接下来我们来学习KubeEdge在边缘端的架构设计。下面我们回到架构设计图,
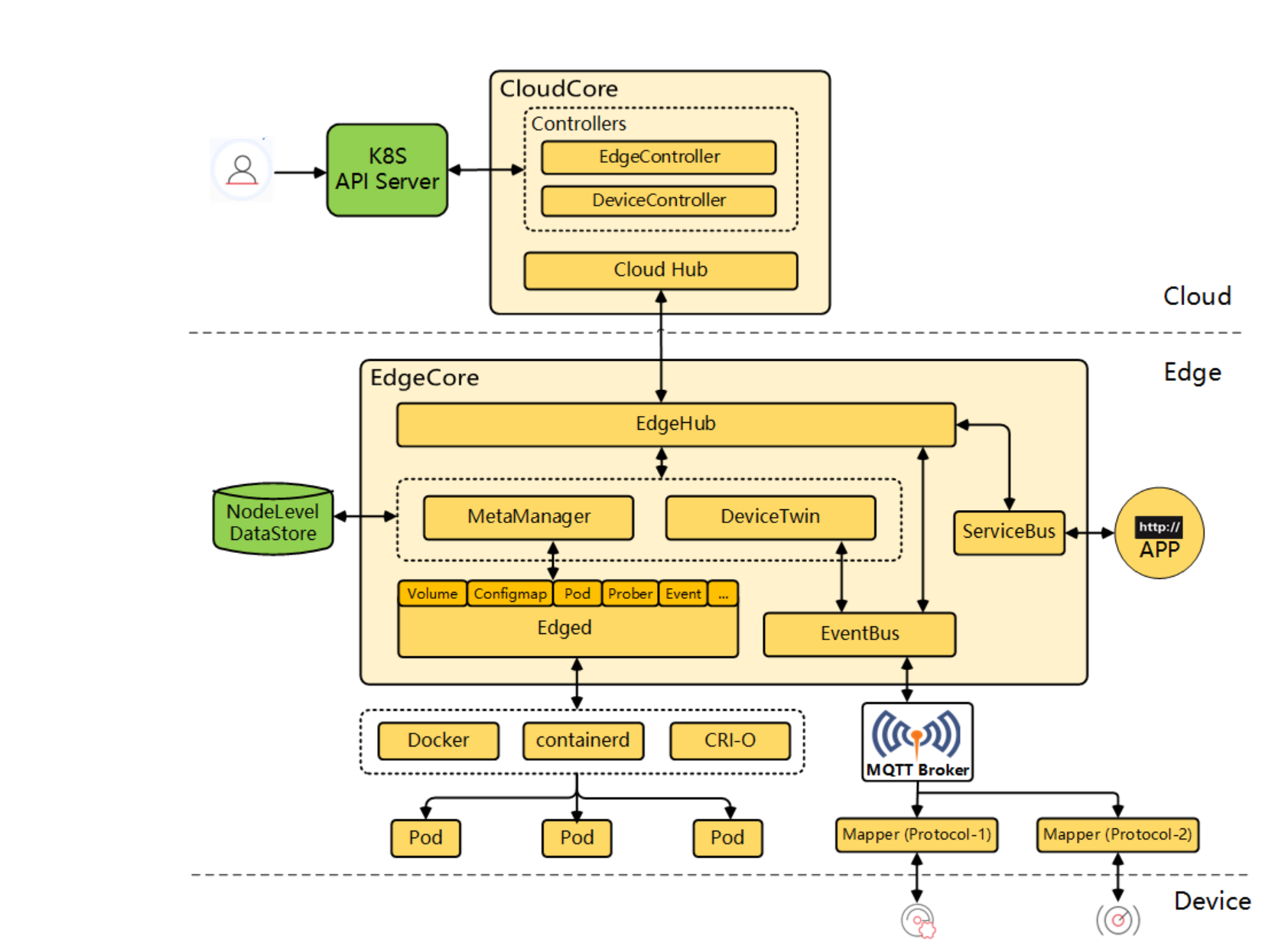
从这张架构设计图当中,我们可以看出Edge就是边缘端和云端类似的,它也运行着一个自己的应用叫做EdgeCore,EdgeCore6个组成部分,
其中EdgeHub我们前面在讲云边通信方式的时候已经提到过,它是负责整个边缘的一个流量的入口和出口的,然后所以说我们的重点就是要去看一下这5个部分,它们是怎样去工作的,以及它们如何去协同工作的。
它们分别就是 Edged 就是边缘的一个后台进程,这是边缘的一个核心模块。
然后就是MetaManager 原数据管理,
代码写注释
还有就是DeviceTwin 设备孪生,
另外是 EventBus/ServiceBus。
下面我们就来去看一下这些模块是如何工作的。
