文章目录
前言
HTTP是应用层的协议,文本传输协议(Hyper Text Transfer Protocol,HTTP),是一个简单的请求-响应协议,它通常运行在TCP上。
废话不多说,先看看请求报文长啥样
HTTP请求
整体请求格式:
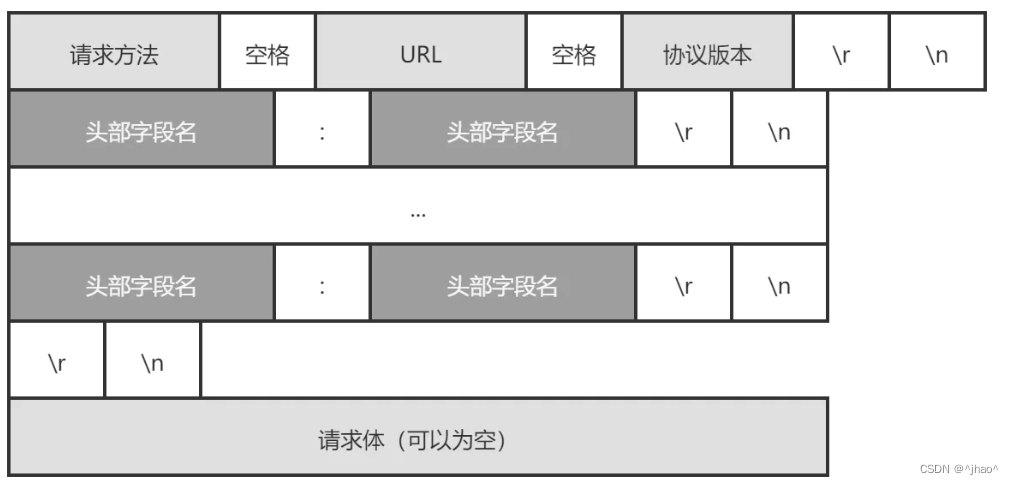
除了报文主题,其他的内容都是应用层协议添加的报头信息,只有报文主题是有效载荷
请求方法:

http是一个应用层协议,底层是tcp协议!http需要使用tcp来完成数据通信的能力!

对于URL的理解
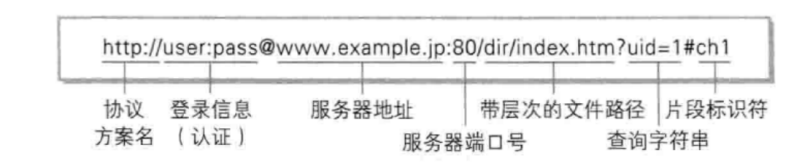
- Linux下的路径是以
/作为分割符的,而windows下的路径是以\作为分隔符的。 #片段标识符,前面的内容不变,#后面发生改变,表示访问的页面的一个小分支。/?#都是特殊字符是不能直接在url上展示,会通过encode,decode进行编码,在url不会直接出现。

- 以及汉字也会经过encode和decode的过程。
转义的规则如下:
将需要转码的字符转为16进制,然后从右到左,取4位(不足4位直接处理),每2位做一位,前面加上%,编码成%XY
格式

- 报头部分以
冒号+空格作为分隔符。如下图:

空行存在的必要性及每一层协议都要解决两个问题:
将报头和有效载荷进行分离(这里的空行就是将空行和有效载荷进行分离)- 采用
特殊字符方案,将自己的有效载交付给上层协议(分用)
HTTP本质:
所谓的http协议,就是对一串字符串做文本处理。
HTTP常见Header(请求方法)
Content-Type: 数据类型(text/html等)
Content-Length: Body的长度
Host: 客户端告知服务器, 所请求的资源是在哪个主机的哪个端口上;
User-Agent: 声明用户的操作系统和浏览器版本信息;
referer: 当前页面是从哪个页面跳转过来的;
location: 搭配3xx状态码使用, 告诉客户端接下来要去哪里访问;
Cookie: 用于在客户端存储少量信息. 通常用于实现会话(session)的功能;
注意:
- Content-Length字段不仅是服务器告知客户端发送数据的多少,当客户端要发送数据给服务器的时候也需要将该字段带上。
- 其中Host字段在代理的时候会用到。
- Connection:keepalive表示长链接,表示请求网页的时候不会关闭套接字,直到你关闭浏览器才关闭套接字。
长链接的好处:
举个例子,如今的一张网页都有可能存在大量的内容,而这些内容实际上被返回给我们客户端的时候,不是一次性返回的,收到MSS的限制等等,所以需要发送多次,这个时候若采用短链接,就会频繁的将申请套接字与释放套接字,对于效率来说有所损失,对于服务器也会增加负担,长链接就是在将数据全部发完之后再去关闭文件描述符。

