第四届字节跳动青训营讲师非常用心给大家整理了课前、中、后的学习内容,同学们自我评估,选择性查漏补缺,便于大家更好的跟上讲师们的节奏,祝大家学习愉快,多多提问交流~
第一节:用户数据分析理论与最佳实践
前言
在前面的课程中我们讲了很多技术层面的知识,而这些技术是如何服务于企业做数据分析的,同学们缺少一些场景来直观地感受。本课程的目的就是让同学们直观且系统地看一下企业是如何构建各种数据分析工具,以及分析人员是如何使用这些工具来做数据分析的。
本节课程分为两个部分,分别讲述数据分析偏基础的概览和进阶的机器学习的应用。由于篇幅有限,有些内容我们会一笔带过,但是我们期望能培养起同学们的兴趣,自主地去查阅相关书籍或博客文章。
用户数据分析理论与最佳实践(基础篇)
用户数据分析简介
为什么要做用户数据分析
在企业竞争越来越激烈,获客成本越来越高的背景下,如何高效地优化产品和精细化投放运营是当前企业竞争的关键,而用户数据分析正是我们保持此竞争力的重要手段(难道还有别的手段?有,靠抄袭,靠砸钱),我们通过数据来驱动用户增长、降低成本和提高收益。
当下互联网的行情不太好,大家也知道,企业们也在“勒紧裤腰带过日子“,盲目扩张、砸钱抢市场的情况在当下会收敛很多。
什么是方法论
这里我仅指互联网行业,我的理解就是一些有经验的人,体系化的把这些做事的手段和思考进行抽象整合后,沉淀下来作为理论,而“后人”按照这个“套路”来执行就好了。学习方法论,能大大减少你去探索的成本。但是在这个互联网飞速发展的时期,这个套路有可能过时,所以大家需要保持敏锐,不要过于迷信某些方法论。
数据分析的各个环节
在真正进入到具体的分析案例之前,我们先来整体看一下,数据分析有哪些环节。
这里包含4个部分。数据源、分析工具、可视化以及贯穿全程的指标体系。
首先我们先看一下数据源,没有数据,我们的数据分析就无从谈起。数据源包括很多种,我们最常见的是埋点和业务DB中的数据以及二次加工的如统计和挖掘出的数据。
有了数据源,我们也不要着急马上去写sql查数,我们看一下有哪些工具来支持我们去做数据分析。企业提供了除了非常基础的sql(也算是一种编程)和代码编程外,还有很多好用的工具,比如可视化查询、分群圈选和当下热门的行为分析工具。
可视化这一块,其实并不是独立的部分,很多分析工具里集成了可视化的能力,但是为了方便同学们理解,我们单独拎出来这一块来讲解。
而指标体系是我们数据分析的脉络,我们做个各种分析其实都会围绕着指标体系来做。指标体系会在真正开始建设之前就进行规划,并在业务发展过程中不断完善。
接下来我们分别介绍一下各个环节。
\
指标体系
一句话介绍指标体系:结合业务战略目标和业务场景,系统化梳理构建的指标集合。我们构建的指标集合通常是分级的,以满足不同级别的人的数据使用需求。
我们以手游业务为例看一下指标体系是什么,当然这个例子不全,仅作为示意用。
这里除了常见的业务指标还有安全风控、服务质量相关的,比如外挂封禁账号数、应用crash率、fps等。整个指标体系所涵盖的指标数量在复杂的业务场景中,可能几百个。
那我们搭建指标体系有什么用途呢?这里我列了一些,大家可以先行体会一下:
- 衡量经营状况
- 统一口径和统一认知
- 团队牵引
- 支撑后续制定目标和衡量目标
- 发现问题
- 定位问题
近两年,企业们为了能更前置地促进业务发展,又引申出一个叫“北极星指标”(也叫第一关键指标)的概念。通过这个(也有可能不止1个)指标的牵引,来指引各部门抓住重心。
数据源
业务DB数据大家会比较熟悉,常见的是一些关系型数据,我们不展开讲了。这里我们详细讲一下埋点数据。
埋点数据是什么呢?它是指上报的记录着触发原因和状态信息的日志数据。按照上报方来看,可以划分为“服务端埋点”和“客户端埋点”。按照上报形式,可以划分为“代码埋点”、“可视化全埋点”。企业最常用的是代码埋点。
埋点包含哪些要素呢?who when where how what how_much。举个例子:“张三”于“北京时间2022年1月2号12点整”在“游戏商城”用“xx支付”的形式“充值”了“500元”钻石。那企业中埋点数据上报的格式是什么样呢?我们看下面这个例子:
{
"event_name":"game_purchase",
"event_time":1641776400,
"user_info":{
"user_id":"1111",
"role_id":"2222",
"device_id":"3333"
},
"params":{
"server_id":1001,
"item_id":123,
"amount":50000,
"platform":"game_mall",
"pay_type":"xx pay"
},
"location_info":{
"zone_area":"Asia/Shanghai"
},
"headers":{
"device_os":"android",
"app_version":"12.3.4",
"channel":"xxx",
"ip":"x.x.x.x",
"sys_language":"zh-CN",
"app_language":"zh-CN"
}
}
复制代码这里我们可以看到,除了上面那些参数外,还会上报很多其他属性,这些属性是我们极其常用的,所以企业内的sdk默认会采集上报。
了解了埋点的格式之后,那我们需要在什么时候上报呢?这个就跟具体的业务场景有关系了。你要分析什么数据就在对应的时机采集埋点数据。
分析工具
我们先整体看一下各工具的对比情况。同学内简单了解下即可。
分析工具这块我们主要讲一下最常用的sql和比较热门的行为分析工具。
数据表与SQL
表的基本构成:表名、表字段、表字段类型等。
SQL:结构化查询语言,用来操作表的语言。细分为DDL(数据定义语言)和DML(数据操纵语言)等。
在工作中,这些表的建模和查询sql是需要做精心优化的,以提升查询性能并减少资源浪费。
思考题:这里举个简单的例子,大家想一下sql怎么写。
表:用户登录日志表t
表字段:os,device_id,province,login_time,log_date
查询:筛选最近30天和AB省份,统计各个log_date、os的设备活跃数
回顾了sql之后,我们就要进一步引入指标和维度的概念,这个在可视化的时候需要用到。
理解指标和维度
指标是数据的量化统计,维度是数据分组的方式。
那大家思考一下:
- 上面的sql例子中维度是什么?指标是什么?
- 除了上面的去重数,你还能想到哪些常用的指标算子?
- 用户的付费金额、登录次数这类的数值,可以作为维度吗?
行为分析-事件分析
行为分析工具包括很多模型,我们把用户日常最高频使用的功能进行了固化,用户只需在界面配置自己要分析的埋点、属性筛选和分组项,即可在几秒内查询出数据结果。由于篇幅有限,这里我们仅介绍下企业最常用的事件分析。
我们可以看到,左侧是查询配置区,右侧是展示区。左侧我们可以配置指标、筛选项和分组项,分别对应了sql的select、where、group by。这个比较好理解。
数据可视化
先看一下常见的图表样式:
我们可以看到图表的样式很多,但也需要注意,选择什么样的样式是看怎么方便你去做数据洞察,不要仅为了花里胡哨而去使用这些图表。
思考题:除了这些,你还能想到其他哪些图表类型。
可以参考开源可视化图表库Echarts
数据分析的流程和案例
分析流程和分析思路
一个完整的数据分析流程是这样的:
暂时无法在飞书文档外展示此内容
接下来我们以企业应用经营过程中用户的生命周期为视角,看下可以做数据分析的环节。生命周期我们此处使用AARRR模型更方便大家理解。
暂时无法在飞书文档外展示此内容
案例
Acquisition(获取) -广告素材分析
数据如下:
一些指标概念:
激活CPA:平均获取1个新增设备花费的成本
新增CPA:平均获取1个新增账号花费的成本
次留:当天新增的用户有少比例在次日又活跃了
3留:当天新增的用户有少比例在第3日又活跃了
2日LTV:平均每个用户前两天带来的收入
2日ROI:2日LTV/新增CPA
其他指标同理
通过这份数据,大家觉得应该优先加大哪个素材的推广力度呢?
Activation(激活)-新用户激活转化分析
这是一份漏斗转化数据。
如果某一步出现很低的转化率,你有什么优化建议吗?
Retention(留存)-新用户激活转化分析
这是一份游戏各玩法参与率的数据,你能得出什么结论?
数据分析常见的问题
- 上游数据质量不高
- 不验证就全量上线
- 优化策略短期有利而长期有损
- 过分挖掘用户信息,不注重用户隐私保护
总结
总结:
上半节课我们简单讲了下企业是如何使用各种分析工具来分析数据的,并一起看了一些案例,希望大家能有所收获。接下来我们看一下机器学习在企业实际应用场景中的实践。
思考题:
打开你手机的一款应用,你觉得哪些环节可以做数据分析,你觉得可能存在哪些优化点?
用户数据分析理论与最佳实践(进阶篇)
概述
下半节课程主要分为四个方面:
- 介绍机器学习概览
- 介绍特征工程
- 介绍聚类算法
- 介绍聚类画像分析
课前部分给出一些机器学习和大数据的基础知识点,作为课堂内容的前置基础,请同学们按需提前自行学习;
课中部分对课堂内容作一些细节上的补充,旨在帮助同学们加深对课题的理解;
课后部分作为重点总结,帮助同学们梳理复习本课程涵盖的核心内容。
课前 (必须)
大数据 理论基础
机器学习理论基础
| 快速入门 | 推荐描述 | 相关链接 |
|---|---|---|
| 吴恩达《Machine Learning》 | 这绝对是机器学习入门的首选课程,没有之一!即便你没有扎实的机器学习所需的扎实的概率论、线性代数等数学基础,也能轻松上手这门机器学习入门课,并体会到机器学习的无穷趣味。 | 课程主页- www.coursera.org/learn/machi… github.com/fengdu78/Co… |
| 周志华《机器学习》 | 被大家亲切地称为“西瓜书”。这本书非常经典,讲述了机器学习核心数学理论和算法,适合有作为学校的教材或者中阶读者自学使用,入门时学习这本书籍难度稍微偏高了一些。 | 读书笔记- www.cnblogs.com/limitlessun… github.com/Vay-keen/Ma… datawhalechina.github.io/pumpkin-boo… zhuanlan.zhihu.com/c_101385029… |
| 李航 《统计学习方法》 | 包含更加完备和专业的机器学习理论知识,作为夯实理论非常不错 | 读书笔记- www.cnblogs.com/limitlessun… github.com/SmirkCao/Li… zhuanlan.zhihu.com/p/36378498 |
机器学习算法流程
暂时无法在飞书文档外展示此内容
课中
机器学习
为什么要机器学习?
- 人工智能时代已经到来(个性化推荐、机器翻译、人脸识别......)
- 大数据成为热议的内容(数据多,产生快,形式杂,组织乱)
- 解决实际的业务决策问题(业务需要从大数据中挖掘数据背后隐藏的价值)
什么是机器学习?
机器学习并不是近年来才出现的领域。早在上个世纪50年代,来自 IBM 的 Arthur Samuel 就给出了机器学习最早的定义:
举个上世纪基于机器学习开发的产品案例——垃圾邮件过滤系统。这种系统有两种开发思路:
- 第一种是传统编程,开发者把垃圾邮件的特性总结出一系列的规则(比如邮件正文含有“促销”、“折扣”等字眼则大概率是垃圾邮件),再转成代码进行条件判断。但这也意味着对抗者在感知到特定规则后可以利用其绕过该系统,使得开发者不得不一直根据垃圾邮件的演进而增加新的规则,代码会越写越长,难以维护。
- 另一种是开发一个能自己从数据中学习隐藏规则的系统。开发者不再编写具体的规则,只要更新数据就能使系统主动识别出数据所蕴含的规则变化,主动调整自身策略,无需开发者介入规则的调整。
简而言之,机器学习是搭建一个能够自主从数据(或经验)中学习潜在规则的系统。在合适的情景下,尤其是解决复杂问题时,它能有效简化系统和代码,并大大降低后期策略迭代与维护的成本。
- 机器学习就是把无序的数据转换为有用的信息
- 从数据中自动分析获得模型,并利用模型对未知数据进行预测
- 机器学习算法流程:获取数据、数据探测、特征工程、构建数据集、建模调参、模型评估
暂时无法在飞书文档外展示此内容
机器学习算法有哪些?
