作者:半身风雪
上一节:JVM 中常见的垃圾回收器
JVM 调优
前言
性能调优包含多个层次,比如:架构调优、代码调优、JVM调优、数据库调优、操作系统调优等。 架构调优和代码调优是JVM调优的基础,其中架构调优是对系统影响最大的。
先来看一张JVM 内存分代的划分图:
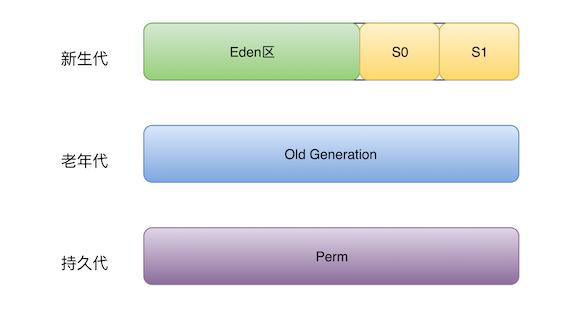
一、堆空间如何设置
在分代模型中,各分区的大小对 GC 的性能影响很大。如何将各分区调整到合适的大小,分析活跃数据的大小是很好的切入点。
**活跃数据的大小:**应用程序稳定运行时长期存活对象在堆中占用的空间大小,也就是 Full GC 后堆中老年代占用空间的大小。
可以通过 GC 日志中 Full GC 之后老年代数据大小得出,比较准确的方法是在程序稳定后,多次获取 GC 数据,通过取平均值的方式计算活跃数据的大小。
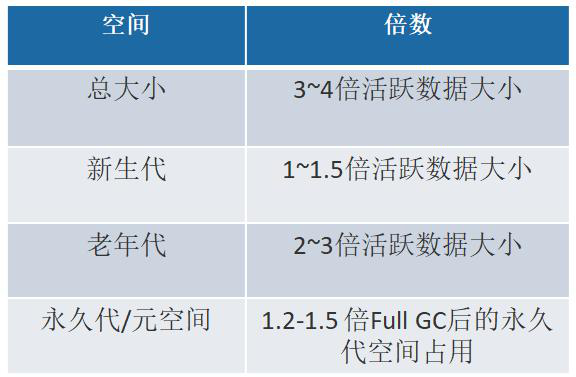
例如,根据 GC 日志获得老年代的活跃数据大小为 300M,那么各分区大小可以设为:
-
总堆:1200MB = 300MB × 4
-
新生代:450MB = 300MB × 1.5
-
老年代:750MB = 1200MB - 450MB
二、扩容新生代能提高 GC 效率吗?
通常情况下,由于新生代空间较小,Eden 区很快被填满,就会导致频繁 Minor GC,因此可以通过增大新生代空间来降低 Minor GC 的频率。例如在相同的内存分配率的前提下,新生代中的 Eden 区增加一倍,Minor GC 的次数就会减少一半。