LLVM编译技术应用分析
参考文献链接
https://mp.weixin.qq.com/s/_d5HR9yHdwhGYozr9IaU_A
https://mp.weixin.qq.com/s/bWT7FBH8PsLqFeeGotLEnQ
https://mp.weixin.qq.com/s/iwVQ_r0SljakMGqWQL2KXA
https://mp.weixin.qq.com/s/MfV1FkwQSNokZuzedizALA
LLVM eBPF 汇编编程
引言
1.1 主流开发方式:从 C 代码直接生成 eBPF 字节码
eBPF 相比于 cBPF(经典 BPF)的优势之一是:Clang/LLVM 为提供了一个编译后端, 能从 C 源码直接生成 eBPF 字节码(bytecode)。(写作时,GCC 也提供了一个类似 的后端,但各方面都没有 Clang/LLVM 完善,因此后者仍然是生成 eBPF 字节码 的最佳参考工具)。
将 C 代码编译成 eBPF 目标文件非常有用,因为 直接用字节码编写高级程序是非常耗时的。此外,截至写作时, 还无法直接编写字节码程序来使用 CO-RE 等复杂特性。
因此,Clang 和 LLVM 仍然是 eBPF 工作流不可或缺的部分。
1.2 特殊场景需求:eBPF 汇编编程更合适
但是,C 方式不适用于某些特殊的场景,例如:
- 只是想测试特定的 eBPF 指令流
- 对程序的某个特定部分进行深度调优
在这些情况下,就需要直接编写或修改 eBFP 汇编程序。
1.3 几种 eBPF 汇编编程方式 - 直接编写 eBPF 字节码程序。也就是编写可直接加载运行的 二进制 eBPF 程序,
• 这肯定是可行的,但过程非常冗长无聊,对开发者极其不友好。
• 此外,为保证与 tc 等工具的兼容,还要将写好的程序转换成目标文件(object file),因此工作量又多了一些。 - 直接用 eBPF 汇编语言编写,然后用专门的汇编器 (例如 ebpf_asm)将其汇编(assemble)成字节码。
• 相比字节码(二进制),汇编语言(文本)至少可读性还是好很多的。 - 用 LLVM 将 C 编译成 eBPF 汇编,然后手动修改生成的汇编程序, 最后再将其汇编(assemble)成字节码放到对象文件。
- 在 C 中插入内联汇编,然后统一用 clang/llvm 编译。
以上几种方式 Clang/LLVM 都支持!先用可读性比较好的方式写, 然后再将其汇编(assembling)成另字节码程序。此外,甚至能 dump 对象文件中包含的程序。
将会展示第三种和第四种方式,第二种可以认为是第三种的更加彻底版,开发的流程 、步骤等已经包括在第三种了。
2 Clang/LLVM 编译 eBPF 基础
在开始汇编编程之前,先来熟悉一下 clang/llvm 将 C 程序编译成 eBPF 程序的过程。
2.1 将 C 程序编译成 BPF 目标文件
下面是个 eBPF 程序:没做任何事情,直接返回零,
// bpf.c
int func() {
return 0;
}
如下命令可以将其编译成对象文件(目标文件):
注意 target 类型指定为 bpf
$ clang -target bpf -Wall -O2 -c bpf.c -o bpf.o
某些复杂的程序可能需要用下面的命令来编译:
$ clang -O2 -emit-llvm -c bpf.c -o - |
llc -march=bpf -mcpu=probe -filetype=obj -o bpf.o
以上命令会将 C 源码编译成字节码,然后生成一个 ELF 格式的目标文件。
1.2 查看 ELF 文件中的 eBPF 字节码
默认情况下,代码位于 ELF 的 .text 区域(section):
$ readelf -x .text bpf.o
Hex dump of section ‘.text’:
0x00000000 b7000000 00000000 95000000 00000000 …
这就是编译生成的字节码!
以上字节码包含了两条 eBPF 指令:
b7 0 0 0000 00000000 # r0 = 0
95 0 0 0000 00000000 # exit and return r0
如果对 eBPF 汇编语法不熟悉,可参考:
- 简洁文档: (https://github.com/iovisor/bpf-docs/blob/master/eBPF.md)
- 详细文档: (https://www.kernel.org/doc/Documentation/networking/filter.txt)
有了以上基础,接下来看如何开发 eBPF 汇编程序。
3 方式一:C 生成 eBPF 汇编 + 手工修改汇编
本节需要 Clang/LLVM 6.0+ 版本(clang -v)。
译文基于 10.0,结果与原文略有差异。
C 源码:
// bpf.c
int func() {
return 0;
}
3.1 将 C 编译成 eBPF 汇编(clang)
其实前面已经看到了,与将普通 C 程序编译成汇编类似,只是这里指定 target 类型是 bpf (bpf target 与默认 target 的不同,见 Cilium 文档 BPF 和 XDP 参考指南):
Cilium:BPF 和 XDP 参考指南:
http://docs.cilium.io/en/latest/bpf/#llvm
$ clang -target bpf -S -o bpf.s bpf.c
查看生成的汇编代码:
$ cat bpf.s
.text
.file “bpf.c”
.globl func # – Begin function func
.p2align 3
.type func,@function
func: # @func
%bb.0:
r0 = 0
exit
.Lfunc_end0:
.size func, .Lfunc_end0-func
# – End function
.addrsig
接下来就可以修改这段汇编代码了。
3.2 手工修改汇编程序
因为汇编程序是文件,因此编辑起来很容易。作为练手,在程序最后加上一行汇编指令 r0 = 3:
$ cat bpf.s
.text
.file “bpf.c”
.globl func # – Begin function func
.p2align 3
.type func,@function
func: # @func
%bb.0:
r0 = 0
exit
r0 = 3 # -- 这行是手动加的
.Lfunc_end0:
.size func, .Lfunc_end0-func
# – End function
.addrsig
这行放在了 exit 之后,因此实际上没任何作用。
3.3 将汇编程序 assemble 成 ELF 对象文件(llvm-mc)
接下来将 bpf.s 汇编(assemble)成包含字节码的 ELF 对象文件。这 里需要用到 LLVM 自带的与机器码(machine code,mc)打交道的工具 llvm-mc:
$ llvm-mc -triple bpf -filetype=obj -o bpf.o bpf.s
bpf.o 就是生成的 ELF 文件!
3.4 查看对象文件中的 eBPF 字节码(readelf)
查看 bpf.o 中的字节码:
$ readelf -x .text bpf.o
Hex dump of section ‘.text’:
0x00000000 b7000000 00000000 95000000 00000000 …
0x00000010 b7000000 03000000 …
看到和之前相比,
• 第一行(包含前两条指令)一样,
• 第二行是新多出来的(对应的正是新加的一行汇编指令),作用:将常量 3 load 到寄存器 r0 中。
至此,已经成功地修改了指令流。接下来就可以用 bpftool 之 类的工具将这个程序加载到内核,任务完成!
3.5 以更加人类可读的方式查看 eBPF 字节码(llvm-objdump -d)
LLVM 还能以人类可读的方式 dump eBPF 对象文件中的指令,这里就要用到 llvm-objdump:
-d : alias for --disassemble
–disassemble: display assembler mnemonics for the machine instructions
$ llvm-objdump -d bpf.o
bpf.o: file format ELF64-BPF
Disassembly of section .text:
0000000000000000 func:
0: b7 00 00 00 00 00 00 00 r0 = 0
1: 95 00 00 00 00 00 00 00 exit
2: b7 00 00 00 03 00 00 00 r0 = 3
最后一列显示了对应的 LLVM 使用的汇编指令(也是前面手工编辑时使用的 eBPF 指令)。
3.6 编译时嵌入调试符号或 C 源码(clang -g + llvm-objdump -S)
除了字节码和汇编指令,LLVM 还能将调试信息(debug symbols)嵌入到对象文件, 更具体说就是能在字节码旁边同时显示对应的 C 源码,对调试非常有用,也是 观察 C 指令如何映射到 eBPF 指令的好机会。
在 clang 编译时加上 -g 参数:
-g: generate debug information.
