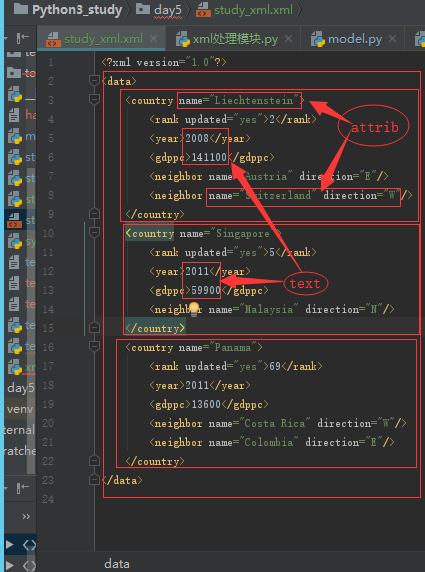
<data>
<country name="Liechtenstein">
<rank updated="yes">2</rank>
<year>2008</year>
<gdppc>141100</gdppc>
<neighbor name="Austria" direction="E"/>
<neighbor name="Switzerland" direction="W"/>
</country>
<country name="Singapore">
<rank updated="yes">5</rank>
<year>2011</year>
<gdppc>59900</gdppc>
<neighbor name="Malaysia" direction="N"/>
</country>
<country name="Panama">
<rank updated="yes">69</rank>
<year>2011</year>
<gdppc>13600</gdppc>
<neighbor name="Costa Rica" direction="W"/>
<neighbor name="Colombia" direction="E"/>
</country>
</data>
XML文件处理,循环遍历取值
import xml.etree.ElementTree as ET
tree = ET.parse('study_xml.xml') #使用parse方法解析这个xml文件
root = tree.getroot() #找到这个解析后的格式化内存地址
# print(root,root.tag) #打印内存地址和标签,tag标签就是大标签
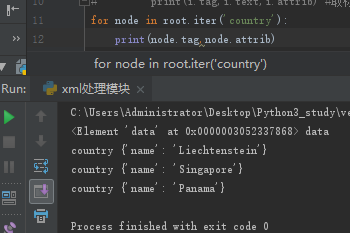
for child in root: #循环取第二层标签内存地址
print(child.tag,child.attrib) #打印标签和属性
for i in child : #再循环第二层标签内存地址
print(i.tag,i.text,i.attrib) #取标签,文本内容和属性(属性就是标签上面 又定义的键值对)

取特定键值对:
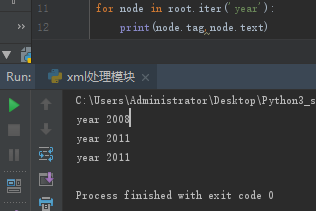
for node in root.iter('year'):
print(node.tag,node.text)
修改和删除xml文档内容
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
import
xml.etree.ElementTree as ET
tree
=
ET.parse(
"xmltest.xml"
)
root
=
tree.getroot()
#修改
for
node
in
root.
iter
(
'year'
):
new_year
=
int
(node.text)
+
1
node.text
=
str
(new_year)
node.
set
(
"updated"
,
"yes"
)
tree.write(
"xmltest.xml"
)
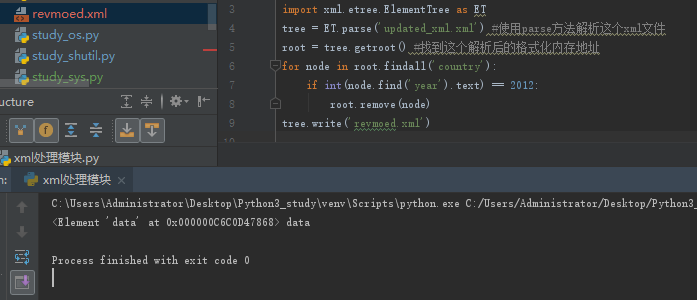
#删除node
for
country
in
root.findall(
'country'
):
rank
=
int
(country.find(
'rank'
).text)
if
rank >
50
:
root.remove(country)
tree.write(
'output.xml'
)
|
删除
自己创建xml文档
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
import
xml.etree.ElementTree as ET
new_xml
=
ET.Element(
"namelist"
)
name
=
ET.SubElement(new_xml,
"name"
,attrib
=
{
"enrolled"
:
"yes"
})
age
=
ET.SubElement(name,
"age"
,attrib
=
{
"checked"
:
"no"
})
sex
=
ET.SubElement(name,
"sex"
)
sex.text
=
'33'
name2
=
ET.SubElement(new_xml,
"name"
,attrib
=
{
"enrolled"
:
"no"
})
age
=
ET.SubElement(name2,
"age"
)
age.text
=
'19'
et
=
ET.ElementTree(new_xml)
#生成文档对象
et.write(
"test.xml"
, encoding
=
"utf-8"
,xml_declaration
=
True
)
ET.dump(new_xml)
#打印生成的格式
|