扩容 Eden 区虽然可以减少 Minor GC 的次数,但会增加单次 Minor GC 时间啊,单次时间增加了,是不是也白忙活了!!!单次 Minor GC 时间由以下两部分组成:T1(扫描新生代)和 T2(复制存活对象到 Survivor 区)如下图:
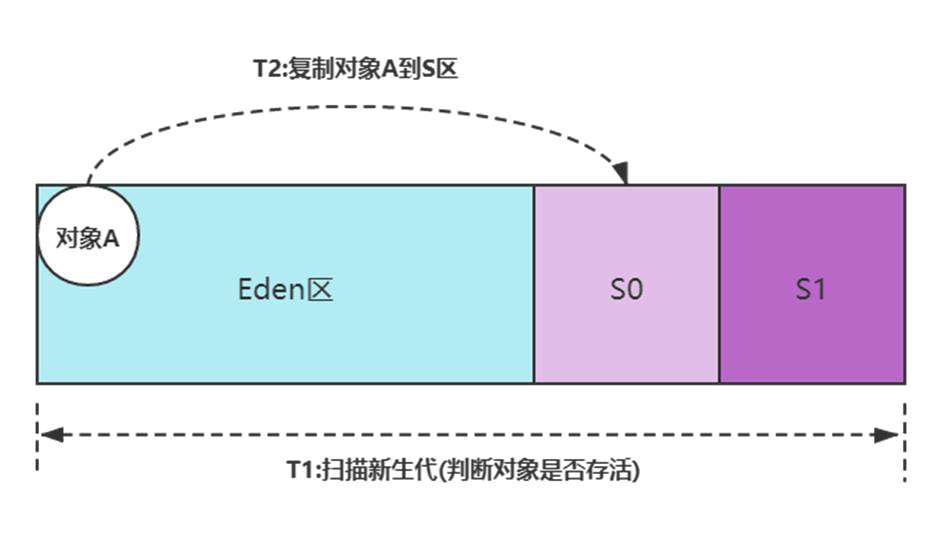
- 扩容前:新生代容量为 R ,假设对象 A 的存活时间为 750ms,Minor GC 间隔 500ms,那么本次 Minor GC 时间= T1(扫描新生代 R)+T2(复制对象 A 到 S)。
- 扩容后:新生代容量为 2R ,对象 A 的生命周期为 750ms,那么 Minor GC 间隔增加为 1000ms,此时 Minor GC 对象 A 已不再存活,不需要把它复制到 Survivor 区,那么本次 GC 时间 = 2 × T1(扫描新生代 R),没有 T2 复制时间。
可见,扩容后,Minor GC 时增加了 T1(扫描时间),但省去 T2(复制对象)的时间,更重要的是对于虚拟机来说,复制对象的成本要远高于扫描成本,所以,单次 Minor GC 时间更多取决于 GC 后存活对象的数量,而非 Eden 区的大小。
所以当 JVM 服务中存在大量短期临时对象,扩容新生代空间后,Minor GC 频率降低,对象在新生代得到充分回收,只有生命周期长的对象才进入老年代。
这样老年代增速变慢,Major GC 频率自然也会降低。
但是如果堆中短期对象很多,那么扩容新生代,单次 Minor GC 时间不会显著增加。
总结的经验就是:
如果应用存在大量的短期对象,应该选择较大的年轻代;如果存在相对较多的持久对象,老年代应该适当增大。
