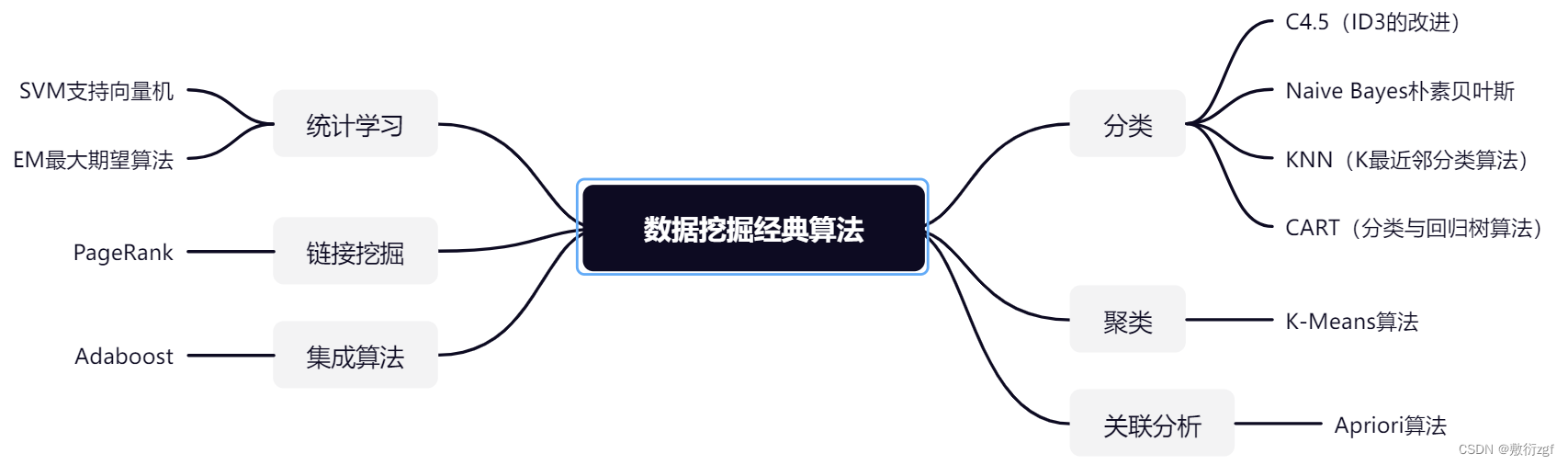
数据挖掘经典十大算法
一、十大经典算法
二、信息量
信息量是对信息的度量,例如时间的度量是秒,我们考虑一个离散的随机变量x时,当我们观察到的这个变量的一个具体值的时候,我们接收到的多少信息
用信息量来衡量,我们接受到的信息量跟具体发生的事件有关。信息的大小跟随机事件的概率有关。
越小概率的事情发生了产生的信息量越大 例如我说自己有超能力
越大概率的事情发生了产生的信息量越小 例如 今天打雷之后下雨了
因此一个具体事件的信息量应该是随着其发生概率而递减的,且不能为负。
那么用什么样的函数形式来表示信息量呢?在数学中对于随着概率增大而减少的函数形式有很多。
例如:如果我们有俩个不相关的事件x和y,那么我们观察到的两个事件同时发生时获得的信息量应该等于观察到的事件各自发生时获得的信息之和
h(x,y) = h(x) + h(y)
由于x,y是两个不相关的事件,那么满足p(x,y) = p(x)*p(y).
我们很容易看出h(x)与p(x)的对数有关(因为只有对数形式的真数相乘之后,能够对应对数的相加形式)两个正数的积的对数,等于同一底数的这两个数的对数的和,即: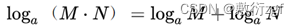
因此我们有信息量公式如下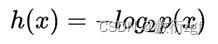
对于公式的两个疑问:
(1)为什么有一个负号
负号是为了确保信息量一定是正数或者是0,不能为负数
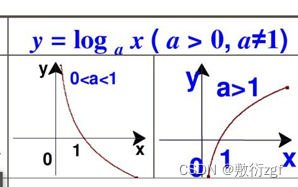
从函数图像中我们可以看出,当a=2,x在【0-1】之间时函数值始终小于0,因此添上负号确保整个函数值大于0.
(2)为什么底数为2
我们只需要信息量满足低概率事件x对应于高的信息量。那么对数的选择是任意的。我们只是遵循信息论的普遍传统,使用2作为对数的底.当然也可以使用e作为对数的底。
三、信息熵 (熵 Entropy)
信息量度量的是一个具体事件发生了所带来的信息,而熵则是在结果出来之前对可能产生的信息量的期望——考虑该随机变量的所有可能取值,即所有可能发生事件所带来的信息量的期望。
既然是所有可能,那就要求和啦
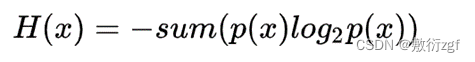
转换形式:
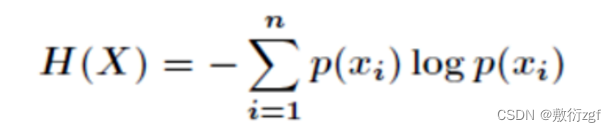
这样我们信息熵的公式就可以得到了。
四、对于信息熵的另一个理解
信息熵还可以作为一个系统复杂程度的度量,如果系统越复杂,出现不同情况的种类越多,那么他的信息熵是比较大的;如果一个系统越简单,出现情况种类很少(极端情况为1种情况,那么对应概率为1,对应的信息熵为0),此时的信息熵较小。