kubernetes api-server Overview
tags: api-server
文章目录

{% youtube %}
https://www.youtube.com/watch?v=_65Md2qar14
{% endyoutube %}
1. 简介
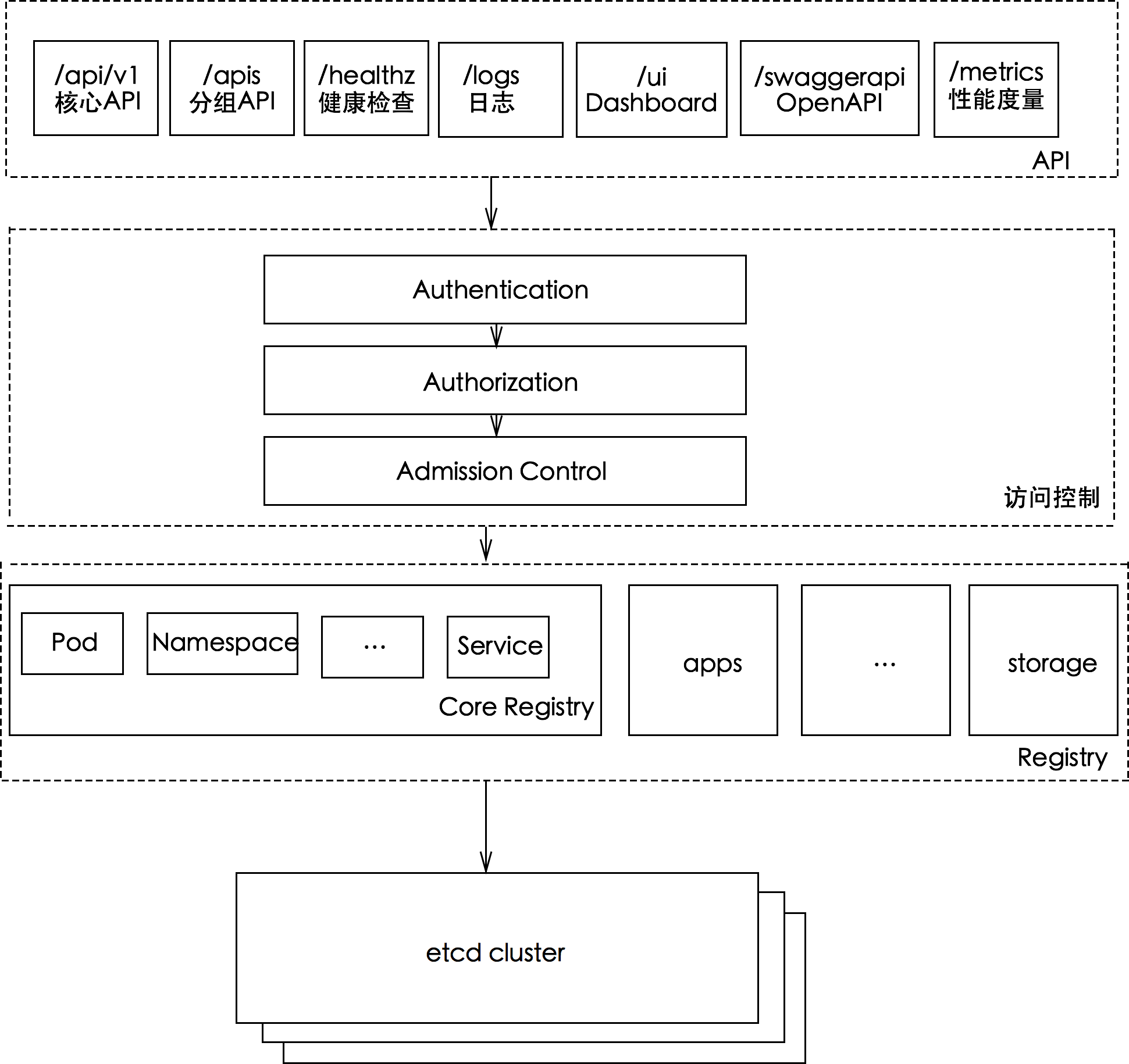
api server 是 Kubernetes 集群的网关。它是 Kubernetes 集群中的所有用户、自动化和组件都可以访问的中心接触点。API Server通过 HTTP 实现 RESTful API,执行所有 API 操作,并负责将 API 对象存储到持久存储后端。
2. 特征
尽管 Kubernetes API Server很复杂,但从管理的角度来看,实际上管理起来相对简单。因为 API Server的所有持久状态都存储在 API Server外部的数据库中,所以服务器本身是无状态的,可以复制以处理请求负载和容错。通常,在高可用集群中,API Server会被复制 3 次。
API Server输出的日志可能非常健谈。它为接收到的每个请求至少输出一行。因此,将某种形式的日志滚动添加到 API Server非常重要,这样它就不会消耗所有可用的磁盘空间。但是,由于 API Server日志对于理解 API Server的操作至关重要,我们强烈建议将日志从 API Server传送到日志聚合服务,以便后续自省和查询以调试用户或组件对 API 的请求。
3. 组成
操作 Kubernetes API Server涉及三个核心功能:
-
API management
服务器公开和管理 API 的过程 -
Request processing
处理来自客户端的单个 API 请求的最大功能集 -
Internal control loops
负责 API Server成功运行所需的后台操作的内部人员。扫描二维码关注公众号,回复: 14487234 查看本文章
4. 原理
kube-apiserver 提供了 Kubernetes 的 REST API,实现了认证、授权、准入控制等安全校验功能,同时也负责集群状态的存储操作(通过 etcd)。
以 /apis/batch/v2alpha1/jobs 为例,GET 请求的处理过程如下图所示:
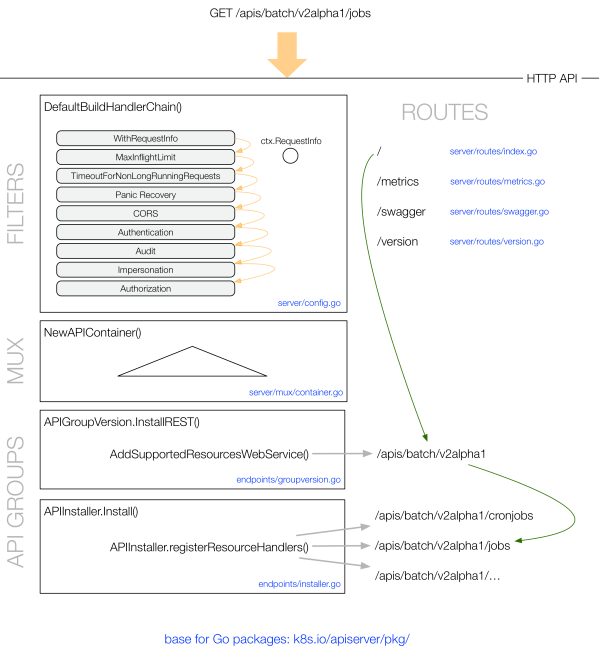
POST 请求的处理过程为:

(图片来自 OpenShift Blog)
5. 命令参数
查看资源与版本
$ kubectl api-versions
admissionregistration.k8s.io/v1beta1
apiextensions.k8s.io/v1beta1
apiregistration.k8s.io/v1
apiregistration.k8s.io/v1beta1
apps/v1
apps/v1beta1
apps/v1beta2
authentication.k8s.io/v1
authentication.k8s.io/v1beta1
authorization.k8s.io/v1
authorization.k8s.io/v1beta1
autoscaling/v1
autoscaling/v2beta1
batch/v1
batch/v1beta1
certificates.k8s.io/v1beta1
events.k8s.io/v1beta1
extensions/v1beta1
metrics.k8s.io/v1beta1
networking.k8s.io/v1
policy/v1beta1
rbac.authorization.k8s.io/v1
rbac.authorization.k8s.io/v1beta1
scheduling.k8s.io/v1beta1
storage.k8s.io/v1
storage.k8s.io/v1beta1
v1
$ kubectl api-resources --api-group=storage.k8s.io
NAME SHORTNAMES APIGROUP NAMESPACED KIND
storageclasses sc storage.k8s.io false StorageClass
