前言
【本章末尾给大家留下了大量的福利】

1.什么是数据库?
>> 存储数据的仓库
2.常见的数据库有哪些?
Oracle>>甲骨文
Mysql>>甲骨文
SQLServer>>微软
Access>>微软
DB2>>IBM
人大金仓>>国产

3.生活中哪些地方使用数据库?
超市商品管理系统>>商品信息
网上购物商城>>商品信息和账户信息
银行管理系统>>账户信息
12306>>账户信息和车次信息
一、数据库发展史
1.1 程序管理阶段
20世纪50年代中前期
特点:数据不能长期保存
1.2 文件系统阶段
20世纪50年代后期-->20世纪60年代中后期
特点:数据缺乏独立性
1.3 数据库系统阶段
20世纪60年代后期
特点:数据实现共享,减少冗余
二、数据库中专业术语
2.1 关系
一个关系就是一张二维表(比如:Excel)
2.2 属性
二维表中的一列叫做属性,或者“字段”或者“列”
2.3 元组
二维表中的一行叫做元组,或者“记录”或者“行”

三、Oracle数据库及连接工具介绍
3.1 Oracle数据库是美国ORACLE公司研发的一款关系型数据库,市场使用率比较高,特点有:安全性高、访问速度快、可以跨平台。主要版本有:Oracle9i、
Oracle10g、Oracle11g、Oracle12c
连接工具介绍:
1)SQL Developer----Oracle 自主研发
2)PL/SQL Developer
3)Navicat
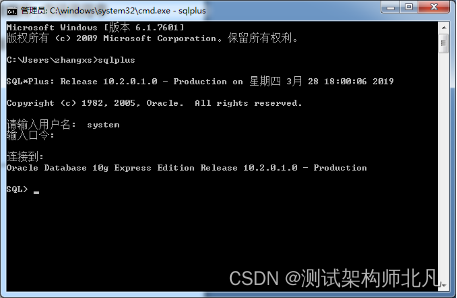
3.2 数据库访问
开始>cmd>DOS>sqlplus>请输入用户名:system
输入口令:123456
连接到:
Oracle Database 10g Express Edition Release 10.2.0.1.0 - Production
SQL>
3.3 表空间
表空间是一个虚拟的概念可以无限大,但是需要由数据文件作为载体。
表空间是用来存储数据库对象(表、视图、索引、列)的容器,表和表空间的关系就像文件和文件夹关系,因为主要存储表,所以称为表空间。
a. 在数据库创建的时候,系统会默认创建表空间(SYSTEM)
b. 可以通过SYSTEM表空间,创建其他表空间
c. 一个数据库中,可以有多个表空间,或者只有一个SYSTEM表空间
3.4 数据类型
3.4.1 字符型
char、varchar、varchar2
(1)char(n)表示固定长度的字符串,n表示字符串的最大长度,当实际要保存的长度小于n时,在字符串的右侧使用空格补齐。
(2)varchar(n)表示可变长度的字符串,n表示字符串的最大长度,当实际要保存的长度小于n时,按照实际长度保存。
(3)varchar2(n)是Oracle公司自主研发的数据库类型,和varchar类型类似,也是可变长度的字符串,但是兼容性更好,在企业开发中,常使用varchar2代替varchar。
3.4.2 数值型
number
(1)number(n)表示整数,n表示整数的最大位数
例如:number(3) 100 999
(2)number(n,m)表示整数或者小数,n表示有效的数值。m表示小数的最大位数,n-m表示整数的最大位数。
例如:number(5,2) 123.45 599.48
3.4.3 日期型
date 表示日期类型,年月日时分秒
默认日期格式DD-MON月-YY
DD---多少号
MON---月份
YY---年份
3.5 SQL语句
结构化查询语句,通过SQL语句,可以对数据库进行操作。
SQL语句分类:
(1)数据定义语言DDL(Data Ddefinition Language)
主要是对数据库中的表进行创建、修改、删除
创建---->create
修改---->alter
删除---->drop
(2)数据操纵语言DML(Data Manipulation Language)
主要是对表中的数据,进行插入、修改、删除
主要为以上操作 即对数据进行操作的,对应上面所说的查询操作 DQL与DML共同构建了多数初级程序员常用的增删改查操作。而查询是较为特殊的一种 被划分到DQL中。
插入---->insert
修改---->update
删除---->delete
(3)TCL 事务控制语句
主要是对数据进行提交和回滚
提交事务---->commit
回滚事务---->rollback
TCL_事务控制语言
TCL 溯
transaction 事务 -- DML
定义为把一连串的操作作为单个逻辑工作单元处理
----- 例如:银行转账
事务特性 ACID
原子性 atomicity 所有的数据修改 要么一起执行 要么不执行
一致性 congsistency 所有的数据修改同时得到反应
隔离性 isolation 另一个事务需要在此事务结束之后才能执行
持久性 durability 数据变动是永久的
使用事务的优点:
他们保证了数据的一致性
使用事务使得数据修改更为灵活而且修改过程是可控的
即使在用户处理失败或者系统发生故障时数据仍然是安全的
事务保证DML(数据操纵语言)语句对于数据的所作的变动是一致的
隐式事务 DDL
显式事务 DCL - commit
commit 语句完成显式事务,并且使得所有的修改是永久有效的
rollback 语句终止当前事务,使得数据库返回到以前的状态
实例:
- select * from student;
- update student set sex = '人' where stuNo = '00011';
- commit;
- rollback; -- 回滚至上一commit之后
- show autocommit; -- 默认off
- set autoCommit on;
- set autoCommit off;
- create table AA(
- AA char(10)
- ); -- 隐式commit
- select * from bankcount;
- -- 多条语句 事务
- update bankcount set money = money - 10000 where countno = '110 000 2000 888';
- update bankcount set money = money + 10000 where countno = '110 000 2000 889';
- rollback;
- commit;
- -- rollback 定义保存点 savePoint;
- SAVEPOINT aa;
- update bankcount set money = money + 10000 where countno = '110 000 2000 888';
- SAVEPOINT bb;
- update bankcount set money = money - 10000 where countno = '110 000 2000 889';
- rollback to bb; -- 回滚之保存点之后
- commit;
在下列情况下,数据修改自动被回滚:
1. 系统崩溃或发生故障.
2. SQL*Plus 意外终止.
隔离性:
上锁防止多个用户同时修改数据.
上锁可以是隐式或显式的.
上锁的一些基本内容:
上锁可预防并发事务之间的破坏性的交互.
上锁是自动施行的,无须用户干预.
上锁把操作限制到可能的最小粒度.
只有在事务结束后,上锁才被解除.
DML行数据排它锁
事务排它锁
(4)数据查询语言DQL(Data Query Language)
主要是对数据进行查询(数据库学习的重点)
查询---->select
3.6 创建表
格式:
create table 表名(
列名1 数据类型 primary key,
列名2 数据类型,
......
