IO性能对于一个系统的影响是至关重要的。一个系统经过多项优化以后,瓶颈往往落在数据库;而数据库经过多种优化以后,瓶颈最终会落到IO。而IO性能的发展,明显落后于CPU的发展
Memchached也好,NoSql也好,这些流行技术的背后都在直接或者间接地回避IO瓶颈,从而提高系统性能。
一、硬盘类型
硬盘的类型主要分为两类,SSD(固态硬盘)和 HDD(机械硬盘)。很多现代数据库对 SSD 都有很好的优化,在绝大多数情况下,一个需要考虑随机访问的系统,使用 SSD 是最好的选择。只有在使用类似 Kafka 这样的,纯顺序读写的系统时,我们才优先选择单价更低的 HDD。
机械硬盘
传统磁盘本质上一种机械装置,如FC, SAS, SATA磁盘,转速通常为5400/7200/10K/15K rpm不等。影响磁盘的关键因素是磁盘服务时间,即磁盘完成一个I/O请求所花费的时间,它由寻道时间、旋转延迟和数据传输时间三部分构成。
寻道时间:
寻道时间 (Tseek) 是指将读写磁头移动至正确的磁道上所需要的时间。寻道时间越短,I/O操作越快,目前磁盘的平均寻道时间一般在3-15ms。
旋转延迟:
旋转延迟 (Trotation) 是指盘片旋转将请求数据所在扇区移至读写磁头下方所需要的时间。显然,这是一个只有机械硬盘才有的参数。旋转延迟取决于磁盘转速,通常使用磁盘旋转一周所需时间的1/2表示。比如,7200 rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms,而转速为15000 rpm的磁盘其平均旋转延迟为2ms。
数据传输时间:
数据传输时间(Ttransfer)是指完成传输所请求的数据所需要的时间,它取决于数据传输率,其值等于数据大小除以数据传输率。 IDE/ATA 理论上能达到133MB/s,SATA II 可达到300MB/s的接口数据传输率。在实际的数据库 transaction 中,数据传输时间往往远小于前两部分消耗时间。
一些简单计算:
上面的几个数字,并不是互相独立的。首先,寻道时间和转速的关系非常密切。磁盘是旋转的,读写头是固定的。当我们需要读写磁盘某个扇区某个磁道的数据,我们需要把对应的扇区转到读写头处。平均来说,这个过程就是磁盘转半圈所需的时间,这个时间就是旋转延迟时间。比如,7200 rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms。
常见硬盘的旋转延迟时间为:
- 7200 rpm的磁盘平均旋转延迟大约为60*1000/7200/2 = 4.17ms
- 10000 rpm的磁盘平均旋转延迟大约为60*1000/10000/2 = 3ms,
- 15000 rpm的磁盘其平均旋转延迟约为60*1000/15000/2 = 2ms。
而寻找数据的过程,除了磁盘的转动,磁头也需要在轴上进行平移,这两个时间综合起来,就是寻道时间。这个时间和磁头移动速度,磁碟的存储密度都有关系。我们可以对比上文的旋转延迟和下面的常见磁盘平均物理寻道时间,从而得到一个感性的认识:
- 7200转/分的STAT硬盘平均物理寻道时间是9ms
- 10000转/分的STAT硬盘平均物理寻道时间是6ms
- 15000转/分的SAS硬盘平均物理寻道时间是4ms
通过上面的数据,我们还可以计算理论的 IOPS 数据(IO per second,每秒访问次数): IOPS = 1000 ms/ (寻道时间 + 旋转延迟),可以忽略数据传输时间。
- 7200 rpm的磁盘IOPS = 1000 / (9 + 4.17) = 76 IOPS
- 10000 rpm的磁盘IOPS = 1000 / (6+ 3) = 111 IOPS
- 15000 rpm的磁盘IOPS = 1000 / (4 + 2) = 166 IOPS
这个指标,反映了磁盘处理随机读写请求的能力,对于大多数数据库系统来说,这是一个至关重要的参数。
固态硬盘
SSD(solid state drive)本质上和 U盘比较类似,它没有活动的机械部件,靠的是一块块的闪存颗粒来存储数据。由于这些闪存彼此之间并无干扰,因此可以以类似 RAID0 的方式来提高访问速度。它的读写寻址不涉及磁头移动和磁盘转动,因此可以提供很高的 IOPS。
下面是根据我的经验,一些常见的 SSD 系统的性能指标:
- 读 IOPS: 大概在 2,3w到10w 不等。
- 写 IOPS: 从几千到几万不等,一般要低于读的 IOPS。
- 吞吐量:我用过的比较老的机器,通常读吞吐量在 200-400多 MB/s,写吞吐量在100-200 MB/s 之间。比较新的系统上,读写吞吐量能达到 1000/900 MB/s
- IO latency:各大云服务商提供的 SSD 云盘,大概是 300 μs 左右。我自己使用过的公司机房服务器,有些比较老的会低一点,总体大概在1.6ms 到300μs 间浮动。较新的 SSD,比如 MacBook Pro 上面,这个指标能到 20μs 左右。
需要注意的是,很多云服务商,如 Amazon,AliYun,它们提供的 SSD 的 IOPS 是和容量挂钩的。这个也很好理解,因为大容量的 SSD 背后是更多的 NAND Flash,相当于更多的磁盘组成了 Raid0,速度自然更快。
二、IO 系统的分层
IO系统三层结构:
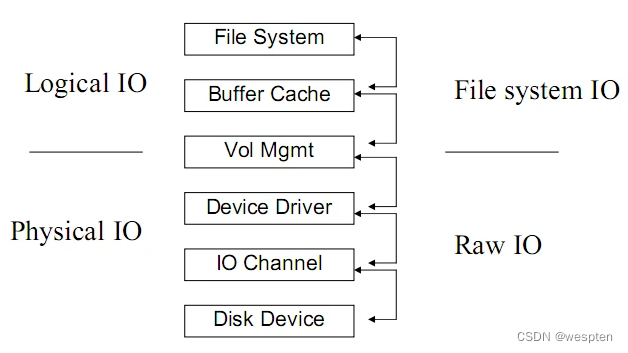
上图层次比较多,但总的就是三部分。磁盘 (存储)、 VM (卷管理)和文件系统 。专有名词不好理解,打个比方说:磁盘就相当于一块待用的空地。
LVM 相当于空地上的围墙(把空地划分成多个部分),文件系统则相当于每块空地上建的楼房(决定了有多少房间、房屋编号如何,能容纳多少人住)。
而房子里面住的人,则相当于系统里面存的数据。
2.1 文件系统 — 数据如何存放?
对应了上图的 File System 和 Buffer Cache 。
File System (文件系统):解决了空间管理的问题 ,即:数据如何存放、读取。
Buffer Cache :解决数据缓冲的问题。对读,进行 cache ,即:缓存经常要用到的数据;对写,进行buffer ,缓冲一定数据以后,一次性进行写入。
2.2 VM 磁盘空间不足了怎么办?
对应上图的 Vol Mgmt 。
VM 其实跟 IO 没有必然联系。他是处于文件系统和磁盘(存储)中间的一层。 VM 屏蔽了底层磁盘对上层文件系统的影响 。当没有 VM 的时候,文件系统直接使用存储上的地址空间,因此文件系统直接受限于物理硬盘,这时如果发生磁盘空间不足的情况,对应用而言将是一场噩梦,不得不新增硬盘,然后重新进行数据复制。而 VM 则可以实现动态扩展,而对文件系统没有影响。另外, VM 也可以把多个磁盘合并成一个磁盘,对文件系统呈现统一的地址空间,这个特性的杀伤力不言而喻。
2.3 存储 — 数据放在哪儿?如何访问?如何提高IO 速度?
对应上图的 Device Driver 、 IO Channel 和 Disk Device
数据最终会放在这里,因此,效率、数据安全、容灾是这里需要考虑的问题。而提高存储的性能,则可以直接提高物理 IO 的性能
2.4 Logical IO vs Physical IO
逻辑 IO 是操作系统发起的 IO ,这个数据可能会放在磁盘上,也可能会放在内存(文件系统的 Cache )里。
物理 IO 是设备驱动发起的 IO ,这个数据最终会落在磁盘上。
逻辑 IO 和物理 IO 不是一一对应的,提升性能就是尽可能的减少逻辑I/O的次数。
三、IO 模型
这部分的东西在网络编程经常能看到,不过在所有IO处理中都是类似的。
3.1 IO 请求的两个阶段
等待资源阶段:IO请求一般需要请求特殊的资源(如磁盘、RAM、文件),当资源被上一个使用者使用没有被释放时,IO请求就会被阻塞,直到能够使用这个资源。
使用资源阶段:真正进行数据接收和发生。
举例说就是排队和服务。
3.2 在等待数据阶段,IO分为阻塞IO和非阻塞IO
阻塞IO:资源不可用时,IO请求一直阻塞,直到反馈结果(有数据或超时)。当前一个 IO 真正完成后,后一个 IO 才可以发出,如 posix 的 read, write 等系统调用。
非阻塞IO:资源不可用时,IO请求离开返回,返回数据标识资源不可用。每个 IO 请求,是否完成,都不会影响后续 IO 的发出,如 glibc 的 aio,以及 linux 的 libaio等等。
3.3 在使用资源阶段,IO分为同步IO和异步IO
同步IO:应用阻塞在发送或接收数据的状态,直到数据成功传输或返回失败。
异步IO:应用发送或接收数据后立刻返回,数据写入OS缓存,由OS完成数据发送或接收,并返回成功或失败的信息给应用。
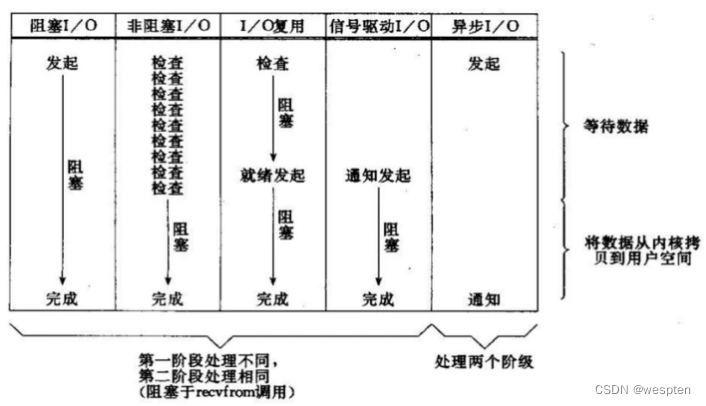
3.4 Unix的5个IO模型划分
- 阻塞IO
- 非阻塞IO
- IO复用
- 信号驱动的IO
- 异步IO
从性能上看,异步IO的性能无疑是最好的。
3.5 各种IO的特点
阻塞IO:使用简单,但随之而来的问题就是会形成阻塞,需要独立线程配合,而这些线程在大多数时候都是没有进行运算的。Java的BIO使用这种方式,问题带来的问题很明显,一个Socket需要一个独立的线程,因此,会造成线程膨胀。
非阻塞IO:采用轮询方式,不会形成线程的阻塞。Java的NIO使用这种方式,对比BIO的优势很明显,可以使用一个线程进行所有Socket的监听(select)。大大减少了线程数。
同步IO:同步IO保证一个IO操作结束之后才会返回,因此同步IO效率会低一些,但是对应用来说,编程方式会简单。Java的BIO和NIO都是使用这种方式进行数据处理。
异步IO:由于异步IO请求只是写入了缓存,从缓存到硬盘是否成功不可知,因此异步IO相当于把一个IO拆成了两部分,一是发起请求,二是获取处理结果。因此,对应用来说增加了复杂性。但是异步IO的性能是所有很好的,而且异步的思想贯穿了IT系统放放面面。
I/O 多路复用模型
类似 BIO,只不过找了一个代理,来挂起等待,并能同时监听多个请求; 数据会由用户进程完成拷贝。
AIO – 异步 I/O 模型
发起请求立刻得到回复,不用挂起等待; 数据会由内核进程主动完成拷贝。
Buffered IO:
读取:硬盘 -> 内核缓冲区 -> 用户缓冲区;
写回:数据会从用户地址空间拷贝到操作系统内核地址空间的页缓存中去,这是 write 就会直接返回,操作系统会在恰当的时机写入磁盘,这就是传说中的 Buffered IO。buffer io 对写 IO 而言有 write back 和 write through。write back 先写入到内存中,一段时间后,由内核线程写入到磁盘。由于内存比磁盘快很多,所以 write back 的速度很快。write back 有一个缺点,就是当你掉电时,可能会丢失数据。这时候 write through 就粉墨登场了,write through 和 write back 相比,在写入内存的同时也写入到磁盘中,那为什么要写入到内存中呢,不是多此一举吗,这可能为了以后读的更快。不过我没有看到有文件系统实现 write through 的,对文件系统来说,buffer io 的写就是 write back 模式。ceph filestore 的写数据部分,也是 write back 模式。
非 Buffered IO (Direct IO):
对于自缓存应用程序来说,缓存 I/O 明显不是一个好的选择。因此出现了 DIRECT IO。然而想象一下,不经内核缓冲区,直接写磁盘,必然会引起阻塞。所以通常 DIRECT IO 与 AIO 会一起出现。
延迟 IO:
其实,说起延迟 IO,就是延迟写(不存在延迟读一说)。延迟写的意思是指:写操作的时候,不仅要写到 kernel 的 page cache 中,还要同时下刷到 disk 中。延迟写的控制,在 open 一个文件的时候指定:
int open(const char *pathname, int flags, ... /* mode_t mode*/);
1) O_SYNC: write 操作,将会被阻住,直到数据和元数据被写到了物理硬盘上。
2) O_DSYNC: write 操作,将会被阻住,直到数据被写到了物理硬盘上。
这里,SYNC 是 synchronous IO 的缩写。字面意思,甚至很多资料,都翻译成同步 IO。我认为,这里的 “同步”,跟我上文提到的同步 / 异步 IO,不是一个概念。如果硬要翻译成同步,那么也是指 kernel cache 和底层硬件 disk 之间的同步。所以,这里 SYNC,我认为理解成 “非延迟”,更加准确一些。