volumeattachments storage.k8s.io false VolumeAttachment
尽管 API 的主要用途是为单个客户端请求提供服务,但在处理 API 请求之前,客户端必须知道如何发出 API 请求。最终,API Server是一个 HTTP 服务器——因此,每个 API 请求都是一个 HTTP 请求。但是必须描述这些 HTTP 请求的特征,以便客户端和服务器知道如何通信。出于探索的目的,让 API Server实际启动并运行非常好,这样您就可以对它进行探索。您可以使用您有权访问的现有 Kubernetes 集群,也可以将minikube 工具用于本地 Kubernetes 集群。为了便于使用该curl工具来探索 API Server,请kubectl在proxy使用以下命令在 localhost:8001 上公开未经身份验证的 API Server的模式:
kubectl proxy
6. API 路径
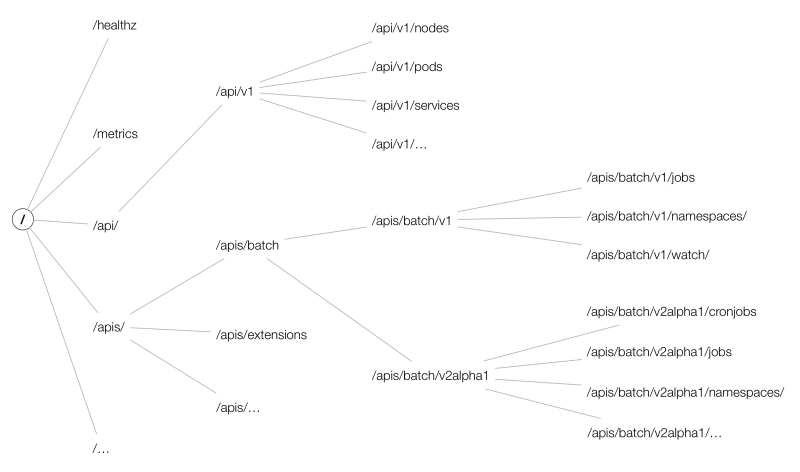
对 API Server的每个请求都遵循 RESTful API 模式,其中请求由请求的 HTTP 路径定义。所有 Kubernetes 请求都以前缀/api/(核心 API)或/apis/(按 API 组分组的 API)开头。这两组不同的路径主要是历史性的。API 组最初不存在于 Kubernetes API 中,因此原始或“核心”对象,如 Pod 和Services,在没有 API 组的情况下维护在'/api/'前缀下。后续 API 一般都添加在 API 组下,因此它们遵循’/apis/<api-group>/'路径。例如,该Job对象是batch API 组的一部分,因此可以在/apis/batch/v1/...下找到。
资源路径的另一个问题是资源是否已命名空间。Namespaces在 Kubernetes 中为对象添加了一层分组,命名空间资源只能在命名空间内创建,并且该命名空间的名称包含在命名空间资源的 HTTP 路径中。当然,有些资源并不存在于命名空间中(最明显的例子是NamespaceAPI 对象本身),在这种情况下,它们的 HTTP 路径中没有命名空间组件。
以下是命名空间资源类型的两种不同路径的组成部分:
-
/api/v1/namespaces/<namespace-name>/<resource-type-name>/<resource-name> -
/apis/<api-group>/<api-version>/namespaces/<namespace-name>/<resource-type-name>/<resource-name>
以下是非命名空间资源类型的两种不同路径的组成部分:
-
/api/v1/<resource-type-name>/<resource-name> -
/apis/<api-group>/<api-version>/<resource-type-name>/<resource-name>
7. 管理 Request
Kubernetes 中 API Server的主要用途是接收和处理 HTTP 请求形式的 API 调用。这些请求要么来自 Kubernetes 系统中的其他组件,要么是最终用户请求。无论哪种情况,它们都由 Kubernetes API Server以相同的方式处理。
7.1 Requests 类型
-
GET
最简单的请求是GET对特定资源的请求。这些请求检索与特定资源关联的数据。例如,对路径/api/v1/namespaces/default/pods/foo的 HTTP请求检索名为foo的 Pod 的数据。 -
LIST
一个稍微复杂但仍然相当简单的请求是acollectionGET或LIST。这些是列出许多不同请求的请求。例如,对路径/api/v1/namespaces/default/podsGET的 HTTP请求检索命名空间中所有 Pod 的集合。requests 还可以选择指定标签查询,在这种情况下,仅返回与该标签查询匹配的资源。 -
POST