$ clang -target bpf -g -S -o bpf.s bpf.c
$ llvm-mc -triple bpf -filetype=obj -o bpf.o bpf.s
-S : alias for --source
–source: display source inlined with disassembly. Implies disassemble object
$ llvm-objdump -S bpf.o
Disassembly of section .text:
0000000000000000 func:
; int func() {
0: b7 00 00 00 00 00 00 00 r0 = 0
; return 0;
1: 95 00 00 00 00 00 00 00 exit
注意这里用的是 -S(显示源码),不是 -d(反汇编)。
4 方式二:内联汇编(inline assembly)
接下来看另一种生成和编译 eBPF 汇编的方式:直接在 C 程序中嵌入 eBPF 汇编。
4.1 C 内联汇编示例
下面是个非常简单的例子,受 Cilium 文档 BPF 和 XDP 参考指南的启发:
// inline_asm.c
int func() {
unsigned long long foobar = 2, r3 = 3, *foobar_addr = &foobar;
asm volatile("lock *(u64 *)(%0+0) += %1" : // 等价于:foobar += r3
"=r"(foobar_addr) :
"r"(r3), "0"(foobar_addr));
return foobar;
}
关键字 asm 用于插入汇编代码。
4.2 编译及查看生成的字节码
$ clang -target bpf -Wall -O2 -c inline_asm.c -o inline_asm.o
反汇编:
$ llvm-objdump -d inline_asm.o
Disassembly of section .text:
0000000000000000 func:
0: b7 01 00 00 02 00 00 00 r1 = 2
1: 7b 1a f8 ff 00 00 00 00 *(u64 *)(r10 - 8) = r1
2: b7 01 00 00 03 00 00 00 r1 = 3
3: bf a2 00 00 00 00 00 00 r2 = r10
4: 07 02 00 00 f8 ff ff ff r2 += -8
5: db 12 00 00 00 00 00 00 lock *(u64 *)(r2 + 0) += r1
6: 79 a0 f8 ff 00 00 00 00 r0 = *(u64 *)(r10 - 8)
7: 95 00 00 00 00 00 00 00 exit
对应到最后一列的汇编,大家应该大致能看懂。
4.3 小结
这种方式的好处是:源码仍然是 C,因此无需像前一种方式那样必须手动执行编译( compile)和汇编(assemble)两个分开的过程。
5 结束语
通过两个极简的例子展示了两种 eBPF 汇编编程方式:
- 手动生成并修改一段特定的指令流
- 在 C 中插入内联汇编
这两种方式我认为都是有用的,比如在 Netronome,经常用前一种方式做单元测试, 检查 nfp 驱动中的 eBPF hw offload 特性。
LLVM 支持编写任意的 eBPF 汇编程序(但提醒一下:编译能通过是一回事,能不能通过校验器是另一回事)。
LLVM/Clang 命令用法
一、测试代码
1.//test.cpp
2.#include <stdio.h>
3.int main(int argc, char ** argv){ - printf(“Hello World!\n”);
- return 0;
6.}
二、编译成可执行文件
1.clang -isysrootxcrun --show-sdk-pathtest.cpp -o test
三、编译过程
3.1预处理
这一阶段的过程主要是对包含源代码的文件进行处理。主要的处理内容就是将在源文件中包含的头文件加载到文件中,替换宏定义等等。最终生成的文件是以.i 结尾的文件
1.clang -isysrootxcrun --show-sdk-path-E test.cpp -o test.i
3.2 编译生成汇编代码
这个阶段是将预处理得到的文件经由编译器变成汇编语言。汇编语言中的每一条语句都以一种标准的文本格式准确的描述一条地址机器指令。在这个阶段生成的文件才是机器相关的代码。这个阶段生成以.s结尾的汇编文件。
1.clang++ -isysrootxcrun --show-sdk-path-S test.i -o test.s
3.3 汇编生成obj文件
这个阶段就是将上一步得到的汇编文件汇编成机器指令,从而把这些指令打包成为一种可重定向的目标程序格式。这个时候生成以.o结尾的二进制文件。
1.clang -isysrootxcrun --show-sdk-path-c test.s -o test.o
3.4 链接生成可执行文件
这个阶段主要是处理在文件中调用了系统库例如printf等函数,那么就需要将系统库中的printf.o合并到生成的test.o中。生成可执行的二进制文件。
1.clang test.o -o test -v
四、LLVM IR 中间码
4.1 生成LLVM IR
在编译器解析源代码生成AST(抽象语法树)之后就可以根据AST生成中间码LLVM IR。
1.clang -emit-llvm -S test.cpp -o test.ll
1.clang -cc1 -emit-llvm test.cpp -o test.ll
4.2 生成 LLVM bitcode
LLVM bitcode是LLVM IR的二进制表现形式。
1.clang -emit-llvm -c test.cpp -o test.bc
1.clang -cc1 -emit-llvm-bc test.cpp -o test.bc
4.3 LLVM IR转bitcode
1.llvm-as test.ll -o test.bc
4.4 LLVM bitcode 转 LLVM IR
1.llvm-dis test.bc -o test.ll
4.5 LLVM bitcode 多文件链接
1.llvm-link test1.bc test2.bc -o output.bc - 6 执行LLVM bitcode
1.lli test.bc
五、LLVM IR 和 机器汇编
5.1 LLVM bitcode生成机器汇编
1.llc test.bc -o test.s
5.2 LLVM IR 生成机器汇编
1.llc test.ll -o test.s
5.3 LLVM bitcode生成obj
1.clang -cc1 -emit-obj test.bc -o test.o
5.4 LLVM IR 生成obj
1.clang -cc1 -emit-obj test.ll -o test.o
LLVM是如何编译指令的
通过一条指令在LLVM中经过不同阶段的变化,从源程序语言中的语义结构到成为机器二进制码来研究LLVM的工作原理。
不会介绍LLVM是如何工作的,这需要理解LLVM的设计以及code以及各种细节。
总结及流程图见文末
输入代码
从一段C代码开始探险,如下:
int foo(int aa, int bb, int cc) { int sum = aa + bb; return sum / cc;}
将会重点关注除法操作。
ClangClang是作为LLVM的前端使用的,负责将C,C++,以及ObjC源程序转化为LLVM IR。
Clang主要的复杂在于需要正确的parse以及语义分析C++程序;解析C程序还是比较简单的。
Clang的parser会建立一个抽象语法树Abstract Syntax Tree(AST).【译者附:AST,通过构建抽象语法树,在语法分析,语义分析中,可以判断是否程序符合规则。】
Clang主要通过AST进行处理。对于除法操作来说,Clang会在AST中创建一个Binary Operator节点,其带有BO_div操作属性。Clang的代码生成器然后会从该节点产生sdiv LLVM IR指令,因为这是一个有符号整型的除法操作。
LLVM IR
上述程序的LLVM IR如下:
define i32 @foo(i32 %aa, i32 %bb, i32 %cc) nounwind {entry: %add = add nsw i32 %aa, %bb %div = sdiv i32 %add, %cc ret i32 %div}
在LLVM IR中,sdiv是一个Binary Operator,是SDiv指令的subclass。像其他的任何指令一样,可以被LLVM分析并转化。
Backend
译者附:IR之后的操作都可视为后端,不同的c,c++程序都可以被解析为IR。而IR之后则是根据目标机器,使用代码生成器产生对应的指令。
代码生成器 code generator是LLVM中最复杂的一个部分,任务是将相对high-level,不依赖目标机器的LLVM IR转化为 low-level的,依赖目标的机器指令(Machine Instr)。在生成Machine Instr之前,LLVM IR的指令会经过“Selection DAG node”转化。
Selection DAG Node
Selection DAG Node是由Selection DAG Builder在Selection DAG Sel阶段创建的,这是instruction selection的主要部分。【译者附:DAG,有向无环图,在编译器中用来标志指令之间的数据依赖关系和控制关系。】
Selection DAG Isel会走遍IR指令,在指令上调用SelectionDAGBuilder::visit dispatcher。处理SDiv指令的是SelectionDAGBuilder::visitDiv. 需要在DAG中创建一个新的SDNode节点,其操作符为ISD::SDIV.
最初的DAG只是部分依赖目标机器的。在LLVM的命名中,这被叫做“illegal”,因为类型可能无法被目标机器支持。同样,其操作可能也无法支持。
有几种方式来可视化DAG:一种是将 -debug flag传递到LLC,这将会在Selection Phase的过程中创建DAG的文本dump。另一种方式就是使用-view选项,可以dump并display graph。如下就是在DAG创建之后的图像:
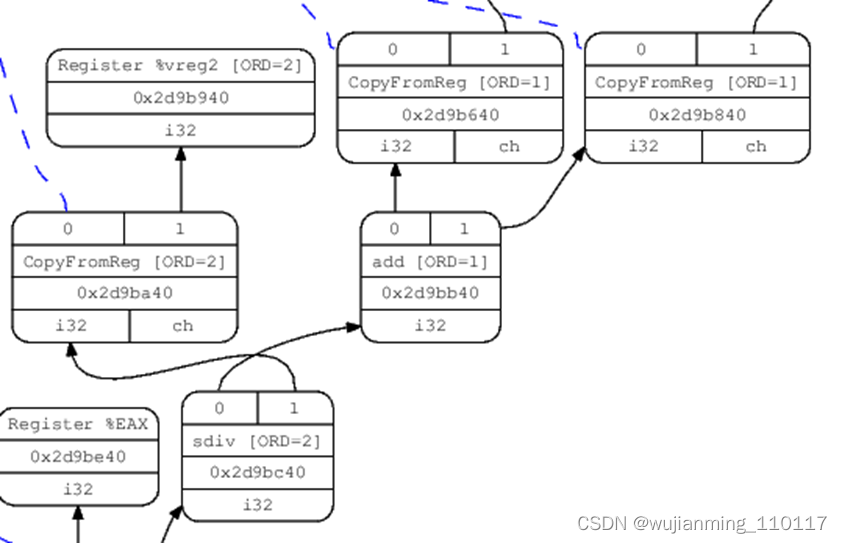
在SelectionDAG从DAG节点真正的输出机器指令之前,这些节点也会经历一些其他的变化。其中最重要的就是类型和操作合法化,通过使用target-specific hook来将所有的操作和类型转为那些机器真正支持的操作和类型。
将SDiv合规化到sdivrem on X86
X86中的idvi指令,同时计算商和余数,并且将结果存到两个不同的寄存器中。而LLVM的指令选择会将同时计算商和余数的指令(叫做ISD::SDIVREM)和只计算商的操作(ISD::SDIV)区分开,因此DAG 节点会在DAG合规化阶段被“legalized”。
代码生成器使用的一个重要的接口:Target Lowering,来将传递target-specific的信息传输到target indepent算法中。目标会实现这个接口来描述LLVM IR指令应该怎样被lowered到合规的Selection DAG操作。
x86的对应接口叫做X86 TargetLowering。在构造函数中,标记了那些操作应当被合规化,ISD::SDIV就是其中之一。如下是该段代码的注释:
// Scalar integer divide and remainder are lowered// to use operations that produce two results, // to match the available instructions. // This exposes the two-result form to trivial CSE,// which is able to combine x/y and x%y into a single instruction.