列名n 数据类型
);
create table stu(
id number(4) primary key,
name varchar2(20),
sex char(3)
);
create table stu2(
id number(4) primary key,
name varchar2(30)
);
练习1:创建一张表,表名为stu3,表中包含的字段有
id number(4) primary key
name varchar2(30)
address varchar2(50)
create table stu3(
id number(4) primary key,
name varchar2(30),
address varchar2(50)
);
练习2:创建一张表,表名为stu5,表中包含的字段有
id number(4) primary key
name varchar (30)
sex char(3)
address varchar2(50)
score number(5.2)
stime date
create table stu5(
id number(4) primary key, --编号
name varchar(30), --姓名
sex char(3), --性别
address varchar2(50), --地址
score number(5,2), --分数
stime date --时间
);
3.7 查看表结构
格式:desc表名;
案例:查看stu表的表结构
desc stu;
练习3:查看stu5表的表结构
desc stu5;
3.8 插入数据
3.8.1 向全部列插入数据
格式: insert into 表名 values(列值1,列值2,......列值n);
说明: 表中的列和values中的列值是一一对应的关系
验证: select * from 表名;
案例: 向stu表中,插入2条记录
(1)desc stu; 3个值
(2)
insert into stu values(1001,'rose','女');
insert into stu values(1002,'jack','男');
insert into stu values(1003,'cat','男');
(3)select * from stu;
练习:向stu2表中插入3条记录并验证
(1)desc stu2; 2个值(ID和name)
(2)
insert into stu2 values(1004,'tedu');
insert into stu2 values(1005,'from');
insert into stu2 values(1006,'come');
(3)select * from stu2;
练习:向stu3表中插入2条记录并验证
(1)desc stu3;
(2)
insert into stu3 values(1007,'大王','杭州');
insert into stu3 values(1008,'小王','成都');
(3)select * from stu3;
3.8.2 向指定列插入数据
insert into 表名(列名1,列名2,......列名n) values(
列值1,列值2,......列值n);
说明:表名中的列名必须和values中的列值是一一对应的关系(数量、顺序、类型)
验证:select * from 表名
案例:向stu表中插入2条记录
ID NAME SEX
109 辰东
110 女
insert into stu(id,name) values(109,'辰东');
insert into stu(id,sex) values(110,'女');
select * from stu;
练习:向stu3表中插入2条记录
ID NAME ADDRESS
234 杨过 null
235 null 终南山
insert into stu3(id,name) values(234,'杨过');
insert into stu3(id,address) values(235,'终南山');
select * from stu3;
练习:向stu5表中插入数据,具体要求如下:
DD-MON月-YY------>'29-3月-19'
1.使用全部列插入方式,插入2条记录
desc stu5;
insert into stu5 values(1,'tom','男','北京',100.55,'29-3月-19');
select * from stu5; -----验证
insert into stu5 values(2,'rose','女','杭州',)
select * from stu5; -----验证
2.使用指定列插入方式,插入2条记录
ID NAME SEX
insert into stu5(id,name,sex) values(4,'lucy','女');
ID SCORE STIME
insert into stu5(id,score,stime) values(5,100,'20-3月-19');
复习:
1.数据类型
字符型
固定char(3) 可变varchar(20) 可变varchar2(30)
数值型
整数number(3) 整数和小数number(5,2)
日期型
date 年月日时分秒 DD-MON月-YY
2.创建表
create table 表名(
列名1 数据类型 primary key,
列名2 数据类型,
......
列名n数据类型
);
3.查看表结构
说明:表结构就是查看表中有几列和每列的数据类型
desc 表名;
4.插入语句
全部列插入数据
insert into 表名 values(列值1,列值2,...列值n);
指定列插入数据
insert into 表名(列名1,列名2,...列名n) values(列值1,列值2,...列值n);
3.9修改(更新)语句
格式: update 表名 set 列名1=该列新值,列名2=该列新值,...列名n=该列新值 where 条件;
说明: 如果没有where条件,修改表中全部数据。
案例:创建一张表stu6,表中包含的字段有:id number(4) primary key,
name varchar2(20)
sex char(3)
address varchar2(50)
score number(5,2)
create table stu6(
id number(4) primary key,
name varchar(20),
sex char(3),
address varchar2(50),
score number(5,2)
);
练习:
insert into stu6 values(101,'tom','男','美国',80);
insert into stu6 values(102,'lucy','女','法国',90);
insert into stu6(id,sex,address,score) values(103,'男','北京','100');
insert into stu6(id,name,sex) values(104,'rose','女');
insert into stu6(id,name,score) values(105,'jack','65');
insert into stu6(id,sex,address) values(106,'男','上海');
select * from stu6;
格式: update 表名 set 列名1=该列新值,列名2=该列新值,...列名n=该列新值 where 条件;
案例:修改stu6表中,编号(id)是102的,地址(address)修改为中国
update stu6 set address='中国' where id=102;
select * from stu6;
练习:修改stu6表中,编号(id)是101的记录,将分数(score)修改为100
答案:
update stu6 set score=100 where id=101;
select * from stu6;
练习:修改stu6表中,编号(id)是103的记录,将姓名(name)修改为lili
答案:
update stu6 set name='lili' where id=103;
练习:修改stu6表中,姓名(name)是rose的记录,将分数(score)修改为80.5
答案:
update stu6 set score=80.5 where name='rose';
练习:修改stu6表中,地址(address)是上海的记录,将姓名(name)修改为xiaoh,分数(score)修改为60.55
答案:
update stu6 set name='xiaoh',score=80.5 where address='上海';
练习:修改stu6表中全部数据,将地址(address)修改为北京---->特殊情况
答案:
update stu6 set address='北京'
3.10删除表中的数据
格式:
delete from 表名 where 条件;
说明:如果没有where条件,删除全部记录。
案例:删除stu6表中,编号(id)是105的记录。
答案:
delete from stu6 where id=105;
select * from stu6;
练习:删除stu6表中,姓名(name)是rose的记录
答案:
delete from stu6 where name='rose';
select * from stu6;
练习:删除stu6表中全部数据---->(特殊情况)
答案:
delete from stu6;
select * from stu6;
3.11删除表
格式:drop table 表名;
案例:删除stu6表
答案:
drop table stu6;
3.12查询语句(重点)
| 英文 |
汉语 |
| table |
表 |
| primary |
主键 |
| insert |
插入 |
| values |
值 |
| update |
更新(修改) |
| set |
设置 |
| where |
哪里 |
| delete |
删除(表中) |
| from |
来自 |
| drop |
删除(表) |
| select |
查询 |
| commit |
保存 |
| distinct |
去重 |
| order by |
排序 |
| asc |
升序 |
| desc |
降序 |
| and |
并且 |
| or |
或者 |
| not |
非(取反) |
