一、cd命令
cd(change directory,切换目录),这是用来切换工作目录的命令(注意目录名称和cd命令之间存在一个空格)。
在介绍cd命令的时候,首先我们来了解相对路径和绝对路径。
绝对路径:路径的写法“一定由跟目录 / 写起”,例如:/data 、/usr等;
相对路径:路径的写法“不是由 / 写起”,相对路径意指相对于目前工作目录的路径;
. 代表此层目录;
.. 代表上一层目录;
- 代表前一个工作目录;
~ 代表目前使用者所在的家目录;
示例:
1. cd / 切换到根目录;
[root@localhost ~]# cd /
[root@localhost /]# 2. cd . 切换到当前目录;
[root@localhost /]# cd .
[root@localhost /]# 3. cd ~ 切换到当前用户的家目录;
[root@localhost /]# cd ~
[root@localhost ~]# 4. cd .. 切换到当前目录的上一级目录;
[root@localhost ~]# cd ..
[root@localhost /]# 5. cd 到指定目录;
[root@localhost ~]# cd /data/psp/ps/
[root@localhost ps]#二、cp和mv命令
cp命令
cp命令用来将一个或多个源文件或者目录复制到指定的目的文件或目录。它可以将单个源文件复制成一个指定文件名的具体的文件或一个已经存在的目录下。
cp命令还支持同时复制多个文件,当一次复制多个文件时,目标文件参数必须是一个已经存在的目录,否则将出现错误。
语法:
cp(选项)(参数)选项:
-a:此参数的效果和同时指定"-dpR"参数相同;
-d:当复制符号连接时,把目标文件或目录也建立为符号连接,并指向与源文件或目录连接的原始文件或目录;
-f:强行复制文件或目录,不论目标文件或目录是否已存在;
-i:覆盖既有文件之前先询问用户;
-l:对源文件建立硬连接,而非复制文件;
-p:保留源文件或目录的属性;
-R/r:递归处理,将指定目录下的所有文件与子目录一并处理;
-s:对源文件建立符号连接,而非复制文件;
-u:使用这项参数后只会在源文件的更改时间较目标文件更新时或是名称相互对应的目标文件并不存在时,才复制文件;
-S:在备份文件时,用指定的后缀“SUFFIX”代替文件的默认后缀;
-b:覆盖已存在的文件目标前将目标文件备份;
-v:详细显示命令执行的操作。注意:
源文件制定源文件列表。默认情况下,cp命令不能复制目录,如果要复制目录,则必须使用-R选项;
目标文件指定目标文件。当“源文件”为多个文件时,要求“目标文件”为指定的目录。
示例:
如果把一个文件复制到一个目标文件中,而目标文件已经存在,那么,该目标文件的内容将被破坏。此命令中所有参数既可以是绝对路径名,也可以是相对路径名。通常会用到.或..的形式。
例如,下面的命令将指定文件复制到当前目录下:
cp ../mary/homework/assign .所有目标文件指定的目录必须是己经存在的,cp命令不能创建目录。如果没有文件复制的权限,则系统会显示出错信息。
将文件file复制到目录/usr/men/tmp下,并改名为file1:
cp file /usr/men/tmp/file1将目录/usr/men下的所有文件及其子目录复制到目录/usr/zh中:
cp -r /usr/men /usr/zh交互式地将目录/usr/men中的以m打头的所有.c文件复制到目录/usr/zh中:
cp -i /usr/men m*.c /usr/zh在Linux下使用cp命令复制文件时候,有时候会需要覆盖一些同名文件,覆盖文件的时候都会有提示:需要不停的按Y来确定执行覆盖。此时可以采用以下方法:
cp aaa/* /bbb复制目录aaa下所有到/bbb目录下,这时如果/bbb目录下有和aaa同名的文件,需要按Y来确认并且会略过aaa目录下的子目录。
cp -r aaa/* /bbb这次依然需要按Y来确认操作,但是没有忽略子目录。
cp -r -a aaa/* /bbb依然需要按Y来确认操作,并且把aaa目录以及子目录和文件属性也传递到了/bbb。
\cp -r -a aaa/* /bbb成功,没有提示按Y、传递了目录属性、没有略过目录。
mv命令
mv命令用来对文件或目录重新命名,或者将文件从一个目录移到另一个目录中。source表示源文件或目录,target表示目标文件或目录。如果将一个文件移到一个已经存在的目标文件中,则目标文件的内容将被覆盖。
mv命令可以用来将源文件移至一个目标文件中,或将一组文件移至一个目标目录中。源文件被移至目标文件有两种不同的结果:
1、如果目标文件是到某一目录文件的路径,源文件会被移到此目录下,且文件名不变。
2、如果目标文件不是目录文件,则源文件名(只能有一个)会变为此目标文件名,并覆盖己存在的同名文件。如果源文件和目标文件在同一个目录下,mv的作用就是改文件名。当目标文件是目录文件时,源文件或目录参数可以有多个,则所有的源文件都会被移至目标文件中。所有移到该目录下的文件都将保留以前的文件名。
语法:
mv(选项)(源文件 目标文件)
源文件:源文件列表。
目标文件:如果“目标文件”是文件名则在移动文件的同时,将其改名为“目标文件”;如果“目标文件”是目录名则将源文件移动到“目标文件”下。
选项:
--backup=<备份模式>:若需覆盖文件,则覆盖前先行备份;
-b:当文件存在时,覆盖前,为其创建一个备份;
-f:若目标文件或目录与现有的文件或目录重复,则直接覆盖现有的文件或目录;
-i:交互式操作,覆盖前先行询问用户,如果源文件与目标文件或目标目录中的文件同名,则询问用户是否覆盖目标文件。用户输入”y”,表示将覆盖目标文件;输入”n”,表示取消对源文件的移动。这样可以避免误将文件覆盖。
--strip-trailing-slashes:删除源文件中的斜杠“/”;
-S<后缀>:为备份文件指定后缀,而不使用默认的后缀;
--target-directory=<目录>:指定源文件要移动到目标目录;
-u:当源文件比目标文件新或者目标文件不存在时,才执行移动操作。示例:
将文件ex3改名为new1:
mv ex3 new1将目录/usr/men中的所有文件移到当前目录(用.表示)中:
mv /usr/men/* .三、touch、mkdir、rm命令
touch命令
linux下新建文件的方式有非常多,比如:使用vi新建文件、使用cp命令拷贝一个文件、可是最经常使用的还是使用touch命令新建一个文件。
语法:
touch [options] filename参数:
-a:改变访问时间
-m:改变改动时间
-t timestamp:改变访问时间和改动时间为timestamp假设不指定不论什么选项。那么touch命令会新建一个文件。
假设指定了-t timestamp选项,那么touch命令会改动文件的访问时间和改动时间为timestamp。
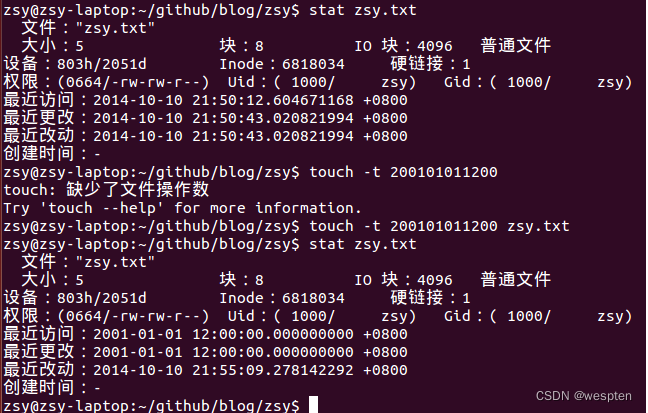
假设使用了-a选项,那么touch命令会改动文件的访问时间为当前时间。
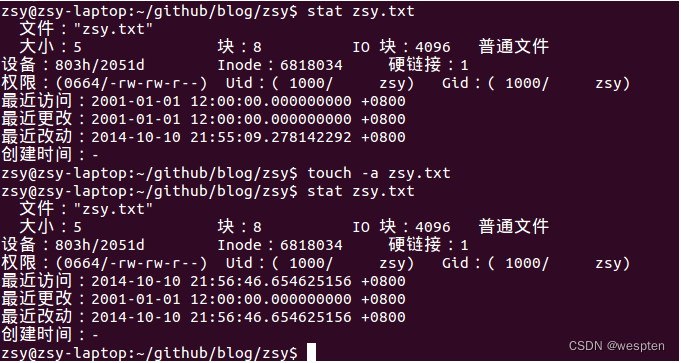
假设使用了-m选项,那么touch命令会改动文件的改动时间为当前时间。
mkdir命令
语法:
mkdir [options] dirname参数:
-p:递归创建文件夹
-mmode:新建文件夹,并设置文件夹的文件訪问模式为mode使用-p选项递归的创建zsy/hxn文件夹:

使用-m选项指定新建文件夹的文件訪问模式为770,即rwxrwx---。

rm命令
Linux系统中rm命令其实是remove的意思,删除一个或多个文件目录。
1. 命令格式:
rm [选项] 文件…2.命令功能:
删除一个目录中的一个或多个文件或目录,如果没有使用- r选项,则rm不会删除目录。如果使用 rm 来删除文件,通常仍可以将该文件恢复原状。
linux系统中rm命令参数说明:
-f, --force 忽略不存在的文件,从不给出提示。
-i, --interactive 进行交互式删除
-r, -R, --recursive 指示rm将参数中列出的全部目录和子目录均递归地删除。
-v, --verbose 详细显示进行的步骤
--help 显示此帮助信息并退出
--version 输出版本信息并退出示例:
实例一:删除文件file,系统会先询问是否删除。
[root@localhost test1]# ll
-rw-r--r-- 1 root root 56 10-26 14:31 log.log
root@localhost test1]# rm log.log
rm:是否删除 一般文件 “log.log”? y
root@localhost test1]# ll
[root@localhost test1]#说明:
输入rm log.log命令后,系统会询问是否删除,输入y后就会删除文件,不想删除则数据 n。
实例二:强行删除file,系统不再提示:
[root@localhost test1]# ll
-rw-r--r-- 1 root root 23 10-26 14:40 log1.log
[root@localhost test1]# rm -f log1.log
[root@localhost test1]# ll
[root@localhost test1]#实例三:删除任何.log文件,删除前逐一询问确认:
[root@localhost test1]# ll
-rw-r--r-- 1 root root 11 10-26 14:45 log1.log
-rw-r--r-- 1 root root 24 10-26 14:45 log2.log
[root@localhost test1]# rm -i *.log
rm:是否删除 一般文件 “log1.log”? y
rm:是否删除 一般文件 “log2.log”? y
[root@localhost test1]# ll
[root@localhost test1]#实例四:将 test1子目录及子目录中所有档案删除:
[root@localhost test]# ll
drwxr-xr-x 7 root root 4096 10-25 18:07 scf
drwxr-xr-x 2 root root 4096 10-26 14:51 test1
drwxr-xr-x 3 root root 4096 10-25 17:44 test2
drwxrwxrwx 2 root root 4096 10-25 17:46 test3
drwxr-xr-x 2 root root 4096 10-25 17:56 test4
drwxr-xr-x 3 root root 4096 10-25 17:56 test5
[root@localhost test]# rm -r test1
rm:是否进入目录 “test1”? y
rm:是否删除 一般文件 “test1/log3.log”? y
rm:是否删除 目录 “test1”? y
[root@localhost test]# ll
drwxr-xr-x 7 root root 4096 10-25 18:07 scf
drwxr-xr-x 3 root root 4096 10-25 17:44 test2
drwxrwxrwx 2 root root 4096 10-25 17:46 test3
drwxr-xr-x 2 root root 4096 10-25 17:56 test4
drwxr-xr-x 3 root root 4096 10-25 17:56 test5
[root@localhost test]#实例五:rm -rf test2命令会将test2 子目录及子目录中所有档案删除,并且不用一一确认:
[root@localhost test]# rm -rf test2
[root@localhost test]# ll
drwxr-xr-x 7 root root 4096 10-25 18:07 scf
drwxrwxrwx 2 root root 4096 10-25 17:46 test3
drwxr-xr-x 2 root root 4096 10-25 17:56 test4
drwxr-xr-x 3 root root 4096 10-25 17:56 test5
[root@localhost test]#实例六:删除以 -f 开头的文件:
[root@localhost test]# touch -- -f
[root@localhost test]# ls -- -f
-f[root@localhost test]# rm -- -f
rm:是否删除 一般空文件 “-f”? y
[root@localhost test]# ls -- -f
ls: -f: 没有那个文件或目录
[root@localhost test]#
也可以使用下面的操作步骤:
[root@localhost test]# touch ./-f
[root@localhost test]# ls ./-f
[root@localhost test]# rm ./-f
rm:是否删除 一般空文件 “./-f”? y
[root@localhost test]#实例七:自定义回收站功能:
[root@localhost test]# myrm(){ D=/tmp/$(date +%Y%m%d%H%M%S); mkdir -p $D; mv "$@" $D && echo "moved to $D ok"; }
[root@localhost test]# alias rm='myrm'
[root@localhost test]# touch 1.log 2.log 3.log
[root@localhost test]# ll
-rw-r--r-- 1 root root 0 10-26 15:08 1.log
-rw-r--r-- 1 root root 0 10-26 15:08 2.log
-rw-r--r-- 1 root root 0 10-26 15:08 3.log
drwxr-xr-x 7 root root 4096 10-25 18:07 scf
drwxrwxrwx 2 root root 4096 10-25 17:46 test3
drwxr-xr-x 2 root root 4096 10-25 17:56 test4
drwxr-xr-x 3 root root 4096 10-25 17:56 test5
[root@localhost test]# rm [123].log
moved to /tmp/20121026150901 ok
[root@localhost test]# ll
drwxr-xr-x 7 root root 4096 10-25 18:07 scf
drwxrwxrwx 2 root root 4096 10-25 17:46 test3
drwxr-xr-x 2 root root 4096 10-25 17:56 test4
drwxr-xr-x 3 root root 4096 10-25 17:56 test5
[root@localhost test]# ls /tmp/20121026150901/
1.log 2.log 3.log
[root@localhost test]#说明:
上面的操作过程模拟了回收站的效果,即删除文件的时候只是把文件放到一个临时目录中,这样在需要的时候还可以恢复过来。