下面我们来看第一个Edged 的模块,Edged 作为边缘端的一个核心模块,它的功能非常的多,这边一共有11个功能模块,

虽然说分了11个模块,但是它其实就逃不开5个组成部分。第一个就是 Pod 的管理对应的这两部分,

它是属于 Pod 的创建、更新、删除,以及 Pod 用什么容器的运行时,它是属于这部分的管理。
然后另外一个就是 Pod 的监控,
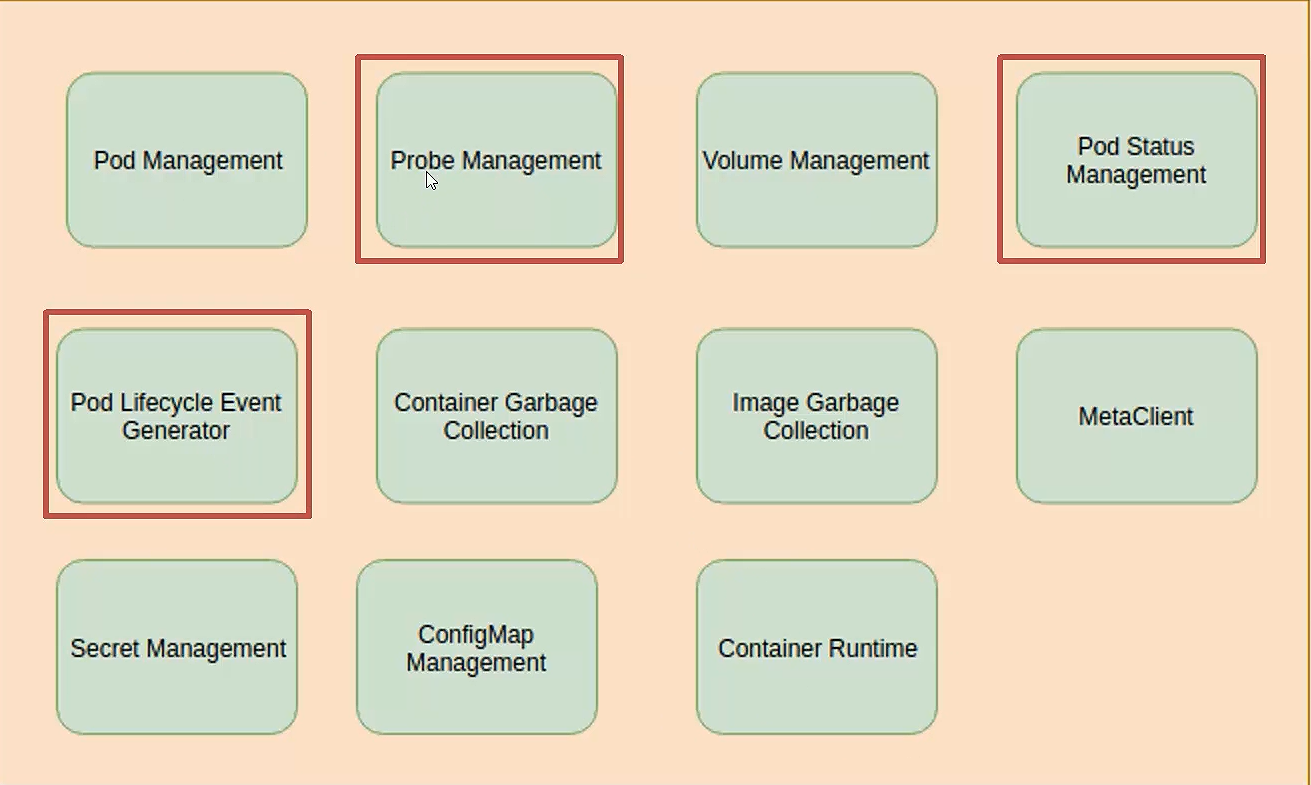
它对应的就是这三个部分,探针管理,Pod的状态管理,以及Pod的生命周期的管理 简称pleg,
这三个部分是和 Pod 的生命周期,以及它的监控,以及它的上报相关的,然后这是第二个部分。
然后第三个部分的话就是它的Edged管理 我们Pod的卷的管理,

分别对应 Volume Management和Secret Management以及ConfigMap Management。
