作者: GreenGuan 原文来源:https://tidb.net/blog/d02ba4a5
为什么要升级?
- 低版本 TiDB 周边组件支持不完善,如低版本的 cdc 的支持并不完善,有内存泄露问题等;
- 实际工作中触发过 TiDB 的 panic bug;
- 在降本增效的大背景下,提升 TiDB 的性能或吞吐量;
- 为社区贡献实际业务场景;
如何升级?
TiDB 的升级分为停机升级和不停机升级,不停机升级又分平滑升级和强制升级(–force),下面简单说明下过程,不对细节过多展开,只介绍核心:
强制升级:
-
下载对应版本软件到目标主机上
-
Upgrading component pd
-
Upgrading component tikv
- 替换软件,不做leader选举,直接重启tikv server
-
Upgrading component tidb
- 在升级tidb节点时,在该tidb上的所有会话将会断开
-
Upgrading component prometheus,grafana,alertmanager
优点:
-
时间短(笔者做过测试,重启一个200G左右的tikv节点耗时1分钟左右)
-
升级结果可控
风险:
-
该升级方式强制升级,升级过程中,如果前端应用请求的leader正好重启,则会有读写失败的情况发生
-
在4步失败时,程序需要有重连机制
平滑升级:
-
下载对应版本软件到目标主机上
-
Upgrading component pd
-
Upgrading component tikv
- 在升级tikv时会滚动驱逐leader(超时默认10分钟,可调),后重启该节点
-
Upgrading component tidb
- 在升级tidb节点时,在该tidb上的所有会话将会断开
-
Upgrading component prometheus,grafana,alertmanager
优点:
- 该升级方式为平滑升级(前提是该节点上的leader可以在规定时长内驱逐完毕),不会有读写失败的情况发生(tidb组件重启时除外)
风险:
-
升级时间较长,举个例子如果有3pd,3tidb,100tikv,那么滚动升级的时间至少为 100(节点数量) * 10m(默认超时时间) + pd + tidb + 监控,我们假设 pd + tidb + 监控的升级时长为 10m,那么升级的总时长为 16h
-
如果在3.1步失败时,群集的版本状态有可能是 一部分新版本,一部分旧版本(笔者曾经遇到过的pd节点为v540 tikv 节点为 v409,好在没出什么问题)
-
在 4 步失败时,程序需要有重连机制(同上)
停机升级:
-
关闭 TiDB 整个实例 (所有组件)
-
软件下载及替换
-
启动 TiDB 实例
**风险:**简单的说就是停服维护
-
要通知前端业务,做好接口或程序侧的异常捕获,不要让error日志暴增而导致的前端应用崩溃
-
在停机维护时一定要做好主机硬件检查,主要有硬盘,内存,主板,电源等,如果能关不能开那就尴尬了,避免黑天鹅事件
我们大致总结下每种升级方式的优缺点如下:
| 优点 | 风险 | |
|---|---|---|
| 平滑升级 | 大部分业务读写不会失败 | 升级时间长升级结果不可控 |
| 强制升级 | 升级时间短升级结果可控 | 部分业务读写失败 |
| 停机升级 | 升级时间短升级结果可控 | 业务在升级时不可用 |
具体可参见官方文档,里面写的很清楚,连接如下:
https://docs.pingcap.com/zh/tidb/v5.4/upgrade-tidb-using-tiup
升级前后关注的核心问题
-
寻找适合的回退方案
-
SQL兼容问题
-
性能回退问题
寻找适合的回退方案
原生的 TiDB 升级没有回退方案,如果需要回退方案,可以有如下方案参考:
| 技术实现 | 优点 | 缺点 | 备注 | |
|---|---|---|---|---|
| 方案一 | 备份 / 恢复 | - 数据可反复使用 | ||
| - 运维成本低 | - 恢复时间长 | |||
| - 无法快速回退,需要业务补数 | 适用于对cdc功能不完善的业务 | |||
| 方案二 | TiDB 从库 | 数据准实时同步 | 有维护etl工具的成本 | 可用pump或ticdc等工具 |
| 方案三 | 业务双写 | - 数据准实时同步 | ||
| - dba运维成本低 | 可能破坏事务原子性 | |||
| 方案四 | 无回退方案 | - | - | - |
方案一:备份/恢复
该方案使用的是TiDB 的 br 备份工具,把备份后的结果备份到本地或s3存储中,使用自动化工具进行恢复,如果您当前的群集对ticdc支持的不完善,那么低版本的 TiDB 可以使用该方法,具体操作可以,全量备份 → 增量备份 → 增量恢复 → 增量恢复。
PS:这种方式比较更适合审计验数的场景
方案二:TiDB从库