| is null |
为空 |
| is not null |
不为空 |
| alter |
修改(表) |
| constraint |
约束 |
| unique |
唯一 |
3.12.1查询全部列数据
格式:select * from 表名;
说明: *:表示全部列
案例:查询emp、dept、salgrade表中的全部数据
emp---->员工表
dept---->部门表
salgrade---->工资等级表
答案:
select * from emp;
select * from dept;
select * from salgrade;
3.12.2查询指定列数据
格式:select 列名1,列名2,......列名n from 表名;
案例:查询emp表中,员工编号(empno),员工姓名(ename),员工职位(job),工资(sal)
select empno,ename,job,sal from emp;
练习:查询emp表中,员工编号(empno),职位(job),入职时间(hiredate),部门编号(deptno)
答案:
select empno,job,hiredate,deptno from emp;
练习:查询dept表中,部门编号(deptno),部门名称(dname),部门地址(loc)
select deptno,dname,loc from dept;
3.12.3 给列起别名
格式:select 列名1 别名1,列名2 别名2,...列名n 别名n from 表名;
案例:查询emp表中,员工编号(empno),员工姓名(ename),职位(job),领导编号(mgr),奖金(comm)
答案:
select empno 员工编号,ename 员工姓名,job 职位,mgr 领导编号,comm 奖金 from emp;
练习:查询salgrade表中,工资等级(grade),最低工资(losal),最高工资(hisal)
答案:
select grade 工资等级,losal 最低工资,hisal 最高工资 from salgrade;
练习:查询dept表中,部门名称(dname),部门地址(loc)
答案:
select dname 部门名称,loc 部门地址 from dept;
3.12.4 去掉重复的列值(去重)
格式:select distinct 列名 from 表名;
案例:去掉部门编号(deptno)重复的列值,在emp表中
select distinct deptno from emp;
练习:查询emp表中,职位(job)的种类(笔试题)
答案:
select distinct job from emp;
练习答案:
create table stu5(
id number(4) primary key, --编号
name varchar(30), --姓名
sex char(3), --性别
address varchar2(50), --地址
score number(5,2), --分数
stime date --时间
);
create table stu01(
sno number(8) primary key,
sname varchar2(20),
sex char(3),
age number(3),
etime date,
address varchar2(50)
);
复习:
1.更新(修改)语句
格式: update 表名 set 列名1=该列新值,列名2=该列新值,...列名n=该列新值 where 条件;
2.删除表中的数据
格式:delete from 表名 where 条件;
3.删除表
格式:drop table 表名;
4.查询全部列数据
格式:select * from 表名;
5.查询指定列数据
格式:select 列名1,列名2,......列名n from 表名;
6.给列名起别名
格式:select 列名1 别名1,列名2 别名2,...列名n 别名n from 表名;
7.去掉重复的列值(去重)
格式:select distinct 列名 from 表名;
3.12.5 排序(order by)
格式:select */列名 from 表名 order by 列名1 asc/desc,列名2 asc/desc;
说明:asc---->升序排列
desc---->降序排列
案例:查询emp表中,员工编号(empno),员工姓名(ename),职位(job),工资(sal),根据员工编号(empno)降序排列。
答案:
select empno,ename,job,sal
from emp
order by empno desc;
练习:
查询emp 表中,编号(empno),姓名(ename),职位(job),入职时间(hiredate),工资(sal),根据工资升序排列。
答案:
select empno,ename,job,hiredate,sal
from emp
order by sal asc;
练习:
查询emp表中,编号(empno),姓名(ename),职位(job),部门编号(deptno),首先根据部门编号升序排列,如果部门编号一致,根据员工编号降序排列。
答案:
select empno,ename,job,deptno
from emp
order by deptno asc,empno desc;
练习:
查询emp表中,编号(empno),姓名(ename),职位(job),工资(sal),首先根据工资升序排序,如果工资一致(相同),再次根据编号(empno)降序排列。
答案:
select empno,ename,job,sal
from emp
order by sal asc,empno desc;
注意:order by 永远放在格式的最后面。
3.12.6 条件查询
格式:select */列名 from 表名 where 条件;
条件包含:关系运算符、逻辑运算符、特殊情况
1)、关系运算符: >、<、=、>=、<=、<>/!=
案例:查询emp表中,工资大于2000的,员工姓名(ename),职位(job),工资(sal),入职时间(hiredate)
答案:
select ename,job,sal,hiredate
from emp
where sal>2000;
练习:查询emp表中,部门编号(deptno)是30号的,员工编号(empno),姓名(ename),工资(sal),部门编号(deptno)
答案:
select empno,ename,sal,deptno
from emp
where deptno=30;
练习:查询dept表中,部门地址(loc)是DALLAS的,部门编号(deptno),部门名称(dname),部门地址(loc)
答案:
select deptno,dname,loc
from dept
where loc='DALLAS';

练习:查询emp表中,工资不等于1250的,员工的编号(empno),姓名(ename),职位(job),工资(sal),根据工资(sal)降序排列
答案:
select empno,ename,job,sal
from emp
where sal!=1250
order by sal desc;
2) 、逻辑运算符:and(与) or(或) not(非) and(与):
并且表示可以使用and连接2个或多个并且关系的表达式(条件)
sal>1000 and sal<5000
案例:查询emp表中,工资在1000~3000之间的,员工编号、姓名、职位、工资
select empno,ename,job,sal
from emp
where sal>1000 and sal<3000;
练习:查询emp表中,工资大于1000并且部门编号是30号部门的,员工的姓名、工资、部门编号(deptno)
答案:
select ename,sal,deptno
from emp
where deptno>1000 and deptno=30;
练习:查询emp表中,职位是MANAGER的并且工资不等于1250的,员工编号,姓名,职位,工资
答案:
select empno,ename,job,sal
from emp
where job='MANAGER' and sal!=1250;
or(或):或者 使用or来连接2个或者多个表达式(条件)
案例:查询dept表中,部门地址(loc)是DALLAS的或者部门编号(deptno)是40号部门的,部门编号,部门名称(dname),部门地址(loc)
答案:
select deptno,dname,loc
from dept
where loc='DALLAS' or deptno=40;
练习:查询emp表中,工资大于等于1200的或者部门编号是30号部门的,员工的姓名,职位,工资,部门编号(deptno)
答案:
select ename,job,sal,deptno
from emp
where sal>=1200 or deptno=30;
not(非):相反
案例:查询emp表中,工资不等于1250的,员工的编号,姓名,工资(使用2种方法)
方法1:
select empno,ename,sal
from emp
where sal<>1250;
方法2:
select empno,ename,sal
from emp
where not sal=1250;
3)、提示情况:
a. 查询列值为null的情况(is null)
案例:查询emp表中,奖金(comm)为空的,员工的编号,姓名,工资,奖金
答案:
select empno,ename,sal,comm
from emp
where comm is null;
练习:查询emp表中,上级领导编号(mgr)为空的,员工的编号,姓名,领导编号
答案:
select empno,ename,mgr
from emp
where mgr is null;
b. 查询列值不为null的情况(is not null)
案例:查询emp表中,奖金不为空的,员工的信息
答案:
select * from emp
where comm is not null;

练习:查询emp表中,有领导编号的,员工的姓名,职位,工资,领导编号(mgr)
答案:
select ename,job,sal,mgr
from emp
where mgr is not null;
练习:查询emp表中,工资大于等于3000并且领导编号不为空的,员工的编号,姓名,工资,领导编号,根据工资升序排列
答案:
select empno,ename,sal,mgr
