一. torch.nonzero()函数解析
1. 官网链接
torch.nonzero(),如下图所示:
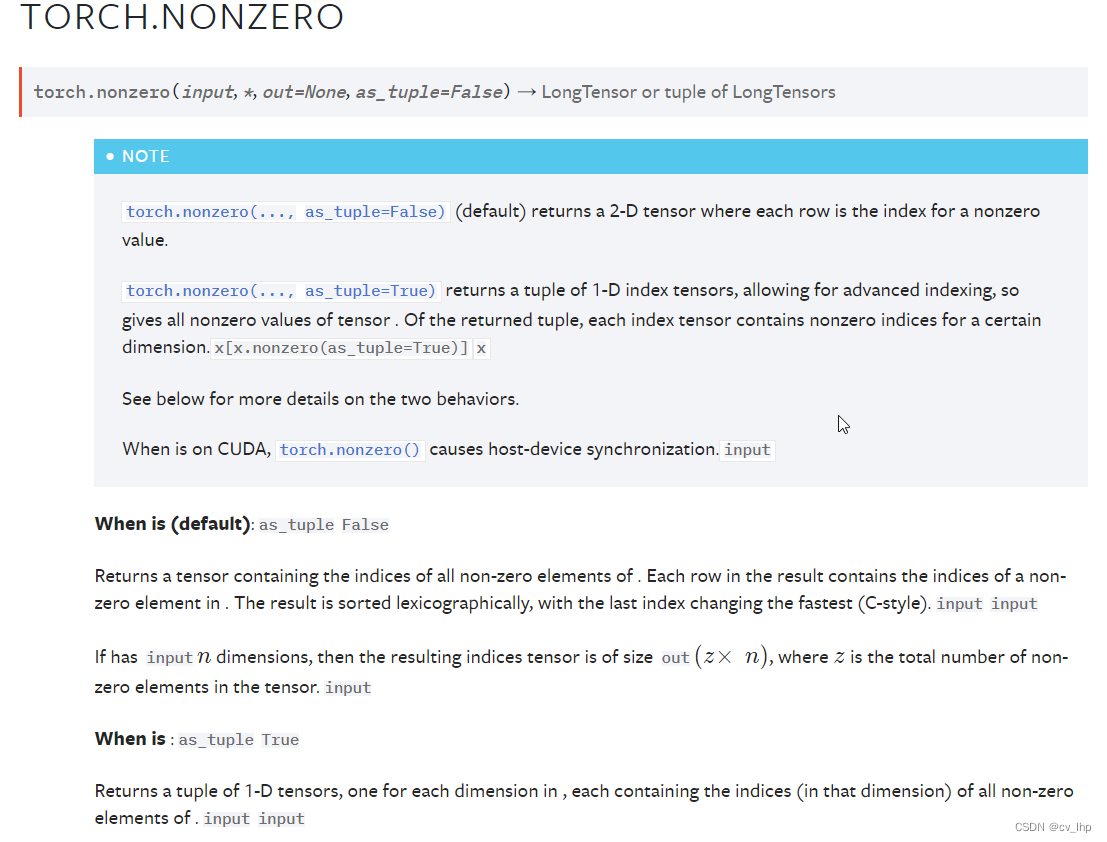
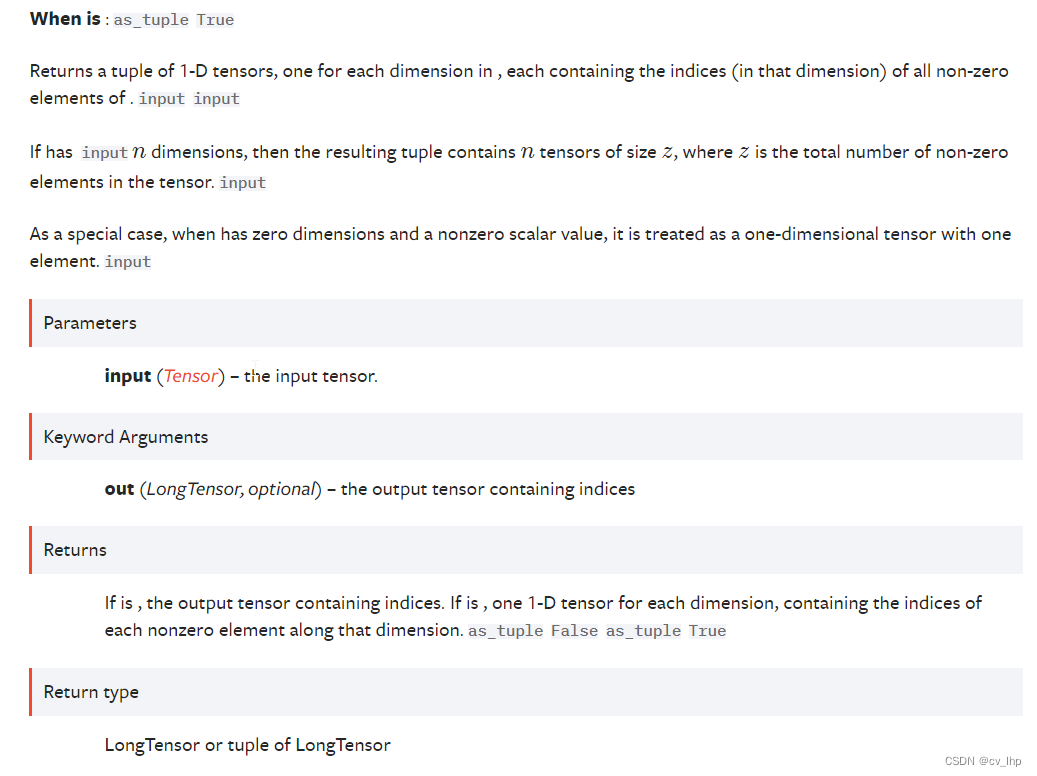
2. torch.nonzero()函数解析
2.1. 输入是一维张量,返回一个包含输入 input 中非零元素索引的张量,输出张量中的每行包含 input 中非零元素的索引,输出是二维张量torch.size(z,1), z 是输入张量 input 中所有非零元素的个数。
2.2. 输入是n维张量,如果输入 input 有 n 维,则输出的索引张量的size为torch.size(z,n) , 这里 z 是输入张量 input 中所有非零元素的个数。
无论输入是几维,输出张量都是两维,每行代表输入张量中非零元素的索引位置(在所有维度上面的位置)。
返回 input中非零元素的索引下标,n维input 中的元素的索引有n 个维度的索引下标。
3. 代码举例
3.1 输入一维张量torch.Size([5]),返回的是输入张量不为零的值在一维向量中的索引位置,输出二维张量torch.Size([4, 1]),4代表输入张量中不为零的个数,1代表在一维张量中的索引位置。
x = torch.tensor([1, 1, 1, 0, 1])
y = torch.nonzero(x)
x,x.shape,y,y.shape
输出结果如下:
(tensor([1, 1, 1, 0, 1]),
torch.Size([5]),
tensor([[0],
[1],
[2],
[4]]),
torch.Size([4, 1]))
3.2 输入二维张量torch.Size([4, 4]),返回的是不为零的值在二维向量中的坐标,例如[0, 0]、[0,2]代表的是二维向量第一行第一列,第一行第三列不为零,输出二维张量torch.Size([6, 2]),6代表输入张量中不为零的个数,2代表在二维张量中的索引位置。
input是2维的,一共有6个非0元素,所以输出是一个torch.Size([6, 2])的张量,表示每个非0元素的索引。读法是从左往右,比如输出张量的第0行[0,0],表示的就是input的第0行的第0个元素是非0元素,同理,输出张量的第1行[0,2],表示的就是input的第1行的第2个元素是非0元素等等。
x = torch.tensor([[0.6, 0.0, 0.9, 0.0],
[0.0, 0.4, 0.0, 0.0],
[0.0, 0.0, 1.2, 0.0],
[0.0, 0.7, 0.0,-0.4]])
y = torch.nonzero(x)
x,x.shape,y,y.shape
输出结果如下:
(tensor([[ 0.6000, 0.0000, 0.9000, 0.0000],