五、Linux磁盘分区
Linux磁盘结构
物理结构
硬盘的物理结构一般由磁头与碟片、电动机、主控芯片与排线等部件组成;当主电动机带动碟片旋转时,副电动机带动一组(磁头)到相对应的碟片上并确定读取正面还是反面的碟面,磁头悬浮在碟面上画出一个与碟片同心的圆形轨道(磁轨或称柱面),这时由磁头的磁感线圈感应碟面上的磁性与使用硬盘厂商指定的读取时间或数据间隔定位扇区,从而得到该扇区的数据内容。
所有的盘片都固定在一个旋转轴上,这个轴即盘片主轴。而所有盘片之间是绝对平行的,在每个盘片的存储面上都有一个磁头,磁头与盘片之间的距离比头发丝的直径还小。所有的磁头连在一个磁头控制器上,由磁头控制器负责各个磁头的运动。磁头可沿盘片的半径方向动作,而盘片以每分钟数千转到上万转的速度在高 速旋转,这样磁头就能对盘片上的指定位置进行数据的读写操作。
- 磁道(Track)
当磁盘旋转时,磁头若保持在一个位置上,则每个磁头都会在磁盘表面划出一个圆形轨迹,这些圆形轨迹就叫做磁道(Track)。信息以脉冲串的形式记录在这些轨迹中,这些同心圆不是连续记录数据,而是被划分成一段段的圆弧(扇区),这些圆弧 的角速度一样。
- 柱面 (Cylinder)
在有多个盘片构成的盘组中,由不同盘片的面,但处于同一半径圆的多个磁道组成的一个圆柱面(Cylinder)。所有盘面上的同一磁道构成一个圆柱,通常称做柱面(Cylinder),每个圆柱上的磁头由上而下从“0”开始编号。数据的读/写按柱面进行,即磁 头读/写数据时首先在同一柱面内从“0”磁头开始进行操作,依次向下在同一柱面的不同盘面即磁头上进行操作,只在同一柱面所有的磁头全部读/写完毕后磁头 才转移到下一柱面,因为选取磁头只需通过电子切换即可,而选取柱面则必须通过机械切换。
电子切换相当快,比在机械上磁头向邻近磁道移动快得多,所以,数据 的读/写按柱面进行,而不按盘面进行。也就是说,一个磁道写满数据后,就在同一柱面的下一个盘面来写,一个柱面写满后,才移到下一个扇区开始写数据。读数 据也按照这种方式进行,这样就提高了硬盘的读/写效率。
- 扇区(Sector)
磁盘上的每个磁道被等分为若干个弧段,这些弧段便是硬盘的扇区(Sector)。硬盘的第一个扇区,叫做引导扇区。操作系统以扇区(Sector)形式将信息存储在硬盘上,每个扇区包括512个字节的数据和一些其他信息。
- 磁头(Head)
在硬盘系 统中,硬盘的每一个盘片都有两个盘面(Side),即上、下盘面,一般每个盘面都会利 用,都可以存储数据。盘面号又叫磁头号,因为每一个有效盘面都有一个对应的读写磁头。
在 linux 中可以使用 fdisk -l 查看一个磁盘的物理结构:
root@centos:~# fdisk -l /dev/sda
Disk /dev/sda:1.84 TiB,2000398934016 字节,3907029168 个扇区
Disk model: ST2000NX0253
单元:扇区 / 1 * 512 = 512 字节
扇区大小(逻辑/物理):512 字节 / 4096 字节
I/O 大小(最小/最佳):4096 字节 / 4096 字节
磁盘标签类型:gpt
磁盘标识符:27E8F38B-1909-4730-B931-D399FF19A594
设备 起点 末尾 扇区 大小 类型
/dev/sda1 2048 4095 2048 1M BIOS 启动
/dev/sda2 4096 976895 972800 475M Microsoft 基本数据
/dev/sda3 976896 3726032895 3725056000 1.8T Linux LVM
输出信息分为两部分。第一部分显示硬盘的基本参数,包括容量、磁头数和扇区数等。第二部分显示硬盘的分区情况。如果硬盘没有分区,这部分是空白;如果已经分区,每行将代表一个分区,各个字段的定义如下:
Device:分区名
Boot:是否允许标准 DOS PC 主引导记录引导该分区(该标记对 Linux 的 GRUB 引导装载程序没有意义)
Start:分区起始柱面
End:分区结束柱面
Blocks:大小为 1k 的块的数量
Id:分区的预期用途(并不是真实用途,82 表示交互分区,83 表示数据分区)
值得一提的是,目前逐渐成为主流的固态硬盘中,虽然没有盘片、磁头、扇区这些物理零件,但固态硬盘的接口规范、定义功能及使用方法上与普通机械硬盘完全相同。因此,逻辑上固态硬盘也有柱面、扇区,磁头等参数。
除 fdisk 外,我们更推荐使用 lsblk 命令来查看系统中所有的硬盘情况,lsblk 会显示系统中除了内存虚拟磁盘外的所有可用块设备的信息:块设备也就是存储以“块”为单位数据的设备,比较典型的如磁盘设备、光盘或者U盘。
root@centos:~# lsblk
NAME MAJ:MIN RM SIZE RO TYPE MOUNTPOINT
sda 8:0 0 1.8T 0 disk
├─sda1 8:1 0 1M 0 part
├─sda2 8:2 0 475M 0 part
└─sda3 8:3 0 1.8T 0 part
├─centos-root 253:0 0 1.7T 0 lvm
└─centos-swap 253:1 0 32G 0 lvm
sdb 8:16 0 931.5G 0 disk
├─sdb1 8:17 0 512M 0 part /boot/efi
└─sdb2 8:18 0 931G 0 part /
sdc 8:32 0 1.8T 0 disk
└─sdc1 8:33 0 1.8T 0 part /home1
sdd 8:48 0 223.6G 0 disk
└─sdd1 8:49 0 223.6G 0 part
lsblk -f 查看系统分区和挂载情况:
root@qsrobot:~# lsblk -f
NAME FSTYPE LABEL UUID MOUNTPOINT
sr0 iso9660 Ubuntu 16.04.6 LTS amd64
2019-02-27-09-57-36-00 /media/rob
sda
├─sda2
├─sda5 swap 8d41e7be-46cf-4de6-afab-fb5242d10d4f [SWAP]
└─sda1 ext4 95a7ce2a-6891-44f6-b0db-729319f8de8d /
设备类型:
块设备:block,存取单位“块”,磁盘;
字符设备:char,存取单位“字符”,键盘;
从上述输出信息中,可以直观地了解到目前系统的硬盘分区及挂载情况。
使用blkid(block id)可以查看设备的全局唯一标识符(UUID,universally unique identifier),如下图:

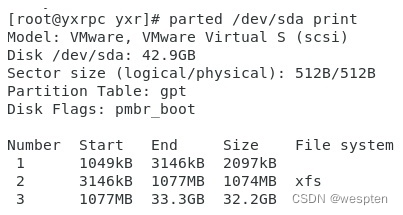
使用parted指令可以列出磁盘的分区信息,如下图。在图中可以看到有三个分区,实际上这三个分区为gpt(引导扇区)、/boot、/和/home和/swap的数据分区。最后一个分区为lvm实际上里面有三个文件系统均为xfs,挂载点为/和/home和/swap。
磁盘的读写原理
系统将文件存储到磁盘上时,按柱面、磁头、扇区的方式进行,即最先是第1磁道的第一磁头下(也就是第1盘面的第一磁道)的所有扇区,然后,是同一柱面的下一磁头,……,一个柱面存储满后就推进到下一个柱面,直到把文件内容全部写入磁盘。
系统也以相同的顺序读出数据。读出数据时通过告诉磁盘控制器要读出扇区所在的柱面号、磁头号和扇区号(物理地址的三个组成部分)进行。磁盘控制器则直接使磁头部件步进到相应的柱面,选通相应的磁头,等待要求的扇区移动到磁头下。在扇区到来时,磁盘控制器读出每个扇区的头标,把这些头标中的地址信息与 期待检出的磁头和柱面号做比较(即寻道),然后,寻找要求的扇区号。待磁盘控制器找到该扇区头标时,根据其任务是写扇区还是读扇区,来决定是转换写电路, 还是读出数据和尾部记录。
找到扇区后,磁盘控制器必须在继续寻找下一个扇区之前对该扇区的信息进行后处理。如果是读数据,控制器计算此数据的ECC码,然 后,把ECC码与已记录的ECC码相比较。如果是写数据,控制器计算出此数据的ECC码,与数据一起存储。在控制器对此扇区中的数据进行必要处理期间,磁 盘继续旋转。其实我们的文件大多数的时候都是破碎的,在文件没有破碎的时候,摇臂只需要寻找1次磁道并由磁头进行读取,只需要1次就可以成功读取;但是如果文件破碎成11处,那么摇臂要来回寻找11次磁道磁头进行11次读取才能完整的读取这个文件,读取时间相对没有破碎的时候就变得冗长。
因此,磁盘IO时的过程包括:
- 第一步,首先是磁头径向移动来寻找数据所在的磁道。这部分时间叫寻道时间。
- 第二步,找到目标磁道后通过盘面旋转,将目标扇区移动到磁头的正下方。
- 第三步,向目标扇区读取或者写入数据。到此为止,一次磁盘IO完成。
所以,单次磁盘IO时间 = 寻道时间 + 旋转延迟 + 存取时间。
- 对于旋转延时,现在主流服务器上经常使用的是1W转/分钟的磁盘,每旋转一周所需的时间为60*1000/10000=6ms,故其旋转延迟为(0-6ms)。
- 对于存取时间,一般耗时较短,为零点几ms。
- 对于寻道时间,现代磁盘大概在3-15ms,其中寻道时间大小主要受磁头当前所在位置和目标磁道所在位置相对距离的影响。
候选的磁盘分区方案:
- 方案一: 255个盘面,C盘是0-100盘面, D盘是101-200个盘面,……
- 方案二:3263个柱面,C盘0-1000个柱面,D盘1001-20001个柱面,……
其实采用哪一种,最主要看的是那种方式性能更快。因为同一分区下的数据经常会一起读取,假如采用第一种,那么这样磁头就需要在3000多个track间不停地跳来跳去,这样磁盘的寻道时间就会翻倍,磁盘性能就会下降。
而对于方案二,假如对于磁盘C,只需要在磁头在1-1000个磁道间移动就可以了,大大降低了寻道时间。(实际上分区并不是从0开始的,磁盘的第一个磁道对应的柱面会被用来安装引导加载程序以及磁盘分区表)。所以,方案二的分区方式可以降低磁盘IO时间中的寻道时间部分,所以所有的操作系统采用的都是方案二,没有用方案一的。
Linux磁盘命名
在为主机添加硬盘前,首先要了解Linux系统下对硬盘和分区的命名方法。
对于 SATA、SCSI 或 USB 接口的硬盘或 U 盘,其命名规则如下:
| 主设备文件名 | 次设置文件名(分区) |
|---|---|
| sd[小写字母] 如 sda、sdb 等 |
sd[小写字母][正整数] 如 sda1、sdc1 等 |
在Linux下对 SCSI 和 SATA 设备是以 sd 命名的,第一个 scsi 设备是 sda,第二个是 sdb,依此类推。一般主板上有两个SCSI接口,因此一共可以安装四个SCSI设备。主 SCSI 上的两个设备分别对应 sda 和 sdb,第二个 SCSI 口上的两个设备对应 sdc 和 sdd。一般硬盘安装在主 SCSI 的主接口上,所以是 sda 或者 sdb,而光驱一般安装在第二个SCSI的主接口上,所以是 sdc。
IDE接口设备是用 hd 命名的,第一个设备是hda,第二个是hdb,依此类推。
| IDE 磁盘 | 描述 | 配置 |
|---|---|---|
| /dev/hda | 1st (Primary) IDE controller | Master |
| /dev/hdb | 1st (Primary) IDE controller | Slave |
| /dev/hdc | 2nd (Secondary) IDE controller | Master |
| /dev/hdd | 2nd (Secondary) IDE controller | Slave |
对于 NVMe(M.2)接口的硬盘,其命名规则如下:
| 主设备文件名 | 次设置文件名(分区) |
|---|---|
| nvme[非负整数] 如 nvme0、nvme1 等 |
sd[非负整数]n[正整数]p[正整数] 如 nvme0n1p1、nvme1n1p3 等 |
对于 CD 或 DVD (ROM)光驱设备,其命名规则如下:
| 主设备文件名 | 次设置文件名(分区) |
|---|---|
| sr[非负整数] 如 sr0、sr1 等 |
光驱不能分区 |
更多设备命名:
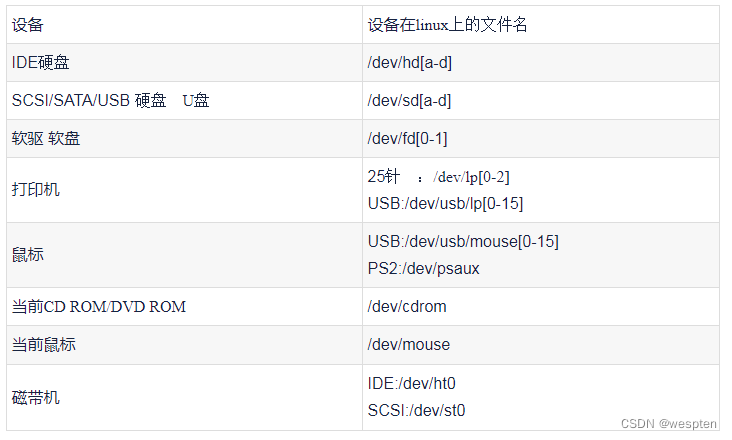
特别要注意的是,Linux 中的存储设备的名字并非固定,在热插拔、重启等操作后,存储设备名字中的序号可能会发生改变。如 sda 变成 sdc,这种改变可能会让系统管理员犯一些低级错误,如误删数据,误分区等,因此通过设备文件操作硬盘之前,一定要确认好设备名称。
在自动化管理和配置文件中,如开机自动挂载配置文件 /etc/fstab,强烈不建议使用设备文件名来指定存储设备,而是应该使用设备的 UUID。
Linux MBR和GPT分区类型
Linux 采用了一种叫“载入”的处理方法,它的整个文件系统中包含了一整套的文件和目录,且将一个分区和一个目录联系起来。这时要载入的一个分区将使它的存储空间在一个目录下获得。
无论有几个分区,分给哪一目录使用,它归根结底就只有一个根目录,一个独立且唯一的文件结构 , Linux中每个分区都是用来组成整个文件系统的一部分。
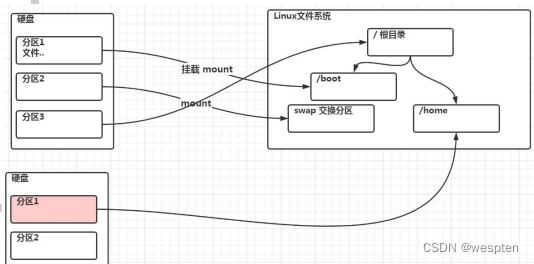
磁盘分区的好处:
优化IO性能、实现磁盘配额、隔离系统和程序、可以采用多个文件系统
分区的方式:
- MBR --- 比较传统的分区
- GPT --- 支持更大的硬盘空间MBR分区
MBR:Master Boot Record(主引导记录),1982年开发而来,使用32位表示扇区数,分区不超过2T 。
特点:支持的分区数量、分区空间有限,MBR只支持不超过2T的硬盘,超过2T的硬盘将只能用2T空间。
MBR分区划分基于磁盘柱面,利用参考柱面号码的方式来处理,从CentOS6开始已经支持采用扇区的方式来划分分区。
其实所谓的“分区”只是针对那个64bytes 的分区表进行设置而已,硬盘默认的分区表仅能写入四组分区信息,这四组分区信息我们称为主(Primary)分区或扩展(Extended)分区。所以,MBR的分区方式为:4个主分区或{3主分区+1扩展(N个逻辑分区)}。
第一个扇区512bytes MBR引导扇区 (0磁道0扇区):
1. MBR的分区是按照分区类型来进行组织的。
2. 把整个硬盘的分区信息放在0磁道0扇区这个512字节大小的空间中 。
3. MBR分区中一块硬盘最多有4个主分区,也可以3主分区+1扩展(N个逻辑分区) ,逻辑分区在扩展分区里面分。
该扇区分为三部分:
- 主引导程序(boot loader)446 bytes: boot loader 启动相关(存放启动相关的文件)
- 主分区表(partition table) 64 bytes:分区表(记录每个硬盘有几个分区,每个分区的开始和结束位置),其中每16bytes用来标识一个分区信息(起始位置和结束位置等信息)
-16bytes: 标识一个分区
- 结束标识 2 bytes: 55AA(两个字节的标志位)
主分区表所在的64个bytes容量中,每16个bytes分为一个项,总共分为四组记录区,每组记录区记录了该区段的起始与结束的柱面号码,等信息。
MBR分区类型:
- 主分区:可以存放数据也可以装系统
- 扩展分区:不能直接存数据,需要在里面划分逻辑分区才能存放数据(相当于一个容器)
- 逻辑分区:
主分区和扩展分区对应数字1--4,/dev/sda3,逻辑分区从数字5开始,/dev/sda5
什么是扩展分区?