上图中,左侧虚线方框中为可于任何时刻显式强制刷新各类缓冲区的调用。
右侧所示为促使刷新自动化的调用:通过禁用 stdio 的缓冲,和在文件输出类的系统调用中启用同步,从而使每个 write () 调用立刻刷新到磁盘。
四、IO 性能的重要指标
最重要的三个指标。
4.1 IOPS
IOPS,Input/Output Per Second,即每秒钟处理的I/O请求数量。IOPS是随机访问类型业务(OLTP类)很重要的一个参考指标。
4.1.2 一块物理硬盘能提供多少IOPS?
从磁盘上进行数据读取时,比较重要的几个时间是:寻址时间(找到数据块的起始位置),旋转时间(等待磁盘旋转到数据块的起始位置),传输时间(读取数据的时间和返回的时间)。其中寻址时间是固定的(磁头定位到数据的存储的扇区即可),旋转时间受磁盘转速的影响,传输时间受数据量大小的影响和接口类型的影响(不用硬盘接口速度不同),但是在随机访问类业务中,他的时间也很少。因此,在硬盘接口相同的情况下,IOPS主要受限于寻址时间和传输时间。以一个15K的硬盘为例,寻址时间固定为4ms,传输时间为60s/15000 * 1/2=2ms,忽略传输时间。1000ms/6ms=167个IOPS。
常见磁盘平均物理寻道时间为:
7200RPM(转)/分的STAT硬盘平均物理寻道时间是9ms,平均旋转延迟大约 4.17ms
10000RPM(转)/分的SAS硬盘平均物理寻道时间是6ms ,平均旋转延迟大约 3ms
15000RPM(转)/分的SAS硬盘平均物理寻道时间是4ms,平均旋转延迟大约 2ms
最大IOPS的理论计算方法:IOPS = 1000 ms/ (寻道时间 + 旋转延迟)。忽略数据传输时间。
7200 rpm的磁盘IOPS = 1000 / (9 + 4.17) = 76 IOPS
10000 rpm的磁盘IOPS = 1000 / (6+ 3) = 111 IOPS
15000 rpm的磁盘IOPS = 1000 / (4 + 2) = 166 IOPS
RAID0/RAID5/RAID6的多块磁盘可以并行工作,所以,在这样的硬件条件下, IOPS 相应倍增。假如, 两块15000 rpm 磁盘的话,166 * 2 = 332 IOPS。
维基上列出了常见硬盘的IOPS