该方案比较推荐,适合ticdc支持比较完善的高版本tidb,不过需要注意在同步过程中tso的推进是否正常。切换时,业务侧可以一步一步切换相关业务,按照 只读 → 弱读 → 写 业务逐步迁移,而且在迁移的过程中可以按照需求调整参数;
方案三:业务双写
业务双写,逐步切换,由业务方自主控制数据的写入。该方案dba就不用过多操心了,完全由业务自己控制,但是需要考虑事务的原子性,既A集群写成功,B集群写失败,那么应由业务侧判断事务到底是否成功;
方案四:无回退方案
如果最长恢复时间可接受,那么回退方案是可以取舍的,设计回退方案的成本较高,产生成本主要是回退实例的主机成本、时间成本(验证回退方案的可行性与稳定性)、以及公司业务方的配合度等诸多因素,其核心就是成本与可用性的取舍。
个人认为在小版本升级时回退方案可以忽略 如540 升级 541 因为改动不多,只做bug fix,但大版本升级确实有必要做回退,因为不可控因素较多。
PS:从5版本后,tidb版本的发布规律为 a.b.c ,a代表架构调整,b代表新功能的加入,c代表注重bug修复,既 调架构.新功能.修bug,自行体会哈
SQL兼容问题
一般笔者常用的有如下三个方案,来规避升级高版本后的SQL不兼容问题,我给他起名叫“三板斧”:
方案一:mysql-replay 工具回放
mysql-replay 是官方提供的一个 SQL 回放的工具,该工具会把 tidb 节点网卡流量用 tcpdump 工具抓下来,然后用工具 mysql-replay 工具进行回放(我看了下 asktug 关于该工具的介绍比较少,后期我可以写下这个工具的使用方法),dba需要观察在回放的目标集群中是否有错误日志即可判别线上流量是否兼容目标集群,适合大面积排查兼容性问题,或者在回放的过程中观察目标集群的 Grafana 面板 Overview → TiDB → Failed Query OPM 看在 tidb 层是否有报错(笔者遇到过有 1062 主键冲突报错,这个可以忽略);
mysql-replay工具git:https://github.com/innerr/workload-sim.tidb.ticat.git
方案二:阅读 TiDB changelog
阅读每个版本的 changelog,阅读时有个技巧,我们只需要关注如下两部分内容即可:兼容性更改 → tidb 、bug修复 → tidb
方案三:业务参与
如果有条件的话可以搭一个新版本的tidb,与业务方一起验证是否有不兼容情况发生,当然这个需要调配业务方的人力资源;
性能回退问题
在升级后有一定概率会遇到性能回退问题,感受最明显的是业务方向DBA反馈SQL变慢了,SQL 语句在 TiDB 中要么基于规则,要么基于代价来选择索引。从这个思路出发,有如下两个方案可规避大部分问题:
方案一:手动收集统计信息
在升级之前,需要对所有的表进行健康度检查,对健康度较低的表手动收集统计信息,让基于代价的索引选择更准确,同时也尽最大可能减小干扰项;
方案二:执行计划重绑
导出已经绑定的执行计划,因为在升级的过程中发现 4 和 5 版本的 mysql.bind\_info 有表结构的差异(新增source ,同时升级后 default\_db 字段为空),最稳的方法就是重新绑定,此时会刷新该表;
PS:5版本有一个叫自动捕获执行计划的功能,既系统自动捕获并绑定最近一次执行计划然后存储在系统表中,这个功能需要根据自己的业务场景斟酌是否打开;
升级 Check Point
前期准备
| Check Point | 说明 |
|---|---|
| 测试升级TiDB所需耗时 | 选择升级方式进行测试(停机,强制,平滑) |
| 调研回退方案 | 方法如上:寻找适合的回退方案 |
| 验证回退方案 | 建议与业务方配合验证回退方案的可行性 |
| 检查主机状态并提前修复 | 检查cpu,内存,主板,磁盘的健康状态 |
| SQL兼容性检查 | 方法如上:SQL兼容问题 mysql-replay工具、阅读 TiDB changelog、业务参与 |
| 防止性能回退 | 方法如上:性能回退问题 手动收集统计信息、执行计划导出 |
| tiup 工具升级 | tiup 工具本身升级到最新版本,而非集群 |
| 与原厂工程师前期沟通 | 建议升级前和原厂工程师沟通升级计划 |
| 与业务方沟通升级方案 | 周知上下游,对有操作的务必做到责任到人,按时操作 |
| 积累升级经验 | 多升级非核心业务线集群,为重要升级积累经验 |
实施过程
| Check Point | 说明 |
|---|---|
| 收集集群各指标 | 为对比升级前后负载差异,使用 clinic 工具 tiup diag collect --from “2022-07-13 00:00:00” --to "2022-07-14 00:00:00" --include system,config,monitor |
| 确认回退方案部署完毕 | DBA确认集群可用性与恢复时间点 业务确认业务数据可用 |