所谓扩展分区,严格地讲它不是一个实际意义的分区,它仅仅是一个指向下一个分区的指针,这种指针结构将形成一个单向链表。
这样在主引导扇区中除了主分区外,仅需要存储一个被称为扩展分区的分区数据,通过这个扩展分区的数据可以找到下一个分区(实际上也就是下一个逻辑磁盘)的起始位置,以此起始位置类推可以找到所有的分区。无论系统中建立多少个逻辑磁盘,在主引导扇区中通过一个扩展分区的参数就可以逐个找到每一个逻辑磁盘。
扩展分区结构:扩展引导记录(EBR)+ 逻辑分区
注:扩展分区中的每个逻辑驱动器都存在一个类似于MBR的扩展引导记录( Extended Boot Record, EBR)。
扩展引导扇区(EBR):类似于MBR的扩展引导记录,扩展引导记录包括一个扩展分区表和该扇区的标签。
扩展引导记录将记录只包含扩展分区中每个逻辑驱动器的第一个柱面的第一面的信息,但是,如果磁盘上没有扩展分区,那么就不会有扩展引导记录和逻辑驱动器。
EBR结构:
逻辑分区前扇区,如扩展分区0号扇区(512bytes);
前446bytes:未使用,全为0;
扩展分区表(64bytes):记录分区状态,每16bytes分为一个项,共四个项。
第一项:指向它自身的引导扇区;
第二项:指向下一个逻辑驱动器的EBR;
注:如果不存在进一步的逻辑驱动器,第二项不会使用,且被记录成一系列零。
第三项:未使用;
第四项:未使用;
结束标识(2bytes): 55AA ,有效性标识;55AA为有效;
MBR分区结构:
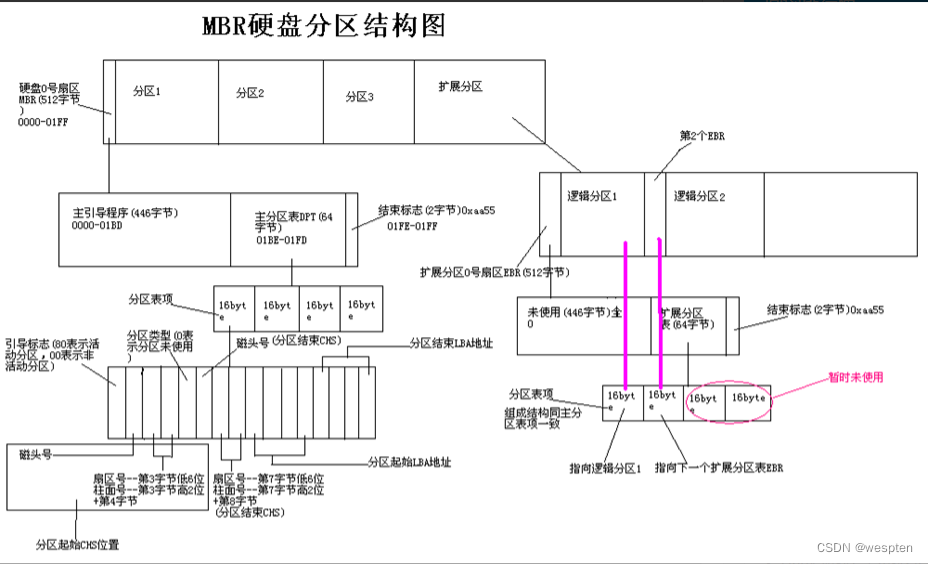
- 主引导程序(偏移地址0000H--0088H),它负责从活动分区中装载,并运行系统引导程序。
- 出错信息数据区,偏移地址0089H--00E1H为出错信息,00E2H--01BDH全为0字节。
- 分区表(DPT,Disk Partition Table)含4个分区项,偏移地址01BEH--01FDH,每个分区表项长1个字节,共64字节。 为分区项1、分区项2、分区项3、分区项4(分区表不是一个文件,而是直接以二进制的形式存放在0扇区) 。
- 结束标志字,偏移地址01FE--01FF的2个字节值为结束标志55AA。
GPT分区
GPT:GUID(Globals Unique Identifiers) partition table 全局唯一标识,是一个较新的分区机制。支持128个分区,支持很大的硬盘很大的分区容量。取消了扩展分区这些概念,全是主分区(MBR使用扩展分区的目的是弥补只能分四个分区的缺陷)。
GPT分区结构:
GPT分配64bits给逻辑块地址,因而使得最大分区大小在2-1个扇区成为了可能。对于每个扇区大小为512字节的磁盘,那意味着可以有9.4ZB(9.4 x 10字节)或8ZiB-512字节 。
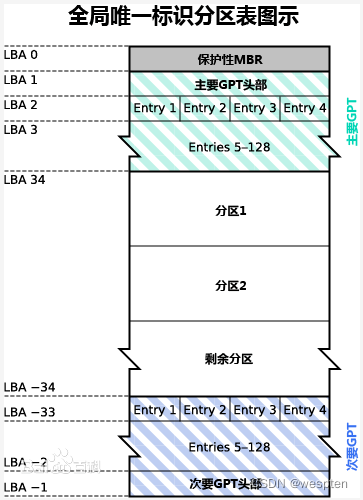
LBA0:保护性MBR,
在GPT分区表的最开头,处于兼容性考虑仍然存储了一份传统的MBR(LBA 0),这个MBR叫做保护性MBR(Protective MBR)。其中包含有磁盘签名,MBR分区表,结束标志。这里没有引导代码,分区表中只有一个分区表项,GPT不会用到,这个分区项只是为了让系统认为磁盘是合法的。
LBA1:主要GPT头部:
主要GPT头部位于1号扇区,会定义分区表的起始位置,结束位置,分区表项个数;
分区表头还记录了这块硬盘的GUID,记录了分区表头本身的位置和大小以及备份分区表头和分区表的位置和大小(在硬盘的最后)。它还储存着它本身和分区表的CRC32校验。固件、引导程序和操作系统在启动时可以根据这个校验值来判断分区表是否出错,如果出错了,可以使用软件从硬盘最后的备份GPT中恢复整个分区表,如果备份GPT也校验错误,硬盘将不可使用。
LBA2-33:分区表项
分区表位于GPT磁盘的2-33号扇区,一共占用32个扇区,能够容纳128个分区表项。每个分区表项大小为128字节。因为每个分区表项管理一个分区,所以GPT磁盘可以创建128个分区。
GPT分区表使用简单而直接的方式表示分区。一个分区表项的前16字节是分区类型GUID。接下来的16字节是该分区唯一的GUID(这个GUID指的是该分区本身,而之前的GUID指的是该分区的类型)。再接下来是分区起始和末尾的64位LBA编号,以及分区的名字和属性。
LBA34:分区区域
GPT分区区域就是用户使用的分区,也是用户进行数据存储的区域。分区区域的起始地址和结束地址由GPT头定义。
LBA -33~-2:分区表备份
分区区域结束后就是分区表备份,其地址在GPT头备份扇区中有描述。分区表备份是对分区表32个扇区的完整备份。如果分区表被破坏,系统会自动读取分区表备份,也能够保证正常识别分区
LBA -1:GPT头备份
GPT头有一个备份,放在GPT磁盘的最后一个扇区,但这个GPT头备份并非完全GPT头备份,某些参数有些不一样。复制的时候根据实际情况更改一下即可。
GPT分区特点:
-
使用128位UUID 表示磁盘和分区GPT分区表自动备份在头和尾两份,并有CRC校验位
-
支持超过2T的磁盘(64位寻址空间),使用64位,支持128个分区,支持8Z(512Byte/block )64Z(4096Byte/block)。fdisk最大只能建立2TB大小的分区,创建一个大于2TB的分区使用parted,gdisk分区工具
-
向后兼容MBR
-
必须在支持UEFI的硬件上才能使用(Intel提出,用于取代BIOS)
-
必须使用64位系统
-
Mac、Linux系统都能支持GPT分区格式
-
Windows 7/8 64bit、Windows Server 2008 64bit支持GPT
GPT分区优点:
与目前普遍使用的主引导记录(MBR)分区方案相比,GPT提供了更加灵活的磁盘分区机制。它具有如下优点:
1、支持2TB以上的大硬盘。
2、每个磁盘的分区个数几乎没有限制(Windows系统最多只允许划分128个分区)。
3、分区大小几乎没有限制。
4、分区表自带备份。在磁盘的首尾部分分别保存了一份相同的分区表,其中一份被破坏后,可以通过另一份恢复;
5、循环冗余检验值针对关键数据结构而计算,提高了数据崩溃的检测几率;
6、虽然MBR提供1字节分区类型代码,但GPT使用一个16字节的全局唯一标识符(GUID)值来标识分区
类型,这使分区类型更不容易冲突;
7、每个分区可以有一个名称(不同于卷标)。
BIOS和UEFI:
BIOS(Basic Input Output System 基本输入输出系统):电脑主板上内置的程序代码。
作用:开机自检、引导操作系统。操作系统开始启动之后,BIOS的任务就完成了 BIOS只能识别到主引导记录(MBR)初始化的硬盘,最大支持2T的硬盘,4个主分区(逻辑分区中的扩展分区除外)。
EFI(Extensible Firmware Interface)可扩展固件接口。是因特尔首先发布出来的,后来各大公司就加入,形成了一个 UEFI的国际组织。
EFI:相当于新版BIOS。
UEFI(Unified Extensible Firmware Interface)统一的可扩展固件接口:支持更大的内存、支持gpt分区和图形界面等。
常用组合方式:
- BIOS+MBR
- UEFI+GPT
运行流程:
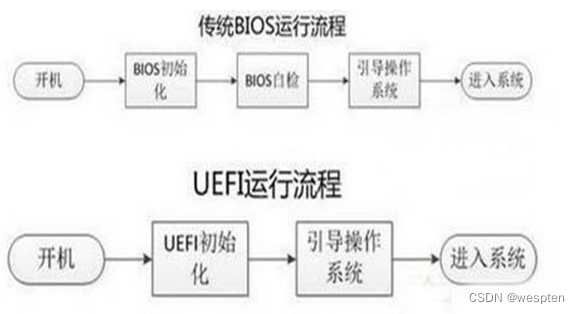
Linux磁盘分区
所谓的磁盘分区指的是告诉操作系统『我这颗磁盘在此分割槽可以存取的区域是由 A 磁柱到 B 磁柱之间的区块』, 如此一来操作系统就能够知道他可以在所指定的区块内进行文件数据的读/写/搜寻等动作了。 也就是说,磁盘分区意即指定分割槽的启始与结束磁柱就是了。
分区是用设备名称加数字命名的。例如 hda1 代表hda这个硬盘设备上的第一个分区。 每个硬盘可以最多有四个主分区,作用是 1-4 命名硬盘的主分区。多个主分区中只能有一个active 主分区作为启动分区。逻辑分区是从5开始的,每多一个分区,每个磁盘上最多可以有 24个扩展分区。
创建分区:
- fdisk --- 一个老牌工具,一般用来管理MBR分区
- gdisk --- 管理GPT分区
fdisk创建分区
fdisk参数:
- p 分区列表
- t 更改分区类型
- n 创建新分区
- d 删除分区
- v 校验分区
- u 转换单位
- w 保存并退出
- q 不保存并退出说明: 开始分区后输入 n,新增分区,然后选择 p ,分区类型为主分区。两次回车默认剩余全部空间。最后输入 w 写入分区并退出,若不保存退出输入 q。
运行 fdisk 来创建主分区:
[root]# fdisk /dev/sdb
Command (m for help): m (Enter the letter "m" to get list of commands)
Command action
a toggle a bootable flag
b edit bsd disklabel
c toggle the dos compatibility flag
d delete a partition
l list known partition types
m print this menu
n add a new partition
o create a new empty DOS partition table
p print the partition table
q quit without saving changes
s create a new empty Sun disklabel
t change a partition's system id
u change display/entry units
v verify the partition table
w write table to disk and exit
x extra functionality (experts only)
Command (m for help): n
Command action
e extended
p primary partition (1-4)
p
Partition number (1-4): 1
First cylinder (1-9729, default 1):
Using default value 1
Last cylinder, +cylinders or +size{K,M,G} (1-9729, default 9729):
Using default value 9729
Command (m for help): w (Write and save partition table)
[root]# mkfs.ext4 -L disk2 /dev/sdb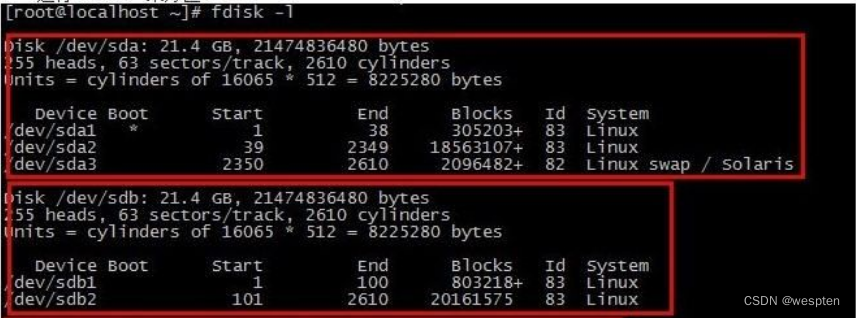
该磁盘有255个heads,也就是说共有255个盘面。2610个柱面(cylinders),也就是说每个盘面上都有2610个磁道, 63 sectors/track说的是每个磁道上共有63个扇区。
命令结果也给出了Sector size的值是512bytes。那我们动笔算一下该磁盘的大小吧。
255盘面 * 2610柱面 * 63扇区 * 每个扇区512bytes ,结果是21.4G和磁盘的总大小相符。
建立第一个扩展区:
命令(输入 m 获取帮助): n
Partition type
p primary (3 primary, 0 extended, 1 free)
e extended (container for logical partitions)
Select (default e): e
Selected partition 4
First sector (25167872-41943039, default 25167872):
Last sector, +sectors or +size{K,M,G,T,P} (25167872-41943039, default 41943039): +6G
Created a new partition 4 of type 'Extended' and of size 6 GiB.