SSD 达到了惊人的100,000。 见下图

固态硬盘没有寻道时间和旋转时间。IO耗时是通过地址查找数据耗时,根据芯片颗粒SLC、MLC,中控芯片、队列深度32~64、接口Sata、PCIE的不同,一般负载非太高时是相对固定值(控制在60%利用率)。
IOPS = 1000/IO耗时。因为SSD比较固定,比如Intel 320 SSD对8K avgrq-sz耗时0.1ms,1000/0.1ms=10000 IOPS。
4.1.3 OS的一次IO请求对应物理硬盘一个IO吗?
在没有文件系统、没有VM(卷管理)、没有RAID、没有存储设备的情况下,这个答案还是成立的。但是当这么多中间层加进去以后,这个答案就不是这样了。物理硬盘提供的IO是有限的,也是整个IO系统存在瓶颈的最大根源。所以,如果一块硬盘不能提供,那么多块在一起并行处理,这不就行了吗?确实是这样的。可以看到,越是高端的存储设备的cache越大,硬盘越多,一方面通过cache异步处理IO,另一方面通过盘数增加,尽可能把一个OS的IO分布到不同硬盘上,从而提高性能。文件系统则是在cache上会影响,而VM则可能是一个IO分布到多个不同设备上(Striping)。
所以,一个OS的IO在经过多个中间层以后,发生在物理磁盘上的IO是不确定的。可能是一对一个,也可能一个对应多个。
4.1.4 IOPS 能算出来吗?
对单块磁盘的IOPS的计算没有没问题,但是当系统后面接的是一个存储系统时、考虑不同读写比例,IOPS则很难计算,而需要根据实际情况进行测试。主要的因素有:
存储系统本身有自己的缓存。缓存大小直接影响IOPS,理论上说,缓存越大能cache的东西越多,在cache命中率保持的情况下,IOPS会越高。
RAID级别。不同的RAID级别影响了物理IO的效率。
读写混合比例。对读操作,一般只要cache能足够大,可以大大减少物理IO,而都在cache中进行;对写操作,不论cache有多大,最终的写还是会落到磁盘上。因此,100%写的IOPS要越狱小于100%的读的IOPS。同时,100%写的IOPS大致等同于存储设备能提供的物理的IOPS。
一次IO请求数据量的多少。一次读写1KB和一次读写1MB,显而易见,结果是完全不同的。
当时上面N多因素混合在一起以后,IOPS的值就变得扑朔迷离了。所以,一般需要通过实际应用的测试才能获得。
4.2 IO Response Time
即IO的响应时间。IO响应时间是从操作系统内核发出一个IO请求到接收到IO响应的时间。因此,IO Response time除了包括磁盘获取数据的时间,还包括了操作系统以及在存储系统内部IO等待的时间。一般看,随IOPS增加,因为IO出现等待,IO响应时间也会随之增加。对一个OLTP系统,10ms以内的响应时间,是比较合理的。下面是一些IO性能示例:
- 一个8K的IO会比一个64K的IO速度快,因为数据读取的少些。
- 一个64K的IO会比8个8K的IO速度快,因为前者只请求了一个IO而后者是8个IO。
- 串行IO会比随机IO快,因为串行IO相对随机IO说,即便没有Cache,串行IO在磁盘处理上也会少些操作。
需要注意,IOPS与IO Response Time有着密切的联系。一般情况下,IOPS增加,说明IO请求多了,IO Response Time会相应增加。但是会出现IOPS一直增加,但是IO Response Time变得非常慢,超过20ms甚至几十ms,这时候的IOPS虽然还在提高,但是意义已经不大,因为整个IO系统的服务时间已经不可取。
4.3 Throughput
为吞吐量。这个指标衡量标识了最大的数据传输量。如上说明,这个值在顺序访问或者大数据量访问的情况下会比较重要。尤其在大数据量写的时候。
吞吐量不像IOPS影响因素很多,吞吐量一般受限于一些比较固定的因素,如:网络带宽、IO传输接口的带宽、硬盘接口带宽等。一般他的值就等于上面几个地方中某一个的瓶颈。
4.4 一些概念
4.4.1 IO Chunk Size
即单个IO操作请求数据的大小。一次IO操作是指从发出IO请求到返回数据的过程。IO Chunk Size与应用或业务逻辑有着很密切的关系。比如像Oracle一类数据库,由于其block size一般为8K,读取、写入时都此为单位,因此,8K为这个系统主要的IO Chunk Size。IO Chunk Size 小,考验的是IO系统的IOPS能力;IO Chunk Size 大,考验的时候IO系统的IO吞吐量。
4.4.2 Queue Deep
熟悉数据库的人都知道,SQL是可以批量提交的,这样可以大大提高操作效率。IO请求也是一样,IO请求可以积累一定数据,然后一次提交到存储系统,这样一些相邻的数据块操作可以进行合并,减少物理IO数。而且Queue Deep如其名,就是设置一起提交的IO请求数量的。一般Queue Deep在IO驱动层面上进行配置。
Queue Deep与IOPS有着密切关系。Queue Deep主要考虑批量提交IO请求,自然只有IOPS是瓶颈的时候才会有意义,如果IO都是大IO,磁盘已经成瓶颈,Queue Deep意义也就不大了。一般来说,IOPS的峰值会随着Queue Deep的增加而增加(不会非常显著),Queue Deep一般小于256。
4.4.3 随机访问(随机IO)、顺序访问(顺序IO)
随机访问的特点是每次IO请求的数据在磁盘上的位置跨度很大(如:分布在不同的扇区),因此N个非常小的IO请求(如:1K),必须以N次IO请求才能获取到相应的数据。
顺序访问的特点跟随机访问相反,它请求的数据在磁盘的位置是连续的。当系统发起N个非常小的IO请求(如:1K)时,因为一次IO是有代价的,系统会取完整的一块数据(如4K、8K),所以当第一次IO完成时,后续IO请求的数据可能已经有了。这样可以减少IO请求的次数。这也就是所谓的预取。
随机访问和顺序访问同样是有应用决定的。如数据库、小文件的存储的业务,大多是随机IO。而视频类业务、大文件存取,则大多为顺序IO。
4.4.4 选取合理的观察指标:
以上各指标中,不用的应用场景需要观察不同的指标,因为应用场景不同,有些指标甚至是没有意义的。
随机访问和IOPS: 在随机访问场景下,IOPS往往会到达瓶颈,而这个时候去观察Throughput,则往往远低于理论值。
顺序访问和Throughput:在顺序访问的场景下,Throughput往往会达到瓶颈(磁盘限制或者带宽),而这时候去观察IOPS,往往很小。
4.5 标定
与 CPU 不同,不同环境下,磁盘的性能指标与厂家标称会不一致。因此,在性能分析前,对所在的计算环境进行标定是很有必要的。
目前主流的第三方IO测试工具有fio、iometer 和 Orion,这三种工具各有千秋。
fio 在 Linux 系统下使用比较方便,iometer 在 window 系统下使用比较方便,Orion 是 oracle 的IO测试软件,可在没有安装 oracle 数据库的情况下模拟 oracle 数据库场景的读写。
4.5.1 FIO
FIO是测试IOPS的非常好的工具,用来对硬件进行压力测试和验证,支持13种不同的I/O引擎,包括:sync,mmap,libaio,posixaio,SGv3,splice,null,network,syslet,guasi,solarisaio等等。
4.5.1.1 安装FIO
在FIO官网地址下载最新文件,解压后./configure、make、make install 就可以使用fio了。
4.5.1.2 fio参数解释
可以使用fio -help查看每个参数,具体的参数左右可以在官网查看how to文档,如下为几个常见的参数描述:
filename=/dev/emcpowerb 支持文件系统或者裸设备,-filename=/dev/sda2或-filename=/dev/sdb
direct=1 测试过程绕过机器自带的buffer,使测试结果更真实
rw=randwread 测试随机读的I/O
rw=randwrite 测试随机写的I/O
rw=randrw 测试随机混合写和读的I/O
rw=read 测试顺序读的I/O
rw=write 测试顺序写的I/O
rw=rw 测试顺序混合写和读的I/O
bs=4k 单次io的块文件大小为4k
bsrange=512-2048 同上,提定数据块的大小范围
size=5g 本次的测试文件大小为5g,以每次4k的io进行测试
numjobs=30 本次的测试线程为30
runtime=1000 测试时间为1000秒,如果不写则一直将5g文件分4k每次写完为止
ioengine=psync io引擎使用pync方式,如果要使用libaio引擎,需要yum install libaio-devel包
rwmixwrite=30 在混合读写的模式下,写占30%
group_reporting 关于显示结果的,汇总每个进程的信息
此外
lockmem=1g 只使用1g内存进行测试
zero_buffers 用0初始化系统buffer
nrfiles=8 每个进程生成文件的数量4.5.1.3 fio测试
测试场景:
100%随机,100%读, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randread -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100read_4k
100%随机,100%写, 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randwrite -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=rand_100write_4k
100%顺序,100%读 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=read -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100read_4k
100%顺序,100%写 ,4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=write -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=sqe_100write_4k
100%随机,70%读,30%写 4K
fio -filename=/dev/emcpowerb -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=4k -size=1000G -numjobs=50 -runtime=180 -group_reporting -name=randrw_70read_4k实际测试:
fio -filename=/dev/sda -direct=1 -iodepth 1 -thread -rw=randrw -rwmixread=70 -ioengine=psync -bs=16k -size=200G -numjobs=30 -runtime=100 -group_reporting -name=mytest -ioscheduler=noop上述命令,进行随机读写测试。队列深度为1。

