一、进程管理
1、什么是进程
进程是已启动的可执行程序的运行实例,进程有以下组成部分:
• 已分配内存的地址空间;
• 安全属性,包括所有权凭据和特权;
• 程序代码的一个或多个执行线程;
程序: 二进制文件,静态 /bin/date, /usr/sbin/httpd,/usr/sbin/sshd, /usr/local/nginx/sbin/nginx等
进程: 是程序运行的过程, 动态,有生命周期及运行状态。
一个进程包含内核中的一部分地址空间和一系列数据结构。其中地址空间是内核标记的一部分内存以供进程使用,而数据结构则用来纪录每个进程的具体信息。
最主要的进程信息包括:
- 进程的地址空间图
- 进程当前的状态( sleeping、stopped、runnable 等)
- 进程的执行优先级
- 进程调用的资源信息
- 进程打开的文件和网络端口信息
- 进程的信号掩码(指明哪种信号被屏蔽)
- 进程的属主
进程类型有哪些?
守护进程: daemon,在系统引导过程中启动的进程,和终端无关进程。
前台进程:跟终端相关,通过终端启动的进程。
注意:两者可相互转化 。
用户和内核空间
进程,线程和协程
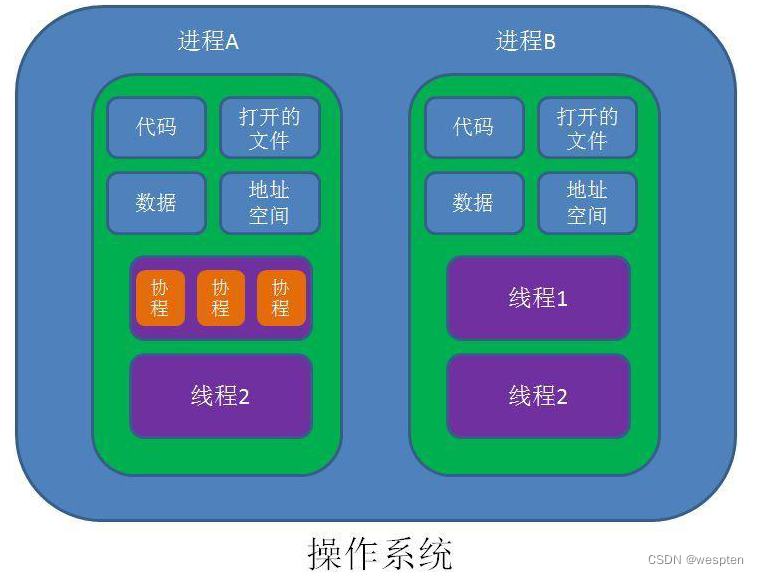
1)进程是资源分配的单位;
2)线程是CPU调度的单位;
3)协程是一种比线程更加轻量级的存在,协程不是被操作系统内核所管理,而完全是由程序所控制(也就是在用户态执行) ;
线程与进程区别
1)地址空间: 线程是进程内的一个执行单元,进程内至少有一个线程,它们共享进程的地址空间,而进程有自己独立的地址空间;
2)资源拥有: 进程是资源分配和拥有的单位,同一个进程内的线程共享进程的资源;
3)线程是处理器调度的基本单位,但进程不是;
4)二者均可并发执行;
5)每个独立的线程有一个程序运行的入口、顺序执行序列和程序的出口,但是线程不能够独立执行,必须依存在应用程序中,由应用程序提供多个线程执行控制;
协程与线程的区别
1)一个线程可以多个协程,一个进程也可以单独拥有多个协程;
2)线程进程都是同步机制,而协程则是异步;
3)协程能保留上一次调用时的状态,每次过程重入时,就相当于进入上一次调用的状态;
4)线程是抢占式,而协程是非抢占式的,所以需要用户自己释放使用权来切换到其他协程,因此同一时间其实只有一个协程拥有运行权,相当于单线程的能力;
5)协程并不是取代线程, 而且抽象于线程之上, 线程是被分割的CPU资源, 协程是组织好的代码流程, 协程需要线程来承载运行, 线程是协程的资源, 但协程不会直接使用线程, 协程直接利用的是执行器(Interceptor), 执行器可以关联任意线程或线程池, 可以使当前线程, UI线程, 或新建新程;
6)线程是协程的资源。协程通过Interceptor来间接使用线程这个资源;
2、进程的生命周期
进程状态转换模型
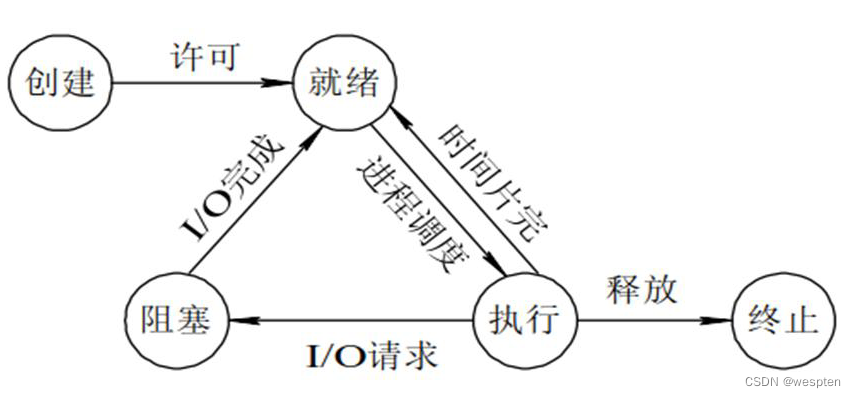
(1) 创建状态:
进程在创建时需要申请一个空白PCB(process control block进程控制块),向其中填写控制和管理进程的信息,完成资源分配。如果创建工作无法完成,比如资源无法满足,就无法被调度运行,把此时进程所处状态称为创建状态。
(2) 就绪状态:
进程已准备好,已分配到所需资源,只要分配到CPU就能够立即运行。
(3) 执行状态:
进程处于就绪状态被调度后,进程进入执行状态。
(4) 阻塞状态:
正在执行的进程由于某些事件(I/O请求,申请缓存区失败)而暂时无法运行,进程受到阻塞。在满足请求时进入就绪状态等待系统调用。
(5) 终止状态:
进程结束,或出现错误,或被系统终止,进入终止状态。无法再执行。
状态之间转换六种情况
(1) 运行——>就绪:
主要是进程占用CPU的时间过长,而系统分配给该进程占用CPU的时间是有限的;
在采用抢先式优先级调度算法的系统中,当有更高优先级的进程要运行时,该进程就被迫让出CPU,该进程便由执行状态转变为就绪状态;
(2) 就绪——>运行:
运行的进程的时间片用完,调度就转到就绪队列中选择合适的进程分配CPU。
(3) 运行——>阻塞:
正在执行的进程因发生某等待事件而无法执行,则进程由执行状态变为阻塞状态,如发生了I/O请求。
(4) 阻塞——>就绪:
进程所等待的事件已经发生,就进入就绪队列。
以下两种状态是不可能发生的:
(5) 阻塞——>运行:
即使给阻塞进程分配CPU,也无法执行,操作系统在进行调度时不会从阻塞队列进行挑选,而是从就绪队列中选取。
(6) 就绪——>阻塞:
就绪态根本就没有执行,谈不上进入阻塞态。
Linux中进程的生命周期
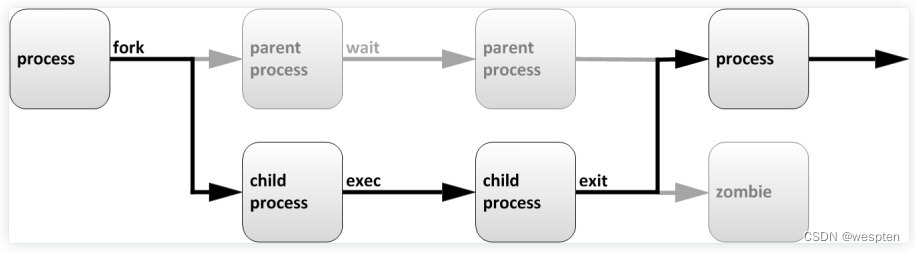
父进程复制自己的地址空间(fork)传建一个新的(子)进程结构。每个新进程分配一个唯一的进程ID(PID),满足跟踪安全性之需,PID和父进程(PPID)是子进程环境的元素,任何进程都可以创建子进程,所有进程都是第一个系统进程的后代:
Centos5/6: init
Centos7: systemd
子进程继承父进程的安全性身份、过去和当前的文件描述符,端口和资源特权,环境变量,以及程序代码。随后,子进程可能exec自己的程序代码,通常,父进程在子进程运行期间处于睡眠(sleeping)状态,当子进程完成时发出(exit)信号请求,在退出时,子进程已经关闭或丢弃了其资源环境,剩余的部分称为僵停(僵尸Zombie)。父进程在子进程退出时收到信号而被唤醒,清理剩余的结构,然后继续执行其自己的程序代码。
在多任务处理操作系统中,每个CPU(或核心)在一个时间点上只能处理一个进程。在进程运行时,它对CPU时间和资源分配的要求会不断变化,从而为进程分配一个状态,它随着环境要求而改变。
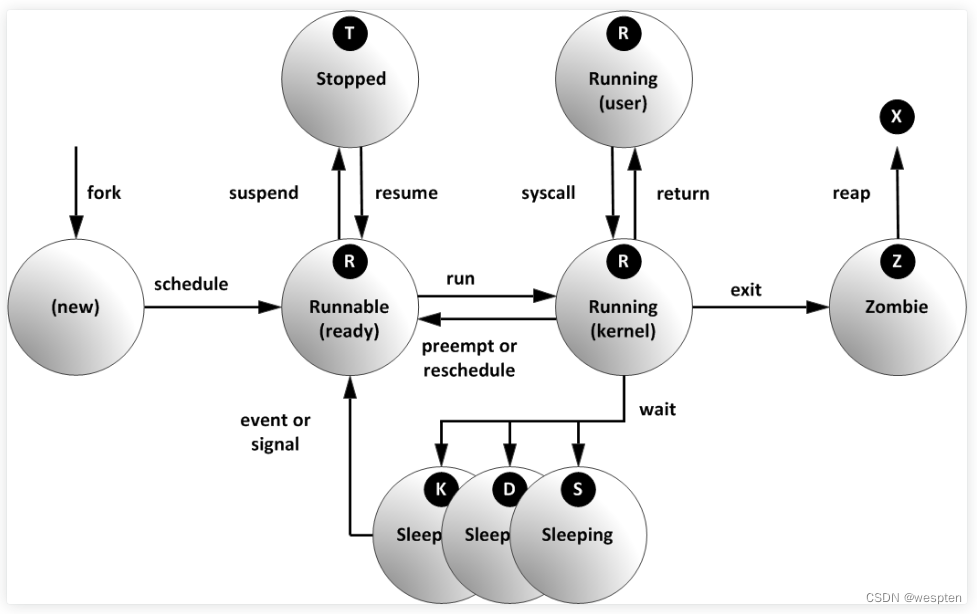
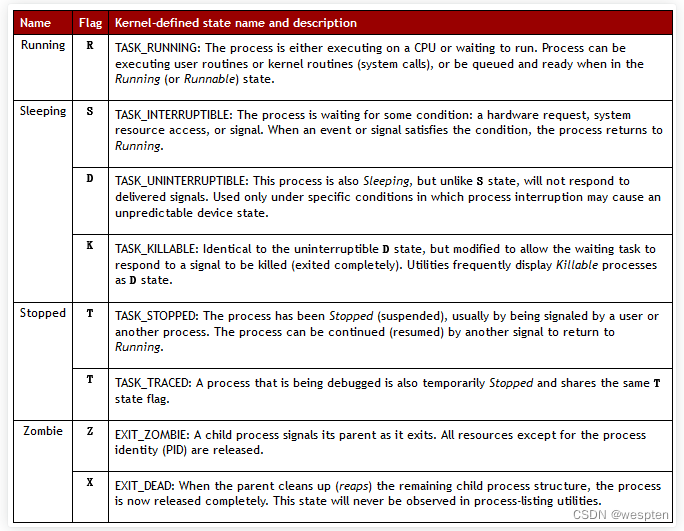
Linux 中,进程有 5 种状态:
1. 运行( running ): (正在运行或在运行队列中等待,表示进程已经获取到了运行所需的所有资源,只是等待相应的 CPU 时间来处理数据);
2. 中断 (休眠中, 受阻在等待某个条件的形成或接受到信号,分为可中断interruptable(操作系统大多数程序都处于该状态)和不可中断uninterruptable);
3. 不可中断 (收到信号不唤醒和不可运行, 进程必须等待直到有中断发生);
4. 僵死 (父进程结束前,子进程不关闭。进程已终止, 但进程描述符存在, 直到父进程使用 wait4() 系统调用后释放);
5.停止 (进程收到 SIGSTOP, SIGSTP, SIGTIN, SIGTOU 信号后停止运行,暂停于内存,但不会被调度,除非手动启动);
ps 命令标识进程的 5 种状态码如下:
1. D 不可中断 uninterruptible sleep (usually IO)
2. R 运行 runnable (on run queue)
S. 中断 sleeping
T. 停止 traced or stopped
Z. 僵死 a defunct (“zombie”) process
3、进程优先级
每个CPU(或CPU核心)在一个时间点上只能处理一个进程,通过时间片技术,Linux实际能够运行的进程(和线程数)可以超出实际可用的CPU及核心数量。Linux内核进程调度程序将多个进程在CPU核心上快速切换,从而给用户多个进程在同时运行的印象。
进程可划分为普通进程和实时进程,那么优先级与nice值的关系图:
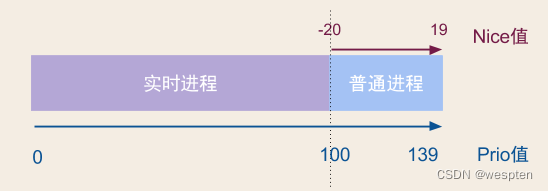
在内核中,进程优先级的取值范围是140个优先级范围,取值范围是从0-139,这个值越小,优先级越高。
nice值的40-20到19-0,映射到实际的优先级范围是100-139,默认为0。
nice 值越高: 表示优先级越低,例如+19,该进程容易将CPU 使用量让给其他进程。
nice 值越低: 表示优先级越高,例如-20,该进程更不倾向于让出CPU。
正常情况下,任何一个进程的优先级都是这个值,即使我们通过nice和renice命令调整了进程的优先级,它的取值范围也不会超出100-139的范围,除非这个进程是一个实时进程,那么它的优先级取值才会变成0-99这个范围中的一个。这里隐含了一个信息,就是说当前的Linux是一种已经支持实时进程的操作系统。
简单来说,实时操作系统需要保证相关的实时进程在较短的时间内响应,不会有较长的延时,并且要求最小的中断延时和进程切换延时。对于这样的需求,一般的进程调度算法,无论是O1还是CFS都是无法满足的,所以内核在设计的时候,将实时进程单独映射了100个优先级,这些优先级都要高与正常进程的优先级(nice值),这样就可以保证实时进程遇险记最高,总是排在前面被处理。
而实时进程的调度算法也不同,它们采用更简单的调度算法来减少调度开销。
优先级值越小表示进程优先级越高,3个进程优先级的概念:
-
静态优先级: 不会时间而改变,内核也不会修改,只能通过系统调用改变nice值的方法区修改。优先级映射公式:
static_prio = MAX_RT_PRIO + nice + 20,其中MAX_RT_PRIO = 100,那么取值区间为[100, 139];对应普通进程; -
实时优先级:只对实时进程有意义,取值区间为[0, MAX_RT_PRIO -1],其中MAX_RT_PRIO = 100,那么取值区间为[0, 99];对应实时进程;
-
动态优先级: 调度程序通过增加或减少进程静态优先级的值,来达到奖励IO消耗型或惩罚cpu消耗型的进程,调整后的进程称为动态优先级。区间范围[0, MX_PRIO-1],其中MX_PRIO = 140,那么取值区间为[0,139];
进程默认启动时的nice值为0,优先级为120。只有根用户才能降低nice值(提高优先性),nice值越小优先级越高,nice的优先级数字范围是-20~19。
进程优先级高程序运行的不一定会很快,它和程序设计有着密切关系,我们调优先级起到的作用是有限的。
nice对将要启动程序时指定优先级:
[[email protected] ~]# nice -n -5 ping -f 127.0.0.1 -S 65507
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,nice | grep -e " PID\|ping" | grep -v grep
PID CMD NI
8214 ping -f 127.0.0.1 -S 65507 -5
[[email protected] ~]#
[[email protected] ~]# nice -5 ping -f 127.0.0.1 -S 65507
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,nice | grep -e " PID\|ping" | grep -v grep
PID CMD NI
8218 ping -f 127.0.0.1 -S 65507 5
[[email protected] ~]#
[[email protected] ~]# nice --5 ping -f 127.0.0.1 -S 65507
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,nice | grep -e " PID\|ping" | grep -v grep
PID CMD NI
8222 ping -f 127.0.0.1 -S 65507 -5
[[email protected] ~]# 4)renice动态调整优先级
将优先级设置为-20(nice的最高优先级):
[[email protected] ~]# ps axo pid,cmd,nice | grep -e " PID\|ping" | grep -v grep
PID CMD NI
7972 ping -f 127.0.0.1 -S 65507 0
[[email protected] ~]#
[[email protected] ~]# renice -n -20 7972
7972 (process ID) old priority 0, new priority -20
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,nice | grep -e " PID\|ping" | grep -v grep
PID CMD NI
7972 ping -f 127.0.0.1 -S 65507 -20
[[email protected] ~]#
[[email protected] ~]# 4、进程通信机制
进程之间相对保持独立,一个进程不能访问另一个进程的地址空间。(内存管理所做的工作)
这样可以保护进程地址空间不会随便被不相干的其他进程访问。可以确保进程的正确运行。
但是另一方面,进程与进程之间需要协作,完成一些大型的任务。在保证进程与进程相对独立的情况下,还需要之间进行有效的沟通。
所以需要进程间通信,进程间通信(IPC,Interprocess communication)就是在不同进程之间传播或交换信息,那么不同进程之间存在着什么双方都可以访问的介质呢?
同一主机间通信:
signal: 信号;
shm: shared memory;
semaphore: 信号量,一种计数器;
不同主机间通信:
socket: IP和端口号;
RPC: remote procedure call;
MQ:消息队列,Kafka,ActiveMQ;
进程的用户空间是互相独立的,一般而言是不能互相访问的,唯一的例外是共享内存区。另外,系统空间是“公共场所”,各进程均可以访问,所以内核也可以提供这样的条件。
此外,还有双方都可以访问的外设。在这个意义上,两个进程当然也可以通过磁盘上的普通文件交换信息,或者通过“注册表”或其它数据库中的某些表项和记录交换信息。广义上这也是进程间通信的手段,但是一般都不把这算作“进程间通信”。
IPC的方式通常有管道(包括无名管道和命名管道)、消息队列、信号量、共享存储、Socket、Streams等。其中 Socket和Streams支持不同主机上的两个进程IPC。
信号量、管道、消息队列是间接通信的,共享内存是直接通信的方式。
直接通信
进程必须正确的命名对方:
- send(P, message) - 发送消息到进程P
- receive(Q, message) - 从进程Q接收信息
通信链路的属性:
- 自动建立链路
- 一条链路恰好对应一对通信进程
- 每对进程之间只有一个链路存在
- 链路可以是单向的,但通常是双向的
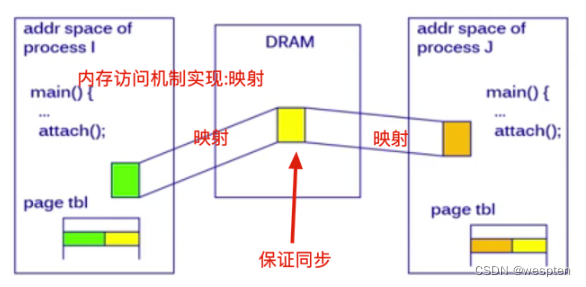
1)共享内存
每个进程都有私有地址空间,共享内存(Shared Memory),指两个或多个进程地址空间内,明确地设置了共享内存段,共享一个给定的存储区。
1. 特点
共享内存是最快的一种 IPC,因为进程是直接对内存进行存取,一个进程写另一个进程立即可见。
因为多个进程可以同时操作,所以需要进行同步 (必须保证我写的时候,别人不能写),由程序员提供同步。
信号量+共享内存通常结合在一起使用,信号量用来同步对共享内存的访问。
没有系统调用干预和没有数据复制。
2. 原型
#include <sys/shm.h>
// 创建或获取一个共享内存:成功返回共享内存ID,失败返回-1
int shmget(key_t key, size_t size, int flag);
// 连接共享内存到当前进程的地址空间:成功返回指向共享内存的指针,失败返回-1
void *shmat(int shm_id, const void *addr, int flag);
// 断开与共享内存的连接:成功返回0,失败返回-1
int shmdt(void *addr);
// 控制共享内存的相关信息:成功返回0,失败返回-1
int shmctl(int shm_id, int cmd, struct shmid_ds *buf);当用shmget函数创建一段共享内存时,必须指定其 size;而如果引用一个已存在的共享内存,则将 size 指定为0 。
当一段共享内存被创建以后,它并不能被任何进程访问。必须使用shmat函数(share memory attach)连接该共享内存到当前进程的地址空间,连接成功后把共享内存区对象映射到调用进程的地址空间,随后可像本地空间一样访问。
shmdt函数(share memory detach)是用来断开shmat建立的连接的。注意,这并不是从系统中删除该共享内存,只是当前进程不能再访问该共享内存而已。
shmctl函数(share memory control)可以对共享内存执行多种操作,根据参数 cmd 执行相应的操作。常用的是IPC_RMID(从系统中删除该共享内存)。
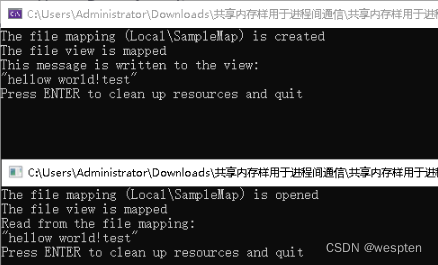
举例说明:sharememory.exe负责往共享内存中写数据,client.exe负责从共享内存中读取数据。
sharememory.cpp:
#include "stdafx.h"
#include <WINDOWS.H>
#define FULL_MAP_NAME L"Local\\SampleMap"
// 开始时的文件偏移量.
#define VIEW_OFFSET 0
// VIEW_SIZE 文件大小 如果是0代表从offset到文件末尾
#define VIEW_SIZE 1024
// 映射文件大小
#define MAP_SIZE 65536
#define MESSAGE L"hellow world!test"
int wmain(int argc, wchar_t* argv[])
{
HANDLE hMapFile = NULL;
PVOID pView = NULL;
// 打开映射文件对象.
hMapFile = CreateFileMapping(
INVALID_HANDLE_VALUE, //使用分页文件共享内存
NULL, // 默认安全属性
PAGE_READWRITE, // 读写
0, // 文件大小的高字节因为此文件小所以用不到
MAP_SIZE, // 文件大小的低字节
FULL_MAP_NAME // 映射文件名
);
if (hMapFile == NULL)
{
wprintf(L"CreateFileMapping failed w/err 0x%08lx\n", GetLastError());
goto Cleanup;
}
wprintf(L"The file mapping (%s) is created\n", FULL_MAP_NAME);
// 将文件映射的视图映射到当前的地址空间
pView = MapViewOfFile(
hMapFile, // 映射对象句柄
FILE_MAP_ALL_ACCESS, // 读写
0, // 便宜高字节
VIEW_OFFSET, //偏移低字节
VIEW_SIZE // 映射到内存的字节数
);
if (pView == NULL)
{
wprintf(L"MapViewOfFile failed w/err 0x%08lx\n", GetLastError());
goto Cleanup;
}
wprintf(L"The file view is mapped\n");
// 内存内放发送内容
PWSTR pszMessage = MESSAGE;
DWORD cbMessage = (wcslen(pszMessage) + 1) * sizeof(*pszMessage);
// 写入内存
memcpy_s(pView, VIEW_SIZE, pszMessage, cbMessage);
wprintf(L"This message is written to the view:\n\"%s\"\n",
pszMessage);
// 等待程序结束后 清空对象
wprintf(L"Press ENTER to clean up resources and quit");
getchar();
Cleanup:
if (hMapFile)
{
if (pView)
{
// Unmap the file view.