机器学习有非常多的种类及相应的算法,主要可以分成三大类:
| 机器学习系统分类 | 学习方式 | 常见算法或应用 |
|---|---|---|
| 监督/非监督学习> 取决于训练是否需要人类的监督 | 监督学习(Supervised Learning)> 训练数据要带上正确的标注(label),让系统明白样本及其对应的类别。- 分类(Classification):预测结果是一系列类型,如分辨图片是猫还是狗- 回归(Regression):预测结果是连续的数,如预测房子的价格> 分类和回归是可以互相转化的,比如使用对数回归做二分类的任务。 | - k-Nearest Neighbors- Linear Regression- Logistic Regression- Support Vector Machines (SVMs)- Decision Trees and Random Forests...... |
| 非监督学习(Unsupervised Learning)> 训练数据没有标注。 |
- 聚类(Clustering) |
- K-Means
- DBSCAN- 可视化和降维(Visualization and dimensionality reduction)
- Principal Component Analysis (PCA)- 异常检测和新奇检测(Anomaly detection and novelty detection)- 关联规则学习(Association rule learning)> 发现数据属性之间的关联,比如超市中购买了烧烤汁、薯片的人也会倾向于买肉 | |
复制代码| 半监督学习(Semisupervised Learning)> 训练数据部分有标注。 | 比如图片或视频分类:先将有标注的数据训练一个教师模型,再用它来预测未标注的数据将其分类和聚类,接着用这些数据训练出学生模型,最后使用原本标注的数据来调优该学生模型。 | | | 批量/在线学习> 取决于系统是否能持续地从数据流中学习并更新 | 批量学习(Batch Learning)> 系统训练时使用所有的训练数据,如果收到新数据,必须与旧数据合并重新训练,对计算机资源有较高的要求。 | 最常见的,不举例了 | | 在线学习(Online Learning)> 系统可以持续读入新数据并更新模型,快速便宜。也适用于在性能、资源较差的设备上训练模型(可以一点一点读数据训练,然后把旧数据丢掉)。 | 这种学习方式存在缺陷:如果传入了异常数据,它的表现会迅速劣化,需要监控。> 在线学习聊天机器人回复安全性的研究聊天机器人在恶意语言训练后被迫下线 | | | 基于实例/模型学习> 取决于系统是直接把新数据与旧数据比较,还是通过建模来预测 | 基于实例学习(Instance-based Learning)> 系统铭记旧数据,比较新数据与旧数据的相似度,来推测新数据所属的类。 | - K-Nearest Neighbors Regression
| | 基于模型学习(Model-based Learning)> 根据数据,选定一种模型进行训练,然后用训练过的模型预测新数据。 | - Linear Regression- Polynomial Regression- ...
| |
上述的系统类型和具体方法并不是互相独立的,可以根据实际问题进行组合。
机器学习的挑战有哪些?
-
在机器学习中,面临的挑战主要来自两大模块:糟糕的算法和糟糕的数据。
-
算法的问题主要有以下两种:
-
过拟合(Overfitting):意味着算法可能过于复杂,不止学到了该学的规则,还将噪音、异常学到心里,使得无法很好预测新样本。
-
欠拟合(Underfitting):意味着算法可能过于简单,没学到精髓。
-
数据的问题具体表现为:
-
-
训练数据太少
- 数据对机器学习系统的影响程度可能比你想象中算法对系统的影响要多。
- 2001年一个关于自然语言歧义消除的研究 Scaling to very very large corpora for natural language disambiguation 中发现,在数据足够多的情况下(比如10亿),即使是非常简单的模型(右图中 Memory-Based 红线),也能在这种复杂问题中表现良好。
- 这意味着,如果数据足够多且廉价,那么是可以减少在算法优化上的投入。
-
-
注意:前提是「数据足够多」,现实中获取巨量数据的成本往往很高,一般是中小型的数据集,所以还是不要轻易放弃算法优化。
-
-
-
训练数据不具备代表性
- 在数据量小的情况下,数据的增减容易引起模型不断变动。
- 在数据量大的情况下,如果样本不具备代表性,那么训练结果也会引入偏差
-
-
比如对线上所有用户做个推荐算法,而训练数据来自市中心区的全体业主。又比如某专家对两亿灵活就业人群提高收入提出诚挚建议:“出租闲置房屋、开私家车拉活”。
-
-
数据本身质量很差
- 噪音、缺漏、异常等会使得系统更难发现内在的规律和模式,需要数据清洗。
-
比如人体扫描仪识别一个人的身材维度,在识别算法较差的情况下,胖子的识别结果可能会很离谱——机器也许认为这个人没有腰,或者把凸出来的腰当成臀部。
-
选取的特征没有相关性
- “Garbage in, garbage out”,训练数据要有足够多的相关特征、尽量减少无关特征,才能让机器学习的系统更好地更快地学习到隐含的规则。
- 需要运用特征工程(Feature Engineering)来获取相关度高的特征集。
-
- 在 大数据 场景下,对资源的要求非常高,比如存储和算力。
特征工程
创造新的特征是一件十分困难的事情,需要丰富的专业知识和大量的时间。机器学习应用的本质基本上就是特征工程。 ——Andrew Ng
概述
- 定义:特征工程是将原始数据转化成更好的表达问题本质的特征的过程。
现实事物中具备着各种各样的信息,比如一张图片有着色彩、纹理、边界等各类型的信息数据。而特征工程要做的,就是将这些“原始数据”进行处理,从中构建出在此问题下,能代表该事物属性的“特征”。
- 意义:数据和特征决定了机器学习的上限,而模型和算法只是逼近这个上限而已。
- 特征工程包含以下几个过程:数据理解、数据预处理、特征构造、特征选择
暂时无法在飞书文档外展示此内容
数据理解
数据是什么样的形式
- 结构化数据与非结构化数据
结构化数据:如一些以表格形式进行存储的数据
非结构化数据:就是一堆数据,类似于文本、报文、日志之类的
- 定量和定性数据
定量数据:指的是一些数值,用于衡量某件东西的数量
定性数据:指的是一些类别,用于描述某件东西的性质
数据预处理
- 数据的质量,直接决定了模型的预测和泛化能力的好坏。它涉及很多因素,包括:准确性、完整性、一致性、时效性、可信性和解释性。而在真实数据中,我们拿到的数据可能包含了大量的缺失值,可能包含大量的噪音,也可能因为人工录入错误导致有异常点存在,非常不利于算法模型的训练。数据清洗的结果是对各种脏数据进行对应方式的处理,得到标准的、干净的、连续的数据,提供给数据统计、模型等使用。
- 数据预处理的主要步骤分为:数据清洗、数据集成、数据规约和数据变换。
数据清洗
数据清洗(data cleaning) 的主要思想是通过填补缺失值、光滑噪声数据,平滑或删除离群点,并解决数据的不一致性来“清理“数据。如果用户认为数据是脏乱的,他们不太会相信基于这些数据的挖掘结果,即输出的结果是不可靠的。
- 缺失值的处理
- 由于现实世界中,获取信息和数据的过程中,会存在各类的原因导致数据丢失和空缺。针对这些缺失值的处理方法,主要是基于变量的分布特性和变量的重要性(信息量和预测能力)采用不同的方法。主要分为以下几种:
-
- 删除变量:若变量的缺失率较高(大于80%),覆盖率较低,且重要性较低,可以直接将变量删除。
- 定值填充:工程中常见用-9999进行替代
- 统计量填充:若缺失率较低(小于95%)且重要性较低,则根据数据分布的情况进行填充。对于数据符合均匀分布,用该变量的均值填补缺失,对于数据存在倾斜分布的情况,采用中位数进行填补。
- 插值法填充:包括随机插值,多重插补法,热平台插补,拉格朗日插值,牛顿插值等
- 模型填充:使用回归、贝叶斯、随机森林、决策树等模型对缺失数据进行预测。
- 哑变量填充:若变量是离散型,且不同值较少,可转换成哑变量,例如性别SEX变量,存在male,fameal,NA三个不同的值,可将该列转换成 IS_SEX_MALE, IS_SEX_FEMALE, IS_SEX_NA。若某个变量存在十几个不同的值,可根据每个值的频数,将频数较小的值归为一类'other',降低维度。此做法可最大化保留变量的信息。
- 异常值处理
- 异常值是数据分布的常态,处于特定分布区域或范围之外的数据通常被定义为异常或噪声。异常分为两种:“伪异常”,由于特定的业务运营动作产生,是正常反应业务的状态,而不是数据本身的异常;“真异常”,不是由于特定的业务运营动作产生,而是数据本身分布异常,即离群点。主要有以下检测离群点的方法:
-
- 简单统计分析:根据箱线图、各分位点判断是否存在异常。
- 3σ原则:若数据存在正态分布,偏离均值的3σ之外.
