系列文章目录
1. 《重构》学习(1)拆分 statement 函数
2. 《重构》学习(2)拆分逻辑与多态使用
3. 《重构》学习(3)概述
4. 《重构》学习(4)常用的重构手法 上
5. 《重构》学习(5)常用的重构手法 下
文章目录
3.7 变量改名
Rename Variable:
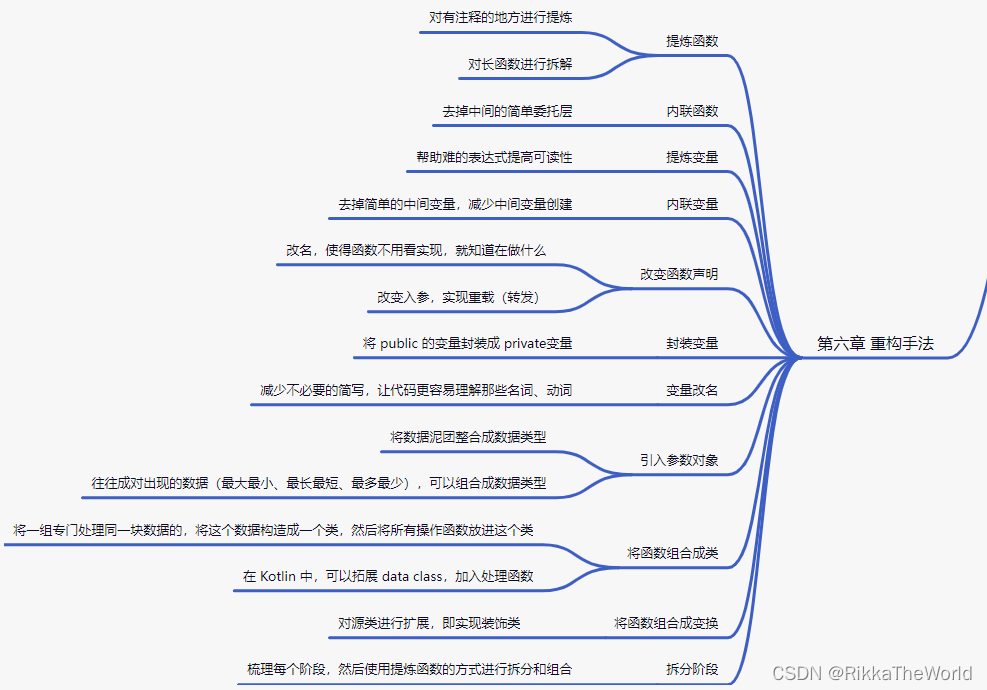
这一节就无须多解释了,变量名称不要取有歧义的,也不要为了图便宜,而经常简写。
例如把 name 简写成 nm, 把 company 简写成 cpy 等。
对于一些常量的改名,如果不能及时更改别的模块引用,可以使用转发来改名,例如原常量:
val CPY_NM = "Google"
可以改成:
val COMPANY_NAME = "Google"
val CPY_NM = COMPANY_NAME
有了这个副本,以后就可以逐渐替换为新的常量值,直到最后无人使用时对原常量删除
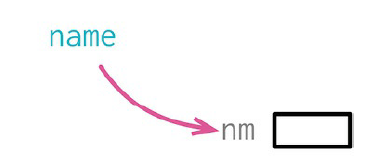
3.8 引入参数对象(Introduce Parameter Object)
将类似于:
fun amountInvoiced(startDate: Date, endDate: Date) {
...}
fun amountReceived(startDate: Date, endDate: Date) {
...}
fun amountOverdue(startDate: Date, endDate: Date) {
...}
改变成:
fun amountInvoiced(aDateRange: DateRange) {
...}
fun amountReceived(aDateRange: DateRange) {
...}
fun amountOverdue(aDateRange: DateRange) {
...}
3.8.1 为什么
上面的示例中出现了 数据泥团,就是一组总是一起出现的数据,这个时候需要将其组合成一个数据结构。
将数据组织成数据结构的好处:
- 让数据项之间的关系变得更加清晰
- 使用新的数据结构,函数的参数列表也能缩短
- 重构之后,所有使用该数据结构的函数,都会通过同样的名字来访问其中的元素,从而提升代码的一致性
- 可以提醒程序员经常去重组程序的行为来使用这些结构, 使得代码层次更深
3.8.2 示例
我们有一个数据,用于查看一组温度列表(reading),我们的函数用于检查哪些温度读数超出了正常范围。
目前温度读数数据如下(这里用一个常量表示):
private val STATION = IntroduceParaStation(
name = "SZ",
reading = listOf(
IntroduceParaTemp(temp = 15, time = "2021-12-10 09:00"),
IntroduceParaTemp(temp = 16, time = "2021-12-10 10:00"),
IntroduceParaTemp(temp = 19, time = "2021-12-10 11:00"),
IntroduceParaTemp(temp = 21, time = "2021-12-10 12:00")
)
)
检查函数和调用方代码如下:
fun call(range: IntroduceParaRange) {
val alerts = readingOutsideRange(STATION, range.temperatureFloor, range.temperatureCeiling)
}
fun readingOutsideRange(station: IntroduceParaStation, min: Int, max: Int): List<IntroduceParaTemp> {
return station.reading.filter {
r ->
r.temp < min || r.temp > max
}
}
这里,调用代码的另一个对象(range)中抽出两项数据,转手又把这一对数据传递给 readingOutsideRange()。 而代表“指定正常范围”的 range 对象用了另外两个名字来表示温度范围的上限和下限,与 readingOutsideRange 中所用打的名字不同。 像这样用两项各不相干的数据来表示一个范围的情况并不少见(最大与最小,最多与最少,最长与最短), 最好是将其组合成一个对象,我们先声明一个数据类型:
data class IntroduceNumberRange(val min: Int, val max: Int)
fun call(operationPlan: IntroduceParaRange) {
val range = IntroduceNumberRange(operationPlan.temperatureFloor, operationPlan.temperatureCeiling)
val alerts = readingOutsideRange(STATION, range)
}
private fun readingOutsideRange(station: IntroduceParaStation, range: IntroduceNumberRange): List<IntroduceParaTemp> {
return station.reading.filter {
r ->
r.temp !in (range.min..range.max)
}
}
这样我们就开始打造了一个真正有 “范围” 意义的 data class, 在观察这些成对出现的数字时,会首先考虑将他们组合成一个有用的类,将其搬移到 “范围” 类中去,简化其使用方法。
3.9 函数组合成类(Combine Functions into Class)

例如将:
data class CombineFunReading(val charge: Int)
fun base(reading: CombineFunReading){
..}
fun taxableCharge(reading: CombineFunReading){
..}
fun calculateBaseCharge(reading: CombineFunReading){
..}
组合成:
data class CombineFunReading(val charge: Int){
fun base() {
}
fun taxableCharge() {
}
fun calculateBaseCharge() {
}
}
3.9.1 为什么
书中用到的语言是 JavaScript, 在 JavaScript 中是可以使用像字典这样比较高级的数据结构, 字典和类不一样,它是以万能的数据集合,所以一些函数的入参可能会是字典而不是类, 所以这种语言可能会遇到上述中“入参不确定是什么类型”的问题。
但 Java、 Kotlin 不同,入参要么是类对象,要么就是基本数据类型,或者函数。
当我们发现一组(个)函数在总是在操作同一块数据类, 我们可以把这种处理提炼到这个数据类中。就跟上面一样,每个 dataclass 可以用来处理自身相关的逻辑。
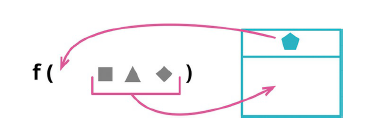
3.10 函数组合成变换(Combine Function into Transform)
例如将:
fun base(reading: CombineFunReading): Int {
..}
fun taxableCharge(reading: CombineFunReading): Int {
...}
优化成:
fun enrichReading(argReading: CombineFunReading): CombineFunReadingWrapper {
val readingWrapper = CombineFunReadingWrapper(argReading)
readingWrapper.base = base(argReading)
readingWrapper.taxableCharge = taxableCharge(argReading)
return readingWrapper
}
data class CombineFunReadingWrapper(val reading: CombineFunReading, var base: Int = 0, var taxableCharge: Int = 0)
3.10.1 为什么
在需求的变更后,我们有可能需要在原来的数据上扩展一些原来没有的函数来计算一些东西。 所以我们就会加一些补丁函数,例如上面例子中,对 Reading 类扩展了两个函数,分别来计算 底款 和 税额, 这种行为就是所谓的“打补丁”。
这种逻辑可能会经常用到派生数据的各个地方, 这个时候我们需要将计算派生数据的逻辑收拢到一处,避免到处重复。
在上面的代码的示例中,我用了 Wrapper 装饰类,来表示对原有类的扩展和派生,这个函数所在的类的整个作用域中,使用这个扩展类。 这就是将函数组合成变化的本质。
相比于 3.9 学到的 将函数组合成类的手法,他们最重要的区别是:
如果代码出现对源数据进行修改, 那么使用 “将函数组合成类” 的方式会感知到,并且函数的输出会没有问题, 而“将函数组合成变换”的方式,就不会感知到源数据的修改,导致有可能出现数据不一致的问题
3.11 拆分阶段 (Split Phase)
例如下面函数:
fun calOrderPrice(orderString: String, priceMap: Map<String, Int>): Int {
// 将账单 String 按逗号,把所有的账单都拆出来
val orderData = orderString.split(",")
// 取出 第0个账单,用 - 拆除第一个物品, 然后根据 map 获取这个武平的单价
val productPrice = priceMap[orderData[0].split("-")[1]] ?: 1
// 做乘法
val orderPrice = orderData[1].toInt() * productPrice
return orderPrice
}
可以优化成:
fun calOrderPrice(orderString: String, priceMap: Map<String, Int>): Int {
val orderRecord = parseOrder(orderString)
return price(orderRecord, priceMap)
}
private fun parseOrder(aString: String): Pair<String, Int> {
val values = aString.split(",")
return Pair(values[0].split("-")[0], values[1].toInt())
}
private fun price(order: Pair<String, Int>, priceMap: Map<String, Int>): Int {
return order.second * (priceMap[order.first] ?: 1)
}
3.11.1 为什么
在 《重构》学习(1)拆分 statement 函数 中,其实就已经说明了, 当一段代码在处理 两件或两件以上 不同的事情时,这就已经产生坏味道了。我们需要梳理阶段,并进行提炼逻辑。
注意,这里和提炼函数的重构手法不同:
提炼函数是仅仅的把一段函数从代码中提炼出去,基本“原封不动”的, 而使用 拆分阶段,还要仔细琢磨函数的执行逻辑,处理输入数据、输出数据, 将每个函数的分工处理的井井有条。
这里就不再做代码范例赘述了。
3.12 小结