VM (long time running) 是 测试用的虚拟机。这台 VM的磁盘性能极低。只有两位数。同一台 ESXi 上的另一台 VM(new build ),磁盘性能很正常。两者的区别在于,前者不是新装,而是一直跑 volume test ,后者是新安装的。
4.6 分析工具
4.6.1 iostat
用途:主要用于监控系统设备的IO负载情况,iostat首次运行时显示自系统启动开始的各项统计信息,之后运行iostat将显示自上次运行该命令以后的统计信息。用户可以通过指定统计的次数和时间来获得所需的统计信息。
缺点:iostat有一个弱点,就是它不能对某个进程进行深入分析,仅对系统的整体情况进行分析。iostat属于sysstat软件包。可以用yum install sysstat 直接安装。
命令格式:
iostat[参数][时间][次数]命令参数:
• -C 显示CPU使用情况
• -d 显示磁盘使用情况
• -k 以 KB 为单位显示
• -m 以 M 为单位显示
• -N 显示磁盘阵列(LVM) 信息
• -n 显示NFS 使用情况
• -p[磁盘] 显示磁盘和分区的情况
• -t 显示终端和CPU的信息
• -x 显示详细信息
• -V 显示版本信息
如上图,每1秒钟显示一次报告:
iostat -x 2 6 /dev/sda1每两秒钟显示一次sda1的统计报告,共显示6次。
CPU 属性值
• %user:CPU处在用户模式下的时间百分比。
• %nice:CPU处在带NICE值的用户模式下的时间百分比。
• %system:CPU处在系统模式下的时间百分比。
• %iowait:CPU等待输入输出完成时间的百分比。
• %steal:管理程序维护另一个虚拟处理器时,虚拟CPU的无意识等待时间百分比。
• %idle:CPU空闲时间百分比。设备属性值
备注:
• 如果%iowait的值过高,表示硬盘存在I/O瓶颈,
• %idle值高,表示CPU较空闲,
• 如果%idle值高但系统响应慢时,有可能是CPU等待分配内存,此时应加大内存容量。
• %idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。
磁盘每一列的含义如下:
• rrqm/s: 每秒进行 merge 的读操作数目。 即 rmerge/s
• wrqm/s: 每秒进行 merge 的写操作数目。即 wmerge/s
• r/s: 每秒完成的读 I/O 设备次数。 即 rio/s
• w/s: 每秒完成的写 I/O 设备次数。即 wio/s
• rsec/s: 每秒读扇区数。即 rsect/s
• wsec/s: 每秒写扇区数。即 wsect/s
• rkB/s: 每秒读 K 字节数。是 rsect/s 的一半,因为扇区大小为 512 字节
• wkB/s: 每秒写 K 字节数。是 wsect/s 的一半
• avgrq-sz: 平均每次设备 I/O 操作的数据大小(扇区)
• avgqu-sz: 平均 I/O 队列长度。
• await: 平均每次设备 I/O 操作的等待时间(毫秒)
• r_await:每个读操作平均所需的时间=[Δrd_ticks/Δrd_ios]
不仅包括硬盘设备读操作的时间,还包括了在kernel队列中等待的时间。
• w_await:每个写操作平均所需的时间=[Δwr_ticks/Δwr_ios]
不仅包括硬盘设备写操作的时间,还包括了在kernel队列中等待的时间。
• svctm: 平均每次设备 I/O 操作的服务时间(毫秒)
• %util: 一秒中有百分之多少的时间用于 I/O 操作,或者说一秒中有多少时间 I/O 队列是非空的。
备注:
• 如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。
• 如果 svctm 比较接近 await,说明 I/O 几乎没有等待时间;
• 如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。
• 如果avgqu-sz比较大,也表示有当量io在等待。 4.6.2 iotop
在某些场景下,我们需要找到占用IO特别大的进程,然后关闭它,需要知道PID或者进程名称,这就需要用到iotop。iotop是一个检测Linux系统进程IO的工具,界面类似top,如下图:

iotop和top一样,也可以通过键入相应键,触发排序选项,例如按o可以在IO活动进程和所有进程之间切换。可以通过左右箭头,选择响应的列进行数据排序。
iotop的常用参数如下:
-h, --help 查看帮助信息
-o, --only 只查看有IO操作的进程
-b, --batch 非交互模式
-n, --iter= 设置迭代次数
-d, --delay 刷新频率,默认是1秒
-p, --pid 查看指定的进程号的IO,默认是所有进程
-u, --user 查看指定用户进程的IO,默认是所有用户
-P, --processes 只看进程,不看线程
-a, --accumulated 看累计IO,而不是实时IO
-k, --kilobytes 以KB为单位查看IO,而不是以最友好的单位显示
-t, --time 每行添加一个时间戳,默认便开启--batch
-q, --quit 不显示头部信息4.6.3 blktrace
blktrace是一柄神器,很多工具都是基于该神器的:ioprof,seekwatcher,iowatcher,这个工具基本可以满足我们的对块设备请求的所有了解。
blktrace的原理
一个I/O请求,从应用层到底层块设备,路径如下图所示:

从上图可以看出IO路径是很复杂的。这么复杂的IO路径我们是无法用短短一篇小博文介绍清楚的。我们将IO路径简化一下:

一个I/O请求进入block layer之后,可能会经历下面的过程:
- Remap: 可能被DM(Device Mapper)或MD(Multiple Device, Software RAID) remap到其它设备
- Split: 可能会因为I/O请求与扇区边界未对齐、或者size太大而被分拆(split)成多个物理I/O
- Merge: 可能会因为与其它I/O请求的物理位置相邻而合并(merge)成一个I/O
- 被IO Scheduler依照调度策略发送给driver
- 被driver提交给硬件,经过HBA、电缆(光纤、网线等)、交换机(SAN或网络)、最后到达存储设备,设备完成IO请求之后再把结果发回。
blktrace 能够记录下IO所经历的各个步骤:

我们一起看下blktrace的输出长什么样子:

第一个字段:8,0 这个字段是设备号 major device ID和minor device ID。
第二个字段:3 表示CPU
第三个字段:11 序列号
第四个字段:0.009507758 Time Stamp是时间偏移
第五个字段:PID 本次IO对应的进程ID
第六个字段:Event,这个字段非常重要,反映了IO进行到了那一步
第七个字段:R表示 Read, W是Write,D表示block,B表示Barrier Operation
第八个字段:223490+56,表示的是起始block number 和 number of blocks,即我们常说的Offset 和 Size
第九个字段: 进程名
其中第六个字段非常有用:每一个字母都代表了IO请求所经历的某个阶段。
Q – 即将生成IO请求
|
G – IO请求生成
|
I – IO请求进入IO Scheduler队列
|
D – IO请求进入driver
|
C – IO请求执行完毕注意,整个IO路径,分成很多段,每一段开始的时候,都会有一个时间戳,根据上一段开始的时间和下一段开始的时间,就可以得到IO 路径各段花费的时间。
我们心心念念的service time,也就是反应块设备处理能力的指标,就是从D到C所花费的时间,简称D2C。
而iostat输出中的await,即整个IO从生成请求到IO请求执行完毕,即从Q到C所花费的时间,我们简称Q2C。
4.6.4 iowatcher
仅仅查看数据进行分析,非常的不直观。工具 iowatcher 可以把 blktrace 采集的信息,转化为图像和动画,方便分析。
iowatcher -t sda.blktrace.bin -o disk.svg
iowatcher -t sda.blktrace.bin --movie -o disk.mp4首先,我们看 VM volume test 的图像:

五、文件系统

文件系统各有不同,其最主要的目标就是解决磁盘空间的管理问题,同时提供高效性、安全性。如果在分布式环境下,则有相应的分布式文件系统。Linux上有ext系列,Windows上有Fat和NTFS。如图为一个linux下文件系统的结构。
其中VFS(Virtual File System)是Linux Kernel文件系统的一个模块,简单看就是一个Adapter,对下屏蔽了下层不同文件系统之间的差异,对上为操作系统提供了统一的接口.
中间部分为各个不同文件系统的实现。
再往下是Buffer Cache和Driver。
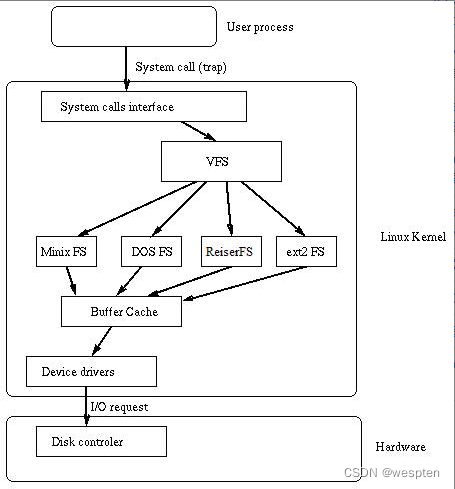
文件系统的结构
各种文件系统实现方式不同,因此性能、管理性、可靠性等也有所不同。下面为Linux Ext2(Ext3)的一个大致文件系统的结构。

Boot Block存放了引导程序。
Super Block存放了整个文件系统的一些全局参数,如:卷名、状态、块大小、块总数。他在文件系统被mount时读入内存,在umount时被释放。

上图描述了Ext2文件系统中很重要的三个数据结构和他们之间的关系。
Inode:Inode是文件系统中最重要的一个结构。如图,他里面记录了文件相关的所有信息,也就是我们常说的meta信息。包括:文件类型、权限、所有者、大小、atime等。Inode里面也保存了指向实际文件内容信息的索引。其中这种索引分几类:
- 直接索引:直接指向实际内容信息,公有12个。因此如果,一个文件系统block size为1k,那么直接索引到的内容最大为12k
- 间接索引
- 两级间接索引
- 三级间接索引
如图:

Directory代表了文件系统中的目录,包括了当前目录中的所有Inode信息。其中每行只有两个信息,一个是文件名,一个是其对应的Inode。需要注意,Directory不是文件系统中的一个特殊结构,他实际上也是一个文件,有自己的Inode,而它的文件内容信息里面,包括了上面看到的那些文件名和Inode的对应关系。如下图:

Data Block即存放文件的时间内容块。Data Block大小必须为磁盘的数据块大小的整数倍,磁盘一般为512字节,因此Data Block一般为1K、2K、4K。
Buffer Cache
Buffer & Cache
虽然Buffer和Cache放在一起了,但是在实际过程中Buffer和Cache是完全不同了。Buffer一般对于写而言,也叫“缓冲区”,缓冲使得多个小的数据块能够合并成一个大数据块,一次性写入;Cache一般对于读而且,也叫“缓存”,避免频繁的磁盘读取。如图为Linux的free命令,其中也是把Buffer和Cache进行区分,这两部分都算在了free的内存。