| 周知业务方停 DDL | 升级期间不要对表结构进行变更 |
| 上下游业务确认 | 确认上下游业务在升级前是否结束、切换或停止 |
| 停自动收集统计信息 | MySQL client: set global tidb_auto_analyze_start_time = '23:57 +0800'; set global tidb_auto_analyze_end_time = '23:58 +0800'; |
| 导出执行计划 | 可写脚本导出,假设叫sqlbind.sql |
| 预检查 region 副本 | pd-ctl: region --jq=".regions[] | {id: .id, peer_stores: [.peers[].store_id] | select(length != 3)}" PS:如果有副本丢失问题(无leader)则需停止升级,先解决副本问题 |
| 暂停 region 调度任务 | pd-ctl: config set region-schedule-limit 0; config set merge-schedule-limit 0; config set replica-schedule-limit 0; |
| 预检查 ssh 连通性 | tiup cluster exec xxx --command id |
| 升级 TiDB | tiup cluster upgrade xxx v5.x.x or tiup cluster upgrade xxx v5.x.x --force |
| 导入执行计划 | 导入并检查执行计划是否生效 source sqlbind.sql show global bindings; |
| 开自动收集统计信息 | 根据自己业务场景设定时间 MySQL client: set global tidb_auto_analyze_start_time = '23:57 +0800'; set global tidb_auto_analyze_end_time = '23:58 +0800'; |
| 手动设置参数提升性能与兼容性 | set global tidb_enable_async_commit = ON; set global tidb_enable_1pc = ON; set global tidb_multi_statement_mode = ON; set global tidb_enable_noop_functions = 1; set config tikv gc.enable-compaction-filter = true; |
| 业务验证读写 | 需要业务方重启一下服务,应用新配置,验证是否有SQL不兼容问题 风险点:可能会启用回退方案 |
| 验证性能是否符合预期 | 与业务方一起判定是否有性能回退现象 风险点:可能会启用回退方案 |
| 备份新版本数据库 | 如果是用 br 备份建议在大版本升级后,用新版本的 br 全量备份一下数据库, 保持工具和db的版本统一 |
| 收集集群信息 | 官方提供工具 clinic 以供升级前后对比 |
后期跟进
| Check Point | 说明 |
|---|---|
| 更新备份脚本 | 新版本 TiDB br备份改造 |
| 更新慢日志收集脚本 | 版本 4 与版本 5 的慢日志有些许差异,如果有logstash 收集的话需要修改一下正则匹配 |
案例分享
案例一、4PD 节点导致的升级失败
案例背景:
在常规检查后,对某集群进行升级命令,本来以为又是一次平安无事的操作,结果发现在升级 pd 节点时超时,升级退出,升级过程中 TiDB duration 飙高;
问题排查:
由于历史原因本集群有4个pd,我们给pd起个别名,pd\_A(leader)、pd\_B、pd\_C、pd\_D
1\. 要升级 pd\_A ,需要先 transfer pd leader,但是 pd\_A 开始报错 \["invalid timestamp"] ,自己开始循环报错,还没法投票出去选别人;
2\. pd\_B 是公投的新王,准备上位,自己还不确定能不能登基,自己也开始报错 \["redirect but server is not leader"]
3\. pd\_C、pd\_D 我选 pd\_B 当 leader
那么问题来了,请问4 pd 达到多数派同意了么,答案必然是没有,核心问题是有一个节点没投出来票,只有半数同意,所以导致leader无法竞选成功,最终升级失败;
解决方案:
对4pd进行缩容后,再次升级,升级成功
案例二、集群A升级经验分享
案例背景:
我们把 TiDB 用作生产环境的 OLTP类业务,而集群 A 属于比较核心的群集,SLA较高,日常平均QPS 5w+,TPS 2w+,单表接近百亿, HA要求保证 99.99%,重要程度可想而知。