当SelectionDAGLegalize :: LegalizeOp看到SDIV节点有Expand flag时,会将其替换为ISD::SDIVREM。这个例子展示了在Selection DAG格式时,一个操作可能经历的变化。
指令选择 - 从 SDNode 到 MachineSDNode
指令生成中的下一步即为instruction selection。LLVM提供了一个通用的table-based instruction selection 机制,该文件通过TableGen工具自动生成。
然而很多目标后端,都选择自己写SelectionDAGIsel :: Select的实现代码来手动处理一些指令。其他的指令会送到叫做SelectCode的auto -generated selector。
X86后端手动编写后端处理代码,来处理ISD::SDIVREM中的一些特殊的情况和优化。在这个阶段创建的DAG节点叫做MachineSDNode,是SDNode的一个subclass,会存有生成实际的机器指令的信息,但是仍然是以DAG node格式的。此时,真正的的X86指令op code会被选择,在这个例子中为X86::IDIV32r。
调度和发射 MachineInstr此时代码还是DAG格式的,但是CPU不会执行DAG,执行的是线性的指令队列。调度的目标是通过给操作节点一个顺序来线性化DAG,最简单的方式就是按照拓扑的方式排序DAG,但是LLVM的代码生成器使用了更为聪明的方式,比如register pressure reduction,来尝试产生更快的代码。
一般每个目标都有自己的hook,来实现指令的调度。
最终,调度器会通过使用InstrEmitter :: EmitMachineNode函数将SDNode转化,发射一系列的指令到MachineBasicBlock。这些指令使用MachineInstr 的格式(MI 格式),DAG可以被销毁了。
通过调用llc -print-machineinstr 来看看产生的machine instruction。看看在instruction selecttion之后的第一次输出:
After Instruction Selection:# Machine code for function foo: SSAFunction Live Ins: %EDI in %vreg0, %ESI in %vreg1, %EDX in %vreg2Function Live Outs: %EAX
BB#0: derived from LLVM BB %entry Live Ins: %EDI %ESI %EDX %vreg2 = COPY %EDX; GR32:%vreg2 %vreg1 = COPY %ESI; GR32:%vreg1 %vreg0 = COPY %EDI; GR32:%vreg0 %vreg3<def,tied1> = ADD32rr %vreg0, %vreg1, %EFLAGS<imp-def,dead>; GR32:%vreg3,%vreg0,%vreg1 %EAX = COPY %vreg3; GR32:%vreg3 CDQ %EAX, %EDX, %EAX IDIV32r %vreg2, %EAX, %EDX<imp-def,dead>, %EFLAGS<imp-def,dead>, %EAX, %EDX; GR32:%vreg2 %vreg4 = COPY %EAX; GR32:%vreg4 %EAX = COPY %vreg4; GR32:%vreg4 RET
End machine code for function foo.
注意输出是按照SSA格式的,其中的一些寄存器使用的是虚拟寄存器(比如%vreg1)。【译者附,SSA,静态单赋值,同一个变量每次赋值,都分配新的变量符号,方便后端进行优化。】
寄存器分配 —从SSA到non-SSA机器指令除了一些定义好的异常,指令选择器产生的代码是SSA(静态单赋值)格式的。尤其是,假想此时有无穷的虚拟寄存器。当然,这是假的。因此,指令产生器的下一步就是调用寄存分配器,该分配器的任务就是使用物理寄存器替换掉虚拟寄存器。异常也是比较重要并且有趣的,因此再多讨论一点。
一些架构中的一些指令只能使用特定的寄存器。一个例子就是x86中的除法操作,要求输入在EDX和EAX寄存器中。指令选择器知道这些限制,因此在上面的代码中可以看到,IDIV32r的输入是物理寄存器,而不是虚拟寄存器。这个是通过X86DAGToDAGISel::Select处理的。
寄存器分配器会处理所有的非固定寄存器,此外,SSA格式的机器指令还会进行一些优化。
输出代码现在原始的C代码已经被翻译为MI 格式,一个使用instruction objects(MachineInstr)组成的MachineFunction。此时,代码生成器完成了工作,可以输出代码。在LLVM中,有两种方式实现:一种是使用JIT来产生可执行的,ready-to-run code到内存中。另一种就是MC,是一种复杂的object-file-and-assembly生成器。MC现在被用于汇编和目标文件生成。MC也允许使用MCJIT,是基于MC layer的JIT-ting 框架。
LLVMTargetMachine::addPassesToEmitMachineCode定义了JIT产生代码的pass序列。调用了addPassesToGenerateCode,该函数调用了所有需要的passes,将IR转为MI格式。下一步,叫做addCodeEmitter,是一个目标特定target-specific的pass用来将MI转化为实际的machine code。因为MI已经十分low-level了,因此可以相对简单的将转化为可运行的machine code。X86代码对应的文件为lib/Target/X86/X86CodeEmitter.cpp。除法操作此处不需要特殊的处理,因为MachineInstr已经包含了opcode和操作数了。和其他的指令一般在emitInstruction中处理。
MCInst
LLVM如果是被用作静态编译器,那么MI被发送到MC layer中,来处理object-file emission,也可以产生汇编文件。
LLVMTargetMachine::addPassesToEmitFile 负责定义需要产生目标文件的一系列操作。实际上MI-to-MCInst转化在AsmPrinter接口的EmitInstruction函数中完成。在X86中,使用X86AsmPrinter::EmitInstruction函数实现,该函数会分派给X86McInstLower来处理。与JIT相似,除法指令和其他指令相同,不需要特殊的处理。
通过传递-show-mc-inst到LLC,可以看到在MC-level创建的指令:
foo: # @foo# BB#0: # %entry movl %edx, %ecx # <MCInst #1483 MOV32rr # # > leal (%rdi,%rsi), %eax # <MCInst #1096 LEA64_32r # # # # # # > cltd # <MCInst #352 CDQ> idivl %ecx # <MCInst #841 IDIV32r # > ret # <MCInst #2227 RET>.Ltmp0: .size foo, .Ltmp0-foo
目标文件(或者汇编代码)的发射是通过MCStreamer 接口实现的。目标文件通过MCObjectStreamer产生,该类会因为实际上的目标文件进一步扩展。比如,ELF 产生是在MCELFStreamer产生的。
MCInst会先经历MCObjectStreamer :: EmitInstruction,然后是针对特定格式的EmitInstToData。最终产生的二进制格式的指令,是目标特定的,这是通过MCCodeEmitter接口(比如X86MCCodeEmitter)。此时的LLVM的代码,一部分是完全通用的,一部分是依赖特定输出目标文件格式的,一部分则是针对特定目标机器的。
Assemblers and Disassemblers
MCInst是一个比较简单的格式。尽可能的去除语义信息,只保存指令的操作码和操作数。像LLVM IR一样,这也是一个内部的表示,可以有不同的编码格式,最常使用的是汇编和二进制文件。
llvm-mc是一个使用MC框架来实现汇编器和反汇编器的工具。在内部,MCInst被用于在二进制和文本格式间进行翻译。此时,工具并不关心是什么编译器产生的汇编或者目标文件。
总结:
- Clang将输入源程序转为LLVM IR。
- SelectionDAGBuilder遍历IR指令产生Selection DAG,此时DAG基本上还是非目标依赖的。
- SelectionDAGLegalize使用TargetLowering对SelectionDAG,针对operation和type进行针对目标依赖的合规化。
- SelectCode进行instruction selection,产生MachineSDNode(仍为DAG格式),包含对应的opcode。
- InstrEmitter::EmitMachineNode产生线性序列的SSA格式的MachineInstr(MI)指令, DAG可以销毁。
- 物理寄存器分配,转为non-SSA模式。
- code emitter产生最终的目标文件。
译者:Backend流程如附图,
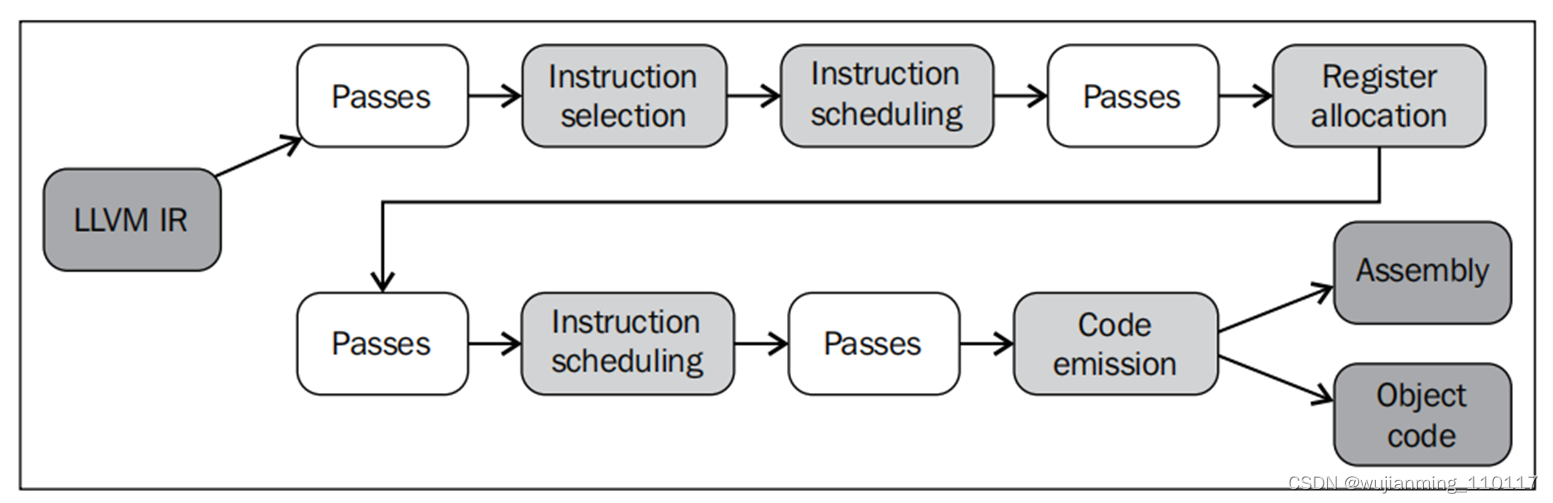
iOS底层LLVM编译流程
LLVM概念
1.编译器
在学习LLVM之前先了解一下什么是编译器?