UnmapViewOfFile(pView);
pView = NULL;
}
// Close the file mapping object.
CloseHandle(hMapFile);
hMapFile = NULL;
}
return 0;
}client.cpp:
// client.cpp : 定义控制台应用程序的入口点。
#include "stdafx.h"
#include <WINDOWS.H>
#define FULL_MAP_NAME L"Local\\SampleMap"
// 开始时的文件偏移量.
#define VIEW_OFFSET 0
// VIEW_SIZE 文件大小 如果是0代表从offset到文件末尾
#define VIEW_SIZE 1024
int wmain(int argc, wchar_t* argv[])
{
HANDLE hMapFile = NULL;
PVOID pView = NULL;
// 尝试打开已经定义的映射文件名.
hMapFile = OpenFileMapping(
FILE_MAP_READ, // 读访问
FALSE, // 不继承名称
FULL_MAP_NAME //映射文件名字
);
if (hMapFile == NULL)
{
wprintf(L"OpenFileMapping failed w/err 0x%08lx\n", GetLastError());
goto Cleanup;
}
wprintf(L"The file mapping (%s) is opened\n", FULL_MAP_NAME);
// 映射文件映射到当前进程的地址空间
pView = MapViewOfFile(
hMapFile, // map的句柄
FILE_MAP_READ, // 读访问
0, // offset的高字节因为此文件不大 所以用不到
VIEW_OFFSET, // offset的低字节
VIEW_SIZE // 要映射到进程的字节数 最大为map文件的大小
);
if (pView == NULL)
{
wprintf(L"MapViewOfFile failed w/err 0x%08lx\n", GetLastError());
goto Cleanup;
}
wprintf(L"The file view is mapped\n");
//读取映射内存中内容
wprintf(L"Read from the file mapping:\n\"%s\"\n", (PWSTR)pView);
// getchar等待输入按键结束程序
wprintf(L"Press ENTER to clean up resources and quit");
getchar();
Cleanup:
if (hMapFile)
{
if (pView)
{
// 卸载映射内存视图.
UnmapViewOfFile(pView);
pView = NULL;
}
// 关闭映射文件对象
CloseHandle(hMapFile);
hMapFile = NULL;
}
return 0;
}运行结果:
间接通信
定向从消息队列接收消息:
- 每个消息对垒都有一个唯一的ID
- 只有它们共享了一个消息队列,进程才能够通信
通信链路的属性:
- 只有进程共享一个共同的消息队列,才建立链路
- 链接可以与许多进程相关联
- 每对进程可以共享多个通信链路
- 链接可以是单向或者双向
操作:
- 创建一个新的消息队列
- 通过消息队列发送和接收消息
- 销毁消息队列
原语的定义如下:
-
send(A, message)
-
receive(A, message)
-
通信链路缓冲
通信链路缓存大小:
- 0容量 - 0 message : 发送方必须等待接收方 (相当于是 同步/阻塞 方式)
- 有限容量 - n messages的有限长度 : 发送方必须等待,如果队列满
- 无限容量 - 无限长度 : 发送方不需要等待
消息传递可以是:
- 阻塞 (同步)
- 非阻塞 (异步)
1)管道
管道,通常指无名管道,是 UNIX 系统IPC最古老的形式,一个程序的输出变为另一个程序的输入。
子进程从父进程继承文件描述符(0 stdin, 1 stdout, 2 stderr)。进程不知道(或不关心)从键盘,文件,程序读取或写入到终端、文件、程序。
$ ls | more两个进程, 管道是缓存,对于ls来说是stdout,对于more来说是stdin:

1. 特点:
它是半双工的(即数据只能在一个方向上流动),具有固定的读端和写端。
它只能用于具有亲缘关系的进程之间的通信(也是父子进程或者兄弟进程之间)。
它可以看成是一种特殊的文件,对于它的读写也可以使用普通的read、write 等函数。但是它不是普通的文件,并不属于其他任何文件系统,并且只存在于内存中。
2. 原型:
#include <unistd.h>
int pipe(int fd[2]); // 返回值:若成功返回0,失败返回-1当一个管道建立时,它会创建两个文件描述符:fd[0]为读而打开,fd[1]为写而打开。
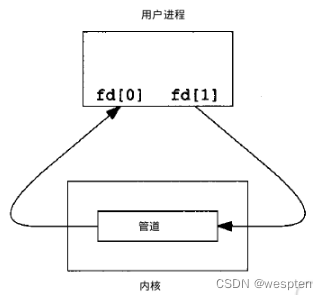
要关闭管道只需将这两个文件描述符关闭即可。
2)FIFO
FIFO,也称为命名管道,它是一种文件类型。
1. 特点
FIFO可以在无关的进程之间交换数据,与无名管道不同。
FIFO有路径名与之相关联,它以一种特殊设备文件形式存在于文件系统中。
2. 原型
#include <sys/stat.h>
// 返回值:成功返回0,出错返回-1
int mkfifo(const char *pathname, mode_t mode);其中的 mode 参数与open函数中的 mode 相同。一旦创建了一个 FIFO,就可以用一般的文件I/O函数操作它。
当 open 一个FIFO时,是否设置非阻塞标志(O_NONBLOCK)的区别:
1. 若没有指定O_NONBLOCK(默认),只读 open 要阻塞,直到某个其他进程为写而打开此 FIFO。类似的,只写 open 要阻塞,直到某个其他进程为读而打开它。
2. 若指定了O_NONBLOCK,则只读 open 立即返回。而只写 open 将出错返回 -1 如果没有进程已经为读而打开该 FIFO,其errno置ENXIO。
3)消息队列
消息队列,是消息的链接表,存放在内核中。一个消息队列由一个标识符(即队列ID)来标识。
1. 特点
消息队列是面向记录的,其中的消息具有特定的格式以及特定的优先级。
消息队列独立于发送与接收进程。进程终止时,消息队列及其内容并不会被删除。
消息队列可以实现消息的随机查询,消息不一定要以先进先出的次序读取,也可以按消息的类型读取。
2. 原型
#include <sys/msg.h>
// 创建或打开消息队列:成功返回队列ID,失败返回-1
int msgget(key_t key, int flag);
// 添加消息:成功返回0,失败返回-1
int msgsnd(int msqid, const void *ptr, size_t size, int flag);
// 读取消息:成功返回消息数据的长度,失败返回-1
int msgrcv(int msqid, void *ptr, size_t size, long type,int flag);
// 控制消息队列:成功返回0,失败返回-1
int msgctl(int msqid, int cmd, struct msqid_ds *buf);在以下两种情况下,msgget将创建一个新的消息队列:
1. 如果没有与键值key相对应的消息队列,并且flag中包含了IPC_CREAT标志位。
2. key参数为IPC_PRIVATE。
函数msgrcv在读取消息队列时,type参数有下面几种情况:
1. type == 0,返回队列中的第一个消息;
2. type > 0,返回队列中消息类型为 type 的第一个消息;
3. type < 0,返回队列中消息类型值小于或等于 type 绝对值的消息,如果有多个,则取类型值最小的消息。
可以看出,type值非 0 时用于以非先进先出次序读消息。也可以把 type 看做优先级的权值。
4)信号量
信号量(semaphore)与已经介绍过的 IPC 结构不同,它是一个计数器。信号量用于实现进程间的互斥与同步,而不是用于存储进程间通信数据。
软件中断通知事件处理,例如:
SIGFPE, SIGKILL, SIGUSRI, SIGSTOP, SIGCONT接收到信号时会发生什么?
- catch: 指定信号处理函数被调用
- ignore: 依靠操作系统的默认操作(abort, memory dump, suspend or resume process)
- mask: 闭塞信号因此不会传送(可能是暂时的,当处理同样类型的信号)
信号在操作系统中是如何工作的?如何实现信号?
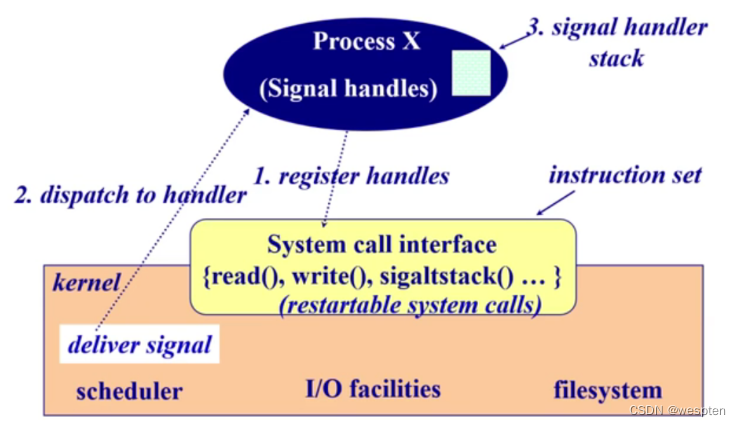
1)应用程序在程序开始执行前,注册针对某一个信号的 handler (系统调用),发送给操作系统。
2)操作系统知道了,当发生这个信号时,会调用应用程序编写的信号处理函数来执行。
3)操作系统收到信号后,处于内核态,当操作系统要切换回用户态,去调用应用的信号处理函数。操作系统修改应用的堆栈,本来应该执行中断的后一条语句变成信号处理函数的入口。
1. 特点
信号量用于进程间同步,若要在进程间传递数据需要结合共享内存。
信号量基于操作系统的 PV 操作,程序对信号量的操作都是原子操作。
每次对信号量的 PV 操作不仅限于对信号量值加 1 或减 1,而且可以加减任意正整数。
支持信号量组。
不能传输要交换的任何数据。
2. 原型
最简单的信号量是只能取 0 和 1 的变量,这也是信号量最常见的一种形式,叫做二值信号量(Binary Semaphore)。而可以取多个正整数的信号量被称为通用信号量。
Linux 下的信号量函数都是在通用的信号量数组上进行操作,而不是在一个单一的二值信号量上进行操作。
#include <sys/sem.h>
// 创建或获取一个信号量组:若成功返回信号量集ID,失败返回-1
int semget(key_t key, int num_sems, int sem_flags);
// 对信号量组进行操作,改变信号量的值:成功返回0,失败返回-1
int semop(int semid, struct sembuf semoparray[], size_t numops);
// 控制信号量的相关信息
int semctl(int semid, int sem_num, int cmd, ...);当semget创建新的信号量集合时,必须指定集合中信号量的个数(即num_sems),通常为1; 如果是引用一个现有的集合,则将num_sems指定为 0 。
五种通讯方式总结:
1. 管道:速度慢,容量有限,只有父子进程能通讯;
2. FIFO:任何进程间都能通讯,但速度慢;
3. 消息队列:容量受到系统限制,且要注意第一次读的时候,要考虑上一次没有读完数据的问题;
4. 信号量:不能传递复杂消息,只能用来同步;
5. 共享内存区:能够很容易控制容量,速度快,但要保持同步,比如一个进程在写的时候,另一个进程要注意读写的问题,相当于线程中的线程安全,当然,共享内存区同样可以用作线程间通讯,不过没这个必要,线程间本来就已经共享了同一进程内的一块内存;
5、Linux进程管理工具
pstree
ps
pidof
pgrep
top
htop
glance
pmap
vmstat
dstat
kill
pkill
job
bg
fg
nohup输出说明:
PID :进程 ID
每个进程都会从内核获取一个唯一的 ID 值。绝大多数用来操作进程的命令和系统调用,都需要用 PID 指定操作的进程对象。
PPID :父进程 ID
在 Unix 和 Linux 系统中,一个已经存在的进程必须“克隆”它自身来创建一个新的进程。当新的进程克隆后,最初的进程便作为父进程存在。
UID & EUID:真实用户 ID 和有效用户 ID
一个进程的 UID 是其创建者的身份标志(也是对其父进程 UID 的复制)。通常只有进程的创建者和超级用户才有操作该进程的权限。
EUID 是一个额外的 UID,用来决定在任意一个特定时间点,一个进程有权限访问的文件和资源。对绝大多数进程而言,UID 和 EUID 是相同的(特殊情况即 setuid)
Niceness
一个进程的计划优先级决定了它能获取到的 CPU 时间。内核有一个动态的算法来计算优先级,同时也会关注一个 Niceness 值,来决定程序运行的优先顺序。1)ps命令总结
查看所有终端中的进程:
[[email protected] ~]# ps a
PID TTY STAT TIME COMMAND
3391 tty1 Ss+ 0:00 /sbin/agetty --noclear tty1 linux
7147 pts/3 Ss+ 0:00 -bash
7148 pts/5 Ss+ 0:00 -bash
7149 pts/4 Ss 0:00 -bash
7442 pts/4 R+ 0:00 ps a
[[email protected] ~]# 查看没有控制终端的进程(TTY 显示为 ?):
[[email protected] ~]# ps x
PID TTY STAT TIME COMMAND
1 ? Ss 0:00 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
2 ? S 0:00 [kthreadd]
3 ? S 0:00 [ksoftirqd/0]
5 ? S< 0:00 [kworker/0:0H]
7 ? S 0:00 [migration/0]
8 ? S 0:00 [rcu_bh]
9 ? S 0:00 [rcu_sched]
10 ? S< 0:00 [lru-add-drain]
11 ? S 0:00 [watchdog/0]
12 ? S 0:00 [watchdog/1]
13 ? S 0:00 [migration/1]
14 ? S 0:00 [ksoftirqd/1]
16 ? S< 0:00 [kworker/1:0H]
17 ? S 0:00 [watchdog/2]
18 ? S 0:00 [migration/2]
19 ? S 0:00 [ksoftirqd/2]查看使用基于用户的信息输出格式:
[[email protected] ~]# ps u
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 3391 0.0 0.0 110092 856 tty1 Ss+ 06:28 0:00 /sbin/agetty --noclear tty1 linux
root 7147 0.0 0.0 115836 2400 pts/3 Ss+ 08:59 0:00 -bash
root 7148 0.0 0.0 115836 2408 pts/5 Ss+ 08:59 0:00 -bash
root 7149 0.0 0.0 115960 2688 pts/4 Ss 08:59 0:00 -bash
root 7460 0.0 0.0 155360 1876 pts/4 R+ 12:27 0:00 ps u
[[email protected] ~]#
[[email protected] ~]# 同时显示:
$ ps aux
USER PID %CPU %MEM VSZ RSS TTY STAT START TIME COMMAND
root 1 0.0 0.1 225428 9548 ? Ss 7月30 0:30 /lib/systemd/systemd --system --deserialize 19
root 2 0.0 0.0 0 0 ? S 7月30 0:00 [kthreadd]
root 4 0.0 0.0 0 0 ? I< 7月30 0:00 [kworker/0:0H]
root 6 0.0 0.0 0 0 ? I< 7月30 0:00 [mm_percpu_wq]
root 7 0.0 0.0 0 0 ? S 7月30 0:03 [ksoftirqd/0]
root 8 0.0 0.0 0 0 ? I 7月30 14:49 [rcu_sched]
...
starky 6874 0.0 0.1 33016 8556 pts/2 Ss 8月07 0:00 bash
starky 7150 0.0 0.0 33016 6044 pts/2 S+ 8月07 0:00 bash
starky 7151 3.1 16.1 4763784 1227932 pts/2 Sl+ 8月07 272:54 java -Xmx1024M -Xms512M -jar minecraft_server.1.12.2.jar nogui
...
root 18447 0.0 0.0 107984 7116 ? Ss 13:55 0:00 sshd: starky [priv]
starky 18535 0.0 0.0 108092 4268 ? S 13:55 0:00 sshd: starky@pts/1
starky 18536 0.0 0.1 33096 8336 pts/1 Ss 13:55 0:00 -bash
root 18761 0.0 0.0 0 0 ? I 13:55 0:00 [kworker/u8:0]
root 18799 0.0 0.0 0 0 ? I 14:01 0:00 [kworker/u8:1]
root 18805 0.0 0.0 0 0 ? I 14:05 0:00 [kworker/0:2]
starky 18874 0.0 0.0 46780 3568 pts/1 R+ 14:10 0:00 ps -aux
redis 19235 0.2 0.0 58548 3736 ? Ssl 8月04 30:03 /usr/bin/redis-server 127.0.0.1:6379
root 20799 0.0 0.0 107548 7504 ? Ss 8月05 0:00 /usr/sbin/cupsd -l
root 28342 0.0 0.4 535068 36940 ? Ss 8月10 0:16 /usr/sbin/apache2 -k start其中带中括号的命令(如 [kthreadd])并不是真正的命令而是内核线程。
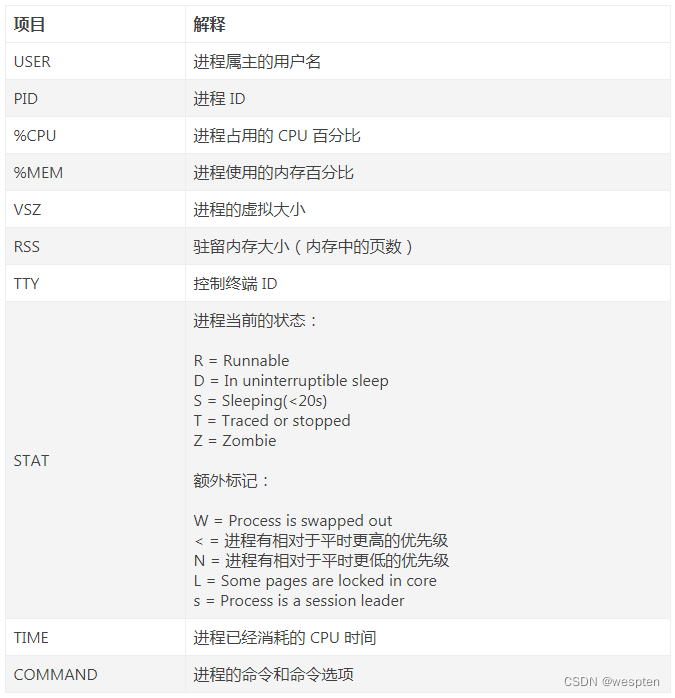
命令输出的各列信息含义如下:
显示进程所有者的信息:
[[email protected] ~]# ps f
PID TTY STAT TIME COMMAND
7149 pts/4 Ss 0:00 -bash
7469 pts/4 S 0:00 \_ bash
7482 pts/4 S 0:00 \_ bash
7519 pts/4 R+ 0:00 \_ ps f
7148 pts/5 Ss+ 0:00 -bash
7147 pts/3 Ss+ 0:00 -bash
3391 tty1 Ss+ 0:00 /sbin/agetty --noclear tty1 linux
[[email protected] ~]#
[[email protected] ~]# pstree -p | grep sshd
|-sshd(3364)-+-sshd(7141)---bash(7147)
| |-sshd(7143)---bash(7148)
| `-sshd(7144)---bash(7149)---bash(7469)---bash(7482)-+-grep(7521)
[[email protected] ~]# 显示支持的属性列表:
[[email protected] ~]# ps L
%cpu %CPU
%mem %MEM
_left LLLLLLLL
_left2 L2L2L2L2
_right RRRRRRRR
_right2 R2R2R2R2
_unlimited U
_unlimited2 U2
alarm ALARM
args COMMAND
atime TIME
blocked BLOCKED
bsdstart START
bsdtime TIME
c C
caught CAUGHT
cgroup CGROUP
class CLS
cls CLS
cmd CMD
comm COMMAND
command COMMAND 显示定制的信息,支持的属性可查看"ps -L":
[[email protected] ~]# ps o pid,%cpu,%mem,cmd,uname,size
PID %CPU %MEM CMD USER SIZE
3391 0.0 0.0 /sbin/agetty --noclear tty1 root 344
7147 0.0 0.0 -bash root 896
7148 0.0 0.0 -bash root 896
7149 0.0 0.0 -bash root 1020
7469 0.0 0.0 bash root 896
7482 0.0 0.0 bash root 896
7541 0.0 0.0 ps o pid,%cpu,%mem,cmd,unam root 1024
[[email protected] ~]#
[[email protected] ~]# 显示指定命令,多个命令用,分隔:
[[email protected] ~]# ps -C ping,vi
PID TTY TIME CMD
7553 pts/3 00:00:00 vi
7554 pts/5 00:00:11 ping
[[email protected] ~]#
[[email protected] ~]# 显示线程:
[[email protected] ~]# ps -L
PID LWP TTY TIME CMD
7149 7149 pts/4 00:00:00 bash
7469 7469 pts/4 00:00:00 bash
7482 7482 pts/4 00:00:00 bash
7590 7590 pts/4 00:00:00 mysqld_safe
7773 7773 pts/4 00:00:00 ps
[[email protected] ~]# 显示所有进程,相当于-A:
[[email protected] ~]# ps -e
PID TTY TIME CMD
1 ? 00:00:00 systemd
2 ? 00:00:00 kthreadd
3 ? 00:00:00 ksoftirqd/0
5 ? 00:00:00 kworker/0:0H
7 ? 00:00:00 migration/0
8 ? 00:00:00 rcu_bh
9 ? 00:00:00 rcu_sched
10 ? 00:00:00 lru-add-drain
11 ? 00:00:00 watchdog/0
12 ? 00:00:00 watchdog/1
13 ? 00:00:00 migration/1
14 ? 00:00:00 ksoftirqd/1
16 ? 00:00:00 kworker/1:0H
17 ? 00:00:00 watchdog/2
18 ? 00:00:00 migration/2
19 ? 00:00:00 ksoftirqd/2
20 ? 00:00:00 kworker/2:0
21 ? 00:00:00 kworker/2:0H
22 ? 00:00:00 watchdog/3
23 ? 00:00:00 migration/3
24 ? 00:00:00 ksoftirqd/3显示完整格式程序信息:
复制代码
[[email protected] ~]# ps -f
UID PID PPID C STIME TTY TIME CMD
root 7149 7144 0 08:59 pts/4 00:00:00 -bash
root 7469 7149 0 12:29 pts/4 00:00:00 bash
root 7482 7469 0 12:29 pts/4 00:00:00 bash
root 7590 1 0 13:03 pts/4 00:00:00 /bin/sh /home/softwares/mysql//bin/mysqld_safe --datadir=/home/softwares/mysql/data/ --
root 7785 7482 0 13:05 pts/4 00:00:00 ps -f
[[email protected] ~]#
[[email protected] ~]# 显示更完整格式的进程信息:
[[email protected] ~]# ps -F
UID PID PPID C SZ RSS PSR STIME TTY TIME CMD
root 7149 7144 0 28990 2688 3 08:59 pts/4 00:00:00 -bash
root 7469 7149 0 28959 2440 3 12:29 pts/4 00:00:00 bash
root 7482 7469 0 28959 2512 1 12:29 pts/4 00:00:00 bash
root 7590 1 0 28328 1644 0 13:03 pts/4 00:00:00 /bin/sh /home/softwares/mysql//bin/mysqld_safe --datadir=/home/software
root 7786 7482 0 38840 1884 3 13:06 pts/4 00:00:00 ps -F
[[email protected] ~]# 以进程层级格式显示进程相关信息:
[[email protected] ~]# ps -H
PID TTY TIME CMD
7149 pts/4 00:00:00 bash
7469 pts/4 00:00:00 bash
7482 pts/4 00:00:00 bash
7787 pts/4 00:00:00 ps
7590 pts/4 00:00:00 mysqld_safe
[[email protected] ~]#
[[email protected] ~]# 指定有效的用户ID或名称:
[[email protected] ~]# ps o pid,cmd,user,euser,ruser
PID CMD USER EUSER RUSER
3391 /sbin/agetty --noclear tty1 root root root
7147 -bash root root root
7148 -bash root root root
7149 -bash root root root
7469 bash root root root
7482 bash root root root
7590 /bin/sh /home/softwares/mys root root root
7809 su yinzhengjie root root root
7827 passwd root root yinzhengjie
7846 ps o pid,cmd,user,euser,rus root root root
[[email protected] ~]#
[[email protected] ~]# ps -u yinzhengjie
PID TTY TIME CMD
7810 pts/5 00:00:00 bash
[[email protected] ~]# 指定真正的用户ID或名称:
复制代码
[[email protected] ~]# ps o pid,cmd,user,euser,ruser
PID CMD USER EUSER RUSER
3391 /sbin/agetty --noclear tty1 root root root
7147 -bash root root root
7148 -bash root root root
7149 -bash root root root
7469 bash root root root
7482 bash root root root
7590 /bin/sh /home/softwares/mys root root root
7809 su yinzhengjie root root root
7827 passwd root root yinzhengjie
7852 ps o pid,cmd,user,euser,rus root root root
[[email protected] ~]#
[[email protected] ~]# ps -u yinzhengjie
PID TTY TIME CMD
7810 pts/5 00:00:00 bash
[[email protected] ~]#
[[email protected] ~]# ps -U yinzhengjie
PID TTY TIME CMD
7810 pts/5 00:00:00 bash
7827 pts/5 00:00:00 passwd
[[email protected] ~]#
[[email protected] ~]# gid或groupname 指定有效的gid或组名称:
[[email protected] ~]# ps -g yinzhengjie
PID TTY TIME CMD
7810 pts/5 00:00:00 bash
7827 pts/5 00:00:00 passwd
[[email protected] ~]# 指定真正的gid或组名称:
[[email protected] ~]# ps -G yinzhengjie
PID TTY TIME CMD
7810 pts/5 00:00:00 bash
7827 pts/5 00:00:00 passwd
[[email protected] ~]# 显示指pid的进程:
[[email protected] ~]# ps
PID TTY TIME CMD
7149 pts/4 00:00:00 bash
7469 pts/4 00:00:00 bash
7482 pts/4 00:00:00 bash
7590 pts/4 00:00:00 mysqld_safe
7857 pts/4 00:00:00 ps
[[email protected] ~]#
[[email protected] ~]# ps -p 7590
PID TTY TIME CMD
7590 pts/4 00:00:00 mysqld_safe
[[email protected] ~]#
[[email protected] ~]# 显示属于pid的子进程:
[[email protected] ~]# ps f
PID TTY STAT TIME COMMAND
7916 pts/5 S+ 0:00 passwd
7149 pts/4 Ss 0:00 -bash
7469 pts/4 S 0:00 \_ bash
7482 pts/4 S 0:00 \_ bash
7948 pts/4 R+ 0:00 \_ ps f
7148 pts/5 Ss 0:00 -bash
7809 pts/5 S 0:00 \_ su yinzhengjie
7147 pts/3 Ss+ 0:00 -bash
7590 pts/4 S 0:00 /bin/sh /home/softwares/mysql//bin/mysqld_safe --datadir=/home/softwares/mysql/data/ --pid-file=/home/softwa
3391 tty1 Ss+ 0:00 /sbin/agetty --noclear tty1 linux
[[email protected] ~]#
[[email protected] ~]#
[[email protected] ~]# ps --ppid 7149
PID TTY TIME CMD
7469 pts/4 00:00:00 bash
[[email protected] ~]#
[[email protected] ~]# ps --ppid 7469