三、JVM 是如何避免 Minor GC 时扫描全堆的?
新生代 GC 和老年代的 GC 是各自分开独立进行的。
新生代对象持有老年代中对象的引用,老年代也可能持有新生代对象引用,这种情况称为“跨代引用”。
因它的存在,所以 Minor GC 时也必须扫描老年代。
JVM 是如何避免 Minor GC 时扫描全堆的?
经过统计信息显示,老年代持有新生代对象引用的情况不足 1%,根据这一特性 JVM 引入了卡表(card table)来实现这一目的。
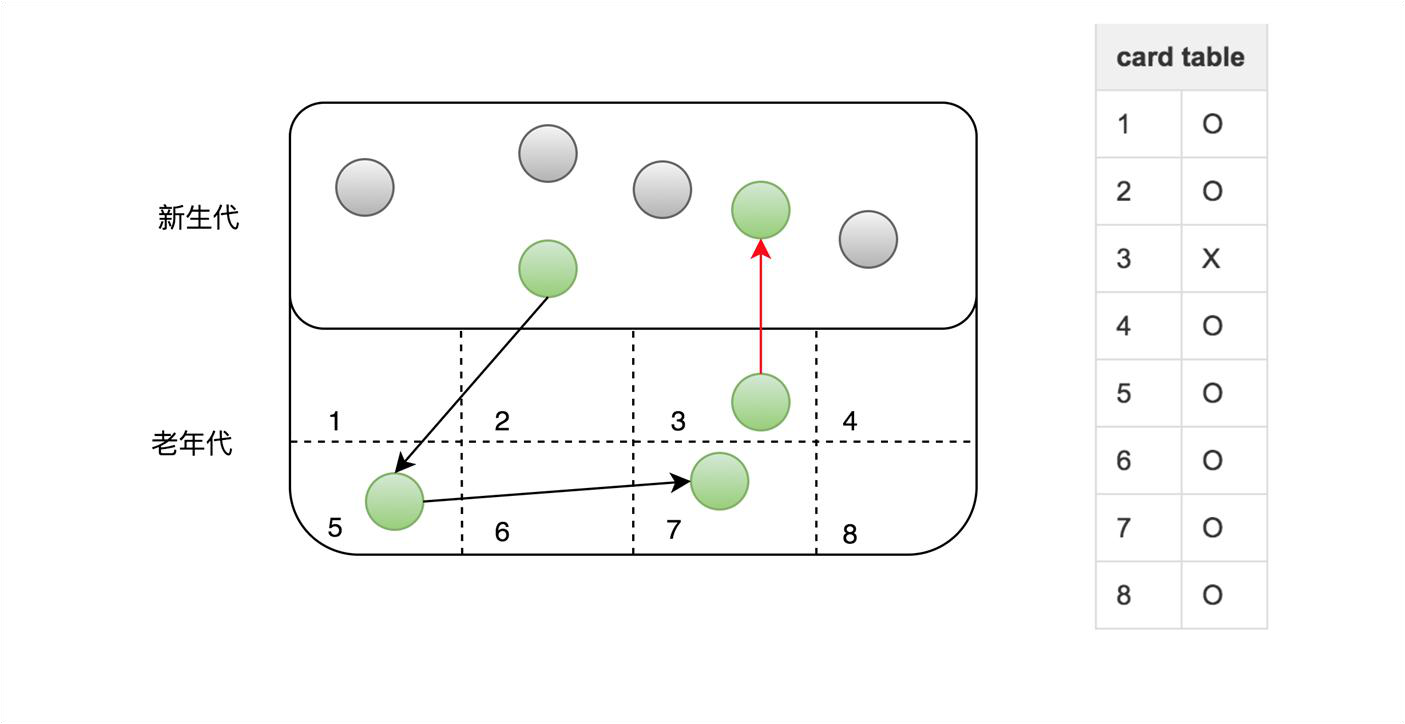
卡表的具体策略是将老年代的空间分成大小为 512B 的若干张卡(card)。卡表本身是单字节数组,数组中的每个元素对应着一张卡,当发生老年代引用新生代时,虚拟机将该卡对应的卡表元素设置为适当的值。如上图所示,卡表 3 被标记为脏,之后 Minor GC 时通过扫描卡表,就可以很快的识别哪些卡中存在老年代指向新生代的引用,这样虚拟机通过空间换时间的方式,避免了全堆扫描。
四、常量池
4.1、Class 常量池(静态常量池)
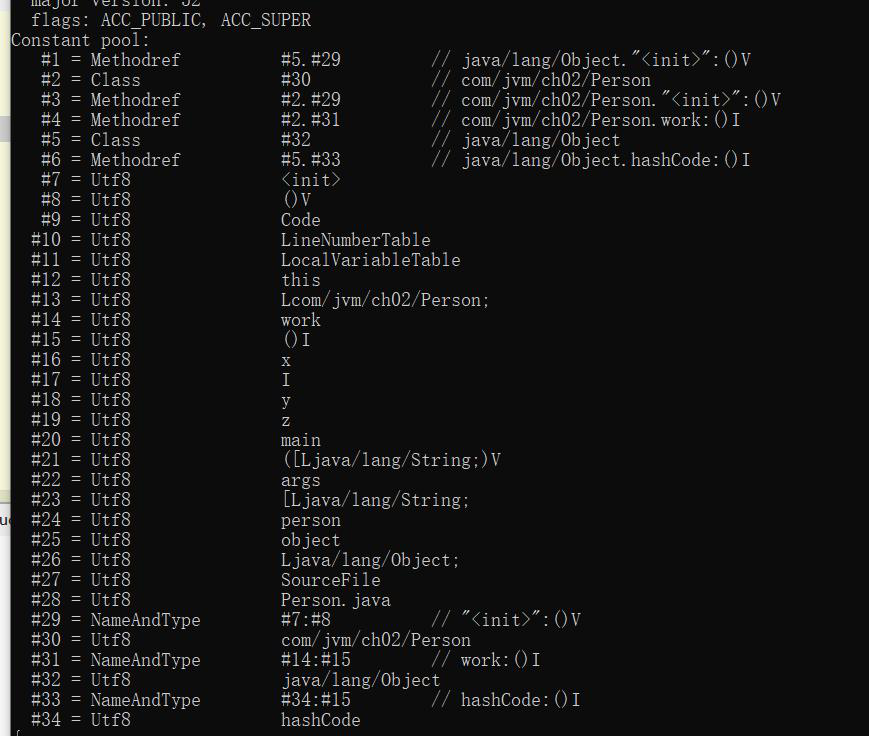
在 class 文件中除了有类的版本、字段、方法和接口等描述信息外,还有一项信息是常量池 (Constant Pool Table),用于存放编译期间生成的各种字面量和符号引用。
-
**字面量:**给基本类型变量赋值的方式就叫做字面量或者字面值。
比如:String a=“b” ,这里“b”就是字符串字面量,同样类推还有整数字面值、浮点类型字面量、字符字面量。