简单讲,编译器就是将一种语言(通常为高级语言)翻译为另一种语言(通常为低级[语言]的程序。
一个现代编译器的主要工作流程:源代码(source code) → 预处理器(preprocessor) → 编译器(compiler) → 目标代码(object code) → 链接器(Linker) → 可执行程序(executables)
源代码一般为高级语言(High-level language), 如C、C++、Java、Objective-C等或汇编语言,而目标则是机器语言的目标代码(Object copy),有时也称作机器代码(Machine code)。
用两种语言来做个对比:解释型语言和编译型语言。
• 解释型语言
下面引入一个Python代码,见下图:
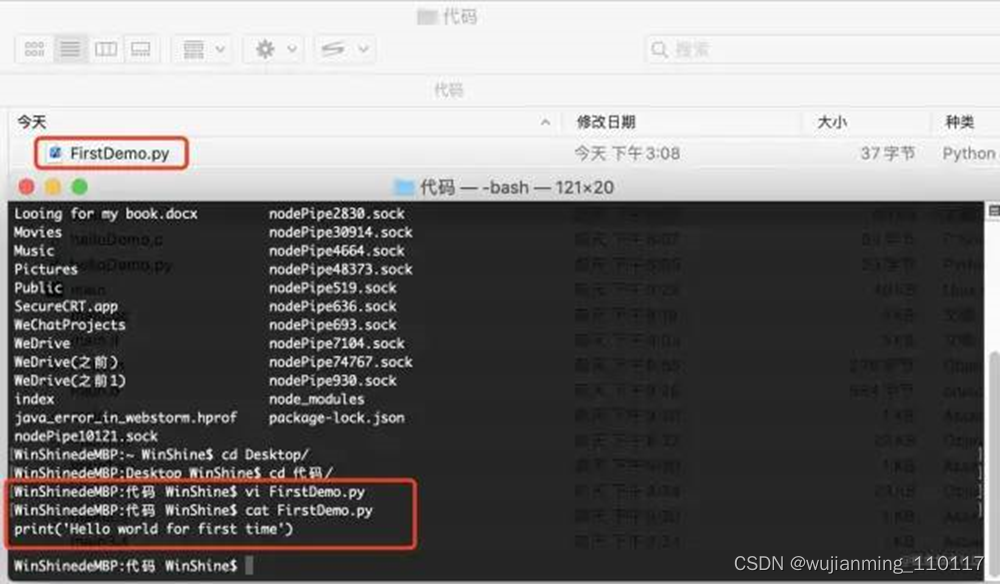
创建一个FirstDemo.py文件,里面只有一行代码,print(‘Hello world for first time’)。通过解释器指令pythop,解释这段代码:
通过上面的流程可以发现解释型语言的运行流程:

解释型语言特点:边解释,边执行,运行速度慢,部分改动无需整体重新编译,不可脱离解释器环境运行。
• 编译型语言
下面引入一个C代码,见下图:
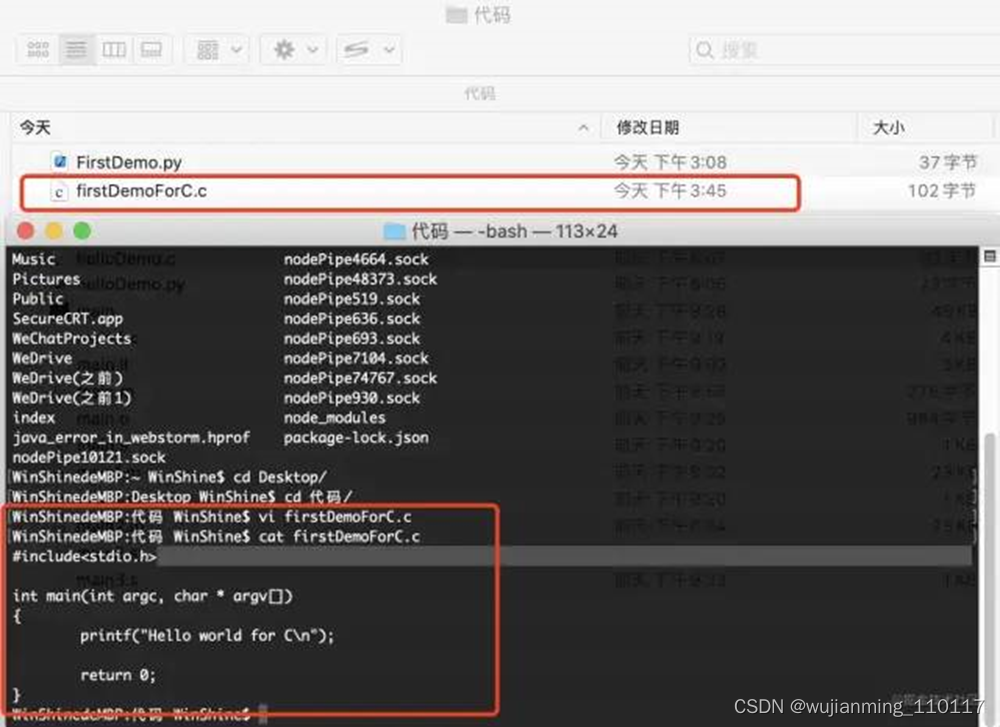
创建一个firstDemoForC.c文件,里面添加了一个main函数。首先通过clang去读取这个代码:
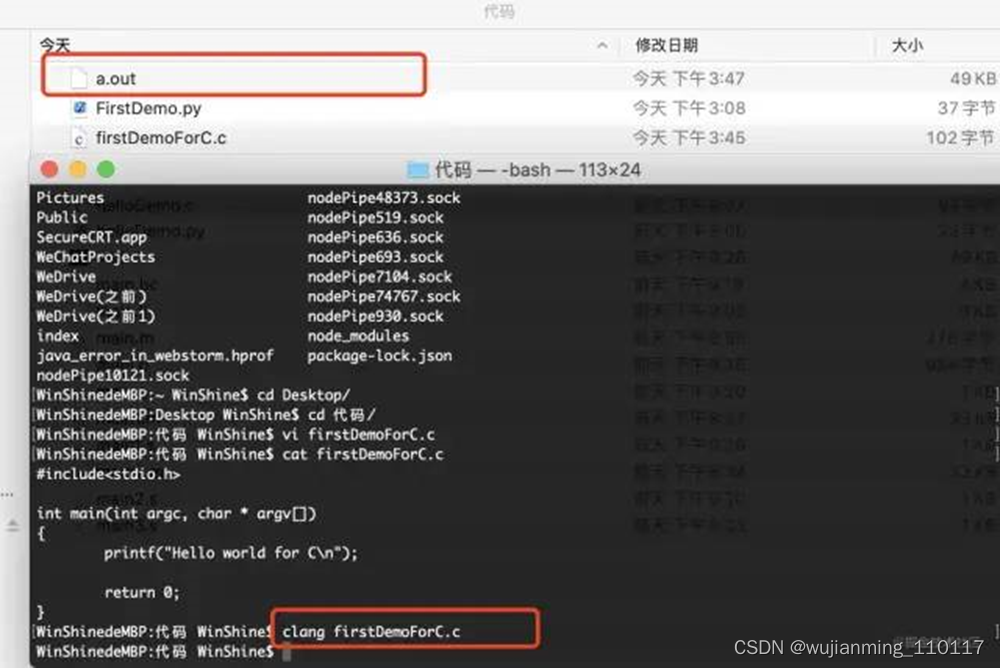
读取之后发现代码并没有立刻执行,而是生成了一个a.out文件。这个文件就是可执行文件。通过./a.out执行这段代码:

通过上面的流程可以发现编译型语言的运行流程:

编译型语言特点:先整体编译,再执行,运行速度快,任意改动需重新编译,可脱离编译环境运行。 解释型语言:读到相应代码就直接执行 编译型语言:先将代码编译成cpu可读的懂的二进制才能执行
2.LLVM概述
LLVM是构架编译器(compiler)的框架系统,以C++编写而成。
用于优化以任意程序语言编写的程序的编译时间(compile-time)、链接时间(link-time)、运行时间(run-time)以及空闲时间(idle-time),对开发者保持开放,并兼容已有脚本。
LLVM计划启动于2000年,最初由美国UIUC大学的Chris Lattner博士主持开展。
2006年Chris Lattner加盟Apple Inc.并致力于LLVM在Apple开发体系中的应用。Apple也是LLVM计划的主要资助者。
目前LLVM已经被Apple、Microsoft、Google、Facebook等各大公司采用。
• 传统编译器的设计