PID TTY TIME CMD
7482 pts/4 00:00:00 bash
[[email protected] ~]# 显示SELinux信息,相当于Z:
[[email protected] ~]# ps -M
LABEL PID TTY TIME CMD
- 7149 pts/4 00:00:00 bash
- 7469 pts/4 00:00:00 bash
- 7482 pts/4 00:00:00 bash
- 7590 pts/4 00:00:00 mysqld_safe
- 7954 pts/4 00:00:00 ps
[[email protected] ~]#
[[email protected] ~]#
[[email protected] ~]# ps Z
LABEL PID TTY STAT TIME COMMAND
- 3391 tty1 Ss+ 0:00 /sbin/agetty --noclear tty1 linux
- 7147 pts/3 Ss+ 0:00 -bash
- 7148 pts/5 Ss 0:00 -bash
- 7149 pts/4 Ss 0:00 -bash
- 7469 pts/4 S 0:00 bash
- 7482 pts/4 S 0:00 bash
- 7590 pts/4 S 0:00 /bin/sh /home/softwares/mysql//bin/mysqld_safe --datadir=/home/softwares/mys
- 7809 pts/5 S 0:00 su yinzhengjie
- 7916 pts/5 S+ 0:00 passwd
- 7955 pts/4 R+ 0:00 ps Z
[[email protected] ~]# 查看pid,cmd,psr(CPU编号,从0开始),ni(NICE)值,pri(priority优先级),rtprio(实时优先级):
复制代码
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio
PID CMD PSR NI PRI RTPRIO
1 /usr/lib/systemd/systemd -- 3 0 19 -
2 [kthreadd] 3 0 19 -
3 [ksoftirqd/0] 0 0 19 -
5 [kworker/0:0H] 0 -20 39 -
7 [migration/0] 0 - 139 99
8 [rcu_bh] 0 0 19 -
9 [rcu_sched] 2 0 19 -
10 [lru-add-drain] 0 -20 39 -
11 [watchdog/0] 0 - 139 99
12 [watchdog/1] 1 - 139 99
13 [migration/1] 1 - 139 99
14 [ksoftirqd/1] 1 0 19 -
16 [kworker/1:0H] 1 -20 39 -
17 [watchdog/2] 2 - 139 99
18 [migration/2] 2 - 139 99
19 [ksoftirqd/2] 2 0 19 -
20 [kworker/2:0] 2 0 19 -
21 [kworker/2:0H] 2 -20 39 -
22 [watchdog/3] 3 - 139 99
23 [migration/3] 3 - 139 99
24 [ksoftirqd/3] 3 0 19 -
26 [kworker/3:0H] 3 -20 39 -
28 [kdevtmpfs] 1 0 19 -查询你拥有的所有进程:
复制代码
[[email protected] ~]# ps -x
PID TTY STAT TIME COMMAND
1 ? Ss 0:00 /usr/lib/systemd/systemd --switched-root --system --deserialize 22
2 ? S 0:00 [kthreadd]
3 ? S 0:00 [ksoftirqd/0]
5 ? S< 0:00 [kworker/0:0H]
7 ? S 0:00 [migration/0]
8 ? S 0:00 [rcu_bh]
9 ? S 0:00 [rcu_sched]
10 ? S< 0:00 [lru-add-drain]
11 ? S 0:00 [watchdog/0]
12 ? S 0:00 [watchdog/1]
13 ? S 0:00 [migration/1]
14 ? S 0:00 [ksoftirqd/1]
16 ? S< 0:00 [kworker/1:0H]
17 ? S 0:00 [watchdog/2]
18 ? S 0:00 [migration/2]
19 ? S 0:00 [ksoftirqd/2]
20 ? S 0:00 [kworker/2:0]
21 ? S< 0:00 [kworker/2:0H]
22 ? S 0:00 [watchdog/3]
23 ? S 0:00 [migration/3]要按tty显示所属进程:
[[email protected] ~]# ps -ft pts/3
UID PID PPID C STIME TTY TIME CMD
root 7147 7141 0 08:59 pts/3 00:00:00 -bash
root 8096 7147 0 14:24 pts/3 00:00:00 ps -ft pts/3
[[email protected] ~]#
[[email protected] ~]#
[[email protected] ~]# ps
PID TTY TIME CMD
7147 pts/3 00:00:00 bash
8097 pts/3 00:00:00 ps
[[email protected] ~]#
[[email protected] ~]# 查找指定进程名所有的所属PID,在编写需要从std输出或文件读取PID的脚本时这个参数很有用:
[[email protected] ~]# ps -ef | grep ssh | grep -v grep
root 3364 1 0 06:28 ? 00:00:00 /usr/sbin/sshd -D
root 7141 3364 0 08:59 ? 00:00:00 sshd: root@pts/3
root 7143 3364 0 08:59 ? 00:00:00 sshd: root@pts/5
root 7144 3364 0 08:59 ? 00:00:17 sshd: root@pts/4
[[email protected] ~]#
[[email protected] ~]# ps -C sshd -o pid=
3364
7141
7143
7144
[[email protected] ~]#
[[email protected] ~]# 检查一个进程的执行时间:
[[email protected] ~]# ps -eo comm,etime,user | grep sshd
sshd 08:00:05 root
sshd 05:28:59 root
sshd 05:28:59 root
sshd 05:28:59 root
[[email protected] ~]# 显示安全信息:
[[email protected] ~]# ps --context
PID CONTEXT COMMAND
7147 - -bash
8135 - ps --context
[[email protected] ~]#
[[email protected] ~]#
[[email protected] ~]# ps -eM
LABEL PID TTY TIME CMD
- 1 ? 00:00:00 systemd
- 2 ? 00:00:00 kthreadd
- 3 ? 00:00:00 ksoftirqd/0
- 5 ? 00:00:00 kworker/0:0H
- 7 ? 00:00:00 migration/0
- 8 ? 00:00:00 rcu_bh
- 9 ? 00:00:00 rcu_sched
- 10 ? 00:00:00 lru-add-drain
- 11 ? 00:00:00 watchdog/0
- 12 ? 00:00:00 watchdog/1
- 13 ? 00:00:00 migration/1
- 14 ? 00:00:00 ksoftirqd/1
- 16 ? 00:00:00 kworker/1:0H[[email protected] ~]# ps -eo euser,ruser,suser,fuser,f,comm,label
EUSER RUSER SUSER FUSER F COMMAND LABEL
root root root root 4 systemd -
root root root root 1 kthreadd -
root root root root 1 ksoftirqd/0 -
root root root root 1 kworker/0:0H -
root root root root 1 migration/0 -
root root root root 1 rcu_bh -
root root root root 1 rcu_sched -
root root root root 1 lru-add-drain -
root root root root 5 watchdog/0 -
root root root root 5 watchdog/1 -
root root root root 1 migration/1 -
root root root root 1 ksoftirqd/1 -
root root root root 1 kworker/1:0H -
root root root root 5 watchdog/2 -
root root root root 1 migration/2 -
root root root root 1 ksoftirqd/2 -
root root root root 1 kworker/2:0 -
root root root root 1 kworker/2:0H -
root root root root 5 watchdog/3 -
root root root root 1 migration/3 -
root root root root 1 ksoftirqd/3 -
root root root root 1 kworker/3:0H -
root root root root 5 kdevtmpfs -2)tastset命令绑定程序到一颗CPU
[[email protected] ~]# ping -f 127.0.0.1 -S 65507 #一个终端执行测试命令[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 2 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 3 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep #不难发现,ping进程总是不断的切换CPU执行。
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 2 0 19 -
[[email protected] ~]#
[[email protected] ~]# taskset -p 7972 #查看7972进程可以运行的CPU个数
pid 7972's current affinity mask: f
[[email protected] ~]#
[[email protected] ~]# taskset -cp 0 7972 #我们将7972进程绑定到计算机第一颗CPU上(计算机计数是从0开始的)
pid 7972's current affinity list: 0-3
pid 7972's new affinity list: 0
[[email protected] ~]#
[[email protected] ~]# taskset -p 7972
pid 7972's current affinity mask: 1
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep #再次查看CPU的运行时所在的CPU核心始终为第一颗CPU(编号为"0")
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#
[[email protected] ~]# ps axo pid,cmd,psr,ni,pri,rtprio | grep -e " PID\|ping" | grep -v grep
PID CMD PSR NI PRI RTPRIO
ping -f 127.0.0.1 -S 65507 0 0 19 -
[[email protected] ~]#3)使用watch实用程序执行重复的输出以实现对就程进行实时的监视
[[email protected] ~]# watch -n 1 'ps -eo pid,ppid,cmd,%mem,%cpu --sort=-%mem | head'4)搜索进程
[[email protected] ~]# ps -ef | grep bash
root 7147 7141 0 08:59 pts/3 00:00:00 -bash
root 7148 7143 0 08:59 pts/5 00:00:00 -bash
root 7149 7144 0 08:59 pts/4 00:00:00 -bash
root 7469 7149 0 12:29 pts/4 00:00:00 bash
root 7482 7469 0 12:29 pts/4 00:00:00 bash
yinzhen+ 7810 7809 0 13:16 pts/5 00:00:00 bash
yinzhen+ 7863 7810 0 13:24 pts/5 00:00:00 bash
yinzhen+ 7881 7863 0 13:24 pts/5 00:00:00 bash
yinzhen+ 7898 7881 0 13:24 pts/5 00:00:00 bash
root 8179 7147 0 14:36 pts/3 00:00:00 grep --color=auto bash
[[email protected] ~]#
[[email protected] ~]#
[[email protected] ~]# ps -ef | grep bash | wc -l
10
[[email protected] ~]#
[[email protected] ~]# pidof bash
7898 7881 7863 7810 7482 7469 7149 7148 7147
[[email protected] ~]#
[[email protected] ~]# 5)远程主机监控
安装glances工具:
[[email protected] ~]# yum -y install glances服务器模式:
[[email protected] ~]# glances -s -B 127.0.0.1 #启用服务端,启动后会自动绑定端口
Glances server is running on 127.0.0.1:61209客户端模式:
[[email protected] ~]# glances -c 127.0.0.1 #连接成功后会弹出如下图所示的监控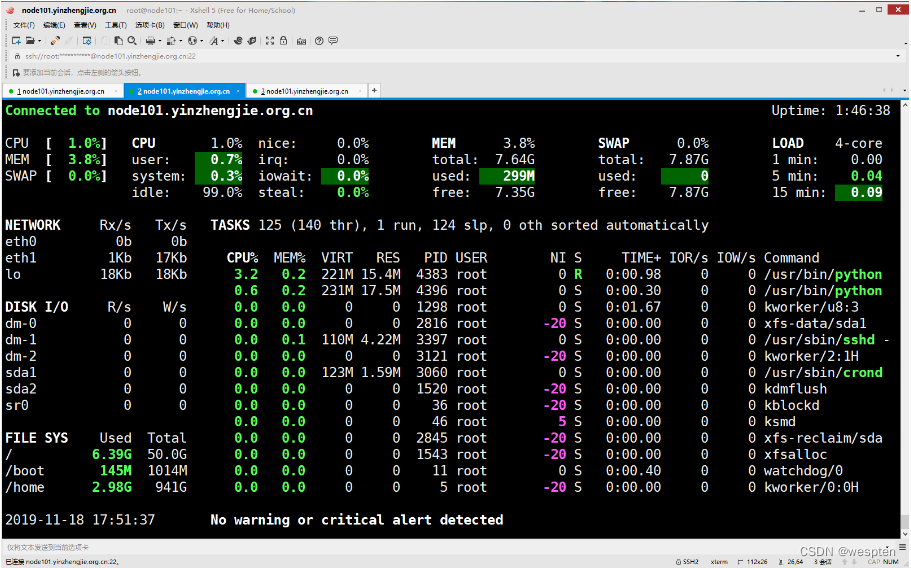
二、kill命令
信号
信号属于进程级别的中断请求。它们可以作为进程间通信的手段,或者由终端发送以杀死、中断、挂起某个进程。
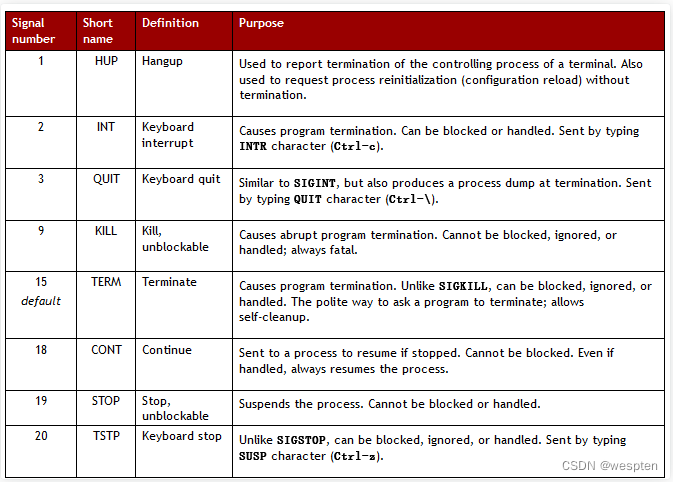
常见信号列表:
Kill 命令
kill 命令常用来终止某个进程,它可以向进程传递任意信号(默认为 TERM)。
语法:
kill [-signal] pid不带任何数字(信号)选项的 kill 命令并不能保证指定进程被杀死,因为 kill 命令默认发送 TERM 信号,而 TERM 是可以被捕获、屏蔽或忽略的。
[root@localhost~]# kill -l //列出所有支持的信号
编号 信号名
1) SIGHUP 重新加载配置
2) SIGINT 键盘中断^C (终止)
3) SIGQUIT 键盘退出
9) SIGKILL 强制终止
15) SIGTERM 终止(正常结束),缺省信号
18) SIGCONT 继续
19) SIGSTOP 停止
20)SIGTSTP 挂起^Z 1) SIGHUP 2) SIGINT 3) SIGQUIT 4) SIGILL 5) SIGTRAP
6) SIGABRT 7) SIGBUS 8) SIGFPE 9) SIGKILL 10) SIGUSR1
11) SIGSEGV 12) SIGUSR2 13) SIGPIPE 14) SIGALRM 15) SIGTERM
16) SIGSTKFLT 17) SIGCHLD 18) SIGCONT 19) SIGSTOP 20) SIGTSTP
21) SIGTTIN 22) SIGTTOU 23) SIGURG 24) SIGXCPU 25) SIGXFSZ
26) SIGVTALRM 27) SIGPROF 28) SIGWINCH 29) SIGIO 30) SIGPWR
31) SIGSYS 34) SIGRTMIN 35) SIGRTMIN+1 36) SIGRTMIN+2 37) SIGRTMIN+3
38) SIGRTMIN+4 39) SIGRTMIN+5 40) SIGRTMIN+6 41) SIGRTMIN+7 42) SIGRTMIN+8
43) SIGRTMIN+9 44) SIGRTMIN+10 45) SIGRTMIN+11 46) SIGRTMIN+12 47) SIGRTMIN+13
48) SIGRTMIN+14 49) SIGRTMIN+15 50) SIGRTMAX-14 51) SIGRTMAX-13 52) SIGRTMAX- 12
53) SIGRTMAX-11 54) SIGRTMAX-10 55) SIGRTMAX-9 56) SIGRTMAX-8 57) SIGRTMAX-7
58) SIGRTMAX-6 59) SIGRTMAX-5 60) SIGRTMAX-4 61) SIGRTMAX-3 62) SIGRTMAX-2
63) SIGRTMAX-1 64) SIGRTMAX给vsftpd进程发送信号1,15:
[root@localhost~]# ps aux |grep vsftpd
root 9160 0.0 0.0 52580 904 ? Ss 21:54 0:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf
[root@localhost~]# kill -1 9160 //发送重启信号
root 9160 0.0 0.0 52580 904 ? Ss 21:54 0:00 /usr/sbin/vsftpd /etc/vsftpd/vsftpd.conf
[root@localhost~]# kill 9160 //发送停止信号
[root@localhost~]# ps aux |grep vsftpd
//1
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 478 0.0 0.1 124144 1572 ? Ss 09:35 0:00 /usr/sbin/crond -n
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo kill -1 478
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 478 0.0 0.1 124144 1572 ? Ss 09:35 0:00 /usr/sbin/crond -n
//15
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo kill 478
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo systemctl start crond
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 22319 0.0 0.1 124140 1548 ? Ss 14:54 0:00 /usr/sbin/crond -n信号测试9,15:
[root@localhost~]# touch file1 file2
[root@localhost~]# tty
/dev/pts/1
[root@localhost~]# vim file1
[root@localhost~]# tty
/dev/pts/2
[root@localhost~]# vim file2
[root@localhost~]# ps aux |grep vim
root 4362 0.0 0.2 11104 2888 pts/1 S+ 23:02 0:00 vim file1
root 4363 0.1 0.2 11068 2948 pts/2 S+ 23:02 0:00 vim file2
[root@localhost~]# kill 4362
[root@localhost~]# kill -9 4363
[root@localhost~]# killall vim //给所有vim进程发送信号
[root@localhost~]# killall httpd信号测试18,19:
[root@localhost~]# ps aux |grep sshd
root 5571 0.0 0.0 64064 1164 ? Ss 09:35 0:00 /usr/sbin/sshd
[root@localhost~]# kill -STOP 5571
[root@localhost~]# ps aux |grep sshd
root 5571 0.0 0.0 64064 1164 ? Ts 09:35 0:00 /usr/sbin/sshd
[root@localhost~]# kill -cont 5571
[root@localhost~]# ps aux |grep sshd
root 5571 0.0 0.0 64064 1164 ? Ss 09:35 0:00 /usr/sbin/sshd
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 22319 0.0 0.1 124140 1568 ? Ss 14:54 0:00 /usr/sbin/crond -n
yang 22427 0.0 0.0 112648 964 pts/2 R+ 15:07 0:00 grep --color=auto crond
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo kill -19 22319
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 22319 0.0 0.1 124140 1568 ? Ts 14:54 0:00 /usr/sbin/crond -n
yang 22431 0.0 0.0 112648 964 pts/2 R+ 15:07 0:00 grep --color=auto crond
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo kill -cont 22319
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ ps aux |grep crond
root 22319 0.0 0.1 124140 1568 ? Ss 14:54 0:00 /usr/sbin/crond -n
yang 22436 0.0 0.0 112648 960 pts/2 R+ 15:08 0:00 grep --color=auto crond踢出一个从远程登录到本机的用户:
[root@localhost~]# pkill --help
pkill: invalid option -- '-'
Usage: pkill [-SIGNAL] [-fvx] [-n|-o] [-P PPIDLIST] [-g PGRPLIST] [-s SIDLIST]
[-u EUIDLIST] [-U UIDLIST] [-G GIDLIST] [-t TERMLIST] [PATTERN]
[root@localhost~]# pkill -u alice
[root@localhost~]# w
15:46:44 up 2:19, 4 users, load average: 0.17, 0.12, 0.08
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
root tty1 :0 21:32 ? 4:22 4:22 /usr/bin/Xorg :
root pts/0 :0.0 15:46 0.00s 0.00s 0.00s w
root pts/3 172.16.8.100 15:46 2.00s 0.01s 0.00s sleep 50000
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ w
15:17:25 up 5:42, 3 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
yang pts/0 123.120.22.32 15:00 21.00s 0.00s 0.00s -bash
yang pts/1 123.120.22.32 15:00 5.00s 0.00s 0.00s w
yang pts/2 123.120.22.32 12:04 13.00s 0.12s 0.02s vim file1
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ pkill -t pts/2 //终止pts/2上所有进程
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ pkill -9 -t pts/2 //终止pts/2上所有进程 并结束该pts/2
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ w
15:20:59 up 5:45, 3 users, load average: 0.00, 0.01, 0.05
USER TTY FROM LOGIN@ IDLE JCPU PCPU WHAT
yang pts/0 123.120.22.32 15:00 3:55 0.00s 0.00s -bash
yang pts/1 123.120.22.32 15:00 3.00s 0.01s 0.00s w
yang pts/2 123.120.22.32 15:20 3.00s 0.00s 0.00s -bash
[yang@iZm5eiwihahzq6ds23gbf6Z ~]$ sudo pkill -u yang
复制代码可以使用kill -9 pid命令强制杀死进程(9 代表 KILL 信号,不可被捕获、屏蔽或忽略)。
kill 命令需要指定进程的 PID 号。
pgrep 命令可以通过程序名称(或其他属性如 UID)筛选进程号,pkill 命令可以直接发送指定信号给筛选结果。
sudo pkill -u ben该命令将发送 TERM 信号给所有属于用户 ben 的进程。
killall 命令可以通过程序名称杀死指定进程的所有实例。如:
sudo killall apache2$ pgrep postgres # 筛选 postgres 进程的 PID 号
25874
25876
25877
25878
25879
25880
25881
$ pgrep -a postgres # 筛选 postgres 进程的 PID 号,并输出详细信息
25874 /usr/lib/postgresql/10/bin/postgres -D /var/lib/postgresql/10/main -c config_file=/etc/postgresql/10/main/postgresql.conf
25876 postgres: 10/main: checkpointer process
25877 postgres: 10/main: writer process
25878 postgres: 10/main: wal writer process
25879 postgres: 10/main: autovacuum launcher process
25880 postgres: 10/main: stats collector process
25881 postgres: 10/main: bgworker: logical replication launcher
$ sudo kill -9 `pgrep postgres` # 杀死 postgres 进程
$ sudo pkill postgres # 同上一条命令
$ sudo killall postgres # 杀死 postgres 进程的所有实例
$ sudo pkill -9 -u postgres # 杀死属于 postgres 用户的所有进程根据进程 PID 号查找进程可以使用:
ps -p <pid> -o comm= 三、前后台进程
1、& 符号
前台进程(也称作交互式进程):由某个终端会话创建和控制的进程。即需要用户控制而不能作为系统服务自动启动。默认情况下,用户创建的进程都是前台进程,前台进程从键盘读取数据,并把处理结果输出到显示器。
后台进程(也称作非交互式进程):不和终端绑定的进程,不等待用户输入。
可以在命令后带上 & 符号,在后台启用一个 Linux 进程执行该命令。
cp emacs-26.2.tar.gz emacs-26.2-copy.tar.gz &
[1] 2051
------
[1]+ Done cp emacs-26.2.tar.gz emacs-26.2-copy.tar.gz-
[1] :这是此终端的后台进程的标号。因为这是第一个后台进程,所以标号为 1。
-
2051 :这是进程号(PID),如果你想要结束这个后台进程,你可以用 kill 命令:
2、nohup命令
& 符号虽然常用,但却有一个不可忽视的缺点:后台进程与终端相关联。一旦终端关闭或者用户登出,进程就自动结束。
如果我们想让进程在以上情况下仍然继续在后台运行,那么我们须要用到 nohup 命令。
当用户注销(logout)或者网络断开时,终端会收到 HUP(是 hangup 的缩写,英语“挂断”的意思)信号从而关闭其所有子进程;终端被关闭时也会关闭其子进程。
我们可以用 nohup 命令使命令不受 HUP 信号影响。
nohup 命令的用法很简单:在 nohup 命令之后接要运行的命令:
nohup memtester 2G > /tmp/memtest.log &使用 nohup 命令后,输出会被默认地追加写入到一个叫 nohup.out 的文件里。
现在,我们的进程已经不受终端关闭或者用户断开连接的影响了,会一直运行。当然了,用 kill 命令还是可以结束此进程的。要获知进程号,可以用我们之前学过的 ps 命令配合 grep 来查找。
ps -ax | grep command上面命令里的 command 指代 nohup 后面跟着的命令。
3、进程前后台切换
假如你要将进程转到后台运行,但是执行命令时忘记了在最后加上 & 符号,如何再使此进程转为后台进程呢?