MTUvsMSS:

HTTP部分字段说明:
-
User-Agent:可以在这个字段找到发送请求的不同的平台,服务器可以根据字段发送不同的页面响应。 并且可以看到是基于Chrome的内核实现的。
举个例子:倘若你在电脑浏览器搜索qq,和手机浏览器下载qq,搜索的页面会有所不同,置顶的优先级不同。 -
User-Agent响应报头也有对应的版本,通信双方都能看到对应的版本。


-
Accept字段表示客户端所能解析的文件格式。
-
Cookie 通常在客户端存储,Session在服务器存储。
B/S vs C/S:
-
用浏览器访问服务器通常叫做B/S模式
-
而C/S就是“Client/Server”的缩写,即“客户端/服务器”模式。
接下来进入回应的报文
回应
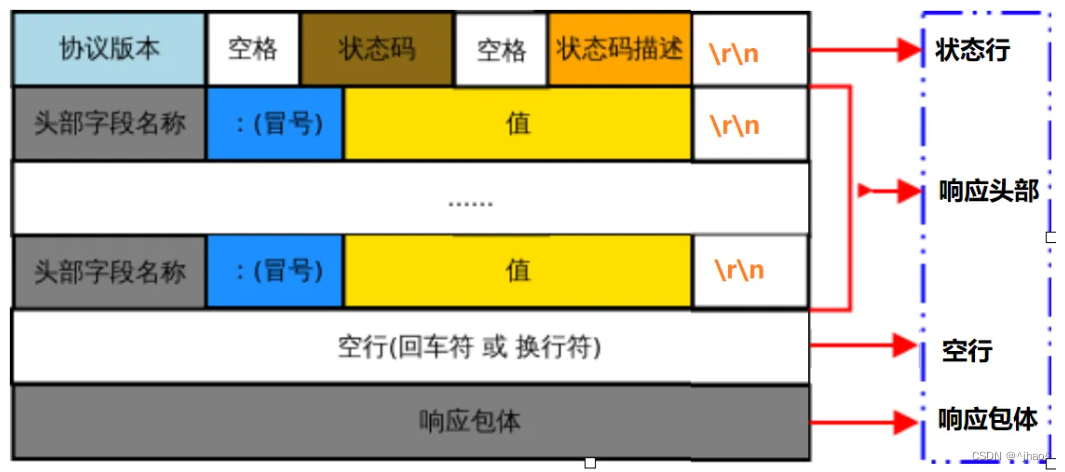
响应状态行的HTTP版本有什么意义?
新老版本共存的情况是常见的,交换双方的版本可以有不同的选择,对于老的版本可以用老的服务器提供服务。
HTTP的状态码:

常见的客户端错误:
-
1xx表示接受的请求正在处理。http请求长时间没有返回,服务器担心客户端太久没有收到回应关闭链接而发送的状态码,表示没有出错,但是需要时间执行。
-
2xx表示成功处理。
-
3XX重定向

-
403表示没有权限,比如你不是vip,却登入爱奇艺会员的视频,就会提示Forbidden信息。
-
404 没有这份资源
-
5开头的是服务端错误:
比如创建线程错误等等。
错误码返回给一些浏览器的表现的可能都不一样,比如说更新书签(重定向)等等。
永久重定向会更改client,对于目标网站地址更新之后的书签。
注意:
- 所谓的404页面,也是返回给客户端的一个页面,只是状态码 为404,描述为Not Fount,网页内容就可以通过回应正文部分即可,把html页面通过getline设置进来即可。
- getline是通过\n结尾,这里这样用只是一种方式,后续我会发表一篇博客关于http项目会有一种通过逐字读取的方案。
- 浏览器当中对于协议的遵守并不是特别严格,即使状态码不严格,网页依旧会回显回来。
- 404属于客户端错误!!
- 响应头部若有正文也需要Content-Length字段。
loacation 告知浏览器要去访问哪里。浏览器会自动重定向。本质是通过浏览器的二次请求来完成的。
一些小tips:
-
比如访问百度,默认就是访问将数据上传给/s来处理,然后form表单没有写method默认是GET方法,所以后面会更上
?传参。 -