- 基于绝对离差中位数(MAD) :这是一种稳健对抗离群数据的距离值方法,采用计算各观测值与平均值的距离总和的方法。放大了离群值的影响。
- 基于距离:通过定义对象之间的临近性度量,根据距离判断异常对象是否远离其他对象,缺点是计算复杂度较高,不适用于大数据集和存在不同密度区域的数据集
- 基于密度:离群点的局部密度显著低于大部分近邻点,适用于非均匀的数据集
- 基于聚类:利用聚类算法,丢弃远离其他簇的小簇。
- 噪声处理
- 噪声是变量的随机误差,是观测点和真实点之间的误差。通常的处理办法:
-
- 对数据进行分箱操作,等频或等宽分箱,然后用每个箱的平均数,中位数或者边界值(不同数据分布,处理方法不同)代替箱中所有的数,起到平滑数据的作用。
- 建立该变量和预测变量的回归模型,根据回归系数和预测变量,反解出自变量的近似值。
数据集成
数据集成将多个数据源中的数据结合成存放在一个一致的数据存储,如数据仓库中。这些源可能包括多个数据库或一般文件。
- 实体识别问题:例如,数据分析者或计算机如何才能确信一个数据库中的 customer_id 和另一个数据库中的 cust_number 指的是同一实体?通常,数据库和数据仓库有元数据——关于数据的数据。这种元数据可以帮助避免模式集成中的错误。
- 冗余问题:一个属性是冗余的,如果它能由另一个表“导出”;如年薪。属性或维度命名的不一致也可能导致数据集中的冗余。用相关性检测冗余:数值型变量可计算相关系数矩阵,标称型变量可计算卡方检验。
- 数据值的冲突和处理:不同数据源,在统一合并时,保持规范化,去重。
数据规约
数据归约技术可以用来得到数据集的归约表示,它小得多,但仍接近地保持原数据的完整性。这样,在归约后的数据集上挖掘将更有效,并产生相同(或几乎相同)的分析结果。一般有如下策略:
- 维度规约
用于数据分析的数据可能包含数以百计的属性,其中大部分属性与挖掘任务不相关,是冗余的。维度归约通过删除不相关的属性,来减少数据量,并保证信息的损失最小。
-
属性子集选择:目标是找出最小属性集,使得数据类的概率分布尽可能地接近使用所有属性的原分布。在压缩的属性集上挖掘还有其它的优点,它减少了出现在发现模式上的属性数目,使得模式更易于理解。
- 逐步向前选择:该过程由空属性集开始,选择原属性集中最好的属性,并将它添加到该集合 中。在其后的每一次迭代,将原属性集剩下的属性中的最好的属性添加到该集合中。
- 逐步向后删除:该过程由整个属性集开始。在每一步,删除掉尚在属性集中的最坏属性。
- 向前选择和向后删除的结合:向前选择和向后删除方法可以结合在一起,每一步选择一个最 好的属性,并在剩余属性中删除一个最坏的属性。
-
单变量重要性:分析单变量和目标变量的相关性,删除预测能力较低的变量。这种方法不同于属性子集选择,通常从统计学和信息的角度去分析。
- pearson相关系数和卡方检验,分析目标变量和单变量的相关性。
- 回归系数:训练线性回归或逻辑回归,提取每个变量的表决系数,进行重要性排序。
- 树模型的Gini指数:训练决策树模型,提取每个变量的重要度,即Gini指数进行排序。
- Lasso正则化:训练回归模型时,加入L1正则化参数,将特征向量稀疏化。
- IV指标:风控模型中,通常求解每个变量的IV值,来定义变量的重要度,一般将阀值设定在0.02以上
- 维度变换
- 维度变换是将现有数据降低到更小的维度,尽量保证数据信息的完整性。介绍以下常用的几种有损失的维度变换方法,将大大地提高实践中建模的效率
-
- 主成分分析 ( PCA )和因子分析( FA ) :PCA通过空间映射的方式,将当前维度映射到更低的维度,使得每个变量在新空间的方差最大。FA则是找到当前特征向量的公因子(维度更小),用公因子的线性组合来描述当前的特征向量。
- 奇异值分解(SVD) :SVD的降维可解释性较低,且计算量比PCA大,一般用在稀疏矩阵上降维,例如图片压缩,推荐系统。
- 聚类:将某一类具有相似性的特征聚到单个变量,从而大大降低维度。
- 线性组合:将多个变量做线性回归,根据每个变量的表决系数,赋予变量权重,可将该类变量根据权重组合成一个变量。
- 流行学习:流行学习中一些复杂的非线性方法。
数据变换
数据变换包括对数据进行规范化,离散化,稀疏化处理,达到适用于挖掘的目的。
-
规范化处理:数据中不同特征的量纲可能不一致,数值间的差别可能很大,不进行处理可能会影响到数据分析的结果,因此,需要对数据按照一定比例进行缩放,使之落在一个特定的区域,便于进行综合分析。特别是基于距离的挖掘方法,聚类,KNN,SVM一定要做规范化处理。
- 最大 - 最小规范化:将数据映射到[0,1]区间,
- Z-Score标准化:处理后的数据均值为0,方差为1,
- Log变换:在时间序列数据中,对于数据量级相差较大的变量,通常做Log函数的变换
-
离散化处理:数据离散化是指将连续的数据进行分段,使其变为一段段离散化的区间。分段的原则有基于等距离、等频率或聚类的方法。数据离散化的原因主要有以下几点:
- 模型需要:比如决策树、朴素贝叶斯等算法,都是基于离散型的数据展开的。如果要使用该类算法,必须用离散型的数据进行。有效的离散化能减小算法的时间和空间开销,提高系统对样本的分类聚类能力和抗噪声能力。
- 离散化的特征相对于连续型特征更易理解。
- 可以有效的克服数据中隐藏的缺陷,使模型结果更加稳定。
- 用数字很容易找到关系(比如“大”、“小”、“双”、“半”),然而当给定字符串时,计算机只能说出它们是“相等”还是“不同”。
- 方法如下:
- 等频法:使得每个箱中的样本数量相等,例如总样本n=100,分成k=5个箱,则分箱原则是保证落入每个箱的样本量=20。
- 等宽法:使得属性的箱宽度相等,例如年龄变量(0-100之间),可分成 [0,20],[20,40],[40,60],[60,80],[80,100]五个等宽的箱。
- 聚类法:根据聚类出来的簇,每个簇中的数据为一个箱,簇的数量模型给定。
- 稀疏化处理:针对离散型且标称变量,无法进行有序的LabelEncoder时,通常考虑将变量做0,1哑变量的稀疏化处理,例如动物类型变量中含有猫,狗,猪,羊四个不同值,将该变量转换成is_猪,is_猫,is_狗,is_羊四个哑变量。若是变量的不同值较多,则根据频数,将出现次数较少的值统一归为一类'rare'。稀疏化处理既有利于模型快速收敛,又能提升模型的抗噪能力。
特征构造
特征构造是指从现有的数据中构造额外特征,这需要我们花大量的时间去研究真实的数据样本,思考问题的潜在形式和数据结构,同时能够更好地应用到预测模型中。
特征构造的操作分为两类:“聚合”和“转换”。
聚合
-
分组统计特征
- 中位数
- 算数平均数
- 众数
- 最小值
- 最大值
- 标准差
- 方差
- 频数
- 分组统计和基础特征结合
......
转换
- 单列特征加/减/乘/除一个常数
- 单列特征单调变换(log、n次方等)
- 线性组合
- 多项式特征
- 比例特征
- 绝对值特征
- 最大值特征
- 最小值特征
- 编码特征(OneHotEncoding、LabelEncoding、Embedding)
.......
特征选择
在实际项目中,可能会有大量的特征可使用,有的特征携带的信息丰富,有的特征携带的信息有重叠,有的特征则属于无关特征,如果所有特征不经筛选地全部作为训练特征,经常会出现维度灾难问题,甚至会降低模型的准确性。因此,需要进行特征筛选,排除无效/冗余的特征,把有用的特征挑选出来作为模型的训练数据。
Filter 方法(过滤式)
先进行特征选择,然后去训练学习器,所以特征选择的过程与学习器无关 。 相当于先对特征进行过滤操作,然后用特征子集来训练分类器。主要思想:对每一维特征“打分”,即给每一维的特征赋予权重,这样的权重就代表着该特征的重要性,然后依据权重排序。
- Chi-squared test(卡方检验)
- Information gain(信息增益)
- Correlation coefficient scores(相关系数)
Wrapper方法(封装式)
直接把最后要使用的分类器作为特征选择的评价函数,对于特定的分类器选择最优的特征子集。主要思想:将子集的选择看作是一个搜索寻优问题,生成不同的组合,对组合进行评价,再与其他的组合进行比较。这样就将子集的选择看作是一个优化问题。
- 递归特征消除算法。
Embedded方法(嵌入式)
将特征选择嵌入到模型训练当中,其训练可能是相同的模型,但是特征选择完成后,还能给予特征选择完成的特征和模型训练出的超参数,再次训练优化。主要思想:在模型既定的情况下学习出对提高模型准确性最好的特征。也就是在确定模型的过程中,挑选出那些对模型的训练有重要意义的特征。
- 用带有L1正则化的项完成特征选择(也可以结合L2惩罚项来优化)、随机森林平均不纯度减少法/平均精确度减少法。
Embedding