建立两个逻辑分区:
命令(输入 m 获取帮助): n
All primary partitions are in use.
Adding logical partition 5
First sector (25169920-37750783, default 25169920):
Last sector, +sectors or +size{K,M,G,T,P} (25169920-37750783, default 37750783): +1G
Created a new partition 5 of type 'Linux' and of size 1 GiB.
命令(输入 m 获取帮助): p
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x4dbeae7b
设备 启动 Start 末尾 扇区 Size Id 类型
/dev/sdb1 2048 8390655 8388608 4G 83 Linux
/dev/sdb2 8390656 16779263 8388608 4G 83 Linux
/dev/sdb3 16779264 25167871 8388608 4G 83 Linux
/dev/sdb4 25167872 37750783 12582912 6G 5 扩展
/dev/sdb5 25169920 27267071 2097152 1G 83 Linux
命令(输入 m 获取帮助): n
All primary partitions are in use.
Adding logical partition 6
First sector (27269120-37750783, default 27269120):
Last sector, +sectors or +size{K,M,G,T,P} (27269120-37750783, default 37750783): +1G
Created a new partition 6 of type 'Linux' and of size 1 GiB.
命令(输入 m 获取帮助): p
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x4dbeae7b
设备 启动 Start 末尾 扇区 Size Id 类型
/dev/sdb1 2048 8390655 8388608 4G 83 Linux
/dev/sdb2 8390656 16779263 8388608 4G 83 Linux
/dev/sdb3 16779264 25167871 8388608 4G 83 Linux
/dev/sdb4 25167872 37750783 12582912 6G 5 扩展
/dev/sdb5 25169920 27267071 2097152 1G 83 Linux
/dev/sdb6 27269120 29366271 2097152 1G 83 Linux
删除分区:
命令(输入 m 获取帮助): d
分区号 (1-6, default 6):
Partition 6 has been deleted.
命令(输入 m 获取帮助): p
Disk /dev/sdb: 20 GiB, 21474836480 bytes, 41943040 sectors
Units: sectors of 1 * 512 = 512 bytes
Sector size (logical/physical): 512 bytes / 512 bytes
I/O size (minimum/optimal): 512 bytes / 512 bytes
Disklabel type: dos
Disk identifier: 0x4dbeae7b
设备 启动 Start 末尾 扇区 Size Id 类型
/dev/sdb1 2048 8390655 8388608 4G 83 Linux
/dev/sdb2 8390656 16779263 8388608 4G 83 Linux
/dev/sdb3 16779264 25167871 8388608 4G 83 Linux
/dev/sdb4 25167872 37750783 12582912 6G 5 扩展
/dev/sdb5 25169920 27267071 2097152 1G 83 Linux
分多个区有以下几个目的:
- 在不损失数据的情况下重装系统,比如独立设置 /home 挂载点,重装系统的时候直接标记回 /home,数据不会有任何损失。
- 针对不同的挂载点的特性分配合适的文件系统以合理发挥性能,比如对 /var 使用reiserfs,对 /home 使用xfs,对 / 使用ext4。
- 针对不同的挂载点开启不同的挂载选项,如是否需要即时同步,是否开启日志,是否启用压缩。
- 大硬盘搜索范围大,效率低
- 磁盘配额只能对分区做设定
- /home、/var、/usr/local 经常是单独分区,因为经常会操作,容易产生碎片
gdisk创建分区
gdisk和fdisk都可以给磁盘分区,gdisk适用于gpt作为引导扇区的情况,fdisk适用与MBR作为引导扇区的情况。两者的使用方法基本一样,下面介绍gdisk的使用方法。
gdisk基本上不用记命令,直接在终端输入gdisk然后根据提示就可以完成操作,如下图。注意要操作的设备就是sda,后面没有任何数字。

输入?之后可以看到gdisk支持的各种命令。使用p显示磁盘分区的信息,输出的信息和lsblk有点像(简略一些)其中Code表示在分区内可能存在的文件类型,如Linux为8300,swap为8200。
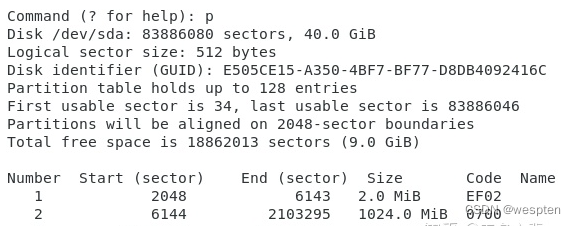
下面建立三个新的分区。已经在上面看到,整个磁盘最大的扇区号为83886046,目前只使用到了65026047。因此可以建立:
- 1G xfs 文件系统(Linux)
- 1G fat 文件系统(Windows)
- 0.5G swap
具体操作过程如下图。
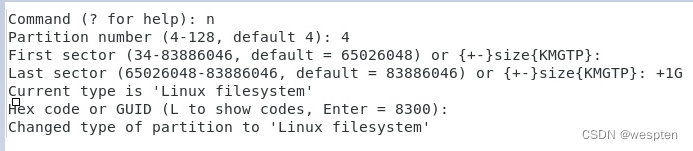
Partition number表示该分区的编号,因为是第四个分区,所以默认值为4;
First sector就是新分区的第一个扇区,默认就是顺序第一个空扇区;
Last sector是新分区的最后一个扇区,默认是整个磁盘最后一个扇区,也就是分配完全部磁盘空间。这里只需要1G,因此写+1G,这种偏移量的表达方式也是可以的;
最后要求选择文件系统类型,选择默认的linux就行。其实这里的文件系统类型不一定是真正的文件系统类型,之后格式化的时候还可以更改文件系统类型。
分配完扇区之后,再次使用p显示当前的分区情况,如下图:
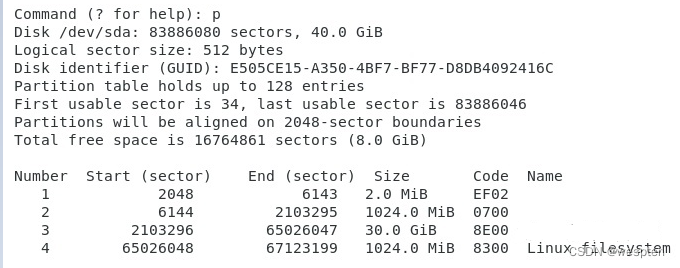
至此就成功完成了分区的操作。要注意的是创建分区只是修改了gpt的内容,对磁盘上相应扇区的内容没有任何改变,之后还要给这一段磁盘空间写入文件系统,即格式化。最后将格式化的磁盘挂载到一个目录下面才能正常使用这一段存储空间。
之后再创建上文提到的其他分区,然后退出gdisk(使用w退出程序)。使用partprobe指令即可更新系统的分区表(分区表/proc/partitions只是一个文本文件,会记录gpt的信息,在/proc/partitions中没有显示分区信息只是该文件还没有更新)
具体操作过程如下图:
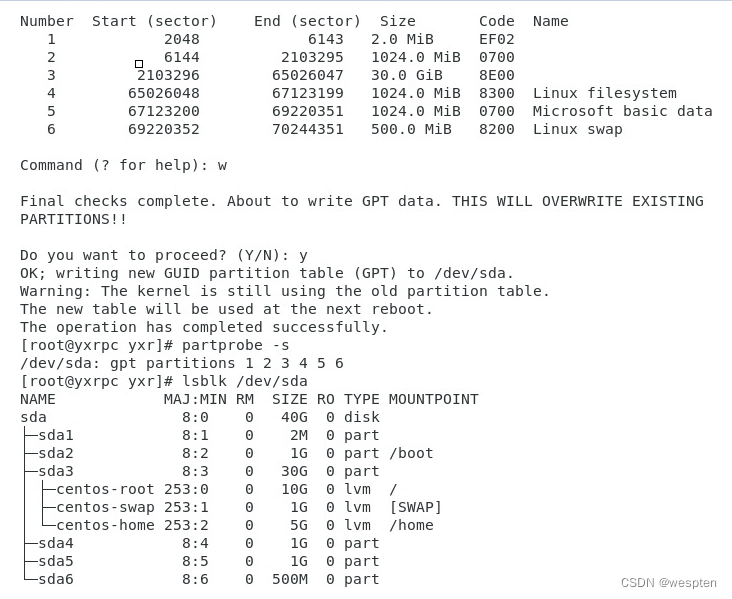
把硬盘上的分区信息同步到内核中
方法一: partprobe命令:
新的分区表已经写入了硬盘,但是没有复制到内存中,我们使用fdisk和lsblk命令看到的都是内存中的分区表。所以使用partprobe命令来同步 。
方法二:- 重启计算机
注意:
分区的设备名称是不稳定的,比如两个扩展分区5和6,删除了5,6会变成5。
查看内核是否已经识别新的分区:`cat /proc/partations` 。
创建swap空间,分区的id要改为82,创建逻辑卷,物理设备分区的id要改成8e fdisk的t选项。
Linux分区备份
备份MBR分区表:
dd命令:直接以二进制的形式来访问磁盘数据 。
dd if(input file)=/dev/sda of(out file)=/data/mbr bs=1(一次读一个字节) count=64(读64次) skip=446(跳过硬盘的前446个字节)dd命令:
按照指定大小的数据块来拷贝文件,并在拷贝的过程中对内容进行转换。
#选项:
- if:源文件(输入文件)
- of:目标文件(目的文件)
- bs:每一块的大小
- count:拷贝多少个
- skip:从输入文件跳过开头多少个块后开始复制 #单位和bs的单位一样
- seek:从输出文件开头跳过多少个块开始复制查看二进制文件的十六进制编码。
#查看二进制文件的十六进制编码:hexdump -C filename
#选项:
-C:输出十六进制对应的字符
-n:显示前多少个字节
#如果不加选项: hexdump filename -- 已两个字节为一组的十六进制倒叙显示
#hexdump命令使用链接:https://www.linuxprobe.com/linux-hexdump.html
#备份的这个分区表文件不能放在本地,因为如果分区表坏了,这个文件也找不到了。六、Linux文件系统
文件系统是对一个存储设备上的数据和元数据进行组织的机制。它的最终目的是把大量数据有组织的放入持久性(persistant)的存储设备中,比如硬盘和磁盘。文件系统(file system)是就是文件在逻辑上组织形式,它以一种更加清晰的方式来存放各个文件。数据被存入到某个分区中。一个典型的Linux分区(partition)包含有下面各个部分:
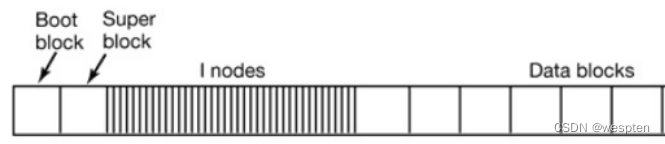
文件是文件系统对数据的分割单元。文件系统用目录来组织文件,赋予文件以上下分级的结构。在硬盘上实现这一分级结构的关键,是使用 inode 来虚拟普通文件和目录文件对象。在Linux系统中,目录也是一种文件。所以/home/sammy 是指向目录文件 sammy 的绝对路径。
磁盘与文件系统:
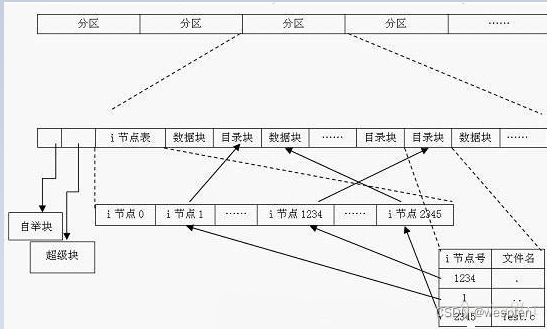
inode
inodes 是实现文件存储的关键。在 Linux 中,文件系统中管理的每个对象(文件或目录)表示为一个 inode。inode 包含管理文件系统中的对象所需的所有元数据(包括可以在对象上执行的操作)。在 Linux 系统中,一个文件可以分成几个数据块存储在分区内。为了搜集各数据块,我们需要该文件对应的inode。每个文件对应一个 inode。这个 inode 中包含多个指针,指向属于该文件各个数据块。当操作系统需要读取文件时,只需要找到对应 inode,收集分散的数据块,就可以收获我们的文件了。

