它只在训练过程中使用,在进行全新场景渲染时会被放弃,以免造成过度拟合。
接下来,在两个模型对齐的阶段,研究人员先使用COLMAP解决任意尺度下的对齐问题。然后通过假设人类始终与地面有至少一个接触点,来进一步估计该场景的比例。

最后,再应用SMPL网格和场景的点云叠加,就形成了新图像的渲染效果。

最终成品显示,该场景NeRF模型方面模型能够有效地去除场景中的人类,并在有限的场景覆盖下生成高质量的新背景渲染图像。

人物NeRF模型方面也能很好的捕捉人体的细节,包括袖子、衣领甚至衣服拉链,甚至在渲染新动作时,能执行难度极大的侧翻动作。

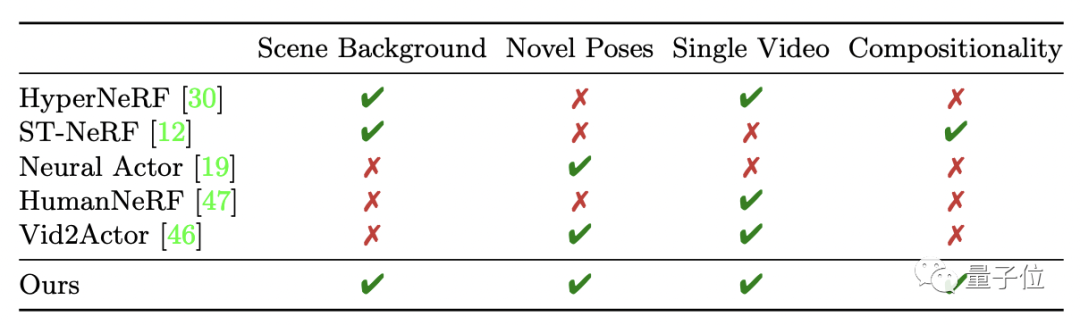
值得一提的是,不同于现行的其他NeRF模型对训练视频要求很高,比如需要多个机位拍摄、曝光要保持不变、背景要干净等等,NeuMan的最大亮点是仅通过用户随意上传的单个视频就能达到同款效果。
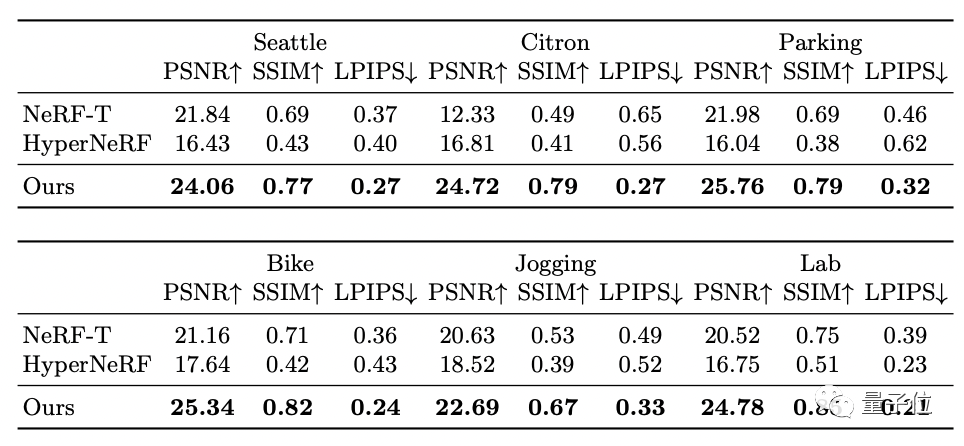
并且,在分别输入六组不同的视频后,数据显示,与此前方法相比,NeuMan的方法生成的视频渲染质量最佳。
不过,研究团队也承认,NeuMan的设计目前还存在一些缺陷。
例如,由于人在活动时手势的变化细微又多变,因此生成视频中对手部细节的把握还不是很准确。
另外,在NeRF模型渲染时,由于系统假设人类始终与地面有至少一个接触点,因此NeuMan不能适用于人与地面接触为零的视频,比如人做后空翻的视频。
要想解决这个问题,需要更智能的几何推理知识,这也是未来研究的一个发展方向。
研究团队
这项研究由苹果机器学习研究中心和英属哥伦比亚大学合作完成。
第一作者Wei Jiang,是英属哥伦比亚大学计算机科学专业的一名四年级博士生,目前在苹果机器学习研究中心实习。
主要研究方向是新视角合成、视觉定位和三维视觉。

他还是英属哥伦比亚大学计算机视觉实验室的一员,导师是Kwang Moo Yi 教授。
硕士毕业于波士顿大学计算机科学专业,本科毕业于浙江工业大学软件工程专业。
参考链接:
[1]https://twitter.com/anuragranj/status/1559606408789708800
[2]https://arxiv.org/abs/2203.12575
[3]https://machinelearning.apple.com/research/neural-human-radiance-field
[4]https://github.com/apple/ml-neuman
[5]https://jiangwei221.github.io/
点击进入—> CV 微信技术交流群
CVPR 2022论文和代码下载
后台回复:CVPR2022,即可下载CVPR 2022论文和代码开源的论文合集
后台回复:Transformer综述,即可下载最新的3篇Transformer综述PDF
目标检测和Transformer交流群成立
扫描下方二维码,或者添加微信:CVer6666,即可添加CVer小助手微信,便可申请加入CVer-目标检测或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer等。
一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
▲扫码或加微信: CVer6666,进交流群
CVer学术交流群(知识星球)来了!想要了解最新最快最好的CV/DL/ML论文速递、优质开源项目、学习教程和实战训练等资料,欢迎扫描下方二维码,加入CVer学术交流群,已汇集数千人!
▲扫码进群
▲点击上方卡片,关注CVer公众号
整理不易,请点赞和在看