要创建资源,需要使用POST请求。请求的主体是应该创建的新资源。在POST请求的情况下,路径是资源类型(例如,/api/v1/namespaces/default/pods)。要更新现有资源,需要PUT向特定资源路径(例如/api/v1/namespaces/default/pods/foo)发出请求。 -
DELETE
当需要删除请求时,将使用DELETE对资源路径(例如/api/v1/namespaces/default/pods/foo)的 HTTP 请求。请务必注意,此更改是永久性的——在发出 HTTP 请求后,资源将被删除。
所有这些请求的内容类型通常是基于文本的 JSON ( application/json),但最近发布的 Kubernetes 也支持 Protocol Buffers 二进制编码。一般来说,JSON 更适合客户端和服务器之间网络上的人类可读和可调试流量,但解析起来更加冗长和昂贵。常用工具 curl,可以提高 API 请求的性能和吞吐量。
除了这些标准请求之外,许多请求还使用 WebSocket 协议来启用客户端和服务器之间的流式会话。此类协议的示例类似attach命令。
7.2 Request 生命周期
为了更好地理解 API Server对每个不同的请求做了什么,我们将拆开并描述对 API Server的单个请求的处理。
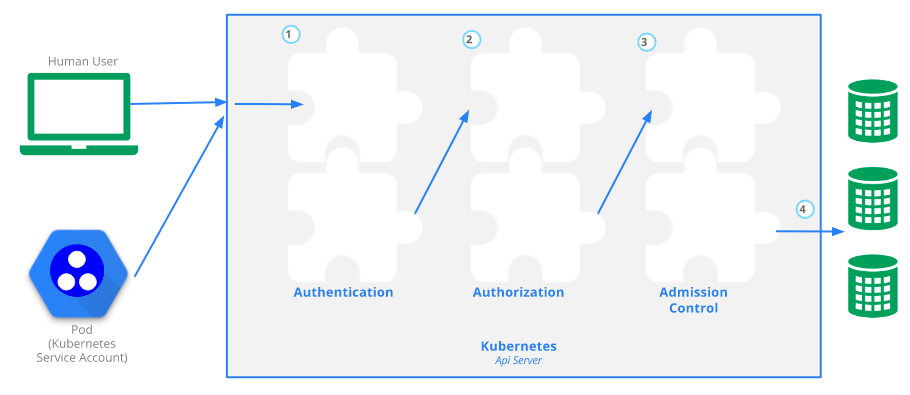
7.2.1 Authentication(认证)
请求处理的第一阶段是身份验证,它建立与请求关联的身份。API Server支持多种不同的身份建立模式,包括客户端证书、承载令牌和 HTTP 基本身份验证。一般来说,应该使用客户端证书或不记名令牌进行身份验证;不鼓励使用 HTTP 基本身份验证。
除了这些建立身份的本地方法之外,身份验证是可插入的,并且有几个使用远程身份提供者的插件实现。其中包括对 OpenID Connect (OIDC) 协议以及 Azure Active Directory 的支持。这些身份验证插件被编译到 API Server和客户端库中。这意味着您可能需要确保命令行工具和 API Server的版本大致相同或支持相同的身份验证方法。
API Server还支持基于远程 webhook 的身份验证配置,其中身份验证决策通过不记名令牌转发委托给外部服务器。外部服务器验证来自最终用户的不记名令牌,并将身份验证信息返回给 API Server
7.2.2 RBAC/授权
在 API Server确定请求的身份后,它会继续对其进行授权。对 Kubernetes 的每个请求都遵循传统的 RBAC 模型。要访问请求,身份必须具有与请求关联的适当角色。Kubernetes RBAC 是一个丰富而复杂的话题,因此,我们用一整章的时间来详细介绍RBAC它的运作方式。就本 API Server摘要而言,在处理请求时,API Server会确定与请求关联的身份是否可以访问请求中的动词和 HTTP 路径的组合。如果请求的身份具有适当的角色,则允许继续。否则,返回 HTTP 403 响应。
7.2.3 Admission control(准入控制)
在请求经过身份验证和授权后,它会进入准入控制。身份验证和 RBAC 确定是否允许发生请求,这基于请求的 HTTP 属性(标头、方法和路径)。准入控制确定请求是否格式正确,并可能在处理请求之前对其进行修改。准入控制定义了一个可插拔的接口:
- apply(request): (transformedRequest, error)
如果任何准入控制器发现错误,则拒绝该请求。如果请求被接受,则使用转换后的请求而不是初始请求。准入控制器被串行调用,每个接收前一个的输出。
因为准入控制是一种通用的、可插入的机制,所以它被用于 API Server中的各种不同功能。例如,它用于向对象添加默认值。它还可以用于强制执行策略(例如,要求所有对象都具有特定标签)。此外,它还可以用来做一些事情,比如向每个 Pod 注入一个额外的容器。服务网格 Istio 使用这种方法透明地注入其 sidecar 容器。
准入控制器非常通用,可以通过基于 webhook 的准入控制动态添加到 API Server。
7.2.4 Validation(验证)
请求验证发生在准入控制之后,尽管它也可以作为准入控制的一部分来实现,尤其是对于基于 Webhook 的外部验证。此外,仅对单个对象执行验证。如果它需要更广泛的集群状态知识,则必须将其实现为准入控制器。
