线程定义
**定义:**线程是轻量级的进程(LWP:light weight pocess),在Linux环境下线程的本质仍然是进程。在计算机上运行的程序是一组指令及指令参数的组合,指令按照既定的逻辑控制计算机运行。操作系统会以进程为单位,分配系统资源,可以这样理解,进程是资源分配的最小单位,线程是操作系统调度执行的最小单位。
线程和进程之间的区别:
• 进程有自己独立的地址空间,多个线程公用同一个地址空间
- 线程更加节省系统空间,效率不仅可以保持的,而且能够更加高
- 在一个地址空间中多个线程独享:每个线程都有属于自己的栈区,寄存器(内核中管理的)
- 在一个地址空间中多个线程共享:代码区,堆区,全局数据区,打开的文件(文件描述符表)都是线程共享的
• 线程是程序是最小执行单位,进程是操作系统系统中最小的资源分配单位
- 每个进程对应一个虚拟地址空间,一个进程只能抢一个CPU时间片
- 一个地址空间中可以划分出多个线程,在有效的资源基础上,能够抢更多的CPU时间片
每个线程去抢CUP片都是随机的,是概率问题。下图是理想状态
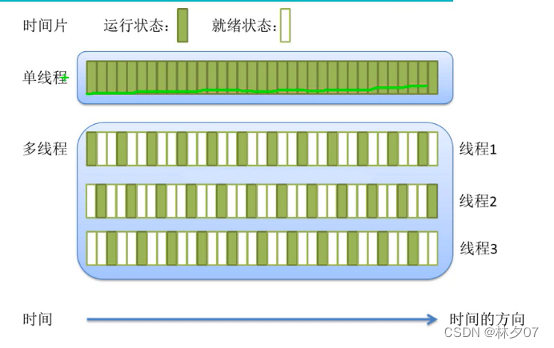
-
CPU的调度和切换:线程的上下文切换比进程要快的多
上下文切换:进程/线程分时复用CPU时间片,在切换之前会将上一个任务得到状态进程保存,下次切换会这个任务时候,加载这个状态继续运行,任务从保存到再次加载这个过程就是一次上下文切换。状态保存在寄存器中。 -
线程更加廉价,启动速度更快,退出也快,对系统资源的冲击小。
在处理多任务程序的时候使用多线程比使用多进程要更加有优势,但是线程并不是越多越好,如何控制线程的个数呢?
- 文件IO操作:文件IO对CPU是使用率不高,因此可以分时复用CPU时间片,线程的个数=2*CPU核心数(效率最高)
- 处理复杂算法(主要是CPU进行运算,压力大),线程的个数=CPU的核心数(效率最高)
创建线程
线程函数
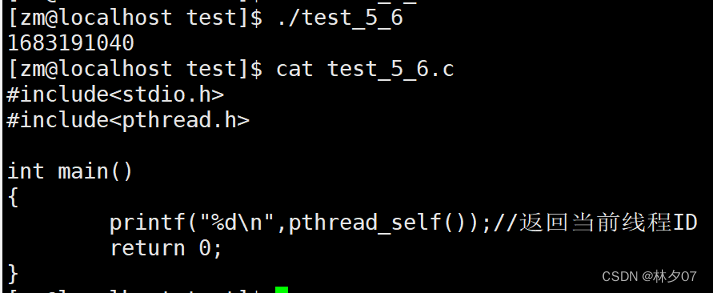
每个线程都有一个唯一的线程ID,ID类型为:pthread_t,这个ID类型为一个无符号长整型数,如果想要得到当前线程的ID,可以调用如下函数:
头文件:#include<pthread.h>
函数原型:pthread_t pthread_self(void);//返回当前线程ID
下面是在linux下测试的数据图。
pthread_create
在一个进程中调用线程创建函数,就可以达到一个线程,和进程不同,需要给每个创建出的线程指定一个处理的函数,否则这个线程无法工作。
头文件:#include<pthread.h>
函数原型:int pthread_create(pthead_t *thread, const pthead_attr_t *attr, void *(*start_routine)(void *), void * arg);
线程库得到名字叫lpthread,全名:libpthread.so libpthread.a
参数:
- thead:传出参数,是无符号长整型,线程创建成功,会将线程ID写入到这个指针指向的内存中。
- attr:线程的属性,一般情况下使用默认属性即可,写NULL
- start_routine:函数指针,创建出的子线程的处理动作,也就是该函数在子线程中执行。
- arg:作为实参传递到start_routine指针指向的函数内部。(如果参数多可以定义一个结构体然后传入一个结构体就好了)
**返回值:**线程创建成功返回0,创建失败返回对应的错误号。
由于pthread库不是Linux系统默认的库,连接时需要使用库libpthread.a,所以在使用pthread_create创建线程时,在编译中要加-lpthread参数 test_5_6_2
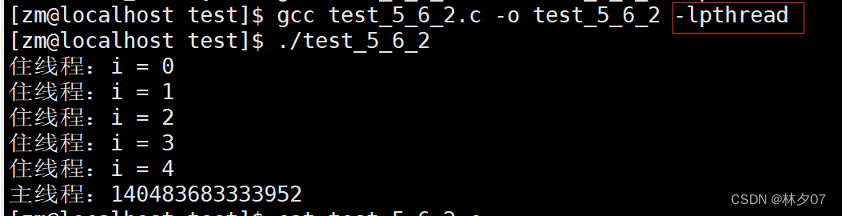
下面是源码:
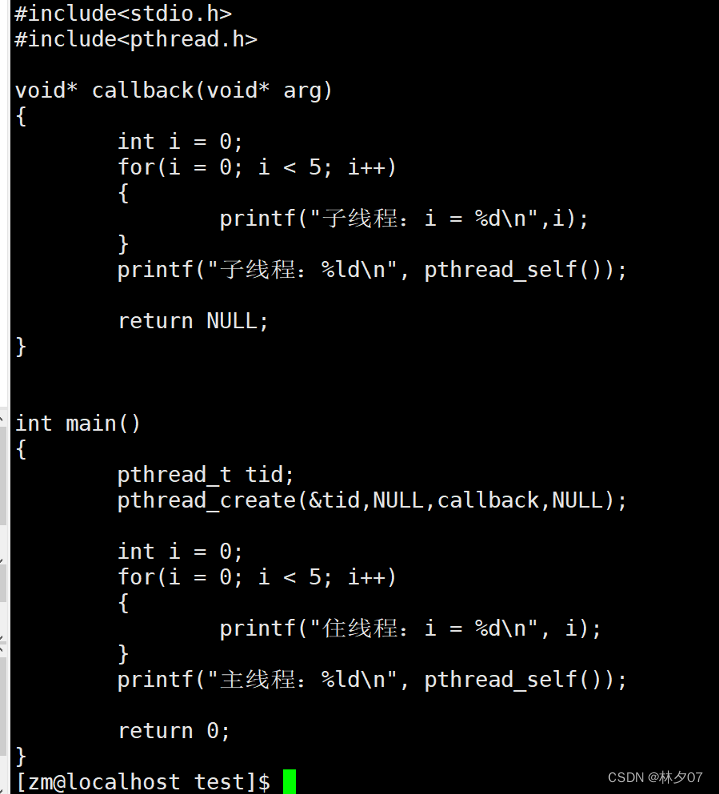
为什么没有输出子进程数据?
原因: 因为程序是从main函数开始执行,从主线程进来之后,然后创建出来子线程,有可能子线程还没有抢到时间片,主线程就执行完毕了,就会把地址空间释放了,子线程的家就没有了。因此子线程所有的资源也就被释放了。
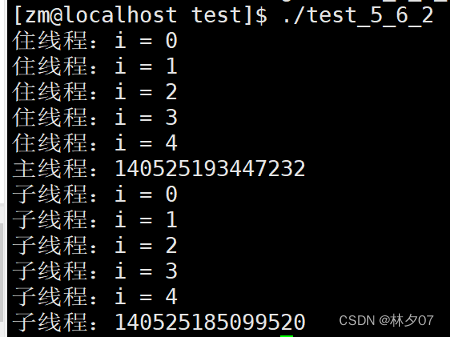
解决方案: 我们可以让主线程等一会,sleep(2),表示主线程睡眠3秒,睡眠就会放弃CPU资源,不消耗系统资源
当我们加入sleep(3)时执行如下:
线程退出
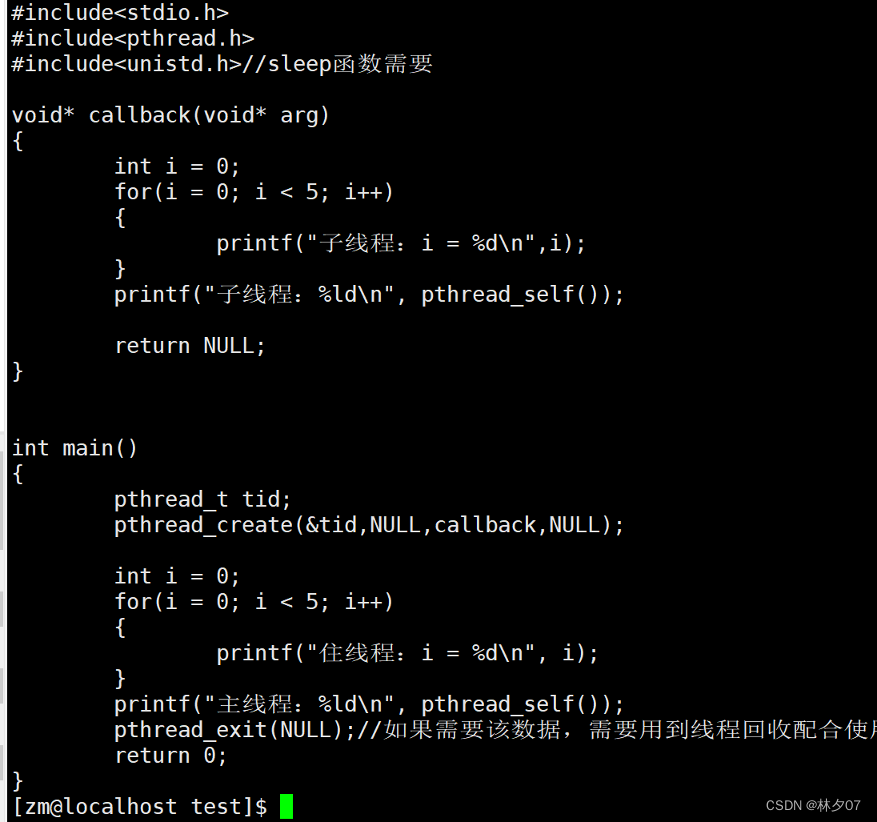
在编写多线程程序的时候,如果想要让线程退出,但是不会导致虚拟地址空间的释放(针对于主线程),我们就可以调用线程库退出函数,只要调用该函数当前线程就马上退出了,并且不会影响到其他线程的正常运算,不管是在子线程或者主线程都可以使用。
头文件: #include<pthread.h>
函数原型: void pthread_exit(void *retval);
参数: 线程退出的时候携带的数据,当前子线程的主线程会得到该数据,(需要配合线程回收使用)如果不需要使用,就指定为NULL
测试结果:
源代码:
线程回收
线程函数
线程和进程一样,子线程退出的时候其内核资源主要由主线程回收,线程库中提供的线程回收函数叫pthread_join(),这个函数是一个阻塞函数,如果还有子线程在运行,调用该函数就会阻塞,子线程退出函数解除阻塞进行资源回收,函数被调用一次,只能回收一个线程,如果有多个子线程则需要循环回收。释放的实际是内核区的资源。
通过线程回收函数还可以获得到子线程退出时传递出来的数据
头文件: #include<pthread.h>
函数原型:int pthread_join(pthread_t thread, void **retval);
说明 :子线程在运行这个函数就会阻塞,子线程退出,函数解除阻塞,回收对应子线程的资源,类似于回收进程使用的函数wait()
参数:
- thread:要被回收的子线程的线程ID
- retavl:二级指针,指向一级指针的地址,是一个传出参数,这个地址中存储了pthread_exit()传递出来的数据,如果不需要这个参数,可以指定为NULL
返回值: 线程回收成功返回0,回收失败返回错误号。
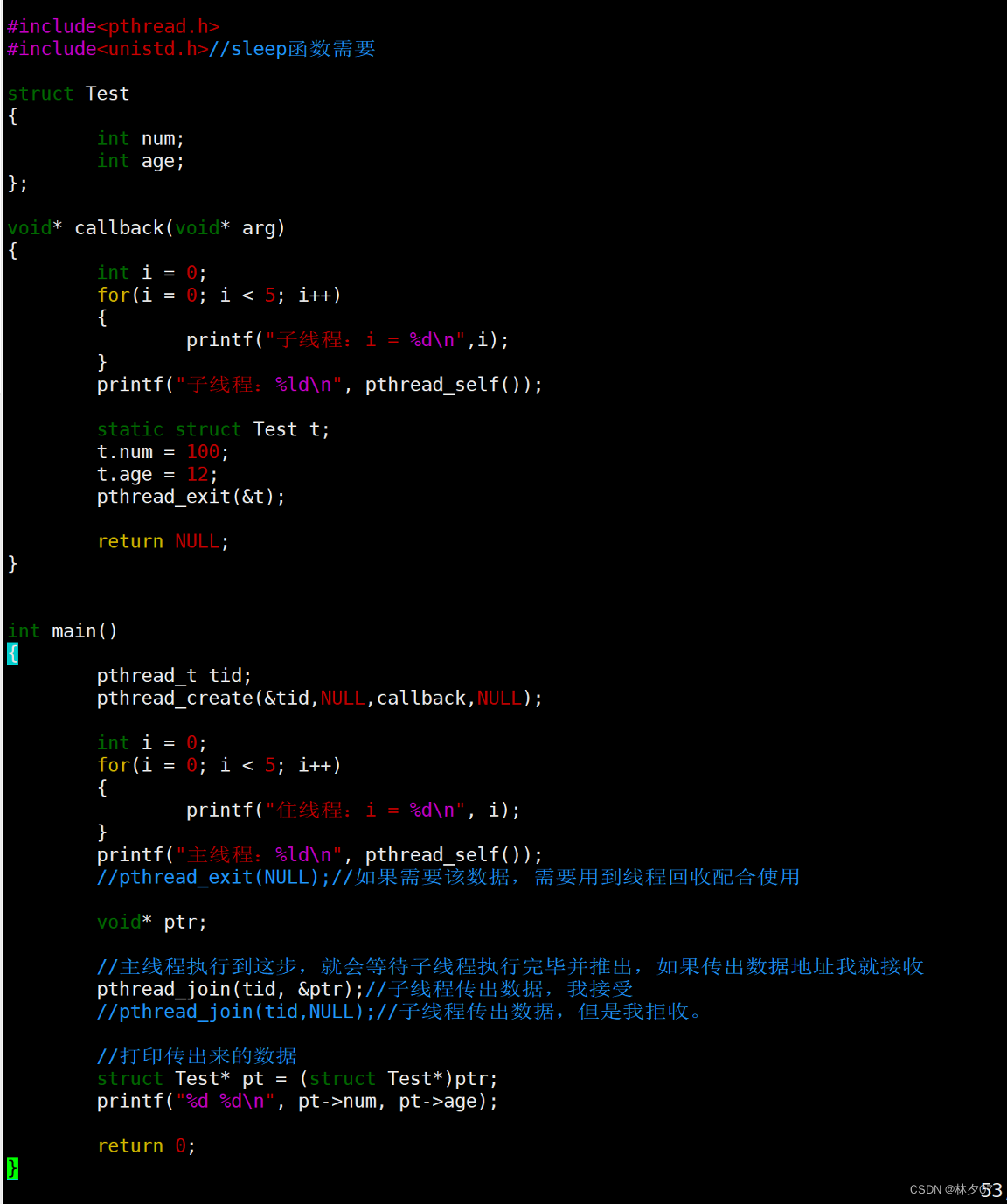
返回时候切记不能返回堆区变量,所以我们这时候把变量定义为全局变量或者静态变量延长声明周期。还可以把变量创建到主线程的栈空间。
使用子线程栈且定义为static变量
使用主线程栈
下图为把变量创建到主线程的栈空间。
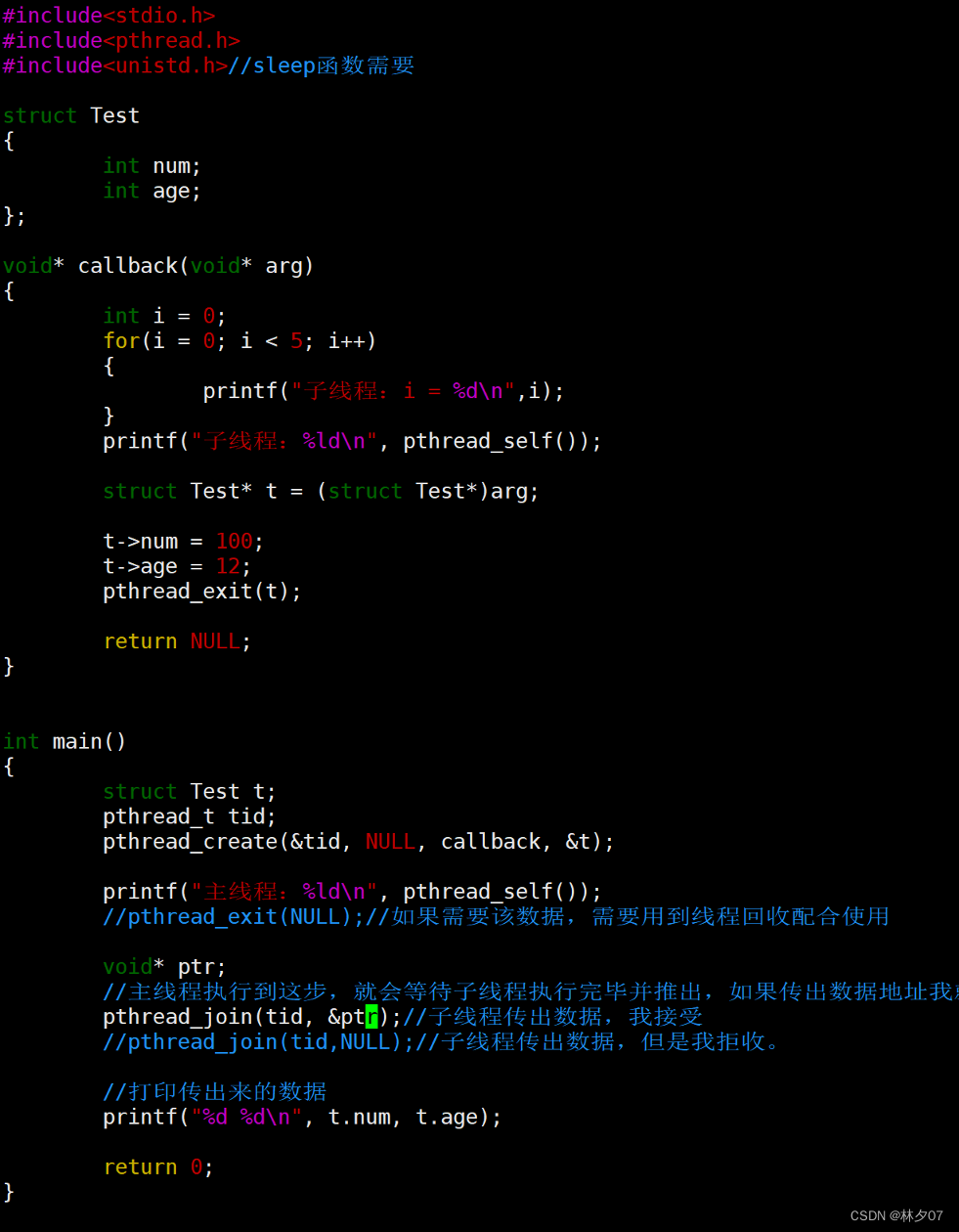
create函数创建时候将t的地址传入callback函数,然后callback函数将传入的类型进行强制转换然后赋值,然后执行线程退出函数,主函数使用join回收函数接受。
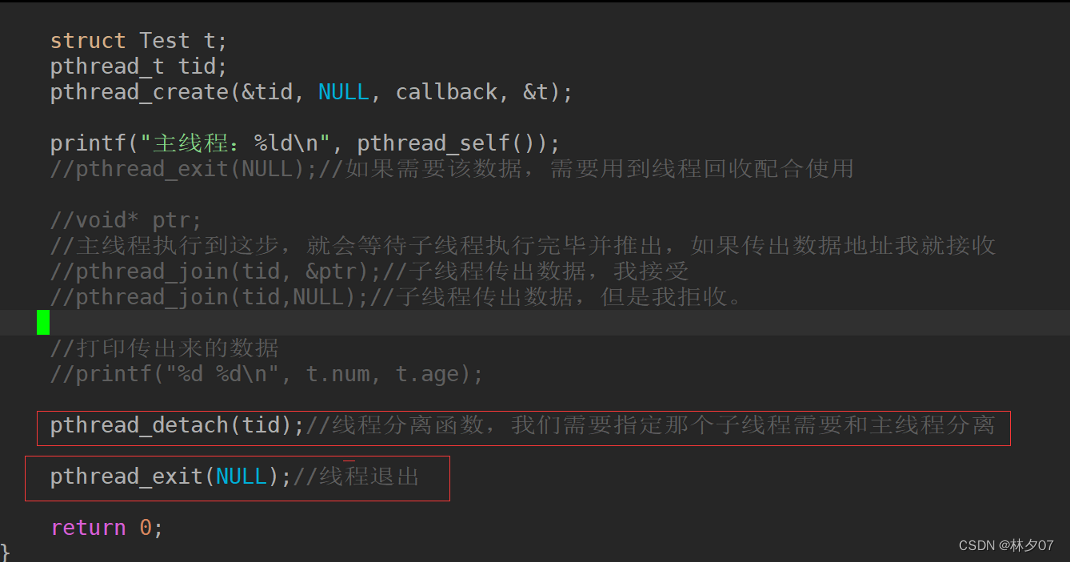
线程分离函数
在某些情况下,程序中的主线程有属于自己的业务处理流程,如果让主线程负责子线程的资源回收,调用pthread_join()只要子线程不退出主线程就会一直阻塞,主线程的任务也就不能被执行了。
在线程库函数中为我们提供了线程分离函数pthead_detach(),调用这个函数之后指定的子线程可以与主线程分离,当子线程退出的时候,其占用的内核资源就被系统的其他进程接管并回收了。线程分离之后的主线程中使用pthread_join()就回收不到子线程的资源。
测试代码:
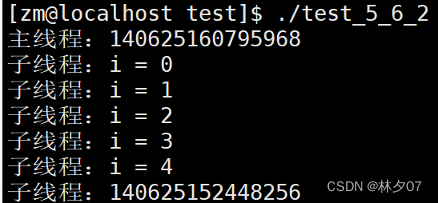
测试结果:
其他线程函数
线程取消
线程取消就是在某些特定的情况下在一个线程杀死另一个线程。使用这个函数杀死一个线程需要俩步:
- 在线程A中调用线程取消函数pthead_cancel(),指定杀死线程B,这时线程B是死不了的。
- 在线程B中进行一次系统调用(从用户区切换到内核区),否则线程B可以一直运行。(类似于我吃了毒药,但是只要我不动就没事)
头文件:#include<pthead.h>
函数原型:int pthread_cencel(pthead_t thread);
参数:要被杀死的线程
返回值:函数调用成功返回0,调用失败返回错误码
系统调用:
- 直接调用Linux系统库函数
- 调用标准的C库函数,为了实现某些功能,在Linux平台下标准C库函数会调用相关的系统函数。
下图中红线框起来的区域不会被执行,因为线程已经被杀死了,调用printf函数就相当于执行系统调用,然后就死掉了。
源代码:
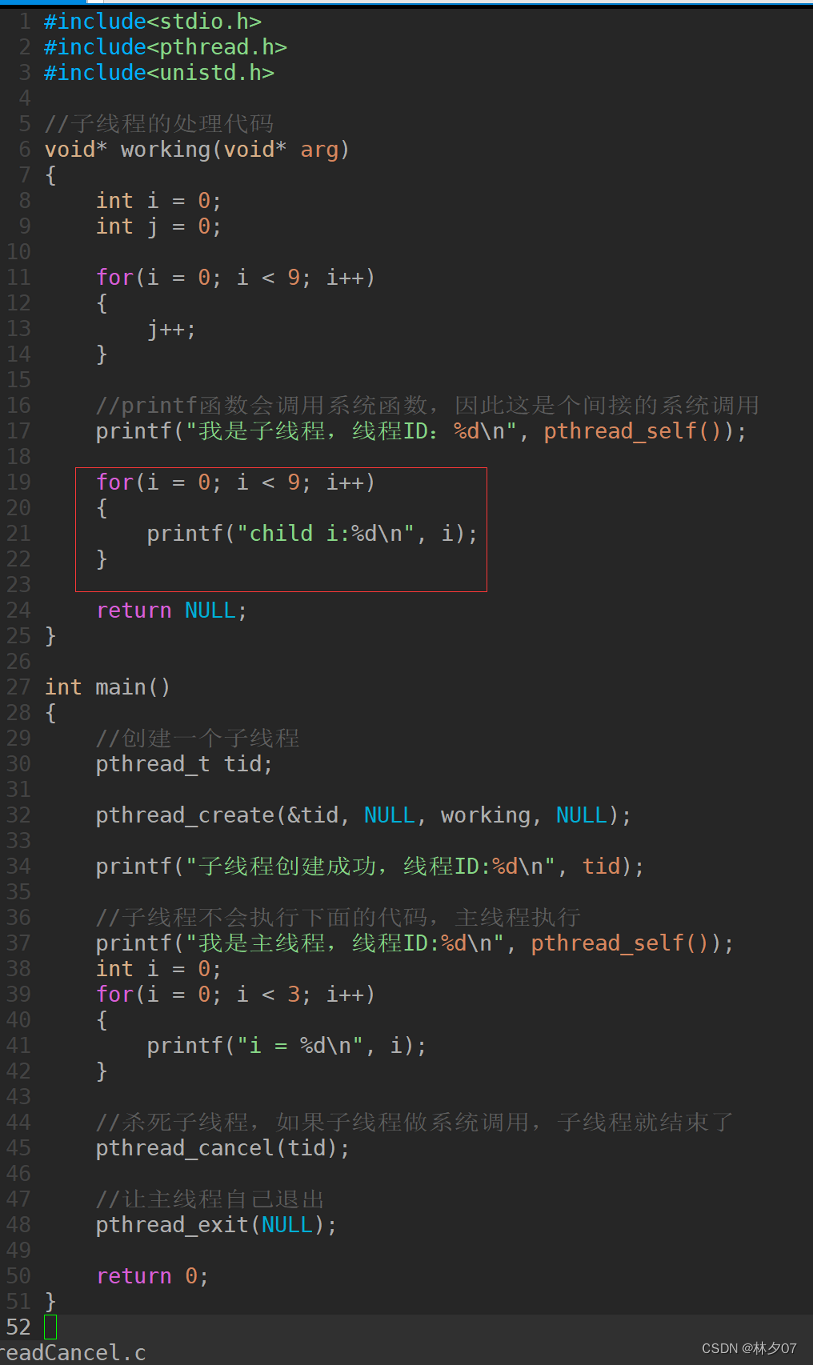
测试代码:
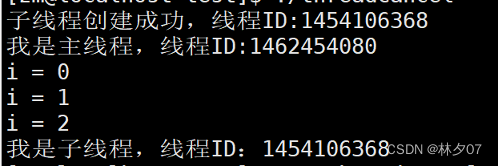
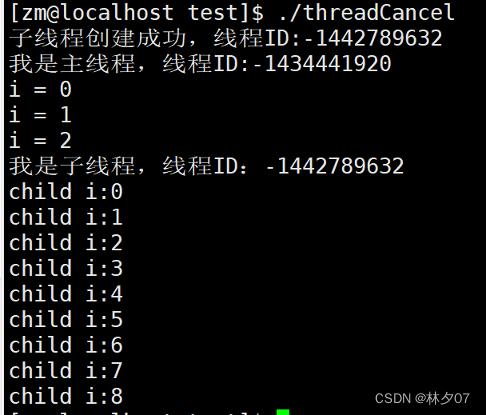
下图是把杀死进程注释掉后的结果 我们可以发现下面的图就把上面代码中红色区域的输出来了。
线程ID比较
在Linux中线程ID本质就是一个无符号长整型,因此可以直接使用比较操作符比较俩个线程的ID,但是线程库是可以跨平台使用的。在某些平台上pthread_t可能不是一个单纯的整型,这种情况下比较俩个线程的ID必须使用函数,
函数原型如下:
头文件:#include<pthread.h>
函数原型:int pthread_equal(pthread_t t1, pthread_t t2);
参数:t1和t2就是要比较的线程ID
返回值:如果俩个线程ID相等返回非0值,如果不相等返回0;