- 编译器前端(Frontend)
编译器前端的任务是解析源代码。会进行:词法分析、语法分析、语义分析,检查源代码是否存在错误,然后构建抽象语法树,LLVM的前端会生成中间代码IR。 - 优化器(Optimizer)
优化器负责进行各种优化。改善运行时间,例如消除冗余计算等。 - 后端(Backend)
也可以叫代码生成器(CodeGenerator),将代码映射到目标指令集。生成机器语言,并且进行机器相关的代码优化。
随着高级语言越来越多,终端类型种类的增加,所使用的的CPU架构等也不尽相同。
所以为了适配多种环境,不得不设计不同的编译器,而这些编译器前端和后端往往是捆绑在一起的。
• LLVM设计思路
LLVM的设计之初,即将编译器前端(Frontend)和后端(Backend)进行了分离。
将前端和后端针对不同的架构,按照独立的项目进行研发,而均采用通用的代码形式IR。

当编译器决定支持多种语言或多种硬件架构时,LLVM最重要的地方就体现出来了,使用通用的代码表示形式(IR),是用来在编译器中表示代码的形式。
所以LLVM可以为任何编程语言独立编写前端,并且可以为任意硬件架构独立编写后端。
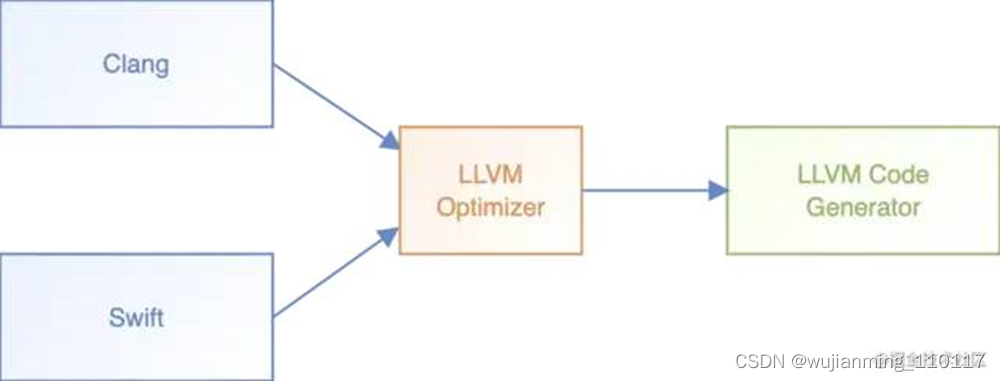
• iOS编译架构
Objective C/C/C++使用的编译器前端是Clang,Swift是Swift,后端都是LLVM。
3.Clang
Clang是LLVM项目中的一个子项目。是基于LLVM架构的轻量级编译器,诞生之初是为了替代GCC,提供更快的编译速度。
是负责编译C、C++、Objective-C语言的编译器,属于整个LLVM架构中,编译器前端。对于开发者来说,研究Clang可以给带来很多好处。
编译流程
通过命令可以打印源码的编译阶段。引入下面一个案例,main.m中添加代码
int main(int argc, const char * argv[]) { return 0;}
(滑动显示更多)
通过指令clang -ccc-print-phases main.m,查看编译流程:
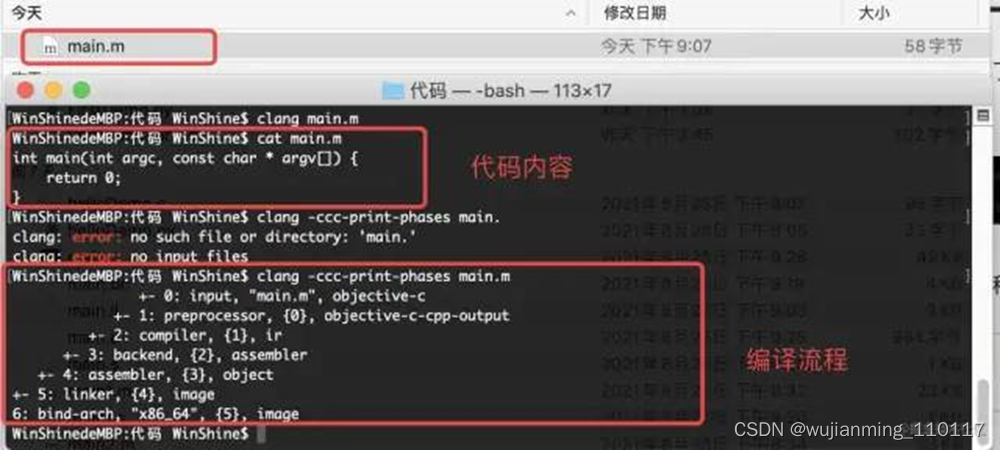
流程说明:
- 输入文件:找到源文件
- 预处理阶段:这个过程处理包括宏的替换,头文件的导入
- 编译阶段:进行词法分析、语法分析、检测语法是否正确,最终生成IR
- 后端:这里LLVM会通过一个一个的Pass(节点)去优化,每个Pass做一些事情,最终生成汇编代码
- 生成目标文件
- 链接:链接需要的动态库和静态库,生成可执行文件
- 通过不同的架构,生成对应的可行文件
1.预处理
执行如下指令:clang -E main.m,对源代码进行预处理。见下面流程:
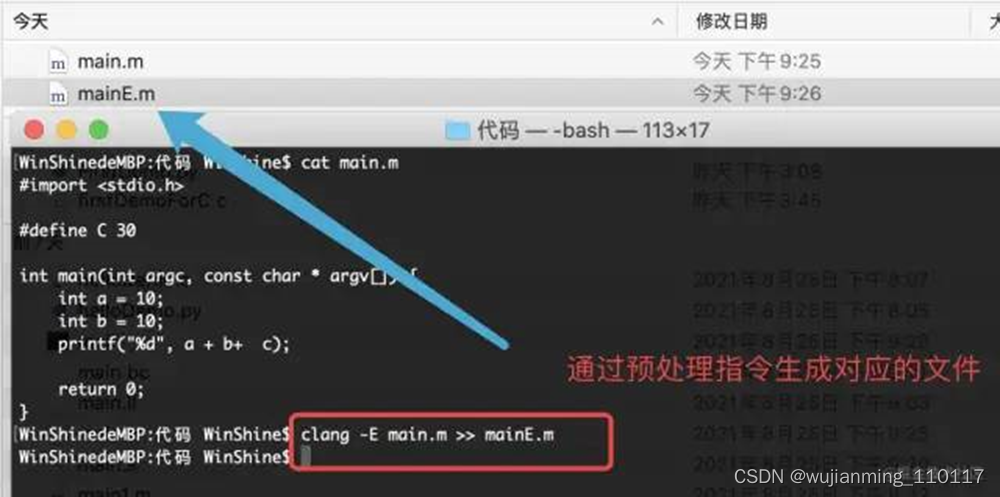