请求验证确保请求中包含的特定资源有效。例如,它确保Service对象的名称符合 DNS 名称的规则,因为最终 a 的名称Service将被编程到 KubernetesService发现 DNS 服务器中。通常,验证是作为按资源类型定义的自定义代码来实现的。
7.3 特殊 requests
除了标准的 RESTful 请求之外,API Server还有许多专门的请求模式,为客户端提供扩展功能:
/proxy, /exec, /attach, /logs
第一类重要的操作是与 API Server的开放的、长时间运行的连接。这些请求提供流数据而不是立即响应。
该logs操作是我们描述的第一个流式请求,因为它最容易理解。事实上,默认情况下,logs根本不是流式传输请求。/logs客户端通过附加到特定 Pod 的路径末尾(例如 /api/v1/namespaces/default/pods/some-pod/logs)然后指定容器名称来请求获取 Pod 的日志作为 HTTP 查询参数和 HTTP GET请求。给定一个默认请求,API Server会以纯文本形式返回截至当前时间的所有日志,然后关闭 HTTP 请求。但是,如果客户端请求跟踪日志(通过指定follow查询参数),HTTP 响应由 API Server保持打开状态,并且在通过 API Server从 kubelet 接收新日志时将新日志写入 HTTP 响应。这种连接如图 4-1所示。。

logs是最容易理解的流式传输请求,因为它只是让请求保持打开状态并流入更多数据。其余操作利用 WebSocket 协议进行双向流数据。它们实际上还对这些流中的数据进行了多路复用,以通过 HTTP 启用任意数量的双向流。如果这一切听起来有点复杂,它确实是,但它也是 API Server表面区域的一个有价值的部分。
API Server实际上支持两种不同的流协议。它支持 SPDY 协议,以及 HTTP2/WebSocket。SPDY 正在被 HTTP2/WebSocket 取代,因此我们将注意力集中在 WebSocket 协议上。
完整的 WebSocket 协议超出了本书的范围,但它在许多其他地方都有记录。为了理解 API Server,您可以简单地将 WebSocket 视为一种将 HTTP 转换为双向字节流协议的协议。
然而,在这些流之上,Kubernetes API Server实际上引入了一个额外的多路复用流协议。这样做的原因是,对于许多用例,API Server能够为多个独立的字节流提供服务是非常有用的。例如,考虑在容器中执行命令。在这种情况下,实际上需要维护三个流(stdin、stderr和stdout)。
此流的基本协议如下:为每个流分配一个从 0 到 255 的数字。该流编号用于输入和输出,它在概念上模拟单个双向字节流。
对于通过 WebSocket 协议发送的每一帧,第一个字节是流号(例如,0),帧的其余部分是在该流上传输的数据(图 4-2)。
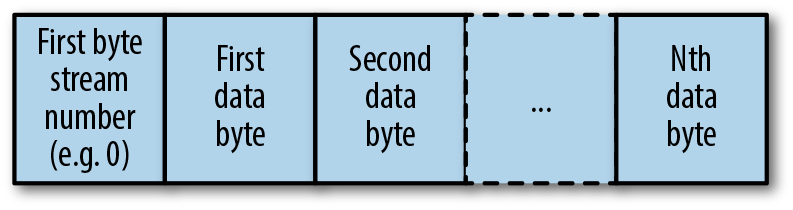
图 4-2。Kubernetes WebSocket 多通道框架的示例
使用此协议和 WebSockets,API Server可以在单个 WebSocket 会话中同时多路复用 256 字节流。
此基本协议用于会话exec,attach具有以下通道:
-
0
stdin用于写入进程的流。不会从此流中读取数据。 -
1
用于从进程stdout读取的输出流。stdout不应将数据写入此流。 -
2
用于从进程stderr读取的输出流。stderr不应将数据写入此流。
endpoint用于在/proxy客户端与集群内运行的容器和服务之间转发网络流量,而这些endpoint不会暴露在外部。为了流式传输这些 TCP 会话,协议稍微复杂一些。除了多路复用各种流之外,流的前两个字节(在流号之后,所以实际上是 WebSockets 帧中的第二和第三个字节)是正在转发的端口号,因此单个 WebSockets 帧用于/proxy查找如图4-3 所示。

7.4 Watch operations