-
**符号引用 :**符号引用以一组符号来描述所引用的目标。符号引用可以是任何形式的字面量,JAVA 在编译的时候一个每个 java 类都会被编译成一个 class 文件,但在编译的时候虚拟机并不知道所引用类的地址(实际地址),就用符号引用来代替,而在类的解析阶段(后续 JVM 类加载会具体讲到)就是为了把这个符号引用转化成为真正的地址的阶段。
一个 java 类(假设为 People 类)被编译成一个 class 文件时,如果 People 类引用了 Tool 类,但是在编译时 People 类并不知道引用类的实际内存地址,因此只能使用符号引用(org.simple.Tool)来代替。而在类装载器装载 People 类时,此时可以通过虚拟机获取 Tool 类的实际内存地址,因此便可以既将符号 org.simple.Tool 替换为 Tool 类的实际内存地址。
4.2、运行时常量
运行时常量池(Runtime Constant Pool)是每一个类或接口的常量池(Constant_Pool)的运行时表示形式,它包括了若干种不同的常量: 从编译期可知的数值字面量到必须运行期解析后才能获得的方法或字段引用。(这个是虚拟机规范中的描述,很生涩)
运行时常量池是在类加载完成之后,将 Class 常量池中的符号引用值转存到运行时常量池中,类在解析之后,将符号引用替换成直接引用。 运行时常量池在 JDK1.7 版本之后,就移到堆内存中了,这里指的是物理空间,而逻辑上还是属于方法区(方法区是逻辑分区)。