from emp
where sal>=3000 and mgr is not null
order by sal asc;

c. between...and 在什么到什么之间
说明: between...and可以获取最小边界值和最大边界值
案例:查询emp表中,工资在1000~3000之间的员工的编号,姓名,工资
方法1:
select empno,ename,sal
from emp
where sal between 1000 and 3000;
方法2:
select empno,ename,sal
from emp
where sal>=1000 and sal<=3000;
案例:查询emp表中,员工编号是7521,7566,7782,7934的员工信息(笔试题)
答案:
select * from emp
where empno=7521 or empno=7566 or empno=7782 or empno=7934;
d. in 表示比较一个列中的几个列值用in
格式:
select */列名 from 表名 where 列名 in(列值1,列值2...列值n);
说明:列值的写法由列名的类型决定
案例:查询emp表中,员工编号是7521,7566,7782,7934的员工信息(笔试题)
答案:
select * from emp where empno in(7521,7566,7782,7934);
练习:查询emp表中,员工的职位是CLERK,MANAGER,ANALYST的,员工的信息
答案:
select * from emp where job in('CLERK','MANAGER','ANALYST');
e. 模糊查询(重点)
格式:
select 列名 from 表名 where 列名 like 条件;
说明:
条件包含:
1)% 表示0个或者多个任意字符
2)_ 表示任意一个字符
案例:查询emp表中,员工姓名第一个字母(首)是以S开头的,员工的编号,姓名,职位
分析: Sldjsfljs fsf 或者 S===>S%
select empno,ename,job
from emp
where ename like 'S%';
案例:查询emp表中,员工姓名最后一个字母(尾字母)是N结尾的,员工的编号,姓名,职位
答案:
select empno,ename,job
from emp
where ename like '%N';
复习:
1.排序(order by)
select */列名 from 表名 order by 列名1 asc/desc,列名2 asc/desc;
2.条件查询
a.关系运算符(><= >= <= <>/!=)
select */列名 from 表名 where 列名=列值;
sal>2000 sal<1000 deptno=30 job='MANAGER' sal<>1250
b.逻辑运算符(and or not)
select */列名 from 表名 where 条件 and 条件;
sal>1000 and sal<3000
deptno=30 and sal>4000
sal<>1250 and job='SALES'
deptno=10 or deptno=20 or deptno=30
sal<>1250 not sal=1250
c.特殊情况
1)查询列值为空的情况(is null)
格式:select */列名 from 表名 where 列名 is null;
2)查询列值不为空的情况(is not null)
格式:select */列名 from 表名 where 列名 is not null;
3)between...and 和sal>=1000 and sal<=300 相同意思
格式:select */列名 from 表名 where 列名 between 初值 and 终值;
4)in
格式:select */列名 from 表名 where 列名 in(列值1,列值2,...列值n);
5)模糊查询
格式:select 列名 from 表名 where 列名 like 条件;
条件包含:
%:表示0个或者多个任意字符
_:表示1个任意字符
%N%:查询包含有N的字符
练习:查询emp表中,员工姓名倒数第2个字母是N的,员工的编号,姓名,职位
答案:
分析:dfetNw Nq===>%N_
select empno,ename,job
from emp
where ename like '%N_';
练习:查询emp表中,员工姓名整数第3个字母是N的,员工的编号,姓名,职位
答案:
select empno,ename,job
from emp
where ename like '__N%';
案例:查询emp表中,员工姓名中不包含字母N的,员工的编号,姓名,职位
答案:
select empno,ename,job
from emp
where not ename like '%N%';
练习:查询emp表中,员工姓名不包含字母K并且在10号和20号部门中的,员工的编号,姓名,职位,部门编号,根据员工编号降序排列
答案:
方法1
select empno,ename,job,deptno
from emp
where not ename like '%K%' and (deptno=10 or deptno=20)
order by empno desc;
方法2
select empno,ename,job,deptno
from emp
where not ename like '%K%' and deptno in(10,20)
order by empno desc;
3.12.7处理空值的函数
案例:查询emp表中,员工的编号,姓名,工资,年薪(工资*12)
答案:
select empno,ename,sal,sal*12 from emp;
案例:查询emp表中,员工的编号,姓名,工资,年薪(工资*12+奖金)
答案:
select empno,ename,sal,comm,sal*12+comm from emp;
说明:如果数值类型,通过“+”和null连接在一起,结果为null。
使用nvl函数,处理空值的情况:
nvl(列名,数值):表示可以将列值是null的,替换成数值。
例如:800x12+null=null
800x12+0=9600
select empno,ename,sal,comm,sal*12+nvl(comm,0) from emp;
select empno,ename,sal,comm,sal*12+nvl(comm,100) from emp;
3.12.8聚合(分组)函数
count:
(1)count(*/列名)
*表示:统计表中数据的总数量
列名表示:统计列值不为空的,数据的总数量
案例:查询emp表中,员工的总数量
答案:
select count(*) 员工总数 from emp;
练习:查询emp表中,奖金不为空的,员工的总数量
答案:
select count(comm) from emp;
练习:查询emp表中,员工职位种类的总数量
答案:
select count(distinct job) from emp; -----distinct去重
sum:
(2)sum(列名)表示统计列值累加之和
案例:查询emp表中,员工的工资总数
答案:
select sum(sal) 工资总数 from emp;
练习:查询emp表中,员工奖金(comm)之和
答案:
select sum(comm) 员工奖金 from emp;
avg
(3)avg(列名)求平均数
案例:查询emp表中,员工的平均工资
答案:
select avg(sal) 平均工资 from emp;
练习:查询emp表中,员工奖金的平均值
答案:
select avg(comm) 奖金平均值 from emp;
min
(4)min(列名)求最小值
案例:查询emp表中,员工的最低工资
答案:
select min(sal) 最低工资 from emp;
练习:查询emp表中,员工是30号部门的,最低工资是多少
答案:
select min(sal)
from emp
where deptno=30;
max
(5)max(列名)求最大值
案例:查询emp表中,员工编号的最大值
答案:
select max(empno) 员工编号 from emp;
练习:查询emp表中,员工总数,工资总和,平均工资,最低工资,最高工资,并起别名
答案:
select count(*) 员工总数,sum(sal) 工资总和,avg(sal) 平均工资,min(sal) 最低工资,max(sal) 最高工资 from emp;
3.12.9 分组查询
说明:分组查询就是将数据分成几组,根据某一列,相同的数据分成一组,完成后,对每一组的数据使用聚合函数,聚合函数经常和分组查询一起使用。
格式:
select 列名/聚合函数 from 表名
where 条件
group by 列名
order by 列名/聚合函数 asc/desc
案例:查询emp表中,每个部门的编号,部门的工资总和,部门单独最高工资总和,部门最高工资
答案:
select deptno,sum(sal),max(sal)
from emp
group by deptno;
案例:查询emp表中,每个部门的编号,部门平均工资,部门最低工资,根据部门编号升序排列
答案:
select deptno,avg(sal),min(sal)
from emp
group by deptno
order by deptno asc;
练习:查询emp表中,工资大于1000的,每个部门的编号,部门的工资总和,部门的最低工资,根据部门编号降序排列
答案:
select deptno,sum(sal),min(sal)
from emp
where sal>1000
group by deptno
order by deptno desc;
练习:查询emp表中,工资在1000-5000之间的,每个职位的名称,职位的人数,职位的最高工资,根据职位的人数降序排列
答案:
select job,count(*),max(sal)
from emp
where sal between 1000 and 5000
group by job
order by count(*) desc;
3.12.10 having 语句
说明:在分组查询得到结果后,对结果再次进行筛选(过滤),having经常和分组查询一起使用。
格式:
select 列名/聚合函数 from 表名
where 条件
group by 列名
