1. 数与地址比较
1.1 数值比较
a = 'morgan'
b = 'morgan'
print(a == b) #Return True for value1.2 地址比较
a = 'morgan@'
b = 'morgan@'
print(a is b) #Return False for address
print(id(a)) #Return the variable value address1.3 小数据池
仅存在于str,int类型数据类型;意义在于节省空间。
- int:-5~256 #共用一个空间
- str:
- 不能含有特殊字符。
- 单个元素*int不能超过21次
2. 编码
二进制与可读字符间的转换。
- 字节:8位是一个字节
- 字符:
1. 内容的最小组成单位
2. 中国的‘中’代表一个字符
3. abc,‘a’代表一个字符- 不同编码之间的二进制是不能呼吸识别的。
- 对文件的存储,及传输不能是unicode
- Python 3.x:
int
bool
str:内部为unicode编码
list
dict
tuple
bytes:所有功能与str都一样,只是编码不同
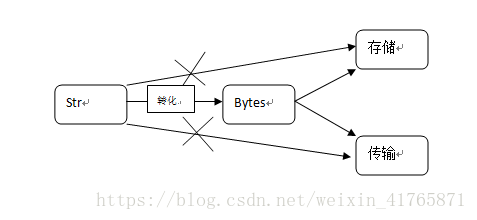
2.1 转码
s = 'morgan'
b = s.encode('utf-8') #str--->bytes
c = b.decode('utf-8') #bytes--->str
print(b) #输出:b'morgan'
print(c) #输出:morgan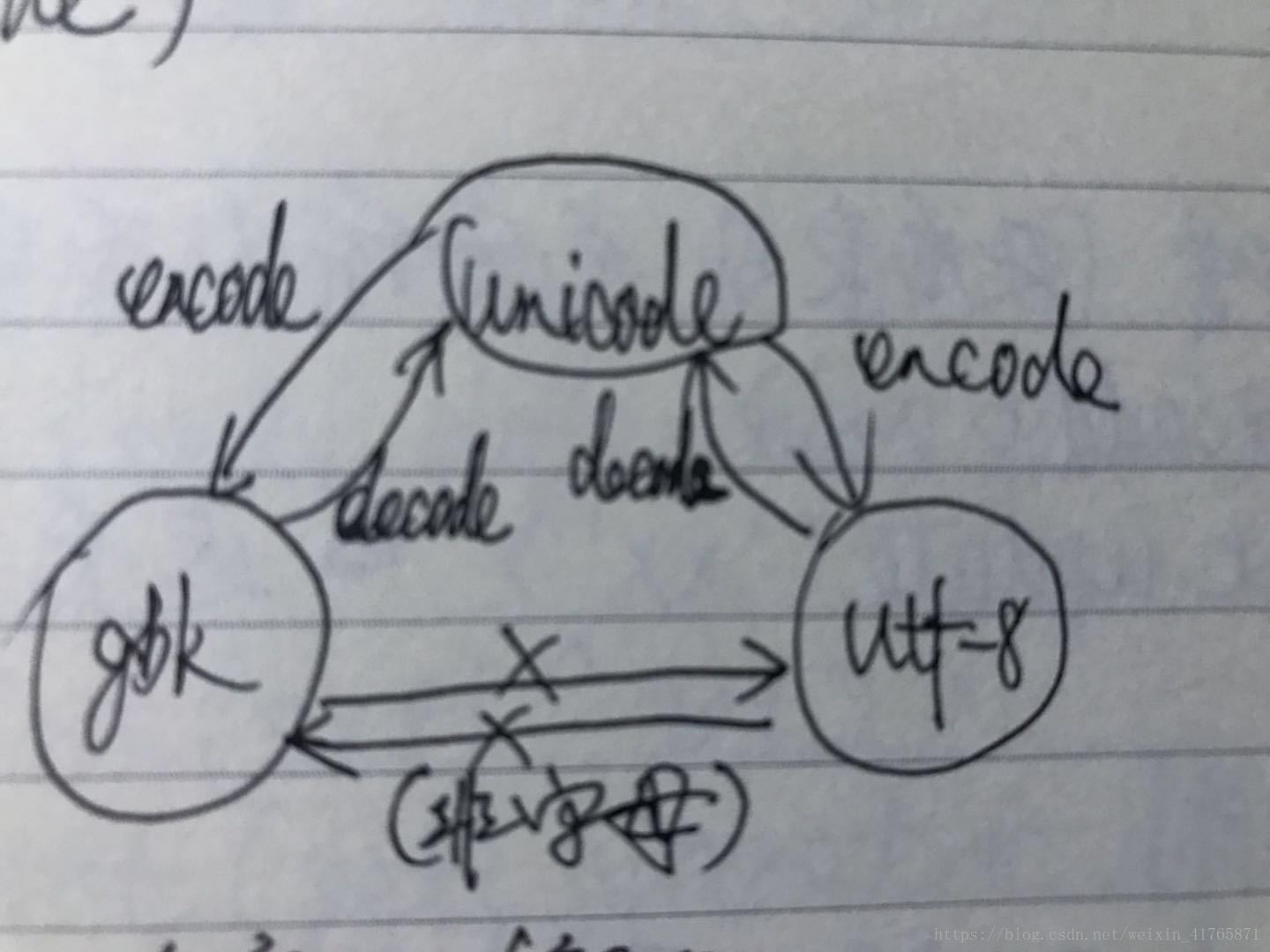
3. 集合
用于去重,关系测试;在金融方面应用多。
3.1要求
- 要求它里面的数据,可哈希且元素不重复
- 本身是不可哈希的
3.2面试题
- set={}
- 问题1:列表如何去重?
- 解法步骤:set(list)—–>list(set(list))
- 问题2:去重后保留原来顺序
- 解法步骤:用算法去重
3.3增加
没有索引,无序所以不能改。
s = {1,2,3,3}
print(s) #print: {1,2,3}
b = s.add{4}
print(b) #print: {1,2,3,4}
c = b.update('morgan') #Add with iterable items
print(c) #print: {1, 2, 3, 4, 'o', 'a', 'n', 'g', 'm', 'r'}3.4删除
s = {1,2,3,3}
s.pop()
print(s) #随机删除一个元素
s.remove(1) #按元素删除
print(s) #print: {2,3}
s.clear()
print(s) #return: set()
del s
print(s) #集合对象不存在3.5查看
用for循环查看集合元素。
s = {1,2,3,4}
for i in s:
print(i)3.6关系测试
s1 = {1,2,3,4}
s2 = {2,3,5}3.6.1交集
print(s1 & s2) #print: {2,3}
print(s1.intersection(s2))3.6.2并集
print(s1 | s2) #print: {1,2,3,4,5}
print(s1.union(s2))3.6.3差集
print(s1 - s2) #print: {1, 4}
print(s2 - s1) #print: {5}
print(s1.difference(s2)) #print: {1, 4}3.6.4反交集
print(s1 ^ s2) #print: {1, 4, 5}
print(s1.symmetric_difference(s2))3.6.5父子集
s1 = {1,2}
s2 = {1,2,3}
print(s2 > s1) #print: True
print(s1.issubset(s2)) 3.6.6超集
s1 = {1,2}
s2 = {1,2,3}
print(s2 > s1) #print: True
print(s2.issuperset(s1)) 3.6.7冻集
set是可变的,有add(),remove()等方法。既然是可变的,所以它不存在哈希值。
frozenset是冻结的集合,它是不可变的,存在哈希值,好处是它可以作为字典的key,也可以作为其它集合的元素。缺点是一旦创建便不能更改,没有add,remove方法。
f = frozenset('a')
adic = {f:1,'b':2} #正确
s = set('a')
bdic = {s:1, 'b':2} #错误:`TypeError: unhashable type: 'set'`
- 还有一点需要注意,不管是set还是frozenset,Python都不支持创建一个整数的集合。
seta=set(1) #错误
setb=set('1')#正确4.深浅copy
赋值
s1 = [1,2]
s2 = s1
s1.append(5)
print(s1, s2) #s1 == s2浅copy
第一层各自独立,从第二层开始,共用有一个内存地址
s1 = [1,2]
s2 = s1.copy()
s1.append(5)
print(s1, s2) #print: s1 != s2;[1, 2, 5] [1, 2]
s1 = [1,2,[11,22]]
s2 = s1.copy()
s1[-1].append(5)
print(s1, s2) #print: [1, 2, [11, 22, 5]] [1, 2, [11, 22, 5]]深copy
无论多少层,都是互相独立的
from copy import deepcopy
s1 = [1,2,[11,22]]
s2 = deepcopy(s1)
s1[-1].append(5)
print(s1, s2) #print: [1, 2, [11, 22, 5]] [1, 2, [11, 22]]切片
全切就是浅copy
s1 = [1,2,[11,22]]
s2 = s1[:]
s1[-1].append(5)
print(s1, s2) #print: [1, 2, [11, 22, 5]] [1, 2, [11, 22, 5]]
s1 = [1,2]
s2 = s1[:]
s1.append(5)
print(s1, s2) #print: s1 != s2;[1, 2, 5] [1, 2]5.文件操作
- 文件路径(path)
- 编码方式(encoding)
- 操作方式:读写。。。(mode)
f1 = open('d:\xx.txt, encoding='utf-8',mode='r')
print(f1.read())
f1.close()
- f1:文件句柄
- open()调用的内置函数,内置函数调用的系统内部的open
- 一切对文件的操作都是基于文件句柄
错误解析- UnicodeDecodeError: 文件编码与读写编码不一致
- 路径错误:
- r’d:\xxx.txt’
- 加转义字符‘/’
读写追加
- 读:r/rb/r+/r+b
- 写:w/wb/w+/w+b
- 追加:a/ab/a+/a+b
读
- r(全读)—>read()
- rb(读取非文字文件)
- r:read(n) #读一部分(n为字符)
- rb:read(n) #读一部分(n为字节)
- readline() #按行读取
- readlines() #全读取为列表
- for遍历—->读取文件
f1 = open('d:\xx.txt, encoding='utf-8',mode='r')
for line in f1:
print(line)
f1.close()写
没有文件,新建文件,如果有源文件,则先清空在写入新内容
f1 = open('d:\xx.txt, encoding='utf-8',mode='w')
f1.write('xx')
f1.close()
f1 = open('x.jpg',mode='rb')
content = f1.read()
f2 = open('y.jpg',mode='wb')
f2.write(content)
f1.close()
f2.close()追加
f1 = open('log', encoding='utf-8',mode='a')
f1.write('xx')
f1.close()
f1.write('\nxx') #一行一行追加r+=rw
f1 = open('log',encoding='utf-8',mode='r+')
print(f1.read())
f1.write(6)
f1.close() #最好不要写/读w+
f1 = open('log', encoding='utf-8',mode='w+')
f1.write('xx')
f1.seek(0) #调光标,保留以前的内容
print(f1.read())
f1.close()a+(a+r)
f1 = open('log',encoding='utf-8',mode='a+')
f1.write('xx')
f1.seek(0)
print(f1.read())
f1.close()其他方法
- readable
- writeable
- seek/tell #应用于断点续传
f1=open('log',encoding='utf-8',mode='a+')
f1.read(3)
print(f1.tell()) #查看光标位置
f1.close()
- seek(0) #光标调到开头
- seek(0, 2) #光标调到最后
- truncate #截取data按字节对源文件截取,必须在a/a+模式使用
with open('log1',encoding='utf-8',mode='r') as f1
open('log2',encoding='utf-8',mode='r') as f2
print(f1.read())不用主动关闭文件句柄,一个with可以打开多个文件
with open('log1',encoding='utf-8',mode='r') as f1:
print(f1.read())
f1.close()
with open('log2',encoding='utf-8',mode='r') as f2
f2.write(6)要主动关闭文件
文件的改
过程:
1. 读出源文件(以读模式)
2. 以写模式打开一个新文件
3. 将源文件读出按要求修改,将修改后文件写入新文件
4. 删除源文件
5. 将新文件重命名源文件
6.函数
重复代码多,可读性差。
def 关键字 函数名():
函数体
函数执行:函数名()
函数以功能为导向return:
终止函数
给函数执行者返回值
返回none(return后面什么都不加)
return None—结果也是None
返回多个值,以元组类型返回- 传参
实参:将实际值传入函数
形参:- 实参角度:
位置参数
6.1 位置参数(按顺序一一对应)
def func1(a,b,c):
pass
func1(1,2,3)
- 三元运算
ret = a if a>b else b
6.2关键字传参
def func2(a,b):
print(a,b)
func2(b=1,a=3)6.3混合传参
位置/关键字参数
def func3(a,b,c,d):
print(a,b,c,d)
func3(1,2,5,d=3)6.3形参角度:
- 位置参数
- 默认参数
- 动态参数
6.3.1位置参数
6.3.2默认参数
经常用,要在位置参数后面
while True:
name = input("fill in name").strip()
sex = input("fill in sex).strip()
login(name, sex)
def login(name, sex='male'):
with open('register',encoding='utf-8',mode='a') as f1:
f1.write('{},{}\n'.format(name,sex))6.3.3动态参数
args:所有位置参数tuple
kwargs:所有关键字参数dict
def func(*args,**kwargs):
print(args)
print(kwargs)
func(1,2,3,'morgan',c=7)
- 函数定义时候:*代表聚合
- 函数执行时候:*代表打散
func([1,2],(22,33))—–>(1,2,22,33)- 列表,元组—>*
- dict—->**
6.3.4形参顺序:
def func(a,b,*args,sex=’male’,**kwargs)