概览简介
embedding,即嵌入,起先源自于NLP领域,称为**「词嵌入(word embedding)」**,主要是利用背景信息构建词汇的分布式表示,最终可以可以得到一种词的向量化表达,即用一个抽象的稠密向量来表征一个词。
那么embedding 其实就是一种稠密向量的表示形式。在 embedding 大行其道之前 oneHot 才是最靓的仔。如果和我们比较熟悉的 oneHot 对比起来理解,顿时会发现 embedding 这个玄里玄乎的概念,实际上 so easy。直观上看 embedding 相当于是对 oneHot 做了平滑,而 oneHot 相当于是对 embedding 做了 max pooling。
解释性理解
比如 RGB(三原色,red,green,blue)任何颜色都可以用一个 RGB 向量来表示,其每一维度都有明确的物理含义(和一个具体的物理量相对应)。当然 RGB 这个例子比较特殊,和我们一般意义的 embedding,还不一样,因为 RGB 的特殊性就在,他的每一维度都是事先规定好的,所以解释性很强。而一般意义的 embedding 则是神经网络倒数第二层的参数权重,只具有整体意义和相对意义,不具备局部意义和绝对含义,这与 embedding 的产生过程有关,任何 embedding 一开始都是一个随机数,然后随着优化算法,不断迭代更新,最后网络收敛停止迭代的时候,网络各个层的参数就相对固化,得到隐层权重表(此时就相当于得到了我们想要的 embedding),然后再通过查表可以单独查看每个元素的 embedding。
产生过程
理解Word2Vec 之 Skip-Gram 模型 mp.weixin.qq.com/s/lANKP0dUH…
图解word2vec mp.weixin.qq.com/s/oIxCPNXEU…
意义作用
- 「经过Embedding向量化表达后的数据,其实变得更加适合深度神经网络的训练和学习,也有利于工业界数据的工程化处理。」高维稀疏数据对于机器学习的参数学习和相关计算都不太友好(「高维易引发“维度之灾”,使空间距离很难有效衡量,另外高维经常使参数数量变得非常多,计算复杂度增加,也容易导致 过拟合 ;稀疏容易造成梯度消失,导致无法有效完成参数学习」),因此通常特别稀疏的高维离散数据更适合使用Embedding代替传统One-Hot编码方式。
- 此外,「Embedding虽然是一种降维表示,但是却携带了语义信息,而且这种表示方式并不局限于词,可以是句子、文档、物品、人等等,Embedding能够很好地挖掘嵌入实体间的内部关联,即便降维也能保留这种潜在关系」,这简直就是“神来之笔”,怪不得说万物皆可Embedding。
应用场景
- 在深度学习网络中作为Embedding层,完成从高维稀疏特征向量到低维稠密特征向量的转换;
- 作为预训练的Embedding特征向量,与其他特征向量连接后一同输入深度学习网络进行训练;
- 通过计算用户和物品的Embedding相似度,Embedding可以直接作为 推荐系统 或计算广告系统的召回层或者召回方法之一。
聚类算法
概览简介
聚类算法是机器学习中涉及对数据进行分组的一种算法。在给定的数据集中,我们可以通过聚类算法将其分成一些不同的组。在理论上,相同的组的数据之间有相似的属性或者是特征,不同组数据之间的属性或者特征相差就会比较大。聚类算法是一种非监督学习算法,并且作为一种常用的数据分析算法在很多领域上得到应用。
- 常用的聚类方法:
-
- K-means
- DBSCAN
- 层次聚类;
这些常用聚类方法所依赖的常用聚类特征较为偏向统计学类特征。
常用聚类特征:
- 人口属性:性别、年龄、地域等等;
- 常用指标:活跃度、时长、消费次数等等;
- 消费偏好:用户使用不同功能的时长占比、点击占比,每天进入该app的启动方式等等。
聚类所使用的统计特征无法反应用户的行为细节。因此,我们也就需要比统计特征更具有区分客户特性的特征。
常用聚类方法各自的优点和缺点:
| 聚类算法 | 优点 | 缺点 |
|---|---|---|
| 基于距离——K-means | 实现简单快速、聚出的类别相对均匀 | 受初始点选择影响较大、无法自定义距离、无法识别离群点、需要事先确定簇的数量 |
| 基于密度——DBSCAN | 可以识别离群点、对特殊分布效果好 | 聚出的类别欠均匀、受密度定义影响较大、不擅长处理密度不均的数据 |
| 层次聚类 | 对特殊分布效果好、类的层次关系具有一定价值 | 有时聚出的类别欠均匀、内存不友好 |
应用场景
- 指标波动场景。举例:某个重要的KPI发生变化时,我们会思考是不是某个特定人群导致了这个波动,然后针对这样的波动找到应对的办法;
- 精细化运营。举例:在做某个业务的增长,我们会思考哪些是潜力用户,在定位到潜力用户后进一步思考如何更好地承接他们;
- PMF(Product-Market Fit)。即研究给什么样的细分人群提供什么样的内容才能达到最好的匹配效果。
K-Means
概览
K-means 聚类算法可能是大家最为熟悉的聚类算法。它在许多的工业级数据科学和机器学习课程中都有被讲解。并且容易理解和实现相应功能的代码 。
k-means聚类
- 首先,我们确定要聚类的数量,并随机初始化它们各自的中心点。为了确定要聚类的数量,最好快速查看数据并尝试识别任何不同的分组。中心点是与每个数据点向量长度相同的向量,是上图中的“x”。
- 通过计算当前点与每个组中心之间的距离,对每个数据点进行分类,然后归到与距离最近的中心的组中。
- 基于迭代后的结果,计算每一类内,所有点的平均值,作为新簇中心。
- 迭代重复这些步骤,或者直到组中心在迭代之间变化不大。您还可以选择随机初始化组中心几次,然后选择看起来提供最佳结果。
k-means的优点是速度非常快,因为我们真正要做的就是计算点和组中心之间的距离;计算量少!因此,它具有线性复杂性o(n)。
另一方面,k-means有两个缺点。首先,您必须先确定聚类的簇数量。理想情况下,对于一个聚类算法,我们希望它能帮我们解决这些问题,因为它的目的是从数据中获得一些洞察力。k-means也从随机选择聚类中心开始,因此它可能在算法的不同运行中产生不同的聚类结果。因此,结果可能不可重复,缺乏一致性。
K值选择
关于聚类的簇数量最优选择,可参考此文章****www.biaodianfu.com/k-means-cho… ,常用肘部法和轮廓系数法。
模型评估
模型评估方法可参考此文章 juejin.cn/post/699791…
聚类画像分析工具
概览简介
一个基于聚类的用户画像分析工具,以对用户群体进行标注及定位,(1)帮助运营分析师PM等洞察群体用户在站内的消费、投稿内容生态情况;(2)研究用户与内容的关系和演变,理解业务增长的变化,制定用户与内容的增长策略,以使得用户分析更简便、更灵活、更快获取数据背后所隐藏的价值。
流程
分析过程
| # | 环节 | 目的 | 详情 | 示意截图 |
|---|---|---|---|---|
| 1 | 样本选定 | 确定聚类分析的样本范围 | 一共提供三种方式圈选人群1. 定义条件筛选样本,条件都是比较通用的,比如年龄、性别、vv_finish_1w(过去一周用户的完播次数,用来保证用户兴趣的显著性),缺点是条件比较少。2. 上传圈选ID列表,主要服务于用户所需的条件并不在第一种方式里,可以直接离线圈选好用户,然后通过上传csv文件即可。这种方式更多的是用于一次性实验分析,**如果设置成周期调度,但由于已是上传固定的用户,没法根据你离线选好条件随时间动态变化用户,所以就成了固定用户的周期任务。**3. 输入hive表名称,也是服务于用户所需的条件并不在第一种方式里,但是你需要有hive表的写权限,调度频次可设置成一次性实验分析,也可周期调度。如果需要周期调度,请将hive表对应的任务设置成天级调度(由表里的数据来决定哪些用户需要参与聚类) 。平台会在周期调度时间到来时读取表里的数据,完成任务的执行。相比第二种,用户可随时间动态变化,但需要hive表写权限。 | |
| 2 | 向量获取 | 获取选定样本中用户在短视频内的行为向量(64维) | 行为向量是一种描述用户在短视频内行为的特征向量。可以粗略理解为,倾向于消费/点赞/收藏/分享同一类视频或倾向于与同一类创作者互动的用户,将会拥有相似的特征向量。**选择Embedding作为模型特征的依据:**1. 用户行为的语义特征2. 线下分析反映线上效果 | |
| 3 | 算法聚类 | 基于64维用户推荐向量,通过k-means算法,将相似的用户分成一组,不相似用户分成不同组。 | **选择k-means算法的依据:**1. 用户64维推荐向量在空间中的分布是球状分布且凸集的数据,k-means所求的目标函数是所有点到距离其最近的中心点的距离平方和最小,这样我们就要求解一个凸优化问题。 |