1. Ctrl + Z:转到后台,并暂停运行
因为 top 命令的作用是实时地显示各种系统信息和进程列表。这时,我们按下 Ctrl + Z 这个组合键
可以看到终端显示了:
top
[1]+ Stopped topstopped 是英语“停止的”的意思,我们又看到 [1] 这个熟悉的信息,表示这是此终端第一个后台进程。
所以表示 top 命令被放到了后台,此进程还是驻留在内存中,但是被暂停运行了。这个时候命令提示符又出现了,我们可以做其他事情了。
2. bg 命令:使进程转到后台
经过上面的 Ctrl + Z 操作,我们可怜的 top 进程已经被“打入冷宫”(转入后台,并且被暂停运行了)。
bg 命令的作用是将命令转入后台运行。假如命令已经在后台,并且暂停着,那么 bg 命令会将其状态改为运行。
不加任何参数,bg 命令会默认作用于最近的一个后台进程,也就是刚才被 Ctrl + Z 暂停的 top 进程。如果后面加 %1,%2 这样的参数(不带 %,直接 1,2 这样也可以),则是作用于指定标号的进程。因为进程转入后台之后,会显示它在当前终端下的后台进程编号。例如目前 top 进程转入了后台,它的进程编号是 1(可以由 [1]+ 推断)。依次类推,bg %2 就是作用于编号为 2 的后台进程。
3. jobs 命令:显示后台进程状态
jobs 命令的作用是显示当前终端里的后台进程状态。虽然我们可以用 ps 命令来查看进程状态,但是 ps 命令输出的进程列表太长了。
jobs 命令的输出共分三列:
1. 显示后台进程标号:比如上例中 top 进程的标号是 1,grep 进程的标号是 2,如果还有其他后台进程,那么就会有 [3],[4]等等。这个标号和 PID(进程号)是不一样的。这个标号只是显示当前终端下的后台进程的一个编号;
2. 显示后台进程状态:比如 Stopped 是“停止的”的意思,Running 是“运行的”的意思。还有其他状态;
3. 命令本身;4. fg 命令:使进程转到前台
与 bg 命令相反,fg 命令的作用是:使进程转为前台运行。
用法也很简单,和 bg 一样,如果不加参数,那么 fg 命令作用于最近的一个后台进程;如果加参数,如 %2,那么表示作用于本终端中第二个后台进程。
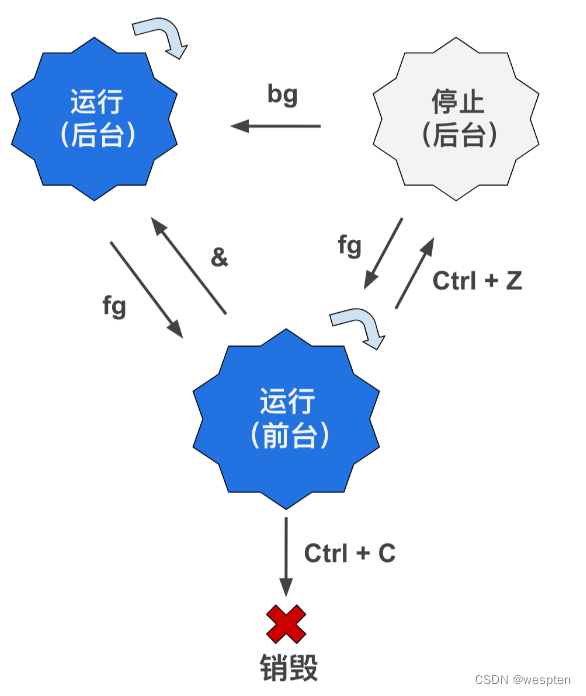
解释一下上图:
如果我们运行一个程序,默认情况下,它会成为一个前台运行的进程。我们可以按组合键 Ctrl + C 来销毁此进程。
我们也可以使此进程在后台运行。假如运行程序时就用 & 放在命令最后,那么进程就会在后台运行。
假如在进程运行起来后,按 Ctrl + Z,则进程会转到后台,并且停止。此时如果运行 bg 命令,则进程重新运行,并继续在后台。
fg 命令可以使进程转到前台,并且运行。
往往通过 jobs 命令查看当前的任务,使用 fg 命令将后台执行的进程调到前台执行。
使用 Ctrl + Z 组合键(发送 SIGSTOP 信号)挂起当前进程(前台),并使用 bg 命令令其在后台继续执行。
[root@localhost~]# sleep 3000 & //运行程序(时),让其在后台执行
[root@localhost~]# sleep 4000 //^Z,将前台的程序挂起(暂停)到后台
[2]+ Stopped sleep 4000
[root@localhost~]# ps aux |grep sleep
root 8895 0.0 0.0 100900 556 pts/0 S 12:13 0:00 sleep 3000
root 8896 0.0 0.0 100900 556 pts/0 T 12:13 0:00 sleep 4000
[root@localhost~]# jobs //查看后台作业
[1]- Running sleep 3000 &
[2]+ Stopped sleep 4000
[root@localhost~]# bg %2 //使用 bg 命令将作业2调至后台继续执行
[root@localhost~]# fg %1 //将后台执行的作业1调到前台执行
[root@localhost~]# kill %1 //kill 1,终止PID为1的进程
[root@localhost~]# (while :; do date; sleep 2; done) & //进程在后台运行,但输出依然在当前终端
[root@localhost~]# (while :; do date; sleep 2; done) &>/dev/null &三、Linux计划任务
每个人在生活当中或多或少都有一些工作,有的工作是按照一定周期循环的, 例如每天固定时间的闹铃、工作打卡等等; 有的工作则是临时发生的,例如刚好有亲友到访,需要你在一个特定的时间去车站迎接! 这个时候 Linux 的计划任务就可以派上场了! 在不考虑硬件与我们服务器的连接状态下,我们的 Linux 可以帮你提醒很多任务, Linux 是通过 crontab 与 at 来实现计划任务的。
计划任务在系统当中到底有什么作用呢?
(一)进行日志的切割 (log rotate): Linux 会主动的将系统所发生的各种信息都记录到日志中。随着使用时间的增长,日志文件会越来越大!我们知道大型文件不但占容量还会造成读写效能的困扰, 因此适时的将日志文件数据挪一挪,让旧的数据与新的数据分别存放,这样既能记录日志信息又能提高读写效率。这就是 logrotate 的任务!
(二)日志文件分析 logwatch 的任务: 如果系统发生了问题等,绝大部分的错误信息都会被记录到日志文件中, 因此系统管理员的重要任务之一就是分析日志。但你不可能手动通过 vim 等软件去查看日志文件,因为数据量太大! 我们可以通过一个叫“ logwatch ”的程序分析日志信息,在启动邮件服务的前提下,你的 root 老是会收到标题为 logwatch 的信件
(三)建立 locate 的数据库: 有时候我们会通过locate命令来查询文件。而文件名数据库是放置到 /var/lib/mlocate/ 中。 这个数据库也是通过计划任务定期的执行updatedb命令去更新的
(四)RPM 软件日志文件的建立:系统会经常安装或卸载软件包。为了方便查询,系统也会将这些软件包的名称进行记录! 所以计划任务也会定期帮助我们更新rpm数据库
(五)移除临时文件: 软件在运行中会产生一些临时文件,但是当这个软件关闭时,这些临时文件可能并不会主动的被删除。有些时候这些文件对于系统来讲没有什么用处了,还占用磁盘空间。系统通过计划任务来定期来删除这些临时文件!
1、at
at 是个可以处理仅执行一次就结束工作的命令,需要一个叫atd的服务支持,所以这个服务要启动。
1)atd 服务启动
在使用at之前我们要确保atd服务是运行的,这个需要我们去检查一下,因为并不是所有的发行版linux默认都是开启这个服务的,但是在CentOS中是默认开启的:
[root@localhost ~]# systemctl status atd
● atd.service - Job spooling tools
Loaded: loaded (/usr/lib/systemd/system/atd.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-01-13 09:34:03 CST; 1h 17min ago
#查询atd服务的状态
[root@localhost ~]# systemctl is-enabled atd
enabled
#查询是否开启默认启动
如果没有启动
[root@localhost ~]# systemctl start atd
# 启动
[root@localhost ~]# systemctl enable atd
#设置为开启启动2)at的工作模式
at在运行的时候会将定义好的工作以文本文件的方式写入 /var/spool/at/ 目录内,该工作便能等待 atd 这个服务的调用,但是处于安全考虑,并不是所有的人都可以使用 at 计划任务!所以系统给我们提供了两个文件 /etc/at.allow 与 /etc/at.deny 来进行 at 的使用限制! 加上这两个文件后, at 的工作情况其实是这样的:
先找寻 /etc/at.allow 这个文件,写在这个文件中的用户才能使用 at ,没有在这个文件中的用户则不能使用 at (即使没有写在 at.deny 当中);
如果 /etc/at.allow 不存在,就寻找 /etc/at.deny 这个文件,若写在这个 at.deny 的用户则不能使用 at ,而没有在这个 at.deny 文件中的用户,就可以使用 at ;
如果两个文件都不存在,那么只有 root 可以使用 at 这个命令。
在大多数发行版当中,由于假设系统上的所有用户都是可信任的, 因此系统通常会保留一个空的 /etc/at.deny 文件,允许所有人使用 at 。如果有需要的话可以手动建立at.allow文件
3)at的使用
单一计划任务的进行就使用 at 这个命令!将 at 加上一个时间即可!基本的语法如下:
[root@localhost ~]# at [-mldv] TIME
[root@localhost ~]# at -c 工作序号
选项与参数:
-m :当 at 的工作完成后,发邮件通知用户,需要mail服务
-l :at -l 相当于 atq,查看用户使用at定制的工作
-d :at -d 相当于 atrm ,删除一个工作;
-v :详细信息;
-c :查看指定工作的具体内容。
TIME:时间格式
HH:MM ex> 16:00
在今天指定的时刻进行,若该时刻已超过,则明天的这个时间进行此工作。
HH:MM YYYY-MM-DD ex> 16:00 2021-07-30
指定在某年某月的某一天的时间进行该工作!
HH:MM[am|pm] [Month] [Date] ex> 04am Jun 15 另外一种年月日和时间的指定方式
HH:MM[am|pm] + number [minutes|hours|days|weeks] ex> now + 5 minutes 五分钟之后
ex> 04am + 3 days 三天后的上午四点查看计划任务:
at -l
atq查看计划任务内容:
at -c jobid删除计划任务:
atrm jobid创建计划任务:
at 时间保存:
ctrl dat在使用过程中的时间指定很重要,另外在使用过程中如果涉及到路径的指定,强烈建议使用绝对路径,定义完成at之后使用键盘上的ctrl+d结束。
有的时候我用at定义完计划任务之后,发现命令有错误,此时我们就可以使用atq 与 atrm 进行管理:
[root@localhost ~]# atq
[root@localhost ~]# atrm 工作编号
[root@localhost at]# atq
2 Fri Feb 21 16:00:00 2020 a root
# 在 2020-02-21 的 16:00 有一项工作,该项工作是root设置的,工作编号为2
[root@localhost ~]# atrm 2
[root@localhost ~]# atq # 没有任何信息,表示该工作被移除了! 这样,你可以利用 atq 来查询,利用 atrm 来删除。
具体演示:
╭─[email protected] ~
╰─➤ yum install at -y #因为at不是本机自带所以需要下载at
已加载插件:fastestmirror, langpacks
... #省略加载内容
更新完毕:
at.x86_64 0:3.1.13-24.el7
完毕!
╭─[email protected] ~
╰─➤ systemctl restart atd #运行at
╭─[email protected] ~
╰─➤ systemctl enable atd #设置开机自启
╭─[email protected] ~
╰─➤ at 10:00 #输入“at 时间”;开始设置at ,支持am、pm
at> touch /home/cjk #输入任务内容
at> echo "hello" >> /home/cjk<EOT> #输入完毕,按Ctrl+D保存
job 2 at Wed May 15 10:00:00 2019
╭─[email protected] ~
╰─➤ at -l #查询at任务
2 Wed May 15 10:00:00 2019 a root #任务id+时间
╭─[email protected] ~
╰─➤ atq #查询at任务
2 Wed May 15 10:00:00 2019 a root
╭─[email protected] ~
╰─➤ at -c 2 #at -c 任务id 查询at任务
... #省略加载内容
touch /home/cjk
echo "hello" >> /home/cjk
marcinDELIMITER4dbc8ae5
╭─[email protected] ~
╰─➤ atrm 2 # atrm +任务id --->删除任务
╭─[email protected] ~
╰─➤ atq
╭─[email protected] ~
╰─➤ 三天后的下午 5 点执行/bin/ls:
[root@localhost ~]# at 5pm+3 days
at> /bin/ls
at> <EOT>
job 7 at 2013-01-08 17:00
明天17点钟,输出时间到指定文件内:
[root@localhost ~]# at 17:20 tomorrow
at> date >/root/2013.log
at> <EOT>
job 8 at 2013-01-06 17:204)batch:系统有空时才进行后台任务
利用 at 来直接定义计划任务但是如果系统当前非常忙碌话,能不能让指定的工作在较闲的时候执行呢?那就是batch。
batch是at的一个辅助工具,也是利用at进行工作的,只是加入一些判断功能。它会在 CPU 的工作负载小于 0.8 的时候,才执行指定的工作! 这个负载指的是 CPU 在单一时间点所负责的工作数量。不是 CPU 的使用率! 比如说,如果我运行一个程序,这个程序可以使CPU 的使用率持续达到 100% , 但是 CPU 的负载接近与1,因为 CPU 仅负责一个工作,而我同时运行了两个这样的程序,那么 CPU 的使用率还是 100% ,但是工作负载则变成 2 了。
也就是说,当 CPU 的负载越大,CPU 必须要在不同的工作之间进行频繁的切换。所以会非常忙碌! 而用户还要额外进行 at 完成工作,就不太合理!所以才有 batch 命令的产生!
CentOS从7开始,batch 已经不再支持时间参数了,所以我们在使用batch定制计划任务的时候可以这样输入:
root@localhost at]# batch
warning: commands will be executed using /bin/sh
at> cp /etc/passwd /root
at> <EOT>
job 4 at Mon Jan 13 11:31:00 2020
[root@localhost at]# cd
[root@localhost ~]# ls
公共 模板 视频 图片 文档 下载 音乐 桌面 anaconda-ks.cfg initial-setup-ks.cfg passwd所以,batch可以通过cpu负载自动判断是否可以执行指定的工作。
2、crontab
crontab 这个命令所设定的工作将会按照一定的周期去执行! 可循环的时间为分钟、小时、日期、每周、每月等。crontab 除了可以使用命令执行外,也可以通过编辑 /etc/crontab 来支持,与at相同,crontab也需要一个叫crontd的服务。
1)crond服务启动
相对于 at 是仅执行一次的工作,周期执行的计划任务则是由 crond这个系统服务来控制的。同样各位在使用的时候也要确认一下此服务的状态:
[root@localhost ~]# systemctl status crond
● crond.service - Command Scheduler
Loaded: loaded (/usr/lib/systemd/system/crond.service; enabled; vendor preset: enabled)
Active: active (running) since Mon 2020-01-13 09:34:03 CST; 2h 0min ago
[root@localhost ~]# systemctl is-enabled crond
enabled3)crontab的使用
用户使用的是 crontab 这个命令来定义周期性的计划任务,但是为了安全性的问题, 与 at 同样的,我们可以限制使用 crontab 的用户账号!使用的限制数据有:
/etc/cron.allow: 将可以使用 crontab 的账号写入其中,若不在这个文件内的用户则不可使用 crontab;
/etc/cron.deny: 将不可以使用 crontab 的账号写入其中,若未记录到这个文件当中的用户,就可以使用 crontab 。
与 at 一样,以优先级来说, /etc/cron.allow 比 /etc/cron.deny 要高, 一般系统默认是提供 /etc/cron.deny , 你可以将允许使用 crontab 用户写入 /etc/cron.deny 当中,一个账号一行。crontab 建立计划任务会存放在 /var/spool/cron/ 目录中,
crontab 的使用:
[root@localhost ~]# crontab
-u :只有root可以使用,指定其它用户的名称
-e :建立计划任务
-l :查看计划任务
-r :删除所有计划任务,若只删除一项,只能使用-e进行编辑
[root@localhost ~]# crontab -e
#执行后会打开一个vim的页面,每个任务一行
0 12 * * * cp /etc/passwd /root
分 时 日 月 周 工作内容编辑完毕之后输入“ :wq ”保存退出, 在cron中每项工作 (每行) 的格式都是具有六个字段,这六个字段的意义为:
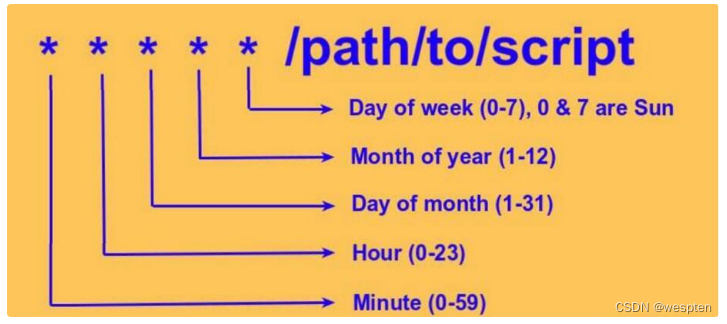
| 分钟 | 小时 | 日期 | 月份 | 周 | 命令 |
|---|
比较有趣的是那个『周』!周的数字为 0 或 7 时,都代表『星期天』的意思!
[root@localhost ~]# crontab -l #查看root的计划任务
0 16 1 * * cp /etc/passwd /root
root@localhost ~]# crontab -u oracle -l
#查看指定用户的计划任务
no crontab for oracle
[root@localhost ~]# crontab -r #删除所有计划任务
[root@localhost ~]# crontab -l
no crontab for root注意:crontab在使用的时候如果遇到路径,同样建议使用绝对路径,如果只是要删除某个项目,使用 crontab -e 来重新编辑,如果使用 -r 的参数,是会将所有的 crontab 内容都删掉。
4)crontab的配置文件
crontab -e是针对用户 来设计的,系统的计划任务是通过/etc/crontab文件来实现的,我们只要编辑/etc/crontab 这个文件就可以,由于cron的最低检测时间是分钟,所以编辑好这个文件,系统就会自动定期执行了:
[root@localhost ~]# cat /etc/crontab
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# For details see man 4 crontabs
# Example of job definition:
# .---------------- minute (0 - 59)
# | .------------- hour (0 - 23)
# | | .---------- day of month (1 - 31)
# | | | .------- month (1 - 12) OR jan,feb,mar,apr ...
# | | | | .---- day of week (0 - 6) (Sunday=0 or 7) OR sun,mon,tue,wed,thu,fri,sat
# | | | | |
# * * * * * user-name command to be executed与crontab -e的内容类似,但是多了几个部分:
SHELL=/bin/bash shell类型
PATH=/sbin:/bin:/usr/sbin:/usr/bin 执行文件搜索位置
MAILTO=root 发生错误时通知邮件发送给谁
* * * * * user-name command to be executed
#比crontab -e多了一个执行者的身份,因为并不是所有工作都需要root用户去执行额外的文件
crond有三个相关联的地方,他们分别是:
/etc/crontab 系统计划任务的配置文件
/etc/cron.d/ 此目录和下面的几个目录都是系统计划任务存放运行脚本的位置。
/etc/cron.hourly/
/etc/cron.daily/
/etc/cron.weekly/
/etc/cron.monthly/
/var/spool/cron/root 计划任务存放路径
/var/spool/cron/* 用户定制的计划任务存放位置
演示:
╭─[email protected] ~
╰─➤ crontab -e -u du #指定du用户创建crontab
no crontab for du - using an empty one
crontab: installing new crontab
╭─[email protected] ~
╰─➤ crontab -lu du #查看crontab
45 4 1,10,22 * * /usr/bin/systemctl restart network
*/30 18-23 * * * /usr/bin/systemctl restart network
30 2 * * 7 /usr/bin/cp /etc/fstab /tmp/fstab-`date “+\%F_\%T” `
╭─[email protected] ~
╰─➤ crontab -eu du #打开du用户的crontab任务文件,把任务注释掉以删除的某个任务
#计划任务都会被保存在 /var/spool/cron/,文件命名就是用户名:
crontab: installing new crontab
╭─[email protected] ~
╰─➤ crontab -lu du
#45 4 1,10,22 * * /usr/bin/systemctl restart network #用“#”把任务注释掉
*/30 18-23 * * * /usr/bin/systemctl restart network
30 2 * * 7 /usr/bin/cp /etc/fstab /tmp/fstab-`date “+\%F_\%T” ` #计划任务不识别%需用 \ 转译
╭─[email protected] ~
╰─➤ crontab -ru du #-r删除crontab,会删除整个文件,删除所有任务;
╭─[email protected] ~
╰─➤ crontab -lu du
no crontab for du
##最后重启crontab生效3、anacron
有些时候,在cron需要执行相应工作的时候,你的系统关机了,该如何处理?这个时候就需要使用anacron。anacron 并不是用来取代 crontab 的,anacron 存在的目的就在于处理由于一些原因导致cron无法完成的工作。
anacron 用于以天为单位的频率运行命令。cron 也适合在那些不会 24X7 运行如笔记本以及桌面电脑的机器上运行每日、每周以及每月的计划任务(LCTT 译注:不适合按小时、分钟执行任务)。
假设你有一个计划任务(比如备份脚本)要使用 cron 在每天半夜运行,也许你以及睡着,那时你的桌面/笔记本电脑已经关机。你的备份脚本就不会被运行。然而,如果你使用 anacron,你可以确保在你下次开启桌面/笔记本电脑的时候,备份脚本会被执行。
其实 anacron 也是每个小时被 crond 执行一次,然后 anacron 再去检测相关的工作任务有没有被执行,如果有未完成的工作, 就执行该工作任务,执行完毕或无须执行任何工作时,anacron 就停止了。我们可以通过/etc/cron.d/0hourly的内容查看到:
[root@localhost ~]# cat /etc/cron.d/0hourly
# Run the hourly jobs
SHELL=/bin/bash
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
01 * * * * root run-parts /etc/cron.hourly由于 anacron 默认会以一天、七天、一个月为期去检测系统未进行的 crontab 任务,因此对于某些特殊的使用环境非常有帮助。
那么 anacron 又是怎么知道我们的系统何时关机?这就得要使用 anacron 读取的时间记录文件 (timestamps) 了! anacron 会去分析现在的时间与时间记录文件所记载的上次执行 anacron 的时间,两者比较后若发现有差异, 那就是在某些时刻没有进行 crontab !此时 anacron 就会开始执行未进行的 crontab 任务了!