在预处理之后,输出mainE.m文件,查看mainE.m文件:
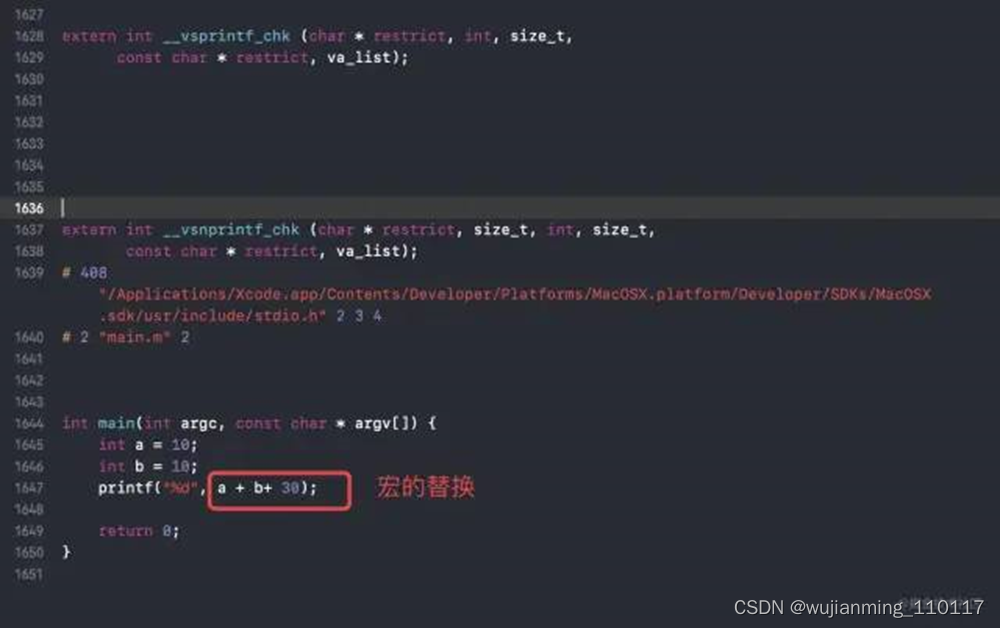
打开mainE.m源文件会发现,其进行了宏的替换,如上面案例中宏c直接替换成了30;进行头文件的导入。
2.编译阶段
• 词法分析
预处理完成后就会进行词法分析,这里会把代码切成一个个Token,比如大小括号,等于号以及字符串等。词法分析指令为:
clang -fmodules -fsyntax-only -Xclang -dump-tokens main.m
(滑动显示更多)
参考下面的案例:
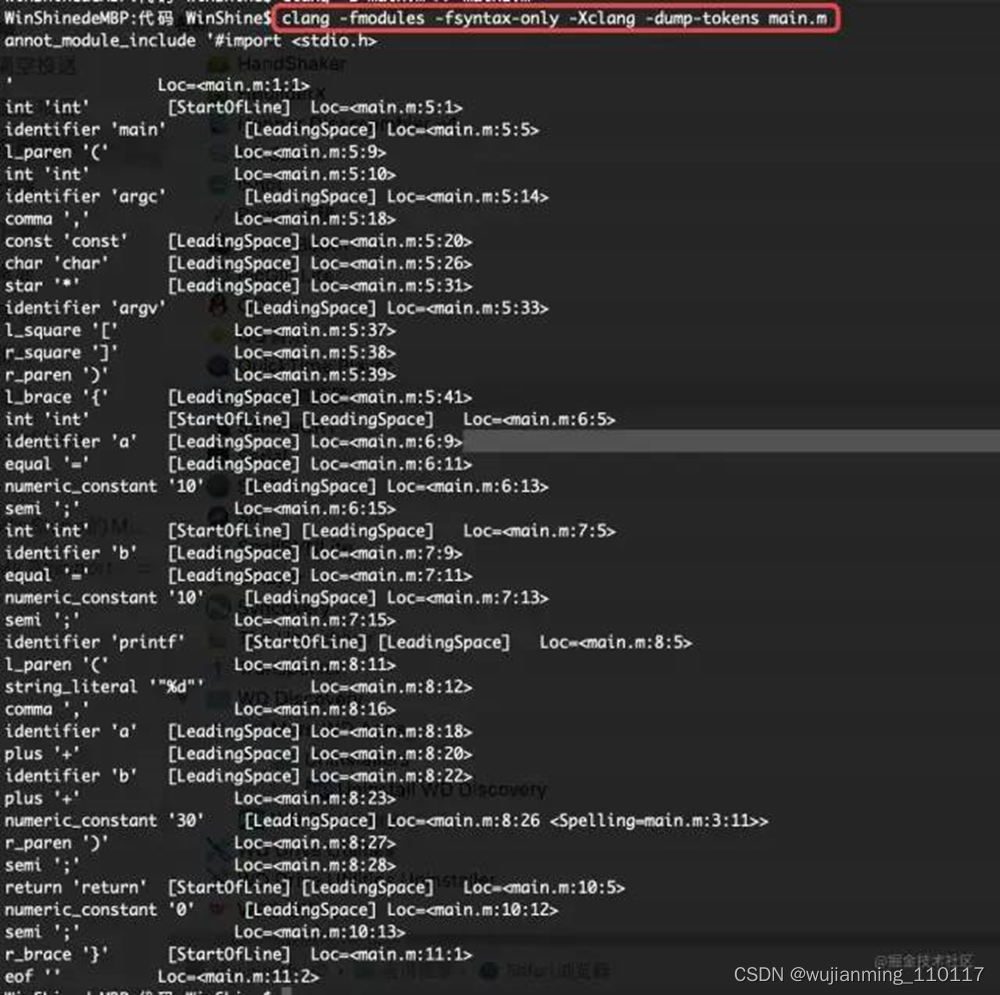
通过指令的输出可以看到,语法分析会将源码进行切割并检测。比如分号,逗号,int等。
• 语法分析
词法分析完成之后就是语法分析,任务是验证语法是否正确。在词法分析的基础上将单词序列组合成各类语法短语。
如:程序,语句,表达式等等,然后将所有节点组成抽象语法树(Abstract Syntax Tree,AST)。语法分析程序判断源程序在结构上是否正确。语法分析指令:
clang -fmodules -fsyntax-only -Xclang -ast-dump main.m
(滑动显示更多)
语法分析输出结果:
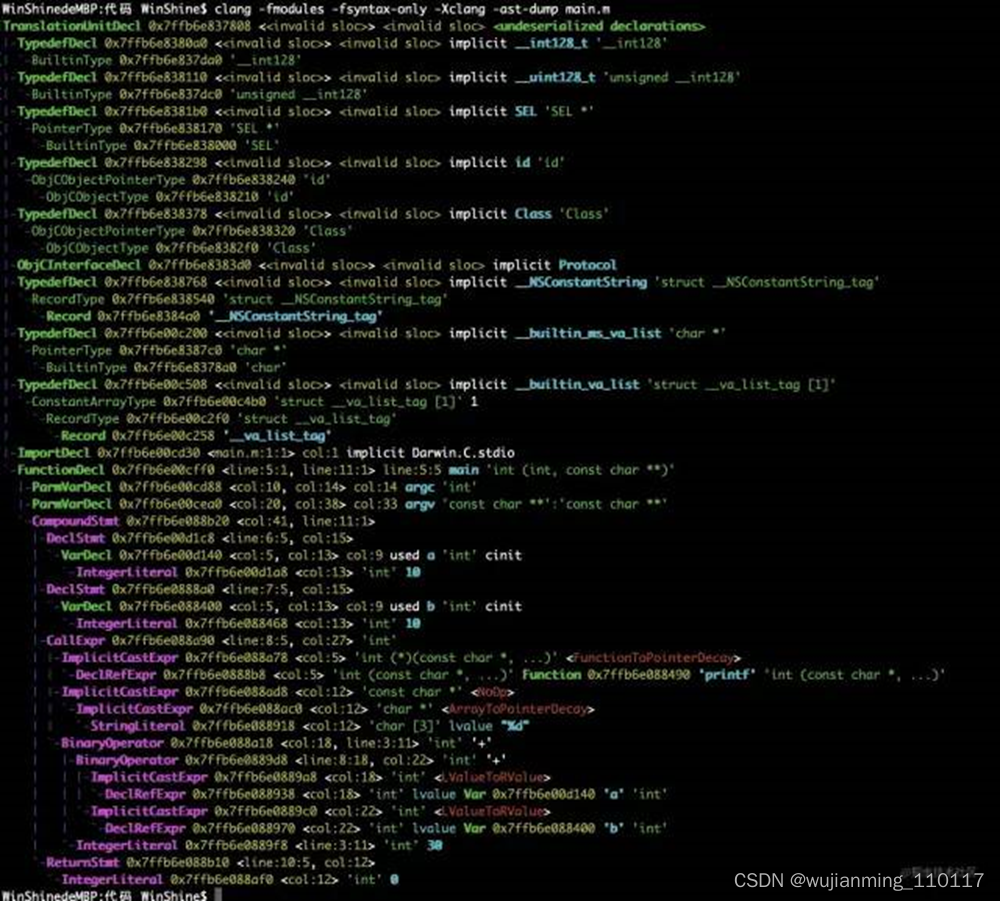
通过上面的输出可以发现,其是一个树结构,比如下面的FunctionDecl,表示一个方法,在源码的第五行,名称为main,返回值为int,传入两个参数一个是int,一个是const char **。见下图:
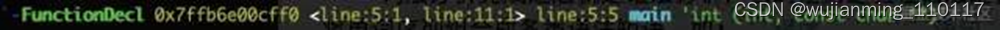
这里需要注意的是,一旦生成抽象语法树,如果源码中存在语法错误,就会报错,而上面的预处理和词法分析不会报错。
如在源码中设置一个语法错误,通过语法分析指令进行进行编译,就会报错,见下面案例:
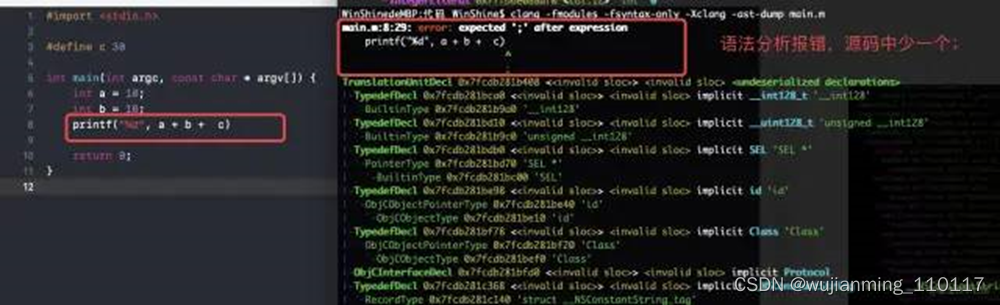
• 生成中间代码IR(intermediate representation)
完成以上步骤后,就开始生成中间代码IR了,代码生成器(Code Generation)会将语法树自顶向下遍历逐步翻译成LLVM IR。
通过下面指令可以生成.ll的文件,查看IR代码。
clang -S -fobjc-arc -emit-llvm main.m
(滑动显示更多)
通过上面的指令获取main.ll文件,其结构见下图:
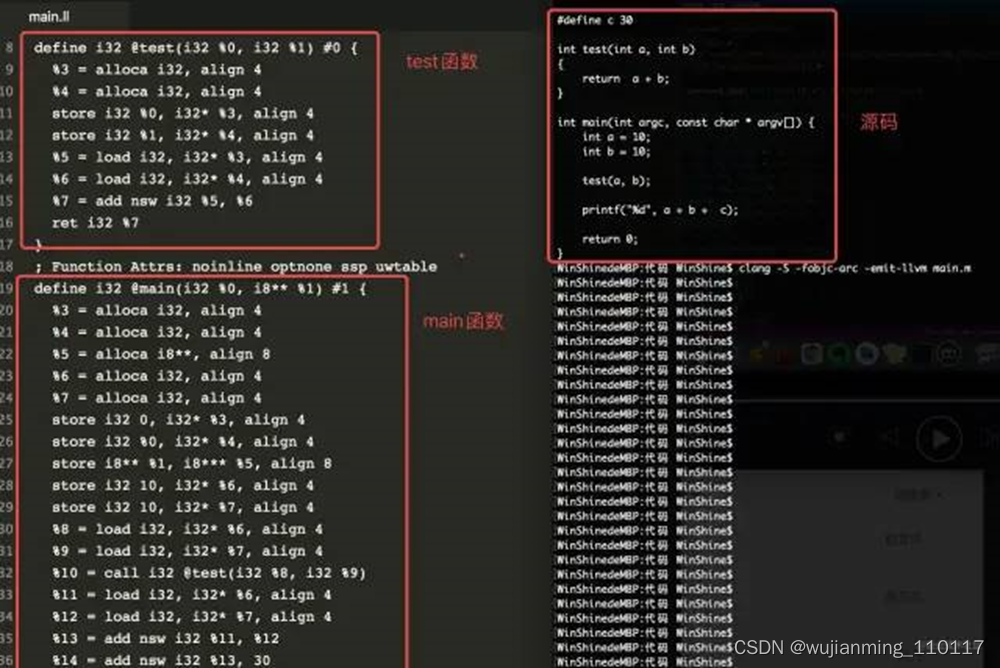
o IR的基本语法
@ 全局标识
% 局部标识
alloca 开辟空间
align 内存对齐