读取文件:
在Linux中,我们通过解析路径,根据沿途的目录文件来找到某个文件。目录中的条目除了所包含的文件名,还有对应的inode编号。当我们输入$cat /var/test.txt时,Linux 将在根目录文件中找到 var 这个目录文件的inode编号,然后根据 inode 合成 var 的数据。随后,根据 var 中的记录,找到 text.txt 的 inode 编号,沿着 inode 中的指针,收集数据块,合成 text.txt 的数据。整个过程中,会参考三个inode:
- 根目录文件的 inode:2,用于找到 var 的 inode id
- var 目录文件的 inode:10747905,用于找到 test.txt 的 inode id
- text.txt 文件的 inode: 10749034,用于找到 data blocks
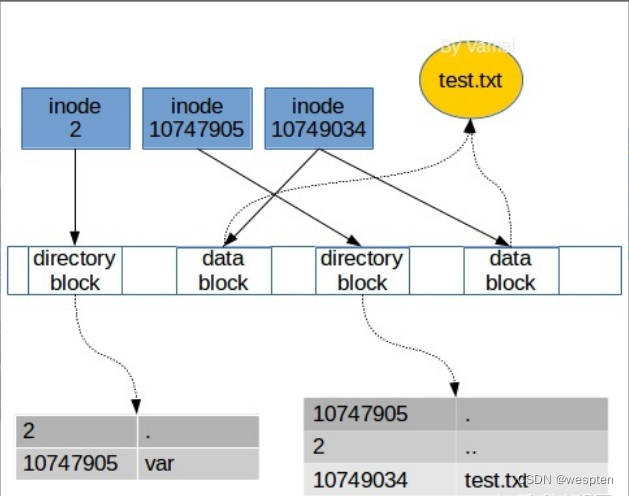
因此,当我们读取一个文件时,实际上是在目录中找到了这个文件的inode编号,然后根据inode的指针,把数据块组合起来,放入内存供进一步的处理。当我们创建一个文件时,是分配一个空白 inode 给该文件,将其 inode 编号记入该文件所属的目录,然后选取空白的数据块,让 inode 的指针指向这些数据块,并放入内存中的数据。
循环设备
在类Unix系统中,/dev/loop 是一种伪设备,这种设备使得文件可以如同块设备一般被访问。在目录上挂载包含文件系统的文件一般需要两步:
- 用一个循环设备节点连接文件。
- 在目录上挂载该循环设备
具体步骤:
dd if=/dev/zero of=file.img bs=1k count=10000 //创建一个初始化文件
losetup /dev/loop0 file.img //创建一个循环设备
mke2fs -c /dev/loop0 10000 //创建文件系统
mkdir /mnt/point1 //创建挂载点
mount -t ext2 /dev/loop0 /mnt/point1 //挂载Linux挂载多分区img文件
制作个1G大小的img文件并分区:
fallocate -l $(( 1024 * 1024 *1024 )) file.img如果util-linux版本>=2.21可直接挂载为多分区loop设置,然后挂载到目录:
#自动选择设备名
losetup -f --show -P file.img
#指定设置名
losetup -P /dev/loop100 file.img
mount /dev/loop100p1 /mnt/
umount /mnt
losetup -d /dev/loop100否则指定起始分区位置和大小挂载指定分区,先查看各分区起始位置和大小:
fdisk -l file.img
Device Boot Start End Sectors Size Id Type
file.img1 2048 206847 204800 100M 83 Linux
file.img2 206848 2097151 1890304 923M 83 Linux如果挂载第一个分区,起始为第2048个扇区,204800个扇区大小,每个扇区512 byte,挂载时设置起始位置2048512,大小204800512:
losetup -f --show -o 1048576 --sizelimit 104857600 file.img也可安装kpartx挂载:
kpartx -v -a file.img
kpartx -d /dev/loop100
mount /dev/mapper/loop0p1 /mnt/文件系统的结构
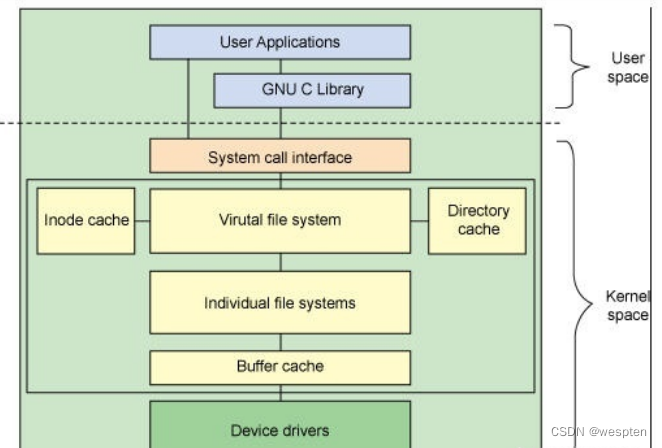
用户空间包含一些应用程序(例如,文件系统的使用者)和 GNU C 库(glibc),它们为文件系统调用(打开、读取、写和关闭)提供用户接口。系统调用接口的作用就像是交换器,它将系统调用从用户空间发送到内核空间中的适当端点。
VFS 是底层文件系统的主要接口,它是 Linux 内核中的一个软件抽象层。。这个组件导出一组接口,然后将它们抽象到各个文件系统,各个文件系统的行为可能差异很大。有两个针对文件系统对象的缓存(inode 和 dentry)。它们缓存最近使用过的文件系统对象。因为有 VFS 存在,Linux 允许众多不同的文件系统共存,并支持跨文件系统的文件操作。它通过一些数据结构及其方法向实际的文件系统如 ext2,vfat 提供接口机制。
每个文件系统实现(比如 ext2、JFS 等等)导出一组通用接口,供 VFS 使用。缓冲区缓存会缓存文件系统和相关块设备之间的请求。例如,对底层设备驱动程序的读写请求会通过缓冲区缓存来传递。这就允许在其中缓存请求,减少访问物理设备的次数,加快访问速度。可以使用 sync 命令将缓冲区缓存中的请求发送到存储媒体(迫使所有未写的数据发送到设备驱动程序,进而发送到存储设备)。

VFS (虚拟文件系统)
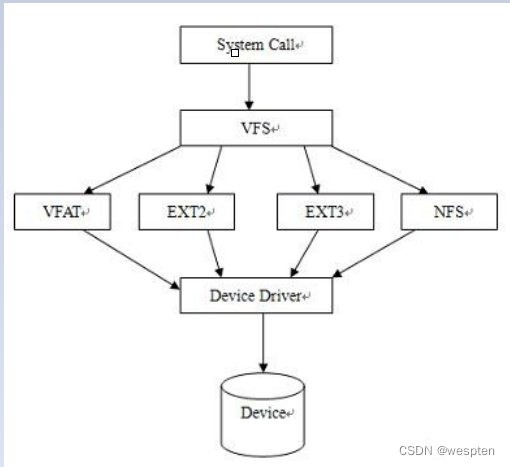
Linux 中允许众多不同的文件系统共存,如 ext2, ext3, vfat 等。通过使用同一套文件 I/O 系统调用即可对 Linux 中的任意文件进行操作而无需考虑其所在的具体文件系统格式;更进一步,对文件的 操作可以跨文件系统而执行。
如下图所示,我们可以使用 cp 命令从 vfat 文件系统格式的硬盘拷贝数据到 ext3 文件系统格式的硬盘;而这样的操作涉及到两个不同的文件系统。

Virtual File System是不同文件系统和上层接之间口的中间层。
VFS调用 vfat 的读文件方法将 a.txt 的数据读入内存;再将 a.txt 在内存中的数据映射到b.txt对应的内存空间后,VFS调用ext3的写文件方法将b.txt写入磁盘;从而实现了最终的跨文件系统的复制操作。
“一切皆是文件”是 Unix/Linux 的基本哲学之一。不仅普通的文件,目录、字符设备、块设备、 套接字等在 Unix/Linux 中都是以文件被对待;它们虽然类型不同,但是对其提供的却是同一套操作界面。操作文件时需先打开;打开文件时,VFS 会知道该文件对应的文件系统格式;当VFS把控制权传给实际的文件系统时,实际的文件系统再做出具体区分,对不同的文件类型执行不同的操作。这也就是“一切皆是文件”的根本所在。
从物理介质读文件的具体过程:
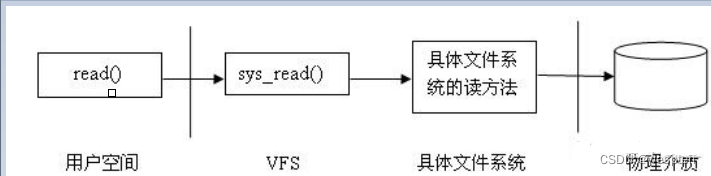
当在用户应用程序调用文件 I/O read()操作时,系统调用 sys_read() 被激发,sys_read() 找到文件所在的具体文件系统,把控制权传给该文件系统,最后由具体文件系统与物理介质交互,从介质中读出数据。
Linux 文件系统类型
ReiserFS:
ReiserFS 是一种文件系统格式。Linux内核从2.4.1版本开始支持ReiserFS。ReiserFS原先是Novell公司的SuSE Linux Enterprise采用的默认文件系统,直到2006年10月12日其宣称将在未来的版本改采 ext3 为默认。
和同样在 Linux Kernel 2.4 版本下的 ext2 及 ext3 相比较,处理 4KB 以下的小文件时(tail packing enable),ReiserFS 的速度快了 10 到 15 倍[3]。但是,有些目录的操作在 ReiserFS 上面并不同步,(包括像 unlink(2)),可能会导致一些重度依赖文件锁(file-based lock)机制的应用程序上面数据的毁损。
ReiserFS 在一个单一复合B+树中存储文件的亚数据信息(stat item)、目录文件信息(directory items)、索引节点中的块列表(indirect items),这些信息都有唯一的标识号作为B+树的索引值。
ext2:
是ext文件文件系统升级版本,Red Hat Linux7.2版本以前的系统默认。
都是ext2文件系统,1993年发布,最大支持16TB的分区和最大2TB的文件。
ext3:
是ext2的升级版本,最大区别是带日志功能,以及在系统突然停止时。
提高文件系统的可靠性。支持最大的16TB的分区和最大2TB的文件。
ext4:
ext3文件系统的升级,ext4在性能、伸缩性和可靠性方面进行了大量的改进。
ext4的变化天翻地覆,向下兼容ext3,最大1EB文件系统(分区)和16TB文件,无限数量子目录
Extends连续数据块概念,多级分配、延迟分配、持久预分配、快速FSCK、日志校验、无日志模式、在线碎片整理、inode增强、默认启用barrier等。是centos 6.3的默认文件系统。
vfat:
vfat 文件系统(也称为 FAT32)没有日志功能,且缺乏完整的 Linux 文件系统实现所需的许多特性。
它可用于在 Windows 和 Linux 系统之间交换数据,因为 Windows 和 Linux 都能读取它。不要将这个文件系统用于 Linux,除非要在 Windows 和 Linux 之间共享数据。
XFS 文件系统:
XFS 文件系统拥有日志功能,包含一些健壮的特性,并针对可伸缩性进行了优化。XFS 通常是相当快的。在大文件操作方面,XFS 在所有测试中一直处于领先地位。XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。
IBM JFS 文件系统:
IBM 的 Journaled File System (JFS),目前用于 IBM 企业服务器,专为高吞吐量服务器环境而设计。它可用于 Linux,包含在几个发行版中。要创建 JFS 文件系统,使用 mkfs.jfs 命令。
VFS支持的文件系统
Linux的文件系统: Ext系列[ext2(无日志功能), ext3, ext4](CentOS 5/6)
xfs(CentOS 7单个文件大小无上限), reiserfs, btrfs
光盘:iso9660
网络文件系统:nfs, cifs
集群文件系统:gfs2, ocfs2
内核级分布式文件系统:ceph
Windows的文件系统:vfat, ntfs
伪文件系统:proc, sysfs, tmpfs, hugepagefs
Unix的文件系统:UFS, FFS, JFS
交换文件系统:swap
用户空间的分布式文件系统:mogilefs, moosefs, glusterfs