4)anacron的配置文件
anacron 任务被列在 /etc/anacrontab 中,任务可以使用下面的格式(anacron 文件中的注释必须以 # 号开始)安排。
cat /etc/anacrontab
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/usr/local/sbin:/usr/local/bin:/sbin:/bin:/usr/sbin:/usr/bin
HOME=/root
LOGNAME=root
# These replace cron's entries
1 5 cron.daily run-parts --report /etc/cron.daily
7 10 cron.weekly run-parts --report /etc/cron.weekly
@monthly 15 cron.monthly run-parts --report /etc/cron.monthly
@daily 10 example.daily /bin/bash /home/aaronkilik/bin/backup.sh period delay job-identifier command从上面的格式中:
- period - 这是任务的频率,以天来指定,或者是@daily 、@weekly、@monthly 代表每天、每周、每月一次。你也可以使用数字:1 - 每天、7 - 每周、30- 每月,或者N - 几天。
- delay - 这是在执行一个任务前等待的分钟数。
- job-id - 这是写在日志文件中任务的独特名字。
- command - 这是要执行的命令或 shell 脚本。
anacron 会检查任务是否已经在 period 字段指定的时间被被执行了。如果没有,则在等待 delay 字段中指定的分钟数后,执行 command字段中指定的命令。
一旦任务被执行了,它会使用 job-id (时间戳文件名)字段中指定的名称将日期记录在 /var/spool/anacron 目录中的时间戳文件中。
要浏览示例文件,输入:
$ ls -l /var/spool/anacron/
total 12
-rw------- 1 root root 9 Jun 1 10:25 cron.daily
-rw------- 1 root root 9 May 27 11:01 cron.monthly
-rw------- 1 root root 9 May 30 10:28 cron.weeklyanacron 其实是一个程序并非一个服务!这个程序在系统当中已经加入 crontab 的工作!同时 anacron 会每个小时被主动执行一次!所以 anacron 的配置文件应该放置在 /etc/cron.hourly目录中:
[root@localhost ~]# cat /etc/cron.hourly/0anacron
#!/bin/sh
# Check whether 0anacron was run today already
.
.
.
/usr/sbin/anacron -s
实际上,也仅仅是执行anacron -s命令,这个命令会根据/etc/anacrontab文件的定义去执行各项工作anacrontab:
[root@localhost ~]# cat /etc/anacrontab
# /etc/anacrontab: configuration file for anacron
# See anacron(8) and anacrontab(5) for details.
SHELL=/bin/sh
PATH=/sbin:/bin:/usr/sbin:/usr/bin
MAILTO=root
# the maximal random delay added to the base delay of the jobs
RANDOM_DELAY=45 #最大随机延迟时间,单位是分钟
# the jobs will be started during the following hours only
START_HOURS_RANGE=3-22 #仅执行延迟多少个小时之内的任务
#period in days delay in minutes job-identifier command
1 5 cron.daily nice run-parts /etc/cron.daily
7 25 cron.weekly nice run-parts /etc/cron.weekly
@monthly 45 cron.monthly nice run-parts /etc/cron.monthly
@daily 10 example.daily /bin/bash /home/aaronkilik/bin/backup.sh
间隔时间(天) 延迟时间(分钟) 工作名称 执行的内容anacrontab 文件的重要变量:
- START_HOURS_RANGE - 这个设置任务开始运行的时间范围(也就是任务只在这几个小时内运行)。
- RANDOM_DELAY - 这定义添加到用户定义的任务延迟的最大随机延迟(默认为 45)。
以 /etc/cron.daily/ 那一行的为例,每隔一天,在开机后的第5分钟去执行cron.daily目录下的脚本。
每天运行 /home/aaronkilik/bin/backup.sh 脚本,如果运行时是关机的,anacron 会在机器开机十分钟之后运行它,而不用再等待 7 天。
cron 以及 anacron 的比较:
| ron | anacron |
|---|---|
| 它是守护进程 | 它不是守护进程 |
| 适合服务器 | 适合桌面/笔记本电脑 |
| 可以让你以分钟级运行计划任务 | 只能让你以天为基础来运行计划任务 |
| 关机时不会执行计划任务 | 如果计划任务到期,机器是关机的,那么它会在机器下次开机后执行计划任务 |
| 普通用户和 root 用户都可以使用 | 只有 root 用户可以使用(使用特定的配置启动普通任务) |
cron 和 anacron 主要的区别在于 cron 能在那些持续运行的机器上有效地运行,而 anacron 是针对那些会在一天内或者一周内会关机的机器。
4、计划任务编写实例
每1分钟执行一次command
* * * * * command每小时的第3和第15分钟执行
3,15 * * * * command 在上午8点到11点的第3和第15分钟执行
3,15 8-11 * * * command 每隔两天的上午8点到11点的第3和第15分钟执行
3,15 8-11 */2 * * command每个星期一的上午8点到11点的第3和第15分钟执行
3,15 8-11 * * 1 command 每月1、10、22日的4:45重启network服务
45 4 1,10,22 * * /usr/bin/systemctl restart network
每周六、周日的1:10重启network服务
10 1 * * 6,7 /usr/bin/systemctl restart network
每天18:00至23:00之间每隔30分钟重启network服务
*/30 18-23 * * * /usr/bin/systemctl restart network
每隔两天的上午8点到11点的第3和第15分钟执行一次重启
3,15 8-11 */2 * * /usr/sbin/reboot
每周日凌晨2点30分,运行cp命令对/etc/fstab文件进行备份,存储位置为/backup/fstab-YYYY-MM-DD-hh-mm-ss;
30 2 * * 7 /usr/bin/cp /etc/fstab /tmp/fstab-`date “+\%F_\%T”`
一月一号的4点重启smb
0 4 1 1 * /usr/bin/systemctl restart smb #4点钟只执行一次命令,正确答案;
* 4 1 1 * /usr/bin/systemctl restart smb #四点到五点执行了60次命令,错误答案:
每月1、10、22日的4 : 45重启smb
45 4 1,10,22 * * /usr/bin/systemctl restart smb晚上11点到早上7点之间,每隔一小时重启smb
0 23-0/1,1-7/1 * * * /usr/bin/systemctl restart smb
0 23,0,1,2,3,4,5,6,7 * * * /usr/bin/systemctl restart smb
每一小时重启smb
0 * * * * /usr/bin/systemctl restart smb每晚的21:30重启smb
30 21 * * * /usr/bin/systemctl restart 每周六、周日的1:10重启smb
10 1 * * 6,0 /usr/bin/systemctl restart 每天18 : 00至23 : 00之间每隔30分钟重启smb
0,30 18-23 * * * /usr/bin/systemctl restart 每星期六的晚上11:00 pm重启smb
0 23 * * 6 /usr/bin/systemctl restart 每月的4号与每周一到周三的11点重启smb
0 11 4 * mon-wed /usr/bin/systemctl restart 每小时执行/etc/cron.hourly目录内的脚本
01 * * * * root run-parts /etc/cron.hourly四、系统快键键
1、系统命令分类
系统所有命令分为三类。内部命令,别名命令,外部命令。
优先级:别名命令>内部命令>外部命令
1)内部命令
内部命令是指集成在特定shell中的命令,当用户登录时,会自动启用shell,而对应shell程序中包含一些常见工具。比如默认的/bin/bash/shell中就集成的很多内部命令,对这些命令,我们可以通过enable命令查看:
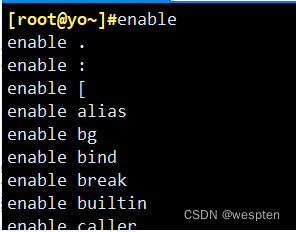
内部命令的执行内效率很高,那么如何判断那些是内部命令呢?我们可以通过type命令判断:

我们看到,结果直接提示我们enable是shell中的内置命令(builtin)。
2)外部命令
外部命令就是没有集成在shell程序中的命令外部命令可以在磁盘找到对应的文件。具体表现为一个可执行文件。例如:

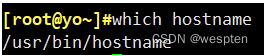
结果提示我们reboot在磁盘的存储路径为/usr/sbin/reboot(是绝对路径的就是外部命令)。查看外部命令的对应路径可以通过which实现:
所有的外部命令都能在磁盘上找到对应的路径。
那么,当我们在终端输入外部命令时,系统是如何在成千上万的磁盘文件中找到我们输入的外部命令的呢?系统不会为了执行一个外部命令,临时搜索所有磁盘文件的,那样的话效率会相当的低。在系统中,有一个叫PATH的变量,里面保存了外部命令存放的路径:

当执行一个外部命令时,系统就会按PATH中存放的路径查找。
但是,如果我们每次执行都需要进行磁盘查找,还是会比较慢,由此,我们引申出一个概念:缓存。事实上,当我们第一次执行外部命令过后,系统都会自动将外部命令的路径记录到内存的缓存区中,第二次执行这条外部命令时,就会在缓存区找到路径并执行,大大提高效率。我们可以通过一个命令hash查看已经执行过的外部命令以及存放路径: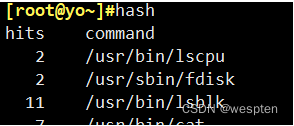
但是,这样也会有不好的地方,比如当我们有时候将外部命令移动过再执行这条命令会导致报错:

那么这个报错有解决方法吗?有的:

系统的查找执行顺序是先在hash表中查找,存在就执行,如果不存在,就去PATH路径下查找,如果PATH路径也没有,就会报错。
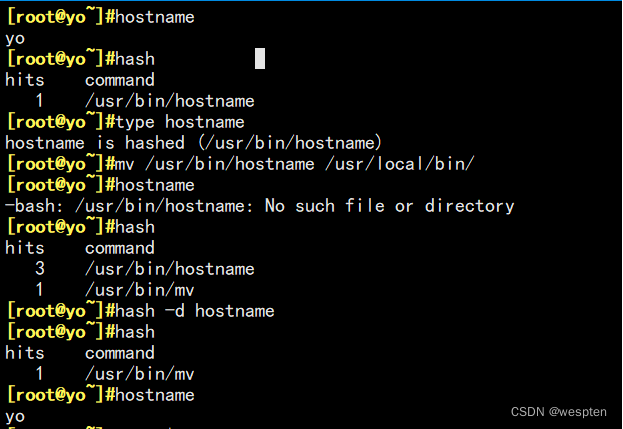
由图可已看出。当我们执行过一个名叫hostname的外部命令时,会在hash表中缓存一个路径,hash的本意是提高效率,但是当我们将hostname文件的路径移动后,第二次执行这条命令,系统依旧会去hash表中寻找路径,但是这时其本来路径中已经没有了hostname的文件,系统在缓存的路径中找不到,系统就会报错。
这时我们可以执行hash -d +命令的方式,去除掉已经过时的这条缓存路径,这样,当我们再一次执行这条命令时,系统就会去再一次根据PATH提供的路径去磁盘寻找,就不会报错。当然 ,因为hash表是在内存中存在的,这样系统不工作时,缓存就会自动清空,我们也可以exit退出重连,也可以解决问题。
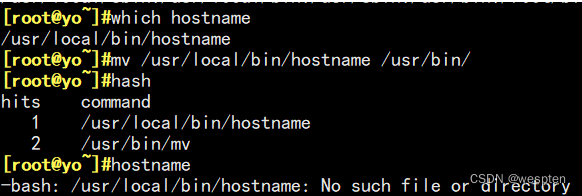

总结:如果不是内部命令,将查询hash对应的缓存区,是否有改命令对应的路径,如果有,按对应路径执行;如果找不到,将按照PATH环境变量指定路径查找,找到并执行,如果变量中有多个目录有该命令,则执行第一个。
3)别名
所谓别名,就是将一些常用的内部或外部命令,起一个较短的名称。对于一些常用但又较长的命令,可以起一个较短的别名大大提高效率。
如果定义的别名和某个内部或外部命令重合时,系统会优先执行别名,那么当我们不想执行别名而是重名的原本命令该怎么办呢?可以利用\别名或'别名'指定为原本命令。
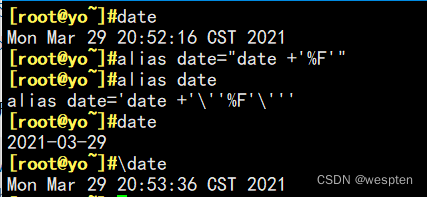
修改用户环境变量文件,仅对当前用户有效:
vim /root/.bashrc //Or ~/.bashrc
alias rm=‘rm -i‘ #用户环境变量修改别名。
alias cp=‘cp -i‘
alias mv=‘mv -i‘ 全局环境变量文件:
vim /etc/bashrc
alias rm=‘rm -i‘
alias cp=‘cp -i‘
alias mv=‘mv -i‘
export LANG=zh_CN.gb2312 #修改系统识别语言。
export PS1=‘【\u(用户名)@\h(主机名) \w(工作目录)】\$‘ #修改终端“#”前显示的信息。2、查看系统状态常用命令
(1)df -h #查看分区状态。
(2)mount #查看文件系统类型。
(3)du -h -max-depth=1 目录名 #查看目录文件大小,批量查找。
(4)du -sh #查看目录文件大小。
(5)w #查看用户登陆IP,tty,启动时间,与负载。
(6)date #查看当前时间。
(7)clock #查看硬件时间。
(9)tty #查看当前自身的虚拟终端。
(10)file 文件名 #查看文件类型。
(11)stat 文件名 #查看文件详细信息。
(12)free -m #查看内存使用情况。
(13)cat /proc/cpuinfo #查看CPU硬件信息。
(14)cat /proc/meminfo #查看内存硬件信息。
(15)uname –r #查看内核版本。
(16)cat/etc/issue #查看系统版本。
(17)last #查看用户登陆启动情况。
(18)lastlog #查看有那些用户IP登陆过服务器。
(19)tail /var/log/messages #查看系统服务启动错误日志。
(20)tail /var/log/maillog #查看系统邮件服务错误日志。
(21)tail /var/log/secure #查看系统安全访问日志。
(22) wall “内容” #在服务器上发送广播信息。
(23) hwclock -w #同步系统时间。
(24) write 用户名 /dev/pts/1 /回车“内容” #指定发给用户终端。
(25) echo “内容” /dev/pts/0 #指定内容从定向到虚拟终端。
(26) alias #查看系统别名。3、系统快捷键
(1)alias lr=“ls –lthr” #简化命令,手动创建别名。
(2)unalias lr #取消别名。
(3)Tab键 #补全Linux命令和文件,安装bash-completion以更好支持参数补全
(4)ctrl+R #输入匹配。
(5)!1035 #执行hisotryID号。
(6)cd - #返回上次的目录。
(7)cd !$ #执行上一条语句的最后一段(上一个参数的对象)
(8)!/etc #取上一条的命令。
(9) !vi或!vim #可以打开最近打开的文件。
(10)ctrl+A(ctrl+a) #输命令数跳到行首。
(11)ctrl+e #输命令跳到行尾。
(12)ctrl+u #删除行后所有内容。
(13)ctrl+k #删除行前所有内同。
(14)ctrl+l #清屏。
(15) ctrl+w #删除光标前一个参数
(16) ctrl+c #中断前台执行的命令
(17) ctrl+d #中断后台执行的命令
(18)echo $? #反馈值。0真确,1正确。
(19)echo $PATH #查看当前目录可执行的命令目录。
(20)etho $PWD #查看当前目录位置。
(21)etho $LANG #查看当前所使用的识别语言。
(22)etho $HOME #查看当前用户的家目录。
(23) etho $PS1 #查看“#”前显示的信息。五、系统备份与恢复
1、数据备份简介
Linux服务器中哪些数据需要备份?
1)Linux系统重要数据
/root/目录:/root目录是管理员的家目录
/home/目录:/home目录是普通用户家目录,如果是生产环境的服务器,这个目录中也会保存大量的重要数据,应该备份。
/etc/目录:系统重要的配置文件保存目录。
/var/spool/cron/: 定时任务
/boot: 引导分区
2)安装服务的数据
我们这里拿最常见的apache服务和mysql服务举例:
apache需要备份如下内容:
配置文件:RPM包安装了apache,需要备份/etc/httpd/conf/httpd.conf。源码包安装的apache则备份 /usr/local/apache2/conf/httpd.conf。
网页主目录:RPM包安装的apache需要备份/var/www/html/目录中所有数据。源码包安装的apache需要备份 /usr/local/apache2/htdocs/目录中所有数据。
日志文件:RPM包安装的apache需要备份/var/log/httpd/目录中所有日志。源码包安装的apache需要备份 /usr/local/apache2/logs/目录中所有日志。
备份策略有哪些?