1. 需要对满足不同条件的人群进行聚类,所以人群数据量存在着量级差异,量级可达千万级甚至亿级,而且每一个用户的向量是64维。
1. 系统上每天有很多聚类任务需要执行
1. 综上,所以算法复杂度不能过高,不然算法需要花很多时间去训练,且机器资源紧张,进而影响整体任务的执行效率。3. 可理解性和算法稳定性
1. **可理解性:** 设定人群的业务方有过对人群进行探查,从而有一定的认知,了解用户群体大概可分为哪些群体,所以可直接指定群体的数量,并不太强需要由算法的其他参数形式去发现群体应该分为多少个。**当然系统也提供了自动发现人群数的功能,方便对未知群体通过算法来发现最优的分群数量。**
1. **算法稳定性:** 当前任务中cluster_id所表示的含义,在下一个调度周期时,需要使得对应的cluster_id保持同一个含义,即**基于上一周期的聚类结果初始化本周期的聚类任务的cluster中心点**,这样能保证算法中cluster含义的稳定性,从而帮助业务方快速review cluster的内容,以确认内容与之前对比是否发生变化。综上三个要素的考量,选择K-Means算法,该算法简单易懂,适合大数据量且复杂度低。同时能设定所需要分群的数量,以及群体中心点的初始化数据。当然在初次对用户群体进行聚类的时候,选用了K-Means++算法的思想,这样能尽可能消除随机选择初始点带来的结果差异的问题。同时选用MiniBatchKMeans <https://scikit-learn.org/stable/modules/clustering.html#mini-batch-k-means>的思想,以小批量的随机数据进行训练,减少运算时间,且效果并没有变差很多,反而增加了泛化能力。**算法工具包:**- **Python** **Sklearn:** 利用python的sklearn机器学习package里的clustering算法,选择KMeans或者MiniBatchKMeans,来进行聚类。单机本地执行机制,执行速率快,准确度不受影响,但是受本地内存资源的限制,如果本地内存资源足够大,完全可以run。- **Spark** **Scala Mllib:** 利用Spark scala的Mllib机器学习package里的clustering算法,选择KMeans,来进行聚类。Spark yarn 分布式执行机制,执行速率不稳定,时快时慢,受yarn 队列资源此刻资源的限制,如果yarn队列资源充足,执行效率会大大加快,且相对稳定。 | 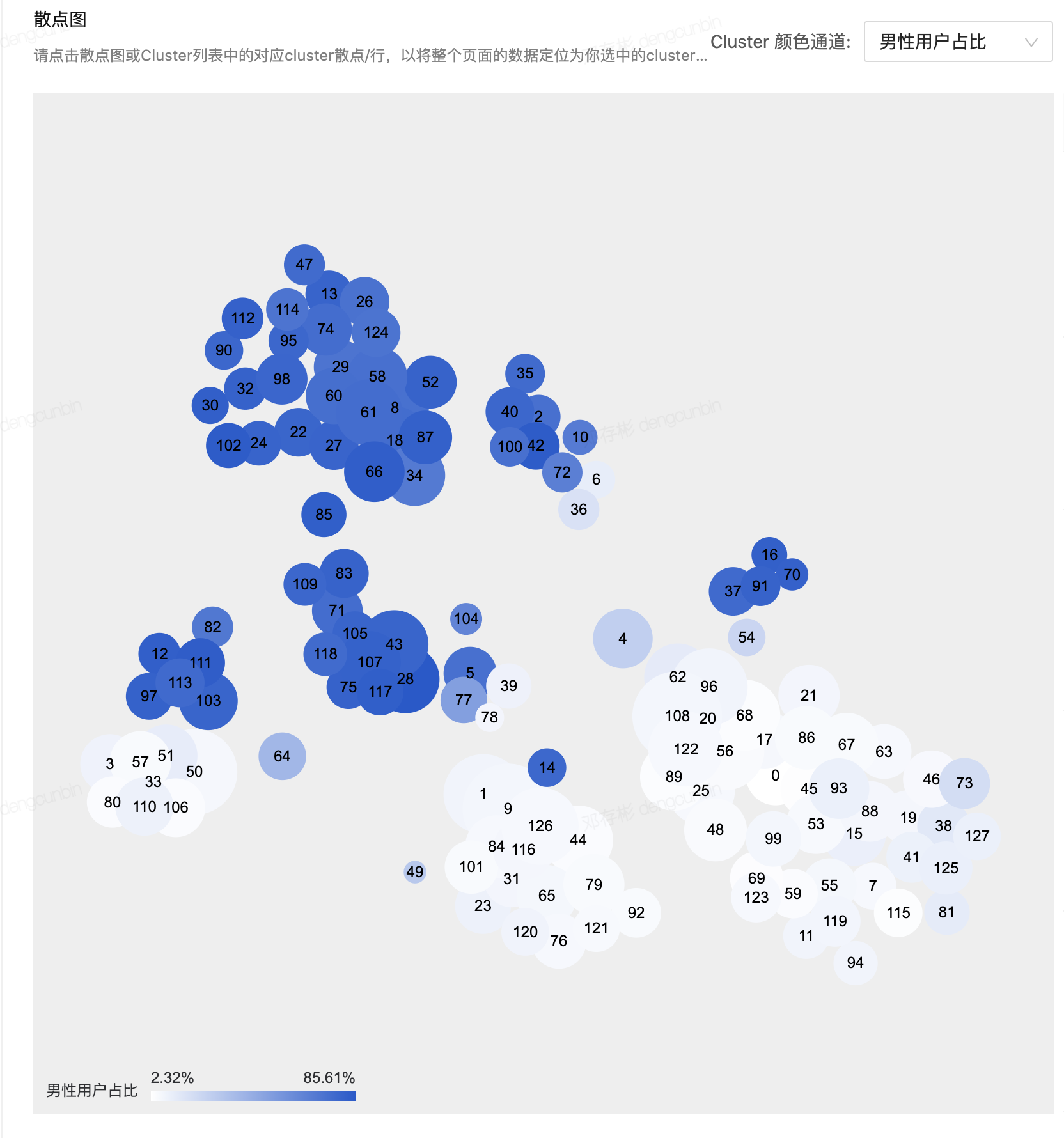 |
复制代码| 4 | Cluster Level 可视化分析 | 通过为用户提供各种各样的可视化数据,辅助用户得出以下结论:- cluster的定性分析
- cluster代表什么类型的用户- cluster的定量分析
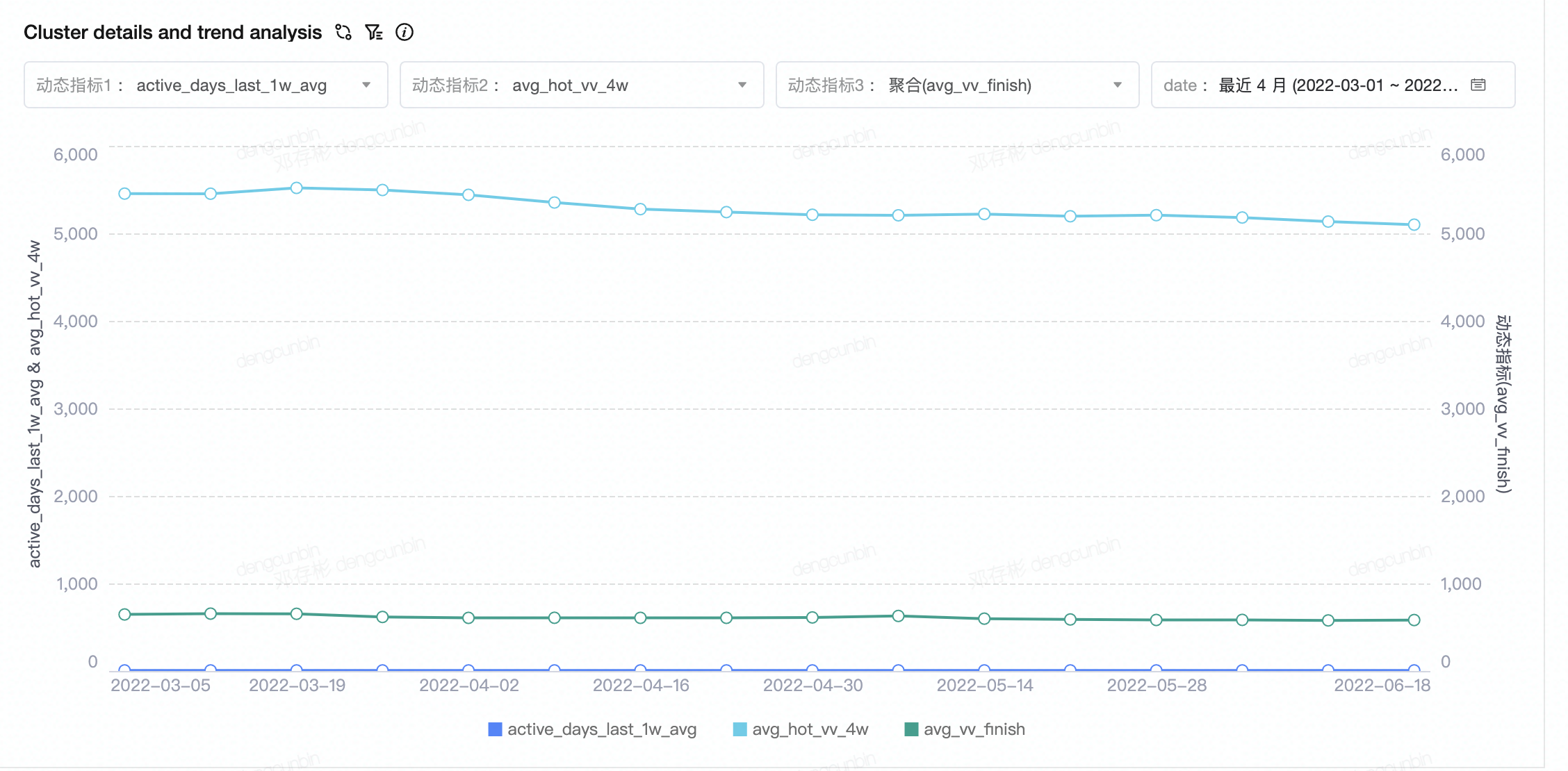
- cluster的核心指标,对比分析及变动趋势- cluster的指标趋势变化分析
- cluster任务周期运行,可发现指标随时间的变化趋势。- cluster之间指标相对关系,发现North Star cluster
- cluster指标在二维坐标系里的相对关系,发现北极星cluster
- > 北极星指标(North Star Metric),也叫作第一关键指标(One Metric That Matters),是指在产品的当前阶段与业务/战略相关的绝对核心指标。它一旦确立就像北极星一样,指引团队向同一个方向迈进(去提升这一指标)。在数据监测中,北极星指标指决定性意义的数据监测指标。 | - 右侧为通过[t-SNE](https://distill.pub/2016/misread-tsne/)算法将64维的cluster中心向量降维到2维的示意图,可以粗略理解为:
- 拥有相似行为的用户被聚类进了各自的cluster中
- cluster间的相似程度与分布存在相关关系。cluster与cluster之间在空间距离越接近,那么它们的画像越相似- cluster的定性指标
- Top Unique Videos
- **基于****TF-IDF****思想**,构造cluster与cluster之间具有区分性偏好的top播放视频
- Random Publish Vidoes
- 随机抽样投稿
- Top Favorite Videos
- 视频收藏次数
- Word Cloud
- 词云分布
- Top Unique Words
- **基于****TF-IDF****思想**,构造cluster与cluster之间具有区分性偏好的top播放视频
- Random Avatars
- 随机抽样头像
- ......- cluster的定量分析
- Age/ Gender/OS Breakdown
- 年龄/性别/操作系统的分布
- VV(video view)
- 视频播放次数
- VVed
- 视频被播放次数
- Publish/Share/Like/Comment
- 投稿/分享/点赞/评论
- Active Days
- 活跃天数
- Retention Rate 2d/7d
- 2d/7d 留存率
- ......- cluster 稳定性分析
- cluster中心点漂移diff
- 表示两次聚类任务实例cluster中心点向量的漂移距离,用来判断群体兴趣偏好是否整体发生变化;该值持续保持在0.5以下的某个水平线上下浮动就是群体偏好没改变。
- 相邻两个周期同一个cluster的用户占比
- 表示上次聚类任务的用户所属cluster与本次聚类任务的用户所属cluster是一致的比例,该值越大,cluster越稳定,用于观察cluster群体用户变化情况。
- 直接review cluster的定性与定量指标,发现偏好内容及指标是否有变化。 | - **定性指标**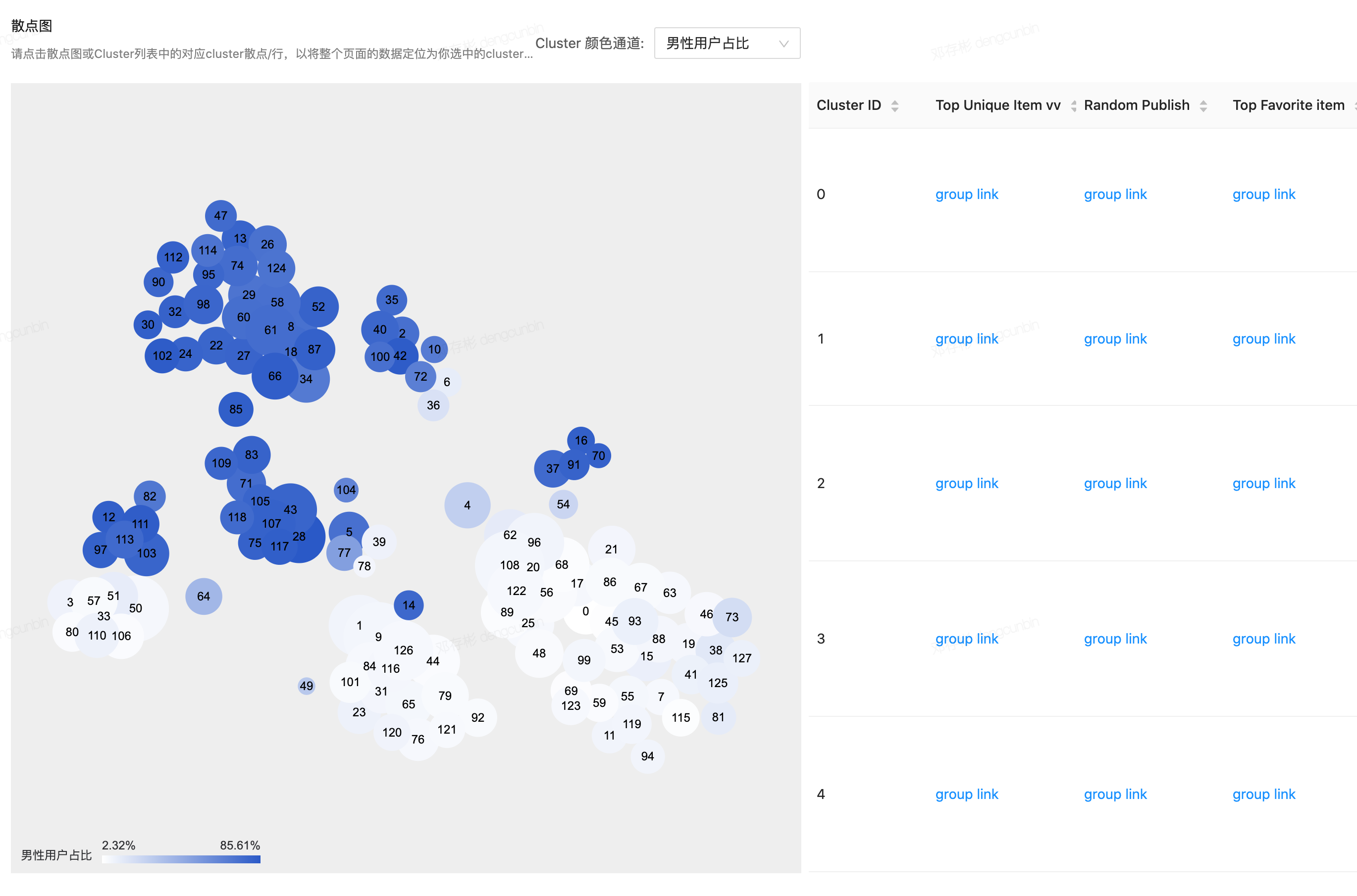- **定量指标**- **趋势图**
- - **North Star**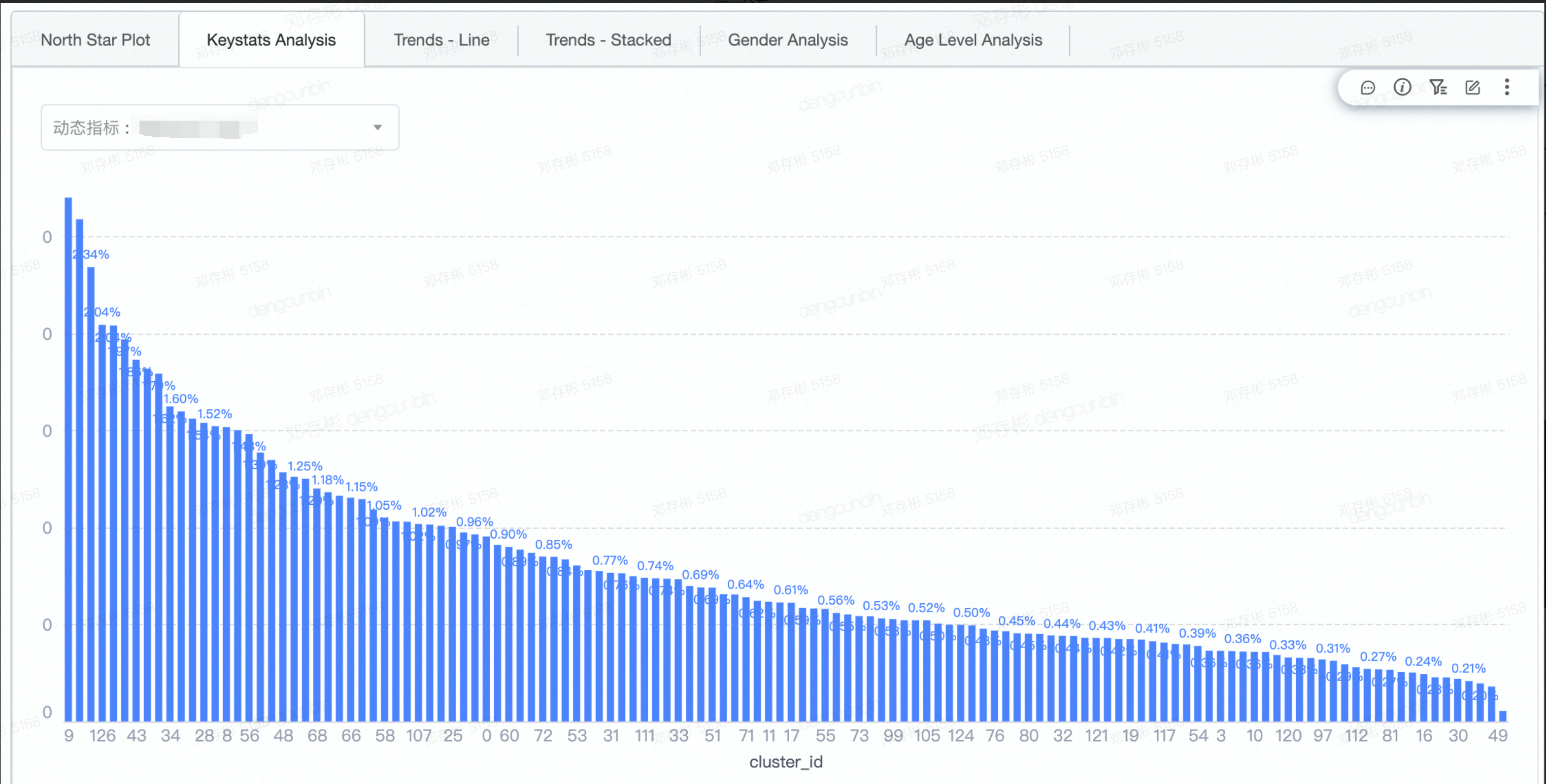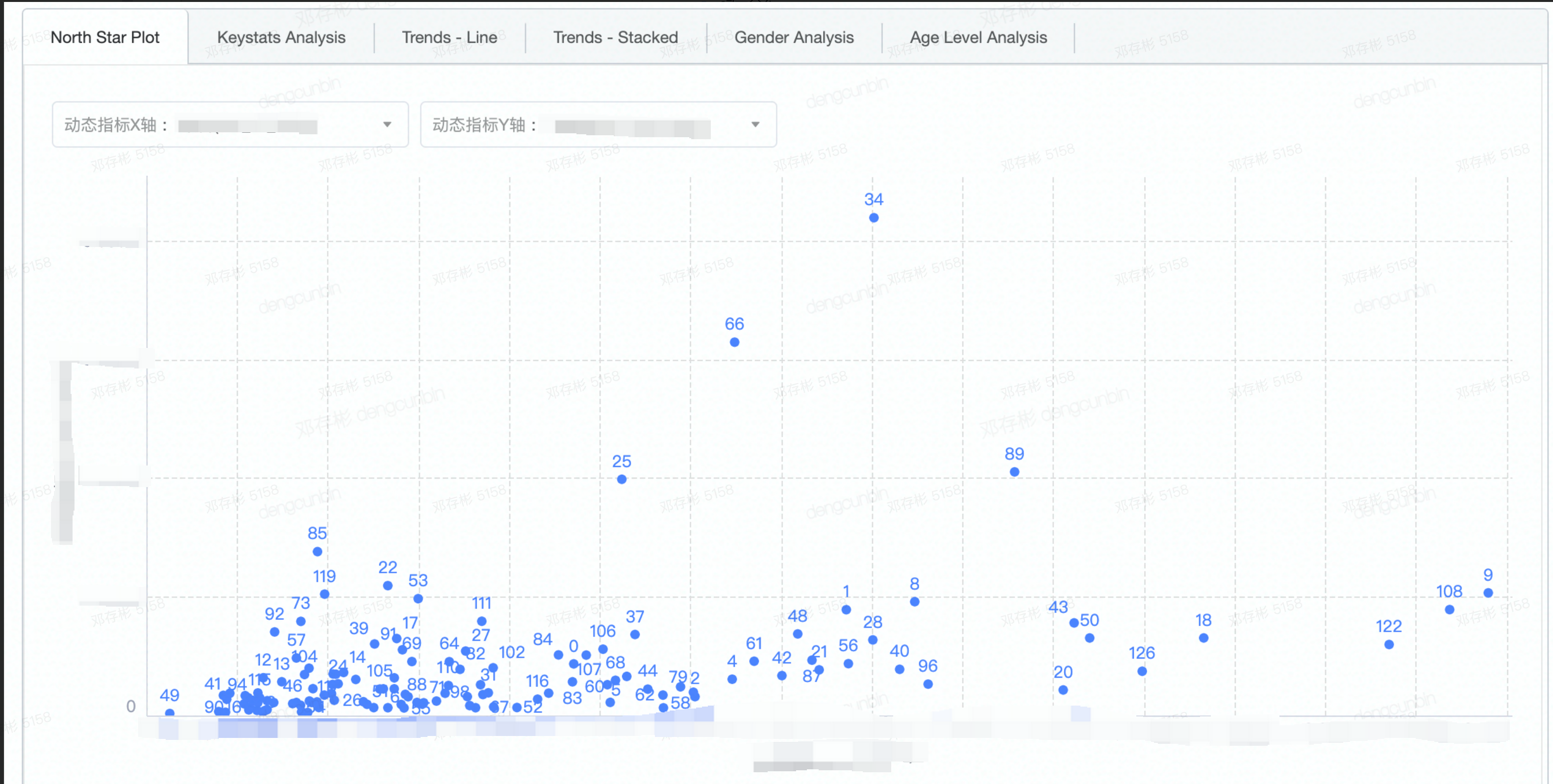**稳定性分析**- **cluster中心点漂移** **diff**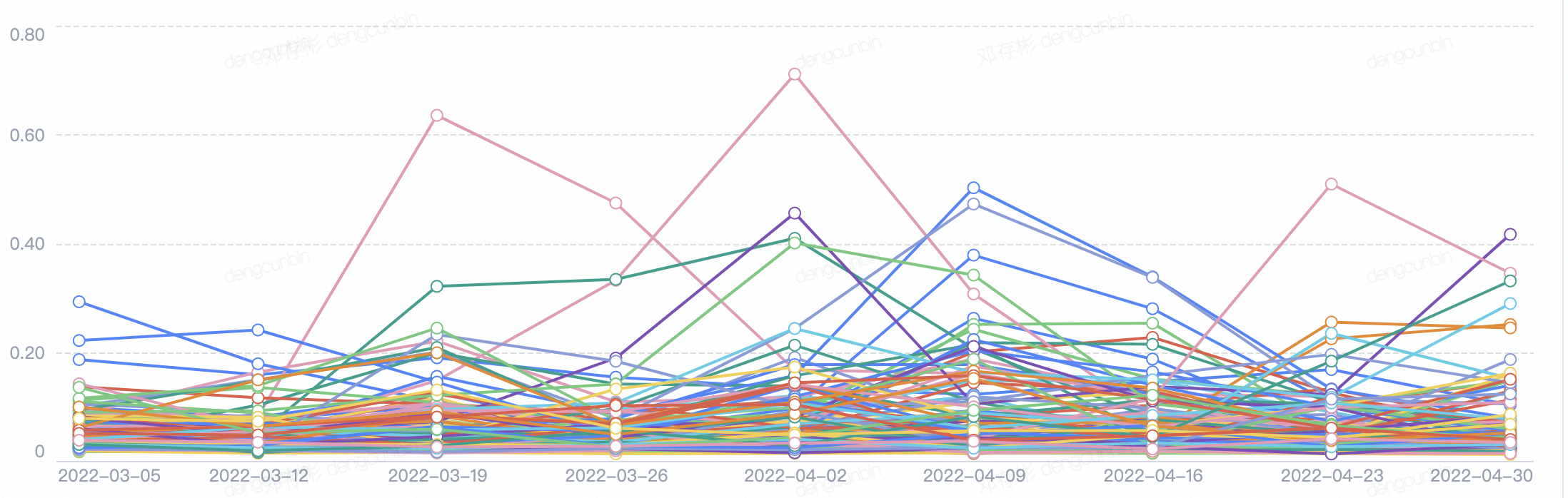- **相邻两个周期同一个cluster的用户占比**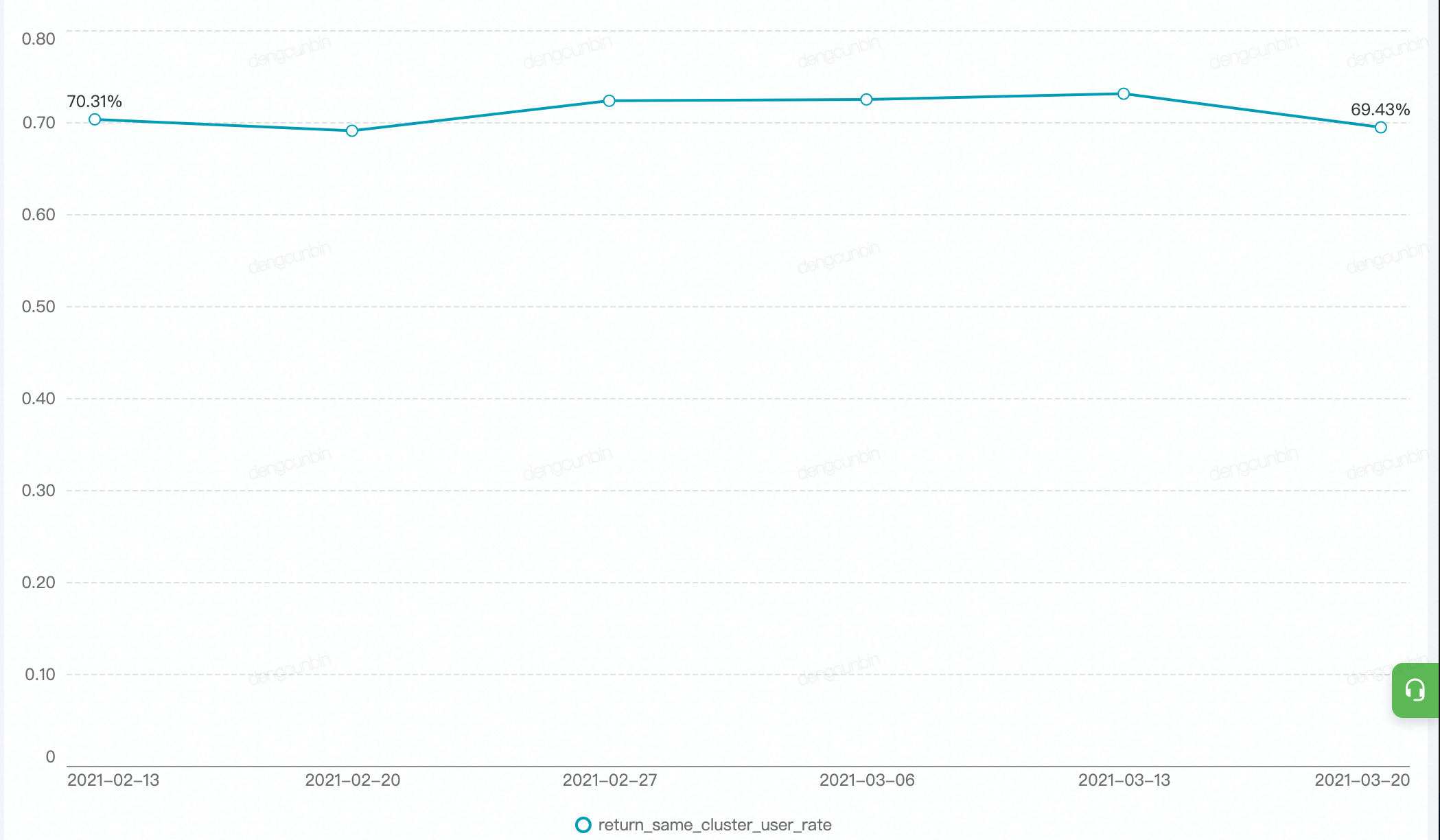 |
复制代码| 5 | 人工标注 | 通过将用户在Cluster可视化分析中得出的定性+定量的结论进行标注 | - cluster与tribe是一对多的关系- 标注逻辑会被保存至之后周期性运行的任务中,方便用户快速查看标注后的指标数据,但是用户有必要每周确认匹配逻辑是否发生了迁移。 | | | 6 | Tribe Level 可视化分析 | 通过用户标注的cluster-tribe匹配逻辑,渲染tribe level分析页面,为用户提供对tribe进行跟踪分析的能力。 | - 所呈现的指标与Cluster Level一致 | |
应用场景
- 用户群体的兴趣偏好,帮助理解站内人群的结构
- 内容消费情况,帮助理解哪些内容更受欢迎
- 发现核心群体,基于其喜欢的内容,制定增长策略
课后
- 梳理回顾特征工程、聚类算法的使用场景
- 理解Embedding的产生原理及应用场景
- 理解可视化分析的指标设计的目的
参考资料
-
特征工程
- github.com/apachecn/fe…
- mp.weixin.qq.com/s/4ZieS11ai…
- mp.weixin.qq.com/s/9L5vQvHuq…
- mp.weixin.qq.com/s/RqdFq76jM…
- mp.weixin.qq.com/s/_m2IioVpF…
- mp.weixin.qq.com/s/crnirNPWb…
- mp.weixin.qq.com/s/B9S9pAK3u…
- mp.weixin.qq.com/s/VQ5zrrGIs…
- mp.weixin.qq.com/s/0ryfSsAxe…
- mp.weixin.qq.com/s/Vv_wvx-8P…
- mp.weixin.qq.com/s/AtRJvGqJt…
-
模型评估和调优
-
降维算法
-
Embedding
第二节:大数据可视化理论与案例分析
概述
本手册旨在帮助学员对数据可视化的概念和原理有一个整体的认知,辅助学员课前预习生疏概念,课中理解讲课思路及重点内容,课后进行重点回顾以及扩展阅读。
本手册可以作为学生学习数据可视化的“学习指南”,按照手册所列内容,结合扩展资料进行系统的学习和实践。
