分类目录:《系统学习Python》总目录
除了作为工厂来生成多个实例对象之外,类也可引入新组件(称为子类)来进行修改,而不对已有组件进行原处的修改。如我们所见,由类产生的实例对象会继承该类的属性。Python也可让类继承其他类,因而敬开了编写类层次结构的大门,通过在较低层次的地方可以覆盖已有的属性从而让行为特定化。实际上,越深入层次的下端,软件就会变得越特定化。类和模块在这一点上看也是有区别的,因为模块的属性存在于一个单一、扁平的命名空间中(该命名空间不接受定制化)。在Python中,实例从类中继承,而类继承于父类。以下是属性继承机制的核心观点:
- 父类列在
class语句头部的括号中:如果要继承另一个类的属性,你只需把该类列在新的class语句头部行的括号中就可以了。进行继承的类称为子类,而被子类继承的类就是其父类。 - 类从其父类中继承属性:就像实例继承其类中所定义的属性名称一样,类也会继承其父类中定义的所有属性名称。当访问属性时,如果它不存在于子类中,Python就会自动搜索这个属性。
- 实例会继承所有可访问类的属性:每个实例会从创建它的类以及该类的父类中获得名称。当搜索一个名称时,Python首先会检查实例,然后是它的类,最后是所有父类。
- 每个
object.attribute引用都会启动一个新的独立的搜索:Python会对每个属性访问表达式进行对类树的独立搜索。这包括在class语句块外对实例和类的引用(例如x.attr),以及在类方法函数内对self实例参数属性的引用。方法中的每个se1f.attr表达式都会启动对self及其上层的类的attr属性的搜索。 - 逻辑的修改是通过创建子类,而不是修改父类:如果在树中层次较低的子类中重新定
义父类中的名称,子类就可替代并定制所继承的行为。
这种搜索的最终结果和主要目的就是类支持了程序的分解和定制,这比运今为止所见到的其他所有语言工具都要好。另外,这样做可以把程序的冗余度降到最低(从而减少维护本),也就是把操作分解为单一、共享的实现。此外,这样编写程序也可让我们对已有的程序代码进行定制,而不是在原处进行修改或是从头开始。
严格来讲,Python的继承比这里所述的还要丰富一些,尤其当考虑到新式的描述符和元类时。但是在本文和绝大多数Python应用程序代码中,我们可以安心地将讨论范围限制在实例和它们的类中。我们将在后面的文章中形式化地定义继承。
为了进一步展示继承的作用,下个例子是建立在《类(class)代码的编写基础与实例:类生成多个实例对象》例子基础之上的。首先,我们会定义一个新的类SecondClass,继承FirstClass所有变量名,并提供其自己的一个变量名:
class SecondClass(FirstClass):
def display(self):
print('Blog="%s"' % self.data)
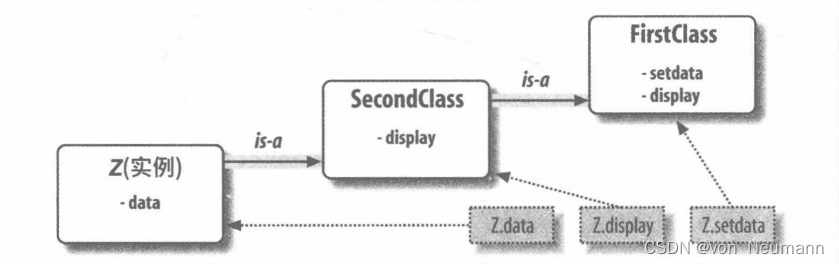
在类树中较低的扩展类中重新定义变量名,从而覆盖了继承的变量名。在这里SecondClass重新定义了方法display,从而定制了它的实例的display方法。
SecondClass定义了display方法来用不同格式打印。通过定义一个和FirstClass中的属性同名的属性,SecondClass有效地取代其父类内的display属性。回想一下,继承搜索会从实例往上进行,首先到子类,然后到父类,直到所找的属性名称首次出现为止。在这个例子中,因为SecondClass中的变量名display会首先在FirstClass内被找到、所以SecondClass覆盖了FirstClass中的display。有时候,我们把这种在树中较低处发生的通过重新定义取代属性的动作称为重载。
最终结果就是SecondClass改变了方法display的行为,进而完成了FirstClass的特定化。此外,SecondClass(及其所有实例)依然会继承FirstClass的setdata方法。用一个例子来说明:
z = SecondClass()
z.setdata('hy592070616')
z.display()
输出:
Blog="hy592070616"
就像往常一样,我们调用SecondClass创建了其实例对象。setdata依然是执行FirstClass中的版本,但是这里的display属性是来自SecondClass,并打印定制的内容。上图描绘了这里涉及的命名空间。
这里有一件和OOP相关的至关重要的事情要留意:SecondClass引入的特定化完全是在FirstClass外部完成的。也就是说,特定化不会影响当前存在的或未来的FirstClass对象,就像上一个例子中的x:
x.display()
输出:
hy592070616
我们并没有修改FirstClass,而是对它进行了定制。当然这是有意而为之的例子,但作为一条规则,因为继承可以让我们像这样在外部组件中(也就是在子类中)进行修改,所以类支持的扩展和重用通常比函数或模块都更好。
类是模块内的属性
当class语句执行时,这只是赋值给对象的变量,而对象可以用任何普通的表达式引用。例如,如果FirstClass是写在模块文件内,而不是在交互式命令行下输入的,那么就可将其导人并使用在class头部行定义的名称:
from modulename import FirstClass
class Secondclass(FirstClass):
def display(self):
print('Blog="%s"' % self.data)
或者,其等效写法如下:
import modulename
class Secondclass(modulename.FirstClass):
def display(self):
print('Blog="%s"' % self.data)
就像其他一切事物一样,类名称总是存在于模块中,所以必须遵循Python的所有规则。例如,单一模块文件内可以有一个以上的类。与模块内其他语句一样,class语句会在导人时执行并定义名称,而这些变量名会变成独立的模块属性。更通用的情况是,每个模块可以混合任意多的变量、函数以及类,而模块内的所有名称的行为都相同。这在food.py文件中展示如下:
var=1
def func(): ...
class Spam: ...
class Ham: ...
class Eggs: ...
即便模块和类碰巧有相同名称,也是如此。例如,考虑下面的person.py的文件:
class person: ...
我们需要像往常一样通过模块获取类:
import person
x = person.person()
虽然这个路径看上期是多余的,但实际上却是必需的:person.person指的是person模块内的person类。如果只写person则只会取得模块而不是类,除非你使用from语句:
from person import person
x = person()
就像其他的变量一样,如果没有预先导入并从其所在文件中访问,那么我们是无法看见文件中的类的。如果这让你感到令人困惑,就别让模块和该模块内的类使用相同名称。实际上,按照Python中的命名惯例,类名应该以一个大写字母开头,以使得它们更容易被识别。此外,虽然类和模块都是附加了属性的命名空间,它们是非常不同的两种源代码结构:模块反应了整个文件,而类只是文件内的语句。