-

-
其中input type设置为password可以让输入的信息不回显。
-
如果client是GET提交,有两个现象:
所有的参数会拼接到域名+路径后面,并且是回显出来的!
所有的参数提交到服务端,会拼接到url后面!
URL传参的长度大概在2KB左右。
GET缺点:对于私密信息不够友好。
POST方法也是不安全,但凡没有加密的都是不安全的。
POST:
提交的数据可以很大,提交的数据更具有私密性,但是都不安全。
HTTP的特点
- HTTP本身是无连接的。类似udp套接字客户端向服务器发起请求不需要连接,直接发起请求。HTTP本身不需要建立链接;而HTTPS才有链接,对于安全性的一些考量。
- HTTP本身是无状态的:
HTTP请求和请求,响应与响应之间,是不会有记录的,http不会记录自己发起http请求的上下文,不会对历史请求有任何记忆能力。
但这与我们所平时接触的不太一样,因为我们平日登入B站,然后登入过后访问里面的某个视频。我,我们并不需要重新登入。这个功能不是http帮我们实现的,而是由cookie来帮我们实现的。 - HTTP发起请求的时候,有基于长连接的,也有基于短连接的。
Cookie是啥,是为了用户方便而诞生的产物。
Cookie
Cookie就是让http附有了一些技术特点,让http具有保存状态的能力。http的会话能力。如果浏览器不具备保存能力,当我们每一次跳转都可能需要重新进行身份认证,所以cookie的诞生就是为了方便用户。
Cookie相关概念:
-
Cookie就是存储再浏览器(客户端),当服务器http发送数据给浏览器,会将Cookie数据携带在http当中发送给浏览器。
-
浏览器就会保存服务器的Cookie数据,下次访问他的固定的网页就发送对应的Cookie数据即可,其中访问的部分数据也就是域的概念。
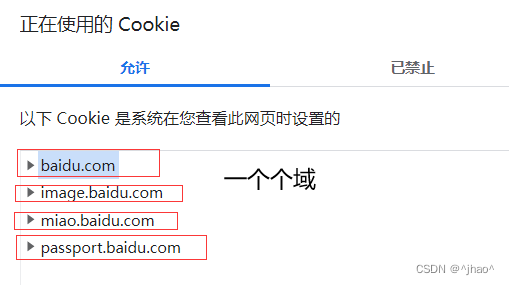
-
Cookie文件就是保存在浏览器的一个临时小文件(硬件级)。
每一个http request都会携带Cookie的信息(后面的代码当中有截图),发送给服务器!所以服务器也一定会支持cookie技术。(对于这个cookie数据的验证环节,就一定不是http完成的。)而认证逻辑是由提供服务的server服务器的对应的程序员来编写的。
Cookie"文件":
有些浏览器,Cookie有内存级别,也有文件级别的。所以说不一定是文件,内存级的只能在当前进程未退出的情况下使用,而文件级别就是浏览器下的某个路径下建立了一个文件。

当你删除了cookie数据,再次登入的时候就会登入不上去。
那么只用Cookie就可以了吗?
只用Cookie的危害
那么存在以下几个问题:
- 若是文件级别的,将你的Cookie“文件”发送给我,我的电脑就能以你的身份登入网站?这样是否会出现盗取信息的风险?
- 万一电脑被注入了木马等恶意程序,盗取浏览器的所有Cookie信息,作为一个不法分子,就有可能盗用你的个人信息!!有个人私密信息泄露的风险。
- 账户敏感数据频繁在网络当中传输。
例如:qq也是一个网络通信,内部一定存在Cookie,并且才会频繁有人qq被盗用。
自然腾讯也有很多措施,例如申诉账号。
Cookie不行,Session来凑。
Session
Session存在的意义是因为当只有cookie,敏感数据(账号,密码)等需要频繁在网络当中传输,这样子很容易被中间人截取。所以引入Session id,即让客户端的cookie文件只存放Session id,标识服务器的唯一一个文件,后续客户端发送数据发送的Cookie数据也变少了。
Cookie + Session = 保持会话状态
Session的特点:
- Session是一个文件,存放在服务器,文件名具有唯一性,一般一个用户有一个Session文件。而给客户端返回的就是一个
Session id。敏感信息全部保存在服务器端,客户端只存放Session id。 - Session id具有唯一性,在浏览器端sid也要在浏览器端用Cookie文件进行保存。
- 即引入了Cookie后,返回给用户的不再是隐私信息,而是Session id,这样子网络的传输过程中也不怕获取方直接获取敏感信息,服务器通过Session id还能通过一些手段判断访问方。
- 浏览器就可以通过Session id在文件在服务器上有对应的Session文件就可以实现会话认证。