having 条件
order by 列名/聚合函数 asc/desc;
where和having区别:
where是对整张表进行过滤,而且可以单独使用
having 是对分组后的数据进行过滤,而且不可以单独使用,必须和group by一起使用
案例:查询emp表中,部门平均工资大于2000的,部门的编号,部门的人数,部门的平均工资
答案:
select deptno,count(*),avg(sal)
from emp
group by deptno
having avg(sal)>2000;
练习:查询emp表中,工资在1000-5000之间的,每个职位的名称,职位的最高工资,职位的平均工资,要求职位的最高工资小于3000,根据平均工资降序排列
答案:
select job,max(sal),avg(sal)
from emp
where sal between 1000 and 5000
group by job
having max(sal)<3000
order by avg(sal) desc;
练习:查询emp表中,员工姓名不包含字母K,每个部门的编号,部门的人数,部门的最低工资,部门的最高工资,要求部门的最低工资大于1000,根据部门人数升序排列,如果人员一致,根据部门编号降序排列
答案:
select deptno,count(*),min(sal),max(sal)
from emp
where ename not like '%K%'
group by deptno
having min(sal)>1000
order by count(*) asc,deptno desc;
复习:
1.处理空值的函数
nvl(列名,数值) 如果列值中有空null,使用数值代替null
2.聚合函数
count(*/列名) 统计个数(总数量)
sum(列名) 求和
avg(列名) 求平均数
min(列名) 求最小值
max(列名) 求最大值
3.分组查询
select 列名/聚合函数
from 表名
where 条件
group by 列名
order by 列名/聚合函数 asc/desc;
4.having语句
select 列名/聚合函数
from 表名
where 条件
group by 列名
having 条件
order by 列名/聚合函数 asc/desc;

3.12.11 常用字符处理函数
1) length(列名/字符串) 表示统计列值/字符串的个数(长度)
案例:查询emp表中,员工的姓名及姓名的长度
答案:
select ename,length(ename)
from emp;
2) dual----->虚拟表,主要用于各种函数的测试
案例:查询helloworld字符串的长度
答案:
select length('helloworld') from dual;
3) substr(参数1,参数2,参数3) 字符串截取
参数1:要截取的字符串或者列名
参数2:从哪里开始截取,如果是正数表示从正数第几位开始截取,如果是负数表示 从倒数第几位开始截取
参数3:截取的个数
案例:
select substr('helloworld',3,4) from dual;
案例:
select substr('helloworld',-3,2) from dual;
练习:查询emp表中,员工的姓名以及姓名最后2个字母
答案:
select ename,substr(ename,-2,2) from emp;
4) ||字符串拼接
案例:
select '床前明月光' || ',疑是地上霜' || ',举头望明月' from dual;
3.12.12 常用数值处理函数
1) round(数值,位数) 四舍五入函数
如果位数>0时,数值保留几位小数,如果位数=0时,不保留小数,如果位数<0时,小数点前第几位进行四舍五入
select round(34.736,2) from dual; ---->34.74
select round(34.736,1) from dual; ---->34.7
select round(34.736,0) from dual; ---->35
select round(34.736,-1) from dual; ---->30
select round(34.736,-2) from dual; ---->0
2) trunc(数值,位数) 截取函数
如果位数>0时,数值保留几位小数,如果位数=0时,不保留小数,如果位数<0时,舍弃小数点之前第几位
select trunc(34.736,2) from dual; ---->34.73
select trunc(34.736,1) from dual; ---->34.7
select trunc(34.736,0) from dual; ---->34
select trunc(34.736,-1) from dual; ---->30
select trunc(34.736,-2) from dual; ---->0
3.12.13 常用日期处理函数
1) 常见的日期格式
默认日期格式 dd-mon月-yy
年月日 yyyy-mm-dd
年月日时分秒 yyyy-mm-dd hh24:mi:ss
2) sysdate 获取当前系统日期时间
案例:查询当前系统日期
select sysdate from dual;
练习:查询昨天、今天、明天的日期(笔试题)
select sysdate-1,sysdate,sysdate+1 from dual;
3) to_char(日期类型,'日期格式的一部分')
案例:查询当前系统时间的年份
select to_char(sysdate,'yyyy') from dual;
练习:查询当前系统时间的月份
答案:
select to_char(sysdate,'mm') from dual;
练习:查询emp表中,12月份入职的员工的,编号,姓名,职位,工资,入职时间(hiredate)---笔试题
答案:
select empno,ename,job,sal,hiredate
from emp
where to_char(hiredate,'mm')='12';
4) to_date('特殊日期类型的字符串','日期格式') 将字符类型的数据转换为日期类型,经常用于插入语句 varhcar---->date
案例:向emp表中插入3条新记录
empno ename hiredate
1234 TOM 2018-11-11 (yyyy-mm-dd)
1235 LUCY 2018-12-20
1236 ROSE 2019-4-20
答案:
insert into emp(empno,ename,hiredate) values(1234,'TOM',to_date('2018-11-11','yyyy-mm-dd'));
insert into emp(empno,ename,hiredate)
values(1235,'LUCY',to_date('2018-12-20','yyyy-mm-dd'));
insert into emp(empno,ename,hiredate)
values(1236,'ROSE',to_date('2019-4-20','yyyy-mm-dd'));
3.12.14 连接(关联)查询---重点
说明:要查询的数据,分布在不同的表中,为了一次将不同表中的数据查询出来,使用连接查询。
格式:
select 别名1.*/列名,别名2.*/列名,... 别名n.*/列名
from 表1 别名1,表2 别名2,......表n 别名n
where 关联条件;
等值连接查询
说明:关联条件是通过“=”相连接的
案例:查询emp表中,员工的编号,姓名,职位,工资以及dept表中,部门编号,部门名称
答案:
select e.empno 员工编号,e.ename 员工姓名,e.job 员工职位,e.sal 员工工资,d.deptno 部门编号,d.dname 部门名称
from emp e,dept d
where e.deptno=d.deptno;
练习:查询emp表中,工资在1000-5000之间的,员工编号,姓名,工资以及dept表中部门名称,部门地址
答案:
select e.empno 员工编号,e.ename 员工姓名,e.sal 员工工资,d.dname 部门名称,d.loc 部门地址
from emp e,dept d
where e.deptno=d.deptno and e.sal>1000 and e.sal<5000;
练习:查询emp表中,员工姓名不包含字母N,员工的编号,姓名,职位以及dept表中部门编号,部门名称,部门地址(loc),根据员工编号降序排列
答案:
select e.empno 员工编号,e.ename 员工姓名,e.job 员工职位,d.deptno 部门编号,d.dname 部门名称,d.loc 部门地址
from emp e,dept d
where e.deptno=d.deptno and not e.ename like '%N%'
order by e.empno desc;
练习:查询emp表中,员工姓名不包含字母K并且在20号和30号部门中的,员工的编号,姓名,职位以及dept表中全部列的数据,根据员工编号升序排列
答案:
select e.empno,e.ename,e.job,d.*
from emp e,dept d
where e.deptno=d.deptno and not e.ename like '%K%' and d.deptno in(20,30)
order by e.empno asc;
非等值连接查询
说明:关联条件不是通过“=”相连接的
案例:查询emp表中,员工的编号,姓名,工资,以及salgrade表中,工资等级(grade),最低工资(losal)
答案:
select e.empno,e.ename,e.sal,s.grade,s.losal
from emp e,salgrade s
where e.sal between s.losal and s.hisal;
练习:查询emp表中,工资在1000-3000之间的,员工的编号,姓名,工资以及salgrade表中的全部列,根据工资等级(grade)升序排列,如果工资等级一致,根据员工编号降序排列
答案:
select e.empno,e.ename,e.sal,s.*
from emp e,salgrade s
where e.sal>1000 and e.sal<3000 and e.sal between s.losal and s.hisal