i32 32个bit,4个字节
store 写入内存
load 读取数据
call 调用函数
ret 返回
• IR优化
上面生成的IR代码是没有经过优化的,其实在平时阅读代码时,经常会看下面的一些定义:
#define fastpath(x) (__builtin_expect(bool(x), 1))#define slowpath(x) (__builtin_expect(bool(x), 0))
(滑动显示更多)
o fastpath:可以理解为快速流程,对更有可能执行的流程进行优化,调高运行速度;
o slowpath:基本流程,不被优化的。
在XCode中也有相应的优化设置入口:
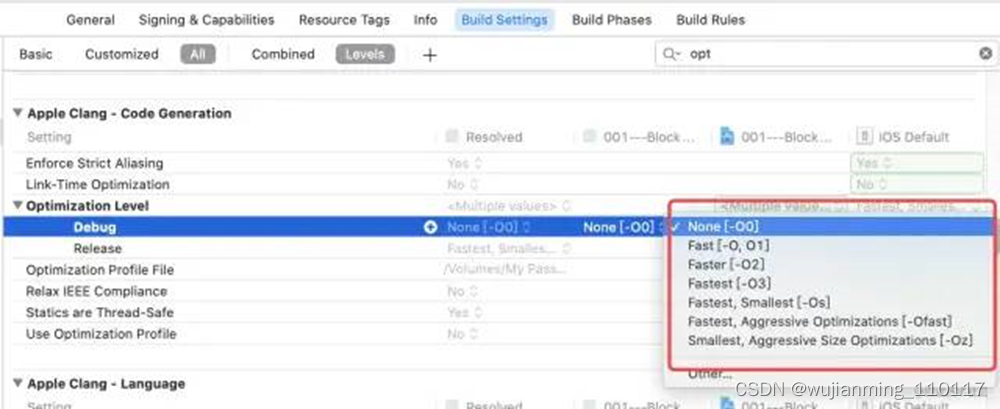
LLVM的优化级别分别是-O0 -O1 -O2 -O3 -Os(第一个是大写英文字母O)。可以通过下面的指令获取优化后的IR代码,也就是.ll文件:
clang -Os -S -fobjc-arc -emit-llvm main.m -o main.ll
(滑动显示更多)
通过上面的指令,进行优化后获取的IR代码见下图:
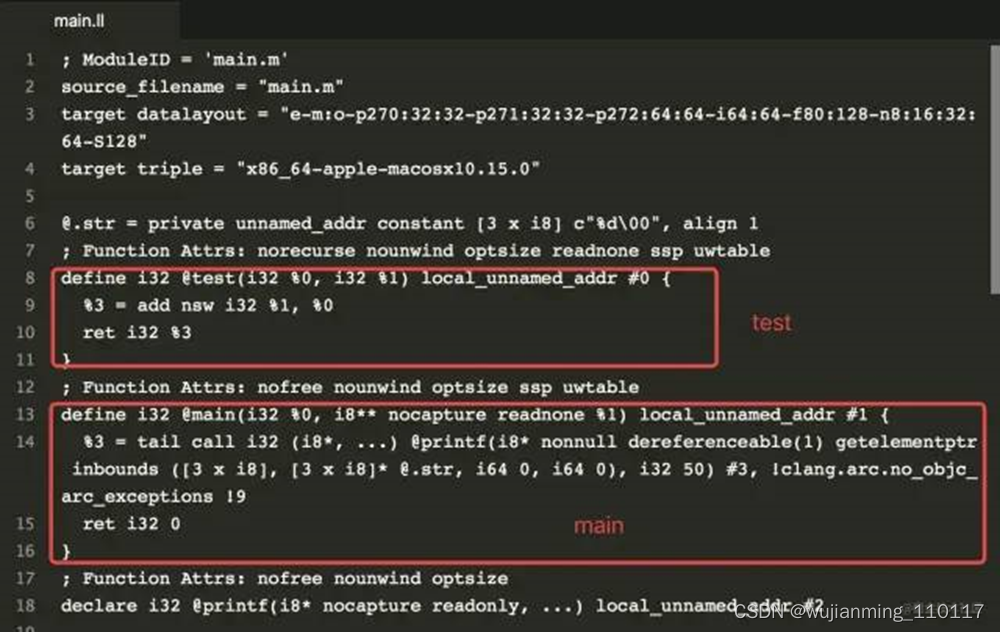
相较于优化前,代码精简了很多。
这里需要注意的是,通常debug模式下,优化模式选择None -O0,也就是不优化,避免一些保留代码被屏蔽,从而影响调试。而release模式设置为Fastest,Smallest -Os。
• bitCode
Xcode7以后开启bitCode苹果会做进一步的优化,生成.bc的中间代码。通过优化后的IR代码生成.bc代码。对应指令为:
•
clang -emit-llvm -c main.ll -o main.bc
(滑动显示更多)
3.后端生成汇编代码
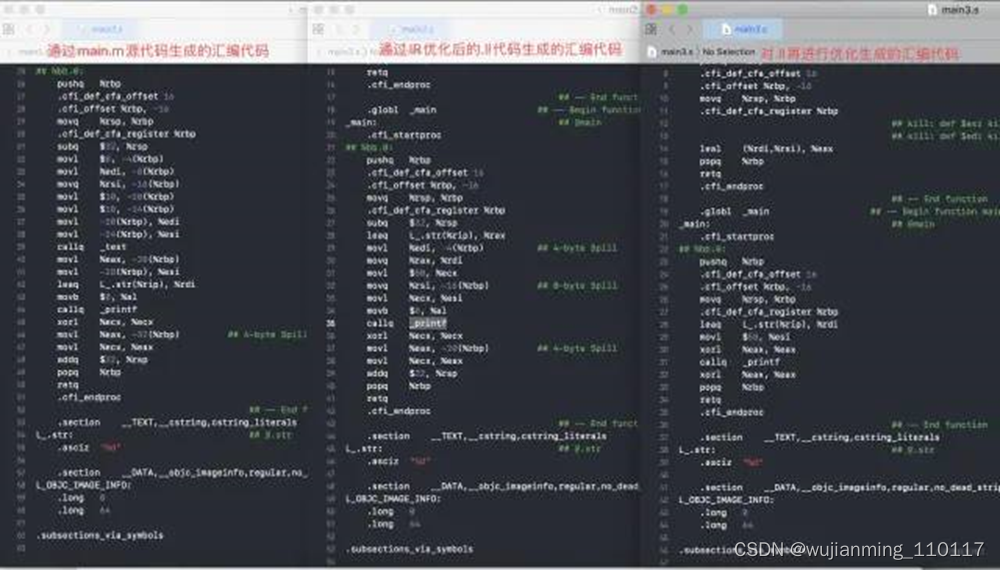
通过最终的.bc或者.ll代码生成汇编代码:
clang -S -fobjc-arc main.bc -o main.s clang -S -fobjc-arc main.ll -o main.s
(滑动显示更多)
生成汇编代码也可以进行优化:
clang -Os -S -fobjc-arc main.m -o main.s
(滑动显示更多)
采用相同的案例,分别三种方式生成汇编代码,可以看到其优化效果。在进行IR优化后生成的.ll文件,依然可以进行优化生成回应的汇编代码。
在不同的节点上都可以进行优化。见下图:
4.生成目标文件(汇编器)
目标文件的生成,是汇编器以汇编代码作为输入,将汇编代码转换为机器代码,最后输出目标文件(object file)。指令为:
clang -fmodules -c main.s -o main.o
(滑动显示更多)