为什么数据存储在服务器是相对安全的:
- 服务器端上的数据基本是安全的,因为企业端的安全级别是非常高的,有着一批安全系统工程师,并且可能服务器上部署钓鱼端口,黑客不知道是否是漏洞还是钓鱼执法,所以黑客也不会轻易攻击服务器。
- 黑名单,白名单,服务拒绝,网络攻防,陷阱等等手段,企业的服务器不会轻易被攻击。通过各种安全策略就能保证大部分的安全。
上述方法只解决了个人隐私信息不会在服务器端泄漏。
那有没有可能不法分子获取了我的浏览器的Session id访问服务器,以我的身份从事非法工作呢?
- cookie信息和session信息本身都是有时间限制的,session id可能到时间是会失效的。
- 有地址相关审核技术,比如前一秒我还在深圳登入,下一秒我就在黑龙江登入。所以有时候访问一些网址需要获取地址,这也是对于一个安全性的考量。
- 即服务器可以识别ip是否有异地登入的情况,就直接将
服务器内部的对应的session文件删掉,即使客户端拿着session id访问就需要重新登入,并且此时非法登入者不知道账号和密码,这些信息都在服务器当中。
以上就解决了HTTP无状态的问题。
HTTP写入Cookie的验证
Set-Cookie的使用方法:即在响应头部当这种添加Set-Cookie: xxxx即可。

注意:
- 没有说明Cookie保存的路径,默认都是内存级的Cookie。
- Set-Cookie之后客户端发送数据都会将Cookie带上。

测试demo
注释当中有包括重定向,Set-Cookie的测试。
Socket.hp
#include <iostream>
#include <string>
#include <cstdlib>
#include <unistd.h>
#include<fcntl.h>
#include <strings.h>
#include <sys/socket.h>
#include <netinet/in.h>
#include <arpa/inet.h>
namespace ns_socket
{
class Socketer{
public:
static int Socket()
{
int sock = socket(AF_INET,SOCK_STREAM,0);
if(sock < 0)
{
//std::cerr << "socket";
exit(2);
}
int opt = 1;
setsockopt(sock,SOL_SOCKET,SO_REUSEADDR,&opt,sizeof(opt));
return sock;
}
static void Bind(int sockfd,int port)
{
struct sockaddr_in local;
local.sin_family = AF_INET;
local.sin_addr.s_addr = INADDR_ANY;
local.sin_port = htons(port);
if(bind(sockfd,(struct sockaddr*)&local,sizeof(local)) < 0)
{
std::cerr << "bind";
exit(2);
}
}
static void Listen(int sockfd)
{
#define BACKLOG 5
listen(sockfd,BACKLOG);
}
static bool SetNonBlock(int fd)
{
int fl = fcntl(fd,F_GETFL);
if(fcntl(fd,F_SETFL,fl|O_NONBLOCK) == -1)
return false;
return true;
}
};
}
HttpServer.cc
#include"Socket.hpp"
#include<iostream>
#include<sys/epoll.h>
#include<sys/types.h>
#include<sys/socket.h>
#include<fstream>
#include<string>
#include<sstream>
using namespace std;
using namespace ns_socket;
#define NUM 10
#define HOME_PAGE "wwwroot/index.html"
int main()
{
int lsock = Socketer::Socket();
Socketer::Bind(lsock,8080);
Socketer::Listen(lsock);
for(;;)
{
struct sockaddr_in peer;
socklen_t len = sizeof(peer);
int fd = accept(lsock,(struct sockaddr*)&peer,&len);
if(fd < 0)
{
cerr << "accept error" << endl;
continue;
}
char buffer[10240];
ssize_t s = recv(fd,buffer,sizeof(buffer)-1,0);
string response_buffer;
if(s > 0)
{
buffer[s] = 0;
cout << buffer << endl;
//假设一次能读取完成
string body;
//response_buffer += "HTTP/1.0 200 OK\r\n";
response_buffer += "HTTP/1.0 200 OK\r\n";
response_buffer +="Set-Cookie: name=value; name2=value2; name3=value3 \r\n";
response_buffer += "Content-Type: text/html\r\n";
std::ifstream in(HOME_PAGE,std::ifstream::in);
if(!in.is_open()){
}
else{
string line;
while(std::getline(in,line)){
body += line;
}
//试试重定向
//response_buffer += "location: https://blog.csdn.net/ArtAndLife/article/details/113965405\r\n";
response_buffer += ("Content-Length: " + to_string((int)body.size()) + "\r\n");
//cout << body.size() <<endl;
//空行
response_buffer += "\r\n";
response_buffer += body;
}
if(send(fd,response_buffer.c_str(),response_buffer.size(),0) < 0)
{
cout << "send error" << endl;
continue;
}
close(fd);
}
else if(s == 0)
{
cout << fd << " is quit.... " <<endl;
close(fd);
}
else
{
//差错处理
}
}
return 0;
}
结果:

