NLP自然语言处理(二)
一、pytorch反向传播和梯度计算方法
pytorch完成线性回归
- tensor中的require_grad参数
a.设置为True,表示会记录该tensor的计算过程,追踪对于该张量的所有操作,每一次计算都会修改其gard_fn属性,用来记录做过的操作。 - tensor中的grad_fn属性
a.用来保存计算的过程 - tensor不保留计算过程
a. with torch.no_grad()
为了防止跟踪历史记录(和使用内存),可以将代码块包装在with torch.no_grad():中,在评估模型中可使用,模型具有requires_grad = True的可训练参数,但是我们不需要在此过程对其进行梯度计算。 - 反向传播:
a. out.backward() 梯度计算,保存到x.gard中
b.导数保存在tensor.grad,默认梯度会累加 - tensor.data
a.获取tensor中值的引用操作(只有值) - tensor.numpy ()
a.当tensor中需要计算梯度的时候,grad_fn不为None的时候,
tensor.data.numpy()、tensor.detach().numpy()能够实现对tensor中的数据的深拷贝,转化为ndarray类型
二、线性回归的实现
基础模型是y = wx+b 其中w和b均为参数,使用 y = 3x + 0.8 来构造数据x,y 最后通过模型应该能得出w和b 的值接近3和0.8
import torch
import matplotlib.pyplot as plt
from numpy import *
learning_rate = 0.01
# 1.准备数据
# y = 3x + 0.8 只有一个x是一维
# 基础模型是y = wx+b 其中w b均为参数,使用 y = 3x + 0.8 来构造数据x,y 最后通过模型应该能得出w b 的值接近3 0.8
# 构造一个500行 1列的数据 rand() 0-1
x = torch.rand([500,1])
y_true = x*3 + 0.8 # x 与 y 都是 500行 1列
# 2.通过模型计算y_predict
# requires_grad=True表示会记录该tensor的计算过程,默认是False
w = torch.rand([1,1],requires_grad=True) # [1,1]是因为x[500,1]与[1,1]相乘是[500,1]
b = torch.tensor(0,requires_grad=True,dtype=torch.float32) # b全为0
# 4.通过循环,反向传播,更新参数
for i in range(2000):
# 3.计算损失值
y_predict = torch.matmul(x, w) + b # matmul()矩阵乘法
loss = (y_true - y_predict).pow(2).mean()
# 先判断w是不是一个数 即不为None
if w.grad is not None :
# 是一个数
w.data.zero_() # 将w _ 就地修改为0 归零操作 每次反向传播前将梯度置0
if b.grad is not None:
b.data.zero_()
loss.backward() # 反向传播
w.data = w.data - learning_rate * w.grad
b.data = b.data - learning_rate * b.grad
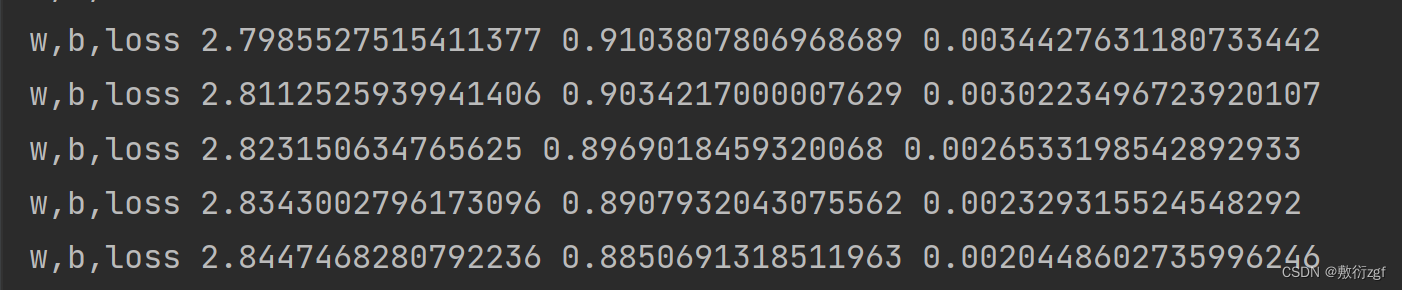
if i % 50 == 0 :
print("w,b,loss",w.item(),b.item(),loss.item()) # 通过item获得w和b的值
# 设置大小
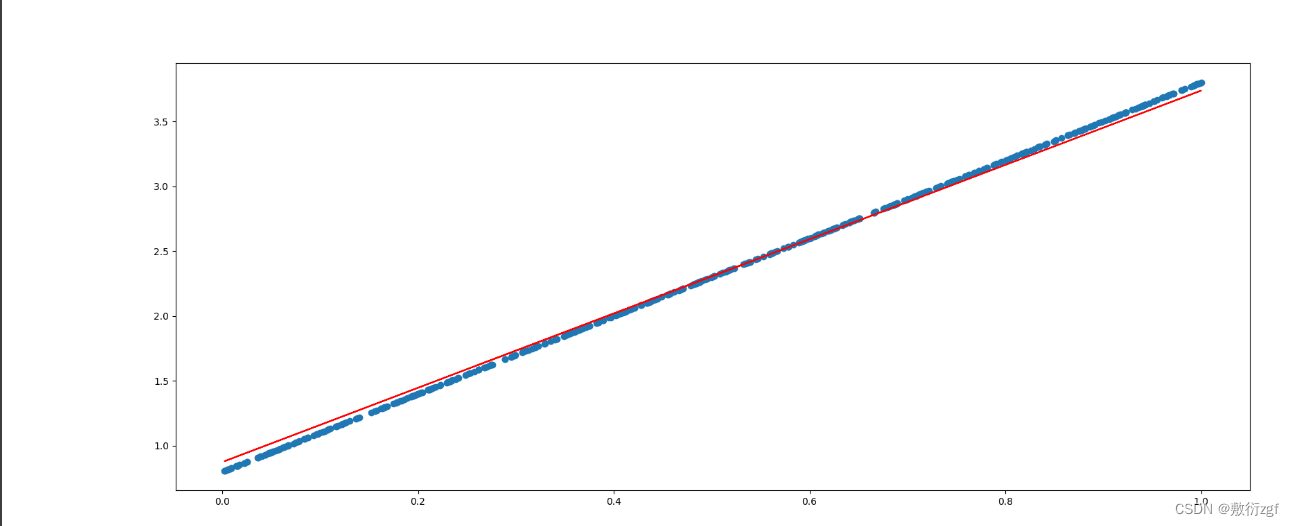
plt.figure(figsize=(20,8))
# 散点图
plt.scatter(x.numpy().reshape(-1),y_true.numpy().reshape(-1))
# 直线
y_predict = torch.matmul(x, w) + b
plt.plot(x.numpy().reshape(-1),y_predict.detach().numpy().reshape(-1),c = 'r')
plt.show()