Secret Management以及ConfigMap Management 为什么归为卷管理?其实因为相当于就是说Secret和ConfigMap,我们在用的时候其实相当于通过挂载卷的方式来使用它们,所以把它这三个统一归纳为 Pod的卷管理。
然后第四部分就是Pod的垃圾回收,

Pod的话我们其实本质其实也是通过镜像去运行,然后运行成容器,所以如果它就会产生很多的一些GC相关的一些东西,所以说这边是它的一个垃圾回收,这是它第四个组成部分。
然后最后一个就是 MetaClient,
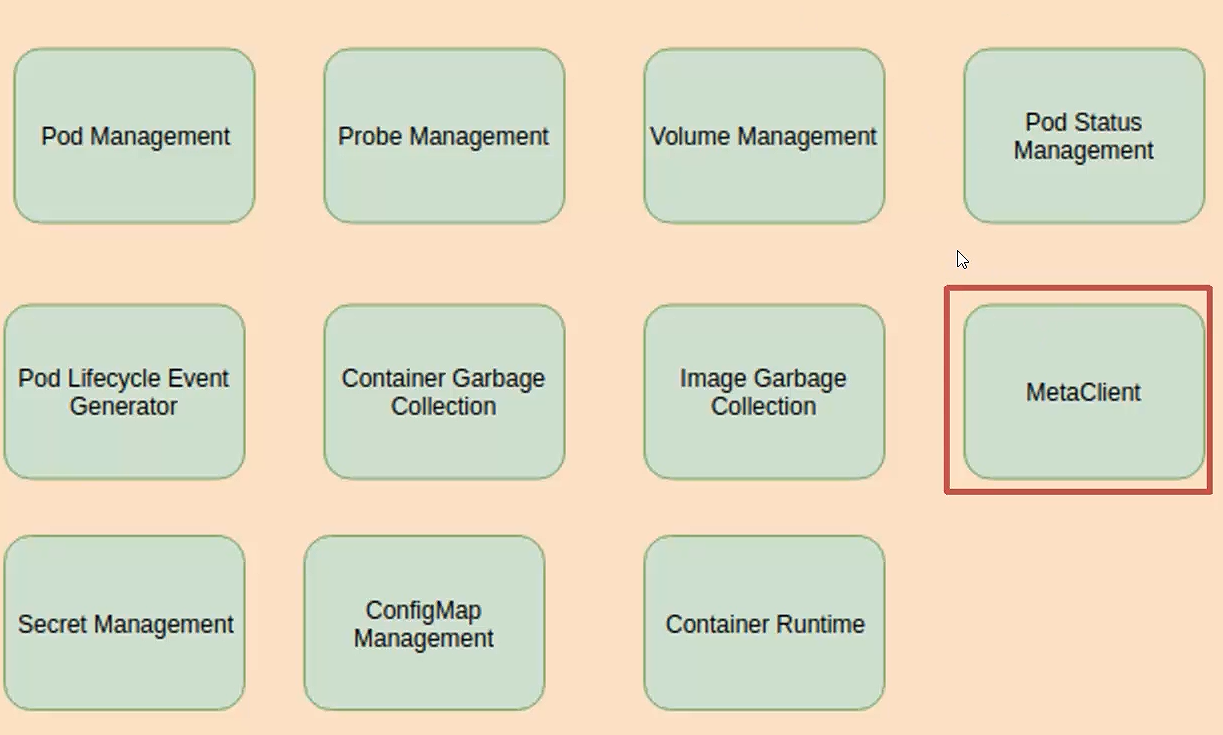
这个MetaClient因为我们不是有一个模块是原数据管理嘛,我们从云端拉下来的数据不是直接给到Edged这边的,
而是通过MetaManager进行缓存,具体MetaManager是如何缓存的?一会我们讲。
然后MetaClient就是MetaManager 把数据给拉过来,然后这样解决一个什么问题?