除了流式数据,API Server还支持 watch API。watch监视更改的路径。因此,不是在某个时间间隔轮询可能的更新,这会引入额外的负载(由于快速轮询)或额外的延迟(由于慢速轮询),使用watch使用户能够通过单个连接获得低延迟更新。当用户通过向?watch=true某个 API Server请求添加查询参数来建立到 API Server的监视连接时,API Server切换到监视模式,并保持客户端和服务器之间的连接打开。同样,API Server返回的数据不再只是 API 对象——它是一个Watch包含更改类型(创建、更新、删除)和 API 对象本身的对象。通过这种方式,客户端可以观察和观察对该对象或对象集的所有更改。
7.5 乐观并发更新
API Server支持的另一个高级操作是能够乐观地执行 Kubernetes API 的并发更新。乐观并发背后的想法是能够在不使用锁的情况下执行大多数操作(悲观并发),并检测何时发生并发写入,拒绝两个并发写入中的后者。被拒绝的写入不会重试(由客户端检测冲突并自己重试写入)。
要理解为什么需要这种乐观并发和冲突检测,了解读/更新/写竞争条件的结构很重要。许多 API Server客户端的操作涉及三个操作:
- 从 API Server读取一些数据。
- 更新内存中的数据。
- 将其写回 API Server。
现在想象一下当这两种读/更新/写模式同时发生时会发生什么。
- 服务器 A 读取对象 O。
- 服务器 B 读取对象 O。
- 服务器 A 更新客户端内存中的对象 O。
- 服务器 B 更新客户端内存中的对象 O。
- 服务器 A 写入对象 O。
- 服务器 B 写入对象 O。
最后,服务器 A 所做的更改将丢失,因为它们被服务器 B 的更新覆盖。
解决这场比赛有两种选择。第一个是悲观锁(pessimistic lock),它可以防止在服务器 A 对对象进行操作时发生其他读取。这样做的问题是它会序列化所有操作,这会导致性能和吞吐量问题。
Kubernetes API Server实现的另一个选项是乐观并发(optimistic concurrency),它假设一切都会顺利进行,并且仅在尝试写入冲突时才检测到问题。为此,对象的每个实例都返回其数据和资源版本。此资源版本指示对象的当前迭代。发生写入时,如果设置了对象的资源版本,则只有当前版本与对象的版本匹配,才能写入成功。如果没有,则返回 HTTP 错误 409(冲突)并且客户端发霉重试。要了解这如何解决刚刚描述的读/更新/写竞争,让我们再次看一下操作:
- 服务器 A 读取版本为 v1 的对象 O。
- 服务器 B 读取版本为 v1 的对象 O。
- 服务器 A 在客户端的内存中更新版本为 v1 的对象 O。
- 服务器 B 更新客户端内存中版本 v1 的对象 O。
- 服务器 A 以版本 v1 写入对象 O;这是成功的。
- 服务器B在v1版本写入对象O,但对象在v2;返回 409 冲突。
8. 访问 API Server
有多种方式可以访问 Kubernetes 提供的 REST API:
- kubectl 命令行工具
- SDK,支持多种语言
- Go
- Python
- Javascript
- Java
- CSharp
其他 OpenAPI 支持的语言,可以通过 gen 工具生成相应的 client
8.1 kubectl
kubectl get --raw /api/v1/namespaces
kubectl get --raw /apis/metrics.k8s.io/v1beta1/nodes
kubectl get --raw /apis/metrics.k8s.io/v1beta1/pods
8.2 kubectl proxy
当然,为了能够向 API 发出请求,有必要了解客户端可以使用哪些 API 对象。此过程通过客户端的 API 发现进行。要查看此过程的实际效果并以更实际的方式探索 API Server,我们可以自己执行此 API 发现。
首先,为了简化事情,我们使用kubectl命令行工具的内置proxy来为我们的集群提供身份验证
$ kubectl proxy --port=8080 &
$ curl http://localhost:8080/api/
{
"versions": [
"v1"
]
}
或者
kubectl proxy