Buffer Cache
Buffer Cache中的缓存,本质与所有的缓存都是一样,数据结构也是类似,下图为VxSF的一个Buffer Cache结构。
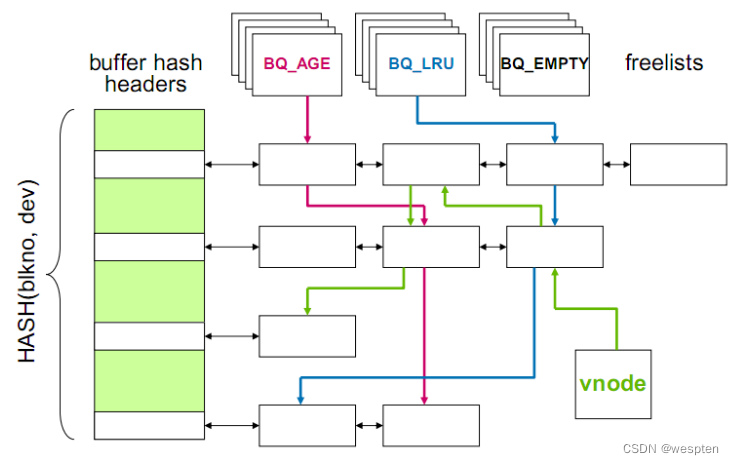
这个数据结构与memcached和Oracle SGA的buffer何等相似。左侧的hash chain完成数据块的寻址,上方的的链表记录了数据块的状态。
Buffer vs Direct I/O
文件系统的Buffer和Cache在某些情况下确实提高了速度,但是反之也会带来一些负面影响。一方面文件系统增加了一个中间层,另外一方面,当Cache使用不当、配置不好或者有些业务无法获取cache带来的好处时,cache则成为了一种负担。
适合Cache的业务:串行的大数据量业务,如:NFS、FTP。
不适合Cache的业务:随机IO的业务。如:Oracle,小文件读取。
块设备、字符设备、裸设备
这几个东西看得很晕,找了一些资料也没有找到很准确的说明。
从硬件设备的角度来看:
- 块设备就是以块(比如磁盘扇区)为单位收发数据的设备,它们支持缓冲和随机访问(不必顺序读取块,而是可以在任何时候访问任何块)等特性。块设备包括硬盘、CD-ROM 和 RAM 盘。
- 字符设备则没有可以进行物理寻址的媒体。字符设备包括串行端口和磁带设备,只能逐字符地读取这些设备中的数据。
从操作系统的角度看(对应操作系统的设备文件类型的b和c):
# ls -l /dev/*lv
brw------- 1 root system 22, 2 May 15 2007 lv
crw------- 2 root system 22, 2 May 15 2007 rlv- 块设备能支持缓冲和随机读写。即读取和写入时,可以是任意长度的数据。最小为1byte。对块设备,你可以成功执行下列命令:dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1。即:在设备中写入一个字节。硬件设备是不支持这样的操作的(最小是512),这个时候,操作系统首先完成一个读取(如1K,操作系统最小的读写单位,为硬件设备支持的数据块的整数倍),再更改这1k上的数据,然后写入设备。
- 字符设备只能支持固定长度数据的读取和写入,这里的长度就是操作系统能支持的最小读写单位,如1K,所以块设备的缓冲功能,这里就没有了,需要使用者自己来完成。由于读写时不经过任何缓冲区,此时执行dd if=/dev/zero of=/dev/vg01/lv bs=1 count=1,这个命令将会出错,因为这里的bs(block size)太小,系统无法支持。如果执行dd if=/dev/zero of=/dev/vg01/lv bs=1024 count=1,则可以成功。这里的block size有OS内核参数决定。
如上,相比之下,字符设备在使用更为直接,而块设备更为灵活。文件系统一般建立在块设备上,而为了追求高性能,使用字符设备则是更好的选择,如Oracle的裸设备使用。
裸设备
裸设备也叫裸分区,就是没有经过格式化、没有文件系统的一块存储空间。可以写入二进制内容,但是内容的格式、其中信息的组织等问题,需要使用它的人来完成。文件系统就是建立在裸设备之上,并完成裸设备空间的管理。
CIO
CIO即并行IO(Concurrent IO)。在文件系统中,当某个文件被多个进程同时访问时,就出现了Inode竞争的问题。一般地,读操作使用的共享锁,即:多个读操作可以并发进行,而写操作使用排他锁。当锁被写进程占用时,其他所有操作均阻塞。因此,当这样的情况出现时,整个应用的性能将会大大降低。如图:
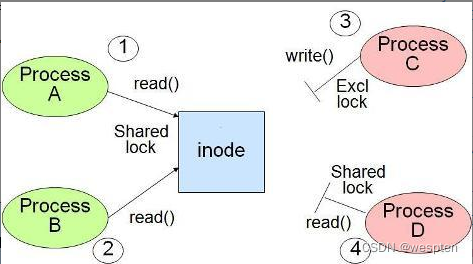
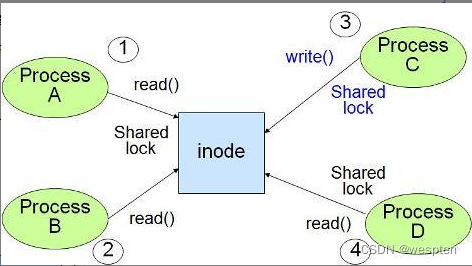
CIO就是为了解决这个问题。而且CIO带来的性能提高直逼裸设备。当文件系统支持CIO并开启CIO时,CIO默认会开启文件系统的Direct IO,即:让IO操作不经过Buffer直接进行底层数据操作。由于不经过数据Buffer,在文件系统层面就无需考虑数据一致性的问题,因此,读写操作可以并行执行。
在最终进行数据存储的时候,所有操作都会串行执行,CIO把这个事情交个了底层的driver。
六、逻辑卷管理
LVM(逻辑卷管理),位于操作系统和硬盘之间,LVM屏蔽了底层硬盘带来的复杂性。最简单的,LVM使得N块硬盘在OS看来成为一块硬盘,大大提高了系统可用性。
LVM的引入,使得文件系统和底层磁盘之间的关系变得更为灵活,而且更方便关系。LVM有以下特点:
· 统一进行磁盘管理。按需分配空间,提供动态扩展。
· 条带化(Striped)
· 镜像(mirrored)
· 快照(snapshot)
LVM可以做动态磁盘扩展,想想看,当系统管理员发现应用空间不足时,敲两个命令就完成空间扩展,估计做梦都要笑醒:)
LVM的磁盘管理方式

LVM几个很重要的概念
· PV(physical volume):物理卷。在LVM中,一个PV对应就是操作系统能看见的一块物理磁盘,或者由存储设备分配操作系统的lun。一块磁盘唯一对应一个PV,PV创建以后,说明这块空间可以纳入到LVM的管理。创建PV时,可以指定PV大小,即可以把整个磁盘的部分纳入PV,而不是全部磁盘。这点在表面上看没有什么意义,但是如果主机后面接的是存储设备的话就很有意义了,因为存储设备分配的lun是可以动态扩展的,只有当PV可以动态扩展,这种扩展性才能向上延伸。
· VG(volume group):卷组。一个VG是多个PV的集合,简单说就是一个VG就是一个磁盘资源池。VG对上屏蔽了多个物理磁盘,上层是使用时只需考虑空间大小的问题,而VG解决的空间的如何在多个PV上连续的问题。
· LV(logical volume):逻辑卷。LV是最终可供使用卷,LV在VG中创建,有了VG,LV创建是只需考虑空间大小等问题,对LV而言,他看到的是一直联系的地址空间,不用考虑多块硬盘的问题。
有了上面三个,LVM把单个的磁盘抽象成了一组连续的、可随意分配的地址空间。除上面三个概念外,还有一些其他概念:
· PE(physical extend): 物理扩展块。LVM在创建PV,不会按字节方式去进行空间管理。而是按PE为单位。PE为空间管理的最小单位。即:如果一个1024M的物理盘,LVM的PE为4M,那么LVM管理空间时,会按照256个PE去管理。分配时,也是按照分配了多少PE、剩余多少PE考虑。
· LE(logical extend):逻辑扩展块。类似PV,LE是创建LV考虑,当LV需要动态扩展时,每次最小的扩展单位。
PV、VG、LV三者关系:

PV把物理硬盘转换成LVM中对于的逻辑(解决如何管理物理硬盘的问题),VG是PV的集合(解决如何组合PV的问题),LV是VG上空间的再划分(解决如何给OS使用空间的问题);而PE、LE则是空间分配时的单位。
LVM整体结构
逻辑卷管理器(LVM)通过将数据在存储空间的逻辑视图与实际的物理磁盘之间进行映射来控制磁盘资源。
实现方式是在传统的物理设备驱动层之上加载一层磁盘设备驱动代码,该磁盘存储逻辑视图供应用程序使用并独立于底层物理磁盘结构。

如下结构层次图描述了固定磁盘存储的管理,各层级之间有明确定义的映射关系(包括卷组(datavg),逻辑卷(lv04和mirrlv),逻辑分区(LP1,…),物理卷(hdisk9),和物理分区(PP8))。

每一个单独的磁盘设备被称为物理卷并赋予一个名称,通常是/dev/hdiskx(x是系统中唯一的整数值)。每一个正在使用的物理卷都属于一个卷组(VG),除非它是作为原始存储磁盘设备或现成备份盘(通常称为热备盘)。每个物理卷包含一定数量相互叠加的磁盘(或盘片),被分成固定大小的物理分区。出于空间分配的考虑,将每一个物理卷划分成五个区域:(外部边缘,外中间,中心,内中间,以及内部边缘),这些可看做通过磁盘盘片垂直切割的圆柱段(参见图3)。每一区域的物理分区数随着磁盘设备总容量而变化。
逻辑卷管理器(LVM)是操作系统命令、库子程序、其他允许用户建立和控制逻辑卷存储的集合。如前文所述,逻辑卷管理器(LVM)通过将数据在存储空间的逻辑视图与实际的物理磁盘之间进行映射来控制磁盘资源。实现方式是在传统的物理设备驱动层之上加载一层磁盘设备驱动代码。该磁盘存储逻辑视图供应用程序使用并独立于底层物理磁盘结构。