order by s.grade asc,e.empno desc;
自连接查询
案例:查询emp表中,员工的编号,姓名,职位,领导编号(mgr),领导姓名
select e.empno,e.ename,e.mgr,e.job,m.ename
from emp e,emp m
where e.mgr=m.empno;
复习:
1. 条件查询
1) select */列名 from 表名 where 条件;
2) select */列名 from 表名 where 列名 is null;
3) select */列名 from 表名 where 列名 is not null;
4) select */列名 from 表名 where 列名 between 初值 and 终值;
5) select */列名 from 表名 where 列名 like 条件
条件: % _ N% %N %N% %N_ _N%
2. 聚合函数
count(*/列名) 统计数量
sum(列名) 求和
avg(列名) 求平均数
min(列名) 求最小值
max(列名) 求最大值
3. 连接查询
select 别名1.*/列名,别名2.*/列名......
from 表1 别名1,表2 别名2......
where 关联条件;
等值连接---> "="
非等值连接---> between...and...
自连接查询---> 说明: 在一张表中,列与列之间存在关联,将一张表看成2张表, 使用等值连接查询来处理。
3.12.15 子查询(嵌套查询)
说明:在一条查询语句的内部,又包含一条查询语句
案例:查询emp表中,工资大于平均工资的,员工的编号,姓名,职位,工资
答案:
select empno,ename,job,sal
from emp
where sal>
1)求出平均工资
select avg(sal) from emp;
2)合成
select empno,ename,job,sal
from emp
where sal>(select avg(sal) from emp);
练习:查询emp表中,工资小于20号部门最高工资的员工的编号,姓名,职位,工资
答案:
select empno,ename,job,sal
from emp
where sal<(select max(sal) from emp where deptno=20);
练习:查询员工所属部门名称是SALES下的,员工的编号,姓名,职位,部门编号
方法1: 连接法
select e.empno,e.ename,e.job,e.deptno,d.dname
from emp e,dept d
where e.deptno=d.deptno and d.dname='SALES';
方法2: 嵌套法
select empno,ename,job,deptno from emp
where deptno=(select deptno from dept where dname='SALES');
练习:查询emp表中,和员工姓名是JONES同一个部门的,员工的编号,姓名,职位,部门编号
答案:
方法1:
select e.empno,e.ename,e.job,e.deptno,d.deptno
from emp e,dept d
where e.deptno=d.deptno and d.deptno=20;
方法2:
select empno,ename,job,deptno
from emp
where deptno=(select deptno from emp where ename='JONES');
3.12.16 事务控制语句(TCL)
1)commit 提交事务(保存)
create table db_test(
id number(4) primary key,
name varchar2(30)
);
insert into db_test values(1,'tom');
insert into db_test values(2,'rose');
insert into db_test values(3,'jack');
select * from db_test;
2)rollback 回滚事务(撤销)
说明:rollback只可以撤销未保存的数据
insert into db_test values(4,'lucy');
insert into db_test values(5,'lili');
select * from db_test;
rollback;
3.12.17 约束
说明:约束就是在数据库表中的列上,设置某些规则,只有满足这些规则,才可以做数据的插入,咱们把这些规则叫做约束
约束的分类:
3.1)主键约束(primary key)
说明:主键约束就是对表中的列进行约束,被主键约束所修饰的列,其列值是唯一且非空的,一张表中只可以有一个主键约束。
案例:创建表时,添加主键约束
create table db_test1(
id number(4) primary key,
name varchar2(30),
age number(3)
);
insert into db_test1 values(1,'tom',23);
insert into db_test1 values(1,'rose',22);
insert into db_test1(name,age) values('jack','20');
------反例
3.2)联合主键(复合主键)---重点
说明:使用primary key 修饰多个列
create table db_test2(
id number(4),
name varchar2(30),
sex char(3),
constraint pk_id_name_test2 primary key(id,name)
);
insert into db_test2 values(1,'tom','男');
insert into db_test2 values(1,'rose','女');
insert into db_test2 values(2,'tom','男');
insert into db_test2 values(1,'tom','男');
练习:创建一张表db_test3,表中包含的字段有
did number(4)
dname varchar(30)
age number(3)
sex char(3)
对did和dname设置联合主键,约束名为pk_did_d name_test3并验证
答案:
create table db_test3(
did number(4),
dname varchar(30),
age number(3),
sex char(3),
constraint pk_did_dname_test3 primary key(did,dname)
);
insert into db_test3 values(1,'tom','20','男');
insert into db_test3 values(1,'lucy','20','女');
insert into db_test3 values(2,'jack','20','男');
insert into db_test3 values(1,'tom','20','男');
3.3)修改表时,添加主键约束
格式:
alter table 表名 add constraint 约束名 primary key(列名1,列名2,......);
案例:创建一张表db_test4,表中包含的字段有id number(4),name varchar(20),age number(3),修改表时,对id列添加主键约束。
create table db_test4(
id number(4),
name varchar(20),
age number(3)
);
alter table db_test4 add constraint pk_id_test4 primary key(id);
insert into db_test4 values(1,'rose',23);
insert into db_test4 values(1,'jack',25);
练习:创建一张表db_test5,表中包含的字段有id number(4),name varchar2(30),score number(4,1),修改表时,对id和name列添加主键约束,约束名为pk_id_name_test5
答案:
create table db_test5(
id number(4),
name varchar2(30),
score number(4,1)
);
alter table db_test5 add constraint pk_id_name_test5 primary key(id,name);
insert into db_test5 values(1,'tom','90');
insert into db_test5 values(2,'jack','80');
insert into db_test5 values(1,'tom','90');
3.4)删除主键约束
格式1:
alter table 表名 drop primary key;
案例:删除表db_test1主键约束
alter table db_test1 drop primary key;
格式2:
alter table 表名 drop constraint 约束名;
说明:可以使用此格式,删除主键约束,唯一约束,检查约束
案例:删除db_test5表中,主键约束,约束名为pk_id_name_test5
alter table db_test5 drop constraint pk_id_name_test5;
练习:删除db_test4表中主键约束,约束名为pk_id_test4
alter table db_test4 drop constraint pk_id_test4;
3.12.17.2唯一约束(unique)
说明:唯一约束可以修饰一个列或者多个列的组合值,防止用户输入重复数据,一张表中可以有多个唯一约束,被唯一约束所修饰的列,可以插入null。
1)创建表时,添加唯一约束
create table db_test6(
id number(4) primary key,
name varchar2(20) unique,
age number(3),
address varchar2(50)
);
insert into db_test6 values(1,'张三','20','北京');