这将创建一个在本地计算机上的端口 8001 上运行的简单服务器。
我们可以使用这个服务器来启动 API 发现的过程。我们首先检查/api前缀:
$ curl localhost:8001/api
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.0.1:6443"
}
]
}
您可以看到服务器返回了一个类型为 的 API 对象APIVersions。这个对象为我们提供了一个versions字段,列出了可用的版本。
在这种情况下,只有一个,但对于/apis前缀,有很多。我们可以使用这个版本继续我们的调查:
$ curl localhost:8001/api/v1
{
"kind": "APIResourceList",
"groupVersion": "v1",
"resources": [
{
….
{
"name": "namespaces",
"singularName": "",
"namespaced": false,
"kind": "Namespace",
"verbs": [
"create",
"delete",
"get",
"list",
"patch",
"update",
"watch"
],
"shortNames": [
"ns"
]
},
…
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "Pod",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"proxy",
"update",
"watch"
],
"shortNames": [
"po"
],
"categories": [
"all"
]
},
{
"name": "pods/attach",
"singularName": "",
"namespaced": true,
"kind": "Pod",
"verbs": []
},
{
"name": "pods/binding",
"singularName": "",
"namespaced": true,
"kind": "Binding",
"verbs": [
"create"
]
},
….
]
}
返回的对象包含/api/v1/路径下暴露的资源列表。
描述 API(元 API 对象)的 OpenAPI/Swagger JSON 规范除了资源类型之外还包含各种有趣的信息。考虑Pod对象的 OpenAPI 规范:
{
"name": "pods",
"singularName": "",
"namespaced": true,
"kind": "Pod",
"verbs": [
"create",
"delete",
"deletecollection",
"get",
"list",
"patch",
"proxy",
"update",
"watch"
],
"shortNames": [
"po"
],
"categories": [
"all"
]
},
{
"name": "pods/attach",
"singularName": "",
"namespaced": true,
"kind": "Pod",
"verbs": []
}
查看此对象,该name字段提供此资源的名称。它还指示这些资源的子路径。由于推断英语单词的复数形式具有挑战性,因此 API 资源还包含一个singularName字段,该字段指示应用于该资源的单个实例的名称。我们之前讨论过命名空间。对象描述中的namespaced字段指示对象是否被命名空间。该kind字段提供了存在于 API 对象的 JSON 表示中的字符串,以指示它是什么类型的对象。该verbs字段是 API 对象中最重要的字段之一,因为它指示可以对该对象执行哪些类型的操作。这pods宾语包含所有可能的动词。动词的大部分效果从它们的名字就很明显了。需要更多解释的两个是watch和proxy。watch表示可以为资源建立监视。监视是一个长时间运行的操作,它提供有关对象更改的通知。proxy是一种专门的操作,它通过 API Server与网络端口建立代理网络连接。目前只有两种资源(Pod 和Services)支持proxy.