浏览器生成一个sessionid,在服务器上生成一个对应的sessionid文件。而此时浏览器也会发送对应的sessionid给服务器!
HTTP响应头部当中使用location是用来做重定向的工具,即通过重复访问来完成。

Cookie+Session != 通信安全
不安全,引入Cookie和Session,只能保证后续私密数据不会在网络当中游走,但是第一次登入的时候难免用户需要采用私密账号进行身份验证,这个时候该采用https来解决。
使用HTTP是不安全的验证:
当我们使用POST方法,也能够看出就在正文部分就有私密信息。

费德勒的报文可能会携带ip地址,这与费德勒的工作原理有关。

只有经过加密的数据,才能保证在理论上是安全的!
HTTPS
HTTPS对比HTTP多了中间的SSL/TLS层,保证了数据传输是安全的!!
数据传输不管是GET还是POST,只要不加密,都是不安全的!!
应用层协议: SSL/TLS(Secure Sockets Layer,Transport Layer Security),加密解密层。当用了就是HTTPS,没用就是HTTP。

SLL也是分层,共两层:
- 封装加密解密
- HTTPS握手,认证双方安全性。
什么是加密解密?
- 哈夫曼编码(压缩算法)本质也是加密解密的方式。
- 解码转码本质也是加密解密。
- 浏览器decode,encode本质也是加密和解密。
常见的加密方式:
对称加密(只有一种钥匙,用什么加密,就用什么解密),非对称加密则不同,可以用公钥加密私钥解密,反之也可以。
对称加密
只有一个秘钥,遇到的问题,密钥传输过程中如何保证安全性。
最简单的加密解密例子:异或
假设5为密钥。传输整数10,10异或5进行加密。得到的结果为x,x在异或5进行解密,就可以拿到10;即双方通过一个密钥实现了加密解密!
缺点:
但是对称加密需要双方都知道密钥,而密钥双方需要知道,只有系统内置或者是通过网络传输,而前者不现实,后者当网络传输时,就有可能密钥遭到篡改!!
光用对称加密无法保证数据传输安全性,因为客户端需要给服务器发消息,需要先将密钥发过去,若发送密钥的过程都是安全的,那么都直接发送数据。
所以http刚开始通信的时候,绝对不能使用对称加密,第一次交换密钥就是一个大问题。为了解决上述问题,引入非对称加密
非对称加密解决了上述问题,但是效率较低。
非对称加密
非对称加密中有公钥和私钥的概念,通常公钥是可以通过网络传输发送给别人,私钥通常主机私有,且公钥加密可以私钥解密;私钥加密也可以公钥解密。
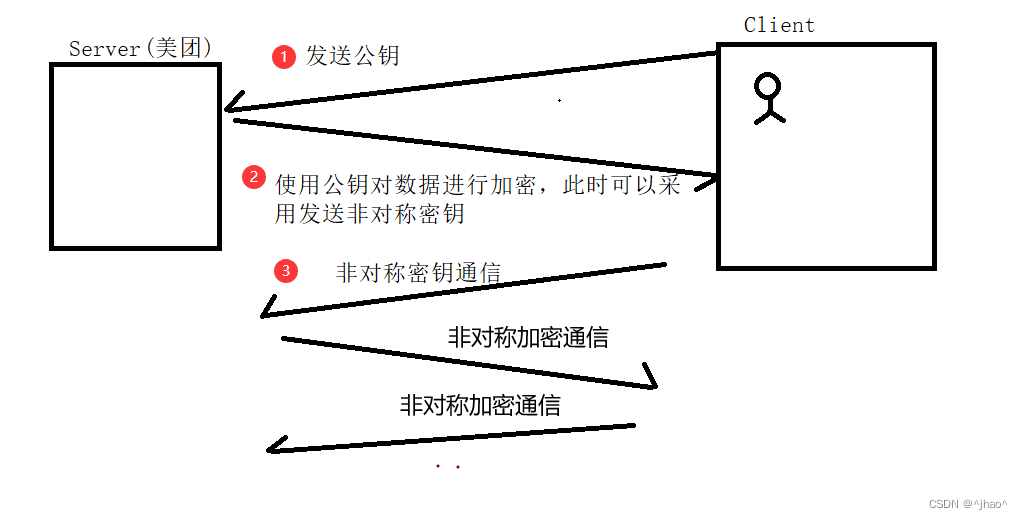
有了以上公私钥的性质,我们如何保证数据传输是安全的?
常见的C/S或者B/S模式都是用户发起请求,此时用户可以将公钥发送给服务器,服务器可以将协商的对称密钥以公钥加密发送回客户端;此时通信的时候,当server给client发消息可以用公钥加密,此时即使别人能拿到数据,但是数据已经被加密了,只有用户一人知道私钥,也说明只有用户能够看到服务器发来的数据。