升级的原因是 TiDB 版本比较旧 ,对于数据下游如 cdc 功能支持不完善,后期我们对会有容灾和多活的需求,由此需要对当前低版本 TiDB 进行升级,以便扩展对数据下游的支持工作。
面临的挑战:
- 集群规模大:规模大指的有两方面,一来TB级别的存储,二来节点数较多 TiDB 20+,TiKV 40+
- 维护窗口短:A集群白天承接 TP 类业务,晚上有 AP 类业务或业务抽数,在升级时业务方要求db不能停;
- 回退方案落地难:我们选择的回退方案是备份恢复,备份结果不稳定(后续会详细说明),并且第一次恢复用了86个小时;
- 集群A涉及的上下游较多,需要解决SQL兼容性问题:几乎牵扯到所有的业务线
- 性能回退:未升级时不确定是否会产生性能回退问题
制定升级方案:
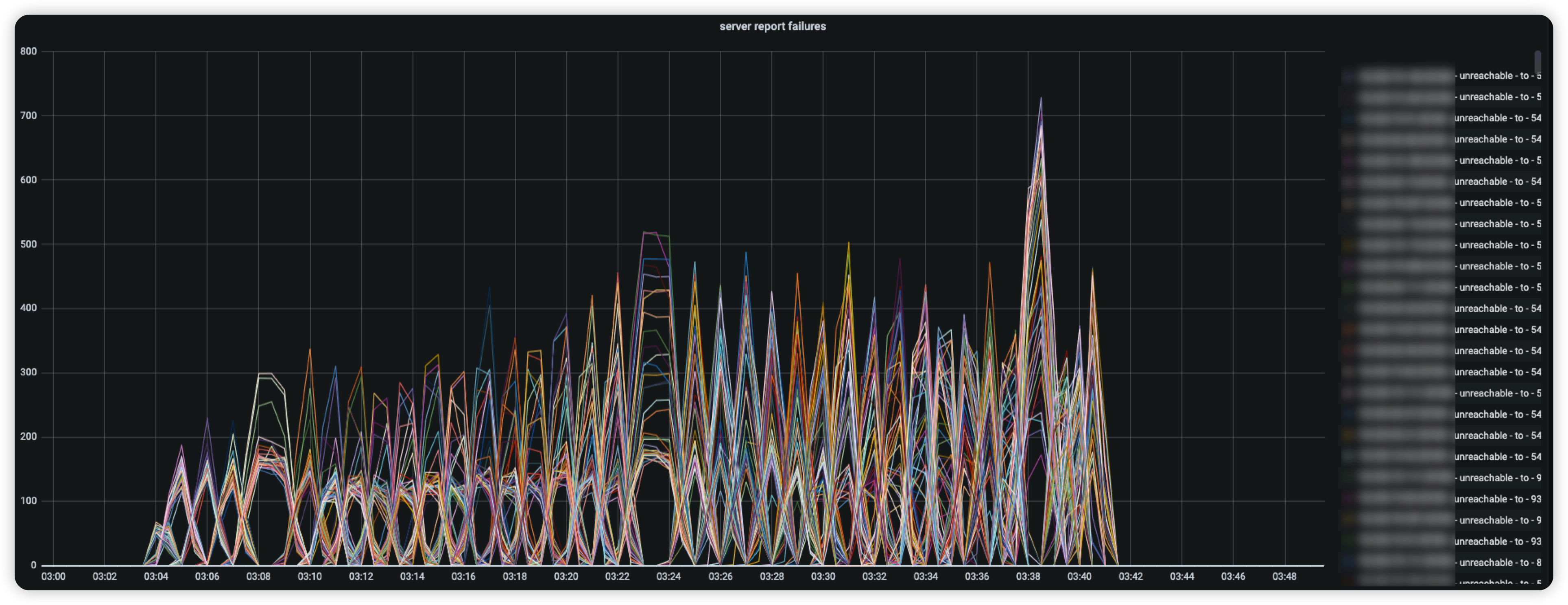
**升级方式:**原厂工程师了解到我们的业务场景后,推荐使用**强制升级**的方法,因为该实例的SLA较高,升级结果必须可控且窗口时间内必须完成升级,所以采取了短、平、快的强制升级方式,这种方式的弊端是在升级的过程中,业务正好在读写某个 region时 TiKV节点会有 unreachable的错误,如下图;
**窗口时间:**在升级当天业务方会在升级前全量抽取db中的重要业务信息,业务侧做好数据兜底方案。同时对于夜间任务,业务方遵循 迁移/切换/推后/错峰 的原则进行任务编排,避免在升级时读写高峰产生的性能压力,排除干扰项;
**回退方案落地:**
**备份:**我们使用 br 备份到自建 S3 存储中。br 与 S3 的交互分为两个阶段, 一、先遍历所有region存储到 s3,二、连接所有 store 和 S3 中的 sst 文件进行 checksum。如果在 checksum 阶段有 IO 或网络超时,整个br任务就会报失败。而的 S3 是抢占式的,在其他租户使用时,会造成性能问题。最终官方建议我们用 minio 的来替代 S3 进行数据库的备份与恢复,一来原厂默认的测试s3就是minio,二来 minio 对与我们来说是独享的服务,没有资源强占全面提升了全量备份的稳定性。
PS:如果遇到 br 备份到自建 S3 失败时,首先需要检查一下 TiDB 的状态,如果正常那么大概率是 s3 不稳定造成的,我总结的报错集锦如下:
ERROR 1: [error="msg:"Io(Os { code: 2, kind: NotFound, message: \"No such file or directory\" })" : [BR:KV:ErrKVUnknown]unknown tikv error"]
ERROR 2: [error="msg:"Io(Os { code: 5, kind: Other, message: \"Input/output error\" })" : [BR:KV:ErrKVUnknown]unknown tikv error"]
ERROR 3: [error="msg:"Io(Os { code: 11, kind: WouldBlock, message: \"Resource temporarily unavailable\" })" "]
ERROR 4: [error="rpc error: code = Unknown desc = Io(Os { code: 107, kind: NotConnected, message: "Transport endpoint is not connected" })"]
ERROR 5: [error="NoCredentialProviders: no valid providers in chain. Deprecated.\n\tFor verbose messaging see aws.Config.CredentialsChainVerboseErrors"]
ERROR 6: [error="msg:"Io(Custom { kind: Other, error: \"failed to put object Error during dispatch: connection error: Connection reset by peer (os error 104)\" })" "]
ERROR 7: [error="error happen in store xxx at xxx:xxx: Io(Custom { kind: Other, error: "failed to put object rusoto error Request ID: None Body: \nERROR 1: InvalidPartOne or more of the specified parts could not be found. The part may not have been uploaded, or the specified entity tag may not match the part's entity tag.....