除了可以对对象执行的操作(描述为动词)之外,还有其他操作被建模为资源类型的子资源。例如,attach命令被建模为子资源:
{
"name": "pods/attach",
"singularName": "",
"namespaced": true,
"kind": "Pod",
"verbs": []
}
8.3 curl
$ TOKEN=$(cat /run/secrets/kubernetes.io/serviceaccount/token)
$ CACERT=/run/secrets/kubernetes.io/serviceaccount/ca.crt
$ curl --cacert $CACERT --header "Authorization: Bearer $TOKEN" https://$KUBERNETES_SERVICE_HOST:$KUBERNETES_SERVICE_PORT/api
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
$ APISERVER=$(kubectl config view | grep server | cut -f 2- -d ":" | tr -d " ")
$ TOKEN=$(kubectl describe secret $(kubectl get secrets | grep default | cut -f1 -d ' ') | grep -E '^token'| cut -f2 -d':'| tr -d '\t')
$ curl $APISERVER/api --header "Authorization: Bearer $TOKEN" --insecure
{
"kind": "APIVersions",
"versions": [
"v1"
],
"serverAddressByClientCIDRs": [
{
"clientCIDR": "0.0.0.0/0",
"serverAddress": "10.0.1.149:443"
}
]
}
9. 调试 API Server
当然,了解 API Server的实现是很好的,但通常情况下,您真正需要的是能够调试 API Server(以及调用 API 的客户端)的实际情况服务器)。实现这一点的主要方式是通过 API Server写入的日志。API Server导出两个日志流——the standard or basic logs,以及更有针对性的审计日志,它们试图捕获发出请求的原因和方式以及更改的 API Server状态。此外,可以打开更详细的日志记录来调试特定问题。
9.1 Basic Logs
默认情况下,API Server记录发送到 API Server的每个请求。此日志包括客户端的 IP 地址、请求的路径以及服务器返回的代码。如果意外错误导致服务器崩溃,服务器也会捕捉到这种恐慌,返回 500,并记录该错误。
I0803 19:59:19.929302 1 trace.go:76] Trace[1449222206]:
"Create /api/v1/namespaces/default/events" (started: 2018-08-03
19:59:19.001777279 +0000 UTC m=+25.386403121) (total time: 927.484579ms):
Trace[1449222206]: [927.401927ms] [927.279642ms] Object stored in database
I0803 19:59:20.402215 1 controller.go:537] quota admission added
evaluator for: {
namespaces}
在此日志中,您可以看到它以I0803 19:59:…发出日志行时的时间戳开始,然后是发出它的行号,trace.go:76最后是日志消息本身。
9.2 Audit Logs
审计日志(Audit Logs)旨在使服务器管理员能够取证恢复服务器的状态以及导致 Kubernetes API 中数据当前状态的一系列客户端交互。例如,它使用户能够回答诸如“为什么要ReplicaSet扩大到 100 个?”、“谁删除了那个 Pod?”等问题。
审计日志有一个可插入的后端,用于记录它们的写入位置。通常,审计日志会写入文件,但也可以将它们写入 webhook。在任何一种情况下,记录的数据都是API 组中类型event的结构化 JSON 对象audit.k8s.io。
审计本身可以通过同一 API 组中的策略对象进行配置。此策略允许您指定将审计事件发送到审计日志的规则。
9.3 激活附加日志
Kubernetes 使用 leveled logging github.com/golang/glog 包进行日志记录。使用 API Server上的标志--v,您可以调整日志记录的详细程度。一般来说,Kubernetes 项目已将日志详细级别 2 ( --v=2) 设置为记录相关但不太垃圾邮件的合理默认值。如果您正在调查特定问题,您可以提高日志记录级别以查看更多(可能是垃圾邮件)消息。由于过多的日志记录会影响性能,我们建议不要在生产中使用详细的日志级别运行。如果您正在寻找更有针对性的日志记录,该--vmodule标志可以提高单个源文件的日志级别。这对于仅限于一小部分文件的非常有针对性的详细日志记录非常有用。
9.4 调试 kubectl 请求
除了通过日志调试 API Server外,还可以通过kubectl命令行工具调试与 API Server的交互。与 API Server一样,kubectl命令行工具通过github.com/golang/glog包记录并支持–v详细度标志。将详细程度设置为级别 10 ( --v=10) 会启用最大程度详细记录。在此模式下,kubectl记录它向服务器发出的所有请求,以及尝试打印curl可用于复制这些请求的命令。请注意,这些curl命令有时不完整。
此外,如果您想直接戳 API Server,我们之前用于探索 API 发现的方法效果很好。Running kubectl proxy在 localhost 上创建一个代理服务器,它会根据本地$HOME/.kube/config文件自动提供您的身份验证和授权凭据。运行代理后,使用该curl命令查看各种 API 请求相当简单。
10. API 版本
在 Kubernetes 中,API 最初是一个 alpha API(例如,v1alpha1)。alpha 名称表示 API 不稳定且不适合生产用例。采用 alpha API 的用户应该预料到 API 表面区域可能会在 Kubernetes 版本之间发生变化,并且 API 本身的实现可能会不稳定,甚至可能会破坏整个 Kubernetes 集群的稳定性。因此,在生产 Kubernetes 集群中禁用了 Alpha API。