在 JDK1.8 中,使用元空间代替永久代来实现方法区,但是方法区并没有改变,所谓"Your father will always be your father"。变动的只是方法区中内容的物理存放位置,但是运行时常量池和字符串常量池被移动到了堆中。但是不论它们物理上如何存放,逻辑上还是属于方法区的。
4.3、字符串常量池
字符串常量池这个概念是最有争议的,我也翻阅了虚拟机规范等很多正式文档,发现没有这个概念的官方定义,所以与运行时常量池的关系不去抬杠,我们从它的作用和 JVM 设计它用于解决什么问题的点来分析它。
以 JDK1.8 为例,字符串常量池是存放在堆中,并且与 java.lang.String 类有很大关系。设计这块内存区域的原因在于:String 对象作为 Java 语言中重要的数据类型,是内存中占据空间最大的一个对象。高效地使用字符串,可以提升系统的整体性能。
五、String 类的分析
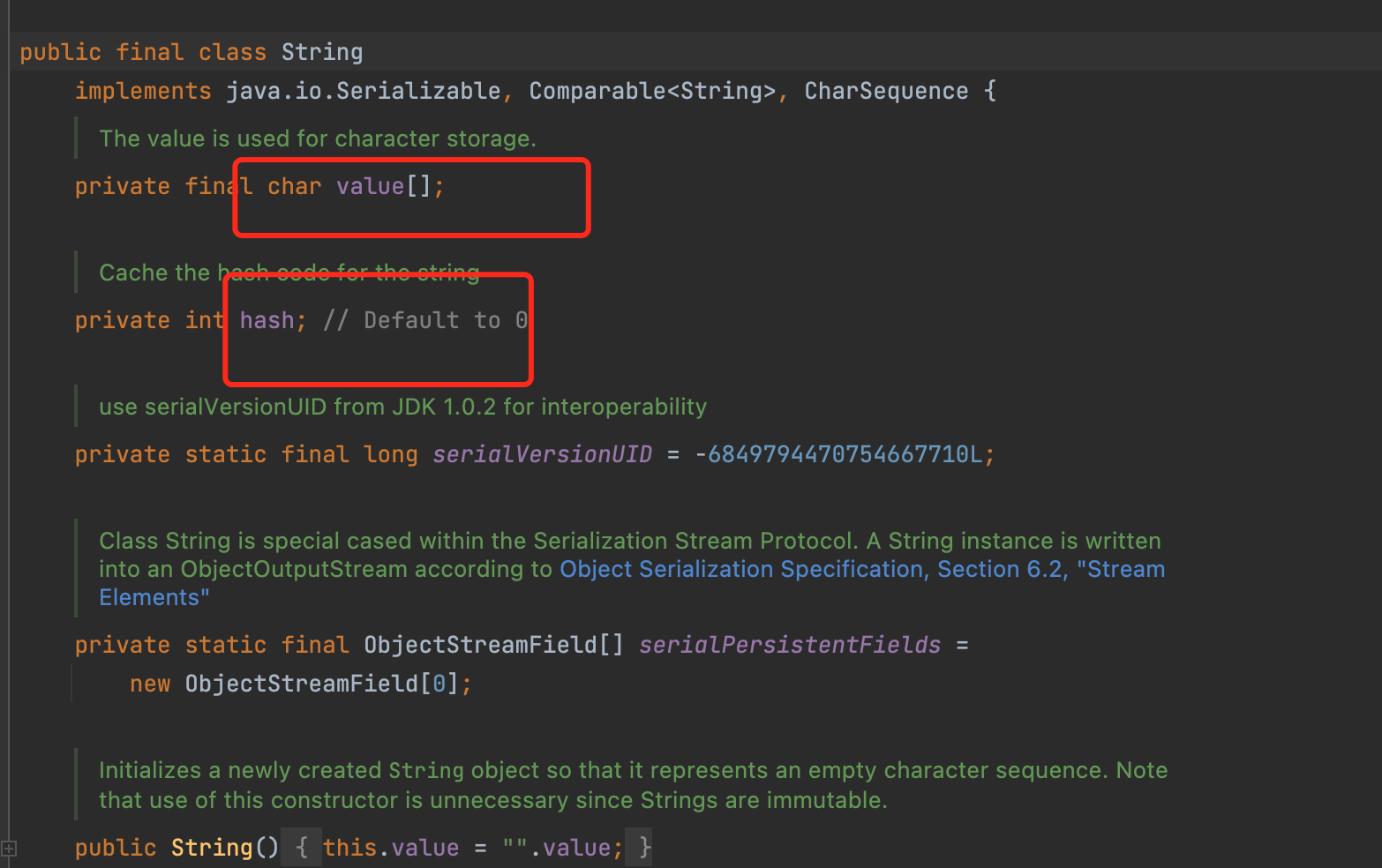
String 对象是对 char 数组进行了封装实现的对象,主要有 2 个成员变量:char 数组,hash 值。
5.1、String 对象的不可变性
了解了 String 对象的实现后,你有没有发现在实现代码中 String 类被 final 关键字修饰了,而且变量 char 数组也被 final 修饰了。
我们知道类被 final 修饰代表该类不可继承,而 char[]被 final+private 修饰,代表了 String 对象不可被更改。Java 实现的这个特性叫作 String 对象的不可变性,即 String 对象一旦创建成功,就不能再对它进行改变。
这样做的好处是什么呢?