insert into db_test6 values(2,'张三','22','京北');
insert into db_test6(id,age,address) values(2,23,'京北');
2)修改表时,添加唯一约束
格式:
alter table 表名 add constraint 约束名 unique(列名1,列名2,......);
案例:修改db_test6表,对address列添加唯一约束,约束名为uq_address_test6
答案:
alter table db_test6 add constraint uq_address_test6 unique(address);
练习:创建一张表db_test7,表中包含的字段有id number(4) pk,name varchar2(20),passwd varchar2(12),money number(7,2),修改表时对name和passwd添加唯一约束,约束名为uq_name_passwd_test7
答案:
create table db_test7(
id number(4) primary key,
name varchar2(20),
passwd varchar2(12),
money number(7,2)
);
insert into db_test6 values(1,'张三','20','北京');
alter table db_test7 add constraint uq_name_passwd_test7 unique(name,passwd);
3)删除唯一约束
格式:
alter table 表名 drop constraint 约束名;
案例:删除db_test7表中唯一约束,约束名为uq_name_passwd_test7
答案:
alter table db_test7 drop constraint uq_name_passwd_test7;
练习:删除db_test6表中唯一约束,约束名为uq_address_test6
alter table db_test6 drop constraint uq_address_test6;
3.12.17.3 检查约束(check)
说明:检查约束就是对表中的列设置某些规则,满足规则就可以插入数据,防止用户输入非法数据。
1) 创建表时,添加检查约束
create table db_test8(
id number(4) primary key,
name varchar2(20) unique,
sex char(3) check(sex in('男','女')),
age number(3),
email varchar2(30)
);
insert into db_test8 values(1,'陆小凤','男','22','[email protected]');
insert into db_test8 values(2,'东方不败','中','30','[email protected]');
2) 修改表时,添加检查约束
格式:
alter table 表名 add constraint 约束名 check(检查条件);
案例:修改db_test8表,对age添加检查约束,要求age范围在【1-150】,约束名为chk_age_test8
答案:
alter table db_test8 add constraint
chk_age_test8 check(age between 1 and 150);
insert into db_test8 values(1,'许仙','女','60','[email protected]');
insert into db_test8 values(3,'白素贞','女','800','[email protected]');
练习:修改db_test 表,对email列添加检查约束,要求email必须包含@,约束名为chk_email_test8
答案:
alter table db_test8 add constraint
chk_email_test8 check(email like '%@%');
insert into db_test8 values(4,'张三丰','男','149','zsfedu.cn');
3) 删除检查约束
格式:
alter table 表名 drop constraint 约束名;
练习:修改db_test 表中,检查约束,约束名为chk_email_test8
答案:
alter table db_test8 drop constraint chk_email_test8;
练习:删除db_test8表中,检查约束,约束名为chk_age_test8
答案:
alter table db_test8 drop constraint chk_age_test8;
3.12.17.4默认值约束(default)
说明:默认值约束就是,对某列添加默认值,当在执行插入操作的时候,如果该列添加默认值约束,插入null(空)时,系统会自动将默认值变为列值。
1)创建表时,添加默认值约束
create table db_test9(
id number(4) primary key,
name varchar2(20) unique,
sex char(3) check(sex in('男','女')),
age number(3) default 18,
stime date default sysdate,
address varchar2(50)
);
insert into db_test9(id,name,sex) values(1,'法海','男');
select * from db_test9;
2)修改表时,添加默认值约束
格式:
alter table 表名 modify 列名 数据类型 default 默认值
案例:修改db_test9,将age 列默认值修改为20岁
alter table db_test9 modify age number(3) default 20;
insert into db_test9(id,name,sex) values(2,'陈美琪','女');
练习:创建一张表,db_test10,表中包含的列有,id number(4) pk,name varchar2(20) uq,address varchar2(50) uq,stime date,修改表时,对stime列添加默认值约束,并验证
答案:
create table db_test10(
id number(4) primary key,
name varchar2(20) unique,
address varchar2(50) unique,
stime date
);
alter table db_test10 modify stime date default sysdate;
insert into db_test10(id,name,address) values(1,'陈美琪','北京');
insert into db_test10(id,name,address) values(2,'陈琪','上海');
3)删除默认值约束
格式:
alter table 表名 modify 列名 数据类型 default null;
案例:删除db_test10表中,stime列上的默认值约束
答案:
alter table db_test10 modify stime date default null;
insert into db_test10(id,name,address) values(2,'许仙','北京');
select * from db_test10;
练习:删除db_test9表中,age列上的默认值约束并验证
答案:
alter table db_test9 modify age number(3) default null;
insert into db_test9(id,name,sex) values(6,'美琪','女');
3.12.17.5 非空约束(not null)
说明:当执行插入操作的时候,被非空约束所修饰的列,其列值不能为null。
1)创建表时,添加非空约束
create table db_test11(
id number(4) primary key,
name varchar2(20) unique,
sex char(3) check(sex in('男','女')),
age number(3) default 18,
address varchar2(50) not null,
email varchar2(30)
);
insert into db_test11(id,name,sex) values(1,'赵敏','女'); ---反例
insert into db_test11(id,name,sex,address) values(1,'赵敏','女','北京');
2)修改表时,添加非空约束
格式:
alter table 表名
modify(列名1 not null)
modify(列名2 not null)
...
modify(列名n not null);
案例:修改db_test11表,对email列添加非空约束
答案:
alter table db_test11 modify(email not null);
insert into db_test11(id,name,sex,address) values(2,'赵微','女','北京');
练习:创建一张表db_test12,表中包含的字段有id number(4) pk,name varlues2(30),passwd varchar2(20),salary number(5),修改表时,对name和passwd添加非空约束,并验证。
答案:
create table db_test12(
id number(4) primary key,
name varchar2(30),
passwd varchar2(20),
salary number(5)
);
alter table db_test12
modify(name not null)
modify(passwd not null);
insert into db_test12(id,salary) values(1,10000);
3)删除非空约束
格式:
alter table 表名
modify(列名1 null)
modify(列名2 null)
...