本手册没有讨论更为前沿的可视化课题,比如智能可视化。
课前预习
课前需要学员尽可能对可视化有一个感性的认知,可以重点了解一下数据可视化发展简史,同时对不同历史阶段的一些经典可视化作品做扩展阅读,增加兴趣。
另外一些演示工具可以提前体验一下:
- TimeStoryTeller:timelinestoryteller.com/
- Facets:github.com/PAIR-code/f…
- Tableau:www.tableau.com/
课中重点
主要内容(手册内容在涵盖课程ppt 内容的同时做了大量细节补充和扩展,章节做了重新编排):
- 定义
- 数据可视化基本流程
- 数据
- 可视化设计
- 交互
- 动画
- 实例
-
定义(Definition)
1.1 什么是可视化(What is Visualization)
在了解数据可视化的概念之前,我们先来了解“可视化”。按照维基百科对可视化的定义(en.wikipedia.org/wiki/Visual…
Visualization is any technique for creating images, diagrams, or animations to communicate a message
根据这个定义,我们可以理解为通过视觉元素(图像,图表,动画等等)来进行信息交流的方式都可以称之为可视化。比如下面的梵高的绘画,奥运会的ICon设计,一个具体的桑吉图都属于可视化。
(星夜-文森特·梵高-1889)
(原图链接)
这里应该还有一个更大的范畴定义,不仅局限于视觉,扩展到人类的整个感知系统。通过听觉、触觉或者味觉也是可以进行信息呈现和交流的。针对盲人,也是可以设计优秀的可视化作品的。
1.2 什么是数据可视化(What is Data Visualization)
Anything that converts data into a visual representation (like charts, graphs, maps, sometimes even just tables)
“数据可视化”和“可视化”的定义很相似,只是增加了一个关键词——“数据”。
下面是几个典型的应用场景。
在科学可视化领域,数据可视化的作用主要是形象化的呈现,方便人们理解和查看。比如医学领域的扫描成像,可以大大提高医生探寻病因的效率。下面是一个人体内细胞运动的可视化作品,以壮美的方式呈现了人体内的微观世界(www.youtube.com/watch?v=NTg…
呈现数据关系的信息可视化是我们见到最多的可视化方式,比如下图通过地理信息以及连线展现唐代人物的迁徙轨迹(cbdb-qvis.pkudh.org/part1_migra…
在计算机诞生之前,可视化都是静态作品,人们只能通过看来理解数据。随着计算机图形的发展,交互成为一个重要研究方向,可视化和图形交互的融合,产生了探索式数据分析。比如下面的数据分析工具Tableau的交互界面(www.tableau.com。
1.3 数据可视化作用(The role of data visualization)
直观展示
一图胜千言。数据可视化最直观的作用就是将数据要阐述的内容直观的展现出来,比如下面著名的“拿破仑东征图”。
Charles Joseph Minard,Map of Napolean's Russian Campaign of 1812
这个图表使用颜色标注了拿破仑进军莫斯科的路线图及败退路线,简单的可视化利用二维平面展现了包括空间、时间、气温、军队的人数等多个维度的信息,使得观察者可以通过一幅图了解整个历史事件的全貌。
数据探索
(Anscombe's quartet)是四组基本的统计特性一致的数据,但由它们绘制出的图表则截然不同。每一组数据都包括了11个(x,y)点。这四组数据由统计学家弗朗西斯·安斯库姆(Francis Anscombe)于1973年构造,他的目的是用来说明在分析数据前先绘制图表的重要性,以及离群值对统计的影响之大。
促进沟通与交流
由于可视化可以高效的阐释数据内含,合理的可视化设计可以更好的帮助作者表达其观点。比如下方的“南丁格玫瑰图((en.wikipedia.org/wiki/File:N…
• 各色块圆饼区均由圆心往外的面积来表现数字 • 蓝色区域:死于原本可避免的感染的士兵数 • 红色区域:因受伤过重而死亡的士兵数 • 黑色区域:死于其它原因的士兵数 • 1854年10月、1855年4月的红黑区域恰好相等 • 1856年1月与2月的蓝、黑区域恰好相等 • 1854年11月红色区域中的黑线指出该月的黑色区域大小
复制代码出于对资料统计的结果会不受人重视的忧虑,弗洛伦斯· 南丁格尔 ****发展出一种色彩缤纷的图表形式,让数据能够更加让人印象深刻。这张图表用以表达军医院季节性的死亡率,从整体上来看: 这张图是用来说明、比较战地医院伤患因各种原因死亡的人数,每块扇形代表着各个月份中的死亡人数,面积越大代表死亡人数越多。这幅图让政府相关官员了解到:改善医院的医疗状况可以显著的降低英军的死亡率。南丁格尔的方法打动了当时的高层,包括军方人士和维多利亚女王本人,于是医事改良的提案才得到支持,甚至挽救了千万人的生命
随着可视化的发展,人们使用更多的应用形式来 传递信息,比如仪表盘,数据大屏等。
-
数据可视化基本流程(Process)
一个可视化作品的诞生,要经历一系列流程,我们将其抽象成如下图所示的四个大的步骤。
(vis.stanford.edu/files/2005-…
第一步 : 数据处理( Abstract Data ) 只有满足特定结构的数据才能做对应的可视化展现,而且为了达到好的可视化效果也需要对数据进行清洗、转换等操作。
第二步 : 可视化设计与表达( Visualization Design) 根据数据特征选择合适的展现模式,在此基础上通过合理的使用视觉编码,来定义最终的可视化展现内容。
第三步:可视化渲染( Rendering and Display)
将定义好的图形转换成为图像,展现给观众。
第四步:可视化交互( Interactivity)
单一的可视化结果并不能满足用户的多方面诉求,用户往往借助交互方式,进一步了解细节或者对数据进行筛选、聚合、分面等,对数据进行多方面的探索。
下面我们详细的对第一、第二、第四步骤 进行讲解。
-
数据(Data)
Data is defined as a collection of meaningful facts which can be stored and processed by computers or humans.
能被存储和处理的信息,都可以被视为数据。我们日常接触到的文本、视频、图像、账单等等都是数据。每一个种类的数据都是一个大的集合,由多条小的数据条目组成,称之为数据集(DataSet)。
数据集分为结构化和非结构化(比如文字、图像),数据可视化只能对结构化数据进行呈现。非结构化数据经过处理之后,可以转换为结构化数据,进一步进行可视化展现。比如文本,我们可以通过自然语言处理、机器学习、文本挖掘等多种手段将其转化为结构化数据。
3.1 数据与数据集分类(Data and Dataset)
数据可以被分为以下五种类别:
- Items:具体的每一条数据
- Attributes:条目的每个字段的属性
- Links:数据之间的关系
- Positions:位置
- Grids:网格
数据集被分为以下五种类别:
- Tables:表格数据
- Networks & Trees:层次结构数据
- Fields:场数据
- Geometry:几何数据
- 其他集合类型:Clusters,Sets,Lists
一个数据集可以由一种或者多种数据类型组成,包含关系如下表:
(Tamara Munzner 《Visualization Analysis & Design》)
下面我们对几种数据集做具体的解构分析。
3.1.1 表格(Tables)
表格是使用行、列和单元格的概念来存储数据的结构,每一行是一条数据,每一列都有一个统一的属性定义。以下面学生信息表为例:
该表格有三条数据,每一条数据都有5个属性(Attribute),ID、Name、Age、Shirt Size、Favorite Fruit。
行列交叉的单元格里面就是具体的值(Value)。
3.1.2 多维表格(Multidimensional Table)
多维表格数据和普通表格数据组织形式上最大的不同的点在于key 的数量。通常一个普通表格的key 就是行号,比如3.1.1 的 学生信息表为例,“第2行的年龄7”这样的描述,我们是可以明确的知道描述的对象的名字是Basil,而且Basil 最喜欢的水果是Pear。 但是对于多维表格数据则需要多个key才能确定一个value。