1)完全备份
完全备份就是指把所有需要备份的数据全部备份,当然完全备份可以备份整块硬盘,整个分区或某个具体的目录。完全备份的好处就是数据恢复方便,因为所有的数据都在同一个备份中,所以只要恢复完全备份,所有的数据就会被恢复。如果完全备份的是整块硬盘,那么甚至都不需要数据恢复,只要把备份硬盘安装上,服务器就会恢复正常。可是完全备份的缺点也很明显,那就是需要备份的数据量较大,备份时间较长,占用的空间较多,所以完全备份不可能每天执行。我们一般会对关键的服务器进行整盘完全备份,如果出现问题,可以很快的使用备份硬盘进行替换,从而减少损失。甚至会对关键服务器搭设一台一模一样的服务器,这样只要远程几个命令(或使用shell脚本自动检测,自动进行服务器替换。)备份服务器就会解体原本的服务器,使我们的故障响应时间缩短为最短。
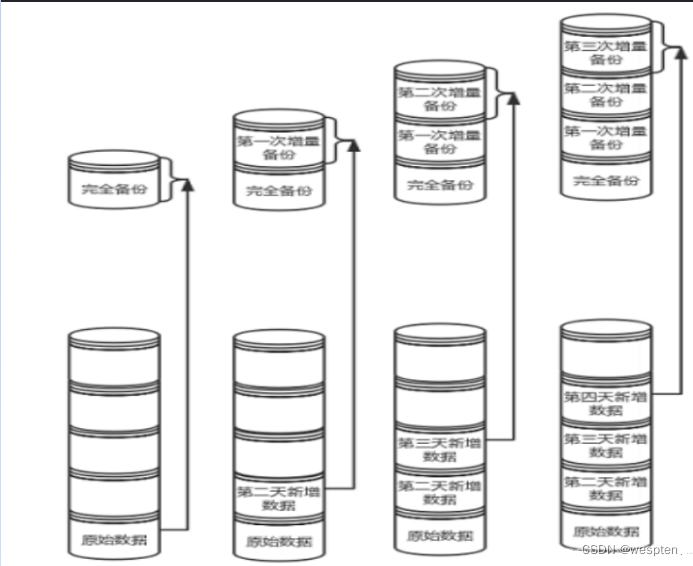
2)增量备份
完全备份随着数据量的加大,备份耗费的时间和占用的空间会越来越多,所以完全备份不会也不能每天进行。这时增量备份的作用就体现出来了。增量备份是指先进行一次完全备份,服务器运行一段时间之后,比较当前系统和完全备份数据之间的差异,只备份有差异的数据而已。服务器继续运行,再经过一段时间运行之后,进行第二次增量备份,第二次增量备份时,当前系统是和第一次增量备份的数据进行比较,也是只备份有差异的数据。而第三次增量备份是和第二次增量备份的数据进行比较,以此类推。
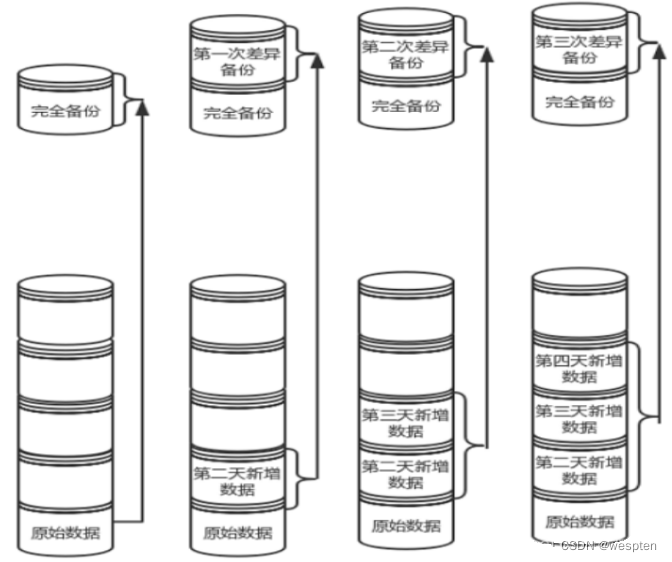
3)差异备份
差异备份也要先进行依次完全备份,但是和增量备份不同的地方是,每次差异备份都是备份和原始的完全备份不同的数据,也就是说差异备份每次备份的参照物是原始的完全备份,而不是上一次的差异备份。
2、dd备份
dd用指定大小的块拷贝一个文件,并在拷贝的同时进行指定的转换。dd备份缺点,就是复制的时间比较长。
1)dd命令参数
1. if=文件名 #输入文件名,缺省为标准输入。即指定源文件。< if=input file >
2. of=文件名 #输出文件名,缺省为标准输出。即指定目的文件。< of=output file >
3. ibs=bytes #一次读入bytes个字节,即指定一个块大小为bytes个字节。
obs=bytes #一次输出bytes个字节,即指定一个块大小为bytes个字节。
bs=bytes #同时设置读入/输出的块大小为bytes个字节。
4. cbs=bytes #一次转换bytes个字节,即指定转换缓冲区大小。
5. skip=blocks #从输入文件开头跳过blocks个块后再开始复制。
6. seek=blocks #从输出文件开头跳过blocks个块后再开始复制。
注意:通常只用当输出文件是磁盘或磁带时才有效,即备份到磁盘或磁带时才有效。
7. count=blocks #仅拷贝blocks个块,块大小等于ibs指定的字节数。
8. conv=conversion #用指定的参数转换文件。
ascii #转换ebcdic为ascii
ebcdic #转换ascii为ebcdic
ibm #转换ascii为alternate ebcdic
block #把每一行转换为长度为cbs,不足部分用空格填充
unblock #使每一行的长度都为cbs,不足部分用空格填充
lcase #把大写字符转换为小写字符
ucase #把小写字符转换为大写字符
swab #交换输入的每对字节
noerror #出错时不停止
notrunc #不截短输出文件
sync #将每个输入块填充到ibs个字节,不足部分用空(NUL)字符补齐。注意:指定数字的地方若以下列字符结尾,则乘以相应的数字:b=512;c=1;k=1024;w=2。
2)dd系统备份与恢复
1. 只备份文件:
dd if=/etc/httpd/conf/httpd.conf of=/tmp/httpd.bak2. 备份分区为一个文件:
dd if=/dev/sda1 of=/tmp/boot.bak
#如果需要进行恢复,执行此命令即可:dd if=/tmp/boot.bak of=/dev/sda13. 备份分区到另一个新分区:
dd if=/dev/sda1 of=/dev/sdb1
#如果需要恢复,只要把输入项和输出项反过来即可4. 整盘备份,将本地的/dev/hdb整盘备份到/dev/hdd:
dd if=/dev/hdb of=/dev/hdd5. 将/dev/hdb全盘数据备份到指定路径的image文件:
dd if=/dev/hdb of=/root/image6. 将备份文件恢复到指定盘:
dd if=/root/image of=/dev/hdb7. 备份/dev/hdb全盘数据,并利用gzip工具进行压缩,保存到指定路径:
dd if=/dev/hdb | gzip > /root/image.gz8. 将压缩的备份文件恢复到指定盘:
gzip -dc /root/image.gz | dd of=/dev/hdb9. 备份与恢复MBR。
备份磁盘开始的512个字节大小的MBR信息到指定文件:
dd if=/dev/hda of=/root/image count=1 bs=512count=1指仅拷贝一个块;bs=512指块大小为512个字节。
恢复:
dd if=/root/image of=/dev/had将备份的MBR信息写到磁盘开始部分。
10. 备份软盘:
dd if=/dev/fd0 of=disk.img count=1 bs=1440k (即块大小为1.44M)11. 拷贝内存内容到硬盘
dd if=/dev/mem of=/root/mem.bin bs=1024 (指定块大小为1k)12. 拷贝光盘内容到指定文件夹,并保存为cd.iso文件
dd if=/dev/cdrom(hdc) of=/root/cd.iso13. 增加swap分区文件大小
dd if=/dev/zero of=/swapfile bs=1024 count=262144 #创建一个大小为256M的文件
mkswap /swapfile #把这个文件变成swap文件
swapon /swapfile #启用这个swap文件
/swapfile swap swap default 0 0 #编辑/etc/fstab文件,使在每次开机时自动加载swap文件14. 销毁磁盘数据
dd if=/dev/urandom of=/dev/hda1注意:利用随机的数据填充硬盘,在某些必要的场合可以用来销毁数据。
15. 测试硬盘的读写速度
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/root/1Gb.file bs=64k | dd of=/dev/null通过以上两个命令输出的命令执行时间,可以计算出硬盘的读、写速度。
16. 确定硬盘的最佳块大小:
dd if=/dev/zero bs=1024 count=1000000 of=/root/1Gb.file
dd if=/dev/zero bs=2048 count=500000 of=/root/1Gb.file
dd if=/dev/zero bs=4096 count=250000 of=/root/1Gb.file
dd if=/dev/zero bs=8192 count=125000 of=/root/1Gb.file通过比较以上命令输出中所显示的命令执行时间,即可确定系统最佳的块大小。
17. 修复硬盘:
dd if=/dev/sda of=/dev/sda 或dd if=/dev/hda of=/dev/hda当硬盘较长时间(一年以上)放置不使用后,磁盘上会产生magnetic flux point,当磁头读到这些区域时会遇到困难,并可能导致I/O错误。当这种情况影响到硬盘的第一个扇区时,可能导致硬盘报废。上边的命令有可能使这些数 据起死回生。并且这个过程是安全、高效的。
18. 利用netcat远程备份
dd if=/dev/hda bs=16065b | netcat < targethost-IP > 1234在源主机上执行此命令备份/dev/hda:
netcat -l -p 1234 | dd of=/dev/hdc bs=16065b在目的主机上执行此命令来接收数据并写入/dev/hdc:
netcat -l -p 1234 | bzip2 > partition.img
netcat -l -p 1234 | gzip > partition.img以上两条指令是目的主机指令的变化分别采用bzip2、gzip对数据进行压缩,并将备份文件保存在当前目录。
19. 将一个大视频文件的第i个字节的值改成0x41(大写字母A的ASCII值)
echo A | dd of=bigfile seek=$i bs=1 count=1 conv=notrunc20. 建立linux虚拟盘,用文件模拟磁盘
在进行linux的实验中,如果没有多余的硬盘来做测试。则可以在linux下使用文件来模拟磁盘,以供测试目的。
1) 以root用户创建一个ASM磁盘所在的目录。
mkdir –p /u01/asmdisks2) 通过dd命令创建6个400M大小的文件,每个文件代表一块磁盘。
[root@book u01]# cd asmdisks
[root@book asmdisks]# dd if=/dev/zero of=asm_disk1 bs=1024k count=400
[root@book asmdisks]# dd if=/dev/zero of=asm_disk2 bs=1024k count=400
[root@book asmdisks]# dd if=/dev/zero of=asm_disk3 bs=1024k count=400
[root@book asmdisks]# dd if=/dev/zero of=asm_disk4 bs=1024k count=400
[root@book asmdisks]# dd if=/dev/zero of=asm_disk5 bs=1024k count=400
[root@book asmdisks]# dd if=/dev/zero of=asm_disk6 bs=1024k count=4003) 将这些文件与裸设备关联。
[root@book asmdisks]# chmod 777 asm_disk*
[root@book asmdisks]# losetup /dev/loop1 asm_disk1
[root@book asmdisks]# losetup /dev/loop2 asm_disk2
[root@book asmdisks]# losetup /dev/loop3 asm_disk3
[root@book asmdisks]# losetup /dev/loop4 asm_disk4
[root@book asmdisks]# losetup /dev/loop5 asm_disk5
[root@book asmdisks]# losetup /dev/loop6 asm_disk6注意:如果要删除通过dd模拟出的虚拟磁盘文件的话,直接删除模拟出的磁盘文件。
也就是asm_disk1、asm_disk2…asm_disk6)还不够,还必须执行losetup -d /dev/loopN,在这里N从1到6。否则,磁盘文件所占用的磁盘空间不能释放。
3) dd定时备份
创建备份文件夹,放脚本的文件夹:
mkdir /backup
mkdir -p /server/scripts写脚本,写好后测试一下是否能用:
vim /server/scripts/sys_bak.sh
#!/bin/bash
time=`date +%F`
tar zcf /backup/etc-$time.tar.gz /etc/
tar zcf /backup/cron-$time.tar.gz /var/spool/cron/
tar zcf /backup/boot-$time.tar.gz /boot/
dd if=/dev/sda of=/backup/mbr.bin bs=512 count=1sh /server/scripts/sys_bak.sh开始编辑定时任务:
crontab -e先改为每分钟执行一次测试:
#backup the system at 24:00 everyday
* * * * * sh /server/scripts/sys_bak.sh &>/dev/null说明:
&>/dev/null
# 不管是标准输出还是错误输出都写入/dev/null
#因为定时任务里输出到所有屏幕的都会以邮件发送给这个定时任务的用户,会占用inode,时间长了后会把这个磁盘inode号用完。查看日志:
tail -f /var/log/cron
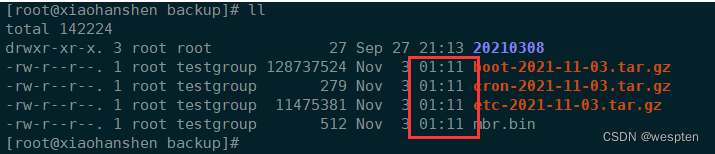
对比时间,确认没有问题将时间改为24:00:
#backup the system at 24:00 everyday
00 00 * * * sh /server/scripts/sys_bak.sh &>/dev/null额外补充 :
每天凌晨2:30备份 数据库 lianxi 到/data/backup/db/:
#!/bin/bash
#备份目录
BACKUP=/data/backup/db
DATETIME=$(date +%Y-%m-%d_%H-%M-%S)
echo $DATETIME
#数据库的地址
HOST=localhost
#数据库用户名
DB_USER=root
#数据库密码
DB_PW=123456
#备份的数据库名
DATABASE=lianxi
#创建备份目录
if [ ! -d "${BACKUP}/${DATETIME}" ]
then
mkdir -p "${BACKUP}/${DATETIME}"
fi
#备份数据库
mysqldump -u${DB_USER} -p${DB_PW} --host=${HOST} -q -R --databases ${DATABASE} | gzip > ${BACKUP}/${DATETIME}/$DATETIME.sql.gz
#将文件处理成 tar.gz
cd ${BACKUP}
tar -zcvf $DATETIME.tar.gz ${DATETIME}
#删除对应的备份目录
rm -rf ${BACKUP}/${DATETIME}
#删除十天前的的备份文件
find ${BACKUP} -atime +10 -name "*.tar.gz" -exec rm -rf {} \;
echo "备份数据库$DATABASE 成功"
4) /dev/null和/dev/zero的区别
1. /dev/null
外号叫无底洞,你可以向它输出任何数据,它通吃,并且不会撑着。它是空设备。任何写入它的输出都会被抛弃。如果不想让消息以标准输出显示或写入文件,那么可以将消息重定向到位桶。
把/dev/null看作"黑洞", 它等价于一个只写文件,所有写入它的内容都会永远丢失.,而尝试从它那儿读取内容则什么也读不到。然而, /dev/null对命令行和脚本都非常的有用。
禁止标准输出:
cat $filename >/dev/null文件内容丢失,而不会输出到标准输出。
禁止标准错误:
rm $badname 2>/dev/null这样错误信息[标准错误]就被丢到太平洋去了
禁止标准输出和标准错误的输出:
cat $filename 2>/dev/null >/dev/null如果"filename"不存在,将不会有任何错误信息提示;如果"filename"不存在,将不会有任何错误信息提示;如果"filename"存在, 文件的内容不会打印到标准输出。因此,上面的代码根本不会输出任何信息。当只想测试命令的退出码而不想有任何输出时非常有用。
cat $filename &>/dev/null这样其实也可以。
自动清空日志文件的内容:
cat /dev/null > /var/log/messages
: > /var/log/messages 有同样的效果, 但不会产生新的进程.(因为:是内建的)
cat /dev/null > /var/log/wtmp特别适合处理这些由商业Web站点发送的讨厌的"cookies"。
隐藏cookie而不再使用:
if [ -f ~/.netscape/cookies ] # 如果存在则删除.
then
rm -f ~/.netscape/cookies
fi
ln -s /dev/null ~/.netscape/cookies现在所有的cookies都会丢入黑洞而不会保存在磁盘上了。
2. /dev/zero
像/dev/null一样, /dev/zero也是一个伪文件, 但它实际上产生连续不断的null的流(二进制的零流,而不是ASCII型的)。 写入它的输出会丢失不见, 而从/dev/zero读出一连串的null也比较困难, 虽然这也能通过od或一个十六进制编辑器来做到。 /dev/zero主要的用处是用来创建一个指定长度用于初始化的空文件,就像临时交换文件
/dev/zero是一个输入设备,你可你用它来初始化文件。该设备无穷尽地提供0,可以使用任何你需要的数目——设备提供的要多的多。他可以用于向设备或文件写入字符串0。
#if=/dev/zero of=./test.txt bs=1k count=1
#ls –l
total 4
-rw-r--r-- 1 oracle dba 1024 Jul 15 16:56 test.txt
#find / -name access_log 2>/dev/null用/dev/zero创建一个交换临时文件:
#!/bin/bash
# 创建一个交换文件.
ROOT_UID=0 # Root 用户的 $UID 是 0.
E_WRONG_USER=65 # 不是 root?
FILE=/swap
BLOCKSIZE=1024
MINBLOCKS=40
SUCCESS=0
# 这个脚本必须用root来运行.
if [ "UID"−ne"UID"−ne"ROOT_UID" ]
then
echo; echo "You must be root to run this script."; echo
exit $E_WRONG_USER
fi
blocks={1:-{1:-MINBLOCKS} # 如果命令行没有指定,
#+ 则设置为默认的40块.
# 上面这句等同如:
# --------------------------------------------------
# if [ -n "$1" ]
# then
# blocks=$1
# else
# blocks=$MINBLOCKS
# fi
# --------------------------------------------------
if [ "blocks"−ltblocks"−ltMINBLOCKS ]
then
blocks=$MINBLOCKS # 最少要有 40 个块长.
fi
echo "Creating swap file of size $blocks blocks (KB)."
dd if=/dev/zero of=FILEbs=FILEbs=BLOCKSIZE count=$blocks # 把零写入文件.
mkswap FILEFILEblocks # 将此文件建为交换文件(或称交换分区).
swapon $FILE # 激活交换文件.
echo "Swap file created and activated."
exit $SUCCESS关于 /dev/zero 的另一个应用是为特定的目的而用零去填充一个指定大小的文件, 如挂载一个文件系统到环回设备 (loopback device)或"安全地" 删除一个文件
创建ramdisk:
#!/bin/bash
# ramdisk.sh
# "ramdisk"是系统RAM内存的一段,
#+ 它可以被当成是一个文件系统来操作.
# 它的优点是存取速度非常快 (包括读和写).
# 缺点: 易失性, 当计算机重启或关机时会丢失数据.
#+ 会减少系统可用的RAM.
# 10 # 那么ramdisk有什么作用呢?
# 保存一个较大的数据集在ramdisk, 比如一张表或字典,
#+ 这样可以加速数据查询, 因为在内存里查找比在磁盘里查找快得多.
E_NON_ROOT_USER=70 # 必须用root来运行.
ROOTUSER_NAME=root
MOUNTPT=/mnt/ramdisk
SIZE=2000 # 2K 个块 (可以合适的做修改)
BLOCKSIZE=1024 # 每块有1K (1024 byte) 的大小
DEVICE=/dev/ram0 # 第一个 ram 设备
username=`id -nu`
if [ "username"!="username"!="ROOTUSER_NAME" ]
then
echo "Must be root to run \"`basename $0`\"."
exit $E_NON_ROOT_USER
fi
if [ ! -d "$MOUNTPT" ] # 测试挂载点是否已经存在了,
then #+ 如果这个脚本已经运行了好几次了就不会再建这个目录了
mkdir $MOUNTPT #+ 因为前面已经建立了.
fi
dd if=/dev/zero of=DEVICEcount=DEVICEcount=SIZE bs=$BLOCKSIZE
# 把RAM设备的内容用零填充.
# 为何需要这么做?
mke2fs $DEVICE # 在RAM设备上创建一个ext2文件系统.
mount DEVICEDEVICEMOUNTPT # 挂载设备.
chmod 777 $MOUNTPT # 使普通用户也可以存取这个ramdisk.
# 但是, 只能由root来缷载它.
echo "\"$MOUNTPT\" now available for use."
# 现在 ramdisk 即使普通用户也可以用来存取文件了.
# 注意, ramdisk是易失的, 所以当计算机系统重启或关机时ramdisk里的内容会消失.
# 拷贝所有你想保存文件到一个常规的磁盘目录下.
# 重启之后, 运行这个脚本再次建立起一个 ramdisk.
# 仅重新加载 /mnt/ramdisk 而没有其他的步骤将不会正确工作.
# 如果加以改进, 这个脚本可以放在 /etc/rc.d/rc.local,
#+ 以使系统启动时能自动设立一个ramdisk.
# 这样很合适速度要求高的数据库服务器.
exit 03、网络复制工具rsync
rsync 是 linux系统下的数据镜像备份工具,可用于本地文件复制,也可与其他 SSH、rsync 主机远程同步文件和目录。
优点
(1)可以镜像保存整个目录树和文件系统。
(2)可以很容易做到保持原来文件的权限、时间、软硬链接等等。
(3)无须特殊权限即可安装。
(4)快速:第一次同步时 rsync 会复制全部内容,但在下一次只传输修改过的文件。rsync 在传输数据的过程中可以实行压缩及解压缩操作,因此可以使用更少的带宽。
(5)安全:可以使用scp、ssh等方式来传输文件,当然也可以通过直接的socket连接。
(6)支持匿名传输,以方便进行网站镜像。
(7)跨平台:可在不同操作系统之间同步数据。
缺点