当我们云和边断开之后,MetaManager 由于把数据已经缓存下来了,MetaClient就保证从MetaManager那里能够取到数据,
就能保证Edged 这些 Pod 它能够照常的运行,
只是说它的状态不能完成上传到云端而已,仅此而已。
所以说我们离线状态下 Pod 依然能够照常的运行,这个是 Edged 它相关的一些功能模块。
紧接着我们就去看一下 MetaManager 的功能,
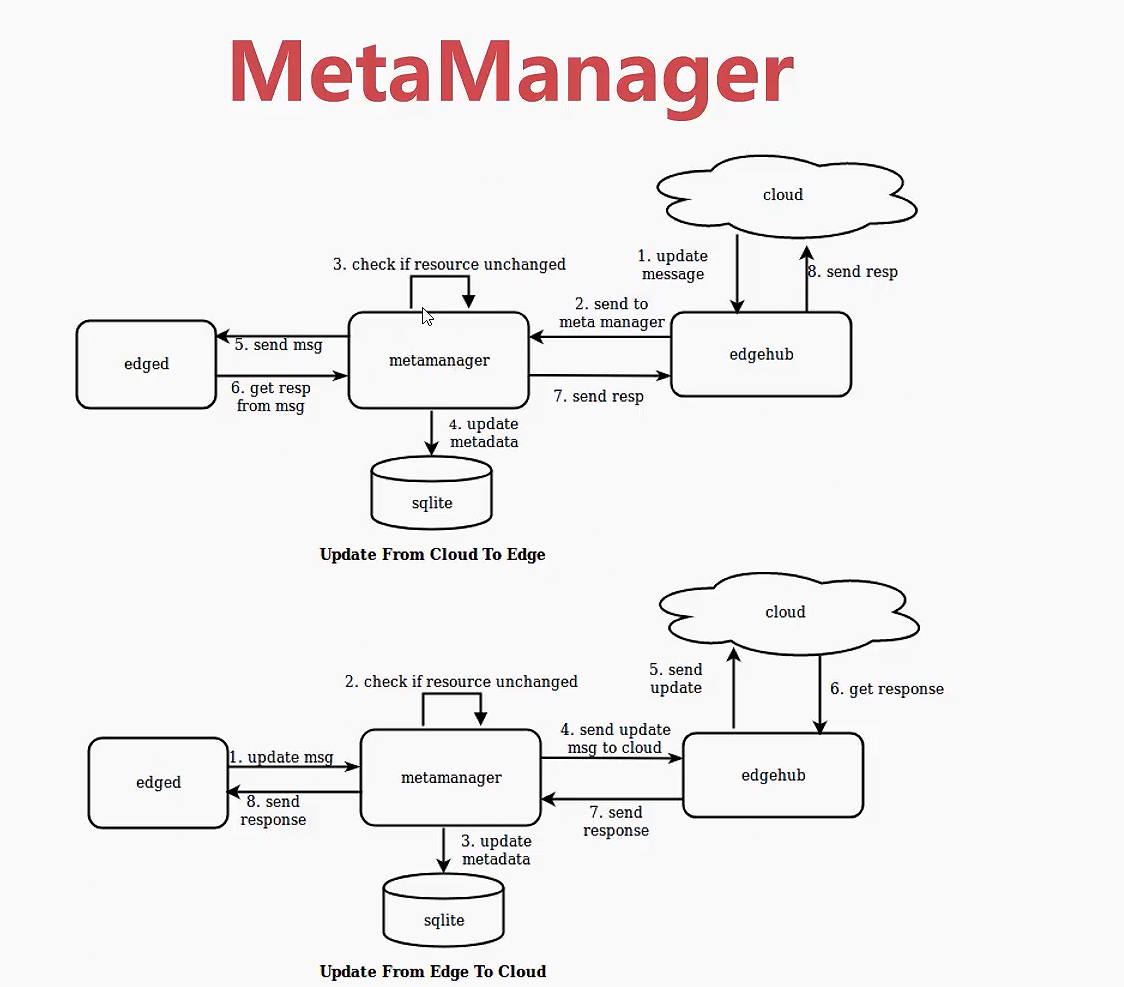
MetaManager的话,我们从这张图上可以看出,它是作为一个中间数据的缓存,它 用的数据库就是 sqlite,sqlite就是轻量级的数据库,
说明我们这些数据量不大,都是一些源数据。然后云端它发到边缘端这边是通过 edgehub,
我们知道通过边缘端的网络的代理去把数据接过来,接过来之后它是先把它存到 MetaManager 里面,
然后 edged 再从 MetaManager 里面去请求数据,
然后从边到云也是一个类似的道理,
edged 它计算的结果,它不会说直接发给edgehub,由edgehub直接上报到云端,
而是通过edged发到 MetaManager 作为一个中间缓存。这样的话哪怕我们 edgehub 它发布到云端,也就是网络断开的情况下,它会把它的状态一直存在 MetaManager 里面,直到网络恢复之后,再通过 edgehub 上传到我们的云端。
那么总结一下MetaManager 它要解决的问题如下,
我们云和边网络断开情况下,服务依然能够照常运行的问题,然后这也是 MetaManager的一个功能。
下面我们来看一个和MetaManager类似的一个功能模块,叫做DeviceTwin,这边是它的从云到边的一个流向图,

这边从云端它发送这个消息发到edgehub,它发送了什么消息,这个和我们前面讲云端架构设计那里就串联起来了。
我们讲云端架构设计那里,

有两个 Controller,一个是EdgeController,还有一个就是DeviceController,
DeviceController它就监听KubeEdge,在KubeEdge下面的自定义资源,device和device model的资源的状态。