逻辑卷管理器(LVM)通过同样的方式来管理RAID磁盘阵列。RAID阵列被当做单一磁盘来处理,即使在绝大多数情况下它的容量相当可观。
安装成功后,系统有一个卷组(root卷组称为rootvg),包括了启动系统所必须的逻辑卷以及安装脚本指定的其他逻辑卷。连接到系统的其他物理卷可被添加到卷组中(使用extendvg命令),或用于创建新卷组(使用mkvg命令)。
卷组和物理卷有如下关系:
- 单个系统上,一个或多个物理卷可组成一个卷组。
- 物理卷不能在卷组之间共享。
- 整个物理卷成为卷组的一部分。
- LVM独立于物理卷。因此不同类型的物理卷可组成一个卷组。
每个卷组内,定义了一个或多个逻辑卷。逻辑卷是用来存储数据的磁盘区域,对于应用来说是连续的,但是在实际物理卷上有可能非连续。逻辑卷可以扩展、重定位、跨越多个物理卷,并且其内容可以复制以提供更好地灵活性和可扩展性。
每一个逻辑卷包含一个或多个逻辑分区(LPs)。每一个逻辑分区对应至少一个物理分区。如果逻辑卷是镜像保护的,那么系统会分配额外的物理分区用以存储各逻辑分区的复制数据。为了保证可用性,这些数据通常位于不同的物理卷,但有时出于性能的考虑,也可能位于同一物理卷。
逻辑卷可通过命令或SMIT菜单形式创建或修改。
逻辑卷只能属于一个卷组。一个逻辑卷可以:
- 位于一个物理卷
- 跨越一个卷组的多个物理卷
- 多个镜像位于同一卷组的不同物理卷
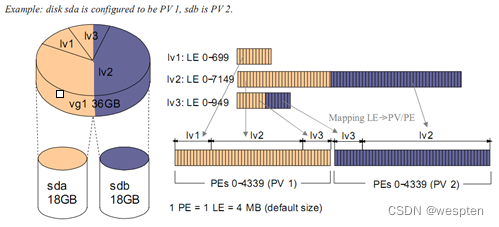
如下图,为两块18G的磁盘组成了一个36G的VG。此VG上划分了3个LV。其PE和LE都为4M。其中LV1只用到了sda的空间,而LV2和LV3使用到了两块磁盘。
串联、条带化、镜像
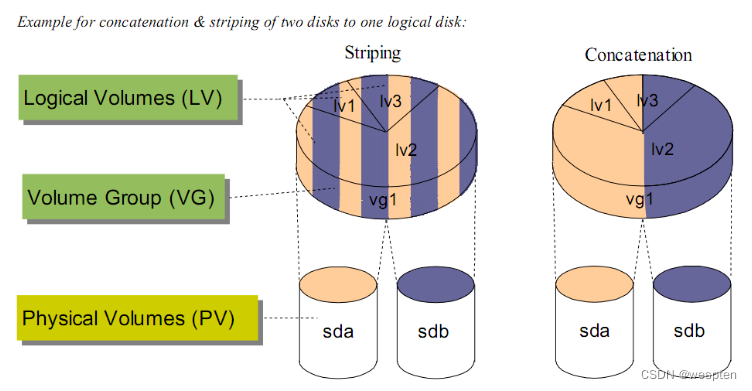
串联(Concatenation): 按顺序使用磁盘,一个磁盘使用完以后使用后续的磁盘。
条带化(Striping): 交替使用不同磁盘的空间。条带化使得IO操作可以并行,因此是提高IO性能的关键。另外,Striping也是RAID的基础。如:VG有2个PV,LV做了条带数量为2的条带化,条带大小为8K,那么当OS发起一个16K的写操作时,那么刚好这2个PV对应的磁盘可以对整个写入操作进行并行写入。

Striping带来好处有:
并发进行数据处理。读写操作可以同时发送在多个磁盘上,大大提高了性能。
Striping带来的问题:
· 数据完整性的风险。Striping导致一份完整的数据被分布到多个磁盘上,任何一个磁盘上的数据都是不完整,也无法进行还原。一个条带的损坏会导致所有数据的失效。因此这个问题只能通过存储设备来弥补。
· 条带大小的设定很大程度决定了Striping带来的好处。如果条带设置过大,一个IO操作最终还是发生在一个磁盘上,无法带来并行的好处;当条带设置国小,本来一次并行IO可以完成的事情会最终导致了多次并行IO。
镜像(mirror)
如同名字。LVM提供LV镜像的功能。即当一个LV进行IO操作时,相同的操作发生在另外一个LV上。这样的功能为数据的安全性提供了支持。如图,一份数据被同时写入两个不同的PV。

使用mirror时,可以获得一些好处:
· 读取操作可以从两个磁盘上获取,因此读效率会更好些。
· 数据完整复杂了一份,安全性更高。
但是,伴随也存在一些问题:
· 所有的写操作都会同时发送在两个磁盘上,因此实际发送的IO是请求IO的2倍
· 由于写操作在两个磁盘上发生,因此一些完整的写操作需要两边都完成了才算完成,带来了额外负担。
· 在处理串行IO时,有些IO走一个磁盘,另外一些IO走另外的磁盘,一个完整的IO请求会被打乱,LVM需要进行IO数据的合并,才能提供给上层。像一些如预读的功能,由于有了多个数据获取同道,也会存在额外的负担。
快照(Snapshot)

快照如其名,他保存了某一时间点磁盘的状态,而后续数据的变化不会影响快照,因此,快照是一种备份很好手段。
但是快照由于保存了某一时间点数据的状态,因此在数据变化时,这部分数据需要写到其他地方,随着而来回带来一些问题。
七、Driver & IO Channel
这部分值得一说的是多路径问题。IO部分的高可用性在整个应用系统中可以说是最关键的,应用层可以坏掉一两台机器没有问题,但是如果IO不通了,整个系统都没法使用。如图为一个典型的SAN网络,从主机到磁盘,所有路径上都提供了冗余,以备发生通路中断的情况。
· OS配置了2块光纤卡,分别连不同交换机
· SAN网络配置了2个交换机
· 存储配置了2个Controller,分别连不同交换机

如上图结构,由于存在两条路径,对于存储划分的一个空间,在OS端会看到两个(两块磁盘或者两个lun)。可怕的是,OS并不知道这两个东西对应的其实是一块空间,如果路径再多,则OS会看到更多。还是那句经典的话,“计算机中碰到的问题,往往可以通过增加的一个中间层来解决”,于是有了多路径软件。他提供了以下特性:
· 把多个映射到同一块空间的路径合并为一个提供给主机
· 提供fail over的支持。当一条通路出现问题时,及时切换到其他通路
· 提供load balance的支持。即同时使用多条路径进行数据传送,发挥多路径的资源优势,提高系统整体带宽。
Fail over的能力一般OS也可能支持,而load balance则需要与存储配合,所以需要根据存储不同配置安装不同的多通路软件。
多路径除了解决了高可用性,同时,多条路径也可以同时工作,提高系统性能。
八、RAID
Raid很基础,但是在存储系统中占据非常重要的地位,所有涉及存储的书籍都会提到RAID。RAID通过磁盘冗余的方式提高了可用性和可高性,一方面增加了数据读写速度,另一方面增加了数据的安全性。
RAID 0
对数据进行条带化。使用两个磁盘交替存放连续数据。因此可以实现并发读写,但带来的问题是如果一个磁盘损坏,另外一个磁盘的数据将失去意义。RAID 0最少需要2块盘。

RAID 1
对数据进行镜像。数据写入时,相同的数据同时写入两块盘。因此两个盘的数据完全一致,如果一块盘损坏,另外一块盘可以顶替使用,RAID 1带来了很好的可靠性。同时读的时候,数据可以从两个盘上进行读取。但是RAID 1带来的问题就是空间的浪费。两块盘只提供了一块盘的空间。RAID 1最少需要2块盘。
RAID 5 和 RAID 4
使用多余的一块校验盘。数据写入时,RAID 5需要对数据进行计算,以便得出校验位。因此,在写性能上RAID 5会有损失。但是RAID 5兼顾了性能和安全性。当有一块磁盘损坏时,RAID 5可以通过其他盘上的数据对其进行恢复。
如图可以看出,右下角为p的就是校验数据。可以看到RAID 5的校验数据依次分布在不同的盘上,这样可以避免出现热点盘(因为所有写操作和更新操作都需要修改校验信息,如果校验都在一个盘做,会导致这个盘成为写瓶颈,从而拖累整体性能,RAID 4的问题)。RAID 5最少需要3块盘。