(1)客户端需要对多个文件数据块进行多次计算与比较验证码,对 CPU 的消耗比较大;服务端需要根据原文件和客户端传送过来的差异数据进行文件内容重组,对 IO 的消耗比较大。
(2)rsync 每次同步都需要先进行所有文件的扫描和计算、对比,最后才能进行差量传输。如果文件数量达到了百万甚至千万量级,扫描所有文件将是非常耗时的。而且如果改动的只是其中很小的一部分,这就是非常低效的方式。
(3)rsync 不能实时的去监测、同步数据,虽然它可以通过 crontab 守护进程的方式进行触发同步,但是两次触发动作一定会有时间差,这样就导致了服务端和客户端数据可能出现不一致,无法在应用故障时完全的恢复数据(无法实现实时同步),而且繁忙的轮询会消耗大量的资源。
适用场景
由 rsync 工作原理可知,需要同步的文件改动越频繁,则客户端需要计算和比较的数据块验证码就越多(遇到数据块内容不相同时,只能跳过一个字节继续往后计算与比较,相同则可跳过一个数据块),对 CPU 的消耗就会越大;需要同步的文件越大,服务端每次都需要从一个很大的文件中复制相同的数据块进行新文件重组,几乎相当于直接 cp 了一个大文件,对 IO 的消耗也就越大。
所以 rsync 适合对改动不频繁、大小比较小的文件进行同步,对于改动频繁的大文件,只能偶尔同步一次,相当于备份的功能,而不是同步。
使用 rsync 进行数据同步时,第一次进行全量备份,以后则是增量备份,利用 rsync 算法(差分编码),只传输差异部分数据。
1)安装
yum install rsync2)配置
rsyncd 服务配置文件 /etc/rsyncd.conf:
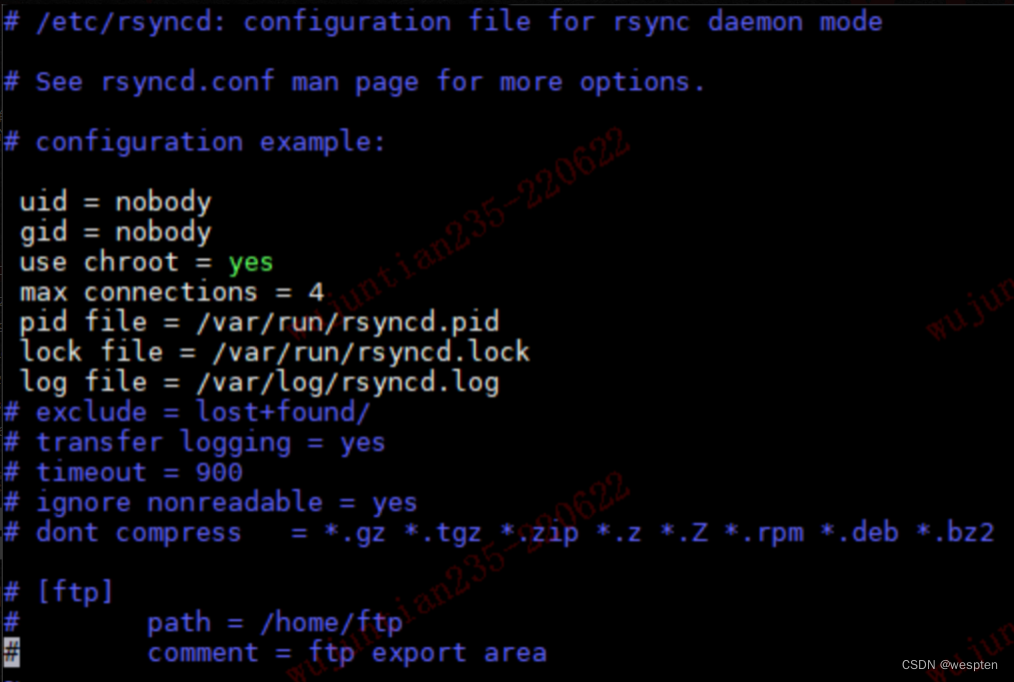
默认使用端口 873,可通过配置项目 port 进行修改。
3)三种工作模式
(1)本地复制
将本地目录 /var/rsync-src/ 下的文件同步至本地目录 /var/rsync-dest/:
rsync -r /var/rsync-src/ /var/rsync-dest/(2)将本地数据同步到远程(push)
将本地目录 /var/rsync-src/ 下的文件同步至远程主机 10.101.11.11 目录 /var/rsync-dest/:
rsync -r /var/rsync-src/ [email protected]:/var/rsync-dest/(3)将远程数据同步到本地(pull)
将远程主机 10.101.11.11 目录 /var/rsync-dest/ 下的文件同步至本地目录 /var/rsync-dest/:
rsync -r [email protected]:/var/rsync-dest/ /var/rsync-dest/4)两种认证协议
rsync 进行远程同步时需要认证远程主机的账号密码,支持两种认证方式:ssh 协议认证与 rsync 协议认证。
(1)ssh 认证
rsync 默认使用 ssh 协议进行远程登录和数据传输。远程主机需要开启 sshd 服务,rsync 在传输数据之前会先与远程主机进行一次 ssh 登录认证,然后通过 ssh 隧道进行数据传输。只需数据同步双方安装 rsync,但不必启动 rsyncd 服务。
可用 -e 选项指定协议:
rsync -r -e ssh /var/rsync-src/ [email protected]:/var/rsync-dest/也可省略 -e:
rsync -r /var/rsync-src/ [email protected]:/var/rsync-dest/使用 ssh 认证与传输的缺点是不安全:
<1>登录认证使用的账号是远程主机可登录的系统账号,且需要手动输入密码;
<2>同步数据不受目录限制。
(2)rsync 协议认证
与 ssh 认证不同,rsync 协议认证不需要依赖远程主机的 sshd 服务,但需要远程主机开启 rsyncd 服务,本地 rsyncd 服务可不必开启。另外,rsync 协议认证不是直接使用远程主机的真实系统账号,而是虚拟账号和虚拟密码,且可实现无需手动输入密码,同时 rsync 协议认证需要配置模块对远程同步的目录进行限制。对比 ssh 认证,rsync 协议认证安全性更高。
下面直接实践。(远程主机为服务端,本地主机为客户端)
<1> rsyncd 配置(远程)
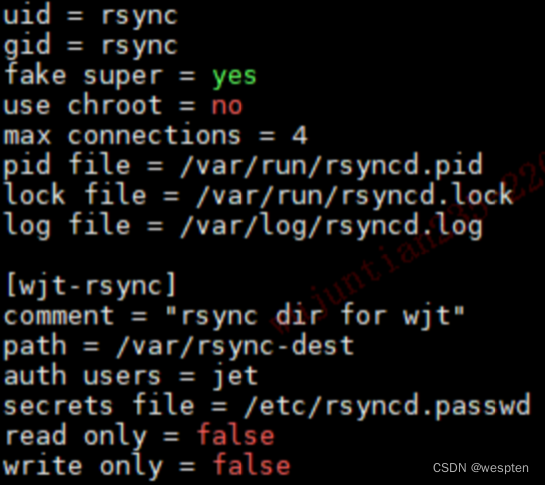
这里定义了一个模块,名为 wjt-rsync。
path:模块 wjt-rsync 对应的真实目录 /var/rsync-dest。此处是对客户端可操作目录的限制。
auth users:用于数据认证与传输的虚拟账号 jet,客户端以虚拟账号 jet 登录成功后,会转换成配置项 uid 指定的系统用户身份 rsync,以该身份完成对目标目录的读写操作。此处是对客户端操作权限的限制。
secrets file:虚拟账号与密码设置文件。
fake super:true 表示 uid 可以不为 root。
read only:指定当前模块是否只读,false 表示可读写,即可上传文件,true 表示只读,不可上传文件,默认为 true。
write only:true 表示不能下载,false 表示可下载,默认为 false。
<2> 创建用户与组(远程)
useradd rsync -s /sbin/nologin -M<3>设置虚拟账号密码(远程)
echo "jet:123456" > /etc/rsyncd.passwd<br>chmod 600 /etc/rsyncd.passwd<4>修改同步目录属主(远程)
chown -R rsync.rsync /var/rsync-dest<5>开启 rsyncd 服务(远程)
systemctl start rsyncd<6>请求同步(本地)
rsync -r /var/rsync-src/ [email protected]::wjt-rsync也可以使用 url 格式语法:
rsync -r /var/rsync-src/ rsync://[email protected]/wjt-rsync可通过配置本地密码文件实现无需手动输入密码:
echo 123456 > /etc/rsync.jet.passwd
chmod 600 /etc/rsync.jet.passwd
rsync -r /var/rsync-src/ [email protected]::wjt-rsync --password-file=/etc/rsync.jet.passwd或者通过环境变量进行设置(变量名是固定的):
export RSYNC_PASSWORD=123456
rsync -r /var/rsync-src/ [email protected]::wjt-rsync两种认证方式的本质区别:
ssh 协议认证连接的两端是通过管道完成通信和数据传输的,当连接到远程主机时,将在远程主机 fork 出 rsync 进程使其成为 rsync server;而 rsync 协议认证是事先在远程主机上运行 rsync 守护进程,监听套接字等待客户端的连接,建立连接后所有通信方式都是通过套接字完成的。
5)更多功能选项
(1)-a:归档模式,表示递归传输并保持文件属性。
(2)-v:显示同步过程中详细信息(文件列表)。可以使用"-vvvv"获取更详细信息。
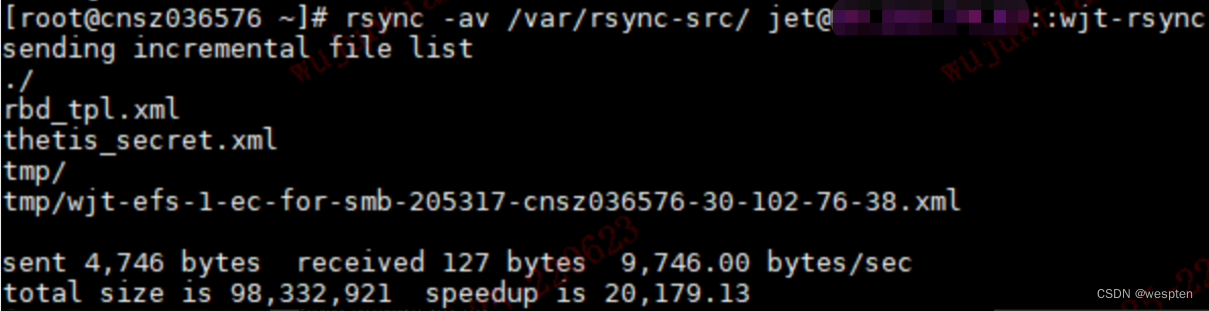
建立链接:

开始传送增量文件列表:
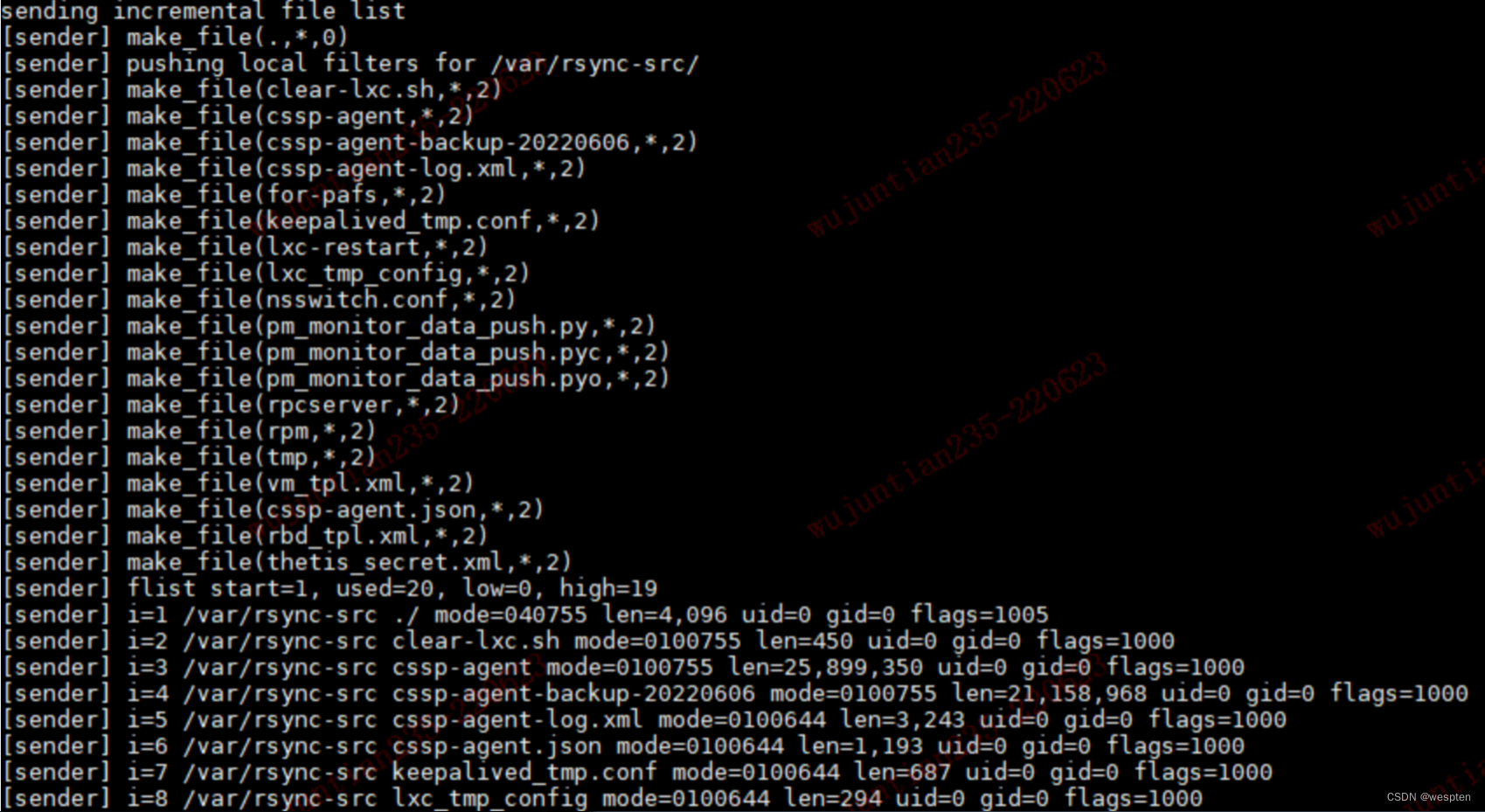
开始传送文件数据:
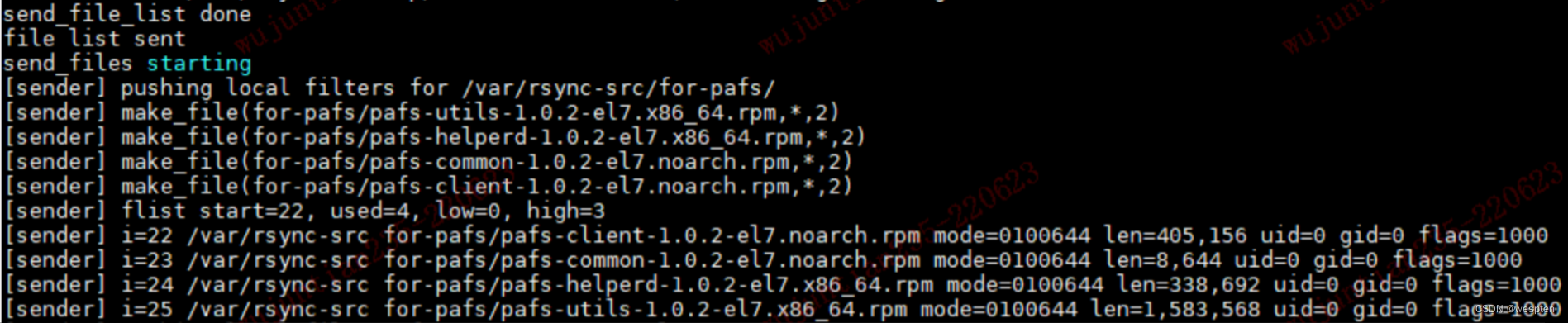
同步完成,输出统计信息:
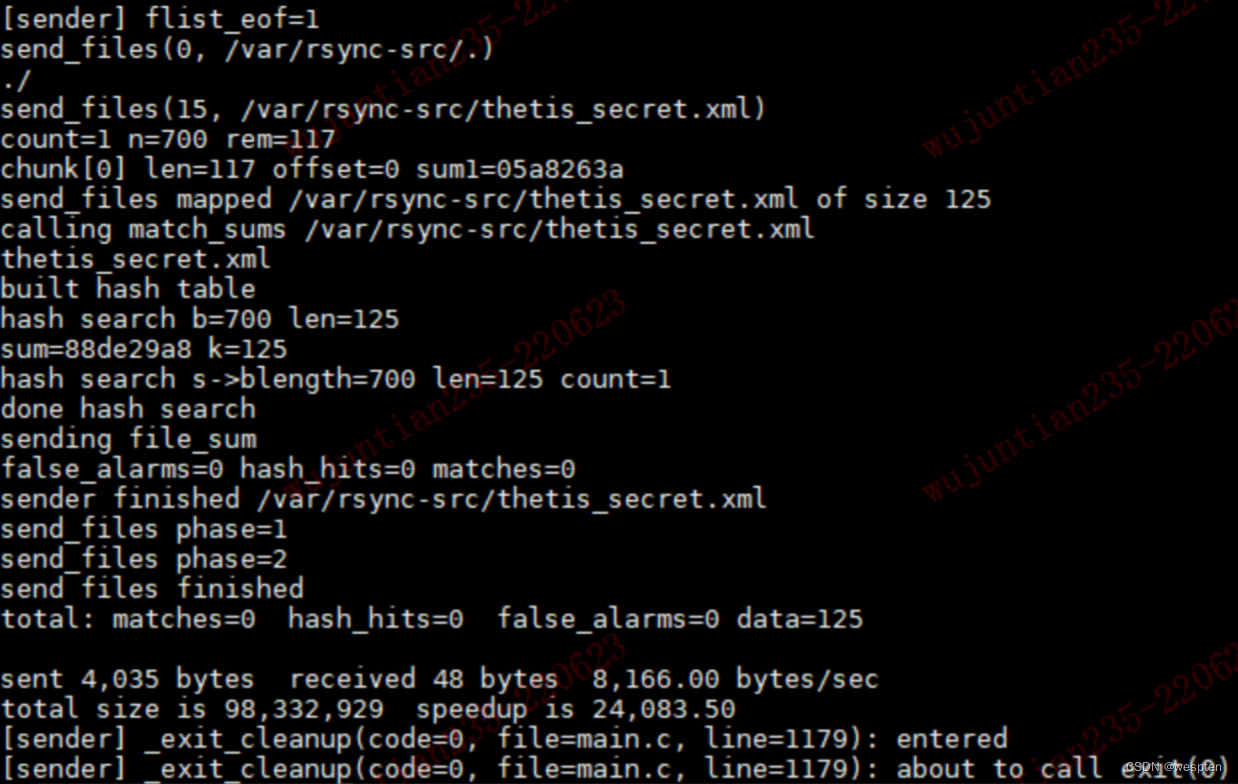
(3)-z:传输时进行压缩提高效率。
(4)-n:模拟执行,不会真正执行。
(5)--delete:删除只存在于目标目录、不存在于源目录的文件(服务端计算文件数据块校验码之前先执行此动作,--exclude 指定的文件会被标记为保护文件,不会被删除,但可通过 --delete-exclude 取消保护,强制删除)。
(6)--exclude:排除某些文件或目录,不参与操作。
(7)--include:指定必须参与操作的文件或目录,--include必须在--exclude之前。
(8)--link-dest:基准目录,指定基准目录以后,rsync 会将源目录与基准目录之间变动的部分同步到目标目录。那些没变动的文件则会生成硬链接,硬链接指向上一次备份的对应文件,这与全量备份类似,但其数据量小很多(使用 rsync 实现全量备份的大致做法:使用备份时间命名区分多次备份的多个目标目录,每次备份之前,先将基准目录设置为上一次备份的目标目录,恢复时直接找到对应时间点的目录,里面的文件即是当时全部的文件数据)。
(9)--bwlimit:限速传输,单位 MB/s。
......(还有更多功能选项)
6)rsync + inotify 实时同步
Inotify 是 Linux 内核从 2.6.13 开始引入的特性,它是一个内核用于通知用户空间程序文件系统变化的机制。
Inotify 监控文件系统操作,比如读取、写入和创建,基于事件驱动,可以做到对事件的实时响应,高效,而且没有轮询造成的系统资源消耗。
(1)检查当前系统内核是否支持 inotify
uname -r若内核版本大于 2.6.13 则支持,或者:
grep INOTIFY_USER /boot/config-$(uname -r)若输出 CONFIG_INOTIFY_USER=y,则支持。
(2)安装
yum install inotify-toolsinotify-tools 包含了两个命令:inotifywait 与 inotifywatch。
(1)inotifywait:在被监控的文件或目录上等待特定文件系统事件发生,执行后处于阻塞状态,适合在shell脚本中使用。
(2)inotifywatch:用于收集文件系统的统计数据,例如发生了多少次 inotify 事件,某文件被访问了多少次等等。
内核参数
/proc/sys/fs/inotify/ 目录下包含三个文件,分别设置 inotify 相关的三个内核参数。
(1)max_queued_events:inotify 事件队列可容纳的事件数量,超出的事件被丢弃,但会触发队列溢出Q_OVERFLOW事件。
(2)max_user_instances:每个用户可运行的 inotifywait 或 inotifywatch 命令的进程数。
(3)max_user_watches:每个 inotifywait 或 inotifywatch 命令可以监控的文件数量。如果监控的文件数目巨大,需要根据情况适当增加此值。
默认设置:

事件
inotify 监控的文件系统事件:
(1)access:文件被访问。
(2)modify:文件被修改。
(3)attrib:文件元数据被修改。
(4)open:文件被打开。
(5)create:在被监控的目录中创建了文件或目录。
(6)delete:删除了被监控目录中的某个文件或目录。
......(还有更多事件)
注意:
对文件的某个操作往往会触发多个事件,用户应用程序需要自己防止做出重复响应。
不指定监控事件,分别打开两个 shell 窗口,使用 inotifywait 和 inotifywatch 监控某个目录:
mkdir /var/inotify-test
inotifywait -m /var/inotify-test
inotifywatch -v /var/inotify-test在此目录下创建两个文件:
touch /var/inotify-test/file1
touch /var/inotify-test/file2看看 inotify 监控发生了什么:
其中 inotifywait 的信息是在进程运行过程中输出的,而 inotifywatch 的信息是在进程结束时输出的。
以上测试没有指定监听事件,所以监听的是所有的事件,可以通过 -e 选项来指定监听事件,如:
inotifywait -m -e create,modify,delete /var/inotify-test有了 inotify 之后,通过 inotify 监控文件系统变化,发生变化则触发 rsync 执行同步,这样就解决了 rsync 无法实时同步的问题。
编写一个同步测试脚本 /var/inotify-test/real_time_sync:
配置rsync:
vim /etc/rsyncd.conf
uid = root
gid = root
use chroot = no
max connections = 4
log file = /var/log/rsyncd.log
pid file = /var/run/rsyncd.pid[git] #自定义模块名为git
path = /home/gitlab/data/backups/
ignore errors read only = false
list = true
hosts allow = 192.168.1.0/24
auth users = rsync_git
secrets file = /etc/rsync.password
mkdir -p /home/gitlab/data/backupsecho
echo '123456' > /etc/rsync.password
chmod 600 /etc/rsync.password
systemctl enable rsyncd && systemctl start rsyncd#!/bin/bash# Defined parameterhost01=192.168.1.253 #inotify-slave的ip地址src=/home/gitlab/data/backups/ #本地监控的目录dst=git #自定义的rsync服务的模块名user=rsync_git #rsync服务的虚拟用户rsync_passfile=/etc/rsync.password #本地调用rsync服务的密码文件inotify_home=/usr/bin #inotify的安装目录if [ ! -e "$src" ] || [ ! -e "${rsync_passfile}" ] || [ ! -e "${inotify_home}/inotifywait" ] || [ ! -e "/usr/bin/rsync" ]then
echo "Check File and Folder"fi
inotifywait -mrq --timefmt '%d/%m/%y %H:%M' --format '%T %w %f' -e modify,delete,create,attrib,move,moved_to $src | while read filesdo
rsync -avz --delete $src $user@$host01::$dst --password-file=${rsync_passfile} >/dev/null 2>&1donechmod +x /root/inotify.shnohup bash /var/inotify-test/real_time_sync &设置脚本自启动:
echo 'nohup /bin/bash /root/inotify.sh &' >> /etc/rc.d/rc.localchmod +x /etc/rc.d/rc.local实时同步测试:
源服务器执行:
echo 'lzxlzx' > /home/gitlab/data/backups/lzx.txt目标服务器查看:
ll /home/gitlab/data/backups/
总用量 7
-rw-r--r-- 1 root root 7 12月 25 16:28 lzx.txtcat /home/gitlab/data/backups/lzx.txt
lzxlzx当源服务器/home/gitlab/data/backups/下文件发生变化(增加、删除、内容更改)时,会实时同步文件到目标服务器/home/gitlab/data/backups/下。
优点:只同步发生改动的文件或目录,而不是同步一整个监控目录,降低了资源消耗,提升了速度。
不足:单次文件操作触发了多个事件从而发起多次 rsync,并未对此做出处理。
7)sersync
sersync 是基于 rsync + inotify-tools 开发的工具,它克服了 inotify 的缺陷,可以过滤重复事件减轻负担,并且自带 crontab 功能、多线程调用 rsync、失败重传等功能。当同步数据量不大时,还是建议使用 rsync + inotify,当数据量很大(几百G甚至1T以上)时,建议使用 rsync + sersync。
4、xfs文件系统备份与恢复
xfs文件系统支持备份功能,使用xfsdump命令和xfsrestore可以完成备份与恢复。xfsdump实现了针对文件系统进行备份的功能centos7中默认选用的文件系统xfs。
XFS文件系统备份:
xfs文件系统的备份不光通过xfsdump可以进行完整备份,而且还可以进行增量备份。
XFSdump使用注意事项:
xfsdump不支持对没有挂载的文件系统进行备份,需要备份请挂载之后备份。
xfsdump必须使用root身份才能够有权限执行。
xfsdump只能备份xfs文件系统。
xfsdump备份过的数据只能被xfsrestore解析。
xfsdump默认只支持备份文件系统,并不支持特定某个目录的备份。
xfsdump是通过文件系统的UUID来辨别各个备份文件,因此不能备份两个具有相同UUID的文件系统(UUID重复的概率 无限接近于0,可以忽略不记)。
选项:
-L:xfsdump会记录每次备份的说明标签。
-M:指定存储媒介的说明标签。
-l:指定备份的级别(0-9),0级别是完整备份。1-9是增量备份。
-f:指定转储的目的地。转储的目的地可以是路径设备、常规文件等。
-I:从/var/lib/xfsdump/inventory列出目前备份的信息状态(没有备份过没有此路径)。第一步:使用新的分区,格式化分区,并进行挂载
[root@localhost ~]# mkfs.xfs /dev/sdb1
[root@localhost ~]#mkdir /test #创建挂载点
[root@localhost ~]#mount /dev/sdb1 /test #挂载准备备份测试文件:
[root@localhost ~]# cd /test/
[root@localhost test]# cp /etc/passwd ./
[root@localhost test]# mkdir ./linux
[root@localhost test]# touch ./linux/a
[root@localhost test]# tree /test/
/test/
├── passwd
└── linux
└── a第二步:备份
1、备份整个分区。 (这个功能就像是虚拟机的快照,服务器被黑后,进行快速恢复)
xfsdump -f 备份文件存放位置 被备份路径或设备文件。
注意:被备份的路径可以写/dev/sdb1 或/test ,但是不能写成/test/ ,即 test后不能有/
[root@localhost test]# xfsdump -f /opt/dump_sdb1 /dev/sdb1
dump_sdb1 #指定备份标签.2、指定备份时免交互操作,方便后期做定时备份
[root@localhost sdb1]# xfsdump -f /opt/dump_2 /test -L dump_2 -M sdb1
-L :<session label> #每次备份的 session 标签,这里写此次备份的描述
-M :<media label> #媒体标签,这里写对哪个设备进行备份排错:
改:xfsdump -f /opt/dump_2 /test/ -L dump_2 -M sdb1
为:xfsdump -f /opt/dump_2 /test -L dump_2 -M sdb1 #test后,不要有/3、指定只备份分区中某个目录
参数:-s 文件路径 只对指定的文件进行备份,-s指定时,路径写的是相对路径(-s可以是文件或目录)例:对/test/xuegod 目录进行备份:
[root@localhost opt]# xfsdump -f /opt/dump_linux -s linux /test -L
dump_linux -M sdb14、查看备份信息与内容
备份成功后,我们就可以在/var/lib/xfsdump/inventory目录下看到生成的档案信息:
[root@localhost opt]# xfsdump -I(字母大写i)测试恢复:先删除之前创建的内容:
[root@localhost opt]# cd /test/
[root@localhost test]# ls
passwd linux
[root@localhost sdb1]# rm -rf ./*第三步:文件系统恢复
格式:xfsrestore -f 指定恢复文件的位置 指定存放恢复后的文件的路径:
[root@localhost opt]# xfsrestore -f /opt/dump_sdb1 /test/
[root@localhost ~]# ls /test/ #查看恢复情况恢复单个文件如下:
[root@localhost test]# mkdir /tmp/test
[root@localhost test]# xfsrestore -f /opt/dump_sdb1 -s passwd /tmp/test/
#恢复单个文件
[root@localhost test]# xfsrestore -f /opt/dump_sdb1 -s linux /tmp/test/
#恢复目录5、增量备份文件系统实战
(1)准备一个备份目录进行备份:
[root@localhost test]# tree /test/
/test/
├── passwd
└── linux
└── a(2)对上面的内容进行第一次全备:
[root@localhost test]# xfsdump -f /opt/test-full /test -L test-full -M sdb1(3)增加一些内容,然后进行第1次增量备份:
[root@localhost test]# touch /test/1.txt /test/2.txt
[root@localhost test]# xfsdump -l 1 -f /opt/test-back1 /test -L test-bak1 -M sdb1
-l <level> 做一个等级为1的备份(4)再次增加内容,然后进行level 2级别的增量备
[root@localhost test]# touch /test/linux/a.txt /test/xuegod/b.txt
[root@localhost test]# xfsdump -l 2 -f /opt/test-back2 /test -L test-bak2 -M sdb1
[root@localhost ~]# rm -rf /test/* #删除所有数据现在进行恢复,要想恢复全部全部数据,包括新添加的文件,如何恢复?