一旦 API 成熟,它就会成为 beta API(例如,v1beta1)。Beta 指定表明 API 通常是稳定的,但可能存在错误或最终的 API 表面改进。通常,假设 Kubernetes 版本之间的 beta API 是稳定的,并且向后兼容是一个目标。但是,在特殊情况下,Beta API 可能仍然在 Kubernetes 版本之间不兼容。同样,beta API 旨在保持稳定,但可能仍然存在错误。Beta API 通常在生产 Kubernetes 集群中启用,但应谨慎使用。
最后,API 变得普遍可用(例如,v1)。通用可用性 (GA) 表明 API 是稳定的。这些 API 带有向后兼容性保证和弃用保证。在 API 被标记为计划删除后,Kubernetes 会将该 API 保留至少三个版本或一年,以先到者为准。弃用也不太可能。只有在开发出更好的替代方案后,API 才会被弃用。同样,GA API 是稳定的,适用于所有生产用途。
Kubernetes 的特定版本可以支持多个版本(alpha、beta 和 GA)。为了实现这一点,API Server始终具有三种不同的 API 表示:外部表示,即通过 API 请求进入的表示;内部表示,它是在 API Server中用于处理的对象的内存表示;和存储表示,它被记录到存储层以持久化 API 对象。API Server中的代码知道如何在所有这些表示之间执行各种转换。API 对象可以作为v1alpha1版本提交,作为v1对象存储,然后作为v1beta1对象或任何其他任意支持的版本检索。
11. 替代编码
除了支持请求对象的 JSON 编码外,API Server还支持另外两种请求格式。请求的编码由请求上的 Content-Type HTTP 标头指示。如果缺少此标头,则假定内容为application/json,表示 JSON 编码。第一个替代编码是 YAML,由application/yamlContent Type 指示。YAML 是一种基于文本的格式,通常被认为比 JSON 更易于阅读。几乎没有理由使用 YAML 进行编码以与服务器通信,但在某些情况下它可能很方便(例如,通过 手动将文件发送到服务器curl)。
请求和响应的另一种替代编码是协议缓冲区编码格式。Protocol Buffers 是一个相当有效的二进制对象协议。使用协议缓冲区可以为 API Server带来更高效和更高吞吐量的请求。事实上,许多 Kubernetes 内部工具都使用协议缓冲区作为它们的传输。Protocol Buffers 的主要问题是,由于它们的二进制性质,它们在有线格式中更难可视化/调试。此外,目前并非所有客户端库都支持 Protocol Buffers 请求或响应。协议缓冲区格式由application/vnd.kubernetes.protobufContent-Type 标头指示。
12. 常见响应代码
因为 API Server是作为 RESTful 服务器实现的,所以来自服务器的所有响应都与 HTTP 响应代码保持一致。除了典型的 200 表示 OK 响应和 500 表示内部服务器错误之外,以下是一些常见的响应代码及其含义:
-
202
公认。已收到创建或删除对象的异步请求。结果以状态对象响应,直到异步请求完成,此时将返回实际对象。 -
400
错误的请求。服务器无法解析或理解该请求。 -
401
未经授权。在没有已知身份验证方案的情况下接收到请求。 -
403
禁止。已收到并理解请求,但禁止访问。 -
409
冲突。已收到请求,但它是更新旧版本对象的请求。 -
422
无法处理的实体。请求已正确解析,但未通过某种验证.
13. API Server Internals
除了操作 HTTP RESTful 服务的基础知识之外,API Server还有一些内部服务来实现部分 Kubernetes API。通常,这些类型的控制循环在称为控制器管理器的单独二进制文件中运行。但是有一些控制循环必须在 API Server内运行。在每种情况下,我们都会描述其功能以及它存在于 API Server中的原因。
14. CRD Control Loop
自定义资源定义 (CRD) 是可以添加到正在运行的 API Server的动态 API 对象。因为创建 CRD 的行为本质上会创建 API Server必须知道如何提供服务的新 HTTP 路径,所以负责添加这些路径的控制器位于 API Server内部。随着委托 API Server的增加(在后面的章节中描述),这个控制器实际上已经大部分从 API Server中抽象出来了。它目前仍默认在进程中运行,但也可以在进程外运行。
CRD 控制回路的操作如下:
for crd in AllCustomResourceDefinitions:
if !RegisteredPath(crd):
registerPath
for path in AllRegisteredPaths:
if !CustomResourceExists(path):
markPathInvalid(path)
delete custom resource data
delete path
自定义资源路径的创建相当简单,但自定义资源的删除稍微复杂一些。这是因为删除自定义资源意味着删除与该类型资源关联的所有数据。这样一来,如果 CRD 被删除,然后在稍后的某个日期被读取,旧数据就不会以某种方式复活。
因此,在可以删除 HTTP 服务路径之前,首先将该路径标记为无效,以便无法创建新资源。然后,与 CRD 关联的所有数据都被删除,最后,路径被删除。
15. OpenAPI 规范服务
当然,了解可用于访问 API Server的资源和路径只是访问 Kubernetes API 所需信息的一部分。除了 HTTP 路径之外,您还需要知道要发送和接收的 JSON 有效负载。API Server还提供路径,为您提供有关 Kubernetes 资源模式的信息。这些模式使用 OpenAPI(以前的 Swagger)语法表示。您可以在以下路径下拉 OpenAPI 规范:
/swaggerapi
在 Kubernetes 1.10 之前,服务于 Swagger 1.2- /openapi/v2
Kubernetes 1.10 及更高版本,服务于 OpenAPI (Swagger 2.0)
OpenAPI 规范本身就是一个完整的主题,超出了本书的范围。无论如何,您不太可能需要在 Kubernetes 的日常操作中访问它。然而,各种客户端编程语言库是使用这些 OpenAPI 规范生成的(值得注意的例外是 Go 客户端库,它目前是手动编码的)。因此,如果您或用户在通过客户端库访问 Kubernetes API 的某些部分时遇到问题,那么第一站应该是 OpenAPI 规范,以了解 API 对象是如何建模的。
参考: