汽车-ARM-PCIE-服务器-FPGA-ASIC分析
参考文献链接
https://mp.weixin.qq.com/s/BRY2ExcWztl7vf69UyNAUw
https://mp.weixin.qq.com/s/z2XsXUiLovEAMLo3GJw0Lw
https://mp.weixin.qq.com/s/3k2ZQC5U2eoWmp62t_A1VA
https://mp.weixin.qq.com/s/bluSjR21J72tKZipTKQ9Og
https://mp.weixin.qq.com/s/9VoEgizWU8wNjfGVYDEX1g
https://mp.weixin.qq.com/s/fwoBLHxgio1MSPB6n8x6WQ
智能驾驶:算力现状及解决方案
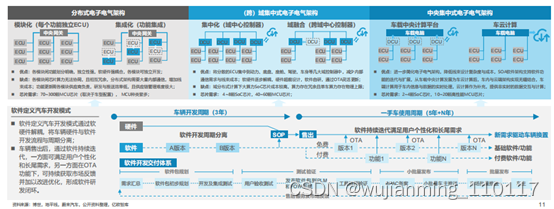
传统功能汽车采用分布式电子电气架构,离散化的ECU软硬件紧耦合且各ECU之间独立性较强,硬件资源无法共享且形成数据孤岛,对用户新需求反馈的整体周期长达20个月以上,难以形成持续快速迭代的软件开发模式。
因此,软件定义汽车开发模式驱动整车电子电气架构由分布式向中央集中式演进,其核心是车载计算的集中化发展,高集成化的域控制器、车载中央计算平台是关键。
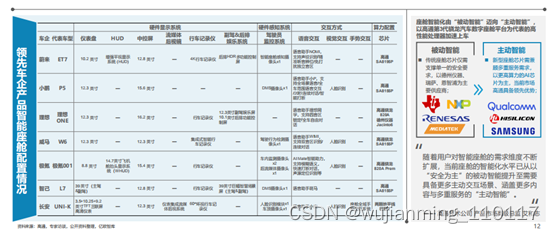
智能座舱是实现千人千面汽车驾乘体验的重心所在,新势力车企与领先自主品牌车企率先发力,“大屏化”、“多屏化”、“多模态交互”、“一芯多屏”成为座舱发展的热门趋势,伴随着传感器规模的增长与交互模式的复杂化,智能座舱对芯片的算力需求亦水涨船高。
座舱高算力需求驱动下,以高通第3代汽车数字座舱平台为代表的高性能处理器成为领先车企旗舰车型的主流选择,骁龙系列芯片加速上车。
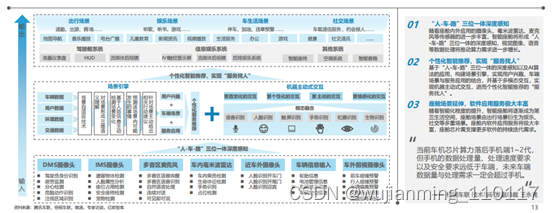
在感知、交互、场景应用持续升级的背景下,座舱芯片需支撑大规模传感器数据处理、持续攀升的AI算法数量与海量应用软件服务,座舱数据量与处理需求将超过手机,算力需求飞速增长。作为操作系统级车联网解决方案供应商,梧桐车联认为座舱计算平台大算力发展已成必然趋势。大算力的座舱SoC芯片将减少组件数量,降低架构复杂程度,智能座舱计算平台将持续向集成式解决方案演进。
伴随着ADAS辅助驾驶功能在新车市场上渗透率的不断提升,新势力与领先自主品牌车企在智能驾驶领域的厮杀日益激烈,智能驾驶传感器配置走向“内卷”,以蔚来、小鹏、极狐为代表的车型更是率先宣布激光雷达量产上车。当前智能驾驶芯片市场呈现Mobileye与英伟达二分天下之势,以地平线、海思为代表的本土化芯片厂商凭借AI计算与大算力优势在自主品牌车企市场中占据一席之地,率先实现国产芯片量产上车。
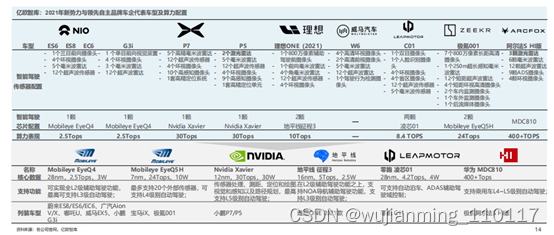
为保证车辆在全生命周期内的持续软件升级能力,主机厂在智能驾驶上采取“硬件预置,软件升级”的策略,通过预置大算力芯片,为后续软件与算法升级优化提供足够发展空间。以蔚来、智己、威马、小鹏为代表的主机厂在新一代车型中均将智能驾驶算力提升至500~1000Tops级别。

对于L3级别及以上的智能驾驶系统而言,传感器数量的增加及分辨率的提升带来海量数据处理需求,算法模型的复杂程度亦大幅提升,驱动算力需求迅速增长。软硬件解耦的智能驾驶芯片是实现算法持续迭代升级的基础,以英伟达为代表的开放算法生态的芯片更受主机厂青睐。
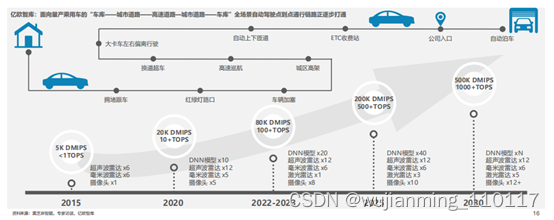
以高通、英伟达为代表的国际芯片巨头在大算力芯片上具备绝对领先优势。以地平线、海思、黑芝麻智能、芯驰科技为代表的本土自主芯片厂商上发力追赶,在产品力上跻身领先梯队。芯片的绝对算力高低固然重要,但对于主机厂开发量产车型而言,芯片选择需兼顾算力、成本、功耗、易用性、同构性等多重因素。因此,如何在有限算力下帮助客户算法软件最高效地运行是衡量芯片厂商竞争力的核心标准。

大算力芯片的上车应用离不开车载计算平台的支撑。为支持并兼容L3及以上智能驾驶系统数量与类型繁多的传感器与执行器需求,车载计算平台多采用异构芯片硬件方案,以满足系统接口与算力需求。异构芯片硬件方案包括采用单板卡集成多种架构芯片的方案,以及采用同时集成多个架构单元的SoC芯片的方案。车载计算平台可通过提高单芯片算力、复制堆叠计算单元等方式实现算力的弹性拓展。

由于车载计算芯片仍在不断发展中,车载计算平台的异构芯片形态将长期存在。相较传统ECU,车载计算平台的复杂度呈数倍提升,面临功耗、散热、电磁、质量等多重挑战。此外,由于能效比、工艺制程以及芯片堆叠带来的功耗、散热与成本挑战,车载计算平台算力存在物理上限。
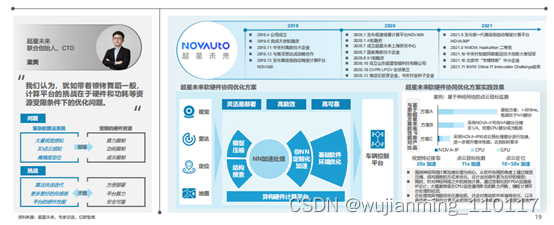
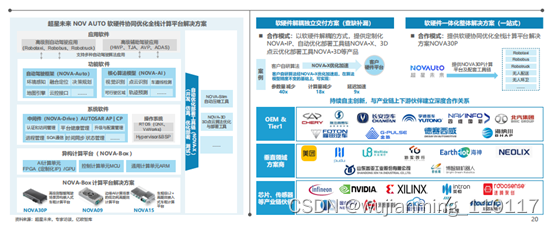
超星未来核心产品包括:NOVA-Box 自动驾驶计算平台、NOVA-X 自动模型优化工具链、NOVA-3D点云算法优化加速与部署工具、NOVA-IP面向自动驾驶域的定制加速IP库、NOVA-Drive高可靠性中间件、NOVA-Auto自动驾驶框架、NOVA-AI自动驾驶核心算法模型等。
超星未来已与赛灵思、德赛西威、英恒科技、宇通客车、陕汽商用车、普渡机器人、奇瑞、文远知行等一线汽车供应商、主机厂、机器人和自动驾驶公司建立战略合作关系。
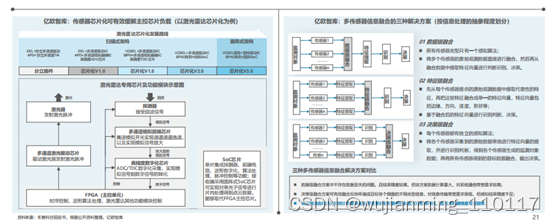
根据信息处理的抽象程度,多传感器信息融合可分为数据级、特征级、决策级三种解决方案。通过传感器芯片化与多传感器信息特征融合解决方案的结合,在传感器端完成原始数据的特征提取,在车载计算平台完成特征数据融合、识别判断和决策,可有效缓解车载计算平台计算负载。
随着车规级芯片制程的逐步突破,受限于车端物理环境,芯片制程将到达极限,摩尔定律下单芯片算力增长难以持续,车端算力终将到达物理上限。为满足智能座舱与智能驾驶的持续深化发展,智能汽车算力供给模式将走向“云-网-边-端”融合计算,实现算力供给的弹性拓展。
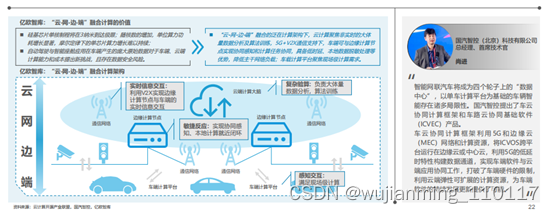
通过云端、通信网端、边端、车端的连接融合,可建立一个充满计算和通信能力的环境,形成智能汽车算力服务网络。新的计算架构下,5G+V2X提供更高效的通信管道,云端、边端、车端之间可实现近实时的数据交互。智能汽车与边缘计算节点实现协同感知和计算任务协同,具备低时延、本地数据脱敏处理等优势,车载计算平台聚焦现场级计算需求,云计算则聚焦非实时的大体量数据分析与算法训练。
FPGA和ASIC
从ASIC 在比特币挖矿机时代的发展历史,可以看出 ASIC 在专用并行计算领域所具有的得天独厚的优势:算力高,功耗低,价格低,专用性强。谷歌最近曝光的专用于人工智能深度学习计算的TPU、其实也是一款 ASIC。人工智能时代逐步临近,FPGA、ASIC这几块传统领域的芯片,将在人工智能时代迎来新的爆发。
土耳其伊斯坦布尔 ElectraIC 总经理兼管理合伙人 Ates Berna 最近在 LinkedIn 上发布了一份总结比较图表,展示了 FPGA 和 ASIC 之间的差异。
虽然这不是一个详细的图表,但我认为它是一个很好的破冰船,当你需要一个相当复杂的高性能、非标准 IC 来解决设计挑战时,它会导致关于你在 FPGA 和 ASIC 之间做出的选择。
经常收到 FPGA 与 ASIC 的问题,我认为讨论 Berna 发布的图表很有价值。因此,这里对图表中的项目进行了更详细的逐行讨论:
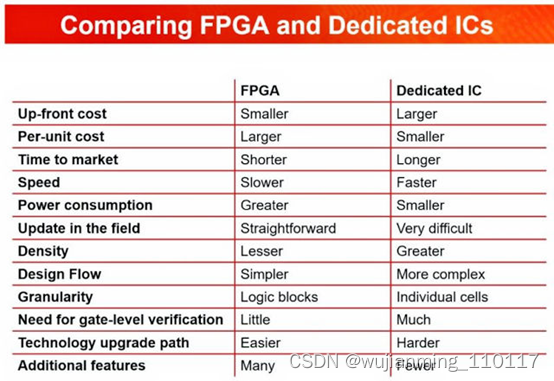
这是我对这张图表的逐行讨论:
预付费:ASIC 的前期成本很高。首先,ASIC 开发工具的成本。您需要一个相当大的工具链来开发 ASIC,您必须租用或购买,并且您需要知道如何使用这些工具。如果您的设计团队没有这些知识,您需要将培训团队的成本包括在您的前期成本清单中。此外,您将产生相当大的 NRE(非经常性工程)费用,大约为数十万或数百万美元,您将支付给硅代工厂以构建您的 ASIC。NRE 费用用于支付掩模制造和检查,在代工厂繁忙的制造计划中预留一个位置来制造您的 ASIC、芯片测试和分拣、封装和最终测试。相比之下,FPGA 是现成的部件,因此没有代工 NRE 费用,FPGA 工具比 ASIC 设计工具便宜得多,大概低三个数量级。根据 FPGA 的不同,您甚至可以通过分销方式购买零件并在第二天获得。
单位成本:这就是 ASIC 大放异彩的地方。因为您通常设计 ASIC 以满足您的确切设计要求,所以您只购买您真正想要的硅片。很少或没有浪费。因此,假设您有预计的产品销量来证明创建 ASIC 的合理性,那么 ASIC 的单位成本应该低于 FPGA。这是因为 FPGA 的芯片开销很大。首先,您的设计可能无法 100% 使用任何给定的 FPGA。如果幸运的话,您可能会获得 90% 的利用率。通常,您可能无法使用多达 10% 或更多的 FPGA 资源来满足可布线性和时序目标,因为布线拥塞太大,并且如果您尝试使用整个 FPGA,信号会变得太长和太慢。此外,FPGA 上的信号路由矩阵非常丰富,以确保您可以在 FPGA 上路由您的设计。
上市时间:到目前为止,FPGA 是上市时间的领先者。如果您已准备好制造 pcb,则可以在 FPGA 设计完成的同一天发货。您需要做的就是将最终配置闪存到板上的 EEPROM 中,对其进行测试、封装并发货。相反,当您完成 ASIC 设计时,您会将设计运送到硅代工厂并举行流片派对。然后,您等待几个月,而代工厂会接受您的设计、检查、制造芯片、测试芯片、封装芯片,然后将封装好的 ASIC 寄回给您。当您收到完成的 ASIC 盒时,您可以构建和测试您的电路板。同时,来自竞争对手的类似产品,但基于 FPGA,在您等待从代工厂取回 ASIC 的那几个月里,将一直在您的市场上销售。如果上市时间对您来说至关重要,那么 FPGA 可能是您的最佳选择。
速度:假设您的设计人员知道他们在做什么,ASIC 从任何给定的 IC 工艺节点中提取最高性能。由于 FPGA 的大型(电容式)可编程路由矩阵,相对于 ASIC 的性能,任何给定的 IC 工艺节点的性能都会损失大约一个数量级。
能量消耗:这并不明显,但 FPGA 在单位成本和速度方面的硅效率低下也增加了 FPGA 相对于 ASIC 的功耗。FPGA 上的所有这些额外的路由矩阵晶体管都会泄漏,从而导致更高的静态功耗。由于有序 FPGA 中所需的曼哈顿布线,FPGA 中固有的较长布线会为每条布线增加电容,从而导致更高的动态功耗。但是,FPGA 供应商可以反击其 FPGA 中的额外功耗。
例如,莱迪思半导体为其 Nexus FPGA 选择了 28nm FDSOI 工艺技术,以降低静态功耗。有很多这样的设计技巧可以降低功耗,但是 FPGA 有大芯片,大芯片有很多电容,
现场更新:这是一个容易理解的。基于 SRAM 的 FPGA 很容易在现场重新编程。更改存储在闪存中的配置并更新您的设计。在 FPGA 设计的早期,您必须从其 IC 插座中拔出旧配置的 EPROM 或 EEPROM,然后插入一个新配置来执行现场更新。如今,您很可能通过 USB 或 JTAG 端口进行可重编程设计。一些最终产品设计允许无线更新,尽管允许无线硬件更新存在许多安全问题。
相反,更新 ASIC 通常需要换板(在无线行业中称为上门服务)。一些 ASIC 设计结合了来自 eFPGA 供应商(如 Achronix、Flex Logix、Menta 或 QuickLogic)的嵌入式 FPGA (eFPGA) 结构,以实现有限数量的现场更新而无需上门服务。如果您想采用这种方法,您甚至可以获得名为 OpenFPGA 的开源 FPGA 结构生成器和工具集。但是,如果您在 ASIC 中嵌入 FPGA 架构,那么 ASIC 就变成了 FPGA,不是吗?
密度:因为器件密度与单位成本密切相关,所以同样适用 FPGA 与 ASIC 的论点,只是增加了一点。在任何给定的工艺技术中,由于 FPGA 的路由开销和资源利用限制,您总是可以设计一个更大的设备,一个具有更多资源的 ASIC,如上所述。
设计流程:与 ASIC 不同,FPGA 的物理设计在您看到设备之前已经为您完成并由 FPGA 供应商验证,尽管有勘误表。您通常会使用一个供应商的工具链来设计 FPGA 配置,尽管一些富有的设计公司使用来自三大 EDA 供应商之一的 ASIC 级布局布线工具:Cadence、Siemens/Mentor 和 Synopsys。对于 ASIC 设计,您通常会采用混合搭配的方法,从三大 EDA 公司购买 EDA 工具,也许还从尚未被三大 EDA 公司之一吸收的新 EDA 初创公司购买一些额外的设计工具.
粒度:ASIC 的数字粒度是一个门,或者在某些情况下是一个晶体管。FPGA 必须具有更粗的粒度,大约为一个逻辑单元。否则,FPGA 的布线开销将变得完全不切实际。ASIC 和 FPGA 之间的这种粒度差异导致 FPGA 更高的单位成本和相对缺乏密度。
需要门级验证:FPGA 和 ASIC 一样需要设计级验证。但是,FPGA 在门级不是细粒度的,因此它们不需要门级验证。您将每个门都放置在 ASIC 设计中,因此您需要验证每个门。
技术升级路径:理论上,在一个 FPGA 供应商的产品线中从一个 FPGA 系列升级到下一个系列会更容易。例如,通过三个 Xilinx 7 系列器件迁移设计相对容易:Artix、Kintex 和 Virtex。然而,迁移到其他供应商的 FPGA 也意味着迁移到其他 FPGA 供应商的设计工具,这并不是特别容易,尽管它并不像某些人可能认为的那么困难。工程师们已经设法掌握了不止一个 FPGA 供应商的工具链。他们只是在进行更改时抱怨很多。ASIC 没有技术升级路径。要升级 ASIC,您需要设计、验证和制造新的 ASIC。
附加功能:在这里,我必须与上面的图表不同。尽管 FPGA 供应商长期以来一直在寻找附加功能块以添加到他们的 FPGA 中,但 FPGA 上可用的几乎任何东西都可以作为 IP 设计或购买并放置在 ASIC 上。这可能并不容易,但通常是可能的。关于 ASIC IP 的声明包括嵌入式 FPGA IP。也许该图表旨在表明更容易利用 FPGA 供应商塞进其部件中的许多其他前沿特性。例如,FPGA 供应商在过去 20 年一直引领着高速 SerDes 设计。如果您想要一个快速的 SerDes,您可能会在 FPGA 供应商的最新设备上找到最快的,尤其是 Achronix、Intel 和 Xilinx。
当然还有很多其他的设计考虑没有出现在上面的图表中。例如,在 FPGA 和 ASIC 之间有一个中间步骤——结构化 ASIC——与 ASIC 相比,它以更低的 NRE 成本提供了 ASIC 的许多(但不是全部)优势。十五年前,许多公司提供结构化 ASIC,并建议它们是下一代门阵列。由于许多商业原因,仅剩下一家商业结构化 ASIC 供应商——英特尔——它在 2018 年收购了最后一家结构化 ASIC 供应商 eASIC。
尽管触发本文的图表并不全面,但它确实为在 FPGA 和 ASIC 之间做出决定提供了一个很好的起点。到目前为止,这篇文章应该已经戳到了某人的痛处,所以请随时发表评论,让我们知道您的想法。
科技巨头涌入ARM

涉及ARM商业模式及体系优势、ARM应用场景、苹果等巨头开始拥抱ARM生态、国内应用ARM及ARM公司内核研发的进展等。
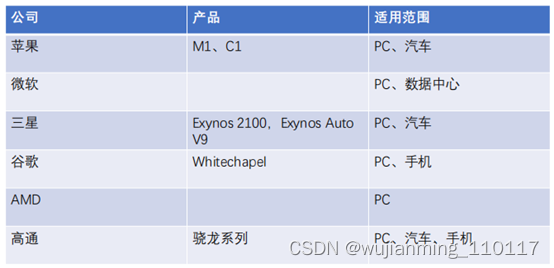
根据EETimes 分析师Colin Barnden的预测,Apple Car将搭载基于ARM架构的C1芯片,并支持眼球追踪等AI功能。新造车势力高通、Nvidia以及海思,以及传统汽车芯片供应商瑞萨、TI、NXP等,都是ARM在汽车领域的重要合作伙伴。
众多科技巨头的参与,共同拓展ARM在PC和数据中心的应用。目前谷歌、苹果、微软、三星、AMD都有制造ARM芯片的计划,几乎囊括了重量级的科技公司半壁江山。从业务范围来看,PC、数据中心是主要的应用方向。从软件生态来说,越来越多的应用开始支持ARM芯片,例如微软Office、金山Office、Photoshop等。
独特的商业模式确保中国生态的形成。ARM的版权授予模式给合作伙伴提供了有力的保障。我们看到ARM中国形成了自己的四大内核芯片“周易”、“星辰”、“山海”、“玲珑”,能够为中国的客户提供有力的支撑。2020年10月,吉利汽车宣布与ARM中国联合成立芯擎科技,计划生产车规级的芯片以及自动驾驶芯片。
ARM在加速革新汽车芯片
基于ARM内核的处理器芯片的应用覆盖了汽车电子的方方面面, 包括车载信息娱乐、车身控制、动力系统、安全系统、舒适系统等。2020年ARM推出新的Cortex-A78AE,带来了更高性能的CPU内核,还首次采用了AE级GPU Mail-G78AE和ISP Mail-C71AE,与上一代Cortex-A78AE(2018年)相比,IPC提升30%,性能更高。

ARM于2021年3月份发布了Arm® Cortex®-R系列的最新产品Cortex-R52+,更好的支持汽车电子设计的电子化趋势。
智能座舱市场
根据ICVTank公布的数据显示,2019年全球智能座舱行业市场规模达364亿美元,2022年有望达到461亿美元;中国2019年中国智能座舱行业市场规模达441.1亿元,2022年有望达到739亿元。
2019年,Arm携手通用汽车、丰田、DENSO、博世、大陆集团、英伟达、恩智浦共同成立自动驾驶汽车计算联盟(AVCC),开拓ARM自动驾驶布局,目前已经发展到19名成员。

众多IT巨头在ARM行业的布局
据Geekbench 跑分显示,搭载 M1 芯片、配备 8GB RAM 的 MacBook Air 单核得分为 1687,多核得分为 7433。与现有设备相比,MacBook Air 的 M1 芯片性能优于所有 iOS 设备。
苹果后续的芯片研发计划
根据彭博社的消息,苹果正在研发M1芯片的后续产品,新版MacBook Pro、新款iMac和新Mac Pro将会使用,最早将于明年推出。目前的M1芯片配备了8个GPU 核心,苹果正在测试16个GPU核和32个GPU核心的型号,将会用于计划在2021年晚些时候推出的高端台式电脑,以及计划在2022年推出的全新小尺寸Mac Pro。苹果还计划在2021年底或2022年开发128核的芯片。
苹果后续的M1X设计为12核、M2为16核,包括12颗高性能核心(大核)和4颗效率核心(小核),性能将是当前M1的四倍强,M1X则是M1的两倍强。
AMD/谷歌/微软正在研发ARM芯片
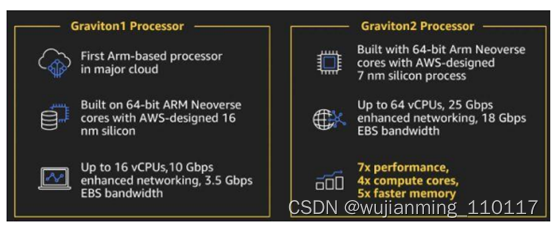
2020年11月,根据Twitter用户@Mauri QHD的报道,在苹果发布M1芯片之后,AMD已经在设计ARM的芯片原型,包含集成RAM和没有集成RAM的两个版本。
2020年12月,根据外媒Axios报道,谷歌正在研发基于ARM的移动处理器,命名为Whitechapel,它将应用在未来的Pixel智能手机和Chromebook笔记本。该芯片基于三星的5nm制程,包含八个ARM内核,并能提高Google Assistant应用的性能。
2020年12月,根据彭博报道,微软计划制造ARM芯片,用于Azure 云平台和Surface设备。目前微软旗下的云服务Azure和Surface大多主要使用基于x86架构的Intel芯片,不过微软已经在慢慢从英特尔转向其他公司,例如在其Surface Pro X设备中就尝试使用和高通合作生产的基于ARM的芯片SQ1。
亚马逊云计算AWS已经使用ARM处理器
2020年6月,据Silicon ANGLE报道,亚马逊云计算部门宣布第六代亚马逊弹性计算服务(EC2)现在开放服务,其中三种计算资源产品由公司自己研制的基于ARM架构的Graviton2处理器支持。和x86的同类产品相比,亚马逊使用自家ARM处理器的三款产品(通用M6g、计算优化C6g和内存优化R6g)的性价比高出40%。
2020年12月,ARM宣布将利用AWS为其云计算使用,包括将大部分电子设计自动化(EDA)工作负载迁移到云端。Arm正在利用基于AWS Graviton2的实例(由Arm Neoverse核心提供支持)将EDA工作负载迁移到AWS,在AWS上可以实现工作流时间以及吞吐量极大的改进,从而提升整体工作流程效率。
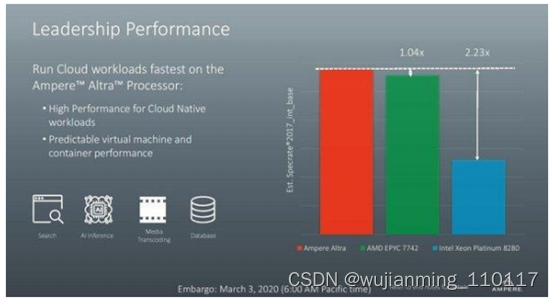
Ampere发布了首款80核的ARM服务器处理器
2020年3月,Ampere发布了Ampere Altra处理器,是首款80核的ARM服务器处理器,提供强大性能的同时拥有高能效。Ampere Altra处理器拥有80个核心,功耗为210 W,采用了台积电的7nm工艺,适用于数据分析、人工智能、数据库、存储、边缘计算、网络托管和云本地应用等用例。根据VentureBeat报道,Ampere认为该芯片比64核的AMD EPYC处理器和英特尔28核的高端Xeon“Cascade Lake”芯片速度更快。
2020年,众多合作伙伴和客户已经宣布对Ampere Altra的支持,正在提供样品,已开发平台或已构建解决方案。Oracle建立了一个基于Ampere Altra的平台并优化了其软件;NVIDIA宣布将GPU和DPU加速带入Arm生态系统,并与Ampere合作扩展了两个插槽的Ampere AltraMt。
Arm新型Cortex-A78C CPU发布专为笔记本电脑设计
Cortex-A78C支持多达8个大型CPU内核集群的更均质的多大内核计算。与Cortex-A78相比,八核配置可带来更多可扩展的多线程性能改进,还可以将L3高速缓存的内存增加到8MB,进一步提高性能。Cortex-A78C提供了有关数据和设备安全性的更新以确保设备上的数据保持安全。
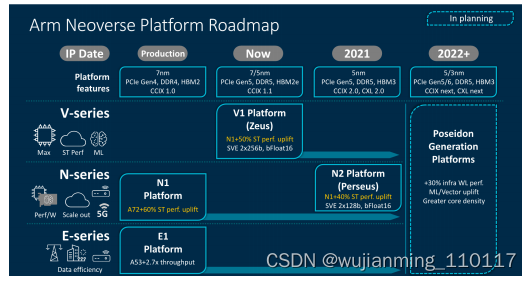
ARM 全新Neoverse 平台推出
NeoverseV1和Neoverse N2全新推出,Neoverse性能指标再度升级。NeoverseV1作为V系列的第一个平台,与N1相比,其单线程性能可提升超过50%,为高性能云、高性能计算与机器学习等市场带来庞大的应用潜力。Neoverse N2被定位为可提供更高性能计算的解决方案,用来满足横向扩展的性能需求,相比于N1单线程性能提升了40%。
ARM中国-玲珑
2020年12月3日,ARM中国发布了首款多媒体产品线,命名为“玲珑”,同时推出了首款产品“玲珑”i3/i5 ISP处理器。玲珑ISP处理器可广泛适用于安防监控、AIoT及智能汽车等领域的视频、图像处理工作,满足不同场景的数据处理需求。该产品线是ARM中国继“周易”、“星辰”、“山海”之后的第四条自主IP产品线。
ARM中国-周易
“周易”是一个开放通用的人工智能平台,拥有软件框架Tengine和人工智能处理单元(AIPU),能够带来最高达0.256TOPS的运算能力。
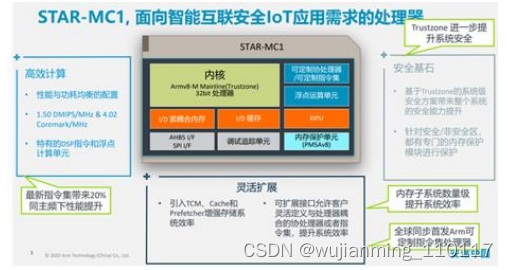
ARM中国-星辰
“星辰”处理器是安谋中国CPU设计团队设计的一款嵌入式处理器,基于最新的Armv8-M架构,可用于微控制器或者集成片上系统等芯片类型。“星辰”处理器针对物联网设备的需求进行了优化,能够充分满足物联网设备在实时控制,数字信号处理,安全运行,极低功耗,极小面积等方面的需求。
ARM中国-山海
“山海”是面向物联网设备的信息安全方案,通过一系列的固件和硬件组合,“山海”安全方案为物联网设备提供了全面而完整的安全防护,用户数据,算法和驱动程序等敏感信息都能得到完整的防护。
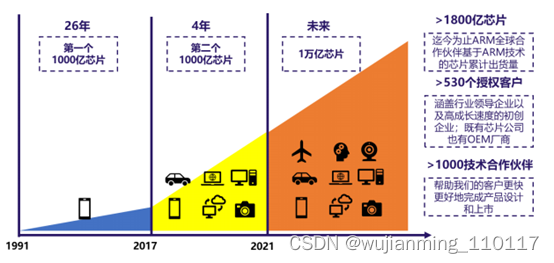
ARM发展远景
从移动端到PC端、服务器端再到汽车端、IoT端,ARM架构正在逐步走向一个庞大的生态系统。预计到2035年,将有超过1万亿台智能电子设备实现互联,从各种传感器、门禁卡、手机、家电、汽车,到工业机械、通信基站、数据中心、云服务器,基于Arm架构的芯片无处不在。
飞腾腾锐D2000/S2500/DCS
在2020年12月29日飞腾的生态发布会上,飞腾发布了全新一代基于ARM的腾锐D2000,性能大幅跃升。腾锐D2000 集成了 8 个飞腾自主研发的高性能处理器内核 FTC663,兼容 64 位 ARMv8 指令集,主频 2.3~2.6GHz,TDP 功耗 25W,支持飞腾自主定义的处理器安全架构标准 PSPA 1.0,满足更复杂应用场景下对性能和安全可信的需求。
在2020年7月,飞腾发布了腾云S2500处理器,最多64个FTC663架构的核心,提供128-512核心配置。在ARMv8指令集兼容的现有产品中,S2500在单核计算能力、单芯片并行性能、单芯片cache一致性规模、访存带宽等指标上都处于国际先进水平。S2500主要应用于高性能、高吞吐率服务器领域,如对处理能力和吞吐能力要求很高的行业大型业务主机、高性能服务器系统和大型互联网数据中心等。
2020年,基于飞腾CPU自主研发的、首套百分之百全国产化的100万千瓦级分散控制系统(DCS)华能“睿渥”,在华能玉环电厂成功投运,这标志着我国高参数、大容量发电领域核心控制设备实现完全自主可控,相关技术成果也进入大规模推广应用阶段,可从根本上消除电力网络安全的重大隐患。
华能“睿渥”DCS CPU采用了天津飞腾的FT-2000+/64、FT-2000/4、FT-1500A/4。
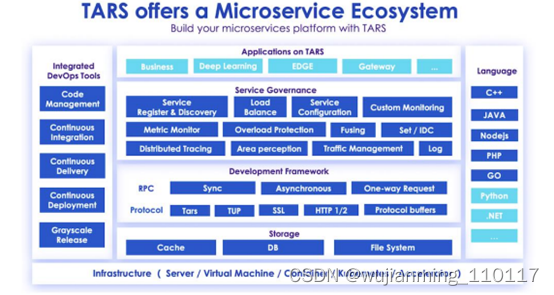
腾讯微服务框架TARS成功移植至Arm架构
2020年3月,腾讯宣布TARS微服务开发框架已成功移植至ArmCPU架构。TARS是一个成熟的高性能微服务开发框架,支持多种编程语言,如今已广泛应用于腾讯的在线社交、金融服务、边缘计算、汽车、游戏和安全等数百项核心业务中。
统信软件支持ARM架构
统信 UOS 推出 ISO 定制工具,支持 amd64、mips64、arm64 架构。这是专为厂商打造的镜像制作工具,用于满足厂商对硬件适配、产线安装等需求,既支持对程序和驱动 deb 包的二次定制,也支持对脚本的重新配置。统信 UOS 官网显示,运行 ISO 定制工具须同时满足以下几点:必须在统信 UOS 操作系统上运行;必须在 amd64、mips64、或 arm64 架构上运行。
百度云智峰会发布ARM私有云
2020年12月17日 “2020 ABC SUMMIT百度云智峰会”上,百度智能云ARM云总经理沈鹏飞分享了百度ARM云生态布局,重磅发布了主打“端云同构”的ARM私有云一体机与ARM私有容器云一体机。
字节跳动拟布局ARM服务器
在字节跳动的官网上,目前开放了大量的ARM相关职位,包括ARM服务器系统的性能和功耗优化,ARM服务器产品架构端到端设计和优化等,涉及到ARM的应用、建模、仿真、系统分析等诸多环节。这是在继苹果、三星、微软、谷歌等巨头之后中国互联网巨头进入ARM行业,产业趋势进一步得到加强。
服务器品牌有哪些?如何选择服务器?有哪些参数?

一、服务器品牌
服务器的品牌非常多,应用在各个领域中,我们来看下服务器用的多品牌有哪些。

不止这些,还有中兴、清华同方、富士通、海康等等,也是大家用的多的品牌。
那么问题来了,如何选择服务器呢?主要参数有哪些?
二、服务器品牌选购主要参数有哪些?
1、带宽:服务器5M带宽在线多少人?
我这里详细的给你介绍下,带宽和同时在线人数的计算,也方便后面有想了解的朋友在你这个提问上寻找答案。
首先,服务器带宽说的5M带宽,实际上是5Mbps/8=625KB,需要是独享带宽,共享的话因为他人的因素无法计算。
然后计算你的网站大小,普通大小的网站页面(图片少,压缩过,代码优化)只有几K,我们姑且按照50K计算。
所以 625kb/50k=12.5人,大概同时在线12.5人访问这个50KB的页面是没有问题的。
要值得注意,这个是同时,也就是传统意义上的同一秒,只要有先后发送请求的顺序就可以错开,所以5M带宽严格意义上是很大的,如果你的页面小,几乎可以满足千人在线,因为大部分的人都是点击后浏览页面的,不会说一直给你发送请求。
2、CPU
中央处理器(CPU,Central Processing Unit)是是一台计算机的运算核心和控制核心。
计算机的性能在很大程度上由CPU的性能决定,而CPU的性能主要体现在其运行程序的速度上。影响运行速度的性能指标包括CPU的工作频率、Cache容量、指令系统和逻辑结构等参数。
主频:主频也叫时钟频率,单位是兆赫(MHz)或千兆赫(GHz),用来表示CPU的运算、处理数据的速度。通常,主频越高,CPU处理数据的速度就越快;
缓存(Cache):实际工作时,CPU往往需要重复读取同样的数据块,而缓存容量的增大,可以大幅度提升CPU内部读取数据的命中率,而不用再到内存或者硬盘上寻找,以此提高系统性能。但是由于CPU芯片面积和成本的因素来考虑,缓存都很小;
核心数:般情况下每个核心都有一个线程,几核心就有几线程,但是intel发明了超线程技术,可以让单核模拟多核心工作,intel的超线程可以让单核心具有两个线程,双核四线程 ;
线程数 :线程数多当然速度就快,但功耗就大 ;

从英特尔品牌来看,主要有酷睿、至强、奔腾、凌动、赛扬、安腾和应用在物联网领域的几大品类。PC多以酷睿系列为主,至强则是服务器级处理器的唯一选择。在真实的场景中,确实有玩家将至强E3处理器应用在PC之上,这主要是因为服务器级CPU会比一般PC能支持更大的缓存和多处理(安装了多个物理CPU)。
3、芯片组
这里说的芯片组,是X86系统独有的,一般RISC处理器都是SoC,芯片即为系统;X86比较独特,以前是由CPU、南桥、北桥组成一个系统,现在是由CPU+PCH形成一个系统。因为接口和总线太多,太复杂,又由于X86系统一直传承着继承性,兼容性等特点,所以多个处理器可以匹配不同主板,同一个主板可以适配多种处理器,所以这样做了功能拆分。
4、内存
服务器采用专用的ECC校验内存,并且应当与不同的CPU搭配使用。通常情况下,内存数量越大,服务器的性能越高。特别是对于数据库服务、代理服务、Web服务等网络服务而言,内存数量显得尤其重要。通常情况下,入门级服务器的内存不应该小于2GB,工作组级的内存不小于4GB,部门级的内存不小于8GB。

5、硬盘
SATA:Serial ATA接口,即串行ATA,采用串行技术以获得更高的传输速度及可靠性。目前是第二代即SATAII。
SCSI:全称为“SmallComputer System Interface”(小型计算机系统接口),具有应用范围广、多任务、带宽大、CPU占用率低,以及热插拔等优点,主要应用于中、高端服务器和高档工作站。
SAS:Serial Attached SCSI接口,即串行SCSI, 采用串行技术以获得更高的传输速度。目前仍然是第一代。
SSD:固态存储硬盘(Solid State Disk)其特别之处在于没有机械结构,以区块写入和抹除的方式作读写的功能,与目前的传统硬盘相较,具有低耗电、耐震、稳定性高、耐低温等优点。

另外,为了扩充数据存储空间,保证数据存储的安全性,成倍提高数据读取速度,部门级和企业级服务器还往往采用SAS RAID卡,将若干硬盘组建为磁盘阵列。入门级服务器可采用廉价的SATA RAID卡,以实现相似的功能。
6、网卡
既然服务器要为网络中其他计算机提供服务,自然就要实现与其他计算机之间的通讯。即使服务器的处理能力很高,如果无法快速响应客户端的请求,那么,就会给网络传输造成瓶颈。因此,服务器应当连接在传输速率最快的端口上,并最少配置一块千兆网卡。对于某些有特殊应用的服务器(如FTP服务器、文件服务器或视频点播服务器),还应当配置两块千兆网卡。需要注意的是,千兆网卡通常需要安装在64位PCI插槽中。
7、冗余
可靠性是服务器最重要的指标。既然服务器在网络中的作用如此重要,那就要求服务器必须非常稳定,以便能随时为客户端能提供服务,也就是说,服务器需要不间断地工作。另外,所有重要数据都存储在服务器上,一旦硬盘损坏,数据将全部丢失。为了保证系统的可靠性,服务器采用了专门的技术。
磁盘冗余。磁盘冗余采用两块或多块硬盘来实现磁盘阵列,即使一块硬盘损坏,也不会丢失数据。
部件冗余。由于所有硬件设备都有发生故障的可能,因此,许多重要硬件设备都不止一个,例如,网卡、电源、风扇,这样可以保证部分硬件损坏之后,服务器仍然能够正常运行。
热插拔。所谓热插拔,是指带电进行硬盘或板卡的插拔操作,实现故障恢复和系统扩容。既然服务器是7×24小时工作的,那么,即使在更换或添加硬盘,甚至在插拔板卡时也不能停机。因此,热插拔对于服务器则言,就显得非常重要。
8、可扩展性
服务器的可扩展性既被用于部件冗余以保证运行的稳定性,同时,也被用于提升系统配置、增加功能。因此,服务器除了有较多的硬盘位置、内存插槽、CPU插座外,还拥有丰富的板卡插槽。如果硬盘数量较多,还应当能够扩充电源模块。
当然还有一些其它的参数,这里就不一一介绍。
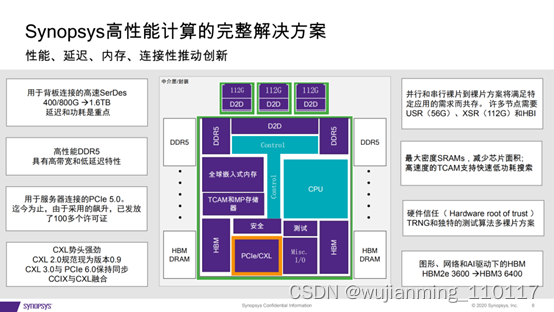
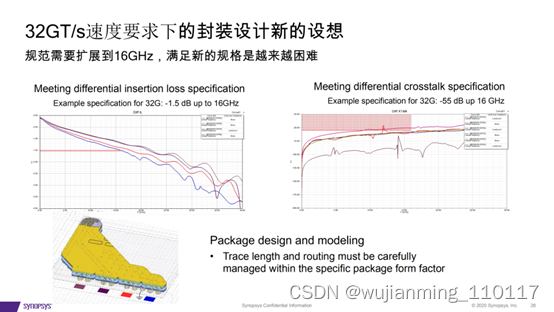
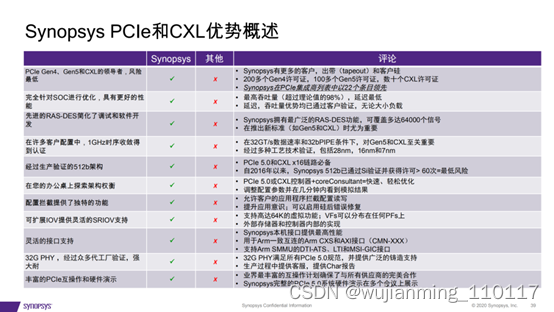
设计PCIe 5.0和CXL

1、85%的企业将把他们的数据中心转移到云上,推动新的设计
• 商业、娱乐、游戏、学校和非营利组织大量转向在线服 务
• 新冠疫情时代推动云用量增长,“基本服务”需求旺盛
• 从3月到4月,Azure不得不增加110 TB的容量和12 个新的边缘服务站点
• Microsoft团队会议记录时长在2周内从9亿分钟/每天 增加至27亿分钟/每天
• q 使用Amazon Web services(AWS)、Microsoft Azure、 Google Cloud的服务将本地数据中心迁移到云端→推动 新设计开始。
2、数据中心半导体市场将在2027年达到1770亿美元
• 2018年数据中心市场为705亿美 元(复合年增长率为10.81%),到 2027年预计达1776亿美元。
• 很多公司正在设计基于7nm到 3nm的先进工艺芯片,需要大量 IP才能通过认证
• OpenAI表示:“在最大规模的人工 智能训练中芯片,计算能力呈指 数级增长,倍增时间达3.5个月。”
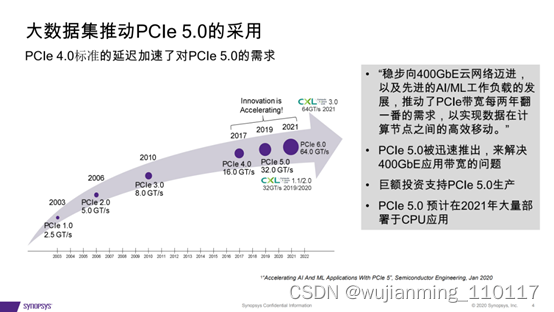
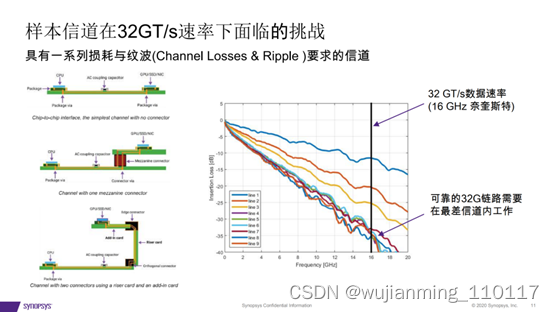
3、大数据集推动PCIe 5.0的采用
• “稳步向400GbE云网络迈进, 以及先进的AI/ML工作负载的发 展,推动了PCIe带宽每两年翻 一番的需求,以实现数据在计 算节点之间的高效移动。”
• PCIe 5.0被迅速推出,来解决 400GbE应用带宽的问题
• 巨额投资支持PCIe 5.0生产
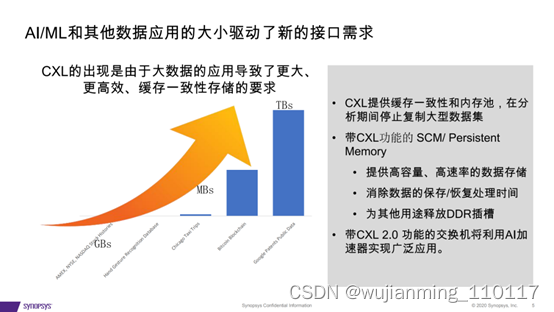
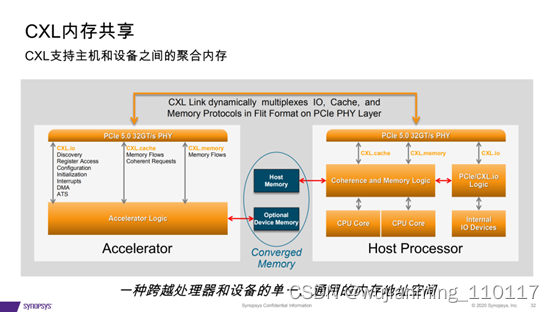
4、CXL的出现是由于大数据的应用导致了更大、 更高效、缓存一致性存储的要求
• CXL提供缓存一致性和内存池,在分析期间停止复制大型数据集;
• 带CXL功能的 SCM/ Persistent Memory;提供高容量、高速率的数据存储;
• 消除数据的保存/恢复处理时间;为其他用途释放DDR插槽。
• 带CXL 2.0 功能的交换机将利用AI加 速器实现广泛应用。
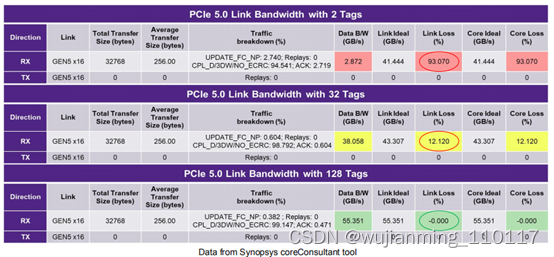
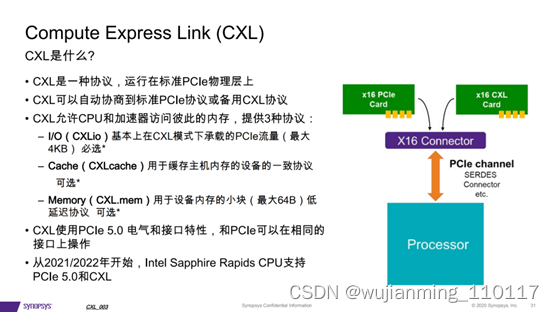
5、CXL是什么?
• CXL是一种协议,运行在标准PCIe物理层上
• CXL可以自动协商到标准PCIe协议或备用CXL协议
• CXL允许CPU和加速器访问彼此的内存,提供3种协议:
– I/O(CXLio)基本上在CXL模式下承载的PCIe流量(最大 4KB) 必选*
– Cache(CXLcache)用于缓存主机内存的设备的一致协议 可选*
– Memory(CXL.mem)用于设备内存的小块(最大64B)低 延迟协议 可选*
• CXL使用PCIe 5.0 电气和接口特性,和PCIe可以在相同的 接口上操作
• 从2021/2022年开始,Intel Sapphire Rapids CPU支持 PCIe 5.0和CXL
6、CXL为3种不同的设备类型定义了独特的应用程序
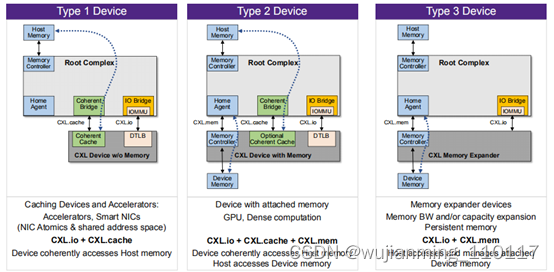
7、谁需要CXL?
计算应用 – 人工智能处理器 – 汽车高级驾驶辅助系统 – 机器学习系统 – 面部识别引擎 – 其他协处理器缓存系统内存 – 智能网络信息中心。
内存扩展设备 – 线性存储器 – 字节可寻址(vs块)SSD后续程序 – 非易失性存储器控制器 – NVDIMM、MRAM等 – 专用内存扩展 – GDDR、计算存储。
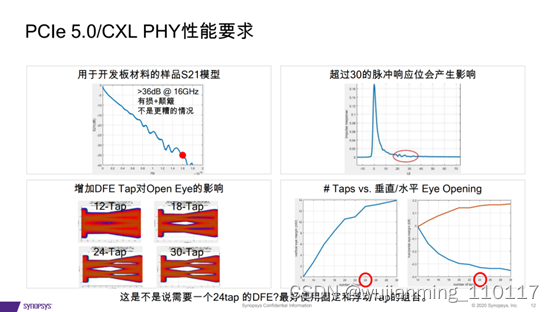
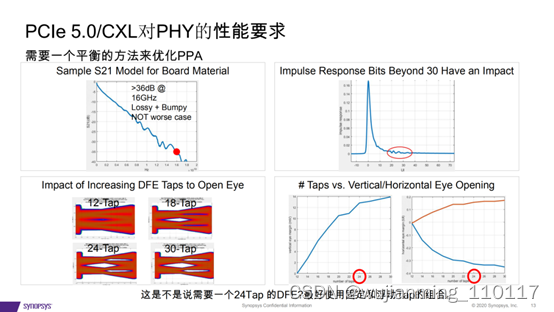
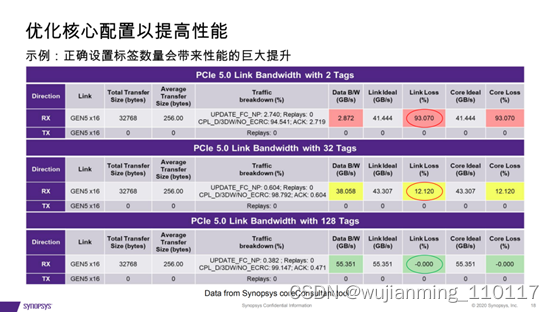
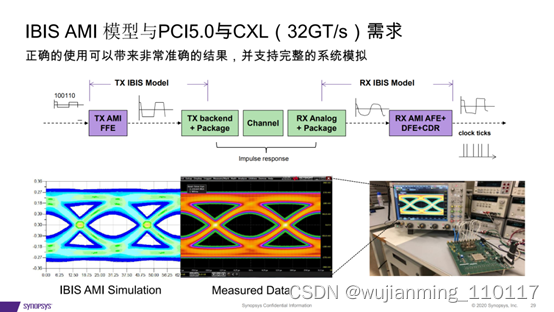
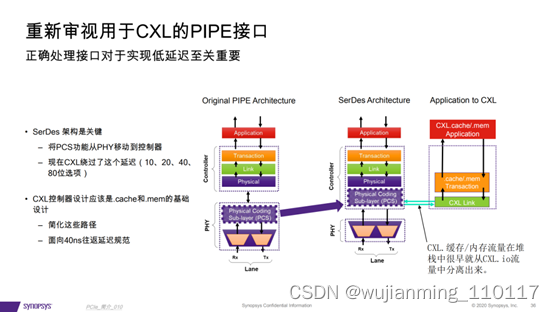
实现PCI Express 5.0和CXL设计的最大吞吐量和最低延

在这里插入图片描述









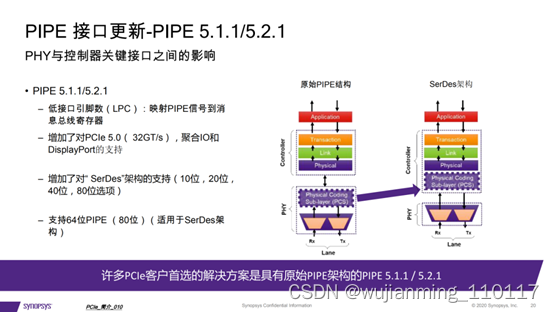
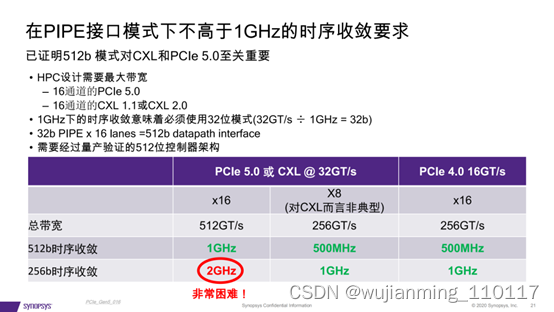
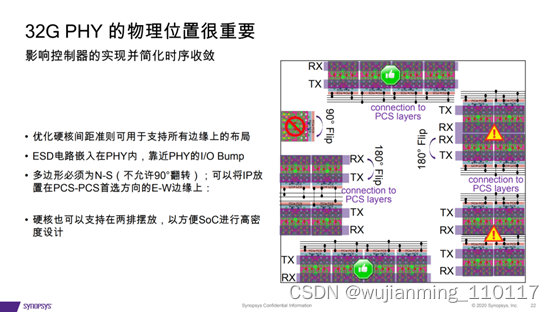
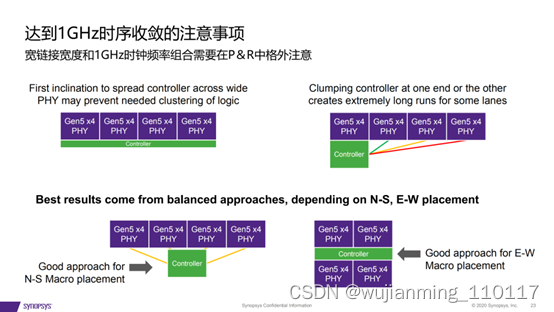











ARM v9与v8版本
自Arm在2011年10月首次发布Armv8架构以来,已经过去了近十年的时间。这对Arm来说是一个相当可观的十年,因为在这段时间内,他们的指令集架构受到移动市场和服务器市场的高度关注,并铆足劲在包括笔记本电脑和台式机设备市场发力。过去多年里,Arm对ISA进行了改进,也对体系结构进行了各种更新和扩展。当中一些可能很重要,有些可能也是一瞥而过。
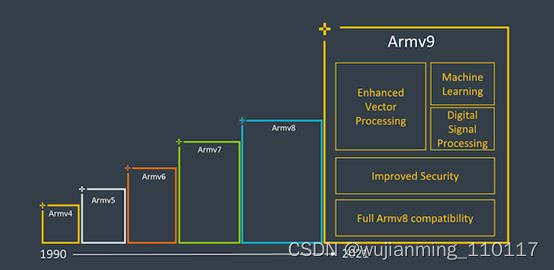
近日,作为Arm的Vision Day活动的一部分,该公司正式发布了该公司的新一代Armv9架构的首个细节,为Arm未来十年内成为下一个3000亿芯片的计算平台奠定了基础。
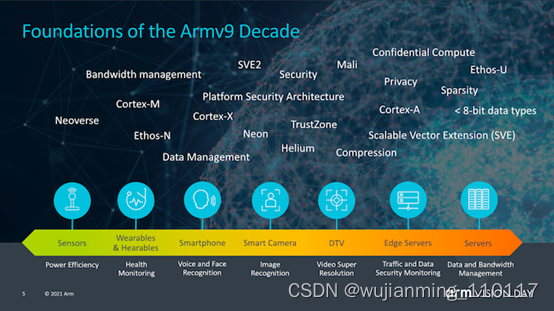
读者可能会问的一个大问题是,Armv9与Armv8究竟有何不同,能让架构获得如此大的提升。确实,从纯粹的ISA角度来看,v9可能不像v8相比v7那样实现根本性的跳跃,后者引入了AArch64,一个完全不同的执行模式和指令集,该指令集与AArch32相比具有更大的微体系结构分支,例如扩展寄存器,64位虚拟地址空间和更多改进。
Armv9继续使用AArch64作为基准指令集,但是在其功能上增加了一些非常重要的扩展,以保证architecture numbering的增加,并且允许Arm不仅可以获得对AArch64进行某种软件重新基准化v9的新功能,还能保持我们多年来在v8上获得的扩展。
Arm认为新架构Armv9有三个主要支柱,即安全性、AI以及改进的矢量和DSP功能。对于v9,安全性是一个非常重要的主题,我们将深入探讨新扩展和功能的新细节,但是首先谈到的DSP和AI功能应该很简单。

新的Armv9兼容CPU所承诺的最大的新功能可能是开发人员和用户可以立即看到的——SVE2作为NEON的后继产品。
可伸缩矢量扩展(SVE)的于2016年首次亮相,并首次在富士通的A64FX CPU内核中实现,该芯片已为日本排名第一的超级计算机Fukagu提供支持。SVE的问题在于,新的可变矢量长度SIMD指令集的第一次迭代的范围相当有限,并且更多地针对HPC工作负载,缺少了许多仍由NEON涵盖的更通用的指令。
SVE2于2019年4月发布,旨在通过用所需指令补充新的可扩展SIMD指令集来解决此问题,以服务于类似DSP等目前仍在使用NEON的工作负载。
除了增加的各种现代SIMD功能外,SVE和SVE2的优势还在于其可变的向量大小,范围覆盖了128b到2048b,让其无论在什么硬件运行,都允许向量的可变粒度为128b。如果纯粹从向量处理和编程的角度来看,这意味着软件开发人员将只需要编译一次其代码,并且如果将来某个CPU带有本地的512b SIMD execution pipelines,该代码将能够充分利用单元的整个宽度。同样,相同的代码将能够在具有较低硬件执行宽度能力的保守设计上运行,这对于Arm设计从物联网、移动到数据中心的CPU而言至关重要。在保留Arm体系结构的32b编码空间的同时,它还可以完成所有这些工作。然而类似X86这样的架构则需要根据矢量尺寸增加新的指令和扩展。

机器学习也被视为Armv9的重要组成部分,因为Arm认为在未来几年中,越来越多的ML工作负载将变得司空见惯,当中包括了对性能或电源效率有至关重要要求的场景中。那就让在专用加速器上运行ML工作负载变成长久的需要,与此同时,我们还会继续在CPU上运行较小范围的ML工作负载。
矩阵乘法指令(Matrix multiplication instructions )是此处的关键,它将代表生态系统中将更大范围采用v9 CPU作为基本功能所迈出的重要一步。
通常,我认为SVE2可能是保证升级到v9的最重要因素,因为它是更确定的ISA功能,可以在日常使用中与v8 CPU区别开来,并且可以保证软件生态系统能够正常运行,这与现有的v8堆栈有所不同。对于服务器领域的Arm来说,这实际上已经成为一个相当大的问题,因为软件生态系统仍在基于v8.0的软件包基础上,不幸的是,该软件包缺少了最重要的v8.1大型系统扩展。
使整个软件生态系统向前发展,并假设新的v9硬件具有新的体系结构扩展功能,这将有助于推动事情发展,并可能解决某些当前情况。
但是,v9不仅涉及SVE2和新指令,它还非常注重安全性,在安全性方面我们将看到一些更根本的变化。
介绍机密的计算架构
在过去的几年中,安全性和硬件安全性漏洞已成为芯片行业的头等大事,Spectre,Meltdown等漏洞的出现及其所有同级边信道攻击都表明,重新思考如何保证安全成为了一个基本需求。Arm希望用来解决这一总体问题的方法是通过引入Arm机密计算体系结构(Arm Confidential Compute Architecture:CAA)来重新设计安全应用程序的工作方式。
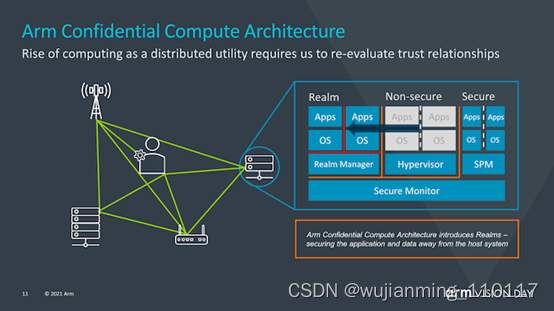
在继续之前,我想提箱一下,今天的披露仅仅是对新CCA运作方式的高层次解释,Arm说,有关新安全机制的确切工作原理的更多细节将在今年夏天的晚些时候公布。
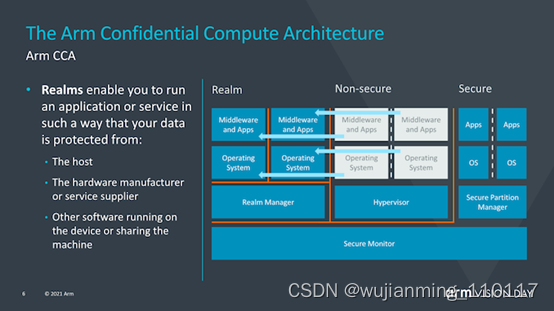
CCA的目标是从当前的软件堆栈情况中获得更大的收益,在当前的软件堆栈情况下,在设备上运行的应用程序必须固有地信任它们所运行的操作系统和虚拟机管理程序。传统的安全模型是基于以下事实建立的:更高特权的软件层被允许查看较低层的执行,然而当操作系统或系统管理程序被以任何方式损害时,这就可能成为了一个问题。
CCA引入了动态创建““realms”的新概念,可以将其视为对OS或虚拟机管理程序完全不透明的安全容器化执行环境。系统管理程序将仍然存在,但仅负责调度和资源分配。而“realm”将由称为“ealm manager”的新实体管理,其被认为是一段新的代码,大致大小约为hypervisor的1/10。
realm内的应用程序将能够“证明”领域管理器以确定其是否可信任,这对于传统的虚拟机管理程序而言是不可能的。
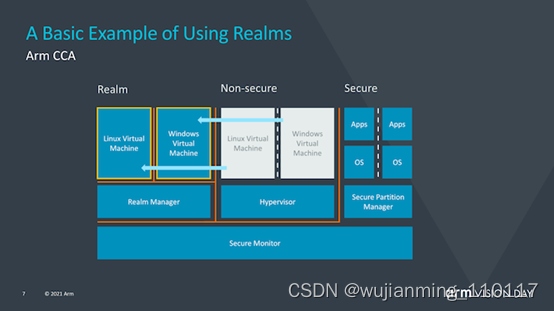
Arm并没有深入探讨究竟是什么造成了realm与操作系统和虚拟机管理程序的非安全世界之间的这种隔离,但听起来确实像硬件支持的地址空间,但它们无法相互交互。
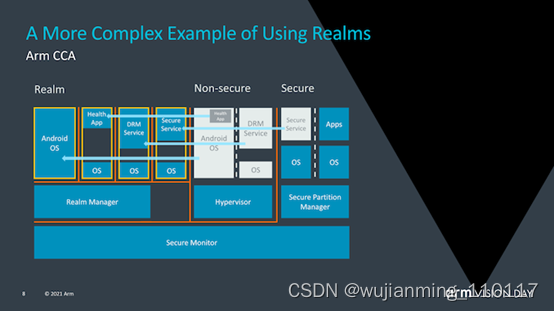
使用realms的优势在于,它极大地减少了设备上运行的给定应用程序的信任链,并且OS对安全性问题变得越来越透明。与当今需要企业或企业使用带有授权软件堆栈的专用设备的情况相反,需要监督控制的关键任务应用程序将能够在任何设备上运行。
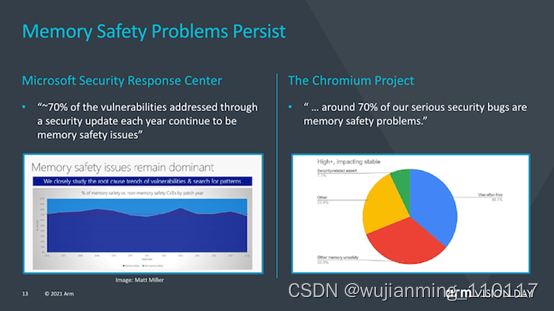
MTE(memory tagging extensions)并不是v9的新功能,而是随v8.5一起引入的,MTE或内存标记扩展旨在帮助解决世界软件中两个最持久的安全问题。缓冲区溢出(Buffers overflows)和无用后使用(use-after-free)是持续的软件设计问题,在过去的50年中,这些问题一直是软件设计的一部分,并且可能需要花费数年的时间才能对其进行识别或解决。MTE旨在通过在分配时标记指针并在使用时进行检查来帮助识别此类问题。
未来的Arm CPU路线图
这与v9没有直接关系,但是与即将到来的v9设计的技术路线图紧密相关,Arm还谈到了有关他们在未来2年中对v9设计的预期性能的一些观点。
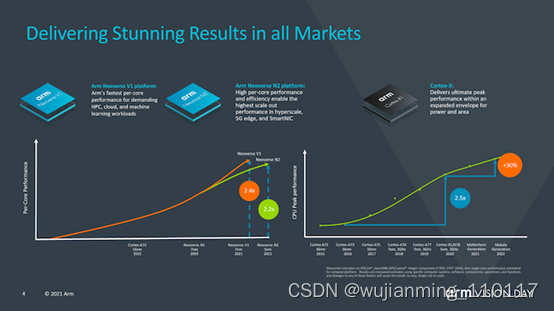
Arm谈到了移动市场在今年如何将带有X1的设备性能提升了2.4倍(此处我们仅指ISO流程设计的IPC),该性能是几年前推出的Cortex-A73的两倍。
有趣的是,Arm还谈到了Neoverse V1设计及其如何达到A72类似设计性能的2.4倍,并透露他们期待着他今年晚些时候发布的首批V1设备。
对于代号为“ Matterhorn”和“ Makalu”的下一代移动IP内核,该公司公开了这两代产品的合计预期IPC增益为30%,其中不包括SoC设计人员可以获得的频率或任何其他其他性能增益。这实际上代表着这两种新设计的世代增加了14%,并且如幻灯片中的性能曲线所示,这表明相对于自A76以来Arm在过去几年所管理的工作而言,改进的步伐正在放缓。不过,该公司指出,进步速度仍然远远超过行业平均水平。但潭门也坦言,这被一些行业参与者拖累了。
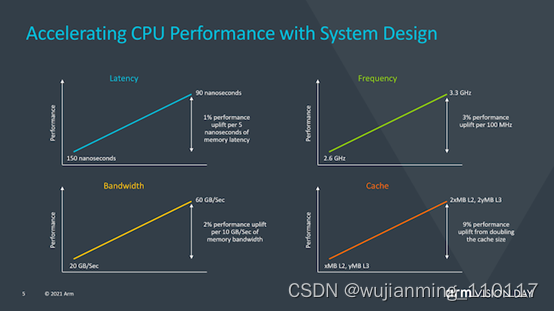
Arm还提供了一张很有意思的幻灯片,该幻灯片旨在关注系统侧对性能的影响,而不仅仅是CPU IP性能。从这里提供的一些数据可以看到,例如每5ns的内存延迟中有1%的性能,这是我们现在已经广泛讨论了几代的数字,但是Arm在这里还指出,排除了是否通过改善内存路径,增加缓存或优化频率功能来改善实现的其他各个方面,他们可以使用整整一代的CPU性能提升,我认为这是对SoC供应商当前保守方法的一种评价,这些方法没有充分利用X1内核的预期性能余量,并且随后也未达到新内核的预期性能预测。

Arm继续将CPU视为未来最通用的计算模块。尽管专用的加速器或GPU将会占有一席之地,但它们很难解决一些重要问题,例如可编程性,保护性,普遍性(本质上是在任何设备上运行它们的能力)以及经过验证的正常工作的能力。当前,计算生态系统在运行方式上极为分散,不仅设备类型不同,而且设备供应商和操作系统也不同。
SVE2和Matrix乘法可以极大地简化软件生态系统,并允许计算工作负载以更统一的方法向前迈进,该方法将来将可以在任何设备上运行。

最后,Arm还分享了有关Mali GPU未来的新信息,并透露该公司正在开发VRS等新技术,尤其是Ray Tracing。这一点令人非常令人惊讶,也表明AMD和Nvidia引入RT推动的台式机和控制台生态系统也有望将移动GPU生态系统推向RT。
Armv9设计即将在2022年初面世
今天的公告以一种非常高级的形式出现,我们希望Arm在接下来的几个月中,在公司通常的年度技术披露中,更多地谈论Armv9的各种细节和新功能,例如CCA。
总的来说,Armv9似乎是更基本的ISA转变(可以看作SVE2)与软件生态系统的总体重新基准的结合,以汇总v8扩展的最后十年,并为下一个十年奠定基础Arm体系结构。
Arm于去年下半年已经谈论过Neoverse V1和N2,我确实希望N2至少最终是基于v9而设计发布的。Arm进一步透露,更多基于Armv9的 CPU设计(可能是移动端Cortex-A78和X1的后续产品)将于今年推出,而新的CPU可能已经被通常的SoC供应商所采用,并且有望成为在2022年初在商用设备中出现。
参考文献链接
https://mp.weixin.qq.com/s/BRY2ExcWztl7vf69UyNAUw
https://mp.weixin.qq.com/s/z2XsXUiLovEAMLo3GJw0Lw
https://mp.weixin.qq.com/s/3k2ZQC5U2eoWmp62t_A1VA
https://mp.weixin.qq.com/s/bluSjR21J72tKZipTKQ9Og
https://mp.weixin.qq.com/s/9VoEgizWU8wNjfGVYDEX1g
https://mp.weixin.qq.com/s/fwoBLHxgio1MSPB6n8x6WQ