生成目标文件,见下图:
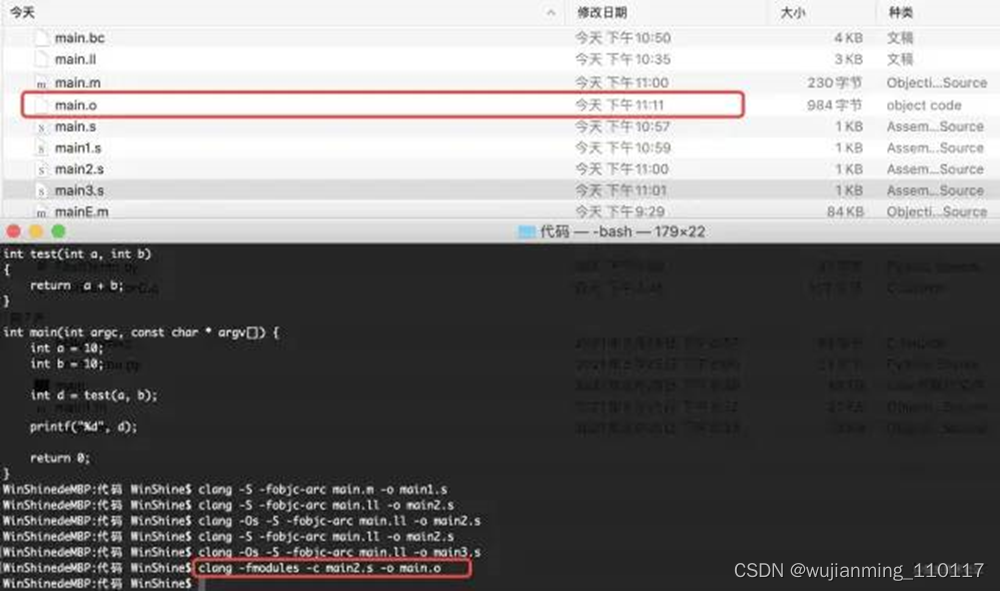
其中main.o文件即为目标文件,但是此时生成的目标文件是不可执行的。通过nm命令,查看下main.o中的符号:
$xcrun nm -nm main.o (undefined) external _printf 0000000000000000 (__TEXT,__text) external _test 000000000000000a (__TEXT,__text) external _main
(滑动显示更多)
• _printf是一个undefifined external的
• undefifined表示在当前文件暂时找不到符号_printf
• external表示这个符号是外部可以访问的
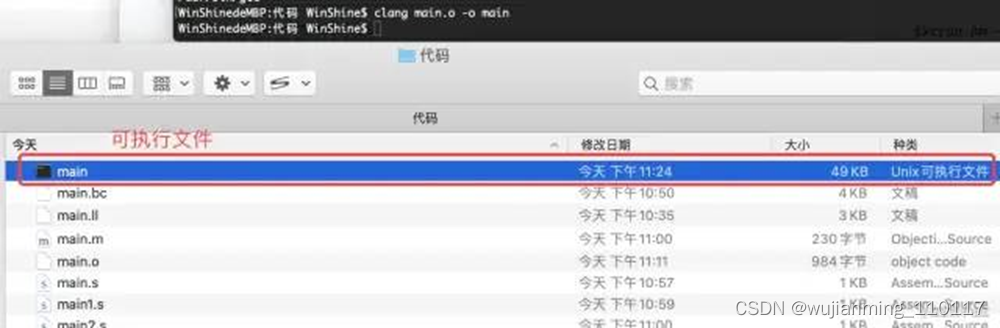
此时就需要链接,链接器把编译生成的.o文件和(.dylib .a)文件链接生成一个mach-o文件。
clang main.o -o main
生成对应的可执行文件,见下图:
查看链接之后的符号:
$xcrun nm -nm main (undefined) external _printf (from libSystem) (undefined) external dyld_stub_binder (from libSystem)0000000100000000 (__TEXT,__text) [referenced dynamically] external __mh_execute_header000000100000f6d (__TEXT,__text) external _test000000100000f77 (__TEXT,__text) external _main
(滑动显示更多)
可以发现此时的外部函数有2个,_printf和dyld_stub_binder,都来自libSystem库。dyld_stub_binder这个函数的作用是进行运行时绑定流程。
链接是在编译时,用来确定外部函数来自哪个动态库;绑定是在运行时,将对应方法的实现地址与符号进行绑定。
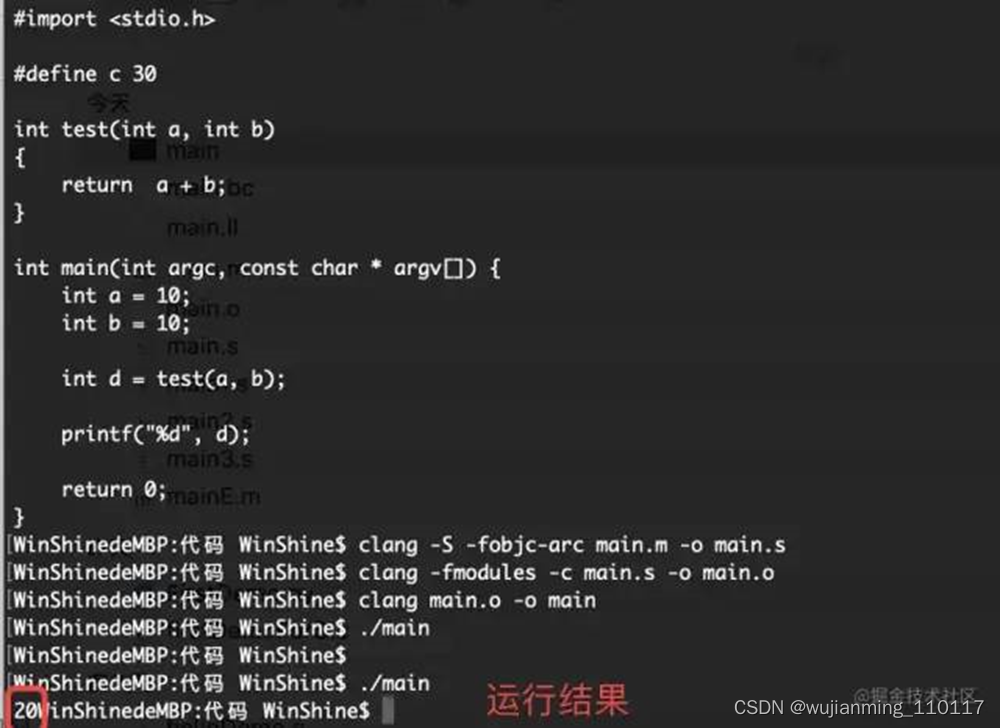
可执行文件运行结果:
参考文献链接
https://mp.weixin.qq.com/s/_d5HR9yHdwhGYozr9IaU_A
https://mp.weixin.qq.com/s/bWT7FBH8PsLqFeeGotLEnQ
https://mp.weixin.qq.com/s/iwVQ_r0SljakMGqWQL2KXA
https://mp.weixin.qq.com/s/MfV1FkwQSNokZuzedizALA