上述方案能够解决的是引入Cookie,Session,但是第一次发送数据的时候依旧会发送敏感数据在网上,并且是没有加密发送。所以这种方式能够保证安全。
但是对称加密的速度比非对称加密快很多(非对称加密需要大量因式分解,所以效率低),所以如果频繁使用对称加密,会导致效率变低;所以,这里采用客户端发送公钥的时候,服务器可以协商采用对称加密,将密钥用公钥加密发送给Client,让双方都能够看到唯一的密钥。
问题1: 所有的client和server提前都必须内置公钥和私钥?
如果能直接内置,直接用对称加密不就好了?所以说这个点很难做到,但是做到了就能实现安全通信。
HTTPS保持安全和效率兼顾的方案:
前期ssl握手期间,使用非对称加密,来交换对称秘钥。通信期间使用对称加密保证数据安全。
对于加密算法的理解:
对摘要进行加密生成数据指纹,此时只要对摘要稍作修改,形成的指纹都可能差异巨大。
对称密钥的密钥是进行加密解密的;而非对称加密的通常用公钥进行加密,私钥进行解密。
HTTPS建立通信的大致过程:
相当于现在我的主机需要通信,我的机器当中有私钥A,那么我可以将公钥A公开给外部,这样子当我发送数据给对端机的时候,对端机得知我需要通信,发送数据时用公钥A加密,这样只有我才能对密码进行解密,但此时只能单向通信。所以对端必须也有一个秘钥B,公开公钥B,让我以后的数据都用公钥B加密进行传输。此时我们可以就此交换密钥。双方拿到对称密钥后采用对称加密,这样安全,又高效。
存在的问题(中间人攻击)
中间人的企图永远都是想要的通信中的数据,而不是双方握手时的数据。
在于第一次发起请求后,前面两次发送的信息都是明文的,server发来公钥的时候可能存在一个中间人,截取了server发来的公钥,换成了自己的公钥!!

Server端有(公钥A,私钥a),中间人截获了server响应的公钥,中间人自己也可以用一套非对称密钥(公钥M,私钥m)。中间人可以保留server发来的公钥A。篡改公钥为自己的公钥M,站在客户端的角度,我们并不知道发来的公钥是否时server端的。
client此时就会将自己的对称密钥(假设对称密钥为D),就会用中间人的公钥M对自己的对称密钥D进行加密。client此时以为是用了server的公钥进行加密,而不知道用的是中间人的公钥进行了加密。
这样子中间人就能获取client发给服务器的所有信息,并且可以随意进行篡改。中间人对client发来的信息可以随便解密,并且此时只有中间人有能力进行解密。中间人可以篡改资料后再发送给server,用保留着的公钥A进行加密,发送给server。中间人对于client发送的信息,可以解密后用server的公钥A进行加密。server此时也得到了对称密钥,但是这个对称密钥是与中间人进行通信的。
证书的出现,保证了即使能够让中间人看到公钥,但是不能修改,否则会被客户端识别。
证书
证书当中有公钥字段,这个字段是明文的,并且会携带数据指纹,数据指纹是通过原始数据通过摘要后加密生成的,能够保证证书当中携带的内容没有被篡改,而客户端可以通过原始内容摘要+指纹用公钥解密后的结果对比知道是否数据有被篡改。

证书是采用CA的私钥进行加密,通常我们都不是用私钥进行加密,但是这里这样子使用,是因为这样只有CA才能够对数据进行加密,只不过加密的数据大家都知道是什么。
那么这样做的目的是什么?
- 当客户端用公钥解密时发现错误,就可以知道证书被人篡改!
- 只有CA有权利对证书进行加密,其他人都没有权限,所以大家都可以依托他,他就是权威的第三方;只要是CA认证通过,我们就可以说证书没有被篡改,里面的公钥就是我要访问服务器的公钥。

