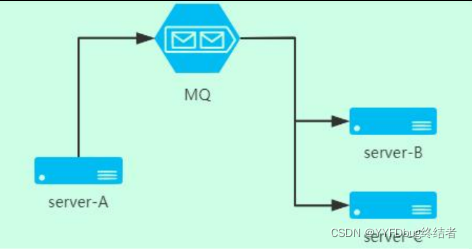
消息队列的架构图:

生产者发送消息的流程:
– 消息的发送者(Producer)和RabbitMQ建立连接,获取通道.
– 生产者发送消息到指定虚拟机中的交换机(exchange),
– 交换机通过routhingKey来获取对应的队列.
消费者消费消息的流程:
– 消息的消费者(Consummer)和RabbitMQ建立连接,获取通道.
– 消费者实时监控队列.
– 一旦队列有相应的数据的时候,就会把消息推送到指定消费者.
MQ的作用是什么?
场景的实例:
主要是还是来自于互联网的业务场景,例如,马上即将开始的春节火车票抢购,大量的用户需要同一时间去抢购;以及大家熟知的阿里双11秒杀, 短时间上亿的用户涌入,瞬间流量巨大(高并发),比如:6000万人准备在凌晨12:00准备抢购一件商品,但是商品的数量缺是有限的100-500件左右。
这样真实能购买到该件商品的用户也只有几百人左右, 但是从业务上来说,秒杀活动是希望更多的人来参与,也就是抢购之前希望有越来越多的人来看购买商品。
但是,在抢购时间达到后,用户开始真正下单时,秒杀的服务器后端缺不希望同时有几百万人同时发起抢购请求。
我们都知道服务器的处理资源是有限的,所以出现峰值的时候,很容易导致服务器宕机,用户无法访问的情况出现。
一.流量的削峰
解决方案:
1.消息队列解决削峰
要对流量进行削峰,最容易想到的解决方案就是用消息队列来缓冲瞬时流量,把同步的直接调用转换成异步的间接推送,中间通过一个队列在一端承接瞬时的流量洪峰,在另一端平滑地将消息推送出去。
消息队列中间件主要解决应用耦合,异步消息, 流量削锋等问题。常用消息队列系统:目前在生产环境,使用较多的消息队列有 ActiveMQ、RabbitMQ、 ZeroMQ、Kafka、MetaMQ、RocketMQ 等。
在这里,消息队列就像“水库”一样,拦蓄上游的洪水,削减进入下游河道的洪峰流量,从而达到减免洪水灾害的目的。
2.流量削峰漏斗:层层削峰
针对秒杀场景还有一种方法,就是对请求进行分层过滤,从而过滤掉一些无效的请求。
分层过滤其实就是采用“漏斗”式设计来处理请求的,如下图所示:

二.降低系统的耦合性
看这两个架构图,第一种 BC 都直接依赖 A 服务,那么如果 A 中的接口修改,BC 都要跟着做修改,耦合度高。

第二种,通过 MQ 来作为中间件收发消息,BC 只依赖收到的消息而不是具体的接口,这样即使 A 服务修改或者增加其他服务,都只要订阅MQ就行。
在你的系统中哪一个业务中使用到了mq?
用户秒杀支付的订单金额用到了MQ的业务.
一般的服务,我们的请求访问到系统都是直接请求,这样的模式在用户访问量不大的情况下,问题不是很大。
但是如果用户请求达到了一定的瓶颈或者产生了一些问题,我们就需要考虑优化我们的架构设计,MQ 中间件正是解决办法之一。
下面以秒杀系统为例分析问题
秒杀系统瞬间百万并发,怎么处理?一般秒杀系统会进行请求过滤,无效、重复都会被过滤一遍,剩下的才真正进入到秒杀服务、订单服务。
但即使这样并发仍然很高,如果网关把全部请求都转发到下游订单服务,一样会压垮下游系统,造成服务不可用甚至雪崩。

真实的秒杀系统更复杂 ,包含 Nginx 、网关、注册中心、redis 缓存、mysql 集群、消息队列集群
解决方式就是将上游处理的较快的任务,加入到队列处理,下游逐一消费队列,直到所有队列消费完成。
假如秒杀服务处理请求数:1000/s,
下游订单服务处理请求书:60/s,
为了不给下游订单服务造成压力,秒杀后的信息发送到队列,订单服务就可以从容淡定的每秒处理十个,而不是直接塞 1000 个请求
- 页面按钮点击一次置灰
- 每秒透过请求数限制,例如 100/s,可以使用 Nginx ,sentinel
- 过滤同一用户的重复请求,通过用户唯一标识、商品信息,
- 通过消息队列存储成功的秒杀信息,下游订单系统处理
为什么要使用rabbitmq而不用其他的mq?
rabbitmq相比于其他的消息队列,消息延迟几乎是微妙级,对于用户来说体验很高,他的消息可靠性高,它的吞吐量一般,对于用户来说非常的安全,企业首选rabbitmq.
activemq现在来说企业不会用这个队列,它的吞吐量差,消息延迟毫秒级,相比于rabbitrmq的性能差一点,消息的可靠性一般,综上所述,所以企业不会使用activemq.
rocketmq,企业中也会考虑用的,它的吞吐量高,消息延迟毫秒级,消息延迟相对于rabbitmq弱一点,消息的可靠性高,一些公司也会用到这个队列,对于追求消息的低延迟会选择rabbitmq.
kafka,他的单机吞吐量非常高,消息延迟毫秒级别,消息的可靠性一般,kafka正因为吞吐量非常高的特性,大数据辉用到kafka这个队列.