RAID 6
RAID 6与RAID 5类似。但是提供了两块校验盘(下图右下角为p和q的)。安全性更高,写性能更差了。RAID 0最少需要4块盘。

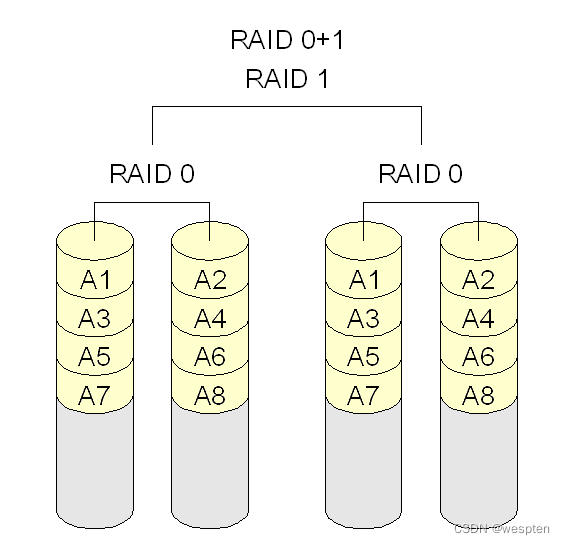
RAID 10(Striped mirror)
RAID 10是RAID 0 和RAID 1的结合,同时兼顾了二者的特点,提供了高性能,但是同时空间使用也是最大。RAID 10最少需要4块盘。

需要注意,使用RAID 10来称呼其实很容易产生混淆,因为RAID 0+1和RAID 10基本上只是两个数字交换了一下位置,但是对RAID来说就是两个不同的组成。因此,更容易理解的方式是“Striped mirrors”,即:条带化后的镜像——RAID 10;或者“mirrored stripes”,即:镜像后的条带化。比较RAID 10和RAID 0+1,虽然最终都是用到了4块盘,但是在数据组织上有所不同,从而带来问题。RAID 10在可用性上是要高于RAID 0+1的:
· RAID 0+1 任何一块盘损坏,将失去冗余。如图4块盘中,右侧一组损坏一块盘,左侧一组损坏一块盘,整个盘阵将无法使用。而RAID 10左右各损坏一块盘,盘阵仍然可以工作。
· RAID 0+1 损坏后的恢复过程会更慢。因为先经过的mirror,所以左右两组中保存的都是完整的数据,数据恢复时,需要完整恢复所以数据。而RAID 10因为先条带化,因此损坏数据以后,恢复的只是本条带的数据。如图4块盘,数据少了一半。
RAID 50
RAID 50 同RAID 10,先做条带化以后,在做RAID 5。兼顾性能,同时又保证空间的利用率。RAID 50最少需要6块盘。

总结:
· RAID与LVM中的条带化原理上类似,只是实现层面不同。在存储上实现的RAID一般有专门的芯片来完成,因此速度上远比LVM块。也称硬RAID。
· 如上介绍,RAID的使用是有风险的,如RAID 0,一块盘损坏会导致所有数据丢失。因此,在实际使用中,高性能环境会使用RAID 10,兼顾性能和安全;一般情况下使用RAID 5(RAID 50),兼顾空间利用率和性能。
九、DAS、SAN和NAS

DAS:有PATA、SATA、SAS等,主要是磁盘数据传输协议。
-
单台主机。在这种情况下,存储作为主机的一个或多个磁盘存在,这样局限性也是很明显的。由于受限于主机空间,一个主机只能装一块到几块硬盘,而硬盘空间时受限的,当磁盘满了以后,你不得不为主机更换更大空间的硬盘。
-
独立存储空间。为了解决空间的问题,于是考虑把磁盘独立出来,于是有了DAS(Direct Attached Storage),即:直连存储。DAS就是一组磁盘的集合体,数据读取和写入等也都是由主机来控制。但是,随之而来,DAS又面临了一个他无法解决的问题——存储空间的共享。接某个主机的JBOD(Just a Bunch Of Disks,磁盘组),只能这个主机使用,其他主机无法用。因此,如果DAS解决空间了,那么他无法解决的就是如果让空间能够在多个机器共享。因为DAS可以理解为与磁盘交互,DAS处理问题的层面相对更低。使用协议都是跟磁盘交互的协议
-
独立的存储网络。为了解决共享的问题,借鉴以太网的思想,于是有了SAN(Storage Area Network),即:存储网络。对于SAN网络,你能看到两个非常特点,一个就是光纤网络,另一个是光纤交换机。SAN网络由于不会之间跟磁盘交互,他考虑的更多是数据存取的问题,因此使用的协议相对DAS层面更高一些。光纤网络:对于存储来说,与以太网很大的一个不同就是他对带宽的要求非常高,因此SAN网络下,光纤成为了其连接的基础。而其上的光纤协议相比以太网协议而言,也被设计的更为简洁,性能也更高。光纤交换机:这个类似以太网,如果想要做到真正的“网络”,交换机是基础。
-
网络文件系统。存储空间可以共享,那文件也是可以共享的。NAS(Network attached storage)相对上面两个,看待问题的层面更高,NAS是在文件系统级别看待问题。因此他面的不再是存储空间,而是单个的文件。因此,当NAS和SAN、DAS放在一起时,很容易引起混淆。NAS从文件的层面考虑共享,因此NAS相关协议都是文件控制协议。NAS解决的是文件共享的问题;SAN(DAS)解决的是存储空间的问题。NAS要处理的对象是文件;SAN(DAS)要处理的是磁盘。为NAS服务的主机必须是一个完整的主机(有OS、有文件系统,而存储则不一定有,因为可以他后面又接了一个SAN网络),他考虑的是如何在各个主机直接高效的共享文件;为SAN提供服务的是存储设备(可以是个完整的主机,也可以是部分),它考虑的是数据怎么分布到不同磁盘。NAS使用的协议是控制文件的(即:对文件的读写等);SAN使用的协议是控制存储空间的(即:把多长的一串二进制写到某个地址)

如图,对NAS、SAN、DAS的组成协议进行了划分,从这里也能很清晰的看出他们之间的差别。
NAS:涉及SMB协议、NFS协议,都是网络文件系统的协议。
SAN:有FC、iSCSI、AOE,都是网络数据传输协议。
DAS:有PATA、SATA、SAS等,主要是磁盘数据传输协议。
从DAS到SAN,在到NAS,在不同层面对存储方案进行的补充,也可以看到一种从低级到高级的发展趋势。而现在我们常看到一些分布式文件系统(如hadoop等)、数据库的sharding等,从存储的角度来说,则是在OS层面(应用)对数据进行存储。从这也能看到一种技术发展的趋势。
跑在以太网上的SAN
SAN网络并不是只能使用光纤和光纤协议,当初之所以使用FC,传输效率是一个很大的问题,但是以太网发展到今天被不断的完善、加强,带宽的问题也被不断的解决。因此,以太网上的SAN或许会成为一个趋势。
-
FCIP
如图两个FC的SAN网络,通过FCIP实现了两个SAN网络数据在IP网络上的传输。这个时候SAN网络还是以FC协议为基础,还是使用光纤。

-
iFCP
通过iFCP方式,SAN网络由FC的SAN网络演变为IP SAN网络,整个SAN网络都基于了IP方式。但是主机和存储直接使用的还是FC协议。只是在接入SAN网络的时候通过iFCP进行了转换

-
iSCSI
iSCSI是比较主流的IP SAN的提供方式,而且其效率也得到了认可。

对于iSCSI,最重要的一点就是SCSI协议。SCSI(Small Computer Systems Interface)协议是计算机内部的一个通用协议。是一组标准集,它定义了与大量设备(主要是与存储相关的设备)通信所需的接口和协议。如图,SCSI为block device drivers之下。
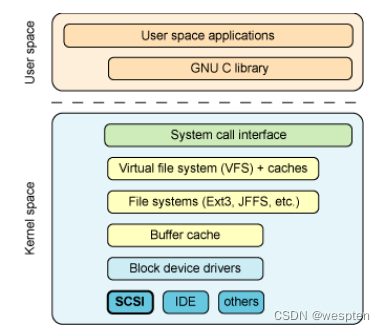
从SCIS的分层来看,共分三层:
高层:提供了与OS各种设备之间的接口,实现把OS如:Linux的VFS请求转换为SCSI请求
中间层:实现高层和底层之间的转换,类似一个协议网关。
底层:完成于具体物理设备之间的交互,实现真正的数据处理。