要点:
- 证书公钥是出厂自带的,这是为了避免又需要通过网络传输。
- 服务器对证书进行hash算法生成摘要,使用CA的私钥进行加密, 加密过后形成数据指纹,颁发的证书就可以在最后携带上指纹信息。
- 操作系统,浏览器当中内置了各种权威的根认证机构的各种证书(公钥)。

- 证书当中的一些字段:
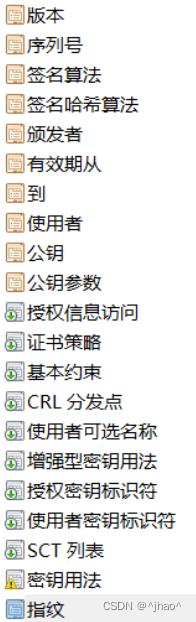
- 服务器和网站需要申请CA认证,CA认证的时候是通过私钥进行加密,然后公钥是内置在每台主机内的。
- 公钥是证书的一部分,证书最后形成签名。即申请证书的时候,也需要把server的公钥也提交给CA,CA会将公钥填充到证书,整体进行生成数据指纹。
- 而凡是能用CA公钥解密成功,也就能够证明证书肯定是有效的。
如何区分公钥的合法性
有权威机构对网站或者服务器进行合法认证的。
如:CA认证
权威机构会给网站或服务器颁发数字证书。
如何理解证书与摘要的关系:
server发送回client的证书当中包含server的公钥,以及域名等等信息。
证书如何保证自己的合法性:
1.证书是否是合法的!
2.如何证明证书没有被篡改过?
中间人对于证书篡改是否有用呢?
没用了,此时客户端用CA公钥解密立马能发现数据指纹对不上,马上知道数据被篡改了。
中间人能修改证书后面的数据指纹吗?
- 指纹是通过CA的私钥进行加密的,只有申请了CA的服务器或网站才能对这个信息进行修改,若是中间人想要修改其中的公钥混淆客户端,那么中间人需要能够知道数据指纹,而这基本上很难做到。
- 除非中间人也进行CA认证,但是修改了之后证书的域名也就是中间人的域名了,信息都变成中间人的;相当于在途中将数据进行了拦截;这样子中间人的意图就达不到了,因为中间人想要的是双方建立通信后真正想要发送的数据!!而两份证书都是合法的,就是中间人这样做的目的不见了。并且此时客户端是有能力看到域名是否不对劲的!!
- 即便中间人随意修改了,client解密的时候,对于证书的解密只用CA的公钥解密,client不相信其他任何人的公钥信息,中间人生成的数据指纹在client这端是毫无意义的。
- 世界上的任何一份证书数据+指纹,没有任何人可以修改。修改在这里我想表达的是只修改一部分(如公钥),然后生成一份指纹。因为CA本身会审核你的域名,公钥等信息是否是你服务器的然后帮你生成数据指纹。
结论:
在证书的加持下,中间人顶多看到的是服务器的公钥,但是没有办法对公钥进行修改。
现在有两套密钥:
一套是CA的,CA本身有私钥公钥,只用于合法性认证的。
一套是Server的,是用来进行对称密钥协商的。
为什么采用证书的方式来保证安全:
公钥私钥算法的权威性由CA保证,CA不给外部如何加密和解密。只提供认证功能。浏览器不需要内置各种加密算法,而CA本身集成了。而浏览器厂商之所以相信CA,是因为这样子浏览器访问的更安全,并且利益不冲突。
最终流程图
1.前两次随机数是验证双方的算法是否生效,即选择算法的过程;后续服务器向客户端发送证书,公钥,跟客户端说发送完了。第三次随机数是由客户端发送给服务器的并且是加密的,双方的对称密钥就由随机数1+随机数2+随机数3组合而成。
2.若在HTTPS协商阶段之后,依旧无法通信,server就有理由怀疑了存在中间人了