实验步骤:
1、先恢复完全备份
2、情况1: 恢复最后一次增量备份(如果两次增量备份都是1级的,所以只需要恢复最后一个增量就可以了。
3、情况2:如果你做的是第一次是1级备份,第二次是2级备份。在恢复时,需要先恢复完全备份,然后是1级备,最后是2级备)
例:对做了完全备份,1级备份,2级备份的数据时行恢复
[root@localhost ~]# xfsrestore -f /opt/test-full /test/
[root@localhost ~]# xfsrestore -f /opt/test-back2 /test/ #故意先恢复back2,可以恢复成功,但是数据不全
[root@localhost ~]# tree /test/ #查看,发现没有1.txt ,2.txt
/sdb1/
├── passwd
└── test
├── a
├── a.txt
└── b.txt
[root@localhost ~]# xfsrestore -f /opt/test-back1 /test/
[root@localhost ~]# tree /test/ #到此,数据恢复成功了
/test/
├── 1.txt
├── 2.txt
├── passwd
└── xuegod
├── a
├── a.txt
└── b.txt使用xfsdump工具进行备份也有很大的限制:
1.只能备份已挂载的文件系统
2.必须使用root的权限才能操作
3.只能备份XFS文件系统
4.备份后的数据只能让xfsrestore解析
5.不能备份两个具有相同UUID的文件系统
5、ext文件系统备份与恢复
1)dump备份
语法:
[root@localhost~]# dump [选项] 备份之后的文件名 源文件或目录
选项:
-level: 就是我们说的0-9十个备份级别
-f 文件名: 指定备份之后的文件名
-u: 备份成功之后,把备份时间记录在/etc/dumpdates文件
-v: 显示备份过程中更多的输出信息
-j: 调用bzlib库压缩备份文件,其实就是把备份文件压缩为.bz2格式
-W: 显示允许被dump的分区的备份等级及备份时间“-level”只需要写”0-9“备份级别即可;“0”代表完全备份,“1”代表第一次增量备份......以此类推。
[root@localhost~]# dump -0 [备份之后的文件名] [原文件或目录]- 备份分区
执行一次完全备份,指定备份文件名为boot.bz2,并压缩和更新备份时间。
[root@192 ~]# dump -0uj -f /root/boot.bz2 /boot/
DUMP: Date of this level 0 dump: Sat Apr 9 16:09:55 2022
DUMP: Dumping /dev/sda1 (/boot) to /root/boot.bz2
DUMP: Label: none
......
DUMP: Average transfer rate: 4634 kB/s
DUMP: Wrote 111620kB uncompressed, 101955kB compressed, 1.095:1
DUMP: DUMP IS DONE
[root@192 ~]# ll -h
总用量 100M
-rw-------. 1 root root 1.3K 11月 18 18:30 anaconda-ks.cfg
-rw-r--r--. 1 root root 100M 4月 9 16:10 boot.bz2查看/root/下已经有了boot.bz2的文件,这里以/boot/目录为各位做演示,正常环境并不建议大家随意更改。
查看备份时间文件:
[root@192 ~]# cat /etc/dumpdates
/dev/sda1 0 Sat Apr 9 16:09:55 2022 +0800显示什么时间备份了什么分区。
复制日志文件到/boot分区:
[root@192 ~]# cp /var/log/boot.log /boot/增量备份/boot分区,并压缩:
[root@192 ~]# dump -1uj -f /root/boot1.bz2 /boot/
DUMP: Date of this level 1 dump: Sat Apr 9 16:26:02 2022
DUMP: Date of last level 0 dump: Sat Apr 9 16:09:55 2022
DUMP: Dumping /dev/sda1 (/boot) to /root/boot1.bz2
......
DUMP: Average transfer rate: 0 kB/s
DUMP: Wrote 60kB uncompressed, 14kB compressed, 4.286:1
DUMP: DUMP IS DONE"-1uj"中的“1”表示第一次增量备份。
[root@192 ~]# cat /etc/dumpdates
/dev/sda1 0 Sat Apr 9 16:09:55 2022 +0800
/dev/sda1 1 Sat Apr 9 16:26:02 2022 +0800
[root@192 ~]# ll -h /root/
总用量 100M
-rw-------. 1 root root 1.3K 11月 18 18:30 anaconda-ks.cfg
-rw-r--r--. 1 root root 15K 4月 9 16:26 boot1.bz2
-rw-r--r--. 1 root root 100M 4月 9 16:10 boot.bz2再次查看备份时间文件,多出了一个boot1.bz2,这里可以看出第二次备份只备份了新加的文件。
查询分区的备份时间及备份级别:
[root@192 ~]# dump -W
Last dump(s) done (Dump '>' file systems):
> /dev/sda2 ( /) Last dump: never
/dev/sda1 ( /boot) Last dump: Level 1, Date Sat Apr 9 16:26:02 2022看到sda2没有备份过,于2022年16点进行过sda1增量备份。
- 备份文件或目录
备份/etc/目录:
[root@192 ~]# dump -0j -f /root/etc.dimp.bz2 /etc/
DUMP: Date of this level 0 dump: Sat Apr 9 17:09:05 2022
DUMP: Dumping /dev/sda2 (/ (dir etc)) to /root/etc.dimp.bz2
......
DUMP: Wrote 39730kB uncompressed, 12576kB compressed, 3.160:1
DUMP: DUMP IS DONE完全备份/etc/目录,只能使用0级别进行完全备份,而不再支持增量备份。
使用1级别进行备份:
[root@192 ~]# dump -1j -f /root/etc.dimp.bz2 /etc/
DUMP: Only level 0 dumps are allowed on a subdirectory
DUMP: The ENTIRE dump is aborted.此时就会报错。
2)restore恢复
语法:
[root@localhost~]# restore [模式选项] [选项]
模式选项:restore命令常用有以下四种,这四个模式不能混用
-C: 比较备份数据和实际数据的变化
-i: 进入交互模式,手工选择需要恢复的文件
-t: 查看模式,用于查看备份文件中拥有哪些数据
-r: 还原模式,用于数据还原
选项:
-f 指定备份文件的文件名比较模式
备份好的/boot文件做实验;把/boot目录中的grub文件改个名字:
[root@192 boot]# mv grub grub.backup
[root@192 boot]# restore -C -f /root/boot.bz2
Dump tape is compressed.
Dump date: Sat Apr 9 16:09:55 2022
Dumped from: the epoch
Level 0 dump of /boot on 192.168.48.148:/dev/sda1
Label: none
filesys = /boot
restore: unable to stat ./grub/splash.xpm.gz: No such file or directory
restore: unable to stat ./grub: No such file or directory
Some files were modified! 2 compare errorsrestore发现grub文件丢失。
注:如果真的丢失可还原备份好的文件至/boot目录中。
[root@192 boot]# mv grub.backup/ grub
[root@192 boot]# restore -C -f /root/boot.bz2
Dump tape is compressed.
Dump date: Sat Apr 9 16:09:55 2022
Dumped from: the epoch
Level 0 dump of /boot on 192.168.48.148:/dev/sda1
Label: none
filesys = /boot将文件名恢复之后,再次restore比较此时备份数据和实际数据完全相同。
查看模式
[root@192 boot]# restore -t -f /root/boot.bz2
Dump tape is compressed.
Dump date: Sat Apr 9 16:09:55 2022
Dumped from: the epoch
Level 0 dump of /boot on 192.168.48.148:/dev/sda1
Label: none
2 .
11 ./lost+found
12 ./efi
13 ./efi/EFI
14 ./efi/EFI/centos
8193 ./grub2
......查看备份的压缩包中到底有哪些文件。
还原模式
还原上面备份的boot.bz2以及boot1.bz2数据:
[root@192 ~]# mkdir boot.bak还原前需要提前创建一个目录用来存放恢复后的数据:
[root@192 ~]# cd boot.bak/
#需要进入boot.bak目录中,不然就会直接解压到了root目录当中
[root@192 boot.bak]# restore -r -f /root/boot.bz2
Dump tape is compressed.
[root@192 boot.bak]# restore -r -f /root/boot1.bz2
Dump tape is compressed.
[root@192 boot.bak]# ls
boot.log grub2 lost+found vmlinuz-0-rescue-42eca8fea9e249628f407fe3de70973c
config-3.10.0-1062.el7.x86_64 initramfs-0-rescue-42eca8fea9e249628f407fe3de70973c.img restoresymtable vmlinuz-3.10.0-1062.el7.x86_64
efi initramfs-3.10.0-1062.el7.x86_64.img symvers-3.10.0-1062.el7.x86_64.gz
grub initramfs-3.10.0-1062.el7.x86_64kdump.img System.map-3.10.0-1062.el7.x86_64解压缩,恢复备份及增量备份数据。
还原文件:
[root@192 boot.bak]# restore -r -f etc.dump.bz2还原/etc/目录的备份etc.dump.bz2。
6、文件系统误删除恢复
ext4文件系统上删除文件:可以恢复: extundelete ,ext3恢复使用:ext3grep。
windows恢复误删除的文件: final data v2.0 汉化版 和 easyrecovery。
Linux文件系统由三部分组成:文件名,inode,block
windows也由这三部分组成:
a.txt -->inode --> block
文件名 存放文件元数据信息 真正存放数据查看inode号:
[root@localhost ~]# ls -i a.txt
440266 a.txt常识: 每个文件,有一个inode号。
查看inode中的文件属性; 通过stat命令查看inode中包含的内容
查看inode信息:
[root@localhost ~]# stat a.txtmkfs.ext3将空文件格式化为ext3文件系统,指定生成inode-size大小为128的ext文件系统,默认为256:
[root@localhost ~]# mkfs.ext3 -I 128 test.ext3 查看文件系统类型:
[root@localhost ~]# file test.ext3
test.ext3: Linux rev 1.0 ext3 filesystem data, UUID=8f008c7a-dc08-4efe-86ca-d0fcd6c61dab (large files)block块是真正存储数据的地方。
记录block指针:
[root@localhost test]# debugfs /dev/loop1 -R "ls -d /test"
debugfs 1.45.6 (20-Mar-2020)
98305 (12) . 2 (12) .. 98306 (4072) passwd
[root@localhost test]# debugfs /dev/loop1 -R "imap <98306>"
debugfs 1.45.6 (20-Mar-2020)
Inode 98306 is part of block group 12
located at block 393218, offset 0x0080
[root@localhost test]# debugfs /dev/loop1 -R "blocks <98306>"
debugfs 1.45.6 (20-Mar-2020)
16994
[root@localhost test]# rm -f passwd //模拟文件删除
[root@localhost test]# debugfs /dev/loop1 -R "ls -d /test"
debugfs 1.45.6 (20-Mar-2020) //删除后的文件inode带有尖括号显示
98305 (12) . 2 (4084) .. <98306> (4072) passwd
[root@localhost test]# debugfs /dev/loop1 -R "blocks <98306>"
debugfs 1.45.6 (20-Mar-2020)
//文件被删除后,原inode的block指针被填0,获取为空rm命令是逻辑删除, 假删除。误删除文件后,第一件事就是要避免误删除的文件内容被覆盖。
卸载需要恢复文件的分区或者以只读的方式挂载:
mount -o remount,ro /mnt这里需要强度的是虽然将ext文件系统挂载到了系统的/ext目录下,但是文件系统本身也有根目录(区别于系统根目录),因此这里使用ls -d /test,而非ls -d /ext3/test。
在删除文件之前特地记录了inode中block的值,也就是磁盘中该文件的真实位置。使用dd命令读取该block位置的文件。
删除文件后根据删除前的block仍能在磁盘中找到该文件。因此要想成功恢复被删除的文件,关键在于如何从journal日志中找到inode副本中的block值。
1. dd误删除恢复
使用debugfs的logdump获取日志中inode副本:
[root@localhost test]# debugfs /dev/loop1 -R "logdump -i <98306>"
debugfs 1.45.6 (20-Mar-2020)
Inode 98306 is at group 12, block 393218, offset 128
Journal starts at block 1, transaction 2
FS block 393218 logged at sequence 47, journal block 369 (flags 0x2)
(inode block for inode 98306):
Inode: 98306 Type: bad type Mode: 0000 Flags: 0x0
Generation: 0 Version: 0x00000000
User: 0 Group: 0 Size: 0
File ACL: 0
Links: 0 Blockcount: 0
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x00000000 -- Thu Jan 1 08:00:00 1970
atime: 0x00000000 -- Thu Jan 1 08:00:00 1970
mtime: 0x00000000 -- Thu Jan 1 08:00:00 1970
Blocks: //该副本中为空
FS block 393218 logged at sequence 50, journal block 397 (flags 0x2)
(inode block for inode 98306):
Inode: 98306 Type: regular Mode: 0644 Flags: 0x0
Generation: 4264657513 Version: 0x00000001
User: 0 Group: 0 Size: 1825
File ACL: 0
Links: 1 Blockcount: 8
Fragment: Address: 0 Number: 0 Size: 0
ctime: 0x622b71c8 -- Fri Mar 11 23:59:04 2022
atime: 0x622b71c8 -- Fri Mar 11 23:59:04 2022
mtime: 0x622b71c8 -- Fri Mar 11 23:59:04 2022
Blocks: (0+1): 16994 //被删除文件的inode副本中的block指针
.....
No magic number at block 1620: end of journal.使用logdump 命令在journal日志中找到了多个indoe为98306的副本,这里只展示了两个。第一个block记录为空,在第二个副本中找到了原始block的指针,且与之前记录的文件block指针值一致,证明该方法有效,可成功恢复文件。
使用dd从磁盘中dump恢复文件:
[root@localhost test]# dd if=/dev/loop1 bs=4096 count=1 skip=16994 2>/dev/null
root:x:0:0:root:/root:/bin/bash
bin:x:1:1:bin:/bin:/sbin/nologin
daemon:x:2:2:daemon:/sbin:/sbin/nologin
adm:x:3:4:adm:/var/adm:/sbin/nologin
lp:x:4:7:lp:/var/spool/lpd:/sbin/nologin
...// 确定该block的文件就是被删除的文件内容
[root@localhost test]# dd if=/dev/loop1 bs=4096 count=1 skip=16994 of=passwd
1+0 records in
1+0 records out
4096 bytes (4.1 kB, 4.0 KiB) copied, 6.0939e-05 s, 67.2 MB/s
[root@localhost test]# ll -h
total 4 //文件恢复成功!
-rw-r--r-- 1 root root 4K Mar 12 00:50 passwd文件恢复成功!没有使用任何数据恢复软件,仅使用linux自带的命令恢复了被删除的文件。
注意:使用dd命令dump恢复的文件MD5值不一样。
[root@localhost test]# md5sum /etc/passwd
5e39a7f4aa25cd0de397c1685597460b /etc/passwd
[root@localhost test]# md5sum passwd
118c4d51a0425cf6d028076a54ba7fa9 passwd
[root@localhost test]# diff -Naur /etc/passwd passwd
--- /etc/passwd 2022-03-10 11:04:45.106866879 +0800
+++ passwd 2022-03-12 00:50:51.000000000 +0800
@@ -34,3 +34,4 @@
lighthouse:x:1000:1000::/home/lighthouse:/bin/bash
zgao:x:0:1001::/home/zgao:/bin/bash
redis:x:991:984:Redis Database Server:/var/lib/redis:/sbin/nologin
+
\ No newline at end of file很明显两者的md5并不相同,但用cat看到的内容却一样。因为dd命令是按照bs的大小来dump文件的,因为文件系统block-size为4096,整块一起dump包括了文件结尾填0部分,所以两者的md5值会不同。
2. extundelete误删除恢复
下载extundelete:
链接:https://pan.baidu.com/s/1n0dtGnhffcH7XrLv0TqUsw
提取码:a5m7
安装:
[root@localhost src]# ls
extundelete-0.2.4.tar.bz2
[root@localhost src]# tar xjvf extundelete-0.2.4.tar.bz2
[root@localhost src]# cd extundelete-0.2.4
[root@localhost extundelete-0.2.4]# yum install -y e2fsprogs-devel gcc*
[root@localhost extundelete-0.2.4]# ./configure #检查系统安装环境
[root@localhost extundelete-0.2.4]# make -j 4 #编译,把源代码编译成可执行的二进制文件。 -j 4 使用4进程同时编译,提升编译速度或者使用4核CPU同时编译。
[root@localhost extundelete-0.2.4]# make install #编译安装install 和cp 有什么区别,install 复制时可以指定权限 cp不可以:
[root@localhost ~]# install -m 777 /bin/find /opt/a.sh
[root@localhost ~]# ll /opt/创建测试分区:
[root@localhost ~]# fdisk /dev/sdb
[root@localhost ~]# partx -a /dev/sdb1 #获得新分区表
Or
[root@localhost ~]# reboot在根下删除文件了,想恢复:
方法1: 立即断电,然后把磁盘以只读方式,挂载到另一个电脑中进行恢复。
方法2:把extundelete在虚拟机上(虚拟机系统要和服务器版本一样),提前安装好后再复制到U盘中,把U盘插入服务器,恢复时,恢复的文件要保存到U盘中,(不要让恢复的数据写到/下,那样会覆盖之前删除的文件)。
使用新的分区:
[root@localhost ~]# mkdir /tmp/sdb1 #创建挂载点
[root@localhost ~]# mkfs.ext4 /dev/sdb1 #把/dev/sdb1分区文件系统格式化成ext4
[root@localhost ~]# mount /dev/sdb1 /tmp/sdb1 #把/dev/sdb1分区挂到/tmp/sdb1
或者
[root@localhost ~]# echo “/dev/sdb1 /tmp/sdb1 ext4 defaults 0 0” >> /etc/fstab
[root@localhost ~]# cat /etc/fstab
/dev/mapper/VolGroup-lv_root / ext4 defaults 1 1
UUID=0c3a8811-c256-45e9-b613-2a7eb4f247d1 /boot ext4 defaults 1 2
/dev/mapper/VolGroup-lv_swap swap swap defaults 0 0
tmpfs /dev/shm tmpfs defaults 0 0
devpts /dev/pts devpts gid=5,mode=620 0 0
sysfs /sys sysfs defaults 0 0
proc /proc proc defaults 0 0
/dev/cdrom /media/cdrom iso9660 defaults 0 0
/dev/sdb1 /tmp/sdb1 ext4 defaults 0 0
[root@localhost ~]# mount -a
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 18G 1.3G 16G 8% /
tmpfs 499M 0 499M 0% /dev/shm
/dev/sda1 485M 33M 427M 8% /boot
/dev/sr0 3.6G 3.6G 0 100% /media/cdrom
/dev/sdb1 1020M 34M 935M 4% /tmp/sdb1复制一些测试文件,然后把这些文件再删除,然后演示恢复:
[root@localhost ~]# cp /etc/passwd /tmp/sdb1
[root@localhost ~]# cp /etc/hosts /tmp/sdb1
[root@localhost ~]# echo aaa > a.txt
[root@localhost ~]# mkdir -p /tmp/sdb1/a/b/c
[root@localhost ~]# cp a.txt /tmp/sdb1/a
[root@localhost ~]# cp a.txt /tmp/sdb1/a/b
[root@localhost ~]# touch /tmp/sdb1/a/b/kong.txt
[root@localhost ~]# yum install -y tree
[root@localhost ~]# tree /tmp/sdb1
/tmp/sdb1
├── a
│ ├── a.txt
│ └── b
│ ├── a.txt
│ ├── c #空目录
│ └── kong.txt #空文件
├── hosts
├── lost+found
└── passwd
4 directories, 5 files删除文件:
[root@localhost ~]# cd /tmp/sdb1
[root@localhost sdb1]# ls
a hosts lost+found passwd
[root@localhost sdb1]# rm -rf a hosts passwd
[root@localhost sdb1]# ls
lost+found6卸载需要恢复文件的分区或者以只读的方式挂载:
[root@localhost sdb1]# cd /root
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 18G 1.3G 16G 8% /
tmpfs 499M 0 499M 0% /dev/shm
/dev/sda1 485M 33M 427M 8% /boot
/dev/sr0 3.6G 3.6G 0 100% /media/cdrom
/dev/sdb1 1020M 34M 935M 4% /tmp/sdb1
[root@localhost ~]# mount -o remount,ro /tmp/sdb1 #以只读的形式重新挂载/tmp/sdb1所在分区
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 18G 1.3G 16G 8% /
tmpfs 499M 0 499M 0% /dev/shm
/dev/sda1 485M 33M 427M 8% /boot
/dev/sr0 3.6G 3.6G 0 100% /media/cdrom
/dev/sdb1 1020M 34M 935M 4% /tmp/sdb1
[root@localhost ~]# touch /tmp//sdb1/testfile
touch: cannot touch `/tmp//sdb1/testfile’: Read-only file system或者:
[root@localhost ~]# umount /tmp/sdb1 #卸载/tmp/sdb1所在分区
[root@localhost ~]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/mapper/VolGroup-lv_root 18G 1.3G 16G 8% /
tmpfs 499M 0 499M 0% /dev/shm
/dev/sda1 485M 33M 427M 8% /boot
/dev/sr0 3.6G 3.6G 0 100% /media/cdrom开始恢复:
方法一:通过inode结点恢复
方法二:通过文件名恢复
方法三:恢复某个目录,如目录a下的所有文件:
方法四:恢复所有的文件
[root@localhost extundelete-0.2.4]# mkdir /test #创建一个目录使用于存放恢复的数据
[root@localhost extundelete-0.2.4]# cd /test
[root@localhost test]#通过inode结点查看被删除的文件名字:
[root@localhost test]# extundelete /dev/sdb1 --inode 2
File name | Inode number | Deleted status
. 2
… 2
lost+found 11
passwd 12 Deleted
hosts 13 Deleted
a 7377 Deletedext4文件系统的分区根目录的inode值为2,xfs分区根目录的inode值为64。
[root@localhost test]# ls -id /boot/ #xfs文件系统
64 /boot/
[root@localhost test]# ls -id /tmp/sdb1
2 /tmp/sdb1方法一:通过inode结点恢复:
[root@localhost test]# ls
[root@localhost test]# extundelete /dev/sdb1 --restore-inode 12
NOTICE: Extended attributes are not restored.
Loading filesystem metadata … 9 groups loaded.
Loading journal descriptors … 61 descriptors loaded.
[root@localhost test]# ls
RECOVERED_FILES
[root@localhost test]# ls RECOVERED_FILES/
file.12
[root@localhost test]# diff /etc/passwd RECOVERED_FILES/file.12 #对比文件内容,没有任何输出,说明恢复后的文件内容没有变化方法二:通过文件名恢复:
[root@localhost test]# extundelete /dev/sdb1 --restore-file passwd
[root@localhost test]# diff /etc/passwd RECOVERED_FILES/passwd #对比文件内容,没有任何输出,说明恢复后的文件内容没有变化方法三:恢复某个目录,如目录a下的所有文件:
[root@localhost test]# extundelete /dev/sdb1 --restore-directory a
[root@localhost test]# tree RECOVERED_FILES/a/
RECOVERED_FILES/a/
├── a.txt
└── b
└── a.txt
1 directory, 2 files方法四:恢复所有的文件:
[root@localhost test]# rm -rf RECOVERED_FILES/*
[root@localhost test]# extundelete /dev/sdb1 --restore-all
[root@localhost test]# ls RECOVERED_FILES/
a hosts passwd
[root@localhost test]# tree RECOVERED_FILES/
RECOVERED_FILES/
├── a
│ ├── a.txt
│ └── b
│ └── a.txt
├── hosts
└── passwd
2 directories, 4 files删除前:
[root@localhost ~]# tree /tmp/sdb1
/tmp/sdb1
├── a
│ ├── a.txt
│ └── b
│ ├── a.txt
│ ├── c #空目录
│ └── kong.txt #空文件
├── hosts
├── lost+found
└── passwd
4 directories, 5 files恢复后:
[root@localhost test]# tree RECOVERED_FILES/
RECOVERED_FILES/
├── a
│ ├── a.txt
│ └── b
│ └── a.txt
├── hosts
└── passwd
2 directories, 4 files注意:extundelete在恢复文件的时候不能自动创建空文件和目录。