选择合适的文件系统
选择合适的下一代 Linux 文件系统一直很简单。那些只寻求原始性能的人通常倾向于使用 ReiserFS,而那些更关心数据完整性特性的人则首选 ext3/4。
然而,随着 XFS 的 Linux 版的发布,事情突然变得令人困惑。尤其是,对于 ReiserFS 是否依然是下一代文件系统性能方面的佼佼者,人们开始感到疑惑。
XFS 的性能非常接近 ReiserFS,并在大多数测试指标上都超过了 ext3。
目前,ReiserFS 和 ext3 删除文件要比 XFS 快得多。
创建文件系统
Linux 使用 mkfs 命令来创建文件系统,使用 mkswap 命令创建交换空间。mkfs 命令实际上是几个特定文件系统的命令的前端,比如面向 ext3 的 mkfs.ext3,面向 ext4 的 mkfs.ext4 以及面向 ReiserFS 的 mkfs.reiserfs。
你的文件系统上安装的是什么文件系统支持?使用 ls /sbin/mk* 命令即可得到答案。
格式化分区: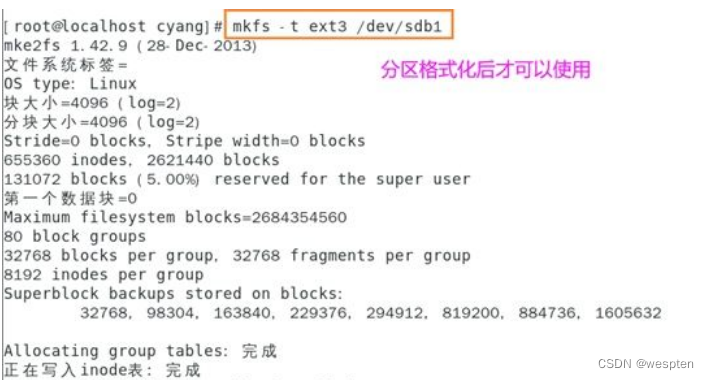
当要格式化为xfs文件系统的时候就是用mkfs.xfs,这里直接使用默认参数进行格式化,如下图。
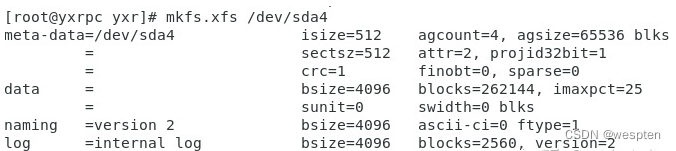
实际上和xfs_info显示的信息和lsblk一样。
每块硬盘都分为若干个分区,每个分区都有自己的文件系统。Windows为这些文件系统各自指定了一个字母。不过 GNU/Linux 使用唯一的树形结构来管理文件,而每个文件系统都挂载于树形结构的某个位置。
正如 Windows 需要有 C: 驱动器一样,GNU/Linux 必须能够将根文件系统挂载于文件树的根(/)上。当根挂载完成之后,您就可以将其它文件系统挂载于树形结构各种挂载点上。根结构下的任何目录都可以作为挂载点,而您也可以将同一文件系统同时挂载于不同的挂载点上。挂载点实际上就是linux中的磁盘文件系统的入口目录:
关于文件系统的三个易混淆的概念:
- 创建:以某种方式格式化磁盘的过程就是在其之上建立一个文件系统的过程。创建文件系统时,会在磁盘的特定位置写入关于该文件系统的控制信息。
- 注册:向内核报到,声明自己能被内核支持。一般在编译内核的时侯注册;也可以加载模块的方式手动注册。注册过程实 际上是将表示各实际文件系统的数据结构struct file_system_type 实例化。
- 安装:也就是我们熟悉的mount操作,将文件系统加入到 Linux 的根文件系统的目录树结构上;这样文件系统才能被访问。
linux 下一切皆文件!换言之就是linux操作系统将系统中的一切都作为文件来管理。在windows中我们常见的硬件设备(打印机、网卡、声卡...)、磁盘分区等,在linux中统统都被视作文件,对设备、分区的访问就是读写对应的文件。
格式化命令:
mkfs.ext3 /dev/sdb1 //格式化分区成 ext3
mkfs.ext2 /dev/sdb1 //格式化分区成 ext2查询与挂载命令:
命令格式:
mount [选项] [设备名] [挂载点]选项:
-t fstype:指定要挂载的文件系统的类型,如果不清楚,可以使用-t auto 让系统自己选择最合适的文件系统类型进行挂载
-r:以只读的方式挂载文件系统
-w:以读写的方式挂载文件系统(默认选项)
-o:设置挂载属性
-a:挂载/etc/fstab文件中记录的设备
-L 卷标名: 挂载指定卷标的分区,而不是安装设备文件名挂载查询系统中已经挂载的设备,-l会显示卷标名称:
mount [-l]依据配置文件/etc/fstab 的内容,自动挂载:
mount -a设置挂载属性:
mount [-t 文件系统] [-L 卷标名] [-o 特殊选项] 设备文件名 挂载点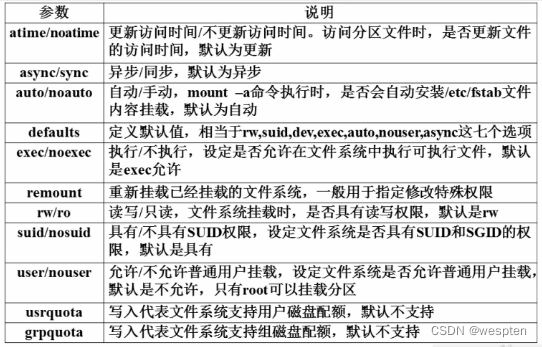
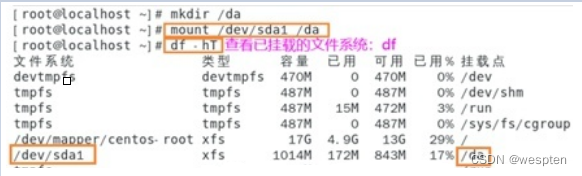
将“/dev/sda1”挂载到“/da”目录下:
重新挂载 /boot 分区,并使用noexec权限:
mount -o remount,noexec /home挂载光盘:
mkdir /mnt/cdrom #建立挂载点
mount -t iso9660 /dev/cdrom /mnt/cdrom
mount /dev/sr0 /mnt/cdrom 挂载u盘:
fdisk -l #查看u盘设备文件名
mount -t vfat /dev/sdb1 /mnt/usb/注意: linux 默认是不支持NTFS文件系统的
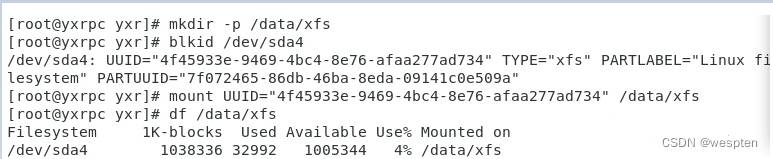
首先要使用blkid查询/dev/sda4的UUID(其实直接使用/dev/sda4也可以成功挂载)。最后用df指令查看/data/xfs是否成功挂载:
开机直接挂载 :
echo "/dev/sr0 /mnt iso96660 defaults 0 0" >> /etc/fstab格式:
1.需挂载设备
2.挂载点
3.文件系统
4.挂载选项
5备份(0默认不备份,1也没有实际意义需配合工具)
6. 是否开机是否挂载并检查系统完整性(0不检查,1检查,填写2或者3,代表第2个第3个检查)
案例:
VMWare下Linux增加硬盘并配置开机挂载
CentOS6和7的安装和简单配置,由于使用的是1C1G20G的虚拟硬件,不足以满足实际业务需求,此文档讲述如何给虚拟机增加硬盘并配置开机自动挂载。
具体操作过程如下:
1,关机,如已关机可忽略;
2,打开虚拟机配置,点击添加选项;
在后续配置中选择硬盘,点击下一步:

选择硬盘接口,点击下一步:
选择创建虚拟磁盘:
输入磁盘容量,并选择将虚拟磁盘拆分成多个文件。如果硬盘够大且分区格式支持大文件,可选将虚拟硬盘存储为单个文件,以提升性能:
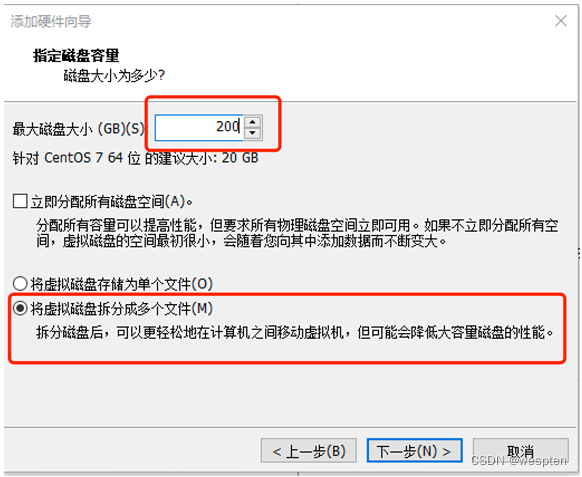
指定虚拟磁盘文件名,点击确认。默认情况下与虚拟机保存在同一个目录中,如不想保存在同一目录,可点击浏览另行指定:

完成后即可在虚拟机配资中看到新硬盘,点击确定,回到虚拟机控制台,并开机:
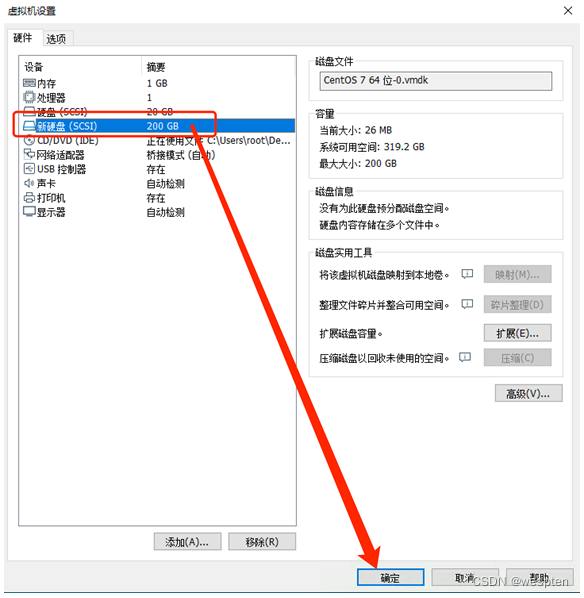
现在已添加完成虚拟硬件。
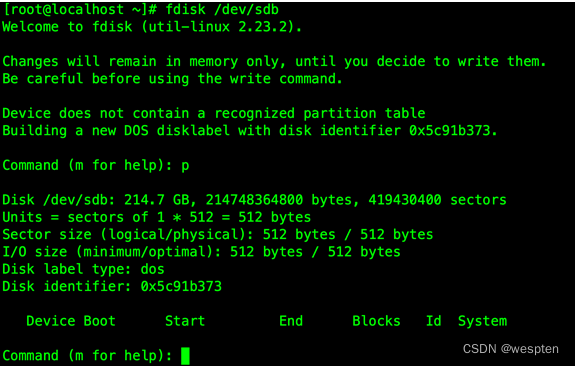
fdisk -l查看设备情况,可看到新硬盘是/dev/sdb,下面对其分区:

fdisk /dev/sdb命令对该磁盘分区,按p查看当前分区情况,确定该磁盘没有分区:
按n,新建分区,然后按p,新建主分区,按1,确定分区号,1号,其它选项均可按回车键选择默认:
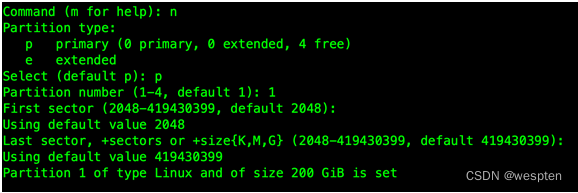
再按p查看当前分区情况,如显示新分区/dev/sdb1则创建完成,按w写入磁盘。再次提醒,任何错误操作可能导致数据全部丢失。
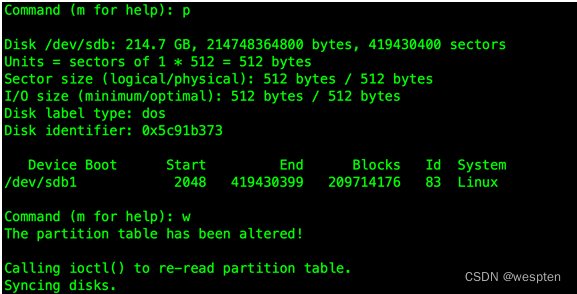
至此,分区创建完成,下一步格式化磁盘。
格式化磁盘,这里使用mkfs命令,这里使用ext4分区格式,命令有下面两种写法,任选一种即可:
mkfs.ext4 /dev/sdb1
mkfs -t ext4 /dev/sdb1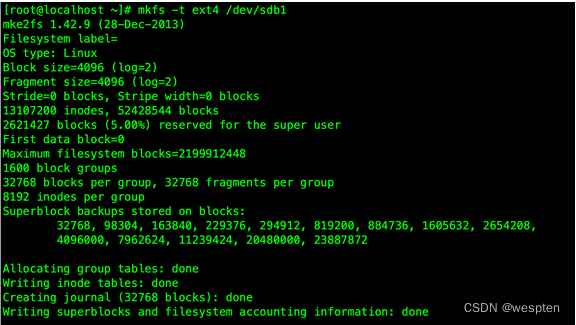
磁盘格式化完毕,下面将新硬盘挂载到/mnt,命令如下:
mount -t ext4 /dev/sdb1 /mnt此语句格式为 mount -t 分区格式 要挂载的分区路径 挂载目标路径
修改目标路径可将新分区挂载至其它路径下。
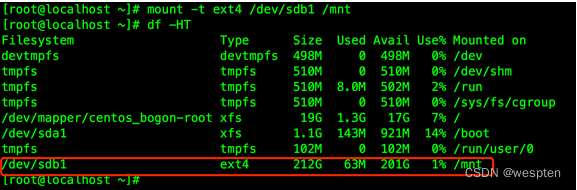
当前情况下,新硬盘只本次开机有效,如不想每次手动挂载,需修改/etc/fstab配置文件使系统在开机时自动挂载之。
将下列语句写入到/etc/fstab文件末尾,注意只有两个0之间是空格,其他字段之间是tab分隔符:
/dev/sdb1 /mnt ext4 defaults 0 0此语句格式是:要挂载的设备 挂载目标位置 分区格式 挂载参数 备份配置 检查配置。
如果备份配置和检查配置为0则不检查也不备份。
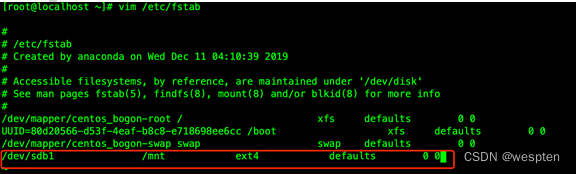
保存退出,配置将在下次启动时生效,如下图:
卸载光盘:
umount /dev/sr0如果卸载文件系统提示:“busy状态,不可卸载时”,使用fuser命令查看正在使用该文件系统的用户信息。
命令格式:
fuser [选项] 文件系统名或文件名选项:
-a:显示所有在命令行中指定的文件系统信息(至少被一个进程访问的文件才会被显示)
-k:杀死访问文件的进程
-i:在杀死使用文件的用户进程之前提示确认
-u:显示使用文件系统的进程的所有者信息
-v:按进程查看命令ps的显示模式显示文件的使用者信息(PID,USER)
查看已挂载的文件系统 df:
语法:
df【选项】 【挂载点】选项:
-a 显示所有的文件系统信息,包括特殊文件系统,如 /proc /sysfs
-h 使用习惯单位显示容量,如kb,mb等
-T 显示文件系统类型
-m 以mb为单位显示容量
-k 以kb为单位显示容量命令用于查看已挂载磁盘的总容量、使用容量、剩余容量等,可以不加任何参数,默认是按k为单位显示的。
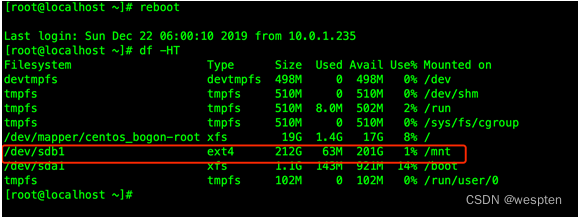
[root@db01 init.d]# df -h
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 45G 4.4G 39G 11% /
tmpfs 1004M 0 1004M 0% /dev/shm
/dev/sda1 485M 39M 421M 9% /boot
/dev/sdb2 79G 184M 75G 1% /oracle
/dev/sdb1 20G 172M 19G 1% /soft注:文件系统 大小 已使用 可用 使用比例 挂载路径。
[root@db01 init.d]# df -aT
Filesystem Type 1K-blocks Used Available Use% Mounted on
/dev/sda3 ext4 46972284 4553340 40032872 11% /
proc proc 0 0 0 - /proc
sysfs sysfs 0 0 0 - /sys
devpts devpts 0 0 0 - /dev/pts
tmpfs tmpfs 1027148 0 1027148 0% /dev/shm