下图所示的一个多维表格数据,我们通过简单的行号或者选取一个键都没办法确定一个明确的数据条目,比如我们想得到一个销售值,那么应该描述成为“ Timeid 为1,pid 11 的销售值为25”,更复杂的数据需要更多的键来组合定位。
www.javatpoint.com/data-wareho…
将两个维度的数据聚合在一起就是一个 “面” ,第三个维度方向上多个面就形成了一个 “体”, 如上图右侧所示,这就是数据立方体基本概念 。
我们将每一个面平铺到表格中,就是一个数据透视表,如下图:
www.javatpoint.com/data-wareho…
如上面表格,每个item 是一个普通表格,行号或者Time 都可以作为唯一的key。
3.1.3 网络和树(Networks or Trees)
网络和树数据,核心概念就是“关系”。必须要显示的定义数据条目之间的关联关系才能绘制出网络图和树图。
上图左侧是比较常见的图数据的配置结构,每一个 node 就是一个 data item,node中的属性就是 attributes。 Edges 中定义的就是节点的关系,对应于 Links 。
3.1.4 场(Fields)
场数据,用于描述磁场、电场、风场等数据,存储结构是网格(grid),每个网格中一般是向量、标量或者张量。
结合上图左右两侧对照,场数据以网格形式存储,右侧的“gridWidth”和“gridHeight”定义了网格的大小(行列数量),field 下面定义了各单元格的值(value)。下图显示了一个风场的可视化效果。
3.1.5 几何数据(Geometry (Spatial))集
几何数据集是几何图形数据的几何,通常用来描述地理信息。
如地图,由多个几何图形拼装而成,在定义地图的数据中会定义具体的几何图形类型及位置信息。
3.2 属性分类(Attribute Types)
数据集中的数据条目都会包含一个或者多个属性(Attribute),属性分为分类(Categorical)和排序(Ordered)属性。排序属性又分为顺序(Ordinal)和定量(Quantitative)两种类别。
结合上图中的学生信息表,我们具体分析一下。第一列的 ID 数值是序号,数字类型,属于Quantitative 字段。第二列 Name 属于 Categorical 字段。第三列 Favorite Fruit 属于 Categorical 字段。第四列 Age ,数字类型 属于 Quantitative 字段。第五列 Gender ,性别属于 Categorical 字段。第六列 Shirt Size ,衣服尺寸虽然不是数字,但是它可以进行大小排序,属于 Ordinal 字段。
上面我们已经了解了数据集类型,数据集类型决定我们选择什么样的可视化形式来展现数据,具体到展现的细节,则是由属性(Attribute)来决定。
-
可视化设计(Visual Design)
-
认知(Cognition)与 知觉(Perception)
Visualization is really about external cognition, that is, how resources outside the mind can be used to boost the cognitive capabilities of the mind. 可视化是一个帮助人们对 外部信息进行认知的过程,也就是说,是一个使用大脑以外的视 觉资源与信号,来帮助增强大脑认知能力的过程 -- Stuart Card
从符号学层面来讲,人类将符号传递到大脑,随后对符号进行解码,根据大脑中的知识来得到符号具体表达的意义。
读取一张图片和接收其他信息一样,依赖我们已经掌握的知识(signifier),我们只能识别我们知道的事情(signified)。我们识别一个符号到它所要表达的意义,实际上需要一个转换“函数”,这个函数就是Code,也就是一个心理认知过程。
关于进一步的知觉感知的研究总结,我们可以抽象人们识别可视化的三个步骤:
- Perception of raw visual signals,e.g. color, shape, etc. 原始信号感知
- Pattern recognition 模式识别
- Reasoning and Analysis 推理分析
Colin Ware ·《Information Visualization Perception for Design》·2004
可视化设计的目标就是要在以上三个步骤中,缩短人类的认知过程,达到准确高效的传递信息的目的。
编码
合理准确的可视化编码,可以提高人们在感知过程中各个步骤的速度和准确性
格式塔 理论 格式塔理论(Gestalt Laws)较为系统的对人类如何发现图形元素之间的相关性进行了全 面总结,被广泛的应用在了视觉设计当中,利用格式塔理论进行设计将有助于用户快速 识别图形符号所构成的“群组模式”。
节省墨水
为了减少冗余可视化元素对读者的影响,在设计过程中,要尽量让每一个符号都有数据意义。
An excellent visualization design gives to the viewer the greatest number of ideas in the shortest time with the least ink in the smallest space. 一个出色的可视化设计可在最短的时间内,使用最少的空间、用最少的笔墨为观众提供最多的信息内涵 -- --Edward R. Tufte
准确度
很多可视化设计会出现扭曲数据的情况,我们需要对夸张程度(或者准确程度)进行度量。
下面我们分别来论述这些方法和策略。
4.2 可视化编码
再回到第3节关于数据的论述,我们基于数据集类型来选取合适的可视化形式,接下来需要根据具体的 数据条目(Item)的特性来确定合适的图元(Mark),最后根据 属性(Atrribute)来配置合适的视觉通道,对图元进行修饰。
4.2.1 Mark
根据数据条目的不同,将Mark分为两个类别:
1. Items / Nodes
2. Links
根据数据维度的不同,我们可以选取点、线、面来进行表达数据。对于关系数据,则需要使用 Links 来展现。
4.2.2 通道(Channels)
选取了Mark之后,需要进一步描述Mark的具体视觉特性,这些特性称之为视觉通道(Visual Channels)
A visual channel is a way to control the appearance of marks
视觉通道有很多,下图以6种通道和3种Mark相组合,可以很直观的体会二者之间的关系。
(John Krygier and Denis 《Making Maps: A Visual Guide to Map Design for GIS》)
4.2.3 编码(Encode)
从数据到视觉通道的转换过程,被称之为视觉编码(Visual Encoding)。
不同的数据属性需要用不同的通道来进行编码才能达到更好的效果,上图将通道分成两组,分别对应分类数据和可排序数据。下面我以一个简单柱形图为例,进行拆解:
上图左侧是柱形图的配置数据,每个数据条目分为映射到X轴的Value,映射到Y轴的Value,还有一个分组字段“g”。
我们的目标是用来比对不同时间段的数值大小,所有Mark 选择 “点”类型,形状为 rect。X 轴是分类数据,我们按照数据条目的个数和出现顺序依次映射到X轴区间的位置(Position)上。Y 轴数据是 数字类型,映射到矩形的高度上。 分组字段是分类数据,我们通过颜色来进行编码。这样就形成了上图右侧的柱形图。
4.2.4 编码有效性(Effectiveness)
由于人类感知系统的特点,在不同场景下需要设计不同的编码策略,来提升感知速度和准确性。以下几项研究,对当前可视化设计有着深远影响。
预感知图形
经过科学家的实验论证,部分图形可以被人类大脑在非常短的时间内识,比如形状、长短、大小等。
在可视化设计过程中,尽可能的使用具有预感知特性的图形,可以加速感知处理的第一个过程。
更多详细内容可以阅读 www.csc2.ncsu.edu/faculty/hea…
有效性排序
一些研究人员对不同的视觉通道对不同数据进行编码进行单变量效果对比,得出有效性排名,下图是研究之一。
Robert E. Roth《Visual Variables》www.researchgate.net/publication…
You must consider a continuum of potential interactions between channels for each pair,ranging from the orthogonal and independent separable channels to the inextricably combined integral channels.