modify(列名n null);
案例:删除db_test11表中,email列上的非空约束
答案:
alter table db_test11
modify(email null);
练习:删除db_test12表中,name和passwd列上的非空约束
答案:
alter table db_test12
modify(name null)
modify(passwd null);
总结:
主键约束(primary key) --联合主键
唯一约束(unique)
检查约束(check) --性别/数值/包含
默认值约束(default) --日期
非空约束(not null)
3.12.18 索引(index)
说明:索引是建立在表中列上的数据库对象,用来提高查询速度。
1) 创建索引
格式:
create index 索引名称 on表名(列名);
案例:创建一张表db_test13,表中包含的字段有:id number(4) pk,name varchar2(20),address varchar2(50),对name列添加索引,索引名称为index_name_test13
答案:
create table db_test13(
id number(4) primary key,
name varchar2(20),
address varchar2(50)
);
create index index_name_test13 on db_test13(name);
说明:
>> 被主键约束所修饰的列,系统自带索引
>> 被唯一约束所修饰的列,系统自带索引
练习:在db_test13表中的,address列上,添加索引,索引名称为index_address_test13
答案:
create index index_address_test13 on db_test13(address);
2) 删除索引
格式:drop index 索引名称;
案例:删除db_test13表中,index_name_test13索引
答案:drop index index_name_test13;
练习:删除db_test13表中,index_address_test13索引
答案:drop index index_address_test13;
3.12.19 序列(sequence)
说明:序列是数据库中的一个对象,通过序列可以生成自动增长的数字,经常使用序列生成的数字,作为主键所在的列值。
1) 创建序列
格式:create sequence 序列名称;
2) nextval
通过nextval可以生成一个新数字,初始值为1
create sequence seq_id;
select seq_id.nextval from dual;
案例:创建一张表db_test14表中包含的字段有:id number(4) pk,name varchar2(20),使用序列生成自动增长的数字,作为主键所在的列值,进行数据的插入操作
答案:
create table db_test14(
id number(4) primary key,
name varchar2(20)
);
create sequence seq_id_test14;
insert into db_test14 values(seq_id_test14.nextval,'孙悟空');
insert into db_test14 values(seq_id_test14.nextval,'猪八戒');
insert into db_test14 values(seq_id_test14.nextval,'沙和尚');
select * from db_test14;
3)序列的属性
1)设置初始值 start with 初始值;
2)增长步长 increment by 步长;
3)最小值 minvalue 最小值;
4)最大值 maxvalue 最大值;
案例:创建一个序列,序列名称为seq_aid,初始值为5,增长步长为10,最小值为1,最大值为100
答案:
create sequence seq_aid
start with 5
increment by 10
minvalue 1
maxvalue 100;
3.12.20视图(view)
说明:视图就是一张虚拟表,通过视图,可以查询一张或者多张表的数据。
1) 创建视图
格式:
create view 视图名称
as
查询语句;
案例:查询emp表中,员工的编号,姓名,职位,工资,入职时间,将结果作为视图view_emp01;
答案:
create view view_emp01
as
select empno,ename,job,sal,hiredate from emp;
select * from view_emp01;
练习:创建一个视图,视图名称为view_dept01,查询dept表中的全部数据作为视图结果并验证。
答案:
create view view_dept01
as
select * from dept
select * from view_dept01;
练习:创建一个视图,view_emp_dept01,查询emp表中全部数据,以及dept表中,部门名称和部门地址将结果给视图view_emp_dept01
答案:
create view view_emp_dept01
as
select e.*,d.dname,d.loc
from emp e,dept d
where e.deptno=d.deptno;
select * from view_emp_dept01;
数据库--视图(view)
1、创建视图
格式:
create view 视图名称
as
查询语句;
案例:创建一个视图,名称为v_emp,查询emp表中全部数据作为视图结果
答案:
create view v_emp
as
select * from emp;
select * from v_emp;
案例:查询emp表中的全部数据以及dept表中部门名称(dname),部门地址(loc),将结果赋值给视图v_emp01
答案:
create view v_emp01
as
select e.*,d.dname,d.loc
from emp e,dept d
where e.deptno=d.deptno;
案例:查询员工编号(empno),员工姓名(ename),工资(sal),部门编号(deptno),部门名称(dname),部门地址(loc),根据工资升序排列,如果工资一致,根据员工编号降序排列
答案:
select empno,ename,sal,deptno,dname,loc
from v_emp01
order by sal asc,empno desc;
练习:查询工资在1000-3000之间的员工的编号,姓名,工资,部门名称,部门地址,根据工资降序排列
答案:
select empno,ename,sal,deptno,dname
from v_emp01
where sal>1000 and sal<3000
order by sal desc;
2、修改视图(view)
格式:
create or replace view 视图名称
as
查询语句;
select * from v_emp;
案例:修改视图v_emp,查询部门编号是10号和20号的,员工的编号,姓名,职位,部门编号
create or replace view v_emp
as
select empno,ename,job,deptno
from emp
where deptno in(10,20);
练习:修改v_emp01视图,查询emp表中全部数据以及salgrade表中全部数据,作为v_emp01结果
e.sal between s.losal and s.hisal
create or replace view v_emp01
as
select e.*,s.*
from emp e,salgrade s
where e.sal between s.losal and s.hisal;
3、使用视图实现对表的操作
create view v_dept
as
select * from dept;
3.1 插入数据
insert into v_dept values(50,'软件测试','北京');
insert into v_dept values(60,'软件研发','上海');
3.2 更新数据
案例:将部门编号是50号部门的,部门地址修改为京北
update v_dept set loc='京北'
where deptno=50;
select * from dept;
案例:将部门编号是60号部门的,部门地址修改为海上
update v_dept set loc='海上'
where deptno=60;
select * from dept;
3.3 删除数据
案例:删除部门编号是50号和60号的部门信息
delete from v_dept
where deptno in(50,60);
4、只读视图(重点)
说明:此视图只能查询,不能修改。
格式:
create view 视图名称
as
查询语句
with read only;
案例:创建v_dept01只读视图并验证
create view v_dept01
as
select * from dept
with read only;
insert into v_dept01 values(70,'软件测试','周广');
5、删除视图
格式:
drop view 视图名称;
案例:删除视图v_emp,v_emp01
drop view v_emp;
drop view v_emp01;
重点:学习资料学习当然离不开资料,这里当然也给你们准备了600G的学习资料
需要的先关注再私我关键字【000】免费获取哦 注意关键字是:000
疑惑:为什么要先关注呢? 回:因为没关注的话私信回了你看不到
项目实战
app项目,银行项目,医药项目,电商,金融

大型电商项目
全套软件测试自动化测试教学视频
300G教程资料下载【视频教程+PPT+项目源码】
全套软件测试自动化测试大厂面经
python自动化测试++全套模板+性能测试

听说关注我并三连的铁汁都已经升职加薪暴富了哦!!!!