/dev/sda1 ext4 495844 39256 430988 9% /boot
/dev/sdb2 ext4 82568880 188160 78186468 1% /oracle
/dev/sdb1 ext4 20642428 176064 19417788 1% /soft
none binfmt_misc 0 0 0 - /proc/sys/fs/binfmt_misc
注:
-a, --all include dummy file systems
-T, --print-type print file system type
单个文件大小:
[root@db01 init.d]# df -h /mnt
Filesystem Size Used Avail Use% Mounted on
/dev/sda3 45G 4.4G 39G 11% /统计目录或文件大小 du:
语法:
du 【选项】 【目录或文件名】选项:
-a 显示每个子文件的磁盘占用量。默认只统计子目录的磁盘占用量
-h 使用习惯单位显示容量,如kb,mb等
-s 统计总占用量,而不列出子目录和子文件的占用量
–max-depth=1 子目录深度
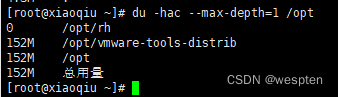
-c 列出明细的同时,增加汇总值查询 /opt 目录的磁盘占用情况,深度为 1:
du和df的区别:
df命令是从文件系统考虑的,不光要考虑文件占用的空间,还要统计被命令或程序占用的空间(最常见的就是文件以及删除,但是程序并没有释放空间)
du命令是面向文件的,只会计算文件或目录占用的空间。
文件系统修复命令fsck:
fsck 分区设备文件名(谨慎使用)
选项:
-a:不用显示用户提示,自动修复文件系统
-y:自动修复。和-a作用一直,不过有些文件系统只支持-ydumpe2fs 命令是查询指定分区详细文件系统信息的命令:
选项:
-h 尽显示超级块中信息,而不显示磁盘块组的详细信息centos 6:
dumpe2fs -h /dev/sda1 //查看ext2/ext3/ext4 文件系统信息的命令centos 7:
xfs_growfs /dev/sda1 //查看xfs 文件系统信息的命令工作实用磁盘情况指令:
统计/opt 文件夹下文件的个数:
ls -l /opt | grep “^-” | wc -l统计/opt 文件夹下目录的个数:
ls -l /opt | grep “^d” | wc -l统计/opt 文件夹下文件的个数,包括子文件夹里的:
ls -lR /opt | grep “^-” | wc -l统计/opt 文件夹下目录的个数,包括子文件夹里的:
ls -lR /opt | grep “^d” | wc -l查看哪个目录最大:
[root@db01 mnt]# du -sm *|sort -rn
3381 Packages
217 images
38 isolinux
17 repodata
17 Server
1 media.repo
…查看前10个最占空间的文件或目录:
[root@db01 Packages]# du -sm * |sort -rn|head -10
93 qt-doc-4.6.2-26.el6_4.noarch.rpm
84 eclipse-pde-3.6.1-6.13.el6.x86_64.rpm
49 texlive-texmf-fonts-2007-38.el6.noarch.rpm
47 kdebase-workspace-wallpapers-4.3.4-24.el6.noarch.rpm
47 gimp-help-2.4.2-5.1.el6.noarch.rpm
41 kdegames-4.3.4-5.el6.x86_64.rpm
41 java-1.6.0-openjdk-1.6.0.0-1.66.1.13.0.el6.x86_64.rpm
39 valgrind-3.8.1-3.2.el6.x86_64.rpm
36 eclipse-cdt-7.0.1-4.el6.x86_64.rpm
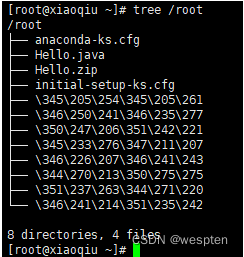
31 valgrind-3.8.1-3.2.el6.i686.rpm以树状显示目录结构 tree 目录 , 注意,如果没有 tree ,则使用 yum install tree 安装:
文件系统总结:
- 挂载点必须是一个目录。
- 一个分区挂载在一个已存在的目录上,这个目录可以不为空,但挂载后这个目录下以前的内容将不可用。对于其他操作系统建立的文件系统的挂载也是这样,卸载后,目录以前的文件都还在,不会有任何丢失。
- 目录只占磁盘里的一个inode,存放文件属性等信息。
- 任何一个分区都必须挂载到某个目录上。
- 目录是逻辑上的区分。分区是物理上的区分。
- 磁盘Linux分区都必须挂载到目录树中的某个具体的目录上才能进行读写操作。
- 根目录是所有Linux的文件和目录所在的地方,需要挂载上一个磁盘分区。
- 一个分区可以挂在多个目录,但反过来一个目录只能是一个分区的挂载点。
七、Linux逻辑卷
由于传统的磁盘管理不能对磁盘进行磁盘管理,因此诞生了LVM技术,LVM技术最大的特点就是对磁盘进行动态管理。由于LVM的逻辑卷的大小更改可以进行动态调整,且不会出现丢失数据的情况。
LVM(Logic Volume Manager)是逻辑卷管理的简称。它是Linux环境下对磁盘分区管理的一种机制。对于其他的的UNIX(AIX/HP/SUM)操作系统,以及Windows系统也有类似的磁盘管理软件。
LVM管理的方式非常简单,就是通过将底层的物料磁盘抽象并封装起来,然后以逻辑的方式呈现给上层应用。
逻辑卷管理的3个概念:
PV(physical volume) 物料卷:物理卷是底层真正提供容量,一个物理卷可以是整个磁盘、或磁盘上的分区。
VG (Volume Group) 卷组:卷组是可用物理硬盘的集合,可以逻辑地看成一块大硬盘,一个卷组由一个或多个物理卷组成。
LV (Logical volume)逻辑卷:每个卷组中可以定义一个或多个逻辑卷,逻辑卷是位于物理分区上的信息集合。
PE (Physical Extend)
我们的LVM磁盘管理中PE的默认大小是4M大小(可以指定大小),其实PE就是我们逻辑卷管理的最基本单位(一旦确定将不能改变)。
比如说我有一个400M的硬盘,那么在将其格式化成PV的时候,其实际就是将这块物理硬盘划分成了100个的PE,因为PE默认的大小就是4M。

dm: device mapper,将一个或多个底层块设备组织成一个逻辑设备的模块;
/dev/dm-#lvm工具安装与使用
yum install lvm2
常用的 LVM 部署命令 :
| 命令 |
说明 |
| pvcreate |
pvcreate 设备全路径名,物理卷的创建 |
| pvmove |
物理卷的删除 |
| vgscan |
检测系统中所有磁盘 |
| vgck |
vgck [卷组名]检测卷组中卷组描述区域信息的一致性。 |
| vgdisplay |
vgdisplay [卷组名] 显示卷组的属性信息 |
| vgrename |
vgrename 原卷组名 新卷组名 |
| vgchange |
#vgchange -a y|n [卷组名] //改变卷组的相应属性,是否可分配 #vgchange -l 最大逻辑卷数 //卷组可容纳最大逻辑卷数 #vgchange -x y|n [卷组名] //卷是否有效 |
| vgexport |
卷组的输入 |
| vgimport |
卷组的输出 |
| pvs |
#显示PV的显示信息 |
| vgcfgbackup |
vgcfgbackup [卷组名] //把卷组中VGDA信息备份到"/etc/vmconf"目录中的文件 |
| vgcfgrestore |
vgcfgrestore -n [卷组名] 物理卷全路径名 //从备份文件中得到指定物理卷的信息 |
| vgcreate |
卷组创建 |
| vgmove |
卷组删除 |
| vgextend |
卷组扩展 |
| vgreduce |
卷组缩小 |
| vgmerge |
卷组合并 |
| vgsplit |
卷组拆分 |
| vgs |
显示VG简要信息 |
| lvcreate |
逻辑卷创建 |
| lvremove |
逻辑卷删除 |
| lvextend |
逻辑卷扩展 |
| lvreduce |
逻辑卷缩小 |
| lvmdiskscan |
检查所有的SCSI,IDE等存储设备 |
| lvscan |
检测逻辑卷的状态 |
| lvdisplay |
显示LV属性信息 |
| lvchange |
修改LV属性信息,-ay:标记LV为可用状态, -an:标记lv为不可用状态 |
| lvs |
显示LV 简要信息 |
总结:
| 功能/命令 | 物理卷管理 | 卷组管理 | 逻辑卷管理 |
| 扫描 | pvscan | vgscan | lvscan |
| 建立 | pvcreate | vgcreate | lvcreate |
| 显示 | pvdisplay | vgdisplay | lvdisplay |
| 删除 | pvremove | vgremove | lvremove |
| 扩展 | vgextend | lvextend | |
| 缩小 | vgreduce | lvreduce |
创建 LVM 过程:
(1)挂载物理磁盘;
(2)将物理磁盘初始化为物理卷PV;
(3)将一个或多个物理卷PV转变为一个卷组VG。
(4)从VG中创建逻辑卷。
(5)根据实际需要将逻辑卷挂载使用。
(6)根据需要对磁盘or逻辑卷进行扩展和缩减。
LVM磁盘管理最常用的案例
01、创建PV、创建VG、创建LV
02、格式化LV并挂载文件系统使用
03、在线扩容,缩小文件系统
04、删除LV、删除VG、删除PV
05、逻辑卷快照
LVM添加顺序:PV-->VG-->LV
LVM删除顺序:LV-->VG-->PV
逻辑卷可在线扩展,但必须离线缩减,缩减很危险,缩减前进行备份。
扩展逻辑卷后文件系统也要扩容。
缩减逻辑卷前要先缩减文件系统。
创建逻辑卷
使用一块硬盘的两个分区 /dev/sdb2 /dev/sdb3,或者两个硬盘/dev/sdb 、 /dev/sdc。
1、创建pv(Physical volume物理卷)
在分区或磁盘内写入一段元数据(标识当前分区或磁盘是一个pv)
pvcreate /dev/sdb2 /dev/sdb3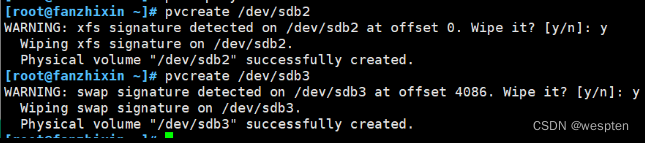
如果报错:
Device /dev/sdb excluded by a filter.