**恢复:**初次进行恢复时,回滚集群我们采用了 16 个 kv 节点,恢复时间用了 86 个小时,这显然是不能接受的。我们咨询了原厂工程师,建议增加 TiKV 的数量,于是我们尝试同机房搭建集群(TiKV数量少)、跨机房搭建集群(TiKV 数量多)、不同性能主机搭配搭建集群,发现缩短恢复时间需要这么几个条件,同机房、TiKV节点数量不宜过多、主机性能相当的群集恢复效率最高。最终,最快恢复时长 10TB+数据 4h50m,平均恢复时长为7小时左右。
PS:v4.0.1 的 br 备份工具比 v4.0.16 的要 40% 左右,我感觉可能是 v4.0.16在校验部分做了更多的工作,v4.0.1 的 br 恢复与 v4.0.16 处理逻辑也不一样,尤其是对 分区表 ddl 功能,v4.0.1 能成功 v4.0.16 报错 [error="[ddl:-1]json: cannot unmarshal array into Go value of type string"]
**SQL兼容性:**使用上文提及的三个方案,不做过多赘述
**性能回退问题:**使用上文提及的两个方案,不做过多赘述
PS:如果使用了上述两个方案还是有性能回退问题,可以尝试推动业务方修改事务提交方式,由乐观改为悲观
begin pessimistic;
xxx;
commit;
升级流程:
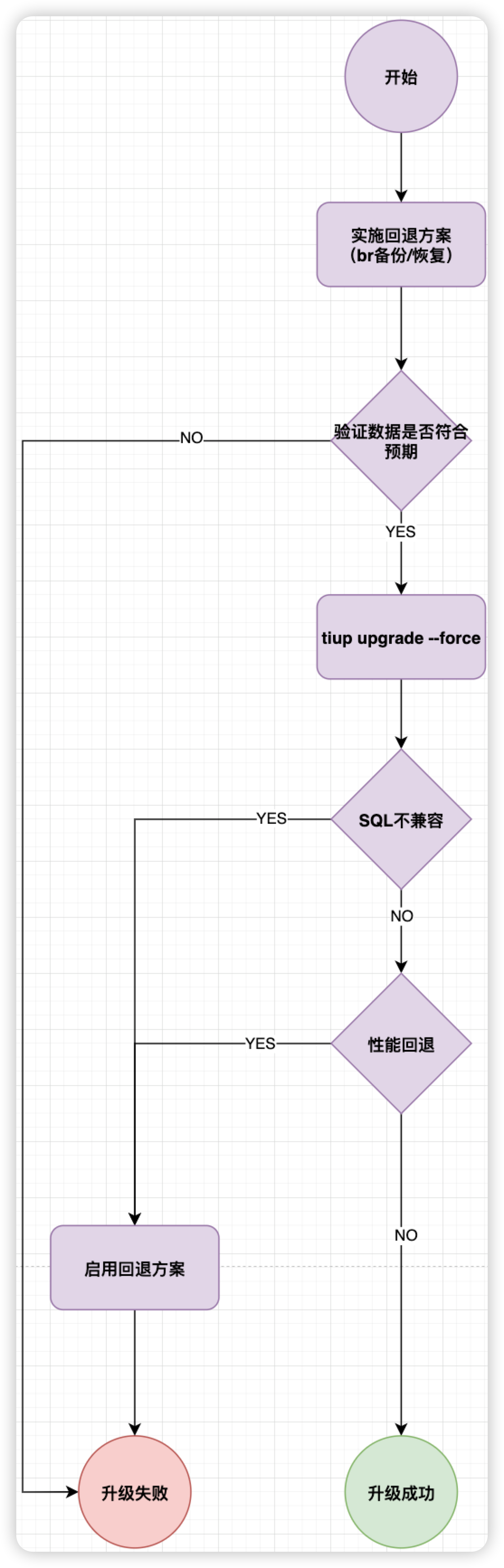
升级后的收益:
- 升级后给我最大的感受是,5版本比4版本更稳定,尽可能去避免抖动产生的性能问题
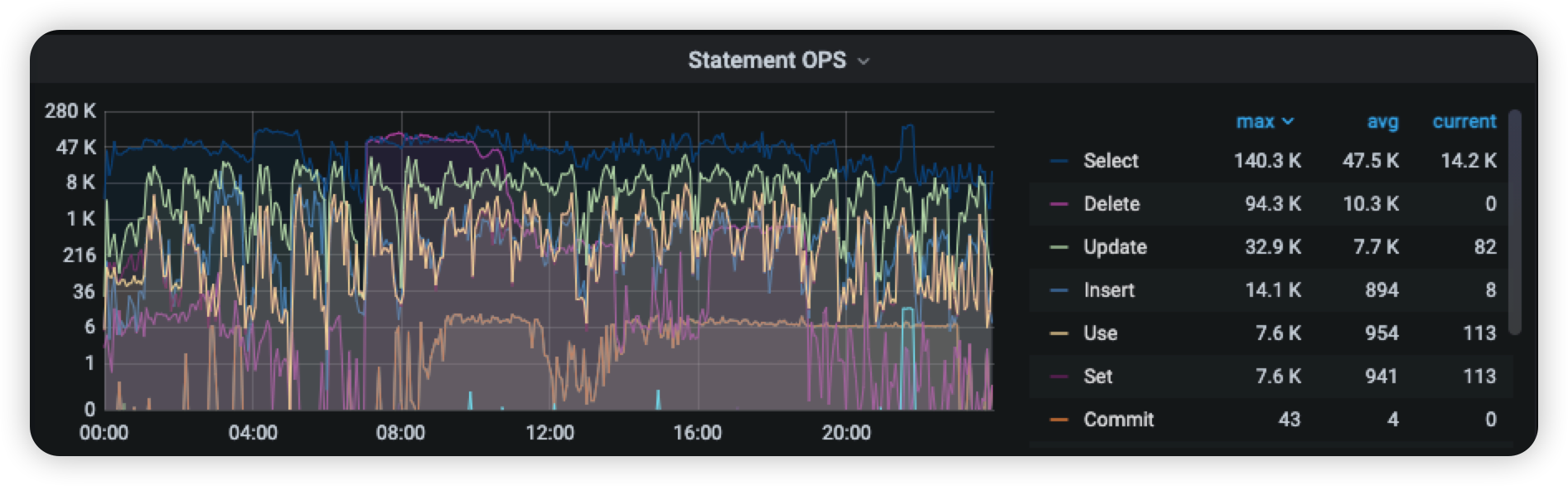
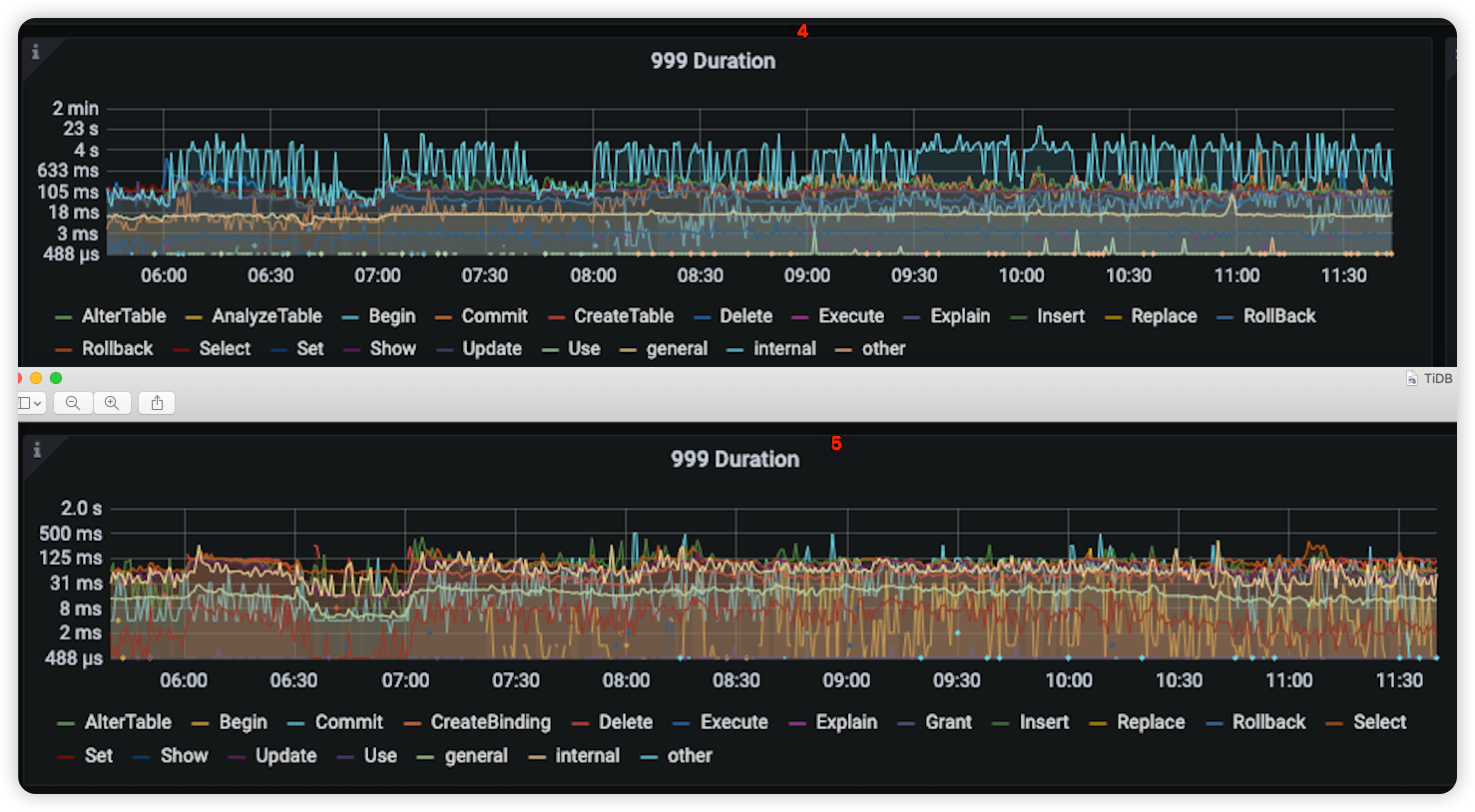
Query summary 在相同时段 TiDB 内部自动执行的 SQL 语句 999 分位 由之前的4s 稳定在125ms左右提升了 97% ,并解决了性能抖动问题
- CPU方面的性能提升,Raft Store CPU升级后都在报警阈值以下运行
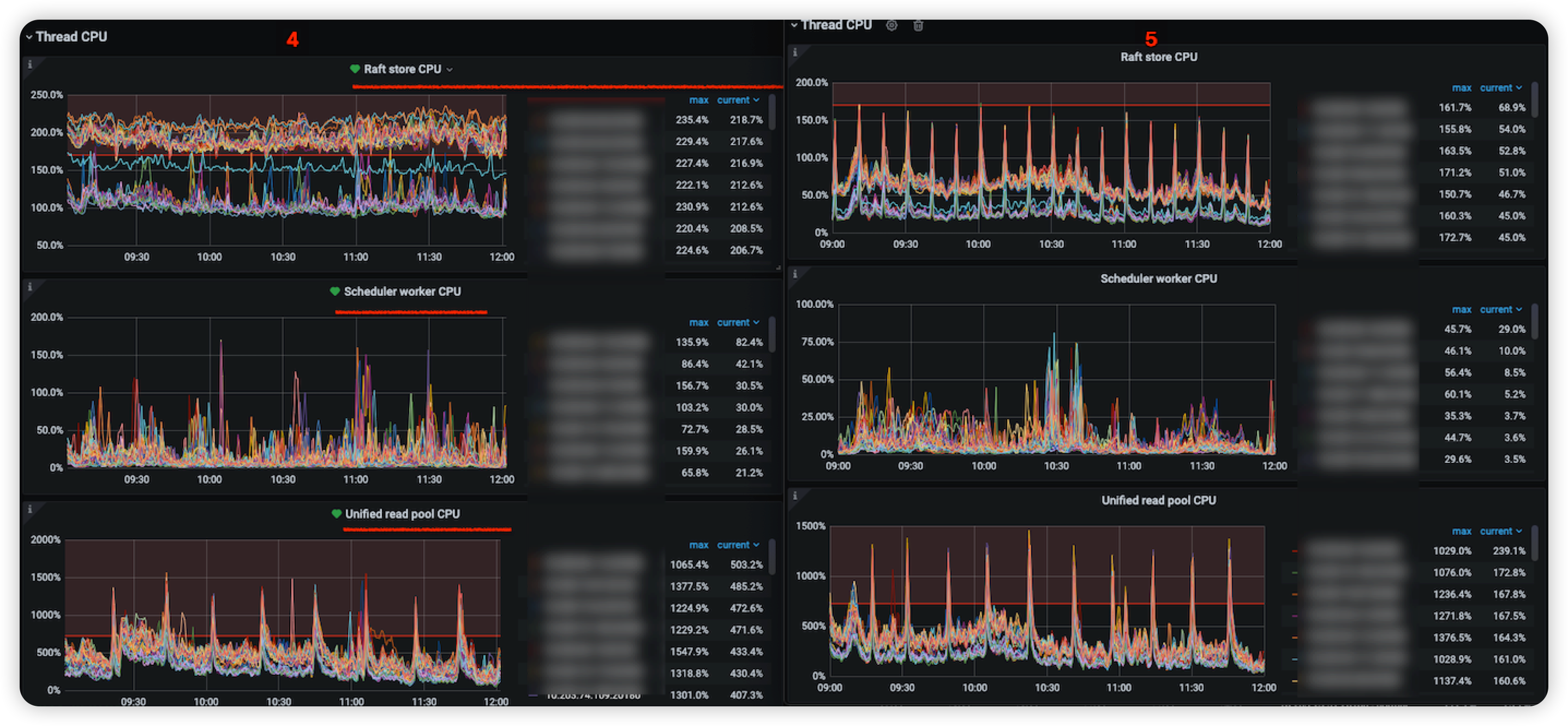