--Tamara Munzner
但是在实际应用场景中,往往一个可视化作品需要组合多个通道,不同通道组合对读者的影响,实际研究不是很多,下图是其中之一。
(Tamara Munzner 《Visualization Analysis & Design》)
4.3 格式塔理论
格式塔针对人类对特定视觉模式的识别给了很好的分类,该理论同样适用于数据可视化设计。下面我们举例介绍6种原则。
邻近原则(proximity)
空间中距离相近的元素有被看作一体的趋势。人们会很自然的根据距离来对视觉对象进行分组。上图的分组柱形图,我们会很自然的把临近的柱子分为一组,其次才是观察颜色分组。
相似原则(similarity)
刺激物的形状、大小、颜色、强度等物理属性方面比较相似时,这 些刺激物就容易被组织起来而构成一个整体。如下图中,根据颜色和形状,将数据分为两组。
连通性原则 (Element Connectedness)
如果一些元素与其他元素相连时,我们认为这些元素是统一体。如下面的箱型图,如果没有中间的线上线相连,上下两条线是不会被看做一个整体进行分析的。
连续性原则 (Good continuation)
如果一个图形的某些部分可以被看作是连接在一起的,那么这些部分就相对容易被我们视为一个整体。如下面的折线图的连线,虽然是断开的多段线,但是我们仍然视之为一条折线。
封闭的原则(closure)
有些图形是一个没有闭合的残缺的图形,但主体有一种使其闭合的倾向。如下面的形状词云。
共同命运原则(common fate)
如果一个对象中的一部分都向共同的方向去运动,那这些共同移动的部分就易被感知为一个整体。如下方左图,我们会按照相似原则把每行看作一个分组,但是右侧由于共同的运动方向,我们会把每列看作一个分组。
4.4 谎言因子
本小节内容主要参考《The Visual Display of Quantitavive Information》一书,图片也来源于此书。
谎言因子(Lie Factor, LF)的概念由德国慕尼黑工业大学Rüdiger Westermann教授提出,用于衡量可视化中所表达的数据量与数据之间的夸张程度的度量方法。
- 当LF=1时,我们认为图表没有对数据实时进行扭曲,是一个可信的可视化设计
- 在实际当中,应当确保各部分图形元素的 LF 在 [0.95, 1.05] 范围内,否则,所产生的图 表认为已经丧失了基本可信度
我们以下图为例做一个简单分析。
在上图中,1978年的长0.6英寸线条代表18 m/g,而1985年5.3英寸线条代表27.5 m/g,数字差异计算:
(27.5 – 18) / 18 = 0.53
复制代码图形差异计算:
(5.3 – 0.6) / 0.6 = 7.83
复制代码谎言因子计算:
LF = 7.83 / 0.53 =14.8
复制代码从结果看,大大夸大了数据事实。
下图是修正过的可视化设计。
4.5 数据-墨水比
可视化的核心是数据与信息,可视化作品的大部分笔墨应该集中在数据与信息的呈现上。为此,Tufte 提出了一个衡量标准 Data-ink ratio: Data-ink ratio 表示图表中不可删除的数据的部分占整个图表的比例,其定义如下: Data-ink ratio = data-ink / total ink used to print the graphic
在数据可视化中,数据的重要性高于一切。因此,在进行可视化设计时,应遵循以下两条原则: 1.在合理范围内,最大化 data-ink ration(Maximize the data-ink ration, within reason) 2.在合理范围内,去除冗余的 data-ink(Erase redundant data-ink ration, within reason)
下面是一张普通的散点图。图表中大部分的 data ink 用于数据的呈现(如点、label、坐标轴),剩余少部分的 non-data-ink 用于 ticks、边框 等,这张图表的 Data-ink-ratio 大概在 80% 左右。
极少图表的 Data-ink ratio 能够达到 1。如下面这张图表,所有的线条都是在展现数据,而且图表的坐标轴设计也十分简洁(如红框所示),也就是说,这张图表没有任何可以去除但不影响数据表达的部分了。
下面两个图表都是错误的设计。左图几乎所有的 data-ink 都用在了与数据表达无关的 网格 上;右图则忽略了数据的展示,它们的 Data-ink ratio 都约为 0。
下图是修正后的正确设计,这个图表的 Data-ink ratio 约为 0.7。
(更多内容参考:zhuanlan.zhihu.com/p/524878535…
-
交互(Interaction)
静态的数据展示并不能满足用户需求,很多时候我们需要提供交互形式,使得用户可以对数据进行多维度的探索。《Visualization Analysis & Design》一书对交互进行了分类,分为以下9种。
- Change 改变
- Juxtapose 并列
- Filter 过滤
- Select 选择
- Partition 拆分
- Aggregate 聚合
- Navigate 导航
- Superimpose 叠加
- Embed 镶嵌
随着场景和技术的发展,更多样的交互形式也在不断的出现,但是目标都是为了进行更好的数据探索分析。下面我们看几个具体的例子。
第一个例子应用导航功能来切换数据,结合地理位置的变换来讲述内容。
第二个例子是在图可视化中常见的交互场景,通过缩放对数据进行过滤,点击节点查看有关联的其他节点信息。
solutions-public.toucantoco.com/demo/22005?…
第三个例子展示的是数据分面,形式变换的例子。
第四个例子是一个刷选操作的例子。
-
动画(Animation)
动画在可视化作品中的作用受到的关注越来越多,目前人们比较关注的作用有如下几个方面:
- 体现数据变化过程
- 引导观众的注意力
- 增强美观度
根据动画的对象,我们可以将动画分为图元动画、组件动画和全局动画。同时,人们也对经常使用的动画效果进行了抽象和总结,比如缩放、旋转、飞入、飞出等。根据动画的实际又有入场、出场、更新等分类方式。
6.1 图元动画
下图是对图元动画的一个简单总结。
我们看几个示例。
- 缩放动画
- 渐变动画
- 飞入动画
- 失焦退场
6.2 全局动画
全局动画简单总结如下:
-
全局遮罩转场
-
全局 - 局部切换
-
粒子流动效果
- morphing 动画
echarts.apache.org/examples/zh…
-
实例(Cases)
最后我们给大家展示一些具体的数据集的可视化实现方案。
7.1 多维数据可视化
人们直接去分析多维数据,往往是非常困难的,借助可视化可以极大的提升效率。对多维数据进行可视化的方法也很多,这里简单介绍几种。
7.1.1 散点图 & 散点图矩阵
普通散点图可以通过大小、颜色和位置表达三个维度的数据,但是这对于更多维的数据来讲是远远不够的,于是诞生了散点图矩阵。
散点图矩阵中每个散点图表示两个维度之间的数据关系。我们看下面的例子(www.jiqizhixin.com/articles/20…
假设有如下图所示的数据:
每一行代表一个国家一年的观察数据,列代表变量(这种格式的数据被称作整洁数据,tidy data),其中有两个类别列(国家和洲)和四个数值列。这些列简单易懂:life_exp 是出生时的预期寿命,以年为单位,popis 是人口数量,gdp_per_cap 是人均 GDP(以国际元)为单位。只考虑数值类型属性之间的关系, 可生成如下的散点图矩阵:
散点图矩阵可以进一步扩展为普通的矩阵,如下图:
7.1.2 平行坐标轴
平行坐标轴方法中,数据的不同维度被显示为平行的坐标轴,数据元素被表示为一根折线。
这种方法适用于所有表格类型的数据,而且支持异构数据的展现。平行坐标轴方法也扩展出多种显示形式。
7.1.3 Glyph
Glyph 是可以同时使用多个视觉通道,例如 图形(shape)、颜色(colour)、文本(texture)、大小(size)、角度(orientation)、比例(aspect ratio)、曲率(curvature)的一种组合图元。同时每个glyph 可以单独被识别出来,为多场融合可视化提供了可能。
比如人脸图,可以通过五官要素对多个变量进行编码。
From 《The Grammar of Graphics》
下图的是一个温度计组件。水银高度和温度计宽度可以用来展现两个变量。通常可以作为散点图的变种。
from《The Grammar of Graphics》
由于Glyph的灵活性,为创造更自由形式的可视化效果提供了可能,比如下面的向日葵图。
www.researchgate.net/publication…
7.2 树(图)可视化
点线图
邻接图
通过可视化节点之间的相邻位置关系以展现树的拓扑结构,节点的大小,宽度,可以用来展现另外一个数据维度。
包含图
邻接矩阵
7.3 地理信息可视化
地球是一个球体,但是我们需要将球体展现在二维平面上,这就涉及到地图投影,常见的投影方式为魔卡托投影。地图可视化涉及到的视觉属性有 面积、形状、方向、方位、距离和比例尺等。
墨卡托投影的过程其实非常简单,就是将地球展开成一个圆柱,再将圆柱展开成平面。
(更多内容参考 zh.wikipedia.org/zh-cn/%E9%B…
下面我们看几种常见的地图可视化例子。
区域分布地图
等高线地图
commons.wikimedia.org/wiki/File:C…
统计地图
统计地图是虚拟地图,以地图的形式来展现数据。
7.4 叙事可视化
在叙事场景中,为了能让用户结合上下文来理解可视化内容,会增加一些与数据条目无法直接映射的元素。另外一个叙事作品,要从主题到形式,到叙事节奏都进行精心的设计。
下图展现的是人类历史以来大规模传染病的事件。
这幅可视化作品首先从叙事形式上,采用象征发展历程的一个道路形象设计,采用透视效果来表达这一主题。使用了非常形象的病毒形象,采用了易于区分的颜色进行分类,病毒的体积和影响人数做映射。通过这个可视化作品,我们可以非常容易的看到人类历史上那些年底爆发了超大规模的传染性疾病。
下面这个作品具有强烈的政治意图,人文关怀。
这幅作品展现的是一年中因为枪击事件而死亡的人数,巧妙的利用动画来展现一个人从生到死的过程。利用小球下坠来表达死亡。同时,一条曲线的两段对比强烈的颜色表达生和死。这个作品最大的亮点在于故事情节的设计,让读者看清表达含义之后,通过快速的视觉冲击来表达情感。节奏由慢到快,跳动的数字和主视图形成联动。
学习资料(Learning)
基础理论
1.《The Visual Display of Quantitative Information》
- 《Visualization Analysis & Design》
- 《信息可视化交互设计》
4.《Making Maps: A Visual Guide to Map Design for GIS》
- 其他
编程实践
- 《Interactive Data Visualization for the Web》
- 《The Grammar of Graphics》
- 《Fundamentals of Data Visualization》
- D3.js : d3js.org/
工具体验
- TimeStoryTeller:timelinestoryteller.com/
- Facets:github.com/PAIR-code/f…
- Tableau:www.tableau.com/