Device /dev/sdc excluded by a filter.可能是因为此硬盘已经分区,存在分区表。
2、查看创建的pv
pvspvdisplay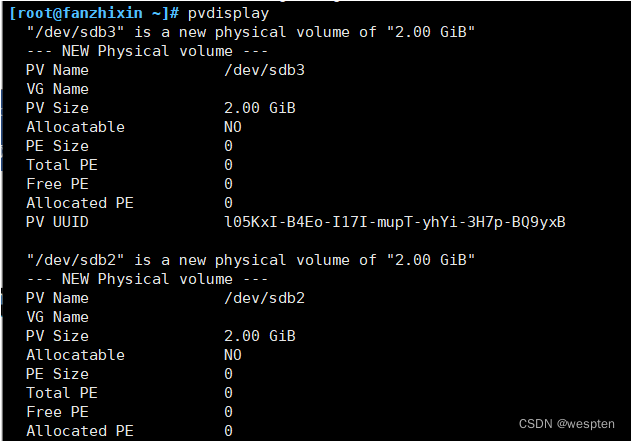
3、创建VG(Volume group 卷组)
将指定的PV,逻辑上进行组合成一个大的存储池。
-s 参数,可指定PE大小,默认为4MB
把两块硬盘设备加入到fantest 卷组中,然后查看卷组的状态:
vgcreate fantest /dev/sdb2 /dev/sdb34、查看创建的VG
vgs
vgdisplay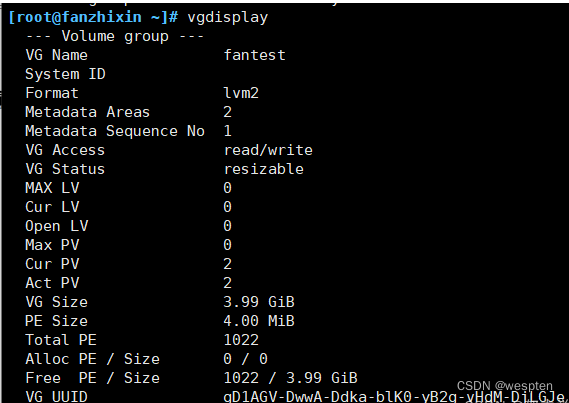
5、创建LV(Logical volume逻辑卷)
切割出一个约为 150MB 的逻辑卷设备,这里需要注意切割单位的问题。在对逻辑卷进行切割时有两种计量单位。
-L参数:第一种是以容量为单位,所使用的参数为-L。例如,使用-L 150M 生成一个大小为 150MB 的逻辑卷。
![]()
-l参数:另外一种是以基本单元的个数为单位,所使用的参数为-l。每个基本单元的大小默认为 4MB。例如,使用-l 37 可以生成一个大小为 37×4MB=148MB 的逻辑卷。
![]()
使用所有空闲空间:lvcreate -n opt -l 100%FREE centos。

6、查看LV
lvs
lvdisplay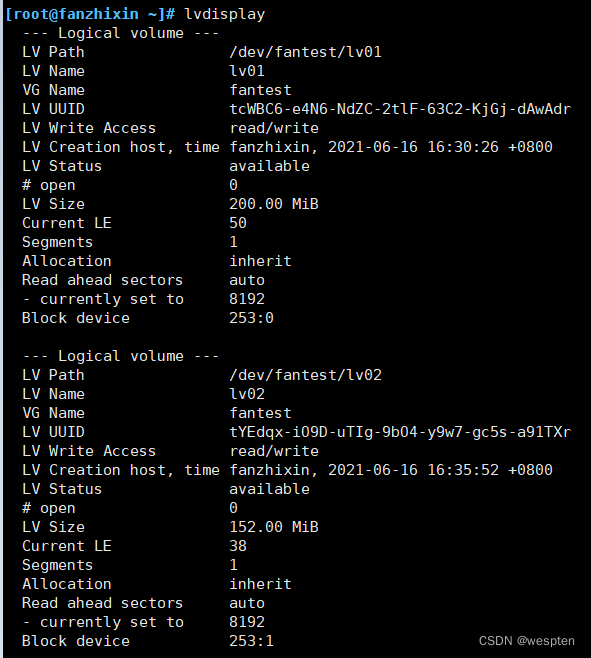
7、格式化LV,创建文件系统
把生成好的逻辑卷进行格式化,创建文件系统。
# mkfs -t xfs /dev/fantest/lv01
Or
# mkfs.ext4 /dev/fantest/lv01
8、挂载lv
创建一个目录,用于挂载lv:
mkdir /home/lv01
mount /dev/fantest/lv01 /home/lv01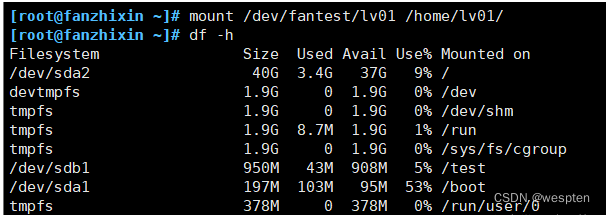
把挂载信息写入到配置文件,使其永久生效:
echo "/dev/fantest/lv01 /home/lv01 xfs defaults 0 0" >> /etc/fstab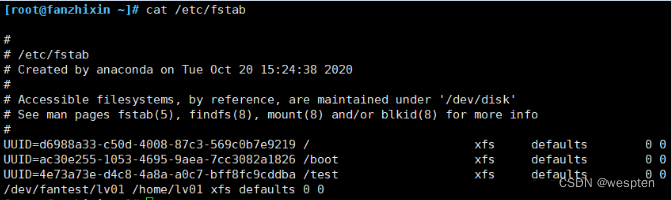
扩容逻辑卷
只要卷组(VG)中有足够的资源,就可以一直为逻辑卷(LV)扩容。
查看VG的资源情况:

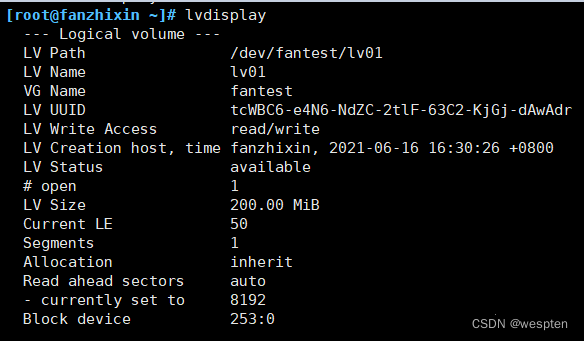
2、逻辑卷扩容
-l参数:另外一种是以基本单元的个数为单位,所使用的参数为-l。每个基本单元的大小默认为 4MB。例如,使用-l 37 可以生成一个大小为 37×4MB=148MB 的逻辑卷
具体操作与-L参数相似,参考下方办法即可
-L参数:是以容量为单位,所使用的参数为-L。例如,使用-L 150M 生成一个大小为 150MB 的逻辑卷。
先查看未扩容前,逻辑卷资源占用情况:
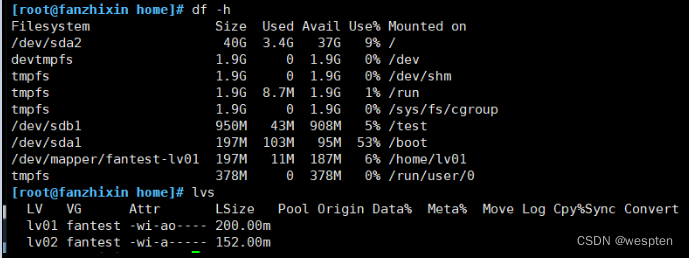
执行以下命令,扩容逻辑卷(LV):
lvextend -L +100M /dev/fantest/lv01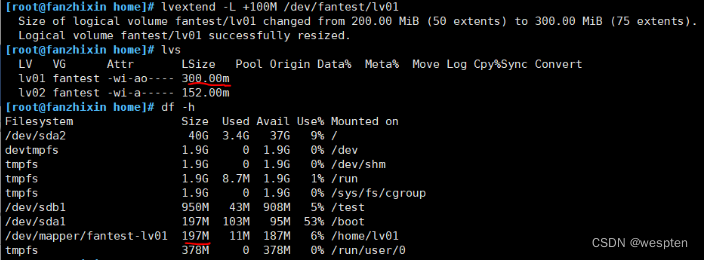
执行以下命令,扩容xfs文件系统 或者在lvextend 命令中加入-r 参数
xfs_growfs /home/lv01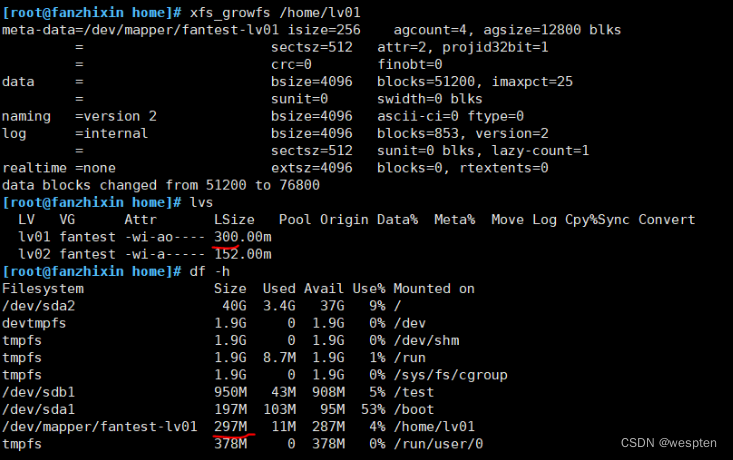
3、如果VG没有足够空间可分配,则先创建PV,扩容卷组(VG)后再扩容逻辑卷(LV)
扩展前查看资源情况:
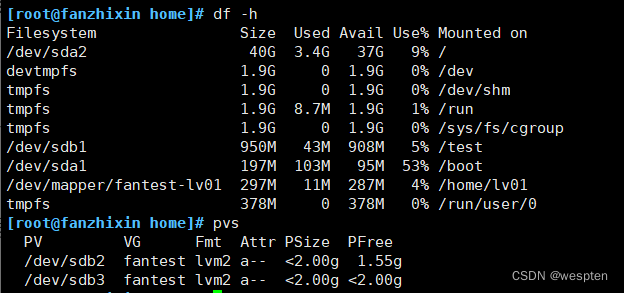
先创建pv:
pvcreate /dev/sdb4扩容VG:
vgextend fantest /dev/sdb4缩小逻辑卷
相较于扩容逻辑卷,在对逻辑卷进行缩容操作时,其丢失数据的风险更大。所以在生产环境中执行相应操作时,一定要提前备份好数据。另外 Linux 系统规定,在对 LVM 逻辑卷进行缩容操作之前,要先检查文件系统的完整性(当然这也是为了保证我们的数据安全)。在执行缩容操作前记得先把文件系统卸载掉。
tips:缩小逻辑卷时,剩余的空间大小必须为一个PV的大小以上
1、迁移数据
这里拿/home 测试,先将/home下内容备份删除,并卸载/home:
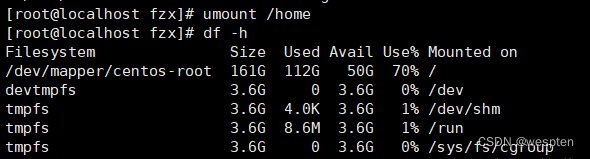
注意:如果出现以下情况,可用此命令查看目录占用情况fuser -mv /home。

2、缩小逻辑卷
ext文件系统:
将逻辑卷大小调整为10G。
resize2fs /dev/centos/home 10Gresize2fs命令是用来增大或者收缩未加载的“ext2/ext3/ext4”文件系统的大小。
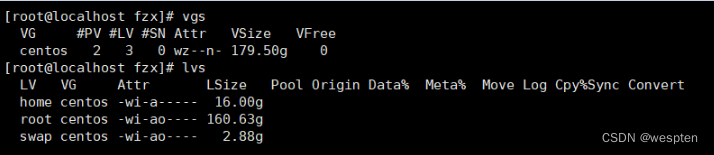
xfs文件系统:
缩小home 逻辑卷的大小为3G。
lvreduce -L 3G /dev/centos/home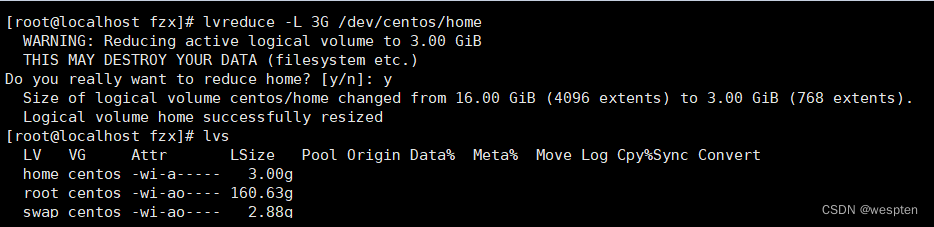
把生成好的逻辑卷进行格式化,创建文件系统:
mkfs.xfs -f /dev/centos/home删除逻辑卷
当生产环境中想要重新部署 LVM 或者不再需要使用 LVM 时,则需要执行 LVM 的删除
操作。为此,需要提前备份好重要的数据信息,然后依次删除逻辑卷、卷组、物理卷设备,这个顺序不可颠倒。
1、取消逻辑卷与目录的挂载关联,删除配置文件中永久生效的设备参数。
umount /home/lv01
vi /etc/fstab
2、删除逻辑卷设备
lvremove /dev/fantest/lv01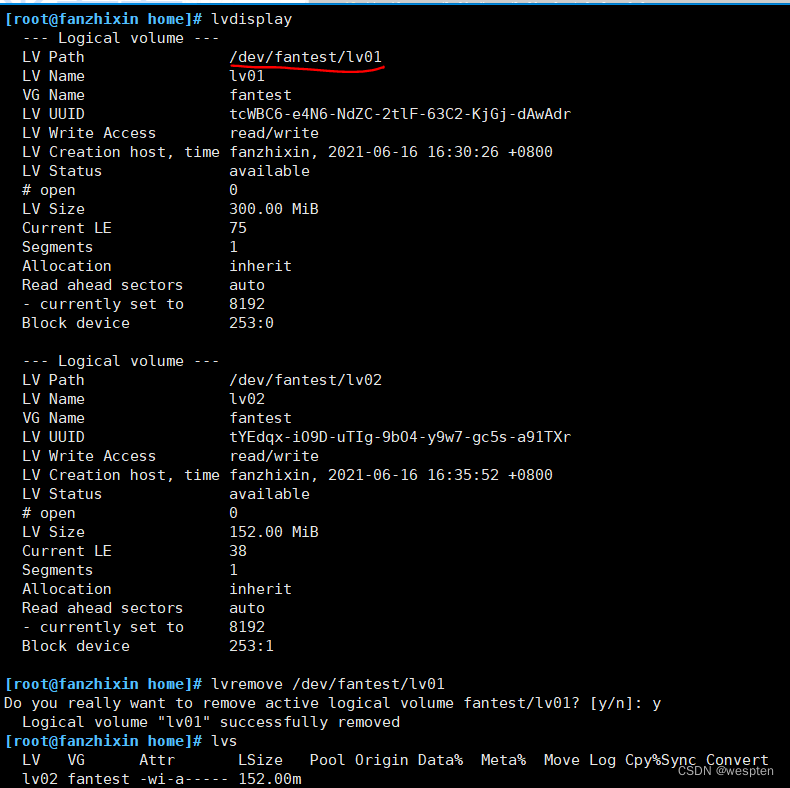
3、删除卷组,此处只写卷组名称即可,不需要设备的绝对路径:
vgremove fantest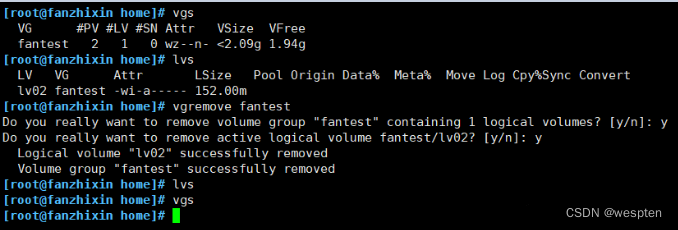
4、删除物理卷设备
pvremove /dev/sdb3 /dev/sdb
逻辑卷快照
LVM 的快照卷功能有两个特点:
➢ 快照卷的容量必须等同于逻辑卷的容量;
➢ 快照卷仅一次有效,一旦执行还原操作后则会被立即自动删除。
1、使用-s 参数生成一个快照卷,使用-L 参数指定切割的大小。另外,还需要在命令后面写上是针对哪个逻辑卷执行的快照操作。
lvcreate -L 100M -s -n kuaizhao /dev/fantest/fan2、在逻辑卷所挂载的目录中创建一个 100MB 的垃圾文件,然后再查看快照卷的状态。可以发现存储空间占的用量上升了。
dd if=/dev/zero of=/home/lvm_test/test.txt count=1 bs=100M3、为了校验 kuaizhao 快照卷的效果,需要对逻辑卷进行快照还原操作。在此之前记得先卸载掉逻辑卷设备与目录的挂载。
umount /home/lvm_test如果报错:
umount: /home/lvm_test: target is busy.
(In some cases useful info about processes that use
the device is found by lsof(8) or fuser(1))可能是有用户正在占用目录:
lvconvert --merge /dev/fantest/kuaizhao4、快照卷会被自动删除掉,并且刚刚在逻辑卷设备被执行快照操作后再创建出来的 100MB 的垃圾文件也被清除了。
mount /dev/fantest/fan /home/lvm_test