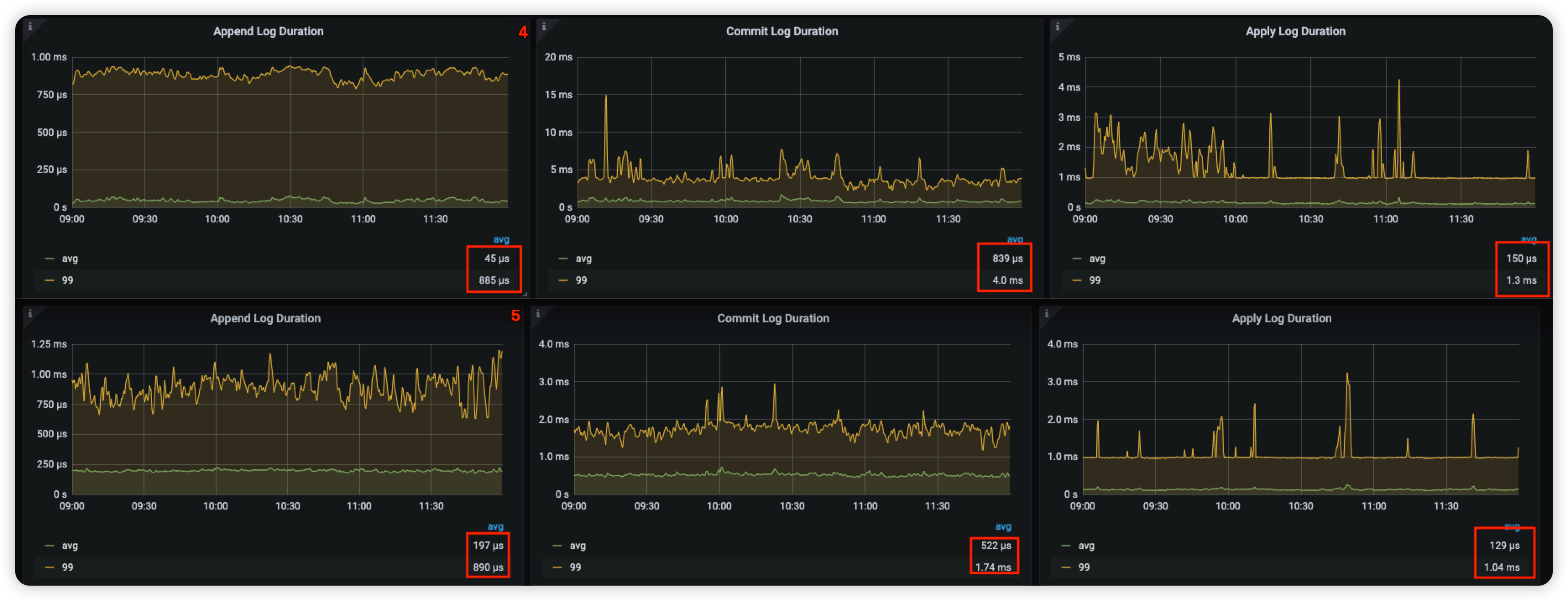
- 写性能能提升: 相比 v4.0.1 TiKV 对 gRPC 模块进行了优化,优化了 Raft 日志复制速度,降低了 Commit Log Duration 和 Store Duration。
| Avg Duration | v4.0.1(µs) | v5.4.1(µs) |
|---|---|---|
| Append Log Duration | 45 | 197 |
| Commit Log Duration | 839 | 522 |
| Apply Log Duration | 150 | 129 |
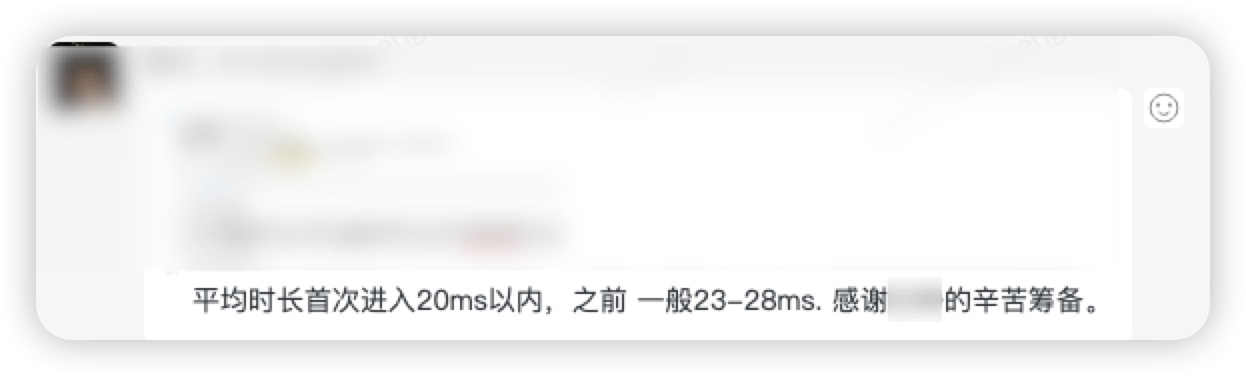
业务方反馈:

简单提一下 5版本带来性能收益,我们从读写两方面来解读
写:异步提交事务 (Async Commit) 与 1pc 提交,异步事务主要解决的是降低事务提交的延迟,1pc提交指的是只涉及一个 Region 的事务会大幅降低事务提交延迟并提升吞吐;
读:默认开启 Coprocessor cache 功能 降低读取数据的延时;
降低性能抖动:开启 GC in Compaction filter 功能,我理解是在冷数据compation 为sst的同时做GC,减少单独的GC worker做GC时的读MVCC版本时的压力;
写在最后
升级数据库是非常核心的项目,因为数据是有状态的并不是 DBA 可以单纯的自行判定是否正常,所以升级需要各业务方联动配合。对于DBA来说 tiup cluster upgrade 一条命令就升上去了,但是升级后业务方是否认可这次升级,是我们需要思考的地方,同时升级的前置、检查、回退、沟通工作一定要做到位,尽量避免黑天鹅事件;简单一句话:不要把升级项目置于被动中
最后十分感谢原厂工程师苏丹和东玫,感谢你们为这个项目协调的资源与升级计划的审核,有原厂的专业指导,大大降低了升级的风险,同时提升了集群升级的成功率,升级后的效果得到了广大 TiDB 使用方的普遍认可。