[ 0.0000, 0.4000, 0.0000, 0.0000],
[ 0.0000, 0.0000, 1.2000, 0.0000],
[ 0.0000, 0.7000, 0.0000, -0.4000]]),
torch.Size([4, 4]),
tensor([[0, 0],
[0, 2],
[1, 1],
[2, 2],
[3, 1],
[3, 3]]),
torch.Size([6, 2]))
3.3. 输入三维张量torch.Size([2, 3, 4]),返回的是不为零的值在三维向量中的坐标,将下面例子看作图像,那么图像维度大小[2,3,4]对应于[channels, width, height],例如[0, 0, 3]代表的是第一个通道第一行第一列不为零,输出二维张量torch.Size([13, 3]),13代表输入张量中不为零的个数,3代表在三维张量中的索引位置。
输出张量按行依次从左往右读,第0个通道第0行第0列的元素非0,第0个通道第1行第0列的元素非0,……,第1个通道第2行第2列的元素非0,第1个通道第2行第2列的元素非0。
x = torch.randn(2,3,4)
y = (x>0.1)
z = torch.nonzero(y)
x,x.shape,y,y.shape,z,z.shape
输出结果如下:
(tensor([[[ 0.3326, -0.9972, -0.4871, -1.3885],
[ 0.4679, -1.7913, 2.0604, 0.3150],
[-0.6156, -0.5204, 0.2902, -0.0780]],
[[ 1.2206, -0.7150, -0.1662, 0.5120],
[ 0.2907, 0.1285, 0.8520, -1.2698],
[ 0.5176, -0.3800, 0.4408, 0.5073]]]),
torch.Size([2, 3, 4]),
tensor([[[ True, False, False, False],
[ True, False, True, True],
[False, False, True, False]],
[[ True, False, False, True],
[ True, True, True, False],
[ True, False, True, True]]]),
torch.Size([2, 3, 4]),
tensor([[0, 0, 0],
[0, 1, 0],
[0, 1, 2],
[0, 1, 3],
[0, 2, 2],
[1, 0, 0],
[1, 0, 3],
[1, 1, 0],
[1, 1, 1],
[1, 1, 2],
[1, 2, 0],
[1, 2, 2],
[1, 2, 3]]),
torch.Size([13, 3]))