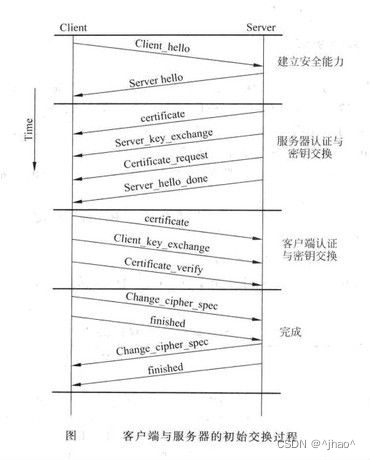
当用公钥对第三随机数加密时,相当于对称密钥已经安全交换了,只有client和server各自知道,所以这个时候中间人已经毫无作用了。中间人已经没有办法拿到对称密钥了。
补充环节:
补充:md5的理解
md5的功能:
生成消息摘要的散列值,并且同一份内容生成的散列值永远都是一样的。
md5是不可逆的:
加密过程会造成信息的损失,所以从数据指纹找到起始的内容,在目前是没有很好的方法的。
只要加密了,一定安全吗?
- 所有加密解密的算法,都是与CPU的算力有关,只不过要付出的投入比可能要比产出比多的多,所以破解也就变得不现实。
- 所谓安全:是破解的成本远远大于破解的收益。
什么叫做数据散列算法
通过哈希算法提取文本中的部分内容,提取出来的部分内容叫做摘要。
什么叫做数据指纹:
对摘要进行加密的结果。
为什么采用md5:
- 凡是对原始文本(账号+密码)做任何修改,在进行摘要形成指纹之后,得到的指纹数据差别巨大。
- 这种技术典型完成摘要+加密的算法为md5。
为什么我们要加密:
- 企业端如B站,用户的密码信息是必须经过加密的,保存在公司的数据库当中。
- 数据库存储的是对先前保存的密码通过数据摘要+md5加密处理过的。即公司数据库只有密码指纹。此时密码只有用户直到,连公司都不知道,也就保证了数据的安全。
- md5后的指纹是通常固定的长度(128比特位),能让数据库的表看起来更加的和谐。
企业如何知道我们登入的账号和密码是正确的:
- 登入的时候,通过输入用户名+密码,企业端拿到用户名+密码,通过相同的数据摘要+md5,得到一个数据指纹,然后和数据库的指纹做对比。
- 但是企业可能在用户注册的时候,是通过用户名+密码还会
加特殊的字符串(由公司决定),然后数据摘要+md5后插入数据库,所以在用户登入的时候,也会再插入相同的字符串后再摘要+加密,再去数据库进行对比。这样做原因:让你的密码级别更高,这也就是加盐(salt)。
公钥加密的,只能用私钥解密。私钥解密,可以用公钥解密,但是一般公钥是公开的,所以用私钥加密没有意义。(除证书那块外,证书只希望你别改,你想看就看)。
非对称加密基于大指数的因式分解,几秒~十几秒才能解决一个数据。
最后补充一点点
补充:md5不安全的原因
两种常见的情况,md5可能会不安全的情况:
- 当官网下载东西,但是东西很慢,所以这个时候第三方的很快,但如何保证里面的内容没有植入其他内容。官网一般会有文件的md5值,所以这个问题可以供我们做比较。
- 当数据库当中的密码是md5加密的,被内部的不法分子看到了,那么是否他们就有办法使用我们的账户?
这个也不太行,因为第二原像攻击也没有很好的破解方法,所以很难通过数据指纹找到原数据。
md5不安全:
但是有一点:消息内容和md5的值不是一一对应的,而是多对一的,这也是md5不安全的原因之一。
md5生成的过程:
- 填充对其:当内容不足512比特位的整数倍的时候,就需要补齐,并且最后的64位要固定流出来表示内容的大小,中间剩余的部分第一个放1,其余放0.
- 分块:每一个512字节称之为一块。在一个梦幻值的基础上,再将md5输出值分成 a,b,c,d,每一个部分32比特位,然后通过与或非的方法进行计算,进行若干论。
- 多轮压缩:就是轮询计算若干论生成最终结果的过程。
md5不安全的原因:
有三种方法能够证明md5是不安全。
- 原像攻击:从数据指纹找到原始数据,目前是没有办法的,即使采用暴力从0遍历到2^128次方(0~FFF…)是不太现实的。
- 第二原像攻击:给定md5和消息,是否能找到另一个消息也生成这个md5呢?并没有有效的方案
- 抗碰撞性:最宽松标准,只要找到两个消息能够生成同一个数据指纹就算成功。在王小云的带领下能够在15分钟~1小时内找到两组数据能够生成同一组数据,但是这两个数据通常没有意义。2007年Marc对此进行了研究,它能够用同一份原始内容生成两个内容不一样的消息,并且有意义且md5值相同,这个也是相同前缀碰撞。即可以生成相同的前缀内容,生成相同的数据摘要,他们的md5相同,大概需要几十小时。
目前只能做到通过一个原数据生成两个不同的数据摘要,他们的md5结果相同;以及通过原始内容作为前缀,生成一个后缀不相同的内容,他们最终生成的md5值相同。
所以只有抗碰撞性目前是有可能被破解的,如果是病毒软件可能披着普通软件的外壳进行植入,但杀毒软件能进行识别。