- 保证 String 对象的安全性。假设 String 对象是可变的,那么 String 对象将可能被恶意修改。
- 保证 hash 属性值不会频繁变更,确保了唯一性,使得类似 HashMap 容器才能实现相应的 key-value 缓存功能。
- 可以实现字符串常量池。在 Java 中,通常有两种创建字符串对象的方式,一种是通过字符串常量的方式创建,如 String str=“abc”;另一种是字符串变量通过 new 形式的创建,如 String str = new String(“abc”)。
5.2、String 的创建方式及内存分配的方式
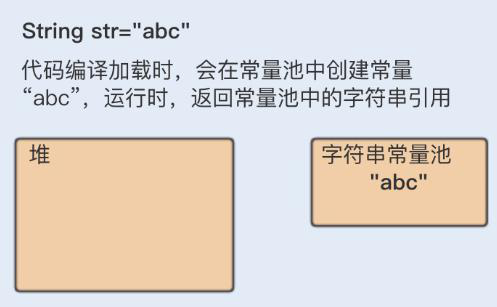
1、String str=“abc”;
当代码中使用这种方式创建字符串对象时,JVM 首先会检查该对象是否在字符串常量池中,如果在,就返回该对象引用,否则新的字符串将在常量池中被创建。这种方式可以减少同一个值的字符串对象的重复创建,节约内存。(str 只是一个引用)
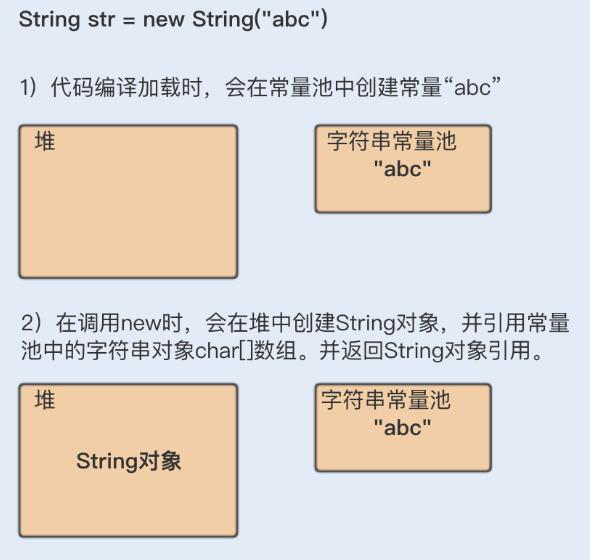
2、String str = new String(“abc”)
首先在编译类文件时,"abc"常量字符串将会放入到常量结构中,在类加载时,“abc"将会在常量池中创建;其次,在调用 new 时,JVM 命令将会调用String 的构造函数,同时引用常量池中的"abc” 字符串,在堆内存中创建一个 String 对象;最后,str 将引用 String 对象。
3、String str2=“ab”+“cd”+ “ef”;
编程过程中,字符串的拼接很常见。前面我讲过 String 对象是不可变的,如果我们使用 String 对象相加,拼接我们想要的字符串,是不是就会产生多个对象呢?例如上面代码:
分析代码可知:首先会生成 ab 对象,再生成 abcd 对象,最后生成 abcdef 对象,从理论上来说,这段代码是低效的。
编译器自动优化了这行代码,编译后的代码,你会发现编译器自动优化了这行代码,如下
String str= “abcdef”;
4、大循环使用+
public void mode(){
String str = "abcd";
for (int i = 0; i < 1000; i++) {
str = str + i;
}
}
5.3、intern
String 的 intern 方法,如果常量池中有相同值,就会重复使用该对象,返回对象引用。
String a = new String("tiger").intern();
String b = new String("小明").intern();
if (a == b){
System.out.println("a == b");
}else {
System.out.println("a != b");
}
- new Sting() 会在堆内存中创建一个 a 的 String 对象,king"将会在常量池中创建
- 在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
- 调用 new Sting() 会在堆内存中创建一个 b 的 String 对象。4、在调用 intern 方法之后,会去常量池中查找是否有等于该字符串对象的引用,有就返回引用。
- 所以 a 和 b 引用的是同一个对象。
总结
本篇文章,主要讲解了JVM 调优的相关知识点,从堆、扩容、避免Minor GC 到常量池,再到最后的String 类的一个分析,文章类容不多,但是有些面试