那么其实device它也是一些字段的信息,然后由DeviceController发给CloudHub,由CloudHub再发到EdgeHub,
其实发过来的就是一些字段的信息,严格来说就是一个字段,它的期望值和实际值的这样一个信息,
然后发到这边,发这边的话也不是说直接就发到EventBus这边,由EventBus直接使用,而是通过DeviceTwin这种方式把它给缓存下来。
然后这样的好处就在于当我们云端和网络和边缘端断开之后,然后EventBus它用到的指令 就是缓存下来的指令,
同样的从边到云也是类似的道理,
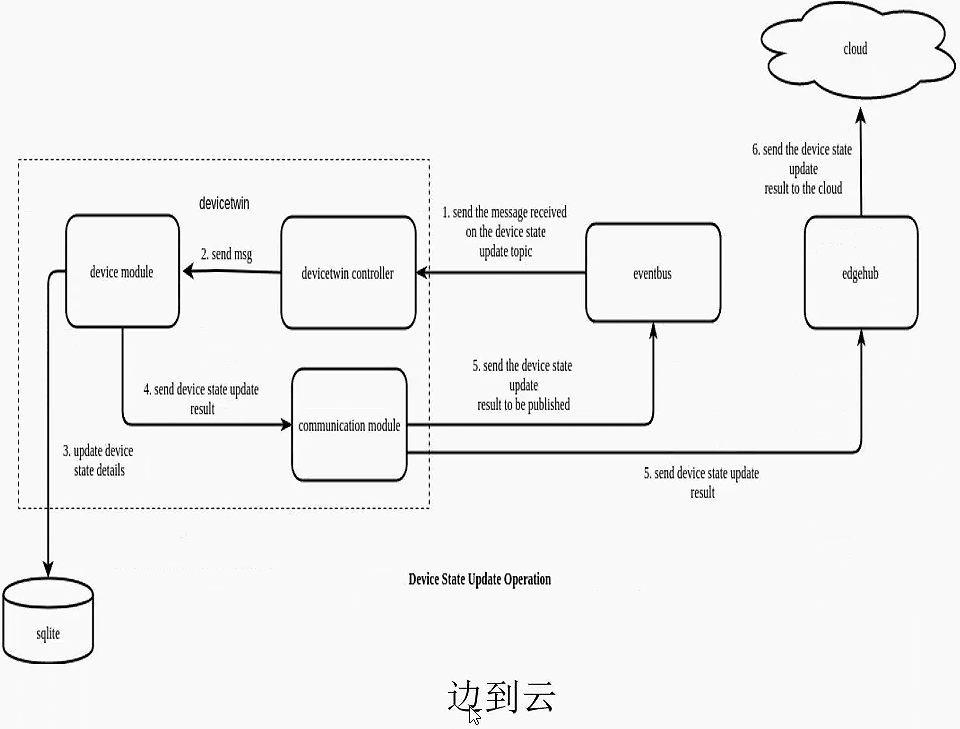
EventBus它会更改它的状态。就之前我们举了一个例子就是温度的例子,假设云端希望的是23度,然后边缘端这边通过去改变,通过去调节一些设备,导致我们的温度变成24度,它也要把实际值进行上报。但是如果这边它就是断开了,然后EventBus就不能把它的实际的状态完成上报,
所以说就一直存在DeviceTwin里面,直到网络恢复,它把它的实际的状态再进行上报,这样的话云端就能够获取到当前的一个运行的状态。
DeviceTwin 它能实现的原理和我们上面讲的 MetaManager 原理是一样的,让我们云边网络断开的情况下能够照常的运行,只有它们解决的问题不一样,
MetaManager要解决的是我们的 Pod 运行问题,
然后 DeviceTwin 它解决的是我们边缘端接入的设备的运行问题,这是DeviceTwin的功能。
下面我们来看一下KubeEdge边缘端的另外的两个功能模块,分别是ServiceBus和EventBus,这两个模块它们的相似之处都在于它们都是属于是消息总线,那么既然是消息的话,对实时性要求就要高一些,就不像这种DeviceTwin它把数据先缓存下来,再发到EventBus这边,
然后这边的话通过云端发到 EdgeHub,EdgeHub直接就要发到EventBus,或者是ServiceBus上面,然后马上进行一些处理。
同时边缘端,云端去报也是类似的道理,它也不经过缓存了,它直接发到 EdgeHub,由 EdgeHub直接上升到云端,这是两个消息总线的功能。
关注我,为思考点赞!